 Marie Claire Capolei
Marie Claire Capolei Emmanouil Angelidis
Emmanouil Angelidis Egidio Falotico
Egidio Falotico Henrik Hautop Lund
Henrik Hautop Lund Silvia Tolu
Silvia Tolu- 1Automation and Control Group, Department of Electrical Engineering, Technical University of Denmark, Copenhagen, Denmark
- 2Landesforschungsinstitut des Freistaats Bayern, An-Institut, Technical University of Munich, Munich, Germany
- 3The BioRobotics Institute, Scuola Superiore Sant'Anna, Pisa, Italy
One of the big challenges in robotics is to endow agents with autonomous and adaptive capabilities. With this purpose, we embedded a cerebellum-based control system into a humanoid robot that becomes capable of handling dynamical external and internal complexity. The cerebellum is the area of the brain that coordinates and predicts the body movements throughout the body-environment interactions. Different biologically plausible cerebellar models are available in literature and have been employed for motor learning and control of simplified objects. We built the canonical cerebellar microcircuit by combining machine learning and computational neuroscience techniques. The control system is composed of the adaptive cerebellar module and a classic control method; their combination allows a fast adaptive learning and robust control of the robotic movements when external disturbances appear. The control structure is built offline, but the dynamic parameters are learned during an online-phase training. The aforementioned adaptive control system has been tested in the Neuro-robotics Platform with the virtual humanoid robot iCub. In the experiment, the robot iCub has to balance with the hand a table with a ball running on it. In contrast with previous attempts of solving this task, the proposed neural controller resulted able to quickly adapt when the internal and external conditions change. Our bio-inspired and flexible control architecture can be applied to different robotic configurations without an excessive tuning of the parameters or customization. The cerebellum-based control system is indeed able to deal with changing dynamics and interactions with the environment. Important insights regarding the relationship between the bio-inspired control system functioning and the complexity of the task to be performed are obtained.
1. Introduction
Controlling a robotic system that operates in an uncertain environment can be a difficult task if the analytical model of the system is not accurate. Models are the most essential tools in robotic control (Francis and Wonham, 1976), however, modeling errors are frequently inevitable in complex robots, for instance humanoids and soft robots. Such redundant modern robots are mechanically complex and often interacts with unstructured dynamical environments (Nakanishi et al., 2008; Nguyen-Tuong et al., 2009). Traditional hand-crafted models and standard physics-based modeling techniques do not sufficiently take into account all the unknown nonlinearities and complexities that these system present. This lack consequentially leads to a reduced tracking accuracy or, in the worst case, to unstable null-space behavior.
Modern autonomous and cognitive robots are requested to adapt not only the decisions but also the forces exerted in any varying condition and environment. The selected movement can not be executed properly if the robot does not adjust the forces according to the changing dynamics. Because of this, modern learning control methods should automatically generate model based on sensor data streams, so that the robot is not a closed entity, but a system that interacts, and evolves through the interaction with a dynamic environment.
In this paper, we intend to design an adaptive learning algorithm to control the movements of a complex nonlinear dynamical system. In particular, we assume that: the Jacobian poorly describes the actual system; the robot interacts with one or more unmodeled external objects; the sensor-actuator system is distributed and not all the states are observable or can be describe with parametric function designed off-line; the action/state space is continuous and high-dimensional. The control system should solve the inverse dynamics control problem of a multiple-joint robotic system affected by static and dynamic external disturbances during the execution of a repeated task. The controller is envisioned to reduce the tracking accuracy of each actuator through force-based control input.
In early days of adaptive self-tuning control, models were learned by fitting open parameters of predefined parametric models (Atkeson et al., 1986; Annaswamy and Narendra, 1989; Wittenmark, 1995; Khalil and Dombre, 2002). Although this method had great success in system identification and adaptive control techniques (Ljung, 2007), the estimation of the open parameters can lead to several problems, such as: slow adaptation; unmodeled behavior and persistent excitation issue (Narendra and Annaswamy, 1987); inconsistency of the estimated physical parameters (Ting et al., 2006); unstable reaction to high estimation error. In recent years, non-parametric approach has been shown to be an efficient tool in the resolution and prevention of the aforementioned problems thanks to the adaptation of the model to the data complexity (Nguyen-Tuong and Peters, 2011), and several methods have been proposed (Farrell and Polycarpou, 2006), such as neural networks (Patino et al., 2002), and statistical methods (Kocijan et al., 2004; Nakanishi and Schaal, 2004; Nakanishi et al., 2005).
In the eighties, Narendra's research group at Yale University exploited the adaptability of artificial neural networks (ANNs) to identify and control nonlinear dynamical systems (Narendra and Mukhopadhyay, 1991a,b, 1997; Narendra and Parthasarathy, 1991). Their experiments showed that the versatility of the ANNs resulted beneficial for controlling the different behaviors that characterize complex dynamical systems. Although the robustness of the classic parametric method in most of the control scenarios, ANNs were largely used in adaptive control to overcome uncertainties, unmodeled nonlinearities and to handle more complex state space systems (Glanz et al., 1991; Sontag, 1992; Zhang et al., 2000; Patino et al., 2002; He et al., 2016, 2018). As matter of fact, the non-linear components and the layered structure that distinguish the ANNs facilitate the mapping and constrain the effects of nonlinearities. Furthermore, the on-line adjustment of the parameters respect to the input-output relationship without any strict structural parameterization results advantageous for adapting to time-dependent changes.
In the Nighties thanks to the extended application of ANNs in robotics, Juyang Weng introduced the Autonomous Mental Development approach (AMD) to artificial intelligence (Weng et al., 1999a; Weng and Hwang, 2006). Weng theories were mainly inspired by how the biological systems efficiently calibrate their movements under internal and environmental changes. Accordingly to AMD the robot have to be embodied in the environment, and its processing is not preprogrammed but is the result of the continuous and real-time interaction within the two systems (Weng et al., 1999b, 2000; Weng, 2002). Respect to classic parametric approaches, the developing artificial agent creates and adapts models describing itself and its relation with the environment rather than learning and estimating parameters of a mathematical model built off-line. These theories found large application for high level cognition tasks (see Vernon et al., 2007 for a review) but were also applied to low level control in visually-guided robots (Metta et al., 1999; Ugur et al., 2015; Luo et al., 2018).
With the aim of mimicking artificially the motor efficiency of the biological system, James S. Albus proposed a neural network-based learning algorithm for robotic controller based on theories of central nervous system (CNS) structure and function: the “cerebellar model articulation controller,” commonly known as CMAC module (Albus, 1972). Several studies in literature demonstrated that, the anatomy and physiology of the cerebellum is suitable for the acquisition, development, storage and use of the internal models describing the interaction within body and environment (Wolpert et al., 1998). Moreover, the cerebellum is composed by separated regions which functionality relies both on the internal structure of the circuit and on the connection with other CNS areas (Houk and Wise, 1995; Caligiore et al., 2017): each region receives both the desired movements from the cortex and the sensory information from tendons, joints and muscles spindles and elaborates a signal that corrects whereas other CNS region are lacking. As matter of fact, subjects affected by cerebellum damage often present motor deficit, such as uncoordinated and ballistic multiple-joint movements (Schmahmann, 2004). For this reason in the last decades, scientists tried to explain the roles of the cerebellum in motor control, especially its contribution to sensory acquisition and timing and its involvement in the prediction of the sensory consequences of action. Moreover, this adaptive control nature motivated several researchers toward a deeper understanding of the cerebellum for robotics application.
Two main research lines born since Marr and Albus proposed the first artificial cerebellum-like network as pattern-classifier for controlling a robotic manipulator (Marr, 1969; Albus, 1972): the first research line focuses on purely industrial application and has as major representative W. Thomas Miller; the second research line, mainly represented by Mitsuo Kawato, deep-rooted in neuroscience and kept investigating on the biological evidence of the cerebellum structure and functionalities in relation to other CNS areas (Kawato et al., 1987; Kawato, 1999).
Miller applied the CMAC module in a closed loop vision-based controller to solve the forward mapping with direct modeling (Miller, 1987). Although the advantages, such as the rapid algorithmic computation based on least-mean-square training and the fast incremental learning, this approach lack of generalization and is sensitive to noise and large error (Miller et al., 1990). Over the years, researchers have been focusing on solving these drawbacks and the CMAC module has been mostly used as non-linear function approximator to boost the tracking accuracy of the adaptive controller and mitigate the effects of the approximation errors (Lin and Chen, 2007; Chen, 2009; Guan et al., 2018; Jiang et al., 2018). Although the promising results obtained by these applications of the CMAC network, this industrial research line did not completely exploit the overall capabilities and components of the cerebellum. It is worthy to note that the CMAC module mimic the cerebellar circuit only at the granular-purkinje level, for this reason only the mapping and classification functionalities are exploited.
The neuroscientific research line has been investigating mainly on the layered structure of the cerebellar circuit proposing several synaptic plasticity models (Luque et al., 2011, 2014, 2016; Casellato et al., 2015; D'Angelo et al., 2016; Antonietti et al., 2017), network models (Chapeau-Blondeau and Chauvet, 1991; Buonomano and Mauk, 1994; Ito, 1997; Mauk and Donegan, 1997; Yamazaki and Tanaka, 2007; Dean et al., 2010), adaptive linear filter model (Fujita, 1982; Barto et al., 1999; Fujiki et al., 2015), and combination of both (Tolu et al., 2012, 2013). These cerebellar-like models were embedded into bio-inspired control architectures to analyze how the cerebellum adjusts the output of the descending motor system of the brain during the generation of movements (Kawato et al., 1987; Ito, 2008), and how it predicts the action, minimizes the sensory discrepancy and cancels the noise (Nowak et al., 2007; Porrill and Dean, 2007). The experiments regarded the generation of voluntary movements with both simulated and real robots, e.g., eye blinking classical conditioning (Antonietti et al., 2017), vestibulo-ocular task (Casellato et al., 2014), the gaze stabilization (Vannucci et al., 2016), and perturbed arm reaching task operating in closed-loop (Garrido Alcazar et al., 2013; Tolu et al., 2013; Luque et al., 2016; Ojeda et al., 2017). From the analysis of the literature, it then emerged that research groups have treated the robots as stand-alone systems without interactions with the environment, while the real world is more complex and every external interaction counts. It is worth mentioning that the previous works have been employed for motor learning and control of simplified objects.
