 Yanbo Li
Yanbo Li Qing He*
Qing He*- College of Big Data and Information Engineering, Guizhou University, Guiyang, China
Aspect Sentiment Triplet Extraction (ASTE) is a challenging task in natural language processing (NLP) that aims to extract triplets from comments. Each triplet comprises an aspect term, an opinion term, and the sentiment polarity of the aspect term. The neural network model developed for this task can enable robots to effectively identify and extract the most meaningful and relevant information from comment sentences, ultimately leading to better products and services for consumers. Most existing end-to-end models focus solely on learning the interactions between the three elements in a triplet and contextual words, ignoring the rich affective knowledge information contained in each word and paying insufficient attention to the relationships between multiple triplets in the same sentence. To address this gap, this study proposes a novel end-to-end model called the Dual Graph Convolutional Networks Integrating Affective Knowledge and Position Information (DGCNAP). This model jointly considers both the contextual features and the affective knowledge information by introducing the affective knowledge from SenticNet into the dependency graph construction of two parallel channels. In addition, a novel multi-target position-aware function is added to the graph convolutional network (GCN) to reduce the impact of noise information and capture the relationships between potential triplets in the same sentence by assigning greater positional weights to words that are in proximity to aspect or opinion terms. The experiment results on the ASTE-Data-V2 datasets demonstrate that our model outperforms other state-of-the-art models significantly, where the F1 scores on 14res, 14lap, 15res, and 16res are 70.72, 57.57, 61.19, and 69.58.
1. Introduction
In recent years, significant advancements in deep learning have been attributed to the development of more efficient algorithms, advancements in hardware capabilities, and the availability of extensive datasets. These progressions have paved the way for the emergence of diverse types of dynamic neural networks (DNN) tailored to address specific challenges across various domains. For instance, deep learning has been instrumental in surface defect recognition in the realm of computer vision (Shi et al., 2023), Artificial Intelligence (AI) systems based on deep learning algorithms can effectively detect and analyze arc faults in electrical systems (Tian et al., 2023) and recurrent neural networks (RNN) are designed to capture temporal dependencies and sequential patterns, thus making them well suited for tasks involving gesture recognition and classification. Moreover, the utilization of graph structures for learning purposes has demonstrated tremendous potential in various fields. For example, in the domain of blockchain technology, graph structure learning methods have been employed to enhance the analysis of transaction networks and identify the characteristics of the transaction (Wang et al., 2023). Additionally, improved graph structure learning methods (Liu et al., 2023) based on the foundational graph neural network (GNN) have been proposed in order to further enhance the capabilities of graph-based learning.
In the field of natural language processing (NLP), comments of consumers serve as a valuable resource for gathering information that can aid in enhancing the performance of robots and their associated products or services. With the proliferation of social media communities, the availability of consumer-generated content has expanded significantly, presenting an opportunity to leverage this data for insights and improvements. By employing methods designed for text information, robots can significantly enhance their ability to understand the intent and meaning behind a comment of consumer. These methods enable robots to extract the most valuable information from user input, leading to more accurate and meaningful interactions. Aspect Sentiment Triplet Extraction (ASTE) (Peng et al., 2020) is concerned with identifying the triplets from a given comment. Each triplet includes an aspect term, corresponding opinion term, and the sentiment polarity of this aspect term. For instance, in Figure 1, this comment from restaurant domain comprises two triplets: (menu, limited, negative) and (dishes, excellent, positive). Aspect sentiment triplet extraction plays a crucial role in enabling a more fine-grained understanding of text by capturing sentiments toward specific aspects or features. This capability facilitates context-aware analysis, supports decision-making processes, analyzes customer feedback, and aids in brand monitoring and reputation management.
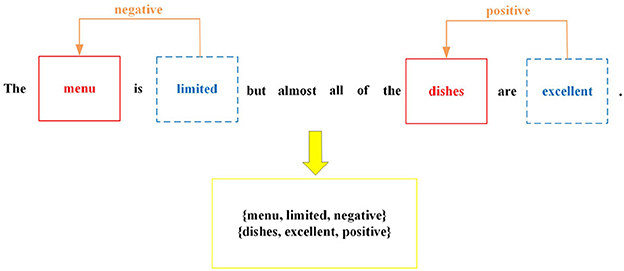
Figure 1. An example of ASTE. The aspect terms are highlighted in red. The terms in blue are opinion terms and the origin words that denote their sentiment polarity. All triplets are shown in the yellow box.
Aspect Sentiment Triplet Extraction (ASTE) is a fine-grained task of Aspect-based Sentiment Analysis (ABSA) (Pontiki et al., 2014). ABSA aims to extract aspect terms and identify the corresponding sentiment polarity from a given sentence. It typically includes subtasks such as Aspect Terms Extraction (ATE) (Yin et al., 2016; Xin et al., 2018; Wu et al., 2020b), Opinion Terms Extraction (OTE) (Jebbara and Cimiano, 2017; Jordhy et al., 2019; Li et al., 2019), and Aspect-based Sentiment Classification (ASC) (Tang et al., 2016; Ma et al., 2017; He et al., 2018). ASTE is the combination of these subtasks and initially proposed in the study by Peng et al. (2020) with a two-stage pipeline approach. This method predicts all aspect terms, opinion terms, and sentiment polarities in the first stage. In the second stage, aspect terms are paired with their corresponding opinion terms to obtain triplets. However, this approach is susceptible to error propagation. To overcome this limitation, Xu et al. (2020) propose a position-aware tagging scheme and develop a union model that uses sequence labeling to extract triplets. This method is the first end-to-end model in the ASTE task. Similarly, Wu et al. (2020a) present a grid tagging scheme named GTS that uses a unified grid markup task to extract triplets in an end-to-end manner.
During sentiment analysis, it is observed that every word in a sentence possesses a unique emotional intensity. For instance, while words such as “likable” and “charming” both convey a positive sentiment polarity, their degrees of positivity differ. However, it has been noted that current networks relying on graph convolutional network tend to utilize solely syntactic dependencies for graph construction, thereby ignoring the commonsense knowledge information (Erik et al., 2009) associated with each word. Furthermore, such models typically overlook the relationships between multiple triplets present in the same sentence.
To overcome the aforementioned limitations of existing models, this study presents a novel approach that takes into account both affective knowledge information and the implicit relationship between different potential triplets in the same sentence. The proposed method employs a part-of-speech (POS) based approach to identify potential aspect terms and opinion terms within sentences, then formulates a fresh approach for generating an adjacency matrix, which fuses the affective score of each word from SenticNet (Ma et al., 2018) with the syntax dependency in two parallel modules, leading to the generation of a potential aspect terms enhanced adjacency matrix and a potential opinion terms enhanced adjacency matrix. These adjacency matrices are, then, input into a graph convolutional network (GCN) (Kipf and Welling, 2016) to extract features separately. GCN is a neural network architecture that has the ability to extract both contextual and syntactic representations from the adjacency matrix by aggregating the features of neighboring nodes. Additionally, this study utilizes a multi-target position-aware function in each GCN module, which assigns different weights to all words based on the position of potential aspect words or opinion words. This facilitates interaction between different potential triplets in a sentence and reduces interference from other words on triplet extraction. Finally, the hidden representations produced by the encoder layer, and two GCN modules are used via GTS for triplet extraction.
The main contributions of our study can be summarized as follows:
• We propose an innovative Dual Graph Convolutional Networks Integrating Affective Knowledge and Position Information (DGCNAP) for the ASTE task in an end-to-end manner.
