 Haotian Wu
Haotian Wu Shigang Yue2,3
Shigang Yue2,3 Cheng Hu
Cheng Hu
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
PERSPECTIVE article
Front. Neurorobot. , 25 January 2024
Volume 18 - 2024 | https://doi.org/10.3389/fnbot.2024.1349498
This article is part of the Research Topic Swarm Neuro-Robots With the Bio-Inspired Environmental Perception View all 7 articles
Insects exhibit remarkable abilities in navigating complex natural environments, whether it be evading predators, capturing prey, or seeking out con-specifics, all of which rely on their compact yet reliable neural systems. We explore the field of bio-inspired robotic vision systems, focusing on the locust inspired Lobula Giant Movement Detector (LGMD) models. The existing LGMD models are thoroughly evaluated, identifying their common meta-properties that are essential for their functionality. This article reveals a common framework, characterized by layered structures and computational strategies, which is crucial for enhancing the capability of bio-inspired models for diverse applications. The result of this analysis is the Strategic Prototype, which embodies the identified meta-properties. It represents a modular and more flexible method for developing more responsive and adaptable robotic visual systems. The perspective highlights the potential of the Strategic Prototype: LGMD-Universally Prototype (LGMD-UP), the key to re-framing LGMD models and advancing our understanding and implementation of bio-inspired visual systems in robotics. It might open up more flexible and adaptable avenues for research and practical applications.
In the realm of robotics, the ability to detect impending collisions is essential for navigation and interaction with dynamic environments. Conventional methods employed for visual detection in robotics are often hard-coded and rigid, typically require large amounts of data for training, lacking the necessary adaptability to respond to the complex and sophisticated movements encountered in real-world settings.
The natural world, particularly the realm of insects, offers valuable lessons on visual processing under complex scenes. Like robots, many insect species face similar visual challenges to navigate and survive in a high dynamic environment (Borst et al., 2010; Borst and Helmstaedter, 2015). These challenges are visual motion perceptions that the animals perceive and calculate through their highly effective visual neural structures. They display an exceptional capacity to detect dynamic motion visually, a key skill for avoiding predators and navigating through complex environments. Neuro-physiological and anatomical studies indicate that these abilities are dependent on designated sensory neural pathways (Judge and Rind, 1997; Peron and Gabbiani, 2009; Zhu et al., 2018). Researchers have already taken note of these abilities and used it as inspiration to develop new, biologically plausible neural models in the field of robotics, e.g., Meng et al. (2010) and Hu et al. (2017).
Within this context, the Locusts' Lobula Giant Movement Detectors (LGMDs) and its related neural models have garnered considerable interest. These models have been comprehensively analyzed, researched, and replicated for their proficiency in detecting swift motion cues of looming, which indicates the presence of a nearby object (Fu et al., 2019; Chang et al., 2023). Despite significant advances, these models still face challenges in flexibility and adaptability in our view.
Our perspective contributes to this rapidly-growing field by uncovering a compelling pattern: across different models and applications, we found a common framework, characterized by simple yet effective computational strategies. By examining the meta-properties of the LGMD models, we suggest that a wider outlook permits the combination of these models into a single paradigm. The renewed approach may be the key to re-framing LGMD models, thus advancing our understanding and implementation of bio-inspired visual systems, simplifying the route to generalization. It presents an innovative approach, offering a more adaptable framework over LGMD models, marking a significant advancement in the methodology of robotic vision systems.
Manipulating meta-properties offers great potential for innovation, enabling the exploration of new directions in research and practical applications. It has the potential to enhance robotic visual systems, as well as catalyze the emergence of new ideas, ushering in an era of more intuitive and adaptive robotic perception. These advancements may prove promising in the realms of micro-robot navigation, automatic driving, and swarm robotics.
The LGMD neurons are first discovered in locust by O'Shea and Williams (1974), and has been tested, As illustrated in Figure 1A, the LGMD neurons are composed of two neighboring neurons: LGMD1 and LGMD2, both of which contain extensive dendrite trees with fan-like shapes within their pre-synaptic regions. There have been many computational models inspired by both of them, e.g., Rind and Bramwell (1996), Yue and Rind (2009), i Badia and Verschure (2004), Bermúdez i Badia et al. (2010), Fu and Yue (2015), and Fu et al. (2018).
