 Yanqiu Li
Yanqiu Li Huan Liu1
Huan Liu1- 1School of Data Science and Artificial Intelligence, Jilin Engineering Normal University, Changchun, China
- 2Department of Basic Sciences, Jilin Jianzhu University, Changchun, China
Redundant manipulators are universally employed to save manpower and improve work efficiency in numerous areas. Nevertheless, the redundancy makes the inverse kinematics of manipulators hard to address, thus increasing the difficulty in instructing manipulators to perform a given task. To deal with this problem, an online learning fuzzy echo state network (OLFESN) is proposed in the first place, which is based upon an online learning echo state network and the Takagi–Sugeno–Kang fuzzy inference system (FIS). Then, an OLFESN-based control scheme is devised to implement the efficient control of redundant manipulators. Furthermore, simulations and experiments on redundant manipulators, covering UR5 and Franka Emika Panda manipulators, are carried out to verify the effectiveness of the proposed control scheme.
1 Introduction
To improve production efficiency and set themselves free from manpower, robots have come into being and undergone expeditious and substantial progress, with plentiful and triumphant applications in numerous areas (Sun et al., 2023b; Liu et al., 2024). Therefore, redundant manipulators that possess more degrees of freedom (DOFs) than non-redundant ones to fulfill a specific task stand out and have been subject to in-depth and comprehensive investigations (Liao et al., 2016; Liu et al., 2023). More precisely, by virtue of the additional DOFs, they are capable of executing some secondary tasks while performing the primary task, such as obstacle avoidance, optimizing joint torques, and enhancing operability (Jin et al., 2017a; Sun et al., 2022a). For that reason, research on the mechanisms and applications of redundant manipulators is in full swing. However, it is worth mentioning that the additional DOFs result in troubles and challenges for controlling manipulators efficiently and precisely (Zhang et al., 2019; Zhao et al., 2020). Therefore, it imports the demand to devise and construct a potent control scheme of redundant manipulators (Jin et al., 2017b; Liao et al., 2022).
With a sophisticated and ingenious nervous system, humans are capable of performing a variety of complicated and intractable missions by learning from recent experiences, which is the most prominent difference and superiority compared with other creatures (Wang et al., 2016; Liao et al., 2024b). Therefore, this has opened up a new avenue for the control of manipulators. That is, manipulators can accomplish the assigned task with high efficiency by simulating the learning ability of humans. Taking the neural network (NN) (Su et al., 2023a; Wei and Jin, 2024) and fuzzy inference system (FIS) (Vargas et al., 2024) into account, both of them attempt to simulate the thinking and decision-making processes of humans in a certain way. Therefore, they have garnered the attention of researchers, and a lot of effort has been put into integrating them with manipulator control systems to improve the completion of the task and meet the requirements of different scenarios. For instance, Yoo and Ham (2000) present adaptive control schemes for manipulators, in which the parameter uncertainty is handled via the FIS. Afterward, aiming at the tracking control of the end-effector for manipulators, an FIS-based controller is designed by Yilmaz et al. (2022), in which the centers and widths of the membership functions are adjusted adaptively, thus promoting the learning power of the controller. Recently, Yilmaz et al. (2023) devised an FIS-based output-feedback controller for the joint space tracking of manipulators, in which the demands for joint velocity and knowledge of manipulators are eliminated.
