 Michele Nicastro1,2*
Michele Nicastro1,2* Ben Jeurissen1,2,3
Ben Jeurissen1,2,3 Quinten Beirinckx1,2
Quinten Beirinckx1,2 Céline Smekens1,2,4
Céline Smekens1,2,4 Dirk H. J. Poot5
Dirk H. J. Poot5 Jan Sijbers1,2
Jan Sijbers1,2 Arnold J. den Dekker1,2
Arnold J. den Dekker1,2- 1imec-Vision Lab, Department of Physics, University of Antwerp, Antwerp, Belgium
- 2μNEURO Research Centre of Excellence, University of Antwerp, Antwerp, Belgium
- 3Lab for Equilibrium Investigations and Aerospace, Department of Physics, University of Antwerp, Antwerp, Belgium
- 4Siemens Healthcare NV/SA, Groot-Bijgaarden, Belgium
- 5Biomedical Imaging Group Rotterdam, Department of Radiology and Nuclear Medicine, Erasmus MC, Rotterdam, Netherlands
Multi-slice (MS) super-resolution reconstruction (SRR) methods have been proposed to improve the trade-off between resolution, signal-to-noise ratio and scan time in magnetic resonance imaging. MS-SRR consists in the estimation of an isotropic high-resolution image from a series of anisotropic MS images with a low through-plane resolution, where the anisotropic low-resolution images can be acquired according to different acquisition schemes. However, it is yet unclear how these schemes compare in terms of statistical performance criteria, especially for regularized MS-SRR. In this work, the estimation performance of two commonly adopted MS-SRR acquisition schemes based on shifted and rotated MS images respectively are evaluated in a Bayesian framework. The maximum a posteriori estimator, which introduces regularization by incorporating prior knowledge in a statistically well-defined way, is put forward as the estimator of choice and its accuracy, precision, and Bayesian mean squared error (BMSE) are used as performance criteria. Analytic calculations as well as Monte Carlo simulation experiments show that the rotated scheme outperforms the shifted scheme in terms of precision, accuracy, and BMSE. Furthermore, the superior performance of the rotated scheme is confirmed in real data experiments and in retrospective simulation experiments with and without inter-image motion. Results show that the rotated scheme allows regularized MS-SRR with a higher accuracy and precision than the shifted scheme, besides being more resilient to motion.
1. Introduction
Multi-slice (MS) super-resolution reconstruction (SRR) methods have been proposed to improve the inherent trade-off between spatial resolution, signal-to-noise ratio (SNR), and scan time in magnetic resonance imaging (MRI) (Greenspan, 2008; Plenge et al., 2012; Poot et al., 2012; Van Dyck et al., 2020; Askin Incebacak et al., 2021; Vis et al., 2021) and to replace direct 3D acquisition methods when these are not effective or possible, as is often the case, for example, in T2-weighted imaging (Greenspan, 2008; Plenge et al., 2012). MS-SRR consists in estimating a 3D isotropic high-resolution (HR) image, hereafter referred to as MS-SRR image, from a series of anisotropic MS images with a low through-plane resolution, where each of the low resolution MS images is acquired in a distinct fashion to ensure that the acquired dataset contains complementary resolution information about the HR image to be reconstructed (Van Reeth et al., 2012).
Two MS-SRR acquisition strategies are commonly applied that have been demonstrated to fulfill this requirement. According to these strategies, the MS images are acquired with (i) sub-voxel shifts in the through-plane direction (Greenspan et al., 2002), (ii) slice orientations rotated around a common frequency (Shilling et al., 2008, 2009) or phase-encoding axis (Poot et al., 2012; Van Steenkiste et al., 2015, 2016). These acquisition strategies were first compared in the same works in which the MS-SRR rotated acquisition scheme was proposed (Shilling et al., 2008, 2009). In Shilling et al. (2009), the shifted and rotated MS-SRR acquisition schemes were compared in terms of the mean squared error (MSE) and sharpness of the MS-SRR image using simulation and real data experiments, respectively. In these experiments, iterative algorithms based on the projection onto convex sets (POCS) method (Stark and Oskoui, 1989) were adopted that converge to a Maximum Likelihood solution of the non-regularized MS-SRR problem. Results with the rotated scheme showed a sharper MS-SRR image with a lower MSE than the shifted scheme. However, since MS-SRR estimation involves solving an ill-conditioned inverse problem, unregularized estimators, although unbiased, often have an unacceptably high variance. Furthermore, when unregularized estimators are used, small modeling errors may lead to reconstruction artifacts that prevent the MS-SRR image's diagnostic use (Khattab et al., 2020). These artifacts can be minimized by regularizing the MS-SRR problem, as qualitatively shown by Shilling et al. (2008). Nevertheless, up to now, to the authors' knowledge, no statistical evaluation of MS-SRR acquisition strategies has been performed that takes account of the effect of regularization.
In this paper, a Bayesian framework is proposed that allows such an evaluation. Analytical expressions are derived for the accuracy, precision, and Bayesian mean squared error (BMSE) of the maximum a posteriori (MAP) estimator of the MS-SRR image, where the MAP estimator is put forward since it imposes regularization by incorporating prior knowledge of the MS-SRR image in a statistically well-defined way (Kay, 1993). The derived measures are then used as performance criteria to evaluate and compare the two MS-SRR acquisition strategies described above. The results of this evaluation are validated in Monte Carlo simulations and real data experiments. Furthermore, the impact of patient motion on the estimation performance of the acquisition protocols is investigated with retrospective simulations. The proposed analysis in a Bayesian framework, which is novel in super-resolution reconstruction, aims to pave the way toward optimal experiment design that allows to determine the optimal MS-SRR image acquisition strategy on a rigorous statistical basis. A preliminary version of this study, based on analytical calculations and numerical simulations only, was published as a proceedings paper (Nicastro et al., 2021).
2. Materials and methods
2.1. Theory
2.1.1. MS-SRR forward model
Let represent the noiseless HR magnitude image to be reconstructed, with Nr the number of voxels. Furthermore, let , with n = 1, …, N, be the n-th noiseless MS magnitude image, consisting of Ns voxels with an anisotropic voxel-size characterized by the anisotropy factor (AF), which is defined as the ratio of the through-plane resolution to the in-plane resolution. Next, let θn = (txn, tyn, tzn, ϕxn, ϕyn, ϕzn) be a rigid transformation parameter vector, where txn, tyn, tzn are the translation parameters, expressed in mm, and ϕxn, ϕyn, ϕzn the rotation angles around axis x, y, and z, respectively, expressed in degrees (°), with the center of rotation matching the center of the image. Then, sn can be modeled as:
with , , and linear operators that describe a geometric transformation, space-invariant blurring, and down-sampling, respectively. The motion operator M applies the rigid transformation defined by θn. The blurring operator B models the point-spread function (PSF) of the MRI acquisition method. For MS acquisition methods, the PSF can be assumed separable and therefore modeled as the product of three 1D PSFs that are applied in the three orthogonal directions aligned with the MR image coordinate axes. The 1D PSFs in the in-plane directions (frequency- and phase-encoding) are modeled by a periodic sinc while the 1D PSF in the through-plane direction (slice-encoding) can be well-approximated by a Gaussian function having a full-width half maximum equal to the slice thickness (Van Reeth et al., 2012). The down-sampling operator D decimates the image in the slice-encoding direction by the factor AF by keeping only every AF-th voxel.
The MS images can be represented as a matrix-vector multiplication s(r) = Ar, where and , with . For an efficient implementation of the operators, we adopted the set of shears transformations method proposed by Poot et al. (2010).
2.1.2. MAP estimator
Let be the vector containing the voxel intensities of the acquired MS images. Since these MS images are disturbed by noise, is modeled as a random variable. MS-SRR involves the estimation of the HR image r from the MS images . In this work, we follow a Bayesian estimation approach, in which the HR image r to be estimated is viewed as a realization of a random variable with distribution p(r). This so-called prior distribution p(r), being the joint distribution of the elements of r, summarizes our initial state of knowledge about r before any images are acquired. After the images are acquired, our knowledge about r has increased and is now summarized by , which is known as the posterior probability density function (PDF) of r given . According to Bayes' theorem, can be expressed as
where is the conditional PDF of given r and is a normalization constant. When is viewed as a function of r for a fixed data set , it is called the likelihood function. The conditional PDF of the magnitude images can be derived from the MS-SRR forward model described in Equation (1) and the assumed noise statistics.
