 Ming Gao
Ming Gao Runmin Liu
Runmin Liu Jie Mao
Jie Mao- 1College of Sports Science and Technology, Wuhan Sports University, Wuhan, China
- 2College of Sports Engineering and Information Technology, Wuhan Sports University, Wuhan, China
Electroencephalogram (EEG) is often used in clinical epilepsy treatment to monitor electrical signal changes in the brain of patients with epilepsy. With the development of signal processing and artificial intelligence technology, artificial intelligence classification method plays an important role in the automatic recognition of epilepsy EEG signals. However, traditional classifiers are easily affected by impurities and noise in epileptic EEG signals. To solve this problem, this paper develops a noise robustness low-rank learning (NRLRL) algorithm for EEG signal classification. NRLRL establishes a low-rank subspace to connect the original data space and label space. Making full use of supervision information, it considers the local information preservation of samples to ensure the low-rank representation of within-class compactness and between-classes dispersion. The asymmetric least squares support vector machine (aLS-SVM) is embedded into the objective function of NRLRL. The aLS-SVM finds the maximum quantile distance between the two classes of samples based on the pinball loss function, which further improves the noise robustness of the model. Several classification experiments with different noise intensity are designed on the Bonn data set, and the experiment results verify the effectiveness of the NRLRL algorithm.
Introduction
Brain computer interface (BCI) is a system that collects the signals from the brain to communicate with computers or other devices (Gummadavelli et al., 2018; Jiang et al., 2020). As an efficient way for the human brain to directly communicate with peripheral devices, the BCI does not need to rely on the peripheral nervous system and muscles. Electroencephalogram (EEG) signals, as a biomarker, play an important role in BCI. EEG is often used in clinical diagnosis to determine the presence and type of epilepsy (Fahimi et al., 2019; Jiang et al., 2019). The epileptic seizure process has several different periods: interictal, pre-seizure, and seizure. The waveform, frequency, and signal characteristics of different stages are different in EEG. Based on the analysis of the characteristics of epilepsy EEG, many studies can generally be divided into two directions: epilepsy detection and epilepsy prediction (Jiang et al., 2017; Gu et al., 2021). The epilepsy detection algorithm uses signal processing, machine learning, and deep learning to extract signal features, and distinguishes the EEG signals between the interictal period and the seizure period. The epilepsy prediction algorithm distinguishes the EEG signals in the pre-seizure period and the seizure period. The prediction task is more difficult than the detection task. First of all, there is no uniform definition of epilepsy prediction and internal standards in the industry. Secondly, compared with the EEG signal in the seizure period, the signal pattern of the EEG signals in the pre-seizure period and the EEG signals in the intermittent period are more similar, so the algorithm is required to be more robust.
Both epilepsy detection and epilepsy prediction are essentially classification tasks in machine learning (Ni et al., 2020). Several studies focus on the classification of EEG information, which involve both epilepsy detection tasks and epilepsy prediction tasks. Zhou et al. (2018) represented the epilepsy EEG signal into a two-dimensional image, and then they constructed a convolutional neural network to automatically learn the transformed image. This method borrows the idea of image processing to analyze the EEG signals and broaden the method of signal processing. Birjandtalab et al. (2017) performed non-linear dimensionality reduction on EEG signals after extracting time-frequency features. This feature processing method can reflect the non-linear relationship of the data in the process of low-dimensional mapping. Ramakrishnan and Muthanantha (2018) computed the approximate entropy value, the maximum Lyapunov component, and the correlation coefficient dimension on different sub-bands of epilepsy EEG signals, and introduced fuzzy rules to fuzzify the features. The authors believe that fuzzy rules are the natural choice of using human professional knowledge to build machine learning systems, which is closely related to people’s way of thinking. Wang et al. (2017) explored multiple bands of the EEG signal by considering the maximum and standard deviation characteristics of each band. Then they constructed the feature vector of the EEG and used a one-to-one self-organization strategy to create a high high-precision epilepsy detection system. Sun et al. (2019) intercepted and analyzed the pre-seizure data, and they used recurrent autoencoders on multivariate signals to extracted EEG features. Liu et al. (2019) transformed the EEG signal into spectral data through the combination of dimensionality reduction and short-time Fourier transform. Then, the authors constructed a shallow convolutional neural network (CNN) network to automatically learn data features. Yu et al. (2020) used the local mean decomposition (LMD) method to obtain the feature matrix of the EEG signals, and they used a CNN model to implement feature extraction and combined Bayesian linear discriminant analysis to obtain the prediction result.
In supervised learning, the support vector machine (SVM) represented by least squares regression (LSR) is a simple and effective method. The core idea of LSR is to learn the non-linear projection from the original data to the feature space, and the obtained projection vector of the original data is also used as the data representation in the label space. For example, discriminative LSR method include multiclass classification (Xiang et al., 2012), groupwise retargeted LSR method (Ling and Geng, 2019), regularized label relaxation linear regression (Fang et al., 2018), double relaxed regression for classification (Han et al., 2019), and so on. For epilepsy data, the scalp EEG data will have more impurity signals and noise signals. Moreover, dimensional explosion and information redundancy problems are common in EEG signals. Learning a discriminatively compact data representation is a very critical problem in pattern recognition. At present, there are many methods based on subspace learning and least squares classifier to learn good classifiers. For example, to combine projection learning with the task of exploring label information, Meng et al. (2020) proposed a constrained discriminative projection learning for joint optimization of subspace learning and classification problems, which used low-rank constraints to learn robust subspaces to connect the original visual features and target output.
Subspace learning essentially tries to find a suitable low-dimensional space in which the discriminative representation of the original features is preserved as much as possible. In recent years, low-rank learning has achieved relatively good results in matrix analysis, data recovery, and data denoising. At the same time, low-rank representation is an effective means to describe the structure of high-dimensional data, and it is a generalized form of sparsity in matrix space. That is, low-rank representation can describe the low-dimensional subspace structure of high-dimensional data, thus its component in the subspace becomes the most important factor in characterizing the data. In addition, low-rank representation effectively introduces low-rank constraints into the data matrix, which can help to construct discriminative feature subspaces and eliminate outliers. Inspired by this idea, the noise robustness low-rank learning (NRLRL) algorithm is proposed for EEG signal classification. NRLRL learns a low-rank subspace that connects the original data space and the label space. It fully considers the correlation information and local structure of samples, and it guarantees the minimum rank of the coefficient matrix constructed of data under its self-expression. By integrating the multi-class asymmetric least squares SVM classifier with low-rank representation, NRLRL is insensitive to noise and outliers. The experiments performed on noisy EEG signals are shown that our algorithm is noise robust. NRLRL has several advantages as follows: (1) since the low-rank representation follows the minimum rank criterion, NRLRL is robust when reconstructing the original data with noise and outliers. (2) By full use of supervised information and pinball loss function, an asymmetric least square SVM is jointly learned into our objection function, so that NRLRL explores a robust classifier in the framework of low-rank learning. (3) Local constraints based on low-rank representations are used based on supervision information. The criteria of low-rank representations for minimum within-class and maximum between-classes are adopted to capture the discriminative structure of the data.
