 Yan Chen1,2†
Yan Chen1,2† Wenlong Hang
Wenlong Hang Shuang Liang
Shuang Liang Guanglin Li
Guanglin Li Jing Qin
Jing Qin- 1School of Computer Science and Technology, Nanjing Tech University, Nanjing, China
- 2Key Laboratory of Child Development and Learning Science, Ministry of Education, Southeast University, Nanjing, China
- 3Smart Health Big Data Analysis and Location Services Engineering Lab of Jiangsu Province, Nanjing University of Posts and Telecommunications, Nanjing, China
- 4CAS Key Laboratory of Human-Machine Intelligence-Synergy Systems, Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences, Shenzhen, China
- 5Guangdong-Hong Kong-Macao Joint Laboratory of Human-Machine Intelligence-Synergy Systems, Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences, Shenzhen, China
- 6School of Nursing, The Hong Kong Polytechnic University, Hong Kong, China
In recent years, emerging matrix learning methods have shown promising performance in motor imagery (MI)-based brain-computer interfaces (BCIs). Nonetheless, the electroencephalography (EEG) pattern variations among different subjects necessitates collecting a large amount of labeled individual data for model training, which prolongs the calibration session. From the perspective of transfer learning, the model knowledge inherent in reference subjects incorporating few target EEG data have the potential to solve the above issue. Thus, a novel knowledge-leverage-based support matrix machine (KL-SMM) was developed to improve the classification performance when only a few labeled EEG data in the target domain (target subject) were available. The proposed KL-SMM possesses the powerful capability of a matrix learning machine, which allows it to directly learn the structural information from matrix-form EEG data. In addition, the KL-SMM can not only fully leverage few labeled EEG data from the target domain during the learning procedure but can also leverage the existing model knowledge from the source domain (source subject). Therefore, the KL-SMM can enhance the generalization performance of the target classifier while guaranteeing privacy protection to a certain extent. Finally, the objective function of the KL-SMM can be easily optimized using the alternating direction method of multipliers method. Extensive experiments were conducted to evaluate the effectiveness of the KL-SMM on publicly available MI-based EEG datasets. Experimental results demonstrated that the KL-SMM outperformed the comparable methods when the EEG data were insufficient.
Introduction
Brain-computer interface (BCI) systems enable machines to accurately perceive the mental states of human beings, thereby establishing an effective user interface between humans and machines. There are several kinds of BCI paradigms, such as steady-state visual evoked potentials (Allison et al., 2008), P300 (Salvaris and Sepulveda, 2009), and motor imagery (MI) (Pfurtscheller and Neuper, 2001). Among them, the MI-based BCI is widely used because of its self-paced fashion, and it does not require any external stimuli (Pfurtscheller and Da Silva, 1999). Electroencephalography (EEG) is the most extensively used technique to record neuronal activity in the brain due to its high temporal resolution, portability, and non-invasiveness. EEG-based motor imagery BCI has shown great potential in many applications, such as rehabilitating the sensory-motor functions of disabled patients (Ang et al., 2011; Al-Qaysi et al., 2018) and facilitating smart living for healthy people (Vourvopoulos et al., 2017; Wang et al., 2019).
Although many machine learning algorithms have been developed to implement MI-based BCI with great success, most of them need to collect a considerable amount of labeled EEG data for model training, which is exceedingly time-consuming and labor-intensive. Insufficient labeled EEG data weaken the generalization capability of the classifier in the prediction. An intuitive solution to this problem is to leverage historical EEG data from the source domain (source subject) in modeling the target domain (target subject). However, this approach may engender some challenges. Owing to the EEG pattern variations between different subjects (Morioka et al., 2015), directly using the EEG data of the source domain may cause performance degradation. Furthermore, because the original EEG data contains personal information, the data of other subjects may not always be available for constructing the classifier for privacy reasons (Agarwal et al., 2019). Thus, exploring an effective knowledge transfer strategy that can protect the personal information of a source subject is highly desirable in the MI-based BCI.
From the perspective of transfer learning (Pan and Yang, 2009), the model knowledge of the source domain can potentially be leveraged to address these problems. Generally, EEG-based learning methods involve two steps: EEG feature extraction and classification. The model knowledge of the source domain can either be integrated into the feature extraction process (Kang et al., 2009; Samek et al., 2013), or be used in modeling the classifier (Azab et al., 2019). Specifically, Kang et al. (2009) proposed leveraging the linear combination of covariance matrices of the source subjects as reference during the feature extraction of the target EEG data. Azab et al. (2019) proposed the construction of multiple-source models and transfer of the weighted multiple-source model knowledge to the target domain. Deng et al. (2013) proposed a knowledge-leverage-based fuzzy system that can leverage the model knowledge from the source domain in order to make up for the lack of labeled target data as well as privacy protection.
Although it has been empirically demonstrated that the aforementioned methods are effective in dealing with EEG classification in scenarios where the labeled data are limited, these methods always need to transform the input data into vectors before classification. It is well known that EEG signals record brain activities over a period of time from multiple channels, which are naturally represented as matrices. Transforming the input matrices into vectors may destroy the correlation of rows or columns within matrix-form EEG features. Thus, several classification methods that can directly handle these matrix-form data have been developed accordingly. For example, Wolf et al. (2007) proposed modeling the regression matrix of a support vector machine (SVM), which is the sum of the k rank-one orthogonal matrices (rank-k SVM). Pirsiavash et al. (2009) proposed a bilinear SVM (BSVM) based on factorizing the regression matrix into the product of two low-rank matrices. Although these methods can capture the correlation within matrix data, pre-determining the rank of the regression matrix requires a tedious tuning procedure. Luo et al. (2015) proposed combining the nuclear norm and squared Frobenius norm of the regression matrix to derive the support matrix machine (SMM). The cornerstone of the SMM uses the nuclear norm of the regression matrix as the convex approximation of the matrix rank; thus, its optimization problem becomes more tractable and can be solved using the alternating direction method of multipliers (ADMM) method. Based on SMM, Zheng et al. proposed multiclass SMM (Zheng et al., 2018c) and sparse SMM (Zheng et al., 2018b) for EEG data. Although existing matrix classification methods can effectively deal with the matrix-form EEG data, they have not taken the transferrable knowledge into consideration to improve EEG classification performance. They may suffer from the weak generalization capability when the available EEG data are insufficient.
We propose a novel knowledge-leverage-based matrix classification method for MI-based EEG classification at the first time. The proposed knowledge-leverage-based SMM (KL-SMM) can address the above-mentioned problems by integrating the model knowledge from the source domain and a few labeled target EEG data. It possesses the powerful capability of the SMM for learning matrix-form data. Furthermore, the model knowledge of the source domain can be used to compensate for the deficiency in learning due to the lack of labeled target EEG data. Different from most current model parameter transfer learning methods, the proposed method can propagate the structural information from the source model to the target model. Hence, the generalization capability can be greatly enhanced by transferring the model knowledge and structural information of the source domain. Instead of directly using the source EEG data, the KL-SMM can afford privacy protection by leveraging only the model knowledge of the source domain. In addition, it can be efficiently optimized through the ADMM method. We conducted extensive experiments on two publicly available EEG datasets to validate the effectiveness of the proposed method. As demonstrated by the experimental results, the KL-SMM can achieve promising results in scenarios with few labeled target EEG data.