Nowadays, parallel imaging is commonly adopted in MRI clinical practice to reduce scan time, allowing to reconstruct the magnitude MR image from sub-sampled acquisitions of the k-space from multiple coils. Generalized autocalibrating partially parallel acquisitions (GRAPPA) (Griswold et al., 2002) and sensitivity encoding (SENSE) (Pruessmann et al., 1999) are the two most often used parallel imaging approaches. When GRAPPA is adopted in combination with the spatially matched filter (SMF) technique (Walsh et al., 2000), or when SENSE is adopted, the reconstructed magnitude images follow a Rician distribution (Walsh et al., 2000; Aja-Fernández et al., 2014). Additionally, when the SNR is larger than 3, the Rician distribution can be well approximated by a Gaussian distribution (Gudbjartsson and Patz, 1995). Under these assumptions and assuming all voxel intensities to be statistically independent and the standard deviation of the noise σ to be temporally and spatially invariant, can be expressed as follows:
Furthermore, the prior distribution p(r) can be modeled as a stationary Gaussian Markov random field (MRF) (Bardsley, 2013). This corresponds to the assumption of a multivariate Gaussian prior of the form:
which is parameterized by its mean and precision (inverse-covariance) matrix . This precision matrix, which is sparse and positive definite, encodes statistical correlations between the intensity of an HR image voxel and that of its neighboring voxels. Let be the voxel intensities from the neighborhood surrounding the i-th HR voxel, where Nn is the number of neighborhood voxels, and ∂i represents the neighborhood voxels' indices. Following the conditional auto-regression approach proposed by Besag (1974), we first define for each voxel ri its neighborhood conditional PDF p(ri|r∂i) as the conditional PDF of the intensity ri of the i-th HR voxel given the intensities of its neighboring voxels r∂i. Then, we assume all neighborhood conditional PDFs to be Gaussian and of the form:
where is the vector of the so-called field potentials, or regression coefficients. Indeed, it follows from Equation (5) that the i-th HR image voxel intensity can be described by an auto-regressive model:
where ui is a sample from a white Gaussian noise process with variance λ2. Furthermore, it can be demonstrated (Rue and Held, 2005) that Equation (5) holds if and only if the prior p(r) takes the form of Equation (4) with:
The maximum a posteriori (MAP) estimator can then be obtained by maximizing with respect to r. Hence, by combining Equations (2) and (4), we obtain:
Note that the MAP estimator (Equation 8) corresponds with a regularized least squares estimator, which has the following closed-form solution:
2.1.3. Bayesian MSE
The BMSE of the MAP estimator described by Equation (9) is proposed as a performance criterion to compare the shifted and rotated MS-SRR acquisition schemes. Before deriving the BMSE, let us first define the component-wise MSE of for a fixed value of r as:
with the expectation operator over the conditional PDF .
The MSE described by Equation (10) can be decomposed as the sum of a variance term and a squared bias term (van den Bos, 2007):
where and are the covariance matrix and the bias vector of , which are element-wise defined as:
and
respectively. It can be shown straightforwardly that for the MAP estimator defined in Equation (9), the variance component and the bias component of the MSE assume the following closed-form expressions:
with
Next, the component-wise BMSE of is obtained as (Kay, 1993; Ben-Haim and Eldar, 2009):
with , 𝔼r[·], and the expectation operators over the joint PDF , the prior distribution p(r), and the conditional PDF , respectively. Note that it follows from Equations (10), (11), and (17) that, similar to the MSE, the BMSE can be decomposed into two terms:
where the first term corresponds with the variance (Equation 12) of the MAP estimator (Equation 9), which does not depend on r, and the second term corresponds with the expected value of the squared bias of the MAP estimator, where the expected value is taken over the prior distribution p(r). It can be shown that this second term assumes the following closed-form expression:
2.2. MS-SRR protocols comparison
The comparison was conducted taking into account different combinations of AF and numbers of acquired MS images N for the MS-SRR protocols, but keeping the same scan time for all the experiments. Assuming an interleaved fast spin-echo (FSE) protocol, the acquisition time tacq is given by (Bernstein et al., 2004):
where TR is the repetition time, ⌈·⌉ is the round-up operator, FOVse is the field of view in the slice-encoding direction, PIacc is the parallel imaging acceleration factor, ETL the echo-train length, and resse the slice thickness, where AF = resse/resip, with resip being the in-plane voxel size. TR, FOVse, PIacc, ETL, and resip were kept fixed for all protocols. Furthermore, the ratio N/AF was set equal to 2. This choice ensures that all acquisition protocols require the same scan time, while at the same time the MS-SRR estimation problem is not under-determined (N/AF ≥ 1) (Shilling et al., 2009), and the k-space is efficiently sampled when the MS images are acquired with the rotated scheme (Van Steenkiste et al., 2015).
The acquisition protocols included in the comparison are summarized in Table 1. An HR protocol representing a conventional HR MS acquisition with AF = 1 was included as a reference and repeated twice to equal the scan time of the SR protocols. In the SRrot protocols, the acquired images were rotated around the phase-encoding axis so that the phase-encoding axis is the same for all the MS images. The rigid transformation parameter vector for the n-th acquired MS image assumes the form θn = [0, 0, 0, 0, ϕyn, 0] and θn = [0, 0, tzn, 0, 0, 0] for the SRrot and SRsh protocols, respectively. For the SRrot protocols, the rotation angles around the phase-encoding axis were equidistantly chosen in the open interval [0, 180), with steps of 180/N, whereas, for the SRsh protocols, the shifts along the slice-encoding direction were equidistantly chosen in the closed interval [−AF(N − 1)/(2N), AF(N − 1)/(2N)], with steps of AF/N. The acquisition geometries of the MS-SRR shifted and rotated schemes for the case of AF = 2, N = 4, and resip = 1 mm are represented in Figure 1.
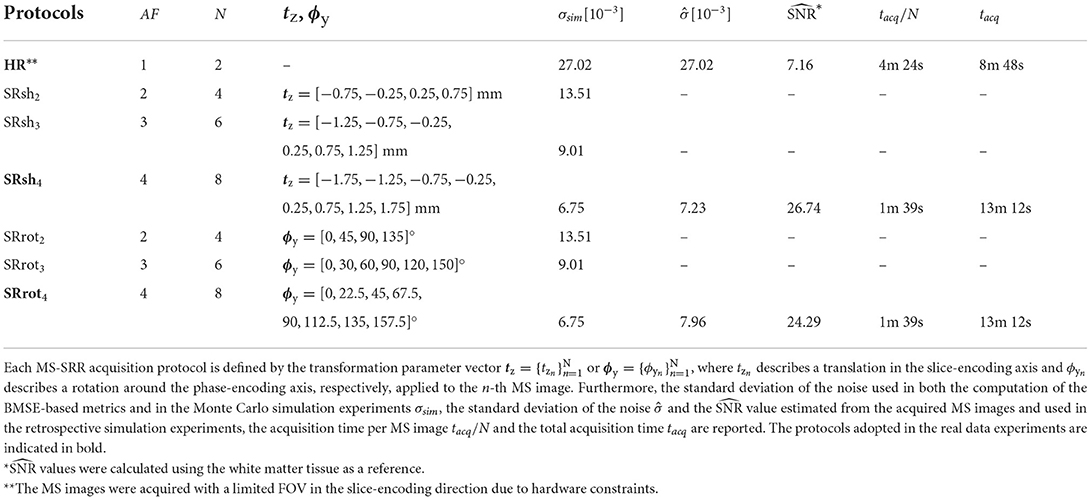
Table 1. MS-SRR acquisition protocols included in the comparison.
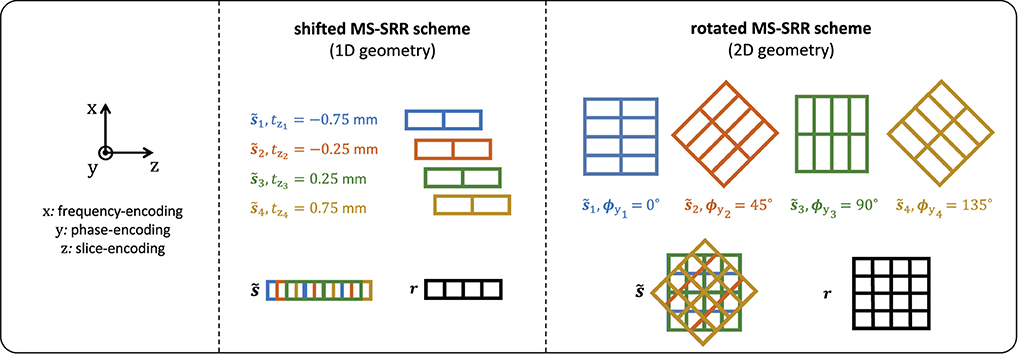
Figure 1. Acquisition geometries of the MS-SRR shifted and rotated schemes: AF = 2, N = 4, and resip = 1 mm.
2.2.1. MS-SRR protocols comparison in terms of BMSE
A simplified 2D framework is proposed to compare the MS-SRR protocols in terms of the BMSE and its separate squared bias and variance components by exploiting the inherent 1D acquisition geometry of the shifted scheme and the 2D acquisition geometry of the rotated scheme (Figure 1). The proposed framework allows to evaluate the MS-SRR problem in 2D by restricting the analysis to a single slice along the phase encoding direction and neglecting the blurring component in the same direction. This simplification is expected to reduce the computational complexity and memory consumption without influencing the results of our comparison, since this blurring affects all protocols equivalently.
2.2.1.1. 2D training and validation datasets
The prior hyperparameters α, , and λ, introduced in Section 2.1.2, were learned from a training dataset composed of 100 noiseless HR 2D T2-weighted magnitude brain images of resolution 1 × 1 mm2 and size 217 × 217. These images were simulated from 10 of the 20 3D anatomical brain models available in the Brainweb database (Cocosco et al., 1997) as follows. Each anatomical model consists of a set of discrete 3D tissue membership volumes, one for each tissue class: background, cerebrospinal fluid, gray matter, white matter, fat, muscle, skin, skull, blood vessels, connective tissue, dura mater, and bone marrow. T2-weighted brain volumes were generated from the 3D anatomical models by applying the spin-echo decay model (Jung and Weigel, 2013):
where ri is the i-th voxel intensity, TE is the echo-time, and ρi, T1i, and T2i are the i-th voxel proton density, longitudinal relaxation, and transverse relaxation values, fixed for each tissue to the mean value of its respective distribution at 3T reported by Sabidussi et al. (2021). TR and TE were independently sampled for each image within the training dataset from uniform distributions with ranges [10, 14] s and [80, 120] ms, respectively. A series of 2D slices of resolution 1 × 1 mm2 was then simulated from three orthogonal acquisition planes (sagittal, transverse, and coronal), by down-sampling and then slicing the T2-weighted volumes. The thus obtained images, representing independent realizations of r, and characterized each by a unique morphology, orientation and contrast, compose the 2D training dataset. The same approach was used to simulate the Nv = 100 additional 2D T2-weighted magnitude brain images that compose the 2D validation dataset from the 10 remaining anatomical brain models.