Background
Low-Rank Representation
Give a set of data samples X = [x1,…,xn], each sample xi ∈ Rdin X can be represented as a linear combination of atoms from a dictionary A:
where C = [c1,…,cn] ∈ Rn×mis the coefficient matrix rank representation.
As a common practice in low-rank learning, the dictionary A is set to X, i.e.,
Eq. (2) uses the data set itself to represent the data, which is called the self-expression of the data. Each data sample in data set X can be represented by:
By minimizing the rank of the coefficient matrix C, Eq. (1) can be written by:
whererank(C) is the rank function of C.
Considering the existence of noise and outliers in the data sample, the structure of the original data X is taken as two parts: one is the linear combination of the dictionary X and a low-rank coefficient matrix C, and the second part is noise (error) matrix, i.e.,
Then the low-rating representation can be defined as follows:
where ||⋅||2,0means the ℓ2,0-norm operator. μ is the trade-off parameter. In Eq. (6), the term ||E||2,0 encourages the sparseness of the error components.
The low-rank optimization problem of Eq. (6) is a non-convex NP-hard problem. To find its unique optimal solution, it is necessary to perform convex relaxation of Eq. (6). The kernel norm is the best convex approximation of the rank function on the unit sphere in the matrix spectral norm (Candès and Recht, 2009). Therefore, the convex kernel norm can be used to approximate the non-convex rank function, and the ℓ2,0 norm can be relaxed to its ℓ2,1norm (Raghunandan et al., 2010). Then Eq. (6) can be written as the following convex optimization problem
where ||⋅||* means the nuclear norm operator, and||⋅||2,1means the ℓ2,1-norm operator.
Asymmetric Least Squares Support Vector Machine
The loss function in the least squares SVM (LS-SVM) pays attention to both the correctly classified and incorrectly classified samples. It minimizes the squared error of the classifier as follows,
In fact, the above loss function is noise sensitive, especially the noises around the separation hyperplane. Many extensions of least squares loss function have been proposed to solve this problem, such as iteratively reweighted least square (Leski, 2015) and asymmetric square function (Leski, 2015), asymmetric squared loss (Huang et al., 2014). Using the statistical property to lower quantile value, the asymmetric squared loss is defined as:
where w and b are the hyperplane parameter and bias parameter of SVM classifier, respectively. p is the lower quantile value parameter.
The aLS-SVM uses the expectile distance and maximizes the expectile distance between different classes. The aLS-SVM has the following optimization problem:
where α is the regularization parameter. This optimization problem can be solved by quadratic programming method.
Noise Robustness Low-Rank Learning Algorithm
The Noise Robustness Low-Rank Learning Model
Given a set of data points X = [x1,…,xn] and their labels Y = [y1,…,yn] are distributed in K classes. yk = [y1,k,y2,k,…,yn,k] is the class label vector of n training samples associated with the k-th class. Considering the influence of noise or outliers, the main goal of our algorithm is to find the lowest rank representation C and the best classifier based on C.
First, to increase discrimination capability, the local preservation with label embedding is incorporated into the learning process. Different from the traditional local preservation term in low-rank learning, the label information is embedded into the k-nearest neighborhood relationships. For sample xi, its low-rank is expressed as ci. Without considering the label information of the sample, if xj is in the k-nearest neighbor of xi, their corresponding low-rank representations cj and ci should be closer to each other. Obviously, this strategy is not suitable for classification tasks. Based on the basic classification principles of within-class compactness and between-classes separation, the label information is introduced into the k-nearest neighborhood relationships. The within-class matrix Bwithin and between-classes matrix Bbetween are accordingly defined, and their elements can be defined as,
where N(xj) returns the k-nearest neighbors of xj.
In the NRLRL, the original data is projected into a low-dimensional subspace by low-rank representation. NRLRL shows the similarity within the class and the difference between classes of the data. To achieve this goal, the label embedded local preservation term is defined as,
where L = Lbetween − Lwithin, Lbetween = Bbetween − Bbetween, Lwithin = Bwithin − Bwithin. Bbetween and Bwithin are diagonal matrices, and their elements are , , separately. Tr(⋅) is the trace operator.
The label embedded local preservation term is to ensure that if the nearest neighbors xi and xj are from the same class, their low-rank codes ci and cj are also close to each other. At the same time, if the nearest neighbors xi and xj are from different classes, their low-rank codes ci and cj are separated as much as possible. In such a low-rank learning stage, the ideal non-linear local structure of EEG data is preserved.
To promote the discriminative ability of low-rank representation vectors, a multi-class aLS-SVM classification term is embedded into the NRLRL algorithm. The multi-class aLS-SVM classification term L(C)includes two parts
where l(ci,yk,i,wk,bk) is the loss function associated with the k-th aLS-SVM.
The squared pinball loss in NRLRL can be written as
where .
Bedding the local preservation with label embedding term and multi-class aLS-SVM classification term into the Eq.(7), the objective function of NRLRL can be written as
where λ,γ, and η are regularization parameters.
The loss function term is decomposed into the sum of the loss term of each sample, and it can be seen that the contribution of each data sample to the objective function is linearly cumulative. L(C,W,b) includes a class-by-class loss function term l(ci,yk,i,wk,bk)on the low-rank representation, so that the obtained lowest-rank representations are highly correlated within the class. EEG signals belonging to the same class usually contain the common discriminative features. The lowest-rank representation obtained by Eq. (16) has the characteristics of strong within-class correlation and between-class difference for classification tasks.
To reduce the time costs, the Frobenius norm is used to replace the nuclear norm, the objective function of NRLRL can be re-written as:
For simplicity of expression, combining the two terms and Tr(CTLC), Eq. (17) can be written as:
From Eq. (18), we can see that the NRLRL algorithm consists of three sub-problems, namely the parameters of C, E, and aLS-SVM classifier. These three sub-problems can be solved alternately until the NRLRL algorithm converges. We use the alternating direction multipliers method (ADMM) (Luo et al., 2017) to solve Eq. (18). The augmented Lagrangian function corresponding to Eq. (18) can be written as:
where θ and δ are Lagrange multipliers, and μ is the penalty parameter.
Optimization of the Objective Function
According to the ADMM algorithm, the parameters in Eq. (19) can be updated alternately, that is, when one parameter is updated, other parameters are fixed until the NRLRL algorithm converges.
