 Stefano Brivio
Stefano Brivio Denys R. B. Ly
Denys R. B. Ly Elisa Vianello
Elisa Vianello Sabina Spiga
Sabina Spiga- 1CNR - IMM, Unit of Agrate Brianza, Agrate Brianza, Italy
- 2Université Grenoble Alpes, CEA, Leti, Grenoble, France
Spiking neural networks (SNNs) are a computational tool in which the information is coded into spikes, as in some parts of the brain, differently from conventional neural networks (NNs) that compute over real-numbers. Therefore, SNNs can implement intelligent information extraction in real-time at the edge of data acquisition and correspond to a complementary solution to conventional NNs working for cloud-computing. Both NN classes face hardware constraints due to limited computing parallelism and separation of logic and memory. Emerging memory devices, like resistive switching memories, phase change memories, or memristive devices in general are strong candidates to remove these hurdles for NN applications. The well-established training procedures of conventional NNs helped in defining the desiderata for memristive device dynamics implementing synaptic units. The generally agreed requirements are a linear evolution of memristive conductance upon stimulation with train of identical pulses and a symmetric conductance change for conductance increase and decrease. Conversely, little work has been done to understand the main properties of memristive devices supporting efficient SNN operation. The reason lies in the lack of a background theory for their training. As a consequence, requirements for NNs have been taken as a reference to develop memristive devices for SNNs. In the present work, we show that, for efficient CMOS/memristive SNNs, the requirements for synaptic memristive dynamics are very different from the needs of a conventional NN. System-level simulations of a SNN trained to classify hand-written digit images through a spike timing dependent plasticity protocol are performed considering various linear and non-linear plausible synaptic memristive dynamics. We consider memristive dynamics bounded by artificial hard conductance values and limited by the natural dynamics evolution toward asymptotic values (soft-boundaries). We quantitatively analyze the impact of resolution and non-linearity properties of the synapses on the network training and classification performance. Finally, we demonstrate that the non-linear synapses with hard boundary values enable higher classification performance and realize the best trade-off between classification accuracy and required training time. With reference to the obtained results, we discuss how memristive devices with non-linear dynamics constitute a technologically convenient solution for the development of on-line SNN training.
1. Introduction
Spiking Neural Networks (SNNs) received a renewed wave of interest from a computational point of view as a tool to move the huge overload in data analysis from the cloud to the edge. Indeed, they couple the neural network computing power with spike coding of information, which is considered a valid approach to reduce power requirement for the real-time analysis of unstructured data. This enables the process of in-situ decision making of autonomous systems (Indiveri et al., 2013). SNNs are a complementary solution to conventional Neural Networks (NNs), which compute with real-valued numbers and are currently used to remotely analyze the data uploaded to the cloud or at the edge only for inference, without online training (Yu, 2018). Both NNs and SNNs require specific hardware to boost their performance and computing speed. On one side, hardware accelerators of NNs, like graphical processing units and tensor processing units, are now widespread in the market. On the contrary, hardware supporting SNNs are mainly based on research platforms. In both cases, though, the lack of parallelism and separation between storage and computing units is still an issue, for which solutions are under investigation. To this aim, emerging memory devices, compatible with back-end of the production line of CMOS technology, and in particular resistive switching random access memories (RRAM), also named memristive devices, are considered among the best candidates for hardware solutions supporting NNs and SNNs. In particular, the so-called neuromorphic systems intend to use memristive devices to update, during training, and store, for inference, the synaptic weights of a network.
Since well-established robust and reliable training algorithms, like the back-propagation of the gradient, is available for NNs, the requirements for memristive devices for NN accelerators have already been determined (Chen et al., 2015; Gokmen and Vlasov, 2016; Sidler et al., 2016; Ambrogio et al., 2018; Fumarola et al., 2018; Moon et al., 2018). It has been shown that the memristive dynamics of the synapses, i.e., the evolution of the memristor conductance driven by train of identical pulses, determines the performance of the network (Chen et al., 2015; Gokmen and Vlasov, 2016; Sidler et al., 2016; Fumarola et al., 2018; La Barbera et al., 2018; Brivio et al., 2019a). In particular, NN accelerators trained through back-propagation require a memristive conductance evolving through many evenly-spaced levels (linear dynamics) (Chen et al., 2015; Gokmen and Vlasov, 2016; Sidler et al., 2016; Fumarola et al., 2018). The same agreement on the required memristive synaptic dynamics in SNN can hardly be reached because various training protocols have been investigated with different results (Brivio et al., 2019a). Currently, SNN training attempts include on-line spike-based procedures (Payvand et al., 2018; Brivio et al., 2019a; Donati et al., 2019) and off-line conventional training of a non-spiking NN that must be afterwards converted into an equivalent SNN (Diehl et al., 2015, 2016; Sengupta et al., 2019). The former allows exploiting the full potential of memristive devices tuneability to achieve a real-time on-line adaptive operation. Among the spike-based training procedures, supervised learning rules inspired by the back-propagation exist (Urbanczik and Senn, 2014; Müller et al., 2017; Donati et al., 2019), which are seldom investigated for systems including realistic simulations of memristive devices (Nair et al., 2017; Payvand et al., 2018). On the contrary, the literature is extremely rich of reports dealing with networks trained by supervised (Brivio et al., 2019a) and unsupervised versions of the so-called Spike Timing Dependent Plasticity (STDP) (Diehl and Cook, 2015; Garbin et al., 2015; Querlioz et al., 2015; Ambrogio et al., 2016; La Barbera et al., 2018). Few reports indicate that non-linear memristive dynamics may be beneficial for STDP-based SNNs (La Barbera et al., 2018; Brivio et al., 2019a). A comprehensive review about neural networks and spiking neural networks including also memristive devices can be found in Bouvieret al. (2019). In addition, the deployment of all the various emerging technologies for brain-inspired computing is extensively described in Spiga et al. (2020).
In this paper, we aim at moving the first steps toward the optimization of the training of a SNN through system-level simulations as a function of various experimentally-inspired memristive dynamics. Neuron model, training protocol, and architecture are also compatible with a hardware implementation in CMOS technology, as in the silicon chip described in Valentian et al. (2019) and Regev et al. (2020). The investigated memristive dynamics include linear and non-linear evolution bounded within extreme maximum and minimum values, as well as a non-linear evolution asymptotically approaching the boundary values (details are reported below). The response of the network is monitored throughout its training against the classification of hand-written digits from the MNIST dataset (Lecun et al., 1998). We choose this particular task in order to allow a direct comparison with other results reported in the literature for NNs (Chen et al., 2015; Garbin et al., 2015; Ambrogio et al., 2018) and SNNs. (La Barbera et al., 2018; Brivio et al., 2019a) Furthermore, the comparison among the various memristive dynamics is performed in a quantitative manner through the definition of figures of merit that apply to any mathematical formulation for synaptic dynamics. We found that non-linear dynamics bounded within extreme values is the most versatile dynamics, which guarantees the best classification performance and the best compromise between training duration and classification accuracy. This result marks a clear difference with respect to the recent finding related to conventional neural network accelerators trained through the back-propagation algorithm, which, according to a general agreement, require linear synapses (Chen et al., 2015; Gokmen and Vlasov, 2016; Ambrogio et al., 2018; Fumarola et al., 2018).
2. Methods
2.1. Network Architecture and Training
Figure 1A presents the two-layers fully-connected feed-forward SNN simulated for the classification of hand-written digits from the MNIST dataset (Lecun et al., 1998). Simulations are performed with the event-based N2D2 simulator tool (Bichler et al., 2013). The full MNIST dataset is presented only once for training (60,000 training digits), then testing (10,000 testing digits). Each digit is composed of 28 × 28 pixels. The input layer converts the input digit with a spike frequency encoding: each input neuron generates a spike train with a spiking rate finput proportional to the gray level of the corresponding input pixel. finput ranges from fMIN = 83 Hz to fMAX = 22.2 kHz with a total of 256 different gray levels. Spike trains are generated according to a Normal distribution. Each input digit is presented to the network for 350 μs during the training phase. The input layer is composed of 28 × 28 input neurons fully-connected by weighted synapses to the output layer composed of 500 Leaky Integrate-and-Fire (LIF) output neurons with a leak time constant τleak = 120.0 μs. Note that after an output neuron fires a spike, it cannot integrate any incoming spikes for a refractory period trefrac = 1 ns. It also prevents all the other neurons of the layer from integrating incoming spikes for a period tinhibit = 10 μs, referred to as lateral inhibition. This allows implementing a Winner-Take-All (WTA) network between all the neurons (Bichler et al., 2013). In addition, a slight delay in the firing time of output neurons has been introduced: when an output neuron reaches its threshold value, it fires a spike after a delay temit. The parameter temit for each output neuron has been randomly drawn from a normal distribution with a mean value μ = 0.1 ns and a standard deviation σ = 1 ps. This facilitates the implementation of the WTA process. These parameters have been optimized by a genetic algorithm. The network is trained with an unsupervised simplified Spike-Timing-Dependent Plasticity (STDP) rule (Figure 1B) (Suri et al., 2011; Querlioz et al., 2015): if the post-synaptic neuron spikes after the pre-synaptic neuron within a STDP time window tSTDP = 60.0 μs, the synapse increases its synaptic weight by a quantity δw+ (synaptic potentiation event). Otherwise, its synaptic weight is decreased by a quantity δw− (synaptic depression event). Quantities δw+ and δw− follow different dynamics models described in the following section. The weights are bounded between [0, 1] and are initialized to the value of 0.8 before training. From a hardware point of view, the initialization of devices to a predefined value is more straightforward than a random initialization. In particular, the weight value of 0.8 (i.e., high memristive conductance) is coherent with an initialization performed in hardware with only an electroforming step, which is required for a large class of memristive devices (Brivio and Menzel, 2020). Furthermore, the initialization does not influence the obtained classification performances as demonstrated in Querlioz et al. (2013).