2.2.1.2. 2D MRF prior hyperparameters
The prior hyperparameters α, , and λ were estimated from the image voxels within the 2D training dataset and their respective 2D neighborhoods of size p × p, with . The parameters α and λ were estimated by solving the Yule-Walker equations using a least-squares estimator (Eshel, 2011). The kernel size of the voxel neighborhoods was defined by testing increasing odd values of p, starting from p = 3, until a stable estimate of λ was found. We defined the estimate of λ to be stable if the relative difference of for the current value of p with respect to the value of for the previous value of p was <1%. The condition was met for p = 11. All the elements of the prior mean were set equal to the mean intensity of the images within the training dataset, thus ensuring the prior is translation-invariant.
2.2.1.3. Quantitative metrics
The BMSE and its separate variance and squared bias components were computed using the closed-form expressions introduced in Section 2.1.3. For each acquisition protocol, since the SNR is expected to increase proportionally with the slice thickness, the standard deviation of the noise σsim was set to match , where is the standard deviation of the noise estimated from the (pre-processed) MS images acquired in the real data experiments using the HR protocol. The real data experiments and the estimation of the standard deviation of noise from the acquired MS images will be further described in Section 2.2.3.1. The values of σsim and are reported in Table 1.
Voxel-wise BMSE-based metrics were calculated as follows:
where , , and are the Bayesian Root Mean Squared Error, Standard Deviation, and Bayesian Root Mean Squared Bias, respectively, and with K−1 (and hence Q, see Equation 17) defined using the prior hyper-parameters values estimated as described in Section 2.2.1.2. In this work, the estimation performance of different acquisition schemes is compared using the measures SD and BRMSB to separately quantify their estimation precision and accuracy, respectively, while the BRMSE, which incorporates both measures, is put forward as the decisive performance criterion.
2.2.2. Monte Carlo validation
2.2.2.1. Monte Carlo simulations
Monte Carlo experiments were performed to assess the generalizability of the BMSE-based metric results to brain images outside the training dataset (i.e., to ensure that the estimated prior did not overfit the brain image samples within the training dataset). To this end, Nv = 100 ground truth 2D HR images were extracted from a validation dataset generated as described in Section 2.2.1.1 and composed of brain images having different morphologies and contrasts than those within the training dataset.
First, noiseless MS images were simulated for the protocols HR, SRrot4 and SRsh4 using the MS-SRR forward model described by Equation (1). Next, the images were corrupted with additive white Gaussian noise, where the standard deviation of the noise for each image was chosen to correspond with its value assumed in the computation of the BMSE-based metrics. The conjugate gradient (CG) method (Hestenes and Stiefel, 1952) was used to solve the minimization problem described by Equation (8). The CG method optimization procedure is initialized at and stopped when the ratio between the 2-norm of the derivative of the cost function evaluated at the current iteration and at the initialization point is <10−4.
2.2.2.2. Quantitative metrics
Monte Carlo estimates of the BMSE and its separate variance and squared bias components were computed, where the mean was calculated over Ne = 50 noise realizations for each of the Nv = 100 ground truth images included in the validation dataset, yielding:
with the nv-th ground truth image, and the ne-th MS-SRR estimate of . Next, the Monte Carlo estimates of the BMSE-based metrics defined in Equations (22–24) were computed as:
2.2.3. Real data and retrospective simulation experiments
2.2.3.1. Real data acquisition
Real data experiments were conducted for the acquisition protocols HR, SRrot4, and SRsh4 on a healthy volunteer after written informed consent in accordance with local ethics. The magnitude MS images were acquired in an interleaved fashion using a T2-weighted 2D FSE sequence on a Siemens Magnetom Prisma 3T system. TR/TE was set to 12,150/97 ms. The resolution was 1 × 1 × 1 mm3 for the HR protocol and 1 × 1 × 4 mm3 for the SRrot4 and SRsh4 protocols. The FOV was 256 × 256 × 192 mm3 for the SR protocols, while it was reduced to 256 × 256 × 128 mm3 for the HR protocol, since 128 was the maximum number of slices for acquisition allowed by the system. The acquisition time for a single MS image tacq/N and the total acquisition time tacq for all the protocols are reported in Table 1. The HR protocol scan time is approximately equal to 2/3 of the SR protocols scan time, as only 2/3 of the field of view of the SR protocols is covered. GRAPPA with an acceleration factor of 2 was adopted in combination with the SMF technique, which is provided as “adaptive combine” on the employed MRI scanner. Two repetitions of the experiment (test-retest) were performed for each protocol.
2.2.3.1.1. Image preprocessing
The preprocessing stage is composed of two steps: (i) intensity-normalization of the acquired MS images, (ii) correction of the acquired MS images for inter-image motion.
The purpose of the first step is to allow the use of the prior hyper-parameters values estimated from the synthetic training dataset on the acquired MR data. To this end, the voxel intensities of the MS-SRR image estimated from the acquired MS images have to be in the same range as the voxel intensities of the images within the synthetic training dataset. This can be achieved by normalizing the intensity of the acquired MS images, since the MS-SRR image preserves the intensity range of the images from which it is estimated. The intensity-normalization was performed using the white matter (WM) tissue as a reference. Four regions of interest (ROIs) were selected in the WM region of each of the acquired MS images for all the protocols. The mean WM intensity value was computed by averaging all the voxel intensities within the ROIs. A scaling factor was then applied so that the so-computed mean WM intensity matched the WM intensity value predicted by the model (Equation 21) used to generate the images within the training dataset. Examples of the intensity-normalized acquired MS images are represented in Figure 2.
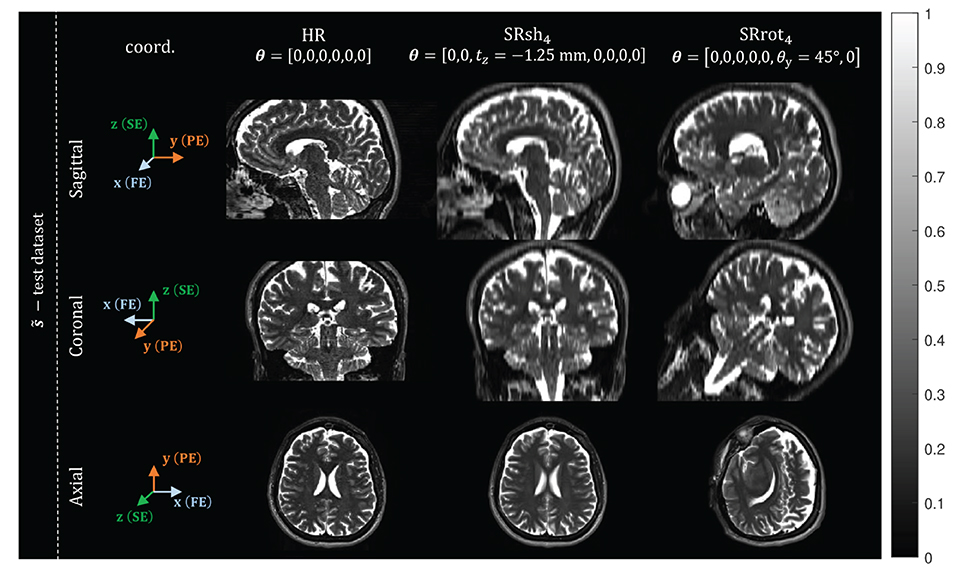
Figure 2. Examples of intensity-normalized acquired MS images: views from orthogonal planes of one of the MS images from the test dataset, for each protocol. The MR image coordinate system is reported in the first column, where FE, PE, and SE, represent the frequency-encoding (x-axis), phase-encoding (y-axis), and slice-encoding (z-axis) directions, respectively. For each MS image, the corresponding rigid transformation parameter vector θ is shown.
In the second step, all the acquired MS images from both the test and retest dataset were jointly corrected for rigid motion by using an iterative approach, presented in Figure 3. First, a MS-SRR image was estimated from all the MS images simultaneously by solving Equation (8) using the CG method, where the initialization point and stopping criterion were set as in Section 2.2.2. Then, a multi-scale 3D rigid registration between each MS image and the MS-SRR image was performed using the function “mrregister” from the MRtrix3 toolbox (RRID:SCR_006971; Tournier et al., 2019), and the affine transformation matrix of each MS image was updated. The procedure is iterated until the condition was met, where is the MS-SRR image estimated from all the acquired MS images in the i-th iteration, ||·||2 is the 2-norm operator, and the optimization tolerance tol was set to 0.01.
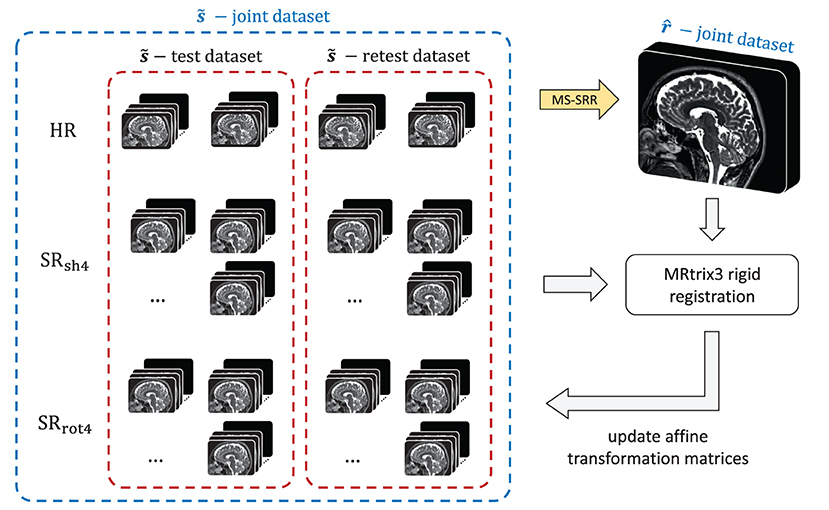
Figure 3. Workflow of the model-based iterative registration algorithm for joint motion correction of the MS images.