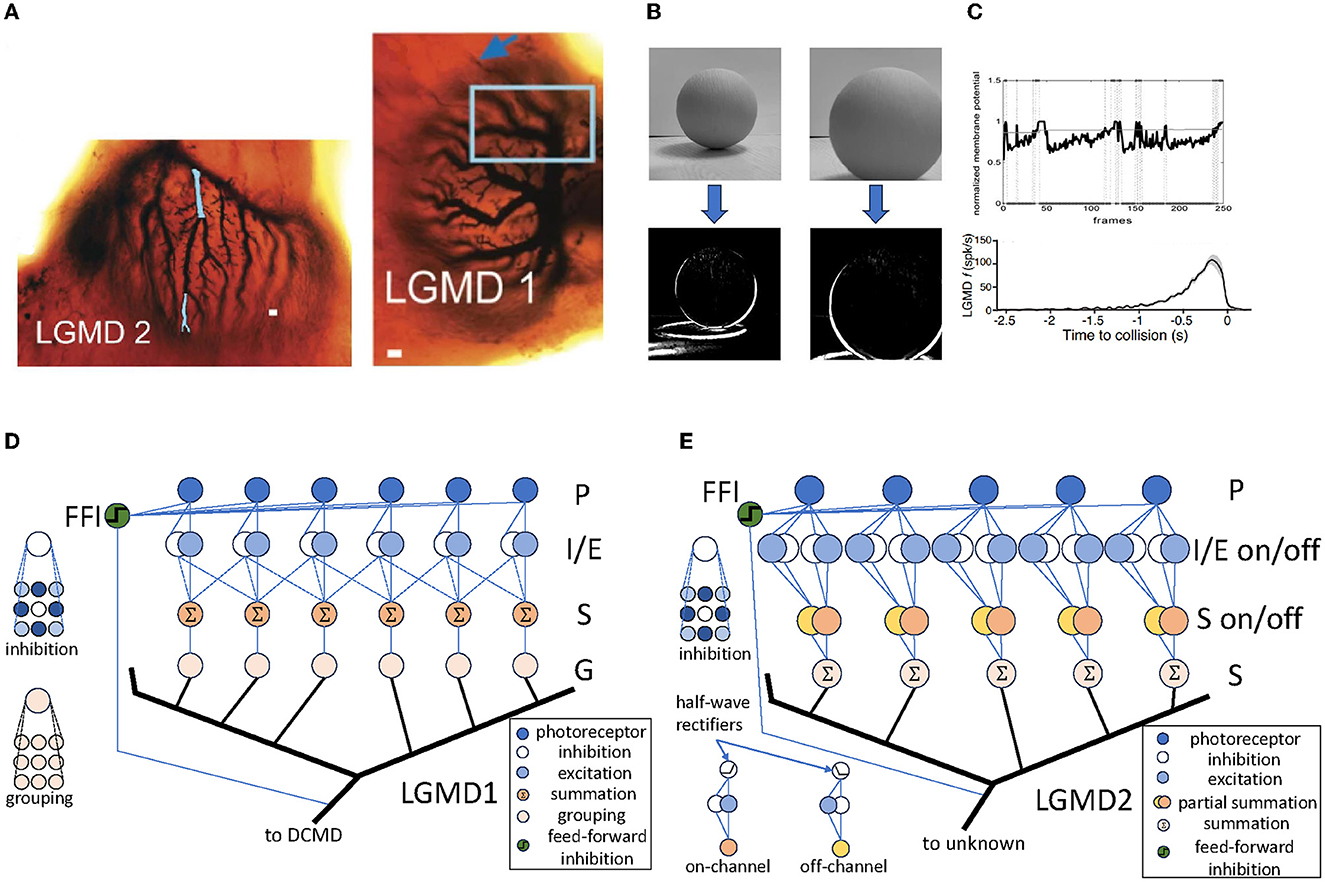
Figure 1. The LGMD neurons and their computational models. (A) The structure of LGMD1 and LGMD2 neurons in locust, which is adapted from Rind et al. (2016). The figure depicts the abundant dendrite trees with fan-shaped structures in the pre-synaptic regions of both neurons. The scale bars in LGMD1 and LGMD2 are 10 and 5μm, respectively. (B) The responds to a computer-generated visual stimuli of an LGMD1 model, illustrating the middle layer's response of the model, which effectively identified the shape of the looming object. The model is based on Yue and Rind (2006). (C) The responds of the LGMD models and neurons, which is adapted from Dewell and Gabbiani (2018). The standard LGMD neuron response is depicted in the upper, whilst the lower portrays the LGMD model's response identically to the actual neuron. (D) One possible LGMD1 model, which is based on Yue and Rind (2006). This is a standard LGMD1 model with four feed-forward connection layers and one hyper-layer connection layer. (E) One possible LGMD2 model, which is based on Fu and Yue (2015). This is a typical LGMD2 model, similar to LGMD1, with “on” and “off” pathways split from the I/E layer and then reconnected in the S layer.
