 Katsunori Oyama1*
Katsunori Oyama1* Toshiki Isogai2Yohei Nakayama3,4Ryoki Kobayashi3,5Daisuke Kitano6
Toshiki Isogai2Yohei Nakayama3,4Ryoki Kobayashi3,5Daisuke Kitano6 Kenji Karako7
Kenji Karako7 Kaoru Sakatani7,8
Kaoru Sakatani7,8- 1Department of Computer Science, College of Engineering, Nihon University, Koriyama, Japan
- 2Graduate School of Computer Science, Nihon University, Koriyama, Japan
- 3Research Institute of Oral Science, Nihon University School of Dentistry at Matsudo, Matsudo, Japan
- 4Department of Periodontology, Nihon University School of Dentistry at Matsudo, Matsudo, Japan
- 5Department of Infection and Immunology, Nihon University School of Dentistry at Matsudo, Matsudo, Japan
- 6Division of Cardiology, Department of Medicine, Nihon University School of Medicine, Itabashi, Japan
- 7Department of Human and Engineered Environmental Studies, Graduate School of Frontier Sciences, The University of Tokyo, Kashiwa, Japan
- 8Institute of Gerontology, The University of Tokyo, Bunkyo, Japan
Introduction: This study aimed to investigate the effectiveness of data augmentation to improve dementia risk prediction using machine learning models. Recent studies have shown that basic blood tests are cost-effective in predicting cognitive function. However, developing models that address various conditions poses challenges due to constraints associated with blood test results and cognitive assessments, including high costs, limited sample sizes, and missing data from tests not performed in certain facilities. Despite being often limited by small sample sizes, periodontal examination data have also emerged as a cost-effective screening tool.
Methods: To address these challenges, this study explored the effectiveness of data augmentation using the Synthetic Minority Over-sampling Technique for Regression with Gaussian noise (SMOGN), a Generative Adversarial Network (GAN), and a Conditional Tabular GAN (CTGAN) on periodontal examination and blood test data. The datasets included parameters such as cognitive assessment results from the Mini-Mental State Examination (MMSE), demographic characteristics, periodontal examination data, and blood test results. Linear regression models, random forests, and deep neural networks were used to evaluate the effectiveness of the synthesized data.
Results: This study used measured data from 108 participants and the synthesized data generated from the measured data. External validity was evaluated using a different dataset of 41 participants with missing items. The results suggested that normal GANs have the advantage of investigating models in data diversity, whereas CTGANs preserve the data structure and linear relationships in tabular data from the measured data, which drastically improves linear regression models.
Discussion: Importantly, by interpolating sparse areas in the distribution, such as age, the synthesized models maintained prediction accuracy for test data with extreme inputs. These findings suggest that GAN-synthesized data can effectively address regression problems and improve dementia risk prediction.
1 Introduction
The rapidly increasing older population has led to a rise in the prevalence of dementia, including Alzheimer’s disease (AD). The number of people living with dementia across the world is expected to increase from 55 million in 2019 to 139 million in 2050 (1). Accurate diagnosis remains complex because of the subtleties of mental status assessment and the similarity of AD to other types of dementia. Mild cognitive impairment (MCI), often a precursor to AD, is widely recognized as crucial for early detection and intervention.
Blood tests, which have recently been correlated with Mini-Mental State Examination (MMSE) scores (2, 3), have emerged as a promising tool for cognitive screening. However, because of a variety of factors, machine learning models trained on blood test data often face limitations in accurately predicting dementia risks. One significant challenge is heterogeneity in patient data, including a wide range of biomarkers and cognitive scores. This variability can lead to inconsistencies in model performance, especially when dealing with multifaceted diseases such as dementia. Additionally, standard analytical models often struggle with the sparse and imbalanced nature of medical datasets, which can result in overfitting or the underrepresentation of certain patient groups. To address these issues, there is a growing need for innovative approaches capable of effectively handling diverse and incomplete data while maintaining predictive accuracy and reliability.
