 Xudie Ren
Xudie Ren Shenghong Li
Shenghong Li Hao Ge2
Hao Ge2- 1School of Electronic Information and Electrical Engineering, Shanghai Jiao Tong University, Shanghai, China
- 2Shanghai Data Miracle Intelligent Technology Co., Ltd., Shanghai, China
For a learning automaton, a proper configuration of the learning parameters is crucial. To ensure stable and reliable performance in stochastic environments, manual parameter tuning is necessary for existing LA schemes, but the tuning procedure is time-consuming and interaction-costing. It is a fatal limitation for LA-based applications, especially for those environments where the interactions are expensive. In this paper, we propose a parameter-free learning automaton (PFLA) scheme to avoid parameter tuning by a Bayesian inference method. In contrast to existing schemes where the parameters must be carefully tuned according to the environment, PFLA works well with a set of consistent parameters in various environments. This intriguing property dramatically reduces the difficulty of applying a learning automaton to an unknown stochastic environment. A rigorous proof of ϵ-optimality for the proposed scheme is provided and numeric experiments are carried out on benchmark environments to verify its effectiveness. The results show that, without any parameter tuning cost, the proposed PFLA can achieve a competitive performance compared with other well-tuned schemes and outperform untuned schemes on the consistency of performance.
1. Introduction
Learning Automata (LA) are simple self-adaptive decision units that were firstly investigated to mimic the learning behavior of natural organisms (Narendra and Thathachar, 1974). The pioneering work can be traced back to the 1960s by the Soviet scholar (Tsetlin, 1961, 1973). Since then, LA has been extensively explored and it is still under investigation as well in methodological aspects (Agache and Oommen, 2002; Papadimitriou et al., 2004; Zhang et al., 2013, 2014; Ge et al., 2015a; Jiang et al., 2015) as in concrete applications (Song et al., 2007; Horn and Oommen, 2010; Oommen and Hashem, 2010; Cuevas et al., 2013; Yazidi et al., 2013; Misra et al., 2014; Kumar et al., 2015; Vahidipour et al., 2015). One intriguing property that popularizes the learning automata-based approaches in engineering is that LA can learn the stochastic characteristics of the external environment it interacts with, and maximize the long-term reward it obtains through interacting with the environment. For a detailed overview of LA, one may refer to a new comprehensive survey (Oommen and Misra, 2009) and a classic book (Narendra and Thathachar, 2012).
In the case of LA, accuracy and convergence rate become two major measurements to evaluate the effectiveness of a LA scheme. The former is defined as the probability of a correct convergence and the latter as the average iterations for a LA to get converged1. Most of the reported schemes in the field of LA have two or more tunable parameters, making themselves capable of adapting to a particular environment. An automaton's accuracy and convergence rate highly depend on the selection of those parameters. Generally, ensuring a high accuracy is of uppermost priority. According to the ϵ-optimality property of LA, the probability of converging to the optimal action can be arbitrarily close to one, as long as the learning resolution is large enough. However, it will raise another problem. Taking the classic Pursuit scheme for example, as Figure 1 illustrates, the number of iterations required for convergence grows nearly linearly with the resolution parameter, while the accuracy grows logarithmically. This implies a larger learning resolution can lead to higher accuracy, but at the cost of much more interactions with the environment. This dilemma necessitates parameter tuning to find a balance between convergence rate and accuracy.
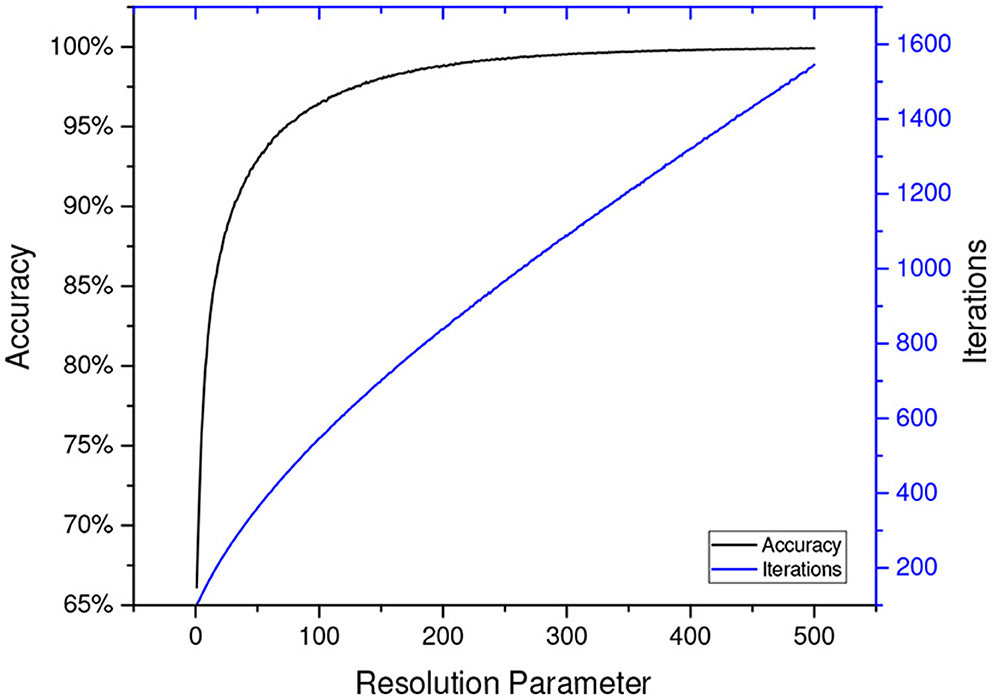
Figure 1. The accuracy and iterations with different resolution parameters for DPri (Oommen and Lanctôt, 1990) in benchmark environment E1, which is defined in Papadimitriou et al. (2004). The results are averaged over 250,000 replications.2
In literature, the performance of various LA schemes is evaluated by comparing their convergence rates on the premise of a certain accuracy. The learning parameters of various schemes are tuned through a standard procedure to ensure the accuracies are kept at the same level, so that the convergence rates can be fairly compared. For deterministic estimator-based learning automata, the smallest value of the resolution parameter that yielded a hundred percent accuracy in a certain number of experiments is selected. The situation is more sophisticated when concerning the stochastic estimator-based schemes (Papadimitriou et al., 2004; Ge et al., 2015a; Jiang et al., 2015), because extra configurable parameters should be set to control the perturbation added. Parameter tuning is intended to balance the trade-off between speed and accuracy. However, the interaction cost can be tremendous itself3, due to its trial and error nature. In practical applications, especially where interacting with environments could be expensive, e.g., drug trials, destructive tests, and financial investments, the enormous cost for parameter tuning is undesired. Therefore, we believe, the issue of learning parameter configurations deserves more attention in the community, which gives impetus to our work.
The scope of this research is confined to designing a learning scheme for LA in which the parameter tuning can be omitted, and that's why it is called parameter-free in the title. It is noted that the term parameter-free does not imply that no configurable parameters are involved in the proposed model, but indicates a set of parameters for the scheme that can be universally applicable to all environments. This paper is an extension of our preliminary work (Ge et al., 2015b). The proposed scheme in Ge et al. (2015b) can only operate in two-action environments, whereas in this paper, our proposed scheme can operate in both two-action environments as well as multi-action environments. In addition, in this paper, optimistic initial values are utilized to improve the performance further. Moreover, a rigorous theoretical analysis of the proposed scheme and a comprehensive comparison among recently proposed LA schemes are provided in this paper which was not included in Ge et al. (2015b).