• We conceive a novel method to introduce affective knowledge information into the adjacency matrix generated by sentences in the ASTE task.
• We design a multi-target position-aware function in the GCN layer to reduce interference and capture the associations between different potential triplets in the same sentence.
• Our experimental results on four benchmark datasets demonstrate the effectiveness of our model in the ASTE task.
2. Related work
Unlike traditional sentiment analysis that aims to identify the sentiment polarity of the whole document or sentence, ABSA aims to predict sentiment polarity of specific aspect terms. In recent research, most models use attention mechanisms. Wu et al. (2022) proposed a phrase dependency graph attention network to aggregate directed dependency edges and phrase information. Liang et al. (2022) adopted a graph convolutional network based on affective knowledge to leverage the affective dependencies of the sentence; thus, both the dependencies of contextual words and aspect words and the affective information between opinion words and the aspect are considered.
To establish a comprehensive solution for ABSA, ASTE aims to complete multiple subtasks of ABSA simultaneously. In the ASTE task, existing methods can be divided into two types: pipeline methods and end-to-end methods. Peng et al. (2020) are the first to propose a complete solution for the ASTE task, employing a two-stage pipeline approach. However, models constructed using this pipeline approach are rather simple and are easily affected by error propagation. To avoid this problem, end-to-end models have been proposed and can be summarized as follows. Xu et al. (2020) first developed an end-to-end method named position-aware tagging scheme. Similarly, Wu et al. (2020a) proposed grid tagging scheme to extract triplets simultaneously. Considering ASTE is the combination of all basic tasks of ABSA, Chen et al. (2022) proposed an end-to-end approach which decomposes ASTE into three subtasks, namely, target tagging, opinion tagging, and sentiment tagging. Chen et al. (2021) proposed a novel method which transforms ASTE task into a multi-turn machine reading comprehension task and propose a bidirectional MRC framework to address this challenge. Another end-to-end method (Dai et al., 2022) proposed a sentiment-dependence detector based on a dual-table structure that starts from two directions, aspect-to-opinion and opinion-to-aspect, to generate two sentiment-dependence tables dominated by two types of information. Shi et al. (2022) proposed an interactive attention mechanism to jointly consider both the contextual features and the syntactic dependencies in an iterative interaction manner. Previous tag-based joint extraction methods have been observed to struggle with effectively handling one-to-many and many-to-one relationships between aspect terms and opinion terms within sentences. This limitation has motivated researchers to explore alternative approaches, such as those that operate at the span level rather than relying on tagging schemes. A tagging-free approach (Mukherjee et al., 2021) is proposed to capture the span-level semantics while predicting the sentiment between an aspect-opinion pair. Li et al. (2022) proposed a span-sharing joint extraction framework to extract aspect terms and their corresponding opinion terms simultaneously in the last step, thereby avoiding error propagation. Hu et al. (2023) used a span GCN for syntactic constituency parsing tree and a relational GCN (R-GCN) for commonsense knowledge graph to build an end-to-end model for the ASTE task. Moreover, a double-embedding mechanism-character-level and word-vector embeddings are introduced for the first time. Zhang et al. (2022) propose a dual convolutional neural network with a span-based tagging scheme to extract multiple entities directly under the supervision of span boundary detection.
3. Approach
Existing models have achieved good performance on the ASTE task. However, a significant number of these methods disregard the abundant affective knowledge present in individual words of a sentence, as well as the interdependence of various triplets. To address this limitation, we introduce affective knowledge information in our framework while constructing the dependency graph. Additionally, we utilize a multi-target position-aware function to capture the interdependence of multiple triplets in the same sentence, and it can also mitigate the adverse effects of noisy words.
This section commences with a definition of the ASTE task followed by an elaborate elucidation of our proposed methodology, Dual Graph Convolutional Networks Integrating Affective Knowledge and Position Information (DGCNAP), for the ASTE task.
3.1. Definition of ASTE
Given an n-word sentence , the ASTE task aims at identifying all sentiment triplet sets , where “at” denotes the aspect term, “ot” denotes the opinion term, “s” denotes the sentiment of the aspect term in this set, and s∈{positive, negative, neutral}.
3.2. The DGCNAP framework
The overall architecture of DGCNAP model is shown in Figure 2. The model takes two parallel channels to joint potential aspect term and potential opinion term enhanced features extraction, leveraging affective knowledge, graph convolutional network, and multi-target position-aware function to improve accuracy and capture the complex relationships between aspect and opinion terms in sentences.
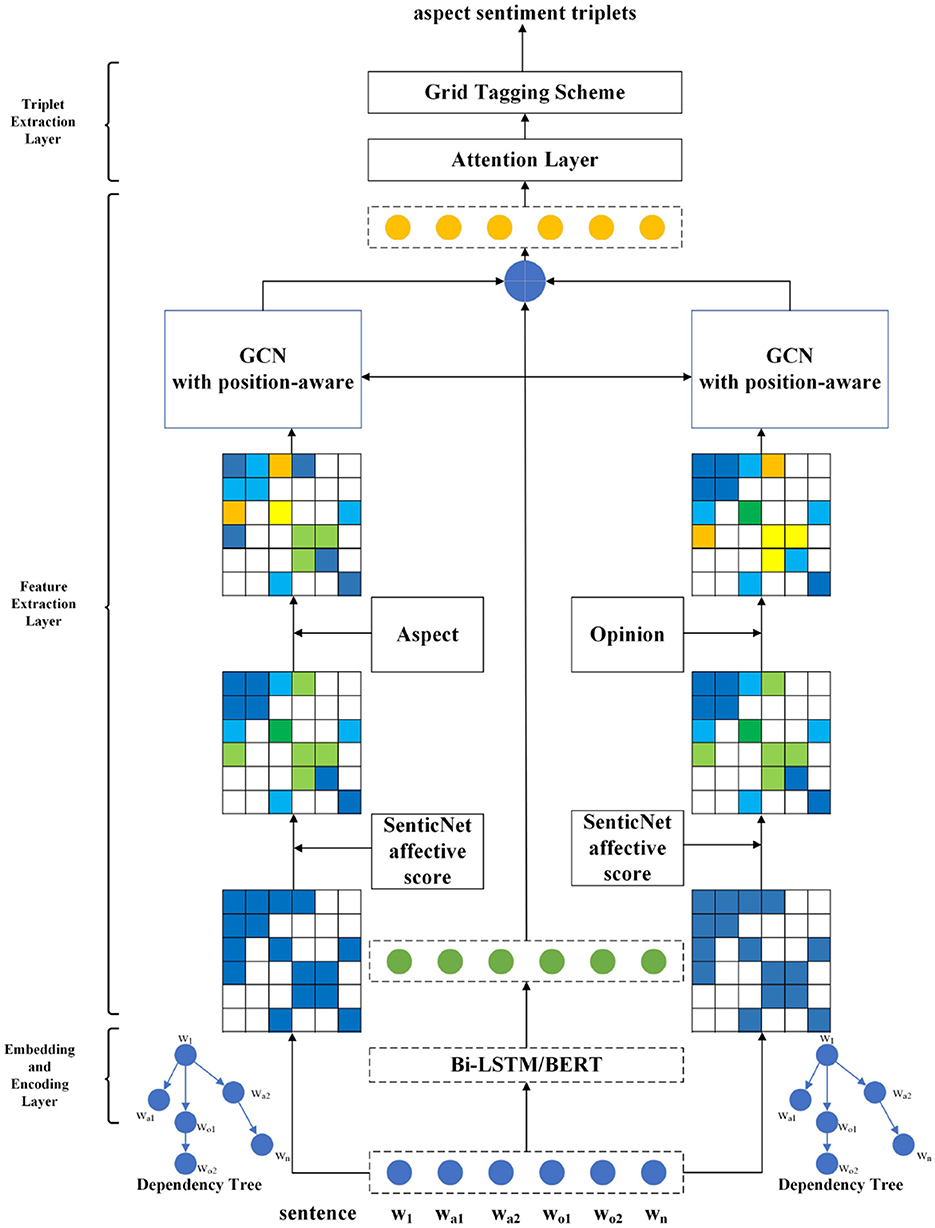
Figure 2. Architecture of DGCNAP.
