 Samuel Schmidgall
Samuel Schmidgall Julia Ashkanazy
Julia Ashkanazy Wallace Lawson
Wallace Lawson Joe Hays
Joe Hays- U.S. Naval Research Laboratory, Washington, DC, United States
The adaptive changes in synaptic efficacy that occur between spiking neurons have been demonstrated to play a critical role in learning for biological neural networks. Despite this source of inspiration, many learning focused applications using Spiking Neural Networks (SNNs) retain static synaptic connections, preventing additional learning after the initial training period. Here, we introduce a framework for simultaneously learning the underlying fixed-weights and the rules governing the dynamics of synaptic plasticity and neuromodulated synaptic plasticity in SNNs through gradient descent. We further demonstrate the capabilities of this framework on a series of challenging benchmarks, learning the parameters of several plasticity rules including BCM, Oja's, and their respective set of neuromodulatory variants. The experimental results display that SNNs augmented with differentiable plasticity are sufficient for solving a set of challenging temporal learning tasks that a traditional SNN fails to solve, even in the presence of significant noise. These networks are also shown to be capable of producing locomotion on a high-dimensional robotic learning task, where near-minimal degradation in performance is observed in the presence of novel conditions not seen during the initial training period.
1. Introduction and Related Work
The dynamic modification of neuronal properties underlies the basis of learning, memory, and adaptive behavior in biological neural networks. The changes in synaptic efficacy that occur on the connections between neurons play an especially vital role. This process, termed synaptic plasticity, is largely mediated by the interaction of pre- and post-synaptic activity between two synaptically connected neurons in conjunction with local and global modulatory signals. Importantly, synaptic plasticity is largely believed to be one of the primary bases for enabling both stable long-term learning and adaptive short-term responsiveness to novel stimuli (Martin et al., 2000; Zucker and Regehr, 2002; Liu et al., 2012).
An additional mechanism that guides these changes is neuromodulation. Neuromodulation, as the name suggests, is the process by which select neurons modulate the activity of other neurons; this is accomplished by the use of chemical messaging signals. Such messages are mediated by the release of chemicals from neurons themselves, often using one or more stereotyped signals to regulate diverse populations of neurons. Dopamine, a neuromodulator commonly attributed to learning (Schultz et al., 1997; Frank et al., 2004; Hosp et al., 2011), has been experimentally shown to portray a striking resemblance to the Temporal-Difference (TD) reward prediction error (Montague et al., 1996; Schultz et al., 1997; Niv et al., 2005) and more recently distributional coding methods of reward prediction (Dabney et al., 2020). Such signals have been shown to play a critical role in guiding the effective changes in synaptic plasticity, allowing the brain to regulate the location and scale with which such changes are made (Gerstner et al., 2018). The conceptual role of dopamine has largely shaped the development of modern reinforcement learning (RL) algorithms, enabling the impressive accomplishments seen in recent literature (Mnih et al., 2013; Bellemare et al., 2017; Barth-Maron et al., 2018; Haarnoja et al., 2018). While dopamine has primarily taken the spotlight in RL, many other important neuromodulatory signals have largely been excluded from learning algorithms in artificial intelligence (AI). For example, acetylcholine has been shown to play a vital role in motor control, with neuromodulatory signals often sent as far as from the brainstem to motor neurons (Zaninetti et al., 1999). Modeling how these neuromodulatory processes develop, as well as how neurons can directly control neuromodulatory signals are likely critical steps toward successfully reproducing the impressive behaviors exhibited by the brain.
Both historically and recently, neuroscience and AI have had a fruitful relationship, with neuroscientific speculations being validated through AI, and advancements in the capabilities of AI being a result of a better understanding of the brain. A major contributor toward enabling this, particularly in AI, is through the application of backpropagation for learning the weights of Artificial Neural Networks (ANNs). Although backpropagation is largely believed to be biologically implausible (Bengio et al., 2015), networks trained under certain conditions using this algorithm have been shown to display behavior remarkably similar to biological neural networks (Banino et al., 2018; Cueva and Wei, 2018).
The promising advances toward more brain-like computations have led to the development of SNNs. These networks more closely resemble the dynamics of biological neural networks by storing and integrating membrane potential to produce binary spikes. Consequently, such networks are naturally suited toward solving temporally extended tasks, as well as producing many of the desirable benefits seen in biological networks such as energy efficiency, noise robustness, and rapid inference (Pfeiffer and Pfeil, 2018). However, until recently, the successes of SNNs have been overshadowed by the accomplishments of ANNs. This is primarily due to the use of spikes for information transmission, which does not naturally lend itself toward being used with backpropagation. To circumvent this challenge, a wide variety of learning algorithms have been proposed including Spike-Timing Dependent Plasticity (STDP) (Masquelier et al., 2009; Bengio et al., 2017; Kheradpisheh et al., 2018; Mozafari et al., 2018), ANN to SNN conversion methods (Diehl et al., 2015; Rueckauer et al., 2017; Hu et al., 2018), Eligibility Traces (Bellec et al., 2020), and Evolutionary Strategies (Pavlidis et al., 2005; Carlson et al., 2014; Eskandari et al., 2016; Schmidgall, 2020). However, a separate body of literature enables the use of backpropagation directly with SNNs typically through the use of surrogate gradients (Bohte et al., 2002; Sporea and Grüning, 2012; Lee et al., 2016; Shrestha and Orchard, 2018). These surrogate gradient methods are primary contributors for many of the state-of-the-art results obtained using SNNs from supervised learning to RL. Counter to biology, temporal learning tasks such as RL interact with an external environment over multiple episodes before synaptic weight updates are computed. Between these update intervals, the synaptic weights remain unchanged, diminishing the potential for online learning to occur. Recent work by Miconi et al. (2018) transcends this dominant fixed-weight approach specifically for the recurrent weights of ANNs by presenting a framework for augmenting traditional fixed-weight networks with Hebbian plasticity, where backpropagation updates both the weights and parameters guiding plasticity. In follow-up work, this hybrid framework was expanded to include neuromodulatory signals, whose parameters were also learned using backpropagation (Miconi et al., 2019).
Learning-to-learn, or meta-learning, is the capability to learn or improve one's own learning ability. The brain is constantly modifying and improving its own ability to learn at both the local and global scale. This was originally theorized to be a product of neurotransmitter distribution from the Basal Ganglia (Doya, 2002), but has also included contributions from the Prefrontal Cortex (Wang et al., 2018) and the Cerebellum (Doya, 1999) to name a few. In machine learning, meta-learning approaches aim to improve the learning algorithm itself rather than retaining a static learning process (Hospedales et al., 2020). For spiking neuro-controllers, learning-to-learn through the discovery of synaptic plasticity rules offline provides a mechanism for learning on-chip since neuromorphic hardware is otherwise incompatible with on-chip backpropagation. Many neuromorphic chips provide a natural mechanism for incorporating synaptic plasticity (Davies et al., 2018; van Albada et al., 2018), and more recently, neuromodulatory signals (Mikaitis et al., 2018).
Despite the prevalence of plasticity in biologically-inspired learning methods, a method for learning both the underlying weights and plasticity parameters using gradient descent has yet to be proposed for SNNs. Building off of Miconi et al. (2019), which was focused on ANNs, this paper provides a framework for incorporating plasticity and neuromodulation with SNNs trained using gradient descent. In addition, five unique plasticity rules inspired by the neuroscientific literature are introduced. A series of experiments are conducted with using a complex cue-association environment, as well as a high-dimensional robotic locomotion task. From the experimental results, networks endowed with plasticity on only the forward propagating weights, with no recurrent self-connections, are shown to be sufficient for solving challenging temporal learning tasks that a traditional SNN fails to solve, even while experiencing significant noise perturbations. Additionally, these networks are much more capable of adapting to conditions not seen during training, and in some cases displaying near-minimal degradation in performance.
