
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Neurol., 14 April 2025
Sec. Cognitive and Behavioral Neurology
Volume 16 - 2025 | https://doi.org/10.3389/fneur.2025.1564657
This article is part of the Research TopicInnovations in the assessment and treatment of TBI and co-occurring conditions in military connected populationsView all 6 articles
 Katrina Monti1,2,3*
Katrina Monti1,2,3* Katie Williams1,2,3
Katie Williams1,2,3 Brian Ivins1,4
Brian Ivins1,4 Jay Uomoto5Jami Skarda-Craft3
Jay Uomoto5Jami Skarda-Craft3 Michael Dretsch1,3,4
Michael Dretsch1,3,4Introduction: Microinteraction Ecological Momentary Assessment (miEMA) addresses the challenges of traditional self-report questionnaires by collecting data in real time. The purpose of this study was to examine the feasibility and usability of employing miEMA using a smartwatch in military service members undergoing traumatic brain injury (TBI) rehabilitation.
Materials and methods: Twenty-eight United States active duty service members with a TBI history were recruited as patients from a military outpatient TBI rehabilitation center, enrolled in either a 2-week or 3-week study arm, and administered miEMA surveys via a custom smartwatch app. The 3-week arm participants were also concurrently receiving cognitive rehabilitation. Select constructs evaluated with miEMA included mood, fatigue, pain, headache, self-efficacy, and cognitive strategy use. Outcome measures of adherence were completion (percentage of questions answered out of questions delivered) and compliance (percentage of questions answered out of questions scheduled). The Mobile Health Application Usability Questionnaire (MAUQ) and System Usability Scale (SUS) assessed participants’ perceptions of smartwatch and app usability.
Results: Completion and compliance rates were 80.1% and 77.4%, respectively. Mean participant completion and compliance were 81.1% ± 12.0% and 78.1% ± 13.0%, respectively. Mean participant completion increased to 87.7% ± 8.8% when using an embedded question retry mechanism. Mean participant survey set completion was 69.8% ± 18.3% during the early morning but remained steady during the late morning/early afternoon (85.7% ± 12.8%), afternoon (86.2% ± 12.6%), and late afternoon/evening (85.0% ± 14.7%). The mean overall item score for the MAUQ was 6.3 ± 1.1 out of 7. The mean SUS score was 89.0 ± 7.2 out of 100 and mean SUS percentile ranking was 96.4% ± 8.4%.
Conclusion: Overall adherence was similar to previous studies in civilian populations. Participants rated the miEMA app and smartwatch as having high usability. These findings suggest that miEMA using a smartwatch for tracking symptoms and treatment strategy use is feasible in military service members with a TBI history, including those undergoing rehabilitation for cognitive difficulties.
Persistent or variable symptoms occur in a subset of patients following mild traumatic brain injury (TBI) (1–3), and the ability to monitor symptom changes and treatment compliance is a critical component of TBI rehabilitation. Conventional approaches to assess and monitor symptoms rely on the use of self-report questionnaires which are often administered at multiple visits. Questionnaire selection may vary depending on the provider, symptomology, and treatment goals. Self-report questionnaires require patients to retrospectively recall and aggregate symptoms over a period of time, often over the previous 2 weeks or 30 days. This traditional approach has inherent challenges, specifically recall biases and questionnaire fatigue, which can significantly affect the quality and validity of self-reported data (4). Inaccurate or unreliable self-reports could lead to medically inappropriate or ineffective treatment decisions. The nature of traditional self-report questionnaires makes them inadequate for capturing evolving symptomology within real-world contexts over time. Military service members may be especially subject to questionnaire fatigue due to the many surveys they are asked to complete (5) (i.e., Climate Assessment surveys, military medical treatment facility [MTF] experience surveys, annual Periodic Health Assessments, and surveys related to the morale, family support, readiness, and health risks and behaviors across the Department of Defense). Therefore, approaches to assess and obtain more accurate and ecologically valid data for various symptoms, monitor treatment compliance, and assess other social, psychological, and behavioral factors related to TBI while minimizing survey fatigue are needed in military patient populations to optimize treatment intervention efforts.
Ecological Momentary Assessment (EMA), a term originally devised by Stone and Shiffman (6), is an in-situ experience sampling method that has demonstrated promise in addressing the previously stated challenges to inform just-in-time adaptive interventions (6–8). EMA has been used to assess symptoms, behaviors, and other factors related to substance abuse (9), suicidal ideations and relevant risk factors (10), post-traumatic stress disorder (11), and mood disorders (12). Standard EMA approaches allow for the collection of intensive longitudinal data through repeated assessments of variables and outcomes of interest that occur throughout a person’s daily life and within their natural settings. These data include timestamped momentary measures obtained while they are interacting with their work, community, and home environments (8). In this way, subjective experiences captured in real-time can account for within-day variations, avoid the pitfalls of retrospective recall, minimize survey fatigue, and optimize the ecological validity of responses (6). Standard EMA question sets may consist of dozens of questions, response options may be multiple choice, open-ended, or sliding scale, and questions may take 1–2 minutes (min) to answer (13, 14). EMA questions are usually delivered through a mobile phone or other personal digital device (13, 14). Despite the observed advantages of EMA compared to traditional questionnaires, interruption burden and intrusiveness remain important limitations and where participant engagement and data quality have been shown to reduce over time (15–18).
There is a growing body of evidence that the use of Microinteraction Ecological Momentary Assessment (miEMA) may be preferable to standard EMA because microinteractions have been shown to reduce interruption burden and device interaction time without adversely affecting the high temporal density of subjective data collection (19–21). The miEMA approach, originally developed by Intille and colleagues (21), involves the delivery of a single question per interruption answered at a glance with a single tap, thereby creating the microinteraction. Questions are cognitively simple with limited response options (e.g., yes/no, scale of 1 to 10). Prompts are delivered through a wearable platform, such as a smartwatch, that is compatible with the individual’s daily life. Questions and response options are structured in a way to require minimal mental effort and must be simple enough to fit on the smartwatch screen without requiring scrolling or compromising readability (13).
The miEMA approach has shown promise in research conducted in civilian populations (13, 19, 21). However, it is unknown if the miEMA experience sampling method is feasible in active duty military sample receiving outpatient TBI rehabilitation, including those undergoing cognitive rehabilitation. Requirements of daily military duties, including both structured routines that differ from civilian occupational routines and interruptions to routines to perform military-related activities (e.g., field training, range operations, training exercises) which may interfere with intensive miEMA data collection. Given the types of military specialties, operational tempo, and general requirements of military service, it is unknown if military personnel will have similar rates of adherence to civilian populations. This pilot study evaluated the feasibility and usability of miEMA delivered through a smartwatch in a sample of military personnel recruited from an outpatient, interdisciplinary TBI program. The sample consisted of two groups completing either a 2-week or 3-week trial of miEMA data collection. The purpose of the 3-week study arm, which consisted of patients concurrently undergoing cognitive rehabilitation, was to also evaluate treatment adherence through individualized Cognitive Survey prompts; however, these results are beyond the scope of the current manuscript.
The regional MTF’s Clinical Informatics team developed a custom miEMA application (app) called the Clinical Symptom Tracking & Assessment in Real Time (C-STAR) that operates on a smartwatch (Samsung Galaxy Active 2 with a 44 mm watch face) running on the Tizen Operating System. Figure 1 shows example questions displayed on the smartwatch face delivered through the C-STAR app. The decision to develop a custom app was due to the lack of commercial miEMA smartwatch app options available at the time. The C-STAR system has two components: the smartwatch and a secure online survey platform. Select constructs evaluated with miEMA surveys included mood, fatigue, pain, headache, self-efficacy, and cognitive strategy use. All miEMA surveys, except for the individualized Cognitive and Self-efficacy Survey prompts were readily downloaded from the online survey platform to the smartwatch by research staff. Due to the personalized nature of the Cognitive and Self-efficacy Survey prompts, the app engineer had to upload the selected prompts to the C-STAR online survey platform and a research team member then downloaded them to the smartwatch. Surveys were scheduled on the smartwatch when the research staff member selected the surveys for the participant in the “Survey Setup” feature of the app. At the end of each week of the participant’s smartwatch trial, the participant’s response data was converted to a Quick Response code on the C-STAR app for easy and safe transfer from the smartwatch to a Defense Health Agency (DHA) computer using a bar code scanner plugged in via USB port. Survey data were converted to an Excel file (Microsoft 365, Version 2,402) for analysis. The C-STAR app does not require pairing to a mobile device or smartphone and only requires the internet to download new surveys from the online survey platform to the smartwatch. The Bluetooth and Wi-Fi functions were turned off prior to returning the smartwatch to the participant.

Figure 1. Microinteraction Ecological Momentary Assessment Questions from Fatigue Survey on Smartwatch Face.
All survey questions met miEMA criteria: (1) one question presented at a time, (2) structured to be answered at a glance (within 3 to 5 seconds (s)), and (3) structured to be answered with one tap (yes/no or scale type questions) to create the microinteraction (13). Participants were required to tap a “Submit” button that appeared on the smartwatch screen simultaneously with the response options to record their response. An example of a survey question as displayed on the smartwatch is presented in Figure 1. When the prompt appeared on the smartwatch face, the smartwatch alerted the participant that a prompt was delivered (first alert) with a vibrotactile pattern (no audio) of continuous intensity lasting approximately 5 s. The vibrotactile pattern consisted of one 1-s pulse vibration, 1-s pause, four short vibrating pulsations over 1 s, 1-s pause, and then one 1-s pulse vibration. Vibrations paused for 5 s, then if the participant had not yet responded, the smartwatch would vibrate with a pattern of two 1-s pulse vibrations of continuous intensity (second alert). The prompt remained on the screen until the participant submitted a response or until 20 s passed since the first alert. If the participant entered their response, they had to then tap the “Submit” button, which appeared on the screen simultaneously with the response options. A response could be changed until the participant tapped the “Submit” button. Once the participant tapped the “Submit” button, a message confirming their response was submitted appeared on the smartwatch screen stating, “Response Recorded At (time).” If a participant did not answer the prompt after the second alert, then the prompt disappeared after 20 s since the first alert and a message appeared informing the participant, “Previous Survey Was Missed.” The only functions enabled on the smartwatch while the participant was wearing it were the time, heart rate, and the miEMA app. All other functions were disabled or removed before issuing the smartwatch to the participant.
