 Jinqiang Wang
Jinqiang Wang Dianguo Cao*
Dianguo Cao*
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Neurorobot. , 28 October 2022
Volume 16 - 2022 | https://doi.org/10.3389/fnbot.2022.997134
This article is part of the Research Topic Biomedical signals and Artificial Intelligence Towards Smart Robots Control Strategies View all 5 articles
The inability of new users to adapt quickly to the surface electromyography (sEMG) interface has greatly hindered the development of sEMG in the field of rehabilitation. This is due mainly to the large differences in sEMG signals produced by muscles when different people perform the same motion. To address this issue, a multi-user sEMG framework is proposed, using discriminative canonical correlation analysis and adaptive dimensionality reduction (ADR). The interface projects the feature sets for training users and new users into a low-dimensional uniform style space, overcoming the problem of individual differences in sEMG. The ADR method removes the redundant information in sEMG features and improves the accuracy of system motion recognition. The presented framework was validated on eight subjects with intact limbs, with an average recognition accuracy of 92.23% in 12 categories of upper-limb movements. In rehabilitation laboratory experiments, the average recognition rate reached 90.52%. The experimental results suggest that the framework offers a good solution to enable new rehabilitation users to adapt quickly to the sEMG interface.
Surface electromyography (sEMG) signals are electrical signals that occur on the surface of human skin when the motor unit motion potential of a motor-associated muscle propagates along the muscle fibers (Vigotsky et al., 2018; Medved et al., 2020). These signals contain a wealth of information including muscle contraction force and joint torque (Disselhorst-Klug et al., 2009). In recent years, extensive research has been conducted into human–robot collaborative robots, teleoperated surgical robots, rehabilitation robots, wearable monitoring devices, and medical diagnosis based on sEMG signals (Ghassemi et al., 2019; Li et al., 2020; Luo et al., 2020a, 2021; Qi and Aliverti, 2020; Su et al., 2020, 2022; Qi et al., 2021). In particular, for stroke patients and patients with limb muscle injuries, a rehabilitation method in which the healthy side drives the affected side (an exoskeleton robot drives the limb on the affected side by recognizing the movements of the healthy side) can accelerate neurological remodeling and rehabilitation. However, people in these groups cannot provide a large dataset for training classifier models because of their limited physical fitness (Fang et al., 2020). Moreover, muscle strength, amount of subcutaneous fat, skin impedance, the fixed position of the electrodes, the degree of muscle fatigue, and limb posture all differ significantly among different users. All of this makes it difficult for new users to fit models trained on other users (Lobov et al., 2018).
Owing to these problems, there has been much research on various aspects of sEMG, including signal preprocessing, feature extraction, feature optimization, and classification (Elamvazuthi et al., 2015; Bi et al., 2019; Simao et al., 2019). For instance, Pan et al. (2018) developed a general sEMG interface for continuous prediction of coordinated movements between the palmar fingers and wrist flexion/extension. This model can be customized based on the musculoskeletal model of the individual user, and it can fit multiple users, including upper-limb amputees. User-generic musculoskeletal models capture generalized relationships between neuromuscular signals and human-generated limb movements. The successful application of this model reportedly relies on recording sEMG signals of specific muscles. This means that the patient must determine the exact location of the upper extremity muscles, which poses some challenges in practical applications for upper extremity rehabilitation patients. Xue et al. (2021) proposed a new framework called CCA-OT to handle the problem of multi-user gesture recognition. The CCA-OT framework reduces the differences in the distribution of the feature matrix. However, it was reported that the data distribution differed significantly between the training and testing sets of the framework. The framework incorporates a new feature dimension of 45 dimensions, so there is room for further optimization. Matsubara and Morimoto (2013) proposed a bilinear model comprising (i) user-related and (ii) motion-related linear factors; it extracts user-independent features from users and classifies them with a support vector machine (SVM) classifier, and the classification recognition rate indicated that the model outperformed non-multi-user methods. However, the dimensions of the style and content variables were chosen by trial and error, which added to the difficulty of the experiment, and the performance of the model was affected significantly by the electrode placement offset. Despite some progress, considerable challenges remain in applying these findings to clinical implementation (Samuel et al., 2019; Jarque-Bou et al., 2021).
Herein, a novel multi-user sEMG framework is proposed, based on discriminative canonical correlation analysis (DCCA) and adaptive dimensionality reduction (ADR), to reduce the variability of human sEMG, eliminate complex redundant information, improve recognition rates, and even reduce the training time required for classifier models. First, we propose an ADR optimization method based on the derived DCCA algorithm and design an ADR–DCCA architecture suitable for multiple-user action recognition. Then, the ADR–DCCA framework is verified to be superior to other CCA extensions through comparative experiments. Finally, the ADR-DCCA framework is used for an upper limb rehabilitation task in which the healthy side of the user drives the affected side. The contributions of this work can be summarized as follows.
• The DCCA algorithm is applied to the variability of human sEMG to project the views of two sEMGs of different users into a low-dimensional uniform style space. In this space, the intra-class correlation of the new features is guaranteed to be maximized and the inter-class correlation is minimized.
• The ADR optimization method is proposed; this is the main contribution of this work. This method selects the most suitable dimension for motion recognition from the new features, which effectively reduces the redundant information.
The framework presented here can further extract the common information of training users and new users, effectively reduce personality information, and find the most suitable dimension for new users' action classification. New users can adapt to the sEMG interface using only a few sets of actions. In addition, the framework can be used to build an accurate model for a new user when two channels of the sEMG signal are missing. It is important for the patient to quickly obtain a model of the healthy side to drive the affected side. A multi-user contralateral-driven rehabilitation system is shown in Figure 1.
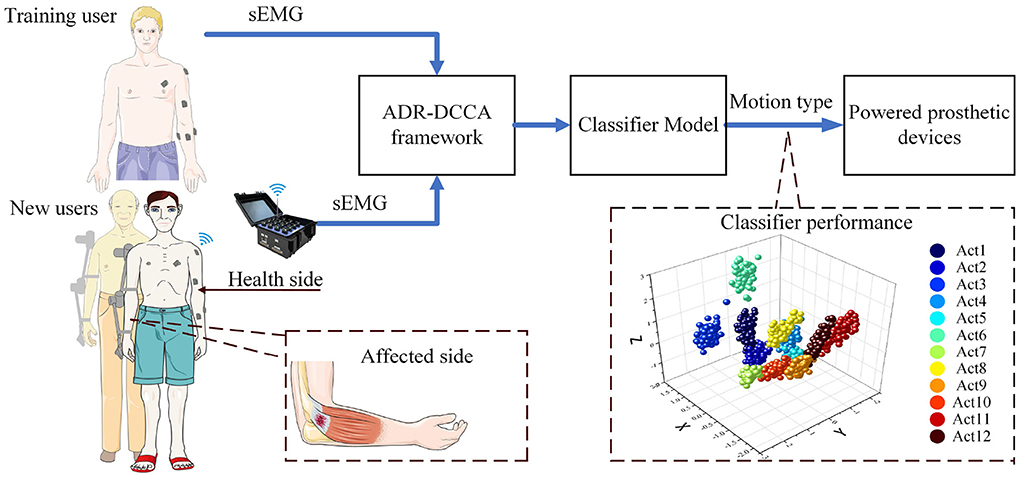
Figure 1. A multi-user health-side-driven rehabilitation system with an ADR-DCCA framework. The sEMG signals are collected from the healthy side arm of a new user and processed accordingly in the ADR-DCCA framework. The recognition is done by an upper limb exoskeleton robot.