In addition to blood tests, recent research has highlighted the potential role of periodontal examination data in dementia risk assessment. Some studies have suggested a close relationship between cognitive function, oral health, and systemic metabolic function in older adults, with the number of healthy teeth being a significant predictor (4). However, to the best of our knowledge, the combination of periodontal examination and blood test results have never been investigated for cost-effective and rapid screening of dementia risk. It is because the integration of periodontal examination data with blood tests still faces the obstacles, including the associated high costs, limited sample sizes, and missing data from unperformed tests, while periodontal health is increasingly recognized for its potential links with cognitive function, offering a promising avenue for early dementia detection.
Recent studies applying generative adversarial networks (GANs) for clinical applications, including diagnosis, prediction, and anomaly detection, can mostly be found in the field of medical imaging (5, 6). This is the first study to integrate periodontal examination and blood test data and to apply synthesized models from tabular data for dementia risk prediction, which aim to address the challenges of data scarcity and heterogeneity in medical datasets that often impede accurate dementia risk prediction. This approach represents a step forward for cost-effective and rapid screening methods in early-stage dementia risk assessment.
2 Methods
Data augmentation techniques such as SMOGN, GAN, and CTGAN were applied to generate synthesized datasets after preprocessing the measured data to handle missing values, as shown in Figure 1. The synthesized datasets were then used for training three basic machine learning models: linear regression (LR), random forest (RF), and deep neural network (DNN). Prediction errors and the robustness of the synthesized models were evaluated through 10 repeated hold-out validation process with different random seeds to ensure the reliability and generalizability of the synthesized data and models.
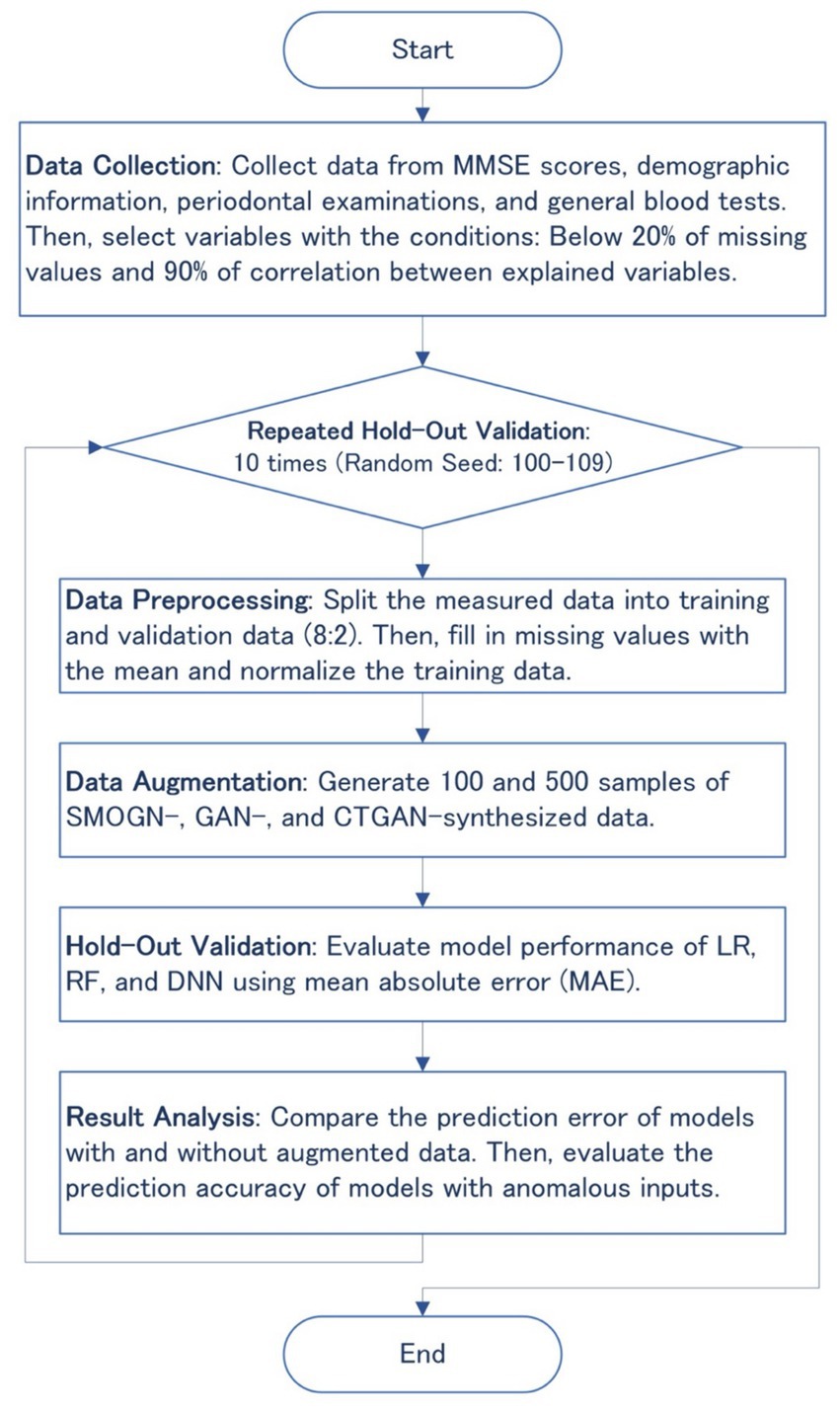
Figure 1. Flowchart of the overall methodology, including data collection, preprocessing, augmentation, hold-out validation, and result analysis.
