 Li Zhang
Li Zhang Mingliang Wang
Mingliang Wang Mingxia Liu
Mingxia Liu Daoqiang Zhang
Daoqiang Zhang- 1College of Computer Science and Technology, Nanjing Forestry University, Nanjing, China
- 2College of Computer Science and Technology, Nanjing University of Aeronautics and Astronautics, Nanjing, China
- 3Department of Radiology and Biomedical Research Imaging Center, University of North Carolina at Chapel Hill, Chapel Hill, NC, United States
Deep learning has recently been used for the analysis of neuroimages, such as structural magnetic resonance imaging (MRI), functional MRI, and positron emission tomography (PET), and it has achieved significant performance improvements over traditional machine learning in computer-aided diagnosis of brain disorders. This paper reviews the applications of deep learning methods for neuroimaging-based brain disorder analysis. We first provide a comprehensive overview of deep learning techniques and popular network architectures by introducing various types of deep neural networks and recent developments. We then review deep learning methods for computer-aided analysis of four typical brain disorders, including Alzheimer's disease, Parkinson's disease, Autism spectrum disorder, and Schizophrenia, where the first two diseases are neurodegenerative disorders and the last two are neurodevelopmental and psychiatric disorders, respectively. More importantly, we discuss the limitations of existing studies and present possible future directions.
1. Introduction
Medical imaging refers to several different technologies that are used to provide visual representations of the interior of the human body in order to aid the radiologists and clinicians to detect, diagnose, or treat diseases early and more efficiently (Brody, 2013). Over the past few decades, medical imaging has quickly become a dominant and effective tool and represents various imaging modalities, including X-ray, mammography, ultrasound, computed tomography, magnetic resonance imaging (MRI), and positron emission tomography(PET) (Heidenreich et al., 2002). Each type of these technologies gives various pieces of anatomical and functional information about the different body organs for diagnosis as well as for research. In clinical practice, the detail interpretation of medical images needs to be performed by human experts, such as the radiologists and clinicians. However, for the enormous number of medical images, the interpretations are time-consuming and easily influenced by the biases and potential fatigue of human experts. Therefore, from the early 1980s, doctors and researchers have begun to use computer-assisted diagnosis (CAD) systems to interpret the medical images and to improve their efficiency.
In the CAD systems, machine learning is able to extract informative features that describe the inherent patterns from data and play a vital role in medical image analysis (Wernick et al., 2010; Wu et al., 2016; Erickson et al., 2017; Li et al., 2019). However, the structures of the medical images are very complex, and the feature selection step is still carried out by the human experts on the basis of their domain-specific knowledge. This results in a challenge for non-experts to utilize machine learning techniques in medical image analysis. Therefore, the handcrafted feature selection is not suitable for medical images. Though the sparse learning and dictionary learning have demonstrated the validity of these techniques for automatically discovering discriminative features from training samples, the shallow architectures of these algorithms limit their representational power (Pandya et al., 2019).
Compared to the traditional machine learning algorithms, deep learning automatically discovers the informative representations without the professional knowledge of domain experts and allows the non-experts to effectively use deep learning techniques. Therefore, deep learning has rapidly becomes a methodology of choice for medical image analysis in recent years (LeCun et al., 2015; Schmidhuber, 2015; Goodfellow et al., 2016; Lian et al., 2018). Due to enhanced computer power with the high-tech central processing units (CPU) and graphical processing units (GPU), the availability of big data, and the creation of novel algorithms to train deep neural networks, deep learning has seen unprecedented success in the most artificial intelligence applications, such as computer vision (Voulodimos et al., 2018), natural language processing (Sarikaya et al., 2014), and speech recognition (Bahdanau et al., 2016). Especially, the improvement and successes of computer vision simultaneously prompted the use of deep learning in the medical image analysis (Lee et al., 2017; Shen et al., 2017).
Currently, deep learning has fueled great strides in medical image analysis. We can divide the medical image analysis tasks into several major categories: classification, detection/localization, registration, and segmentation (Litjens et al., 2017). The classification is one of the first tasks in which deep learning giving a major contribution to medical image analysis. This task aims to classify medical images into two or more classes. The stacked auto-encoder model was used to identify Alzheimer's disease or mild cognitive impairment by combining medical images and biological features (Suk et al., 2015). The detection/localization task consists of the localization and identification of the landmarks or lesion in the full medical image. For example, deep convolutional neural networks were used for the detection of lymph nodes in CT images (Roth et al., 2014). The segmentation task is to partition a medical image into different meaningful segments, such as different tissue classes, organs, pathologies, or other biologically relevant structures (Sun et al., 2019a). The U-net was the most well-known deep learning architecture, which used convolutional networks for biomedical image segmentation (Ronneberger et al., 2015). Registration of medical images is a process that searches for the correct alignment of images. Wu et al. (2013) utilized convolutional layers to extract features from input patches in an unsupervised manner. Then the obtained feature vectors were used to replace the handcrafted features in the HAMMER registration algorithm. In addition, the medical image analysis contains other meaningful tasks, such as content-based image retrieval (Li et al., 2018c) and image generation and enhancement (Oktay et al., 2016) in combination with image data and reports (Schlegl et al., 2015).
There are many papers have comprehensively surveyed the medical image analysis using deep learning techniques (Lee et al., 2017; Litjens et al., 2017; Shen et al., 2017). However, these papers usually reviewed all human tissues, including the brain, chest, eye, breast, cardiac, abdomen, musculoskeletal, and others. Almost no papers focus on one specific tissue or disease (Hu et al., 2018). Brain disorders are among the most severe health problems facing our society, causing untold human suffering and enormous economic costs. Many studies successfully used medical imaging techniques for the early detection, diagnosis, and treatment of the human brain disorders, such as neurodegenerative disorders, neurodevelopmental disorders and psychiatric disorders (Vieira et al., 2017; Durstewitz et al., 2019). We therefore pay more close attention to human brain disorders in this survey. About 100 papers are reviewed, most of them published from 2016 to 2019, on deep learning for brain disorder analysis.
The structure of this review can roughly be divided into two parts, the deep learning architectures and the usage of deep learning in brain disorder analysis and is organized as follows. In section 2, we briefly introduce some popular deep learning models. In section 3, we provide a detailed overview of recent studies using deep learning techniques for four brain disorders, including Alzheimer's disease, Parkinson's disease, Autism spectrum disorder, and Schizophrenia. Finally, we analyze the limitations of the deep learning techniques in medical image analysis and provide some research directions for further study. For the convenience of readers, the abbreviations of terminologies used in the following context are listed in the Supplementary Table 1.
2. Deep Learning
In this section, we introduce the fundamental concept of basic deep learning models in the literature, which have been wildly applied to medical image analysis, especially human brain disorder diagnosis. These models include feed-forward neural networks, deep generative models (e.g., stacked auto-encoders, deep belief networks, deep Boltzmann machine, and generative adversarial networks), convolutional neural networks, graph convolutional networks, and recurrent neural networks.
2.1. Feed-Forward Neural Networks
In machine learning, artificial neural networks (ANN) aim to simulate intelligent behavior by mimicking the way that biological neural networks function. The simplest artificial neural networks is a single-layer architecture, which is composed of an input layer and an output layer (Figure 1A). However, despite the use of non-linear activation functions in output layers, the single-layer neural network usually obtains poor performance for complicated data patterns. In order to circumvent the limitation, the multi-layer perceptron (MLP), also referred to as a feed-forward neural network (FFNN) (Figure 1B), which includes a so-call hidden layer between the input layer and the output layer. Each layer contains multiple units which are fully connected to units of neighboring layers, but there are no connections between units in the same layer. Given an input visible vector x, the composition function of output unit yk can be written as follows:
where the superscript represents a layer index, M is the number of hidden units, and bj and bk represent the bias of input and hidden layer, respectively. f(1)(·) and f(2)(·) denote the non-linear activation function, and the parameter set is . The back-propagation(BP) is an efficient algorithm to evaluate a gradient in the FFNN (Rumelhart et al., 1986). The BP algorithm is to propagate the error values from the output layer back to the input layer through the network. Once the gradient vector of all the layers is obtained, the parameters θ can be updated. Until the loss function is converged or the predefined number of iterations is reached, the update process stops and the network gets the model parameters θ.
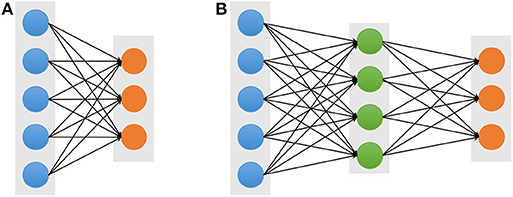
Figure 1. Architectures of the single-layer (A) and multi-layer (B) neural networks. The blue, green, and orange solid circles represent the input visible, hidden, and output units, respectively.
2.2. Stacked Auto-Encoders
An auto-encoder (AE), also known as an auto-associator, learns the latent representations of input data (called encode) in an unsupervised manner and then uses these representations to reconstruct output data (called decode). Due to the simple and shallow structure, the power representation of a typical AE is relatively limited. However, when multiple AEs are stacked to form a deep network, called stacked auto-encoders (SAE) (Figure 2), the representation power of an SAE can be obviously improved (Bengio et al., 2007). Because of the deep structural characteristic, the SAE is able to learn and discover more complicated patterns inherent in the input data. The lower layers can only learn simpler data patterns, while the higher layers are able to extract more complicated data patterns. In a word, the different layers of an SAE represent different levels of data information (Shen et al., 2017). In addition, various AE variations, denoising auto-encoders (DAE) (Vincent et al., 2008), sparse auto-encoders (sparse AE) (Poultney et al., 2007), and variational auto-encoders (VAE) (Kingma and Welling, 2013), have been proposed and also can be stacked as SAE, such as the stacked sparse AE (SSAE) (Shin et al., 2013). These extensions of auto-encoders not only can learn more useful latent representations but also improve the robustness.
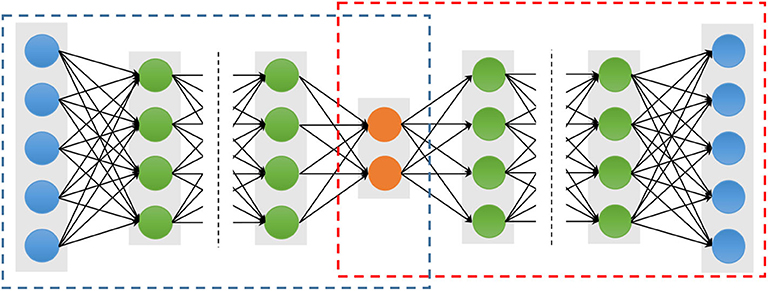
Figure 2. Architectures of a stacked auto-encoder. The blue and red dotted boxes represent the encoding and decoding stage, respectively. The blue solid circles are the input and output units, which have the same number nodes. The orange solid circles represent the latent representation, and the green solid circles represent any hidden layers.
To avoid the drawback of the BP algorithm, which can cause the gradient falling into a poor local optimum (Larochelle et al., 2009), the greedy layer-wise approach is considered to training parameters of an SAE (Hinton and Salakhutdinov, 2006). The important character of the greedy layer-wise is to pre-train each layer in turn. In other words, the output of the l-th hidden layers is used as input data for the (l + 1)-th hidden layer. The process performs as pre-training, which is conducted in an unsupervised manner with a standard BP algorithm. The important advantage of the pre-training is able to increase the size of the training dataset using unlabeled samples.
2.3. Deep Belief Networks
A Deep Belief Network (DBN) stacks multiple restricted Bolztman machines (RBMs) for deep architecture construction (Hinton et al., 2006). A DBN has one visible layer and multiple hidden layers as shown in Figure 3A. The lower layers form directed generative models. However, the top two layers form the distribution of RBM, which is an undirected generative model. Therefore, given the visible units v and L hidden layers h(1), h(2), …, h(L), the joint distribution of DBN is defined:
where P(h(l)|h(l+1)) represents the conditional distribution for the units of the hidden layer l given the units of the hidden layer l + 1, and P(h(L−1), h(L)) corresponds the joint distribution of the top hidden layers L − 1 and L.
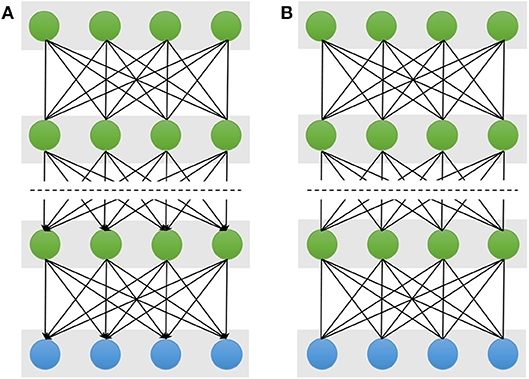
Figure 3. Schematic illustration of Deep Belief Networks (A) and Deep Boltzmann Machine (B). The double-headed arrow represents the undirected connection between the two neighboring layers, and the single-headed arrow is the directed connection. The top two layers of the DBN form an undirected generative model and the remaining layers form directed generative model. But all layers of the DBM are undirected generative model.
