 Kecheng Shi
Kecheng Shi Rui Huang
Rui Huang Zhinan Peng
Zhinan Peng Fengjun Mu2,3
Fengjun Mu2,3
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Neurosci., 17 November 2021
Sec. Neuroprosthetics
Volume 15 - 2021 | https://doi.org/10.3389/fnins.2021.704603
This article is part of the Research TopicNeural Interface for Cognitive Human-Robot Interaction and CollaborationView all 11 articles
The human–robot interface (HRI) based on biological signals can realize the natural interaction between human and robot. It has been widely used in exoskeleton robots recently to help predict the wearer's movement. Surface electromyography (sEMG)-based HRI has mature applications on the exoskeleton. However, the sEMG signals of paraplegic patients' lower limbs are weak, which means that most HRI based on lower limb sEMG signals cannot be applied to the exoskeleton. Few studies have explored the possibility of using upper limb sEMG signals to predict lower limb movement. In addition, most HRIs do not consider the contribution and synergy of sEMG signal channels. This paper proposes a human–exoskeleton interface based on upper limb sEMG signals to predict lower limb movements of paraplegic patients. The interface constructs an channel synergy-based network (MCSNet) to extract the contribution and synergy of different feature channels. An sEMG data acquisition experiment is designed to verify the effectiveness of MCSNet. The experimental results show that our method has a good movement prediction performance in both within-subject and cross-subject situations, reaching an accuracy of 94.51 and 80.75%, respectively. Furthermore, feature visualization and model ablation analysis show that the features extracted by MCSNet are physiologically interpretable.
The development of artificial intelligence technology and wearable sensors has promoted the rise of human–robot interaction. As the core of human–robot interaction, an human–robot interface (HRI) enables direct communication with a robot via physical or biological signals, which has received widespread attention in the past decade (Simao et al., 2019; Fang et al., 2020). Exoskeleton is a typical application scenario of HRI, and some HRI based on physical signals, such as inertial measurement units or pressure signals, have been used in the walking-assistant exoskeleton to realize the movement prediction of patients with hemiplegia/paraplegia (Beil et al., 2018; Ding et al., 2020; Zhu et al., 2020a). In recent years, with the decoding of biological signals, HRI based on biological signals (such as electroencephalogram and electromyography) have been designed, opening up the possibility of realizing more natural and efficient movement predictions between human and exoskeleton (Suplino et al., 2019; Ortiz et al., 2020; Zhuang et al., 2021). For paraplegic patients, the loss of lower limb motor and sensory function makes the exoskeleton difficult to predict the patients' movement, and the previous work has not yet proposed a high-efficiency HRI specifically for paraplegic patients. Therefore, it is urgent to propose an HRI with high movement prediction accuracy for paraplegic patients.
Brain–computer interface (BCI) is an HRI based on electroencephalogram (EEG). It can directly obtain patients' motion intention from the EEG signal and without actual limb movement, so the BCI has been used to predict the movement of paraplegic patients (Tariq et al., 2018; Wang et al., 2018; Gu et al., 2020). The BCI consists of three main processing stages (Lotte et al., 2018): data collection and processing stage, where EEG data is recorded and preprocessed; feature extraction stage, where meaningful information is extracted from the EEG data; and classification stage, where a motion intention is interpreted from the data. The EEG signal's signal-to-noise ratio is low. It is susceptible to interference from the environment and the patient's own limb movement and mood, and the signal between different people is quite different (Rashid et al., 2020). The movement prediction accuracy of BCI is usually unstable, which is unacceptable for the exoskeleton movement assistance tasks of paraplegic patients.
Compared with the EEG signal, the sEMG signal has a higher signal-to-noise ratio and is less interfered with by external factors. Therefore, the sEMG-based human–robot interface (MHRI) has been earlier and more widely used in the walking-assistant exoskeleton (Kawamoto et al., 2003; Wang et al., 2021). The previous MHRI mostly used the sEMG signal of the lower limb muscles to predict movements. However, the sEMG signal of the lower limbs of paraplegic patients is weak or even no signal. So recent studies have attempted to use the sEMG signal of the upper body muscles to predict the lower limb movement (Villa-Parra et al., 2018). Similarly, MHRI also includes three stages of data collection and processing, feature extraction, and classification. Each stage relies on manual specifications. Many outstanding studies have shown that feature extraction is crucial for MHRI movement prediction, and it determines the upper limit of the prediction accuracy (Phinyomark et al., 2012; Samuel et al., 2018). Feature extraction often requires significant subject-matter expertise and a priori knowledge about the expected sEMG signal (Xiong et al., 2021). It is tough and time consuming to obtain an optimal feature set manually for different subjects.
Deep learning has largely alleviated the need for manual feature extraction, achieving state-of-the-art performance in fields such as computer vision and natural language processing (Hinton et al., 2012). In fact, deep convolutional neural networks (CNNs) can automatically extract appropriate features from the data. It has succeeded in many challenging image classification tasks (Huang et al., 2017; Jeyaraj and Nadar, 2019), surpassing methods that rely on handcrafted features (Hinton et al., 2012; Huang et al., 2017). Although most research still relies on handcrafted features, many recent works have explored the application of deep learning in MHRI (Allard et al., 2016; Cote-Allard et al., 2019; Jabbari et al., 2020). This kind of MHRI mostly combines long short-term memory networks (LSTM) and CNNs simply, ignoring the difference in contribution and synergy of sEMG feature channels of different subjects under the same movement. Moreover, most researchers do not pay much attention to whether the features extracted by CNNs have physiological significance.
In this paper, a channel synergy-based MHRI is proposed for lower limb movement prediction in paraplegic patients. It uses the sEMG signals of 12 upper limb muscles to predict the lower limb movements. The proposed movement prediction model uses LSTM, depthwise and separable convolutions to extract the spatiotemporal features of multi-channel sEMG signals, and introduces an attention module to extract the synergy of different sEMG feature channels. An sEMG data acquisition experiment is designed to verify the proposed channel synergy-based network (MCSNet). The experimental results verify that MCSNet's prediction accuracy is better than the traditional machine learning-based MHRI and two mainstream deep learning-based MHRI in both within-subject and cross-subject situations. Furthermore, we visualize the features extracted through MCSNet model and perform model ablation analysis. The analysis results show that the features proposed by MCSNet are physiologically interpretable.
In summary, the main contributions of this paper are shown as follows:
• A channel synergy-based MHRI is proposed for lower limb movement prediction of paraplegics. It uses the sEMG signals of upper limb to predict lower limb movements, and extracts the contribution, spatiotemporal, and synergy features among different sEMG channels, which improves the accuracy of lower limb movement prediction.
• This paper visualizes the features proposed by the MCSNet model and performs the model ablation analysis, and the results show that the features proposed by MCSNet are physiologically interpretable.
Human–robot interfaces used to predict the movement of patients with damaged limb are mainly divided into BCI and MHRI.
The research of neuroengineering promotes the development of BCI, and it is mainly used in the field of medical rehabilitation to realize the perception of user intent. An entire BCI includes three main processing stages of data collection and processing, feature extraction, and classification (Lotte et al., 2018). Traditional BCI mainly extracts some manual normative time-domain, frequency-domain, and spatial domain features (Lee et al., 2019), and then uses machine learning methods to construct the mapping between features and different movements (Kaper et al., 2004; Wang et al., 2017). Wang et al. proposed a BCI based on support vector machine (SVM). It uses the common space pattern (CSP) model to extract the spatial features of the subject's motor imagery (MI) EEG signals, and uses the SVM model to realize the classification of lower limb movements (Wang et al., 2017).