The contribution of this paper can be summarized as follows:
1. To the best of our knowledge, we present the first parameter-free scheme in the field of LA, for learning in any stationary P-model stochastic environment. The meaning of the terminology parameter-free is two-fold: (1) The learning parameters do not need to be manually configured. (2) Unlike other estimator-based schemes, initializations of estimators are also unnecessary in our scheme.
2. Most conventional LA schemes in literature employ a stochastic exploration strategy, on the contrary, we design a deterministic gradient descent-like method instead of probability matching as the exploration strategy to further accelerate the convergence rate of the automaton.
3. The statistics behavior of the proposed parameter-free learning automata (PFLA) is analyzed and rigorous proof of the ϵ-optimality property is provided as well.
4. Comprehensive comparison among recently proposed LA schemes is given to validate the theoretical analyses and demonstrate that PFLA is superior to other methods concerning tuning cost.
This paper proceeds as follows. Section 2 describes our philosophy and some related works. Section 3 presents the primary results of the paper: a parameter-free learning automaton scheme. Section 4 discusses the theoretical performance of the proposed scheme. Section 5 provides a numerical simulation for verifying the proposed scheme. Finally, Section 6 concludes this paper.
2. Related works
Consider a P-model environment which could be mathematically defined by a triple < 𝔸, 𝔹, ℂ >, where
• 𝔸 = {a1, a2, …, ar} represents a finite action set
• 𝔹 = {0, 1} denotes a binary response set
• ℂ = {c1, c2, …, cr} is a set of reward probabilities corresponding to 𝔸, which means Pr{ai gets rewarded}=ci. Each ci is assumed to lie in the open interval (0, 1).
Some other major notations that are used throughout this paper are defined in Table 1.
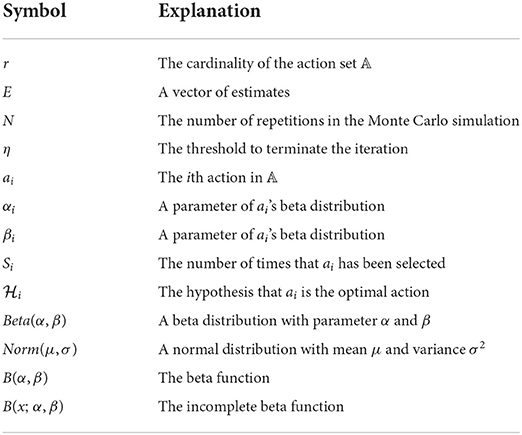
Table 1. Notations used in this paper.
The aim of LA is to identify the optimal action am, which has the maximum reward probability, from 𝔸 through interacting with the environment. The general philosophy is to collect feedback from the environment and use this information to extract evidence that supports an optimal assertion.
Then we are faced with two challenges:
1. How to organize the information gathered and make full use of them?
2. When is the time to make an assertion that claims one of the actions is optimal?
2.1. Information utilization
Lots of work have been done for the first challenge. Although the reward probabilities ℂ are unknown to us, we can construct consistent estimators to guarantee that the estimates of the reward probabilities can converge to their true values as the quantity of samples increases.
As the feedback for one action can be modeled as a Bernoulli distributed random variable in P-model environments, there are two ways to construct such estimators currently.
1. One is from the frequentist's perspective. The most intuitive approach is to utilize the likelihood function, which is a basic quantitative measure over a set of predictions with respect to observed data. In the context of parameter estimation, the likelihood function is naturally viewed as a function of the parameters ci to be estimated. The parameter that maximizes the likelihood of the observed data is referred to as the maximum likelihood estimate (MLE). MLE-based LA (Oommen and Lanctôt, 1990; Agache and Oommen, 2002) are proved to be a great success, achieving a tremendous improvement in the rate of convergence compared with traditional variable structure stochastic automata. However, as we revealed in Ge et al. (2015a), MLE suffers from one principle weakness, i.e., MLE is unreliable when the quantity of samples is small.
Several efforts have been devoted to improving MLE. The concept of stochastic estimator was employed in Papadimitriou et al. (2004) so that the influence of lacking samples can be reduced by introducing controlled randomnesses to MLE. In Ge et al. (2015a), we proposed an interval estimator-based learning automata DGCPA, in which the upper bound of a 99% confidence interval of ci is used as estimates of reward probabilities. Both of these two LA schemes broke the records of convergence rate when proposed, which confirmed the defect of traditional MLE.
2. On the other hand, there are attempts from the Bayesian perspective. Historically, one of the major reasons for avoiding Bayesian inference is that it can be computationally intensive under many circumstances. The rapid improvements in available computing power over the past few decades can, however, help overcome this obstacle, and Bayesian techniques are becoming more widespread not only in practical statistical applications but also in theoretical approaches to modeling human cognition. In Bayesian statistics, parameter estimation involves placing a probability distribution over model parameters. Concerning LA, the posterior distribution of ci with respect to observed data is a beta distribution.
In Zhang et al. (2013), DBPA was proposed where the posterior distribution of estimated is represented by a beta distribution Beta(α, β), the parameter α and β record the number of times that a specific action has been rewarded and penalized, respectively. Then the 95th percentile of the cumulative posterior distribution is utilized as an estimation of ci.
One of the main drawbacks of the way that information is being used by existing LA schemes is that they summarize beliefs about ci, such as the likelihood function or the posterior distribution, into a point estimate, which obviously may lead to information loss. In the proposed PFLA, we insist on taking advantage of the entire Bayesian posterior distribution of ci for further statistical inference.
2.2. Optimal assertion
For the second challenge, as the collected information accumulates, we become more and more confident to make an assertion. But when is the exact timing?
The quantity of samples before the convergence of existing strategies is indirectly controlled by its learning parameters. Actually, the LA is not aware of whether it has collected enough information or not, as a consequence, its performance completely relies on the manual configuration of learning parameters inevitably. As far as we're concerned, there is no report describing a parameter-free scheme for learning in multi-action environments, and this research area remains quite open.
However, there are efforts from other research areas that shed some light on this target. In Granmo (2010), a Bayesian learning automaton (BLA) was proposed for solving the two-armed Bernoulli bandit (TABB) problem. The TABB problem is a classic optimization problem that explores the trade-off between exploitation and exploration in reinforcement learning. One distinct difference between learning automata and bandit-playing algorithms is the metrics used for performance evaluation. Typically, accuracy is used for evaluating LA algorithms while regret is usually used in bandit playing algorithms. Despite being presented with different objectives, BLA is somewhat related to our study and inspired our work. Therefore, the philosophy of BLA is briefly summarized as follows: The BLA maintains two beta distributions as estimates of the reward probabilities for the two arms (corresponding to actions in the LA field). At each time instance, two values are randomly drawn from the two beta distributions, respectively. The arm with the higher random value is selected, and the feedback is utilized to update the parameter of the beta distribution associated with the selected arm. One advantage of BLA is that it doesn't involve any explicit computation of Bayesian expression. In Granmo (2010), it has been claimed that BLA performs better than UCB-tuned, the best performing algorithm reported in Auer et al. (2002).
Inspired by Granmo (2010), we constructed the PFLA by using Bayesian inference to enable convergence self-judgment in this paper. In contrast to Granmo (2010), however, the probability of each arm being selected must be explicitly computed to judge the convergence of the algorithm. In addition, due to the poor performance of probability matching, we developed a deterministic exploration strategy. The technical details are provided in the next section.
3. A parameter-free learning automaton
In this section, we introduce each essential mechanism of our scheme in detail.