In this paper we present a robotic control architecture to overcome modeling error and to constrain the effects of uncertainties and external disturbances. The proposed controller is composed of a static component based on a classic feedback control methods, and of an adaptive decentralized neural network that mimic the functionality and morphology of the cerebellar circuit. The cerebellar-like module add feed-forward corrective torque to the feedback controller action (Ito, 1984; Miyamoto et al., 1988). A non-parametric nonlinear function approximation algorithm have been employed to map on-line and to reduce the high dimensional and redundant input space. The algorithm creates the internal model describing the interaction within system and environment. This model is kept under development throughout the execution of the task. The neural network mimic the composition of the cerebellar microcircuit. The layered structure of the network constrains the effects of nonlinearities and external perturbations. The network weights are based on non-linear and multidimensional learning rules that mimic the cerebellar synaptic plasticities (Garrido Alcazar et al., 2013; Luque et al., 2014).
This manuscript extends the previous works under three main aspects: 1. cerebellar-like network topology and input data; 2. feedback control-input; 3. dynamic control under external changing conditions. With the aim at giving more insights into the capacity of the cerebellum of generating control terms in the framework of accurate control tasks, the following research questions come naturally to mind: can a control system be generalized to control robotic agents by endowing them with adaptive capabilities? Can accurate and smooth actions in a dynamic environment be performed by the extrapolation of valuable sensory-motor information from heterogeneous dynamical stimuli? Does this sensory-motor information extrapolation facilitate the motor prediction and adaptation in changing conditions? The tests were carried out in the Neuro-robotics Platform (Falotico et al., 2017) with the virtual humanoid robot iCub. The robot arm has to follow a planned movement overcoming the disturbances provoked by a table attached to the hand and a ball running on it. A similar example was solved by employing a conventional control law together with computer vision techniques (Awtar et al., 2002; Levinson et al., 2010). However, this approach assumes a fixed robot morphology defined and described before running the experiment, and there is no run-time adaptation to the “biological changes” as we see in human beings. Balancing a table with a ball running on it is a relevant example of how humans learn to calibrate, coordinate, and adapt their movements, hence, we investigate how robots can achieve this task following the biological approach. Probst et al. (2012) also followed the biological approach; they tackled the problem taking into account the dynamics of the system, four different forces are found by means of a liquid state machine and applied in four different points of the table to achieve the balancing task. A supervised learning rule is used for the training step, which concludes that after 2,500 s no further improvement of the performance is obtained.
Hence, the main advantages of our model are: the low amount of (sometimes implausible) prior information for the control, a fast reactive robotic control system, an on-line self-adaptive learning system. Thanks to these features the robot can perform a determinate physical task and adapt to changing conditions. In conclusion, this approach introduces a fast and flexible control architecture that can be applied to different robotic platforms without any/excessive customization.
In the first section that follows, we present the control architecture, the adopted cerebellar-like model and the description of the method. In the second section, we report the experimental setup as well as the results of the comparison study of four control system approaches including the respective analysis. Finally, we will discuss the main findings of the study correlating them to previous literature.
2. Materials and Methods
In this section, we present our bio-inspired approach to solve the problem of controlling the right arm of the ICub humanoid robot despite the occurrence of an external perturbation. The experiment consists of a simulated humanoid robot that executes a requested movement using three controlled joints of the right arm. During the simulation, a ball is launched on the table that is attached to the robot's right hand; the ball is free to roll on the table, as illustrated in Figure 1B. The movements of the ball are provoked by the shaking of the robot arm and consequentially of the table. The key information about the external system components (e.g., the ball and table) are reported in Table 1.
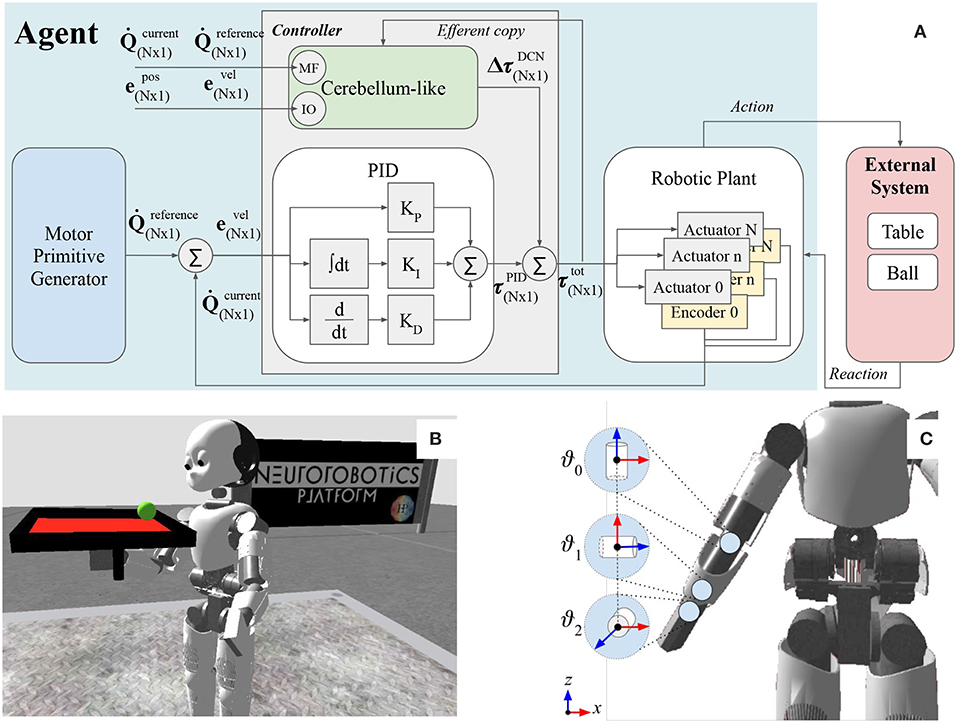
Figure 1. (A) The figure illustrates the main components of the functional architecture scheme and the link with the artificial robot agent and the external system. (B) The humanoid Icub holding the table-ball system in the simulation environment NRP. (C) Three controlled joints: wrist prosup ϑ0, wrist yaw ϑ1, wrist pitch ϑ2.
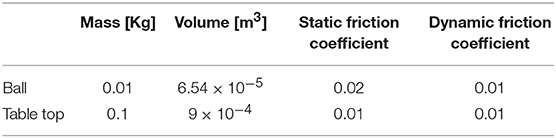
Table 1. External system features.
The proposed control architecture (Figure 1A) is composed of three main building blocks: the robotic plant, which is the physical structure (section 2.1); the motor primitive generator, which is responsible of the trajectory generation (section 2.2); the controller, which elaborates the torque commands to move each motor to the desired set point (section 2.3).
2.1. Robotic Plant
The Icub humanoid robot is 104 cm tall and it is equipped with a large variety of sensors (such as gyroscopes, accelerometers, F/T sensors, encoders, two digital cameras) and 53 actuated joints that move the waist, head, eyes, legs, arms, and hands. During the experimental tests, eight revolute joints of the right arm were actuated: four joints were kept constant to maintain the arm up (e.g., elbow, shoulder roll, shoulder yaw, and shoulder pitch), and three joints were controlled in effort by the proposed control system (namely wrist prosup, wrist yaw and wrist pitch). The axis orientation of the controlled actuators are illustrated in Figure 1C. Additional information about the actuated joints are reported in Table 2. In this work, we used the encoder to only read the state of the controlled joints (e.g., angular position, and velocity) and save it in the process variables,
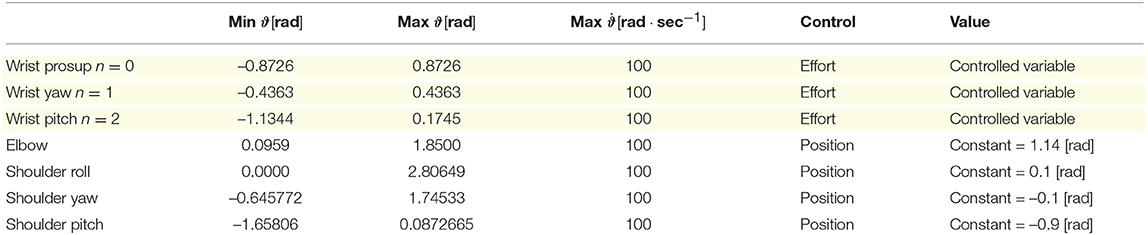
Table 2. Actuated joints information: the wrist actuators (highlighted in yellow) are controlled in effort while the elbow and shoulder motors are kept to a constant angular position.
2.2. Motor Primitive Generator
The motor primitive generator plans the trajectory for each actuated joint and communicates the reference value to the control system at each time step. The reference angular position and velocity of each joint are defined as oscillators with fixed amplitude, natural frequency and phase,
where N = 2. The temporal frequency is f = 0.25Hz, while the oscillations A amplitude and φ phase of each joint are set to:
2.3. Controller
The controller block (Figure 1A) is composed of a static component based on classic control methods (section 2.3.1), and of an adaptive decentralized block representing the bio-inspired regulator, i.e., the cerebellar-like circuit (section 2.3.2). Both sub-blocks receive information about the Qc, process variables measured from the encoders located in the robotic plant (Equations 1, 2), and the Qr, reference trajectory signals from the motor primitive generator (Equations 3, 4). The controller directly sends the τtot total control input to the robot servo controller which actuates the joints for δt = 0.5s. The τtot total control input is expressed as the result of a feed-forward compensation (as the AFEL architecture proposed by Tolu et al., 2012),
τtot where and (where n = 0, …, N) are the contributions from the static and the adaptive bio-inspired controller respectively.