2.2.3.1.2. Standard deviation of the noise and SNR
For each pair of pre-processed test-retest MS images, the standard deviation of the noise σn and the signal-to-noise ratio SNRn were estimated for each protocol from the WM ROIs previously selected in the image pre-processing step as described in Section 2.2.3.1.1. The “difference method” described in Dietrich et al. (2007) was applied, yielding:
with σdiffn the standard deviation of the n-th difference image in the ROIs and μsumn the mean signal intensity value of the n-th sum image in the ROIs. Finally, the N estimates of the noise standard deviation and SNR were averaged to obtain single overall estimates and for each protocol, which are reported in Table 1.
2.2.3.1.3. 3D training datasetThe 3D training dataset, composed of 100 HR 3D T2-weighted brain images, was simulated from the 20 anatomical brain models available in the Brainweb database. Similarly to as described in Section 2.2.1.1 for the 2D case, T2-weighted brain volumes with different contrasts were generated from the anatomical models according to Equation (21) and subsequently down-sampled to a resolution of 1 × 1 × 1 mm3.
2.2.3.1.4. 3D MRF prior hyperparametersThe prior hyperparameters for the real data experiments were learned from a training dataset composed of 100 noiseless HR 3D T2-weighted magnitude brain images of resolution 1 × 1 × 1 mm3. The generation of this 3D training dataset is described in Section 1 of the Supporting Information. The prior hyperparameters α, λ, and were estimated from the image voxels within the 3D training dataset and their respective 3D neighborhoods using the approach described in Section 2.2.1.2. For the estimation of α and λ, a neighborhood size of 11×11×11 was selected, again using the same approach as in Section 2.2.1.2.
2.2.3.2. Retrospective simulation experiments
The real data experiments described in Section 2.2.3 were replicated in retrospective simulations, using as ground truth the MS-SRR image estimated from all the pre-processed acquired MS images from all the protocols simultaneously. The acquisition process was simulated for the protocols HR, SRrot4 and SRsh4 using the MS-SRR forward model in Equation (1). The simulated images were corrupted with Rician noise. Additionally, patient motion was simulated as abrupt inter-image motion by modifying the rigid transformation parameter vector of the n-th MS image as follows (Ramos-Llordén et al., 2017):
where θn is the original rigid transformation parameter vector, is the motion-corrupted rigid transformation parameter vector, and is a vector-valued, zero mean, Gaussian random variable with covariance matrix , with σmot the standard deviation of each of the elements of dn and I ∈ ℝ6×6 the identity matrix. Different levels of motion were simulated by sampling σmot in the closed interval [0, 1]mm/°, with steps of 0.01mm/° between [0, 0.1], which will be referred to as the minor motion range, and with steps of 0.1 between (0.1, 1], which will be referred to as the major motion range, where represents the motion-free scenario. The standard deviation of the noise and the prior hyper-parameters were set as in the real data experiments.
2.2.3.3. Quantitative metrics
The MS-SRR images were estimated for each protocol and for each repetition of the experiment (Ne = 2, test-retest) in both real data and retrospective simulation experiments by solving Equation (8) using the CG method from the acquired and retrospectively simulated MS images, respectively, where the initialization point and stopping criterion were set as in Section 2.2.2. In the retrospective simulations, the MSE and its separate variance and squared bias components were estimated, where the mean was calculated over Ne = 2 repetitions of the experiment:
with r the ground truth image, and the ne-th MS-SRR estimate of r. MSE-based metrics were computed as:
where , and are the Root Mean Squared Error, and Root Mean Squared Bias, respectively. RMSE is a combined measure of accuracy and precision, while RMSB quantifies the estimation accuracy only. The median RMSE, SD, and RMSB values were computed from the voxel values of each respective map within a brain mask. The brain mask was calculated using the Brain Extraction Tool (BET) of the FSL toolbox (RRID:SCR_002823; Woolrich et al., 2009) from the MS-SRR image estimated from all the pre-processed MS images acquired adopting the HR protocol simultaneously. In the real data experiments, only the estimation precision SD could be assessed due to the absence of a ground truth.
3. Results
3.1. MS-SRR protocols comparison in terms of BMSE
The BRMSB, SD, and BRMSE maps computed using the closed-form expressions (Equations 22–24) and their distributions inside an ROI are reported in Figure 4, where the ROI was defined as the part of the FOV that is common to all the MS images of all the MS-SRR acquisition protocols included in the comparison. The median values were computed for each distribution and reported below the respective maps and in Table 2.
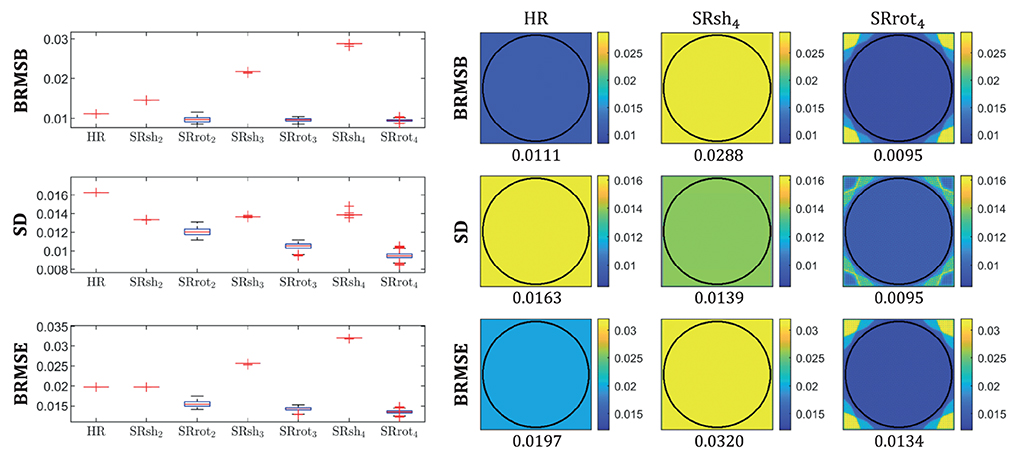
Figure 4. Boxplots of BRMSE, SD, and BRMSB computed for each protocol inside an ROI (left) and the respective parametric maps (right) for the protocols HR, SRrot4, and SRsh4. For each box, the central mark indicates the median, and the bottom and top edges of the box indicate the 25th and 75th percentiles, respectively, and the outliers are plotted individually using the “+” marker symbol (MATLAB, 2020). Each box has a sample size of 35,629 voxels. For each map, the median value computed inside an ROI is reported. The ROI was defined as the part of the field of view common to all the acquired images of all the acquisition protocols, which corresponds with the area inside the circle plotted in the maps.
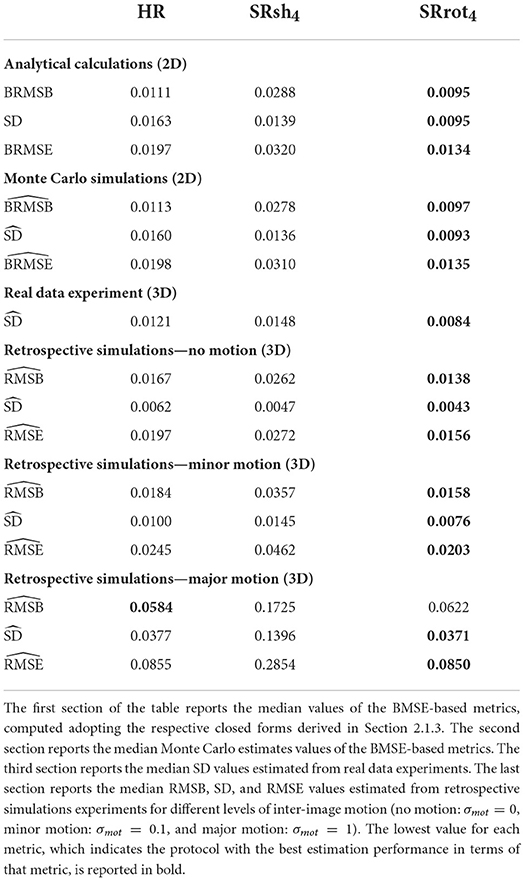
Table 2. Quantitative comparison results for the HR, SRsh4, and SRrot4 protocols.
BRMSB quantifies the estimation accuracy of the protocols, where a lower BRMSB value corresponds with a higher estimation accuracy. It follows from Figure 4 that the SRrot protocols provide a slightly lower BRMSB value than the reference protocol, whereas the BRMSB value provided by the SRsh protocols is substantially larger than that of the HR reference protocol. For the SRsh protocols, BRMSB increases for increasing values of AF up to a factor of 2.7 difference between SRsh4 and HR, while it slightly decreases with AF for the SRrot protocols. SD quantifies the estimation precision of the protocols, where a lower SD value corresponds with a higher precision. Both the SRrot and SRsh protocols provide a lower SD than the reference protocol HR, with the SRrot protocols outperforming the SRsh protocols. For the SRrot protocols, the SD decreases for increasing values of AF up to a factor of 1.7 difference between SRrot4 and HR, while it slightly increases with AF for the SRsh protocols. On balance, the accuracy and precision components together result in higher BRMSE values for the SRsh protocols and substantially lower BRMSE values for the SRrot protocols, compared to the reference protocol HR. For the SRsh protocols, BRMSE increases for increasing values of AF up to a factor of 1.7 difference between SRsh4 and HR. For the SRrot protocols, on the other hand, BRMSE decreases with AF up to a factor of 1.5 difference between SRrot4 and HR. In conclusion, the SRrot protocols outperform the competing protocols in terms of BRMSE, SD, and BRMSB.