The remainder of this paper is organized as follows: Section “Related Works” is a review of related works. In Section “Matrix Learning Preliminaries”, the notations and preliminaries of the SMM are introduced. The KL-SMM model and its learning algorithm are described in Section “Knowledge-Leverage-Based SMM”. In Section “Experiments”, the details of extensive experiments and analyses are presented. The conclusions of the paper are presented in Section “Conclusion”.
Related Works
Transfer learning has emerged as a novel technique for retaining and reusing knowledge learned from historical tasks for new tasks. As described above, transfer learning generally refers to the knowledge-leverage-based learning mechanism, which can extract useful knowledge from the source domain and propagate them as the supervision information for modeling the target domain. According to the types of transferred knowledge of the source domain, most current research on transfer learning for EEG classification can be broadly divided into the following categories: (1) instance transfer, (2) feature representation transfer, and (3) model parameter transfer (Wang et al., 2015).
For the first category, it is assumed that the partial source EEG data can be selected and considered together with few labeled target EEG data. The source EEG data are obtained through either instance selection or importance sampling cross-validation (Li et al., 2010; Hossain et al., 2016, 2018; Zanini et al., 2018). For example, Hossain et al. (2016) proposed an instance selection strategy based on active learning. The selected source EEG data were then used together with available target-labeled EEG data to train the target model. Li et al. (2010) demonstrated the possibility of weighing the source EEG data through the importance sampling cross-validation strategy, following which the source data with high weights were used to estimate the target classifier.
The aim of the feature representation transfer method is to learn a good feature representation, which has some relevant source knowledge encoded within it, for the target subject. Most feature representation transfer learning methods were developed based on the common spatial patterns (CSP) through the modification of the covariance matrix or optimization function (Kang et al., 2009; Lotte and Guan, 2010; Samek et al., 2013). For example, Samek et al. (2013) developed an extension of the CSP. They proposed learning a stationary subspace in which the stationary information of multiple subjects can be transferred. In addition to the above-mentioned shallow feature representation transfer learning methods, several deep transfer learning methods (Fahimi et al., 2019; Hang et al., 2019) have been proposed. In general, these methods apply the domain adaptation techniques in a task-specific layer to incorporate the learned source and target deep features into a common feature space. For example, Hang et al. (2019) proposed leveraging the maximum mean discrepancy and the center-based discriminative feature learning techniques simultaneously to reduce the domain shift, demonstrating a performance improvement in the MI-based BCI.
The third category is the model parameter transfer, which assumes that the source subjects and target subjects share some parameters or prior distributions of the models. Model parameter transfer learning methods always leverage source models to model the target subjects in EEG classification. For example, Azab et al. (2019) proposed a logistic regression-based transfer learning method. The linear combination of multiple-source models was transferred for the construction of the target domain. In Alamgir et al. (2010); Jayaram et al. (2016), Alamgir et al. proposed a multi-task learning method to improve the generalization performance of the EEG classification for individual subjects using subject-specific information, as well as the shared model knowledge inherent in all available subjects.
Despite these successes, most current transfer learning methods require the direct use of source EEG data, which may cause the issue of privacy disclosure, especially for biomedical information. Furthermore, existing transfer learning methods used for EEG recognition always built on that the input data are vectors. However, transforming EEG data, which are naturally represented as matrices, into vectors will destroy their structural information. The proposed method belongs to the third category. Unlike the previous transfer learning methods, the KL-SMM can incorporate model knowledge from the source domain, thereby guaranteeing privacy protection to some extent; it can also directly handle matrix-form EEG data.
Matrix Learning Preliminaries
Among the current matrix learning methods, the SMM (Luo et al., 2015) and its variants [e.g., (Zheng et al., 2018a)] are applied in many fields, owing to their simplicity and effectiveness. In this section, we present some notations and preliminary knowledge on the SMM, which are the foundation of the proposed KL-SMM method.
Mathematical Notations
Matrices are denoted by bold uppercase letters (i.e., X) in the following. For a matrix X ∈ ℝd1×d2 of rank r, it can be expressed as rank(X) = r. The condensed singular value decomposition (SVD) of X is denoted as , where UX ∈ ℝd1×r and VX ∈ ℝd2×r satisfy and , and ∑X = diag(σ1(X),σ2(X),…,σr(X)) with σ1(X)≥σ2(X)≥⋯≥σr(X) > 0.
Definition 1. Given any τ > 0, the singular value thresholding (SVT) (Cai et al., 2010) of matrix X is defined as
where Sτ[∑X] = diag({σ1(X)−τ} +,{σ2(X)−τ} +,…,{σr(X)−τ} +) and {z} + = max(z,0).
Let be the Frobenius norm of X, denotes the nuclear norm of X, and the subdifferential of ∥X∥* can be defined as follows.
Definition 2. The subdifferential of ∥X∥*, that is, ∂∥X∥* (Candes and Recht, 2009), can be formulated as
where ∥Z∥2 = σ1(Z) denotes the spectral norm of Z.
SMM
The matrix classifier, SMM, is defined as a penalty function plus a hinge loss. The penalty function, i.e., spectral elastic net, which enjoys the property of grouping effect as well as keeping a low-rank representation. The hinge loss enjoys the property of large margin while contributing to the sparseness and robustness of the classifier. The objective function of the SMM can be formulated as follows:
Specifically, the spectral elastic net can be represented as a combination of the squared Frobenius matrix norm and nuclear norm ∥W∥* on the regression matrix W.
The objective function of the SMM can be solved through the ADMM method; thus, Eq. (3) is reformulated as
where + b]} + and G(S) = τ∥S∥*.
According to the augmented Lagrangian function in Eq. (4), (W,b) and S can be iteratively computed in two steps:
where k denotes the iteration index. ρ > 0 is a hyperparameter, and Λ is a Lagrangian multiplier.
Knowledge-Leverage-Based SMM
Generally, the current SMM and its variants belong to the data-driven method that always focuses on achieving impressive classification performance with sufficient training data. In practice, it is necessary to collect sufficient EEG data for each subject to establish a subject-specific classifier. However, long-term recording EEG data may exhaust the subject. Therefore, to model the target domain using insufficient EEG data, we proposed a novel algorithm to enhance the generalization capability of the SMM on the target domain by leveraging the useful knowledge underlying the source domain.
The framework of the KL-SMM for an EEG-based MI BCI is illustrated in Figure 1. To model the target domain, two main types of information, the model knowledge of the source domain and few labeled target EEG data, are used simultaneously.
