 Zefeng Liang1†
Zefeng Liang1† Huan Wang
Huan Wang Kaixiang Yang
Kaixiang Yang- 1School of Computer Science and Engineering, South China University of Technology, Guangzhou, China
- 2Guangdong Institute of Scientific and Technical Information, Guangzhou, China
- 3State Key Laboratory of Industrial Control Technology, Zhejiang University, Hangzhou, China
- 4College of Engineering, Huaqiao University, Quanzhou, China
The imbalance problem is widespread in real-world applications. When training a classifier on the imbalance datasets, the classifier is hard to learn an appropriate decision boundary, which causes unsatisfying classification performance. To deal with the imbalance problem, various ensemble algorithms are proposed. However, conventional ensemble algorithms do not consider exploring an effective feature space to further improve the performance. In addition, they treat the base classifiers equally and ignore the different contributions of each base classifier to the ensemble result. In order to address these problems, we propose a novel ensemble algorithm that combines effective data transformation and an adaptive weighted voting scheme. First, we utilize modified metric learning to obtain an effective feature space based on imbalanced data. Next, the base classifiers are assigned different weights adaptively. The experiments on multiple imbalanced datasets, including images and biomedical datasets verify the superiority of our proposed ensemble algorithm.
1. Introduction
Many applications face imbalance problems (Farrand et al., 2020; Khushi et al., 2021; Zhang et al., 2021). The imbalance problem is caused by the difference in the number of samples in each class. When the classifiers are trained on imbalanced datasets, the classifiers tend to favor the majority class and predict more samples to be the majority class. Therefore, the minority class samples can not be correctly classified, which is called the imbalance problem. The imbalance problem is widespread in the applications, so more and more researchers focus on dealing with the imbalance problem.
To solve the imbalance problem, researchers have proposed various methods from different perspectives. Cost-sensitive method (Elkan, 2001) is a typical one. The cost-sensitive method assigns different classification losses to each class. The minority class has a higher classification loss than the majority class, such that the classifiers pay more attention to the minority class and get a correct result. Resampling is another typical method. Resampling methods remove or synthesize samples from the original data to balance the number of samples in each class, including undersampling, oversampling, and hybrid sampling. Undersampling (He and Garcia, 2009) method removes the majority class samples by some informed rules. Undersampling can produce a more clear decision boundary while the information of the excluded samples is lost.
On the other hand, the oversampling method proposes to generate the synthesis of minority class samples until the data is balanced. The synthesis samples may lie in the overlapped area and make the distribution worsen. To overcome the disadvantages, the hybrid sampling is investigated. As a two-stage strategy, hybrid sampling method combines undersampling and oversampling (I., 1976; Han et al., 2005). Other researchers combine the clustering method with oversampling (Barua et al., 2011).
Ensemble learning is widely used in solving the imbalance problem. Ensemble learning trains different classifiers and gets the result by integrated voting, which contains boosting and bagging (Ho, 1998; Skurichina and Duin, 2002; Chawla et al., 2003; Wang and Yao, 2009; Chen et al., 2010). Ensemble learning plays an essential role in the imbalance classification tasks (Bi and Zhang, 2018).
Nevertheless, the traditional imbalance algorithms have the following problems. Most algorithms do not consider mapping the imbalance data to another feature space for better classification performance. In addition, the importance of base classifiers is different, so it is inappropriate to treat the voting weight of base classifiers equally.
Metric learning is a hot topic in machine learning, which has been utilized in practical applications (Cao et al., 2019; Bai et al., 2021). Metric learning learns a feature space that is more effective than the original space. Euclidean distance is a common measure. However, Euclidean distance can not reflect the relationship correctly in the overlapped area. Consequently, some researchers capture the distance between samples by finding a transformation that can increase the distance between dissimilar samples and reduce the distance of similar samples (Köstinger et al., 2012). When training on the imbalance datasets, metric learning also suffers from imbalance problems (Gautheron et al., 2019). It needs to be modified before training on the imbalance datasets.