The structure of this paper is as follows. Section 2 describes the CCA and DCCA methods and then introduces the multi-user sEMG motion recognition framework. Section 3 describes the experimental data acquisition scheme. Section 4 shows the effectiveness of the proposed multi-user sEMG interface through multiple sets of comparative tests and analyses. Finally, Section 5 concludes the paper and discusses possible extensions and future directions.
CCA technique, which was introduced by Hotelling in 1936 (Hotelling, 1992), is a multivariate statistical method for studying the correlation between two sets of variables. It quantifies the association between two sets of variables and transforms the analysis of the correlation into an analysis between linear combinations of the two sets of variables. CCA has been widely used in the fields of data mining, machine learning, signal processing, biomedical engineering, healthcare data analysis, genetics, etc. However, to our knowledge, researchers have not yet addressed the problem of processing new feature dimensions after projection. Here, we develop an ADR-DCCA framework by combining the values of the fitness functions of SVM.
In our framework, an improved CCA method maps the sEMG features of different individuals into the same low-dimensional space to train a classifier model, which improves the applicability and generalization ability of the model to some extent. Considering the properties of the training user feature matrix and the new user calibration feature matrix, we define two column vectors, and . Here, c is the motion category; n is the number of samples of the same type of motion; p and q are the number of features of a single sample in X and Y, respectively; and X and Y are standardized by column and expressed as
The basic idea of CCA is to find the variables and that maximize the correlation coefficient between the linear combinations Ui = XAi and Vi = YBi, Ai ∈ A, Bi ∈ B, Ui ∈ U, Vi ∈ V(Hardoon et al., 2004; Sun et al., 2005). We choose the pair with the highest correlation coefficient in the linear combinations as the first set of canonical variables, the pair with the second-highest correlation coefficient as the second group of canonical variables, and so on until the correlation between X and Y is extracted (Sun et al., 2010); the correlation coefficient between canonical variables is called the canonical correlation coefficient. The optimization problem for Ui and Vi is given by
To simplify the expression, we let cov(X, Y) = C12, cov(X, X) = C11, cov(Y, Y) = C22, and we add the qualification to limit the occurrence of linear transformations of variables A and B. Then, the optimization function is
Using Lagrange multipliers, we convert the above optimization problem into a conditional extreme-value problem. By solving Equation (4), it is easy to obtain
From Equations (5) and (6), we know that and have the same eigenroots λ2, with A and B as the corresponding eigenvectors. The feature roots are arranged from largest to smallest, and the feature vectors are arranged in order of the corresponding feature roots. The feature vector that corresponds to the largest feature root is transformed m times according to the qualification to obtain the first set of A1, B1.
After that, we keep solving for the second set of canonical variables. Find variables A2 and B2 that maximize the correlation between U2 = XA2 and V2 = YB2 under the qualification . The first pair of canonical variables has been extracted, so the second pair should be extracted without the information in the first pair (orthogonal to the first pair). We add a new qualification, , with which we obtain
It is clear that the results A2, B2 of Equations (7) and (8) are the same A, B as those obtained from Equations (5) and (6). Therefore, the eigenvector corresponding to the next-largest eigenvalue is the one that we seek. Continuing in this way, it is easy to obtain the rth pair of eigenvectors, where r < min(p, q).
DCCA is based on CCA, which finds the largest intra-class correlation while minimizing the correlation across classes. DCCA can effectively improve the robustness of the generated features, thereby improving the performance of the whole system (Gatto and dos Santos, 2017). We define the vector, k ∈ (1, c), and then the intra-class correlation matrix is
We also define the row vector 1n = [1, ⋯ , 1]1 × (c×n); then, the inter-class correlation matrix is
As both the X and Y datasets are column normalized, we have . DCCA can be described as solving
Given the specificity of enk, it is easy to prove that
Therefore, the optimization function can be written as
and using Lagrangian multipliers to tackle Equation (13) gives
Solving this system of equations shows that and have the same characteristic root λ2 and that A and B are the corresponding eigenvectors, which is the same conclusion as that obtained with CCA.
The above derivation leads to the conclusion that DCCA seeks a pair of linear transformations or non-linear changes to maximize the intra-class correlation of two sets of features while ensuring the minimum inter-class correlation. The new features extracted by DCCA in different categories of the same feature set are statistically uncorrelated; thus, redundant information in different categories of features is eliminated. The proposed architecture is able to train classifier models with less data than traditional pattern recognition methods. The training data maintains a somewhat linear or non-linear relationship with the new test data, which helps new rehabilitation users to obtain accurate models faster. To the best of our knowledge, its use in developing an sEMG interface for multi-user is novel. We mapped the DCCA theory into the sEMG signal feature matrix and designed the framework shown in Figure 2, in which DCCA analyzes the training user feature matrix X and the new user calibration feature matrix Y1 (which is used to tune the parameters of the framework). The parameters that give strong correlation between the training user features and the new user features are obtained, which in this case are two independent matrices, namely, A and B. Then, new training features are obtained by A interacting with training user features X.
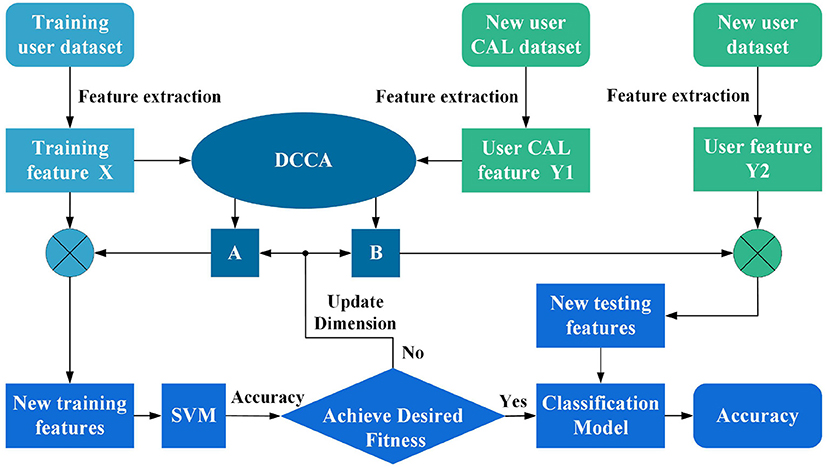
Figure 2. A multi-user surface electromyography (sEMG) motion-recognition framework was designed using discriminative canonical correlation analysis (DCCA) and adaptive dimensionality reduction (ADR).
In this framework, the dimension of A is changed continuously according to the fitness function information provided by the SVM until the best model is found. Specifically, a1 denotes the first column of A, a2 denotes the first two columns of A, and so on; al (1 ≤ l ≤ r) denotes the first l columns of A. Thus, we can easily obtain the matrix Ul of different dimensions under the action of al. By defining the SVM fitness function f(t), the value of the fitness function f(Ul) can be obtained. The ADR problem can be expressed as an optimization problem for the following functions:
Finally, the new testing features are obtained based on the new user feature matrix Y2 and the matrix Bl.
In the experiments described here, a customized Delsys wireless sEMG acquisition device was used for multichannel acquisition of sEMG signals. This device is a distributed contact electrode, which has the advantages of flexible placement and wireless convenience and is not affected by the lack of channels. The sampling rate of each sEMG channel of this device is 2,000 Hz with 16-bit resolution. The sEMG signals were displayed and stored in a PC client using sEMG-recorder software developed in-house, and the data for each action were saved in a separate .csv file.