As for training a DBN, there are two steps, including pre-training and fine-tuning. In the pre-training step, the sDBN is trained by stacking RBMs layer by layer to find the parameter space. Each layer is trained as an RBM. Specifically, the l-th hidden layer is trained as an RBM using the observation data from output representation of the (l − 1)-th hidden layer, and this repeats, training each layer until the we reach the top layer. After the pre-training is completed, the fine-tuning is performed to further optimize the network to search the optimum parameters. The wake-sleep algorithm and the standard BP algorithm are good at fine-tuning for generative and discriminative models, respectively (Hinton et al., 1995). For a practical application problem, the obtained parameters from the pre-training step are used to initiate a DNN, and then the deep model can be fine-tuned by a supervised learning algorithm like BP.
2.4. Deep Boltzmann Machine
A Deep Boltzmann Machine (DBM) is also constructed by stacking multiple RBMs as shown in Figure 3B (Salakhutdinov and Larochelle, 2010; Salakhutdinov, 2015). However, unlike the DBN, all the layers of the DBM form an entirely undirected model, and each variable within the hidden layers are mutually independent. Thus, the hidden layer l is conditioned on its two neighboring layer l − 1 and l + 1, and its probability distribution is P(h(l)|h(l−1), h(l+1)). Given the values of the neighboring layers, the conditional probabilities over the visible and the L set of hidden units are given by logistic sigmoid functions:
Note that in the computation of the conditional probability of the hidden unit h(l), the probability incorporate both the lower hidden layer h(l−1) and the upper hidden layer h(l+1). Due to incorporate the more information from the lower and upper layers, the representational power of a DBM is more robust in the face of the noisy observed data (Karhunen et al., 2015). However, the character makes the conditional probability of DBM P(h(l)|h(l−1), h(l+1)) more complex than those of the DBN, P(h(l)|h(l+1)).
2.5. Generative Adversarial Networks
Due to their ability to learn deep representations without extensively annotated training data, Generative Adversarial Networks (GANs) have gained a lot of attention in computer vision and natural language processing (Goodfellow et al., 2014). GANs consist of two competing neural networks, a generator G and a discriminator D, as shown in Figure 4. The generator G parameterized by θ takes as input a random noise vector z from a prior distribution pz(z; θ) and outputs a sample G(z), which can be regarded as a sample drawn from the generator data distribution pg. The discriminator D that takes an input G(z) or x, and outputs the probability D(x) or D(G(z)) to evaluate that the sample is from the generator G or the real data distribution. GANs simultaneously train the generator and discriminator where the generator G tries to generate realistic data to fool the discriminator, while the discriminator D tries to distinguish between the real and fake samples. Inspired by the game theory, the training process is to form a two-player minimax game with the value function V(G, D) as follow:
where pdata(x) denotes the real data distribution. After training alternately, if G and D have enough capacity, they will reach a point at which both cannot improve because pg = pdata. In other words, the discriminator is unable to distinguish the difference between a real and a generated sample, i.e., D(x) = 0.5. Although vanilla GAN has attracted considerable attention in various applications, there still remain several challenges related to training and evaluating GANs, such as model collapse and saddle points (Creswell et al., 2018). Therefore, many variants of GAN, such as Wasserstein GAN (WGAN) (Arjovsky et al., 2017) and Deep Convolutional GAN (DCGAN) (Radford et al., 2015) have been proposed to overcome these challenges.
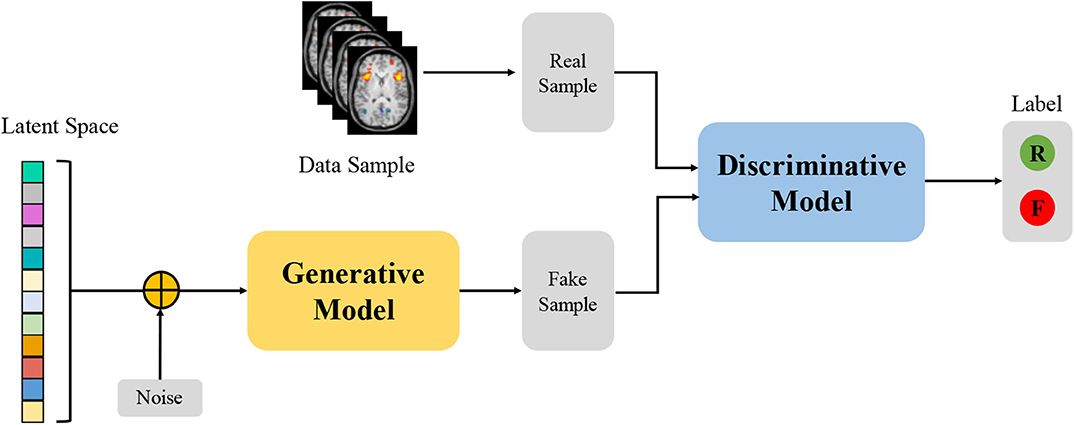
Figure 4. Architecture of Generative Adversarial Networks. “R” and “F” represents the real and fake label, respectively.
2.6. Convolutional Neural Networks
Compared to the SAE, DBN, and DBM, utilizing the inputs in vector form which inevitably destroys the structural information in images, the convolutional neural network (CNN) is designed to better retain and utilize the structural information among neighboring pixels or voxels and to required minimal preprocessing by directly taking two-dimensional (2D) or three-dimensional (3D) images as inputs (LeCun et al., 1998). Structurally, a CNN is a sequence of layers, and each layer of the CNN transforms one volume of activations to another through a differentiable function. Figure 5 shows a typical CNN architecture (AlextNet model) for a computer vision task, which consists of three type neural layers: convolutional layers, pooling layers and fully connected layers (Krizhevsky et al., 2012). The convolutional layers are interspersed with pooling layers, eventually leading to the fully connected layers. The convolutional layer takes the pixels or voxels of a small patch of the input images, called the local receptive field and then utilizes various learnable kernels to convolve the receptive field to generate multiple feature maps. A pooling layer performs the non-linear downsampling to reduce the spatial dimensions of the input volume for the next convolutional layer. The fully connected layer input the 3D or 2D feature map to a 1D feature vector. The local response normalization is a non-trainable layer and performs a kind of “lateral inhibition” by normalizing over local input regions.
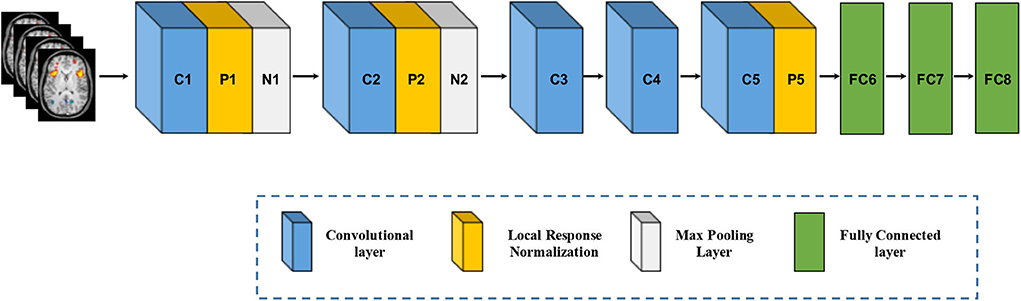
Figure 5. Architecture of convolutional neural networks. Note that an implicit rectified linear unit (ReLU) non-linearity is applied after every layer. The natural images as input data in Krizhevsky et al. (2012) are replaced by brain MR images.
The major issue in training deep models is the over-fitting, which arises from the gap between the limited number of training samples and a large number of learnable parameters. Therefore, various techniques are designed to make the models train and generalize better, such as dropout and batch normalization to just name a few. A dropout layer randomly drops a fraction of the units or connections during each training iteration (Srivastava et al., 2014). It has also been demonstrated that dropout is able to successfully avoid over-fitting. In addition, batch normalization is another useful regularization and performs normalization with the running average of the mean–variance statistics of each mini-batch. It is shown that using batch normalization not only drastically speeds up the training time but also improves the generalization performance (Ioffe and Szegedy, 2015).
2.7. Graph Convolutional Networks
While the CNN has achieved huge success in extracting latent representations from Euclidean data (e.g., images, text, and video), there are a rapidly increasing number of various applications where data are generated from the non-Euclidean domain and needs to be efficiently analyzed. Researchers straightforwardly borrow ideas from CNN to design the architecture of graph convolutional networks (GCN) to handle complexity graph data (Kipf and Welling, 2016). Figure 6 shows the process of a simple GCN with graph pooling layers for a graph classification task. The first step is to transform the traditional data to graph data, and the graph structure and node content information are therefore regarded as input. The graph convolutional layer plays a central role in extracting node hidden representations from aggregating the feature information from its neighbors. The graph pooling layers can be interleaved with the GCN layers and coarsened graphs into sub-graphs in order to obtained higher graph-level representations for each node on coarsened sub-graphs. After multiple fully connected layers, the softmax output layer is used to predict the class labels.
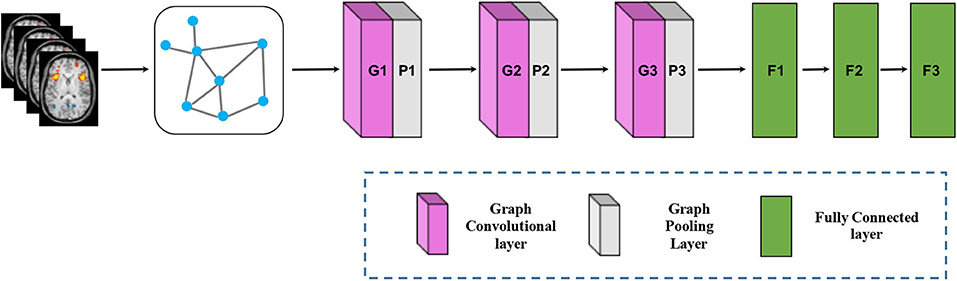
Figure 6. Architecture of graph convolutional networks. To keep the figure simple, the softmax output layer is not shown.
Depending on the types of graph convolutions, the GCN can be categorized into spectral-based and spatial-based methods. Spectral-based methods formulated graph convolution by introducing filters from the perspective of graph single processing. Spatial-based methods defined graph convolution directly on the graph, which operates on spatial close neighbors to aggregate feature information. Due to drawbacks to spectral-based methods from three aspects, efficiency, generality, and flexibility, spatial-based methods have attracted more attention recently (Wu et al., 2019).
2.8. Recurrent Neural Networks
A recurrent neural network (RNN) is an extension of an FFNN, which is able to learn features and long-term dependencies from sequential and time-series data. The most popular RNN architecture is the long-short-term memory (LSTM) (Hochreiter and Schmidhuber, 1997), which is composed of a memory cell Ct, a forget gate ft, an input gate it, and an output gate ot (Figure 7A). The memory cell transfers relevant information all the way to the sequence chain, and these gates control the activation signals from various sources to decide which information is added to and removed from the memory cell. Unlike a basic RNN, the LSTM is able to decide whether to preserve the existing memory by the above-introduced gates. Theoretically, if the LSTM learns an important feature from the input sequential data, it can keep this feature over a long time, thus captures potential long-time dependencies. One popular LSTM variant is the Gated Recurrent Unit (GRU) (Figure 7B), which merges the forget and input gates into a single “update gate,” and combines the memory cell state and hidden state into one state. The update gate decides how much information to add and throw away, and the reset gate decides how much previous information to forget. This makes the GRU is simpler than the standard LSTM (Cho et al., 2014).
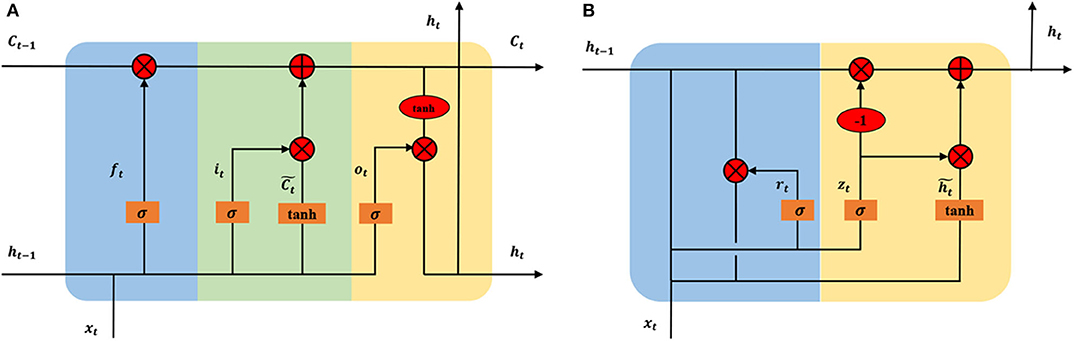
Figure 7. Architectures of long short-term memory (A) and gated recurrent unit (B) In the subfigure (A), the blue, green, and yellow represent the forget gate ft, input, gate it, and output gate ot, respectively. In the subfigure (B), the blue and yellow represent the reset gate rt and update gate zt, respectively. xt is input vector and ht is the hidden state. To keep the figure simple, biases are not shown.
2.9. Open Source Deep Learning Library
With the great successes of deep learning techniques in various applications, some famous research groups and companies have released their source codes and tools in deep learning. Due to these open source toolkits, people are able to easily build deep models for their applications even if they are not acquainted with deep learning techniques. Supplementary Table 2 lists the most popular toolkits for deep learning and shows their main features.
