 Wataru Ohata
Wataru Ohata Jun Tani
Jun Tani
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Neurorobot., 07 September 2020
Volume 14 - 2020 | https://doi.org/10.3389/fnbot.2020.00061
This article is part of the Research TopicClosing the Loop: From Human Behavior to Multisensory RobotsView all 5 articles
When agents interact socially with different intentions (or wills), conflicts are difficult to avoid. Although the means by which social agents can resolve such problems autonomously has not been determined, dynamic characteristics of agency may shed light on underlying mechanisms. Therefore, the current study focused on the sense of agency, a specific aspect of agency referring to congruence between the agent's intention in acting and the outcome, especially in social interaction contexts. Employing predictive coding and active inference as theoretical frameworks of perception and action generation, we hypothesize that regulation of complexity in the evidence lower bound of an agent's model should affect the strength of the agent's sense of agency and should have a significant impact on social interactions. To evaluate this hypothesis, we built a computational model of imitative interaction between a robot and a human via visuo-proprioceptive sensation with a variational Bayes recurrent neural network, and simulated the model in the form of pseudo-imitative interaction using recorded human body movement data, which serve as the counterpart in the interactions. A key feature of the model is that the complexity of each modality can be regulated differently by changing the values of a hyperparameter assigned to each local module of the model. We first searched for an optimal setting of hyperparameters that endow the model with appropriate coordination of multimodal sensation. These searches revealed that complexity of the vision module should be more tightly regulated than that of the proprioception module because of greater uncertainty in visual information flow. Using this optimally trained model as a default model, we investigated how changing the tightness of complexity regulation in the entire network after training affects the strength of the sense of agency during imitative interactions. The results showed that with looser regulation of complexity, an agent tends to act more egocentrically, without adapting to the other. In contrast, with tighter regulation, the agent tends to follow the other by adjusting its intention. We conclude that the tightness of complexity regulation significantly affects the strength of the sense of agency and the dynamics of interactions between agents in social settings.
Humans are social beings by nature, and each individual regularly interacts with others in various ways. Even though individuals act based on their intentions or wills, they sometimes acts in agreement with others, doing something collaboratively, while at other times they disagree. Either case may be conscious or unconscious. What determines such the type of interaction and how? To evaluate this problem, we consider possible relationships between agency of each individual and social interactions between individuals. Then, we introduce predictive coding and active inference to formulate the problem in a computational framework and we propose a specific hypothesis to predict the type of interaction. We deliver a schematic of our computational model and experimental setup to evaluate the hypothesis and conclude the section by highlighting some critical findings.
In social interactions, agents sometimes cooperate by sharing intentions so as to derive mutual benefits, while at other times they cause conflicts by following their own intentions and ignoring the interests of others. Although how such complexities in social interactions emerge is not obvious, we hypothesized that dynamic characteristics of agency in social interactions might shed light on underlying mechanisms. Recently, the study of agency has attracted considerable attention from researchers in various disciplines, including philosophy, psychology, cognitive science, and neuroscience. Specifically, the sense of agency (SoA) (Gallagher, 2000; Synofzik et al., 2008; Moore et al., 2009) refers to congruence between an agent's intention or belief in an action and its anticipated outcome, which endows the agent with the sense that “I am the one generating this action”. Along with studies in experimental psychology, building a computational model of SoA is also important in order to explore the nature of agency (Legaspi and Toyoizumi, 2019). In the study of computational models of agents, predictive coding (PC) (Rao and Ballard, 1999; Tani and Nolfi, 1999; Lee and Mumford, 2003; Friston, 2005, 2018; Hohwy, 2013; Clark, 2015) and active inference (AIF) (Friston et al., 2009, 2010; Baltieri and Buckley, 2017; Buckley et al., 2017; Pezzulo et al., 2018; Oliver et al., 2019) have recently attracted considerable attention since they provide rigid theoretical frameworks for defining perception and action generation. In the framework of PC and AIF, an agent's intention or belief can be formulated as a predictive model, and it is thought that congruence between the prediction of action outcomes and observations reinforces the SoA (Friston, 2012).
In situations involving social interaction, however, where multiple agents interact, it becomes challenging for each agent to sustain its SoA, because other agents, having their own intentions, may not act as desired. If social agents are required to coordinate actions so as to obtain benefits by minimizing possible conflicts, we speculated that the strength of agency should be arbitrated among those agents during some conflicts. Let us consider a dyadic synchronized imitation as an example of social interaction, wherein two agents attempt to synchronously imitate one another's movement patterns using predictions based on prior learning. In addition, let us assume a setting in which two agents imitate one another in sequences of movement patterns based on memorized transition rules, in which unpredictable transitions in movement patterns are included. For example, either movement pattern B or C can appear after movement pattern A (see also section 3.2). In this setting, agent 1 may opt for movement pattern B after A, acting as a leader with strong agency and agent 2 may just follow agent 1 by generating pattern B with weak agency. This can result in successful mutual imitation without generating conflict. However, if both agents maintain strong agency, each may generate its own pattern (B or C) without compromise, resulting in conflict.
While investigating agency in social interactions, we concluded that it would also be worthwhile to consider how agency and mirror neuron systems (MNS) (Kilner et al., 2007; Rizzolatti and Fogassi, 2014) might be related, since MNS are thought to contribute to various types of social cognitive behavior, including imitation (Hurley, 2005). MNS was first discovered in area F5 of the monkey premotor cortex (Di Pellegrino et al., 1992; Gallese et al., 1996), and it is activated when monkeys execute their own actions, as well as when observing those performed by others. Because MNS uses observations of an action to generate the same action, it may participate in imitative behaviors, which are thought to be the basis of various higher cognitive functions (Kohler et al., 2002; Oztop et al., 2006, 2013; Aly and Tapus, 2015). A natural question regarding such an MNS mechanism is how the agency of each individual can be exerted if MNS is the default mode. Intention to generate an action could conflict with an automatic response to imitate an action demonstrated by others. Although modeling studies of MNS have also been conducted from the view point of PC and AIF using Bayesian frameworks (Kilner et al., 2007; Friston et al., 2011) and by using deterministic recurrent neural networks (RNNs) (Ito and Tani, 2004; Ahmadi and Tani, 2017; Hwang et al., 2020), the aforementioned problem of agency has not been well-considered.
Next, let us consider how the strength of agency can be modeled using a framework of PC and AIF. For this purpose, first we briefly review the concepts of PC and their mathematical properties, as follows. In PC, perception is thought to be achieved via iterative interactions between a prior expectation of a sensation and a posterior inference from a sensory outcome. The prior expectation of the sensation can be modeled by statistical generative models that map the prior of the latent variable to the sensory expectation. The posterior inference can be carried out by taking the error between the expected sensation and its outcome and by updating the posterior of the latent variable in the direction of minimizing the error, under the constraint of minimizing Kullback-Leibler divergence (KL divergence) between the posterior distribution and that of the prior. Typically, both the prior and the posterior are represented by Gaussian distributions with parameters of mean and variance, as will be described later. This is equal to maximizing the lower bound of the logarithm of marginal likelihood (a.k.a evidence lower bound) expressed by two terms: accuracy and complexity.
where X is the observation, z is the latent variable, qϕ(z|X) is the approximate posterior, and θ and ϕ are the parameters of the model. Accuracy is the expectation of log-likelihood with respect to the approximate posterior, which represents reconstruction of the observation with the approximate posterior. Complexity is the KL divergence between the approximate posterior and the prior, which serves to regularize the model. Importantly, in maximizing the lower bound, the interplay between these two terms characterizes how the model behaves in learning and prediction (Higgins et al., 2017). Maximization of the lower bound is equivalent to minimization of free-energy proposed by (Friston, 2005).
Next, AIF is described briefly. AIF explains that action or motor commands should be generated so that their sensory outcomes coincide with expected outcomes. As a simple example, consider how expected proprioception in terms of robot joint angles can be achieved by generating sufficient motor torque. This can be done with an inverse model that maps expected joint angles to the required motor torques, or by employing a PID controller such that necessary motor torque to minimize errors between expected joint angles and actual angles can be derived by means of a simple error feedback mechanism. Both PC and AIF attempt to minimize error between the expected sensation and the actual outcome; however, in PC this is accomplished by changing the intention via the posterior inference and by changing the environment state through action in AIF. When PC and AIF are performed in tandem, while an agent acts on the environment, an agent with a more precise prior (smaller variance) should behave with strong agency, being less likely to change its own intention, and more likely to change the environmental state. On the other hand, an agent with a less precise prior (with larger variance) should behave with weaker agency, being more likely to change its own intention than the environmental state.
Although PC and AIF have attracted much attention from brain modeling researchers, it is unusual to see them used in computational studies employing learnable neural network models, especially those that can handle continuous spatio-temporal patterns characterized in multimodal sensory inputs. To this intent, Ahmadi and Tani (Ahmadi and Tani, 2019) recently proposed so-called, Predictive-coding-inspired Variational Recurrent Neural Network (PV-RNN). PV-RNN is a type of variational recurrent neural network that approximates the posterior at each time step in sequential patterns with variational inference, and is formalized by employing predictive coding. By making predictions in the form of the sequential prior (Chung et al., 2015) with time-varying parameterized Gaussian distribution, PV-RNN enables the model to represent strength of intention or agency. (Ahmadi and Tani, 2019) introduced a hyper parameter w called the meta-prior, which weights regulation of the complexity term in the evidence lower bound (the second term in Equation 2). They found that a model trained with looser regulation of the complexity term, achieved by setting the meta-prior to a larger value, develops more deterministic dynamics with higher estimated precision in the sequential prior, whereas a model trained with tighter regulation, accomplished by setting the meta-prior to a smaller value, develops more probabilistic dynamics with lower estimated precision. In another attempt to implement free-energy minimization with an artificial neural network, (Pitti et al., 2020) proposed a spiking neural network architecture that minimizes free-energy to model the fronto-striatal system in the brain.
(Chame and Tani, 2019) used PV-RNN to conduct a human-robot interaction experiment using a single perceptual channel of proprioception. Although their analysis of the experiments was preliminary, they suggested that when the model is trained under looser regulation of the complexity term, the model tends to behave egocentrically, adapting less to proprioceptive inputs, whereas under tighter regulation of the complexity term, the network tends to behave more passively, adapting more to proprioceptive inputs. However, such network characteristics, once developed through learning under particular conditions to regulate the complexity term, cannot be changed thereafter. In social interactions, it is natural that agents act differently, depending on the social context at a given moment. Sometimes they tend to preserve their prior intention by acting perversely, and at other times they change it more easily by adapting to intentions of others. The current study examines whether such shifts in strength of agency can be achieved during the interaction phase by changing the value of the meta-prior from the default strength set in the learning phase.
Here, we explain the general concept underlying our computational model, experimental design, and obtained results. We first proposed an artificial neural network model that can be applied to an imitative interaction task using multimodal sensation of vision and proprioception by extending PV-RNN. PV-RNN is used because to our knowledge this network model is the only RNN-type model that can instantiate predictive coding and active inference in a continuous spatio-temporal domain by following a Bayesian framework. The proposed model is comprised of a multi-layered PV-RNN with a branching structure, in which two branches responsible for perception of vision and proprioception are connected through an associative module. In addition, the current model inherits the structure of Multiple Timescale Recurrent Neural Network (MTRNN) (Yamashita and Tani, 2008). MTRNN extracts a temporal hierarchy contained in sequential patterns (Yamashita and Tani, 2008; Nishimoto and Tani, 2009; Hwang et al., 2020). By assigning faster timescales to the peripheral sensory modules for vision and proprioception and slower timescales to the associative module, hierarchical multimodal integration from sensory-motor levels to abstract intention levels should be achieved.