3.1. Self-judgment
Consider a P-model environment with r available actions, as we have no prior knowledge about these actions, each of them is possible to be the optimal one. We refer to these r possibilities as r hypotheses so that each hypothesis represents the event that action ai is the optimal action.
As we discussed in Section 2, the Bayesian estimates of each action's reward probability just intuitively are beta distributed random variables, denoted as E = {e1, e2, …, er}, where ei ~ Beta(αi, βi).
Because the propositions are mutually exclusive and collectively exhaustive, apparently we have . Therefore, we can simply assert that αi is the optimal action once is greater than some predefined threshold η. For this reason, the explicit computation of is necessary here to make that assertion.
3.1.1. Two-action environments
In the two-action case, can be formulated in the following equivalent forms:
The above formulas can be easily implemented by a programming language with a well-defined log-beta function, thus the exact calculation of can be completed within . However, in multi-action cases, the closed-form of is too complex and it's somewhat computationally intensive to calculate it directly. So in our scheme, a Monte Carlo simulation is adopted for evaluating in a multi-action environment.
3.1.2. Multi-action environments
The closed-form calculation of is feasible for a small action set, but it becomes much more difficult as the number of actions increases.
Monte Carlo methods are a broad class of computational algorithms that rely on repeated random sampling to obtain numerical results.
In multi-action environments, in order to evaluate , an intuitive approach is to generate random samples from the r beta distributions and count how often the sample from Beta(αi, βi) is bigger than any other samples. In that way, the following Monte-Carlo simulation procedure is proposed.
Suppose the number of simulation replications is N. Since ei follows Beta(αi, βi), let be one of the r random samples at the nth replication.
Then, can be simulated as
where is an indicator function such that
It is simple to verify that .
3.2. Exploration strategy
In conventional estimator-based learning schemes, which are the majority family of LA, a stochastic exploration strategy is employed. A probability vector for choosing each action is maintained in the automaton and is properly updated under the guidance of the estimator and environment feedback after every interaction. However, such a probability vector does not exist in our scheme. Instead, a vector of probabilities indicating the chance of each action being the best one is maintained in our scheme. The exploration strategy in Granmo (2010) is the so-called probability matching, which occurs when an action is chosen with a frequency equivalent to the probability of that action being the best choice. In Ge et al. (2015b), we constructed a learning automata by adding an absorbing barrier to BLA and applying it as a baseline for comparison. The numerical simulation shows the low performance of the probability matching strategy in designing parameter-free LA. Therefore, a novel deterministic exploration strategy is proposed accordingly to overcome this pitfall.
Because is the stop criterion of our scheme, in order to pursue a rapid convergence, one straightforward and obvious approach is maximizing the expected increment of over the action set.
3.2.1. Two-action environments
In two-action environments, if is greater than , then we suppose action a1 is more likely to be the optimal one, and thus attempt to find out the action that will lead to the maximal expected increment of , or vice versa.
We denote as g(α1, β1, α2, β2), and the following recurrence relations are derived (Cook, 2005):
where .
Hence, given that action a1 is chosen, the conditional expected increment of is:
because c1 is unknown to us, we can approximate the above equation as
In the same way, we have
(18) and (19) indicate that no matter which action is picked, the expected difference of will approximately be zero, which makes it difficult for us to make decisions.
Our solution is to select the action that gives the expected maximum possible increment to , as we did in Ge et al. (2015b). More specifically, if is greater than , then we try to find out the action that could probably lead to the expected maximal increment of , that is
Otherwise, we try to maximize
The events that can lead to increments of are “action a1 is selected and rewarded” and “action a2 is selected and punished.” Hence the optimization objective of (20) can be simplified as:
By employing the Maximum Likelihood Estimate of c1 and c2, (22) can be written as
The same conclusion holds also for situation .
As a result, the strategy adopted in two-action environments is selecting the action which has been observed less between the two candidate actions at every time instance, as (24) reveals.
3.2.2. Multi-action environments
In multi-action environments, the automaton has to distinguish the best action from the action set. Intuitively, we can maximize the expected increment of over the selection of actions, however, the closed form of is complicated, making the exact solution computationally intractable.
However, from an alternative perspective, the automaton only needs to determine which is the best of the top two possibly optimal actions. That is, for the two actions which are most possible to be the optimal action, denoted as action ai1 and action ai2, we only have to maximize the probability Pr(ei1 > ei2) or Pr(ei2 > ei1), exactly the same as it in two-action environments. So we come to the conclusion that, in the proposed scheme, our exploration strategy is similar to (24).
3.3. Initialization of beta distributions
In our scheme, each estimation ei is represented by a beta distribution ei ~ Beta(αi, βi). The parameters αi and βi record the number of times that action ai has been rewarded and punished, respectively.
In the beginning, as we know nothing about the actions, a non-informative (uniform) prior distribution is advised to infer the posterior distribution. So αi and βi should be set identically to 1, exactly the same as in Granmo (2010) and Zhang et al. (2013).
However, as clarified in Sutton and Barto (2018), initial action values can be used as a simple way of encouraging exploration. The technique of optimistic initial values is applied, which has been reported as a quite effective simple trick on stationary problems.
Therefore, in our scheme, the prior distribution is Beta(2, 1) for inferring the posterior distribution, i.e., all beta random variables are initialized as αi = 2, βi = 1.
The estimates of all actions' reward probability are intentionally biased toward 1. The impact of the bias is permanent, though decreasing over iterations. When an action has been sampled just a few times, the bias contributes a large proportion to the estimate, thus further exploration is encouraged. By the time an action has been observed many times, the impact of the biased initial value is negligible.
Finally, the overall process of PFLA is summarized in Algorithm 1.

Algorithm 1. Parameter-free learning automaton.
4. Performance analysis
In this section, the statistical performance of the proposed scheme is analyzed, an approximate lower bound of the accuracy is derived and the ϵ-optimality of the proposed scheme is further proved.
4.1. An approximate lower bound of the accuracy
As declared in Owen (2013), from the central limit theorem (CLT), we know that the error of Monte Carlo simulation has approximately a normal distribution with zero mean and variance σ2/N. Hence, if we denote the error between and its Monte-Carlo estimate as ϵi, then we get
where is the Monte-Carlo estimate of and is the variance of I(xi).
We may note that the right-hand side of (29) is irrelevant to the characteristics of the environment. In other words, the performance of the proposed scheme only depends on the selection of η and N. That is the theoretical foundation of the parameter-free property.
As the outcome of I(xi) is binary, in the worst case, the maximum of is 0.25. When N equals 1,000, the probability density function of ϵi is shown in Figure 2, which quantitatively depicts the error. Obviously, the error is so small that could be ignored.
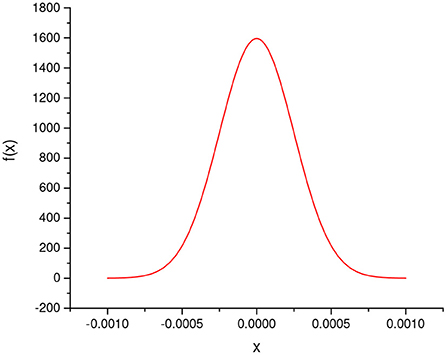
Figure 2. The probability density function of .
Therefore, the approximate lower bound of is η. According to the Bayesian theory, the accuracy of our scheme is approximately larger than η.
Next, we shall describe the behavior of the proposed scheme more precisely. Like the pioneers have done in previous literature, the ϵ-optimality of the proposed scheme will be derived.