2.3.1. Feedback Controller
The static control system refers to the classic feedback control scheme with PID regulator. It is defined static due to its time-constant control terms. The closed-loop system continuously computes the angular velocity error of each joint as the difference between the reference (Equation 4) and the process variable (Equation 2),
The error (where n = 0, …, N) is used to apply correction to each controlled joint in terms of effort,
according to the independent joint control law expressed as:
where the integration time window is Δt = 10 samples. The regulator is tuned to weakly operate in a linearized condition which excludes the presence and disturbance of the ball, hence the proportional, integrative and derivative terms are static and set respectively to,
2.3.2. Cerebellar-Like Model
The proposed cerebellar-like network has been designed to solve robotic problems (Figure 2). In particular, the sensory input and the corrective action in output refer to entities regarding the actuated motors, such as motor angular position, velocity or effort. Electrophysiological evidence about the encoding of movement kinematics has been found at all levels of the cerebellum; for example, in this review (Ebner et al., 2011), reported that the mossy fibers (MF) inputs encode the position, direction, and velocity of limb movements. Moreover, many hypotheses suggest that the cerebellum directly contributes to the motor command required to produce a movement. In our model, the input-output relationship is based on the previous suggestions and the signal propagation throughout the cerebellar network layers is in accordance with the robotic control application. The main design concept is that the signal propagating inside the circuit have the same dimension of the ΔτDCN output signal from the Deep Cerebellar Nuclei (DCN). The propagated signal is modulated inside the network by other signals that are correlated with the intrinsic features of the controlled plant, such as position and velocity terms, in order to have a complete description of the state.
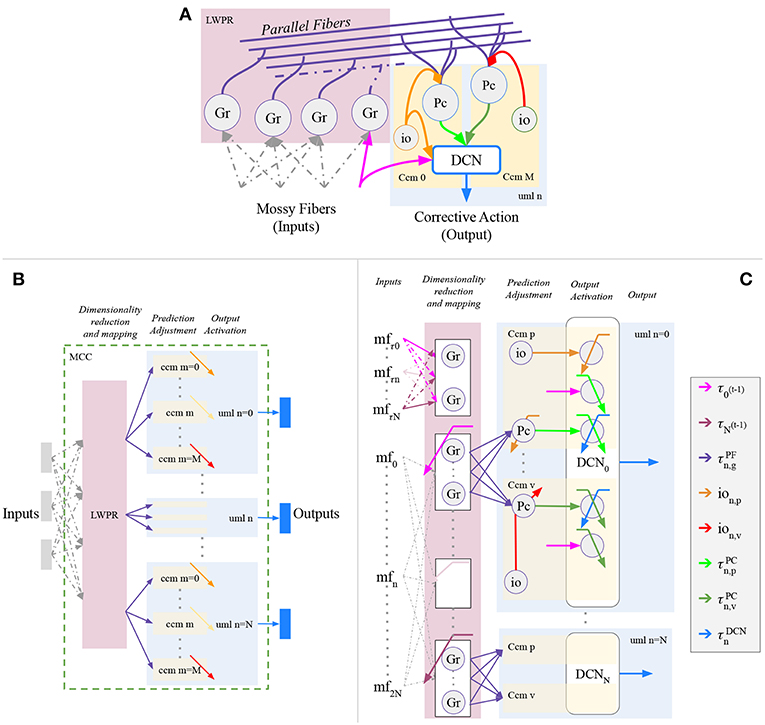
Figure 2. Proposed cerebellar-like circuit in analogy with D'Angelo et al. (2016). (A) canonical micro-circuit. Proposed cerebellar-like neural network (B) structural partition and (C) details.
The neural network structure is divided into separated modules (Figure 2B), or namely Unit Learning Machine (uml) (Tolu et al., 2012, 2013). Assuming that the robot plant is composed by N controllable object, then each uml is specialized on the n-th controlled object (where n = 0, …, N), or rather the DCN output of the uml will be the cerebellar contribution for the specific object. The uml itself is separated into M sub-modules which represent the canonical cerebellar microcircuit (ccm). Each ccm is specialized with respect to a specific feature describing the behavior of the n-th controlled object. The overall umls and other structures, that are dedicated to the dimensionality reduction and mapping of the sensory information, compose together the Modular Cerebellar Circuit (MCC).
In the proposed experiment, the canonical cerebellar microcircuits (ccm) of each controlled object are specialized in p position and in v velocity. In details, the Purkinje layer of each n−th uml presents a pair of Purkinje cells (PC) (Figure 2C), specialized in position Pcn, p and velocity Pcn, v respectively through different climbing fibers (ion, p, and ion, v). Moreover, the bio-inspired controller receives the same sensory information of the feedback controller (section 2.3.1), but it is intended to correct the eϑn angular position error, whereas the PID corrects the angular velocity error. This is solved through the connection inferior olive-deep cerebellar nuclei (IO-DCN), which conveys information about the angular position error. An additional aspect, the inferior olive signals differs from Kawato's feedback error learning theory (Kawato, 1990) and our previous experiments (Tolu et al., 2012, 2013), because the Jacobian does not correctly approximate the system, therefore the required conditions are not satisfied and it is not efficient to compare the motor signals.
The mossy fibers transmit the information about the current and reference state of the controlled joints in terms of angular velocity to the granular cells (Gr),
The granular layer-parallel fibers network is the circuit area committed to the mapping of the mossy fibers signals and to the prediction of the next output given the current sensory input (Marr, 1969; Albus, 1971). As in our previous works (Tolu et al., 2012, 2013), we artificially represented this network with the Locally Weighted Projection Regression algorithm (LWPR) (Vijayakumar and Schaal, 2000). The LWPR resulted an efficient method for the fast on-line approximation of non-linear functions in high dimensional spaces. Given the MF(t) mossy fibers input vector (Equation 9), the LWPR creates G local linear models that in our scheme represent the Grg granular cells (for g = 0, …, G). Each linear model employs the MF(t) to make a prediction of the control input (where n=1,…,N). The total output of the granular-parallel fibers network is the weighted mean of all the linear models specialized in velocity,
where and are defined in Vijayakumar and Schaal (2000).
In our scheme, there are two Purkinje cells per controlled joint Pcn, p and Pcn, v (where n = 0, …, N). The 1 synapses connecting the parallel fibers and the Pcn, p (PF-PC connection) (Garrido Alcazar et al., 2013), are modulated by the ion, p inferior olive (IO) signal,
that transmits the information about the ẽϑn normalized angular position error of the n−th joint,
while the 1 synaptic strengths between the parallel fibers and the Pcn, v, are modulated by the ion, v inferior olive signal,
that transmits the information about the normalized angular velocity error of the n−th joint (Equation 6). The weighting kernel tends to support the control actions that lead to an error lower than a specific threshold ethresh,
Respect to our previous work (Tolu et al., 2012, 2013) the output signals of the Purkinje cells are directly function of the prediction instead of the weights,
Afterwards, the Purkinje cells signals are scaled by the synaptic weights and 2 (Garrido Alcazar et al., 2013), that are modulated by the Purkinje cells and the deep cerebellar nuclei activities (PC-DCN),
resulting in the input signals,
In addition, the deep cerebellar nuclei receives the input signals , from the mossy fibers and from the inferior olive. In our proposed circuit, the mossy fibers connected to the deep cerebellar nuclei (MF-DCN) conveys the information about the last control input sent to each controlled joint (Equation 5). This input is scaled by the synaptic weights and 3 (Garrido Alcazar et al., 2013), modulated by the respective n−th Purkinje cells activities,
The inferior olive contribution in the deep cerebellar nuclei (IO-DCN) is given by the ion, p (Equation 11), which is modulated by the 4 synaptic weight (Luque et al., 2014),
The final cerebellar corrective term is the result of the modulated control input subtracted by the prediction modulated by the current error together with the modulated contribution of the error itself,
or rather,
2.4. Proposed Experiments and Performance Measures
The proposed control scheme has been applied in four different experiments with the aim at analyzing the advantages of the bio-inspired controller in presence of dynamical disturbances. In details, the four experiments differ from the presence of the ball and the cerebellar-like controller contribution (Figure 3):
• Experiment I: control input without both cerebellum contribution and ball disturbance,
• Experiment II: control input with cerebellum contribution, without ball disturbance,
• Experiment III: control input without cerebellum contribution, with ball disturbance,
• Experiment IV: control input with both cerebellum contribution and ball disturbance,
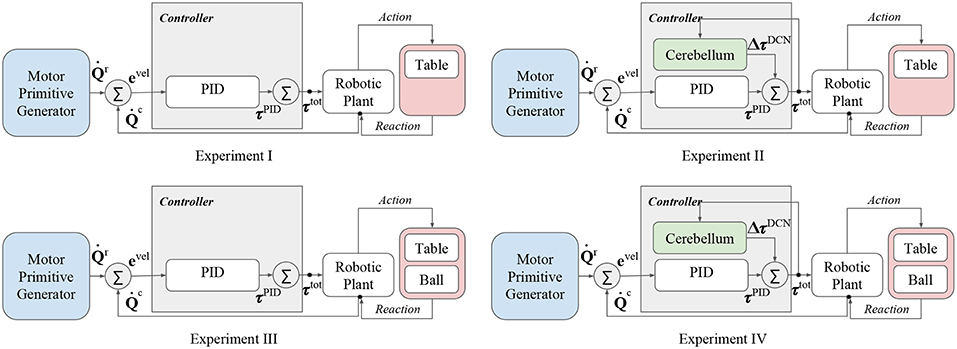
Figure 3. Functional architectures representing the proposed experiments.
The performance of each experiment will be measured by analysis of the mean absolute error (MAE) evolution computed for the angular position error of each controlled joint (Equation 12),
The MAE is computed for every trajectory period T = 8 s (Equation 3).
3. Results
The software describing the system is based on the ROS (Quigley et al., 2009) messaging architecture and is integrated in the Neurorobotics Platform (NRP) (Falotico et al., 2017). The NRP is a simulation environment based on ROS and Gazebo (Koenig and Howard, 2004) which includes a variety of robots, environments and a detailed physics simulator. The three wrist motors are controlled in effort through the Gazebo service ApplyJointEffort, while the elbow and the three shoulder motors are controlled in position through their specific ROS topic. The sensory information from the encoders are received with a sampling frequency of fsampl = 50 Hz. The computer used for the test has the Ubuntu 16.04 Operating system (OS type 64−bit), the Intel Core™ i7 − 7700HQ Q1BVQDIuODBHSHo= × 8 processor, and the GeForce GTX 1050/PCIe/SSE2 graphics card.
Each experiment was performed 20 times with a total duration of about 3 min. The recorded data was saved in.csv files and processed for the analysis. The results are expressed as mean value of the 20 tests, and σ standard deviation or 95% confidence interval. In each experiment, the cerebellar-like circuit is activated after t = 40 s (or 10th iteration), which is the moment all the actuated joints reach a stable configuration (included the shoulder joints and the elbow). In experiments II and IV, the ball is launched on the table after t = 5 s (purple vertical line in the figures).