The entire network model is considered a generative model that predicts incoming visual sensation and proprioception simultaneously through a generative process along with a top-down pathway from the associative module to both of the sensory modules. The resultant prediction error for each sensory modality is back-propagated through time (Werbos, 1974; Rumelhart et al., 1985) (BPTT) and through each module to the associative module, by which the latent state in each module is modulated so as to maximize the evidence lower bound shown in the Equation (2). This corresponds to the posterior inference. The network is trained through supervised learning by maximizing the evidence lower bound.
However, coordinating multimodal sensations appropriately is still not an easy problem when intrinsic complexity and randomness in spatio-temporal patterns differ in each modality (Ogata et al., 2010; Valentin et al., 2019). Studies on cue integration in multimodal sensation have shown that inferences about the hidden state of the environment should be accomplished by assigning the greatest weight to information obtained from the most reliable sensory modality (Battaglia et al., 2003). In predictive coding, reliability can be represented by the accuracy estimated for each modality of the sensory model, provided that its generalization is preserved by minimizing model complexity adequately when the amount of training data is limited. We speculate that the complexity term should be regulated adequately for each sensory modality during training, such that the best generalization can be achieved for each. Since each PV-RNN module can be assigned different values of the meta-prior, the above could be achieved by searching for an adequate value of each meta-prior though trial and error during the learning phase.
The proposed model was evaluated by simulating “pseudo” imitative interaction using visuo-proprioceptive sequence patterns recorded from human demonstrators. Although human-robot interaction should be studied in a physical system to allow the human and the robot to respond to each other in an online fashion, it is difficult for the current system to work in real time because inference of the posterior using PV-RNN is computationally intensive, especially when pixel-level vision is used as one of the sensory modalities. Therefore, the current study focuses on simulation experiments using pre-recorded data.
First, we investigated how changing the tightness used to regulate the complexity term for each sensory module in the learning phase affects the quality of integrating multimodal sensation in an imitative interaction. For this purpose, we examined possible effects of assigning different values of the meta-prior to the vision module and the proprioceptive module, on performance characteristics in learning, as well as in the resulting imitative interaction. Our results suggest that regulating complexity more in the vision module than in the proprioception module facilitates better imitation performance in multi-modal sensation after learning, because visual sensory information contains more randomness than proprioceptive information.
Second, as the main motivation of the current study, we investigated how changing the tightness used to regulate the complexity term in the entire network after the learning phase affects the strength of agency. Using a network trained by tuning the meta-priors assigned to each sensory module in the previous experiment, we examined how increasing or decreasing meta-prior values throughout the network compared to those used during learning affects imitative behavior. We found that a network that tightly regulates the complexity term by setting smaller values of the meta-prior tends to follow human movement patterns by adapting its internal states. On the other hand, the network that loosely regulates the complexity term by setting larger values of the meta-prior tends to generate more egocentric/self-centered movement patterns with less sensitivity to changes or fluctuations in human movement patterns by adapting its internal state less. The current paper presents a detailed analysis of the underlying mechanisms accounting for these observed phenomena.
Below, the Model section details the proposed model. It describes an overall system, learning process, derivation of the evidence lower bound of the proposed model, how the trained model was tested in pseudo imitative interaction, and implementation of the model. The Experiment section explains the experimental design, procedures of data preparation, and the results of the two experiments. The Discussion section summarizes the experimental results and discusses their implications.
This subsection describes briefly how multimodal imitative interaction of agents perceiving visuo-proprioceptive sensory inputs can be modeled using concepts of predictive coding and active inference. Among various types of imitation, synchronized imitation is considered in the current study by virtue of its simplicity. In synchronized imitation, the agent is required to imitate target patterns demonstrated by its counterpart by predicting them on the basis of prior learning. Although target patterns to imitate are structurally the same as previously learned patterns, they could involve marginal variations, as in speed, amplitude, and shape. Synchronized imitation can be achieved by means of iterative cycling of sensory input predictions during the demonstration, generation of corresponding movement, and updating the latent state of the network using the resulting sensory prediction error. To generate movement, one step, look-ahead prediction of proprioception is fed into an inverse model (Kawato et al., 1987), which is often implemented by a PID feedback controller in robots. A PID feedback controller computes an optimal motor torque as the motor command to minimize the error between the predicted proprioception (the target joint angles) and the actual proprioception (the actual joint angles). This corresponds to active inference (Friston et al., 2010, 2011), as described previously. The latent state can be updated using a scheme called error regression (Tani and Nolfi, 1999; Ito and Tani, 2004; Ahmadi and Tani, 2019; Hwang et al., 2020), by which sensory perception assumed in a predictive coding framework can be performed.
Now we look at how the PV-RNN (Ahmadi and Tani, 2019) can be used to implement the model for multimodal imitative interaction of a robot agent receiving visuo-proprioceptive sensory inputs based on frameworks of predictive coding and active inference. Figure 1 shows the overall system view, consisting of a PV-RNN, a robot, and a human counterpart. The human demonstrates movement patterns to the robot both visually and kinesthetically, guiding the robot's posture via a motion capture suit. Unfortunately, it was infeasible for the proposed system to work stably in real-time because posterior inference using an error-regression scheme, detailed in section 2.4, requires intensive computation. Hence, in the current study, we simulated the imitative interaction between a human and a robot shown in Figure 1 as a pseudo imitative interaction in which pre-recorded body movements sampled from a human serve as the robot counterpart using the setting shown in Figure 1C.
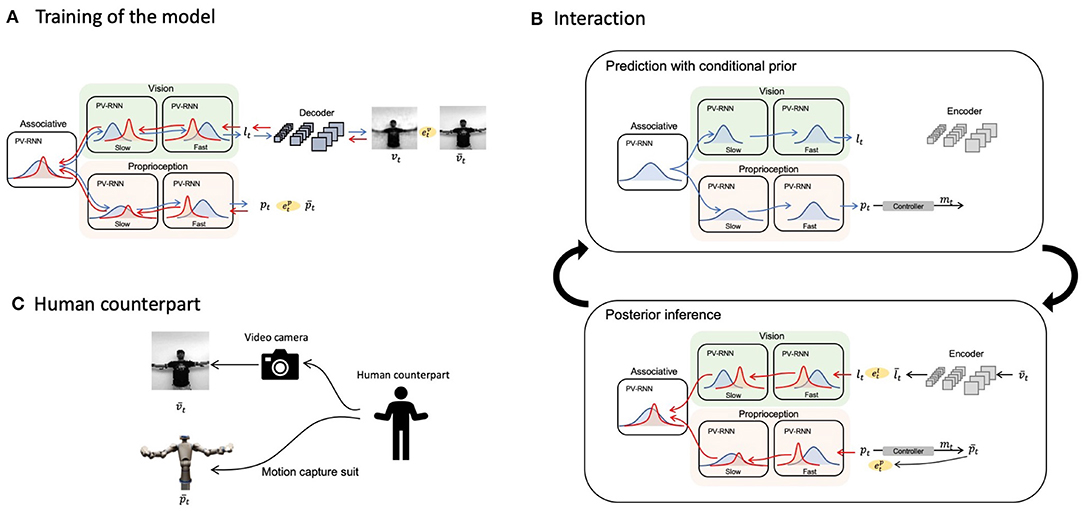
Figure 1. Overall schematic of the proposed model. Blue and red bell curves represent prior and posterior distributions, respectively. Blue and red arrows illustrate information flows of the prediction with conditional prior and posterior inferences, respectively. (A) The training scheme of the proposed network model. (B) The cycle of prediction with conditional prior and posterior inferences during an interaction with a human. (C) A diagram of providing the configuration of a human counterpart to the network.
PV-RNN is considered a generative model, formulated in a continuous spatio-temporal domain, employing a variational Bayes framework, as described previously. It infers the posterior at each time step using variational inference, in which the reconstruction error is minimized with regularization of the KL divergence between the inferred posterior and the conditional prior. This is implemented by means of a so-called error-regression scheme, detailed in section 2.4.
A PV-RNN inherits the concept of a Multiple Timescale Recurrent Neural Network (MTRNN)(Yamashita and Tani, 2008), which is characterized by its architecture because it allocates different timescale dynamics to different layers. Higher layers are endowed with slower timescale dynamics and lower layers with faster dynamics, as inspired by recent cognitive neuroscience evidence (Newell et al., 2001; Huys et al., 2004; Smith et al., 2006; Kording et al., 2007). Introduction of multiple timescale dynamics can enhance abstraction and generalization in learning by extracting action-primitive hierarchies or chunking structures from observed multimodal sensory inputs (Yamashita and Tani, 2008; Choi and Tani, 2018; Hwang et al., 2020).
These characteristics of variational Bayes frameworks and MTRNN enable PV-RNN to utilize hierarchically organized probabilistic representation, i.e., while the network extracts a hierarchical structure from an observation, it also assigns a different degree of uncertainty within the hierarchy. For example, given a task in which the network is required to predict a sequence of body movements comprised of a small number of primitive patterns, the network can be certain about details of the primitive patterns, but less certain about the sequence of the primitives. In such a case, the lower level of the network responsible for prediction of details of each primitive movement shows small uncertainty, while the higher level in charge of prediction of the order of those primitive patterns shows high uncertainty.
Sensory modules for proprioception and vision were modeled with multi-layered PV-RNNs and modules were connected via an associative module, also based on a PV-RNN. Figure 1A depicts a schematic of the proposed model and how it is trained. The associative module generates the prior, conditioned by the latent state at the previous time step in this module. The prior is then fed to both the proprioception and vision modules along the top-down pathway. Each sensory module also generates a prior at each time step conditioned by the previous latent state of the module, computed using top-down information provided by the associative module, by which predictions of sensory inputs, proprioception and vision, are generated in the subsequent time step. Note that the vision module predicts a low-dimensional vector, which is then fed to a CNN-type decoder (LeCun et al., 1989, 1998) to generate actual pixel visual images, in order to reduce computational costs.
A dataset of visuo-proprioceptive patterns demonstrated by human participants is used to train the model. To generate these data, a human wearing a motion-capture suit demonstrates body movements while simultaneously recording a video. The motion capture suit maps the human's body configuration into the humanoid robot's joint angle values. These synchronized joint-angle trajectories and videos serve as the target of the model. The whole network is optimized simultaneously so as to maximize the evidence lower bound of the model via BPTT. The design of body movement patterns used in this study is detailed in section 3.2.
Figure 1B describes how the trained model performs imitative interactions. An imitative interaction involves a cycle of predictions with conditional prior and posterior inferences. At each time step, the network predicts proprioception pt and a low-dimensional latent representation of vision lt with the prior conditioned by the latent variable in each module at the previous time step. The proprioceptive prediction pt is supplied to the controller, followed by computation of motor commands mt to achieve the expected joint positions and generation of the movement. Then, a new visual image and proprioception are acquired. The raw pixel image is fed to a CNN-type encoder that has been separately trained to obtain the target for the low-dimensional latent representation . Resultant prediction errors and are computed in vision and proprioception, respectively, which are then used to infer the posterior in each PV-RNN layer with regulation of the KL divergence between the inferred posterior and the conditional prior so that the lower bound is maximized by BPTT. This optimization process to infer the posterior is iterated a fixed number of times at each sensory-motor sampling time step, and the optimized posterior is used to make the best prediction with the conditional prior to the succeeding time step.