2. Differentiable Plasticity
Section 2.1 begins by describing the dynamics of an SNN. Using these dynamic equations, section 2.2 then introduces the generalized framework for differentiable plasticity of an SNN as well as some explicit forms of differentiable plasticity rules. First, the Differentiable Plasticity (DP) form of Linear Decay is introduced, primarily due to the conceptual simplicity of its formulation. Next, the DP form of Oja's rule (Oja, 1983) is presented as DP-Oja's. This rule is introduced primarily because, unlike Linear Decay, it provides a natural and simple mechanism for stable learning, namely a penalty on weight-growth. The next form is based on the Bienenstock, Cooper, and Munro (BCM) rule (Bienenstock et al., 1982), named DP-BCM. Like Oja's rule, the BCM rule provides stability, except in this case the penalty accounts for a given neuron's deviation from the average spike-firing rate. Finally, a respective set of neuromodulatory variants for the Oja's and BCM differentiable plasticity rules are presented in section 2.3, as well as a generalized framework for differentiable neuromodulation. The rules described in this section serve primarily to demonstrate an explicit implementation of the generalized framework on two well-studied synaptic learning rules.
2.1. Spiking Neural Network
We will begin by describing the dynamics of an SNN, and then proceed in the following sections to describe a set of plasticity rules that can be applied to such networks. We begin with the following set of equations:
The superscript l ∈ ℕ represents the index for a layer of neurons and t ∈ ℕ discrete time. We further define n(l) ∈ ℕ to represent the number of neurons in layer l. From here, ε(·) is a spike response kernel which is used to generate a spike response signal, a(l)(t) ∈ ℝn(l−1), by convolving incoming spikes s(l−1)(t) ∈ 𝔹n(l−1), 𝔹 = {0, 1} over ε(·). We further define the binary vector s(0)(t) to represent sensory input obtained from the environment. Often in practice, the effect of ε(·) provides an exponentially decaying contribution over time, which consequently has minimal influence after a fixed number of steps. Exploiting this concept, ε(·) may be represented as a finite weighted decay kernel with dimensionality K, which is chosen heuristically as the point in time with which ε(·) has minimal practical contribution. v(·) is chosen in a similar manner, where v(·) is the refractory kernel, convolving together with spikes s(l)(t) to produce the refractory response v * s(l)(t) ∈ ℝn(l). Additionally, W(l) ∈ ℝn(l)×n(l−1) numerically represents the synaptic strength between each neuron connected from layer l − 1 and l, which, as a weight is multiplied by a(l)(t) and further summed with the refractory response v * s(l)(t) to produce the membrane potential u(l)(t) ∈ ℝn(l). The membrane potential stores the weighted sum of spiking activity arriving from incoming synaptic connections, referred to as the Post Synaptic Potential (PSP).
We further define the spike function fs(·) as:
In these equations, the function fs(·) produces a binary spike based on the neuron's internal membrane potential, ui(t), i ∈ ℕ indexing an individual neuron. When ui(t) passes a threshold ϑ ∈ ℝ, the respective binary spike is propagated downstream to a set of connected neurons, and the internal membrane potential for that neuron is reset to a baseline value ur ∈ ℝ, which is often set to zero. The function enabling this is referred to as a dirac-delta, δ(t), which produces a binary output of one when t = 0 and zero otherwise. Here, tf ∈ ℝ denotes the firing time of the fth spike, so that when t = t(f) then δ(t − t(f)) = 1.
Like an artificial neural network, fs(·) can be viewed as having similar functionality to an arbitrary non-linear activation function ϕ(·). Unlike the ANN however, fs(·) has an undefined derivative making the gradient computation for backpropagation particularly challenging. To enable backpropagation through the non-differentiable aspects of the network, the Spike Layer Error Reassignment in Time (SLAYER) algorithm is used (Shrestha and Orchard, 2018). SLAYER overcomes such difficulties by representing the derivative of a spike as a surrogate gradient and uses a temporal credit assignment policy for backpropagating error to previous layers. Although SLAYER was used in this paper, we note that any spike-derivative approximation method will work together with our methods.
2.2. Spike-Based Differentiable Plasticity
To enable differentiable plasticity we utilize the SNN dynamic equations described in (1–5), however now both the weights and the rules governing plasticity are optimized by gradient descent. This is enabled through the addition of a synaptic trace variable, E(l)(t) ∈ ℝn(l)×n(l−1), which accumulates traces of the local synaptic activities between pre- and post-synaptic connections. An additional plasticity coefficient, α(l) ∈ ℝn(l)×n(l−1), is often learned which serves to element-wise scale the magnitude and direction of the synaptic traces independently from the trace dynamics. By augmenting our SNN we obtain:
The Hadamard product, ⊙, is used to represent element-wise multiplication. The primary modifications from the fixed-weight SNN framework in (1–3) are in the addition of the synaptic trace E(l)(t) and plasticity coefficient α(l) in (7). Without this modification, the underlying weight W(l) remains constant from episode-to-episode in the same way as (2). However, the additional contribution of the synaptic trace E(l)(t) enables each weight value to be modified through the interaction of local or global activity. The differentiable plasticity and neuromodulated plasticity frameworks presented in this work are concerned with learning such local and global signals, respectively. Proceeding, we present three different methods of synaptic plasticity followed by a section describing neuromodulated plasticity. We additionally note that this framework is not limited to these particular plasticity rules and can be expanded upon to account for a wide variety of different methods.
2.2.1. Generalized
Neuronal activity can be represented by a diverse family of forms. Plasticity rules have been proposed using varying levels of abstraction, from spike rates and spike timing, all the way to modeling calcium-dependent interactions. To encapsulate this wide variety in our work, we abstractly define a vector ρ(l)(t) to represent activity for a layer of neurons l at time t. In many practical instances, time t may represent continuous time, however our examples and discussions are primarily concerned with the evolution of discrete time, which is the default mode from which many models of spiking neurons operate. Likewise, the activity vector ρ(l)(t) may be represented by a variety of different sets, such as 𝔹n(l) or ℝn(l) for spike-timing or rate-based activity; this is primarily dependent on which types of activity the experimenter desires to model. The generalized equation for differentiable plasticity is expressed as follows:
Here, E(l)(t + Δτ) is updated after a specified time interval Δτ ∈ ℕ. In these equations, F(·) is a function of the pre- and post-synaptic activity, ρ(l−1)(t) and ρ(l)(t), as well as E(l)(t) at the current time-step and L(l) which represents an arbitrary set of functions describing local neuronal activity from either pre- or post-synaptic neurons. In practice, E(l)(t = 0) is often set to zero at the beginning of a new temporal interaction.
2.2.2. DP-Linear Decay
Perhaps the simplest form of differentiable plasticity is the linear decay method:
Let the set L(l) = {η(l)}, with η(l) ∈ ℝ. In this equation, E(l)(t + Δτ) is computed using the local layer-specific function η(l), representing the rate at which new local activity ρ(l)(t)(ρ(l−1)(t))⊺ ∈ ℝn(l)×n(l−1) is incorporated into the synaptic trace, as well as the degree to which prior synaptic activity will be 'remembered' from (1 − η(l))E(l)(t). While the parameters regulating E(l)(t + Δτ) will generally approach values that produce stable weight growth, in practice E(l)(t) is often clipped to enforce stable bounds. Here, the local variable η(l) acts as a free parameter and is learned through gradient descent.