In recent times, a surge of research has come into view in the realm of the echo state network (ESN), a sort of recurrent neural network (RNN), which overcomes certain problems hindering the investigations and applications of RNNs, such as gradient vanishing and gradient exploding (Rodan and Tino, 2011; Chen et al., 2023). The core of ESN lies in the reservoir, which is a large, sparse network in charge of capturing the dynamic behavior of input information. Particularly in the ESN, both input and reservoir weights are generated at random, and one needs to put effort into obtaining the output weights by figuring out the weighted sum of outputs (Lukoševičius, 2012). Considering another network, the extreme learning machine (ELM) (Huang et al., 2006) is a feedforward network with a hidden layer. Weights and biases for the hidden layer are appointed randomly, while the training of the network focuses on determining output weights through the least squares method. Therefore, from the perspective of this point, the ELM, ESN, and FIS share a certain similarity, and thus, a great deal of work has been carried out that builds and verifies the bridges between them (Sun et al., 2007; Ribeiro et al., 2020). By integrating these networks and taking advantage of their strengths, some extraordinary work is presented and utilized in various domains to address different issues. Concentrating on function approximation and classification problems, a fuzzy ELM with the capacity for online learning was devised by Rong et al. (2009). Compared with other existing mechanisms it presents remarkable superiority with decent accuracy and reduced training time. Motivated by this, aiming at efficient control of redundant manipulators, this study proposes an online learning fuzzy ESN (OLFESN). To be more specific, the proposed OLFESN is designed, based on an online learning strategy for ESN, to erect an efficient control scheme for redundant manipulators, while the FIS is also incorporated to improve the accuracy and efficiency of the proposed network. Then, a corresponding control scheme for redundant manipulators is constructed. The rest of this study is organized as follows: Section 2 makes known some preliminary steps to lay the foundation for this study. Then, the OLFESN is proposed, based on which the control scheme for redundant manipulators is devised in Section 3. In Section 4, simulations and experiments are carried out to investigate the feasibility and effectiveness of the proposed control scheme. In the end, Section 5 concludes this study.
2 Preliminaries
In this section, the forward kinematics of redundant manipulators, the Takagi–Sugeno–Kang (TSK) fuzzy system, and ESN are briefly reviewed, which are the bases of the proposed OLFESN.
2.1 Forward kinematics of redundant manipulators
The forward kinematics equation that depicts the non-linear transformation of redundant manipulators from the joint angle q ∈ ℝa to the Cartesian position r ∈ ℝb with a > b can be depicted as
where ϒ(•) signifies the non-linear mapping function, which depends upon the structural properties of redundant manipulators (Sun et al., 2022b; Zhang et al., 2022). Where after, evaluating the derivative of Equation (1) in terms of time contributes to
in which J(q) = ∂ϒ(q)/∂q ∈ ℝb × a denotes the Jacobian matrix; denotes the angular velocity; denotes the velocity of the end-effector (Yan et al., 2024). Heretofore, the non-linear transformation (Equation 1) is converted to the affine system (Equation 2) with the convenience of gaining the redundancy solution of redundant manipulators (Sun et al., 2023a).
2.2 Takagi–Sugeno–Kang fuzzy system
In the TSK fuzzy system with given input , the k-th rule can be depicted as Kerk et al. (2021) and Zhang et al. (2023):
where is the index of the fuzzy rule with being the number of fuzzy rules; Amk denotes the fuzzy subset of the m-th element of input α in the k-th rule; χk signifies the output of the k-th rule; is the consequent coefficient of the k-th rule. Considering the m-th element of input in the k-th rule, the degree to which it matches the fuzzy subset Amk is measured by its membership function ζAmk(αm), which can be any bounded non-constant piecewise continuous function (Rezaee and Zarandi, 2010). Let ⊗ denote the fuzzy conjunction operation, and then the firing strength (if part) of the k-th rule is defined as
where pk is the parameter of membership function ζ(•) in the k-th rule. Normalizing (Equation 4), there is
Ultimately, for the input α, the output of the TSK fuzzy model can be obtained as
with θk = (θk1, θk2, ⋯ , θkm).
2.3 Echo state network
The ESN is composed of an input layer, a reservoir, and an output layer, which enjoy l, r, and o neurons, respectively (Calandra et al., 2021). For a complete network, the input layer, reservoir, and output layer re connected by input weights and output weights , respectively, while the internal neurons of the reservoir are connected to each other by dint of (Chen et al., 2024a). In particular, the spectral radius of Wres needs to be < 1 to capture the echo state property. At the time of step i, designate input and reservoir states as and , respectively. The reservoir is updated through
and the output of the network is
with . Furthermore, for working out the output weights, keep track of reservoir state and outputs in matrices and , respectively, during training, where ĩ denotes the number of training samples. Where after, by solving
the output weights are obtained
where the superscripts T and −1 represent transpose and inversion operations of a matrix, respectively (Su et al., 2023b; Liao et al., 2024a).
3 Online learning fuzzy echo state network
Stimulated by the commonalities between ESN and FIS, OLFESN is proposed in this section. Then, an OLFESN-based control scheme for redundant manipulators is devised.