In this article, we propose an ensemble learning framework that combines metric learning and resampling. The metric learning is employed by building a feature space from the imbalanced dataset. The classifier is trained on the balanced datasets after oversampling on the feature space to reduce the impact of imbalance. Finally, the classifier is integrated by adaptive weighted voting.
The contributions of the article are as follows:
1) An imbalanced version of the large margin nearest neighbor (LMNN) algorithm is proposed to alleviate the influence of imbalanced data distribution and learn a robust feature space.
2) An GA-based weighting scheme is designed to adaptively optimize the importance of different classifiers.
3) Extensive experiments are conducted on various imbalanced datasets to verify the effectiveness of the proposed approach.
The main framework is as follows: Section 2 introduces the related work about resampling, ensemble learning, and metric learning; Section 3 discusses the proposed ensemble framework in detail; Section 4 shows the experiments about our proposed methods and discusses the result of the experiments. Section 5 draws the conclusion and future study.
2. Related Work
The resampling method contains undersampling and oversampling. To get a balanced dataset, undersampling methods remove the majority of samples randomly or by informed rules. Tomek link (Batista et al., 2004) removes samples that are of a different class from the neighbor. Undersampling can reduce the imbalance problem, while it may suffer from information loss. When the number of samples in each class is quite different, most of the majority of class samples are removed. Hence, the information of the majority of class is lost severely. On the other hand, oversampling proposes to generate synthesis minority class samples to balance the dataset. SMOTE (Chawla et al., 2002) propose to generate samples by interpolating between a given sample and its neighbors. The synthesis sample is generated as follows:
In which xn is the neighbor of sample xi and r is a random value between [0, 1]. Adaptive Synthetic sampling approach (ADASYN) (He et al., 2008) makes different samples generate different numbers of synthetic samples. Some methods combine oversampling with clustering to overcome the problem that synthesized samples are located in the overlapped area. Majority Weighted Minority Oversampling Technique (MWMOTE) (Barua et al., 2014) generates minority samples within the cluster. Additionally, geometric-SMOTE (Douzas and Bacao, 2019) proposes a universal method that can be used in most oversampling methods. Mahalanobis Distance-based Over-sampling technique (MDO) (Abdi and Hashemi, 2016) and its variant (Yang et al., 2018) propose to generate samples in the principal component space.
Euclidean distance is a traditional measure to reflect the similarity between samples. However, dissimilar samples may be closer to the similar samples in the overlapped area, which is inefficient to apply Euclidean distance. Metric learning learns a feature space that can reflect the relationship between samples more correctly. In the feature space, similar samples are closer while dissimilar samples are separated apart. To achieve this goal, many metric learning algorithms have been proposed. LMNN (Weinberger and Saul, 2009) minimizes the distance between the anchor sample and its neighbors of the same class. At the same time, the anchor sample maintains a margin with neighbors of a different class. Information-theoretic metric learning (ITML) (Davis et al., 2007) makes distribution on the feature space similar to the Gaussian distribution. Some methods utilize metric learning on imbalanced datasets. Imbalance metric learning (IML) (Gautheron et al., 2019) modified LMNN by assigning different weights to sample pairs. Distance Metric by Balancing KL-divergence (DMBK) (Feng et al., 2019) balances the divergence of each class on the feature space. Iterative metric learning (Wang et al., 2018) learns a feature space for the area near each testing data.
Ensemble learning integrates classifiers to improve the robustness and performance of classification results. EasyEnsemble (Liu et al., 2009) trains several classifiers on the subset, which contains part of majority class samples and whole minority class samples. BalanceCascade (Liu et al., 2009) splits the majority class samples as several subsets and trains AdaBoost classifiers based on the subsets. Yang et al. (2021) proposes an ensemble framework based on subspace feature space ensemble and metric learning.