2.2.3. DP-Oja's
Among the most studied synaptic learning rules, Oja's rule simplistically provides a natural system of stability and effective correlation (Oja, 1982). This rule balances potentiation and depression directly from the synaptic activity stored in the trace, which cause a decay proportional to its magnitude. Mathematically, Oja's rule enables the neuron to perform Principal Component Analysis (PCA) which is a common method for finding unsupervised statistical trends in data (Oja, 1983). Building off of this work, we incorporate Oja's rule into our framework as Differentiable Plasticity Oja's rule (DP-Oja's). Rather than a generalized representation of activity, DP-Oja's rule uses a more specific rate-based representation, where ρ(l)(t) = r(l)(t) ∈ ℝn(l). To obtain r(l)(t), spike averages are computed over the pre-defined interval Δτ. DP-Oja's rule is defined as:
Similar to (10), we let the set L(l) = {η(l)} contain the local layer-specific value η(l) that governs the incorporation of novel synaptic activity. Differing however, E(l)(t) is used twice. The term E(l)(t) being multiplied by (1 − η(l)) on the left-side of (11) serves a similar purpose compared with (10), however on the right-hand side of the addition this value penalizes unbounded growth, acting as an unsupervised regulatory mechanism. Here, like in (10), η(l) acts as a free parameter learned through gradient descent.
2.2.4. DP-BCM
Another well-studied example of plasticity is the BCM rule (Bienenstock et al., 1982). The BCM rule has been shown to exhibit similar behavior to STDP under certain conditions (Izhikevich and Desai, 2003), as well as to successfully describe the development of receptive fields (Shouval et al., 1970; Law and Cooper, 1994). BCM differs from Oja's rule in that it has more direct control over potentiation and depression through the use of a dynamic threshold which often represents the average spike rate of each neuron. In this example of differentiable plasticity, we describe a model of BCM, where the dynamics governing the plasticity as well as the stability-providing sliding threshold are learned through backpropagation, which we refer to as Differentiable Plasticity BCM (DP-BCM). This rule can be described as follows:
As in (11), the DP-BCM uses a rate-based representation of synaptic activity, where ρ(l)(t) = r(l)(t). Here, we let the set of local functions . To begin, ψ(l) ∈ ℝn(l−1) is a bias vector that remains static during interaction time, and the parameter ϕ(l)(t) ∈ ℝn(l−1) is its dynamic counterpart. These parameters enable the addition of a sliding-boundary, ϕ(l)(t) + ψ(l), which determines whether activity results in potentiation vs. depression. The dynamics of this boundary are described in (14). Otherwise, ω(·) serves as an arbitrary function of the pre-synaptic activity r(l−1)(t), and determines the rate at which new information is incorporated into the ϕ(l)(t) trace. For our experiments we let ω(·) = I(·), which is the identity function. This altogether has the effect of slowly incorporating the observed rate of pre-synaptic activity r(l−1)(t) into ϕ(l)(t). Finally, η(l) ∈ ℝ provides the same utility as in (10). Comparatively, the BCM rule is more naturally suited for regulating potentiation and depression than Oja's, which primarily regulates depression through synaptic weight decay. Among the local functions, ψ(l), , and η(l) are free parameters learned through gradient descent.
2.3. Spike-Based Differentiable Neuromodulation
In addition to differentiable plasticity, a framework for differentiable neuromodulation is also presented. Neuromodulation, or neuromodulated plasticity, allows the use of both learned local signals, as well as learned global signals. These signals modulate the effects of plasticity by scaling the magnitude and direction of synaptic modifications based on situational neuronal activity. This adds an additional layer of learned supervision, enabling the potential for learning-to-learn, or meta-learning. Adding neuromodulation provides an analogy to the neuromodulatory signals observed in biological neural networks, which provide a rich set of biological processes to take inspiration from.
As before, we present the equation for generalized neuromodulated plasticity and further describe a series of more specific neuromodulation rules.
2.3.1. Generalized Neuromodulated Plasticity
The generalized equation for neuromodulated plasticity is as follows:
In this equation, G(·) has the same functionality as F(·) in (9) except for the addition of neuromodulatory signals M. Here, the values contained in M may be represented by a wide variety of functions, however it differs from L(l) in that the elements may express global signals. Global signals may be computed at any part of the network, or by a separate network all together. Additionally, global signals may be incorporated that are learned independent of the modulatory reaction, such as dopamine-inspired TD-error from an independent value-prediction network, or a function computing predictive feedback-error signals as is observed in the cerebellum (Popa and Ebner, 2019).
2.3.2. NDP-Oja's
Building off of (11), Oja's synaptic update rule is augmented with a neuromodulatory signal that linearly weights the neuronal activity of post-synaptic neurons. This neuromodulated variant of Oja's rule (NDP-Oja's) is described as follows:
Where the parameter weights the post-synaptic activity r(l)(t), which modulates the right-hand trace dynamics in (16). Importantly, the effect of the gradient in learning M(l)(t) ∈ ℝn(l) also contributes toward modifying the parameters producing the post-synaptic activity r(l)(t) rather than simply having a passive relationship. This enables more deliberate and effective control of the neuromodulatory signal. In this equation, both and η(l) are free parameters learned through gradient descent. Otherwise, the role of each parameter is identical to (11).
2.3.3. NDP-BCM
In a similar manner, Equations (12–14) for DP-BCM are augmented with a neuromodulatory signal that linearly weights the neuronal activity of post-synaptic neurons, which is referred to as Neuromodulated Differentiable Plasticity BCM (NDP-BCM). This rule can be described as follows:
As above, the learned parameter weights the post-synaptic activity r(l)(t), which is then distributed to modulate the right-hand trace dynamics in (18). Otherwise, each parameter follows from (12–14). Similarly, ψ(l), , and η(l) as well as are free parameters learned through gradient descent.
3. Results
The results of this work demonstrate the improvements in performance that differentiable plasticity provides over fixed-weight SNNs, as well as the unique behavioral patterns that emerge as a result of differentiable plasticity. Presented here are two distinct environments which require challenging credit assignment.
3.1. Noisy Cue-Association: Temporal Credit-Assignment Task
Experience-dependent synaptic changes provide critical functionality for both short- and long-term memory. Importantly, such a mechanism should be able to disentangle the correlations between complex sensory cues with delayed rewards, where the learning agent often has to wait a variable amount or time before an action is made and a reward is received. A common learning experiment in neuroscience analyzes the performance of rodents in a similar context through the use of a T-maze training environment (Kuśmierz et al., 2017; Engelhard et al., 2019). Here, a rodent moves down a straight corridor where a series of sensory visual cues are arranged randomly on the left and right of the rodent as it walks toward the end of the maze. After the sensory cues are displayed, there is a delay interval between the cues and the decision period. Finally, at the T-junction, the rodent is faced with the decision of turning either left of right. A positive reward is given if the rodent chooses the side with the highest number of visual cues. This environment poses unique challenges representative of a natural temporal learning problem, as the decision-making agent is required to learn that reward is independent of both the temporal order of each cue as well as the side of the final cue.