We selected a time-contingent sampling strategy so that the miEMA survey prompts for each construct were scheduled to be delivered over 10 h of the day (8 a.m. – 6 p.m.) coinciding with the regular duty day and included weekends. The 10-h day was categorized into four 2.5-h blocks of time (henceforth, referred to as “windows”). The windows were categorized as 8 a.m. to 10:30 a.m. (early morning; window 1), 10:30 a.m. to 1 p.m. (late morning/early afternoon; window 2), 1 p.m. to 3:30 p.m. (afternoon; window 3), and 3:30 p.m. to 6 p.m. (late afternoon/evening; window 4). The timing of the delivery of each survey was randomized within each window. Prompts were delivered even if the smartwatch was being charged or not being worn by the participant. Only the initial questions from each survey set and every Cognitive Survey prompt were scheduled. Follow-up questions in survey sets were not scheduled, but their delivery was contingent upon the participant’s response behavior. For example, the initial prompt for the Headache Survey (“I have a headache”) was a scheduled prompt; however, delivery of the first follow-up prompt (“My headache is…”) was triggered only if the participant responded “yes” to the initial question. The delivery of the second follow-up question in the Headache Survey set (“Headache is interfering with my activities?”) was only delivered if the participant submitted a response to the second question.
Participants were instructed not to respond to a prompt if doing so would incur risk (i.e., while driving, performing risky military activities, or operating machinery). If a participant missed an initial question in a survey set, then a question retry mechanism was activated and the missed question was delivered a second time within the same window of time, within about 15 min. The retry mechanism offered the participant a second opportunity to respond to a missed initial question in a survey set. Retry questions and follow-up questions were not scheduled but were delivered based on the participant’s response behavior. If the participant missed the retry question, the question was not delivered a third time, but was recorded as another missed response. Follow-up questions in survey sets did not have a built-in retry mechanism; therefore, if a participant did not answer a follow-up question, the prompt was recorded as having a missed response and any additional follow-up questions in the survey set, if applicable, were not delivered. Cognitive Survey prompts also did not have a built-in retry mechanism; therefore, if a participant did not answer a Cognitive Survey prompt, the prompt was recorded as a missed response. Cognitive Survey prompts were scheduled as two separate surveys since the prompts addressed two separate skills or behaviors; therefore, the delivery of these prompts was not contingent upon a response to a previous Cognitive Survey prompt. For example, if a participant missed the first Cognitive Survey prompt, then it was recorded as a missed response, but the second Cognitive Survey prompt was still delivered.
Each of the selected survey sets was scheduled to be delivered once during each of the four windows, except for the Self-efficacy and Alcohol Surveys which were only scheduled to be delivered once a day during the early morning window (window 1). The timing of survey delivery during each window was randomized to minimize non-response bias and improve the generalizability of the data collected over the trial in various contexts. For example, if a participant was administered the Mood Survey (two questions), Headache Survey (three questions), and Cognitive Survey (two prompts), then each survey would be initiated once during each window, or four times daily, but the timing of the delivery of each survey was randomized during each window. The number of prompts delivered was based on which miEMA surveys were selected, how many questions were in the selected survey sets, and the participant’s response behavior. In the example described, if a participant responded “yes” to every initial Headache Survey question, thus endorsing headache every time, responded to the two follow-up Headache Survey questions, and responded to every question delivered for both the Mood and Cognitive Surveys, then the total number of delivered questions would be seven for each window, or 28 questions in 1 day, and 196 questions over 7 days.
This was a prospective study with temporally-dense repeated measures delivered through a custom miEMA smartwatch app over two or three weeks.
Participants were 28 United States (U.S.) service members enrolled at a military outpatient interdisciplinary TBI rehabilitation center at the Madigan Army Medical Center, Joint Base Lewis-McChord, Washington. Participants in the 3-week study arm were patients at the TBI center who were referred by their cognitive rehabilitation provider. Participants were included in the study if they were (1) currently active duty military, Reserves, or National Guard; (2) between the ages of 20 and 65 years; (3) self-reported a history of TBI that occurred during military service; (4) reported any of the following persistent TBI-related symptoms: headache, mood changes, fatigue or energy loss, sleep difficulties, and/or cognitive difficulties; and (5) were able and willing to wear a smartwatch throughout the day including while on duty (for 14 days for the 2-week arm and for 21 days for the 3-week arm). Additional inclusion criteria for the 3-week participants were: (1) currently enrolled in cognitive rehabilitation treatment at the clinic and demonstrated commitment and (2) interest in changing or learning more about their own performance, as determined by their cognitive rehabilitation provider. Individuals who (1) endorsed active suicidal ideation or psychotic symptoms or (2) were concurrently enrolled in a specialty behavioral health intensive outpatient program or specialty substance abuse program were excluded from participating. All participants had at least one clinically diagnosed TBI verified in their medical record. The protocol for this study was reviewed and approved by the Madigan Army Medical Center Institutional Review Board (Protocol # 222049).
Once research staff determined an individual’s eligibility to participate in the study, participants were enrolled in one of two study arms. Participants enrolled in the 3-week study arm were patients undergoing interdisciplinary TBI rehabilitation and referred by their cognitive rehabilitation provider due to current engagement in cognitive rehabilitation for TBI. Participants enrolled in the 2-week study arm were also patients undergoing interdisciplinary TBI rehabilitation but were not concurrently undergoing cognitive rehabilitation for TBI. Upon completing consenting procedures, research staff collected demographic information, administered the Neurobehavioral Symptom Inventory (NSI), and elicited lifetime TBI history through a semi-structured interview using the Ohio State University TBI-Identification Method. All participants attended a 15-min Smartwatch Orientation in which the research staff member briefed the participant on the functionality of the smartwatch, including how to operate and navigate the smartwatch interface. Each participant was shown and then asked to demonstrate their ability to respond to questions on the miEMA app. Every participant was given a “Smartwatch and miEMA Orientation” handout for reference before departing the orientation. Contact information was provided to each participant should they encounter any technical issues with the smartwatch at any time during the trial. Upon conclusion of the orientation, the participant received the smartwatch and charger to take home for the duration of their study participation. Participants were instructed to wear the smartwatch from 8 a.m. to 6 p.m. daily on their preferred wrist.
All participants were required to attend weekly research appointments at the TBI center which were scheduled during the Smartwatch Orientation. Weekly research appointments for the 3-week trial participants coincided with their clinical visits with their cognitive rehabilitation provider so that they returned the smartwatch to research staff before their clinical visit and retrieved the smartwatch after their clinical visit. Weekly research appointments for the 2-week trial participants coincided with their clinical visits with providers at the TBI center so that they returned the smartwatch to research staff before their clinical visit and retrieved the smartwatch after their clinical visit. During their clinical visit, research staff downloaded response data from the smartwatch and uploaded a new schedule of prompts. Participants were instructed to charge the smartwatch any time between 6 p.m. and 8 a.m., which typically coincided with sleep hours, so as not to conflict with smartwatch wear during the hours of miEMA prompt delivery. Participants were compensated for their time with a $25 gift card upon concluding their study participation and returning the smartwatch and charger. Participants were not directly compensated for high adherence or for meeting any prescribed adherence goals.
Detailed descriptions of the following measures are presented in the Supplementary materials.
Characteristics of each miEMA survey are presented in Table 1. The miEMA survey set options in the C-STAR app included Mood (two prompts), Alcohol (one prompt), Self-efficacy (one prompt), Headache (three prompts), Fatigue (three prompts), Pain (three prompts), and Cognitive (two prompts delivered as two separate survey sets) Surveys. The Mood, Alcohol, Headache, Fatigue, and Pain Surveys were standardized survey sets. The Cognitive Surveys assessed cognitive strategy use and were individualized to the participant. The provider and participant co-selected the Cognitive Survey statements from a 120-item bank based on the participant’s specific challenges and treatment goals. The Self-efficacy Survey statements were created by the research staff member based on the aspect of Self-efficacy the participant wanted to monitor (i.e., “I can engage in daily activities”).