Figure 1D shows a schematic of a typical LGMD1 model, illustrating the sequential process of signal transmission and processing. Initially, the input video signal passes through the photoreceptor (P) layer, symbolizing the perception of the luminance changes in each pixels. The signal then bifurcates into two distinct pathways within the inhibition/excitation (I/E) layer. This crucial junction serves to filter out irrelevant elements of movement, ensuring that only relevant information is passed on. The signals then converge in the summation (S) layer, signifying an activation process through which only the correct signals can pass. This layer acts as a critical node to reassemble and integrate the signals. Finally, the signals progress through the grouping (G) layer, culminating in the activation of the LGMD neuron. This model also contains an additional layer, the feed-forward inhibition (FFI), which shuts down the entire model if the visual stimuli becomes too large. Figures 1B, C shows its detection results against looming objects, where all looming objects are correctly detected in all results.
Similarly, a typical LGMD2 model is illustrated in Figure 1E. The LGMD2 neuron is the neighboring partner of the LGMD1, which is modeled as two pathways—the “on” and “off” pathway (O'Shea and Williams, 1974; O'Shea and Rowell, 1976). Compared to LGMD1, the signals of LGMD2 in the I/E and S layers are separated into on and off pathways then gathered in the S layer. This brings LGMD2 a unique characteristic that it only sensitives to dark objects approaching against a light background, and is not sensitive to white or light objects approaching against a dark background, representing a preference for light-to-dark luminance changes.
These models show complex intra-layer structures where each layer performs particular processing functions. For example, the LGMD1 model uses pattern convolution in its inhibition layers to imitate genuine inhibition processes observed in locust neurons. In this model, summation and averaging operations simulate the average reaction of similar locust neurons. These layers possess a close correlation with genuine neuronal response signals. Inter-layer connections within these models display consistent connectivity patterns such as one-to-one, one-to-many, and many-to-one connections. This can be Time delays of varying values are implemented for these connections to account for temporal aspects of information processing. Furthermore, global responses of insect neurons are depicted through cross-layer connections, acting as a switch to the models' output.
The models' functions are mainly linear, which we believe simplifies the computational procedures and supports the modeling of biological systems through linear transformations and responses. Both the LGMD1 and LGMD2 models, for instance, employ a summation process to depict the total response of each cell. Such a linear structure enables the development of a hyper-layer network representation in which the processing function of each layer includes input, processing and output. This integrated description permits a common expression of different properties found in different models, and enables model transformations by modifying these meta-properties. This framework highlights the potential of bio-plausible models to process information efficiently and adapt effectively, reflecting the computational proficiency of nature.
Based on the shared structures of the above-mentioned models, we believe that the construction of a unified description—The LGMD-Universally Prototype(LGMD-UP)—has become possible. To provide typical examples, we will employ the extensively examined LGMD1 and LGMD2 models.
The LGMD1 model typically comprises four network layers and a feed-forward global suppressor—the P, I/E, S, G layers, and the FFI suppressor. The input signal, post-processed in the P layer, passes to the I/E layer. At this stage, the signal splits into two pathways for specialized processing. The signals from these pathways merge in the S layer, culminating in a response in the G layer. At the same time, the FFI layer can be activated in response to excessive P-layer connections, effectively suppressing global signal output. The LGMD2 is similar, but it splits into two pathways in the I/E layer, then the signals are again gathered together in the S layer.