Rather than visual cues specifically, the cues in our experiment produce a time period of high-spiking activity that is input into a distinct set of neurons for each cue (Figure 1). Additionally, a similarly-sized set of neurons begins producing spikes near the T-junction indicating a decision period, from which the agent is expected to produce a decision to go left or right. Finally, the last set of neurons produce noise to make the task more challenging. The cue-association task has been shown to be solvable in simulation with the use of recurrent spiking neural networks for both Backpropagation Through Time (BPTT) and eligibility propagation (E-Prop) algorithms (Bellec et al., 2020). However, using the same training methods, a feedforward spiking neural network without recurrent connections is not able to solve this task. In the Miconi et al. (2019) experiments, results were shown for ANNs with plastic and neuromodulated synapses on only the recurrent weights. In this experiment, we determine whether non-recurrent feedforward networks with plastic synapses are sufficient for solving this same task. Here, we consider both DP-BCM and DP-Oja's rules as well as the respective neuromodulatory variants described in sections 2.2, 2.3. We also collect results from an additional environment where each population of neurons has a significantly higher probability of spiking randomly, as well as a reduced probability of spiking during the actual cue interval (Figure 2).

Figure 1. (A) A graphical visualization of the cue-association T-Maze, where the cues are sequentially presented followed by a delay and decision period. The right cue is shown in red, the left in blue. (B) Displayed is the sensory neuron input activity. From bottom to top, the activity of ten neurons each represent left and right cues, followed by ten neurons for an action decision cue, and finally ten neurons that have activity with no relationship to the task. Membrane potential for the output neurons, and the spiking activity of a random subset of 10 hidden neurons for neuromodulated Oja's rule (C,D) and non-modulated Oja's rule (E,F). The blue and red curves here correspond to the neuron representing the decision for choosing left or right, respectively, also corresponding to the left and right cue colors in (A,B). In (D), only 5 of the 10 neurons were actively spiking, whereas in (F) all 10 were.
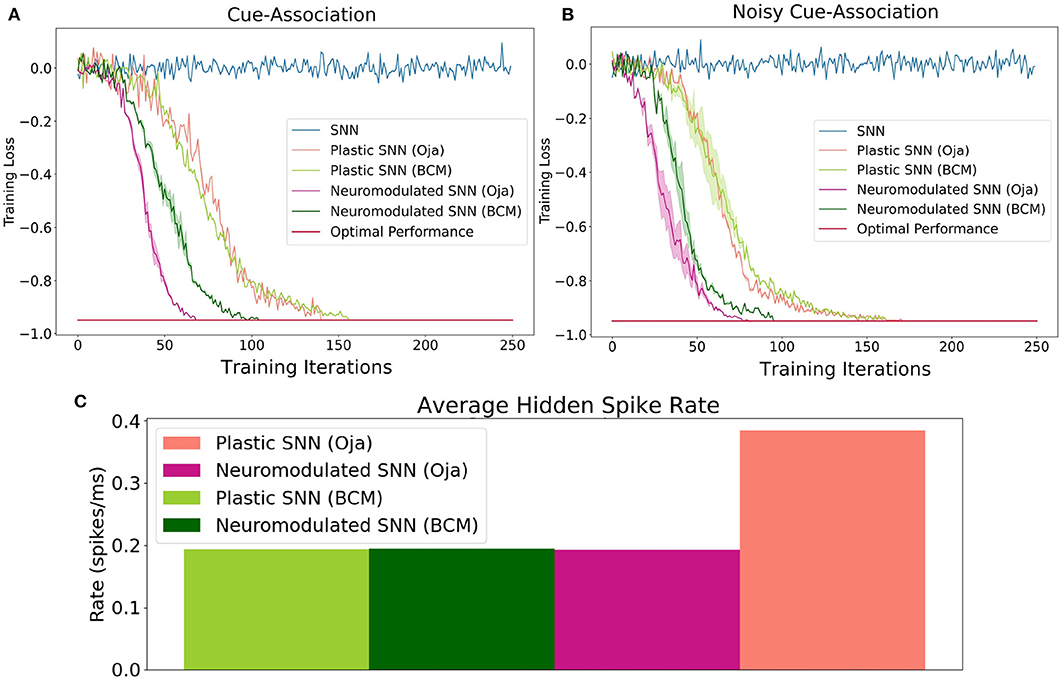
Figure 2. The performance of Oja's and BCM plastic and neuromodulated learning rules on the low-noise (A) and high-noise (B) environments. (C) The average spike firing rate of hidden layer neurons in the high-noise environments for plastic and neuromodulated Oja's and BCM. Once the average network training loss is less than −0.97, which here is consider optimal, the training is halted. Training accuracy is defined as the ratio of correct cues averaged over a series of trials. To perform gradient descent, training loss is this value multiplied by −1.
The input layer is comprised of 40 neurons: 10 for the right-sided cues, 10 for the left-sided cues, 10 neurons which display activity during the decision period, and 10 neurons which produce spike noise (Figure 1B). The hidden layer is comprised of 64 neurons, where each neuron is synaptically connected to every neuron in the input layer. Finally, the output layer is similarly fully-connected with two output neurons (Figure 3).
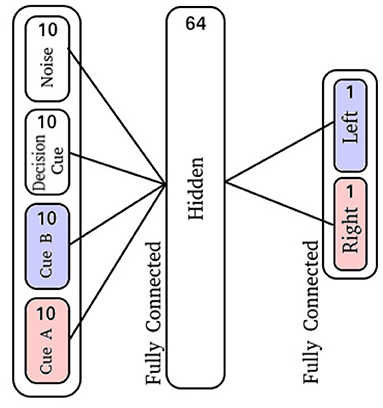
Figure 3. Cue-Association network diagram.
Output activity is collected over the decision interval averaging the number of spikes over each distinct output neuron. To decide which action is taken at the end of the decision interval, the output activity is used as the 2-dimensional log-odds input for a binomial distribution from which an action is then sampled. To compute the parameter gradients, the policy gradient algorithm is employed together with BPTT and the Adam optimization method (Kingma and Ba, 2014). To compute the policy gradient, a reward of one is given for successfully solving the task, where otherwise a reward of negative one is given. A more in-depth description of the training details is reserved for the section 5.4 of the Appendix.
Accuracy on this task is defined as the ratio of correct cue-decisions at the end of the maze averaged over 100 trials. Training loss is defined as accuracy multiplied by −1, hence the optimal performance is −1. The training results for both the high- and low-noise environments are shown in Figure 2. For both environments, the NDP-BCM and NDP-Oja's consistently outperform both DP-BCM and DP-Oja's, whereas the non-plastic SNN fails to solve the task. The neuromodulated networks learn to solve the task most efficiently, despite having more complex dynamics as well as a larger set of parameters to learn. In comparing the non-modulated plasticity variants, there is minimal difference in learning efficiency for either environment. Interestingly, there was minimal degradation in training performance when transitioning from a low- to high-noise environment as shown in Figures 2A,B.