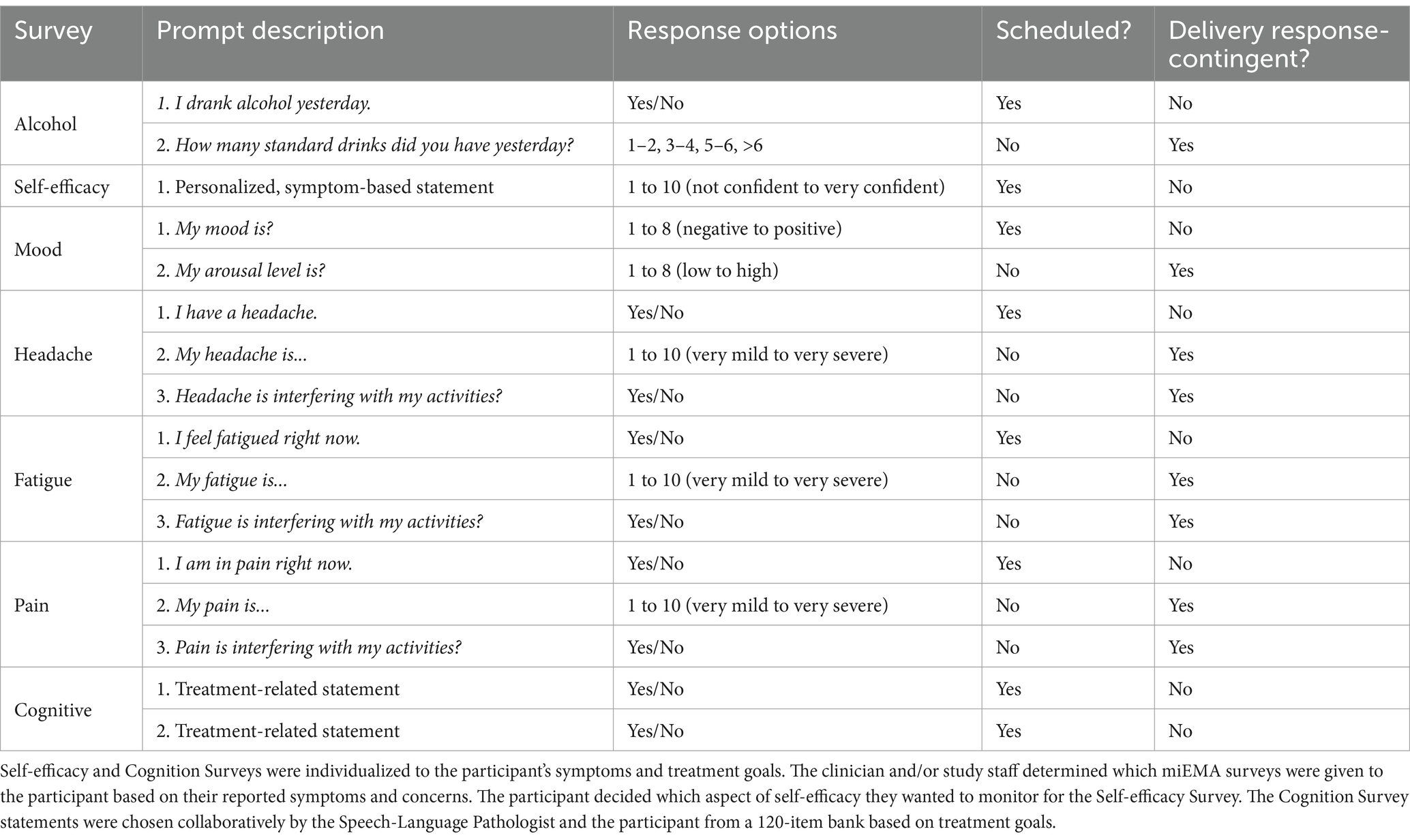
Table 1. Microinteraction ecological momentary assessment (miEMA) survey structure.
All participants were given the miEMA Mood Survey. Research staff used the participant’s NSI responses as well as participant input to determine which additional miEMA surveys would be most relevant. Participants in the 3-week study arm completed individualized Cognitive Surveys to monitor treatment adherence in conjunction with cognitive rehabilitation.
The NSI is a 22-item measure of post concussive symptoms, including headache, fatigue, pain, and mood. Individuals rate the severity of their symptoms over the past month. Responses range from 0 to 4 (0, none; 1, mild; 2, moderate; 3, severe; and 4, very severe), with higher scores indicating more severe symptoms (22). Internal consistency of the NSI is high with a coefficient alpha range from 0.88 to 0.92 (23).
The MAUQ assesses the usability of mobile health apps (24, 25). The full original measure contains 21 items categorized into three subscales. The current study used 12 items that break out into two subscales: (1) Ease of Use and Satisfaction (EOU) and (2) System Information Arrangement (SIA). Each item is rated on a Likert scale from 1 (strongly disagree) to 7 (strongly agree). The language for the MAUQ items was slightly modified for the current study to align with app use and is presented in Supplementary Table S1. The overall MAUQ has strong internal consistency with a Cronbach alpha = 0.932, as well as does the EOU, Cronbach alpha = 0.85, and SIA, Cronbach alpha = 0.91 (25).
The SUS is a 10-item measure used to investigate human factors associated with interfacing with new information technology (26). Individuals rate their level of agreement with statements ranging from 1 (strongly disagree) to 5 (strongly agree). The SUS items can be categorized into two subscales: (1) Usable and (2) Learnable (27). Standard score conversion procedures were used to convert raw scores ranging from 0 to 40 to scores that range from 0 to 100 (28). Internal consistency for the SUS has ranged from 0.70 to 0.95 (29).
Participant adherence was measured as completion and compliance rates as previously defined by Ponnada and colleagues (13). We further characterized response behavior based on the use of the retry mechanism, survey set completion, survey set completion based on time of day, and Cognitive Survey set completion (3-week study arm only).
The prompting frequency (number of prompts delivered per window), number of daily interruptions, questions delivered, responses, possible questions in a survey set, scheduled questions, responses to scheduled questions, and retry questions delivered were measured.
Completion was defined as the percentage of questions answered out of questions delivered. This definition of completion is commensurate with Ponnada and colleagues’ (13) definition of completion from their previous research.
Compliance was defined as the percentage of questions answered out of questions scheduled which was also based on Ponnada and colleagues’ (13) previous definition. For our miEMA app, only the initial questions from each survey set and all Cognitive Survey prompts were scheduled. Retry and follow-up questions were delivered according to participant response behavior and were not scheduled, therefore, these questions were not included in the denominator for compliance.
The mean participant completion rate is an average of all participant completion rates across the sample and for each study arm.
The mean participant compliance rate is an average of all participant compliance rates across the sample and for each study arm.
Mean participant completion using the built-in retry mechanism was defined as the mean percentage of questions answered out of questions delivered, excluding initial questions that were not answered and including retry questions defined as questions that were delivered a second time in the same time window via the retry mechanism. For example, if the participant did not respond to the initial prompt in the Headache Survey (“I have a headache”), then the same question was delivered a second time during the same window using the retry mechanism. The initial unanswered prompt would not count in the denominator, but the retry question delivered using the retry mechanism would count in the denominator whether it was answered or not.
To calculate survey set completion, we first accounted for the total number of possible questions in a survey set based on the number of questions in each survey set for each participant and the duration of their smartwatch trial. Mean participant survey set completion was defined as the mean percentage of questions answered out of total possible questions in a complete survey set, including those not delivered because the preceding question in the survey set was not answered, but excluding initial unanswered questions that were delivered again via the retry mechanism. We also excluded follow-up questions in a survey set that were not delivered because the participant responded “no” to the initial question (i.e., “I feel fatigued right now”) since the follow-up questions would not have been delivered (i.e., “My fatigue is…” and “Fatigue interfering with my activities?”).
We also stratified survey set completion based on the time of day the survey was delivered. We defined survey set completion as described above, then stratified completion rates based on the time of day (Windows 1 through 4).
For the 3-week study arm participants, mean participant cognitive completion was calculated as the mean percentage of responses to the Cognitive Survey prompts out of the number of Cognitive Survey prompts delivered. Participants in the 3-week study arm and their provider selected two cognitive statements per week based on their individual cognitive challenges and goals. All cognitive prompts were scheduled as individual surveys; therefore, the delivery of one cognitive prompt was not contingent upon a response to another cognitive prompt.
Descriptive statistics for select demographics and the types of miEMA Surveys given to participants in each study arm are presented in Table 2. Given the very small group sizes, the similarity in demographics between study arm groups, and the purpose of evaluating treatment adherence in the 3-week study arm that is beyond the scope of this manuscript, we did not perform statistical comparisons between the 2-week and 3-week groups. Of 30 participants enrolled in the study, 28 (93%) completed the smartwatch trial with 15 participants in the 2-week arm and 13 participants in the 3-week arm. Two participants from the 3-week arm withdrew from the study after enrollment. One participant withdrew before starting the smartwatch trial due to a military training conflict and another withdrew after completing 1 week of the smartwatch trial due to a family emergency. The data collected from the withdrawn participant during that 1 week was not included in the analysis. The overall sample had a mean age of 34.9 ± 8.5 years and 14.2 ± 2.3 years of education. Participants were mostly white (68%), male (86%), serving in the Army (89%), and primarily enlisted (89%) who were serving in a combat support military occupational specialty (MOS, 71%).