Recent research has explored the application of deep learning in BCI (Tayeb et al., 2019; Tortora et al., 2020). Tayeb et al. used a CNN architecture to predict the movement of the raw MI EEG signals, achieving an accuracy of 84% (Tayeb et al., 2019). Tortora et al. proposed a gait pattern prediction method based on an LSTM architecture. This method uses the LSTM model to automatically extract and classify the timing features of the EEG signal (Tortora et al., 2020), which can achieve an accuracy of 92.8%. Considering the low signal-to-noise ratio of EEG signals, some research have tried to combine EEG with other signals to improve the movement prediction accuracy. Zhu et al. used the combination of EEG and electrooculogram (EOG) signals to realize the grasping and moving tasks of the robotic arm (Zhu et al., 2020b), with an average accuracy of 92.09%. BCI is unacceptable for the exoskeleton movement assistance tasks of paraplegic patients, because EEG signal is susceptible to interference from the environment and the patient's own limb movement and mood (Rashid et al., 2020).
As the biological signal most relevant to exercise, sEMG has been applied to human–robot interaction for a long time, and the research on MHRI is particularly rich. According to the granularity of movement prediction, traditional MHRI can be divided into two categories, one is MHRI based on motion curve prediction, and the other is MHRI based on motion mode(movement) prediction. The former uses machine learning methods or Hill's musculoskeletal model to build a mapping between handcrafted features and joint angles/torques, which can achieve finer-grained movement prediction. Literature (Suplino et al., 2020) proposed an elbow joint angle estimation model based on a non-linear autoregressive with exogenous inputs neural network. This model can accurately predict the elbow joint's torque and angle during flexion and extension movement, with a mean square error within 7°. This kind of MHRI can only be predicted in one movement. The model involves many parameters and requires high quality of the sEMG signal, which is not suitable for the movement prediction of paraplegic patients.
The MHRI in the back is similar to BCI, which also includes three processing stages. Its main principle is using machine learning methods to map handcrafted features and movements (Afzal et al., 2017; Li et al., 2017; Cai et al., 2019; Kyeong et al., 2019; Tao et al., 2019). Cai et al. proposed an SVM-based upper limb movement prediction method (Cai et al., 2019), which uses the sEMG signal of the uninhibited upper limb muscle of the hemiplegic patient to predict the movement of the patient's shoulder and elbow joints, with an accuracy of 93.56%. Tao et al. proposed a multi-channel lower limb movement prediction method based on back propagation neural network, which can achieve an prediction accuracy of 93.6% in six lower limb movements such as the flexion movement of hip joint (Tao et al., 2019).
Deep learning can automatically extract the best feature set from sEMG signals. Many researchers have explored the application of deep learning in MHRI-based movement prediction methods (Allard et al., 2016; Cote-Allard et al., 2019; Jabbari et al., 2020). Allard et al. proposed a multi-layer CNN gesture prediction model based on sEMG for robot guidance tasks (Allard et al., 2016). The model automatically extracts the frequency domain features of different gesture movements through the CNN architecture, and the average accuracy of gesture prediction for 18 subjects is 93.14%. Considering the effectiveness of the LSTM architecture for timing feature extraction, Jabbari et al. proposed an ankle joint movement prediction model based on the CNN–LSTM architecture. The CNN and LSTM architectures were used to extract the spatial and temporal features of the sEMG signals, respectively, under different ankle joint movements (Jabbari et al., 2020), and the prediction accuracy of five ankle joint movements is 97.55%. Most deep learning-based MHRIs combine LSTM and CNNs simply to extract the timing or time-frequency features of the sEMG signal, but ignore the contribution and synergy differences of the sEMG feature channels of different subjects under the same movement. These are important features for different limb movements (d'Avella et al., 2003).
As a tightly human–machine coupled system, the exoskeleton is a typical application scenario of HRI. The application of HRI on exoskeleton can be divided into movement prediction (Kyeong et al., 2019; Read et al., 2020) and state monitoring (Bae et al., 2019). Movement prediction is to help the exoskeleton recognize the wearer's motion intention and realize natural human–exoskeleton interaction. An HRI based on the wearer's upper limb inertial measurement unit signal and crutches pressure signal was applied to the Ekso exoskeleton (Read et al., 2020). It helps the exoskeleton realize the prediction of standing and walking movements. Kyeong et al. proposed a hybrid HRI based on the wearer's lower limb sEMG signals and the sole pressure signals (Kyeong et al., 2019), achieving the prediction of the gait cycle. HRI based on state monitoring is to help observe the changes in the wearer's physiological state when using the exoskeleton. Bae et al. designed an MHRI for their wrist-rehabilitation exoskeleton robot (Bae et al., 2019). It can monitor whether the wearer has spasticity during the exoskeleton assistance task.
Our work is mainly based on the lower limb movement prediction of the walking-assistant exoskeleton for paraplegia patients. It is most closely related to the MHRI based on deep learning, which uses CNN and LSTM architecture to extract the sEMG signal features of different lower limb movements. In contrast to deep learning-based MHRI, this paper propose a channel synergy-based MHRI, which extracts the contribution and synergy of the sEMG feature channel. Its performance is better than traditional machine learning-based MHRI and two mainstream deep learning-based MHRI.
This section presents the methodology details of the proposed movement prediction model. Section 3.1 describes the overall architecture of the MCSNet model. In section 3.2, we introduce seven traditional MHRIs and two mainstream deep learning-based MHRIs, which are used to compare to the MCSNet model.
Figure 1 visualizes the proposed MCSNet model. The entire model architecture consists of three parts. The first part is data input, input the processed sEMG data; the second part is feature extraction, which mainly contains four blocks, each block establishes the connection between the feature channels of the sEMG signal in different dimensions; the third part is movement classification/prediction, which classifies the extracted features. This section mainly describes the feature extraction part, because it is the core of the entire model. For sEMG trials, it was collected at a 1,500 Hz sampling rate, having C channels and T time samples.
• sEMG is a kind of non-stationary time series data. For movement prediction, extracting more timing features is the basic requirement to improve accuracy. In block 1, for each input sEMG sample segment (size C × 300, multiple shown in Figure 1), we performed a channel-by-channel LSTM step to extract the timing features of different signal channels. Since the deepening of the LSTM layers will cause over-fitting, we found this phenomenon is more serious for sEMG data during the experiment, so we choose to use a single-layer LSTM as the timing feature extraction block. In this process, we define the kth sEMG channel signal as
which k indicates the serial number of the channel. In order to better describe the relationship between the LSTM block and the sEMG feature channel, a more fine-grained channel-by-channel representation is used. The operation with LSTM block is defined as follows:
In Equation (2), each of the sEMG signal channels is used to generate its timing feature independently, the timing feature from all the channels will be contacted into Ftemp, which size is C*L, L represents the length of input signal's sample. Since the input feature channel and in our data acquisition process is opposite the left and right symmetrical relationships on the muscle blocks in the acquisition, the muscles of the symmetry position have similar behavior patterns when the subjects are under various movements, so we use the LSTM units with shared weights used in the corresponding channel.
• In block 2, we perform two convolutional steps in sequence. First, we fit F1 2D convolution filters with a size of (1, 65) and output F1 feature maps containing different timing information. We then use a depthwise convolution of size (C, 1) (Chollet, 2017) to extract spatial features for every channel. This operation provides a direct way to learn spatial filters for different timing information, which can effectively extract different timing and spatial features. The depth parameter D represents the number of spatial filters to be learned for each time series feature map (D = 1 is shown in Figure 1 for illustration purposes). In this block, Ftemp is transformed with the first convolution layer as follows:
In Equations (3) and (4), the size of Fconv and Fd−conv is F1*C*L and (D*F1)*1*L, respectively.