4.2. Proof of ε-optimality
Recall that ei is defined as the estimated reward probability of action ai and follows Beta(αi, βi), which is the posterior distribution of the estimated reward probability. The probability density function of Beta(αi, βi) is , where serves as a normalizing factor such that . Let Zi = αi − 2 and Wi = βi − 1 denote the numbers of times that action ai has been rewarded and penalized, respectively, and Si = Zi + Wi = αi + βi − 3 be the number of times that action ai has been selected.
Based on these preliminaries, the following Lemmas and Theorems are proposed:
Lemma 1. The beta distribution Beta(αi, βi) becomes 1-point Degenerate distribution with a Dirac delta function spike at ci, provided that the number of selecting action ai approaches infinity, i.e., ∀ε > 0,
Proof 1. According to the law of large numbers, we have , as Si → ∞.
Hence
The probability density function takes the form:
where .
Note that g(xi) is a non-negative integrable function, we have
Therefore,
This reveals, as Si → ∞
where ||g||∞,ε is the L∞ norm of g when restricted to |xi − ci| > ε.
By taking both sides of (39) to the Si power, we obtain
Obviously , for the fact that g is continuous and has a unique maximum at ci, thus
as Si → ∞.
Note that and the proof is finished.
Lemma 2. For two or more random variables ei ~ Beta(αi, βi), assume m is the index of action that has the maximum reward probability such that cm = max(ci), then
Proof 2.
From Lemma 1, we know that f(xi; αi, βi) → δ(xi − ci) as Si → ∞.
By using the sampling property of the Dirac delta function, (43) can be simplified as
Note that ∀i ≠ m, as ci ∈ [0, cm], . And finally
This completes the proof.
Remark 1. It is noted that, Lemma 2 implies
Lemma 3. Suppose one component of the vector , say approaches 1 only if the number of each action been selected Si → ∞, for all i ∈ {1, 2, …, r}.
Proof 3. As , for any δ > 0, we have , hence
As a result, for all j ≠ i,
By denoting , we have
Suppose at least one of Si and Sj is not infinity, thus three possible cases should be discussed.
1. Case Si < ∞ and Sj < ∞.
In this case, f(xj; αj, βj) is a continuous function and strictly positive on (0, 1). As is continuous, B(x; αi, βi) is continuously differentiable which implies it is a continuous function. In addition, B(x; αi, βi) is strictly positive on (0, 1). Clearly, the product of two strictly positive continuous functions F(x) is continuous and F(x) > 0 on the interval (0, 1), hence
which contradicts (55).
2. Case Si < ∞ and Sj = ∞.
Similarly, we can prove that B(x; αi, βi) is strictly positive and continuous on (0, 1), and f(x; αj, βj) → δ(x − cj).
Hence, (54) can be written as:
that contradicts the fact that B(x; αi, βi) is strictly positive on (0, 1).
3. Case Si = ∞ and Sj < ∞.
Similarly, we can prove that f(xj; αj, βj) is strictly positive and continuous on (0, 1), and f(xi; αi, βi) → δ(x − ci).
Hence, (54) can be written as:
which implies f(xj; αj, βj) = 0 on (ci, 1), that contradicts the fact that f(xj; αj, βj) is strictly positive on (0, 1).
By summarizing the above three cases, we conclude that the supposition is false and both Si and Sj must be infinity.
As i, j enumerate all the action indexes, the proof is completed.
Remark 2. From Lemma 3 and Remark 1, one can immediately see that given a threshold η → 1, PFLA will converge to the optimal action w.p.1 whenever it gets converged.
Lemma 4. The Monte Carlo estimation of will converge almost surely as the number of Monte Carlo replications N tends to infinity, i.e.,
Proof 4. This lemma can be easily derived according to the strong law of large numbers.
Let us now state and prove the main result for algorithm PFLA.
Theorem 1. PFLA is ϵ-optimal in every stationary random environment. That is, given any ε > 0, there exists a N0 < ∞, a t0 < ∞, and a η0 < 1 such that for all t ≥ t0, N ≥ N0 and η > η0:
Proof 5. The theorem is equivalent to showing that,
From Lemma 4, we know that (61) is equivalent to
And according to Remark 2, we only need to prove that the scheme can definitely get converged, i.e., at least one of the components approaches 1, as t → ∞ and η → 1.
Suppose the scheme has not converged yet at time t1, because exactly one action will be explored at each time instant, we have .
As t1 → ∞, a finite series has an infinite sum, which indicates that at least one of the terms Si has an infinite value.
Then denote the set of actions, whose corresponding observation times Si(t1) → ∞, as 𝔸1, and denote the absolute complement set of 𝔸1 as 𝔸2.
1. If 𝔸2 = ∅, then for any action ai, we have Si → ∞.
By considering Remark 1, we have
2. We will show that if 𝔸2 ≠ ∅, then it is impossible that both the top two possibly optimal actions belong to set 𝔸1.
Denote the action in 𝔸1 with the highest reward probability as am1, then according to Lemma 2, ∀ai ∈ 𝔸1 and i ≠ m1,
While for actions aj ∈ 𝔸2,
As cm1 < 1, and the integrand is strictly positive and continuous. Obviously, (68) is larger than zero trivially.
For actions in 𝔸1 other than am1, , while for actions in 𝔸2, all equal some constants that are larger than zero. Hence, at least one action of the top two most probably optimal actions is from 𝔸2 and this action will be chosen to draw feedback.
As time t → ∞, once 𝔸2 ≠ ∅, one action in 𝔸2 will be explored. As a consequence, we can always find a t0 > t1 such that all actions in 𝔸2 will be explored infinite times and yield an empty 𝔸2.
Combining the above two cases, we may infer that all actions will be explored an infinite number of times and .
This completes the proof.
5. Simulation results
During the last decade, SEri has been considered as the state-of-the-art algorithm for a long time, however, some recently proposed algorithms (Ge et al., 2015a; Jiang et al., 2015) claim a faster convergence than SEri. To make a comprehensive comparison among currently available techniques, as well as to verify the effectiveness of the proposed parameter-free scheme, in this section, PFLA is compared with several classic parameter-based learning automata schemes, including DPri (Oommen and Lanctôt, 1990), DGPA (Agache and Oommen, 2002), DBPA (Zhang et al., 2013), DGCPA* (Ge et al., 2015a), SEri (Papadimitriou et al., 2004), GBSE (Jiang et al., 2015), and LELAR (Zhang et al., 2014).
All the schemes are evaluated in four two-action benchmark environments (Ge et al., 2015b) and five 10-action benchmark environments (Papadimitriou et al., 2004). The actions' reward probabilities for each environment are as follows:
E1 :{0.90, 0.60}
E2 :{0.80, 0.50}
E3 :{0.80, 0.60}
E4 :{0.20, 0.50}
E5 :{0.65, 0.50, 0.45, 0.40, 0.35, 0.30, 0.25, 0.20, 0.15, 0.10}
E6 :{0.60, 0.50, 0.45, 0.40, 0.35, 0.30, 0.25, 0.20, 0.15, 0.10}
E7 :{0.55, 0.50, 0.45, 0.40, 0.35, 0.30, 0.25, 0.20, 0.15, 0.10}
E8 :{0.70, 0.50, 0.30, 0.20, 0.40, 0.50, 0.40, 0.30, 0.50, 0.20}
E9 :{0.10, 0.45, 0.84, 0.76, 0.20, 0.40, 0.60, 0.70, 0.50, 0.30}
The comparison is organized in two ways:
1. Comparison between PFLA and parameter-based schemes with their learning parameters being carefully tuned.
2. Comparison between PFLA and parameter-based schemes without parameter tuning, using either pre-defined or randomly selected learning parameters.