To represent these structures coherently, we use a modular directed graph network (Scarselli et al., 2008), where each node corresponds to a layer, each with different inputs, processing methods and outputs. Nonetheless, a cohesive depiction can still be achieved through a modular representation, as presented in Figure 2A that acts as a summary framework for a solitary layer. This layer encompasses characteristics, for instance:
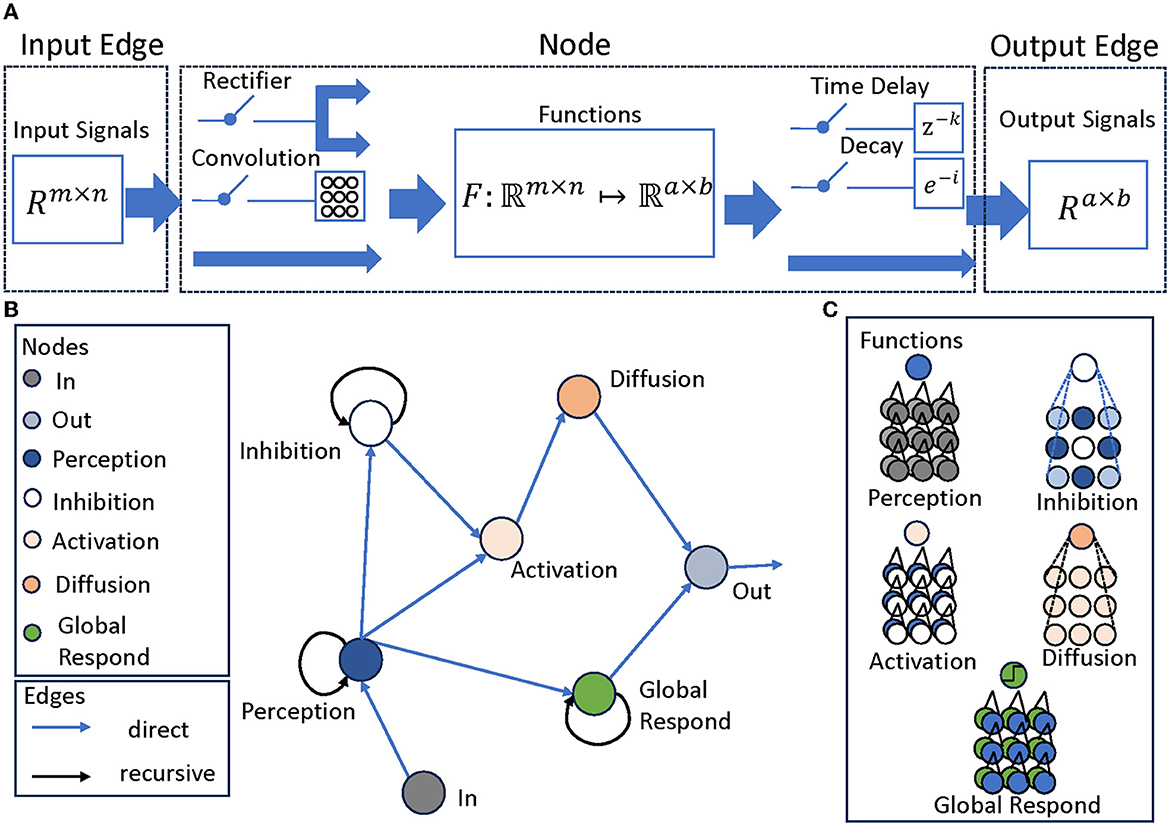
Figure 2. The structure of LGMD-UP. (A) Attributes of the Graph Network, including Input Edge, Node, and Output Edge, each attribute has different properties. Input Edge contain signals of the form Rm×n, it is then go through the Node with a function F:ℜm×n ↦ ℜa×b. There are two optional pre-processing parameters and two optional post-processing parameter. Output Edge are the signals of the form Ra×b. (B) The LGMD models described in Graph Network. The Perception, Inhibition, and Global Respond Mechanisms are recursive structures, while other layers are feed-forward structures. (C) The functions in each node. They may differ from each other, but they all correspond to the layers of current LGMD models. For example, the Perception node calculates the differences between two inputs: its last output and the current in node.