• In block 3, we use a separable convolution, a depthwise convolution of size (1, 15) followed by F2 pointwise convolutions of size (1, 1). The separable convolutions first learn the kernel of each spatiotemporal feature map individually, then optimally merge the outputs afterward, which can explicitly decouple the relationship within and across feature maps. This operation separates the learning of spatiotemporal features from the combination of optimal features, which is very effective for sEMG signals. Because sEMG signals have different synergy between channels when performing different movements (muscle synergy effect, d'Avella et al., 2003), this is similar to a synergy feature, which the separable convolutions can extract. Because the padding is used in the first stage of separable convolution, and the pixel-wised convolution will not change the size of the feature, the output Fsep−conv has the same size as Fd−conv.
• For block 4, we introduced a channel attention module. This operation learns the weights of different synergy features, which can effectively associate movements with the most relevant synergy features and improve the movement prediction accuracy. Moreover, there are differences in the feature contributions of sEMG channels in different subjects under the same movement (muscle compensatory behavior, d'Avella et al., 2006), which will amplify the differences in the synergy feature of different subjects under the same movement. The channel attention module can learn different weights for different subjects to deal with the differences in synergy features, thereby improving the robustness of the entire movement prediction model. The operation of this block can be described as:
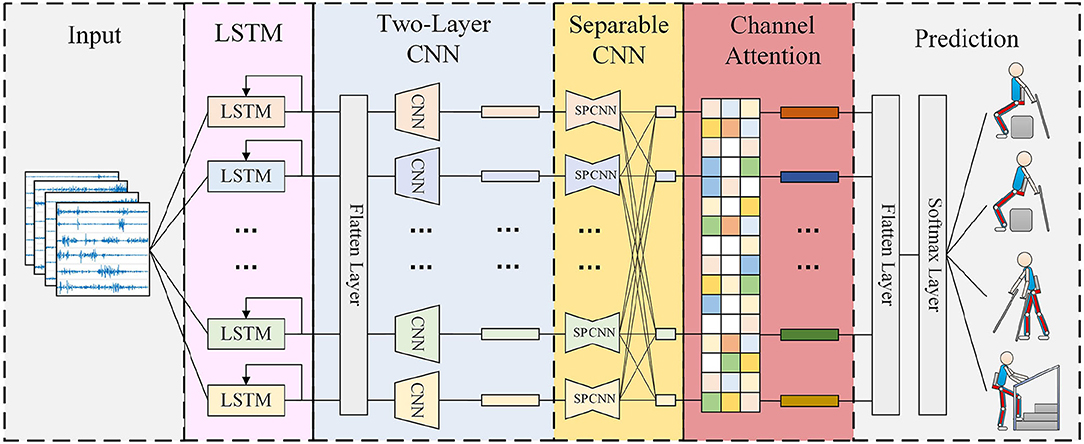
Figure 1. Overall architecture of the MCSNet model. Lines denote the convolutional kernel connectivity between inputs and outputs (called feature maps). The network starts with a channel-by-channel long short-term memory networks (LSTM) (second column) to learn the timing feature, then uses a two-layer convolution (third column) to learn different spatiotemporal features. The separable convolution (fourth column) is a combination of a depthwise convolution followed by a pointwise convolution, which can explicitly decouple the relationship within and across feature maps and learns the synergy feature of surface electromyography (sEMG).
We input the generated attention-based spatiotemporal features into the movement classification/prediction part. As shown in Figure 1, the extracted features first perform a Flatten layer step, and then pass directly to a softmax classification with N units, where N is the number of classes in the data. The entire model architecture uses the cross-entropy loss function to optimize the parameters, and input 10 sEMG samples with time-sequence everytime.
We compared the performance of MCSNet with seven traditional MHRI based on handcrafted features and machine learning models in lower limb movement prediction. In the selection of features, referring to the research conclusions of time domain and frequency domain features in the literature (Phinyomark et al., 2012) and four commonly used feature sets (Englehart and Hudgins, 2003) (Phinyomark et al., 2013), we finally select the feature of Mean Absolute Value (MAV), WaveLength (WL), Zero Crossings (ZC), 6-order AutoRegressive coefficient (6-AR), and average Power Spectral Density (PSD). Furthermore, we choose Linear Discriminant Analysis (LDA), Decision Tree (DT), Naive Bayes (BES), Linear Kernel-based Support Vector Machine (LSVM), Radial Basis Function-based Support Vector Machine (RBFSVM), K Nearest Neighbor (KNN), and Artificial Neural Network (ANN) as the classification/prediction model. We use MATLAB's Classification Learner Toolbox and Neural Net Pattern Recognition Toolbox to implement these models. The hyperparameter settings of each model are shown in Table 1.

Table 1. Parameter list of traditional MHRI movement prediction approaches.
In deep learning, we compared the performance of MCSNet with two-layers CNN (TCNN) and CNN-LSTM models. The TCNN architecture consists of two convolutional layers and a softmax layer which is for classification. The CNN-LSTM architecture includes two LSTM layers, three convolutional layers, and a softmax layer. We implemented these models in PyTorch. For specific details of the model, see https://github.com/mufengjun260/MCSNet.
In general, the most significant difference between MCSNet and traditional MHRI movement prediction approaches is the feature extraction method, and the most significant difference from other deep learning-based movement prediction methods is the network architecture. By comparing with other methods, we can prove the effectiveness of the feature extraction architecture we designed.
In this part, an sEMG signal acquisition experiment based on upper limb muscles is designed to verify the effectiveness of the method proposed in this paper. Section 4.1 describes the process of the acquisition experiment and the process of data preprocessing. Section 4.2 gives the implementation details of model training. In section 4.3, we show the MCSNet movement prediction model results and compare MCSNet with other movement prediction models in the case of within-subject and cross-subject. Section 4.4 explains the results of MCSNet model ablation analysis and feature visualization.
A total of 8 healthy subjects were invited to participate in the experiment. Each subject completed four lower limb movements of standing, sitting, walking, and going up stairs while wearing the AIDER exoskeleton. During this period, the sEMG signals of the subjects' upper limbs were collected.
1. Participants: The eight subjects (7 males, one female) had an average age of 26 years, a height between 165 and 185 cm, and a weight between 59 and 82 kg. All subjects can independently use the AIDER exoskeleton to complete the lower limb movements involved in the experiment, and are in good physical condition with no injuries to the arm. Before the experiment, each subject had been explained the contents of the experiment and signed an informed consent form. This experiment was approved by the Research Ethics Committee of the University of Electronic Science and Technology of China.
2. Procedures: Before the experiment, record the relevant physical parameters of the subject, inform the experimental procedure to the subject, and let the subject use crutches to freely practice the four lower limbs movements of standing, sitting, walking, and going upstairs while wearing the AIDER exoskeleton for 30 min. Then paste sEMG acquisition electrodes on the 12 muscles of the subject's left and right upper limbs, including the deltoid anterior, biceps, and superior trapezius muscles (as shown in Figure 2). Before pasting, wipe the corresponding muscles with alcohol cotton and remove the surface hair with a hair removal knife. The subject puts on the AIDER exoskeleton (Wang et al., 2019), supports the crutches with both hands, stands in the designated position, and completes the sitting, standing, and going upstairs movements 10 times after hearing the instructions, and then completes walking movement 20 times (a complete gait cycle is one time). Each movement is completed within 8 s, all subjects are required to perform the specified movements without using their legs as much as possible to ensure that the collected upper limb sEMG signals are close to the paraplegic patients. After the movement starts, the subject maintains the lower limb movement preparation posture for 2 s (see Figure 3) and then controls the AIDER exoskeleton to complete the corresponding lower limb movement. Throughout the experiment, the camera is turned on to record, and myoMUSCLE (an sEMG acquisition device, Scottsdale, American) is used to collect the sEMG signals of the upper limbs.