Figure 1C denotes how the robot's network model senses movement patterns demonstrated by the human counterpart.
PV-RNN is a generative, inference model based on the graphical representation shown in Figure 2 (this figure will be explained in detail in section 2.4). It is comprised of deterministic variables d, i.e., assumed to follow Dirac delta distributions, and stochastic variables z. The model includes a prior and infers the corresponding posterior by variational inference. We modified the original PV-RNN at four points with respect to dependencies of variables. First, in our model, there are no connections between the output of the network x and z, which exist in the original PV-RNN. This is for simplification of the model, and it was confirmed that removing these connections did not hinder network performance. Second, the current network does not have connections from the lower layer to the higher layer, which the original network does have. This modification is intended to separate more clearly the information flow between top-down generative prediction and bottom-up error propagation. Third, diagonal connections from the higher layer during the previous time step to the lower layer during the succeeding time step are changed to vertical connections during the same time step. Last, the prior distribution of zt at time step 1 has been changed. In the original study, the distribution is simply mapped from d0. In the current study, however, it is assumed that p(z1) follows a unit Gaussian distribution to control the initial sensitivity of the model. Following derivation of the evidence lower bound in (Ahmadi and Tani, 2019) and considering the introduction of the unit Gaussian at time step 1, the evidence lower bound of the proposed visuo-proprioceptive model is derived as
where A, P, and V represent the associative module, the proprioception module, and the vision module, respectively, and l indicates the index of a layer in each module. p1:T and v1:T are time series propriocetive and visual patterns. represents d in all layers at time step 0. denotes the expectation over all distributions of z in the associative module and the proprioception module, and denotes expectation over all distributions of z in the associative module and the vision module. is the deterministic variable in the lowest layer of the proprioception module at time step t, and is that in the lowest layer of the vision module. is the stochastic variable at time step t in the lth layer in each module. and are the prediction errors between the predicted patterns and the target patterns at time step from t to T in proprioception and vision, respectively. p(zu) indicates the unit Gaussian distribution serving as the prior at time step 1. By introducing the meta-prior, which weights the KL divergence between the approximate posterior and the prior in a layer-specific manner, the evidence lower bound of the model is defined as
where indicates the meta-prior in the lth layer at t = 1 in the associative module, the proprioception module, and the vision module, respectively. wl represents the meta-priors in the lth layer after t = 2 in each module. Parameters of the model are optimized by maximizing the lower bound, which corresponds to minimizing the free energy.
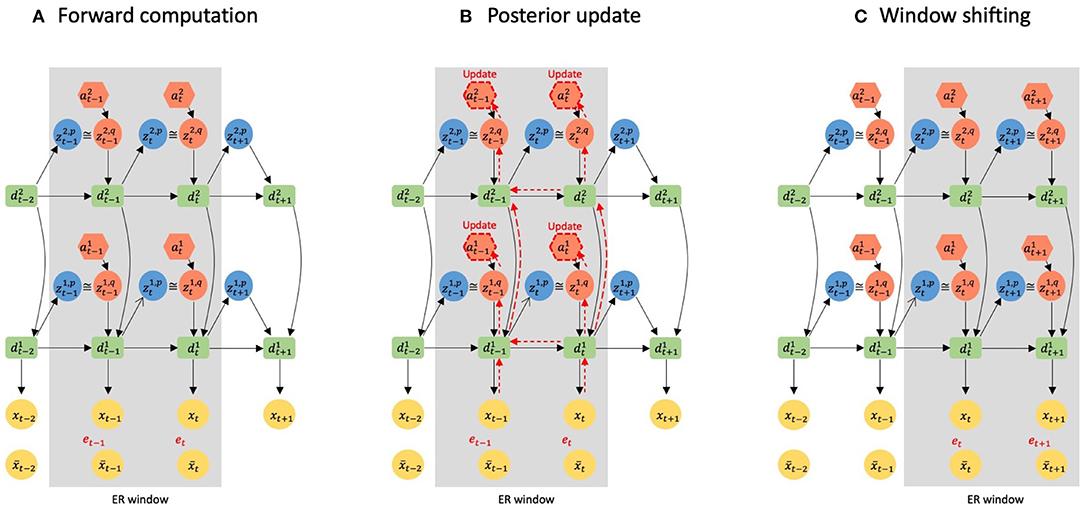
Figure 2. A graphical representation of error-regression with a shifting window. The gray area represents the ER window. Black arrows indicate forward computations. Red arrows indicate how reconstruction errors are propagated to a inside the ER window by BPTT. (A) illustrates the information flow of forward computation at time step t. (B) Shows the update of the posterior inside the ER window at time step t. (C) Shows the window shifting to time step t + 1.
It is noted that unlike other models employing online learning methods (Boucenna et al., 2014, 2016), our model is trained offline with pre-recorded dataset. The entire network model is trained by maximizing the evidence lower bound. Thus, given the time step length T of proprioceptive patterns p1:T and visual patterns v1:T, the cost function to be minimized is defined as
where A, P, and V represent the associative module, the proprioception module, and the vision module. Rp and Rv are the dimensions of proprioceptive patterns and visual patterns to normalize prediction errors, and Rl is the dimension of the distributions of z to normalize the KL divergence. Each output in the vision and proprioceptive modules is represented by a multivariate Gaussian distribution with an estimation of the mean for each dimension and covariant matrix as the identity matrix, for simplicity. This leads to minimization of the mean squared error, which is an estimator of the log-likelihood in the accuracy term when maximizing the lower bound.
Since the prior and posterior distributions are assumed to follow a multivariate Gaussian distribution with a diagonal covariant matrix, the KL divergence in the cost function is analytically computed. Given two n dimensional multivariate Gaussian distributions and where and ,
The parameters of the model, including an adaptive variable a introduced in the following section, are optimized using BPTT. To perform error-regression explained in section 2.4, an encoder was also trained separately.
(Ahmadi and Tani, 2019) proposed a scheme, the error-regression (ER) with shifting window to test the trained model in a way that is consistent with concepts of predictive coding and active inference. In this scheme, the trained network attempts to predict sensory inputs in the next time step while inferring the posterior in the immediate past window of a fixed length, using the reconstruction error in the window. The window is referred to as the ER window in the following. It is essential to note that ER for maximizing the evidence lower bound is conducted by iterating two processes of forward computation (Figure 2A) and posterior update (Figure 2B) for specific times at each sensory sampling time step.
PV-RNN has unique variables a that facilitate updating the posterior. a is time step-specific and has the same dimension as z in each PV-RNN layer. In other words, when a PV-RNN layer with z with its dimensionality n tries to infer the posterior for the last T time steps inside the ER window, the PV-RNN layer has n × T a valuables and updates them to modify the representation of the posterior. A detailed computation scheme of the posterior using the adaptive variable a is found in section 2.5. Importantly, in ER, weights and biases of the network are fixed, and only the adaptive variables a are updated.
Let us consider an example of error-regression in which the length of the ER window is two time steps, and the network has two layers, as shown in Figure 2. Figure 2A illustrates the forward computation at time step t to infer the posterior. In the forward computation, the network computes the conditional prior, p(zt−1|dt−2) and p(zt|dt−1), and the posterior, q(zt−1|dt−2, et−1:t) and q(zt|dt−1, et) in each layer, and generates the prediction with sampling from the posterior distribution inside the window. Then, the reconstruction error et−1 and et, and the KL divergence between respective pairs of the conditional prior and posterior are computed.
Based on the reconstruction error and KL divergence, the inferred posterior is updated to maximize the evidence lower bound. Figure 2B illustrates how the reconstruction error is back-propagated through variables and layers to a, which is responsible for updating the posterior. Using the updated posterior, the network again performs the forward computation. It should be noted that since the q(zt−1|dt−2, et−1:t) has been updated, dt−1 is different from the one before the update; thus, p(z|dt−1) is also changed through the posterior update. The reconstruction error and the KL divergence are further computed, and the posterior is updated. This iterative process of forward computation and posterior update is repeated a fixed number of times to optimize the approximate posterior for maximizing the evidence lower bound computed with given meta-prior values.
After finishing all iterations, the network generates a new sensory prediction xt+1 with a conditional prior using the inferred posterior inside the ER window. Then the ER window shifts one time step and the next target sensation xt+1 is sampled, and the forward computation and the posterior update are reiterated at time step t + 1. In the proposed model, the ER is performed for both visual sensation and proprioception simultaneously, and this scheme of using ER with a shifting window was used to test an imitative interaction after training the entire network, as will be described later.
The proposed model for the imitative interaction via visuo-proprioceptive sensation consists of three modules: an associative module, a proprioception module, and a vision module. This subsection describes a detailed computation scheme in each module.
The associative module is comprised of a PV-RNN. Since we adopted an MTRNN computation scheme in PV-RNN, its computations are as follows.
where is the sum of inputs to lth layer of the associative module. , , and are weight matrices for recurrent connections, the stochastic variable z, and the input from the higher layer, respectively. ba, l is the bias in the lth layer in the associative module, and τa, l is the time constant for MTRNN computation in the lth layer of the associative module. tanh is the activation function. The stochastic variable z is assumed to follow a multivariate Gaussian distribution with a diagonal covariant matrix, and the deterministic variable d predicts mean μ and variance σ of the distribution. That is, for computation of the prior,
where and are the mean and variance for the prior distribution of at time step t in lth layer in the associative module. and are the weight matrices for . and are the biases for each computation. tanh in computation of mean is used for stability of optimization, and exp in σ is for variance to be positive. ϵ is sampled from . To approximate the posterior, PV-RNN has adaptive variables a that are specific to time step and sequence. a is optimized during learning with the prediction error via BPTT. By considering a, the computations of posterior are
where and are mean and variance for the posterior distribution of at time step t in lth layer in the associative module. Note that the weight matrices for d are different from those used to compute the prior. In addition, unlike the peripheral sensory modules of proprioception and vision, the associative module does not predict the sensory output directly, but rather predicts the latent representation of visuo-proprioceptive sequences. Therefore, the weights and biases, as well as the adaptive variable a of the associative module are not optimized instantly from the reconstruction error of the sensory outcomes, but from the error signals mediated through each sensory module.
Proprioceptive patterns are directly generated from the PV-RNN. The highest layer in the proprioception module receives the input from the lowest layer in the associative layer, and its computations are
A proprioceptive pattern at time step t, pt, is generated from the lowest layer of the proprioception module.
For the vision module, a scheme to reduce the computation time is introduced. As described in section 2.4 above, in the proposed imitative interaction scheme, the network is required to infer the posterior for the immediate past at every sensory sampling time step by repeating forward computation and BPTT, which demands intensive computation. Nevertheless, our model is expected to work in actual robots in real-time in the future, which necessitates reducing the model's computational complexity. To reduce the computational demand in the posterior inference in visual perception, we consider a composite network combining a dynamic PV-RNN and static CNNs for decoding and encoding pixel patterns, instead of introducing full recurrent connections in this module. In this composite network, when generating predictive output for the visual input, the PV-RNN part predicts the latent state representation with a relatively low dimension, which is fed to a CNN decoder to generate the corresponding visual pixel image. On the other hand, when receiving the visual input, it is transformed to the latent state representation by a CNN encoder. Then, the prediction error can be computed as the discrepancy in the latent state with a low dimension rather than at the pixel level with high dimension. This reduces the computational burden significantly for conducting the BPTT to infer the posterior during imitative interaction. As in the proprioception module, the highest layer of the vision module receives input from the lowest layer of the associative layer, and its computations are
Then the lowest layer of the PV-RNN predicts the latent state lt at time step t, and the visual pattern vt is generated by the decoder.