1. Input Edge attributes, specifying the source of the signals and the signal size.
2. Node attributes, defining the processing function. For each node, there are two optional pre-processing parameters, which is the convolution and the rectifier. There are also two optional post-processing parameters, which is the time delay coefficient and the decay coefficient.
3. Output Edge attributes, specifying the destination of the signal, and its size.
In each node, two optional pre-processing and two post-processing is applied. The pre-processing procedures, which are the convolution and the rectifier, can be formulated as follows:
where * is the convolution process, K is the convolution kernel with adjustable size. If K∈ℜ, then it's a gain coefficient.
These processes are purely optional, depending on the function and requirements of each node. For example, in LGMD2 models, rectifiers are enabled in the I/E and S layers and disabled in other layers. The convolution (including gain), on the other hand, is more commonly used in the P, I/E, G, and FFI layers in both LGMD1 and LGMD2 models.
Similarly, the post-processing procedures, including time delay and decay can be also formulated as follows:
where fdelay are defined in Laplacian domain.
These processes are also optional, depending on each node's function and demands. For example, time delays are enabled in P and I/E layers in both LGMD1 and LGMD2, decays are used in P layers, FFI layers in both LGMD1 and LGMD2.
We can further formulate this graph network G by a standardized graph description: G = {N, E}, where N is the set of nodes, and E is the set of edges. Let prw represent the pre-processing function, fw represent the processing function and pow represent the post-processing function. Then, the hidden state x and the output y of node can be defined as follows:
where lt are the signals from its input edges, yt is the output at time t. Note that fw can be different in each node, prw and pow are the combinations of optional functions, which are also different in each node.
Using this construction, we obtain a modular LGMDs representation that matches the responses of the original network, fully exposing all structures and connections, as shown in Figure 2B. The network now manifests as a graph network with four distinct meta-properties: Perception, Inhibition, Activation, and Diffusion, with an attached Global Response Mechanism, as shown in Figure 2C. Each mechanism is critical to the overall performance of the system, mirroring intricate processes observed in biological counterparts.
Perception mechanism: The Perception Mechanism represents the initial stage in the model, focusing on detecting luminance changes over time in each cell's domain. It calculates differences between successive frames to pinpoint areas where luminance changes, indicating motion.
Inhibition mechanism: This critical filter assesses candidates identified by the Perception Mechanism and excludes those that do not correspond to approaching movements. Essential for boosting the model's accuracy, it guarantees that only relevant motion cues are conveyed for further processing.
Activation mechanism: The activation mechanism categorizes and sorts the appropriate stimuli that have passed through the inhibition mechanism. It operates as a decision-making procedure by assessing the significance of the stimuli and recognizing ones that need additional processing.
Diffusion mechanism: The Diffusion Mechanism augments and arranges the outcomes from the Activation Mechanism. It enhances the selected stimuli and integrates them into a coherent representation of the approaching object. This mechanism is vital for delivering a thorough and precise depiction of the stimuli.
Global respond mechanism: The Global Respond Mechanism serves as a toggle switch for the entire network. It identifies scenarios where motion detection may be unnecessary or pose potential harm. In such cases, it temporarily deactivates the entire motion detection network, thus ensuring network focus and efficiency is maintained.
The modular design of the LGMD-UP forms the bedrock of its flexibility. With five modular nodes replacing the hyper-layered connections, it facilitates the independent development, testing, and integration of each module in the system, thereby enabling easy customization and scalability of the model. Additionally, the independence of the modules means that changes or improvements can be made in one area without disrupting the entire system. The modular structure of this system has significant advantages in research and development environments–it permits constant testing and iteration. The ability to modify and turn on/off individual parameters in each node ensures that the LGMD-UP can be tailored to meet specific requirements or easily adapt to new challenges.
The graph network framework significantly enhances the efficiency of the LGMD-UP when compared to traditional hyper-layered connections. Due to the independence of each node, this framework allows for easier time updates and parameter changes, which are essential in rapidly evolving fields such as swarm robotics. The graph network also simplifies and unifies structures, making it more efficient than more traditional designs. This efficiency is essential for keeping the visual system in line with technological advances and the diverse requirements of applications.