One observed difference between the activity of the neuromodulated and non-modulated variants of BCM and Oja's rule is their average hidden spike rates. The average spike-firing rate is relatively consistent between NDP-Oja's and NDP-BCM, as well as the DP-BCM, however the DP-Oja's network has almost twice the spike-firing rate of the former three networks (Figure 2). This is thought to be due to Oja's rule primarily controlling synaptic depression through weight decay, which tends to produce larger weight values in active networks. This differs from the BCM rule, which produces a sliding boundary based on the average neuronal spike-firing rate to control potentiation and depression. The neuromodulated variant of Oja's rule however, can control potentiation and depression through the learned modulatory signal, bypassing the weight-value associated decay. This effect is also seen in Figures 1D,F where the spiking activity of 10 randomly-sampled neurons is shown. Again, the NDP-Oja's rule shows drastically lower average spiking activity. This demonstrates that neuromodulatory signals may provide critical information in synaptic learning rules where depression is not actively controlled. Reduced activity is desirable in neuromorphic hardware, as it enables lower energy consumption in practical applications.
To better understand the role of neuromodulation in this experiment, four unqiue cue-association cases are considered (Figures A1–A4 in Appendix). It is observed that the modulatory signals on the output neurons exhibit loose symmetry, whereas the activity on hidden neurons follow a similar dynamic pattern for different cues. Additionally, the plastic-weights are shown to behave differently when deprived of sensory-cues. During this deprivation period, the characteristic potentiation and depression seen in all other cue patterns is absent. It is evident from these experiments that the plasticity and neuromodulation have a significant effect on self-organization and behavior. A more in-depth analysis of the neuronal activity is provided in the Appendix (section 5.6).
3.2. High-Dimensional Robotic Locomotion Task
Locomotion is among the most impressive capabilities of the brain. The utility of such a capability for a learning agent extends beyond biological organisms, and has received a long history of attention in the robotics field for its many practical applications. Importantly, among the most desirable properties of a locomotive robot are adaptiveness, robustness, as well as energy efficiency. However, it is worth noting that the importance of having adaptive capabilities for a locomotive agent primarily serves to enable robust performance in response to noise, varying environments, and novel situations. Since plasticity in networks largely serves as a mechanism toward adapting appropriately to new stimuli, we test the adaptive capabilities of our differentiable plasticity networks in a locomotive robotic learning setting (Figure 4).
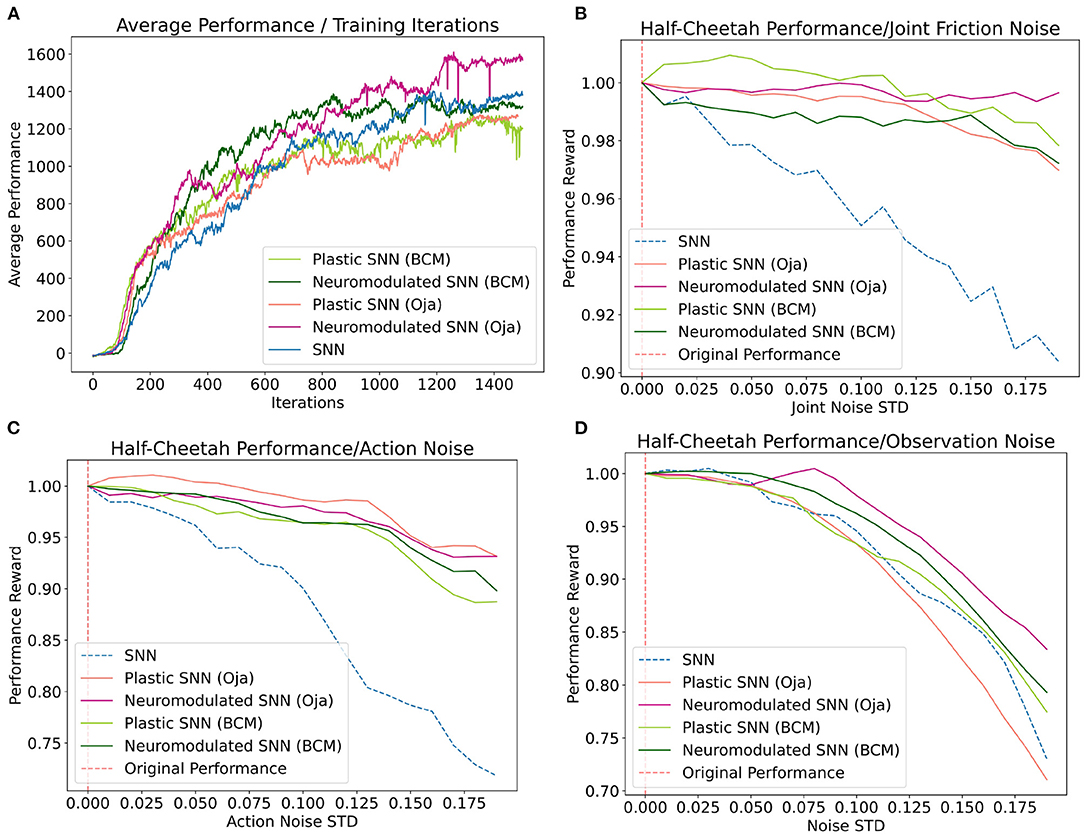
Figure 4. (A) Average performance of each network at each iteration of the training process. (B–D) Average loss in performance as a ratio of the observed performance in response to noise [x-axis] and the original network performance in the absence of noise at x=0. Averages for each noise standard deviation were collected over 100 training episodes.
We thus begin by considering a modified version of the Half-Cheetah environment. Half-Cheetah is a common benchmark used to examine the efficacy of RL algorithms. This environment begins with a robot which loosely has the form of a cheetah, controlling six actuated joints equally divided among the two limbs. Additionally, the robot is restricted to motion in 2-dimensions, hence the name 'Half-Cheetah'. In total, the half-cheetah is a 9-DOF system, with 3 unactuated floating body DOFs and 6 actuated-DOFs for the joints. The objective of this environment is to maximize forward velocity, while retaining energy efficiency. The sensory input for this environment is comprised of the relative angle and angular velocity of each joint for a total of 12 individual inputs. Originally, the environmental measurements are represented as floating point values. These measurements are then numerically clipped, converted into a binary spike representation, and sent as input into the network. The binary spike representation utilized is a probabilistic population representation based on place coding. Similar to the sensory representation, the action outputted by the network is represented by a population of spiking neurons. In each population there exists spiking neurons with equal sized positive and negative sub-populations. The total sum of spikes for each population is then individually collected and averaged over the pre-defined integration interval T ∈ ℕ. Both the equations describing the spike observation and action representation are further discussed in sections 5.2 and 5.3 of the Appendix.
To introduce action variance for this experiment, the output floating point value A(t) is used as the mean for a multivariate Gaussian with zero co-variance, . The log standard deviation, σlog, is a fixed vector that is learned along with the network parameters. To produce an action, the integration interval T was chosen to be 50 time-steps and the action sub-population size to be 100 neurons. With the action floating point dimensionality having been 6, this produced a spike-output dimensionality of 600 neurons. Additionally, using a population size of 50 neurons for each state input and a 12-dimensional input, the spike-input dimensionality was also 600 neurons. Each network model in this experiment is comprised of 2 fully-connected feed-forward hidden layers with 64 neurons each (Figure 5).
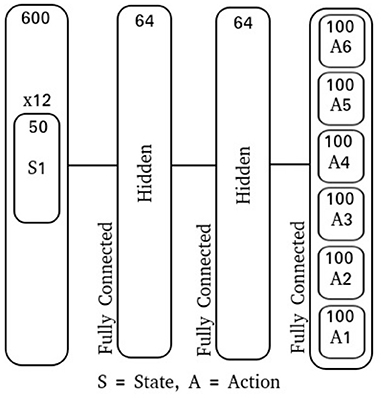
Figure 5. Locomotion network diagram.