3. Proposed Methodology
In this section, we propose an ensemble framework combining metric learning with oversampling. Figure 1 shows the overall framework of our proposed algorithm. First, the metric learning methods based on the imbalance problem(denoted as ImLMNN) are applied for getting a better feature space L. The data X is transformed by mapping matrix L and gets the mapped data X*. Then, the feature space Si is constructed. Next, the oversampling method is employed for getting a balance training dataset . Finally, different classifiers are applied in balance datasets and voting for the result. The pseudo-code is shown in the Algorithm 1.
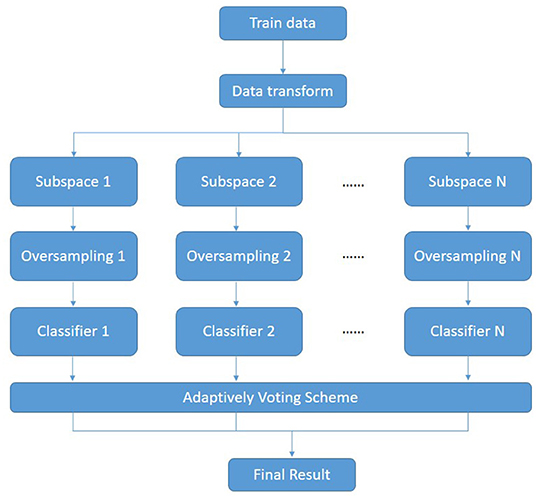
Figure 1. The overall framework of ensemble algorithm.

Algorithm 1. Imbalance Ensemble Framework.
We aim at finding a feature space that can better describe the sample relationship to improve the performance of classifiers. LMNN transforms data to a latent feature space, in which similar samples are closer while dissimilar samples are separated apart. The loss function of LMNN is as follows:
where
The loss function of LMNN contains fpush(L) and fpull(L). fpull(L) reduces the distance between the anchor and its similar neighbors, while fpush(L) penalizes the distance between dissimilar samples. [z]+ = max(z, 0) is the hinge loss. yil = 1 when xi and xl belong to the same class, otherwise yil = 0.
However, the LMNN algorithm is inappropriate directly to apply in imbalanced datasets. To solve this problem, we assign different weights to samples. The weight wi of sample xi is as follows:
The loss of samples is divided by the number of samples Nc in the corresponding class, such that the impact caused by the imbalance problem is alleviated. To emphasize the samples near decision boundaries, we compute the sum of the density of majority class and minority class as density δi. The density δi is defined as follows:
and describe the aggregation of samples in neighboring areas about majority class and minority class. k and h are the number of neighbor samples in calculating and , respectively. When the density is large, the samples in class c are close to xi. Therefore, a large sum of density δi reflects that sample xi is close to samples of both majority and minority classes or in the inner of class with high density.
Outliers and noises are also in the border area. To alleviate the influence of outliers and noises, we divide sample weight by which is the distance between sample xi and the center of class c. The center of class c is defined as:
Therefore, the overall objective function of the data transformation algorithm is:
The diagram of data transformation is shown in Figure 2. Similar to LMNN, Equation (9) contains fpull which pulls similar samples closer and fpush which push dissimilar samples separate apart. In addition, each sample has a different weight to deal with the imbalance problem.
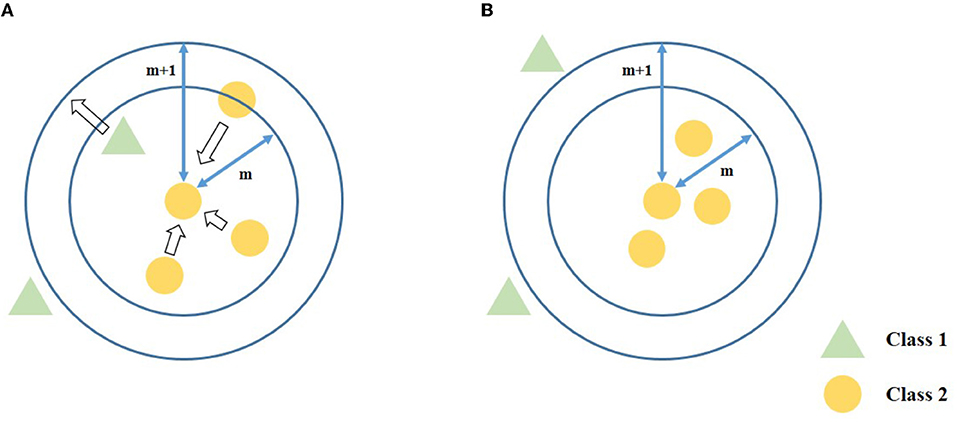
Figure 2. The diagram of proposed data transformation. After the data transformation, the similar neighbors are closer, while the dissimilar neighbor samples are pushed and hold a certain distance to the anchor sample. (A) Before data transformation. (B) After data transformation.