3. Applications in Brain Disorder Analysis With Medical Images
The human brain is susceptible to many different disorders that strike at every stage of life. Developmental disorders usually first appear in early childhood, such as autism spectrum disorder and dyslexia. Although psychiatric disorders are typically diagnosed in teens or early adulthood, their origins may exist much earlier in life, such as depression and schizophrenia. Then, as people age, people become increasingly susceptible to Alzheimer's disease, Parkinson's disease, and other dementia diseases. In this section, we select four typical brain disorders, including Alzheimer's disease, Parkinson's disease, Autism spectrum disorder and Schizophrenia. Alzheimer's disease and Parkinson's disease are both neurodegenerative disorders. Autism spectrum disorder and Schizophrenia are neurodevelopmental and psychiatric disorders, respectively.
3.1. Deep Learning for Alzheimer's Disease Analysis
Alzheimer's disease (AD) is a neurological, irreversible, progressive brain disorder and is the most common cause of dementia. Until now, the causes of AD are not yet fully understood, but accurate diagnosis of AD plays a significant role in patient care, especially at the early stage. For the study of AD diagnosis, the best-known public neuroimaging dataset is from the Alzheimer's Disease Neuroimaging Initiative (ADNI), which is a multi-site study that aims to improve clinical trials for the prevention and treatment of AD. The ADNI study has been running since 2004 and is now in its third phase (Mueller et al., 2005). Researchers collect, validate, and utilize data, including MRI and PET images, genetics, cognitive tests, cerebrospinal fluid (CSF), and blood biomarkers as predictors of the disease. Up to now, the ADNI dataset consists of ADNI-1, ADNI-GO, ADNI-2, and ADNI-3 and contains more than 1,000 patients. According to the Mini-Mental State Examination (MMSE) scores, these patients were in three stages of disease: normal control (NC), mild cognitive impairment (MCI), and AD. The MCI subject can be divided into two subcategories: converted MCI (cMCI) and stable MCI (sMCI), based on whether a subject converted to AD within a period of time (e.g., 24 months). The ADNI-GO and ADNI-2 provided two different MCI groups: early mild cognitive impairment (EMCI) and late mild cognitive impairment (LMCI), determined by a Wechsler Memory Scale (WMS) neuropsychological test.
Recently, plenty of papers have been published on the deep learning techniques for AD diagnosis. According to different architectures, these methods can be roughly divided into two subcategories: DGM-based and CNN-based methods. The DGM-based methods contained the DBN, DNM, SAE, and AE variants. Li et al. (2015) stacked multiple RBMs to construct a robust deep learning framework, which incorporated the stability selection and the multi-task learning strategy. Suk et al. (2014) proposed a series of methods based on deep learning models, such as the DBM and SAE (Suk et al., 2015, 2016). For example, the literature (Suk et al., 2015) applied the SAE to learn the latent representations from sMRI, PET, and CSF, respectively. Then, a multi-kernel SVM classifier was used to fuse the selected multi-modal features. Liu et al. (2015) also used SAE to extract features from multi-modal data, and a zero-masking strategy was then applied to fuse these learned features. Shi et al. (2017a) adopted multi-modality stacked denoising sparse AE (SDAE) to fuse cross-sectional and longitudinal features estimated from MR brain images. Lu et al. (2018) developed a multiscale deep learning network, which took the multiscale patch-wise metabolism features as input. This study was perhaps also the first study to utilize such a large number of FDG-PET images data. Martinez-Murcia et al. (2019) used a deep convolution AE (DCAE) architecture to extract features, which showed large correlations with clinical variables, such as age, tau protein deposits, and especially neuropsychological examinations. Due to small labeled samples in neuroimaging dataset, Shi et al. (2017b) proposed a multimode-stacked deep polynomial network (DPN) to effectively fuse and learn feature representation from a small multimodel neuroimaging data.
CNN-based methods learned all levels of features from raw pixels and avoided the manual ROIs annotation procedure and can be further subdivided into two subcategories: 2D-CNN and 3D-CNN. Gupta et al. (2013) pre-trained a 2D-CNN based on sMRI data through a sparse AE on random patches of natural images. The key technique was the use of cross-domain features to present MRI data. Liu and Shen (2014) used a similar strategy and pre-trained a pre-trained deep CNN on ImageNet. Sarraf et al. (2016) first used the fMRI data in deep learning applications. The 4D rs-fMRI and 3D MRI data were decomposed into 2D format images in the preprocessing step, and then the CNN-based architecture received these images in its input layer. Billones et al. designed a DemNet model based on the 16-layer VGGNet. The DemNet only selected the coronal image slices with indices 111–130 in 2D format images under the assumption that these slices covered the areas, which had the important features for the classification task (Billones et al., 2016). Liu et al. (2018b) proposed a novel classification framework that learned features from a sequence of 2D slices by decomposing 3D PET images. Then hierarchical 2D-CNN was built to capture the intra-slice features, while GRU was adopted to extract the inter-slice features.
The 3D brain images need to be decomposed into 2D slices in the preprocessing step, and this results in 2D-CNN methods discarding the spatial information. Many 3D-CNN methods were therefore proposed, and these can directly input 3D brain images. Payan and Montana (2015) pre-trained a 3D-CNN through a sparse AE on small 3D patches from sMRI scans. Hosseini-Asl et al. (2016) proposed a deep 3D-CNN, which was built upon a 3D CAE (Convolutional AE) to capture anatomical shape variations in sMRI scans. Liu et al. used multiple deep 3D-CNN on different local image patches to learn the discriminative features of MRI and PET images. Then, a set of upper high-level CNN was cascaded to ensemble the learned local features and discovered the latent multi-modal features for AD classification (Liu et al., 2018a). Karasawa et al. (2018) proposed deeper 3D-CNN architecture with 39 layers based on a residual learning framework (ResNet) to improve performance. Liu et al. (2018d) designed a landmark-based deep feature learning framework to learn the patch-level features, which were an intermediate scale between voxel-level and ROI-level. The authors firstly used a data-driven manner to identify discriminative anatomical landmarks from MR images, and they then proposed a 3D-CNN to learn patch-based features. This strategy can avoid the high-dimensional problem of voxel-level and manual definition of ROI-level. Subsequently, Liu et al. (2018c) developed a deep multi-instance CNN framework, where multiple image patches were used as a bag of instances to represent each specific subject, and then the label of each bag was given by the whole-image-level class label. To overcome the missing modality in multi-modal image data, Li et al. (2014) proposed a simple 3D-CNN to predict the missing PET images from the sMRI data. Results showed that the predicted PET data achieved similar classification accuracy to the true PET data. Additionally, the synthetic PET data and the real sMRI data obviously outperformed the single sMRI data. Pan et al. (2018) used Cycle-GAN to learn bi-directional mapping sMRI and PET to synthesize missing PET scans based on its corresponding sMRI scans. Then, landmark-based 3D-CNN was adapted for AD classification on the mixed image data. Tables 1, 2 summarized the statistic information of each paper reviewed above for AD diagnosis.
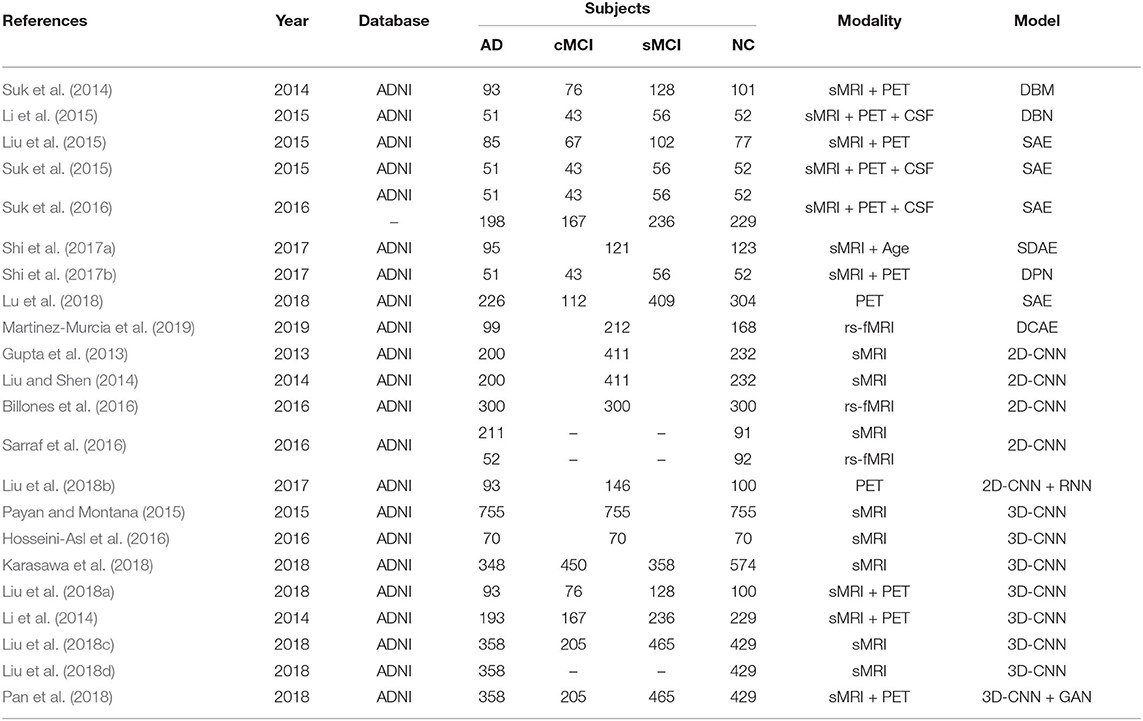
Table 1. Overview of papers using deep learning techniques for AD diagnosis.
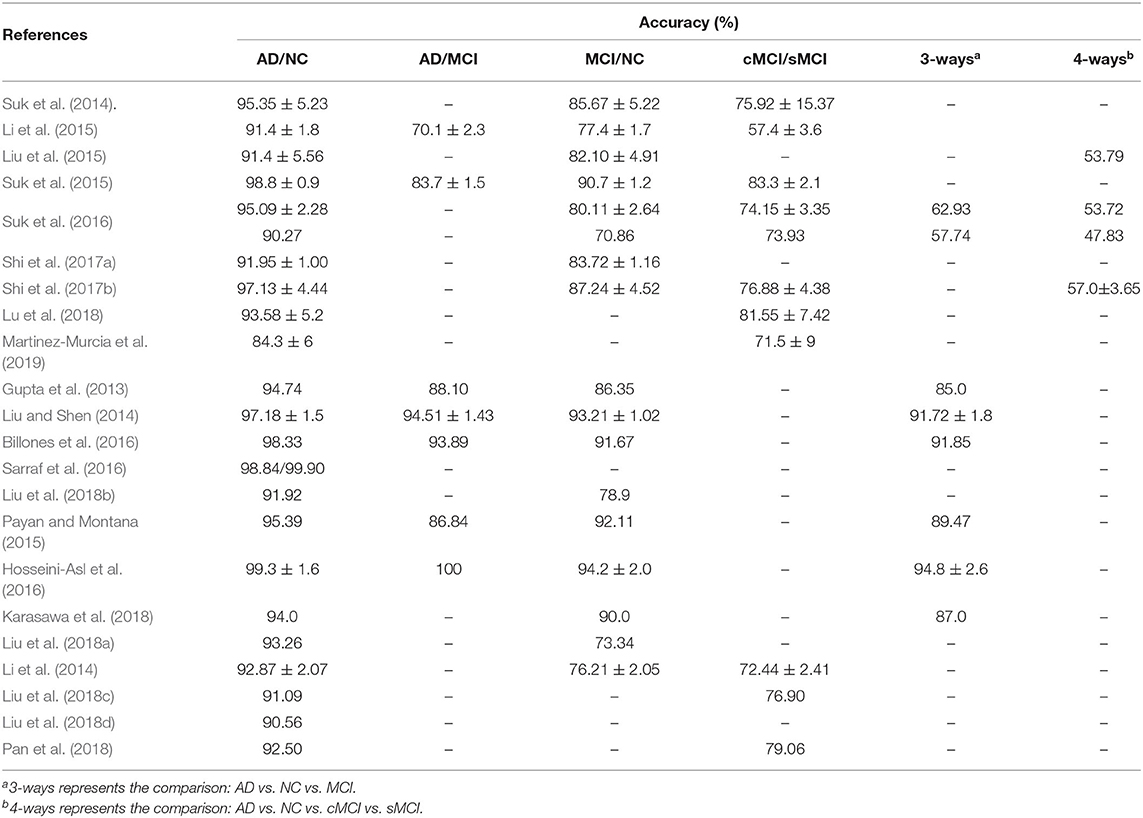
Table 2. The classification performance of papers for AD diagnosis.
As an early stage of AD, MCI had a conversion rate as high as 10–15% per year in 5 years, but MCI was also the best time for treatment. Therefore, an effective predictive model construction for the early diagnosis of MCI had become a hot topic. Recently, some research based on GCN has been done for MCI prediction. Yu et al. (2019) and Zhao et al. (2019) both used the GCN, which combines neuroimaging information and the demographic relationship for MCI prediction. Song et al. (2019) implemented a multi-class the GCN classifier for classification of subjects on the AD spectrum into four classes. Guo et al. (2019) proposed PETNET model based on the GCN to analyzes PET signals defined on a group-wise inferred graph structure. Tables 3, 4 summarized the four papers for MCI prediction.