3.2. Monte Carlo validation
Monte Carlo estimates of the BMSE-based metrics computed using the expressions in Equations (25–30) for the protocols HR, SRrot4, and SRsh4 are presented in Figure 5. The median values computed inside the ROI are reported below the maps as well as in Table 2, where the ROI corresponded with the one visualized in Figure 4. These median values are in agreement with the median values computed from the BRMSB, SD, and BRMSE maps that were reported in Section 3.1.
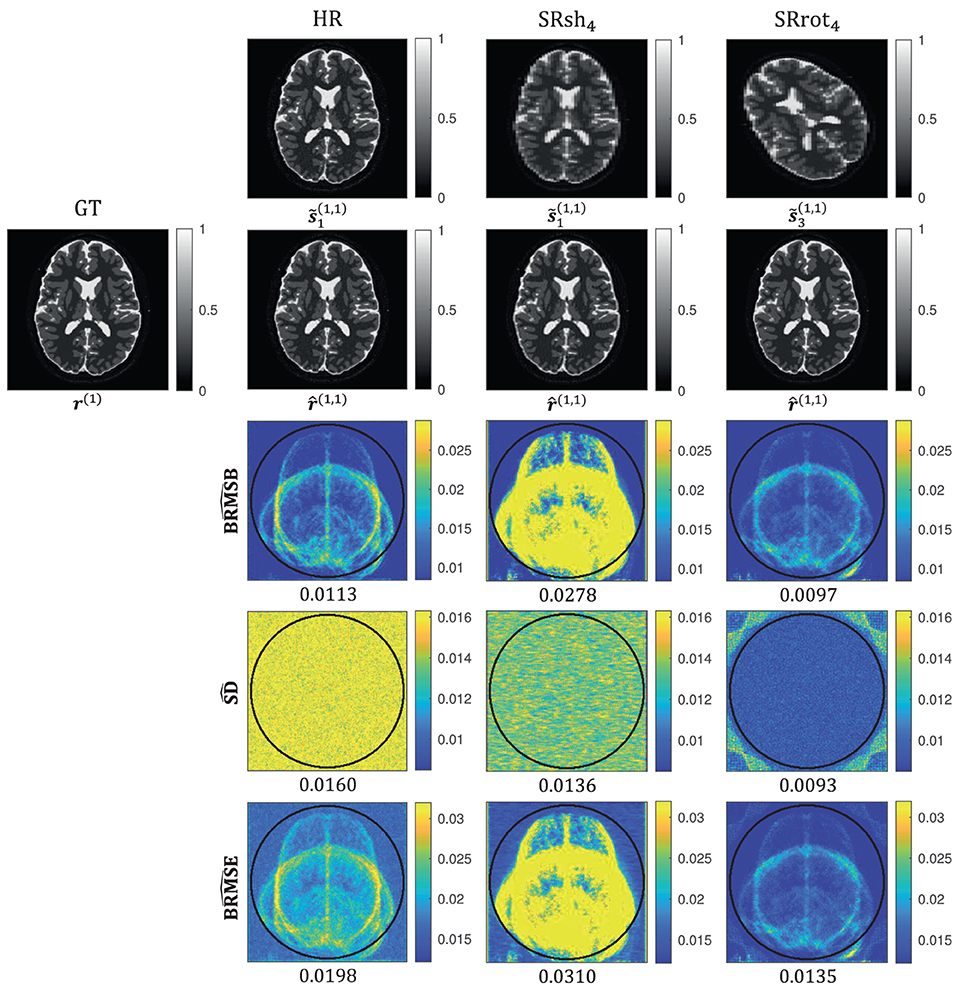
Figure 5. Monte Carlo simulation results for the protocols HR, SRrot4, and SRsh4. In the first two rows, , , and represent the nv-th image from the validation dataset, the n-th noise-corrupted MS image simulated using the nv-th image from the validation dataset as ground truth in the ne-th repetition of the experiment, and the MS-SRR image estimated from , respectively. In the last three rows, the Monte Carlo estimates , , and are shown. For each map, the median value computed inside an ROI is reported. The ROI was defined as the part of the field of view common to all the acquired images of all the acquisition protocols, which corresponds with the area inside the circle plotted in the maps.
3.3. Real data and retrospective experiments
3.3.1. Real data experiments
Orthogonal views of the MS-SRR image estimated for each protocol from the acquired MS images of the first repetition of the experiment are reported in Figure 6. Reconstruction artifacts in the slice-encoding direction are noticeable in the MS-SRR image estimated from the shifted MS images. The SD maps calculated for each protocol from the MS-SRR images of the two repetitions of the experiment are reported in Figure 7 and Table 2. The median SD was computed from the voxels inside a brain mask for each protocol, computed as described in Section 2.2.3.3. It follows from Figure 7 that SRrot4 provides the highest estimation precision among the acquisition protocols included in the comparison, followed by the HR protocol and the SRsh4 protocol, in descending order.
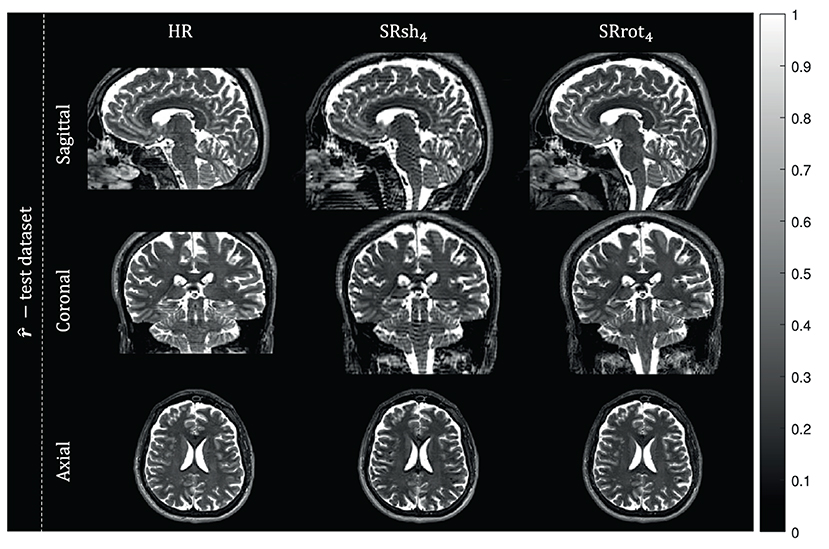
Figure 6. Real data results: MS-SRR images. The views from orthogonal planes of the MS-SRR images estimated from the test dataset for each protocol are shown.
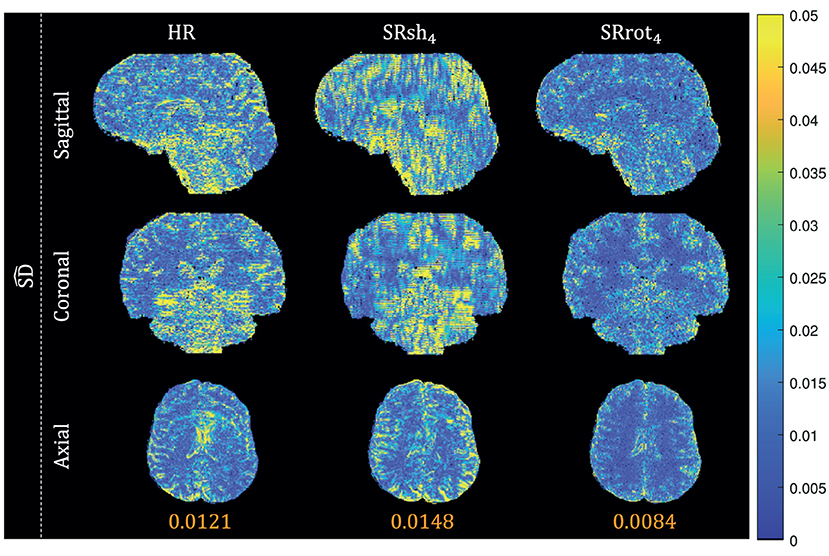
Figure 7. Real data results: SD maps. The views from orthogonal planes of the SD map for each protocol are shown, and the median value computed inside a brain mask for each SD map is reported.