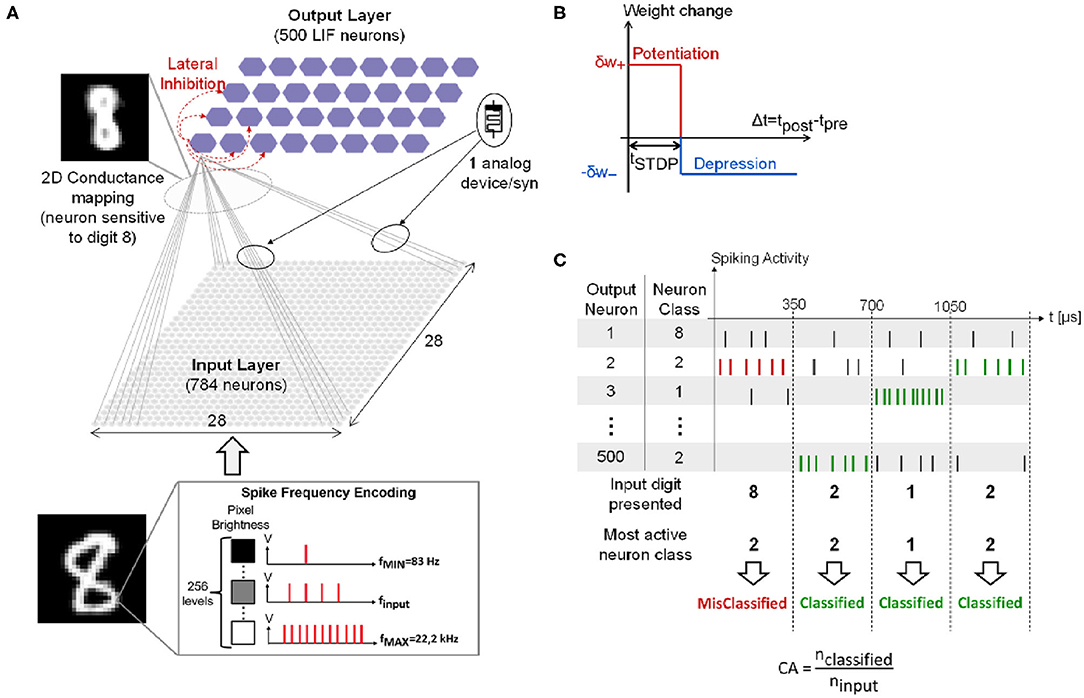
Figure 1. (A) Simulated SNN for the MNIST classification. (B) Simplified STDP learning rule. (C) Example of spiking activity of four output neurons when four different input digits are presented, and Classification Accuracy (CA) definition. Adapted with permission from Ly et al. (2018). @IOP Publishing (2018). All rights reserved.
During the training phase, each output neuron becomes sensitive to a specific class of digit as illustrated in the 2D conductance mapping in the top left of Figure 1A (class of digit “8”). After training, each output neuron is associated with the digit it is the most sensitive to. This represents the class of the neuron. To assess network performance during the testing phase, the Classification Accuracy (CA) is computed as defined in Figure 1C. Each input digit is presented to the network for 350 μs and the output neuron that spikes the most within this time window—the most active neuron—corresponds to the network response. If the most active neuron class coincides with the input digit, the digit is successfully classified (green spikes). Otherwise, the digit is misclassified (red spikes). The CA is calculated as the ratio between the number of successfully classified digits, nclassified, and the number of input digits, ninput (bottom of Figure 1C). As there are multiple ways to hand-write the same digit, increasing the number of output neurons allows for an improvement of network performance as demonstrated in Querlioz et al. (2015). Indeed, this enables the network to have at its disposal several neurons specialized to different hand-writings of the same digit. As shown in Querlioz et al. (2015), the increase of CA with the number of output neurons saturates after 500 output neurons.
It is worth pointing out that the network architecture and operation are implemented according to the real hardware possibilities of the current CMOS and memristive technologies. In particular, contrary to Querlioz et al. (2015) who implemented the same network as the present one, homeostasis, which, e.g., adjusts each individual output neuron threshold on the basis on its instantaneous firing rate, is not included. As a matter of fact, Querlioz et al. (2015) shows that homeostasis can improve the classification accuracy by about 10%. On the other hand, the hardware implementation of homeostasis would require memory banks to store each individual neuron threshold values and one additional capacitor per neuron to probe each neuron firing rate, which will have a prohibitive impact on the required silicon real estate (Dalgaty et al., 2019). Some pioneering works are trying to address this issue with the help of memristive technology (Dalgaty et al., 2019), but a hardware-compatible homeostatic process over a large number of neurons has not been elaborated yet.
Furthermore, the classification scheme can also be improved with a voting procedure that takes into account the average firing rate of each neuron pool as in Diehl and Cook (2015), instead of considering only the individual neuron that fires the most as in the present implementation. However, the voting procedure based on the individual neuron firing rate eases the circuit complexity and is only marginally influencing the network performances. Indeed, Querlioz et al. (2015) obtained a classification accuracy (94.5%) very close to that of Diehl et al. (95%).
2.2. Models for Memristive Dynamics
The synaptic dynamics corresponds to the evolution of the weight of an artificial synapse (proportional to the memristive device conductance) when subjected to a train of identical pulses. Considering bipolar memristive synapses, trains of pulses of a given voltage polarity can lead to weight potentiation and trains of pulses with the opposite polarity lead to weight depression. As evident from the recent literature (Fumarola et al., 2018) and pointed out by part of the present authors in Frascaroli et al. (2018), the more general memristive conductance dynamics usually follows a non-linear evolution with a slow approach to the maximum and minimum values. Such dynamics can be described by a non-linear soft-bound (NL-SB) model, which has a particular importance in the field of computational neuroscience. Indeed, Fusi and Abbott (2007) demonstrated that NL-SB synapses generally endow a SNN with a larger memory capacity (capacity of storage of memories) compared to synapses whose weight evolve linearly between two boundary values. This latter synaptic model will be referred to as linear hard-bound (L-HB) synapses in the following. Fusi and Abbott (2007) showed that L-HB synapses perform better than NL-SB ones only in the particular case of a balanced network, i.e., a network in which the rate of potentiation is the same as the rate of depression events. From an experimental point of view, a memristive dynamics is usually approximated with a L-HB dynamics by interrupting a NL-SB one after a certain number of pulses at the cost of reduced conductance window, . Examples of experimental reports can be found in Jang et al. (2015), Wang et al. (2016), and Bousoulas et al. (2017). A third generic case, which we will call non-linear hard-bound (NL-HB), consists in a non-linear dynamics interrupted at arbitrary boundary values. The boundary values are strictly reached after a certain finite number of consecutive weight increase or decrease events. As already mentioned, the NL-SB case is different because the weight boundaries are reached as asymptotic values after an infinite number of pulses (from a experimental point of view, tests up to few thousand pulses have been performed; Brivio et al., 2019a). The investigated L-HB and NL-SB dynamics in potentiation (conductance increase) and depression (conductance decrease) are shown in Figures 2A,B as solid and dotted lines, respectively. Figures 2C,D report various investigated NL-HB cases, for potentiation and depression operations as solid and dotted lines, respectively. The examples reported in Figure 2 correspond to specific mathematical expressions and parameterizations of the dynamics models as described in the following.
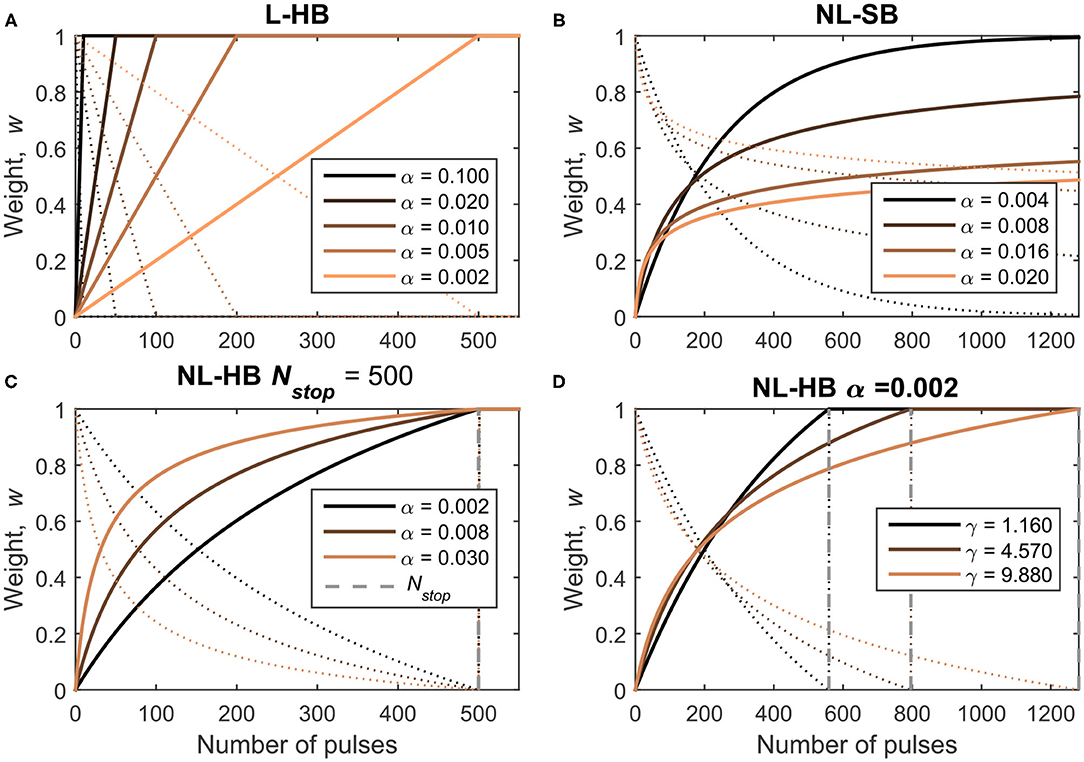
Figure 2. Investigated dynamics: (A) Linear Hard-Bound (L-HB); (B) Non-Linear Soft-Bound (NL-SB) and (C,D) Non-Linear Hard-Bound (NL-HB). Dynamics are plotted as a function of the number of pulses for potentiation and depression operations (straight and dotted lines, respectively). The various dynamics cases are defined in Table 1.
Formally, the weight dynamics can be expressed in a differential form in the continuous domain as a variation of the weight, dw, per pulse, dn. The weights are always positive because they are represented by the conductance value of a physical device. Furthermore, it must be pointed out that hard-bound cases are experimentally obtained by interrupting a generic soft-bound dynamics, which therefore reduces the conductance window of hard-bound cases. Despite this fact, all the dynamics cases are simulated with the same conductance window considering the weight as the normalized version of the conductance between [0, 1], as plotted in Figure 2. Therefore, for all the following equations one should consider w ∈ [0, 1] and outside the interval [0, 1]. In particular, the L-HB dynamics is given by
with α± ∈ (0, 1] and where the (·)+ and the (·)− stand for potentiation and depression, respectively. Following Fusi and Abbott (2007), Frascaroli et al. (2018), and Brivio et al. (2019a), the NL-SB equation is given by
with α± ∈ (0, 1] and γ±≥1. It is evident from Equation (2) that the weight variation tends to nullify as w approaches the boundary values. The NL-HB dynamics is the truncated version of the NL-SB properly re-scaled between 0 and 1, as follows
where α± ∈ (0, 1], γ± ∈ [1, +∞). Nstop, ± are the values of n at which the corresponding NL-SB dynamics is truncated to get a NL-HB one. wstop, ± are the normalization terms that depend on the value of Nstop, ±, as shown in the Supplementary Material.