5.1. Comparison with well-tuned schemes
Firstly, the parameter-based schemes are simulated with carefully tuned best parameters. The procedure for obtaining the best parameters is elaborated in the Appendix. The proposed PFLA, by contrast, takes identical parameter values of η = 0.99 and N = 1,000 in all nine environments.
The results of the simulations are summarized in Tables 2, 3. The accuracy is defined as the ratio between the number of correct convergence and the number of experiments, whilst the iteration as the averaged number of required interactions between automaton and environment for a correct convergence. It is noted that the initialization cost of estimators is also included. The number of initializations for each action is 10.
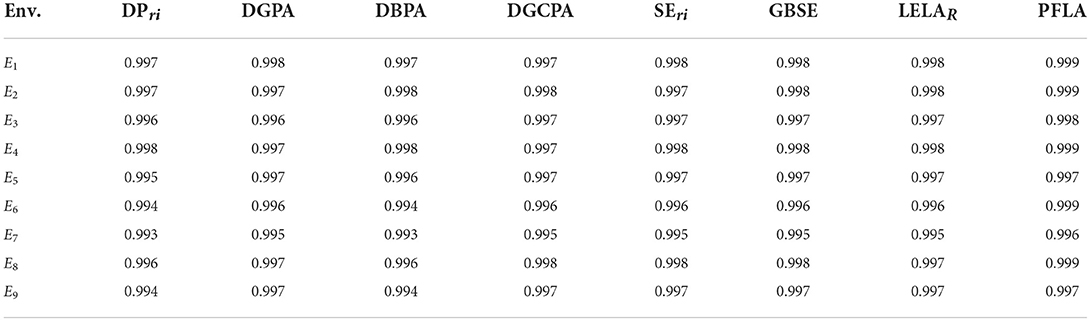
Table 2. Accuracy (number of correct convergences/number of experiments) of the compared algorithms in environments E1 to E9, when using the “best” learning parameters (250,000 experiments were performed for each scheme in each environment).
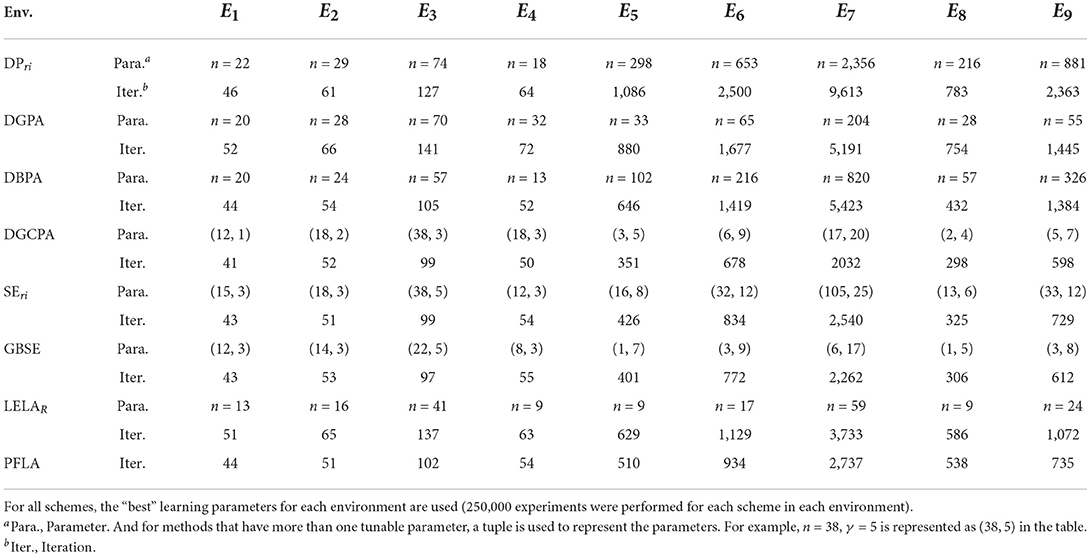
Table 3. Comparison of the average number of iterations required for convergence of the compared algorithms in environments E1 to E9.
In Table 2, PFLA converges with relatively high accuracy consistently, coinciding with our analytical results in Section 4, and verifying the effectiveness of our proposed parameter-free scheme. And since the accuracies of all schemes are close, their convergence rates can be “fairly” compared4.
In the aspect of convergence rate, obviously, in Table 3, PFLA is outperformed by the top performers, namely SEri, GBSE, and DGCPA*. Figure 3 depicts the improvements of the competitors over PFLA. Take E7 as an example, the convergence rate of PFLA is improved by DGCPA*, SEri, and GBSE with 25.76, 7.20, and 17.35%, respectively. While other schemes, DPri, DGPA, and LELAR are outperformed by PFLA significantly. Generally speaking, FPLA is faster than deterministic estimator-based schemes and slower than stochastic estimator-based algorithms.
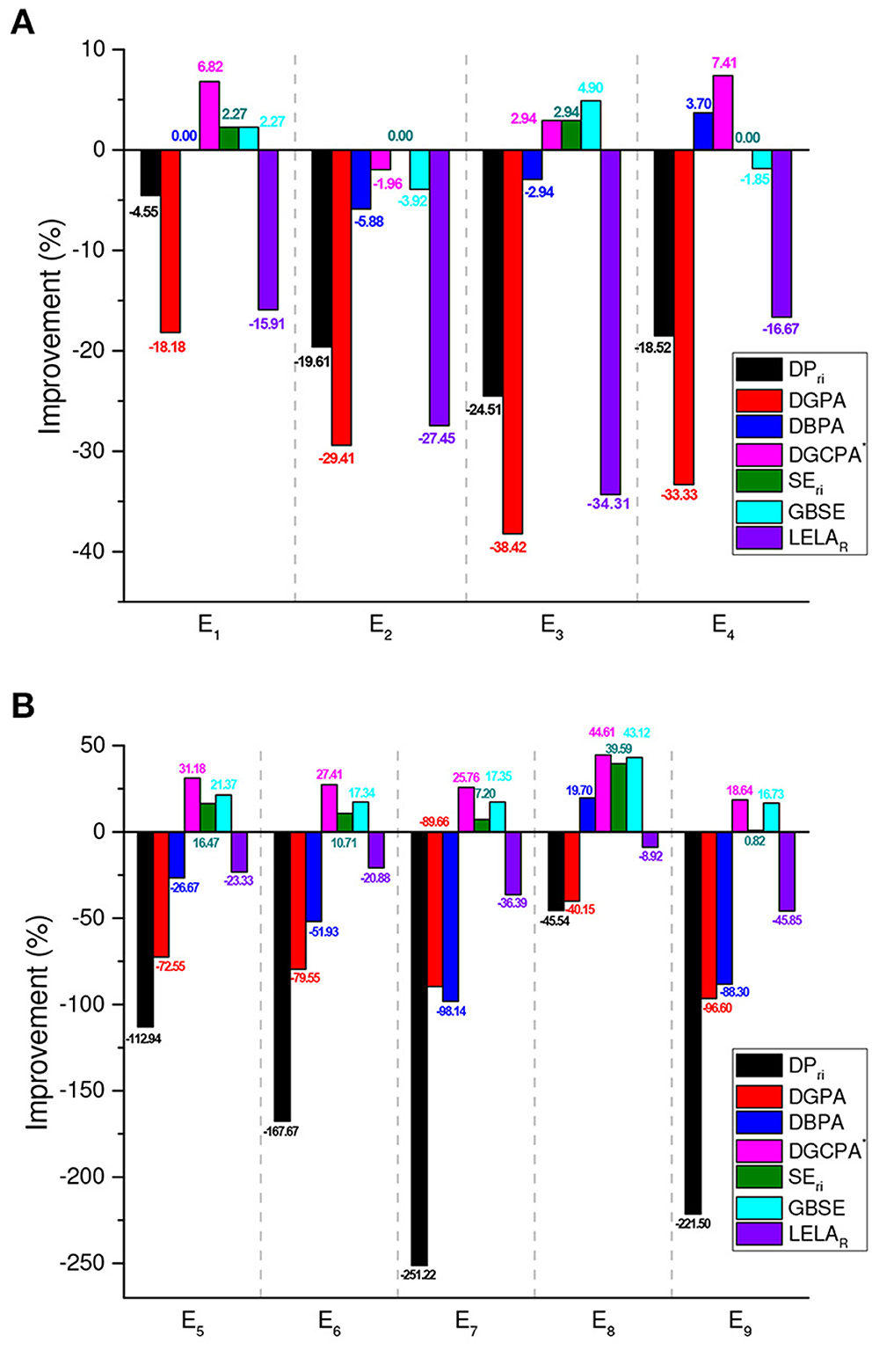
Figure 3. Convergence rate improvements of the compared algorithms relative to PFLA in benchmark environments, calculated by using . (A) Two-action environments. (B) Ten-action environments.