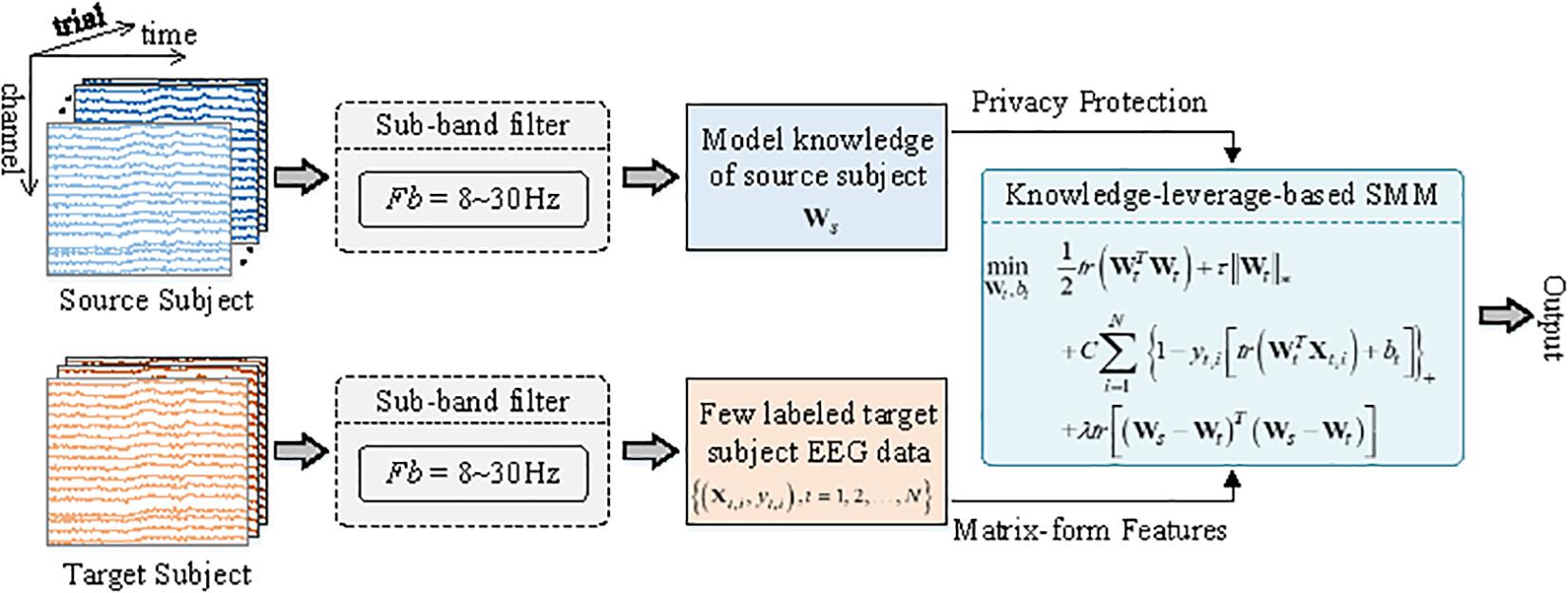
Figure 1. Framework of the proposed KL-SMM for EEG-based motor imagery BCI. Both source EEG data and target EEG data are first bandpass filtered in the frequency range of 8∼30 Hz. SMM is then applied to learn source model Ws. The source model (only needed) enables the classification model realize the privacy protection. An objective function of the proposed KL-SMM is then implemented by using the source model and the matrix-form features extracted from few labeled target data.
KL-SMM Model
A dataset Ds = {(Xs,1,ys,1),(Xs,2,ys,2),⋯,(Xs,Ns,ys,Ns)} in source domain, it consists of Ns trials labeled EEG signals. Xs,i ∈ ℝp×q denotes the ith trial with p×q dimension. ys,i is the corresponding class label of Xs,i. A dataset Dt = {(Xt,1,yt,1),⋯,(Xt,N,yt,N),Xt,N + 1,⋯,Xt,Nt} in the target domain, it consists of N labeled EEG trials and (Nt−N) unlabeled trials, where N≪(Nt−N).
For modeling the target domain, we proposed to integrate the labeled target EEG data and source model as follows:
Here, L(⋅,⋅) denotes the loss function. denotes the matrix classifier to be learned. Eq. (7) includes two terms, where the first term is used to learn from labeled target EEG data, and the second term is designed to leverage the model knowledge (i.e., Ws) underlying the source domain. The goal is to exploit the desired KL-SMM by approximating its model to the source model. The parameter λ is adopted to balance the influence between the two terms above.
As in the SMM, we introduced the spectral elastic net penalty to capture the correlation information within the matrix-form EEG data. Furthermore, the hinge loss function was adopted, owing to its inherent characteristic of sparseness and robustness. Above all, the objective function of the proposed KL-SMM can be formulated as follows:
where the parameter C > 0 is used to maintain a balance between fitting the labeled target EEG data and minimizing the complexity of the solution.
Parameter Learning for KL-SMM
Because the Eq. (8) is convex in both Wt and bt, an alternating iterative strategy based on the ADMM method can be used to derive the learning algorithm of the KL-SMM. Specifically, by introducing an auxiliary variable St, the objective function of the KL-SMM can be equivalently reformulated as
where + bt]}+ + λtr[(Ws−Wt)T(Ws−Wt)] and G(St) = τ∥St∥*.
The parameter optimization of Eq. (9) can be solved using the augmented Lagrangian algorithm
where Λ is the Lagrangian multiplier, and ρ > 0 is a hyperparameter. Theorems 1 and 2 provide the calculations of parameters St and (Wt,bt).
Theorem 1. For the fixed Wt, using the Lagrangian multiplier Λ and any positive scalar τ > 0, ρ > 0 in Eq. (10), St can be optimized using the following update rule:
Proof of Theorem 1: Supposing Wt is fixed, the optimization problem in Eq. (10) is equivalent to minimizing the function as follows:
Because J(St) is convex, with respect to St, if with can be proven, we can conclude that is a solution to Eq. (12). The derivation of J(St) with respect to St can be expressed as
To further simplify this equation, let the SVD of (ρWt−Λ) be denoted as . In the equation, ∑a represents the diagonal matrix with diagonal entries greater than τ. ∑b represents the remaining part of the SVD with diagonal entries less than or equal to τ. Ua and Va (Ub and Vb) are matrices that correspond to the left and right singular vectors of the diagonal matrix ∑a (∑b). In terms of Definition 1, can be reformulated as . Substituting into Eq. (13), we have
Let , because Ua, Ub, Va, Vb are column orthogonal, we can easily verify that , ZVa = 0, and ∥Z∥2≤1. Thus, we have . Theorem 1 is proved.