(1) Update C by fixing E, wk, and bk. Eq. (19) is converted to the following problem:
Let the derivative of Eq. (19) with respect to ci be zero, the solution of ci is:
(2) Update E by fixing C, wk, and bk. Using the same calculation and reduction strategy by Liu et al. (2013). Eq. (19) is converted to the following problem:
Then the solution of E can be obtained by:
where θiis the ith column vector of the matrix θ.
(3) Update wk and bk by fixing E and C. Eq. (19) is converted to the following problem:
Eq. (24) is a multi-class aLS-SVM problem, and the optimal parameters wk and bk can be obtained by the aLS-SVM algorithm.
The training procedure of NRLRL is summarized in Algorithm 1.
Algorithm 1. The training procedure of NRLRL is summarized.

Experiment
Datasets and Experimental Settings
This study used EEG signals are from Bonn University. The data set consists of five subsets (groups A to E), each of which consists of 100 EEG segments with a single channel duration of 23.6 s and 4,097 samples. The fragments in groups A-B were taken from five healthy subjects, and the fragments in groups {C, D, E} were taken from patients with epilepsy. The groups C and D recorded the signal during the intermittent period of epileptic seizures. The group E recorded the signal during the seizure. The signals of the five groups of EEG data are shown in Figure 1. In the experiment, the 4,097 data points were divided into three data blocks to obtain the research samples, that is, a data block is a sample, representing the EEG information in about 8 s. Therefore, the sample size of this paper is 3 × 100 = 300 in each group, and each sample has 1,365 features of sampling points. We design two types of classification tasks on the Bonn dataset. One is the binary classification task: non-epileptic condition (sets {A, B, C, D, E}) and epileptic condition (set E). The other is the three classes of classification task: normal (sets {A, B}), interictal (sets {C, D}), and ictal (set E).
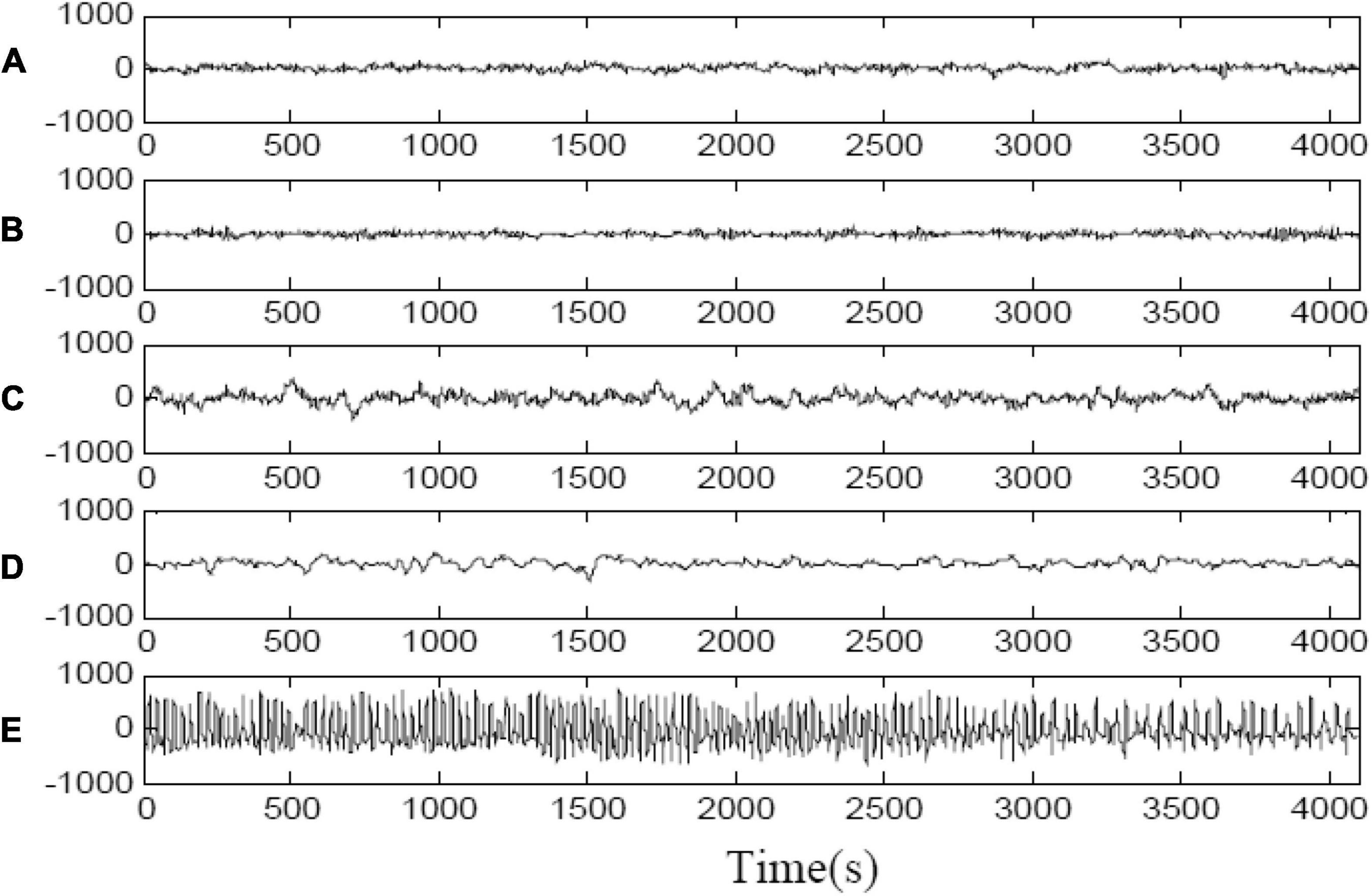
Figure 1. Sample electroencephalogram (EEG) signals in each group in Bonn dataset. (A) Epileptic EEG signals measured from healthy people with eyes open. (B) Epileptic EEG signals measured from healthy people with eyes closed. (C) Epileptic EEG signals obtained in hippocampal formation of the opposite hemisphere of brain during seizure free intervals. (D) Epileptic EEG signals obtained from within epileptogenic zone during seizure free intervals. (E) Epileptic EEG signals measured during seizure activity.
We use the following algorithms as the comparison algorithms: DLSR (Xiang et al., 2012), LC-KSVD (Jiang et al., 2013), SRRS (Li and Fu, 2016), LRSD (Kong et al., 2017), aLS-SVM (Huang et al., 2014), and LRDLSR (Chen et al., 2020). The parameters of these comparison methods are set to their default settings. In NRLRL, the dictionary size is set from {40, …, 320}, three regularization parameters are set from {2–5, …, 23}, the k-nearest neighbor parameter is set from {3, …, 11}, and the pinball loss parameter p is set from {40, …, 360}. We adopt the one-by-one strategy to select the optimal parameters.