3.3. Embedding and encoding layers
In this study, we employ two types of encoders to learn hidden representations: the first is the Bi-directional Long Short-Term Memory (Bi-LSTM) (Hochreiter and Schmidhuber, 1997) network and the second is the pre-trained language model BERT (Devlin et al., 2019).
For the Bi-LSTM-based encoder, we utilize double embedding to obtain the initial word representation and capture the contextual meaning of words in a specific domain. The specific-domain embedding was pre-trained based on the skip-gram model, where each word is represented as a bag of character n-grams. A vector representation is associated with each character n-gram; words are represented as the sum of these representations. We concatenate the 300-dimension general-domain embedding and the 100-dimension specific-domain embedding to form the final word representation , where dw and ds denote the dimensions of word embedding. After that, we input the embedding matrix into a Bi-LSTM to obtain the hidden contextual representations of the input sentence, where dI denotes the hidden state dimension of Bi-LSTM:
For the BERT-based encoder, we first add the [CLS] token at the beginning of the sentence and the [SEP] token at the end. Next, we feed the sequence into BERT for context encoding by converting it into a vector that sums its token embedding, segment embedding, and position embedding. Finally, we input the vector v into the transformer encoder (Vaswani et al., 2017), to obtain the hidden contextual representation :
3.4. Generate enhanced graph
Part-of-speech (POS) is a linguistic concept that categorizes words based on their grammatical roles and syntactic functions within a sentence. Each word in a sentence is assigned a specific part-of-speech tag, which provides information about its linguistic characteristics and relationships with other words. As shown in Figure 3, the aspect terms “menu” and “dishes” are both annotated as nouns, and the opinion terms “limited” and “excellent” are both annotated as adjectives. In the proposed approach, nouns are considered as potential aspect terms, while adjectives are identified as potential opinion terms.

Figure 3. An example of part-of-speech tagging.
Dependency graph is a useful way to represent the grammatical relationships between words in a sentence. We use the dependency tree of each input sentence to construct a unidirectional dependency graph with self-loop. D∈ℝn×n denotes the adjacency matrix obtained from the graph:
Because the parent node is also affected by the child node, Dj, i = Di, j.
To incorporate affective knowledge into the construction of the dependency graph, we take the absolute value of the SenticNet affective score and use it as a weight for the corresponding edge in the adjacency matrix. By doing so, we can assign more weight to words with stronger sentiment intensity when computing the graph convolution operation, and our model can learn meaningful information from words containing emotionally intense, thereby contributing to increased accuracy in predicting sentiment polarity corresponding to aspect terms:
where SenticNet(wi)∈[−1, 1] denotes the SenticNet affective score of word wi. When SenticNet(wi) approaches -1, the word conveys a strong negative sentiment. Conversely, as SenticNet(wi) approaches 1, the word expresses a strong positive sentiment. In cases where SenticNet(wi) is equal to 0, the word wi is considered neutral or is not included in the SenticNet database. We exploit SenticNet 6, which contains 200,000 concepts. Some examples of SenticNet are shown in Table 1.
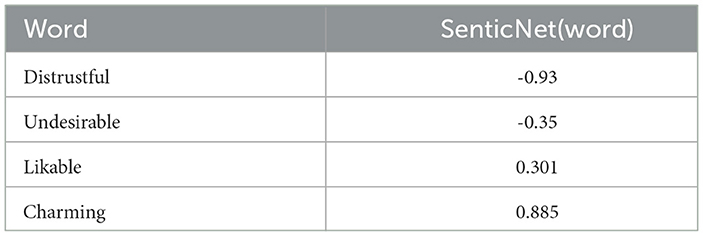
Table 1. Examples of SenticNet.
To enhance the sentiment dependencies that exist between potential aspect words and contextual words, as well as between potential opinion words and contextual words, we incorporate potential aspect word weights and potential opinion word weights as the target score into the generation of the adjacency matrix:
To learn the syntactic information features enhanced by aspect words and opinion words, respectively, we employ two parallel channels. The first channel generates an adjacency matrix that has been augmented by both aspect words and SenticNet affective score, whereas the second channel generates an adjacency matrix that has been enhanced by both opinion words and SenticNet affective score. To effectively integrate the SenticNet affective score with the aspect word weight or opinion word weight, we use the following formula to generate the final enhanced adjacency matrix and :
When encountering a word that is neither a potential aspect word nor a potential opinion word, and its corresponding SenticNet affective score is 0, the utilization of the bias value of 0.23841 results in an output of 1, with consideration to the precision of five decimal places.
3.5. Feature extraction layer
A two-layer GCN is utilized for contextual feature extraction in each channel. The syntactic dependencies for the potential aspect words or opinion words are captured by feeding the enhanced adjacency matrix Aa∈ℝn×n and the hidden contextual representations into the GCN module in the left channel. Additionally, the enhanced adjacency matrix Ao∈ℝn×n and the hidden contextual representations are input into the GCN module of another channel. Inspired by (Zhang et al., 2019), prior to this convolution, we utilize the hidden contextual representations as input into the multi-target position-aware function and to augment the importance of context words close to the potential aspect words or opinion words in two separate channels. Considering that there may be multiple potential aspect terms and opinion terms in one sentence, the function is as follows:
where is the position weight to i-th token for the t-th potential aspect term or opinion term in the sentence in two parallel channels, respectively. This function enables the model to effectively avoid noise generated during dependency parsing, resulting in improved performance and more accurate capture of the relevant syntactic dependencies.