3.1 OLFESN
Considering (Equation 4), the firing strength (if any) in the TSK fuzzy system involves multiple fuzzy conjunction operations, providing sufficient computing power for thoroughly exploring and utilizing input information. Furthermore, each rule is normalized to ensure that different rules have a comparable contribution to the system. Similarly, in the ESN, it is the reservoir that is responsible for implementing the above function, by which the low-dimensional input is mapped to a high-dimensional dynamic space. In addition, the outputs of different reservoirs are adjusted to the same extent with the aid of the activation function f(•), which plays the same role as Equation (5). Therefore, the reservoir is adopted to reveal the firing strength normalized in the proposed OLESN. Specifically, the OLESN with reservoirs is established as follows:
Given training samples , the state of the k-th reservoir is updated via
where fk(•) denotes the activation function of the k-th reservoir, and ĩ is the number of training samples. Collect all states of the k-th reservoir in Ξk = [ιk1, ιk2, ⋯ , ιkĩ, and then integrate all reservoirs elicited
Thus, the output of the fuzzy ESN (FESN) can be formulated as
with Y = [y1, y2, ⋯ , yĩ]. Similarly to Equation (10), output weights are obtained via
At this point, the derivation of FESN is complete. Therewith, taking into account the need for online learning, the OLFESN is proposed, which incorporates the FESN and the online learning strategy for ESN. To be more specific, when data shows up constantly, the OLFESN is summarized as follows:
3.2 Initialization phase
a. Given the initial training samples , update and transcribe the state of all reservoirs using Equation 11.
b. Taking advantage of Equation 12, figure out the initial state matrix Λ0 for FESN.
c. Compute the initial output weights with and Y0 = [y1, y2, ⋯ , yĩ0].
d. Let p = 0.
3.3 Sequential learning phase
a. With the new sample set
solve problem
where ĩp+1 signifies the count of samples in the (p+1)-th set; Λp+1is the corresponding reservoir state, obtained by Equations 11, 12; .
b. Let with .
c. Update output weights
d. Let p = p + 1. (Back to step 2).
Remark 1: For the case that the new samples come out one by one, with the aid of the Sherman-Morrison formula (Chen et al., 2024b), Equation 16 is further simplified as
3.4 OLFESN-based control scheme
In this section, an OLFESN-based control scheme for redundant manipulators is developed for performing the given missions. At moment t, define θa (t) and Δθa (t) as the actual joint angle and actual joint angle increment, respectively. Meanwhile, the actual and desired positions of the end-effector are denoted by ζa (t) and ζd (t), respectively. Correspondingly, at moment t+1, the desired position increment for the end-effector is expressed as Δζ(t+1) = ζd(t)−ζa(t). Incorporate θa(t), Δθa(t), and Δζ(t + 1), which is the input of the OLFESN and denoted by x(t) for the convenience of subsequent expressions. Then, applying Equations 11–13, we gain the joint angle increment Δθa(t + 1) for the next moment, i.e., the output of OLFESN. Hence, the control signal for the next moment is acquired, i.e., θa(t+1) = θa(t) + Δθa(t + 1 ).
Note that, in the OLFESN, there is a premise that sample (x(t), y(t)) is accessible all the time. However, for the proposed scheme, the desired joint angle increment Δθd(t+1), i.e., y(t), is unrevealed in reality. In addition, taking into account output weights Wout, it ought to be updated in real-time to generate the control signal. An accepted wisdom is making use of the teaching signal to update output weights Wout. More specifically, the error ϵ(t+1) between the desired joint angle increment Δθd(t+1) and the actual one Δθa(t+1) plays a part in the teaching signal in the proposed scheme.
Informed by Equation (2), the transformation between joint angle increment Δθ(t) and position increment Δζ(t) of the end-effector is devised as
Then, we have
Solving Equation 19, the teaching signal is collected as
Until now, the proposed control scheme for redundant manipulators based on the above-mentioned teaching signal and OLFESN has been constructed as
which is outlined and summarized in Algorithm 1.

Algorithm 1. Proposed Control Scheme
4 Illustrative examples
In this section, simulations on redundant manipulators are devised and executed, covering a 6-DOF manipulator and a 7-DOF one, to verify the effectiveness and feasibility of the proposed scheme (Equation 21).