After the data transformation, we extract M features to build the subspace Si:
The feature is extracted N times to generate N subspace. In the subspace, the dataset is still imbalanced, which affects the classifier's performance. To solve this problem, oversampling is utilized in each feature subspace. Specifically, the subset is . The Syni is the synthesis minority data that is generated by SMOTE on feature subspace Si and helps to form a new balanced subset with the original subspace.
The classifier ci is trained on the balance subset and votes for obtaining the result. However, the performance of each classifier is different. The contribution of each classifier in voting should be determined by the classification result, rather than being treated equally. Therefore, we utilize the weight assign process to progressively vote. In detail, the GA algorithm is applied to obtain the weight of each classifier adaptively. The detailed description is shown as Algorithm 2.

Algorithm 2. Adaptive weight Procedure.
First, the initial genes G = (g1, g2, …gn) is generated as the weight of the classifier, in which n is the number of subspace and gi is the weight of classifier i. Next, the GA algorithm finds the n individual and does crossover and mutation. Given two parent genes and with length S, the crossover method exchanges part of features in genes. Suppose the exchange occurs at position α (α ∈ [1, S]), then the genes after the exchange are:
The mutation may occur in each position of genes. Suppose the mutation happens in position γ (γ ∈ [1, S]) of gene gk, then we have:
in which is a random value. After crossover and mutation, the child's genes are generated. We calculate the fitness of parent genes Fparentl (l ∈ [1, n]) and child genes Fchildh (h ∈ [1, nchild]). The fitness is set as AUC value. Finally, the parent genes are replaced by child genes with higher fitness values. When the iteration is over, the optimal classifier weight is obtained.
We can get the final result by weighted voting integration. The result of classifier ci is denoted as yi. Then, the final result is
4. Experiment
In this section, we show the experiments about the proposed ensemble framework and compare the algorithm on various datasets from UCI (Dua and Graff, 2017) and KEEL (Alcala-Fdez et al., 2010). Our algorithm is also applied in the Fashion-mnist image dataset. Finally, we analyze the effect of parameters on our proposed algorithm.
4.1. Datasets
To evaluate the performance of our algorithm, we choose eight datasets from UCI and KEEL with different attributes, such as imbalance ratio (IR), number of samples, and features. The attributes are shown in Table 1 in detail.
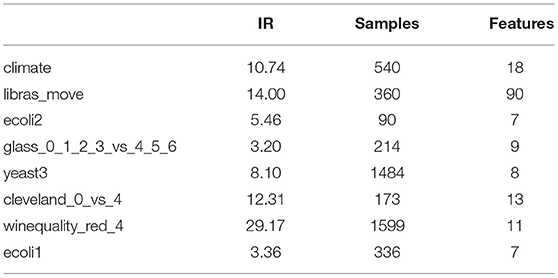
Table 1. The attributes of datasets.
4.2. Evaluation Criteria
Accuracy is the typical criterion to evaluate the performance of the algorithm. However, due to the imbalance problem, accuracy is inappropriate for imbalance learning. AUC (Fawcett, 2004) is the area under the receiver operating characteristic curve, which is not sensitive to the imbalance data, and it is widely used in imbalance learning. In the experiments, we use AUC as evaluation criteria.