The process of GCN is as follows:
where denotes the output of the l-th GCN layer. The output of potential aspect term-enhanced GCN layer is , and the output of potential opinion term-enhanced GCN layer is . After that, the final output of Features Extraction Layer H can be computed as follow:
3.6. Triplet extraction layer
In previous research (Wu et al., 2020a), GTS has been demonstrated to be a highly effective module for extracting triplets from the ASTE task. Therefore, in this study, we have adopted GTS as the decoding algorithm in our proposed model. The output of the Features Extraction Layer is passed through a self-attention layer to extract high-level features. The resulting output is, then, fed into the GTS module. In the GTS module, the relation of two words of the sentence is tagged by set {A, O, Pos, Neu, Neg, N}. Specifically, the symbols “A” and “O” indicate that the two terms belong to the same triplet, and that they are an aspect term and an opinion term, respectively. The tags “Pos,” “Neu,” and “Neg” denote the sentiment polarity of the triplet. The symbol “N” represents that there is no association between the two words.An example of the GTS tagging scheme is shown in Figure 4. The following inference strategy is used to predict probability distribution of word pair (wi, wj) as follows:
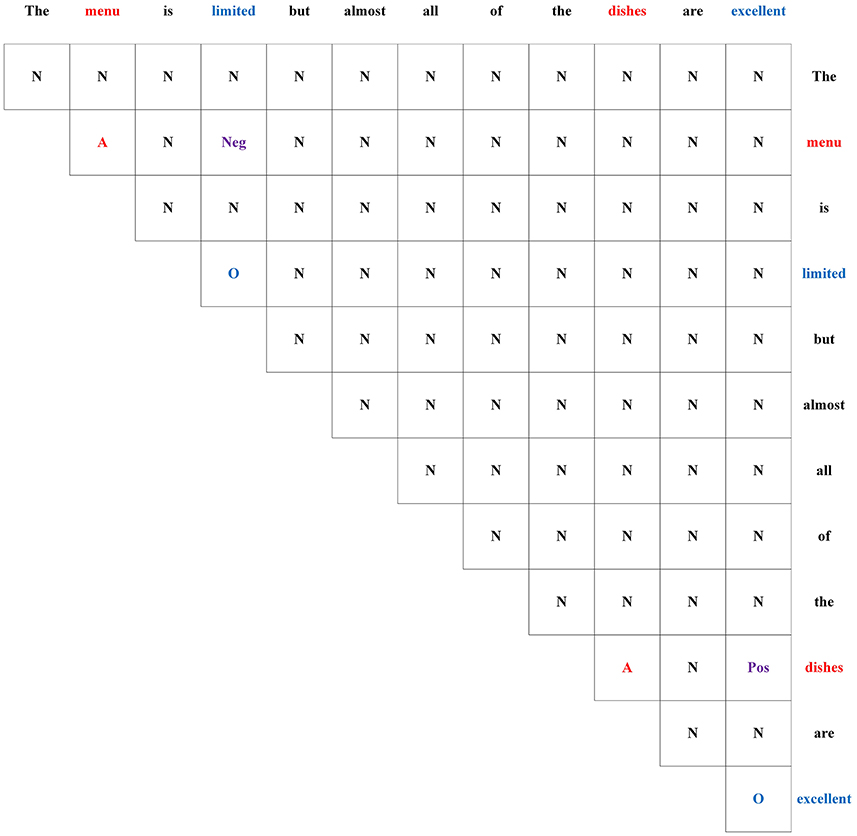
Figure 4. A tagging example with GTS.
where Wq, Ws, bq, and bs are learnable parameters, represents all predicted probability between the word wi and other words, t denotes the t-th inference, and [.;.] represents the vector concatenation operation. The first three equations are used to observe the probability distribution characteristics of each word pair itself and between word pairs. The initial predicted probability and representation of word pair (wi, wj) are set as follows:
where . Finally, the prediction of the last round is used to extract triplets. The decoding algorithm first predicts aspect terms and opinion terms based on the tags on the main diagonal. It, then, determines whether there are any terms among them that can form a pair. Finally, the most predicted sentiment tag is selected as the sentiment polarity of the pair, and the resulting pair and sentiment polarity are combined to form a triplet.
3.7. Loss function
We use the loss function which defined as cross entropy loss between the real label and the predicted label of all word pairs, and the training goal is to minimize it as follows:
4. Experiments
4.1. Datasets
In this study, we have conducted experiments on three public benchmark datasets from the restaurant domain and a public benchmark dataset from laptop domain named ASTE-Data-V2 mentioned in the study by Xu et al. (2020), all of which have been sourced from the SemEval Challenges and contain 5,989 different comments. Additionally, we have also carried out experiments on the ASTE-Data-V1 datasets mentioned in the study by Wu et al. (2020a) and report the results of these experiments. The details of these datasets are shown in Tables 2, 3.

Table 2. Statistics of the ASTE-Data-V1 datasets.

Table 3. Statistics of the ASTE-data-V2 datasets.
4.2. Evaluation metrics
To ensure the accuracy of the model's performance, Precision (P), Recall (R), and F1 Score (F1) are selected as the evaluation metrics, consistent with prior research in this field:
where “TP” denotes the number of the positive cases correctly predicted, and “TN” represents the number of negative cases correctly predicted. By contrary, “FP” represents the number of negative cases incorrectly predicted, and “FN” refers to the number of positive cases incorrectly predicted. Notably, the evaluation of extracted triplets is contingent upon the correct prediction of these three components, and any incorrectness in any of these components will render the triplet as incorrect.
4.3. Experiments settings
For the purpose of comparison with previous research, for the Bi-LSTM contextual encoder, following the design of GTS, we use a 300-dimension general-domain embedding from GloVe (Pennington et al., 2014) with 840 billion tokens and a 100-dimension specific-domain embedding from fastText (Bojanowski et al., 2017) to initialize the word embeddings. The hidden state size of the Bi-LSTM is 300, and the dimension is set to 50. The dropout rate of embedding is set to 0.3. For the BERT-based encoder, the bert-base-uncased is used as encoder, and it contains 12 attention mechanism heads, 12 hidden layers, and 768 hidden units. For these two types of encoders, we set Adam optimizer (Kingma and Ba, 2014) to optimize networks with an initial learning rate of 0.001 for the Bi-LSTM contextual encoder and 5e-5 for the BERT-based encoder. The hidden state size of the GCN is set to 300, and the depth of GCN layer is 2. The batch size is set to 32. We conducted 5 independent runs with randomized initialization and reported the experimental results as the average of these five runs.
4.4. Baselines
To evaluate the effectiveness of DGCNAP in the ASTE task, we present other state-of-the-art models in this task for comparison. These models can be categorized into end-to-end models and pipeline models.
Pipeline models
• CMLA+ (Peng et al., 2020) is a two-stage model based on CMLA (Wang et al., 2017). In the first stage, it extracts aspect terms, opinion terms, and sentiment polarities through a multi-layer attention network. In the second stage, it generates possible triplets based on the output of the first stage, then utilizes a binary classifier to filter out invalid triplets.
• RINANTE+ (Peng et al., 2020) is a two-stage model based on RINANTE (Dai and Song, 2019). The only difference between RINANTE+ and CMLA+ is that RINANTE+ extract aspect terms, opinion terms, and triplets through dependency parsing.
• Li-Unified-R (Peng et al., 2020) is a two-stage framework based on Li-Unified (Li et al., 2019). In the first stage, it uses a customized multi-layer LSTM network to extract targets, opinions, and sentiments. The second stage is similar to CMLA+.
• Peng + PD (Peng et al., 2020) is a pipeline model. It first predicts all possible triplets, then utilize a MLP classifier to judge the rationality of each triplet.
• Peng + LOG (Wu et al., 2020a) is a pipeline model. The author add a model proposed in the study by (Fan et al., 2019), after the model proposed in the study by (Peng et al., 2020).
• IMN-IOG (Wu et al., 2020a) is the combination of the IMM (He et al., 2019) and IOG (Fan et al., 2019) to generate triplets.
End-to-end models
• OTE-MTL (Zhang et al., 2020) is a model that splits the ASTE task into multiple subtasks, then generate triplets through a bi-affine scorer.
• JET (Xu et al., 2020) is a unified framework based on the position-aware tagging scheme to generate triplets through an LSTM layer and a CRF layer.
• GTS (Wu et al., 2020a) is a model that generates triplets by a unified tagging scheme, and the authors design an effective inference strategy to exploit mutual indication between different opinion factors for more accurate extractions.
• PASTE (Mukherjee et al., 2021) is a tagging-free solution built on an encoder–decoder architecture to produce all triplets.
• UniASTE (Chen et al., 2022) is a multi-task learning framework which decompose ASTE into three subtasks.