Table 3. Overview of papers using deep learning techniques for MCI prediction.
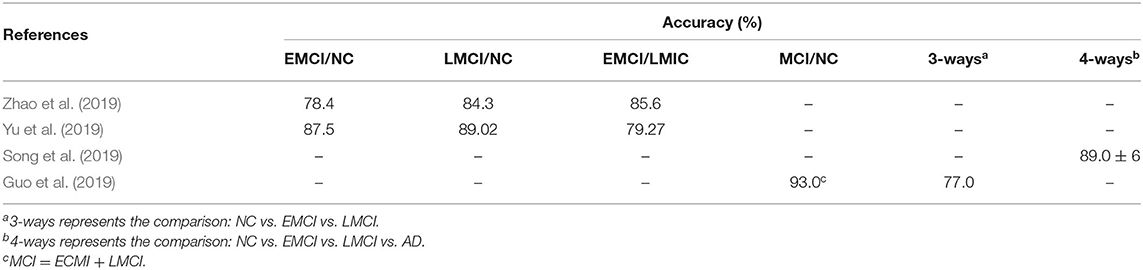
Table 4. The classification performance of papers for MCI prediction.
3.2. Deep Learning for Parkinson's Disease Analysis
Parkinson's disease (PD) is the most common neurodegenerative disorder after Alzheimer's disease, and it is provoked by progressive impairment and deterioration of neurons, caused by a gradually halt in the production of a chemical messenger in the brain. Parkinson's Progression Markers Initiative (PPMI) is an observational clinical study to verify progression markers in Parkinson's disease. The PPMI cohort comprises 400 newly diagnosed PD cases, 200 healthy, and 70 individuals that, while clinically diagnosed as PD cases, fail to show evidence of dopaminergic deficit. This latter group of patients is referred to as SWEDDs (Scans without Evidence of Dopamine Deficit) (Marek et al., 2011).
Some efforts based on deep learning have been done to design algorithms to help PD diagnosis. The Martinez-Murci team has continuously published a series of papers using deep learning techniques for PD diagnosis in a SPECT image dataset. Ortiz et al. (2016) designed a framework to automatically diagnose PD using deep sparse filtering-based features. Sparse filtering, based on ℓ2-norm regularization, extracted the suitable features that can be used as the weight of hidden layers in a three-layer DNN. Subsequently, this team firstly applied 3D-CNN in PD diagnosis. These methods achieved up to a 95.5% accuracy and 96.2% sensitively (Martinez-Murcia et al., 2017). However, this 3D-CNN architecture with only two convolutional layers was too shallow and limited the capability to extract more discriminative features. Martinez-Murcia et al. (2018) therefore proposed a deep convolutional AE (DCAE) architecture for feature extraction. The DCAE overcome two common problems: the need for spatial normalization and the effect of imbalanced datasets. For a strongly imbalanced (5.69/1) PD dataset, DCAE achieved more than 93% accuracy. Choi et al. (2017) developed a deep CNN model (PDNet) consisted of four 3D convolutional layers. PDNet obtained high classification accuracy compared to the quantitative results of expert assessment and can further classify the SWEDD and NC subjects. Esmaeilzadeh et al. (2018) both utilized the sMRI scans and demographic information (i.e., age and gender) of patients to train a 3D-CNN model. The proposed method firstly found that the Superior Parietal part on the right hemisphere of the brain was critical in PD diagnosis. Sivaranjini and Sujatha (2019) directly introduced the AlexNet model, which was trained by the transfer learned network. Shen et al. (2019b) proposed an improved DBN model with an overlapping group lasso sparse penalty to learn useful low-level feature representations. To incorporate multiple brain neuroimaging modalities, Zhang et al. (2018b) and McDaniel and Quinn (2019) both used a GCN model and presented an end-to-end pipeline without extra parameters involved for view pooling and pairwise matching. Transcranial sonography (TCS) had recently attracted increasing attention, and Shen et al. (2019a) proposed an improved DPN algorithm that embedded the empirical kernel mapping the network pruning strategy and dropout approach for the purposes of feature representation and classification for TCS-based PD diagnosis. Table 5 summarized each paper above reviewed for PD diagnosis.
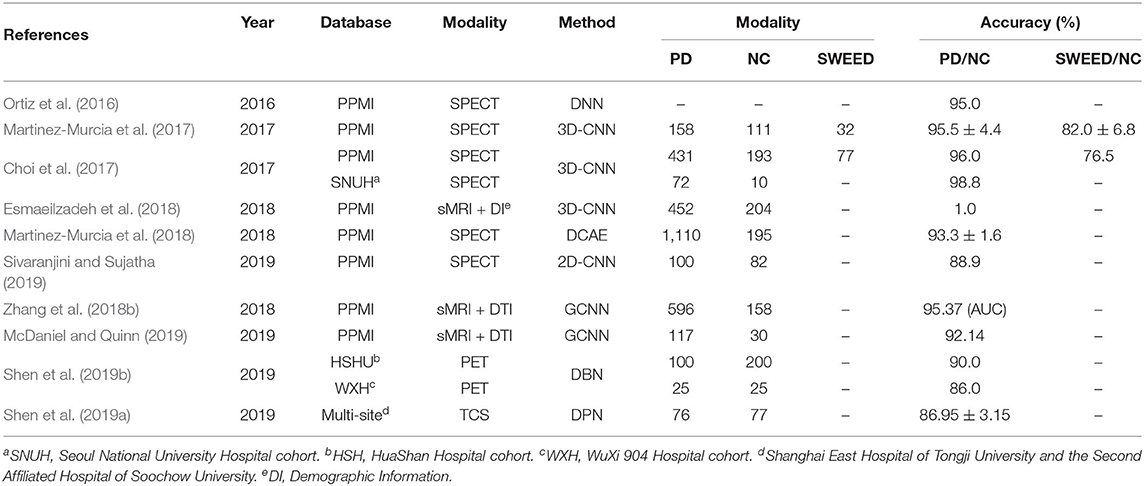
Table 5. Overview of papers using deep learning techniques for PD diagnosis.
Up to now, only some papers have applied deep learning for PD diagnosis based on neuroimaging, and most of them adopt the 3D-CNN model. The traditional machine learning was still a popular and important technology for PD diagnosis, such as sparse feature learning (Lei et al., 2018), unsupervised learning (Singh and Samavedham, 2015), semi-unsupervised learning (Adeli et al., 2018), multi-task learning (Emrani et al., 2017), and classifier design (Shi et al., 2018).
3.3. Deep Learning for Austism Spectrum Disorder Analysis
Autism spectrum disorder (ASD) is a common neurodevelopmental disorder, which has affected 62.2 million ASD cases in the world in 2015. The Autism Imaging Data Exchange (ABIDE) initiative had aggregated rs-fMRI brain scans, anatomical and phenotypic datasets, collected from laboratories around the world. The ABIDE initiative included two large scale collections: ABIDE I and ABIDE II, which were released in 2012 and 2016, respectively. The ABIDE I collection involved 17 international sites and consisted of 1,112 subjects comprised of 539 from autism patients and 573 from NC. To further enlarge the number of samples with better-characterized, the ABIDE II collection involved 19 international sites, and aggregated 1,114 subjects from 521 individuals with ASD and 593 NC subjects (Di et al., 2014).
Many methods have been proposed on the application of deep learning for ASD diagnosis. These methods can be divided into three categories: AE-based methods, convolutional-based methods, and RNN-based methods. AE-based methods used various AE variations or stacked multiple AE to reduce data dimension and discovery highly discriminative representations. Hazlett et al. implemented the basic SAE, which primarily used surface area information from brain MRI at 6- and 12-months-old infants to predict the 24-months diagnosis of autism in children at high familial risk for autism. The SAE contained three hidden layers to reduce 315 dimension measurements to only two features (Hazlett et al., 2017). Two papers both used a stacked multiple sparse AE (SSAE) to learn low dimensional high-quality representations of functional connectivity patterns (Guo et al., 2017; Kong et al., 2019). But the difference was that Guo et al. input the whole-brain functional connectivity patterns and Kong et al. only selected the top 3,000 ranked connectivity features by F-score in descending order. Dekhil et al. (2018) built an automated autism diagnosis system, which used 34 sparse AE for 34 spatial activation areas. Each sparse AE extracted the power spectral densities (PSDs) of time courses in a higher-level representation and simultaneously reduced the feature vectors dimensionality. Choi (2017) used VAE to summarize the functional connectivity networks into two-dimensional features. One feature was identified using a high discrimination between ASD and NC, and it was closely associated with ASD-related brain regions. Heinsfeld et al. (2018) used DAE to reduce the effect of multi-site heterogeneous data and improve the generalization. Due to insufficient training samples, Li et al. (2018a) developed a novel deep neural network framework with the transfer learning technique for enhancing ASD classification. This framework was firstly trained an SSAE to learn functional connectivity patterns from healthy subjects in the existing databases. The trained SSAE was then transferred to a new classification with limited target subjects. Saeed et al. designed a data augmentation strategy to produce synthetic datasets needed for training the ASD-DiagNet model. This model was composed of an AE and a single-layer perceptron to improve the quality of extracted features (Saeed et al., 2019).
Due to collapsed the rs-fMRI scans into a feature vector, the above methods discarded the spatial structure of the brain networks. To fully utilize the whole brain spatial fMRI information, Li et al. (2018b) implemented 3D-CNN to capture spatial structure information and used sliding windows over time to measure temporal statistics. This model was able to learn ASD-related biological markers from the output of the middle convolution layer. Khosla et al. proposed a 3D-CNN framework for connectome-based classification. The functional connectivity of each voxel to various target ROIs was used as input features, which reserved the spatial relationship between voxels. Then the ensemble learning strategy was employed to average the different ROI definitions to reduce the effect of empirical selections, it and obtained more robust and accurate results (Khosla et al., 2018). Ktena et al. (2018) implemented a Siamese GCN to learn a graph-similarity metric, which took the graph structure into consideration for the similarity between a pair of graphs. This was the first application of metric learning with graph convolutions on brain connectivity networks. Parisot et al. (2017) introduced a spectral GCN for brain analysis in populations combining imaging and non-imaging information. The populations were represented as a sparse graph where each vertex corresponded to an imaging feature vector of a subject, and the edge weights were associated with phenotypic data, such as age, gender, and acquisition sites. Like the graph-based label propagation, a GCN model was used to infer the classes of unlabeled nodes on the partially labeled graphs. There existed no definitive method to construct reliable graphs in practice. Thus, Anirudh and Thiagarajan (2017) proposed a bootstrapped version of GCN to reduce the sensitivity of models on the initial graph construction step. The bootstrapped GCN used an ensemble of the weekly GCN, each of which was trained by a random graph. In addition, Yao et al. (2019) proposed a multi-scale triplet GCN to avoid the spatial limitation of a single template. A multi-scale templates for coarse-to-fine ROI parcellation were applied to construct multi-scale functional connectivity patterns for each subject. Then a triple GCN model was developed to learn multi-scale graph features of brain networks.
Several RNN-based methods were proposed to fully utilize the temporal information in the rs-fMRI time-series data. Bi et al. (2018) designed a random NN cluster, which combined multiple NNs into a model, to improve the classification performance in the diagnosis of ASD. Compared to five different NNs, the random Elman cluster obtained the highest accuracy. It is because that the Elman NN fit handling the dynamic data. Dvornek et al. (2017) first applied LSTM to ASD classification, which directly used the rs-fMRI time-series data, rather than the pre-calculated measures of brain functional connectively. The authors thought that the rs-fMRI time-series data contained more useful information of dynamic brain activity than single and static functional connectivity measures. For clarity, the important information of the above-mentioned papers was summarized in Table 6.
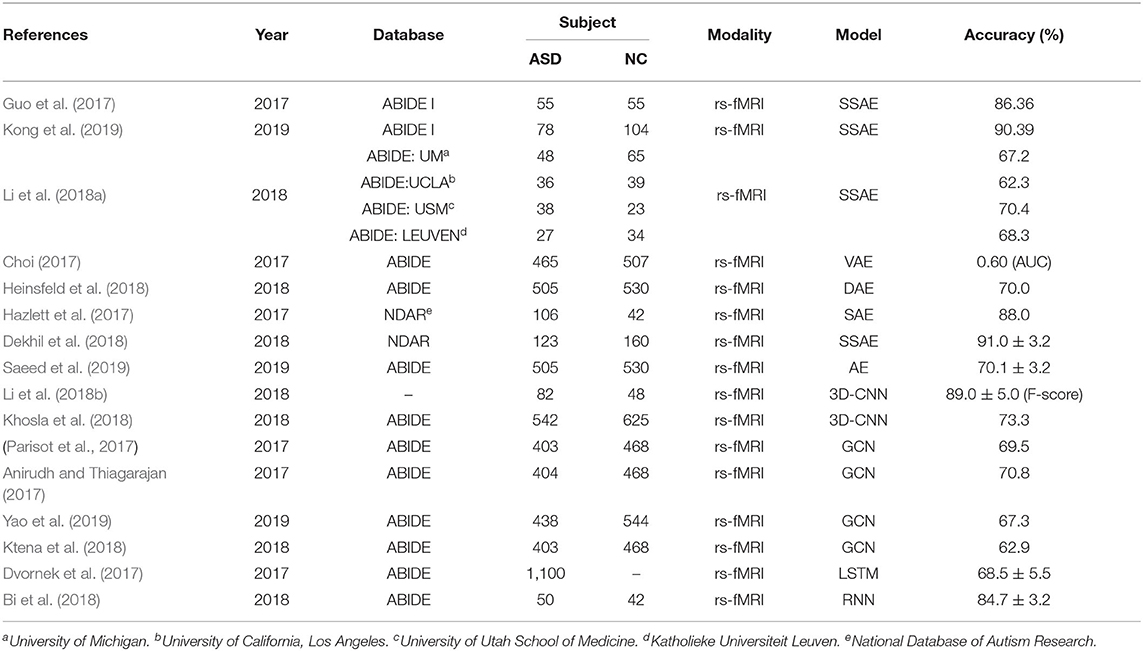
Table 6. Overview of papers using deep learning techniques for ASD diagnosis.