4.1 UR5
A UR5 manipulator is employed with the aid of the proposed scheme (Equation 21) in this simulation, which possesses 6 DOFs and is explicitly revealed in Zheng et al. (2019) and Chico et al. (2021). The task is to track a four-leaf clover path within 20 s, where the initial angle state is θ(0) = [0; −π/2; 2π/3; 0; 0; 0] rad. With regard to OLFESN, the input weights Win and internal connection weights of reservoir Wres are randomly initialized to [−0.5, 0.5] by using MATLAB's 2022 rand(•) function. In addition, we bring in a total of three reservoirs, each with 500 neurons and the hyperbolic tangent function (tanh(•)), while the spectral radius is set to 0.8. Specifically, simulation results are exhibited in Figure 1, where Figure 1A illustrates the position errors of the end-effector during task execution. One can observe that the manipulator, with the aid of the proposed scheme (Equation 21), does the job with flying colors, and the position error of the end-effector is of the order 10−4 m. Correspondingly, trails of joint angles and task completion are shown in Figures 1B, C, respectively. Note that, during the task, the joint angles of the manipulator are evolving in a gentle manner, which is capable of reducing the wear between mechanical components to a certain extent, thus elongating the service life of the manipulator. In the end, Figure 1C further indicates that the task of tracking the four-leaf clover path is commendably accomplished by the manipulator, with the actual trajectory synthesized by the proposed scheme (Equation 21) excellently covering the desired one.
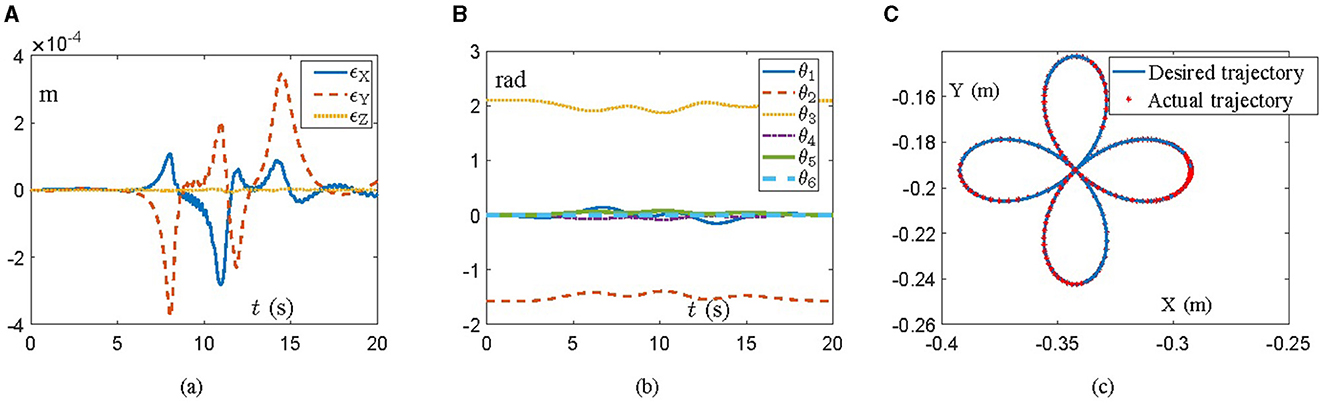
Figure 1. Simulative experiment results on the UR5 manipulator synthesized by the proposed scheme (Equation 21) for tracking a four-leaf clover path. (A) Profiles of the tracking error. (B) Profiles of the joint angle. (C) The desired trajectory and the actual trajectory.
4.2 Franka Emika panda manipulator
In this part, the simulation of a Franka Emika Panda manipulator is designed and carried out to further verify the effectiveness and feasibility of the proposed scheme (Equation 21). The Franka Emika Panda is a 7-DOF manipulator with structural information covered by Shahid et al. (2020) and Gaz et al. (2019), which is necessary to track a tricuspid valve trajectory within 20 s. The initial angle state is θ(0) = [0; −π/4; 0; −3π/4; 0;π/2; π/4] rad, while the other parameters are in line with those in Section 4.1. Figure 2 reveals simulation results, where position errors of the end-effector are exhibited in Figure 2A. Viewing position errors, one can lightly draw the conclusion that the Franka Emika Panda manipulator controlled by the proposed scheme (Equation 21) finishes the given task successfully, with the position error being of the order 10−5 m. Then, pay attention to the variation of joint angles and task completion, which are depicted in Figures 2B, C, respectively. All these results indicate the success of the task, which further verifies the feasibility and effectiveness of the proposed scheme (Equation 21) in the field of robot control. Furthermore, the corresponding simulation experiments are executed on the virtual robot experimentation platform (V-REP) to vividly simulate task execution. Snapshots of the Franka Emika Panda manipulator with the aid of the proposed scheme (Equation 21) are displayed in Figure 3, from which we can observe that the Franka Emika Panda manipulator safely and efficiently performs the task of tracking the tricuspid valve trajectory, thus further verifying the reliability of the above simulation results and the practicability of the proposed scheme (Equation 21).