The experiments involved eight participants (called N1 to N8) who were in good physical condition and had healthy limbs. The participants comprised seven men and one woman between the ages of 23 and 27 years; they participated voluntarily and were informed of the subject matter and signed an informed-consent form prior to participating in the experiments. The sEMG signals were recorded from the subject's right arm. Based on human physiology and upper-limb muscle distribution, we chose the deltoid (channel 1), pectoralis major (channel 2), biceps brachii (channel 3), triceps brachii (channel 4), flexor carpi radialis (channel 5), extensor carpi radialis (channel 6), extensor carpi ulnaris (channel 7), and flexor carpi ulnaris (channel 8). Position tracking was performed to determine the exact positions of the electrodes according to the criteria developed by the SENIAM (Surface ElectroMyoGraphy for the Non-Invasive Assessment of Muscles) European concerted action in the Biomedical Health and Research Program (BIOMED II) of the European Union (Hermens et al., 2000). The accurate muscle positioning is shown in Figure 3. Prior to data acquisition, the subjects' electrode pasting locations were cleared to prevent interference from hair; the skin at the relevant locations was then wiped with alcohol, and the electrodes were disinfected and finally pasted onto the prescribed muscle positions.
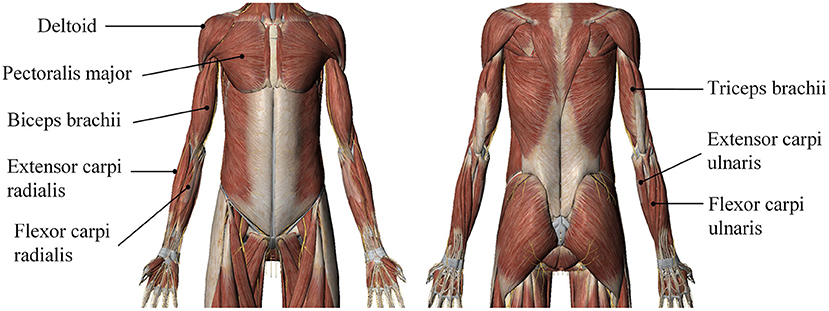
Figure 3. A map of precise locations of muscles for upper-limb movements.
During acquisition, each participant used no more than 80% of their maximum voluntary contraction to maintain control of their movements (Cheng et al., 2018). To ensure that the force used by the subject in performing the motion was within the required range, each subject was evaluated for force using a high-definition haptic device from QUANSER prior to data collection. During the recording process, the subject was asked to perform the following 12 upper-limb motor movements to the best of their ability with moderate constant force contractions: (i) palm extension, (ii) fist clenching, (iii) wrist abduction, (iv) wrist adduction, (v) wrist extension, (vi) wrist flexion, (vii) elbow flexion, (viii) elbow extension, (ix) elbow flexion and shoulder flexion, (x) elbow flexion and shoulder extension, (xi) shoulder horizontal adduction, and (xii) shoulder horizontal abduction (see Figure 4). When the subject heard a beep from the computer, they performed the specified movement, holding the final position for 3 s and then resting for 3 s before the next movement. Each subject completed the 12 movements 100 times, and in total 9,600 sets of experimental data were recorded from the eight participants. Considering that participants might become fatigued during sEMG collection, data were collected for no more than 5 min at a time.
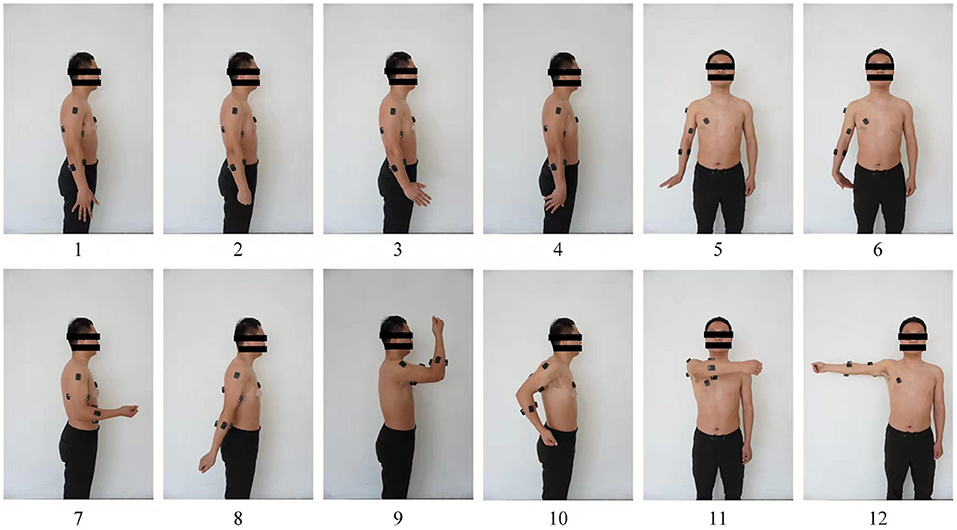
Figure 4. Upper-limb movements defined in present study: 1—palm extension; 2—fist clenching; 3—wrist abduction; 4—wrist adduction; 5—wrist extension; 6—wrist flexion; 7—elbow flexion; 8—elbow extension; 9—elbow flexion and shoulder flexion; 10—elbow flexion and shoulder extension; 11—shoulder horizontal adduction; 12—shoulder horizontal abduction.
In this section, we describe how we evaluated the recognition capability of the proposed ADR-DCCA framework to show its feasibility. The preprocessing, feature extraction, and classification processes were carried out in the sEMG signal-processing pipeline.
In multichannel sEMG studies, preprocessing is necessary, mainly to reduce noise (Brunelli et al., 2015). In sEMG signals, this consists mainly of system noise, artifacts, industrial frequency interference, and channel cross-talk (De Luca et al., 2010). In the experiments, we used the wavelet algorithm, chose the sym5 wavelet function with five decomposition layers, and used henrsure to de-baseline and drift the sEMG signal of each channel. The signal was filtered with a fourth-order Butterworth filter to improve the signal-to-noise ratio and to keep the signal in the range of 20–500 Hz while removing external noise and artifacts.
Feature extraction is an important step in signal processing, as it reduces the amount of data while also extracting useful features into low-dimensional data. As EMG signals are known to suffer from lack of smoothness, windowing was performed on the sEMG signals after pre-processing (Ashraf et al., 2021). The window length was 300 samples with a time period of 150 ms, and the window shift was 50 samples with a time period of 25 ms (Luo et al., 2020b). After adding windows to the sEMG data, features including mean absolute value, root mean square, variance (Ahsan et al., 2011), maximum mean absolute value (MMAV), maximum root mean square (MRMS), maximum variance (MVAR) (MMAV, MRMS, and MVAR are improved features by the authors), fourth-order power spectral density, and power spectrum estimation (Zhang et al., 2011; Khushaba, 2014). The dimensionality of the extracted features was 64 features per motion, i.e., 8 channels × 8 features.