3.4. Deep Learning for Schizophrenia Analysis
Schizophrenia (SZ) is a prevalent psychiatric disorder and affects 1% of the population worldwide. Due to the complex clinical symptoms, the pathological mechanism of schizophrenia remains unclear and there is no definitive standard in the diagnosis of SZ. Different from the ADNI for AD diagnosis, the PPMI for PD diagnosis, and the ABIDE for ASD diagnosis, there was not a widely used neuroimaging dataset for the SZ diagnosis. Therefore, some studies have successfully applied source datasets that were available from the medical research centers, universities, and hospitals.
Recently, some studies have successfully applied deep learning algorithms to SZ diagnosis and have seen significant improvement. These methods were divided into two categories: unimodality and multi-modality, according to the types of input data, rather than according to deep learning architectures like AD or ASD diagnosis.
The unimodality category only used a single type of MRI and can furthermore be classified into subclasses: sMRI-methods and fMRI-methods. sMRI-methods discovery latent features from sMRI dataset, which can provide information on the tissue structure of the brain, such as gray matter, white matter, and cerebrospinal fluid. Plis et al. and Pinaya et al. used the DBN model, which only contained three hidden layers, to automatically extract feature for SZ identification. The results achieved a modestly higher predictive performance than the shallow-architecture SVM approach (Plis et al., 2014; Pinaya et al., 2016). Different from the DBN model in Pinaya et al. (2016), Pinaya et al. (2019) trained an SAE to create a normative model from 1,113 NC subjects, then used this model to estimate total and regional neuroanatomical deviation in individual patients with SZ. Ulloa et al. proposed a novel classification architecture that used synthetic sMRI scans to mitigate the effects of a limited sample size. To generate synthetic samples, a data-driven simulator was designed that can capture statistical properties from observed data using independent component analysis (ICA) and a random variable sampling method. Then a 10-layer DNN was trained exclusively on continuously generated synthetic data, and it greatly improves generalization in the classification of SZ patients and NC (Ulloa et al., 2015).
The fMRI-methods extracted discriminative features from rs-fMRI brain images with functional connectivity networks. Kim et al. (2015) learned lower-to-higher features via the DNN model in which each hidden layer was added L1-regularization to control the weight sparsity, and they also achieved 85.8% accuracy. Patel et al. used an SAE model with four hidden layers to separately train on each brain region. The input layer directly uses the complete time series of all active voxels without converting them into region-wise mean time series. This therefore ensured that the model retained more information (Patel et al., 2016). Due to the limited size of SZ dataset, Zeng et al. collected a large multi-site rs-fMRI dataset from seven neuroimaging resources. An SAE with an optimized discriminant item was designed to learn imaging site-shared functional connectivity features. This model can achieve accurate SZ classification performance across multiple independent imaging sites, and the learned features found that dysfunctional integration of the cortical-striatal-cerebellar circuit may play an important role in SZ (Zeng et al., 2018). Qureshi et al. built a 3D-CNN-based deep learning classification framework, which used the 3D ICA functional network maps as input. These ICA maps served as highly discriminative 3D imaging features for the discrimination of SZ (Qureshi et al., 2019). To exploit both spatial and temporal information, Dakka et al. and Yan et al. proposed a recurrent convolutional neural network involving CNN followed by LSTM and GRU, respectively. The CNN extracted spatial features, which then were fed to the followed RNN model to learn the temporal dependencies (Dakka et al., 2017; Yan et al., 2019).
Combined multi-modality brain images can improve the performance of disorder diagnosis. The MLSP2014 (Machine Learning for Signal Processing) SZ classification challenge provided 75 NC and 69 SZ, which both contained sMRI and rs-fMRI brain images. Qi and Tejedor (2016) used deep canonical correlation analysis (DCCA) and deep canonically correlated auto-encoders (DCCAE) to fuse multi-modality features. But in the proposed method, two modalities features directly were combined as 411 dimensional vector, then fed to the three-layer DNN model (Srinivasagopalan et al., 2019). To alleviate the missing modality, the synthetic sMRI and rs-fMRI images were generated by a generator proposed, and they were then used to train a multi-modality DNN (Ulloa et al., 2018). For clarity, the important information of the above-mentioned papers was summarized in Table 7. From this table, it can be seen the datasets for SZ diagnosis come from different universities, hospitals, and medical centers.
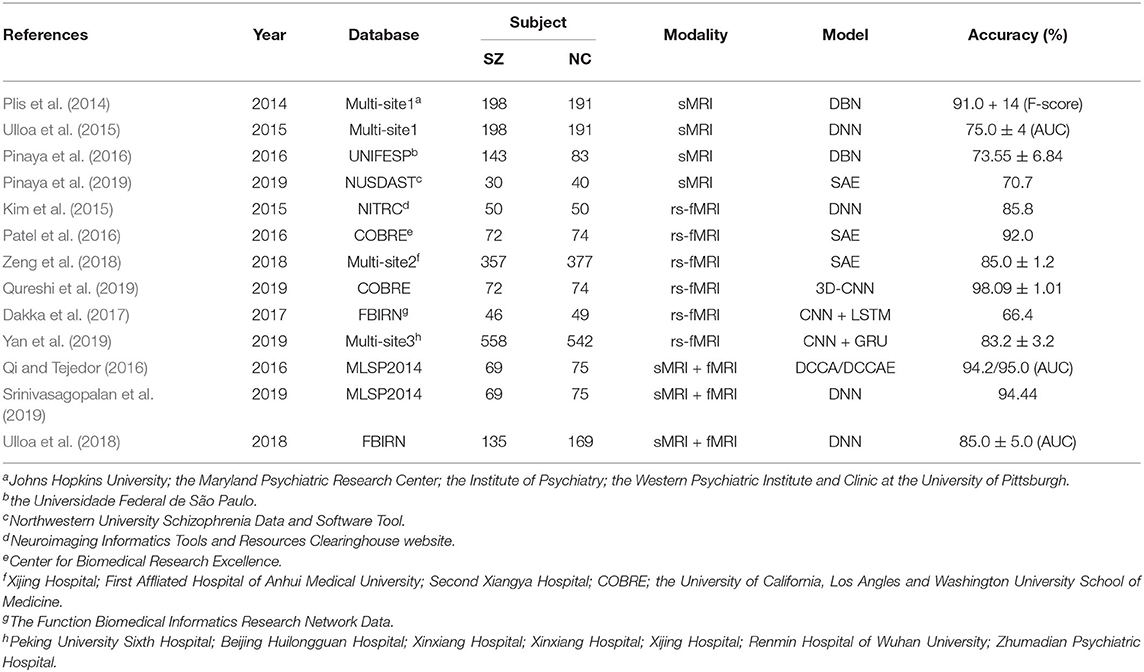
Table 7. Overview of papers using deep learning techniques for SZ diagnosis.
4. Discussion and Future Direction
As can be seen from this survey, consideration research has been reviewed on the subject of deep learning across four brain disorder diseases. Furthermore, the number of publications on medical imaging analysis shows an almost exponential growth in PubMed. Unfortunately, there is no unified deep learning framework that could be generally used for every disease research, even only for human disorder diseases. This is consistent with the “No Free Lunch” theorem, which states that there is no one model that works best for every problem. Thus, different deep learning methods are developed using different imaging modalities for a disease-specific task.
Although deep learning models have achieved great success in the field of neuroimaging-based brain disorder analysis, there are still some challenges that deserve further investigation. We summarize these potential challenges as follows and explore possible solutions.
First, deep learning algorithms highly depend on the configuration of hyper-parameter, which may dramatically fluctuate the performance. The hyper-parameter set composed of two parts: model optimization parameters (e.g., the optimization method, learning rate, and batch sizes, etc.) and network structure parameters (e.g., number of hidden layers and units, dropout rate, activation function, etc.). To obtain the best configuration, hyper-parameter optimization methods, including manual (e.g., grid search and random search) and automatic (e.g., Bayesian Optimization), are proposed. However, the method behind designing the architecture of deep neural networks still depends on the experienced experts. Recently, neural architecture search (NAS) automates this design of network architecture and indeed received new state-of-the-art performance (Zoph and Le, 2016; He et al., 2019). Additionally, another interesting technique called Population-Based Training (PTB), which is inspired by genetic algorithms, bridges and extends parallel search methods and sequential optimization methods. PBT is ability to automatic discovery of hyper-parameter schedules and model selection, which leads to stable training and better final performance (Jaderberg et al., 2017). It indicates that the hyper-parameter optimization may further mine the potential of deep learning in medical analysis.
Second, deep neural networks rely on complicated architectures to learn feature representations of the training data, and then makes its predictions for various tasks. These methods can achieve extremely accurate performances and may even beat human experts. But it is difficult to trust these predictions based on features you cannot understand. Thus, the black-box natural of the deep learning algorithms has restricted the practical clinical use. Some studies begin to explore the interpretability of deep learning in medical image analysis, and aim to show the features that most influence the predictions (Singh et al., 2020). An attention-based deep learning method is proposed and deemed as an interpretable tool for medical image analysis, which inspired by the way human pay attention to different parts of an image or the disease's influence on different regions of neuroimages (Sun et al., 2019b; Huang et al., 2020). The clinical diagnosis information as a modality is fused into the model to improve accuracy as well as give more comprehensive interpretability of outcomes (Hao et al., 2016, 2017; Wang et al., 2019a). Thus, how to improve the interpretability of deep learning model is worth further study and attention.
Third, deep learning methods require a large number of samples to train neural networks, though it is usually difficult to acquire training samples in many real-world scenarios, especially for neuroimaging data. The lack of sufficient training data in neuroimage analysis has been repeatedly mentioned as a challenge to apply deep learning algorithms. To address this challenge, a data augmentation strategy has been proposed, and it is widely used to enlarge the number of training samples (Hussain et al., 2017; Shorten and Khoshgoftaar, 2019). In addition, the use of transfer learning (Cheng et al., 2015, 2017) provides another solution by transferring well-trained networks on big sample datasets (related to the to-be-analyzed disease) to a small sample dataset for further training.
Fourth, the missing data problem is unavoidable in multimodal neuroimaging studies, because subjects may lack some modalities due to patient dropouts and poor data quality. Conventional methods typically discard data-missing subjects, which will significantly reduce the number of training subjects and degrade the diagnosis performance. Although many data-imputing methods have been proposed, most of them focus on imputing missing hand-crafted feature values that are defined by experts for representing neuroimages, while the hand-crafted features themselves could be not discriminative for disease diagnosis and prognosis. Several recent studies (Pan et al., 2018, 2019) propose that we directly impute missing neuroimages (e.g.,PET) based on another modality neuroimages (e.g.,MRI), while the correspondence between imaging data and non-imaging data has not been explored. We expect to see more deep network architectures in the near future to explore the association between different data modalities for imputing those missing data.
Fifth, an effective fusion of multimodal data has always been a challenge in the field. Multimodal data reflects the morphology, structure, and physiological functions of normal tissues and organs from different aspects and has strong complementary characteristics between different models. Previous studies for multimodal data fusion can be divided into two categories, data-level fusion (focus on how to combine data from different modalities) and decision-level fusion (focus on ensembling classifiers). Deep neural network architectures allow a third form of multimodal fusion, i.e., the intermediate fusion of learned representations, offering a truly flexible approach to multimodal fusion (Hao et al., 2020). As deep-learning architectures learn a hierarchical representation of underlying data across its hidden layers, learned representations between different modalities can be fused at various levels of abstraction. Further investigation is desired to study which layer of deep integration is optimal for problems at hand.
Furthermore, different imaging modalities usually reflect different temporal and spatial scales information of the brain. For example, sMRI data reflect minute-scale time scales information of the brain, while fMRI data can provide second-scale time scales information. In the practical diagnosis of brain disorder, it shows great significance for the implementation of early diagnosis and medical intervention by correctly introducing the spatial relationship of the diseased brain regions and other regions and the time relationship of the development of the disease progress (Jie et al., 2018; Zhang et al., 2018a). Although previous studies have begun to study the pathological mechanisms of brain diseases on a broad temporal and spatial scales, those methods usually consider either temporal or spatial characteristics (Wang et al., 2019b,d). It is therefore desirable to develop a series of deep learning frameworks to fuse temporal and spatial information for automated diagnosis of brain disorder.