Following the method of references (Huang et al., 2014; Gu et al., 2019, 2020), 20 and 50% samples are randomly selected and common Gaussian white noise is added. To test the sensitivity of the classifier to noise intensity, the intensity of Gaussian white noise is divided into three types: the mean value is 0, and the variance is set to 5, 10, and 15% of the sample features, respectively. For example, the noise (20%, 10%) indicates that 20% of the samples in the Bonn dataset contain Gaussian white noise, and the variance of the noise is 10% of the sample features.
Classification Result Comparison
First, we perform experiments on the binary classification task. We compare all algorithms in indexes of specificity, sensitivity, and accuracy on the noisy Bonn dataset. The experimental results of the binary classification task are shown in Tables 1–3.
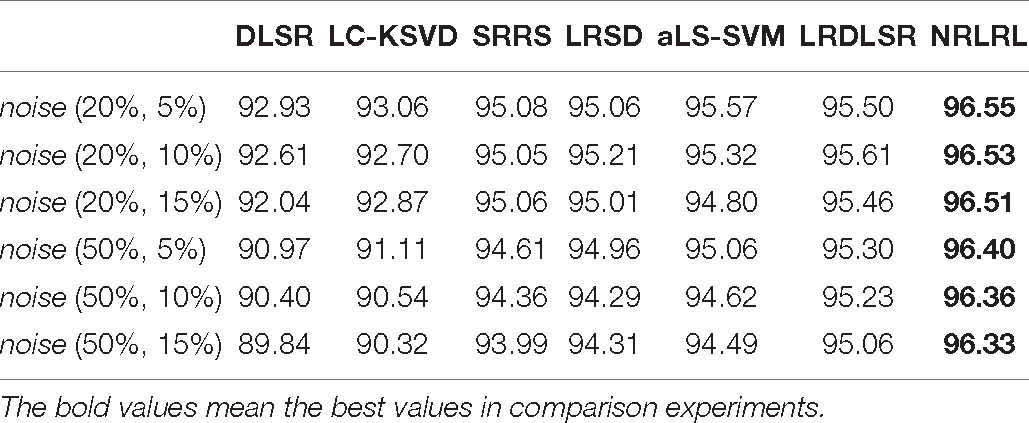
Table 1. The specificity results of binary classification task on the noisy Bonn dataset.

Table 2. The sensitivity results of binary classification task on the noisy Bonn dataset.
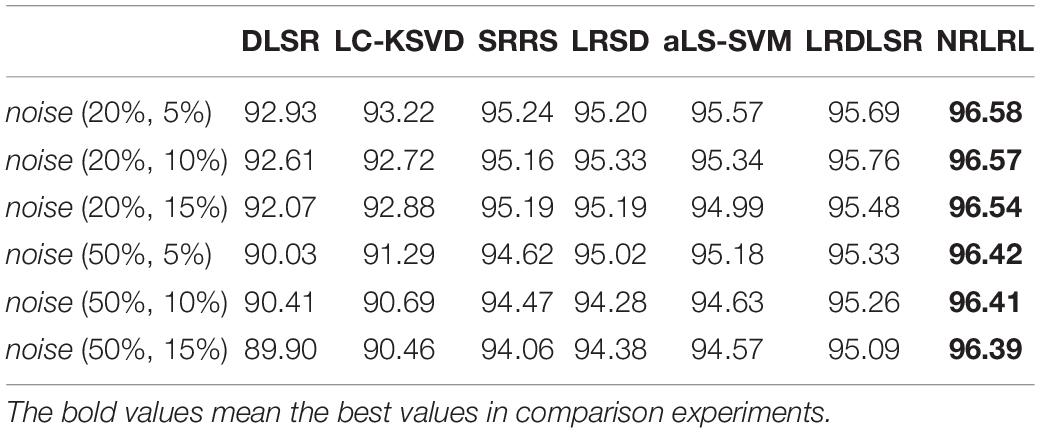
Table 3. The accuracy results of binary classification task on the noisy Bonn dataset.
From the experimental results, it can be seen that (1) with the increase of noise intensity, the specificity, sensitivity, and accuracy of all algorithms show a decline in varying degrees. It can be seen that the characteristic noise of samples will seriously affect the classification effect of the classifier. Especially the DLSR and LC-KSVD algorithms do not consider the impact of the noise sample interference on the classification surface. As the noise intensity increases, the classification result decreases rapidly. (2) SRRS, LRSD, aLS-SVM, LRDLSR, and NRLRL algorithms are all noise-insensitive classification algorithms, therefore the classification results are significantly better than conventional classification algorithms. The proposed NRLRL algorithm achieves the best results in classification performance. The NRLRL algorithm removes the influence of noise on the sample in the lowest rank representation, and it uses the pinball loss function to obtain a noise-insensitive classification classifier by maximizing the distance between the two classes of quantile distances. In addition, the NRLRL algorithm can mine the geometric structure of samples in low-dimensional space by low-rank learning, and fully considers the correlation information and subspace structure between samples. Therefore, the within-class similarity and between-class differences of the data are more prominent, which makes the NRLRL algorithm obtain good classification performance in the presence of noise.
Then, we perform experiments on three class classification task, i.e., classification of EEG data in normal, interictal and epileptic periods. Similarly to the above experiment procedure, we compare all algorithms in indexes of specificity, sensitivity, and accuracy on the noisy Bonn dataset. The experimental results of three classification task are shown in Tables 4–6. From these results, it can be observed that since the complexity of the three class classification is higher than that of the binary class classification, the results of three class classification are lower than those of binary class classification. The proposed NRLRL algorithm achieves the best results of specificity, sensitivity, and accuracy.
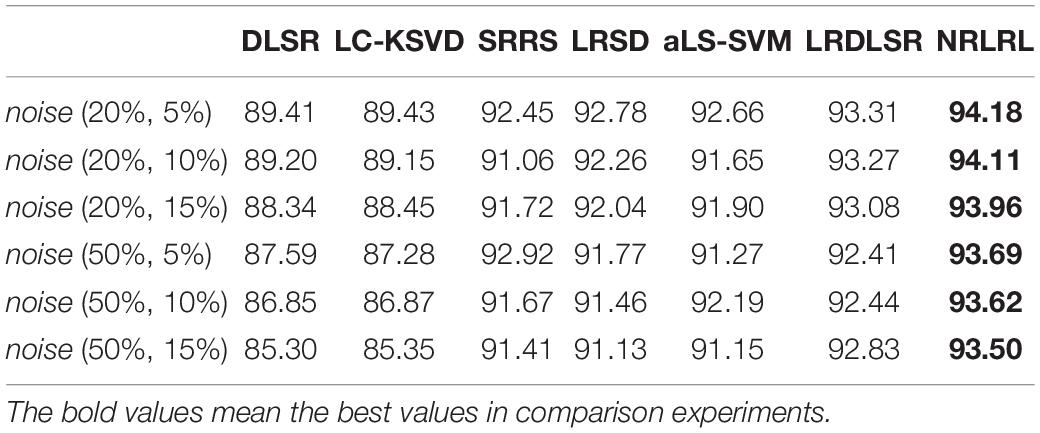
Table 4. The specificity results of three class classification task on the noisy Bonn dataset.