• GCN-EGTS (Hu et al., 2023) is an end-to-end model which is an enhanced Grid Tagging Scheme (GTS) for ASTE, leveraging syntactic constituency parsing tree and a commonsense knowledge graph based on GCNs.
• DGEIAN (Shi et al., 2022) is a framework with an interactive attention mechanism. In addition, the authors add different part-of-speech categories in embedding layer.
4.5. Experimental results
The results of our proposed model in the ASTE task are presented in Tables 4, 5. From the results, it is clear that DGCNAP significantly outperforms all other models in terms of F1 score on all datasets. The observations in Table 4 represent that our DGCNAP also performs better than other baseline models on ASTE-Data-V1 datasets. Our method outperforms DGEIAN on the four datasets and acquires 2.36, 1.12, 0.54, and 2.05 improvements in the F1, respectively. Additionally, we observe that the end-to-end model achieves better performance than the pipeline model. For the Bi-LSTM-based encoder, as shown in Table 5, when compared with the best pipeline model, Peng + PD, DGCNAP achieves F1 scores that are more than 10 percentage points higher in three out of the four datasets. On the other hand, in comparison with the model, our proposed model outperforms it by 2.83, 3.7, 1.55, and 3.62 F1 points on the respective datasets. For the BERT-based encoder, DGCNAP also performs well. From the Table 4, it can be observed that the DGCNAP outperforms by 0.06, 4.16, 0.82, and 3.19 F1 points on four datasets when compared with GTS. Our method outperforms the best BERT-based baseline model UniASTE by 1.63, 1.06, 2.14, and 2.36 F1 points, as shown in Table 5. The comparisons presented above demonstrate that our model effectively leverages the affective knowledge information of individual words, leading to improved model's performance in handling sentences with multiple triplets.
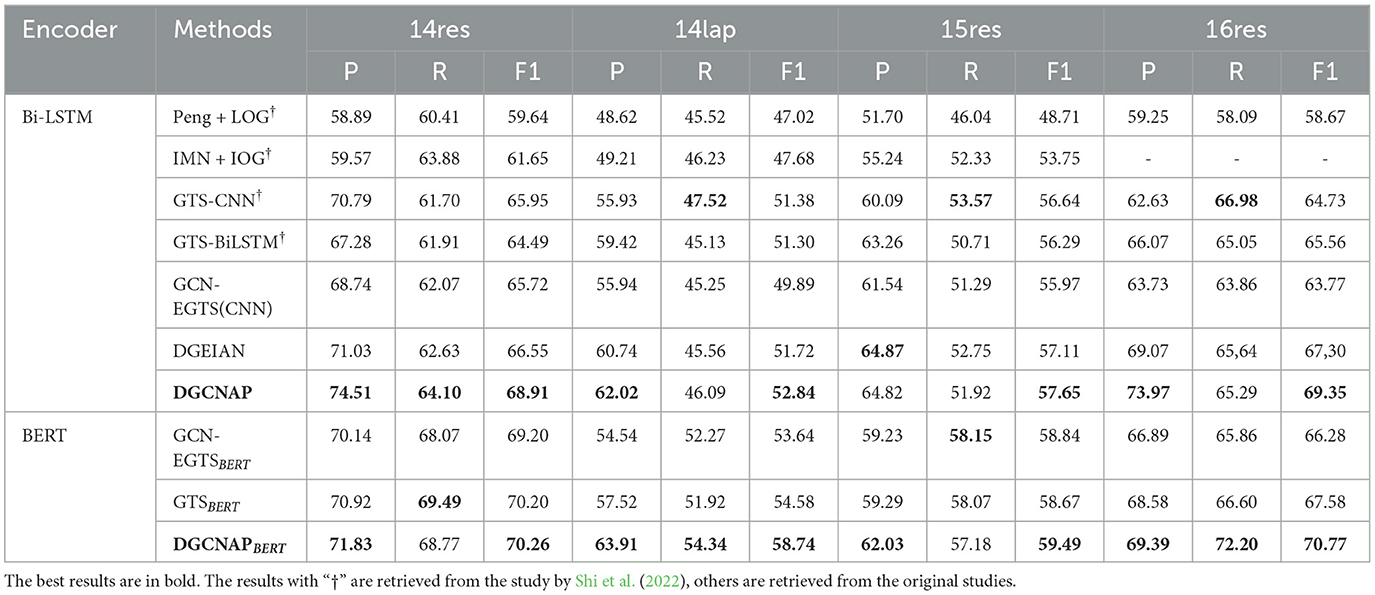
Table 4. Statistics of the ASTE-Data-V1 datasets.
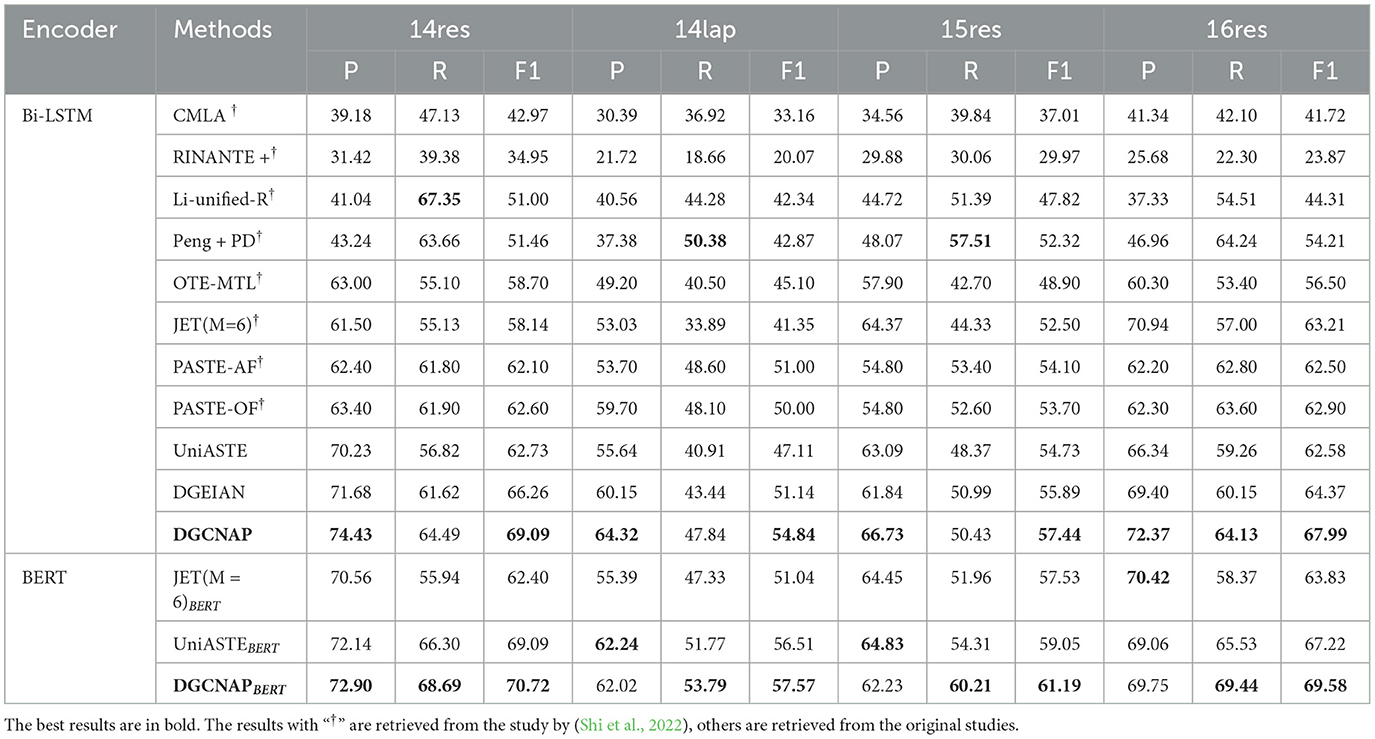
Table 5. Statistics of the ASTE-Data-V2 datasets.