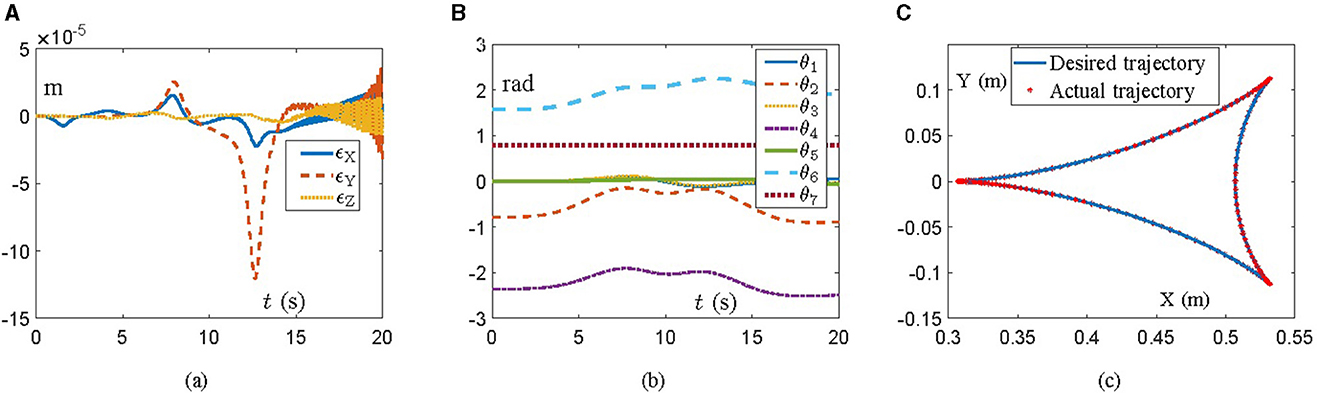
Figure 2. Simulative experiment results on the Frank Emika Panda manipulator synthesized by the proposed scheme (Equation 21) for tracking a tricuspid valve trajectory. (A) Profiles of the tracking error. (B) Profiles of the joint angle. (C) The desired trajectory and the actual trajectory.
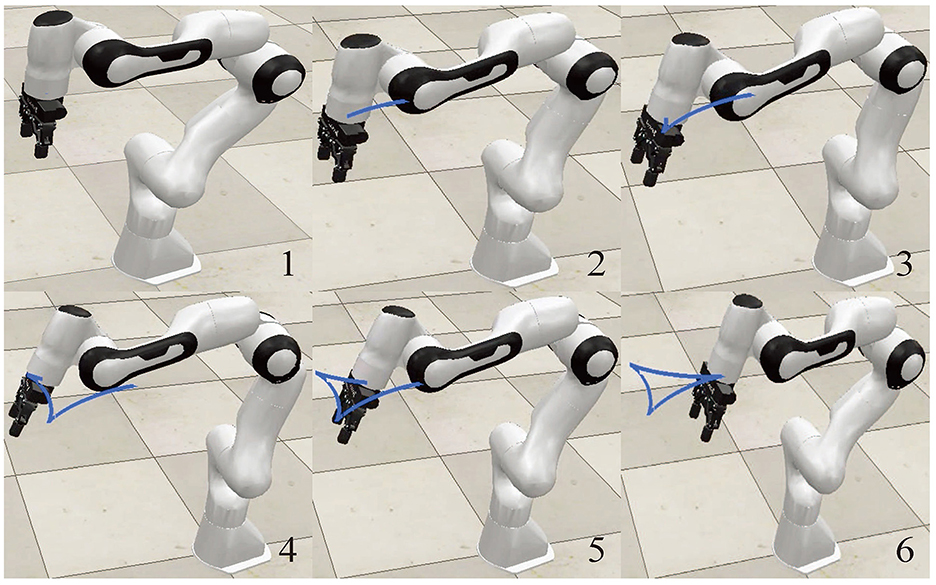
Figure 3. Snapshots of the Franka Emika Panda manipulator simulated on the (V-REP) platform for tracking the tricuspid valve trajectory with the aid of the proposed scheme (Equation 21).