In the imitative interaction, the target of latent dynamics of visual patterns at time step t is computed by the encoder.
To improve the generalization capability of the encoder and decoder, CoordConv architecture (Liu et al., 2018) was introduced.
Using the proposed model, imitative interaction experiments considering human-robot interactions were conducted. Although human-robot interactions ought to be studied in an online fashion to reflect human behavior in response to robot actions, because of the intensive computation required in the error regression scheme, we could not conduct such experiments online. Therefore, the current study examined only the dynamic response of the model network using recorded sequences of visuo-proprioceptive patterns. Therefore, data containing human-demonstrated movement patterns in terms of visuo-proprioceptive sequences were collected both for training the network and for later testing of pseudo-synchronized imitative interaction. After training, the model was tested for pseudo-imitative interaction using novel visuo-proprioceptive patterns with two different scenarios (Experiment 1 and Experiment 2).
Experiment 1 investigated the issue of coordination and integration of different modalities of sensation by changing the tightness used to regulate the complexity term for each sensory module. For this purpose, the network was trained by assigning different values of the meta-prior to the proprioception and vision modules. We examined the different effects of regulating complexity in the two modules on coordination of different modalities by analyzing them in both the learning process and in the pseudo-imitative interaction tested after learning.
Experiment 2 investigated the issue of strength of agency as the main motivation of the current study by changing the tightness used to regulate the complexity term for the entire network from that introduced in the training phase. Accordingly, we selected a network trained and evaluated as successful in Experiment 1 and then the characteristics of the pseudo-imitative interaction were examined by equally adjusting the meta-priors of each module of this trained network to larger or smaller values.
In subsequent experiments, some parameters that determine network structure were set as follows. The associative module consisted of a one-layer PV-RNN, and the proprioception module and the vision module consisted of two layers. These PV-RNN layers were characterized by a time scale imposed on MTRNN computation. That is, the higher layer had a larger time constant, producing slow time-scale dynamics, and the lower layer had smaller time constants, generating fast time-scale dynamics. Therefore, in this study, the higher layer of the proprioception module and the vision module, which receive input from the associative module, are referred to as the slow layer, and the lower layer is referred to as the fast layer. As described in section 2.5.3, the visual perception of the model involves an encoder and a decoder. Their architectures are summarized in Table 1.
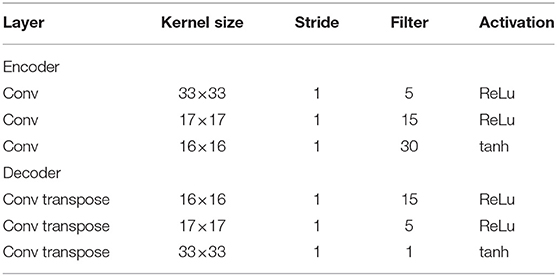
Table 1. The architecture of the encoder and the decoder.
To obtain a dataset of synchronized visuo-proprioceptive sequences, we used a humanoid robot, Torobo (Tokyo Robotics Inc.) and a motion capture suit (Perception Neuron, Noitom Ltd.). Torobo is a human-sized, torso-type humanoid robot with 16 joint-angles, of which 6 are for each arm and 4 are for the torso and head positions. Human body movements can be mapped to joint-angle trajectories of the robot using the motion capture suit. A human experimenter wearing the suit demonstrated a set of body movements, which were mapped as joint-angle trajectories. This demonstration was also recorded with a camera to obtain corresponding visual patterns. The target sequential movement pattern to be learned by the robot was designed by considering a probabilistic finite state machine that can generate probabilistic sequences of three different primitive movement patterns. Those were (A) waving with both arms three times, (B) rotating the torso to the left with the arms three times, and (C) rotating the torso to the right with the arms three times. Primitive pattern A is followed either by primitive pattern B or primitive pattern C with a 50% chance, and primitive patterns B and C are followed by pattern A with a 100% chance (Figure 3A). One sequence consists of 8 probabilistic transitions of primitive movements. Three human participants demonstrated and recorded 10 movement sequences each. In other words, the dataset comprised 30 sequences of visuo-proprioceptive temporal patterns. Recorded visuo-proprioceptive patterns were down-sampled to 3.75 Hz so that one sequence became 400 time steps. Joint-angle trajectories were normalized to a range between −1 and 1. Vision patterns were further converted into gray scale images and down-sized to 64 × 64 pixels (Figure 3B). A summary of the training data is shown in Table 2. Visual trajectories fluctuated far more than proprioceptive trajectories due to various optical conditions, such as illumination and surface reflectiveness.
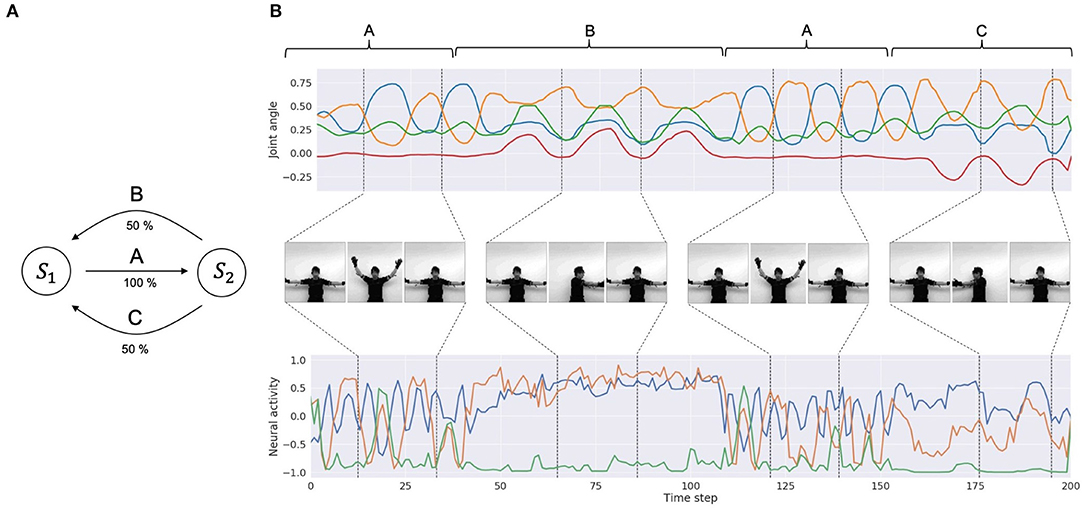
Figure 3. Training data. (A) A diagram of the probabilistic finite state machine. (B) An example of the training dataset. The top row is part of a joint-angle trajectory. The corresponding labels of primitive patterns (A, B, and C) are indicated above the plots. For simplicity, only 4 joint-angles out of 16 representing the movements are shown. The middle row shows corresponding visual pixel images in each period. The bottom row shows visual trajectories in the latent space embedded by the encoder. For simplicity, only three variables out of 20 are shown.

Table 2. A summary of the training data.
Using the training example, the model is required to extract a probabilistic structure such that the primitive pattern of B or C appears with only a 50% chance after every appearance of the primitive A, by estimating precision in transitions of primitives with learning. Such learning should be achieved without providing explicit labels for those primitives, by extracting the underlying chunking and segmentation structure from continuous sensory signals prepared in the dataset. The PV-RNN can achieve such tasks using a multiple timescale RNN scheme combined with a Bayesian inference approach (Ahmadi and Tani, 2019).
This experiment investigates effects of changing the tightness used to regulate the complexity term for each sensory module with regard to coordination and integration of different modalities of sensation. In addition, this experiment provides successfully trained networks with well-balanced complexity between the vision and proprioceptive modules for possible use in Experiment 2. To accomplish this, we examined how assigning different values of the meta-prior to the proprioception and vision modules affects the learning process and performance in the pseudo-imitative interaction. Two sets of meta-priors w1 and w2 were assigned to the model (Table 3). w1 has larger values of the meta-prior in the proprioception module than in the vision module, and they were exchanged in w2. Both w1 and w2 have the same value for the meta-prior in the associative module. First, the model was trained with the w1 and w2 settings, and the learning process was examined, with special attention to each component of the lower bound. To facilitate training, the Adam optimizer (Kingma and Ba, 2014) was utilized with the parameter settings α = 0.001, β1 = 0.9, and β2 = 0.999. The model was trained 10 times with different random initializations of model parameters for 10,000 epochs, and the mean and standard deviation of the prediction errors of proprioception and vision, and the KL divergence of each layer of the model at each epoch were computed.

Table 3. The model configuration in Experiment 1.
Results are summarized in Figure 4. In comparing w1 and w2 conditions, even though the prediction errors in the proprioception and vision modules showed similar behavior (Figures 4A,B), the KL divergence in each module was optimized differently. Despite different values of the meta-prior assigned to the fast layer of the proprioception module, its KL divergences in w1 and w2 conditions were reduced in exactly the same way (Figure 4E). This is not the case in the fast layer of the vision module (Figure 4G). The KL divergence in the slow layer of the proproception module and the slow layer of the vision module showed different values in w1 and w2 settings (Figures 4D,F). Interestingly, although the associative module was set to the same value of meta-prior in w1 and w2 conditions, the KL divergence in the w2 setting reached a larger value than in the w1 setting. This is because the larger value of the meta-prior assigned to the fast layer of the vision module in the w2 condition prevented the vision module from absorbing the fluctuation in observed visual patterns, which resulted in bottom-up fluctuation from the vision module to the associative module, appearing as a discrepancy between the prior and the posterior in this module. Because visual sensation contains more inherent randomness than proprioceptive sensation, as mentioned previously, complexity in this modality should be adequately regulated by setting a smaller meta-prior value. Otherwise, the discrepancy that appears in the visual module tends to leap to the higher associative module without being well-resolved before.
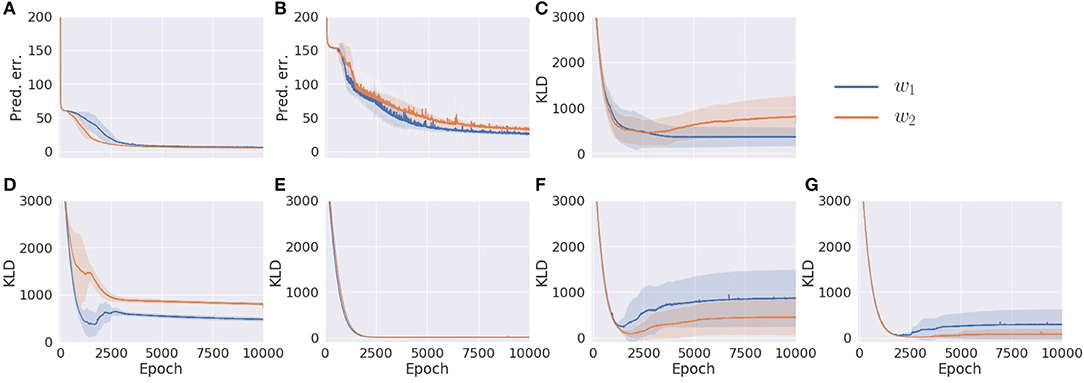
Figure 4. The learning process of the model with two different meta-prior settings. (A) The prediction error in proprioception. (B) The prediction error in vision. (C) The KL divergence in the associative module. (D) The KL divergence in the slow layer of the proprioception module. (E) The KL divergence in the fast layer of the proprioception module. (F) The KL divergence in the slow layer of the vision module. (G) The KL divergence in the fast layer of the vision module. The shadows are the standard deviation of 10 trials with different parameter initializations. Note that values of prediction errors are the sum of the prediction errors at all time steps and sequences normalized by the data dimension.