3. Data Processing: myoMUSCLE (1,500 Hz) collects the upper limb sEMG signal data of each lower limb movement of the subject throughout the whole process. After obtaining the sEMG data, a 50 Hz notch filter is used to remove the power frequency interference of the current, and a 10–450 Hz bandpass filter is used to retain the effective information of the sEMG signal. Since our application is lower limb movement prediction, we only intercept the sEMG data during the movement preparation period (the period when keeping the preparation posture still). In addition, to achieve continuous movement prediction of lower limb, this paper uses 200 ms (including 300-time series data) as a time window to segment the sEMG signal, and the movement step of the time window is 100-time series data.
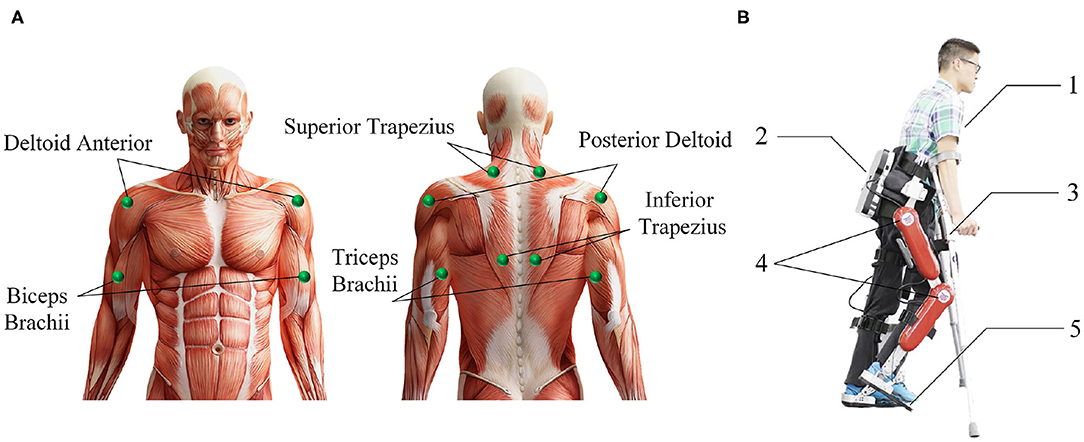
Figure 2. Introduction of the muscle used in the surface electromyography (sEMG) data acquisition experiment and the AssisIve DEvice for paRaplegic patient (AIDER) exoskeleton. (A) The upper limb muscle used in sEMG data acquisition experiment. (B) The AIDER exoskeleton is designed for walking assistance of paraplegic patients, and it can help the paraplegic patient complete some ADL movements such as sitting, standing, walking, and going upstairs movement. 1: The subject; 2: the embedded computer and IMU; 3: the crutches; 4: DC servo motors; 5: intelligent shoes with plantar pressure sensors inside.
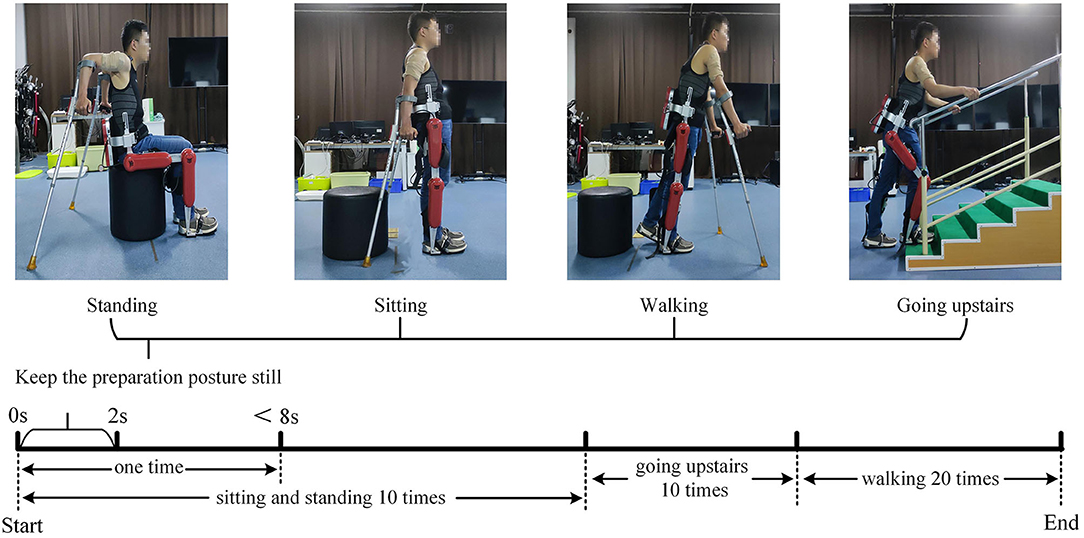
Figure 3. Schematic diagram of surface electromyography (sEMG) data acquisition experiment. The upper part is the preparation posture of the four lower limb movements. We fixed the sEMG acquisition electrode with an elastic bandage to prevent the acquisition electrode from falling off during the experiment. The lower part is the schematic diagram of the experimental acquisition process.
After preprocessing the sEMG data, for the traditional MHRI movement prediction model, use the relevant formula to calculate the features mentioned in section 3.2.1, and then input the features into the Classification Learner Toolbox and Neural Net Pattern Recognition Toolbox to train the prediction model. For the problem of imbalance in the number of samples between movements, we apply a movement class-weight to the loss function. The class-weight we apply is the inverse of the proportion in the training data, with the majority movement class set to 1.
MCSNet and the deep learning-based MHRI movement prediction models are implemented using the PyTorch library (Paszke et al., 2017). In MCSNet, both LSTM's output and hidden unit are of dimension 300, and the network's hyperparameters (D, F1, L) is set to (2, 12, 300). The model with TCNN uses the same dimension as the MCSNet's CNN layers, and the CNN-LSTM model enlarged the deepness of MCSNet's LSTM block, it uses a two-layer LSTM network architecture. Exponential linear units (ELU) (Clevert et al., 2015) are used to introduce the non-linearity of each convolutional layer. To train ours and other deep learning-based models, we use the Adam optimizer to optimize the model's parameters, with default setting described in (Kingma and Ba, 2014) to minimize the categorical cross-entropy loss function. We run 1,000 training iterations (epochs) and perform validation stopping, saving the model weights, which produce the lowest validation set loss. All models are trained on NVIDIA RTX2080Ti, with CUDA10.1 and cuDNN V7.6. Our code implementation can be found in https://github.com/mufengjun260/MCSNet.
We compared the performance of the proposed MCSNet model with other MHRIs in movement classification/prediction in both the within-subject and cross-subject situations.
For within-subject, we divide the data of the same subject according to a ratio of 7:3 and then use 70% of the data to train the model for that subject. Four-fold cross-validation is used to avoid the phenomenon of model overfitting. Simultaneously, repeated-measures analysis of variance (ANOVA) is used to test the results statistically (using the number of subjects and the classification model as factors, and the model classification/prediction result (accuracy) as the response variable).
We compare the performance of both traditional machine learning-based MHRI movement prediction models (LDA, DT, BES, LSVM, RBFSVM, KNN, and ANN) and deep learning-based MHRI movement prediction models (TCNN and CNN-LSTM) with MCSNet. Within-subject results across all models are shown in Figure 4. It can be observed that, across the average lower limb movement prediction accuracy of 7 subjects, MCSNet outperforms traditional machine learning-based and deep learning-based MHRI models. But there is no significant statistical difference (P > 0.05). Among the traditional MHRI movement prediction models, the RBFSVM model has the highest average accuracy of 7 subjects, reaching 90.31%. It is consistent with the conclusions obtained in previous work (Ceseracciu et al., 2010). Table 2 shows the prediction accuracy of each subject under different MHRI movement prediction models. It can be found that the same movement prediction model has a large difference in the accuracy for different subjects (especially the traditional MHRI movement prediction model). In contrast, MCSNet has a high accuracy rate of lower limb movement prediction for all subjects, and the accuracy rate is evenly distributed. It means that MCSNet can effectively extract each subject's lower limb movement feature, thereby achieving good movement prediction.