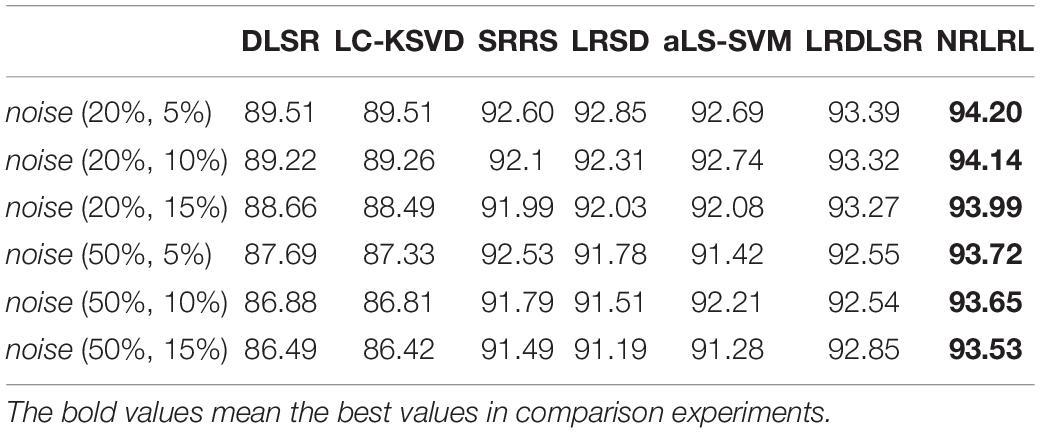
Table 5. The sensitivity results of three class classification task on the noisy Bonn dataset.
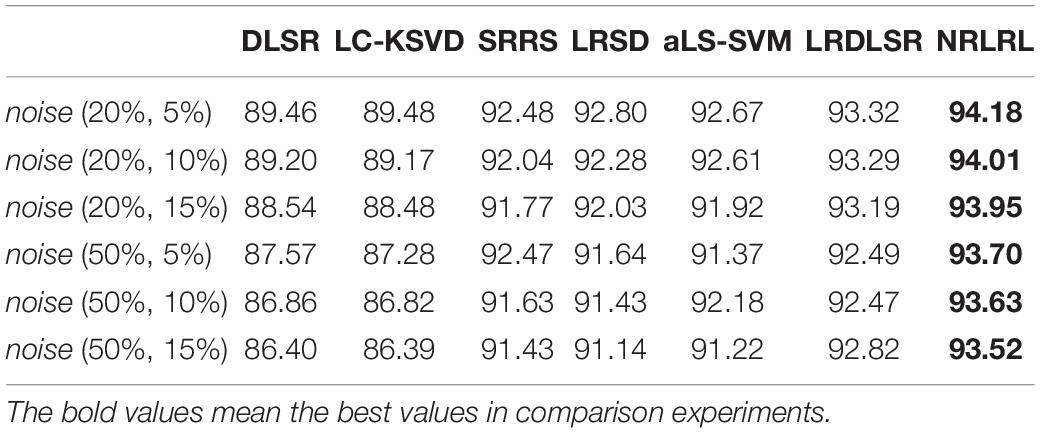
Table 6. The accuracy results of three class classification task on the noisy Bonn dataset.
Parameter Analysis
Here we discuss the key parameters in the NRLRL algorithm on binary classification task noise (20%, 10%) and three class classification noise (50%, 10%).
The k-nearest parameter k-nearest is an important parameter in NRLRL. It determines the neighbor relationship between samples. The k-nearest parameter is set from {3, …, 11}. The classification accuracies of NRLRL with different k-nearest are shown in Figure 2. When k = 7, the classification accuracy is the highest. The appropriate value of k can reflect the local structural information of the sample to the greatest extent. From the results in Figure 2, we can set k = 7 in the NRLRL algorithm for noisy Bonn dataset.
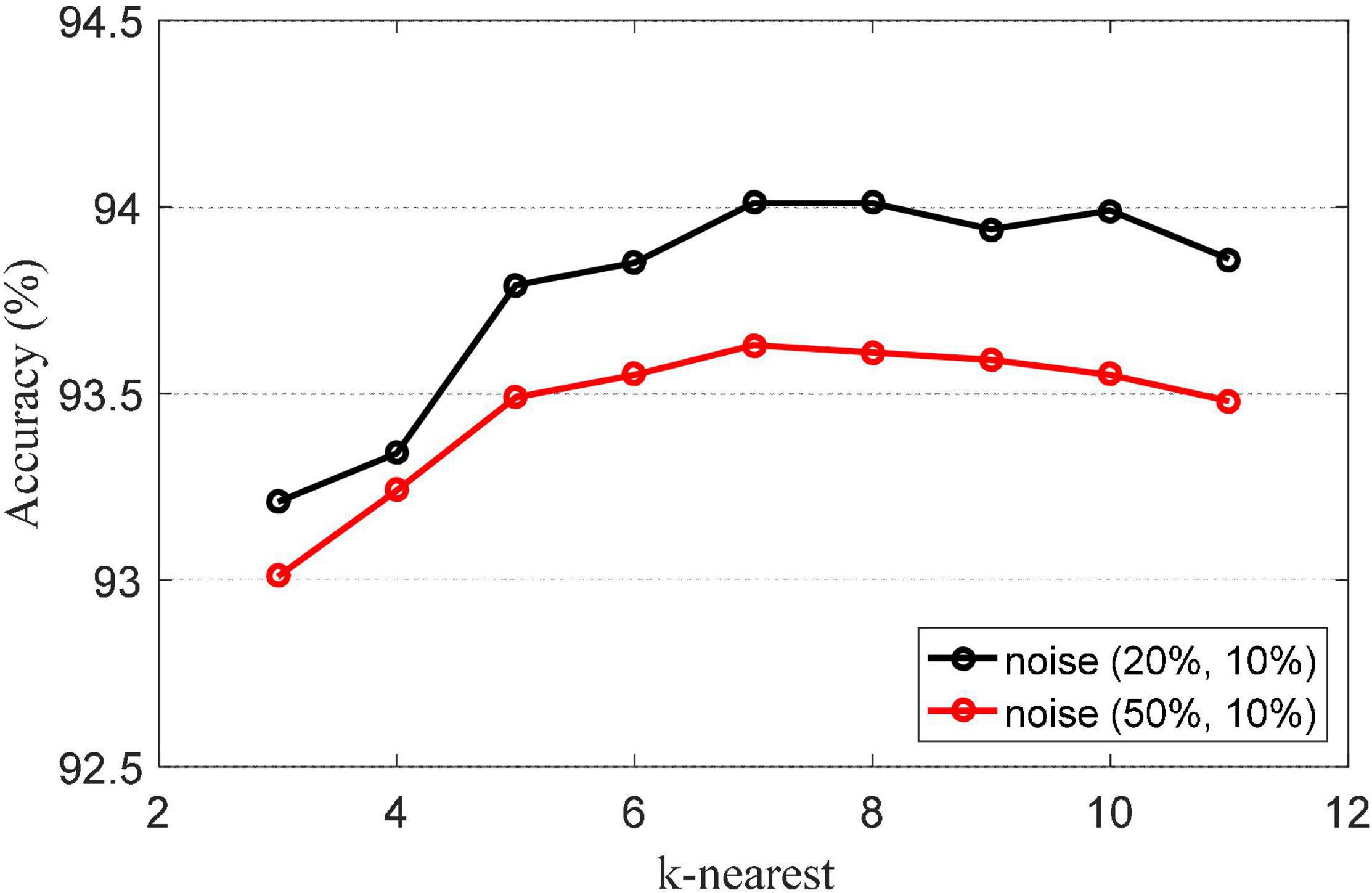
Figure 2. Classification accuracies of noise robustness low-rank learning (NRLRL) with different k-nearest.