Based on the data gathered as described in Section 3, the experiments reported in this section used a fully separate design method for the training and testing sets. That is, one of the eight users was selected as a new user, and the remaining 7 people's data were treated as training user data. We call the process after selecting the new user a trial. There were eight trials in total. According to the seven training users' data, up to seven recognition rates can be determined for each new user. We calculated the average recognition rate for each trial. The above method was used for both Experiment 1 and Experiment 2. Experiment 1 involved (i) testing the present dataset using the CCA-OT framework proposed by Xue et al. (2021), (ii) testing the present dataset using the CCA framework proposed by Khushaba (2014), (iii) testing the present dataset after adding ADR optimization to the framework of (ii), and (iv) testing the present dataset using the proposed ADR-DCCA method. For Experiment 2, Experiment 1 was repeated but with two channels removed randomly from the user test set.
One of the eight participants was selected as a new user, while the other seven were selected as training users. The tests were performed according to the CCA-OT analysis method described by Xue et al. (2021), and the recognition rates for the eight trials are given in Table 1.
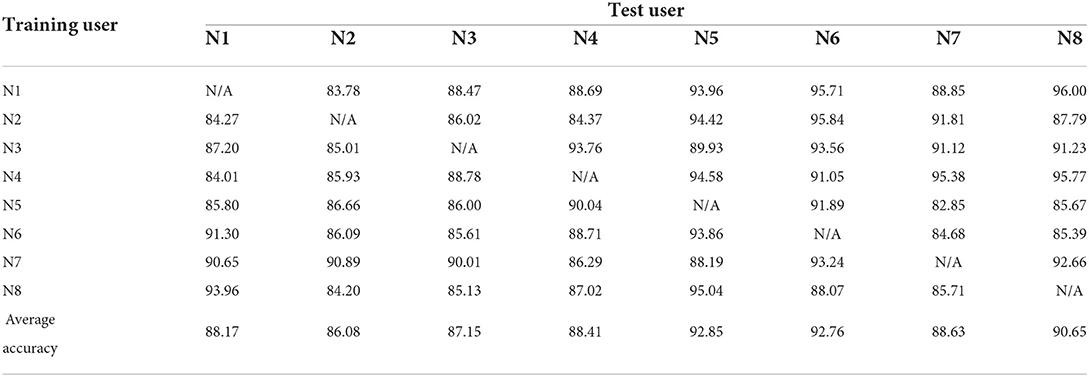
Table 1. Experimental results for user-independent CCA-OT framework.
Testing was carried out according to the CCA method described by Khushaba (2014), which reduces the differences in sEMG signal properties when the same motion is performed by different people. The recognition rates for the eight trials are given in Table 2.
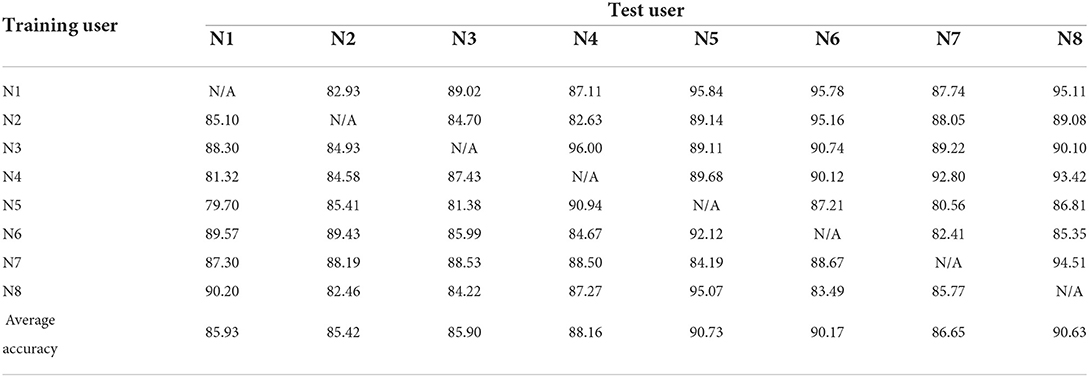
Table 2. Experimental results for user-independent CCA-without-ADR framework.
Following the CCA method described by Khushaba (2014), we performed ADR optimization of the framework. The ADR optimization method chooses the most suitable reconstructed features for user classification. The recognition rates for the eight trials are given in Table 3.
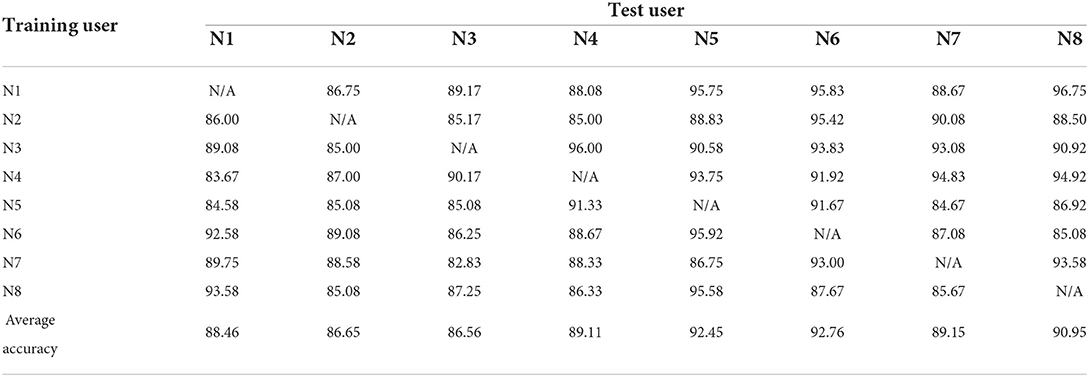
Table 3. Experimental results for user-independent CCA-with-ADR framework.
Using the method proposed herein, data from the training users and new user were fed into the ADR-DCCA framework. The user characteristics were rebuilt into low-dimensional features independent of individual styles via parameter pair optimization, and the user features overcame individual differences. This framework has the advantages of that of Khushaba (2014) while also minimizing the inter-class correlation of different motion features and adaptively selecting new feature dimensions that are most beneficial to the classification performance; this reduces classifier training time and improves classification accuracy. The recognition rates for the eight trials are given in Table 4.
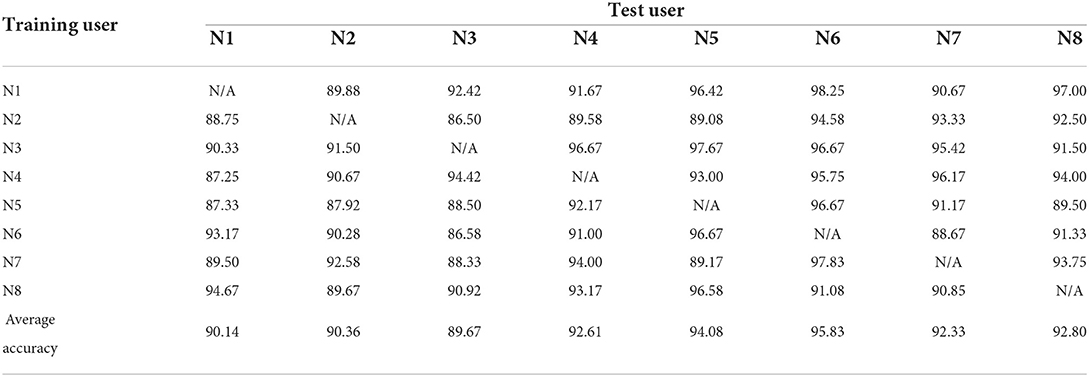
Table 4. Experimental results for user-independent DCCA-with-ADR framework.