We further tested the trained models in the pseudo-imitative interaction. Training of the models stopped after 4,000 epochs. Three novel visuo-proprioceptive sequences recorded from three human participants were prepared for the pseudo-imitative interaction, which also comprised the previous primitive body movements A, B, and C, the lengths of which were 400 time steps. The length of the ER window was set to 30 time steps, and the number of optimization iterations for posterior inference by BPTT at each time step was 30. Namely, at each sensory sampling time step, the network infers the posterior distribution of z responsible for reconstructing the observation inside the ER window, in which the cycle of the forward computation and the posterior update described in section 2.4 repeats 30 times. As in learning, Adam was used to improve optimization with parameter settings α = 0.2, β1 = 0.9, and β2 = 0.999. Evaluation of the error-regression examined how much the reconstruction error in each modality and the KL divergence at each sub-network in the PV-RNN were minimized. That is, at the point when T′ time step window for the immediate past shifts t time steps, i.e., the current time step is t, the adaptive variable a assigned within the window is optimized with the iterative process, and at the last iteration, the reconstruction error and the KL divergence are computed inside the window. Therefore, they are defined as
where t′ is the time step inside the window. Rp and Rl are the dimension of proprioception and the latent space of vision, respectively. Rz is the dimension of z, and the KL divergence is computed for every PV-RNN submodule. Models trained in previous experiments were used. The pseudo-imitative interaction experiment was run 10 times with different random number seeds, and the mean and standard deviation of each quantity were computed. In addition, one-step, look-ahead prediction error, the discrepancy between the prediction in the next time step of the current window and the observation, was computed in the vision module to evaluate prediction accuracy.
Figure 5 exemplifies how the pseudo-imitative interaction developed in the w1 setting in time-lapse. For clarity, only parts involving the proprioceptive interaction are shown. Each column shows the representation of the network when the network finished a posterior inference and made a new prediction at each time step. The first, second, and third row show representations in the associative module, the slow layer in the proprioception module and the fast layer in the proprioception module, respectively. Solid lines indicate the activity of three randomly chosen d neurons, and dashed lines indicate the KL divergence value at each time step in each layer. The fourth row shows joint-angle trajectories. Solid lines are predictions generated by the network, and dashed lines are joint-angle values demonstrated by the human counterpart in the recorded data. The bottom row shows the reconstruction error, inside the ER window, which was minimized by updating a via BPTT under regularization by the KL divergence between the inferred posterior and the conditional prior. In section 2.4, describing the error-regression scheme, the network is illustrated in a way that it only makes the prediction at next time step during the interaction. In this experiment, however, the network was allowed to generate the prediction not only at next time step, but also at subsequent time steps with the conditional prior to visualize the network's long-term prediction. This is also the case in Figure 8.
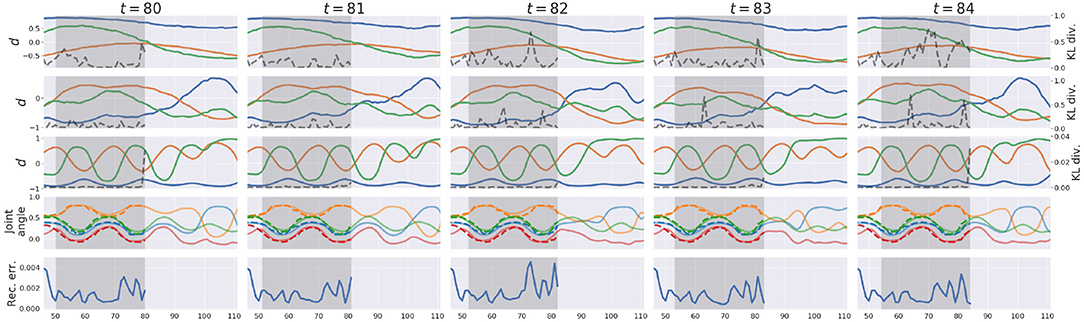
Figure 5. An example of the network representation during testing in w1 setting. Gray areas indicate the ER window. The first, second, and third rows show representations in the associative module, the slow layer in the proprioception module, and the fast layer in the proprioception module, respectively. Solid lines represent activities of three randomly chosen d neurons, and dashed lines represent the value of the KL divergence at each time step. The 4th row shows predictions (solid lines) and sensations (dashed lines) of joint-angles. For clarity, only four joint-angles of 16 are shown. The bottom row shows the reconstruction error in proprioception.
At each time step, the network receives a new sensation, computes the reconstruction error and the KL divergence within the ER window, updates the a such that the lower bound inside the ER window is maximized, and modifies the prediction after the current time step with the conditional prior. In Figure 5, the network continually modified the future prediction as a result of the posterior inference. Since the lower bound summed over time steps inside the ER window is maximized, all as inside the ER window are updated so that the sum of the reconstruction error and the KL divergence weighted by the meta-prior inside the ER window are minimized. Therefore, it is often observed that the value of the reconstruction error or the KL divergence at a certain time step inside the ER window becomes larger at the next time step, which is considered a transient process in the optimization wherein the past is re-interpreted and re-represented in coping with a new entering sensation, in terms of post-diction (Shimojo, 2014). In the w1 setting, larger values of the meta-prior are assigned to lower layers of the network and smaller to higher. In other words, KL divergences in lower layers are weighted more in the lower bound, and while those in higher layers are weighted less. Therefore, KL divergences in lower layers were reduced more, and those in higher layers remained larger after iterative optimization. Owing to MTRNN characteristics of different time-scales among layers, higher layers showed slower dynamics and lower layers showed faster dynamics. It is assumed that higher levels predict switching of primitives and lower levels predict sensory profile changes at each time step. Detailed analysis of this issue was not conducted in the current study since similar phenomena using MTRNN have been reported frequently (e.g., Yamashita and Tani, 2008; Hwang et al., 2020).
Experimental results are summarized in Table 4. The reconstruction error in proprioception was remarkably minimized compared to that in vision, in both conditions w1 and w2. This is because vision involves more noise than proprioception. The reconstruction error in vision was smaller for the w1 condition than the w2 condition. Furthermore, the KL divergence in the associative module was reduced more significantly in the w1 condition than the w2 condition. This occurred because the vision module generalized better with noisy visual patterns in the test of pseudo-imitative interaction in the w1 case than in the w2 case by minimizing the complexity term more. Because fluctuation or randomness in visual sensation was well-resolved in the vision module in the w1 case, the associative module became relatively free from such fluctuation, as evidenced by the smaller KL divergence observed in the associative module. As a result, the one-step, look-ahead prediction was also more accurate.
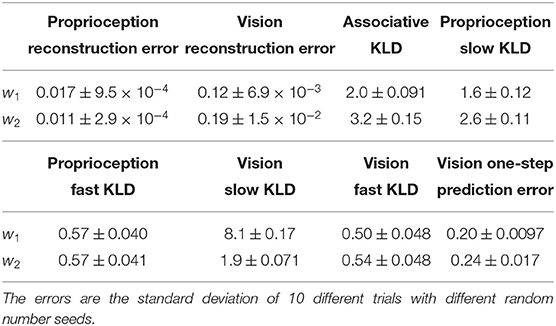
Table 4. The result of the pseudo-imitative interaction experiment.
This experiment was devised to reveal possible effects of changing the tightness used to regulate the complexity term for the entire network on the strength of agency exerted in imitative interaction. Accordingly, we investigated how changes of meta-prior values of the entire network from default values used in learning affect performance characteristics in the pseudo-imitative interaction. We used a network that was trained for 4,000 epochs in Experiment 1 with the w1 setting as the default network. Five meta-prior settings were prepared for testing of imitative interaction: from smaller values of the meta-prior setting W1 to the larger setting W5 with a consistent ratio among all layers of all modules (Table 5). Imitative interaction with different meta-prior settings was performed with the novel visuo-proprioceptive patterns used in Experiment 1. Interactions were analyzed in terms of the quantities introduced in previous experiments. In addition, one-step look-ahead prediction error in proprioception was also measured. Each test with a different meta-prior setting was repeated with 10 network models trained with different initialization weights, but with the same parameters for the purpose of examining these quantities statistically.

Table 5. The values of meta-prior in Experiment 2.
Results are summarized in Figure 6. As a whole, with smaller values of the meta-prior, the reconstruction error was minimized more (Figure 6A), and the KL divergence remained large (Figure 6D), whereas with larger values of the meta-prior, the KL divergence was minimized more (Figure 6D), and the reconstruction error remained large (Figure 6A). This tendency can also be seen in the local proprioception module and vision module, although the reconstruction error in the vision module was not significantly different. In the proprioception module, as values of the meta-prior increased, the reconstruction error in proprioception became large (Figure 6B), and the KL divergence became small, both in the slow layer (Figure 6F) and in the fast layer (Figure 6G). In the vision module, as values of the meta-prior increased, though the reconstruction error in vision did not increase as significantly (Figure 6C, the KL divergence became small in both the slow layer (Figure 6H) and the fast layer (Figure 6I). The KL divergence in the associative module also increased as values of the meta-prior increased (Figure 6E). In addition, with smaller values of the meta-prior, the one-step, look-ahead prediction error was minimized in both proprioception (Figure 6J) and in vision (Figure 6K).
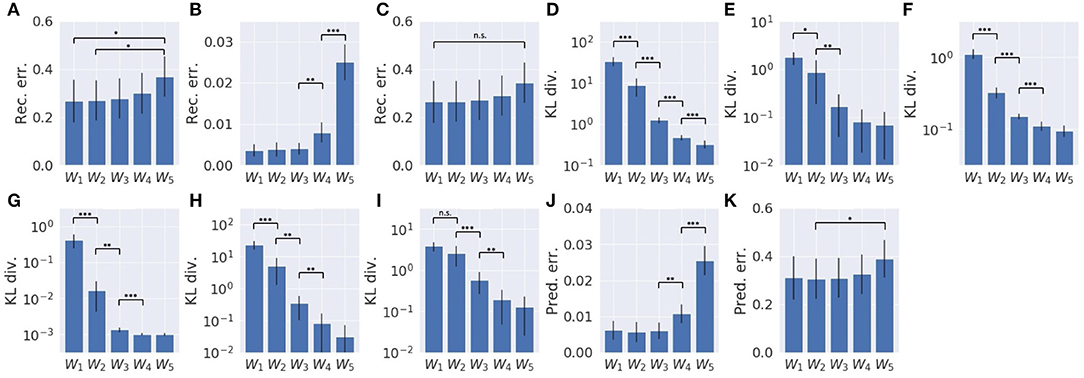
Figure 6. Reconstruction error, KL divergence minimization, and one-step, look-ahead prediction error in error-regression with five meta-prior settings. (A) Sum of reconstruction errors in proprioception and vision. (B) The reconstruction error in proprioception. (C) The reconstruction error in vision. (D) Sum of the KL divergence in all layers. (E) The KL divergence in the associative module. (F) The KL divergence in the slow layer of the proprioception module. (G) The KL divergence in the fast layer of the proprioception module. (H) The KL divergence in the slow layer of the vision module. (I) The KL divergence of the fast layer of the vision module. (J) One-step, look-ahead prediction error in proprioception. (K) One-step, look-ahead prediction error in vision. Error bars represent the standard deviation of 10 models with different weight initialization. Asterisks represent the statistical significance in t-tests: *p < 0.05, **p < 0.01, and ***p < 0.001. Note that each graph has a different scale.