It is worth making some additional clarifications. Each dynamics case is described by one or more free parameters which are chosen as described in the following. It is clear from Equations (1) and (2) that α± is the step height when departing from the boundary value for the L-HB and the NL-SB dynamics. Indeed, the weight moves away from the lower boundary value, w = 0 for potentiation (resp. higher boundary value, w = 1 for depression) with a weight change equal to α+ (resp. −α−). For the NL-HB case, the first step height is . In addition, the weight change step is constant throughout the entire weight range for the L-HB case; it decreases from α to 0 for the NL-SB case; and it decreases from to a finite value greater than 0 for the NL-HB case. The parameter γ± introduces an additional non-linearity factor, whose effect can be appreciated from Figure 2B. For each dynamics case, potentiation and depression evolution are considered identical, i.e., with the same values of the free parameters, α+ = α−, γ+ = γ−, and Nstop, + = Nstop, −. As a consequence, the pace of approaching and departing to and from a given weight value is the same only for linear synapses. On the contrary, non-linear synapses are characterized by a certain asymmetry between potentiation and depression. For instance, a NL-SB synapse can be potentiated with a significant rate away from a weight value close to 0 (w≈0). In turn, at the same value, the depression rate is close to 0 because . As a matter of fact, the asymmetry between potentiation and depression dynamics is usually present in real devices (Lee et al., 2015; Frascaroli et al., 2018). The impact of asymmetry between potentiation and depression dynamics on the performances of a neuromorphic system has been investigated in some detail for networks trained through back-propagation of the error (Chen et al., 2015; Agarwal et al., 2016; Fumarola et al., 2018) and only partially in spiking networks (La Barbera et al., 2018). However, a procedure to decouple the effect of asymmetry from that of non-linearity has not been proposed yet.
The memristive evolution in the network is determined by the STDP rule described in the previous section and the Equations (1)–(3). In fact, when the pre- and post-spikes are emitted according to the potentiation (depression) window in Figure 1B, a potentiation (depression) pulse is delivered to the memristive synapse driving a weight change equal to δw+ (δw−). The quantity δw± is determined by the current synaptic weight w and by the dynamics parameters in Table 1 according to Equations (1)–(3). The programming of memristive device with CMOS neuron circuit, in STDP-based schemes, has been investigated in a number of works, which highlighted the need to include compact interface electronics. Pedretti et al. (2017) demonstrated STDP protocols on real 1 transistor-1 memristor structures based on the temporal overlapping on pre- and post-synaptic pulses driven by microcontrollers. Mostafa et al. (2016) designed a memristor/CMOS neuron interface constituted by 4 CMOS transistors to drive weight depression and potentiation operations separately within the framework of a generalized version of STDP. Covi et al. (2018) tested the same structure by wire-connecting a single memristor to two 350 nm technology CMOS neurons. The neurons delivered the correct programming pulses to obtain both analoge and digital memristive responses. In Brivio et al. (2019a), a 6 transistor-1 memristor structure is proposed to control synaptic potentiation, depression, and read operations in an implementation of a generalized version of STDP. The system-level simulation implemented in the present work are compatible with such implementation details.
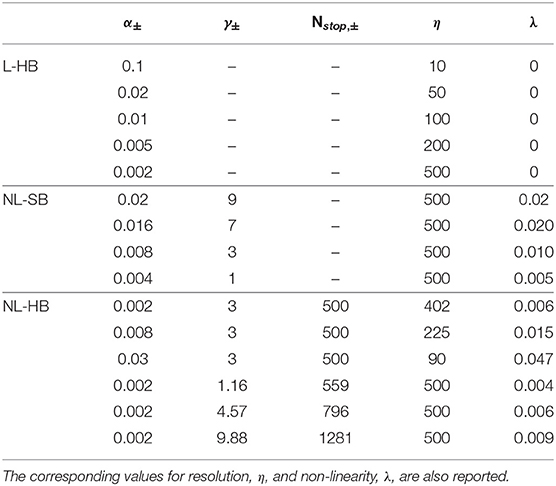
Table 1. List of the investigated dynamics defined by the values of their parameters α, γ, and Nstop.
The main weighting property of a synapse is its resolution, i.e., the number of weight values that it can store. The resolution of a synapse has a direct impact on the performances of a network (Bill et al., 2014; Brivio et al., 2019a). However, while the definition of number of levels is straightforward for L-HB dynamics, the same does not hold true in the case of non-linear weight evolution, because in this case the weight values are not evenly spaced. As a matter of principle, for NL-HB case, the resolution could be evaluated equal to the number of update events that are necessary to bring the weight from one boundary value (e.g., 0) to the opposite (i.e., 1), i.e., exactly Nstop. However, this is not a proper definition because the weight can be driven from 0 to 1 with the same number of steps but through various and very different trails. In particular, Figure 2C reports three NL-HB cases for which the same number of pulses is required to cover the full weight range but show very different dynamics. It is reasonable to associate different resolutions (or effective number of levels) to the three examples. In addition, it is worth pointing out that the number of pulses required to cover the full weight range is not a good definition for the NL-SB, which strictly requires an infinite number of steps to reach the boundary values. Indeed, the non-linear cases reported in Figure 2 should be associated to different resolutions from a purely mathematical point of view. These considerations are completely independent from the effect of the noise and variability that unavoidably affect any real memristive device (Yu et al., 2013; Frascaroli et al., 2015, 2018; Covi et al., 2016; Brivio et al., 2017, 2019b). The impact of noise and variability has been investigated for some specific networks and some applications, demonstrating a general tolerance of neuromorphic systems against memristive synapse variability and noise (Querlioz et al., 2013; Garbin et al., 2014; Burr et al., 2015; Covi et al., 2016; Bocquet et al., 2018). Since we want to restrict the present study to a purely theoretical basis on the very impact of synaptic dynamics on network performances, the effect of noise and variability are left to a future work.
For the reasons above, we arbitrarily define an estimator for the resolution (effective number of levels) of the memristive device which can be applied to any generic dynamics expressed as a weight variation (dw) per pulse (dn) in the continuous domain, [f±(w) must be differentiable for w ∈ (0, 1)]. The resolution, η, is defined as
Equation (4) returns the correct number of levels for the trivial L-HB case, i.e., equal to the number of pulses to go from one boundary to the other one, and a reasonable estimate for the non-linear cases, as discussed in the Supplementary Material. η assumes analytical expressions for the dynamics cases under study, as reported in the Supplementary Material. It is just worth noticing that for the L-HB case and is proportional to for the NL-SB (in agreement with Fusi and Abbott, 2007) and the NL-HB cases.
According to the discussion above and to the recent literature, a second property of weight dynamics is its non-linearity (λ), which can be defined as the average curvature of the weight evolution as a function of the number of potentiation or depression pulses, w(n):
where (·)′ and (·)″ indicate the first and the second derivative with respect to n.
In this work, we investigate the impact of these synaptic properties, namely the resolution, η, and the non-linearity, λ, on the training and performance of the SNN described above. In particular, we consider various L-HB, NL-SB, and NL-HB dynamics, as reported in the Table 1 and shown in Figure 2. Note that the L-HB cases are only characterized by different values of the resolution, because only one free parameter exists. For the NL-SB case, it is possible to investigate different dynamics for the same resolution, i.e., with different non-linearities. NL-HB cases are chosen in a way to have the same Nstop, ± (cases 1–3) or the same resolution, η (cases 4–6). We investigate resolution values up to 500 because this is the one that guarantees good performance on MNIST classification on the linear case, according to previous literature results (La Barbera et al., 2018; Brivio et al., 2019a) and as it will be evident also in the following. The free parameters of the various dynamics cases are generally compatible with experimental data as in Frascaroli et al. (2018) and Brivio and Menzel (2020). For the sake of completeness, it is worth noticing that dynamics of a memristive device depends on the properties of the constitutive materials and on the programming conditions. For instance, memristors featuring double insulating layers have been reported to show more gradual conductance evolution than devices with a single insulating material (Park et al., 2016; Wang et al., 2016; Moon et al., 2018; Brivio and Menzel, 2020). The response speed might depend on the diffusivity of the mobile ionic species as well. It is a property of the insulating materials itself, which can also be slightly tuned by doping, strain, or by changing the atomic structure and porosity (Azghadi et al., 2020; Brivio and Menzel, 2020). Furthermore, the programming scheme influences the dynamics. Indeed, strong programming conditions (high voltage or long pulses) result in large conductance changes with a few pulses (Frascaroli et al., 2018). It is worth specifying that all the parameters (α, γ, Nstop) defining the memristive dynamics affect both resolution and non-linearity at the same time. More details can be found in the Supplementary Material.
3. Results
As discussed in the previous paragraph, the mathematical formulation of all the investigated dynamics comprises a parameter α, the only parameter that is present in all investigated synaptic dynamics. In Figure 3, the classification accuracy, CA, is shown to decrease as a function of α for the investigated cases. This observation is expected because is equal to the synaptic resolution of the L-HB dynamics and is proportional to that of the non-linear ones. It is already evident that the non-linear cases perform better than the linear ones for a wide range of the parameter α, in agreement with previous publications (La Barbera et al., 2018; Brivio et al., 2019a). However, only the evolution as a function of α does not catch the entire complexity of the problem because, for the NL-SB and NL-HB cases, α affects both resolution and non-linearity. Indeed, the various types of weight dynamics in Figure 3 follow a different decreasing trend. The maximum reached classification accuracy settles close to 85%, which is lower than the best results on theoretical SNNs (Diehl and Cook, 2015). However, as stated above, the aim of the present work is to test SNNs constituents and architectures that can be possibly realized in hybrid CMOS/memristor technology (Valentian et al., 2019; Regev et al., 2020). As discussed in the Methods section, the inclusion of a homeostatic rule, which is of difficult hardware implementation, would recover a classification accuracy close to the best state of the art results, as demonstrated by Querlioz et al. (2015) with the same network as the one implemented in this work. The values of the collected classification accuracy are reported in the Supplementary Material.