In Experiment 1, the dataset used in this study was tested with four methods, respectively. For each method, results were recorded for eight trials denoted N1 to N8. For the different methods, we plotted the mean values of each trial as histograms. In Figure 5, histograms of the same color show the average recognition accuracy for each test user with the same method, and error bars represent the standard deviation of this user's motion recognition rate on different training sets.
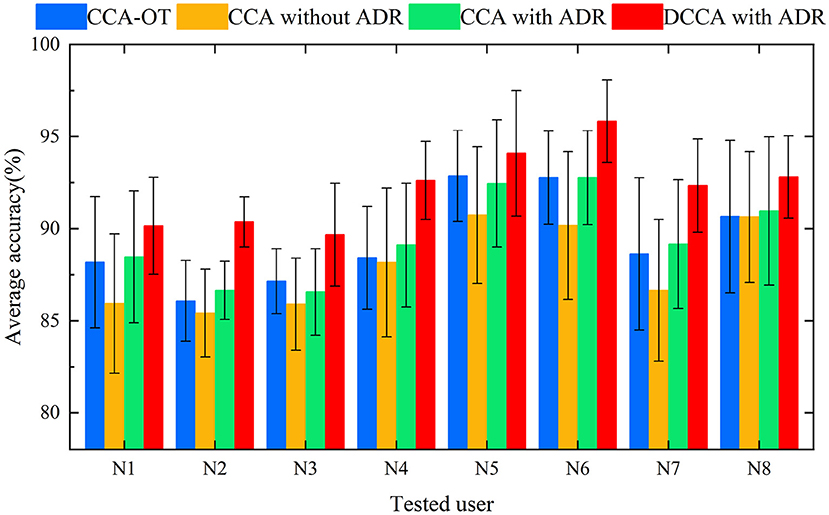
Figure 5. Histogram of average accuracies of 12 campaigns classified by four methods for eight users.
The sEMG data of all test users were reduced randomly by two channels and then tested again as in Experiment 1 to verify the robustness of the method proposed herein. Tables 5–8 record the recognition results of eight trials (N1 to N8) for each method under 4 methods, and the average recognition rate of each trial was calculated. As in Experiment 1, for the different methods we plotted the average result of each test as a histogram. In Figure 6, histograms in the same color show the average recognition accuracy for each test user under the same method, and error bars represent the standard deviation of this user's motion recognition rate on different training sets.
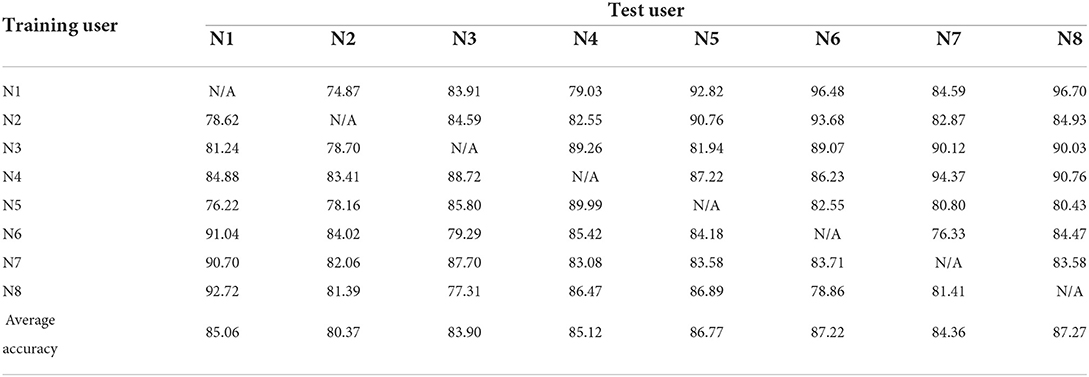
Table 5. Experimental results for user-independent CCA-OT framework (the sEMG data of all test users were reduced randomly by two channels).
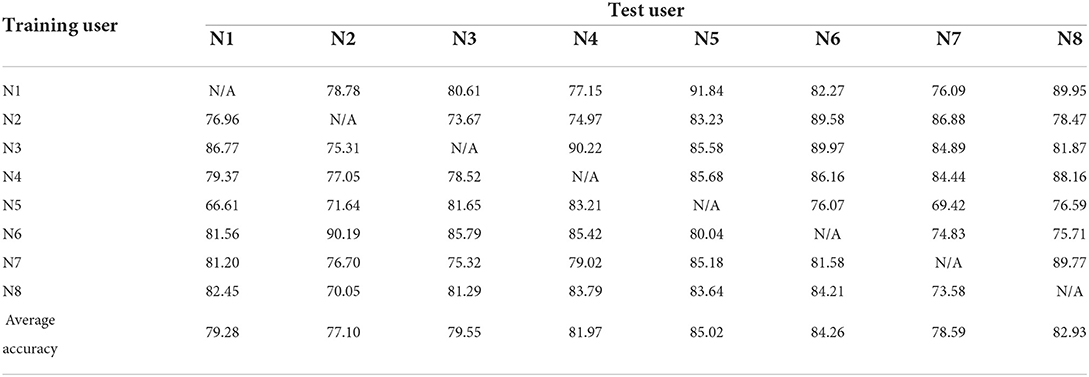
Table 6. Experimental results for user-independent CCA-without-ADR framework (the sEMG data of all test users were reduced randomly by two channels).
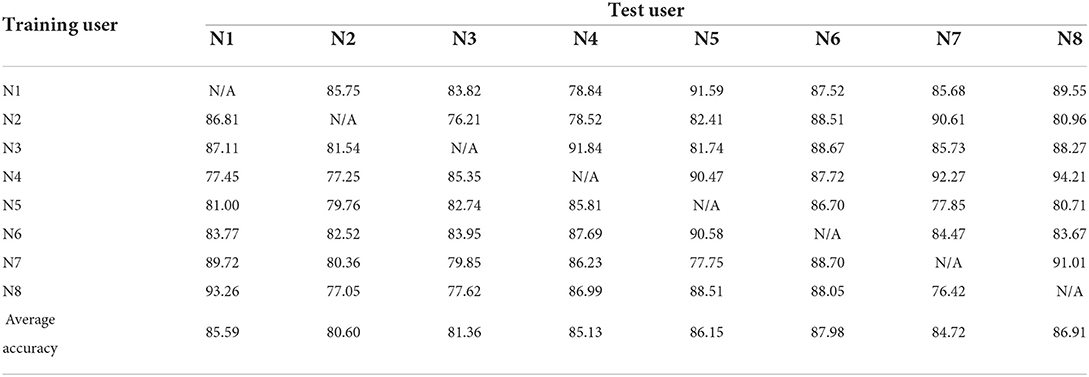
Table 7. Experimental results for user-independent CCA-with-ADR framework (the sEMG data of all test users were reduced randomly by two channels).