To compute the gradients for the network parameters we used BPTT with the surrogate gradient method Proximal Policy Optimization, altogether with the Adam optimization method (Kingma and Ba, 2014; Schulman et al., 2017). For the policy gradient, the reinforcement signal is given for each action output proportional to forward velocity, with an energy penalty on movement. This signal is backpropagated through the non-differentiable spiking neurons using SLAYER, with modifications described in section 5.1 of the Appendix (Shrestha and Orchard, 2018).
Five unique network types are evaluated on the locomotion task: a traditional SNN, the DP-BCM, DP-Oja's, NDP-BCM, and NDP-Oja's. Three unique categories of noise are measured on the trained networks: joint friction noise, action noise, and observation noise. For each of these categories, a noise vector is sampled from a Gaussian distribution with a mean of zero and a specified standard deviation. Then, to obtain an accurate measurement, the performance for an individual network is collected and the objective is averaged over 100 performance evaluations to represent the average performance response for that network at the specified noise standard deviation (Figures 4B–D). Both the noise vector dimensionality and the way in which it is utilized is uniquely defined by the nature of each task. To represent observation noise, a 12-dimensional noise vector , with a standard deviation σ which remains fixed starting at the beginning of an episode, is sampled for each observation at time t, and further summed with the respective observation before conversion to spike representation, Xz(t) = X(t) + z(t). This observation noise is in addition to the spike-firing probability noise, ϑmin, described in section 5.2 of the Appendix. For the action noise, the same sampling process is repeated for a 6-dimensional vector, however here the noise vector plus one is element-wise multiplied with the output action, Az(t) = A(t) ⊙ (1 + z(t)). The joint friction noise rather is sampled at the beginning of a performance episode t = 0 and held constant throughout that episode, z(t) = z(t = 0). The sampled noise is then further summed as a percentage of the originally specified joint friction constants fz(t) at the beginning of the performance evaluation episode, fz(t) = f(t) ⊙ (1 + z(t)).
Despite each network having been trained in the absence of these noise types, the post-training performance response of the networks vary (Figure 4). Overall, the networks augmented with differentiable plasticity are shown to provide more effective adaptive capabilities, where minimal loss in performance was observed during the joint friction and action noise experiment for plastic networks (Figure 4). However, while these networks displayed improvements in robustness over the joint friction and action noise tasks, they did not display improvements on the observation noise task compared with the fixed-weight SNN. In general, the performance of NDP-Oja's was better than NDP-BCM, which may be a result of NDP-BCM's added complexity, hyper-parameter choices, network initialization, or network size. Policy gradient methods tend to favor the model which works best with the particular implementation details (Engstrom et al., 2020).
The activity of the modulatory signals in this task seem to noisily oscillate within a consistent range after the initial timestep (Figure A6 in Appendix). This behavior is observed to be consistent across various noise perturbations, and in the absence of them. However, when deprived of sensory input, as in the case where the robot flips on its back, modulatory oscillations cease almost completely (Figure A5 in Appendix). This differs from the modulatory behavior in the cue-association task where the hidden signals potentiate and decay significantly during the sensory cue sequence. A more in-depth analysis for this task is provided in the Appendix (section 5.8).
Training performance results for both the NDP- and DP-network variants are relatively consistent for each experiment included in Figure 4A. This differs from the cue-association experiment, where NDP-networks converged on the training task around 50 iterations faster than DP-networks. This experiment differs fundamentally in that the locomotion task is inherently solvable without temporal learning capabilities (Schulman et al., 2017), hence deciphering the role and benefit of plasticity and neuromodulation is not trivial. Additionally, neuromodulatory signals in biological networks do not act solely on modifying synaptic efficacy, rather have a whole host of effects depending on the signal, concentration, and region. Perhaps advances in the capabilities of NDP-networks will be a result of introducing these biologically inspired modulations (Zaninetti et al., 1999; Hosp et al., 2011; Dabney et al., 2020).
4. Discussion
We have proposed a framework for learning the rules governing plasticity and neuromodulated plasticity, in addition to fixed network weights, through gradient descent on SNNs, providing a mechanism for online learning. Additionally, we have provided formulations for a variety of plasticity rules inspired by neuroscience literature, as well as general equations from which new plasticity rules may be defined. Using these rules, we demonstrated that synaptic plasticity is sufficient for solving a noisy and complex cue-association environment where a fixed-weight SNN fails. These networks also display an increased robustness to noise on a high-dimensional locomotion task. We also showed that the average spike-firing rate for DP-Oja's rule is reduced to the same observed rates seen in DP-BCM and NDP-BCM in the presence of a neuromodulatory signal, and hence more energy efficient. One potential limitation of this work is that, while gradients provide a strong and precise mechanism for learning in feed-forward and self-recurrent SNNs, there is no straightforward mechanism for backpropagating the gradients of feedback weights which are often incorporated in biologically-inspired network architectures. Another limitation is the computation cost associated with BPTT, which has a non-linear complexity with respect to weights and time. This limitation may be alleviated with truncated BPTT (Tallec and Ollivier, 2017), however this reduces gradient accuracy and hence often performance as well.
The incorporation of synaptic plasticity rules together with SNNs has a history that spans almost the same duration as SNNs themselves. The implications of a framework for learning these rules using the power of gradient descent may prove to showcase the inherent advantages that SNNs provide over ANNs on certain learning tasks. One task that may naturally benefit from this framework is in the domain of Sim2Real, where the behavior of policies learned in simulation are transferred to hardware. Often small discrepancies between a simulated environment and the real world prove too challenging for a reinforcement-trained ANN, especially on fine-motor control tasks. The improved response to noise displayed in our experimental results for DP-SNNs and NDP-SNNs on the robotic locomotion task may benefit the transfer from simulation to real hardware. Additionally, the inherent online learning capabilities of differentiable plasticity may provide a natural mechanism for on-chip learning in neurorobotic systems.
While our framework leverages the work of Miconi et al. (2019) to enter the SNN domain, this work also introduces novel results and further innovations. In the Miconi et al. (2019) experiments, results were shown for networks with plastic and neuromodulated synapses on only the recurrent weights. In their experiment, the cue association process was iterated for 200 time-steps without introducing any noise. They show that only modulatory variants of ANNs with fixed-feedforward weights and neuromodulated self-connecting recurrent weights are capable of solving this task. In our experiment, we extend a similar task to the spike domain and introduce a significant amount of sensory spike-noise. Additionally, the time dependency is more than doubled. We show that not only are neuromodulatory feedforward weights without recurrent self-connections capable of solving this task, but also that feedforward plastic weights are. We also show that the introduction of spike-noise does not decrease training convergence. On the cue association task, we show that with Oja's rule, neuromodulatory signals drastically reduce spike-firing rates compared with the non-modulatatory variant. This reduction in activity does not apply to BCM, which has a natural mechanism for both potentiation and depression. Finally, our experiments showcase a meta-learning capability to adapt beyond what the network had encountered during its training period on a high-dimensional robotic learning task.