Theorem 2. For the fixed St, (Wt,bt) can be optimized using the following update rule:
where Δ = {i|0≤αi≤C,∀i = 1,2,…,N} refers to the Lagrangian multipliers, andα = [α1,α2,⋯,αN]T ∈ ℝN can be obtained using the box constraint quadratic programming solver:
where K = [Kij] ∈ ℝN×N and H = [hi] ∈ ℝN with
Proof of Theorem 2: Given the fixed variable St, the optimization problem in Eq. (10) equals to optimize the following objective function:
The augmented Lagrangian function of Eq. (20) is denoted as
Setting the derivative of with respect to and bt, to 0, we can obtain
Substituting Eq. (22) into Eq. (21), and then setting the derivative of with respect to Wt to 0, we obtain
Substituting Eq. (22) and Eq. (23) into Eq. (21),
Here, θis a constant, which can be represented as . Thus, the dual problem of Eq. (24) can be denoted as
Algorithm 1: The learning procedure for KL-SMM
Input: Training dataset , source model Ws, parameter τ and λ;
Output: Wt, bt;
Initialize: , , v(1) = 1, η ∈ (0,1), ρ > 0, l=1
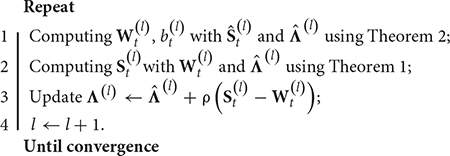
The optimization problem of Eq. (21) can finally be transformed into a QP problem. Substituting the obtained optimal solution α into Eq. (23), it is easy to obtain the value of Wt. Finally, the optimal bt can be calculated as follows:
In practice, averaging these optimal solutions, we can obtain
where Δ = {i|0≤αi≤C,∀i = 1,2,…,N}. Theorem 2 is proved.
For the fixed Wt and St, the Lagrangian multiplier Λ in Eq. (10) can be updated as follows:
The optimal solution is estimated iteratively. The learning procedure for the KL-SMM is given in Algorithm 1.
Computational Complexity
We further analyzed the computational complexity of the KL-SMM. In Algorithm 1, Step 1 computes the parameter (Wt,bt) by solving a QP problem in Eq. (17), which takes time O(N2pq) with Nsamples of p×q dimension. Step 2 computes the eigen decomposition for St in Eq. (11), which takes time O(min(p2q,pq2)). In practice, the dimensions, p and q, of the extracted EEG features are not too high. Thus, the computational complexity of the KL-SMM is dominated by the QP, that is, O(I⋅N2pq), where I denotes the iteration number.
Experiments
In this section, we evaluate the proposed KL-SMM on two publicly available MI EEG datasets [i.e., Datasets IIa and IIb of the BCI competition (Hang et al., 2020)], which can be found in http://www.bbci.de/competition/iv/. We first describe the EEG datasets. Then, the compared methods and corresponding parameter settings are provided. Finally, we present and discuss the experimental results.
EEG Data Description and Preprocessing
(1) BCI competition IV Dataset IIa (Exp.1): This dataset includes 22-channel EEG signals recorded from nine subjects (denoted as S01–S09). During the experiment, each subject was required to perform four kinds of MI tasks, hand (left and right), foot, and tongue. A total of 576 trials of two sessions on different days were collected for each subject. In our experiment, we used the left-hand and right-hand EEG data. In addition, the EEG trials collected from the second day were adopted. Thus, the training and test datasets each contained 72 EEG trials.
(2) BCI competition IV Dataset IIb (Exp.2): This dataset also contains the EEG signals of nine subjects (denoted as B01–B09), which were recorded using three electrodes, C3, Cz, and C4. During the experiment, each subject was instructed to perform left- and right-hand MI tasks for 4.5 s. For each subject, there were five sessions. Sessions 1, 2, and 3 were collected on the first day, and 4 and 5 were collected on the second day. Similar to Exp.1, the EEG trials collected from the second day were used. Specifically, Session 4 was used as the training data, and Session 5 was used as the test data.
With reference to Hang et al. (2020), there was a time interval of [0.5, 3]s after the visual cues in each trial for all the datasets. We bandpass-filtered the EEG signals to 8–30 Hz through a five-order Butterworth filter, which covers the dominated frequency band for MI tasks (Nam et al., 2011). Then, we adopted the spatial filters to detect the MI-related desynchronization/synchronization (ERD/ERS) patterns. Finally, the widely used band-power estimation method (Vidaurre et al., 2005) was used to extract the matrix-form EEG features for all the subjects. To construct the transfer learning tasks, each subject was considered the target domain, and the training data of the remaining subjects constituted the source domain. To evaluate the performance of the KL-SMM, we set three different numbers of labeled target EEG data, that is, the first 8, 14, and 20 training trials. The classification performances on the test data of all the subjects were reported.
Experimental Setup
Baseline Methods
To evaluate the classification performance of the aforementioned transfer tasks, the proposed method was compared with four methods in the experiments: (1) SVM (Vapnik, 1995), (2) BSVM (Pirsiavash et al., 2009), (3) SMM (Luo et al., 2015), and (4) Adaptive SVM (ASVM) (Yang et al., 2007).
Implementation Details
It is known that the format of the input data of both the SVM and ASVM should be vectors or scalars. Thus, we first had to reshape the extracted two-dimensional matrix features into vector features. For the BSVM, SMM, and proposed KL-SMM, the matrix features can be inputted directly. To evaluate the effect of the transfer learning mechanism, because the SVM, BSVM, and SMM are no-transfer baselines, we simply used the labeled target EEG trials as the training data to build these classification models. In addition, for the ASVM and KL-SMM, we also leveraged the source model knowledge in constructing the target classifier. However, unlike the ASVM, the traditional transfer learning method, the KL-SMM can directly process EEG matrix features and fully exploit the structural information.
The optimal parameters were selected using a five-fold cross-validation method on the training group for all comparison methods. Parameter C was assigned by selecting the value from the set {1e−6, 1e-5, 1e-4, 1e-3, 1e−2, 1e−1, 1e0, 1e1}. For the SMM and KL-SMM, we tuned the parameter τ from the set {1e−5, 2e-5, 5e-5, 1e-4, 2e-4, 5e-4, 1e-3, 2e-3, 5e-3, 1e−2, 2e-2, 5e-2, 1e−1, 2e-1, 5e-1, 1e0}. To ensure a fair comparison with the ASVM, an adjustable parameter λA was added to the term of knowledge transfer, which can control how much the knowledge of source domain to transfer. For the KL-SMM and ASVM, parameters λ and λA were set by selecting the value from set {1e−4, 5e−4, 1e−3, 5e−3, 1e-2, 5e-2, 1e-1, 5e-1, 1e0}. To validate the classification performance of our method, we used the following metrics on the test dataset, i.e., Accuracy (ACC), F1 score (F1), and the area under the receiver operating characteristics curve (AUC). Herein, ACC = (TP + TN)/(TP + FN + FP + TN) and F1 = 2×PPV×SEN/(PPV + SEN), where the positive predictive value (PPV) = TP/(TP + FP) and sensitivity (SEN) = TP/(TP + FN).