The comparison of the 4 experiments for each controlled joint are presented separately in 3 parts. In each part, we analyze the joint states, i.e., ϑc, n(t) angular position and velocity (Figures 4, 6, 8), respect to the control action (Figures 5, 7, 9). Moreover, we compared the mean absolute error MAE to measure the performance of the different cases (as reported in Table 3 and illustrated in Figure 10).
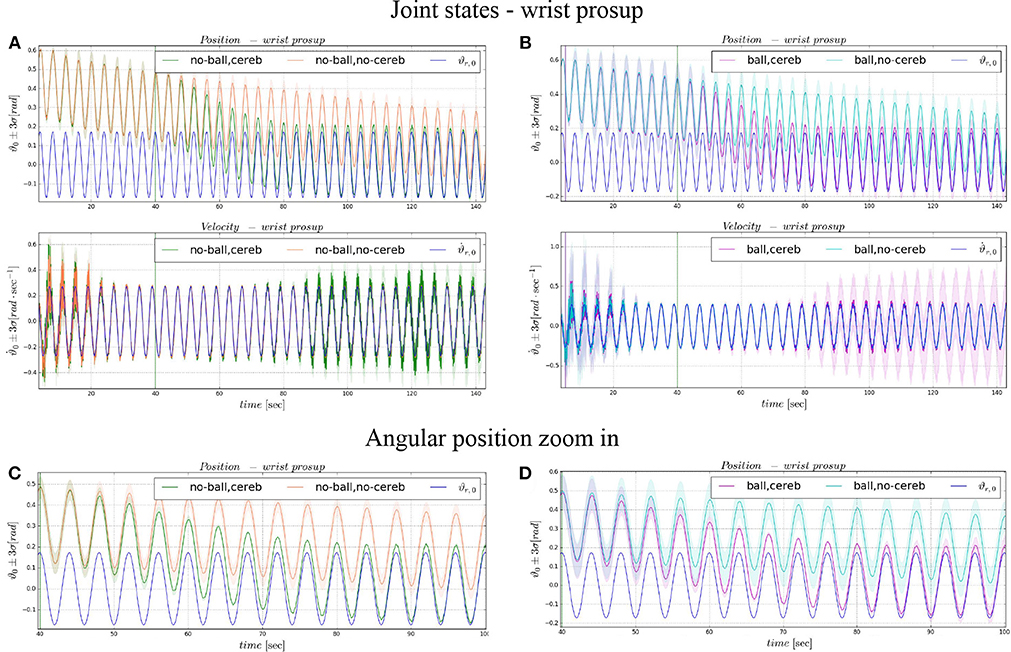
Figure 4. Angular position and velocity wrist prosup: comparison experiment I and II (A), with zoom on the angular position (C); comparison experiment I and II (B), with zoom on the angular position (D). The plots show the results of the 20 tests in terms of mean value (solid line) and 95% confidence interval (colored area). The vertical green line indicates the moment in which the cerebellar-like controller starts giving the corrective action (t = 40s). The vertical purple line indicates the instant the ball is launched on the table (t = 5s).
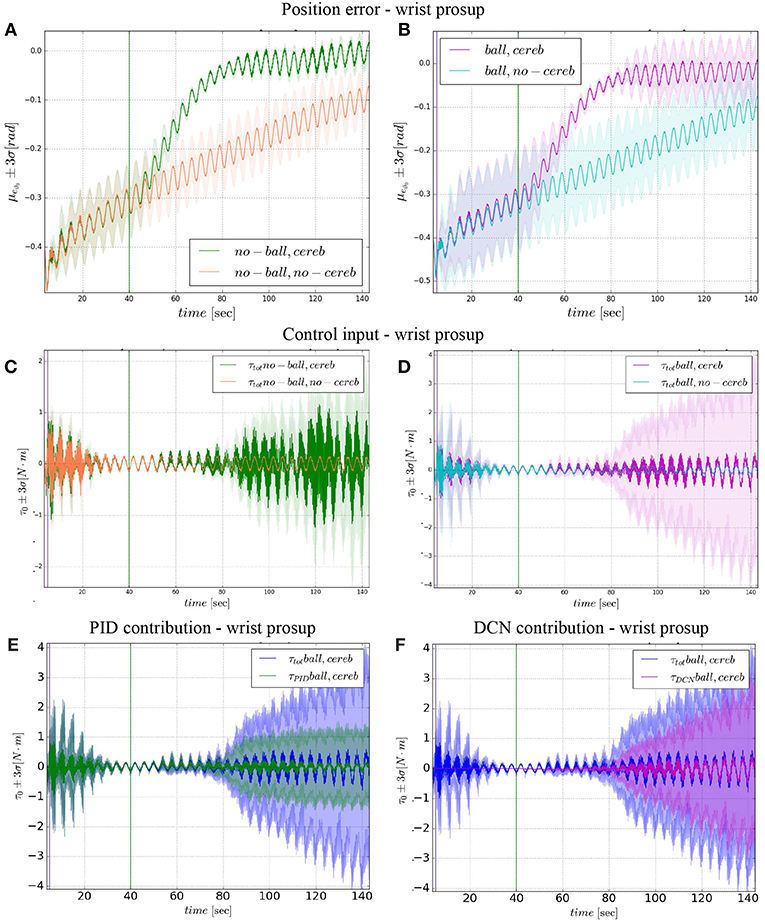
Figure 5. Wrist prosup experimental results. Resulting angular position error eϑ0, comparison experiments I and II (A), comparison experiments III IV (B). Control input evolution, comparison experiments I and II (C), comparison experiments III IV (D). Control input contributions in experiment IV comparisons between: and (E); and (F). The plots show the results of the 20 tests in terms of mean value (solid line) and 95% confidence interval (colored area). The vertical green line indicates the moment the cerebellar-like controller starts giving the corrective action (t = 40s). The vertical purple line indicates the instant the ball is launched on the table (t = 5s).
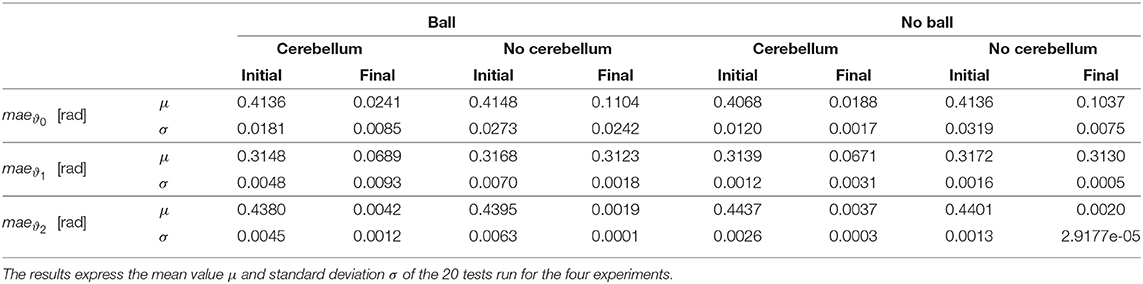
Table 3. The mean absolute error (MAE) of the initial and final period (T = 4 s).
3.1. Wrist Prosup
In the details of Figures 4A,B, the corrective action of the cerebellar-like circuit (Experiments II, IV) leads ϑc, 0 faster to the desired trajectory ϑr, 0 with respect to the case without corrections (Experiments I, III). ϑc, 0(t) starts getting closer to the desired position in about one period T = 4 s after the activation of the cerebellum (Figures 4C,D). In Figures 5A,B it is evident how the angular position error eϑ0 drops when the cerebellum action grows (Figures 5C,D). In particular, the mean absolute error drastically decreased by the 95 and 94% in experiment II and IV respectively, while it only decreased by the 74 and 73% in Experiment I and III (Figure 10A, the numerical results are reported in Table 3). The main difference between experiments with and without ball is the σ standard deviation. In the final period, the experiments with the ball present a larger standard deviation which is 30% (without cerebellum) and 19% (with cerebellum) respect to the NO ball-case.
3.2. Wrist Yaw
The wrist yaw joint is the most affected by the cerebellum action. In Figure 6, it is evident how with only the PID contribution ϑc, 1(t) presents a constant and large offset with respect to ϑr, 1(t). As soon as the cerebellum contribution grows (around the 50 s, Figures 7C,D) the error descends (Figures 7A,B). The mean absolute error decreases by the 78% in experiment II and IV, while it only drops 1% in experiments I and III (Figure 10B). In the last period, the experiments with the ball have a standard deviation 30–33% larger than the NO ball-cases.
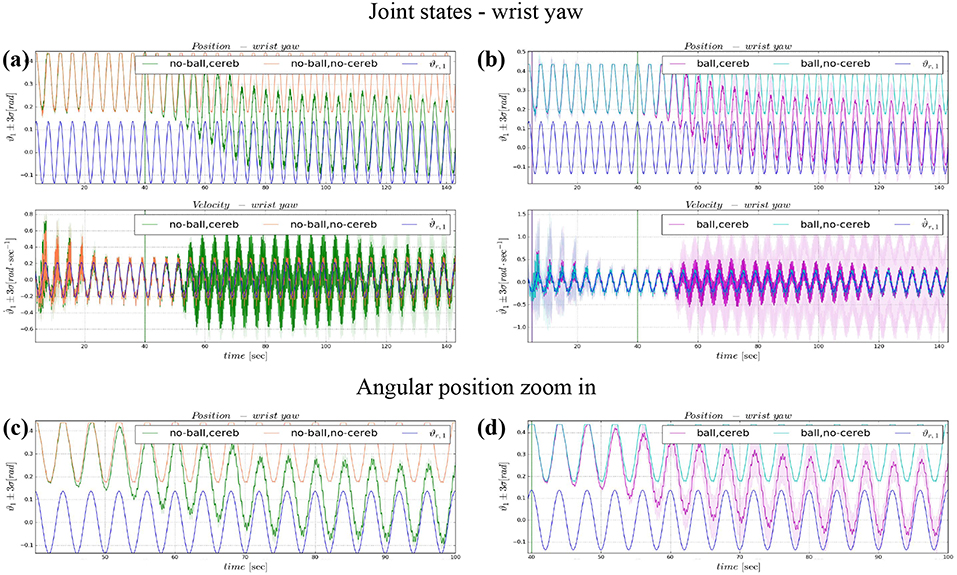
Figure 6. Angular position and velocity wrist yaw: comparison experiment I and II (a), with zoom on the angular position (c); comparison experiment I and II (b), with zoom on the angular position (d). The plots show the results of the 20 tests in terms of mean value (solid line) and 95% confidence interval (colored area). The vertical green line indicates the moment the cerebellar-like controller starts giving the corrective action (t = 40s). The vertical purple line indicates the instant the ball is launched on the table (t = 5s).