2.1 Participants and measurements
We evaluated 108 individuals who were appointed for oral health assessments at Nihon University Itabashi Hospital (mean age ± standard deviation [SD], 69.4 ± 9.7 years; age range, 33–85 years). Written informed consent was obtained from all participants who agreed to additionally take MMSE and blood tests after receiving ethical approval from the Institutional Review Board (approval No.: RK-191210-3). Periodontal examinations, performed by a dentist in the research project, included assessments such as the number of remaining healthy teeth.
Regarding the external validity of the synthesized models, we used a dataset of 41 participants (28 males, 13 females, mean age ± SD, 69.7 ± 5.6 years) from a public health center in Koriyama, Fukushima, Japan, published in a preliminary study (4). The mean MMSE score was 26.7 ± 2.1. Compared with the measured data shown in Table 1, the external validation test dataset lacked thirteen of 27 items; however, the remaining 14 items were commonly available as predictor variables between the measured data and the external validation test dataset: age, sex, white blood cell count (WBC), hemoglobin (Hb), platelet count (Plt), aspartate aminotransferase (AST), alanine aminotransferase (ALT), total cholesterol (T-Cho), triglyceride (TG), blood urea nitrogen (BUN), creatinine (Cr), uric acid (UA), total protein (TP), and number of remaining teeth.
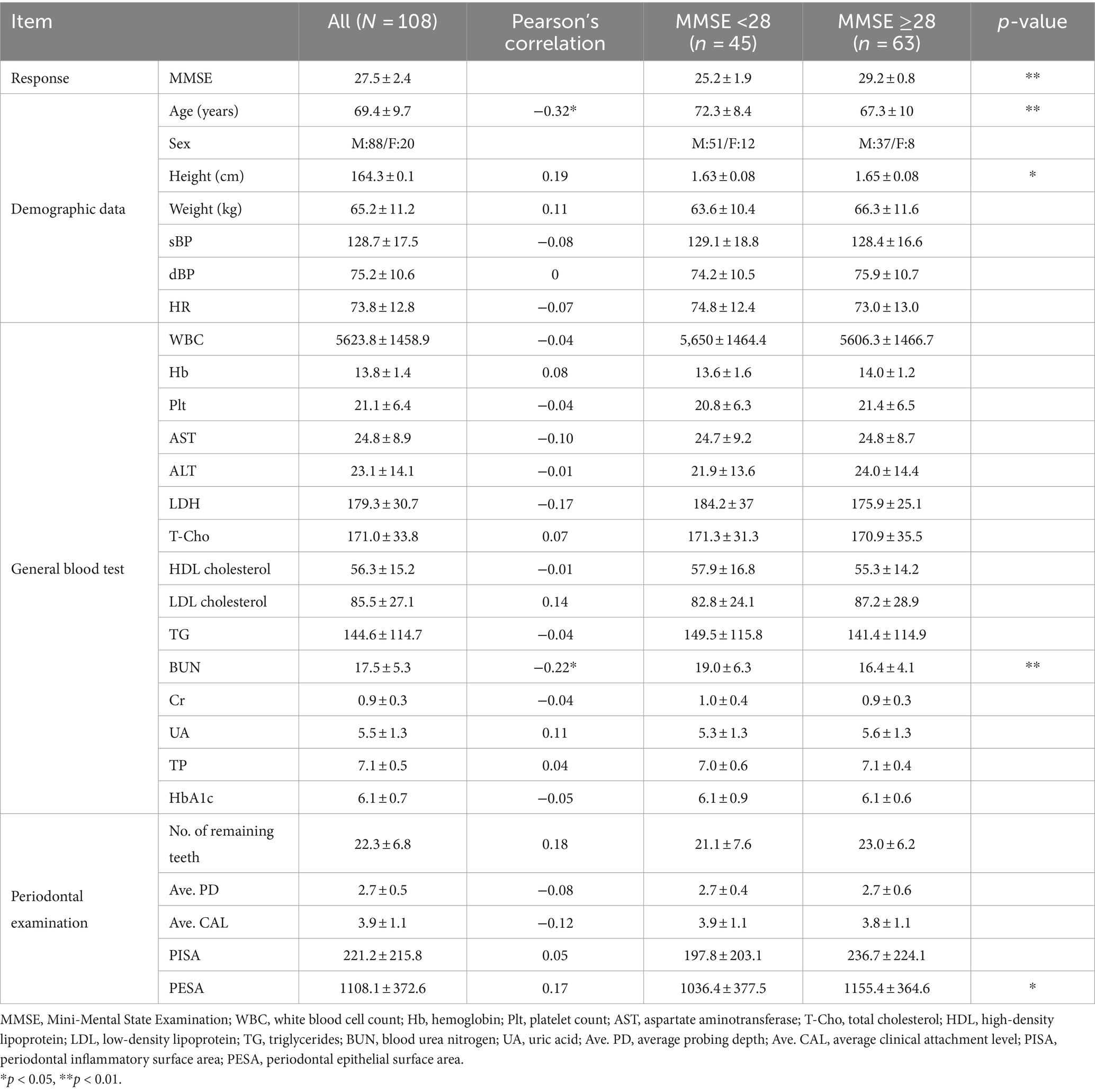
Table 1. Measured data (N = 108) with the parameters of Pearson’s correlation with MMSE scores and statistical difference between two MMSE groups (<28, ≥28).
2.2 Data augmentation
GANs were used to generate synthesized data from our dataset with combinations of sample sizes (100 and 500) and learning epochs (300, 1,000, 3,000, 5,000), while SMOGN served as the base model, effectively balancing the data distribution for oversampling in regression problems. For more details, the learning parameters of SMOGN, GAN, and CTGAN are listed in Supplementary Table S1.
2.2.1 Synthesizer 1—synthetic minority over-sampling technique for regression with Gaussian noise