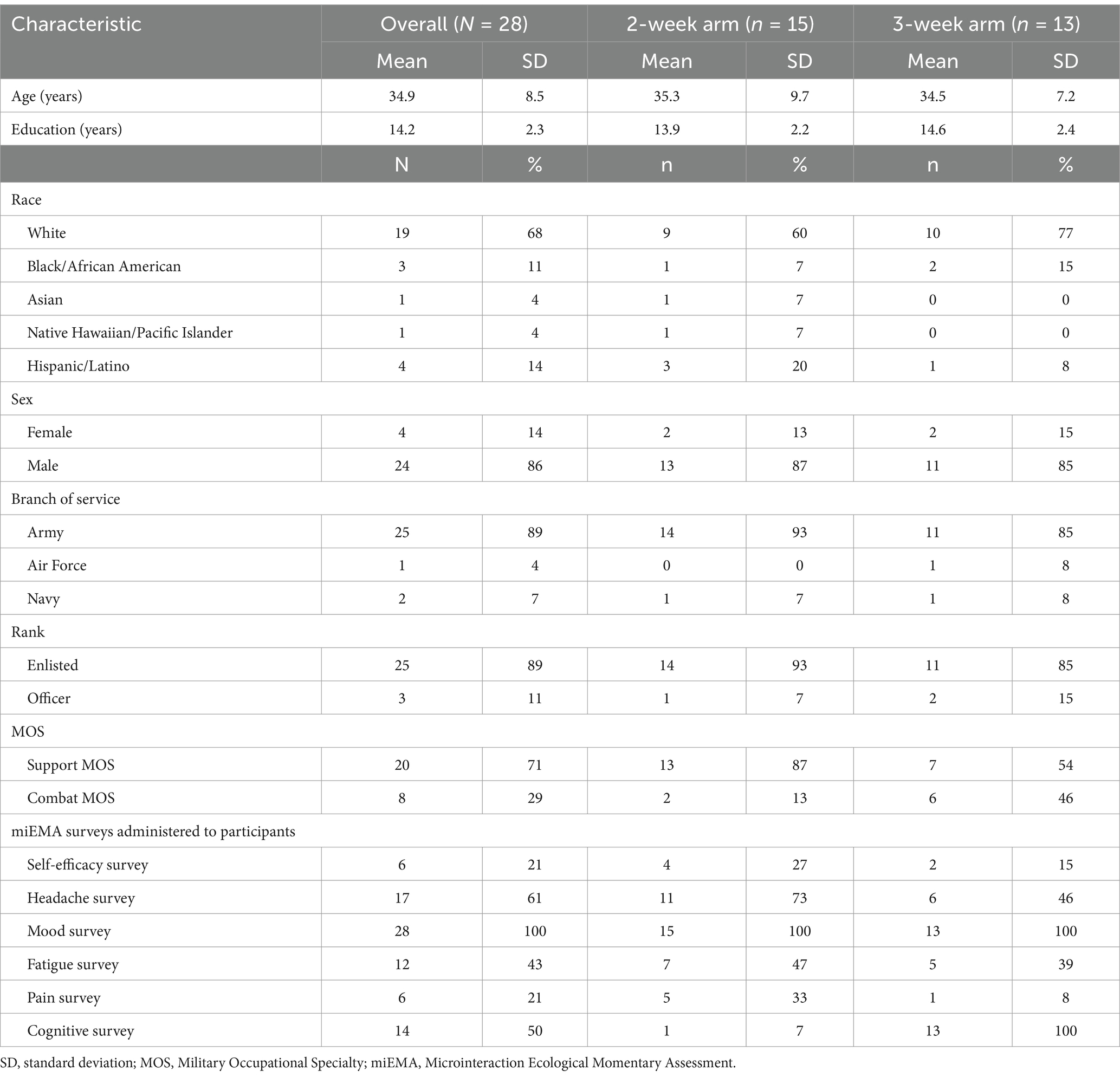
Table 2. Demographic and survey administration characteristics of participants by study arm.
Most participants (n = 25, 89%) were administered three miEMA surveys. Two participants from the 2-week study arm were given only two surveys each and one participant from the 3-week study arm selected four surveys. All participants were administered the Mood Survey. All 3-week arm participants were given a Cognitive Survey tailored to their cognitive rehabilitation treatment plan and goals. One 2-week arm participant selected the individualized Cognitive Survey based on their personal treatment goals. Of the remaining miEMA surveys, 61% (n = 17) of participants selected the Headache Survey across the sample. None of the participants opted to complete the Alcohol Survey.
Characteristics of questions and response metrics are presented in Table 3. Participants received a mean of 23.4 ± 5.4 (range: 12–36) prompts per day depending on how many and which surveys they were given. The average number of prompts delivered to participants during each window was 5.9 ± 1.4 (range: 3–9) and were also dependent upon how many and which surveys participants were given. Descriptive statistics for each type of completion and compliance for the overall sample and for each study arm stratified by week are presented in Table 4.
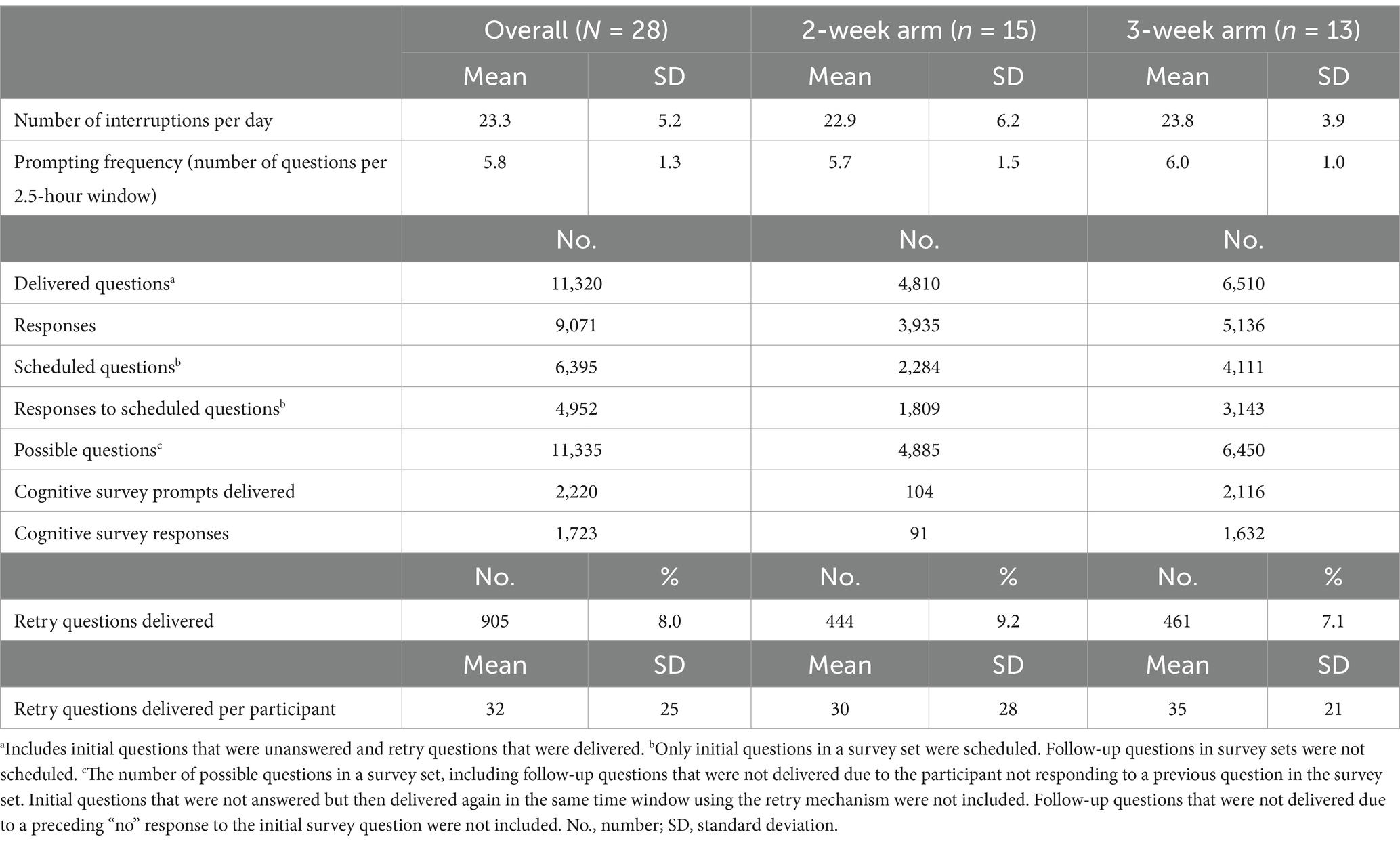
Table 3. Characteristics of questions and response metrics for the sample across all weeks and by study arm.
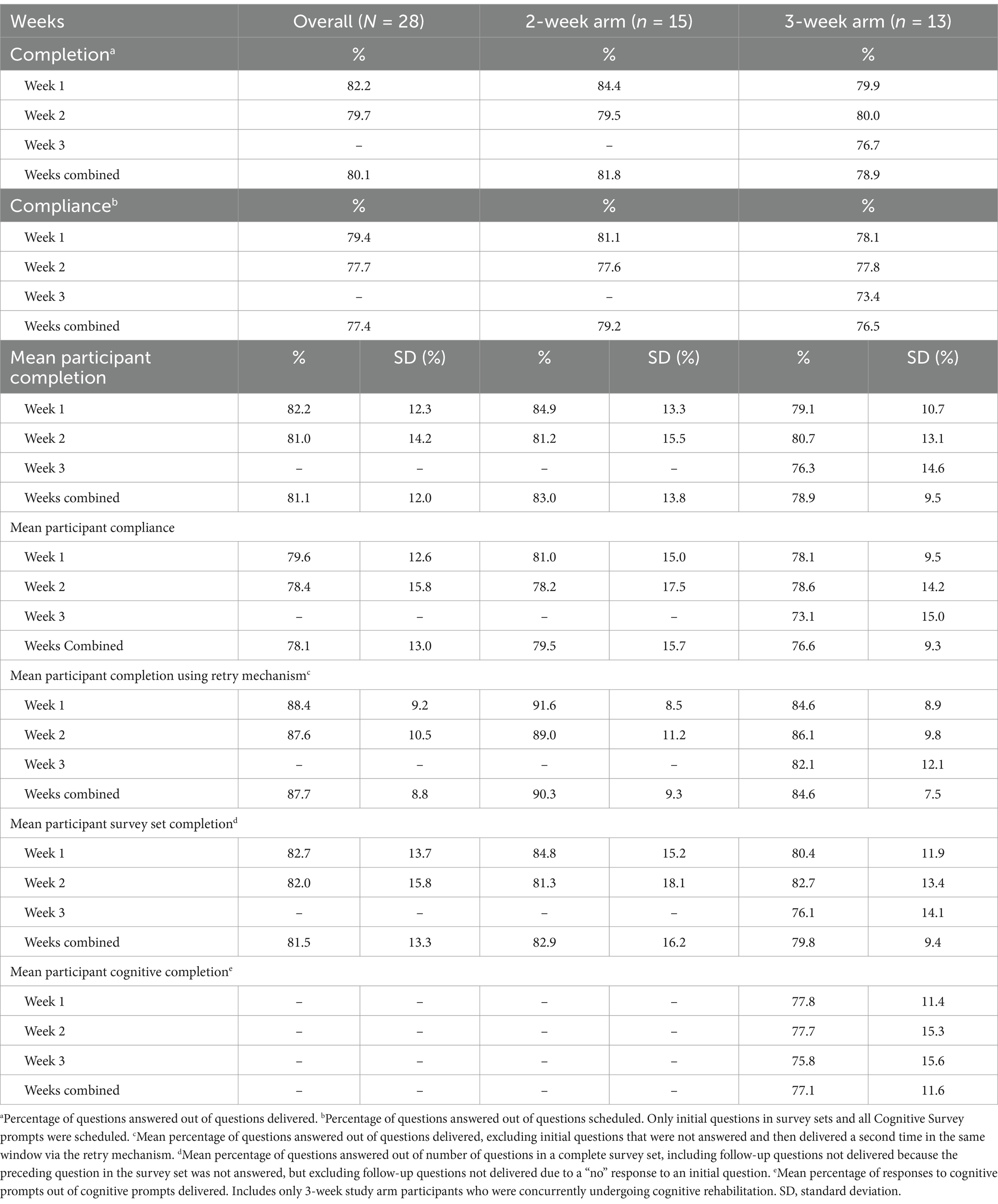
Table 4. Completion and compliance across the sample by week and by study arm.