4.3. Comparison With Other Algorithms
To show the superiority, several algorithms and imbalance ensemble frameworks are compared with our algorithm. Specifically, we choose RandomForest, RUSboost, and BalanceBagging as the baseline. In addition, SMOTE algorithm is also chosen. The baseline algorithms are shown as follows:
1. SMOTE: A typical oversampling method. It generates samples by interpolating between samples and their neighbors.
2. RandomForest: An ensemble framework that uses bagging to build subsets for tree classifiers. The number of trees we set is 15.
3. RUSboost: A hybrid method that combines sampling with boosting. The number of iterations is 15.
4. BalanceBagging: A variant of Bagging that is applied sampling in each bootstrap. The number of subspaces we set is 15.
For our proposed algorithm, the number of subspaces is 15, and the ratio of extracted features is 0.7. To show the ablation experiment, we compare the LMNN ensemble, which replaces our proposed data transformation algorithm ImLMNN with the original LMNN algorithm. We choose linear SVM as the base classifier. The algorithms run five times and calculate average AUC as evaluation criteria. The 5-fold cross-validation is also applied. The result of the experiment is shown in Table 2.
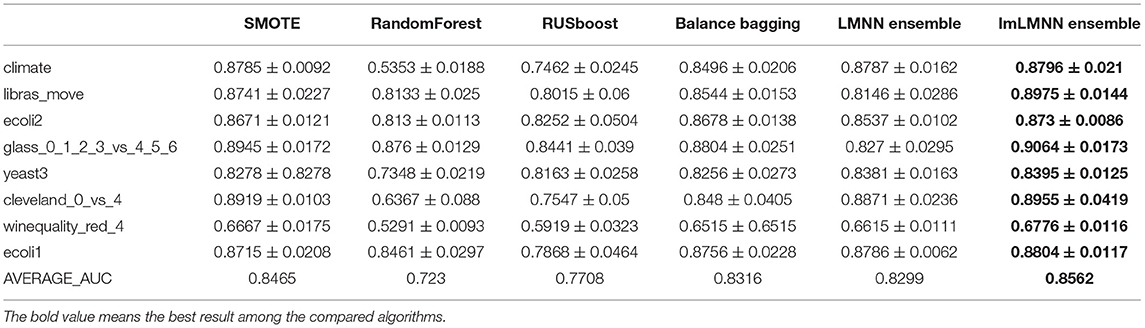
Table 2. Comparisons between imbalance learning algorithm and our proposed method in terms of AUC.
From Table 2, we can see that our algorithm has the highest average AUC on given datasets, which is superior to other compared algorithms. Compared with other algorithms, the proposed algorithm has at least a 1% improvement in average AUC. Also, compared with the ensemble algorithm that applied the original LMNN algorithm as data transformation, our proposed method has a near 3% improvement in average AUC. Our method takes data transformation in the imbalanced datasets into account, which is superior to other compared algorithms.
4.4. Comparison With Different Algorithms on Image Dataset
Our algorithm is applied in the image dataset and compared with other algorithms. Figure 3 shows part of samples in the Fashion-mnist dataset. Fashion-mnist is a famous image dataset that has 784 features and 60,000 samples. The dataset has 10 classes. To build the imbalanced dataset, we choose the T-shirt class as the majority class and the pullover class as the minority class. The majority and minority class samples are 3,000 and 600, respectively, which means the imbalance ratio is 5:1. Considering that the feature size is similar to the number of samples, we set the feature extraction ratio to 0.1. Table 3 shows the result of the experiment.

Figure 3. The Fashion-mnist dataset.

Table 3. Comparisons between imbalance learning algorithm and our proposed method in terms of AUC.
We can see that our method also has the best performance in the Fashion-mnist dataset. The reason is that our proposed method can deal with the imbalance problem in the image dataset.
4.5. The Effect of Parameter
In this section, we show the impact of the parameter in our algorithm. The number of subspaces influences the performance of our ensemble framework. We set the number of subspace to [5,10,15,20]. The parameter experiment result is shown in Figure 4.