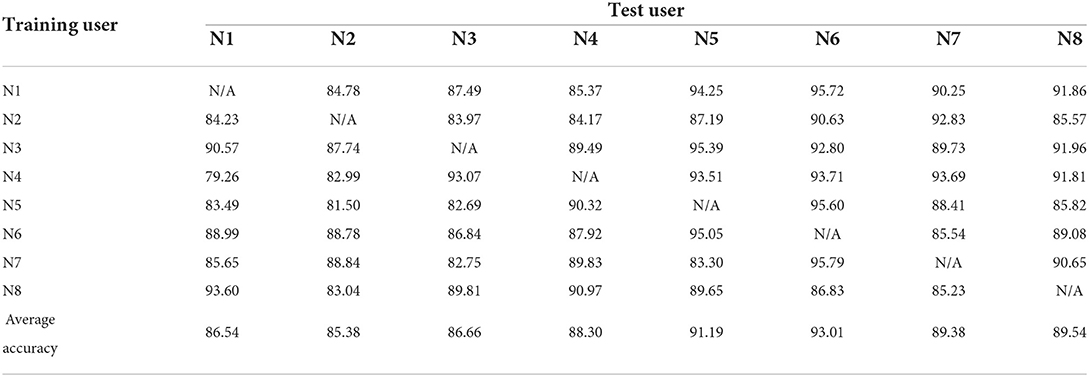
Table 8. Experimental results for user-independent DCCA-with-ADR framework (the sEMG data of all test users were reduced randomly by two channels).
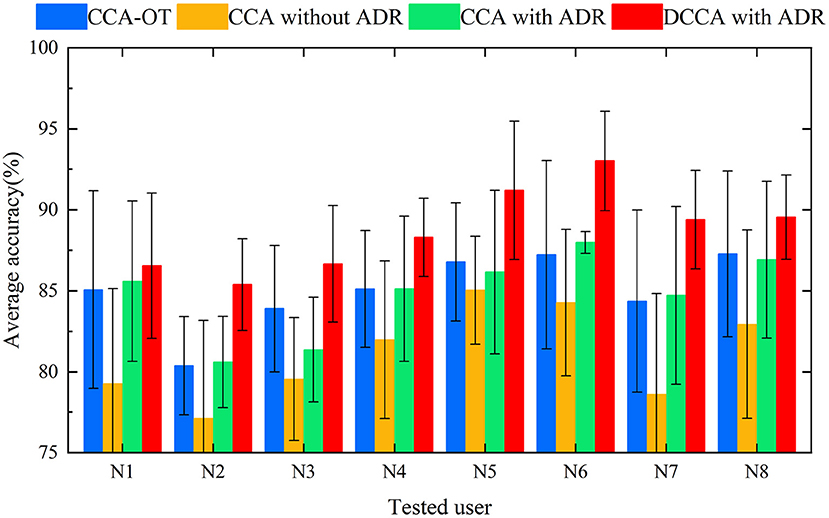
Figure 6. Histogram of average accuracies of 12 campaigns classified by four methods for eight users (randomly reducing the user test set by two channels).
For this subsection, we performed preprocessing and feature extraction and extracted a feature set of 64 features per movement ([6 time-domain features + 2 frequency-domain features] × 8 channels). For the classification, we chose the well-known SVM LIBSVM (Chang and Lin, 2011), as Khushaba (2014) reported that a global SVM performs better in this type of action recognition. In our experimental approach, the training and calibration sets were completely independent, i.e., the training user and the new user were different individuals, and the experimental results were obtained through multiple cross-validations. Khushaba (2014) and Xue et al. (2021) performed CCA (i) between a training feature matrix and an expert feature matrix and (ii) between a test feature matrix and an expert feature matrix. In the present framework, DCCA is used to directly extract the correlation between the training user feature matrix and the new user feature matrix, thereby eliminating the intermediate link. The correlation between the training feature matrix and the test feature matrix is enhanced, and the distribution differences between classes are strengthened. The adaptive dimensionality-reduction method eliminates the redundant information in the high-dimensional features and retains the low-dimensional features that are highly correlated between the new user and the training users. High classification accuracy and good robustness were achieved in classifying 12 categories of upper-limb movements in eight subjects. In Experiment 1, the motion recognition rate of the ADR-DCCA framework proposed in this paper was 92.23; this was 2.89, 4.28, and 2.72 higher than the average recognition rates of the CCA-OT framework, the conventional CCA framework, and the ADR-CCA framework, respectively. In particular, compared with the 26–126 dimensions in the technique described by Khushaba (2014), we used 5–8 dimensions of features that were obtained by fusing 64 dimensions of features, thereby achieving higher accuracy in motion recognition. In Experiment 2, the identification accuracies of the CCA-OT framework, the conventional CCA framework, the ADR-CCA framework, and the ADR-DCCA framework were 85.01, 81.09, 84.81, and 88.75%, respectively. The experimental results show that the framework described herein maintains high classification accuracy even after being deprived of data from two channels, which indicates that the framework is robust. Moreover, the accuracy of motion classification was maintained at 88.75% in the test involving the random removal of two channels, despite the poor performance of the subjects compared with the full-channel subjects. The random channel deletion feature in the proposed framework provides a possible solution for the rehabilitation of muscle-deficient patients and motion recognition of missing channel users.
The training dataset and calibration dataset were passed through the CCA and DCCA algorithms, respectively, to obtain two sets of parameters V. These two sets of V were used to construct each user's test feature matrix. After projection, two new sets of test feature matrices were obtained. The data in the top three columns of the most favorably identified features were plotted as a three-dimensional scatter plot. Figures 7A–D show the post-projection features observed by the CCA method from four directions, and Figures 7E–H show the same for the DCCA method. Compared with the plots for the CCA method, those for the DCCA method have more cohesive color blocks more cohesive and show lower intra-class variance while maintaining good inter-class separability, which is beneficial to classification performance. The results of the three-dimensional scatter plots also verify our hypothesis on the performance of DCCA.
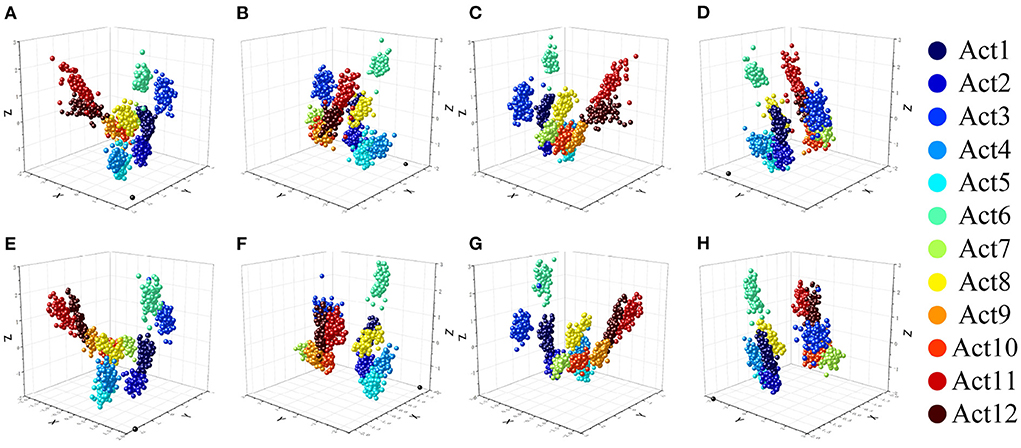
Figure 7. Three-dimensional scatter plots of three new features reconstructed using the CCA framework (A–D) and DCCA framework (E–H). The 12 different-colored balls represent the different motions of the new user (the black ball at the bottom is the coordinate rotation mark).