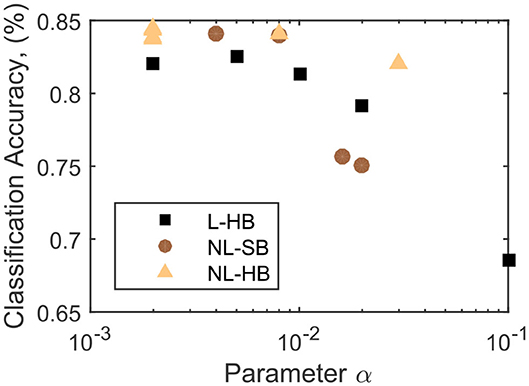
Figure 3. Classification accuracy as a function of the parameter α for the L-HB, NL-SB, and NL-HB cases.
To get a deeper insight on the factors affecting the network performances, the classification accuracy is plotted as a function of η and λ in Figure 4, which reports the first of the main results of the paper taking advantage of the mathematical toolkit described in the previous section. Figure 4A shows that there is a general trend of increasing CA with the synaptic resolution, η. Different resolution values are shown for the dynamics with hard-bounds, linear (squares) and non-linear (triangles), i.e., L-HB and NL-HB. They show a very similar trend with slightly higher CA for the non-linear case. The investigated NL-SB dynamics (circles) share the same resolution (η = 500) but they give different CA results. In particular, for the NL-SB, the CA is reduced by the increase of non-linearity, λ, as shown in Figure 4B. In turn, the non-linearity does not affect significantly the performances of the non-linear synapses with hard bounds, for which the CA remains almost stable over a wide range of λ values. It is important to point out that NL-HB synapses with the highest non-linearity λ = 0.047 are also characterized by the lowest resolution η = 90 (please consider that the symbol color is indicative of the synaptic resolution η, according to the color reported on the right-hand side of the figure). In any case, both the low resolution and the high non-linearity affect the classification performance only by a small amount. In addition, it is worthless to notice that the L-HB synapses are all described by zero non-linearity (λ = 0).
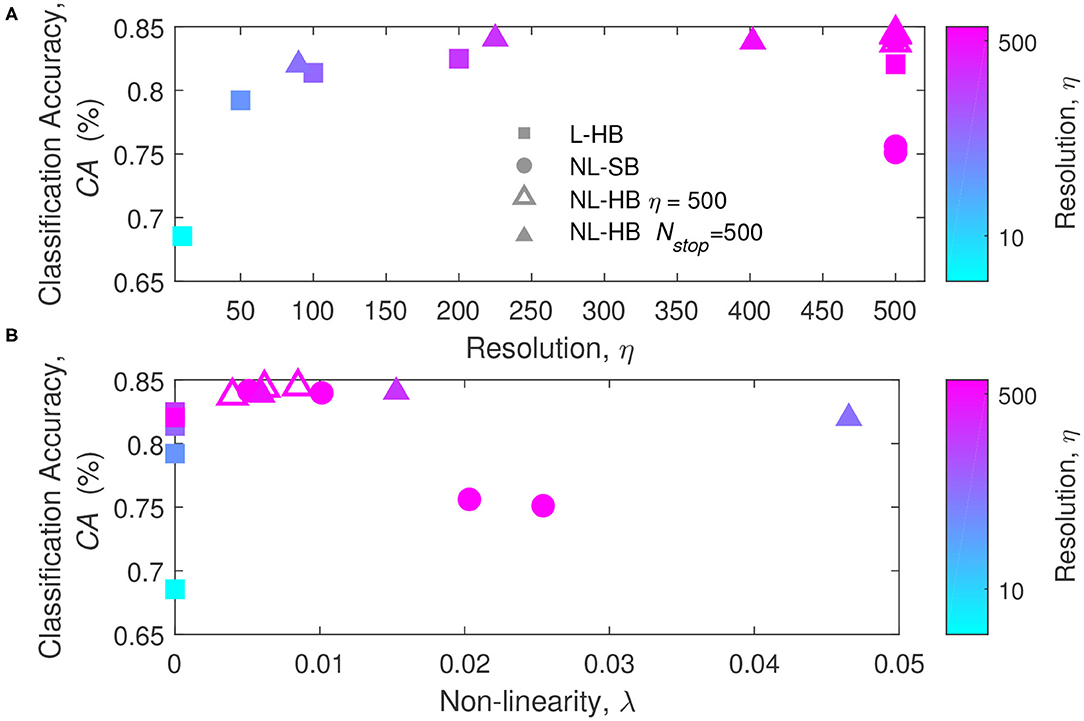
Figure 4. Classification accuracy as a function of the parameters η (A) and λ (B), for the L-HB, NL-SB, and NL-HB cases. The symbols color follow the resolution value, η, according to the color bars reported on the right sides of the panels.
In order to understand the previous results we monitor the learning dynamics, i.e., the CA as a function of the training time (i.e., number of training digits), which usually displays a growth and a saturation toward the final maximum value. The learning dynamics for all the investigated synaptic models are reported in Figure 5 (circles, left axis). With training, the synaptic weights evolve in a way that enables the distinction between the digits. In particular, it is well known that linear synapses, i.e., characterized by weight-independent plasticity, tend to develop bi-modal weight distributions after training (Song et al., 2000; van Rossum et al., 2000; Rubin et al., 2001; Billings and van Rossum, 2009). In this case, the weight values accumulate at the edges of the useful weight range, i.e., [0,1] in the present case. On the contrary, non-linear synapses with weight-dependent plasticity tend to result in a uni-modal weight distribution, with weight values accumulating in a value somewhere in the middle of the allowed weight range (Song et al., 2000; van Rossum et al., 2000; Rubin et al., 2001; Morrison et al., 2008; Billings and van Rossum, 2009; Brivio et al., 2019a). This is the result of the fact that strong (weak) synapses with non-linear dynamics are weakly potentiated (weakly depressed), which was shown to improve the memory capacity of the network on one side and, on the other, limit the synaptic specialization of the classification layer (Fusi and Abbott, 2007; Brivio et al., 2019a). As a matter of fact, in general, weight-dependent synapses and uni-modal distributions are considered less informative (Hennequin et al., 2010), because they correspond to a lower degree of specialization than weight-independent synapses and bi-modal distributions. Conversely, uni-modal distributions are considered more biologically realistic (Morrison et al., 2008). The weight distributions of the investigated cases at the end of the training are reported for the sake of completeness in the Supplementary Figure 2. In order to monitor the development of a weight specialization that enables the network to classify the input images, we analyze the clustering of the weights into two groups as a function of training through the k-means algorithm and consider the distance between the centers of the two clusters as a measure of the network specialization, which we will call weight contrast. Indeed, intuitively the weight contrast can be considered as the ability to take advantage of a wide portion of the available weight range. Other methods to group the weight values into two clusters are analyzed in the Supplementary Material and are in agreement with the k-means algorithm results. The weight contrast is reported in Figure 5 (squares, right axis) for the various dynamics cases. It is possible to notice that the linear cases develop a large weight contrast at the end of training (Figures 5A,B) in agreement with the general discussion above. The non-linear cases show lower weight contrast than the linear cases but with significant variations depending on the dynamics parameters (for instance, cf. Figures 5J,L for two different NL-HB cases). The weight contrast at the end of the training is plotted against the parameters η and λ in Figures 6A,B, respectively. Figure 6A shows that the L-HB case results in about the same contrast for every resolution, while in the NL-SB case the same synaptic resolution can give very different weight contrasts, depending on the non-linearity, λ (Figure 6B). The NL-HB case is the most interesting, because the additional parameter Nstop allows to increase the contrast either by reducing the resolution, as shown by the filled triangles in Figure 6A, or by reducing the non-linearity at equal resolution, as shown by the empty triangles in Figure 6B. Finally, Figure 6C reports the CA as a function of the weight contrast. It shows that L-HB synapses (squares) are all characterized by high contrast but only those with high resolution achieve high classification accuracy (please notice, again, that the symbol color is indicative of the synaptic resolution η, according to the color reported on the right-side of the figure). NL-SB synapses (circles) achieve high CA only when the weight dynamics develops a high contrast. This is obtained by reducing the non-linearity (please compare with Figure 6B). The classification results of the NL-HB synapses (triangles) are almost independent from the weight contrast obtained at the end of the training.
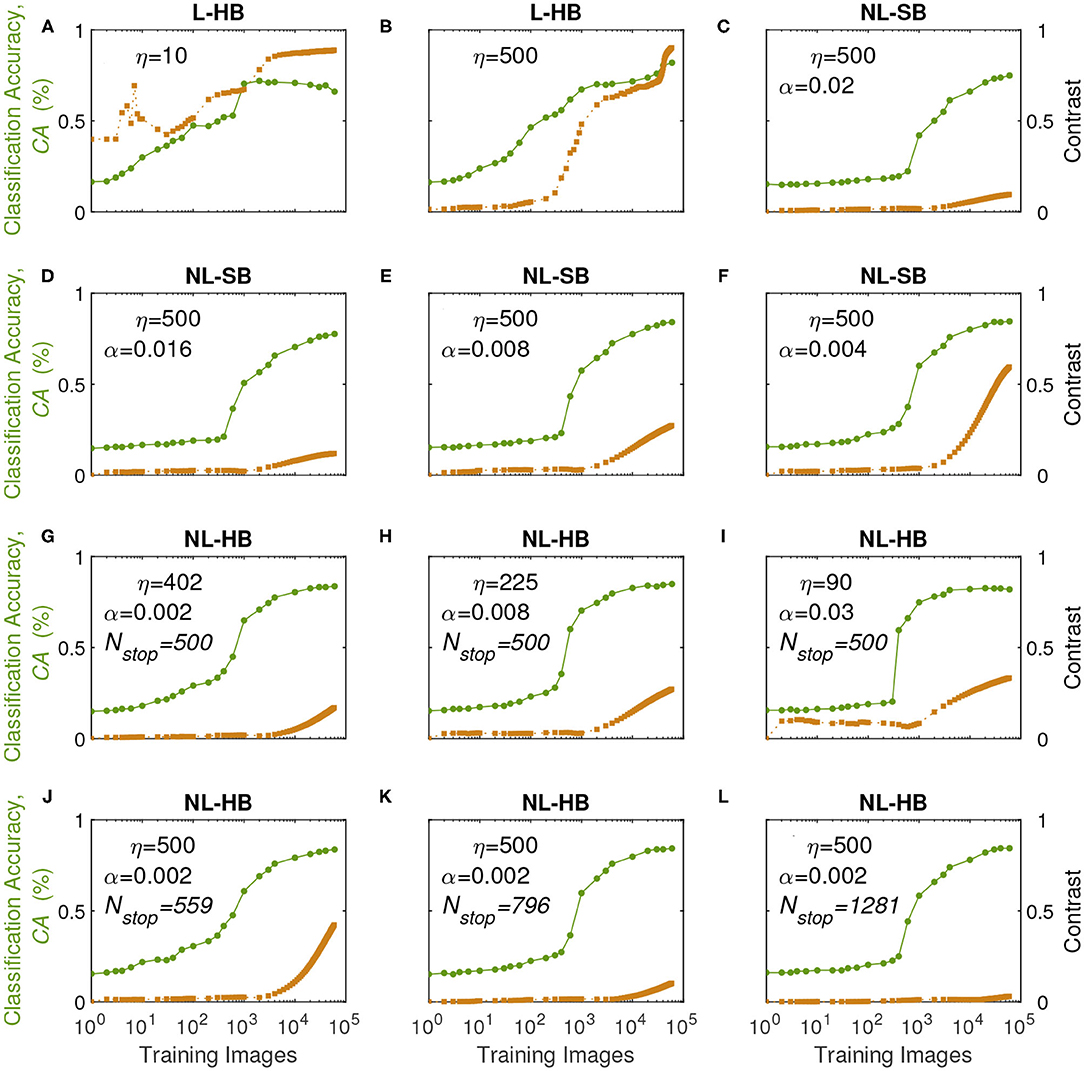
Figure 5. Classification Accuracy (CA, left axis) and weight contrast (right axis, as defined in the main text) as a function of the number of training images presented to the SNN for various dynamics in the different panels.