Another important parameter is m, which is the size of the matrix C. The classification accuracies of NRLRL with different m are shown in Figure 3. The parameter m controls the data structure of the low-rank space. When m is too small, the low-rank representation related to the data is not enough to model its structure in the low-rank space. When m is too large, the redundant information will produce errors of low-rank representation. From the results in Figure 3, we can set m = 240.
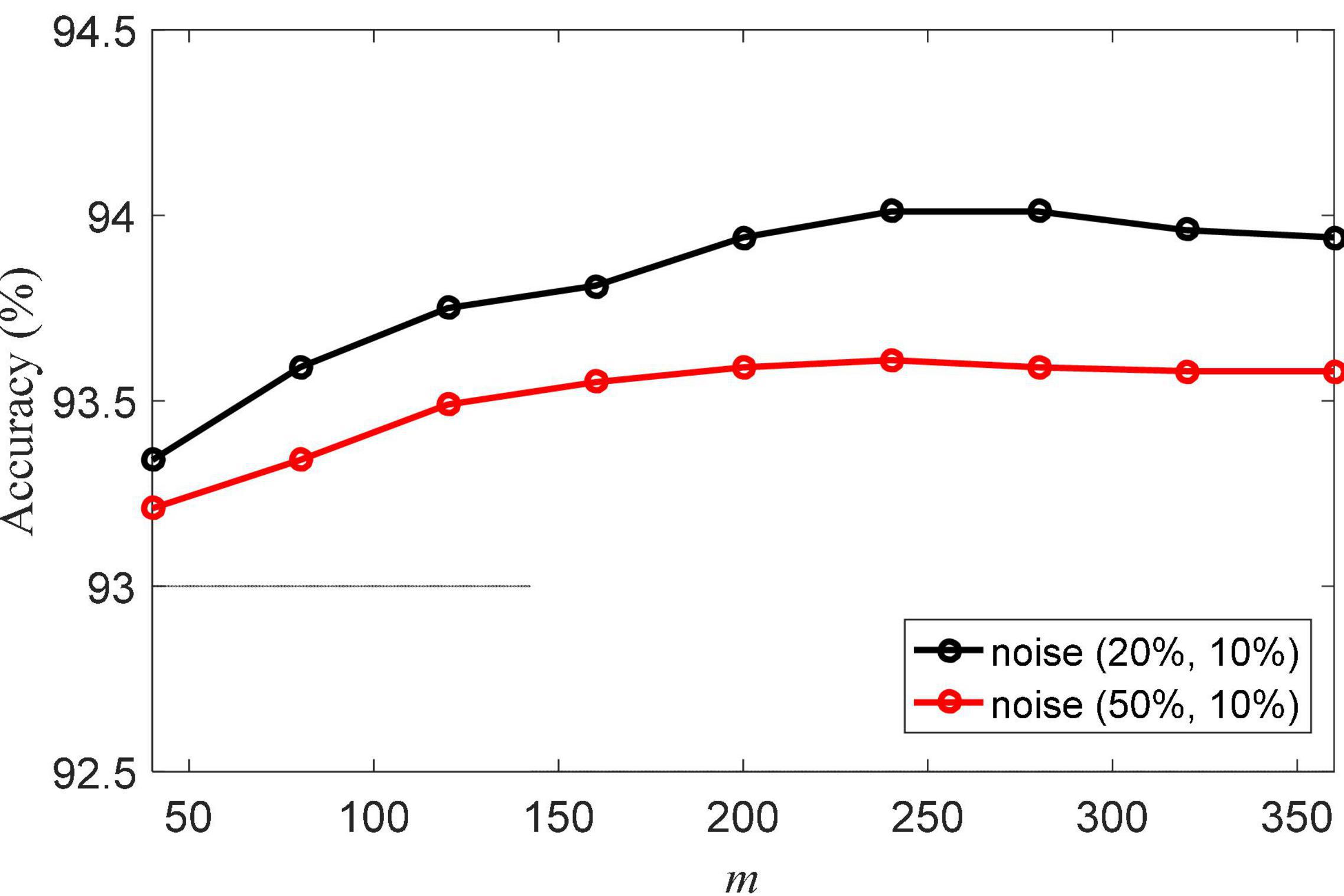
Figure 3. Classification accuracies of noise robustness low-rank learning (NRLRL) with different m.
The pinball loss parameter p is the important parameter in aLS-SVM classifier in NRLRL. The value range of the pinball loss parameter is {0.5, 0.83, 0.95, 0.99}. The classification accuracies of NRLRL with different p are shown in Figure 4. With different values of p, the NRLRL algorithm has achieved high classification accuracy. It shows that the NRLRL algorithm is not sensitive to the p parameter, so the value of p can be fixed to 0.95 in the experiment.