4.6. Ablation study
To investigate the effectiveness of the various components in our proposed model, we conducted a series of ablation experiments on the ASTE-data-V2 datasets using the Bi-LSTM encoder. The results of the ablation experiments are presented in Table 6. “w/o SN” refers to the adjacency matrix that is generated only by sentence dependency syntax, without adding SenticNet affective score to the adjacency matrix, and “w/o PA” indicates the model without the multi-target position-aware function in the GCN layer. “w/o AE” and “w/o OE” correspond to the models without the aspect words-enhanced GCN channel and the opinion words-enhanced GCN channel, respectively.
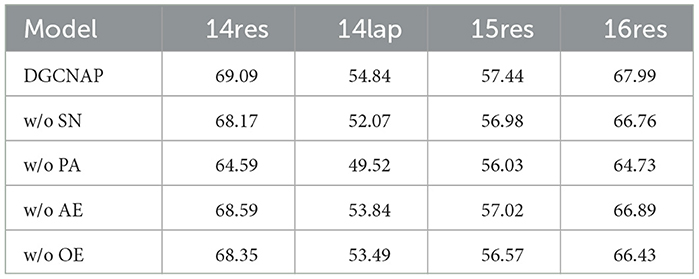
Table 6. Results of ablation study under the metric of F1.
Based on the results of the ablation experiments presented in Table 6, we can draw the following conclusion. First, the SenticNet affective score is a crucial component in enhancing the representation of the dependency graph. The utilization of only the adjacency matrix generated from the dependency syntax tree, without incorporating the SenticNet affective score for enhancement, leads to a reduction in the model's ability to predict sentiment polarity. Second, the multi-target position-aware function is another critical module in our proposed model. The removal of this function leads to a significant decrease in the F1 score, the F1 score drops the most to 5.32 on the 14lap dataset, further highlighting the importance of this function in our model. Finally, the ablation experiments reveal that both the aspect terms-enhanced features and the opinion terms-enhanced features are important for model learning. The removal of either of these two channels leads to an average decrease by 0.76 and 1.13 F1 points, emphasizing their contribution to the overall performance of the DGCNAP model.
4.7. Impact of SenticNet effective score
To investigate the impact of incorporating SenticNet affective score, a series of experiments are conducted on all four ASTE-data-V2 datasets using Bi-LSTM encoder. Specifically, the aim is to explore the impact of using different strategies for incorporating SenticNet effective score. Furthermore, “DGCNAP-ADD” denotes that we generate the final weight of the enhanced graph which is generated by adding the weight of the adjacency matrix to the target score and the absolute value of the SenticNet affective score. The results of the experiments are presented in Table 7, and the corresponding F1 scores are plotted in Figure 5. The experimental results reveal that direct addition of the three values without proper processing during the generation of the final dependency matrix lead to overemphasis of the target words and words with strong emotions. Consequently, the model disregarded the impact of syntactic dependencies and semantic information, leading to undesirable side effects, and resulting in lower performance than the result before adding target weight and SenticNet effective score. Therefore, it is concluded that the incorporation of SenticNet affective score should be carried out with caution as inappropriate usage could have a negative impact on the performance of the model.

Table 7. Results of the different usage of SenticNet effective score under the metric of F1.
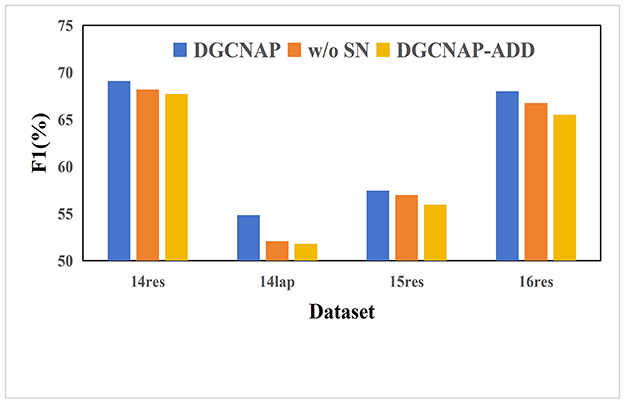
Figure 5. F1 scores for different use methods of SenticNet effective score on ASTE-data-V2 datasets.
4.8. Impact of position-aware function
To evaluate the effectiveness of the multi-target position-aware function in sentences with multiple triplets, we conduct experiments on sentences with varying numbers of aspect terms on ASTE-data-V2 datasets using Bi-LSTM encoder. Since the number of sentences with multiple aspect terms in the lap14, res15, and res16 datasets is limited, we conduct experiments on the res14 dataset of ASTE-data-V2 using Bi-LSTM encoder. The experimental results are presented in Table 8, and the ratios of the F1 score value of sentences with multiple aspect terms to the F1 score value of sentences with one aspect term are plotted in Figure 6. The results indicate that the implementation of the multi-target position-aware function has a positive impact on the model's ability to handle sentences with multiple triplets. Specifically, as the number of aspect terms increases, the decline rate of the F1 score value is observed to decrease slower than before implementing the function.
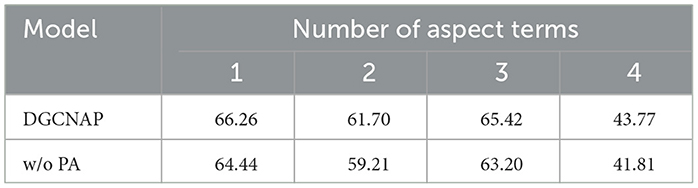
Table 8. Results of the impact of position-aware function study under the metric of F1.
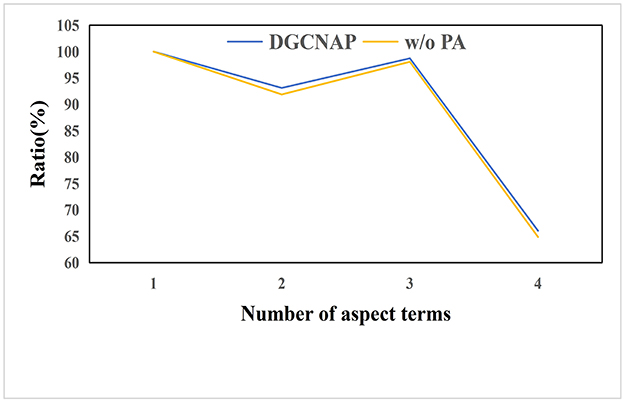
Figure 6. The ratio of F1 value of sentences with multiple aspect words to F1 value of sentences with one aspect word.
4.9. Case study
To show the advantages and disadvantages of DGCNAP, a case study is conducted to compare its performance with that of the GTS model. The results of the study are presented in Table 9. The first sample of the study comprises two triplets, with identical opinion terms. GTS accurately predict only one triplet, while DGCNAP successfully identifies both triplets. The second sample also contains two triplets, but GTS make an erroneous identification of a verb as an opinion term, leading to the prediction of an additional triplet based on the incorrect opinion term. In contrast, DGCNAP accurately recognizes the number of aspect terms and make correct predictions for all triplets. The third sample comprises one triplet. However, due to the fact that GTS does not consider contextual affective knowledge information, it inaccurately determine the sentiment polarity of this triplet. In contrast, DGCNAP accurately predict the sentiment polarity by utilizing the affective knowledge information of each word.