However, taking the parameter tuning cost of the competitors into consideration, the parameter-free property begins to show its superiority. In order to clarify that point, we record the number of interactions between automaton and environment during the process of parameter tuning for each parameter-based scheme. The results are summarized in Table 45. It can be seen that the extra interactions required for parameter tuning by deterministic estimator-based schemes (DGPA, DBPA, and LELAR, except DPri) are slightly less than stochastic estimator-based schemes (DGCPA*, SEri, and GBSE). Both families of schemes cost millions of extra interactions for seeking the best parameter. The proposed scheme can achieve a comparative performance without relying on any extra interactions/information.
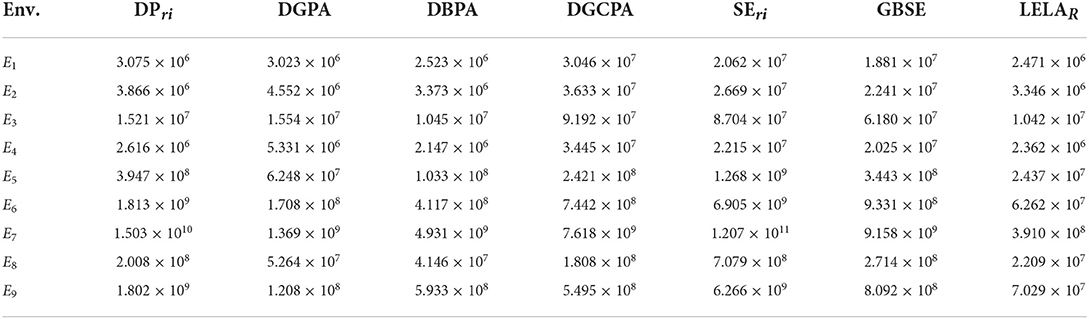
Table 4. The parameter tuning cost (number of extra interactions) of the compared algorithms in environments E1–E9.
For better visualization, a scatter map is used to illustrate the performance of different methods. In the scatter map, each dot represents a specific method discussed in this section. The x-axis indicates the averaged accuracy achieved by each method in the benchmark environments, and the y-axis indicates the averaged iterations need for each method to get converged in the benchmark environments, as shown in Figure 4. It is noted that the iterations are normalized with respect to each environment before being averaged over different environments for each method. As we are always pursuing a method with higher accuracy and convergence rate, the method approaching the right bottom corner of the figure is better than the others. From Figure 4B, we can draw the conclusion that taking the parameter tuning cost of the competitors into consideration, the proposed PFLA is the best of all competitors.
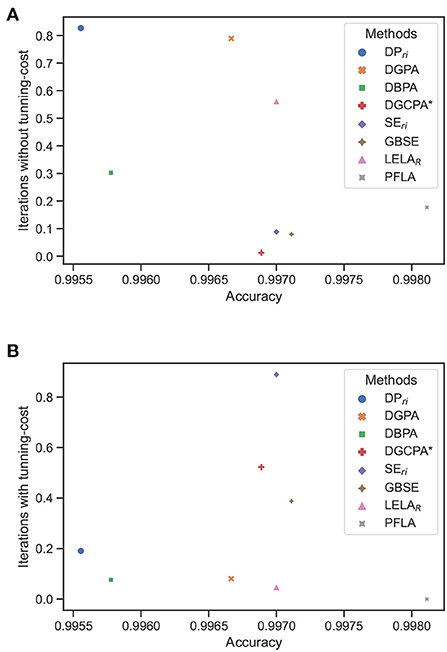
Figure 4. Averaged iterations vs. averaged accuracy in the nine benchmark environments of compared methods. (A) Without considering the parameter tunning cost. (B) With consideration of the parameter tunning cost.
5.2. Comparison with untuned schemes
In this part, the parameter-based algorithms are simulated in benchmark environments without their learning parameter specifically tuned. Their performance will be compared with PFLA under the same condition—no extra information about the environment is available.
5.2.1. Using generalized learning parameter
Firstly, the best parameter in E2 and E6 are applied for learning in other environments respectively to evaluate how well they can “generalize” in other environments. The results are shown in Tables 5, 6, respectively.
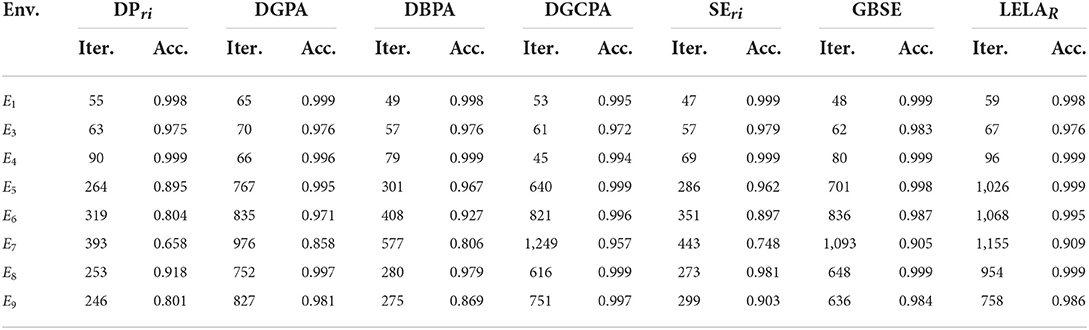
Table 5. Comparison of convergence rate and accuracy of the parameter-based algorithms in all environments other than E2, when using the “best” learning parameters in E2.