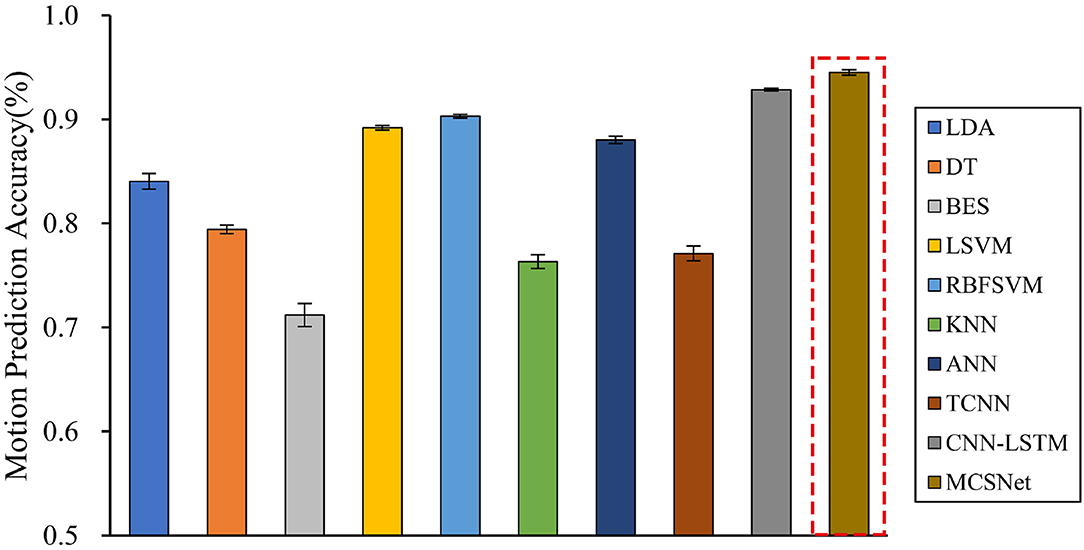
Figure 4. Within-subject movement prediction performance, four-fold cross-validation is used to avoid the phenomenon of model overfitting, averaged over all folds and all subjects. Error bars denote two standard errors of the mean.
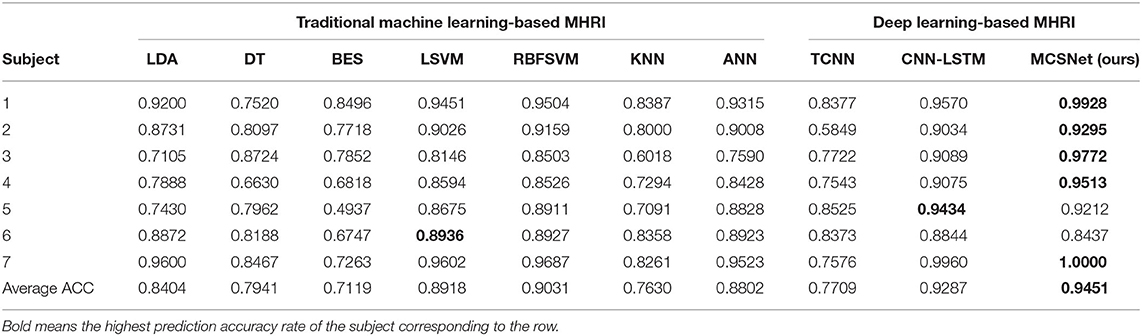
Table 2. Within-subject movement prediction performance (test set ACC).
In the case of cross-subject, we randomly selected the data of three subjects to train the model and selected the data of two subjects as the validation set. The whole process is repeated ten times, producing ten different folds.
Cross-subject prediction results across all models are shown in Figure 5. It can be seen that the traditional and deep learning-based MHRI movement prediction models have poor performance in the cross-subject situation, with an average accuracy rate of about 70%. However, the MCSNet model proposed in this paper can still achieve an accuracy of 80.25% in lower limb movement prediction, which has a significant statistical difference (P < 0.05). This result shows that the MCSNet model proposed in this paper can extract the deep common features of different subjects under the same lower limb movement. The model has good robustness.
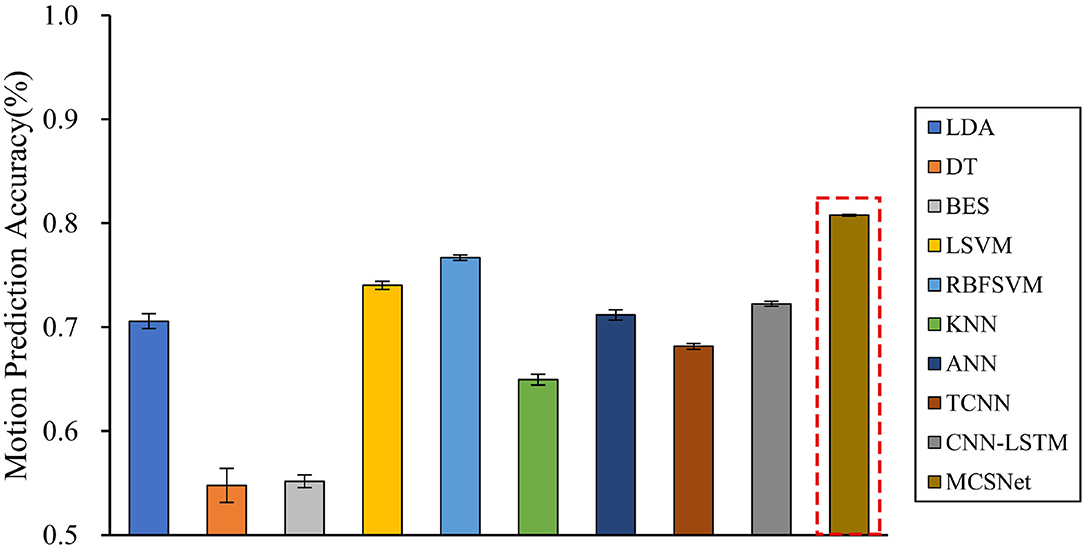
Figure 5. Cross-subject movement prediction performance, averaged over all folds. Error bars denote two standard errors of the mean.
The development of methods for enabling feature explain-ability from deep neural networks has gradually become the focus of attention over the past few years, and has been proposed as an essential component of a robust model validation procedure, to ensure that the classification performance is being driven by relevant features as opposed to noise in the data (Ancona et al., 2017; Montavon et al., 2018). This paper uses data information flow tracking to understand the features proposed by the MCSNet model. Figure 6 shows the average output of all sEMG signal samples about the sitting movement for subject 7. Using the non-negative matrix factorization method, we can intuitively see that the sEMG channel 1, 9, 10, 11 are the main contribution channels for subject 7 to complete the sitting movement (i.e., the muscles corresponding to the channel 1, 9, 10, and 11 assume the main synergistic effect in the sitting movement) (d'Avella et al., 2003). Muscle synergy is an important physiological characteristic for humans to complete different movements. In order to explore whether the MCSNet network can reflect muscle synergy, we extracted the feature output and channel weights of each layer of MCSNet, and realized the information flow tracking of sEMG data through non-negative matrix factorization and weight screening.