To address data imbalances, we applied SMOGN, which enhances minority data representation by generating synthetic samples with a Gaussian noise model (7). This technique ensures that the dataset remains representative of the original distribution for training unbiased models.
2.2.2 Synthesizer 2—GAN
Our standard GAN were implemented using the TensorFlow 2 library. GANs operate using a pair of neural networks—the Generator and the Discriminator—which are trained concurrently through a competitive process. The Generator creates data from random noise, learning to make it indistinguishable from measured data. Conversely, the Discriminator learns to distinguish accurately whether the data presented is generated or real (8). The standard GAN in this study features a Generator and Discriminator, each with three hidden layers. These layers were configured with 256, 128, and 64 units for the Generator, and 128, 64, and 32 units for the Discriminator. We opted for the leaky rectified linear unit activation function to maintain gradient flow during training as a standard model of GAN, with each layer followed by batch normalization. The model was trained using a batch size of 16 and a learning rate of 0.0001 with the ADAM optimizer, which was selected based on preliminary experiments to optimize convergence.
2.2.3 Synthesizer 3—conditional tabular GAN
In addition to the standard GAN, a CTGAN (9) was utilized because of its proficiency in synthesizing tabular data while preserving conditional distributions, which is particularly effective if a medical dataset needs to preserve specific statistical characteristics. The CTGAN open source library in the Synthetic Data Vault project is adept at capturing complex relationships between variables in a table format, making it particularly suitable for medical datasets, which often contain a mix of categorical and continuous features and require the statistical properties of the original data to be retained. In our application, CTGAN was applied to generate synthetic yet realistic and representative patient data, thereby enhancing the training process by providing a richer and more diverse set of samples for improving the generalization capabilities of our dementia risk prediction models. The model was trained with 5,000 epochs, a batch size of 500, and a learning rate of 0.0002 to achieve optimized convergence.