While our experiments showcase the performance of BCM and Oja's plasticity rules, our proposed framework can be applied to a wide variety of plasticity rules described in both the AI and neuroscience literature. Our framework may also be used to experimentally validate biological theories regarding the function of plasticity rules or neuromodulatory signals. Furthermore, the modeling of neuromodulatory signals need not be learned directly through gradient descent. Our method can be extended to explicitly model neuromodulatory signals through a pre-defined global signal. Such signals might include: an online reward signal emulating dopaminergetic neurons [Hosp et al., 2011, Hosp et al. (2011)], error signals from a control system (Popa and Ebner, 2019), or a novelty signal for exploration (DeYoung, 2013). In addition, evidence toward biological theories regarding the function of plasticity rules or neuromodulatory signals may be experimentally validated using this framework. Finally, the addition of neural processes such as homeostasis may provide further learning capabilities when interacting with differentiable synaptic plasticity. The fruitful marriage between the power of gradient descent and the adaptability of synaptic plasticity for SNNs will likely enable many interesting research opportunities for a diversity of fields. The authors see a particular enabling potential in the field of neurorobotics.
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author/s.
Author Contributions
SS designed and performed the experiments as well as the analysis and wrote the paper with JH and JA being active contributors toward editing and revising the paper. WL also provided helpful editing of the manuscript. JH had the initial conception of the presented idea as well as having supervised the project. All authors contributed to the article and approved the submitted version.
Funding
This work was performed at the US Naval Research Laboratory under the Base Program's Safe Lifelong Motor Learning (SLLML) work unit, WU1R36.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fnbot.2021.629210/full#supplementary-material
References
Banino, A., Barry, C., Uria, B., Blundell, C., Lillicrap, T., Mirowski, P., et al. (2018). Vector-based navigation using grid-like representations in artificial agents. Nature 557, 429–433. doi: 10.1038/s41586-018-0102-6
Barth-Maron, G., Hoffman, M. W., Budden, D., Dabney, W., Horgan, D., Dhruva, T. B., et al. (2018). Distributed distributional deterministic policy gradients. arXiv preprint arXiv:1804.08617.
Bellec, G., Scherr, F., Subramoney, A., Hajek, E., Salaj, D., Legenstein, R., et al. (2020). A solution to the learning dilemma for recurrent networks of spiking neurons. Nat. Commun. 11:3625. doi: 10.1038/s41467-020-17236-y
Bellemare, M. G., Dabney, W., and Munos, R. (2017). A distributional perspective on reinforcement learning. arXiv preprint arXiv:1707.06887.
Bengio, Y., Lee, D.-H., Bornschein, J., Mesnard, T., and Lin, Z. (2015). Towards biologically plausible deep learning. arXiv preprint arXiv:1502.04156.
Bengio, Y., Mesnard, T., Fischer, A., Zhang, S., and Wu, Y. (2017). STDP-compatible approximation of backpropagation in an energy-based model. Neural Comput. 29, 555–577. doi: 10.1162/NECO_a_00934
Bienenstock, E., Cooper, L., and Munro, P. (1982). Theory for the development of neuron selectivity: orientation specificity and binocular interaction in visual cortex. J. Neurosci. 2, 32–48. doi: 10.1523/JNEUROSCI.02-01-00032.1982
Bohte, S. M., Kok, J. N., and La Poutre, H. (2002). Error-backpropagation in temporally encoded networks of spiking neurons. Neurocomputing 48, 17–37. doi: 10.1016/S0925-2312(01)00658-0
Carlson, K., Nageswaran, J., Dutt, N., and Krichmar, J. (2014). An efficient automated parameter tuning framework for spiking neural networks. Front. Neurosci. 8:10. doi: 10.3389/fnins.2014.00010
Cueva, C. J., and Wei, X.-X. (2018). “Emergence of grid-like representations by training recurrent neural networks to perform spatial localization,” in International Conference on Learning Representations.
Dabney, W., Kurth-Nelson, Z., Uchida, N., Starkweather, C. K., Hassabis, D., Munos, R., et al. (2020). A distributional code for value in dopamine-based reinforcement learning. Nature 577, 671–675. doi: 10.1038/s41586-019-1924-6
Davies, M., Srinivasa, N., Lin, T.-H., Chinya, G., Cao, Y., Choday, S. H., et al. (2018). Loihi: a neuromorphic manycore processor with on-chip learning. IEEE Micro 38, 82–99. doi: 10.1109/MM.2018.112130359
DeYoung, C. (2013). The neuromodulator of exploration: a unifying theory of the role of dopamine in personality. Front. Hum. Neurosci. 7:762. doi: 10.3389/fnhum.2013.00762
Diehl, P. U., Neil, D., Binas, J., Cook, M., Liu, S., and Pfeiffer, M. (2015). “Fast-classifying, high-accuracy spiking deep networks through weight and threshold balancing,” in 2015 International Joint Conference on Neural Networks (IJCNN) (Killarney: IEEE), 1–8. doi: 10.1109/IJCNN.2015.7280696
Doya, K. (1999). What are the computations of the cerebellum, the basal ganglia and the cerebral cortex? Neural Netw. 12, 961–974.
Doya, K. (2002). Metalearning and neuromodulation. Neural Netw. 15, 495–506. doi: 10.1016/S0893-6080(02)00044-8
Engelhard, B., Finkelstein, J., Cox, J., Fleming, W., Jang, H. J., Ornelas, S., et al. (2019). Specialized coding of sensory, motor and cognitive variables in VTA dopamine neurons. Nature 570, 509–513. doi: 10.1038/s41586-019-1261-9
Engstrom, L., Ilyas, A., Santurkar, S., Tsipras, D., Janoos, F., Rudolph, L., et al. (2020). Implementation matters in deep policy gradients: a case study on PPO and TRPO. arXiv preprint arXiv:2005.12729.
Eskandari, E., Ahmadi, A., Gomar, S., Ahmadi, M., and Saif, M. (2016). “Evolving spiking neural networks of artificial creatures using genetic algorithm,” in 2016 International Joint Conference on Neural Networks (IJCNN), 411–418. doi: 10.1109/IJCNN.2016.7727228
Frank, M. J., Seeberger, L. C., and O,Reilly, R. C. (2004). By carrot or by stick: cognitive reinforcement learning in parkinsonism. Science 306, 1940–1943. doi: 10.1126/science.1102941
Gerstner, W., Lehmann, M., Liakoni, V., Corneil, D., and Brea, J. (2018). Eligibility traces and plasticity on behavioral time scales: experimental support of neohebbian three-factor learning rules. Front. Neural Circ. 12:53. doi: 10.3389/fncir.2018.00053
Haarnoja, T., Zhou, A., Abbeel, P., and Levine, S. (2018). Soft actor-critic: off-policy maximum entropy deep reinforcement learning with a stochastic actor. arXiv preprint arXiv:1801.01290.
Hosp, J., Pekanovic, A., Rioult-Pedotti, M.-S., and Luft, A. (2011). Dopaminergic projections from midbrain to primary motor cortex mediate motor skill learning. J Neurosci. 31, 2481–2487. doi: 10.1523/JNEUROSCI.5411-10.2011
Hospedales, T., Antoniou, A., Micaelli, P., and Storkey, A. (2020). Meta-learning in neural networks: a survey. arXiv preprint arXiv:2004.05439.
Hu, Y., Tang, H., Wang, Y., and Pan, G. (2018). Spiking deep residual network. arXiv preprint arXiv:1805.01352.
Izhikevich, E., and Desai, N. (2003). Relating STDP to BCM. Neural Comput. 15, 1511–1523. doi: 10.1162/089976603321891783
Kheradpisheh, S. R., Ganjtabesh, M., Thorpe, S. J., and Masquelier, T. (2018). STDP-based spiking deep convolutional neural networks for object recognition. Neural Netw. 99, 56–67. doi: 10.1016/j.neunet.2017.12.005
Kingma, D. P., and Ba, J. (2014). ADAM: a method for stochastic optimization. arXiv preprint arXiv:1412.6980.