Finally, the utilization of multi-site data for disease analysis has recently attracted increased attention (Heinsfeld et al., 2018; Wang et al., 2018, 2019c) since a large number of subjects from multiple imaging sites are beneficial for investigating the pathological changes of disease-affected brains. Previous methods often suffer from inter-site heterogeneity caused by different scanning parameters and subject populations in different imaging sites by assuming that these multi-site data are drawn from the same data distribution. Constructing accurate and robust learning models using heterogeneous multi-site data is still a challenging task. To alleviate the inter-site data heterogeneity, it could be a promising way to simultaneously learn adaptive classifiers and transferable features across multiple sites.
5. Conclusion
In this paper, we reviewed the most recent studies on the subject of applying the deep learning techniques in neuroimaging-based brain disorder analysis and focused on four typical disorders. AD and PD are both neurodegenerative disorders. ASD and SZ are neurodevelopmental and psychiatric disorders, respectively. Deep learning models have achieved state-of-the-art performance across the four brain disorders using brain images. Finally, we summarize these potential challenges and discuss possible research directions. With the clearer pathogenesis of human brain disorders, the further development of deep learning techniques, and the larger size of open-source datasets, a human-machine collaboration for medical diagnosis and treatment will ultimately become a symbiosis in the future.
Author Contributions
DZ, ML, and LZ designed this review. LZ and MW searched the literatures. LZ wrote this manuscript. All authors read, edited, and discussed the article.
Funding
This work was supported in part by National Natural Science Foundation of China (NSFC) under grant (Nos. 61802193, 61861130366, 61876082, and 61732006), the National Key R&D Program of China (Grant Nos. 2018YFC2001600, 2018YFC2001602, and 2018ZX10201002), the Natural Science Foundation of Jiangsu Province under grant (No. BK20170934), the Royal Society-Academy of Medical Sciences Newton Advanced Fellowship (No. NAF\R1\180371), and the Fundamental Research Funds for the Central Universities (No. NP2018104).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fnins.2020.00779/full#supplementary-material
References
1. Adeli E., Thung K.-H., An L., Wu G., Shi F., Wang T., et al. (2018). Semi-supervised discriminative classification robust to sample-outliers and feature-noises. IEEE Trans. Pattern Anal. Mach. Intell. 41, 515–522. doi: 10.1109/TPAMI.2018.2794470
2. Anirudh R., and Thiagarajan J. J. (2017). Bootstrapping graph convolutional neural networks for autism spectrum disorder classification. arXiv 1704.07487.
4. Bahdanau D., Chorowski J., Serdyuk D., Brakel P., and Bengio Y. (2016). “End-to-end attention-based large vocabulary speech recognition,” in 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (Shanghai: IEEE), 4945–4949. doi: 10.1109/ICASSP.2016.7472618
5. Bengio Y., Lamblin P., Popovici D., Larochelle H., and Montreal U. (2007). “Greedy Layer-Wise Training of Deep Networks,” in Advances in Neural Information Processing Systems (Vancouver, BC: ACM), 153–160. doi: 10.5555/2976456.2976476
6. Bi X., Liu Y., Jiang Q., Shu Q., Sun Q., and Dai J. (2018). The diagnosis of autism spectrum disorder based on the random neural network cluster. Front. Hum. Neurosci. 12:257. doi: 10.3389/fnhum.2018.00257
7. Billones C. D., Demetria O. J. L. D., Hostallero D. E. D., and Naval P. C. (2016). “DemNet: a convolutional neural network for the detection of Alzheimer's disease and mild cognitive impairment,” in Region 10 Conference, 2016 IEEE (Singapore: IEEE), 3724–3727. doi: 10.1109/TENCON.2016.7848755
9. Cheng B., Liu M., Shen D., Li Z., and Zhang D. (2017). Multi-domain transfer learning for early diagnosis of Alzheimer's disease. Neuroinformatics 15, 115–132. doi: 10.1007/s12021-016-9318-5
10. Cheng B., Liu M., Suk H.-I., Shen D., and Zhang D. (2015). Multimodal manifold-regularized transfer learning for MCI conversion prediction. Brain Imaging Behav. 9, 913–926. doi: 10.1007/s11682-015-9356-x
11. Cho K., Van Merriënboer B., Bahdanau D., and Bengio Y. (2014). On the properties of neural machine translation: encoder-decoder approaches. arXiv 1409.1259. doi: 10.3115/v1/W14-4012
12. Choi H. (2017). Functional connectivity patterns of autism spectrum disorder identified by deep feature learning. arXiv 1707.07932.
13. Choi H., Ha S., Im H. J., Paek S. H., and Lee D. S. (2017). Refining diagnosis of Parkinson's disease with deep learning-based interpretation of dopamine transporter imaging. Neuroimage Clin. 16, 586–594. doi: 10.1016/j.nicl.2017.09.010
14. Creswell A., White T., Dumoulin V., Arulkumaran K., Sengupta B., and Bharath A. A. (2018). Generative adversarial networks: an overview. IEEE Signal Process. Mag. 35, 53–65. doi: 10.1109/MSP.2017.2765202
15. Dakka J., Bashivan P., Gheiratmand M., Rish I., Jha S., and Greiner R. (2017). Learning neural markers of schizophrenia disorder using recurrent neural networks. arXiv 1712.00512.
16. Dekhil O., Hajjdiab H., Shalaby A., Ali M. T., Ayinde B., Switala A., et al. (2018). Using resting state functional MRI to build a personalized autism diagnosis system. PLoS ONE 13:e0206351. doi: 10.1371/journal.pone.0206351
17. Di M. A., Yan C. G., Li Q., Denio E., Castellanos F. X., Alaerts K., et al. (2014). The autism brain imaging data exchange: towards a large-scale evaluation of the intrinsic brain architecture in autism. Mol. Psychiatry 19, 659–667. doi: 10.1038/mp.2013.78
18. Durstewitz D., Koppe G., and Meyer-Lindenberg A. (2019). Deep neural networks in psychiatry. Mol. Psychiatry 24, 1583–1598. doi: 10.1038/s41380-019-0365-9
19. Dvornek N. C., Ventola P., Pelphrey K. A., and Duncan J. S. (2017). “Identifying autism from resting-state fMRI using long short-term memory networks,” in International Workshop on Machine Learning in Medical Imaging (Quebec City, QC: Springer), 362–370. doi: 10.1007/978-3-319-67389-9_42
20. Emrani S., McGuirk A., and Xiao W. (2017). “Prognosis and diagnosis of Parkinson's disease using multi-task learning,” in Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (Halifax, NS: ACM), 1457–1466. doi: 10.1145/3097983.3098065
21. Erickson B. J., Korfiatis P., Akkus Z., and Kline T. L. (2017). Machine learning for medical imaging. Radiographics 37, 505–515. doi: 10.1148/rg.2017160130
22. Esmaeilzadeh S., Yang Y., and Adeli E. (2018). End-to-end Parkinson disease diagnosis using brain MR-images by 3D-CNN. arXiv 1806.05233.
23. Goodfellow I., Bengio Y., Courville A., and Bengio Y. (2016). Deep Learning, Vol. 1. Cambridge, MA: MIT Press.
24. Goodfellow I., Pouget-Abadie J., Mirza M., Xu B., Warde-Farley D., Ozair S., et al. (2014). “Generative adversarial nets,” in Advances in Neural Information Processing Systems, 2672–2680. Available online at: https://papers.nips.cc/paper/5423-generative-adversarial-nets
25. Guo J., Qiu W., Li X., Zhao X., Guo N., and Li Q. (2019). Predicting Alzheimer's disease by hierarchical graph convolution from positron emission tomography imaging. arXiv 1910.00185. doi: 10.1109/BigData47090.2019.9005971
26. Guo X., Dominick K. C., Minai A. A., Li H., Erickson C. A., and Lu L. J. (2017). Diagnosing autism spectrum disorder from brain resting-state functional connectivity patterns using a deep neural network with a novel feature selection method. Front. Neurosci. 11:460. doi: 10.3389/fnins.2017.00460
27. Gupta A., Ayhan M., and Maida A. (2013). “Natural image bases to represent neuroimaging data,” in International Conference on Machine Learning (Atlanta, GA), 987–994.
28. Hao X., Bao Y., Guo Y., Yu M., Zhang D., Risacher S. L., et al. (2020). Multi-modal neuroimaging feature selection with consistent metric constraint for diagnosis of Alzheimer's disease. Med. Image Anal. 60:101625. doi: 10.1016/j.media.2019.101625
29. Hao X., Li C., Du L., Yao X., Yan J., Risacher S. L., et al. (2017). Mining outcome-relevant brain imaging genetic associations via three-way sparse canonical correlation analysis in Alzheimer's disease. Sci. Rep. 7:44272. doi: 10.1038/srep44272
30. Hao X., Yao X., Yan J., Risacher S. L., Saykin A. J., Zhang D., et al. (2016). Identifying multimodal intermediate phenotypes between genetic risk factors and disease status in Alzheimer's disease. Neuroinformatics 14, 439–452. doi: 10.1007/s12021-016-9307-8
31. Hazlett H. C., Gu H., Munsell B. C., Kim S. H., Styner M., Wolff J. J., et al. (2017). Early brain development in infants at high risk for autism spectrum disorder. Nature 542:348. doi: 10.1038/nature21369
33. Heidenreich A., Desgrandschamps F., and Terrier F. (2002). Modern approach of diagnosis and management of acute flank pain: review of all imaging modalities. Eur. Urol. 41, 351–362. doi: 10.1016/S0302-2838(02)00064-7
34. Heinsfeld A. S., Franco A. R., Craddock R. C., Buchweitz A., and Meneguzzi F. (2018). Identification of autism spectrum disorder using deep learning and the ABIDE dataset. Neuroimage Clin. 17, 16–23. doi: 10.1016/j.nicl.2017.08.017
35. Hinton G., and Salakhutdinov R. (2006). Reducing the dimensionality of data with neural networks. Science 313, 504–507. doi: 10.1126/science.1127647
36. Hinton G. E., Dayan P., Frey B. J., and Neal R. M. (1995). The “wake-sleep” algorithm for unsupervised neural networks. Science 268, 1158–1161. doi: 10.1126/science.7761831
37. Hinton G. E., Osindero S., and Teh Y.-W. (2006). A fast learning algorithm for deep belief nets. Neural Comput. 18, 1527–1554. doi: 10.1162/neco.2006.18.7.1527
38. Hochreiter S., and Schmidhuber J. (1997). Long short-term memory. Neural Comput. 9, 1735–1780. doi: 10.1162/neco.1997.9.8.1735
39. Hosseini-Asl E., Gimel'farb G., and El-Baz A. (2016). Alzheimer's disease diagnostics by a deeply supervised adaptable 3D convolutional network. arXiv 1607.00556.
40. Hu Z., Tang J., Wang Z., Zhang K., Zhang L., and Sun Q. (2018). Deep learning for image-based cancer detection and diagnosis'a survey. Pattern Recogn. 23, 134–149. doi: 10.1016/j.patcog.2018.05.014
41. Huang J., Zhou L., Wang L., and Zhang D. (2020). Attention-diffusion-bilinear neural network for brain network analysis. IEEE Trans. Med. Imaging 39, 2541–2552. doi: 10.1109/TMI.2020.2973650
42. Hussain Z., Gimenez F., Yi D., and Rubin D. (2017). “Differential data augmentation techniques for medical imaging classification tasks,” in AMIA Annual Symposium Proceedings. AMIA Symposium 2017 (Washington, DC), 979–984.
43. Ioffe S., and Szegedy C. (2015). Batch normalization: accelerating deep network training by reducing internal covariate shift. arXiv 1502.03167.
44. Jaderberg M., Dalibard V., Osindero S., Czarnecki W. M., Donahue J., Razavi A., et al. (2017). Population based training of neural networks. arXiv 1711.09846.
45. Jie B., Liu M., Lian C., Shi F., and Shen D. (2018). “Developing novel weighted correlation kernels for convolutional neural networks to extract hierarchical functional connectivities from fMRI for disease diagnosis,” in International Workshop on Machine Learning in Medical Imaging (Granada: Springer), 1–9. doi: 10.1007/978-3-030-00919-9_1
46. Karasawa H., Liu C.-L., and Ohwada H. (2018). “Deep 3D convolutional neural network architectures for Alzheimer's disease diagnosis,” in Asian Conference on Intelligent Information and Database Systems (Dong Hoi City: Springer), 287–296. doi: 10.1007/978-3-319-75417-8_27
47. Karhunen J., Raiko T., and Cho K. (2015). “Unsupervised deep learning: a short review,” in Advances in Independent Component Analysis and Learning Machines (Elsevier), 125–142. doi: 10.1016/B978-0-12-802806-3.00007-5
48. Khosla M., Jamison K., Kuceyeski A., and Sabuncu M. R. (2018). “3D convolutional neural networks for classification of functional connectomes,” in Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support (Granada: Springer), 137–145. doi: 10.1007/978-3-030-00889-5_16
49. Kim J., Calhoun V. D., Shim E., and Lee J. H. (2015). Deep neural network with weight sparsity control and pre-training extracts hierarchical features and enhances classification performance: evidence from whole-brain resting-state functional connectivity patterns of schizophrenia. Neuroimage 124, 127–146. doi: 10.1016/j.neuroimage.2015.05.018
51. Kipf T. N., and Welling M. (2016). Semi-supervised classification with graph convolutional networks. arXiv 1609.02907.