3.3.2. Retrospective simulation experiments
Orthogonal views of the MS-SRR image estimated for each protocol from the retrospectively simulated MS images are reported in Figure 8 in the absence of inter-image motion (σmot = 0 mm/°) and in the presence of minor (σmot = 0.1 mm/°) and major (σmot = 1 mm/°) levels of inter-image motion. In the absence of inter-image motion, the MS-SRR images from the HR, SRsh4, and SRrot4 protocols are visually comparable. In the presence of a minor level of inter-image motion, inter-slice intensity artifacts can be found in the SRsh4 MS-SRR image, whereas the HR and SRrot4 MS-SRR images are not visibly impacted. In the presence of a major level of inter-image motion, the motion artifacts for the SRsh4 MS-SRR image become so severe that they impede the delineation of the underlying brain structures. Inter-slice intensity artifacts and blurring artifacts caused by motion also start to appear in the HR and SRrot4 MS-SRR images, respectively, but they are not as severe as the artifacts present in the SRsh4 MS-SRR image. Figure 9 shows the median values within a brain mask of the RMSB, SD, and RMSE maps that were computed for the protocols HR, SRsh4, and SRrot4 in the absence of motion and for the minor and major motion ranges. In the absence of inter-image motion, the relative performance of the different protocols with respect to each other in terms of RMSB, SD and RMSE is as predicted by the BMSE-based analysis that was reported in Section 3.1. However, in the minor motion range, the estimation precision for SRsh4 significantly decreases (i.e., SD increases), leading SRsh4 to be outperformed by HR in terms of estimation precision for σmot ≥ 0.04 mm/°, as observed in the real data experiments. The SRrot4 protocol showed instead consistent performance in the minor motion range, outperforming SRsh4 and HR in terms of the RMSB, SD, and RMSE. Finally, in the major motion range, SRrot4 showed a lower estimation accuracy (i.e., higher RMSB) than the HR protocol for σmot ≥ 0.3 mm/°, whereas SRrot4 kept showing a higher estimation precision (i.e., lower SD) than HR, leading to overall comparable results for SRrot4 and HR in terms of RMSE.
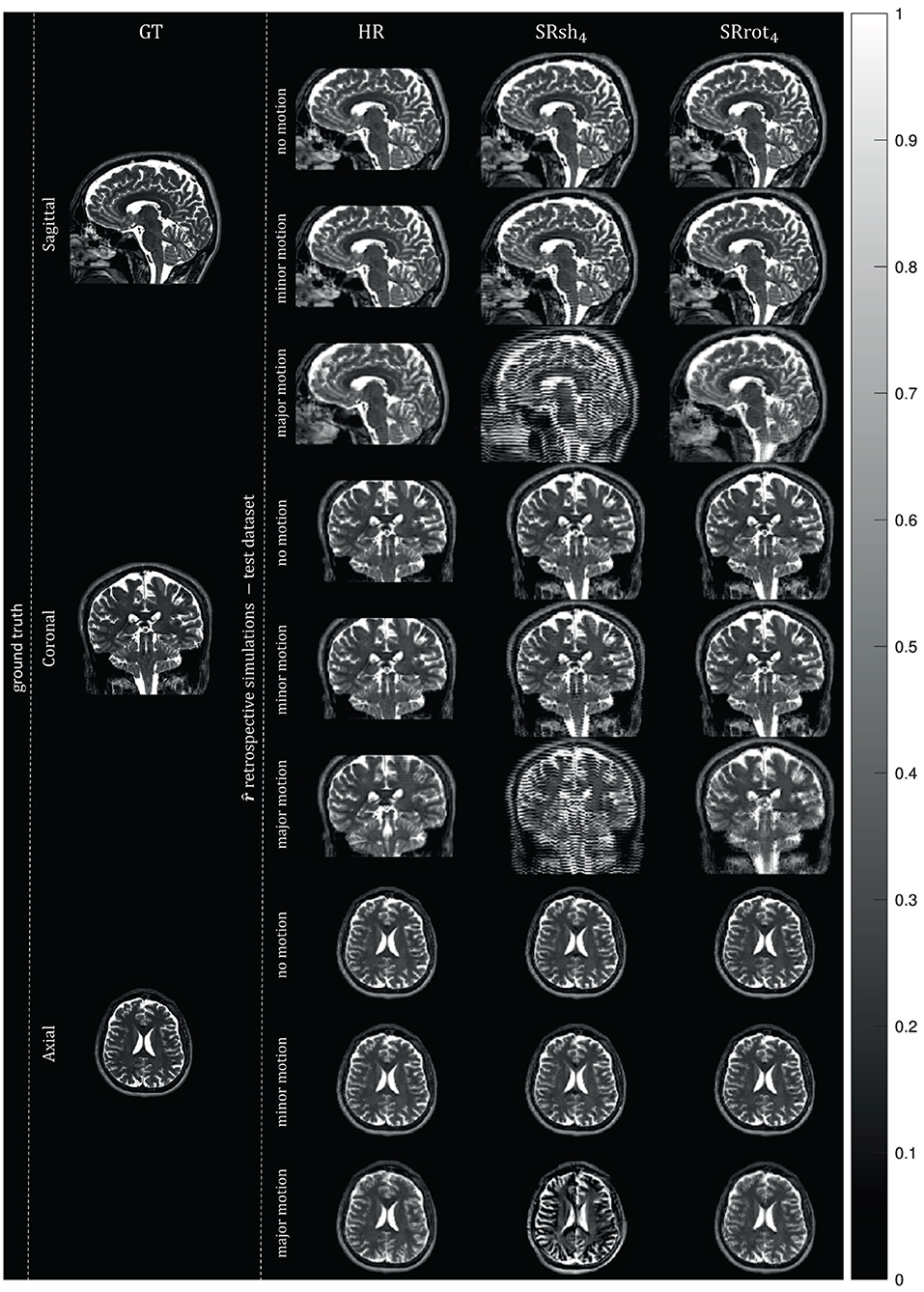
Figure 8. Retrospective simulation results: MS-SRR images. The views from orthogonal planes of the ground truth image, which corresponds to the MS-SRR image estimated from all the pre-processed acquired MS images from all the protocols simultaneously, and the MS-SRR images estimated from the test dataset for each protocol in the absence of motion (σmot = 0 mm/°) and in the presence of motion levels equal to the upper bounds of the minor (σmot = 0.1 mm/°) and major (σmot = 1 mm/°) motion ranges are shown.
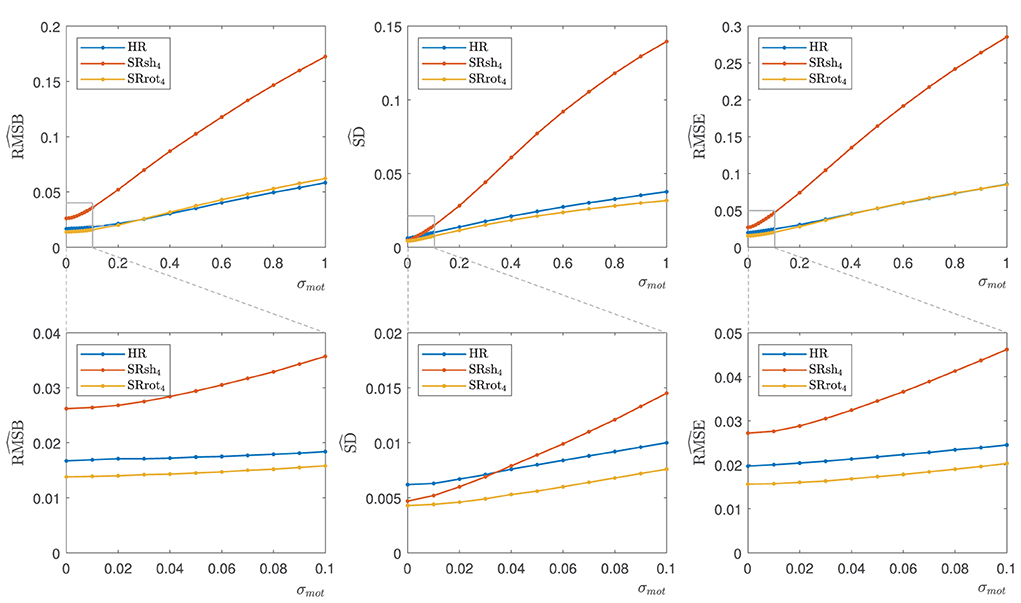
Figure 9. Retrospective simulation results: , , and median values. The median values were calculated for each parameter from the respective parameter map within a brain mask in the absence of motion (σmot = 0) and in the presence of minor (0 mm mm/°) and major (0.1 mm mm/°) levels of inter-image motion. The bottom row shows a zoomed plot corresponding to the indicated area.
4. Discussion
In this work, a Bayesian framework was proposed to compare two commonly adopted MS-SRR acquisition strategies, i.e., the rotated scheme and the shifted scheme, in terms of their estimation performance. This comparison is novel since it allows to include the effect of prior knowledge-based regularization, thereby extending previous work of Shilling et al. (2008, 2009), which focused on non-regularized MS-SRR.
It was shown that the MAP estimator provides higher accuracy and precision, and a lower MSE when applied to data acquired with the rotated scheme than when applied to data acquired with the shifted scheme or the reference scheme that consists of a conventional HR MS acquisition, where the acquisition time for all schemes was equal. This finding was based on analytical calculations of BMSE-based metrics (cfr. Figure 4 and Table 2), which were confirmed by Monte Carlo simulations (cfr. Figure 5), and was supported by real-data experiments (cfr. Figures 6, 7 and Table 2). Furthermore, both real data experiments and retrospective simulation results highlighted a higher resilience to motion for the rotated and reference schemes compared to the shifted scheme (cfr. Figures 8, 9).
A possible explanation for the superior performance of the rotated scheme compared to the shifted scheme is that it allows a more effective sampling of the k-space. Indeed, since a rotation in image space results in a rotation in the frequency domain, the narrow slice selection band is oriented in a different direction of the frequency spectrum of the MS-SRR image to be reconstructed for each MS image. As a result, the dataset acquired with the rotated scheme contains high spatial frequencies in all dimensions. Conversely, when the shifted scheme is adopted, each MS image samples the same part of the k-space, and the MS-SRR estimation relies only on recovering the aliased frequency content by increasing the sampling density in the slice-encoding direction. Additionally, the superior performance of the rotated scheme compared to the reference scheme confirms the conclusions of Plenge et al. (2012) that, by adopting the rotated MS-SRR scheme, it is possible to achieve an improved trade-off between acquisition time, spatial resolution, and estimation precision compared to MS protocols based on HR acquisitions.