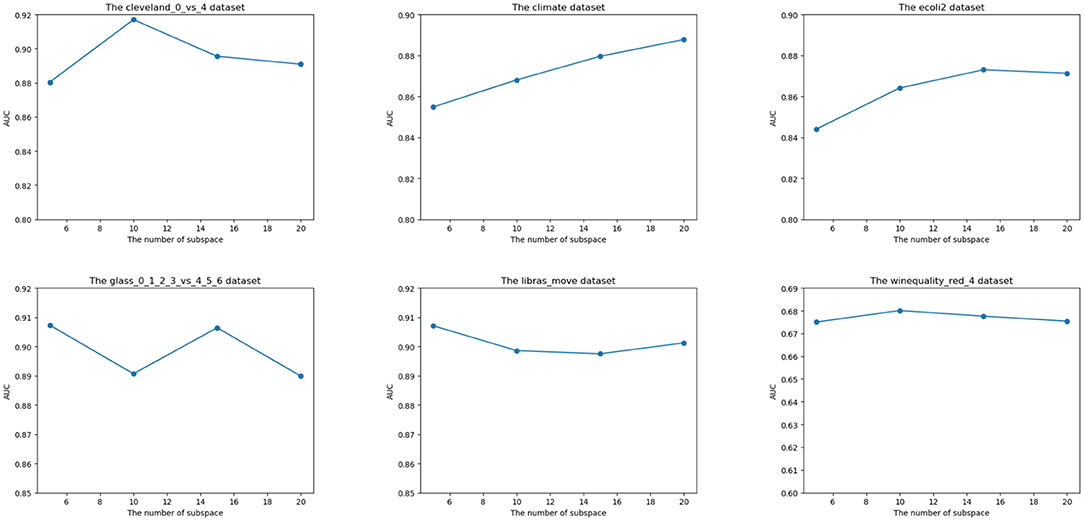
Figure 4. Effect of the number of subspaces on the performance of ensemble on six datasets.
For Cleveland_0_vs_4, ecoli2, and winequality_red_4 datasets, the AUC is improved when the value of subspace is increased. However, when the number of subspaces exceeds a specific number, the AUC decreases as the subspace increases. The reason is that the increasing value of subspaces improves the diversity of subspace, while the excessive subspaces introduce redundant information and are harmful to the algorithm's performance. For other datasets, the trend of AUC is diverse due to the uncertainty of the GA algorithm. Considering the algorithm result on the overall dataset, the proposed number of the subspace is 15.
5. Conclusion and Future Work
In this article, we propose an ensemble framework to deal with imbalanced datasets. We explore an effective feature space to improve the performance of the subsequent procedure. In addition, we propose an adaptive integrated voting process to assign weights for classifiers. The experiments on various real-world imbalanced datasets, including the imbalanced image dataset, show the superiority of the proposed ensemble framework. Finally, we show the experiment to explore the effect of the parameter.
Future study contains several points: (1) Various methods can transform data into other feature spaces, so choosing appropriate methods should be considered. (2) A more effective adaptive weight process should be explored to assign weight based on the performance of the base classifiers.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found at: http://archive.ics.uci.edu/ml/index.php.
Author Contributions
ZL, HW, and KY contributed to conception and design of the study. All authors contributed to manuscript revision, read, and approved the submitted version.
Funding
The work described in this study was partially funded by the National Key Research and Development Program of China under Grant 2019YFB1703600, in part by the National Natural Science Foundation of China No. 62106224 and Key-Area Research and Development Program of Guangdong Province (No. 2018B010107002).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Abdi, L., and Hashemi, S. (2016). To combat multi-class imbalanced problems by means of over-sampling techniques. IEEE Trans. Knowl. Data Eng. 28, 238–251. doi: 10.1109/TKDE.2015.2458858
Alcala-Fdez, J., Fernández, A., Luengo, J., Derrac, J., Garc'ia, S., Sanchez, L., et al. (2010). Keel data-mining software tool: data set repository, integration of algorithms and experimental analysis framework. J. Multiple Valued Logic Soft Comput. 17, 255–287.