5 Conclusion
Based on the online learning strategy for ESN and FIS, an OLFESN has been proposed, in which the new data is allowed to arrive one by one or in blocks. There are no additional restrictions on the size of blocks, thus highly extending the application scenarios of the proposed OLFESN. Subsequently, to cope with the complicated control problem of redundant manipulators, an OLFESN-based control scheme has been constructed from a kinematics point of view. In the end, simulations and experiments on the UR5 and Franka Emika Panda manipulators have been carried out and confirmed the effectiveness and feasibility of the proposed control scheme (Equation 21). Incorporating joint constraints into the proposed scheme (Equation 21) is a future research direction, that is capable of improving the safety and efficiency of task execution.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics statement
The manuscript presents research on animals that do not require ethical approval for their study.
Author contributions
YL: Formal analysis, Funding acquisition, Methodology, Writing – original draft, Writing – review & editing. HL: Data curation, Methodology, Writing – original draft. HG: Data curation, Formal analysis, Writing – original draft.
Funding
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. This work was supported by the Science and Technology Project of Jilin Province under Grant JJKH20240243KJ.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Calandra, M., Patanè, L., Sun, T., Arena, P., and Manoonpong, P. (2021). Echo state networks for estimating exteroceptive conditions from proprioceptive states in quadruped robots. Front. Neurorobot. 15:655330. doi: 10.3389/fnbot.2021.655330
Chen, X., Jin, L., and Hu, B. (2024a). A cerebellum-inspired control scheme for kinematic control of redundant manipulators. IEEE Trans. Industr. Electr. 71, 7542–7550. doi: 10.1109/TIE.2023.3312427
Chen, X., Jin, L., and Li, S. (2024b). An online learning strategy for echo state network. IEEE Trans. Syst. Man Cyber. Syst. 54, 644–655. doi: 10.1109/TSMC.2023.3319357
Chen, X., Liu, M., and Li, S. (2023). Echo state network with probabilistic regularization for time series prediction. IEEE/CAA J. Autom. Sinica 10, 1743–1753. doi: 10.1109/JAS.2023.123489
Chico, A., Cruz, P. J., Vásconez, J. P., Benalcázar, M. E., álvarez, R., Barona, L., et al. (2021). “Hand gesture recognition and tracking control for a virtual UR5 robot manipulator,” in 2021 IEEE Fifth Ecuador Technical Chapters Meeting (ETCM), 1–6.
Gaz, C., Cognetti, M., Oliva, A., Robuffo Giordano, P., and De Luca, A. (2019). Dynamic identification of the Franka Emika Panda robot with retrieval of feasible parameters using penalty-based optimization. IEEE Robot. Autom. Lett. 4, 4147–4154. doi: 10.1109/LRA.2019.2931248
Huang, G.-B., Zhu, Q.-Y., and Siew, C.-K. (2006). Extreme learning machine: theory and applications. Neurocomputing 70, 489–501. doi: 10.1016/j.neucom.2005.12.126
Jin, L., Li, S., Liao, B., and Zhang, Z. (2017a). Zeroing neural networks: a survey. Neurocomputing 267, 597–604. doi: 10.1016/j.neucom.2017.06.030
Jin, L., Liao, B., Liu, M., Xiao, L., Guo, D., and Yan, X. (2017b). Different-level simultaneous minimization scheme for fault tolerance of redundant manipulator aided with discrete-time recurrent neural network. Front. Neurorobot. 11:50. doi: 10.3389/fnbot.2017.00050
Kerk, Y. W., Teh, C. Y., Tay, K. M., and Lim, C. P. (2021). Parametric conditions for a monotone TSK fuzzy inference system to be an n-ary aggregation function. IEEE Trans. Fuzzy Syst. 29, 1864–1873. doi: 10.1109/TFUZZ.2020.2986986