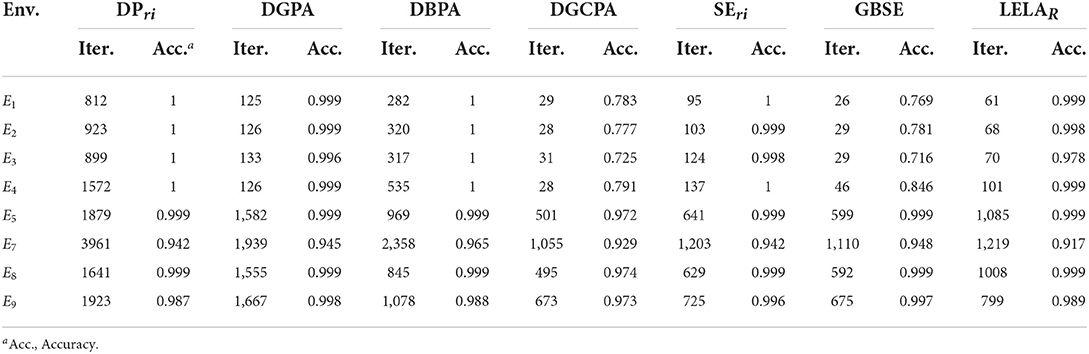
Table 6. Comparison of convergence rate and accuracy of the parameter-based algorithms in all environments other than E6, when using the “best” learning parameters in E6.
5.2.2. Using random learning parameter
Secondly, randomly selected learning parameters are adopted to evaluate the expected performance of each algorithm in fully unknown environments. The random resolution parameter takes value in the range from 90% of the minimal value to 110% of the maximal value of the best resolution parameter in the nine benchmark environments6, and a range from 1 to 20 for the perturbation parameter if needed. The simulation results are demonstrated in Table 7.
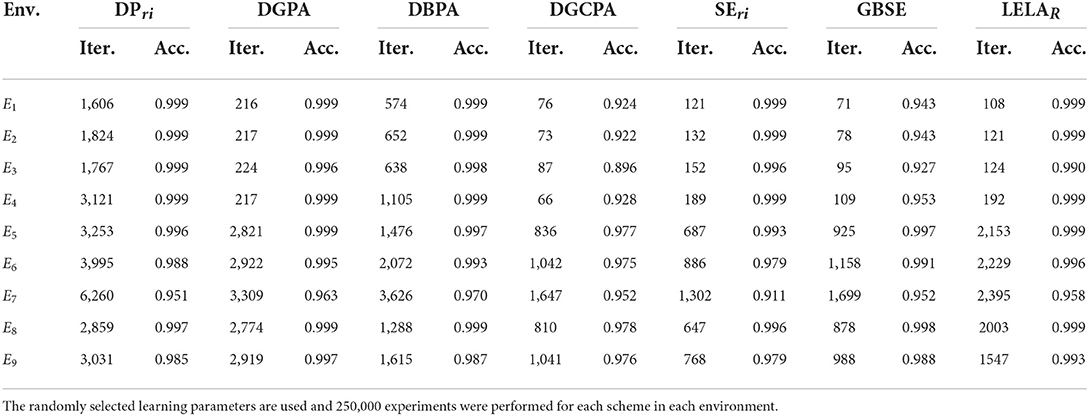
Table 7. Comparison of the average number of iterations required for convergence of the parameter-based algorithms in environments E1 to E9.
From the three tables, there is a significant decline in accuracy in some environments. As the accuracies differ greatly in those cases, the convergence rates cannot be compared directly. Still, several conclusions can be drawn. One is that the performance of untuned parameter-based algorithms is unstable when learning in an unknown environment, and thus cannot be used in practical applications without parameter tuning. Another conclusion is that those algorithms, that use generalized learning parameters or random learning parameters, are either have a lower accuracy or a slower convergence rate than PFLA in the benchmark environment. In other words, none of them can outperform PFLA in both accuracy and convergence rate without the help of prior information.
5.3. Discussion of the fairness of the comparison
Technically speaking, the comparison between PFLA and well-tuned schemes is not fair. This is because the interactions can be perceived as information exchanges between automaton and the environment. So if the number of interactions is unlimited, the algorithm can simply use the empirical distributions. The outperforming of the well-tuned schemes owes to their richer knowledge about the environment acquired during the parameter tuning process. And for this reason, a fair comparison between PFLA and untuned schemes is carried out. Despite the unfairness of the first comparison, the significance lies in providing baselines for evaluating the convergence rate of PFLA qualitatively.
By the way, the comparison within parameter-based algorithms is not fair either, because the amount of prior information acquired is different. This method is widely used by the research community to compare the theoretically best performance of their proposed algorithms, however, the hardness of the algorithm can achieve theoretically best is usually ignored.
6. Conclusion
In this paper, we propose a parameter-free learning automaton scheme for learning in stationary stochastic environments. The proof of the ε-optimality of the proposed scheme in every stationary random environment is presented. Compared with existing schemes, the proposed PFLA possesses a parameter-free property, i.e., a set of parameters that can be universally applicable to all environments. Furthermore, our scheme is evaluated in four two-action and five 10-action benchmark environments and compared with several classic and state-of-the-art schemes in the field of LA. Simulations confirm that our scheme can converge to the optimal action with high accuracy. Although the rate of convergence is outperformed by some schemes that are well-tuned for specific environments, the proposed scheme still shows its intriguing property of not relying on the parameter-tuning process. Our future work includes optimizing the exploration strategy further.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
All authors listed have made a substantial, direct, and intellectual contribution to the work and approved it for publication.
Funding
This research work was funded by the National Nature Science Foundation of China under Grant 61971283, Shanghai Municipal Science and Technology Major Project under Grant 2021SHZDZX0102, and Shanghai AI Innovation and Development Project under Grant 2020-RGZN-02026.
Conflict of interest
Author HG was employed by company Shanghai Data Miracle Intelligent Technology Co., Ltd.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Footnotes
1. ^For this reason, the terms convergence rate and iteration are used interchangeably.
2. ^E1 defined in Papadimitriou et al. (2004) corresponds to E5 defined in Section 5 of this paper.
3. ^The details will be elaborated in Section 5.
4. ^Technically speaking, the comparison is not completely fair, that's the reason the word “fairly” are quoted. An explanation will be given in later subsections.
5. ^It is noted that the numerical value shown in Table 4 may differ according to the way parameter tuning being implemented, still it gives qualitatively evidence to the heavy parameter tuning cost of the parameter-based schemes. The technical details of the parameter tuning procedure used here are provided in the Appendix.
6. ^For example, the resolution parameter of DPri is range from ⌊90% ∗ 18⌋ to ⌈110% ∗ 2356⌉, i.e., from 16 to 2,592.
References
Agache, M., and Oommen, B. J. (2002). Generalized pursuit learning schemes: new families of continuous and discretized learning automata. IEEE Trans. Syst. Man Cybern. Part B 32, 738–749. doi: 10.1109/TSMCB.2002.1049608
Auer, P., Cesa-Bianchi, N., and Fischer, P. (2002). Finite-time analysis of the multi-armed bandit problem. Mach. Learn. 47, 235–256. doi: 10.1023/A:1013689704352
Cook, J. D. (2005). Exact Calculation of Beta Inequalities. Technical report, Technical report, UT MD Anderson Cancer Center Department of Biostatistics.
Cuevas, E., Wario, F., Zaldivar, D., and Pérez-Cisneros, M. (2013). Circle Detection on Images Using Learning Automata. Berlin; Heidelberg: Springer Berlin Heidelberg. 545–570. doi: 10.1007/978-3-642-29694-9_21
Ge, H., Jiang, W., Li, S., Li, J., Wang, Y., and Jing, Y. (2015a). A novel estimator based learning automata algorithm. Appl. Intell. 42, 262–275. doi: 10.1007/s10489-014-0594-1
Ge, H., Yan, Y., Li, J., Ying, G., and Li, S. (2015b). “A parameter-free gradient bayesian two-action learning automaton scheme,” in Proceedings of the International Conference on Communications, Signal Processing, and Systems (Berlin; Heidelberg).