A total of 11,320 prompts were delivered through the C-STAR app and 9,071 responses were collected across the sample. The overall completion rate was 80.1% across the sample. Completion marginally decreased from the first to the second week across the entire sample. In the 3-week study arm, completion reduced by 3.3% from the second to the third weeks. Overall completion was slightly higher in the 2-week study arm than the 3-week study arm.
A total of 6,395 questions were scheduled to be delivered through the C-STAR app with a total of 4,952 responses to scheduled questions for a compliance of 77.4% across the sample. Compliance decreased a small percentage from the first to the second week in both study arms. Compliance further decreased from Week 2 to Week 3 in the 3-week study arm by 4.4%. Compliance was marginally higher in the 2-week study arm than the 3-week study arm.
Mean participant completion was higher in the 2-week study arm than the 3-week study arm for the weeks combined. The mean participant completion rate was 81.1% ± 12.0% across the sample, with a mean difference of 4.1% between study arms. There was a general decline in completion from Week 1 to Week 2 in the 2-week group, in contrast to the slight increase in the 3-week group. However, mean participant completion in the 3-week group declined minimally between Weeks 2 and 3.
Mean participant compliance was slightly higher in the 2-week study arm than the 3-week study arm for the weeks combined. The mean participant compliance rate was 82.2% ± 12.3% across the sample, with a 5.8% mean difference between study arms. Compliance decreased from the first to the second week in the 2-week study arm and slightly increased in the 3-week study arm.
A total of 905 initial questions in survey sets were not answered upon first-time delivery, therefore, these prompts were delivered a second time in the same window via the retry mechanism. Retry questions comprised 8.0% of all delivered questions for the sample across all weeks combined (median = 25 retry questions per participant). Mean participant completion using the retry mechanism was 87.7% ± 8.8% across the sample for all weeks combined. The 2-week study arm had a higher mean completion using the retry mechanism (90.3% ± 9.3%) than the 3-week study arm (84.6% ± 7.5%). The implementation of the retry mechanism increased mean completion rates by 6.6% overall across the entire sample.
We accounted for a total of 11,335 possible questions based on number of questions in each survey set, the response behavior of each participant, and the duration of each participant’s smartwatch trial. Mean participant survey set completion was 81.5% ± 13.3% across the sample for all weeks combined. Survey set completion slightly decreased in the 2-week study arm and increased in the 3-week study arm. There was a decrease in survey set completion in the 3-week study arm from Week 2 to Week 3. The 2-week study arm mean participant survey set completion rate was higher than the 3-week study arm across weeks combined.
Survey set completion for each window across the sample and by study arm is presented separately in Table 5. Mean participant survey set completion rates during each window across the sample for all weeks combined were as follows: Window 1 (early morning) 69.8 ± 18.3%; Window 2 (late morning/early afternoon) 85.7 ± 12.8%; Window 3 (afternoon) 86.2 ± 12.6%; and Window 4 (late afternoon/evening) 85.0 ± 14.7%.
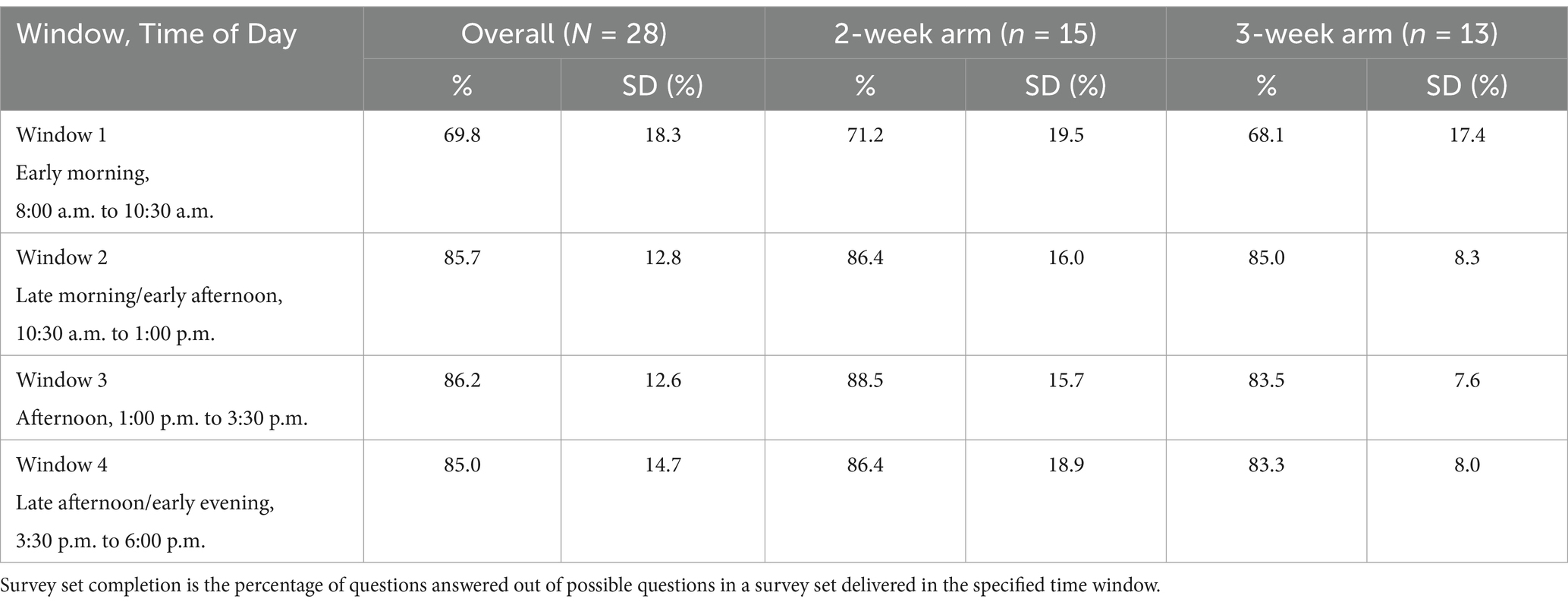
Table 5. Mean participant survey set completion based on window (Time of Day) across the sample and by study arm.
A total of 2,116 Cognitive Survey prompts were delivered to participants in the 3-week study arm with a total of 1,632 responses. Mean participant completion of Cognitive Survey prompts was 77.1% ± 11.6%. This completion rate was consistent across each of the 3 weeks (Week 1: 77.8% ± 11.4%; Week 2: 77.7% ± 15.3%; Week 3: 75.8% ± 15.6%). A single participant in the 2-week study arm requested to do a Cognitive Survey throughout their smartwatch trial; however, since this participant was not concurrently undergoing cognitive rehabilitation, these data were not included in the mean participant cognitive completion analysis.
Results of the MAUQ and SUS are presented in Table 6.