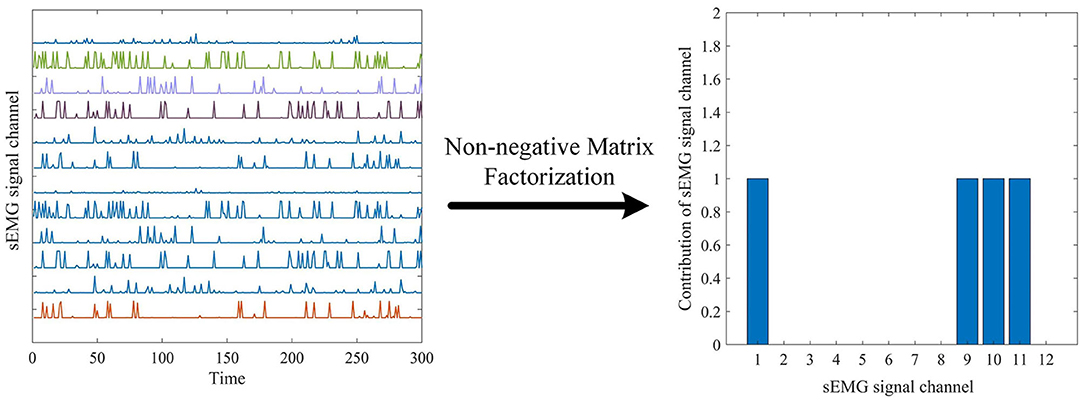
Figure 6. The average output of all surface electromyography (sEMG) signal samples about the sitting movement for subject 7, and non-negative matrix factorization method id used to find the synergy channels.
We performed non-negative matrix decomposition on the output of LSTM and the first convolutional layer, as shown in Figure 7. It can be observed that the main contribution channels of the features extracted by the LSTM and the first convolutional layer are still the channel 1, 9, 10, and 11, which means that the timing features currently extracted by MCSNet mainly come from the sEMG channel 1, 9, 10, and 11, and the synergy characteristics of these four channels are also included. The depthwise convolutional layer's function is to combine different timing feature channels, and then extract different spatiotemporal features. We analyzed the channel weights of the depthwise convolutional layer and focused on the spatiotemporal feature channels, which have a large weight for channel 1, 9, 10, and 11. Because these spatiotemporal feature channels are the main flow direction of the synergy characteristics. The results showed that the synergy characteristics are mainly contained in the spatiotemporal feature channels 11, 13, 15, 16, 22, and 24. In the same way, we analyzed the channel weights of the separable convolutional layer and compared the channels, which the synergy characteristics mainly flow, with the important channels learned by the attention mechanism. The results show that the channels selected by the two are basically the same (as shown in Figure 7). It means that the features extracted by MCSNet can reflect the synergy of muscles.
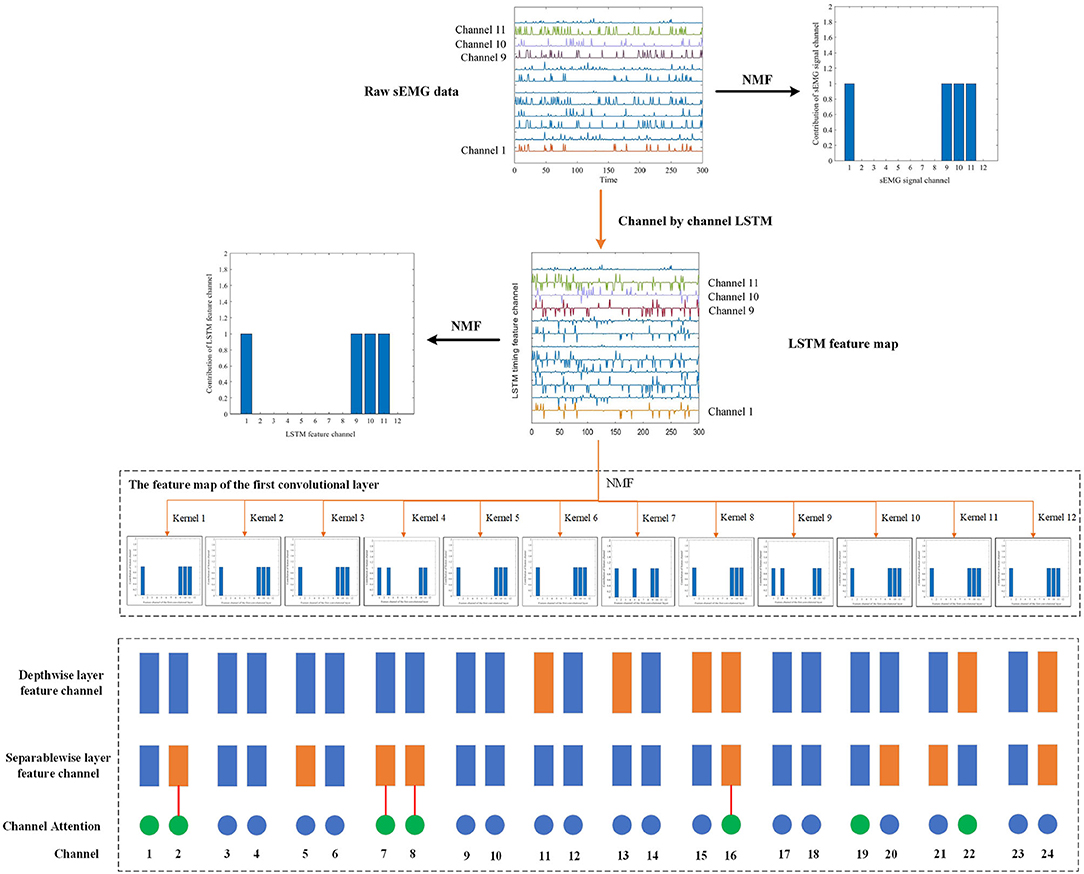
Figure 7. We visualized the synergy characteristics flow of surface electromyography (sEMG) in the sitting movement of subject 7 in the within-subject situation. The figure shows the flow of synergy characteristics in different feature channels of the MCSNet model (orange lines and rectangles). The blue rectangles represent the feature channels of the depthwise and separablewise network layers. The circle represents the weight channel of the attention layer, and the green circle means the channel with a large weight. We found that the channel with a large attention layer weight is basically the same as the channel of the synergy characteristics flow direction. It can be considered that MCSNet can extract the synergy characteristics of the muscle.
In addition, we performed a model ablation analysis on MCSNet under the cross-subject situation, removing depthwise, sparablewise, and attention network structure layers in turn and observing the changes in the prediction performance of the MCSNet model. According to the results in Table 3, removing any network structure layer will significantly reduce the prediction performance of the MCSNet model, which shows that each layer of the MCSNet model plays an essential role in the final prediction results.

Table 3. The result of model ablation analysis.
In this paper, a channel synergy-based human–exoskeleton interface is proposed for lower limb movement prediction in paraplegic patients. It uses the sEMG signals of 12 upper limb muscles as input signals, which can avoid the problem of weak sEMG signals in the lower limbs of paraplegic patients. The interface constructs an channel synergy-based network (MCSNet), it uses LSTM, depthwise, and separable convolutions to extract the spatiotemporal features of multi-channel sEMG signals, and introduces an attention module to extract the synergy of different sEMG feature channels. An sEMG acquisition experiment is designed to verify the effectiveness of the MCSNet model. The results show that MCSNet has a good movement prediction performance in both within-subject and cross-subject situations. Furthermore, feature visualization and the model ablation analysis of MCSNet is performed, the result show that the features extracted by MCSNet are physiologically interpretable. In the future, we consider applying the proposed human–exoskeleton interface to an actual exoskeleton platform. In addition, we will focus on multi-modal movement prediction based on sEMG and EEG.
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: https://github.com/mufengjun260/MCSNet.