We also analyzed how the number of samples in the calibration process affects the classification accuracy, as well as the direct relationship among the number of samples and the new feature dimension. In this case, we tested the performance of the ADR-CCA and ADR-DCCA frameworks by selecting a certain number of samples from the calibration dataset. As shown in Figure 8, the accuracy of the classification significantly improved and the dimensionality of the features effectively decreased as the size of the calibration dataset increased. In addition, we performed experiments in which the classifier was trained directly with calibration data, where both calibration and test data were obtained from the same human body. Figure 8 shows the recognition results obtained when training the classifier with the calibration data in these experiments. Directly training the classifier with the calibration data using 3–4 sets of calibration data clearly resulted in better performance compared with the CCA method. Unfortunately, the classification performance of all three methods did not meet the application requirements. However, the proposed method ADR-DCCA method had the highest classification accuracy at 5–10 sets of calibration data. Smaller calibration datasets were chosen because this study was intended to target specific groups such as rehabilitation patients. Here, 3–10 sets of corrected data were selected for testing, and a good classification effect could be achieved with eight sets. The experimental results indicate that the ADR-DCCA framework has advantages over other CCA extension frameworks for multi-user sEMG interfaces.
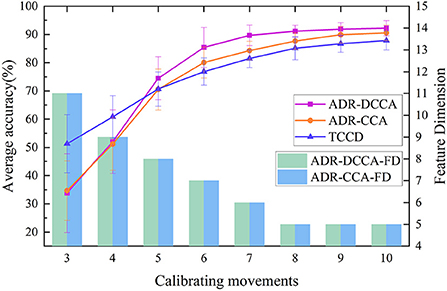
Figure 8. Relationships between sample size and classification accuracy and between sample size and new feature dimensions. ADR-DCCA and ADR-CCA denote the classification accuracy of the ADR-DCCA architecture and ADR-CCA with different numbers of calibration sets, respectively. ADR-DCCA-FD and ADR-CCA-FD are the corresponding feature dimensions under classification accuracy. TCCD indicates the classification accuracy when training the classifier model directly with the calibration dataset.
In order to solve the problem of stroke patients or patients with limb muscle injuries being unable to quickly obtain a suitable contralateral model for rehabilitation training, a suitable multi-user sEMG motion-recognition framework is presented here. First, the training dataset and the new user calibration dataset are projected into the same style space. New features for training users and new users are recreated based on the parameters obtained after the projection. Second, the dimensionality of the new features is optimized iteratively using an adaptive dimensionality-reduction optimization method to obtain the dimensionality of the system features that are most suitable for motion recognition. Finally, a model is constructed that is suitable for new users and shows good classification performance in user test set classification. The experimental results indicate that the DCCA algorithm is effective at extracting the relevant information between the new user test set and the training user feature set, and that the ADR method effectively reduces the redundant information between the two datasets. These are both important factors in the improvement in motion recognition performance obtained with the framework. This framework also better addresses the problem of large differences in muscle-generated sEMG signals when different people perform the same movement and enables new users to engage in contralateral-driven rehabilitation patterns more quickly. The accuracy of motion classification was maintained at 88.75% in the test involving the random removal of two channels, despite the poor performance of the subjects compared with the full-channel subjects. The random channel deletion feature in the proposed framework provides a possible solution for the rehabilitation of muscle-deficient patients and motion recognition of missing channel users. Finally, we tested the proposed method in the rehabilitation laboratory, and the accuracy of action recognition reached 90.52%. In conclusion, our proposed ADR-DCCA method has important potential applications in the field of rehabilitation.
Although this work implemented sEMG-based action recognition for rehabilitation movements of upper limb exoskeleton robots and glove robots, the experiments only considered human variation and channel loss in sEMG action recognition. In fact, there are many sources of uncertainty in sEMG action recognition, including fatigue differences and electromagnetic interference. In addition, the sEMG-based information is limited. In future work, we will continue to improve the proposed framework and integrate EEG signals and acceleration-sensing information to enable it to cope with more non-ideal situations, thereby improving the comprehensive performance of action recognition.
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
The studies involving human participants were reviewed and approved by Qufu Normal University Biomedical Ethics Committee. The patients/participants provided their written informed consent to participate in this study. The animal study was reviewed and approved by Qufu Normal University Biomedical Ethics Committee. Written informed consent was obtained from the individual(s) for the publication of any potentially identifiable images or data included in this article.
JW conceived the study, designed and conducted the experiments, performed the data analysis, and drafted and revised the manuscript. DC and YW provided guidance on the algorithms in the study and analyzed the experimental results. All authors contributed to manuscript revision and read and approved the submitted version.
This work was partially supported by the National Natural Science Foundation of China (Grant 62073187), the Major Scientific and Technological Innovation Project in Shandong Province (Grant 2019JZZY011111), and the Natural Science Foundation of Shandong Province (Grant ZR2022MF236).
The authors thank YW and DC for their help and support, and the College of Engineering of Qufu Normal University for providing the experimental platform.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Ahsan, M. R., Ibrahimy, M. I., and Khalifa, O. O. (2011). “Electromygraphy (EMG) signal based hand gesture recognition using artificial neural network (ANN),” in 2011 4th International Conference on Mechatronics (ICOM) (Kuala Lumpur), 1–6. doi: 10.1109/ICOM.2011.5937135
Ashraf, H., Waris, A., Gilani, S. O., Kashif, A. S., Jamil, M., Jochumsen, M., et al. (2021). Evaluation of windowing techniques for intramuscular EMG-based diagnostic, rehabilitative and assistive devices. J. Neural Eng. 18, 016017. doi: 10.1088/1741-2552/abcc7f
Bi, L., Feleke, A. G., and Guan, C. (2019). A review on EMG-based motor intention prediction of continuous human upper limb motion for human-robot collaboration. Biomed. Signal Process. Control 51, 113–127. doi: 10.1016/j.bspc.2019.02.011
Brunelli, D., Tadesse, A. M., Vodermayer, B., Nowak, M., and Castellini, C. (2015). “Low-cost wearable multichannel surface EMG acquisition for prosthetic hand control,” in 2015 6th International Workshop on Advances in Sensors and Interfaces (IWASI) (Gallipoli: IEEE), 94–99. doi: 10.1109/IWASI.2015.7184964
Chang, C.-C., and Lin, C.-J. (2011). LIBSVM: a library for support vector machines. ACM Trans. Intell. Syst. Technol. 2, 1–27. doi: 10.1145/1961189.1961199