This is because the KL divergence term in the evidence lower bound was weighted more for minimization than was the reconstruction error term. In this situation, the posterior at each time step in the ER window approached its prior p(zt|dt−1) by modulating the adaptive value at, which is fed into the computation of the posterior , while the prior p(zt|dt−1) was less changed. This means that network dynamics were driven mainly by the prior, and were less affected by sensory inputs. Network dynamics become more egocentric by following the prior, which was less modified by looser regulation of the complexity term (i.e., more weighting for the KL divergence term). On the other hand, with tighter regulation (i.e., less weighting of the KL divergence term), network dynamics became more adaptive to changes or fluctuations of sensory inputs by freely modulating the posterior in the direction of error minimization without being much constrained by the prior. In this condition, the prior p(zt|dt−1) at each time step in the window also changes because the posterior q(zt−1|dt−2) at the previous time step, which is mapped to p(zt|dt−1) through dt also changes.
In the course of pseudo-imitative interaction, when the network observes a single time step of a new sensation, it infers sequences of the posterior inside the ER window with the aforementioned iterative computation of the error regression. Figure 7 displays some examples of the posterior inference during the process in which tight regulation of the complexity term (W1 setting) (Figure 7A) and loose regulation of the complexity term (W5 setting) (Figure 7B) are compared. For clarity, part of the network responsible for proprioception is shown. The columns illustrate, given a single time step of sensory observation, how the network inferred the posterior in terms of parameters of the posterior distribution, mean μ, and variance σ of multivariate Gaussian distributions under the effect of different values of the meta-prior through iterations. From the left, each column shows network dynamics before the inference, after 5th, 10th, 15th, 20th, 25th, and 30th iteration of the update of adaptive variable a inside the ER window with BPTT. The first, third, and fifth rows plot the relationship among the mean of the prior μp (blue lines), the mean of the inferred posterior μq (red lines), and the KL divergence (dashed black lines) in the associative module, in the slow and fast layers of the proprioception module, respectively. The second, fourth, and sixth rows plot the variance of the prior σp (blue lines), the variance of the inferred posterior σq (red lines), and the KL divergence (dashed black lines) in the associative module, in the slow and fast layers of the proprioception module, respectively. Although dimensions of z in the fast layer and in the slow layer of the proprioception module are greater than one, only one dimension is plotted for visibility.
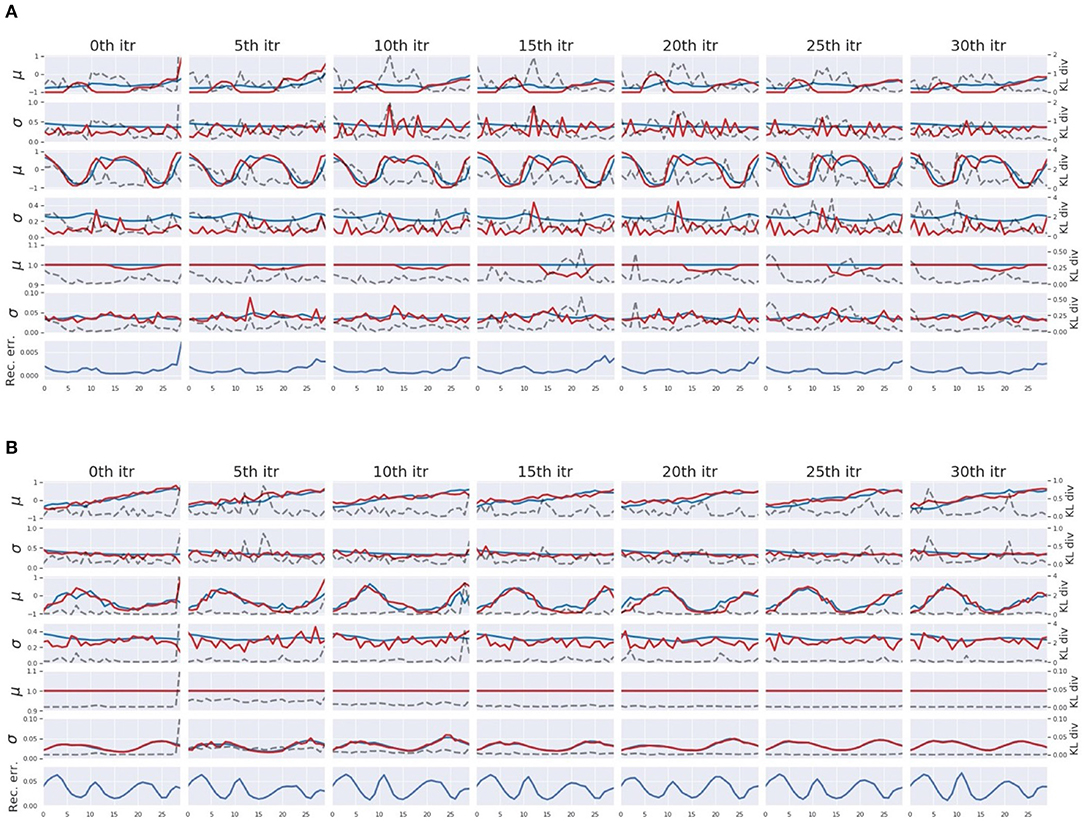
Figure 7. An example of the posterior inference during the pseudo imitative interaction in the W1 setting (A) and in the W5 setting (B). For clarity, only those parts involved in the proprioception module are shown. From the left, each column represents the network representation inside the ER window before the inference, after every 5th iteration up to the 30th iteration of the posterior inference. The first, third, and fifth rows show time trajectories of the mean μ of the z in the associative module, the slow layer of the propriception module, and the fast layer of the proprioception module, respectively. The blue and red lines represent the prior μp and the inferred posterior μq, respectively. The second, fourth, and sixth rows show the time trajectories of variance σ of z in the associative module, the slow layer of the proprioception module, and the fast layer of the proprioception module, respectively. The blue and red lines indicate the prior σp and the inferred posterior σq, respectively. Dashed black lines indicate values of the KL divergence in each layer. The bottom row shows the reconstruction error at corresponding time steps.
In W1 setting, the network is assigned smaller values of the meta-prior, which means that the complexity term is tightly regulated. Therefore, during the course of posterior inference, the inferred posterior is allowed to deviate somewhat from the prior to minimize the reconstruction error compared to the W5 setting with looser regulation. This can be seen in Figure 7A. In the leftmost column, the network encountered a large reconstruction error in the last time step inside the ER window. This reconstruction error was eventually resolved while updating the posterior repeatedly as a result of distributing the KL divergence over the entire network in consideration of values of the meta-prior assigned to each layer. In the W1 setting, the associative module had the smallest value of the meta-prior, the slow layer of the proprioception module had one with a moderate value, and the fast layer of the proprioception module had the largest value of the meta-prior. Thus, the largest discrepancy between the inferred posterior and the prior was allowed in the associative module and the smallest discrepancy in the fast layer of the proprioception module. This can be confirmed by comparing the posterior, the prior, and the value of KL divergence in each layer in Figure 7A.
In contrast, in the W5 setting, the complexity term is loosely regulated with larger values of the meta-prior, which forces the network to keep the KL divergence small during the posterior inference. This can be observed in Figure 7B. During the iteration, the value of the KL divergence was strongly suppressed, and as a result, the reconstruction error remained large even after the posterior update. Compared to Figure 7A, the posterior was inferred so that it was closer to the prior (red lines are closer to blue lines).
Figures 8A,B show examples of time-series plots of related neural activities of the proprioception module, comparing cases of tight (W1 setting) and loose (W5 setting) regulation of the complexity term. Both cases are computed for a situation observing the same visuo-proprioceptive sequence pattern. With tight regulation of the complexity term (Figure 8A top), the observation of the primitive A (dashed lines) was well-reconstructed (solid lines) inside the ER window (gray area) from time steps 120 to 150, due to relatively stronger weighting of the accuracy term compared to the W5 setting. Plots after time step 150 represent future predictions of the expectation of encountering the primitive B. From time steps 150 to 180 (Figure 8A bottom), the agent observed new sensory information where the primitive C instead of the predicted primitive of B was encountered. (Remember that there is a 50% chance of encountering the primitive B or the primitive C.) This new observation was reconstructed inside the ER window. Based on the inferred posterior during this period, the robot updated the future prediction after time step 180 as the primitive C to be continued. Because of relatively stronger weighting in the accuracy term, the posterior was inferred to adapt to reality. The prediction was also updated accordingly (Figure 8A bottom).
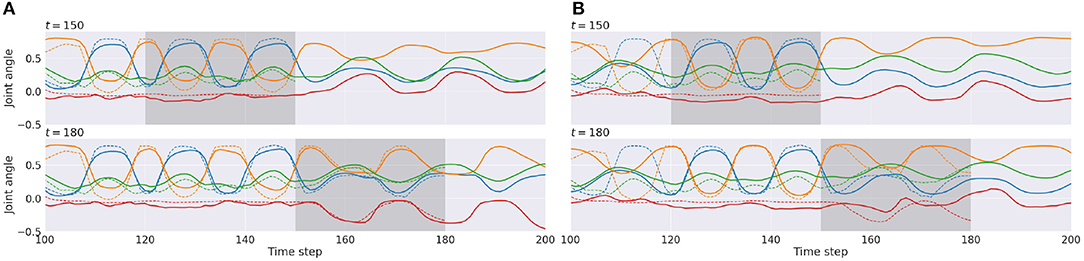
Figure 8. An example of time-series plots of neural activities in the output layer of the proprioception module in the W1 setting (A) and in the W5 setting (B). Reconstruction of the past observation and the future prediction at time step 150 (top) and at time step 180 (bottom) are shown. Solid lines represent prediction outputs, and dashed lines represent observations. The shadowed area indicates the error-regression window. For simplicity, only 4 of 16 joint-angles representing movements are shown.
In the case of loose regulation (Figure 8B top), the observation was still well-reconstructed inside the ER window. This is because primitive pattern A always follows either primitive pattern B or C so that it is easy to predict primitive A. Therefore, the reconstruction error inside the ER window was small from the beginning. Plots after time step 150 represent future predictions expecting primitive pattern B to be encountered. After observing new sensory information in which primitive pattern C instead of the predicted primitive pattern B was encountered between time steps 150 and 180 (Figure 8B bottom); however, the new observation was not reconstructed well inside the ER window. Due to tight regulation of the KL divergence term (loose regulation of the complexity term), the posterior was forced closer to the prior by ignoring the new observation. Consequently, the inferred posterior did not affect the prior as much as in the W1 setting, which resulted in generation of consistent predictions for the future. Actually, the look-ahead prediction made at time step 150, shown in the top row, and the one made at time step 180 in the bottom row are almost the same. These observations imply that both the prediction of the future and the reflection of the past become more adaptive to sensory observation in the case of tighter regulation of the complexity term, whereas they become more persistent regardless of sensory observations in the case of looser regulation.