52. Kong Y., Gao J., Xu Y., Pan Y., Wang J., and Liu J. (2019). Classification of autism spectrum disorder by combining brain connectivity and deep neural network classifier. Neurocomputing 324, 63–68. doi: 10.1016/j.neucom.2018.04.080
53. Krizhevsky A., Sutskever I., and Hinton G. E. (2012). “Imagenet classification with deep convolutional neural networks,” in Advances in Neural Information Processing Systems, eds M. I. Jordan, Y. LeCun, and S. A. Solla (Lake Tahoe, NV: ACM), 1097–1105. doi: 10.1145/3065386
54. Ktena S. I., Parisot S., Ferrante E., Rajchl M., Lee M., Glocker B., et al. (2018). Metric learning with spectral graph convolutions on brain connectivity networks. Neuroimage 169, 431–442. doi: 10.1016/j.neuroimage.2017.12.052
55. Larochelle H., Bengio Y., Louradour J., and Lamblin P. (2009). Exploring strategies for training deep neural networks. J. Mach. Learn. Res. 10, 1–40. doi: 10.1145/1577069.1577070
56. LeCun Y., Bengio Y., and Hinton G. (2015). Deep learning. Nature 521:436. doi: 10.1038/nature14539
57. LeCun Y., Bottou L., Bengio Y., and Haffner P. (1998). Gradient-based learning applied to document recognition. Proc. IEEE 86, 2278–2324. doi: 10.1109/5.726791
58. Lee J.-G., Jun S., Cho Y.-W., Lee H., Kim G. B., Seo J. B., et al. (2017). Deep learning in medical imaging: general overview. Korean J. Radiol. 18, 570–584. doi: 10.3348/kjr.2017.18.4.570
59. Lei H., Zhao Y., Wen Y., Luo Q., Cai Y., Liu G., et al. (2018). Sparse feature learning for multi-class Parkinson's disease classification. Technol. Health Care 26, 193–203. doi: 10.3233/THC-174548
60. Li F., Tran L., Thung K.-H., Ji S., Shen D., and Li J. (2015). A robust deep model for improved classification of AD/MCI patients. IEEE J. Biomed. Health Inform. 19, 1610–1616. doi: 10.1109/JBHI.2015.2429556
61. Li H., Parikh N. A., and He L. (2018a). A novel transfer learning approach to enhance deep neural network classification of brain functional connectomes. Front. Neurosci. 12:491. doi: 10.3389/fnins.2018.00491
62. Li R., Zhang W., Suk H.-I., Wang L., Li J., Shen D., et al. (2014). “Deep learning based imaging data completion for improved brain disease diagnosis,” in International Conference on Medical Image Computing and Computer-Assisted Intervention (Boston, MA: Springer), 305–312. doi: 10.1007/978-3-319-10443-0_39
63. Li X., Dvornek N. C., Papademetris X., Zhuang J., Staib L. H., Ventola P., et al. (2018b). “2-channel convolutional 3D deep neural network (2CC3D) for fMRI analysis: ASD classification and feature learning,” in 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018) (Washington, DC: IEEE), 1252–1255. doi: 10.1109/ISBI.2018.8363798
64. Li Y., Meng F., Shi J., Initiative A. D. N., et al. (2019). Learning using privileged information improves neuroimaging-based CAD of Alzheimer's disease: a comparative study. Med. Biol. Eng. Comput. 57, 1605–1616. doi: 10.1007/s11517-019-01974-3
65. Li Z., Zhang X., Müller H., and Zhang S. (2018c). Large-scale retrieval for medical image analytics: a comprehensive review. Med. Image Anal. 43, 66–84. doi: 10.1016/j.media.2017.09.007
66. Lian C., Liu M., Zhang J., and Shen D. (2018). Hierarchical fully convolutional network for joint atrophy localization and Alzheimer's disease diagnosis using structural MRI. IEEE Trans. Pattern Anal. Mach. Intell. 42, 880–893. doi: 10.1109/TPAMI.2018.2889096
67. Litjens G., Kooi T., Bejnordi B. E., Setio A. A. A., Ciompi F., Ghafoorian M., et al. (2017). A survey on deep learning in medical image analysis. Med. Image Anal. 42, 60–88. doi: 10.1016/j.media.2017.07.005
68. Liu F., and Shen C. (2014). Learning deep convolutional features for MRI based Alzheimer's disease classification. arXiv 1404.3366.
69. Liu M., Cheng D., Wang K., Wang Y., Initiative A. D. N., et al. (2018a). Multi-modality cascaded convolutional neural networks for Alzheimer's disease diagnosis. Neuroinformatics 16, 295–308. doi: 10.1007/s12021-018-9370-4
70. Liu M., Cheng D., and Yan W. (2018b). Classification of Alzheimer's disease by combination of convolutional and recurrent neural networks using FDG-PET images. Front. Neuroinform. 12:35. doi: 10.3389/fninf.2018.00035
71. Liu M., Zhang J., Adeli E., and Shen D. (2018c). Landmark-based deep multi-instance learning for brain disease diagnosis. Med. Image Anal. 43, 157–168. doi: 10.1016/j.media.2017.10.005
72. Liu M., Zhang J., Nie D., Yap P.-T., and Shen D. (2018d). Anatomical landmark based deep feature representation for MR images in brain disease diagnosis. IEEE J. Biomed. Health Inform. 22, 1476–1485. doi: 10.1109/JBHI.2018.2791863
73. Liu S., Liu S., Cai W., Che H., Pujol S., Kikinis R., et al. (2015). Multimodal neuroimaging feature learning for multiclass diagnosis of Alzheimer's disease. IEEE Trans. Biomed. Eng. 62, 1132–1140. doi: 10.1109/TBME.2014.2372011
74. Lu D., Popuri K., Ding G. W., Balachandar R., Beg M. F., Initiative A. D. N., et al. (2018). Multiscale deep neural network based analysis of FDG-PET images for the early diagnosis of Alzheimer's disease. Med. Image Anal. 46, 26–34. doi: 10.1016/j.media.2018.02.002
75. Marek K., Jennings D., Lasch S., Siderowf A., Tanner C., Simuni T., et al. (2011). The parkinson progression marker initiative (PPMI). Prog. Neurobiol. 95, 629–635. doi: 10.1016/j.pneurobio.2011.09.005
76. Martinez-Murcia F. J., Ortiz A., Gorriz J.-M., Ramirez J., and Castillo-Barnes D. (2019). Studying the manifold structure of Alzheimer's disease: a deep learning approach using convolutional autoencoders. IEEE J. Biomed. Health Inform. 24, 17–26. doi: 10.1109/JBHI.2019.2914970
77. Martinez-Murcia F. J., Ortiz A., Gorriz J. M., Ramirez J., Castillo-Barnes D., Salas-Gonzalez D., et al. (2018). “Deep convolutional autoencoders vs PCA in a highly-unbalanced Parkinson's disease dataset: a DaTSCAN study,” in The 13th International Conference on Soft Computing Models in Industrial and Environmental Applications (San Sebastián: Springer), 47–56. doi: 10.1007/978-3-319-94120-2_5
78. Martinez-Murcia F. J., Ortiz A., Górriz J. M., Ramírez J., Segovia F., Salas-Gonzalez D., et al. (2017). “A 3D convolutional neural network approach for the diagnosis of Parkinson's disease,” in International Work-Conference on the Interplay Between Natural and Artificial Computation (Corunna: Springer), 324–333. doi: 10.1007/978-3-319-59740-9_32
79. McDaniel C., and Quinn S. (2019). “Developing a graph convolution-based analysis pipeline for multi-modal neuroimage data: an application to Parkinson's Disease,” in Proceedings of the 18th Python in Science Conference (SciPy 2019) (Austin, TX), 42–49. doi: 10.25080/Majora-7ddc1dd1-006
80. Mueller S. G., Weiner M. W., Thal L. J., Petersen R. C., Jack C., Jagust W., et al. (2005). The Alzheimer's disease neuroimaging initiative. Neuroimag. Clin. 15, 869–877. doi: 10.1016/j.nic.2005.09.008
81. Oktay O., Bai W., Lee M., Guerrero R., Kamnitsas K., Caballero J., et al. (2016). “Multi-input cardiac image super-resolution using convolutional neural networks,” in International Conference on Medical Image Computing and Computer-Assisted Intervention (Athens: Springer), 246–254. doi: 10.1007/978-3-319-46726-9_29
82. Ortiz A., Martínez-Murcia F. J., García-Tarifa M. J., Lozano F., Górriz J. M., and Ramírez J. (2016). “Automated diagnosis of parkinsonian syndromes by deep sparse filtering-based features,” in International Conference on Innovation in Medicine and Healthcare (Puerto de la Cruz: Springer), 249–258. doi: 10.1007/978-3-319-39687-3_24
83. Pan Y., Liu M., Lian C., Xia Y., and Shen D. (2019). “Disease-image specific generative adversarial network for brain disease diagnosis with incomplete multi-modal neuroimages,” in International Conference on Medical Image Computing and Computer-Assisted Intervention (Shenzhen). doi: 10.1007/978-3-030-32248-9_16
84. Pan Y., Liu M., Lian C., Zhou T., Xia Y., and Shen D. (2018). “Synthesizing missing pet from mri with cycle-consistent generative adversarial networks for Alzheimer's disease diagnosis,” in International Conference on Medical Image Computing and Computer-Assisted Intervention (Granada: Springer), 455–463. doi: 10.1007/978-3-030-00931-1_52
85. Pandya M. D., Shah P. D., and Jardosh S. (2019). “Medical image diagnosis for disease detection: a deep learning approach,” in U-Healthcare Monitoring Systems (Elsevier), 37–60. doi: 10.1016/B978-0-12-815370-3.00003-7
86. Parisot S., Ktena S. I., Ferrante E., Lee M., Moreno R. G., Glocker B., et al. (2017). “Spectral graph convolutions for population-based disease prediction,” in International Conference on Medical Image Computing and Computer-Assisted Intervention (Quebec City, QC: Springer), 177–185. doi: 10.1007/978-3-319-66179-7_21
87. Patel P., Aggarwal P., and Gupta A. (2016). “Classification of schizophrenia versus normal subjects using deep learning,” in Tenth Indian Conference on Computer Vision, Graphics and Image Processing (Guwahati), 28. doi: 10.1145/3009977.3010050
88. Payan A., and Montana G. (2015). Predicting Alzheimer's disease: a neuroimaging study with 3D convolutional neural networks. arXiv 1502.02506.
89. Pinaya W. H., Gadelha A., Doyle O. M., Noto C., Zugman A., Cordeiro Q., et al. (2016). Using deep belief network modelling to characterize differences in brain morphometry in schizophrenia. Sci. Rep. 6, 1–9. doi: 10.1038/srep38897
90. Pinaya W. H., Mechelli A., and Sato J. R. (2019). Using deep autoencoders to identify abnormal brain structural patterns in neuropsychiatric disorders: a large-scale multi-sample study. Hum. Brain Mapp. 40, 944–954. doi: 10.1002/hbm.24423
91. Plis S. M., Hjelm D. R., Salakhutdinov R., Allen E. A., Bockholt H. J., Long J. D., et al. (2014). Deep learning for neuroimaging: a validation study. Front. Neurosci. 8:229. doi: 10.3389/fnins.2014.00229
92. Poultney C., Chopra S., Cun Y. L., and Ranzato M. (2007). “Efficient learning of sparse representations with an energy-based model,” in Advances in Neural Information Processing Systems, eds M. I. Jordan, Y. LeCun, and S. A. Solla (Vancouver, BC: ACM), 1137–1144. doi: 10.5555/2976456.2976599
93. Qi J., and Tejedor J. (2016). “Deep multi-view representation learning for multi-modal features of the schizophrenia and schizo-affective disorder,” in IEEE International Conference on Acoustics, Speech and Signal Processing (Shanghai), 952–956. doi: 10.1109/ICASSP.2016.7471816
94. Qureshi M. N. I., Oh J., and Lee B. (2019). 3D-CNN based discrimination of schizophrenia using resting-state fMRI. Artif. Intell. Med. 98, 10–17. doi: 10.1016/j.artmed.2019.06.003
95. Radford A., Metz L., and Chintala S. (2015). Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 1511.06434.
96. Ronneberger O., Fischer P., and Brox T. (2015). “U-net: convolutional networks for biomedical image segmentation,” in International Conference on Medical Image Computing and Computer-Assisted Intervention (Munich: Springer), 234–241. doi: 10.1007/978-3-319-24574-4_28
97. Roth H. R., Lu L., Seff A., Cherry K. M., Hoffman J., Wang S., et al. (2014). “A new 2.5 D representation for lymph node detection using random sets of deep convolutional neural network observations,” in International Conference on Medical Image Computing and Computer-Assisted Intervention (Boston, MA: Springer), 520–527. doi: 10.1007/978-3-319-10404-1_65
98. Rumelhart D. E., Hinton G. E., and Williams R. J. (1986). Learning representations by back-propagating errors. Nature 323:533. doi: 10.1038/323533a0
99. Saeed F., Eslami T., Mirjalili V., Fong A., and Laird A. (2019). ASD-DiagNet: a hybrid learning approach for detection of autism spectrum disorder using fMRI data. Front. Neuroinform. 13:70. doi: 10.3389/fninf.2019.00070
100. Salakhutdinov R. (2015). Learning deep generative models. Annu. Rev. Stat. Appl. 2, 361–385. doi: 10.1146/annurev-statistics-010814-020120
101. Salakhutdinov R., and Larochelle H. (2010). “Efficient learning of deep Boltzmann machines,” in Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics (Sardinia), 693–700.