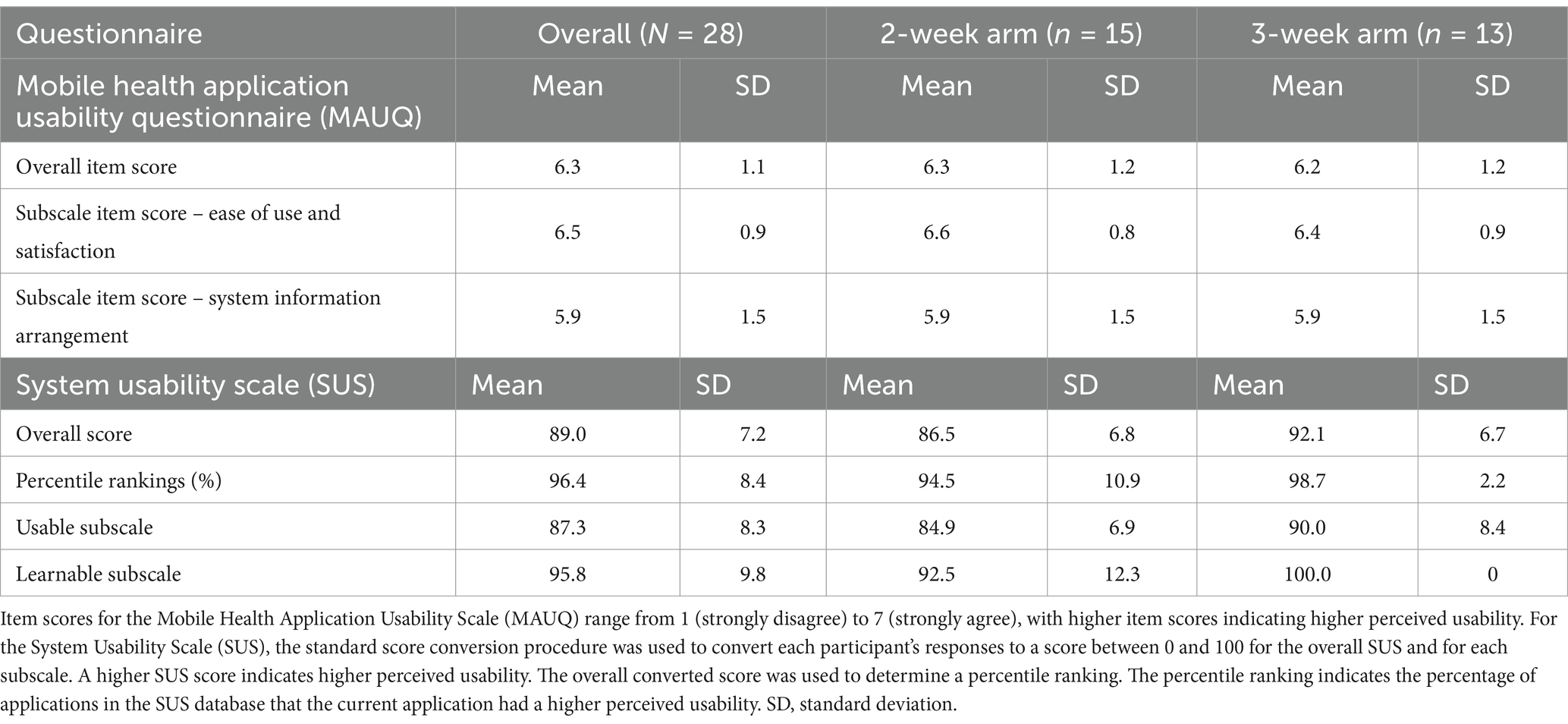
Table 6. Usability survey scores and percentile rankings across sample and by study arm.
The mean overall item score for the MAUQ was 6.3 ± 1.1 across the sample, indicating excellent overall usability of the C-STAR app. Overall MAUQ mean item scores for the 2-week and 3-week study arms were 6.3 ± 1.2 and 6.2 ± 1.2, respectively. Mean item scores for the MAUQ EOU subscale were 6.5 ± 0.9 for the sample, 6.6 ± 0.8 for the 2-week study arm, and 6.4 ± 0.9 for the 3-week study arm, indicating excellent ease of use and satisfaction with the C-STAR app. Mean item score for the MAUQ SIA subscale was 5.9 ± 1.5 for the sample and both study arms, suggesting acceptability in navigating and interacting with the app.
For the SUS, the sample’s mean converted score was 89.0 ± 7.2 out of 100 with a percentile ranking of 96.4 ± 8.4%, indicating excellent perceived system usability. Converted mean SUS scores for the 2-week and 3-week study arms were 86.5 ± 6.8 and 92.1 ± 6.7, respectively. Percentile rankings for the 2-week and 3-week study arms were 94.5% ± 10.9% and 98.7% ± 2.2%, respectively. The mean SUS Usable subscale score was 87.3 ± 8.3 for the sample, 84.9 ± 6.9 for the 2-week study arm, and 90.0 ± 8.4 for the 3-week study arm, indicating high levels of perceived usability of the app and smartwatch system. The mean SUS Learnable subscale score was 95.8 ± 9.8 for the sample, 92.5 ± 12.3 for the 2-week study arm, and 100.0 ± 0 for the 3-week study arm, suggesting that operating the technology was very easy to learn.
The findings from this study complement those published from previous research studies (13, 21) in that we assessed the adherence to and usability of miEMA using a smartwatch for tracking both symptoms and use of cognitive behavioral strategies in service members with a history of TBI. The comparable completion and compliance rates suggest that miEMA was a feasible method of experience sampling in a military TBI population. The temporally dense in-situ data was collected over a period of two and three weeks with high adherence. Smartwatches have demonstrated acceptability (30–32) and higher compliance, lower perceived user burden, and faster response times than standard EMA to deliver miEMA questions (19, 21). The current study findings suggest that miEMA surveys delivered through a digital app on a smartwatch is feasible, easy to learn, and practical to use within the unique ecological contexts of the daily military lifestyle of service members in the garrison environment.
Previous work has demonstrated completion and compliance rates comparable to the current study’s findings (13, 21). Intille et al. (21) observed 87.8% completion and 75.6% compliance rates in a 4-week pilot study in which 19 participants were randomized to use miEMA delivered through a smartwatch (vs. 14 participants randomized to a standard EMA condition via smartwatch). When two outliers were removed from the Intille et al. (21) analysis, completion increased to 91.8% and compliance to 88.2%. Ponnada et al. (13) conducted another pilot study with 15 participants responding to miEMA questions delivered through a smartwatch over 1 month and observed a 76.4% ± 22.3% completion rate. Ponnada and colleagues’ (13) longitudinal follow-on study assessed miEMA adherence in 81 young adults over at least 6 months of smartwatch data collection and observed a mean participant compliance rate of 67.4% ± 13.7% and completion rate of 80.2% ± 13.3%. The current study also demonstrated minimal differences in completion and compliance between weeks in both study arms suggesting that the longitudinal duration of 14 to 21 days had limited impact on adherence measures. Despite a rate of up to 36 interruptions per day (M = 23.4), our study’s findings suggest that miEMA in-situ data collection was manageable and sustainable for the participants for up to 21 days.
It should be highlighted that completion and compliance as previously defined did not fully account for undelivered questions based on nonresponse nor unscheduled follow-up questions in our study. These omissions were likely due to differences in the design of the custom miEMA app in the current study compared to that in previous studies (13, 21). For example, if an initial question (i.e., “I have a headache”) was not answered and the retry question was also not answered, then the follow-up questions in the survey set (i.e., “My headache is…” and “Headache is interfering with my daily activities?”) were not delivered. It was not possible to know in that moment if the participant had a headache or not, and therefore, either one data point was missing (i.e., they did not have a headache) or three data points were missing (i.e., they had a headache, it was a 7 out of 10 in severity, and it was or was not interfering with their daily activities). Regarding compliance, only Cognitive Survey prompts and initial questions in survey sets were scheduled, so retry questions and follow-up questions that were or were not delivered based on response behavior were not factored in when calculating compliance. This definition of compliance did not capture the prompts in which their delivery was contingent upon response behavior (e.g., responses to or missed follow-up questions in survey sets). For example, if a participant responded “yes” to an initial question (i.e., “I have a headache”), then two follow-up questions were expected to be delivered, but since these follow-up questions are not scheduled, then they would not be accounted for in the compliance definition whether they were answered or not.
Given the inherent risks of some daily activities and military duties, the retry mechanism allowed the participant a second opportunity during the same allotted time window to respond to a missed initial question in a survey set. The retry mechanism increased completion across the sample by 6.6% suggesting it’s value in increasing completion without compromising the safety of military personnel as they navigate their daily activities and military duties. We opted not to use the retry mechanism for follow-up questions in survey sets to keep the prompt burden at a manageable level. Retry questions comprised 8% of all delivered questions and appeared to boost rather than hinder completion in the current study. This finding is aligned with previous research that showed increased prompting of cognitively simple structured questions through a smartwatch allowed for predictable response time and minimized interruption cost (21).
Due to the limitations of the definitions for completion and compliance related to our custom app design as discussed above, we developed the definition for survey set completion. Survey set completion accounted for responses to follow-up questions in survey sets, as well as missed responses for undelivered questions based on response behavior. Mean participant survey set completion rates were similar to mean participant completion rates in the current study. However, survey set completion provides a more complete picture of the data that were and were not provided by participants and may be more relevant to the clinical application of a miEMA approach based on our app design.
Mean participant survey set completion based on the time of day was worse during the early morning window (8 a.m. to 10:30 a.m.) and higher for the remainder of the day across the sample. These findings are similar to Ponnada and colleagues’ (33) study in which they observed lower completion rates during the morning window (8 a.m. – 12 p.m., 75% ± 18%) and higher completion rates later in the day (80% ± 14%, 12 p.m. - 4 p.m.; and 81% ± 13%, 4 p.m. - 8 p.m.). EMA methods depend upon the careful timing of assessments (6). Our sampling strategy was based on scheduling prompts to solicit experience data during randomized times across four windows throughout a 10-h day, as this strategy aimed to reduce non-response bias and improve the generalizability of the data collected over time. However, the activities of daily routines may have had an impact on response behavior in our sample.