Experimental Results Analysis
The classification performances of all the comparison methods on 14 labeled target EEG trials on two datasets are given in Tables 1–6. The performance comparison of the KL-SMM with the compared methods in Exp.1 is shown in Tables 1–3. The classification results of all compared methods in Exp. 2 are shown in Tables 4–6. The best classification performance values are highlighted in bold. According to the results, the following conclusions can be drawn.

Table 1. Comparison of ACC using 14 labeled target EEG data in Exp.1.
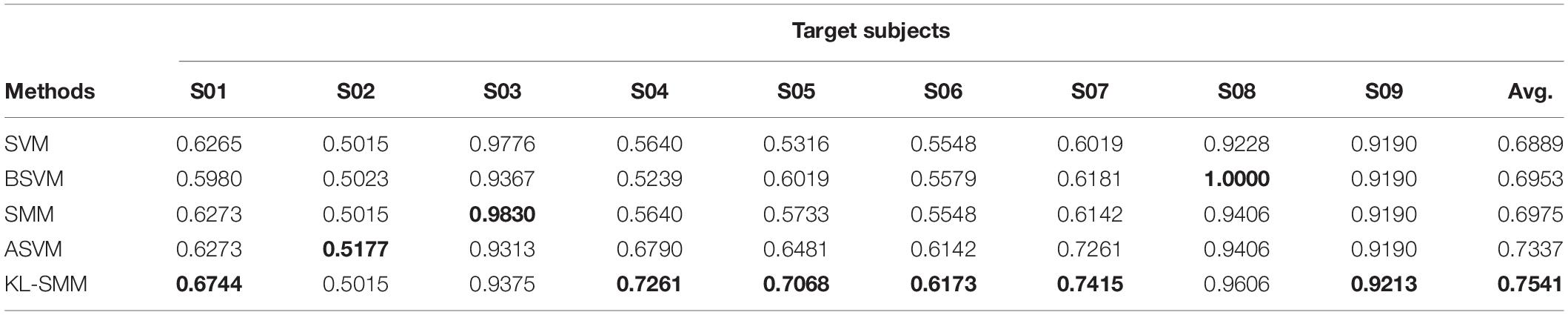
Table 2. Comparison of AUC using 14 labeled target EEG data in Exp.1.
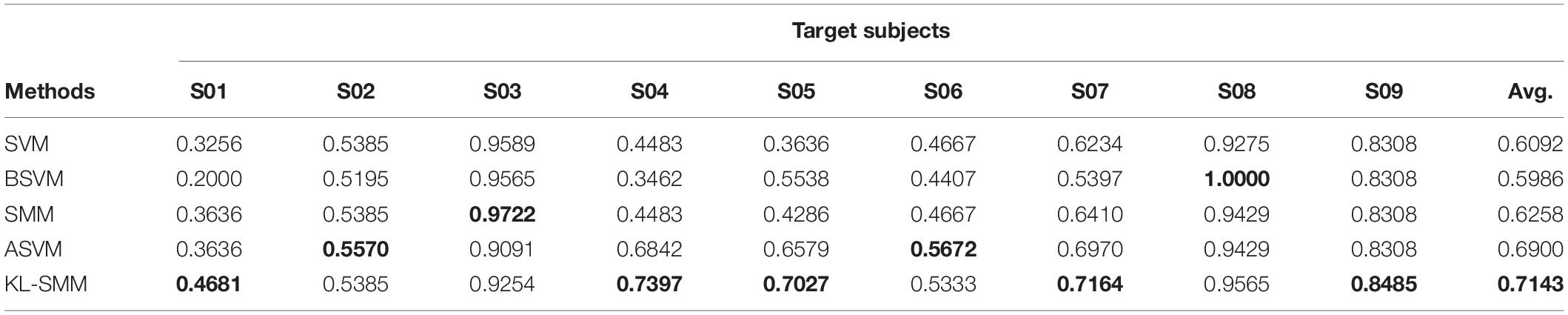
Table 3. Comparison of F1 using 14 labeled target EEG data in Exp. 1.
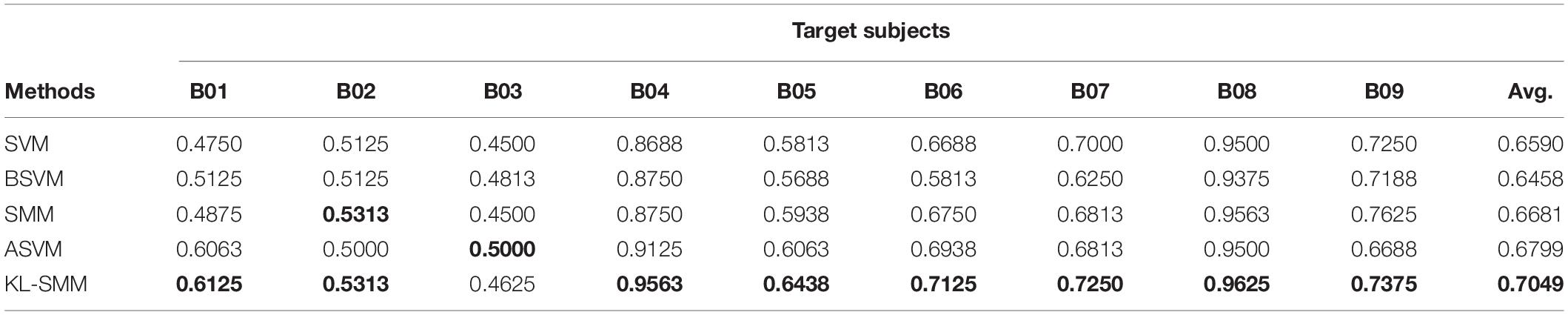
Table 4. Comparison of ACC using 14 labeled target EEG data in Exp. 2.
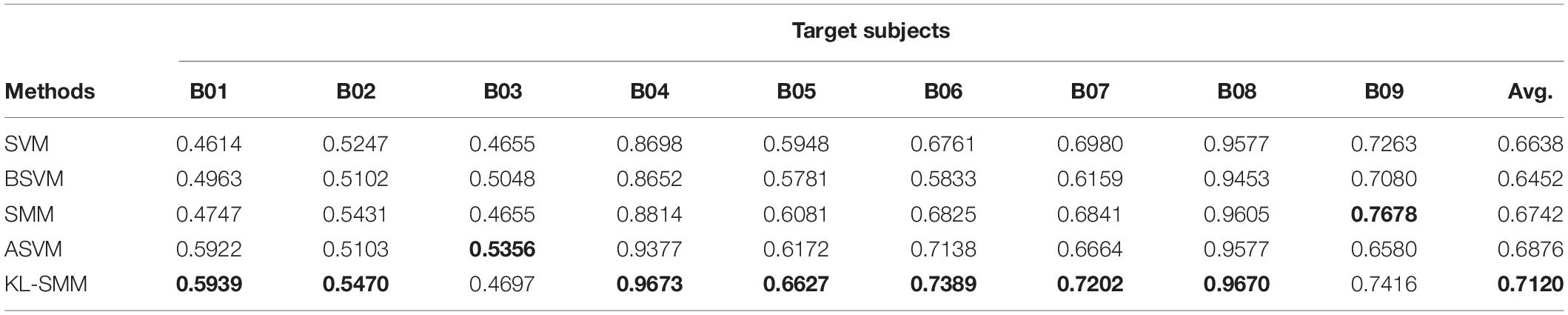
Table 5. Comparison of AUC using 14 labeled target EEG data in Exp. 2.