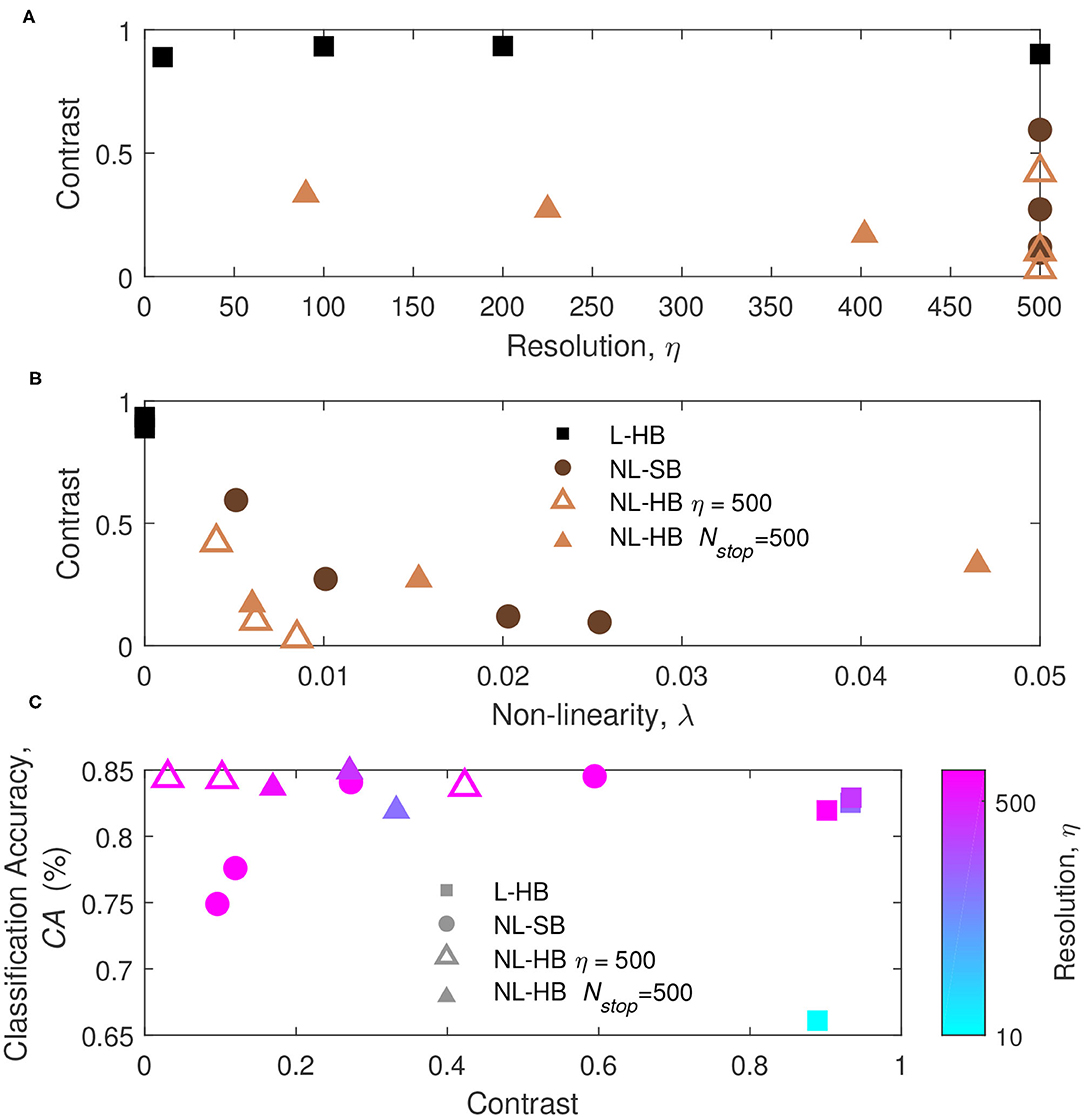
Figure 6. (A,B) Weight contrast at the end of the training as a function of the parameters η and λ, for the L-HB, NL-SB, and NL-HB cases. (C) Classification accuracy, CA, as a function of the weight contrast. The symbols color follow the resolution value, η, according to the color bar reported on the right side of panel.
The results of Figures 4, 6 constitute already a relevant result with respect to the state of the art. Indeed, linear synaptic dynamics is often considered as the best solution for any kind of hardware neural network, so that large efforts are spent to improve linearity of memristor dynamics (Wang et al., 2016; Bousoulas et al., 2017; Chen et al., 2019). Such belief may have raised as a generalization of the results of exemplary works on NN accelerators trained by back propagation of the error generalized to other networks and other training protocols (Burr et al., 2015; Fumarola et al., 2018). As a matter of fact, as mentioned above and shown in Figure 6B, linearity improves weight contrast and sustains the specialization of the network. However, it has been demonstrated that non-linear synapses improve memory lifetime and memory capacity of a network in which the rates of potentiation and depression events are not perfectly balanced (Fusi and Abbott, 2007). Furthermore, van Rossum et al. (2000) pointed out that STDP tends to make potentiated synapses more and more potentiated. Indeed, as a synapse is strengthened, its correlation with the post-synaptic neurons increases thus leading to a further potentiation. Van Rossum et al. demonstrated that this destabilizing tendency of STDP can be profitably counterbalanced by introducing weight-dependent plasticity (i.e., a non-linear dynamics) which produces a certain competition among synapses. The results in Figures 4, 6 can be generically ascribed to a different balance between contrast decrease, increase of memory lifetime, and synaptic competition with increasing non-linearity.
This result marks a difference with respect to memristor-based neural network accelerators trained by global error back-propagation for which the achievement of high weight contrast and bi-modal weight distribution taking advantage of the full weight range is fundamental for a successful training (Sidler et al., 2016; Fumarola et al., 2018).
Another important aspect to consider is the duration of the training process, which for some applications must be reduced to a minimum. To evaluate it, we define the parameter Δtrain as the fraction of training images required to reach 99% of the final classification accuracy over the total number of digits available for training, ntot (with ntot = 60,000 here). In symbols,
The parameter Δtrain is shown as a function of η and λ in Figures 7A,B, respectively. Figure 7A indicates a correlation between the synapse resolution and Δtrain. The correlation is somehow expected in case of a strong tendency to the formation of a bi-modal weight distribution, i.e., linear synapses (squares). Indeed, if the weight values tend to concentrate at the boundary values, the number of steps required to move the weight values from a generic initial one to the boundary scales with the synapse resolution. In agreement with this interpretation, the correlation between Δtrain and η is not perfect for the non-linear cases, because for the same resolution very different Δtrain values are obtained, as shown in Figure 7A in particular for the NL-SB cases (filled circles). Interestingly, the evolution of Δtrain as a function of λ follows opposite trends for soft and hard bound cases (also considering only the points at equal resolution, empty triangles and filled circles), as visible in Figure 7B. It is worth noticing that NL-SB and NL-HB with 500 levels resolution also show the same evolution of contrast as a function of non-linearity, as shown by filled circles and empty triangles in Figure 6B. Therefore, the opposite trends of Δtrain as a function of non-linearity cannot be explained by the need to develop, during training, a weight contrast that scales differently with non-linearity for NL-SB and NL-HB dynamics. On the contrary, the classification accuracy of NL-SB and NL-HB dynamics with the same 500 levels resolution follows opposite trends as a function of non-linearity, as indicated in Figure 4B (though the change for the NL-HB case is very modest). Therefore, the fact that both accuracy and training time follow opposite trends as a function of non-linearity can be an indication that, for non-linear dynamics, the training time is influenced by the maximum classification accuracy allowed by the particular synaptic dynamics. Finally, also considering the training time, the NL-HB cases (triangles) demonstrate more versatility than the other dynamics in reducing the training duration either by reducing the resolution, η (Figure 7A), or increasing the non-linearity, λ (Figure 7B).