2.3 Machine learning models for data analysis
We employed LR, RF, and DNN models to estimate MMSE scores using the measured and synthesized data. The LR served as a baseline for comparison because of its interpretability and previous applications in AD research. RF, which is known for its ability to handle nonlinear data and robustness to noise, was included to assess its performance in our context. The DNNs, which were constructed using Tensor Flow 2, consisted of four hidden layers designed to capture intricate relationships. For more details, the learning parameters of RF and DNN are listed as Supplementary Table S2.
2.3.1 LR
We implemented ordinary least-squares regression as our baseline model because of its interpretability and established use in AD research. This method provides a clear and straightforward way to analyze the linear relationship between predictor variables (e.g., blood test results, periodontal examination data) and MMSE scores.
2.3.2 RF
Recognized for its ability to handle nonlinear relationships and robustness to noise, the RF model was constructed with 300 trees and a maximum depth of 10 using the scikit-learn library. This approach enhances predictive performance and helps control overfitting. The suitability of RF for AD research is supported by its success in similar applications (10).
2.3.3 DNN
The neural network architecture included 19 input neurons, representing demographic, blood test, and periodontal examination data. Four hidden layers with descending neuron counts (256, 128, and 64) were used to process effectively the inputs as reported. We employed the scaled exponential linear unit activation function, which normalizes input signals to improve the training efficiency and stability. Batch normalization was applied after each layer. The network was trained using a batch size of 8 and a learning rate of 0.001 with the ADAM optimizer. These hyperparameters were optimized using a grid search to ensure stable model convergence.
3 Results
3.1 Statistical analysis of measured data
We systematically assessed cognitive function using the MMSE, complemented by demographic and blood test data, to explore correlations with periodontal health indicators, as shown in Table 1. Given the exploratory nature of our study, we reported unadjusted p-values to highlight potential associations. With an average MMSE score of 27.5 ± 2.4, the participants were categorized for further analysis into two groups based on MMSE scores: those with scores <28, which are indicative of possible MCI, and those with scores ≥28, which are considered within the normal cognitive range. The MMSE cut-off score of 27/28 is frequently employed in studies focusing on early detection of cognitive decline among older adults (11). Independent t-tests showed differences in the mean values for age, height, BUN, and PESA between these groups, suggesting their potential influence on cognitive status as determined by the MMSE (p < 0.01 for age and BUN; p < 0.05 for height and PESA).
The blood test items selected in Table 1 are commonly measured parameters in practice, and the periodontal examination items include PISA, PESA, and related computational metrics. For the subsequent machine learning analyses, a total of 27 variables were selected. These were chosen by having <20% missing values and ensuring a correlation coefficient < 0.9 between items to check for multicollinearity.
3.2 Results of data augmentation
For conducting the repeated hold-out validations, we employed SMOGN, GAN, and CTGAN to generate 10 sets of synthesized data from the measured dataset (Table 2). Both GAN and CTGAN were utilized for addition to the measured data for a comparison between them. The Kolmogorov–Smirnov (KS) complement scores indicated that SMOGN and CTGAN replicated the original data distribution more closely than GAN, especially for the MMSE score distribution in which CTGAN reached the highest score of 0.88 ± 0.04. It is noteworthy that GAN extensively extrapolates both in MMSE score and Age distributions around the minimum score (Min.) of the measured data, whereas SMOGN and CTGAN maintain the measured data distribution.