The quantitative agreement among the median values of the BMSE-based metrics and their respective Monte Carlo estimates observed in Table 2 suggests that the statistics of the images of the validation dataset were well described by the prior distribution whose parameters were estimated from the images of the training dataset, even though the images of the validation dataset may have a different contrast and morphology than the images of the training dataset. This shows that the validity of the BMSE-based analysis in this work extends to a more general class of brain images than those used for training. It should be noted that the visual differences between the BRMSB and BRMSE maps in Figure 4 and their respective Monte Carlo estimates and in Figure 5 were expected since the brain images within the validation dataset represent only a specific subset of the images described by the prior. Indeed, the and maps visually resemble the superposition of brain slices from the sagittal, axial, and transversal planes that compose the validation dataset.
Contrary to what was predicted by the BMSE-based metrics, a lower estimation precision for the shifted scheme was found compared to the reference scheme in the real data experiments results. This discrepancy can be attributed to the high sensitivity to motion of the shifted scheme compared to the other acquisition schemes. Indeed, we have observed from the retrospective simulations how even a small amount of motion (e.g., residual uncorrected motion among the MS images after the registration step) can lead to a significant decrease in precision (i.e., increase in SD) for the shifted scheme, which in turn leads the reference scheme to outperform the shifted scheme in terms of estimation precision (Figure 9, σmot ≥ 0.04). Additionally, the retrospective simulations show the shifted scheme MS-SRR images to be more severely impacted by motion artifacts than the rotated and reference schemes MS-SRR images, especially in the presence of major levels of motion (Figure 8). These motion artifacts can be mitigated by increasing the amount of regularization, but at the cost of reduced sharpness (i.e., lower resolution) of the MS-SRR image.
The presented results provide new insights for the optimization of the acquisition design of MS-SRR experiments. For example, in recent works (Hutter et al., 2017; Bastiani et al., 2019; Christiaens et al., 2021), super-resolution diffusion MRI frameworks based on the MS-SRR shifted scheme have been proposed to address neonatal MRI-specific issues, which include the high occurrence of image artifacts induced by the presence of severe motion. Our results suggest that using the rotated scheme instead of the shifted scheme in these frameworks would increase the resilience to such motion artifacts and lead to more accurate and precise MS-SRR estimates.
In this study, the image registration was performed (or assumed to be performed, in the case of the BMSE analytical calculations and MC simulations) as a preprocessing step prior to the actual MS-SRR step. Alternatively, MS-SRR methods have been proposed in the literature that allow the joint estimation of motion parameters along with the MS-SRR image in a unified approach (Shen et al., 2007; Fogtmann et al., 2012; Rezayi and Seyedin, 2017; Beirinckx et al., 2020, 2022). The impact of combining MS-SRR with integrated motion estimation on the accuracy and precision of the MS-SRR image needs further research but is not expected to change the main conclusions of this work.
Furthermore, the use of the proposed BMSE metrics was limited to the comparison of the shifted and rotated MS-SRR acquisition schemes. However, it may well be that there exists an optimal set of acquisition parameters for an MS-SRR experiment beyond these conventional schemes. In future work, we intend to further exploit the proposed Bayesian framework to find the optimal acquisition settings that minimize the estimation error of the MS-SRR image in a statistically well-defined way (Fedorov, 1972, 2010; Chaloner and Verdinelli, 1995). Finally, we intend to extend this approach to MS quantitative SRR (MS-qSRR), which differs from conventional MS-SRR in that HR 3D isotropic parametric maps are estimated instead of a weighted image (Van Steenkiste et al., 2015, 2016; Bano et al., 2019; Beirinckx et al., 2022).
This paper addressed the question: “What is the optimal acquisition strategy for regularized MS-SRR MRI in terms of estimation accuracy and precision? To shift or to rotate?.” To answer this question, a Bayesian framework was developed to compare two commonly applied MS-SRR acquisition schemes, denoted as the shifted and rotated scheme, respectively. In the shifted scheme, the MS images are shifted by different sub-pixel distances in the through-plane direction, whereas in the rotated scheme, the slice orientations are rotated around the phase-encoding axis by different angles. The rotated scheme was shown to outperform the shifted scheme in terms of the accuracy, precision, and mean squared error of the Bayesian MAP estimator. Furthermore, it was shown to be more robust to motion artifacts. Finally, unlike the shifted scheme, the rotated scheme showed an improved trade-off between scan time, spatial resolution, and estimation precision compared to a conventional MS protocol based on direct HR acquisition. The proposed Bayesian framework could be further exploited in optimal experimental design studies to find the acquisition settings of an MS-SRR experiment that minimize the estimation error in a statistically well-defined way.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics statement
Ethical review and approval was not required for the study on human participants in accordance with the local legislation and institutional requirements. The patients/participants provided their written informed consent to participate in this study.
Author contributions
MN, BJ, DP, JS, and AdD conceived and designed the study. MN and CS performed the magnetic resonance imaging scanning. MN, BJ, QB, and DP wrote the MATLAB code. MN conducted the data analysis and wrote the first draft of the manuscript. All authors contributed to the writing, critical review, and approval of the final manuscript.
Funding
This work is part of the project B-Q MINDED which has received funding from the European Union's Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement No. 764513. The authors gratefully acknowledge support from the Research Foundation Flanders (FWO) through project funding G084217N and 12M3119N.
Conflict of interest
Author CS was employed by the company Siemens Healthcare NV/SA.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Aja-Fernández, S., Vegas-Sánchez-Ferrero, G., and Tristán-Vega, A. (2014). Noise estimation in parallel MRI: GRAPPA and SENSE. Magn. Reson. Imaging 32, 281–290. doi: 10.1016/j.mri.2013.12.001
Askin Incebacak, N. C., Sui, Y., Gui Levy, L., Merlini, L., Sa de Almeida, J., Courvoisier, S., et al. (2021). Super-resolution reconstruction of T2-weighted thick-slice neonatal brain MRI scans. J. Neuroimaging 32, 68–79. doi: 10.1111/jon.12929
Bano, W., Piredda, G. F., Davies, M., Marshall, I., Golbabaee, M., Meuli, R., et al. (2019). Model-based super-resolution reconstruction of T2 maps. Magn. Reson. Med. 83, 906–919. doi: 10.1002/mrm.27981
Bardsley, J. M. (2013). Gaussian Markov random field priors for inverse problems. Inverse Probl. Imaging 7, 397–416. doi: 10.3934/ipi.2013.7.397
Bastiani, M., Andersson, J. L. R., Cordero-Grande, L., Murgasova, M., Hutter, J., Price, A. N., et al. (2019). Automated processing pipeline for neonatal diffusion MRI in the developing human connectome project. NeuroImage 185, 750–763. doi: 10.1016/j.neuroimage.2018.05.064
Beirinckx, Q., Jeurissen, B., Nicastro, M., Poot, D. H. J., Verhoye, M., den Dekker, A. J., et al. (2022). Model-based super-resolution reconstruction with joint motion estimation for improved quantitative MRI parameter mapping. Comput. Med. Imaging Graph 2020:102071. doi: 10.1016/j.compmedimag.2022.102071
Beirinckx, Q., Ramos-Llordén, G., Jeurissen, B., Poot, D. H. J., Parizel, P. M., Verhoye, M., et al. (2020). Joint maximum likelihood estimation of motion and T1 parameters from magnetic resonance images in a super-resolution framework: a simulation study. Fundam. Inform. 172, 105–128. doi: 10.3233/FI-2020-1896
Ben-Haim, Z., and Eldar, Y. C. (2009). A lower bound on the Bayesian MSE based on the optimal bias function. IEEE Trans. Inf. Theory 55, 5179–5196. doi: 10.1109/TIT.2009.2030451
Bernstein, M. A., King, K. F., and Zhou, X. J. (2004). Handbook of MRI Pulse Sequences. Elsevier. doi: 10.1016/B978-012092861-3/50021-2
Besag, J. (1974). Spatial interaction and the statistical analysis of lattice systems. J. R. Stat. Soc. Ser. B Stat. Methodol. 36, 192–225. doi: 10.1111/j.2517-6161.1974.tb00999.x
Chaloner, K., and Verdinelli, I. (1995). Bayesian experimental design: a review. Stat. Sci. 10, 273–304. doi: 10.1214/ss/1177009939
Christiaens, D., Cordero-Grande, L., Pietsch, M., Hutter, J., Price, A. N., Hughes, E. J., et al. (2021). Scattered slice SHARD reconstruction for motion correction in multi-shell diffusion MRI. NeuroImage 225:117437. doi: 10.1016/j.neuroimage.2020.117437
Cocosco, C. A., Kollokian, V., Kwan, R. K. S., Pike, G. B., and Evans, A. C. (1997). Brainweb: online interface to a 3D MRI simulated brain database. NeuroImage 5:425.
Dietrich, O., Raya, J. G., Reeder, S. B., Reiser, M. F., and Schoenberg, S. O. (2007). Measurement of signal-to-noise ratios in MR images: influence of multichannel coils, parallel imaging, and reconstruction filters. J. Magn. Reson. Imaging 26, 375–385. doi: 10.1002/jmri.20969
Eshel, G. (2011). Spatiotemporal Data Analysis. Princeton University Press. doi: 10.23943/princeton/9780691128917.001.0001
Fedorov, V. (2010). Optimal experimental design. Wiley Interdiscip. Rev. 2, 581–589. doi: 10.1002/wics.100
Fogtmann, M., Seshamani, S., Kim, K., Chapman, T., and Studholme, C. (2012). “A unified approach for motion estimation and super resolution reconstruction from structural Magnetic Resonance imaging on moving subjects,” in MICCAI Workshop on Perinatal and Paediatric Imaging (Nice), 9–26.