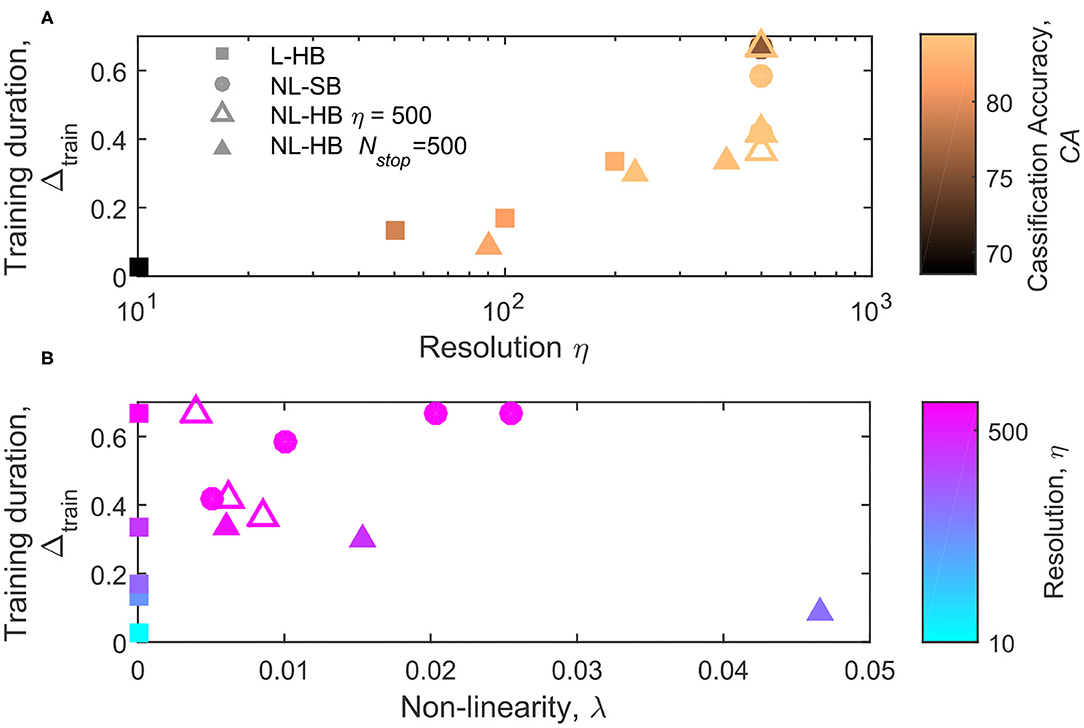
Figure 7. Training duration, Ntrain, as a function of the parameter η (A) and λ (B), for the L-HB, NL-SB, and NL-HB cases. The symbols colors in follow the classification accuracy, CA, in (A) and the resolution value, η, in (B) according to the color bars reported on the right sides of the panels.
All the results are summarized in Figure 8. Figure 8A reports the classification accuracy as a function of the training duration, Δtrain, for the various dynamics. The usual increase of CA with η is evident for the L-HB case, demonstrating that an increase in synaptic resolution produces a higher classification accuracy at the expense of longer training duration. This fact can be appreciated reminding that the symbol color follows the resolution, η, in agreement with the color bar on the right-hand side of the Figure 8. The saturation visible at high Δtrain may be just due to the fact that, during training, further CA increase takes longer and longer time. In Figure 8A, no general trend can be appreciated for NL-SB and NL-HB synapses. For instance, some NL-SB cases present long training times associated to a degraded CA as a consequence of the effect of the non-linearity, according to Figures 4, 7. In addition, for the NL-HB cases, the CA shows a limited dependence on Δtrain. In particular, the point corresponding to the lowest training duration, interestingly, guarantees almost the same classification performances as the points requiring a longer training. This case could be considered as the one realizing the best trade-off between classification accuracy and required training time. As a matter of principle, some applications may require both to maximize the CA and to minimize Δtrain (i.e., maximize 1−Δtrain). For this reason, we can define the SNN efficiency, ϵ, as
which is normalized between 0 and 1. ϵ values are shown in Figures 8B,C as a function of η and λ, respectively (all the achieved values of the performance metrics and a figure reporting the efficiency as a function of accuracy are reported in the Supplementary Material). The maximum efficiency is reached by the NL-HB case with the lowest resolution and the highest non-linearity (top- and left-most triangle in Figure 8B and top- and right-most triangle in Figure 8C, with η = 90 and λ = 0.047). It corresponds to the dynamics with α = 0.03 in Figure 2C, which grants a classification accuracy that is only slightly affected by resolution and non-linearity, as shown in Figure 4. Such highly non-linear and highly weight-dependent NL-HB dynamics resembles a NL-SB one and may endow the network with longer memory lifetime (Fusi and Abbott, 2007) and a higher synaptic competition within a STDP training framework (van Rossum et al., 2000), resulting in an improved synaptic contrast (right-most filled triangle in Figure 6C). Furthermore, the maximum efficiency dynamics takes advantage of a short training time justified by its low resolution, as shown in Figure 7A. In turn, for the L-HB cases (squares), the efficiency is degraded with increasing resolution as a consequence of the increase of the training duration, as shown in Figure 7A. The non-linearity, instead, deteriorates the efficiency of the NL-SB dynamics (circles in Figure 7C) because it both increases the training duration (Figure 7B) and reduces the classification accuracy (Figure 7).
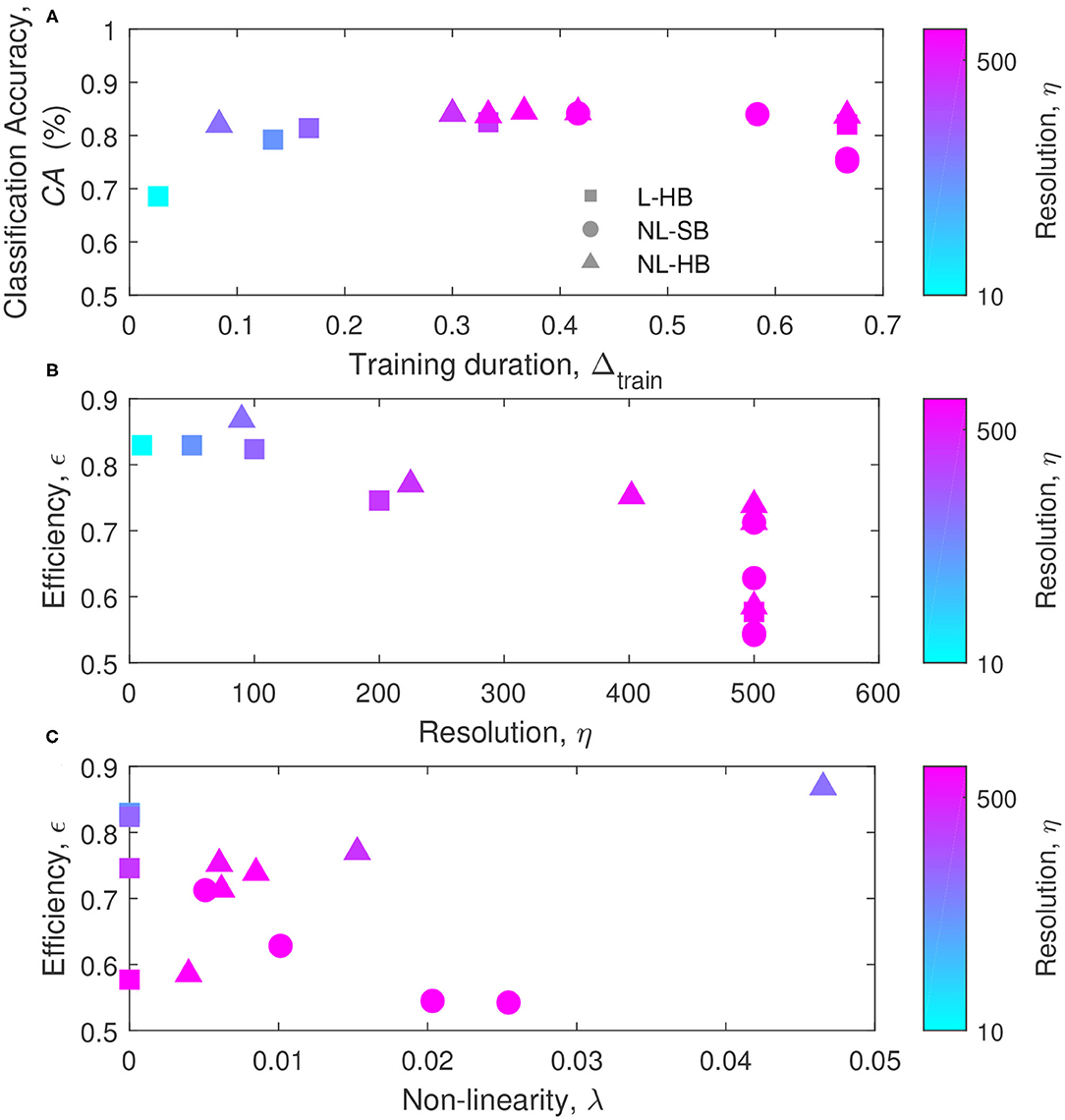
Figure 8. (A) Classification accuracy, CA, as a function of the training duration, Δtrain, for the various dynamics. (B) Efficiency as a function of the resolution, η, and (C) efficiency as a function of the non-linearity, λ. The symbols colors follow the resolution value, η, according to the color bars reported on the right sides of the panels.
4. Conclusions
In conclusion, we analyzed the impact of the synaptic weight dynamics on the performances of a two-layer fully-connected SNN compatible with a hybrid CMOS/memristive implementation and trained through an unsupervised STDP protocol. We chose weight dynamics that can be realized, at least as a matter of principle, through memristive technology. We found that synapses with non-linear dynamics and hard weight boundary values (NL-HB synapses) give performance advantages for a SNN with STDP-based learning in various aspects. First, NL-HB synapses guarantee the best classification accuracy among the investigated dynamics (see Figures 3, 4, 8A) over all the investigated range of resolution, η. It is worth noticing that this is a significant result in the context of the present literature. Indeed, it has been extensively demonstrated in several publications (Chen et al., 2015; Ambrogio et al., 2018; Fumarola et al., 2018; Moon et al., 2018) that linear synapses enable the best classification accuracy of neuromorphic systems that implement in hardware the back-propagation of the global error. This result has been extended, as a supposedly natural consequence, as holding true for SNNs. However, few recent works from the present authors (La Barbera et al., 2018; Brivio et al., 2019a) have given indications that non-linear synapses can perform better than linear ones for SNNs, which resulted in an interesting debate (Berg et al., 2019). In the present work, we put on firmer and quantitative basis the role of non-linearity on the performances of unsupervised and STDP-based SNNs.
Furthermore, for applications in which the training duration has to be minimized, the NL-HB dynamics also realized the best trade-off between classification accuracy and training duration, in agreement with the mathematical definition of efficiency given above (see Figure 8).
All these results are ascribed to the fact that the NL-HB dynamics produces a distinct behavior of the SNN, with respect to L-HB and NL-SB dynamics. Indeed, in case of hard-bounds, the classification accuracy and the weight contrast (ability to take advantage of a wide portion of the available weight range) is minimally affected by the non-linearity (compare NL-SB and NL-HB cases in Figures 4, 6). Moreover, the non-linearity of NL-HB synapses tends to reduce SNN training duration, in clear opposition with the trend of the soft-bound synapses (Figure 7B). This is the reason for the low training duration for the highly non-linear hard bound synapses, which results in a high efficiency, ϵ, according to the definition above (Figure 8).