The adaptability of the LGMD-UP is also based on its graph-network structure, which allows the nodes and edges of the network to be dynamically reconfigured. This in turn establishes sophisticated interrelationships between the model's elements, optimizing processing for specific tasks or environments. For instance, within the context of automated driving, specific mechanisms, like the inhibition mechanism, can be adjusted and independently tested to match the current road and traffic conditions, without impacting other functions. Crucial to its adaptability, the ability to modify the network's configuration and connections according to a variety of demands optimizes the system's capabilities to adjust to various visual scenarios adeptly.
It is also worth noting the distinction between bio-inspired and bio-plausible models in this context. Bio-inspired models extract key biological principles for technological applications, whereas bio-plausible models aim for accuracy and plausibility in simulating actual biological processes. The LGMD model uniquely embodies both approaches, precisely imitates the LGMD neuron in insects that detects fast-approaching objects, thus demonstrating bio-plausibility. Simultaneously, it promotes technological progress in motion detection systems, thereby classifying it as a bio-inspired category as well. This duality highlights the special role of LGMD models in bridging biological accuracy and technological innovation.
In conclusion, our innovative approach to bio-plausible visual systems in robotics, which focuses on the LGMD models of Locusts, demonstrates significant potential for the advancement of robotic perception. The LGMD-UP, which incorporates these discoveries, represents a considerable advancement in our methodology for robotic vision systems. The graph network structure, which takes inspiration from nature's simplicity and efficiency, provides exceptional adaptability and modularity. This feature makes it highly suitable for addressing the dynamic demands of contemporary robotics. The LGMD-UP does not only improve robots' ability to interact with their environment in real-time but also paves the way for further research and development. Our view paves the way for further advancements in this field, encouraging continued exploration and refinement of bio-inspired systems for increasingly intuitive and adaptive robotic perception. Future work can be focused on this perspective, by re-framing and adjusting the LGMD-UP to meet specific requirements of diverse applications.
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
HW: Data curation, Investigation, Software, Visualization, Writing—original draft. SY: Project administration, Writing—review & editing, Conceptualization, Funding acquisition, Resources. CH: Formal analysis, Funding acquisition, Resources, Validation, Writing—review & editing, Methodology.
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work was supported in part by the National Natural Science Foundation of China under Grants 52202492 and 12031003; in part by the European Union's Horizon 2020 Research and Innovation Programme under the Marie Sklodowska-Curie Grant under Agreement 778062 (ULTRACEPT); in part by the China Postdoctoral Science Foundation under Grant 2019M662837; and in part by the Guangzhou Basic and Applied Basic Research Thematic Research Project Grant 2024A04J3970.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Bermúdez i Badia, S., Bernardet, U., and Verschure, P. F. (2010). Non-linear neuronal responses as an emergent property of afferent networks: a case study of the locust lobula giant movement detector. PLoS Comput. Biol. 6, e1000701. doi: 10.1371/journal.pcbi.1000701
Borst, A., Haag, J., and Reiff, D. F. (2010). Fly motion vision. Ann. Rev. Neurosci. 33, 49–70. doi: 10.1146/annurev-neuro-060909-153155
Borst, A., and Helmstaedter, M. (2015). Common circuit design in fly and mammalian motion vision. Nat. Neurosci. 18, 1067–1076. doi: 10.1038/nn.4050
Chang, Z., Fu, Q., Chen, H., Li, H., and Peng, J. (2023). A look into feedback neural computation upon collision selectivity. Neural Netw. 166, 22–37. doi: 10.1016/j.neunet.2023.06.039
Dewell, R. B., and Gabbiani, F. (2018). Biophysics of object segmentation in a collision-detecting neuron. ELife 7, e34238. doi: 10.7554/eLife.34238.055
Fu, Q., Hu, C., Peng, J., and Yue, S. (2018). Shaping the collision selectivity in a looming sensitive neuron model with parallel on and off pathways and spike frequency adaptation. Neural Netw. 106, 127–143. doi: 10.1016/j.neunet.2018.04.001
Fu, Q., Wang, H., Hu, C., and Yue, S. (2019). Towards computational models and applications of insect visual systems for motion perception: a review. Artif. Life 25, 263–311. doi: 10.1162/artl_a_00297
Fu, Q., and Yue, S. (2015). “Modelling LGMD2 visual neuron system,” in 2015 IEEE 25th International Workshop on Machine Learning for Signal Processing (MLSP) (Boston, MA: IEEE), 1–6.