Kuśmierz, Ł., Isomura, T., and Toyoizumi, T. (2017). Learning with three factors: modulating Hebbian plasticity with errors. Curr. Opin. Neurobiol. 46, 170–177. doi: 10.1016/j.conb.2017.08.020
Law, C. C., and Cooper, L. N. (1994). Formation of receptive fields in realistic visual environments according to the Bienenstock, Cooper, and Munro (BCM) theory. Proc. Natl Acad. Sci. U.S.A. 91, 7797–7801. doi: 10.1073/pnas.91.16.7797
Lee, J. H., Delbruck, T., and Pfeiffer, M. (2016). Training deep spiking neural networks using backpropagation. Front. Neurosci. 10:508. doi: 10.3389/fnins.2016.00508
Liu, X., Ramirez, S., Pang, P. T., Puryear, C. B., Govindarajan, A., Deisseroth, K., et al. (2012). Optogenetic stimulation of a hippocampal engram activates fear memory recall. Nature 484, 381–385. doi: 10.1038/nature11028
Martin, S. J., Grimwood, P. D., and Morris, R. G. M. (2000). Synaptic plasticity and memory: an evaluation of the hypothesis. Annu. Rev. Neurosci. 23, 649–711.
Masquelier, T., Guyonneau, R., and Thorpe, S. J. (2009). Competitive STDP-based spike pattern learning. Neural Comput. 21, 1259–1276. doi: 10.1162/neco.2008.06-08-804
Miconi, T., Clune, J., and Stanley, K. O. (2018). Differentiable plasticity: training plastic neural networks with backpropagation. arXiv [Preprint]. arXiv:1804.02464.
Miconi, T., Rawal, A., Clune, J., and Stanley, K. O. (2019). “Backpropamine: training self-modifying neural networks with differentiable neuromodulated plasticity,” in International Conference on Learning Representations.
Mikaitis, M., Pineda Garcia, G., Knight, J. C., and Furber, S. B. (2018). Neuromodulated synaptic plasticity on the spinnaker neuromorphic system. Front. Neurosci. 12:105. doi: 10.3389/fnins.2018.00105
Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., et al. (2013). Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602.
Montague, P. R., Dayan, P., and Sejnowski, T. J. (1996). A framework for mesencephalic dopamine systems based on predictive hebbian learning. J. Neurosci. 16, 1936–1947. doi: 10.1523/JNEUROSCI.16-05-01936.1996
Mozafari, M., Ganjtabesh, M., Nowzari-Dalini, A., Thorpe, S. J., and Masquelier, T. (2018). Combining STDP and reward-modulated STDP in deep convolutional spiking neural networks for digit recognition. arXiv preprint arXiv:1804.00227. doi: 10.1016/j.patcog.2019.05.015
Niv, Y., Duff, M. O., and Dayan, P. (2005). Dopamine, uncertainty and TD learning. Behav. Brain Funct. 1, 6. doi: 10.1186/1744-9081-1-6
Oja, E. (1982). Simplified neuron model as a principal component analyzer. J. Math. Biol. 15, 267–273. doi: 10.1007/BF00275687
Pavlidis, N. G., Tasoulis, O. K., Plagianakos, V. P., Nikiforidis, G., and Vrahatis, M. N. (2005). “Spiking neural network training using evolutionary algorithms,” in Proceedings. 2005 IEEE International Joint Conference on Neural Networks, 2005 (Montreal, QC: IEEE), 2190–2194. doi: 10.1109/IJCNN.2005.1556240
Pfeiffer, M., and Pfeil, T. (2018). Deep learning with spiking neurons: opportunities and challenges. Front. Neurosci. 12:774. doi: 10.3389/fnins.2018.00774
Popa, L. S., and Ebner, T. J. (2019). Cerebellum, predictions and errors. Front. Cell. Neurosci. 12:524. doi: 10.3389/fncel.2018.00524
Rueckauer, B., Lungu, I.-A., Hu, Y., Pfeiffer, M., and Liu, S.-C. (2017). Conversion of continuous-valued deep networks to efficient event-driven networks for image classification. Front. Neurosci. 11:682. doi: 10.3389/fnins.2017.00682
Schmidgall, S. (2020). “Adaptive reinforcement learning through evolving self-modifying neural networks,” in Proceedings of the 2020 Genetic and Evolutionary Computation Conference Companion, GECCO '20 (New York, NY: Association for Computing Machinery), 89–90. doi: 10.1145/3377929.3389901
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. (2017). Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347.
Schultz, W., Dayan, P., and Montague, P. R. (1997). A neural substrate of prediction and reward. Science 275, 1593–1599. doi: 10.1126/science.275.5306.1593
Shouval, H., Intrator, N., Law, C., and Cooper, L. (1970). Effect of binocular cortical misalignment on ocular dominance and orientation selectivity. Neural Comput. 8, 1021–1040. doi: 10.1162/neco.1996.8.5.1021
Shrestha, S. B., and Orchard, G. (2018). “SLAYER: spike layer error reassignment in time,” in Proceedings of the 32nd International Conference on Neural Information Processing Systems, 1419–1428.
Sporea, I., and Grüning, A. (2012). Supervised learning in multilayer spiking neural networks. arXiv preprint arXiv:1202.2249. doi: 10.1162/NECO_a_00396
Tallec, C., and Ollivier, Y. (2017). Unbiasing truncated backpropagation through time. arXiv preprint arXiv:1705.08209.
van Albada, S. J., Rowley, A. G., Senk, J., Hopkins, M., Schmidt, M., Stokes, A. B., et al. (2018). Performance comparison of the digital neuromorphic hardware spinnaker and the neural network simulation software nest for a full-scale cortical microcircuit model. Front. Neurosci. 12:291. doi: 10.3389/fnins.2018.00291
Wang, J. X., Kurth-Nelson, Z., Kumaran, D., Tirumala, D., Soyer, H., Leibo, J. Z., et al. (2018). Prefrontal cortex as a meta-reinforcement learning system. Nat. Neurosci. 21, 860–868. doi: 10.1038/s41593-018-0147-8
Zaninetti, M., Tribollet, E., Bertrand, D., and Raggenbass, M. (1999). Presence of functional neuronal nicotinic acetylcholine receptors in brainstem motoneurons of the rat. Eur. J. Neurosci. 11, 2737–2748.
Keywords: spiking neural network, plasticity, neuromodulation, reinforcement learning, backpropagation, temporal learning, motor learning, robotic learning
Citation: Schmidgall S, Ashkanazy J, Lawson W and Hays J (2021) SpikePropamine: Differentiable Plasticity in Spiking Neural Networks. Front. Neurorobot. 15:629210. doi: 10.3389/fnbot.2021.629210
Received: 13 November 2020; Accepted: 11 August 2021;
Published: 22 September 2021.
Edited by:
Ganesh R. Naik, Western Sydney University, AustraliaReviewed by:
Claudia Casellato, University of Pavia, ItalySumit Bam Shrestha, Intel, United States
Vikas Bhandawat, Drexel University, United States
Erik Christopher Johnson, Johns Hopkins University, United States
Copyright © 2021 Schmidgall, Ashkanazy, Lawson and Hays. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Joe Hays, am9lLmhheXNAbnJsLm5hdnkubWls