Greenspan, H. (2008). Super-resolution in medical imaging. Comput. J. 52, 43–63. doi: 10.1093/comjnl/bxm075
Greenspan, H., Oz, G., Kiryati, N., and Peled, S. (2002). MRI inter-slice reconstruction using super-resolution. Magn. Reson. Imaging 20, 437–446. doi: 10.1016/S0730-725X(02)00511-8
Griswold, M. A., Jakob, P. M., Heidemann, R. M., Nittka, M., Jellus, V., Wang, J., et al. (2002). Generalized autocalibrating partially parallel acquisitions (GRAPPA). Magn. Reson. Med. 47, 1202–1210. doi: 10.1002/mrm.10171
Gudbjartsson, H., and Patz, S. (1995). The Rician distribution of noisy MRI data. Magn. Reson. Med. 34, 910–914. doi: 10.1002/mrm.1910340618
Hestenes, M. R., and Stiefel, E. (1952). Methods of conjugate gradients for solving linear systems. J. Res. Natl. Bur. Stand. 49:409. doi: 10.6028/jres.049.044
Hutter, J., Tournier, J.-D., Price, A. N., Cordero-Grande, L., Hughes, E. J., Malik, S., et al. (2017). Time-efficient and flexible design of optimized multishell HARDI diffusion. Magn. Reson. Med. 79, 1276–1292. doi: 10.1002/mrm.26765
Jung, B. A., and Weigel, M. (2013). Spin echo magnetic resonance imaging. J. Magn. Reson. Imaging 37, 805–817. doi: 10.1002/jmri.24068
Kay, S. M. (1993). Fundamentals of Statistical Signal Processing: Estimation Theory. Prentice-Hall, Inc.
Khattab, M. M., Zeki, A. M., Alwan, A. A., and Badawy, A. S. (2020). Regularization-based multi-frame super-resolution: a systematic review. J. King Saud. Univ. 32, 755–762. doi: 10.1016/j.jksuci.2018.11.010
Nicastro, M., Jeurissen, B., Beirinckx, Q., Smekens, C., Poot, D. H. J., Sijbers, J., et al. (2021). “Comparison of MR acquisition strategies for super-resolution reconstruction using the Bayesian mean squared error,” in Proceedings of the 16th Virtual International Meeting on Fully 3D Image Reconstruction in Radiology and Nuclear Medicine (Leuven), 435–439.
Plenge, E., Poot, D. H. J., Bernsen, M., Kotek, G., Houston, G., Wielopolski, P., et al. (2012). Super-resolution methods in MRI: can they improve the trade-off between resolution, signal-to-noise ratio, and acquisition time? Magn. Reson. Med. 68, 1983–1993. doi: 10.1002/mrm.24187
Poot, D. H. J., Jeurissen, B., Bastiaensen, Y., Veraart, J., Van Hecke, W., Parizel, P. M., et al. (2012). Super-resolution for multislice diffusion tensor imaging. Magn. Reson. Med. 69, 103–113. doi: 10.1002/mrm.24233
Poot, D. H. J., Van Meir, V., and Sijbers, J. (2010). “General and efficient super-resolution method for multi-slice MRI,” in Medical Image Computing and Computer Assisted Intervention (Beijing), 615–622. doi: 10.1007/978-3-642-15705-9_75
Pruessmann, K. P., Weiger, M., Scheidegger, M. B., and Boesiger, P. (1999). SENSE: sensitivity encoding for fast MRI. Magn. Reson. Med. 42, 952–962. doi: 10.1002/(SICI)1522-2594(199911)42:5<952::AID-MRM16>3.0.CO;2-S
Ramos-Llordén, G., den Dekker, A. J., Van Steenkiste, G., Jeurissen, B., Vanhevel, F., Van Audekerke, J., et al. (2017). A unified maximum likelihood framework for simultaneous motion and T1 estimation in quantitative MR T1 mapping. IEEE Trans. Med. Imaging 36, 433–446. doi: 10.1109/TMI.2016.2611653
Rezayi, H., and Seyedin, S. A. (2017). “Huber Markov random field for joint super resolution,” in MVIP 2017: The 10th Iranian Conference on Machine Vision and Image Processing (Isfahan), 93–98. doi: 10.1109/IranianMVIP.2017.8342375
Rue, H., and Held, L. (2005). Gaussian Markov Random Fields. New York, NY: Chapman and Hall; CRC Press. doi: 10.1201/9780203492024
Sabidussi, E. R., Klein, S., Caan, M. W. A., Bazrafkan, S., den Dekker, A. J., Sijbers, J., et al. (2021). Recurrent inference machines as inverse problem solvers for MR relaxometry. Med. Image Anal. 74:102220. doi: 10.1016/j.media.2021.102220
Shen, H., Zhang, L., Huang, B., and Li, P. (2007). A MAP approach for joint motion estimation, segmentation, and super resolution. IEEE Trans. Image Process. 16, 479–490. doi: 10.1109/TIP.2006.888334
Shilling, R. Z., Ramamurthy, S., and Brummer, M. E. (2008). “Sampling strategies for super-resolution in multi-slice MRI,” in 15th IEEE International Conference on Image Processing (San Diego, CA), 2240–2243. doi: 10.1109/ICIP.2008.4712236
Shilling, R. Z., Robbie, T. Q., Bailloeul, T., Mewes, K., Mersereau, R. M., and Brummer, M. E. (2009). A super-resolution framework for 3-D high-resolution and high-contrast imaging using 2-D multislice MRI. IEEE Trans. Med. Imaging 28, 633–644. doi: 10.1109/TMI.2008.2007348
Stark, H., and Oskoui, P. (1989). High-resolution image recovery from image-plane arrays, using convex projections. J. Opt. Soc. Am. A 6:1715. doi: 10.1364/JOSAA.6.001715
Tournier, J.-D., Smith, R., Raffelt, D., Tabbara, R., Dhollander, T., Pietsch, M., et al. (2019). MRtrix3: a fast, flexible and open software framework for medical image processing and visualisation. NeuroImage 202:116137. doi: 10.1016/j.neuroimage.2019.116137
van den Bos, A. (2007). Parameter Estimation for Scientists and Engineers. New York, NY: Wiley-Interscience. doi: 10.1002/9780470173862
Van Dyck, P., Smekens, C., Vanhevel, F., De Smet, E., Roelant, E., Sijbers, J., et al. (2020). Super-resolution magnetic resonance imaging of the knee using 2-dimensional turbo spin echo imaging. Invest. Radiol. 55, 481–493. doi: 10.1097/RLI.0000000000000676
Van Reeth, E., Tham, I. W. K., Tan, C. H., and Poh, C. L. (2012). Super-resolution in magnetic resonance imaging: a review. Concepts Magn. Reson. Part A 40A, 306–325. doi: 10.1002/cmr.a.21249
Van Steenkiste, G., Jeurissen, B., Veraart, J., den Dekker, A. J., Parizel, P. M., Poot, D. H. J., et al. (2015). Super-resolution reconstruction of diffusion parameters from diffusion-weighted images with different slice orientations. Magn. Reson. Med. 75, 181–195. doi: 10.1002/mrm.25597
Van Steenkiste, G., Poot, D. H. J., Jeurissen, B., den Dekker, A. J., Vanhevel, F., Parizel, P. M., et al. (2016). Super-resolution T1 estimation: quantitative high resolution T1 mapping from a set of low resolution T1-weighted images with different slice orientations. Magn. Reson. Med. 77, 1818–1830. doi: 10.1002/mrm.26262
Vis, G., Nilsson, M., Westin, C.-F., and Szczepankiewicz, F. (2021). Accuracy and precision in super-resolution MRI: enabling spherical tensor diffusion encoding at ultra-high b-values and high resolution. NeuroImage 245:118673. doi: 10.1016/j.neuroimage.2021.118673
Walsh, D. O., Gmitro, A. F., and Marcellin, M. W. (2000). Adaptive reconstruction of phased array MR imagery. Magn. Reson. Med. 43, 682–690. doi: 10.1002/(SICI)1522-2594(200005)43:5<682::AID-MRM10>3.0.CO;2-G
Keywords: magnetic resonance imaging, super-resolution, optimal experimental design, Bayesian estimation, image reconstruction
Citation: Nicastro M, Jeurissen B, Beirinckx Q, Smekens C, Poot DHJ, Sijbers J and den Dekker AJ (2022) To shift or to rotate? Comparison of acquisition strategies for multi-slice super-resolution magnetic resonance imaging. Front. Neurosci. 16:1044510. doi: 10.3389/fnins.2022.1044510
Received: 14 September 2022; Accepted: 18 October 2022;
Published: 11 November 2022.
Edited by:
Fabio Baselice, University of Naples Parthenope, ItalyReviewed by:
Sara Gharabaghi, SpinTech MRI, United StatesVijay Venkatraman, The University of Melbourne, Australia
Robert Fekete, New York Medical College, United States
Can Ceritoglu, Johns Hopkins University, United States
Zhen Qiu, Michigan State University, United States
Copyright © 2022 Nicastro, Jeurissen, Beirinckx, Smekens, Poot, Sijbers and den Dekker. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Michele Nicastro, bWljaGVsZS5uaWNhc3RybyYjeDAwMDQwO3VhbnR3ZXJwZW4uYmU=