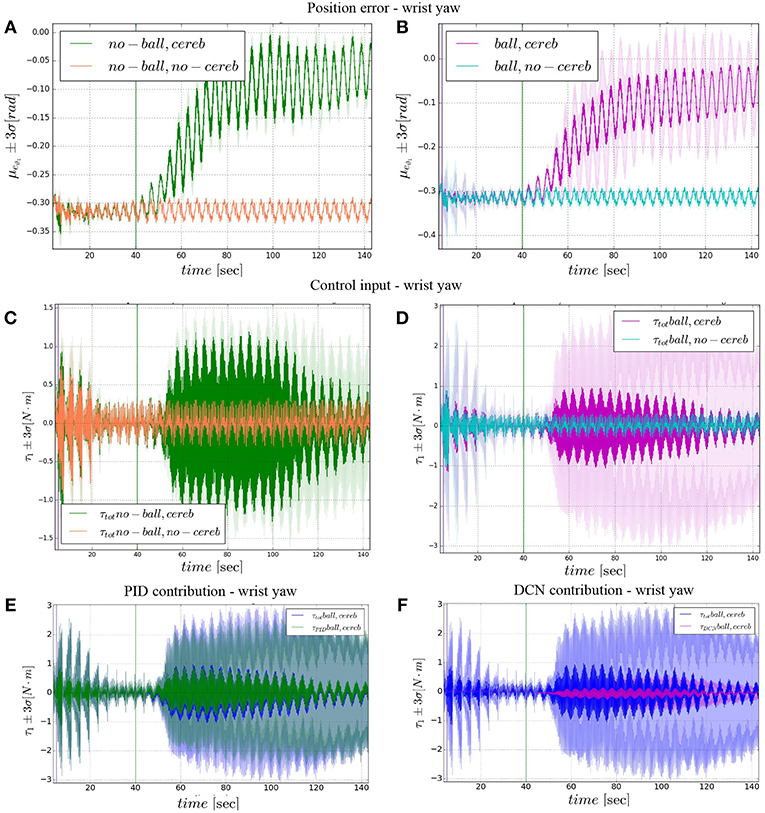
Figure 7. Wrist yaw experimental results. Resulting angular position error eϑ1, comparison experiments I and II (A), comparison experiments III IV (B). The control input evolution, comparison experiments I and II (C), comparison experiments III IV (D). Control input contributions in experiment IV comparisons between: and (E); and (F).The plots show the results of the 20 tests in terms of mean value (solid line) and 95% confidence interval (colored area). The vertical green line indicates the moment the cerebellar-like controller starts providing the corrective action (t = 40s). The vertical purple line indicates the instant the ball is launched on the table (t = 5s).
3.3. Wrist Pitch
On the other hand, the wrist pitch gains from the cerebellar action only when the error is larger than , which is around 40–60 s (Figure 8), taking into account that the cerebellum is started at t = 40 s. The gets more silent (Figures 9C–E) when the angular position error is small (Figures 9A,B). In Figure 10C is more evident how the cerebellum accelerates the corrective action between iteration 10 and 15 where the MAE with the cerebellum (experiment II) is 17% lower respect to experiment I (in experiment IV the MAE is 16% lower respect to experiment III).
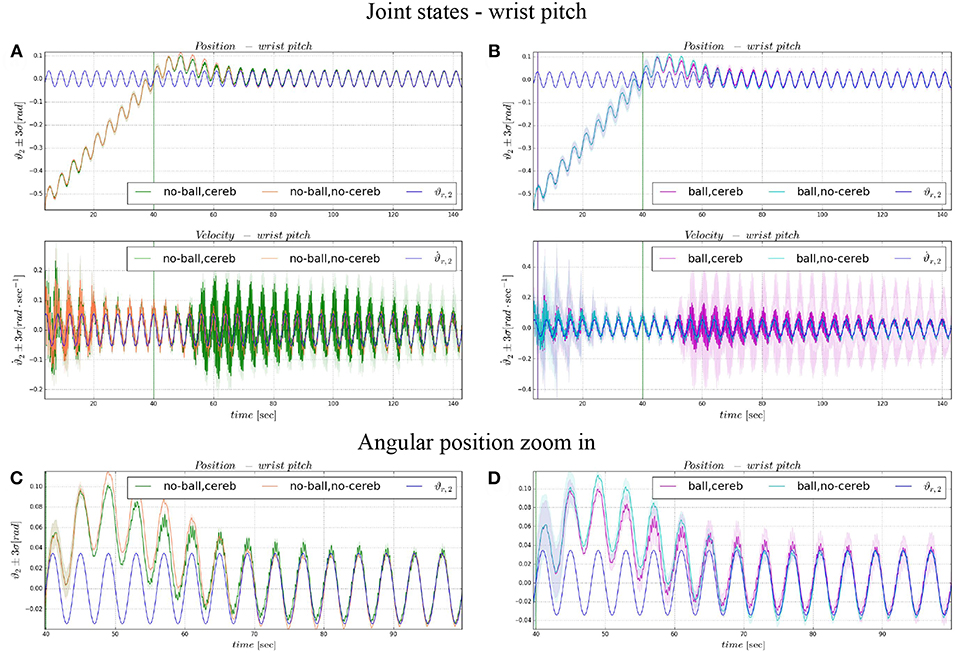
Figure 8. Angular position and velocity wrist pitch: comparison experiment I and II (A), with zoom on the angular position (C); comparison experiment I and II (B), with zoom on the angular position (D). The plots show the results of the 20 tests in terms of mean value (solid line) and 95% confidence interval (colored area). The vertical green line indicates the moment the cerebellar-like controller starts providing the corrective action (t = 40s). The vertical purple line indicates the instant the ball is launched on the table (t = 5s).
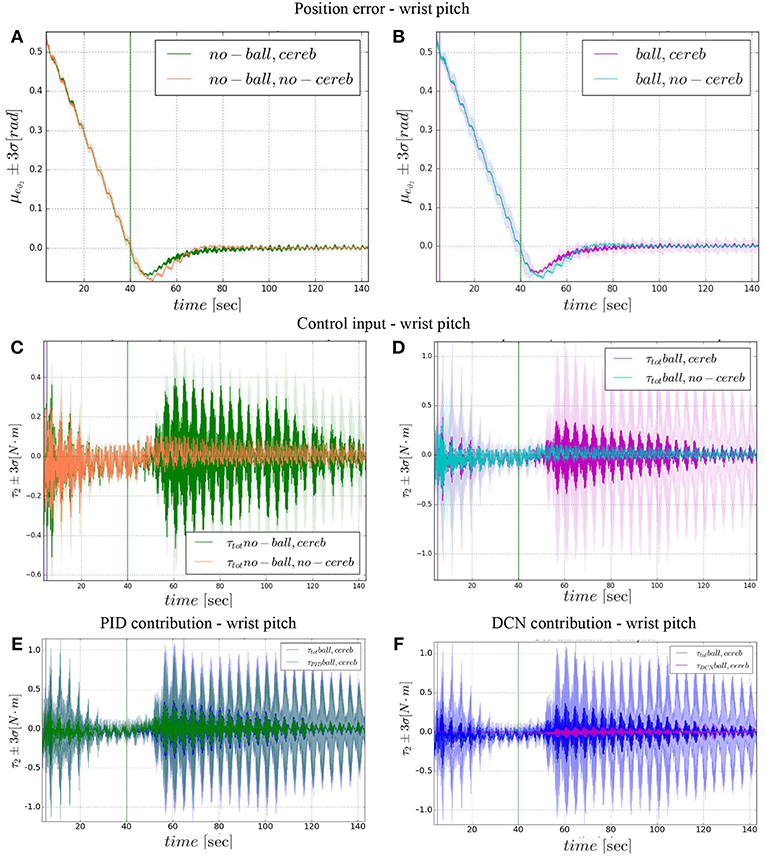
Figure 9. Wrist pitch experimental results. Resulting angular position error eϑ2, comparison experiments I and II (A), comparison experiments III IV (B). The control input evolution, comparison experiments I and II (C), comparison experiments III IV (D). Control input contributions in experiment IV comparisons between: and (E); and (F). The plots show the results of the 20 tests in terms of mean value (solid line) and 95% confidence interval (colored area). The vertical green line indicates the moment the cerebellar-like controller starts providing the corrective action (t = 40s). The vertical purple line indicates the instant the ball is launched on the table (t = 5s).
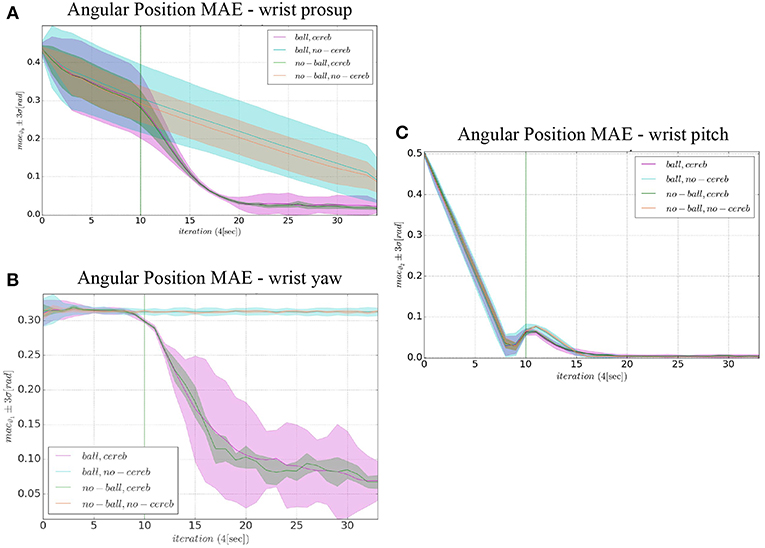
Figure 10. Comparison of the angular position MAE: (A) wrist prosup, (B) wrist yaw and (C) wrist pitch. The plots show the results of the 20 tests in terms of mean value (solid line) and 95% confidence interval (colored area). The vertical green line indicates the moment the cerebellar-like controller starts providing the corrective action (t = 40s or iteration = 10).