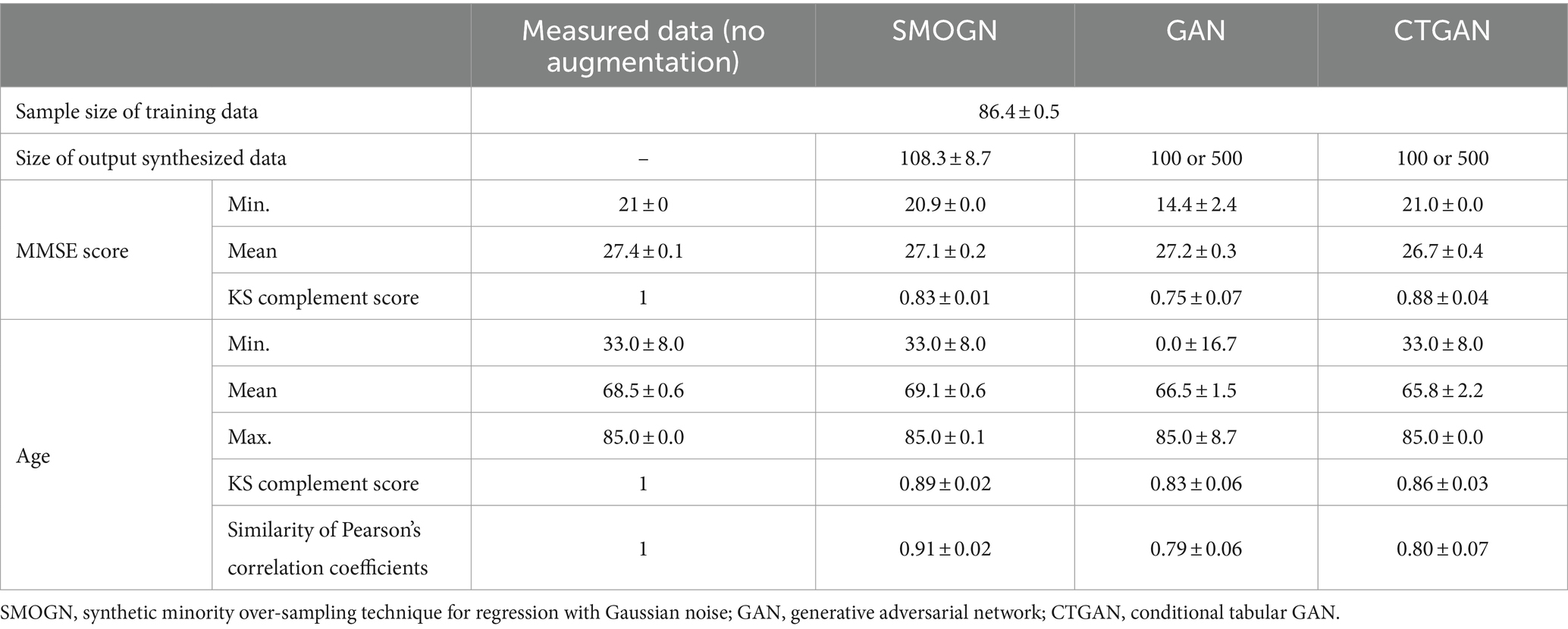
Table 2. Augmentation results: 10 sets of synthesized data for repeated hold-out validation.
To understand how CTGAN interpolates the measured data, distributions of MMSE score and Age are compared as shown in Figure 2. In terms of the age distribution, CTGAN-synthesized data are closer to the measured data with a correlation of −0.27 ± 0.01, and the addition of CTGAN-synthesized data to the measured data only changes the correlation to MMSE scores within 0.05. Age distribution of the synthesized data also is closer to that of the measured data.

Figure 2. Distributions of MMSE scores and age. (A) Distribution of MMSE scores: measured data (blue) and synthesized data (red). (B) Distribution of age: measured data (blue) and synthesized data (red).
3.3 Results of hold-out validation
The LR, RF, and DNN models trained on measured data without periodontal examination items exhibited mean absolute errors (MAEs) of 2.10 ± 0.21, 1.95 ± 0.22, and 2.30 ± 0.27, respectively, in repeated hold-out validation (Table 3). After including periodontal examination items in the models, LR showed an increase in prediction error due to a larger number of variables, while RF and DNN exhibited improvements with mean MAEs of 2.28 ± 0.33, 1.94 ± 0.21, and 2.18 ± 0.23, respectively.