Bai, S., Luo, Y., Yan, M., and Wan, Q. (2021). Distance metric learning for radio fingerprinting localization. Exp. Syst. Appl. 163:113747. doi: 10.3390/s21134605
Barua, S., Islam, M. M., and Murase, K. (2011). A Novel Synthetic Minority Oversampling Technique for Imbalanced Data Set Learning (Shanghai: Springer), 735–744.
Barua, S., Islam, M. M., Yao, X., and Murase, K. (2014). MWMOTE-majority weighted minority oversampling technique for imbalanced data set learning. IEEE Trans. Knowl. Data Eng. 26, 405–425. doi: 10.1109/TKDE.2012.232
Batista, G. E. A. P. A., Prati, R. C., and Monard, M. C. (2004). A study of the behavior of several methods for balancing machine learning training data. SIGKDD Explor. Newsl. 6, 20–29. doi: 10.1145/1007730.1007735
Bi, J., and Zhang, C. (2018). An empirical comparison on state-of-the-art multi-class imbalance learning algorithms and a new diversified ensemble learning scheme. Knowl. Based Syst. 158, 81–93. doi: 10.1016/j.knosys.2018.05.037
Cao, X., Ge, Y., Li, R., Zhao, J., and Jiao, L. (2019). Hyperspectral imagery classification with deep metric learning. Neurocomputing 356, 217–227. doi: 10.1016/j.neucom.2019.05.019
Chawla, N., Bowyer, K., Hall, L., and Kegelmeyer, W. (2002). SMOTE: synthetic minority over-sampling technique. J. Artif. Intell. Res. 16, 321–357. doi: 10.1007/978-3-540-39804-2_12
Chawla, N. V., Lazarevic, A., Hall, L. O., and Bowyer, K. W. (2003). “Smoteboost: improving prediction of the minority class in boosting,” in Knowledge Discovery in Databases: PKDD 2003, 7th European Conference on Principles and Practice of Knowledge Discovery in Databases (Cavtat), 107–119.
Chen, S., He, H., and Garcia, E. A. (2010). Ramoboost: ranked minority oversampling in boosting. IEEE Trans. Neural Netw. 21, 1624–1642. doi: 10.1109/TNN.2010.2066988
Davis, J. V., Kulis, B., Jain, P., Sra, S., and Dhillon, I. S. (2007). Information-Theoretic Metric Learning (Corvallis, OR: Association for Computing Machinery), 209–216.
Douzas, G., and Bacao, F. (2019). Geometric smote a geometrically enhanced drop-in replacement for smote. Inf. Sci. 501, 118–135. doi: 10.1016/j.ins.2019.06.007
Dua, D., and Graff, C. (2017). UCI machine learning repository. Irvine, CA: University of California, School of Information and Computer Science. Available online at: http://archive.ics.uci.edu/ml
Elkan, C. (2001). “The foundations of cost-sensitive learning,” in Proceedings of the 17th International Joint Conference on Artificial Intelligence (San Francisco, CA) 973–978.
Farrand, T., Mireshghallah, F., Singh, S., and Trask, A. (2020). “Neither private nor fair: impact of data imbalance on utility and fairness in differential privacy,” in Proceedings of the 2020 Workshop on Privacy-Preserving Machine Learning in Practice PPMLP'20 (New York, NY: Association for Computing Machinery), 15–19.
Fawcett, T. (2004). Roc graphs: notes and practical considerations for data mining researchers. ReCALL 31, 1–38.
Feng, L., Wang, H., Jin, B., Li, H., Xue, M., and Wang, L. (2019). Learning a distance metric by balancing kl-divergence for imbalanced datasets. IEEE Trans. Syst. Man Cybern. Syst. 49, 2384–2395. doi: 10.1109/TSMC.2018.2790914
Gautheron, L., Habrard, A., Morvant, E., and Sebban, M. (2019). Metric Learning From Imbalanced Data (Portland, OR: Institute of Electrical and Electronics Engineers), 923–930.