4. Discussions
In this work, a bio-mimetic control scheme is presented in the framework of a robotic task, in which simultaneous control of the object dynamics and of the internal force exerted by the robot arm to follow a trajectory with the object attached to it is required. To address multi-joint corrective responses, we induced and combined three-joint wrist motions. Thus adaptation skills are required especially to deal with an external perturbation acting on the robot-object system. The main observation is that plastic mechanisms given by a feed-forward cerebellum-like controller effectively contribute to the learning of the dynamics model of the robot arm-object system and to the adaptive corrections in terms of torque commands applied to the joints. These cerebellar torque contributions, together with feedback (PID) torque outcome, allow the progressive error reduction by incorporating distributed synaptic plasticity based on the feedback from the actual movement.
The results about the three controlled joints showed a fast reactive control in the test cases when the cerebellum-like model is active, which is even more evident when the ball (random perturbation) is present as shown in Figures 4, 6, 8B,D. An incremental velocity control input is then provided to the controller of the system to deal with the perturbation. The purpose of considering a heterogeneous stochastic dynamical stimuli (board and ball) was to test and examine the activation of incremental learning and adaptation of the cerebellum-like controller and at the same time to confirm its coupling with the feedback control inputs. Previous studies have shown that the feedback processes are omnipresent in voluntary motor actions (Scott et al., 2015) and rapid corrective responses occur even for very small disturbances that approach the natural variability of limb motion. In human beings, these corrections commonly require increases in muscle activity generated i.e., by applied loads (Nashed et al., 2015). By analogy, a similar effect can be noticed at joint-level in our system. In the experimental situation, the joints that are more influenced by the limb dynamics (wrist prosup and yaw joints) under the effect of the table and ball increase their control input activity as represented in Figures 5, 7C,D, while the wrist pitch joint has a much more reduced activity re influenced by the limb dynamics (wrist prosup and yaw joints) under the effect of the table and ball increase their control input activity as represented in Figures 9C,D compared to the previous two joints. This phenomena is also reflected in the control input provided by the cerebellum-like model. The bigger the position error is at the beginning of the simulation with only the PID control case (experiments I and III) the more effective the cerebellar-like corrections are (experiments II and IV) as shown in Figures 5, 7, 9A,B. It should be noted that for the wrist pitch joint the PID controller leads to ~0.0 (rad) MAE around 40 s from the beginning of the simulation. However, among all the joints, the fundamental role of the cerebellum in motor control is confirmed by its anticipatory response for decreasing the error as it is appreciated in Figure 10. The control system achieved these result by creating up to 9 Gr receptive fields per uml at the granular level (or rather LWPR). In Figure 11, it is possible to appreciate how the IO inferior olive signals (in blue) of each ccm promptly influence the synaptic weights (in red) between the PF parallel fibers and the PC Purkinje cells (left column), and the contribution of the inferior olive itself on the DCN Deep Cerebellar nuclei corrective action (right column). In the IO-DCN connection details, the synaptic weights rapidly increment in the first tract around 40–60 s where the error is higher and then keep increasing slowly for the final adjustments. On the other hand, the PF-PC connection tends to not over-react at the beginning of the simulation around 40–60 s, while it strengthen when the error decline. We assume that this opposite influence of the IO on the synaptic weights makes possible the filtering and the dumping of any external disturbances or high error.
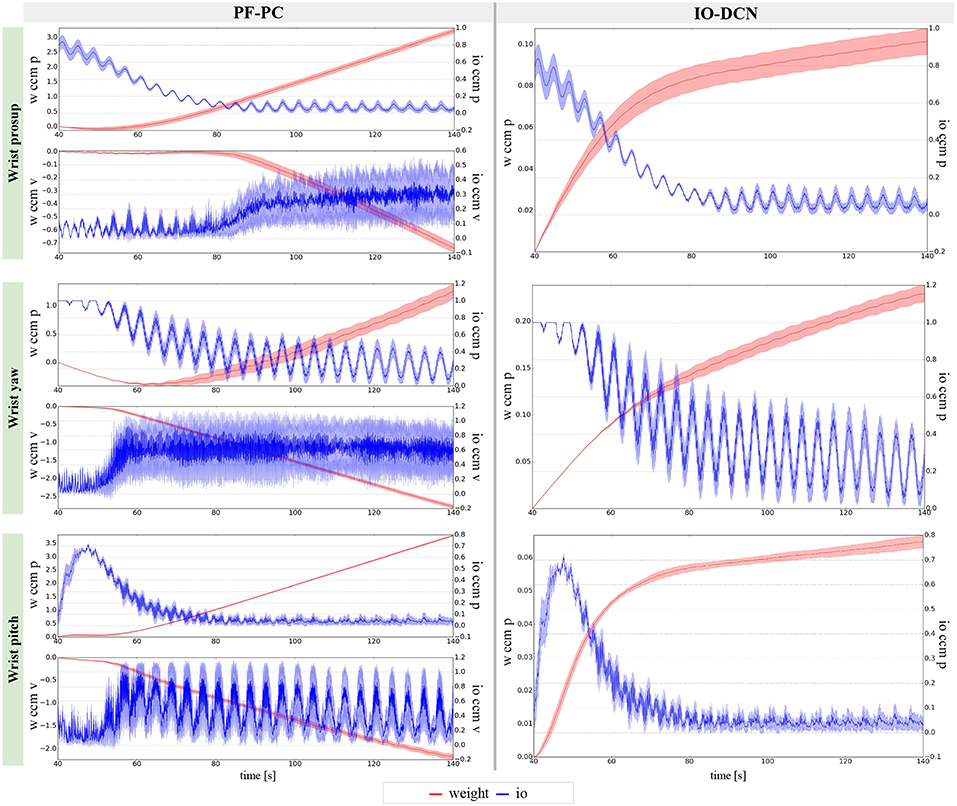
Figure 11. Learning evolution of the cerebellar-like network in experiment IV: influence of the inferior olive on the PC-PF parallel fibers-Purkinje cells and IO-DCN inferior olive-Deep cerebellar nuclei connections. The plots show the results of the 20 tests in terms of mean value (solid line) and 95% confidence interval (colored area).
This control model proposes a plausible explanation on how control feedback is used by the central nervous system (CNS) to correct for intrinsic as well as external sources of disturbances. Furthermore, the bio-mimetic model represents a plausible control scheme for voluntary movements that can be generalized to control robotic agents without mayor tuning of the parameters. Our controller with distributed plasticity allows efficient adjustment of the corrective signal regardless of the dynamic features of the robot arm and of the way the added perturbations affect the dynamics of the arm plant involved. According to this, the controller (cerebellum-like and PID) is adaptable by providing adjustable torque commands among the joints to overcome external dynamic and stochastic perturbations and to have a both fast and precise movement. This replies to our question about if the sensory-motor information extrapolation made by the cerebellum-like facilitates motor prediction and adaptation in changing conditions. It should be noted that the adaptation mechanism adopted here is not constrained to any specific plant or testing framework, and could therefore be extrapolated to other common testing paradigms.
D'Angelo et al. (2016) illustrated in their paper the schematic representation of how the core cerebellar microcircuit is wired inside the whole brain. The proposed cerebellar-like model has been designed in analogy with it. In contrast with Garrido Alcazar et al. (2013), Casellato et al. (2014), Antonietti et al. (2017), the proposed model encodes the movement kinematics at the mossy fibers level (Ebner et al., 2011), and presents a coupling at the Purkinje layer for velocity and position terms representation. Likewise, the synaptic strengths at PC-DCN level as well the synaptic strengths at IO-DCN level are modulated by signals related to position or velocity. The mossy fibers are connected to the DCN and to some granular cells to convey the efference copy or motor command information. The IO cells are devoted to teaching signal error transmission in terms of position and velocity errors. The teaching errors modulate the synaptic strengths at PF-PC and IO-DCN levels.
Tokuda et al. (2017) postulated that high dimensionality problem (high-dimensional sensory-motor inputs vs. low training data) is accomplished by the cerebellum by regulating the synchronous firing activities of the inferior olive (IO) neurons. Though the implementation of coupling mechanisms at the inferior olive cells would be an interesting work to have a better explanation on multiple joint control. This extension could also provide additional insights into the internal connectivity of the cerebellar microcomplex. Further investigation will be possible in the future of how specific properties of the cells, of the network topology and synaptic adaptation mechanisms complement each other in the bio-inspired architecture.
4.1. Neural Basis of Feedback Control for Voluntary Movements
Feedback control of movement is essential to guarantee movement success especially to compensate for perturbation arising from the interaction with the external world. Different brain areas (primary motor cortex, primary somatosensory cortex, cerebellum, supplementary motor area, etc.) are involved during a voluntary movement and cooperate in many levels of hierarchy. Feedback control theory might be the key for understanding how the previous areas plan and control the movement hierarchically. By using control terminology, during the voluntary movement of a limb, the primary motor cortex acts as a controller, and the limb connected to neuronal circuits becomes the controlled object.
The cerebellum learns and provides the internal models that reproduce the inverse or direct dynamics of the body part. Thanks to the cerebellar internal model learning, the primary motor cortex performs the control without an external feedback (Koziol et al., 2014). By our simulations, we suggest that such behavior can be confirmed. Indeed, the cerebellar-like contributions drive the feedback controller toward better accuracy and precision of the movement. In the future, a visual feedback input will be considered to probe the sophistication of feedback control processing and cerebellar-like learning consolidation.
Author Contributions
MC and ST conceived and designed the experiments, analyzed the data, and wrote the paper. MC implemented the architecture and performed the experiments. EA contributed to materials and analysis tools. HL and EF reviewed the paper.
Funding
This work has received funding from the Marie Curie project No. 705100 (Biomodular), from the EU-H2020 Framework Programme for Research and Innovation under the specific grant agreement No. 720270 (Human Brain Project SGA1), and No. 785907 (Human Brain Project SGA2).
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Footnotes
1. ^wpf−pc weighting kernel parameters: LTDmax = 10−3, LTPmax = 10−3, α = 170.
2. ^wpc−dcn weighting kernel parameters: LTDmax = 10−4, LTPmax = 10−4, α = 2.
3. ^wmf−dcn weighting kernel parameters: LTDmax = 10−4, LTPmax = 10−4, α = 2.