In addition, it is interesting to make some considerations from a technological point of view. Memristive devices are characterized by an intrinsic non-linear conductance dynamics. More precisely, we have recently shown that the NL-SB dynamics is the model that faithfully describes the behavior of filamentary memristive devices (Frascaroli et al., 2018; Brivio et al., 2019a). On the other hand, technological efforts have been mainly focused on developing memristive synaptic devices with high resolution and low non-linearity because these are the requirement for hardware neural networks relying on back-propagation of the error. The linear dynamics is usually obtained by truncating the non-linear dynamics in the linear regime. This solution however limits the synapse resolution to a lower values with respect to those that can be obtained with a more complete non-linear dynamics. In fact, in the present study, the dynamics free parameters have been set to realistic values in particular for the non-linear cases. On the contrary, resolutions of 200 and 500 levels can hardly be obtained over a linear conductance evolution (Wang et al., 2016; Bousoulas et al., 2017; Chen et al., 2019). For instance, in one of the best literature results, Wang et al. (2016) reports a nearly linear dynamics over 300 pulses, indicating a resolution close to 300 levels. However, their data is best fitted with a NL-HB models with α = 0.004, γ = 1.02 and a resolution of about 266 levels. Therefore, according to our results, in the case of SNNs with STDP-based unsupervised training, higher classification accuracy values, or efficiency values, can be obtained with non-linear hard-bound synapses relaxing the requirements on resolution and non-linearity for memristive devices. Therefore, high performances for STDP-based SNNs can be obtained with moderately challenging device engineering by embracing, instead of facing, their intrinsic non-linear dynamics. It is worth specifying that simulations have intentionally been performed neglecting any source of variability in the synaptic elements in order to isolate the very effect of synaptic dynamics. From an experimental point of view, the various dynamics may be affected more or less seriously by noise and variability. In particular, we can expect the linear dynamics, being the most challenging in real devices as stated above, to be the most affected by noise and variability. However, a methodological experimental investigation on highly optimized devices is required in order to take into account the different role of dynamics-dependent variability in the simulations.
Finally, the present paper defines a methodology to assess the impact of synaptic dynamics on the performances of a neural network and provides the basis for future works applied to different training protocols, network architectures, applications, and different synaptic dynamics features, e.g., asymmetry between weight depression and potentiation processes and potentially different dynamics evolution, size of the readout layer and, as mentioned above, the impact of dynamics-specific noise and variability features, all of which can have an impact on the trade-offs pointed out in the manuscript.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author Contributions
SB conceived the idea and analyzed the data. DL performed the simulations and contributed to data analysis. EV and SS supervised the activity. All authors contributed to the manuscript writing.
Funding
This work was partially supported by the Horizon 2020 European project MeM-Scales—Memory technologies with multi-scale time constants for neuromorphic architectures (grant agreement No. 871371).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The reviewer HM declared a past co-authorship with two of the authors SB, SS to the handling editor.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fnins.2021.580909/full#supplementary-material
References
Agarwal, S., Plimpton, S. J., Hughart, D. R., Hsia, A. H., Richter, I., Cox, J. A., et al. (2016). “Resistive memory device requirements for a neura algorithm accelerator,” in 2016 International Joint Conference on Neural Networks (IJCNN) (Vancouver, BC), 929–938.
Ambrogio, S., Ciocchini, N., Laudato, M., Milo, V., Pirovano, A., Fantini, P., and Ielmini, D. (2016). Unsupervised learning by spike timing dependent plasticity in phase change memory (PCM) synapses. Front. Neurosci. 10:56. doi: 10.3389/fnins.2016.00056
Ambrogio, S., Narayanan, P., Tsai, H., Shelby, R. M., Boybat, I., Di Nolfo, C., et al. (2018). Equivalent-accuracy accelerated neural-network training using analogue memory. Nature 558:60. doi: 10.1038/s41586-018-0180-5
Azghadi, R., Chen, Y.-C., Eshraghian, J. K., Chen, J., Lin, C.-Y., Amirsoleimani, A., et al. (2020). Complementary metal-oxide semiconductor and memristive hardware for neuromorphic computing. Adv. Intell. Syst. 2:1900189. doi: 10.1002/aisy.201900189
Berg, A., Brivio, S., Brown, S., Burr, G., Deswal, S., Deuermeier, J., Gale, E., et al. (2019). Synaptic and neuromorphic functions: general discussion. Faraday Discuss. 213, 553–578. doi: 10.1039/C8FD90065E
Bichler, O., Roclin, D., Gamrat, C., and Querlioz, D. (2013). “Design exploration methodology for memristor-based spiking neuromorphic architectures with the Xnet event-driven simulator,” in 2013 IEEE/ACM International Symposium on Nanoscale Architectures (NANOARCH) (Brooklyn, NY), 7–12. doi: 10.1109/NanoArch.2013.6623029
Bill, J., and Legenstein, R. (2014). A compound memristive synapse model for statistical learning through STDP in spiking neural networks. Front. Neurosci. 8:412. doi: 10.3389/fnins.2014.00412
Billings, G., and van Rossum, M. C. W. (2009). Memory retention and spike-timing-dependent plasticity. J. Neurophysiol. 101, 2775–2788. doi: 10.1152/jn.91007.2008
Bocquet, M., Hirztlin, T., Klein, J.-O., Nowak, E., Vianello, E., Portal, J.-M., et al. (2018). “In-memory and error-immune differential RRAM implementation of binarized deep neural networks,” in 2018 IEEE International Electron Devices Meeting (IEDM) (San Francisco, CA), 20.6.1–20.6.4. doi: 10.1109/IEDM.2018.8614639
Bousoulas, P., Michelakaki, I., Skotadis, E., Tsigkourakos, M., and Tsoukalas, D. (2017). Low-power forming free TiO2−x/HfO2−y/TiO2−x-trilayer RRAM devices exhibiting synaptic property characteristics. IEEE Trans. Electron Devices 64, 3151–3158. doi: 10.1109/TED.2017.2709338
Bouvier, M., Alexandre, V., Mesquida, T., Rummens, F., Reyboz, M., Vianello, E., et al. (2019). Spiking neural networks hardware implementations and challenges: a survey. ACM J. Emerg. Technol. Comput. Syst. 15, 1–35. doi: 10.1145/3304103
Brivio, S., Conti, D., Nair, M. V., Frascaroli, J., Covi, E., Ricciardi, C., et al. (2019a). Extended memory lifetime in spiking neural networks employing memristive synapses with nonlinear conductance dynamics. Nanotechnology 30:015102. doi: 10.1088/1361-6528/aae81c
Brivio, S., Frascaroli, J., Covi, E., and Spiga, S. (2019b). Stimulated ionic telegraph noise in filamentary memristive devices. Sci. Rep. 9:6310. doi: 10.1038/s41598-019-41497-3
Brivio, S., Frascaroli, J., and Spiga, S. (2017). Role of Al doping in the filament disruption in HfO2 resistance switches. Nanotechnology 28:395202. doi: 10.1088/1361-6528/aa8013
Brivio, S., and Menzel, S. (2020). “Chapter 2 - resistive switching memories,” in Memristive Devices for Brain-Inspired Computing, Woodhead Publishing Series in Electronic and Optical Materials, eds S. Spiga, A. Sebastian, D. Querlioz, and B. Rajendran (Chennai: Woodhead Publishing), 17–61. doi: 10.1016/B978-0-08-102782-0.00002-2
Burr, G. W., Shelby, R. M., Sidler, S., di Nolfo, C., Jang, J., Boybat, I., et al. (2015). Experimental demonstration and tolerancing of a large-scale neural network (165, 000 synapses) using phase-change memory as the synaptic weight element. IEEE Trans. Electron Dev. 62, 3498–3507. doi: 10.1109/TED.2015.2439635
Chen, J., Lin, C., Li, Y., Qin, C., Lu, K., Wang, J., et al. (2019). LiSiOX-based analog memristive synapse for neuromorphic computing. IEEE Electron Dev. Lett. 40, 542–545. doi: 10.1109/LED.2019.2898443
Chen, P. Y., Lin, B., Wang, I. T., Hou, T. H., Ye, J., et al. (2015). “Mitigating effects of non-ideal synaptic device characteristics for on-chip learning,” in 2015 IEEE/ACM International Conference on Computer-Aided Design (ICCAD) (Austin, TX), 194–199.