Table 6. Comparison of F1 using 14 labeled target EEG data in Exp. 2.
From the classification performances of all the comparison methods on the 14 labeled target EEG trials, we found that the proposed KL-SMM method achieved the highest average results in terms of the ACC, AUC, and F1. As shown in Tables 1–3, the proposed KL-SMM outperformed the baseline SMM on average by 5.87%, 5.66%, and 8.85% based on the ACC, AUC, and F1, respectively. As can be observed from the classification results in Tables 4–6, the KL-SMM outperformed the SMM on average by 3.68%, 3.78%, and 5.83% based on the ACC, AUC, and F1, respectively. The promising performances prove that the KL-SMM can leverage the model knowledge of the source subject to boost the generalization capability of the SMM when there are limited labeled EEG trials. In addition, the KL-SMM boosted the classification accuracy for six out of nine subjects in Exp.1, and eight out of nine subjects in Exp.2, respectively. These experimental results further demonstrate the effectiveness of the proposed KL-SMM that leveraged the knowledge underlying the source domain.
The BSVM and SMM outperformed the SVM in most cases. This confirms the ability of the BSVM and SMM to exploit the correlations between rows or columns of EEG matrix features. Notably, the SMM has better classification performance than the BSVM because of its convex objective function that can be effectively optimized by the ADMM method. Furthermore, it can be observed that, owing to its ability to leverage the source model knowledge in modeling the target domain when the labeled target EEG data is very limited, the ASVM yielded better classification results than the SVM. The foundation of the KL-SMM is the SMM, which can leverage the source model knowledge and exploit the structural information within the EEG feature matrices. The experimental results prove that structural information can indeed improve classification performance.
We further studied the effects of different numbers of labeled target EEG instances on the classification performance of the KL-SMM. Figure 2 shows the average classification ACCs when 8, 14, and 20 labeled target EEG trials were available from the target subject. Figures 2A,B show the average classification results of all the compared methods for Exp.1 and Exp.2, respectively. It can be observed that the KL-SMM outperformed the other methods in all the cases. Specifically, the improvement was more pronounced when few labeled target EEG trials were available, as shown in Figure 2B. From these results, we can observe that increasing the number of the labeled target EEG instances improved the average classification ACCs of all the compared methods. This is mainly because more training data may enhance the generalization performance of the classification model. The average ACC of the KL-SMM was significantly better than those of the other methods when there was no knowledge transfer, especially when the labeled target EEG instances were very limited. Overall, compared to other methods, the classification performance of the proposed KL-SMM was superior. The encouraging results were mainly attributed to the fact that the KL-SMM method possessed the matrix learning capability derived from the matrix learning machine, which allowed it to directly handle the matrix-form features, thus retaining the structural information of EEG data. In addition, the KL-SMM achieved a more outstanding classification performance because of its ability to leverage the useful model knowledge of the source domain.
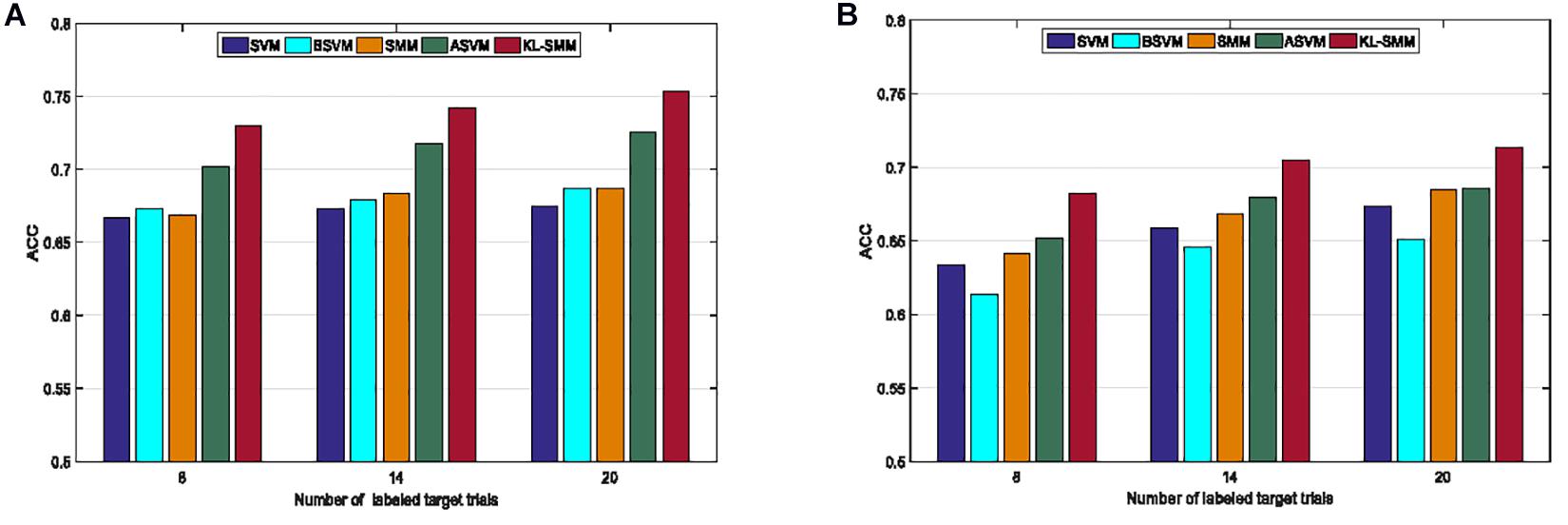
Figure 2. Average classification ACCs of comparison methods with different numbers of labeled target EEG trials in Exp.1 (A) and Exp.2 (B).
Discussion
Statistical Analysis
We further performed a t-test statistical analysis to verify whether there was a significant difference with a confidence level of 95% between the KL-SMM and the other methods. The results of the t-test using different numbers of labeled target EEG trials are shown in Table 3. A p-value less than 0.05 indicates that there are significant differences between the KL-SMM and the other methods. We highlighted the statistically significant differences in boldface. From Table 7, it can be observed that in all cases, the null hypothesis can be rejected. This proves that the KL-SMM significantly outperformed the other methods. This further demonstrated the ability of the KL-SMM to capture the structural information within the EEG data, in addition to a strong transfer learning capability. Therefore, it is suitable for the classification of complex matrix-form EEG data with cross-subject variability.