Liao, B., Han, L., Cao, X., Li, S., and Li, J. (2024a). Double integral-enhanced zeroing neural network with linear noise rejection for time-varying matrix inverse. CAAI Trans. Intell. Technol. 9, 197–210. doi: 10.1049/cit2.12161
Liao, B., Hua, C., Xu, Q., Cao, X., and Li, S. (2024b). Inter-robot management via neighboring robot sensing and measurement using a zeroing neural dynamics approach. Exp. Syst. Applic. 244:122938. doi: 10.1016/j.eswa.2023.122938
Liao, B., Wang, Y., Li, J., Guo, D., and He, Y. (2022). Harmonic noise-tolerant ZNN for dynamic matrix pseudoinversion and its application to robot manipulator. Front. Neurorobot. 16. doi: 10.3389/fnbot.2022.928636
Liao, B., Zhang, Y., and Jin, L. (2016). Taylor O(h3) discretization of ZNN models for dynamic equality-constrained quadratic programming with application to manipulators. IEEE Trans. Neural Netw. Learn. Syst. 27, 225–237. doi: 10.1109/TNNLS.2015.2435014
Liu, M., Li, Y., Chen, Y., Qi, Y., and Jin, L. (2024). “A distributed competitive and collaborative coordination for multirobot systems,” in IEEE Transactions on Mobile Computing, 1–13. doi: 10.1109/TMC.2024.3397242
Liu, Y., Liu, K., Wang, G., Sun, Z., and Jin, L. (2023). Noise-tolerant zeroing neurodynamic algorithm for upper limb motion intention-based human–robot interaction control in non-ideal conditions. Expert Syst. Applic. 213:118891. doi: 10.1016/j.eswa.2022.118891
Lukoševičius, M. (2012). A Practical Guide to Applying Echo State Networks. Berlin, Heidelberg: Springer Berlin Heidelberg, 659–686.
Rezaee, B., and Zarandi, M. F. (2010). Data-driven fuzzy modeling for Takagi–Sugeno–Kang fuzzy system. Inf. Sci. 180, 241–255. doi: 10.1016/j.ins.2009.08.021
Ribeiro, V. H. A., Reynoso-Meza, G., and Siqueira, H. V. (2020). Multi-objective ensembles of echo state networks and extreme learning machines for stream?ow series forecasting. Eng. Applic. Artif. Intell. 95:103910. doi: 10.1016/j.engappai.2020.103910
Rodan, A., and Tino, P. (2011). Minimum complexity echo state network. IEEE Trans. Neural Netw. 22, 131–144. doi: 10.1109/TNN.2010.2089641
Rong, H.-J., Huang, G.-B., Sundararajan, N., and Saratchandran, P. (2009). Online sequential fuzzy extreme learning machine for function approximation and classification problems. IEEE Trans. Syst. Man Cybern. 39, 1067–1072. doi: 10.1109/TSMCB.2008.2010506
Shahid, A. A., Roveda, L., Piga, D., and Braghin, F. (2020). “Learning continuous control actions for robotic grasping with reinforcement learning,” in 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), 4066–4072. doi: 10.1109/SMC42975.2020.9282951
Su D. Chen L. Du X. Liu M. and Jin L. (2023a). Constructing convolutional neural network by utilizing nematode connectome: a brain-inspired method. Appl. Soft Comput. 149:110992. doi: 10.1016/j.asoc.2023.110992
Su, D., Stanimirovic, P. S., Han, L. B., and Jin, L. (2023b). Neural dynamics for improving optimiser in deep learning with noise considered. CAAI Trans. Intell. Technol. 9, 722–737. doi: 10.1049/cit2.12263
Sun, Z., Tang, S., Jin, L., Zhang, J., and Yu, J. (2023a). Nonconvex activation noise-suppressing neural network for time-varying quadratic programming: Application to omnidirectional mobile manipulator. IEEE Trans. Industr. Inf. 19, 10786–10798. doi: 10.1109/TII.2023.3241683
Sun, Z., Tang, S., Zhang, J., and Yu, J. (2023b). Nonconvex noise-tolerant neural model for repetitive motion of omnidirectional mobile manipulators. IEEE/CAA J. Autom. Sinica 10, 1766–1768. doi: 10.1109/JAS.2023.123273
Sun, Z., Tang, S., Zhou, Y., Yu, J., and Li, C. (2022a). A GNN for repetitive motion generation of four-wheel omnidirectional mobile manipulator with nonconvex bound constraints. Inf. Sci. 607, 537–552. doi: 10.1016/j.ins.2022.06.002