Some representative videos related to Experiment 2 can be seen in Supplementary Video 1 and in Supplementary Video 2. for the W1 condition and the W5 condition, respectively. These videos show how prediction of the future as well as reflection of the past can be performed for each condition. Also, further temporal details during the error-regression process can be seen in Supplementary Video 3 and in Supplementary Video 4 for the W1 condition and the W5 condition, respectively. In these videos, there is some divergence between the prior and the posterior in terms of mean and variance and they are dynamically changing inside the ER-W in the W1 condition, whereas these two profiles approximate each other, showing relatively persistent patterns in the W5 condition. These observations accord with our analysis, described previously.
The current study investigated underlying mechanism of the strength of agency in social interaction by proposing a model for imitative interaction using multimodal sensation based on the framework of PC and AIF. We proposed a hypothesis that tightness used to regulate the complexity term in the evidence lower bound in the proposed model should contribute to the strength of agency. This hypothesis was evaluated by conducting simulation experiments on a pseudo-human-robot imitative interaction using the model.
First, we examined possible effects of changing the tightness used to regulate the complexity term for each sensory module during the learning phase in coordination and integration of different modalities of sensation and those in the test imitation phase. Our results showed that the complexity term in the vision module should be regulated more than that of the proprioception module. This is because vision and proprioception are significantly different with respect to their intrinsic randomness, as visual inputs fluctuate more due to optical conditions, such as illumination and surface reflectiveness. We concluded that the complexity term in the vision module should be regulated much more than that for the proprioception module to achieve better generalization in learning.
Next, we investigated the strength of agency as the main focus of the current study by changing the tightness used to regulate the complexity term for the entire network relative to that which was introduced in the training phase. For this purpose, characteristics of pseudo-imitative interaction were examined by scaling the meta-prior of each module equally to larger or smaller values using the network that had been evaluated as successful in the previous experiment. Our results demonstrated that changing the meta-prior this way affects performance characteristics of imitative interaction significantly. With looser regulation of the complexity term, the agent tends to act more egocentrically, without adapting to the other. In contrast, with tighter regulation of the complexity term, the agent tends to follow its human counterpart by adapting its internal state. This result implies that the strength of SoA can be modulated by adjusting the tightness with which the complexity term is regulated after the learning phase.
In the current study, we evaluated this hypothesis by considering a task of imitative interaction between a robot and a human counterpart. In such an imitative interaction, there could be two situations: the robot follows the human's movements, or the human follows the robot's movements. In our experimental results, the agent with tight regulation of the complexity term corresponded to the former case, and that with loose regulation to the latter. These findings could provide new insights into computational modeling studies of MNS. Our group's previous studies (Ahmadi and Tani, 2017; Hwang et al., 2020) on modeling MNS using deterministic RNNs that were applied to robot imitation experiments, introduced a scheme similar to the ER scheme described in the current study, in the sense that both reinterpret past observations and update future predictions. In the model, deterministic latent variables at the onset time step of the immediate past window are updated by means of the ER scheme. Since these latent variables are not constrained by any prior probability distribution (unlike the sequential prior scheme), they adapt to sensory sequences encountered for minimizing the error directly wherein the speed of updating is simply determined by the adaptation rate to update the latent variables.
On the other hand, in the case of the ER, which uses PV-RNN, the update of stochastic latent variables z at each time step inside the ER window are constrained by the sequential prior represented in terms of a Gaussian probability distribution. If the PV-RNN is developed more toward deterministic dynamics by setting the meta-prior with larger values, the sequential prior for each stochastic latent variable should have a peaky distribution with relatively small variance. In such a case, the approximate posterior cannot adapt to the sensory sequence by using the propagated error signal because the current prior is estimated with a strong belief. In contrast, if the PV-RNN is developed toward a more random process by setting the meta-prior with smaller values, at each time step the prior should exhibit a wide distribution with large variance. Then, the posterior can easily adapt to the sensation using the error signal, because the current prior is estimated with a weak belief. Therefore, the PV-RNN can show both mirror neuron-type adaptive response and egocentric behavior, depending on the setting of the meta-prior in interactions among agents. The deterministic RNN models shown in (Ahmadi and Tani, 2017; Hwang et al., 2020), however, can only show mirror neuron-like adaptive responses.
By following the above discussion, one essential advantage of using variational RNNs, such as PV-RNN, compared with conventional deterministic RNNs, is that they can predict not only future contents, but can also estimate predictability of such predictions or in other words, the credibility of prediction, as discussed in formulation of the free-energy princple (Friston, 2005). This sort of cognitive competency of second order prediction by means of representing the belief of prediction, by which the strength of agency can be mechanized, provides modeling of agents, including cognitive robots with more complexity and richness in ways of interacting with other agents, as well as the physical world, as the current study demonstrates, at least partially.
In everyday social interactions, humans don't just follow others, nor do they lead them all the time. Rather humans sometimes follow others and sometimes lead them, depending on the moment-by-moment context or social situation. Psychological studies indicate that turn-taking between following and leading can occur quite spontaneously in various social cognitive behaviors, including conversation (Sacks et al., 1978), mother-infant pre-verbal communication (Trevarthen, 1979) and imitation (Nadel, 2002). In considering possible mechanisms underlying turn-taking, some researchers (Ito and Tani, 2004; Ikegami and Iizuka, 2007) suggest that turn-taking may develop due to potential instability, such as chaos formed in coupled dynamics between two agents in their modeling studies. We consider meta-level dynamics coupling two agents, whereby the value of the meta-prior to regulate the complexity terms in the two agents counteract one another mutually. This could result in autonomous shifts between the leading mode by increasing the meta-prior and the following mode by reducing it.
Future studies should examine the aforementioned mechanism for turn-taking by conducting an online experiment of human-robot interactions. However, the computational cost of online error-regression for the posterior inference has been the major bottleneck for conducting such experiments in real time, and this is why the current study was limited to a simulation of pseudo-imitative interaction using recorded visuo-proprioceptive sequence patterns, rather than introducing actual, real-time, human-robot interaction. Although our group has shown that some real-time experiments using online ER are possible using only the sensory modality of proprioception (Chame and Tani, 2019), it becomes prohibitive when also using vision, with sufficient pixel resolution. Regarding this problem, some may suggest employing other types of variational models, such as a variational recurrent neural network (VRNN) (Chung et al., 2015), because a VRNN demands far less computation time, since the posterior at each time step can be inferred by simple sequential mapping of inputs using an autoencoder (Kingma et al., 2016). However, the current scheme for inference of the posterior through iterative computation for optimization is probably vital for any embodied cognitive systems that require rapid adaptation of internal states to the environment. Actually, Ahmadi and Tani (Ahmadi and Tani, 2019) showed that PV-RNN performs better than VRNN in online prediction in dynamically changing environments by inferring the posterior using the error-regression scheme. Therefore, future studies should explore possible methods for accelerating online error-regression of the model, such as by massive parallelization so as to conduct real-time, human-robot interactions using the current model.
Ethical review and approval was not required for the study on human participants in accordance with the local legislation and institutional requirements. The patients/participants provided their written informed consent to participate in this study.
WO and JT conceived the concepts and models and contributed to the writing. WO conducted the experiments.
This study was supported by funding from Okinawa Institute of Science and Technology Graduate University. This study has also been partially supported by a Grant-in-Aid for Scientific Research(A) in Japan, 20H00001, Phenomenology of Altered Consciousness: An Interdisciplinary Approach through Philosophy, Mathematics, Neuroscience, and Robotics.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
We thank lab members in the Cognitive Neurorobotics Research Unit. We are especially grateful to Ahmadreza Ahmadi and Prasanna Vijayaraghavan for their help in developing the model. We thank Siqing Hou for his help in collecting data. We also thank Steven D. Aird for editing the manuscript.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fnbot.2020.00061/full#supplementary-material
Supplementary Video 1. An example of the pseudo-imitative interaction in W1 condition in Experiment 2.
Supplementary Video 2. An example of the pseudo-imitative interaction in W5 condition in Experiment 2.
Supplementary Video 3. An example of temporal details during the error-regression process in W1 condition in Experiment 2.
Supplementary Video 4. An example of temporal details during the error-regression process in W5 condition in Experiment 2.
Ahmadi, A., and Tani, J. (2017). How can a recurrent neurodynamic predictive coding model cope with fluctuation in temporal patterns? Robotic experiments on imitative interaction. Neural Netw. 92, 3–16. doi: 10.1016/j.neunet.2017.02.015
Ahmadi, A., and Tani, J. (2019). A novel predictive-coding-inspired variational RNN model for online prediction and recognition. Neural Comput. 31, 2025–2074. doi: 10.1162/neco_a_01228
Aly, A., and Tapus, A. (2015). “An online fuzzy-based approach for human emotions detection: an overview on the human cognitive model of understanding and generating multimodal actions,” in Intelligent Assistive Robots, eds S. Mohammed, J. Moreno, K. Kong, and Y. Amirat (Springer), 185–212. doi: 10.1007/978-3-319-12922-8_7
Baltieri, M., and Buckley, C. L. (2017). “An active inference implementation of phototaxis,” in Artificial Life Conference Proceedings 14 (Lyon: MIT Press), 36–43. doi: 10.7551/ecal_a_011
Battaglia, P. W., Jacobs, R. A., and Aslin, R. N. (2003). Bayesian integration of visual and auditory signals for spatial localization. JOSA A 20, 1391–1397. doi: 10.1364/JOSAA.20.001391
Boucenna, S., Cohen, D., Meltzoff, A. N., Gaussier, P., and Chetouani, M. (2016). Robots learn to recognize individuals from imitative encounters with people and avatars. Sci. Rep. 6:19908. doi: 10.1038/srep19908
Boucenna, S., Gaussier, P., Andry, P., and Hafemeister, L. (2014). A robot learns the facial expressions recognition and face/non-face discrimination through an imitation game. Int. J. Soc. Robot. 6, 633–652. doi: 10.1007/s12369-014-0245-z
Buckley, C. L., Kim, C. S., McGregor, S., and Seth, A. K. (2017). The free energy principle for action and perception: a mathematical review. J. Math. Psychol. 81, 55–79. doi: 10.1016/j.jmp.2017.09.004
Chame, H. F., and Tani, J. (2019). Cognitive and motor compliance in intentional human-robot interaction. arXiv preprint arXiv:1911.01753.
Choi, M., and Tani, J. (2018). Predictive coding for dynamic visual processing: development of functional hierarchy in a multiple spatiotemporal scales RNN model. Neural Comput. 30, 237–270. doi: 10.1162/neco_a_01026
Chung, J., Kastner, K., Dinh, L., Goel, K., Courville, A. C., and Bengio, Y. (2015). “A recurrent latent variable model for sequential data,” in Advances in Neural Information Processing Systems (Montreal, QC), 2980–2988.