Hu, C., Arvin, F., Xiong, C., and Yue, S. (2017). Bio-inspired embedded vision system for autonomous micro-robots: the LGMD case. IEEE Trans. Cogn. Dev. Syst. 9, 241–254. doi: 10.1109/TCDS.2016.2574624
i Badia, S. B., and Verschure, P. F. (2004). “A collision avoidance model based on the lobula giant movement detector (LGMD) neuron of the locust,” in 2004 IEEE International Joint Conference on Neural Networks (IEEE Cat. No. 04CH37541), Volume 3 (Budapest: IEEE), 1757–1761.
Judge, S. J., and Rind, F. C. (1997). The locust DCMD, a movement-detecting neurone tightly tuned to collision trajectories. J. Exp. Biol. 200, 2209–2216.
Meng, H., Appiah, K., Yue, S., Hunter, A., Hobden, M., Priestley, N., et al. (2010). A modified model for the lobula giant movement detector and its FPGA implementation. Comput. Vis. Image Understand. 114, 1238–1247. doi: 10.1016/j.cviu.2010.03.017
O'Shea, M., and Rowell, C. F. (1976). The neuronal basis of a sensory analyser, the acridid movement detector system. II. Response decrement, convergence, and the nature of the excitatory afferents to the fan-like dendrites of the LGMD. J. Exp. Biol. 65, 289–308.
O'Shea, M., and Williams, J. (1974). The anatomy and output connection of a locust visual interneurone; the lobular giant movement detector (LGMD) neurone. J. Comparat. Physiol. 91, 257–266.
Peron, S., and Gabbiani, F. (2009). Spike frequency adaptation mediates looming stimulus selectivity in a collision-detecting neuron. Nat. Neurosci. 12, 318–326. doi: 10.1038/nn.2259
Rind, F. C., and Bramwell, D. (1996). Neural network based on the input organization of an identified neuron signaling impending collision. J. Neurophysiol. 75, 967–985.
Rind, F. C., Wernitznig, S., Pölt, P., Zankel, A., Gütl, D., Sztarker, J., et al. (2016). Two identified looming detectors in the locust: ubiquitous lateral connections among their inputs contribute to selective responses to looming objects. Sci. Rep. 6, 35525. doi: 10.1038/srep35525
Scarselli, F., Gori, M., Tsoi, A. C., Hagenbuchner, M., and Monfardini, G. (2008). The graph neural network model. IEEE Trans. Neural Netw. 20, 61–80. doi: 10.1109/TNN.2008.2005605
Yue, S., and Rind, F. C. (2006). Collision detection in complex dynamic scenes using an LGMD-based visual neural network with feature enhancement. IEEE Trans. Neural Netw. 17, 705–716. doi: 10.1109/TNN.2006.873286
Yue, S., and Rind, F. C. (2009). “Near range path navigation using LGMD visual neural networks,” in 2009 2nd IEEE International Conference on Computer Science and Information Technology (Beijing: IEEE), 105–109.
Keywords: bio-plausible, motion detection, visual sensing, robot, environment perception, LGMD
Citation: Wu H, Yue S and Hu C (2024) Re-framing bio-plausible collision detection: identifying shared meta-properties through strategic prototyping. Front. Neurorobot. 18:1349498. doi: 10.3389/fnbot.2024.1349498
Received: 04 December 2023; Accepted: 12 January 2024;
Published: 25 January 2024.
Edited by:
Gian Carlo Cardarilli, University of Rome Tor Vergata, ItalyReviewed by:
Chung-Chuan Lo, National Tsing Hua University, TaiwanCopyright © 2024 Wu, Yue and Hu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Cheng Hu, Y19odUBnemh1LmVkdS5jbg==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.