Military personnel have specific daily routines, which are different from most civilian occupations, as well as intermittent activities that diverge from their daily routines (e.g., range operations, parachute training, military unit functions). Military personnel typically conduct Physical Training in the morning but may also conduct Physical Training midday or in the afternoon, depending on their work schedule. Previous research by Ponnada et al. (34) showed increased participant non-response during periods of vigorous activity. Cauchard et al. (35) observed that running and cycling reduced accuracy in smartwatch vibrotactile pattern recognition compared to more moderate or sedentary activities. A typical duty day morning for military personnel might also include personal hygiene, breakfast, driving to work, preparing for training, reporting to duty, and morning meetings, which may have been contextual factors distracting from responding during the early morning window. Consideration of such activities may influence sampling strategy depending upon the characteristics of the constructs being assessed and anticipated contextual factors for non-response (i.e., scheduling sampling during time windows when an individual is most likely to respond). From a clinical perspective, the individual’s subjective description of constructs to be assessed should also guide the sampling strategy. For example, if a patient reports that their headaches typically occur upon waking early in the morning or late in the evening, then the windows for sampling should extend into or close to these timeframes to capture these data. Understanding how an individual’s daily routines and their observed symptom pattern may affect response behavior can enable the clinician and patient to co-create a sampling strategy that mitigates barriers to adherence and captures symptom data sufficiently.
Mean participant cognitive survey completion was slightly less than the overall sample’s mean participant survey set completion. It is worth noting that the individuals in the 3-week study arm reported a range of cognitive challenges that could have affected their ability to respond to repeated assessments of their use of behavioral strategies throughout their day. Cognitive completion remained consistent across all 3 weeks in the 3-week study arm suggesting that response behavior was manageable within the context of a range of cognitive difficulties and in conjunction with cognitive rehabilitation.
Although previous methods of calculating completion and compliance reliably measure two aspects of response behaviors that represent adherence (13, 21), it remains unknown what the lowest adherence rate would be that still provides clinical utility. Although the evaluation of clinical utility of miEMA is beyond the scope of this article, we began to address this question with a review of the individual miEMA survey set completion results for each of the 3-week study arm participants. The 3-week arm participants were concurrently undergoing cognitive rehabilitation and received Cognitive Surveys personalized to their cognitive difficulties and treatment goals. They followed up with their treating provider weekly to review their miEMA data. Of these participants, the lowest survey set completion rate was 61.4%. This participant still provided 419 responses across four miEMA surveys (Mood, Headache, Fatigue, and Cognitive Surveys) over 21 consecutive days. Specifically, his responses to the Cognitive Survey prompts were sufficient and consistent enough for his treating Speech-Language Pathologist to be able to adjust his weekly treatments and to co-create “just in time” treatment adaptations with the participant. As such, his miEMA data showed increased endorsement of his use of cognitive strategies over the 3-week period. It is worth noting that this participant reported that he gained insights to his symptoms and cognitive functions based on his miEMA data as well as clinical benefit from the adaptive treatment adjustments offered by his treating provider.
Optimal adherence rates may vary between individuals depending on constructs and symptom patterns when considering the clinical utility of miEMA. However, minimizing interruption burden without the loss of considerable data is a known challenge of the miEMA approach (36) and has implications in military populations that may already be prone to survey fatigue. Li and colleagues’ (36) analyses of previous EMA datasets found that using machine learning to skip select questions based on a prediction uncertainty threshold and capping the number of questions in a survey set may reduce interruption burden while mitigating information loss. Achieving a high completion rate would undoubtedly provide more data to consider. However, identifying a “sweet spot,” or a point of diminishing returns, as to the least possible amount of participant-generated miEMA data required to attain optimal clinical applicability may be worthwhile for various constructs, conditions, and settings in future studies.
Participants reported high usability scores on the MAUQ and SUS when rating satisfaction with and usability of the C-STAR app and smartwatch platform.
The overall MAUQ mean item scores and those for the EOU subscale were excellent. The mean item scores for the SIA subscale were satisfactory. All individual item mean scores, except for one item, on the SIA subscale were 6.0 (out of 7) or higher, indicating high perceived usability for how information was arranged in the app. The single exception was the item, “Whenever I made a mistake using the app, I could recover easily and quickly.” The mean score for this item across the entire sample was 4.7 (out of 7). Ponnada and colleagues (13) included an “Undo” option in their miEMA app and reported a 4.2% Undo rate. Participants in their study found the “Undo” feature useful in the situation of accidentally tapping the smartwatch so they could correct their response (13). The C-STAR app did not include an Undo feature; however, participants could opt to change their response until they tapped the “Submit” button. The “Submit” button appeared on the smartwatch face simultaneously with the response options, rather than on a separate screen after a response was entered, to keep device interaction time within the 3 to 5 s microinteraction timeframe. This relatively lower mean item score indicates a specific area for future improvement of the C-STAR app.
The overall mean SUS score, as well as the mean scores for the Usable and Learnable subscales, were high in this sample. The average SUS benchmark score is 68 for digital health apps (excluding physical activity apps), with higher SUS scores correlating with more frequent system (e.g., app, website) use (37). Therefore, the mean overall SUS score of 89.0 suggests that the service members in the current study are highly likely to use the C-STAR app and smartwatch system based on its usability.
This is the first study to evaluate the feasibility and usability of miEMA using a smartwatch in military personnel with a history of TBI. However, this study has some methodological limitations that should be highlighted. Our sample was small and primarily limited to Army service members; therefore, results may not generalize to other groups. Sampling was scheduled to start at 8 a.m. and stop at 6 p.m., so it remains unknown how life events that typically occur outside those hours (e.g., interacting with children and/or partners, after-work activities and responsibilities, extended work hours) may affect response behavior in this population. Additionally, the trial of miEMA data collection was limited to two or three weeks, therefore, it remains unknown how adherence may be affected over longer periods of time in a military patient population.
Future miEMA-related studies should be conducted in other military-connected groups (e.g., Veterans and/or retirees), service branches, and various contextual settings, specifically in field or austere environments (e.g., during field training exercises or deployment). Longitudinal trials of longer duration should also be a focus of future miEMA research in military populations. Sampling strategies and prediction models using machine learning to determine effective methods to reduce interruption burden and minimize information loss, yet still provide acceptable clinical utility should be evaluated in future miEMA studies.
This study demonstrated that miEMA is a feasible method of obtaining temporally-dense real-time subjective experience data in a sample of military personnel with a history of TBI, including those with cognitive challenges. Adherence rates in this military sample were similar to those in civilian populations, despite the differences in routines and work environments between military personnel and civilians. The C-STAR app and smartwatch had high usability ratings indicating that the system was likely compatible with the real-world work and living environments of service members in the sample. Our findings support the feasibility of miEMA to assess multiple constructs observed in service members with TBI and other various conditions and across other applications in the Military Health System.
The views expressed in this manuscript are those of the authors and do not necessarily represent the official policy or position of the Defense Health Agency, Department of Defense, or any other U.S. government agency. This work was prepared under Contract HT0014-22-C-0016 with DHA Contracting Office (NM-CD) HT0014 and, therefore, is defined as U.S. Government work under Title 17 U.S.C.§101. Per Title 17 U.S.C.§105, copyright protection is not available for any work of the U.S. Government. For more information, please contact ZGhhLlRCSUNPRWluZm9AaGVhbHRoLm1pbA==.
The datasets presented in this article are not publicly available due to ethical and privacy restrictions, but may be made available by request to the corresponding author upon required DoD/DHA approval. Requests to access the datasets should be directed to KM, a2F0cmluYS5zLm1vbnRpLmN0ckBoZWFsdGgubWls.
This study involved humans and was approved by the Madigan Army Medical Center Institutional Review Board (Protocol number: 222049). This study was conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
KM: Data curation, Formal analysis, Investigation, Project administration, Supervision, Writing – original draft, Writing – review & editing. KW: Data curation, Formal analysis, Investigation, Visualization, Writing – review & editing, Writing – original draft. BI: Formal analysis, Writing – review & editing. JU: Conceptualization, Data curation, Funding acquisition, Investigation, Methodology, Project administration, Resources, Supervision, Writing – original draft, Writing – review & editing. JSC: Conceptualization, Data curation, Investigation, Resources, Supervision, Writing – review & editing, Project administration. MD: Formal analysis, Writing – review & editing.
The author(s) declare that no financial support was received for the research and/or publication of this article.
We would like to acknowledge Alexander McKenzie from the Madigan Army Medical Center Clinical Informatics Department for developing the C-STAR app and providing app support throughout the study. Thank you to Megan Herodes and Seattle Peterson for contributing to study development and early data collection. We thank the staff and leadership at the JBLM Intrepid Spirit Center for their unwavering support to this study. We are also incredibly grateful for the service members who contributed their time and efforts to this study.
Authors KM and KW were employed by company CICONIX LLC.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The handling editor JRF is currently organizing a Research Topic with the author JU.
The authors declare that no Gen AI was used in the creation of this manuscript.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fneur.2025.1564657/full#supplementary-material
APP, Application; C-STAR, Clinical Symptom Tracking and Assessment in Real Time; DHA, Defense Health Agency; EMA, Ecological Momentary Assessment; EOU, Ease of Use and Satisfaction Subscale; MAUQ, Mobile Health Application Usability Questionnaire; miEMA, Microinteraction Ecological Momentary Assessment; MTF, Military Treatment Facility; MOS, Military Occupational Specialty; NSI, Neurobehavioral Symptom Inventory; SIA, System Information Arrangement Subscale; SUS, System Usability Scale; TBI, traumatic brain injury; USB, Universal Serial Bus.
1. Lange, RT, Brickell, T, French, LM, Ivins, B, Bhagwat, A, Pancholi, S, et al. Risk factors for postconcussion symptom reporting after traumatic brain injury in U.S. military service members. J Neurotrauma. (2013) 30:237–46. doi: 10.1089/neu.2012.2685
2. Lange, RT, Brickell, TA, Ivins, B, Vanderploeg, RD, and French, LM. Variable, not always persistent, postconcussion symptoms after mild TBI in U.S. military service members: a five-year cross-sectional outcome study. J Neurotrauma. (2013) 30:958–69. doi: 10.1089/neu.2012.2743
3. Mac Donald, CL, Barber, J, Jordan, M, Johnson, AM, Dikmen, S, Fann, JR, et al. Early clinical predictors of 5-year outcome after concussive blast traumatic brain injury. JAMA Neurol. (2017) 74:821–9. doi: 10.1001/jamaneurol.2017.0143
4. Stone, AA, Turkkan, JS, Bachrach, CA, Jobe, JB, Kurtzman, HS, and Cain, VS. Chapter 3: remembering what happened: memory errors and survey reports In: AA Stone, editor. The science of self-report: Implications for research practice. Mahwah, NJ: Taylor & Francis e-Library (2009)
5. Miller, LL, and Aharoni, E. Understanding low survey response rates among young U.S military personnel. Santa Monica, CA: RAND Corporation (2015).