Clark, A. (2015). Surfing Uncertainty: Prediction, Action, and the Embodied Mind. Oxford University Press. doi: 10.1093/acprof:oso/9780190217013.001.0001
Di Pellegrino, G., Fadiga, L., Fogassi, L., Gallese, V., and Rizzolatti, G. (1992). Understanding motor events: a neurophysiological study. Exp. Brain Res. 91, 176–180. doi: 10.1007/BF00230027
Friston, K. (2005). A theory of cortical responses. Philos. Trans. R. Soc. B Biol. Sci. 360, 815–836. doi: 10.1098/rstb.2005.1622
Friston, K. (2012). Prediction, perception and agency. Int. J. Psychophysiol. 83, 248–252. doi: 10.1016/j.ijpsycho.2011.11.014
Friston, K. (2018). Does predictive coding have a future? Nat. Neurosci. 21:1019. doi: 10.1038/s41593-018-0200-7
Friston, K., Mattout, J., and Kilner, J. (2011). Action understanding and active inference. Biol. Cybernet. 104, 137–160. doi: 10.1007/s00422-011-0424-z
Friston, K. J., Daunizeau, J., and Kiebel, S. J. (2009). Reinforcement learning or active inference? PLoS ONE 4:e6421. doi: 10.1371/journal.pone.0006421
Friston, K. J., Daunizeau, J., Kilner, J., and Kiebel, S. J. (2010). Action and behavior: a free-energy formulation. Biol. Cybernet. 102, 227–260. doi: 10.1007/s00422-010-0364-z
Gallagher, S. (2000). Philosophical conceptions of the self: implications for cognitive science. Trends Cogn. Sci. 4, 14–21. doi: 10.1016/S1364-6613(99)01417-5
Gallese, V., Fadiga, L., Fogassi, L., and Rizzolatti, G. (1996). Action recognition in the premotor cortex. Brain 119, 593–609. doi: 10.1093/brain/119.2.593
Higgins, I., Matthey, L., Pal, A., Burgess, C., Glorot, X., Botvinick, M., et al. (2017). beta-VAE: learning basic visual concepts with a constrained variational framework. arXiv 2:6.
Hohwy, J. (2013). The Predictive Mind. Oxford University Press. doi: 10.1093/acprof:oso/9780199682737.001.0001
Hurley, S. L. (2005). Perspectives on Imitation: From Neuroscience to Social Science. MIT Press. doi: 10.7551/mitpress/5330.001.0001
Huys, R., Daffertshofer, A., and Beek, P. J. (2004). Multiple time scales and multiform dynamics in learning to juggle. Motor Control 8, 188–212. doi: 10.1123/mcj.8.2.188
Hwang, J., Kim, J., Ahmadi, A., Choi, M., and Tani, J. (2020). Dealing with large-scale spatio-temporal patterns in imitative interaction between a robot and a human by using the predictive coding framework. IEEE Trans. Syst. Man Cybernet. Syst. 50, 1918–1931. doi: 10.1109/TSMC.2018.2791984
Ikegami, T., and Iizuka, H. (2007). Turn-taking interaction as a cooperative and co-creative process. Infant Behav. Dev. 30, 278–288. doi: 10.1016/j.infbeh.2007.02.002
Ito, M., and Tani, J. (2004). On-line imitative interaction with a humanoid robot using a dynamic neural network model of a mirror system. Adapt. Behav. 12, 93–115. doi: 10.1177/105971230401200202
Kawato, M., Furukawa, K., and Suzuki, R. (1987). A hierarchical neural-network model for control and learning of voluntary movement. Biol. Cybernet. 57, 169–185. doi: 10.1007/BF00364149
Kilner, J. M., Friston, K. J., and Frith, C. D. (2007). Predictive coding: an account of the mirror neuron system. Cogn. Process. 8, 159–166. doi: 10.1007/s10339-007-0170-2
Kingma, D. P., and Ba, J. (2014). Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980.
Kingma, D. P., Salimans, T., Jozefowicz, R., Chen, X., Sutskever, I., and Welling, M. (2016). “Improved variational inference with inverse autoregressive flow,” in Advances in Neural Information Processing Systems (Barcelona), 4743–4751.
Kohler, E., Keysers, C., Umilta, M. A., Fogassi, L., Gallese, V., and Rizzolatti, G. (2002). Hearing sounds, understanding actions: action representation in mirror neurons. Science 297, 846–848. doi: 10.1126/science.1070311
Kording, K. P., Tenenbaum, J. B., and Shadmehr, R. (2007). The dynamics of memory as a consequence of optimal adaptation to a changing body. Nat. Neurosci. 10, 779–786. doi: 10.1038/nn1901
LeCun, Y., Boser, B., Denker, J. S., Henderson, D., Howard, R. E., Hubbard, W., et al. (1989). Backpropagation applied to handwritten zip code recognition. Neural Comput. 1, 541–551. doi: 10.1162/neco.1989.1.4.541
LeCun, Y., Bottou, L., Bengio, Y., and Haffner, P. (1998). Gradient-based learning applied to document recognition. Proc. IEEE 86, 2278–2324. doi: 10.1109/5.726791
Lee, T. S., and Mumford, D. (2003). Hierarchical bayesian inference in the visual cortex. JOSA A 20, 1434–1448. doi: 10.1364/JOSAA.20.001434
Legaspi, R., and Toyoizumi, T. (2019). A bayesian psychophysics model of sense of agency. Nat. Commun. 10, 1–11. doi: 10.1038/s41467-019-12170-0
Liu, R., Lehman, J., Molino, P., Such, F. P., Frank, E., Sergeev, A., et al. (2018). “An intriguing failing of convolutional neural networks and the coordconv solution,” in Advances in Neural Information Processing Systems (Montreal, QC), 9605–9616.
Moore, J. W., Wegner, D. M., and Haggard, P. (2009). Modulating the sense of agency with external cues. Conscious. Cogn. 18, 1056–1064. doi: 10.1016/j.concog.2009.05.004
Nadel, J. (2002). “Imitation and imitation recognition: functional use in preverbal infants and nonverbal children with autism,” in The Imitative Mind: Development, Evolution and Brain Bases (Cambridge Studies in Cognitive and Perceptual Development), eds A. Meltzoff and W. Prinz (Cambridge: Cambridge University Press), 42–62. doi: 10.1017/CBO9780511489969.003
Newell, K. M., Liu, Y.-T., and Mayer-Kress, G. (2001). Time scales in motor learning and development. Psychol. Rev. 108:57. doi: 10.1037/0033-295X.108.1.57
Nishimoto, R., and Tani, J. (2009). Development of hierarchical structures for actions and motor imagery: a constructivist view from synthetic neuro-robotics study. Psychol. Res. 73, 545–558. doi: 10.1007/s00426-009-0236-0
Ogata, T., Nishide, S., Kozima, H., Komatani, K., and Okuno, H. G. (2010). Inter-modality mapping in robot with recurrent neural network. Pattern Recogn. Lett. 31, 1560–1569. doi: 10.1016/j.patrec.2010.05.002
Oliver, G., Lanillos, P., and Cheng, G. (2019). Active inference body perception and action for humanoid robots. arXiv preprint arXiv:1906.03022.
Oztop, E., Kawato, M., and Arbib, M. (2006). Mirror neurons and imitation: a computationally guided review. Neural Netw. 19, 254–271. doi: 10.1016/j.neunet.2006.02.002
Oztop, E., Kawato, M., and Arbib, M. A. (2013). Mirror neurons: functions, mechanisms and models. Neurosci. Lett. 540, 43–55. doi: 10.1016/j.neulet.2012.10.005
Pezzulo, G., Rigoli, F., and Friston, K. J. (2018). Hierarchical active inference: a theory of motivated control. Trends Cogn. Sci. 22, 294–306. doi: 10.1016/j.tics.2018.01.009
Pitti, A., Quoy, M., Lavandier, C., and Boucenna, S. (2020). Gated spiking neural network using iterative free-energy optimization and rank-order coding for structure learning in memory sequences (inferno gate). Neural Netw. 121, 242–258. doi: 10.1016/j.neunet.2019.09.023
Rao, R. P., and Ballard, D. H. (1999). Predictive coding in the visual cortex: a functional interpretation of some extra-classical receptive-field effects. Nat. Neurosci. 2:79. doi: 10.1038/4580
Rizzolatti, G., and Fogassi, L. (2014). The mirror mechanism: recent findings and perspectives. Philos. Trans. R. Soc. B Biol. Sci. 369:20130420. doi: 10.1098/rstb.2013.0420
Rumelhart, D. E., Hinton, G. E., and Williams, R. J. (1985). Learning Internal Representations by Error Propagation. Technical report, California Univ San Diego La Jolla Inst for Cognitive Science. doi: 10.21236/ADA164453
Sacks, H., Schegloff, E. A., and Jefferson, G. (1978). “A simplest systematics for the organization of turn taking for conversation,” in Studies in the Organization of Conversational Interaction, ed J. Schenkein (Elsevier), 7–55.
Shimojo, S. (2014). Postdiction: its implications on visual awareness, hindsight, and sense of agency. Front. Psychol. 5:196. doi: 10.3389/fpsyg.2014.00196
Smith, M. A., Ghazizadeh, A., and Shadmehr, R. (2006). Interacting adaptive processes with different timescales underlie short-term motor learning. PLoS Biol. 4:e179. doi: 10.1371/journal.pbio.0040179
Synofzik, M., Vosgerau, G., and Newen, A. (2008). Beyond the comparator model: a multifactorial two-step account of agency. Conscious. Cogn. 17, 219–239. doi: 10.1016/j.concog.2007.03.010
Tani, J., and Nolfi, S. (1999). Learning to perceive the world as articulated: an approach for hierarchical learning in sensory-motor systems. Neural Netw. 12, 1131–1141. doi: 10.1016/S0893-6080(99)00060-X
Trevarthen, C. (1979). Communication and cooperation in early infancy: a description of primary intersubjectivity. Before Speech 1, 530–571.
Valentin, P., Boucenna, S., Gaussier, P., and Pitti, A. (2019). “Robot recognizing vowels in a multimodal way,” in 2019 Joint IEEE 9th International Conference on Development and Learning and Epigenetic Robotics (ICDL-EpiRob), 9th International Conference on Development and Learning and Epigenetic Robotics (ICDL-EpiRob) (Oslo), 103–104.
Werbos, P. (1974). Beyond regression: new tools for prediction and analysis in the behavioral sciences (Ph. D. dissertation). Harvard University, Cambridge, MA, United States.
Keywords: sense of agency, predictive coding, active inference, multimodal perception, human-robot interaction, recurrent neural network, variational Bayes
Citation: Ohata W and Tani J (2020) Investigation of the Sense of Agency in Social Cognition, Based on Frameworks of Predictive Coding and Active Inference: A Simulation Study on Multimodal Imitative Interaction. Front. Neurorobot. 14:61. doi: 10.3389/fnbot.2020.00061
Received: 03 February 2020; Accepted: 28 July 2020;
Published: 07 September 2020.
Edited by:
Robert J. Lowe, University of Gothenburg, SwedenReviewed by:
Sofiane Boucenna, Equipes Traitement de l'Information et Systèmes, FranceCopyright © 2020 Ohata and Tani. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jun Tani, anVuLnRhbmlAb2lzdC5qcA==
†ORCID: Wataru Ohata orcid.org/0000-0003-2590-8982
Jun Tani orcid.org/0000-0002-9131-9206
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.