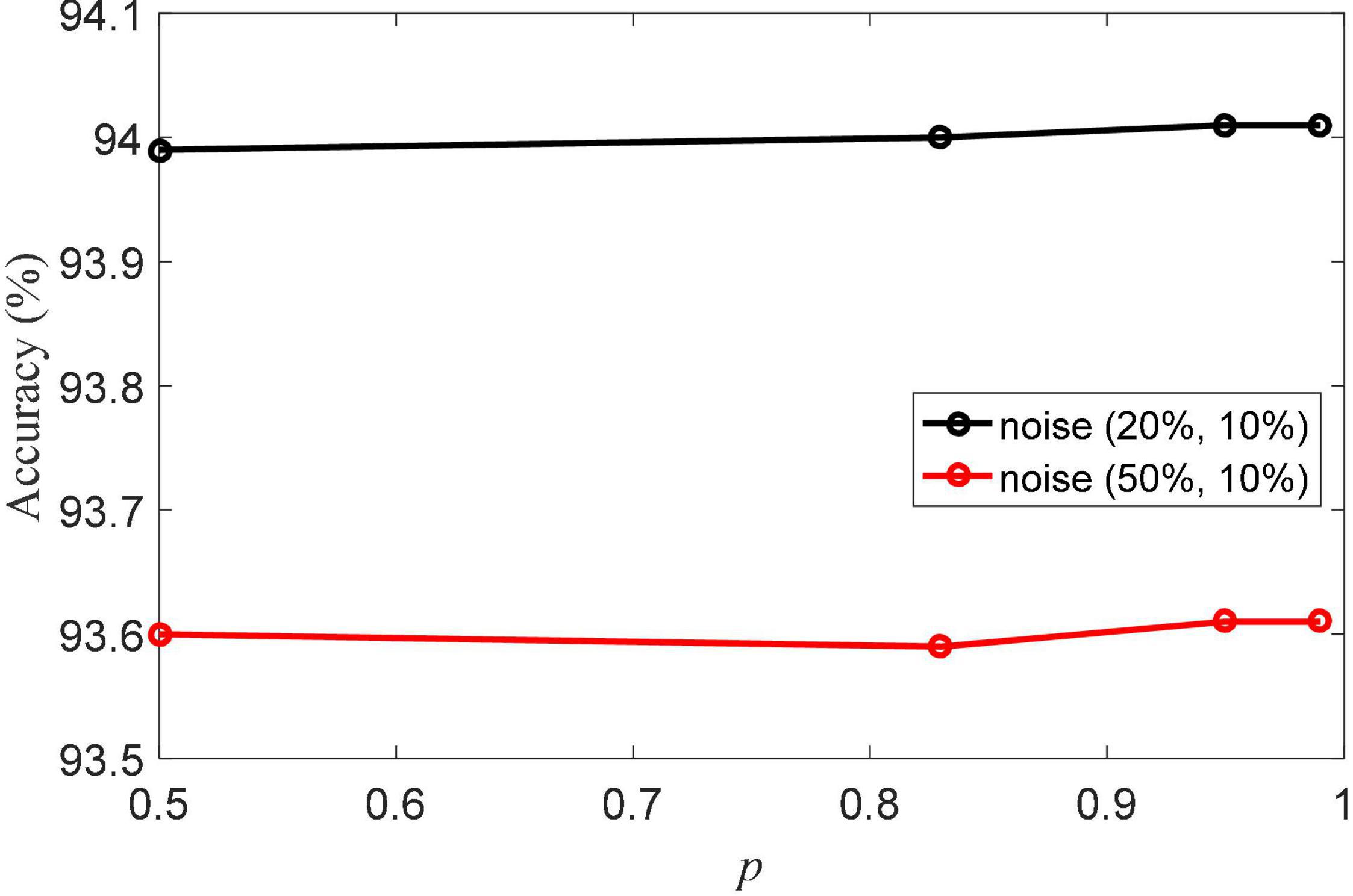
Figure 4. Classification accuracies of noise robustness low-rank learning (NRLRL) with different p.
Conclusion
In this study, the NRLRL algorithm is proposed for EEG signal classification. Different from noise-insensitive SVM learns the classification hyperplane in the original space or kernel space, NRLRL learns a low-rank subspace as the transformation from the original data space to the label space, to improve the overall classification effect. By introducing the criteria of low-rank representations for minimum within-class and maximum between-classes, the discriminative ability of the model has been greatly improved. The pinball loss function is also helpful to improve the noise insensitivity of the model. The effectiveness of the proposed algorithm is verified on the noisy Bonn EEG dataset. Since our algorithm directly uses the EEG sample point as the input features, we will consider applying various feature extraction methods to the NRLRL algorithm in the next stage. The seizure data is often insufficient in epilepsy detection or prediction tasks. To obtain an effective algorithm model, the down-sampling strategy is often performed to make the class balanced. This strategy will cause the loss of signal data. Therefore, research on appropriate imbalanced data classification methods is the focus of the next stage.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: https://github.com/benfulcher/hctsaTutorial_BonnEEG.
Author Contributions
MG conceived and designed the proposed model and wrote the manuscript. RL and JM performed the experiment. All authors read and approved the manuscript.
Funding
This work was supported in part by the Scientific Research Program of Education Department of Hubei Province, China (D20184101), the Higher Education Reform Project of Hubei Province, China (201707), the “East Lake Scholar” of Wuhan Sport University Fund, China, and the Hubei Provincial University Specialty subject group construction Special fund, China.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Birjandtalab, J., Pouyan, M. B., Cogan, D., Nourani, M., and Harvey, J. (2017). Automated seizure detection using limited-channel EEG and non-linear dimension reduction. Comput. Biol. Med. 82, 49–58. doi: 10.1016/j.compbiomed.2017.01.011
Candès, E. J., and Recht, B. (2009). Exact matrix completion via convex optimization. Found. Comput. Math. 9:717. doi: 10.1007/s10208-009-9045-5
Chen, Z., Wu, X. J., and Kittler, J. (2020). Low-rank discriminative least squares regression for image classification. Signal Process. 173:107485. doi: 10.1016/j.sigpro.2020.107485
Fahimi, F., Zhang, Z., Goh, W. B., Lee, T. S., Ang, K. K., and Guan, C. (2019). Inter-subject transfer learning with an end-to-end deep convolutional neural network for EEG-based BCI. J. Neural Eng. 16:026007. doi: 10.1088/1741-2552/aaf3f6
Fang, X., Xu, Y., Li, X., Lai, Z., Wong, W. K., and Fang, B. (2018). Regularized label relaxation linear regression. IEEE Trans. Neural Netw. Learn. Syst. 29, 1006–1018. doi: 10.1109/TNNLS.2017.2648880
Gu, X. Q., Ni, T. G., and Fan, Y. Q. (2019). A fast and robust support vector machine with anti-noise convex hull and its application in large-scale ncRNA data classification. IEEE Access 7, 134730–134741. doi: 10.1109/ACCESS.2019.2941986
Gu, X. Q., Ni, T. G., Fan, Y. Q., and Wang, W. B. (2020). Scalable kernel convex hull online support vector machine for intelligent network traffic classification. Ann. Telecommun. 75, 471–486. doi: 10.1007/s12243-020-00767-2
Gu, X. Q., Zhang, C., and Ni, T. G. (2021). A hierarchical discriminative sparse representation classifier for EEG signal detection. IEEE/ACM Trans. Comput. Biol. Bioinform. 18, 1679–1687. doi: 10.1109/TCBB.2020.3006699
Gummadavelli, A., Zaveri, H. P., Spencer, D. D., and Gerrard, J. L. (2018). Expanding brain-computer interfaces for controlling epilepsy networks: novel thalamic responsive neurostimulation in refractory epilepsy. Front. Neurosci. 12:474. doi: 10.3389/fnins.2018.00474
Han, N., Wu, J., Fang, X. Z., Wong, W. K., Xu, Y., Yang, J., et al. (2019). Double relaxed regression for image classification. IEEE Trans. Circ. Syst. Video Technol. 30, 307–319. doi: 10.1109/TCSVT.2018.2890511
Huang, X., Lei, S., and Suykens, J. (2014). Asymmetric least squares support vector machine classifiers. Computat. Statist. Data Anal. 70, 395–405. doi: 10.1016/j.csda.2013.09.015
Jiang, Y. Z., Chung, F., and Wang, S. (2019). Recognition of multiclass epileptic EEG signals based on knowledge and label space inductive transfer. IEEE Trans. Neural Syst. Rehabil. Eng. 27, 630–642. doi: 10.1109/TNSRE.2019.2904708