The studies involving human participants were reviewed and approved by Ethics Committee of University of Electronic Science and Technology of China. The patients/participants provided their written informed consent to participate in this study. Written informed consent was obtained from the individual(s) for the publication of any potentially identifiable images or data included in this article.
KS designed the movement prediction model, performed the experiments, and drafted the manuscript. RH and FM participated in the design of the movement prediction model and assisted in the manuscript writing. ZP and XY guided writing paper and doing experiments. All authors contributed to the article and approved the submitted version.
This work was supported by the National Key Research and Development Program of China (No. 2018AAA0102504), the National Natural Science Foundation of China (NSFC) (No. 62003073), the Sichuan Science and Technology Program (Nos. 2021YFG0184, 2020YFSY0012, and 2018GZDZX0037), and the Research Foundation of Sichuan Provincial People's Hospital (No. 2021LY12).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Afzal, T., Iqbal, K., White, G., and Wright, A. B. (2017). A method for locomotion mode identification using muscle synergies. IEEE Trans. Neural Syst. Rehabil. Eng. 25, 608–617. doi: 10.1109/TNSRE.2016.2585962
Allard, U. C., Nougarou, F., Fall, C. L., Giguere, P., Gosselin, C., Laviolette, F., et al. (2016). “A convolutional neural network for robotic arm guidance using sEMG based frequency-features,” in 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2016) (Daejeon), 2464–2470.
Ancona, M., Ceolini, E., Öztireli, C., and Gross, M. (2017). Towards better understanding of gradient-based attribution methods for deep neural networks. arXiv preprint arXiv:1711.06104 (Vancouver, BC).
Bae, J.-H., Hwang, S.-J., and Moon, I. (2019). “Evaluation and verification of a novel wrist rehabilitation robot employing safety-related mechanism,” in 2019 IEEE 16th International Conference on Rehabilitation Robotics (ICORR) (Toronto, ON: IEEE), 288–293. doi: 10.1109/ICORR.2019.8779511
Beil, J., Ehrenberger, I., Scherer, C., Mandery, C., and Asfour, T. (2018). “Human motion classification based on multi-modal sensor data for lower limb exoskeletons,” in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (Madrid: IEEE), 5431–5436. doi: 10.1109/IROS.2018.8594110
Cai, S., Chen, Y., Huang, S., Wu, Y., Zheng, H., Li, X., et al. (2019). SVM-based classification of sEMG signals for upper-limb self-rehabilitation training. Front. Neurorobot. 13:31. doi: 10.3389/fnbot.2019.00031
Ceseracciu, E., Reggiani, M., Sawacha, Z., Sartori, M., Spolaor, F., Cobelli, C., et al. (2010). “SVM classification of locomotion modes using surface electromyography for applications in rehabilitation robotics,” in 19th International Symposium in Robot and Human Interactive Communication (Viareggio: IEEE), 165–170. doi: 10.1109/ROMAN.2010.5598664
Chollet, F. (2017). “Xception: deep learning with depthwise separable convolutions,” in 30th IEEE Conference on Computer vision and Pattern Recognition (CVPR 2017) (Honolulu, HI), 1800–1807. doi: 10.1109/CVPR.2017.195
Clevert, D.-A., Unterthiner, T., and Hochreiter, S. (2015). Fast and accurate deep network learning by exponential linear units (ELUs). arXiv preprint arXiv:1511.07289 (San Juan).
Cote-Allard, U., Fall, C. L., Drouin, A., Campeau-Lecours, A., Gosselin, C., Glette, K., et al. (2019). Deep learning for electromyographic hand gesture signal classification using transfer learning. IEEE Trans. Neural Syst. Rehabil. Eng. 27, 760–771. doi: 10.1109/TNSRE.2019.2896269
d'Avella, A., Portone, A., Fernandez, L., and Lacquaniti, F. (2006). Control of fast-reaching movements by muscle synergy combinations. J. Neurosci. 26, 7791–7810. doi: 10.1523/JNEUROSCI.0830-06.2006
d'Avella, A., Saltiel, P., and Bizzi, E. (2003). Combinations of muscle synergies in the construction of a natural motor behavior. Nat. Neurosci. 6, 300–308. doi: 10.1038/nn1010
Ding, M., Nagashima, M., Cho, S.-G., Takamatsu, J., and Ogasawara, T. (2020). Control of walking assist exoskeleton with time-delay based on the prediction of plantar force. IEEE Access 8, 138642–138651. doi: 10.1109/ACCESS.2020.3010644
Englehart, K., and Hudgins, B. (2003). A robust, real-time control scheme for multifunction myoelectric control. IEEE Trans. Biomed. Eng. 50, 848–854. doi: 10.1109/TBME.2003.813539
Fang, B., Zhou, Q., Sun, F., Shan, J., Wang, M., Xiang, C., et al. (2020). Gait neural network for human-exoskeleton interaction. Front. Neurorobot. 14:58. doi: 10.3389/fnbot.2020.00058
Gu, L., Yu, Z., Ma, T., Wang, H., Li, Z., and Fan, H. (2020). EEG-based classification of lower limb motor imagery with brain network analysis. Neuroscience 436, 93–109. doi: 10.1016/j.neuroscience.2020.04.006
Hinton, G., Deng, L., Yu, D., Dahl, G. E., Mohamed, A.-R., Jaitly, N., et al. (2012). Deep neural networks for acoustic modeling in speech recognition. IEEE Signal Process. Mag. 29, 82–97. doi: 10.1109/MSP.2012.2205597
Huang, G., Liu, Z., van der Maaten, L., and Weinberger, K. Q. (2017). “Densely connected convolutional networks,” in 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), IEEE Conference on Computer Vision and Pattern Recognition (Honolulu, HI), 2261–2269. doi: 10.1109/CVPR.2017.243
Jabbari, M., Khushaba, R. N., and Nazarpour, K. (2020). “EMG-based hand gesture classification with long short-term memory deep recurrent neural networks,” in 2020 42nd Annual International Conference of the IEEE Engineering in Medicine Biology Society (EMBC) (Montreal, QC), 3302–3305. doi: 10.1109/EMBC44109.2020.9175279
Jeyaraj, P. R., and Nadar, E. R. S. (2019). Deep Boltzmann machine algorithm for accurate medical image analysis for classification of cancerous region. Cogn. Comput. Syst. 1, 85–90. doi: 10.1049/ccs.2019.0004
Kaper, M., Meinicke, P., Grossekathoefer, U., Lingner, T., and Ritter, H. (2004). Bci competition 2003-data set IIB: support vector machines for the p300 speller paradigm. IEEE Trans. Biomed. Eng. 51, 1073–1076. doi: 10.1109/TBME.2004.826698
Kawamoto, H., Lee, S., Kanbe, S., and Sankai, Y. (2003). “Power assist method for Hal-3 using EMG-based feedback controller,” in 2003 IEEE International Conference on Systems, Man and Cybernetics (Washington, DC), 1648–1653. doi: 10.1109/ICSMC.2003.1244649
Kingma, D. P., and Ba, J. (2014). Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980 (San Diego, CA).