Table 7. Statistical significance comparisons of ACC of KL-SMM and other methods in Exp.1 and Exp.2.
Running Time
Figure 3A shows the running time of the KL-SMM and other methods on a subject, S01, in Exp.1 using 14 labeled target EEG trials. Except for the SVM and ASVM, the KL-SMM achieved comparable computational cost with the traditional matrix leaning method SMM. Furthermore, the KL-SMM required less computational time, compared to the BSVM. It was proven that the running time of the KL-SMM was approximately 1.6 times less that of the SMM. The KL-SMM achieved better classification results, without the increase in computational costs becoming unacceptable. This shows the potential value of the KL-SMM for real-world BCI applications.

Figure 3. (A) Running time for subject S01 using 14 labeled target EEG trials in Exp.1; (B) Parameter sensitivity of KL-SMM for the transfer tasks S04 in Exp.1 and B04 in Exp.2 using 14 labeled target EEG trials, respectively.
Parameter Sensitivity
We further show the effect of free parameter on the performance of KL-SMM, i.e., the knowledge transfer penalty λ. We conduct parameter sensitivity experiments on the transfer tasks S04 in Exp.1 and B04 in Exp.2 using 14 labeled target EEG trials, respectively. We vary the parameter of interest in {1e−4, 5e−4, 1e−3, 5e−3, 1e-2, 5e-2, 1e-1, 5e-1, 1e0}. Figure 3B shows the classification accuracy of our KL-SMM in contrast to SMM represented as dashed lines. It can be found that the accuracy of KL-SMM is improved with the increase of parameter λ, suggesting that taking the model knowledge of source domain into account can benefit for EEG classification. As the parameter value is further increased, the classification performance will decrease due to the distribution discrepancy between the source domain and the target domain.
Conclusion
In this study, we proposed a KL-SMM method for MI-based BCIs. The proposed KL-SMM belongs to the matrix classifier, which can exploit the structural information of EEG data in matrix form. Furthermore, it can leverage the existing source model knowledge in modeling the construction of the target subjects in scenarios of limited labeled target training data. Similar to the SMM, the KL-SMM can be easily optimized using the ADMM. Extensive experimental results on two publicly available MI datasets demonstrate the superiority of the KL-SMM to the compared methods in most cases. However, despite its promising performance, there is still room for improvement. For example, adaptively controlling the penalty λ is critical to determining how much knowledge is transferred. In addition, how to extend KL-SMM to multi-class classification will be investigated in future work.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: http://www.bbci.de/competition/iv/.
Author Contributions
YC is responsible for data processing and data analysis. WH and SL are responsible for manuscript writing. XL and QW is responsible for study design. GL is responsible for experimental design. JQ and K-SC are responsible for manuscript editing. All authors contributed to the article and approved the submitted version.
Funding
This work was supported in part by the Key R&D Program of Guangdong Province, China under Grant (2018B030339001), the National Natural Science Foundation of China under Grants (61802177 and 62072452), the Fundamental Research Funds for the Central Universities under Grant (CDLS-2019-04), the CAS Key Laboratory of Human-Machine Intelligence-Synergy Systems (2014DP173025), and the Hong Kong Research Grants Council under Grant (PolyU 152006/19E).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
Agarwal, A., Dowsley, R., McKinney, N. D., Wu, D., Lin, C. T., De Cock, M., et al. (2019). Protecting privacy of users in brain-computer interface applications. IEEE Trans. Neural Syst. Rehabil. Eng. 27, 1546–1555. doi: 10.1109/tnsre.2019.2926965
Alamgir, M., Grosse-Wentrup, M., and Altun, Y. (2010). “Multitask learning for brain-computer interfaces,” in Processing of the 13th International Conference on Artificial Intelligence and Statistics. (AISTATS), Vol. 9, Washington, DC, 17–24.
Allison, B. Z., McFarland, D. J., Schalk, G., Zheng, S. D., Jackson, M. M., and Wolpaw, J. R. (2008). Towards an independent brain–computer interface using steady state visual evoked potentials. Clin. Neurophysiol. 119, 399–408. doi: 10.1016/j.clinph.2007.09.121
Al-Qaysi, Z. T., Zaidan, B. B., Zaidan, A. A., and Suzani, M. S. (2018). A review of disability EEG based wheelchair control system: coherent taxonomy, open challenges and recommendations. Comput. Methods Progr. Biomed. 164, 221–237. doi: 10.1016/j.cmpb.2018.06.012
Ang, K. K., Guan, C., Chua, K. S. G., Ang, B. T., Kuah, C. W. K., Wang, C., et al. (2011). A large clinical study on the ability of stroke patients to use an EEG-based motor imagery brain-computer interface. Clin. EEG Neurosci. 42, 253–258. doi: 10.1177/155005941104200411
Azab, A. M., Mihaylova, L., Ang, K. K., and Arvaneh, M. (2019). Weighted transfer learning for improving motor imagery-based brain–computer interface. IEEE Trans. Neural Syst. Rehabil. Eng. 27, 1352–1359. doi: 10.1109/tnsre.2019.2923315
Cai, J. F., Candès, E. J., and Shen, Z. (2010). A singular value thresholding algorithm for matrix completion. SIAM J. Optim. 20, 1956–1982. doi: 10.1137/080738970
Candes, E. J., and Recht, B. (2009). Exact matrix completion via convex optimization. Found. Comput. Math. 9, 717–772. doi: 10.1007/s10208-009-9045-5
Deng, Z., Jiang, Y., Choi, K.-S., Chung, F.-L., and Wang, S. (2013). Knowledge-leverage-based TSK fuzzy system modeling. IEEE Trans. Neural Netw. Learn. Syst. 24, 1200–1212. doi: 10.1109/tnnls.2013.2253617
Fahimi, F., Zhang, Z., Goh, W. B., Lee, T.-S., Ang, K. K., and Guan, C. (2019). Inter-subject transfer learning with an end-to-end deep convolutional neural network for EEG-based BCI. J. Neural Eng. 16:026007. doi: 10.1088/1741-2552/aaf3f6
Hang, W., Feng, W., Du, R., Liang, S., Chen, Y., Wang, Q., et al. (2019). Cross-subject EEG signal recognition using deep domain adaptation network. IEEE Access 7, 273–282. doi: 10.1109/ACCESS.2019.2939288
Hang, W., Feng, W., Liang, S., Wang, Q., Liu, X., and Choi, K. S. (2020). Deep stacked support matrix machine based representation learning for motor imagery EEG classification. Compu. Methods Prog. Biomed. 193:105466. doi: 10.1016/j.cmpb.2020.105466
Hossain, I., Khosravi, A., Hettiarachchi, I., and Nahavandi, S. (2018). Multiclass informative instance transfer learning framework for motor imagery-based brain-computer interface. Comput. Intell. Neurosci. 2018:6323414. doi: 10.1155/2018/6323414
Hossain, I., Khosravi, A., and Nahavandhi, S. (2016). “Active transfer learning and selective instance transfer with active learning for motor imagery based BCI,” in Proceeding of the IEEE International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, 4048–4055. doi: 10.1109/IJCNN.2016.7727726
Jayaram, V., Alamgir, M., Altun, Y., Scholkopf, B., and Grosse-Wentrup, M. (2016). Transfer learning in brain-computer interfaces. IEEE Comput. Intell. Mag. 11, 20–31. doi: 10.1109/MCI.2015.2501545
Kang, H., Nam, Y., and Choi, S. (2009). Composite common spatial pattern for subject-to-subject transfer. IEEE Signal Process. Lett. 16, 683–686. doi: 10.1109/lsp.2009.2022557
Li, Y., Kambara, H., Koike, Y., and Sugiyama, M. (2010). Application of covariate shift adaptation techniques in brain–computer interfaces. IEEE Trans. Biomed. Eng. 57, 1318–1324. doi: 10.1109/tbme.2009.2039997
Lotte, F., and Guan, C. (2010). “Learning from other subjects helps reducing brain-computer interface calibration time,” in Proceeding of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Dallas, TX, 614–617. doi: 10.1109/ICASSP.2010.5495183
Luo, L., Xie, Y., Zhang, Z., and Li, W. J. (2015). “Support matrix machines,” in Proceeding of the International Conference on International Conference on Machine Learning, France, 938–947.