4. ^ weighting kernel parameters: MTDmax = −10−4, MTPmax = −10−5, α = 100.
References
Albus, J. S. (1971). A theory of cerebellar function. Math. Biosci. 10, 25–61. doi: 10.1016/0025-5564(71)90051-4
Albus, J. S. (1972). Theoretical and experimental aspects of a cerebellar model. Dissert. Abstr. Int. 33.
Annaswamy, A. M., and Narendra, K. S. (1989). “Adaptive control of simple time-varying systems,” in Proceedings of the 28th IEEE Conference on Decision and Control (Tampa, FL: IEEE), 1014–1018.
Antonietti, A., Casellato, C., D'Angelo, E., and Pedrocchi, A. (2017). Model-driven analysis of eyeblink classical conditioning reveals the underlying structure of cerebellar plasticity and neuronal activity. IEEE Trans. Neural Netw. Learn. Syst. 28, 2748–2762. doi: 10.1109/TNNLS.2016.2598190
Atkeson, C. G., An, C. H., and Hollerbach, J. M. (1986). Estimation of inertial parameters of manipulator loads and links. Int. J. Robot. Res. 5, 101–119.
Awtar, S., Bernard, C., Boklund, N., Master, A., Ueda, D., and Craig, K. (2002). Mechatronic design of a ball-on-plate balancing system. Mechatronics 12, 217–228. doi: 10.1016/S0957-4158(01)00062-9
Barto, A. G., Fagg, A. H., Sitkoff, N., and Houk, J. C. (1999). A cerebellar model of timing and prediction in the control of reaching. Neural Comput. 11, 565–594.
Buonomano, D. V., and Mauk, M. D. (1994). Neural network model of the cerebellum: temporal discrimination and the timing of motor responses. Neural Comput. 6, 38–55.
Caligiore, D., Pezzulo, G., Baldassarre, G., Bostan, A. C., Strick, P. L., Doya, K., et al. (2017). Consensus paper: towards a systems-level view of cerebellar function: the interplay between cerebellum, basal ganglia, and cortex. Cerebellum 16, 203–229. doi: 10.1007/s12311-016-0763-3
Casellato, C., Antonietti, A., Garrido, J. A., Carrillo, R. R., Luque, N. R., Ros, E., et al. (2014). Adaptive robotic control driven by a versatile spiking cerebellar network. PLoS ONE 9:e112265. doi: 10.1371/journal.pone.0112265
Casellato, C., Antonietti, A., Garrido, J. A., Ferrigno, G., D'Angelo, E., and Pedrocchi, A. (2015). Distributed cerebellar plasticity implements generalized multiple-scale memory components in real-robot sensorimotor tasks. Front. Comput. Neurosci. 9:24. doi: 10.3389/fncom.2015.00024
Chapeau-Blondeau, F., and Chauvet, G. (1991). A neural network model of the cerebellar cortex performing dynamic associations. Biol. Cybernet. 65, 267–279.
Chen, C.-S. (2009). “Sliding-mode-based fuzzy cmac controller design for a class of uncertain nonlinear system,” in 2009 IEEE International Conference on Systems, Man and Cybernetics (San Antonio, TX: IEEE), 3030–3034.
D'Angelo, E., Antonietti, A., Casali, S., Casellato, C., Garrido, J. A., Luque, N. R., et al. (2016). Modeling the cerebellar microcircuit: new strategies for a long-standing issue. Front. Cell. Neurosci. 10:176. doi: 10.3389/fncel.2016.00176
Dean, P., Porrill, J., Ekerot, C. F., and Jörntell, H. (2010). The cerebellar microcircuit as an adaptive filter: experimental and computational evidence. Nat. Rev. Neurosci. 11, 30–43. doi: 10.1038/nrn2756
Ebner, T. J., Hewitt, A. L., and Popa, L. S. (2011). What features of limb movements are encoded in the discharge of cerebellar neurons? Cerebellum 10, 683–693. doi: 10.1007/s12311-010-0243-0
Falotico, E., Vannucci, L., Ambrosano, A., Albanese, U., Ulbrich, S., Vasquez Tieck, J. C., et al. (2017). Connecting artificial brains to robots in a comprehensive simulation framework: the neurorobotics platform. Front. Neurorobot. 11:2. doi: 10.3389/fnbot.2017.00002
Farrell, J. A., and Polycarpou, M. M. (2006). Adaptive Approximation Based Control: Unifying Neural, Fuzzy and Traditional Adaptive Approximation Approaches, Vol 48. Hoboken, NJ: John Wiley & Sons.
Francis, B. A., and Wonham, W. M. (1976). The internal model principle of control theory. Automatica 12, 457–465.
Fujiki, S., Aoi, S., Funato, T., Tomita, N., Senda, K., and Tsuchiya, K. (2015). Adaptation mechanism of interlimb coordination in human split-belt treadmill walking through learning of foot contact timing: a robotics study. J. R. Soc. Interface 12:20150542. doi: 10.1098/rsif.2015.0542
Fujita, M. (1982). Simulation of adaptive modification of the vestibulo-ocular reflex with an adaptive filter model of the cerebellum. Biol. Cybernet. 45, 207–214.
Garrido Alcazar, J. A., Luque, N. R., D'Angelo, E., and Ros, E. (2013). Distributed cerebellar plasticity implements adaptable gain control in a manipulation task: a closed-loop robotic simulation. Front. Neural Circuits 7:159. doi: 10.3389/fncir.2013.00159
Glanz, F. H., Miller, W. T., and Kraft, L. G. (1991). “An overview of the cmac neural network,” in [1991 Proceedings] IEEE Conference on Neural Networks for Ocean Engineering (Washington, DC: IEEE), 301–308.
Guan, J., Lin, C.-M., Ji, G.-L., Qian, L.-W., and Zheng, Y.-M. (2018). Robust adaptive tracking control for manipulators based on a tsk fuzzy cerebellar model articulation controller. IEEE Access 6, 1670–1679. doi: 10.1109/ACCESS.2017.2779940
He, W., Chen, Y., and Yin, Z. (2016). Adaptive neural network control of an uncertain robot with full-state constraints. IEEE Trans. Cybernet. 46, 620–629. doi: 10.1109/TCYB.2015.2411285
He, W., Huang, B., Dong, Y., Li, Z., and Su, C. Y. (2018). Adaptive neural network control for robotic manipulators with unknown deadzone. IEEE Trans. Cybernet. 48, 2670–2682. doi: 10.1109/TCYB.2017.2748418
Houk, J. C., and Wise, S. P. (1995). Distributed modular architectures linking basal ganglia, cerebellum, and cerebral cortex: their role in planning and controlling action. Cereb. Cortex 5, 95–110.
Ito, M. (1997). “Cerebellar microcomplexes,” in International Review of Neurobiology, Vol 41 (Cambridge, MA: Academic Press; Elsevier), 475–487.
Ito, M. (2008). Control of mental activities by internal models in the cerebellum. Nat. Rev. Neurosci. 9:304. doi: 10.1038/nrn2332
Jiang, Y., Yang, C., Wang, M., Wang, N., and Liu, X. (2018). Bioinspired control design using cerebellar model articulation controller network for omnidirectional mobile robots. Adv. Mechan. Eng. 10:1687814018794349. doi: 10.1177/1687814018794349
Kawato, M. (1990). “Feedback-error-learning neural network for supervised motor learning,” in Advanced Neural Computers, ed R. Eckmiller (Amsterdam: Elsevier; North-Holland), 365–372. doi: 10.1016/B978-0-444-88400-8.50047-9
Kawato, M. (1999). Internal models for motor control and trajectory planning. Curr. Opin. Neurobiol. 9, 718 – 727.
Kawato, M., Furukawa, K., and Suzuki, R. (1987). A hierarchical neural-network model for control and learning of voluntary movement. Biol. Cybernet. 57, 169–185.
Khalil, W., and Dombre, E. (2002). Modeling, Identification and Control of Robots. London, UK: Butterworth-Heinemann.
Kocijan, J., Murray-Smith, R., Rasmussen, C. E., and Girard, A. (2004). “Gaussian process model based predictive control,” in Proceedings of the 2004 American Control Conference, Vol 3 (Boston, MA: IEEE), 2214–2219.
Koenig, N. P., and Howard, A. (2004). “Design and use paradigms for gazebo, an open-source multi-robot simulator,” in IROS, Vol 4 (Sendai: Citeseer), 2149–2154.
Koziol, L. F., Budding, D., Andreasen, N., D'Arrigo, S., Bulgheroni, S., Imamizu, H., et al. (2014). Consensus paper: the cerebellum's role in movement and cognition. Cerebellum 13, 151–177. doi: 10.1007/s12311-013-0511-x
Levinson, S. E., Silver, A. F., and Wendt, L. A. (2010). “Vision based balancing tasks for the icub platform: a case study for learning external dynamics,” in Workshop on Open Source Robotics: iCub & Friends. IEEE Int'l. Conf. on Humanoid Robotics (Nashville, TN).
Lin, C.-M., and Chen, C.-H. (2007). Robust fault-tolerant control for a biped robot using a recurrent cerebellar model articulation controller. IEEE Trans. Syst. Man Cybernet. Part B 37, 110–123. doi: 10.1109/TSMCB.2006.881905
Ljung, L. (2007). Identification of Nonlinear Systems. Linköping: Linköping University Electronic Press.
Luo, D., Hu, F., Zhang, T., Deng, Y., and Wu, X. (2018). How does a robot develop its reaching ability like human infants do? IEEE Trans. Cognit. Dev. Syst. 10, 795–809. doi: 10.1109/TCDS.2018.2861893
Luque, N. R., Garrido, J. A., Carrillo, R. R., D'Angelo, E., and Ros, E. (2014). Fast convergence of learning requires plasticity between inferior olive and deep cerebellar nuclei in a manipulation task: a closed-loop robotic simulation. Front. Comput. Neurosci. 8:97. doi: 10.3389/fncom.2014.00097
Luque, N. R., Garrido, J. A., Carrillo, R. R., Olivier, J.-M. C., and Ros, E. (2011). Cerebellarlike corrective model inference engine for manipulation tasks. IEEE Trans. Syst. Man. Cybernet. Part B 41, 1299–1312. doi: 10.1109/TSMCB.2011.2138693
Luque, N. R., Garrido, J. A., Naveros, F., Carrillo, R. R., D'Angelo, E., and Ros, E. (2016). Distributed cerebellar motor learning: a spike-timing-dependent plasticity model. Front. Comput. Neurosci. 10:17. doi: 10.3389/fncom.2016.00017
Mauk, M. D., and Donegan, N. H. (1997). A model of pavlovian eyelid conditioning based on the synaptic organization of the cerebellum. Learn. Memory 4, 130–158.