6. Stone, AA, and Shiffman, S. Ecological momentary assessment (Ema) in behavioral medicine. Ann Behav Med. (1994) 16:199–202. doi: 10.1093/abm/16.3.199
7. Shiffman, S, Stone, AA, and Hufford, MR. Ecological momentary assessment. Annu Rev Clin Psychol. (2008) 4:1–32. doi: 10.1146/annurev.clinpsy.3.022806.091415
8. Shiffman, S. Real-time self-report of momentary states in the natural environment: computerized ecological momentary assessment In: S Shiffman, editor. The science of self-report: Implications for research and practice. Mahwah, NJ: Lawrence Erlbaum Associates Publishers (2000). 277–96.
9. Shiffman, S. Ecological momentary assessment (EMA) in studies of substance use. Psychol Assess. (2009) 21:486–97. doi: 10.1037/a0017074
10. Forkmann, T, Spangenberg, L, Rath, D, Hallensleben, N, Hegerl, U, Kersting, A, et al. Assessing suicidality in real time: a psychometric evaluation of self-report items for the assessment of suicidal ideation and its proximal risk factors using ecological momentary assessments. J Abnorm Psychol. (2018) 127:758–69. doi: 10.1037/abn0000381
11. Dornbach-Bender, A, Ruggero, CJ, Schuler, K, Contractor, AA, Waszczuk, M, Kleva, CS, et al. Positive and negative affect in the daily life of world trade center responders with PTSD: an ecological momentary assessment study. Psychol Trauma. (2020) 12:75–83. doi: 10.1037/tra0000429
12. Wenze, SJ, and Miller, IW. Use of ecological momentary assessment in mood disorders research. Clin Psychol Rev. (2010) 30:794–804. doi: 10.1016/j.cpr.2010.06.007
13. Ponnada, A, Wang, S, Chu, D, Do, B, Dunton, G, and Intille, S. Intensive longitudinal data collection using microinteraction ecological momentary assessment: pilot and preliminary results. JMIR Form Res. (2022) 6:e32772. doi: 10.2196/32772
14. Hufford, MR, Shields, AL, Shiffman, S, Paty, J, and Balabanis, M. Reactivity to ecological momentary assessment: an example using undergraduate problem drinkers. Psychol Addict Behav. (2002) 16:205–11. doi: 10.1037/0893-164X.16.3.205
15. Fuller-Tyszkiewicz, M, Skouteris, H, Richardson, B, Blore, J, Holmes, M, and Mills, J. Does the burden of the experience sampling method undermine data quality in state body image research? Body Image. (2013) 10:607–13. doi: 10.1016/j.bodyim.2013.06.003
16. Ram, N, Brinberg, M, Pincus, AL, and Conroy, DE. The questionable ecological validity of ecological momentary assessment: considerations for design and analysis. Res Hum Dev. (2017) 14:253–70. doi: 10.1080/15427609.2017.1340052
17. Eisele, G, Vachon, H, Lafit, G, Kuppens, P, Houben, M, Myin-Germeys, I, et al. The effects of sampling frequency and questionnaire length on perceived burden, compliance, and careless responding in experience sampling data in a student population. Assessment. (2022) 29:136–51. doi: 10.1177/1073191120957102
18. Smyth, JM, Jones, DR, Wen, CKF, Materia, FT, Schneider, S, and Stone, A. Influence of ecological momentary assessment study design features on reported willingness to participate and perceptions of potential research studies: an experimental study. BMJ Open. (2021) 11:e049154. doi: 10.1136/bmjopen-2021-049154
19. Ponnada, A, Haynes, C, Maniar, D, Manjourides, J, and Intille, S. Microinteraction ecological momentary assessment response rates: effect of microinteractions or the smartwatch? Proc ACM Interact Mob Wearable Ubiquitous Technol. (2017) 1:1–16. doi: 10.1145/3130957
20. Jones, M, Taylor, A, Liao, Y, Intille, SS, and Dunton, GF. Real-time subjective assessment of psychological stress: associations with objectively-measured physical activity levels. Psychol Sport Exerc. (2017) 31:79–87. doi: 10.1016/j.psychsport.2017.03.013
21. Intille, S, Haynes, C, Maniar, D, Ponnada, A, and Manjourides, J. μEMA: microinteraction-based ecological momentary assessment (EMA) using a smartwatch. Proc ACM Int Conf Ubiquitous Comput. (2016) 2016:1124–8. doi: 10.1145/2971648.2971717
22. Meterko, M, Baker, E, Stolzmann, KL, Hendricks, AM, Cicerone, KD, and Lew, HL. Psychometric assessment of the neurobehavioral symptom Inventory-22: the structure of persistent postconcussive symptoms following deployment-related mild traumatic brain injury among veterans. J Head Trauma Rehabil. (2012) 27:55–62. doi: 10.1097/HTR.0b013e318230fb17
23. King, PR, Donnelly, KT, Donnelly, JP, Dunnam, M, Warner, G, Kittleson, CJ, et al. Psychometric study of the neurobehavioral symptom inventory. J Rehabil Res Dev. (2012) 49:879–88. doi: 10.1682/JRRD.2011.03.0051
24. Kortum, P, and Sorber, M. Measuring the usability of mobile applications for phones and tablets. Int J Hum Comput Interact. (2015) 31:518–29.
25. Zhou, L, Bao, J, Setiawan, IMA, Saptono, A, and Parmanto, B. The mHealth app usability questionnaire (MAUQ): development and validation study. JMIR Mhealth Uhealth. (2019) 7:e11500. doi: 10.2196/11500
26. Brooke, J. SUS: a “quick and dirty” usability scale In: J Brooke, editor. Usability evaluation in industry. London, UK: Taylor & Francis (1996). 189–94.
27. Lewis, JR, and Sauro, J. The factor structure of the system usability scale In: M Kurosu, editor. Human centered design. Berlin, Heidelberg: Springer Berlin Heidelberg (2009). 94–103.
28. Sauro, J, and Lewis, JR. Standardized usability questionnaires In: J Sauro, editor. Quantifying the user experience: Practical statistics for user research. 2nd ed. Cambridge, MA: Morgan Kaufmann (2016). 198–210.
29. Lewis, JR. The system usability scale: past, present, and future. Int J Hum Comput Interact. (2018) 34:577–90. doi: 10.1080/10447318.2018.1455307
30. Chun, J, Lee, K, and Kim, S. A qualitative study of smartwatch usage and its usability. Hum Factors Ergon Manuf. (2018) 28:20733. doi: 10.1002/hfm.20733
31. Pizza, S, Brown, B, McMillan, D, and Lampinen, A. Smartwatch in vivo In: S Pizza, editor. Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems. New York, USA: Association for Computing Machinery (2016). 5456–69.
32. Nadal, C, Earley, C, Enrique, A, Sas, C, Richards, D, and Doherty, G. Patient acceptance of self-monitoring on a smartwatch in a routine digital therapy: a mixed-methods study. ACM Trans Comput Hum Interact. (2023) 31:1–50. doi: 10.1145/3617361
33. Ponnada, A, Li, J, Wang, S, Wang, WL, Do, B, Dunton, G, et al. Contextual biases in microinteraction ecological momentary assessment (μEMA) non-response. Proc ACM Interact Mob Wearable Ubiquitous Technol. (2022) 6:1–24. doi: 10.1145/3517259
34. Ponnada, A, Thapa-Chhetry, B, Manjourides, J, and Intille, S. Measuring criterion validity of microinteraction ecological momentary assessment (Micro-EMA): exploratory pilot study with physical activity measurement. JMIR Mhealth Uhealth. (2021) 9:e23391. doi: 10.2196/23391
35. Cauchard, JR, Cheng, JL, Pietrzak, T, and Landay, JA. ActiVibe: design and evaluation of vibrations for Progress monitoring In: JR Cauchard, editor. Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems. San Jose California USA: ACM (2016). 3261–71.
36. Li, J, Ponnada, A, Wang, WL, Dunton, G, and Intille, S. Ask less, learn more: adapting ecological momentary assessment survey length by modeling question-answer information gain. Proc ACM Interact Mob Wearable Ubiquitous Technol. (2024) 8:166. doi: 10.1145/3699735
Keywords: microinteraction, ecological momentary assessment, experience sampling, smartwatch, military, traumatic brain injury
Citation: Monti K, Williams K, Ivins B, Uomoto J, Skarda-Craft J and Dretsch M (2025) Feasibility and usability of microinteraction ecological momentary assessment using a smartwatch in military personnel with a history of traumatic brain injury. Front. Neurol. 16:1564657. doi: 10.3389/fneur.2025.1564657
Edited by:
Rüdiger Christoph Pryss, Julius Maximilian University of Würzburg, GermanyReviewed by:
Shannon B. Juengst, University of Texas Southwestern Medical Center, United StatesCopyright © 2025 Monti, Williams, Ivins, Uomoto, Skarda-Craft and Dretsch. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Katrina Monti, a2F0cmluYS5zLm1vbnRpLmN0ckBoZWFsdGgubWls
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.