Cheng, J., Wei, F., Li, C., Liu, Y., Liu, A., and Chen, X. (2018). Position-independent gesture recognition using sEMG signals via canonical correlation analysis. Comput. Biol. Med. 103, 44–54. doi: 10.1016/j.compbiomed.2018.08.020
De Luca, C. J., Donald Gilmore, L., Kuznetsov, M., and Roy, S. H. (2010). Filtering the surface EMG signal: movement artifact and baseline noise contamination. J. Biomech. 43, 1573–1579. doi: 10.1016/j.jbiomech.2010.01.027
Disselhorst-Klug, C., Schmitz-Rode, T., and Rau, G. (2009). Surface electromyography and muscle force: limits in sEMG–force relationship and new approaches for applications. Clin. Biomech. 24, 225–235. doi: 10.1016/j.clinbiomech.2008.08.003
Elamvazuthi, I., Zulkifli, Z., Ali, Z., Khan, M. A., Parasuraman, S., Balaji, M., et al. (2015). Development of electromyography signal signature for forearm muscle. Proc. Comput. Sci. 76, 229–234. doi: 10.1016/j.procs.2015.12.347
Fang, C., He, B., Wang, Y., Cao, J., and Gao, S. (2020). EMG-centered multisensory based technologies for pattern recognition in rehabilitation: state of the art and challenges. Biosensors 10, 85. doi: 10.3390/bios10080085
Gatto, B. B., and dos Santos, E. M. (2017). “Discriminative canonical correlation analysis network for image classification,” in 2017 IEEE International Conference on Image Processing (ICIP) (Beijing), 4487–4491. doi: 10.1109/ICIP.2017.8297131
Ghassemi, M., Triandafilou, K., Barry, A., Stoykov, M. E., Roth, E., Mussa-Ivaldi, F. A., et al. (2019). Development of an EMG-controlled serious game for rehabilitation. IEEE Trans. Neural Syst. Rehabil. Eng. 27, 283–292. doi: 10.1109/TNSRE.2019.2894102
Hardoon, D. R., Szedmak, S., and Shawe-Taylor, J. (2004). Canonical correlation analysis: an overview with application to learning methods. Neural Comput. 16, 2639–2664. doi: 10.1162/0899766042321814
Hermens, H. J., Freriks, B., Disselhorst-Klug, C., and Rau, G. (2000). Development of recommendations for SEMG sensors and sensor placement procedures. J. Electromyogr. Kinesiol. 10, 361–374. doi: 10.1016/S1050-6411(00)00027-4
Hotelling, H. (1992). Relations Between Two Sets of Variates. New York, NY: Springer. doi: 10.1007/978-1-4612-4380-9_14
Jarque-Bou, N. J., Sancho-Bru, J. L., and Vergara, M. (2021). A systematic review of EMG applications for the characterization of forearm and hand muscle activity during activities of daily living: results, challenges, and open issues. Sensors 21, 3035. doi: 10.3390/s21093035
Khushaba, R. N. (2014). Correlation analysis of electromyogram signals for multiuser myoelectric interfaces. IEEE Trans. Neural Syst. Rehabil. Eng. 22, 745–755. doi: 10.1109/TNSRE.2014.2304470
Li, K., Zhang, J., Wang, L., Zhang, M., Li, J., and Bao, S. (2020). A review of the key technologies for sEMG-based human-robot interaction systems. Biomed. Signal Process. Control 62, 102074. doi: 10.1016/j.bspc.2020.102074
Lobov, S., Krilova, N., Kastalskiy, I., Kazantsev, V., and Makarov, V. A. (2018). Latent factors limiting the performance of sEMG-interfaces. Sensors 18, 1122. doi: 10.3390/s18041122
Luo, J., Huang, D., Li, Y., and Yang, C. (2021). Trajectory online adaption based on human motion prediction for teleoperation. IEEE Trans. Autom. Sci. Eng. 1–5. doi: 10.1109/TASE.2021.3111678
Luo, J., Lin, Z., Li, Y., and Yang, C. (2020a). A teleoperation framework for mobile robots based on shared control. IEEE Robot. Autom. Lett. 5, 377–384. doi: 10.1109/LRA.2019.2959442
Luo, J., Liu, C., Feng, Y., and Yang, C. (2020b). A method of motion recognition based on electromyographic signals. Adv. Robot. 34, 976–984. doi: 10.1080/01691864.2020.1750480
Matsubara, T., and Morimoto, J. (2013). Bilinear modeling of EMG signals to extract user-independent features for multiuser myoelectric interface. IEEE Trans. Biomed. Eng. 60, 2205–2213. doi: 10.1109/TBME.2013.2250502
Medved, V., Medved, S., and Kova, I. (2020). Critical appraisal of surface electromyography (sEMG) as a taught subject and clinical tool in medicine and kinesiology. Front. Neurol. 11, 560363. doi: 10.3389/fneur.2020.560363
Pan, L., Crouch, D. L., and Huang, H. (2018). Myoelectric control based on a generic musculoskeletal model: Toward a multi-user neural-machine interface. IEEE Trans. Neural Syst. Rehabil. Eng. 26, 1435–1442. doi: 10.1109/TNSRE.2018.2838448
Qi, W., and Aliverti, A. (2020). A multimodal wearable system for continuous and real-time breathing pattern monitoring during daily activity. IEEE J. Biomed. Health Inform. 24, 2199–2207. doi: 10.1109/JBHI.2019.2963048
Qi, W., Ovur, S. E., Li, Z., Marzullo, A., and Song, R. (2021). Multi-sensor guided hand gesture recognition for a teleoperated robot using a recurrent neural network. IEEE Robot. Autom. Lett. 6, 6039–6045. doi: 10.1109/LRA.2021.3089999
Samuel, O. W., Asogbon, M. G., Geng, Y., Al-Timemy, A. H., Pirbhulal, S., Ji, N., et al. (2019). Intelligent emg pattern recognition control method for upper-limb multifunctional prostheses: advances, current challenges, and future prospects. IEEE Access 7, 10150–10165. doi: 10.1109/ACCESS.2019.2891350
Simao, M., Mendes, N., Gibaru, O., and Neto, P. (2019). A review on electromyography decoding and pattern recognition for human-machine interaction. IEEE Access 7, 39564–39582. doi: 10.1109/ACCESS.2019.2906584
Su, H., Hu, Y., Karimi, H. R., Knoll, A., Ferrigno, G., and De Momi, E. (2020). Improved recurrent neural network-based manipulator control with remote center of motion constraints: experimental results. Neural Netw. 131, 291–299. doi: 10.1016/j.neunet.2020.07.033
Su, H., Qi, W., Schmirander, Y., Ovur, S. E., Cai, S., and Xiong, X. (2022). A human activity-aware shared control solution for medical human–robot interaction. Assem. Autom. 42, 388–394. doi: 10.1108/AA-12-2021-0174
Sun, L., Ji, S., and Ye, J. (2010). Canonical correlation analysis for multilabel classification: a least-squares formulation, extensions, and analysis. IEEE Trans. Pattern Anal. Mach. Intell. 33, 194–200. doi: 10.1109/TPAMI.2010.160
Sun, Q.-S., Zeng, S.-G., Liu, Y., Heng, P.-A., and Xia, D.-S. (2005). A new method of feature fusion and its application in image recognition. Pattern Recogn. 38, 2437–2448. doi: 10.1016/j.patcog.2004.12.013
Vigotsky, A. D., Halperin, I., Lehman, G. J., Trajano, G. S., and Vieira, T. M. (2018). Interpreting signal amplitudes in surface electromyography studies in sport and rehabilitation sciences. Front. Physiol. 8, 985. doi: 10.3389/fphys.2017.00985
Xue, B., Wu, L., Wang, K., Zhang, X., Cheng, J., Chen, X., et al. (2021). Multiuser gesture recognition using sEMG signals via canonical correlation analysis and optimal transport. Comput. Biol. Med. 130, 104188. doi: 10.1016/j.compbiomed.2020.104188
Keywords: surface electromyography, discriminative canonical correlation analysis, adaptive dimensionality reduction, multi-user, motion recognition
Citation: Wang J, Cao D, Li Y, Wang J and Wu Y (2022) Multi-user motion recognition using sEMG via discriminative canonical correlation analysis and adaptive dimensionality reduction. Front. Neurorobot. 16:997134. doi: 10.3389/fnbot.2022.997134
Received: 18 July 2022; Accepted: 06 October 2022;
Published: 28 October 2022.
Edited by:
Ganesh R. Naik, Flinders University, AustraliaReviewed by:
Hang Su, Fondazione Politecnico di Milano, ItalyCopyright © 2022 Wang, Cao, Li, Wang and Wu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Dianguo Cao, Y2FvZGdAcWZudS5lZHUuY24=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.