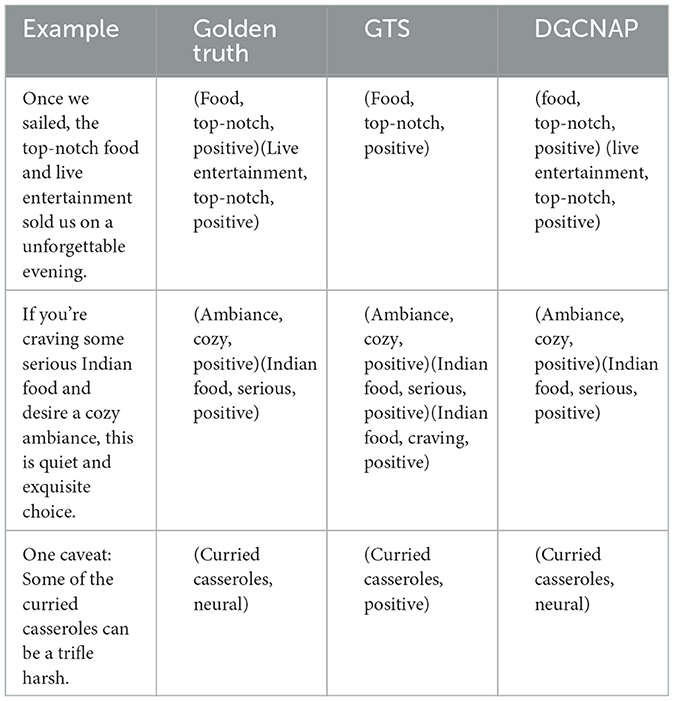
Table 9. Results of case study.
5. Conclusion
This study proposes a novel Dual Graph Convolutional Networks Integrating Affective Knowledge and Position Information (DGCNAP) to the ASTE task, which leverages the contextual features, the affective knowledge information of a single word, and relationship between potential multiple triplets in a same sentence. Specifically, our approach utilize two parallel channels to learn relevant features of potential aspect words and potential opinion words, respectively, by incorporating the SenticNet effective score and the weight of potential aspect words or opinion words when constructing the adjacency matrix. Furthermore, a novel multi-target position-aware function is utilized in the GCN Layer to significantly improve the effectiveness of the model in processing sentences with multiple triplets. The experimental results on four benchmark datasets show the effectiveness of DGCNAP, as it outperforms all other state-of-the-art models significantly in terms of F1 on all datasets. Our analysis on the impact of SenticNet Effective Score and Position-aware Function has demonstrated that these improvements effectively increase the model's ability to identify triplets in sentences. Furthermore, supporting the introduction of affective knowledge can enhance the model's ability to recognize sentiment polarity, while introducing a novel multi-target position-aware function can enhance the interaction between triplets and avoid the impact of noise.
It is noteworthy that one aspect may be associated with multiple opinions and vice versa, and our study has not made improvements to address such situations. For future studies, recognition approaches for handling overlapping triplets will be considered. Additionally, an interactive module will be developed to effectively combine enhancement features of both aspect terms and opinion terms.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
YL: conceptualization. YL and QH: methodology and writing. QH and DZ: funding acquisition and supervision. All authors contributed to manuscript revision, read, and approved the submitted version.
Funding
The research was funded by the National Natural Science Foundation of China Research on the Evidence Chain Construction from the Analysis of the Investigation Documents (62166006), supported by the Guizhou Provincial Science and Technology Projects [Guizhou Science Foundation-ZK (2021) General 335], Guizhou Provincial Science and Technology Projects [Guizhou Province under Grant (2020)1Y254], and Guizhou Science and Technology Projects Research on Spatial Optimization and Allocation of Distributed Scientific and Technological Resources [Qiankehe Support(2023) General 093].
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Bojanowski, P., Grave, E., Joulin, A., and Mikolov, T. (2017). Enriching word vectors with subword information. Trans. Assoc. Comput. Linguis. 5, 135–146. doi: 10.1162/tacl_a_00051
Chen, F., Yang, Z., and Huang, Y. (2022). A multi-task learning framework for end-to-end aspect sentiment triplet extraction. Neurocomputing 479, 12–21. doi: 10.1016/j.neucom.2022.01.021
Chen, S., Wang, Y., Liu, J., and Wang, Y. (2021). Bidirectional machine reading comprehension for aspect sentiment triplet extraction. Proc. Int. AAAI Conf Weblogs. 35, 12666–12674. doi: 10.1609/aaai.v35i14.17500
Dai, D., Chen, T., Xia, S., Wang, G., and Chen, Z. (2022). Double embedding and bidirectional sentiment dependence detector for aspect sentiment triplet extraction. Knowledge Based Syst. 253, 109506. doi: 10.1016/j.knosys.2022.109506
Dai, H., and Song, Y. (2019). “Neural aspect and opinion term extraction with mined rules as weak supervision,” in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (Florence: Association for Computational Linguistics), 5268–5277.
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. (2019). Bert: Pre-training of deep bidirectional transformers for language understanding. Proc. Conf. North Amer. Chapter Assoc. Comput. Linguistics, Hum. Lang. Technol. 1, 4171–4186. doi: 10.48550/arXiv.1810.04805
Erik, C., Amir, H., Catherine, H., and Eckl, C. (2009). “Common sense computing: From the society of mind to digital intuition and beyond,” in Biometric ID Management and Multimodal Communication (Berlin; Heidelberg: Springer), 252–259.
Fan, Z., Wu, Z., Dai, X.-Y., Huang, S., and Chen, J. (2019). Target-oriented opinion words extraction with target-fused neural sequence labeling. Proc. Conf. North Amer. Chapter Assoc. Comput. Linguistics, Hum. Lang. Technol. 1, 2509–2518. doi: 10.18653/v1/N19-1259
He, R., Lee, W. S., Ng, H. T., and Dahlmeier, D. (2018). “Exploiting document knowledge for aspect-level sentiment classification,” in Annual Meeting of the Association for Computational Linguistics, 579–585.
He, R., Lee, W. S., Ng, H. T., and Dahlmeier, D. (2019). “An interactive multi-task learning network for end-to-end aspect-based sentiment analysis,” in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 504–515. doi: 10.18653/v1/P19-1048
Hochreiter, S., and Schmidhuber, J. (1997). Long short-term memory. Neural Comput. 9, 1735–1780. doi: 10.1162/neco.1997.9.8.1735
Hu, Z., Wang, Z., Wang, Y., and Tan, A.-H. (2023). Aspect sentiment triplet extraction incorporating syntactic constituency parsing tree and commonsense knowledge graph. Cognit. Comput. 15, 337–347. doi: 10.1007/s12559-022-10078-4
Jebbara, S., and Cimiano, P. (2017). “Improving opinion-target extraction with character-level word embeddings,” in Proceedings of the First Workshop on Subword and Character Level Models in NLP. Toronto: Association for Computational Linguistics, 159–167.
Jordhy, F., Leylia, K. M., and Akbar, S. A. (2019). “Aspect and opinion terms extraction using double embeddings and attention mechanism for indonesian hotel reviews,” in 2019 International Conference of Advanced Informatics: Concepts, Theory and Applications (ICAICTA) (Yogyakartha: IEEE), 1–6.
Kingma, D., and Ba, J. (2014). “Adam: A method for stochastic optimization,” in 3rd International Conference on Learning Representations (San Diego, CA: ICLR), 1051–1060.