Sun, Z., Wang, G., Jin, L., Cheng, C., Zhang, B., and Yu, J. (2022b). Noise-suppressing zeroing neural network for online solving time-varying matrix square roots problems: a control-theoretic approach. Exp. Syst. Applic. 192:116272. doi: 10.1016/j.eswa.2021.116272
Sun, Z.-L., Au, K.-F., and Choi, T.-M. (2007). A neuro-fuzzy inference system through integration of fuzzy logic and extreme learning machines. IEEE Trans. Syst. Man Cybern. 37, 1321–1331. doi: 10.1109/TSMCB.2007.901375
Vargas, O. S, De León Aldaco, S. E., Alquicira, J. A., Vela-Valdés, L. G., and Núñez, A. R. L. (2024). Adaptive network-based fuzzy inference system (ANFIS) applied to inverters: a survey. IEEE Trans. Power Electr. 39, 869–884. doi: 10.1109/TPEL.2023.3327014
Wang, H., Lee, I.-S., Braun, C., and Enck, P. (2016). Effect of probiotics on central nervous system functions in animals and humans: a systematic review. J. Neurogastroenterol. Motil. 22, 589–605. doi: 10.5056/jnm16018
Wei, L., and Jin, L. (2024). “Collaborative neural solution for time-varying nonconvex optimization with noise rejection,” in IEEE Transactions on Emerging Topics in Computational Intelligence. doi: 10.1109/TETCI.2024.3369482
Yan, J., Jin, L., and Hu, B. (2024). “Data-driven model predictive control for redundant manipulators with unknown model,” in IEEE Transactions on Cybernetics. doi: 10.1109/TCYB.2024.3408254
Yilmaz, B. M., Tatlicioglu, E., Savran, A., and Alci, M. (2022). Self-adjusting fuzzy logic based control of robot manipulators in task space. IEEE Trans. Industr. Electr. 69, 1620–1629. doi: 10.1109/TIE.2021.3063970
Yilmaz, B. M., Tatlicioglu, E., Savran, A., and Alci, M. (2023). Robust state/output-feedback control of robotic manipulators: an adaptive fuzzy-logic-based approach with self-organized membership functions. IEEE Trans. Syst. Man Cybern. 53, 3219–3229. doi: 10.1109/TSMC.2022.3224255
Yoo, B. K., and Ham, W. C. (2000). Adaptive control of robot manipulator using fuzzy compensator. IEEE Trans. Fuzzy Syst. 8, 186–199. doi: 10.1109/91.842152
Zhang, J., Jin, L., and Wang, Y. (2023). Collaborative control for multimanipulator systems with fuzzy neural networks. IEEE Trans. Fuzzy Syst. 31, 1305–1314. doi: 10.1109/TFUZZ.2022.3198855
Zhang, J., Jin, L., and Yang, C. (2022). Distributed cooperative kinematic control of multiple robotic manipulators with an improved communication efficiency. IEEE/ASME Trans. Mechatr. 27, 149–158. doi: 10.1109/TMECH.2021.3059441
Zhang, Y., Li, S., Kadry, S., and Liao, B. (2019). Recurrent neural network for kinematic control of redundant manipulators with periodic input disturbance and physical constraints. IEEE Trans. Cybern. 49, 4194–4205. doi: 10.1109/TCYB.2018.2859751
Zhao, W., Li, X., Chen, X., Su, X., and Tang, G. (2020). Bi-criteria acceleration level obstacle avoidance of redundant manipulator. Front. Neurorobot. 14:54. doi: 10.3389/fnbot.2020.00054
Keywords: echo state network (ESN), fuzzy inference system (FIS), online learning, redundant manipulators, optimization
Citation: Li Y, Liu H and Gao H (2024) Online learning fuzzy echo state network with applications on redundant manipulators. Front. Neurorobot. 18:1431034. doi: 10.3389/fnbot.2024.1431034
Received: 11 May 2024; Accepted: 10 June 2024;
Published: 15 July 2024.
Edited by:
Long Jin, Lanzhou University, ChinaReviewed by:
Xiufang Chen, Lanzhou University, ChinaJiawang Tan, Chinese Academy of Sciences (CAS), China
Copyright © 2024 Li, Liu and Gao. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yanqiu Li, bGl5YW5xaXVAamxlbnUuZWR1LmNu