Han, H., Wang, W.-Y., and Mao, B.-H. (2005). Borderline-Smote: a New Over-Sampling Method in Imbalanced Data Sets Learning (Hefei: Springer), 878–887.
He, H., Bai, Y., Garcia, E. A., and Li, S. (2008). “ADASYN: Adaptive Synthetic Sampling Approach for Imbalanced Learning,” in Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence) (Hong Kong: IEEE), 1322–1328. doi: 10.1109/IJCNN.2008.4633969
He, H., and Garcia, E. A. (2009). Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 21, 1263–1284. doi: 10.1109/TKDE.2008.239
Ho, T. K. (1998). The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 20, 832–844.
Khushi, M., Shaukat, K., Alam, T. M., Hameed, I. A., Uddin, S., Luo, S., et al. (2021). A comparative performance analysis of data resampling methods on imbalance medical data. IEEE Access 9, 109960–109975. doi: 10.1109/ACCESS.2021.3102399
Köstinger, M., Hirzer, M., Wohlhart, P., Roth, P. M., and Bischof, H. (2012). “Large scale metric learning from equivalence constraints,” in 2012 IEEE Conference on Computer Vision and Pattern Recognition (Providence, RI), 2288–2295.
Liu, X., Wu, J., and Zhou, Z. (2009). Exploratory undersampling for class-imbalance learning. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 39, 539–550. doi: 10.1109/TSMCB.2008.2007853
Skurichina, M., and Duin, R. P. W. (2002). Bagging, boosting and the random subspace method for linear classifiers. Pattern Anal. Appl. 5, 121–135. doi: 10.1007/s100440200011
Wang, N., Zhao, X., Jiang, Y., Gao, Y., and BNRist, K. (2018). “Iterative metric learning for imbalance data classification,” Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (Stockholm), 2805–2811.
Wang, S., and Yao, X.. (2009). “Diversity analysis on imbalanced data sets by using ensemble models,” in Proceedings of the IEEE Symposium on Computational Intelligence and Data Mining, CIDM 2009, part of the IEEE Symposium Serie on Computational Intelligence (Nashville, TN), 324–331.
Weinberger, K. Q., and Saul, L. K. (2009). Distance metric learning for large margin nearest neighbor classification. J. Mach. Learn. Res. 10, 207–244.
Yang, K., Yu, Z., Chen, C. L. P., Cao, W., Wong, H.-S., You, J., and Han, G. (2021). Progressive hybrid classifier ensemble for imbalanced data. IEEE Trans. Syst. Man Cybern. Syst. 1–15. doi: 10.1109/TSMC.2021.3051138
Yang, X., Kuang, Q., Zhang, W., and Zhang, G. (2018). Amdo: An over-sampling technique for multi-class imbalanced problems. IEEE Trans. Knowl. Data Eng. 30, 1672–1685. doi: 10.1109/TKDE.2017.2761347
Keywords: imbalance learning, metric learning, information fusion, classification, ensemble learning
Citation: Liang Z, Wang H, Yang K and Shi Y (2022) Adaptive Fusion Based Method for Imbalanced Data Classification. Front. Neurorobot. 16:827913. doi: 10.3389/fnbot.2022.827913
Received: 02 December 2021; Accepted: 25 January 2022;
Published: 28 February 2022.
Edited by:
Xin Jin, Yunnan University, ChinaReviewed by:
Liang Liao, Zhongyuan University of Technology, ChinaPeng Cao, Northeastern University, China
Goksu Tuysuzoglu, Dokuz Eylül University, Turkey
Copyright © 2022 Liang, Wang, Yang and Shi. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Huan Wang, d2FuZ2h1YW42QGVtYWlsLnN6dS5lZHUuY24=; Kaixiang Yang, eWFuZ2thaXhpYW5nQHpqdS5lZHUuY24=
†These authors have contributed equally to this work