Kyeong, S., Shin, W., Yang, M., Heo, U., Feng, J.-R., and Kim, J. (2019). Recognition of walking environments and gait period by surface electromyography. Front. Inform. Technol. Electron. Eng. 20, 342–352. doi: 10.1631/FITEE.1800601
Lee, S.-B., Kim, H.-J., Kim, H., Jeong, J.-H., Lee, S.-W., and Kim, D.-J. (2019). Comparative analysis of features extracted from EEG spatial, spectral and temporal domains for binary and multiclass motor imagery classification. Inform. Sci. 502, 190–200. doi: 10.1016/j.ins.2019.06.008
Li, X., Fang, P., Tian, L., and Li, G. (2017). “Increasing the robustness against force variation in EMG motion classification by common spatial patterns,” in 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC) (Jeju), 406–409. doi: 10.1109/EMBC.2017.8036848
Lotte, F., Bougrain, L., Cichocki, A., Clerc, M., Congedo, M., Rakotomamonjy, A., et al. (2018). A review of classification algorithms for EEG-based brain computer interfaces: a 10 year update. J. Neural Eng. 15:031005. doi: 10.1088/1741-2552/aab2f2
Montavon, G., Samek, W., and Müller, K.-R. (2018). Methods for interpreting and understanding deep neural networks. Digit. Signal Process. 73, 1–15. doi: 10.1016/j.dsp.2017.10.011
Ortiz, M., Ianez, E., Contreras-Vidal, J. L., and Azorin, J. M. (2020). Analysis of the EEG rhythms based on the empirical mode decomposition during motor imagery when using a lower-limb exoskeleton. A case study. Front. Neurorobot. 14:48. doi: 10.3389/fnbot.2020.00048
Paszke, A., Gross, S., Chintala, S., Chanan, G., Yang, E., DeVito, Z., et al. (2017). “Automatic differentiation in pytorch,” in 31st Conference on Neural Information Processing Systems (NIPS 2017).
Phinyomark, A., Phukpattaranont, P., and Limsakul, C. (2012). Feature reduction and selection for EMG signal classification. Expert Syst. Appl. 39, 7420–7431. doi: 10.1016/j.eswa.2012.01.102
Phinyomark, A., Quaine, F., Charbonnier, S., Serviere, C., Tarpin-Bernard, F., and Laurillau, Y. (2013). EMG feature evaluation for improving myoelectric pattern recognition robustness. Expert Syst. Appl. 40, 4832–4840. doi: 10.1016/j.eswa.2013.02.023
Rashid, M., Sulaiman, N., Majeed, A. P. P. A., Musa, R. M., Ab Nasir, A. F., Bari, B. S., et al. (2020). Current status, challenges, and possible solutions of EEG-based brain-computer interface: a comprehensive review. Front. Neurorobot. 14:25. doi: 10.3389/fnbot.2020.00025
Read, E., Woolsey, C., McGibbon, C. A., and O'Connell, C. (2020). Physiotherapists experiences using the ekso bionic exoskeleton with patients in a neurological rehabilitation hospital: a qualitative study. Rehabil. Res. Pract. 2020:2939573. doi: 10.1155/2020/2939573
Samuel, O. W., Zhou, H., Li, X., Wang, H., Zhang, H., Sangaiah, A. K., et al. (2018). Pattern recognition of electromyography signals based on novel time domain features for amputees' limb motion classification. Comput. Electric. Eng. 67, 646–655. doi: 10.1016/j.compeleceng.2017.04.003
Simao, M., Mendes, N., Gibaru, O., and Neto, P. (2019). A review on electromyography decoding and pattern recognition for human-machine interaction. IEEE Access 7, 39564–39582. doi: 10.1109/ACCESS.2019.2906584
Suplino, L., de Melo, G., Umemura, G., and Forner-Cordero, A. (2020). “Elbow movement estimation based on EMG with narx neural networks,” in 2020 42nd Annual International Conference of the IEEE Engineering in Medicine &Biology Society (EMBC) (Montreal, QC: IEEE), 3767–3770. doi: 10.1109/EMBC44109.2020.9176129
Suplino, L. O., Sommer, L. F., and Forner-Cordero, A. (2019). “EMG-based control in a test platform for exoskeleton with one degree of freedom,” in 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC) (Berlin: IEEE), 5366–5369. doi: 10.1109/EMBC.2019.8856836
Tao, Y., Huang, Y., Zheng, J., Chen, J., Zhang, Z., Guo, Y., et al. (2019). “Multi-channel sEMG based human lower limb motion intention recognition method,” in 2019 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM) (Hong Kong), 1037–1042. doi: 10.1109/AIM.2019.8868529
Tariq, M., Trivailo, P. M., and Simic, M. (2018). EEG-based BCI control schemes for lower-limb assistive-robots. Front. Hum. Neurosci. 12:312. doi: 10.3389/fnhum.2018.00312
Tayeb, Z., Fedjaev, J., Ghaboosi, N., Richter, C., Everding, L., Qu, X., et al. (2019). Validating deep neural networks for online decoding of motor imagery movements from EEG signals. Sensors 19:210. doi: 10.3390/s19010210
Tortora, S., Ghidoni, S., Chisari, C., Micera, S., and Artoni, F. (2020). Deep learning-based BCI for gait decoding from EEG with LSTM recurrent neural network. J. Neural Eng. 17:046011. doi: 10.1088/1741-2552/ab9842
Villa-Parra, A. C., Delisle-Rodriguez, D., Botelho, T., Mayor, J. J. V., Delis, A. L., Carelli, R., et al. (2018). Control of a robotic knee exoskeleton for assistance and rehabilitation based on motion intention from sEMG. Res. Biomed. Eng. 34, 198–210. doi: 10.1590/2446-4740.07417
Wang, C., Guo, Z., Duan, S., He, B., Yuan, Y., and Wu, X. (2021). A real-time stability control method through sEMG interface for lower extremity rehabilitation exoskeletons. Front. Neurosci. 15:280. doi: 10.3389/fnins.2021.645374
Wang, C., Wu, X., Wang, Z., and Ma, Y. (2018). Implementation of a brain-computer interface on a lower-limb exoskeleton. IEEE Access 6, 38524–38534. doi: 10.1109/ACCESS.2018.2853628
Wang, Y., Cheng, H., and Hou, L. (2019). c 2 aider: cognitive cloud exoskeleton system and its applications. Cogn. Comput. Syst. 1, 33–39. doi: 10.1049/ccs.2018.0012
Wang, Z., Wang, C., Wu, G., Luo, Y., and Wu, X. (2017). “A control system of lower limb exoskeleton robots based on motor imagery,” in 2017 IEEE International Conference on Information and Automation (ICIA) (Macao), 311–316. doi: 10.1109/ICInfA.2017.8078925
Xiong, D., Zhang, D., Zhao, X., and Zhao, Y. (2021). Deep learning for EMG-based human-machine interaction: a review. IEEE CAA J. Automat. Sigica 8, 512–533. doi: 10.1109/JAS.2021.1003865
Zhu, L., Wang, Z., Ning, Z., Zhang, Y., Liu, Y., Cao, W., et al. (2020a). A novel motion intention recognition approach for soft exoskeleton via IMU. Electronics 9:2176. doi: 10.3390/electronics9122176
Zhu, Y., Li, Y., Lu, J., and Li, P. (2020b). A hybrid BCI based on SSVEP and EOG for robotic arm control. Front. Neurorobot. 14:583641. doi: 10.3389/fnbot.2020.583641
Keywords: human-robot interface, lower limb movement prediction, channel synergy-based network, exoskeleton, paraplegic patients, surface electromyography
Citation: Shi K, Huang R, Peng Z, Mu F and Yang X (2021) MCSNet: Channel Synergy-Based Human-Exoskeleton Interface With Surface Electromyogram. Front. Neurosci. 15:704603. doi: 10.3389/fnins.2021.704603
Received: 03 May 2021; Accepted: 08 October 2021;
Published: 17 November 2021.
Edited by:
Xiaodong Guo, Huazhong University of Science and Technology, ChinaReviewed by:
Bin Fang, Tsinghua University, ChinaCopyright © 2021 Shi, Huang, Peng, Mu and Yang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Rui Huang, cnVpaHVhbmdAdWVzdGMuZWR1LmNu; Xiao Yang, eWFuZ3hpYW9tZWRAaG90bWFpbC5jb20=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.