Metta, G., Sandini, G., and Konczak, J. (1999). A developmental approach to visually-guided reaching in artificial systems. Neural Netw. 12, 1413–1427.
Miller, W. (1987). Sensor-based control of robotic manipulators using a general learning algorithm. IEEE J. Robot. Automat. 3, 157–165.
Miller, W. T., Glanz, F. H., and Kraft, L. G. (1990). Cmas: an associative neural network alternative to backpropagation. Proc. IEEE 78, 1561–1567.
Miyamoto, H., Kawato, M., Setoyama, T., and Suzuki, R. (1988). Feedback-error-learning neural network for trajectory control of a robotic manipulator. Neural Netw. 1, 251–265.
Nakanishi, J., Cory, R., Mistry, M., Peters, J., and Schaal, S. (2008). Operational space control: a theoretical and empirical comparison. Int. J. Robot. Res. 27, 737–757. doi: 10.1177/0278364908091463
Nakanishi, J., Farrell, J. A., and Schaal, S. (2005). Composite adaptive control with locally weighted statistical learning. Neural Netw. 18, 71–90. doi: 10.1016/j.neunet.2004.08.009
Nakanishi, J., and Schaal, S. (2004). Feedback error learning and nonlinear adaptive control. Neural Netw. 17, 1453–1465. doi: 10.1016/j.neunet.2004.05.003
Narendra, K. S., and Annaswamy, A. M. (1987). Persistent excitation in adaptive systems. Int. J. Cont. 45, 127–160.
Narendra, K. S., and Mukhopadhyay, S. (1991a). Associative learning in random environments using neural networks. IEEE Trans. Neural Netw. 2, 20–31.
Narendra, K. S., and Mukhopadhyay, S. (1991b). “Multilevel control of a dynamical systems using neural networks,” in [1991] Proceedings of the 30th IEEE Conference on Decision and Control (Brighton, UK: IEEE), 170–171.
Narendra, K. S., and Mukhopadhyay, S. (1997). Adaptive control using neural networks and approximate models. IEEE Trans. Neural Netw. 8, 475–485.
Narendra, K. S., and Parthasarathy, K. (1991). Gradient methods for the optimization of dynamical systems containing neural networks. IEEE Trans. Neural Netw. 2, 252–262.
Nashed, J. Y., Kurtzer, I. L., and Scott, S. H. (2015). Context-dependent inhibition of unloaded muscles during the long-latency epoch. J. Neurophysiol. 113, 192–202. doi: 10.1152/jn.00339.2014
Nguyen-Tuong, D., and Peters, J. (2011). Model learning for robot control: a survey. Cogn. Proc. 12, 319–340. doi: 10.1007/s10339-011-0404-1
Nguyen-Tuong, D., Seeger, M., and Peters, J. (2009). Model learning with local gaussian process regression. Adv. Robot. 23, 2015–2034. doi: 10.1163/016918609X12529286896877
Nowak, D. A., Topka, H., Timmann, D., Boecker, H., and Hermsdörfer, J. (2007). The role of the cerebellum for predictive control of grasping. Cerebellum 6:7. doi: 10.1080/14734220600776379
Ojeda, I. B., Tolu, S., and Lund, H. H. (2017). “A scalable neuro-inspired robot controller integrating a machine learning algorithm and a spiking cerebellar-like network,” in Biomimetic and Biohybrid Systems - 6th International Conference, Living Machines 2017, Stanford, CA, USA, July 26-28, 2017, Proceedings (Stanford, CA), 375–386.
Patino, H. D., Carelli, R., and Kuchen, B. R. (2002). Neural networks for advanced control of robot manipulators. IEEE Trans. Neural Netw. 13, 343–354. doi: 10.1109/72.991420
Porrill, J., and Dean, P. (2007). Recurrent cerebellar loops simplify adaptive control of redundant and nonlinear motor systems. Neural Comput. 19, 170–193. doi: 10.1162/neco.2007.19.1.170
Probst, D., Maass, W., Markram, H., and Gewaltig, M.-O. (2012). “Liquid computing in a simplified model of cortical layer iv: Learning to balance a ball,” in Artificial Neural Networks and Machine Learning – ICANN 2012, eds A. E. P. Villa, W. Duch, P. Érdi, F. Masulli, and G. Palm (Berlin; Heidelberg: Springer Berlin Heidelberg), 209–216.
Quigley, M., Conley, K., Gerkey, B., Faust, J., Foote, T., Leibs, J., et al. (2009). “Ros: an open-source robot operating system,” in ICRA Workshop on Open Source Software, Vol. 3 (Kobe: IEEE), 5.
Schmahmann, J. D. (2004). Disorders of the cerebellum: ataxia, dysmetria of thought, and the cerebellar cognitive affective syndrome. J. Neuropsych. Clin. Neurosci. 16, 367–378. doi: 10.1176/jnp.16.3.367
Scott, S. H., Cluff, T., Lowrey, C. R., and Takei, T. (2015). Feedback control during voluntary motor actions. Curr. Opin. Neurobiol. 33, 85 – 94. doi: 10.1016/j.conb.2015.03.006
Sontag, E. D. (1992). Feedback stabilization using two-hidden-layer nets. IEEE Trans. Neural Netw. 3, 981–990.
Ting, J. A., Mistry, M., Peters, J., Schaal, S., and Nakanishi, J. (2006). “A bayesian approach to nonlinear parameter identification for rigid body dynamics,” in Robotics: Science and Systems, eds G. S. Sukhatme, S. Schaal, W. Burgard, and D. Fox (Philadelphia, PA; Cambridge, MA: MIT Press), 32–39.
Tokuda, I. T., Hoang, H., and Kawato, M. (2017). New insights into olivo-cerebellar circuits for learning from a small training sample. Curr. Opin. Neurobiol. 46, 58 – 67. doi: 10.1016/j.conb.2017.07.010
Tolu, S., Vanegas, M., Garrido, J. A., Luque, N. R., and Ros, E. (2013). Adaptive and predictive control of a simulated robot arm. Int. J. Neural Syst. 23:1350010. doi: 10.1142/S012906571350010X
Tolu, S., Vanegas, M., Luque, N. R., Garrido, J. A., and Ros, E. (2012). Bio-inspired adaptive feedback error learning architecture for motor control. Biol. Cybernet. 106, 507–522. doi: 10.1007/s00422-012-0515-5
Ugur, E., Nagai, Y., Sahin, E., and Oztop, E. (2015). Staged development of robot skills: behavior formation, affordance learning and imitation with motionese. IEEE Trans. Autonom. Mental Dev. 7, 119–139. doi: 10.1109/TAMD.2015.2426192
Vannucci, L., Tolu, S., Falotico, E., Dario, P., Lund, H. H., and Laschi, C. (2016). “Adaptive gaze stabilization through cerebellar internal models in a humanoid robot,” in Proceedings of the IEEE RAS and EMBS International Conference on Biomedical Robotics and Biomechatronics (Singapore), 25–30.
Vernon, D., Metta, G., and Sandini, G. (2007). A survey of artificial cognitive systems: Implications for the autonomous development of mental capabilities in computational agents. IEEE Trans. Evol. Comput. 11, 151–180. doi: 10.1109/TEVC.2006.890274
Vijayakumar, S., and Schaal, S. (2000). “Locally weighted projection regression: an o (n) algorithm for incremental real time learning in high dimensional space,” in Proceedings of the Seventeenth International Conference on Machine Learning (ICML 2000) (Stanford, CA), 288–293.
Weng, J. (2002). “A theory for mentally developing robots,” in Proceedings 2nd International Conference on Development and Learning. ICDL 2002 (Cambridge, MA: IEEE), 131–140.
Weng, J., Evans, C., Hwang, W. S., and Lee, Y.-B. (1999a). “The developmental approach to artificial intelligence: Concepts, developmental algorithms and experimental results,” in NSF Design and Manufacturing Grantees Conference, Long Beach, CA.
Weng, J., and Hwang, W.-S. (2006). From neural networks to the brain: Autonomous mental development. IEEE Comput. Intell. Mag. 1, 15–31. doi: 10.1109/MCI.2006.1672985
Weng, J., Hwang, W. S., Zhang, Y., and Evans, C. (1999b). “Developmental robots: theory, method and experimental results,” in Processdings 2nd International Conference on Humanoid Robots (Tokyo: Citeseer), 57–64.
Weng, J., McClelland, J., Pentland, A., Sporns, O., Stockman, I., Sur, M., and Thelen, E. (2000). Computational Autonomous Mental Development. Citeseer.
Wittenmark, B. (1995). “Adaptive dual control methods: an overview,” in Adaptive Systems in Control and Signal Processing 1995, ed Cs. Bányász (Elsevier), 67–72.
Wolpert, D. M., Miall, R. C., and Kawato, M. (1998). Internal models in the cerebellum. Trends Cogn. Sci. 2, 338–347.
Yamazaki, T., and Tanaka, S. (2007). The cerebellum as a liquid state machine. Neural Netw. 20, 290–297. doi: 10.1016/j.neunet.2007.04.004
Keywords: biomimetic, cerebellar control, motor learning, humanoid robot, adaptive system, forward model, bio-inspired, neurorobotics
Citation: Capolei MC, Angelidis E, Falotico E, Lund HH and Tolu S (2019) A Biomimetic Control Method Increases the Adaptability of a Humanoid Robot Acting in a Dynamic Environment. Front. Neurorobot. 13:70. doi: 10.3389/fnbot.2019.00070
Received: 29 January 2019; Accepted: 12 August 2019;
Published: 28 August 2019.
Edited by:
Florian Röhrbein, Technical University of Munich, GermanyReviewed by:
Juyang Weng, Michigan State University, United StatesQiuxuan Wu, Hangzhou Dianzi University, China
Copyright © 2019 Capolei, Angelidis, Falotico, Lund and Tolu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Marie Claire Capolei, bWFjY2FAZWxla3Ryby5kdHUuZGs=; Silvia Tolu, c3RvbHVAZWxla3Ryby5kdHUuZGs=