Covi, E., Brivio, S., Serb, A., Prodromakis, T., Fanciulli, M., and Spiga, S. (2016). Analog memristive synapse in spiking networks implementing unsupervised learning. Front. Neurosci. 10:482. doi: 10.3389/fnins.2016.00482
Covi, E., George, R., Frascaroli, J., Brivio, S., Mayr, C., Mostafa, H., et al. (2018). Spike-driven threshold-based learning with memristive synapses and neuromorphic silicon neurons. J. Phys. D Appl. Phys. 51:344003. doi: 10.1088/1361-6463/aad361
Dalgaty, T., Payvand, M., De Salvo, B., Casas, J., Lama, G., Nowak, E., et al. (2019). “Hybrid cmos-rram neurons with intrinsic plasticity,” in 2019 IEEE International Symposium on Circuits and Systems (ISCAS) (Sapporo), 1–5. doi: 10.1109/ISCAS.2019.8702603
Diehl, P. U., and Cook, M. (2015). Unsupervised learning of digit recognition using spike-timing-dependent plasticity. Front. Comput. Neurosci. 9:99. doi: 10.3389/fncom.2015.00099
Diehl, P. U., Neil, D., Binas, J., Cook, M., Liu, S., and Pfeiffer, M. (2015). “Fast-classifying, high-accuracy spiking deep networks through weight and threshold balancing,” in 2015 International Joint Conference on Neural Networks (IJCNN) (Killarney), 1–8. doi: 10.1109/IJCNN.2015.7280696
Diehl, P. U., Zarrella, G., Cassidy, A., Pedroni, B. U., and Neftci, E. (2016). “Conversion of artificial recurrent neural networks to spiking neural networks for low-power neuromorphic hardware,” in 2016 IEEE International Conference on Rebooting Computing (ICRC) (San Diego, CA), 1–8. doi: 10.1109/ICRC.2016.7738691
Donati, E., Payvand, M., Risi, N., Krause, R., and Indiveri, G. (2019). Discrimination of EMG signals using a neuromorphic implementation of a spiking neural network. IEEE Trans. Biomed. Circuits Syst. 13, 795–803. doi: 10.1109/TBCAS.2019.2925454
Frascaroli, J., Brivio, S., Covi, E., and Spiga, S. (2018). Evidence of soft bound behaviour in analogue memristive devices for neuromorphic computing. Sci. Rep. 8, 1–12. doi: 10.1038/s41598-018-25376-x
Frascaroli, J., Volpe, F. G., Brivio, S., and Spiga, S. (2015). Effect of Al doping on the retention behavior of HfO2 resistive switching memories. Microelectron. Eng. 147, 104–107. doi: 10.1016/j.mee.2015.04.043
Fumarola, A., Sidler, S., Moon, K., Jang, J., Shelby, R. M., Narayanan, P., et al. (2018). Bidirectional non-filamentary RRAM as an analog neuromorphic synapse, part ii: impact of Al/Mo/Pr0.7Ca0.3MnO3 device characteristics on neural network training accuracy. IEEE J. Electron Devices Soc. 6, 169–178. doi: 10.1109/JEDS.2017.2782184
Fusi, S., and Abbott, L. F. (2007). Limits on the memory storage capacity of bounded synapses. Nat. Neurosci. 10:485. doi: 10.1038/nn1859
Garbin, D., Bichler, O., Vianello, E., Rafhay, Q., Gamrat, C., Perniola, L., et al. (2014). “Variability-tolerant Convolutional Neural Network for Pattern Recognition applications based on OxRAM synapses,” in 2014 IEEE International, Electron Devices Meeting (IEDM) (San Francisco, CA), 28.4.1–28.4.4. doi: 10.1109/IEDM.2014.7047126
Garbin, D., Vianello, E., Bichler, O., Rafhay, Q., Gamrat, C., Ghibaudo, G., et al. (2015). HfO2-based OxRAM devices as synapses for convolutional neural networks. IEEE Trans. Electron Devices 62, 2494–2501. doi: 10.1109/TED.2015.2440102
Gokmen, T., and Vlasov, Y. (2016). Acceleration of deep neural network training with resistive cross-point devices: design considerations. Front. Neurosci. 10:333. doi: 10.3389/fnins.2016.00333
Hennequin, G., Gerstner, W., and Pfister, J.-P. (2010). STDP in adaptive neurons gives close-to-optimal information transmission. Front. Comput. Neurosci. 4:143. doi: 10.3389/fncom.2010.00143
Indiveri, G., Linares-Barranco, B., Legenstein, R., Deligeorgis, G., and Prodromakis, T. (2013). Integration of nanoscale memristor synapses in neuromorphic computing architectures. Nanotechnology 24:384010. doi: 10.1088/0957-4484/24/38/384010
Jang, J. W., Park, S., Burr, G. W., Hwang, H., and Jeong, Y. H. (2015). Optimization of conductance Change in Pr1−xCaxMnO3-based synaptic devices for neuromorphic systems. IEEE Electron Device Lett. 36, 457–459. doi: 10.1109/LED.2015.2418342
La Barbera, S., Ly, D. R. B., Navarro, G., Castellani, N., Cueto, O., Bourgeois, G., et al. (2018). Narrow heater bottom electrode-based phase change memory as a bidirectional artificial synapse. Adv. Electron. Mater. 4:1800223. doi: 10.1002/aelm.201800223
Lecun, Y., Bottou, L., Bengio, Y., and Haffner, P. (1998). Gradient-based learning applied to document recognition. Proc. IEEE 86, 2278–2324. doi: 10.1109/5.726791
Lee, D., Moon, K., Park, J., Park, S., and Hwang, H. (2015). Trade-off between number of conductance states and variability of conductance change in pr0.7ca0.3mno3-based synapse device. Appl. Phys. Lett. 106:113701. doi: 10.1063/1.4915924
Ly, D. R. B., Grossi, A., Fenouillet-Beranger, C., Nowak, E., Querlioz, D., and Vianello, E. (2018). Role of synaptic variability in resistive memory-based spiking neural networks with unsupervised learning. J. Phys. D 51:444002. doi: 10.1088/1361-6463/aad954
Moon, K., Fumarola, A., Sidler, S., Jang, J., Narayanan, P., Shelby, R. M., et al. (2018). Bidirectional non-filamentary RRAM as an analog neuromorphic synapse, part I: Al/Mo/Pr0.7Ca0.3MnO3 material improvements and device measurements. IEEE J. Electron Devices Soc. 6, 146–155. doi: 10.1109/JEDS.2017.2780275
Morrison, A., Diesmann, M., and Gerstner, W. (2008). Phenomenological models of synaptic plasticity based on spike timing. Biol. Cybern. 98, 459–478. doi: 10.1007/s00422-008-0233-1
Mostafa, H., Mayr, C., and Indiveri, G. (2016). “Beyond spike-timing dependent plasticity in memristor crossbar arrays,” in 2016 IEEE International Symposium on Circuits and Systems (ISCAS) (Montreal, QC), 926–929. doi: 10.1109/ISCAS.2016.7527393
Müller, L. K., Nair, M. V., and Indiveri, G. (2017). “Randomized unregulated step descent for limited precision synaptic elements,” in 2017 IEEE International Symposium on Circuits and Systems (ISCAS) (Baltimore, MD), 1–4. doi: 10.1109/ISCAS.2017.8050217
Nair, M. V., Muller, L. K., and Indiveri, G. (2017). A differential memristive synapse circuit for on-line learning in neuromorphic computing systems. Nano Futures 1:035003. doi: 10.1088/2399-1984/aa954a
Park, J., Kwak, M., Moon, K., Woo, J., Lee, D., and Hwang, H. (2016). TiOx-based RRAM synapse with 64-levels of conductance and symmetric conductance change by adopting a hybrid pulse scheme for neuromorphic computing. IEEE Electron Device Lett. 37, 1559–1562. doi: 10.1109/LED.2016.2622716
Payvand, M., Muller, L. K., and Indiveri, G. (2018). “Event-based circuits for controlling stochastic learning with memristive devices in neuromorphic architectures,” in 2018 IEEE International Symposium on Circuits and Systems (ISCAS) (Florence), 1–5. doi: 10.1109/ISCAS.2018.8351544
Pedretti, G., Milo, V., Ambrogio, S., Carboni, R., Bianchi, S., Calderoni, A., et al. (2017). Memristive neural network for on-line learning and tracking with brain-inspired spike timing dependent plasticity. Sci. Rep. 7, 1–10. doi: 10.1038/s41598-017-05480-0
Querlioz, D., Bichler, O., Dollfus, P., and Gamrat, C. (2013). Immunity to device variations in a spiking neural network with memristive nanodevices. IEEE Trans. Nanotechnol. 12, 288–295. doi: 10.1109/TNANO.2013.2250995
Querlioz, D., Bichler, O., Vincent, A. F., and Gamrat, C. (2015). Bioinspired programming of memory devices for implementing an inference engine. Proc. IEEE 103, 1398–1416. doi: 10.1109/JPROC.2015.2437616
Regev, A., Bricalli, A., Piccolboni, G., Valentian, A., Mesquida, T., Molas, G., et al. (2020). “Fully-integrated spiking neural network using siox-based rram as synaptic device,” in 2020 2nd IEEE International Conference on Artificial Intelligence Circuits and Systems (AICAS) (Genova), 145–148. doi: 10.1109/AICAS48895.2020.9073840
Rubin, J., Lee, D. D., and Sompolinsky, H. (2001). Equilibrium properties of temporally asymmetric hebbian plasticity. Phys. Rev. Lett. 86, 364–367. doi: 10.1103/PhysRevLett.86.364
Sengupta, A., Ye, Y., Wang, R., Liu, C., and Roy, K. (2019). Going deeper in spiking neural networks: VGG and residual architectures. Front. Neurosci. 13:95. doi: 10.3389/fnins.2019.00095
Sidler, S., Boybat, I., Shelby, R. M., Narayanan, P., Jang, J., Fumarola, A., et al. (2016). “Large-scale neural networks implemented with non-volatile memory as the synaptic weight element: impact of conductance response,” in 2016 46th European Solid-State Device Research Conference (ESSDERC) (Lausanne), 440–443. doi: 10.1109/ESSDERC.2016.7599680
Song, S., Miller, K. D., and Abbott, L. F. (2000). Competitive Hebbian learning through spike-timing-dependent synaptic plasticity. Nat. Neurosci. 3, 919–926. doi: 10.1038/78829
Spiga, S., Sebastian, A., Querlioz, D., and Rajendran, B. (2020). Memristive Devices for Brain-Inspired Computing. Chennai: Woodhead Publishing.
Suri, M., Bichler, O., Querlioz, D., Cueto, O., Periola, L., Sousa, V., et al. (2011). “Phase change memory as synapse for ultra-dense neuromorphicsystems: application to complex visual pattern extraction,” in 2011 International Electron Devices Meeting (Washington, DC), 4.4.1–4.4.4.
Urbanczik, R., and Senn, W. (2014). Learning by the dendritic prediction of somatic spiking. Neuron 81, 521–528. doi: 10.1016/j.neuron.2013.11.030
Valentian, A., Rummens, F., Vianello, E., Mesquida, T., de Boissac, C. L., Bichler, O., et al. (2019). “Fully integrated spiking neural network with analog neurons and RRAM synapses,” in 2019 IEEE International Electron Devices Meeting (IEDM), 14.3.1–14.3.4. doi: 10.1109/IEDM19573.2019.8993431
van Rossum, M. C. W., Bi, G. Q., and Turrigiano, G. G. (2000). Stable hebbian learning from spike timing-dependent plasticity. J. Neurosci. 20, 8812–8821. doi: 10.1523/JNEUROSCI.20-23-08812.2000
Wang, Z., Yin, M., Zhang, T., Cai, Y., Wang, Y., Yang, Y., et al. (2016). Engineering incremental resistive switching in TaOx based memristors for brain-inspired computing. Nanoscale 8, 14015–14022. doi: 10.1039/C6NR00476H
Yu, S. (2018). Neuro-inspired computing with emerging nonvolatile memory. Proc. IEEE 106, 260–285. doi: 10.1109/JPROC.2018.2790840
Keywords: spiking neural network, MNIST, neuromorphic, analog memory, STDP, memristive synapse, memristor, memristive devices
Citation: Brivio S, Ly DRB, Vianello E and Spiga S (2021) Non-linear Memristive Synaptic Dynamics for Efficient Unsupervised Learning in Spiking Neural Networks. Front. Neurosci. 15:580909. doi: 10.3389/fnins.2021.580909
Received: 07 July 2020; Accepted: 06 January 2021;
Published: 01 February 2021.
Edited by:
Michael Pfeiffer, Bosch Center for Artificial Intelligence, GermanyCopyright © 2021 Brivio, Ly, Vianello and Spiga. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Stefano Brivio, c3RlZmFuby5icml2aW9AbWRtLmltbS5jbnIuaXQ=