Jiang, Y. Z., Deng, Z. H., Chung, F., Wang, G. J., Qian, P. J., Choi, K., et al. (2017). Recognition of epileptic EEG signals using a novel multiview TSK fuzzy system. IEEE Trans. Fuzzy Syst. 25, 3–20. doi: 10.1109/TFUZZ.2016.2637405
Jiang, Y. Z., Gu, X., Ji, D., Qian, P., Xue, J., Zhang, Y., et al. (2020). Smart diagnosis: a multiple-source transfer TSK fuzzy system for EEG seizure identification. ACM Trans. Multimed. Comput. Commun. Appl. 16, 1–21. doi: 10.1145/3340240
Jiang, Z., Lin, Z., and Davis, L. S. (2013). Label consistent K-SVD: learning a discriminative dictionary for recognition. IEEE Trans. Pattern Anal. Mach. Intell. 35, 2651–2664. doi: 10.1109/TPAMI.2013.88
Kong, W., Liu, Y., Jiang, B., Dai, G., and Xu, L. (2017). “A new EEG signal processing method based on low-rank and sparse decomposition,” in Proceedings of the Cognitive Systems and Signal Processing. ICCSIP 2016. Communications in Computer and Information Science, eds F. Sun, H. Liu, and D. Hu (Singapore: Springer), doi: 10.1007/978-981-10-5230-9_54
Leski, J. M. (2015). Fuzzy (c+p)-means clustering and its application to a fuzzy rule-based classifier: toward good generalization and good interpretability. IEEE Trans. Fuzzy Syst. 23, 802–812. doi: 10.1109/TFUZZ.2014.2327995
Li, S., and Fu, Y. (2016). Learning robust and discriminative subspace with low-rank constraints. IEEE Trans. Neural Netw. Learn. Syst. 27, 2160–2173. doi: 10.1109/TNNLS.2015.2464090
Ling, M. G., and Geng, X. (2019). Soft video parsing by label distribution learning. Front. Comput. Sci. 13, 302–317. doi: 10.1007/s11704-018-8015-y
Liu, G., Lin, Z., Yan, S., Yu, Y., and Ma, Y. (2013). Robust recovery of subspace structures by low-rank representation. IEEE Trans. Pattern Anal. Mach. Intell. 35, 171–184. doi: 10.1109/TPAMI.2012.88
Liu, Q., Cai, J., Fan, S. Z., Abbod, M. F., Shieh, J. S., Kung, Y., et al. (2019). Spectrum analysis of EEG signals using CNN to model patient’s consciousness level based on anesthesiologists’ experience. IEEE Access 7, 53731–53742. doi: 10.1109/ACCESS.2019.2912273
Luo, M., Zhang, L., Liu, J., Guo, J., and Zheng, Q. (2017). Distributed extreme learning machine with alternating direction method of multiplier. Neurocomputing 261, 164–170. doi: 10.1016/j.neucom.2016.03.112
Meng, M., Lan, M., Yu, J., Wu, J., and Tao, D. (2020). Constrained discriminative projection learning for image classification. IEEE Trans. Image Process. 29, 186–198. doi: 10.1109/TIP.2019.2926774
Ni, T. G., Gu, X. Q., and Zhang, C. (2020). An intelligence EEG signal recognition method via noise insensitive TSK fuzzy system based on interclass competitive learning. Front. Neurosci. 14:837. doi: 10.3389/fnins.2020.00837
Raghunandan, H. K., Andrea, M., and Sewoong, O. (2010). Matrix completion from noisy entries. J. Mach. Learn. Res. 11, 2057–2078. doi: 10.1007/s10883-010-9100-1
Ramakrishnan, S., and Muthanantha, M. A. S. (2018). Epileptic seizure detection using fuzzy-rules-based sub-band specific features and layered multi-class SVM. Pattern Anal. Appl. 22, 1161–1176. doi: 10.1007/s10044-018-0691-6
Sun, L., Jin, B., Yang, H., Tong, J., Liu, C., and Xiong, H. (2019). Unsupervised EEG feature extraction based on echo state network. Inform. Sci. 475, 1–17.
Wang, Y., Li, Z., Feng, L., Zheng, C., and Zhang, W. (2017). Automatic detection of epilepsy and seizure using multiclass sparse extreme learning machine classification. Comput. Math. Methods Med. 2017:6849360. doi: 10.1155/2017/6849360
Xiang, S. M., Nie, F. P., Meng, G. F., Pan, C., and Zhang, C. (2012). Discriminative least squares regression for multiclass classification and feature selection. IEEE Trans. Neural Netw. Learn. Syst. 23, 1738–1754. doi: 10.1109/TNNLS.2012.2212721
Yu, Z., Nie, W., Zhou, W., Xu, F., Yuan, S., Leng, Y., et al. (2020). Epileptic seizure prediction based on local mean decomposition and deep convolutional neural network. J. Supercomput. 76, 3462–3476. doi: 10.1007/s11227-018-2600-6
Keywords: electroencephalogram, epilepsy, noise robustness, low-rank learning, pinball loss function
Citation: Gao M, Liu R and Mao J (2021) Noise Robustness Low-Rank Learning Algorithm for Electroencephalogram Signal Classification. Front. Neurosci. 15:797378. doi: 10.3389/fnins.2021.797378
Received: 18 October 2021; Accepted: 05 November 2021;
Published: 24 November 2021.
Edited by:
Kaijian Xia, Changshu No.1 People’s Hospital, ChinaReviewed by:
Yufeng Yao, Changshu Institute of Technology, ChinaTongguang Ni, Changzhou University, China
Copyright © 2021 Gao, Liu and Mao. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jie Mao, bWFvamllQHdoc3UuZWR1LmNu