Kipf, T., and Welling, M. (2016). Semi-supervised classification with graph convolutional networks. arXiv [Preprint]. arXiv: 1609.02907
Li, X., Bing, L., Li, P., and Lam, W. (2019). A unified model for opinion target extraction and target sentiment prediction. Proc. Int. AAAI Conf. 33, 6714–6721. doi: 10.1609/aaai.v33i01.33016714
Li, Y., Lin, Y., Lin, Y., Chang, L., and Zhang, H. (2022). A span-sharing joint extraction framework for harvesting aspect sentiment triplets. Knowledge Based Syst. 242, 108366. doi: 10.1016/j.knosys.2022.108366
Liang, B., Su, H., Gui, L., Cambria, E., and Xu, R. (2022). Aspect-based sentiment analysis via affective knowledge enhanced graph convolutional networks. Knowledge Based Syst. 235, 107643. doi: 10.1016/j.knosys.2021.107643
Liu, Z., Yang, D., Wang, Y., Lu, M., and Li, R. (2023). Egnn: Graph structure learning based on evolutionary computation helps more in graph neural networks. Appl. Soft Comput. 135, 110040. doi: 10.1016/j.asoc.2023.110040
Ma, D., Li, S., Zhang, X., and Wang, H. (2017). “Interactive attention networks for aspect-level sentiment classification,” in Twenty-Sixth International Joint Conference on Artificial Intelligence, 4068–4074.
Ma, Y., Peng, H., and Cambria, E. (2018). “Targeted aspect-based sentiment analysis via embedding commonsense knowledge into an attentive lstm,” in Proceedings of International AAAI Conference, Vol. 32 (New Orleans, LA: AAAI Press), 5876–5883. doi: 10.1609/aaai.v32i1.12048
Mukherjee, R., Nayak, T., Butala, Y., Bhattacharya, S., and Goyal, P. (2021). “PASTE: A tagging-free decoding framework using pointer networks for aspect sentiment triplet extraction,” in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (Punta Cana: Association for Computational Linguistics), 9279–9291.
Peng, H., Xu, L., Bing, L., Huang, F., Lu, W., and Si, L. (2020). Knowing what, how and why: A near complete solution for aspect-based sentiment analysis. Proc. Int. AAAI Conf. 34, 8600–8607. doi: 10.1609/aaai.v34i05.6383
Pennington, J., Socher, R., and Manning, C. (2014). “GloVe: Global vectors for word representation,” in Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) (Doha: Association for Computational Linguistics), 1532–1543. doi: 10.3115/v1/D14-1162
Pontiki, M., Galanis, D., Pavlopoulos, J., Papageorgiou, H., Androutsopoulos, I., and Manandhar, S. (2014). “Semeval-2014 task 4: aspect based sentiment analysis,” in Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014). Toronto: Association for Computational Linguistics, 27–35. doi: 10.3115/v1/S14-2004
Shi, L., Han, D., Han, J., Qiao, B., and Wu, G. (2022). Dependency graph enhanced interactive attention network for aspect sentiment triplet extraction. Neurocomputing 507, 315–324. doi: 10.1016/j.neucom.2022.07.067
Shi, Y., Li, L., Yang, J., Wang, Y., and Hao, S. (2023). Center-based transfer feature learning with classifier adaptation for surface defect recognition. Mech. Syst. Signal Process. 188, 110001. doi: 10.1016/j.ymssp.2022.110001
Tang, D., Qin, B., and Liu, T. (2016). “Aspect level sentiment classification with deep memory network,” in Conference on Empirical Methods in Natural Language Processing (Austin, TX: Association for Computational Linguistics), 214–224.
Tian, C., Xu, Z., Wang, L., and Liu, Y. (2023). Arc fault detection using artificial intelligence: Challenges and benefits. Math Biosci Eng. 20, 12404–12432. doi: 10.3934/mbe.2023552
Vaswani, A., Shazeer, N. M., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., et al. (2017). “Attention is all you need,” in Proceedings of the 31st International Conference on Neural Information Processing Systems. New York: Curran Associates Inc, 6000–6010.
Wang, W., Pan, S. J., Dahlmeier, D., and Xiao, X. (2017). Coupled multi-layer attentions for co-extraction of aspect and opinion terms. Proc. Innov. Appl. Artif. Intell. Conf. 31, 3316–3322. doi: 10.1609/aaai.v31i1.10974
Wang, Y., Liu, Z., Xu, J., and Yan, W. (2023). Heterogeneous network representation learning approach for ethereum identity identification. IEEE Trans. Comput. Soc. Syst. 10, 890–899. doi: 10.1109/TCSS.2022.3164719
Wu, H., Zhang, Z., Shi, S., Wu, Q., and Song, H. (2022). Phrase dependency relational graph attention network for aspect-based sentiment analysis. Knowledge Based Syst. 236, 107736. doi: 10.1016/j.knosys.2021.107736
Wu, Z., Ying, C., Zhao, F., Fan, Z., Dai, X., and Xia, R. (2020a). “Grid tagging scheme for aspect-oriented fine-grained opinion extraction,” in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, 2576–2585. doi: 10.18653/v1/2020.findings-emnlp.234
Wu, Z., Zhao, F., Dai, X.-Y., Huang, S., and Chen, J. (2020b). “Latent opinions transfer network for target-oriented opinion words extraction. Proc. Innov. Appl. Artif. Intell. Conf. 34, 9298–9305. doi: 10.1609/aaai.v34i05.6469
Xin, L., Lidong, B., Piji, L., Wai, L., and Zhimou, Y. (2018). “Aspect term extraction with history attention and selective transformation,” in International Joint Conference on Artificial Intelligence, 4194–4200.
Xu, L., Li, H., Lu, W., and Bing, L. (2020). “Position-aware tagging for aspect sentiment triplet extraction,” in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, 2339–2349. doi: 10.18653/v1/2020.emnlp-main.183
Yin, Y., Wei, F., Dong, L., Xu, K., Zhang, M., and Zhou, M. (2016). “Unsupervised word and dependency path embeddings for aspect term extraction,” in Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence. California: AAAI Press, 2979–2985.
Zhang, C., Li, Q., and Song, D. (2019). “Aspect-based sentiment classification with aspect-specific graph convolutional networks,” in Conf. Empirical Methods Natural Lang. Process (EMNLP) and the 9th Int. Joint Conf. on Natural Lang. Process (IJCNLP), 4560–4570. doi: 10.18653/v1/D19-1464
Zhang, C., Li, Q., Song, D., and Wang, B. (2020). “A multi-task learning framework for opinion triplet extraction,” in Findings of the Association for Computational Linguistics: EMNLP 2020, 819–828.
Keywords: aspect-based sentiment analysis, aspect sentiment triplet extraction, affective knowledge, position-aware function, graph convolutional network (GCN)
Citation: Li Y, He Q and Zhang D (2023) Dual graph convolutional networks integrating affective knowledge and position information for aspect sentiment triplet extraction. Front. Neurorobot. 17:1193011. doi: 10.3389/fnbot.2023.1193011
Received: 24 March 2023; Accepted: 21 July 2023;
Published: 14 August 2023.
Edited by:
Long Jin, Lanzhou University, ChinaReviewed by:
Varun Dutt, Indian Institute of Technology Mandi, IndiaHang Su, Fondazione Politecnico di Milano, Italy
Copyright © 2023 Li, He and Zhang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Qing He, cWhlQGd6dS5lZHUuY24=