102. Sarikaya R., Hinton G. E., and Deoras A. (2014). Application of deep belief networks for natural language understanding. IEEE/ACM Trans. Audio Speech Lang. Process. 22, 778–784. doi: 10.1109/TASLP.2014.2303296
103. Sarraf S.Tofighi G., et al. (2016). DeepAD: Alzheimer's disease classification via deep convolutional neural networks using MRI and fMRI. bioRxiv 070441. doi: 10.1101/070441
104. Schlegl T., Waldstein S. M., Vogl W.-D., Schmidt-Erfurth U., and Langs G. (2015). “Predicting semantic descriptions from medical images with convolutional neural networks,” in International Conference on Information Processing in Medical Imaging (Springer), 437–448. doi: 10.1007/978-3-319-19992-4_34
105. Schmidhuber J. (2015). Deep learning in neural networks: an overview. Neural Netw. 61, 85–117. doi: 10.1016/j.neunet.2014.09.003
106. Shen D., Wu G., and Suk H.-I. (2017). Deep learning in medical image analysis. Annu. Rev. Biomed. Eng. 19, 221–248. doi: 10.1146/annurev-bioeng-071516-044442
107. Shen L., Shi J., Dong Y., Ying S., Peng Y., Chen L., et al. (2019a). An improved deep polynomial network algorithm for transcranial sonography-based diagnosis of Parkinson's disease. Cogn. Comput. 12, 553–562. doi: 10.1007/s12559-019-09691-7
108. Shen T., Jiang J., Lin W., Ge J., Wu P., Zhou Y., et al. (2019b). Use of overlapping group lasso sparse deep belief network to discriminate Parkinson's disease and normal control. Front. Neurosci. 13:396. doi: 10.3389/fnins.2019.00396
109. Shi B., Chen Y., Zhang P., Smith C. D., Liu J., Initiative A. D. N., et al. (2017a). Nonlinear feature transformation and deep fusion for Alzheimer's disease staging analysis. Pattern Recogn. 63, 487–498. doi: 10.1016/j.patcog.2016.09.032
110. Shi J., Xue Z., Dai Y., Peng B., Dong Y., Zhang Q., et al. (2018). Cascaded multi-column RVFL+ classifier for single-modal neuroimaging-based diagnosis of Parkinson's disease. IEEE Trans. Biomed. Eng. 66, 2362–2371. doi: 10.1109/TBME.2018.2889398
111. Shi J., Zheng X., Li Y., Zhang Q., and Ying S. (2017b). Multimodal neuroimaging feature learning with multimodal stacked deep polynomial networks for diagnosis of Alzheimer's disease. IEEE J. Biomed. Health Inform. 22, 173–183. doi: 10.1109/JBHI.2017.2655720
112. Shin H.-C., Orton M. R., Collins D. J., Doran S. J., and Leach M. O. (2013). Stacked autoencoders for unsupervised feature learning and multiple organ detection in a pilot study using 4D patient data. IEEE Trans. Pattern Analysis Mach. Intell. 35, 1930–1943. doi: 10.1109/TPAMI.2012.277
113. Shorten C., and Khoshgoftaar T. M. (2019). A survey on image data augmentation for deep learning. J. Big Data 6, 1–48. doi: 10.1186/s40537-019-0197-0
114. Singh A., Sengupta S., and Lakshminarayanan V. (2020). Explainable deep learning models in medical image analysis. arXiv 2005.13799. doi: 10.3390/jimaging6060052
115. Singh G., and Samavedham L. (2015). Unsupervised learning based feature extraction for differential diagnosis of neurodegenerative diseases: a case study on early-stage diagnosis of Parkinson disease. J. Neurosci. Methods 256, 30–40. doi: 10.1016/j.jneumeth.2015.08.011
116. Sivaranjini S., and Sujatha C. (2019). Deep learning based diagnosis of Parkinson's disease using convolutional neural network. Multimed. Tools Appl. 79, 15467–15479. doi: 10.1007/s11042-019-7469-8
117. Song T.-A., Chowdhury S. R., Yang F., Jacobs H., El Fakhri G., Li Q., et al. (2019). “Graph convolutional neural networks For Alzheimer's disease classification,” in 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019) (Venice: IEEE), 414–417. doi: 10.1109/ISBI.2019.8759531
118. Srinivasagopalan S., Barry J., Gurupur V., and Thankachan S. (2019). A deep learning approach for diagnosing schizophrenic patients. J. Exp. Theor. Artif. Intell. 31, 1–14. doi: 10.1080/0952813X.2018.1563636
119. Srivastava N., Hinton G., Krizhevsky A., Sutskever I., and Salakhutdinov R. (2014). Dropout: a simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 15, 1929–1958. doi: 10.5555/2627435.2670313
120. Suk H.-I., Lee S.-W., Shen D., and Alzheimers Disease Neuroimaging Initiative. (2014). Hierarchical feature representation and multimodal fusion with deep learning for AD/MCI diagnosis. Neuroimage 101, 569–582. doi: 10.1016/j.neuroimage.2014.06.077
121. Suk H.-I., Lee S.-W., Shen D., and Alzheimers Disease Neuroimaging Initiative. (2015). Latent feature representation with stacked auto-encoder for AD/MCI diagnosis. Brain Struct. Funct. 220, 841–859. doi: 10.1007/s00429-013-0687-3
122. Suk H.-I., Lee S.-W., Shen D., and Alzheimers Disease Neuroimaging Initiative. (2016). Deep sparse multi-task learning for feature selection in Alzheimer's disease diagnosis. Brain Struct. Funct. 221, 2569–2587. doi: 10.1007/s00429-015-1059-y
123. Sun L., Shao W., Wang M., Zhang D., and Liu M. (2019a). High-order feature learning for multi-atlas based label fusion: application to brain segmentation with MRI. IEEE Trans. Image Process. 29, 2702–2713. doi: 10.1109/TIP.2019.2952079
124. Sun L., Shao W., Zhang D., and Liu M. (2019b). Anatomical attention guided deep networks for ROI segmentation of brain MR images. IEEE Trans. Med. Imaging 39, 2000–2012. doi: 10.1109/TMI.2019.2962792
125. Ulloa A., Plis S., and Calhoun V. (2018). Improving classification rate of schizophrenia using a multimodal multi-layer perceptron model with structural and functional MR. arXiv 1804.04591.
126. Ulloa A., Plis S., Erhardt E., and Calhoun V. (2015). “Synthetic structural magnetic resonance image generator improves deep learning prediction of schizophrenia,” in 2015 IEEE 25th International Workshop on Machine Learning for Signal Processing (MLSP) (Boston, MA), 1–6. doi: 10.1109/MLSP.2015.7324379
127. Vieira S., Pinaya W. H., and Mechelli A. (2017). Using deep learning to investigate the neuroimaging correlates of psychiatric and neurological disorders: methods and applications. Neurosci. Biobehav. Rev. 74, 58–75. doi: 10.1016/j.neubiorev.2017.01.002
128. Vincent P., Larochelle H., Bengio Y., and Manzagol P.-A. (2008). “Extracting and composing robust features with denoising autoencoders,” in Proceedings of the 25th International Conference on Machine Learning (Helsinki: ACM), 1096–1103. doi: 10.1145/1390156.1390294
129. Voulodimos A., Doulamis N., Doulamis A., and Protopapadakis E. (2018). Deep learning for computer vision: a brief review. Comput. Intell. Neurosci. 2018:7068349. doi: 10.1155/2018/7068349
130. Wang M., Hao X., Huang J., Shao W., and Zhang D. (2019a). Discovering network phenotype between genetic risk factors and disease status via diagnosis-aligned multi-modality regression method in Alzheimer's disease. Bioinformatics 35, 1948–1957. doi: 10.1093/bioinformatics/bty911
131. Wang M., Lian C., Yao D., Zhang D., Liu M., and Shen D. (2019b). Spatial-temporal dependency modeling and network hub detection for functional MRI analysis via convolutional-recurrent network. IEEE Trans. Biomed. Eng. 67, 2241–2252. doi: 10.1109/TBME.2019.2957921
132. Wang M., Zhang D., Huang J., Shen D., and Liu M. (2018). “Low-rank representation for multi-center autism spectrum disorder identification,” in Medical Image Computing and Computer Assisted Intervention-MICCAI 2018 (Cham: Springer International Publishing), 647–654. doi: 10.1007/978-3-030-00928-1_73
133. Wang M., Zhang D., Huang J., Yap P.-T., Shen D., and Liu M. (2019c). Identifying autism spectrum disorder with multi-site fMRI via low-rank domain adaptation. IEEE Trans. Med. Imaging 39, 644–655. doi: 10.1109/TMI.2019.2933160
134. Wang M., Zhang D., Shen D., and Liu M. (2019d). Multi-task exclusive relationship learning for alzheimer's disease progression prediction with longitudinal data. Med. Image Anal. 53, 111–122. doi: 10.1016/j.media.2019.01.007
135. Wernick M. N., Yang Y., Brankov J. G., Yourganov G., and Strother S. C. (2010). Machine learning in medical imaging. IEEE Signal Process. Mag. 27, 25–38. doi: 10.1109/MSP.2010.936730
136. Wu G., Kim M., Wang Q., Gao Y., Liao S., and Shen D. (2013). “Unsupervised deep feature learning for deformable registration of MR brain images,” in International Conference on Medical Image Computing and Computer-Assisted Intervention (Shenzhen: Springer), 649–656. doi: 10.1007/978-3-642-40763-5_80
138. Wu Z., Pan S., Chen F., Long G., Zhang C., and Yu P. S. (2019). A comprehensive survey on graph neural networks. arXiv 1901.00596.
139. Yan W., Calhoun V., Song M., Cui Y., Yan H., Liu S., et al. (2019). Discriminating schizophrenia using recurrent neural network applied on time courses of multi-site fMRI data. EBioMedicine 47, 543–552. doi: 10.1016/j.ebiom.2019.08.023
140. Yao D., Liu M., Wang M., Lian C., Wei J., Sun L., et al. (2019). “Triplet graph convolutional network for multi-scale analysis of functional connectivity using functional MRI,” in International Workshop on Graph Learning in Medical Imaging (Shenzhen: Springer), 70–78. doi: 10.1007/978-3-030-35817-4_9
141. Yu S., Yue G., Elazab A., Song X., Wang T., and Lei B. (2019). “Multi-scale graph convolutional network for mild cognitive impairment detection,” in International Workshop on Graph Learning in Medical Imaging (Shenzhen: Springer), 79–87. doi: 10.1007/978-3-030-35817-4_10
142. Zeng L. L., Wang H., Hu P., Yang B., Pu W., Shen H., et al. (2018). Multi-site diagnostic classification of schizophrenia using discriminant deep learning with functional connectivity MRI. Ebiomedicine 30, 74–85. doi: 10.1016/j.ebiom.2018.03.017
143. Zhang D., Huang J., Jie B., Du J., Tu L., and Liu M. (2018a). Ordinal pattern: a new descriptor for brain connectivity networks. IEEE Trans. Med. Imaging 37, 1711–1722. doi: 10.1109/TMI.2018.2798500
144. Zhang X., He L., Chen K., Luo Y., Zhou J., and Wang F. (2018b). “Multi-view graph convolutional network and its applications on neuroimage analysis for Parkinson's disease,” in AMIA Annual Symposium Proceedings, Vol. 2018 (Washington, DC: American Medical Informatics Association), 1147.
145. Zhao X., Zhou F., Ou-Yang L., Wang T., and Lei B. (2019). “Graph convolutional network analysis for mild cognitive impairment prediction,” in 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019) (Venice: IEEE), 1598–601. doi: 10.1109/ISBI.2019.8759256
Keywords: deep learning, neuroimage, Alzheimer's disease, Parkinson's disease, autism spectrum disorder, schizophrenia
Citation: Zhang L, Wang M, Liu M and Zhang D (2020) A Survey on Deep Learning for Neuroimaging-Based Brain Disorder Analysis. Front. Neurosci. 14:779. doi: 10.3389/fnins.2020.00779
Received: 10 May 2020; Accepted: 02 June 2020;
Published: 08 October 2020.
Edited by:
Jun Shi, Shanghai University, ChinaReviewed by:
Xia Wu, Beijing Normal University, ChinaJinglei Lv, The University of Sydney, Australia
Copyright © 2020 Zhang, Wang, Liu and Zhang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Mingxia Liu, bXhsaXVAbWVkLnVuYy5lZHU=; Daoqiang Zhang, ZHF6aGFuZ0BudWFhLmVkdS5jbg==