Granmo, O.-C. (2010). Solving two-armed Bernoulli bandit problems using a Bayesian learning automaton. Int. J. Intell. Comput. Cybern. 3, 207–234. doi: 10.1108/17563781011049179
Horn, G., and Oommen, B. (2010). Solving multiconstraint assignment problems using learning automata. IEEE Trans. Syst. Man Cybern. Part B 40, 6–18. doi: 10.1109/TSMCB.2009.2032528
Jiang, W., Li, B., Tang, Y., and Philip Chen, C. L. (2015). A new prospective for learning automata: a machine learning approach. Neurocomputing 188, 319–325. doi: 10.1016/j.neucom.2015.04.125
Kumar, N., Misra, S., and Obaidat, M. (2015). Collaborative learning automata-based routing for rescue operations in dense urban regions using vehicular sensor networks. IEEE Syst. J. 9, 1081–1090. doi: 10.1109/JSYST.2014.2335451
Misra, S., Krishna, P., Kalaiselvan, K., Saritha, V., and Obaidat, M. (2014). Learning automata based QoS framework for cloud IAAS. IEEE Trans. Netw. Service Manage. 11, 15–24. doi: 10.1109/TNSM.2014.011614.130429
Narendra, K. S., and Thathachar, M. (1974). Learning automata-a survey. IEEE Trans. Syst. Man Cybern. 4, 323–334. doi: 10.1109/TSMC.1974.5408453
Narendra, K. S., and Thathachar, M. A. (2012). Learning Automata: An Introduction. New York, NY: Courier Dover Publications.
Oommen, B., and Hashem, M. (2010). Modeling a student-classroom interaction in a tutorial-like system using learning automata. IEEE Trans. Syst. Man Cybern. Part B 40, 29–42. doi: 10.1109/TSMCB.2009.2032414
Oommen, B. J., and Agache, M. (2001). Continuous and discretized pursuit learning schemes: various algorithms and their comparison. IEEE Trans. Syst. Man Cybern. Part B 31, 277–287. doi: 10.1109/3477.931507
Oommen, B. J., and Lanctôt, J. K. (1990). Discretized pursuit learning automata. IEEE Trans. Syst. Man Cybern. 20, 931–938. doi: 10.1109/21.105092
Oommen, J., and Misra, S. (2009). “Cybernetics and learning automata,” in Springer Handbook of Automation, ed S. Y. Nof (Berlin; Heidelberg: Springer), 221–235. doi: 10.1007/978-3-540-78831-7_12
Papadimitriou, G. I., Sklira, M., and Pomportsis, A. S. (2004). A new class of ε-optimal learning automata. IEEE Trans. Syst. Man Cybern. Part B 34, 246–254. doi: 10.1109/TSMCB.2003.811117
Song, Y., Fang, Y., and Zhang, Y. (2007). “Stochastic channel selection in cognitive radio networks,” in Global Telecommunications Conference, 2007, GLOBECOM '07 (Washington, DC), 4878–4882. doi: 10.1109/GLOCOM.2007.925
Sutton, R. S., and Barto, A. G. (2018). Reinforcement Learning: An Introduction. Cambridge, MA; London: The MIT Press.
Tsetlin, M. (1973). Automaton Theory and Modeling of Biological Systems. New York, NY: Academic Press.
Tsetlin, M. L. (1961). On the behavior of finite automata in random media. Avtom. Telemekh. 22, 1345–1354.
Vahidipour, S., Meybodi, M., and Esnaashari, M. (2015). Learning automata-based adaptive petri net and its application to priority assignment in queuing systems with unknown parameters. IEEE Trans. Syst. Man Cybern. Syst. 45, 1373–1384. doi: 10.1109/TSMC.2015.2406764
Yazidi, A., Granmo, O.-C., and Oommen, B. (2013). Learning automaton based online discovery and tracking of spatiotemporal event patterns. IEEE Trans. Cybern. 43, 1118–1130. doi: 10.1109/TSMCB.2012.2224339
Zhang, J., Wang, C., and Zhou, M. (2014). Last-position elimination-based learning automata. IEEE Trans. Cybern. 44, 2484–2492. doi: 10.1109/TCYB.2014.2309478
Zhang, X., Granmo, O.-C., and Oommen, B. J. (2013). On incorporating the paradigms of discretization and Bayesian estimation to create a new family of pursuit learning automata. Applied Intell. 39, 782–792. doi: 10.1007/s10489-013-0424-x
Appendix
The standard parameter tuning procedure of learning automata
As emphasized in Section 1, parameter tuning is intended to balance the trade-off between speed and accuracy. And the standard procedure of parameter tuning is pioneered in Oommen and Lanctôt (1990) and become a common practice in follow-up researches (Oommen and Agache, 2001; Agache and Oommen, 2002; Papadimitriou et al., 2004; Zhang et al., 2014; Ge et al., 2015a; Jiang et al., 2015).
The basic idea is, that the smallest value of resolution parameter n that yielded the fastest convergence and that simultaneously resulted in zeros errors in a sequence of NE experiments are defined as “best” parameters. Besides, to reduce the variance coefficient of the “best” values of n, Papadimitriou et al. (2004) advocate performing the same procedure 20 times and computing the average “best” value of n in these experiments. For tuning stochastic estimator-based learning automata, which have a perturbation parameter γ in addition to the well-known resolution parameter n. A two-dimensional grid search should be performed to seek the best parameter pair (n, γ). The method used in Papadimitriou et al. (2004) is to obtain the “best” resolution parameter n for each value of γ, and then evaluate the speed of convergence for each of the (n, γ) pairs and choose the best pair.
Based on these instructions, we use the following procedure for parameter tuning in our experiment:
The resolution parameter is initialized to 1 and increased by 1 each time a wrong convergence emerges until a certain number of successive No Error experiments is carried out. Repeat this process 20 times, averaging over these 20 resulting values, and denote it as the best resolution parameter. The value of number of successive No Error experiments is set as NE = 750, as the same value in Papadimitriou et al. (2004), Zhang et al. (2014), Jiang et al. (2015), and Ge et al. (2015a). For tuning the “best” γ, in our simulation settings, for the four two-action environments, the search range of γ is from 1 to 10; For the five ten-action environments except E7, the search range of γ is from 1 to 20, while for E7, the most difficult one, the range is a little wider, from 1 to 30.
It is noted that the above standard procedure has been widely adopted by the research community, but it does not mean this is the most efficient way. Apparently, it can be improved by several methods, such as random search or two-stage coarse-to-fine search. This issue is worth further investigation and is beyond the scope of this paper.
Keywords: parameter-free, Monte-Carlo simulation, Bayesian inference, learning automaton, parameter tuning
Citation: Ren X, Li S and Ge H (2022) A parameter-free learning automaton scheme. Front. Neurorobot. 16:999658. doi: 10.3389/fnbot.2022.999658
Received: 21 July 2022; Accepted: 22 August 2022;
Published: 23 September 2022.
Edited by:
Yusen He, Grinnell College, United StatesReviewed by:
Yang Wang, East China Normal University, ChinaChong Di, Qilu University of Technology, China
Yujin Zhang, Shanghai University of Engineering Sciences, China
Copyright © 2022 Ren, Li and Ge. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xudie Ren, cmVueHVkaWVAc2p0dS5lZHUuY24=