Morioka, H., Kanemura, A., Hirayama, J.-I., Shikauchi, M., Ogawa, T., Ikeda, S., et al. (2015). Learning a common dictionary for subject-transfer decoding with resting calibration. NeuroImage 111, 167–178. doi: 10.1016/j.neuroimage.2015.02.015
Nam, C. S., Jeon, Y., Kim, Y. J., Lee, I., and Park, K. (2011). Movement imagery-related lateralization of event-related (de) synchronization (ERD/ERS): motor-imagery duration effects. Clin. Neurophysiol. 122, 567–577. doi: 10.1016/j.clinph.2010.08.002
Pan, S., and Yang, Q. (2009). A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 22, 1345–1359. doi: 10.1109/TKDE.2009.191
Pfurtscheller, G., and Da Silva, F. L. (1999). Event-related EEG/MEG synchronization and desynchronization: basic principles. Clin. Neurophysiol. 110, 1842–1857. doi: 10.1016/s1388-2457(99)00141-8
Pfurtscheller, G., and Neuper, C. (2001). Motor imagery and direct brain-computer communication. Proc. IEEE 89, 1123–1134. doi: 10.1109/5.939829
Pirsiavash, H., Ramanan, D., and Fowlkes, C. C. (2009). Bilinear classifiers for visual recognition. Adv. Neural Inform. Process. Syst. 22, 1482–1490.
Salvaris, M., and Sepulveda, F. (2009). Visual modifications on the P300 speller BCI paradigm. J. Neural Eng. 6:046011. doi: 10.1088/1741-2560/6/4/046011
Samek, W., Meinecke, F. C., and Müller, K.-R. (2013). Transferring subspaces between subjects in brain–computer interfacing. IEEE Trans. Biomed. Eng. 60, 2289–2298. doi: 10.1109/tbme.2013.2253608
Vapnik, V. (1995). The Nature of Statistical Learning. Berlin: Springer-Verlag. doi: 10.1007/978-1-4757-2440-0
Vidaurre, C., Schlögl, A., Cabeza, R., Scherer, R., and Pfurtscheller, G. (2005). Adaptive on-line classification for EEG-based brain computer interfaces with AAR parameters and band power estimates. Biomed. Technik Biomed. Eng. 50, 350–354. doi: 10.1515/bmt.2005.049
Vourvopoulos, A., Badia, S. B. I., and Liarokapis, F. (2017). EEG correlates of video game experience and user profile in motor-imagery-based brain–computer interaction. Vis. Comput. 33, 533–546. doi: 10.1007/s00371-016-1304-2
Wang, P., Lu, J., Zhang, B., and Tang, Z. (2015). “A review on transfer learning for brain-computer interface classification,” in Proceeding of the 2015 5th International Conference on Information Science and Technology (ICIST), Piscataway, NJ: IEEE, 315–322. doi: 10.1109/ICIST.2015.7288989
Wang, Z., Yu, Y., Xu, M., Liu, Y., Yin, E., and Zhou, Z. (2019). Towards a hybrid BCI gaming paradigm based on motor imagery and SSVEP. Int. J. of Hum. Comput. Interact. 35, 197–205. doi: 10.1080/10447318.2018.1445068
Wolf, L., Jhuang, H., and Hazan, T. (2007). “Modeling appearances with low rank svm,” in Proceeding of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, 1–6. doi: 10.1007/978-3-319-12000-3_1
Yang, J., Yan, R., and Hauptmann, A. G. (2007). “Adapting SVM classifiers to data with shifted distributions,” in Proceeding of the Seventh IEEE International Conference on Data Mining Workshops, Omaha, NE, 69–76. doi: 10.1109/ICDMW.2007.37
Zanini, P., Congedo, M., Jutten, C., Said, S., and Berthoumieu, Y. (2018). Transfer learning: a riemannian geometry framework with applications to brain–computer interfaces. IEEE Trans. Biomed. Eng. 65, 1107–1116. doi: 10.1109/tbme.2017.2742541
Zheng, Q., Zhu, F., and Heng, P. A. (2018a). Robust support matrix machine for single trial EEG classification. IEEE Trans. Neural Syst. Rehabil. Eng. 26, 551–562. doi: 10.1109/tnsre.2018.2794534
Zheng, Q., Zhu, F., Qin, J., Chen, B. D., and Heng, P. A. (2018b). Sparse support matrix machine. Pattern Recognit. 76, 715–726. doi: 10.1016/j.patcog.2017.10.003
Keywords: motor imagery, brain-computer interface, electroencephalography, support matrix machine, transfer learning
Citation: Chen Y, Hang W, Liang S, Liu X, Li G, Wang Q, Qin J and Choi K-S (2020) A Novel Transfer Support Matrix Machine for Motor Imagery-Based Brain Computer Interface. Front. Neurosci. 14:606949. doi: 10.3389/fnins.2020.606949
Received: 16 September 2020; Accepted: 28 October 2020;
Published: 23 November 2020.
Edited by:
Mohammad Khosravi, Persian Gulf University, IranReviewed by:
Yufeng Yao, Changshu Institute of Technology, ChinaJuan Yang, Soochow University, China
Copyright © 2020 Chen, Hang, Liang, Liu, Li, Wang, Qin and Choi. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Qiong Wang, d2FuZ3Fpb25nQHNpYXQuYWMuY24=
†These authors have contributed equally to this work