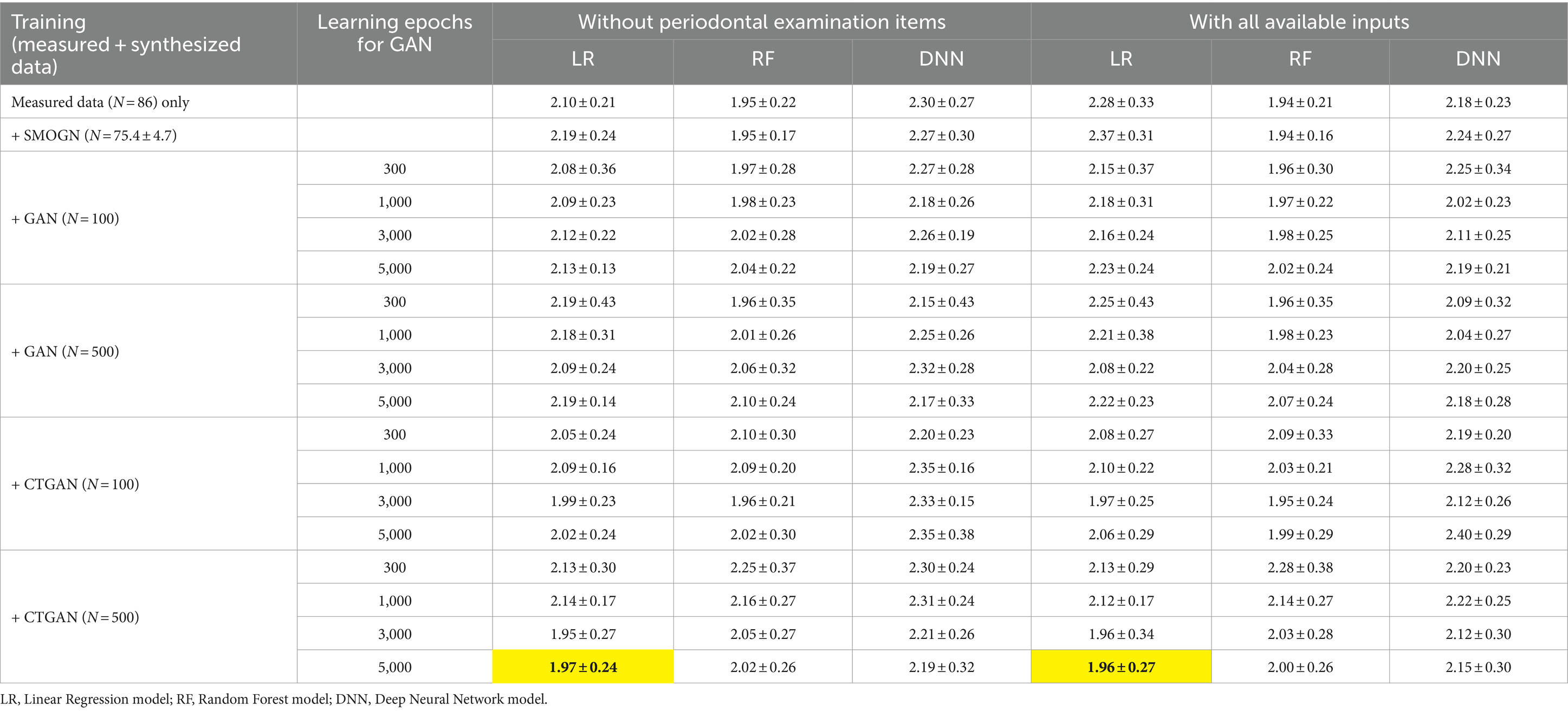
Table 3. Prediction errors in repeated hold-out validation using measured and synthesized data with and without periodontal examination items: most improved MAEs are highlighted.
Interestingly, LR achieved the most significant improvement in prediction errors compared to RF and DNN when CTGAN-synthesized data (N = 500) were added to the measured data, as highlighted in Table 3. This result suggests that LR effectively utilizes CTGAN-synthesized data for dementia risk predictions, which outperforms RF and DNN models under these conditions. Figure 3 illustrate that, compared with the results of the worst models, CTGAN with the certain seed number drastically improved all LR, RF, and DNN models by showing proportional measured and predicted MMSE scores, while the models with a poor augmentation result can diffuse predicted MMSE scores.
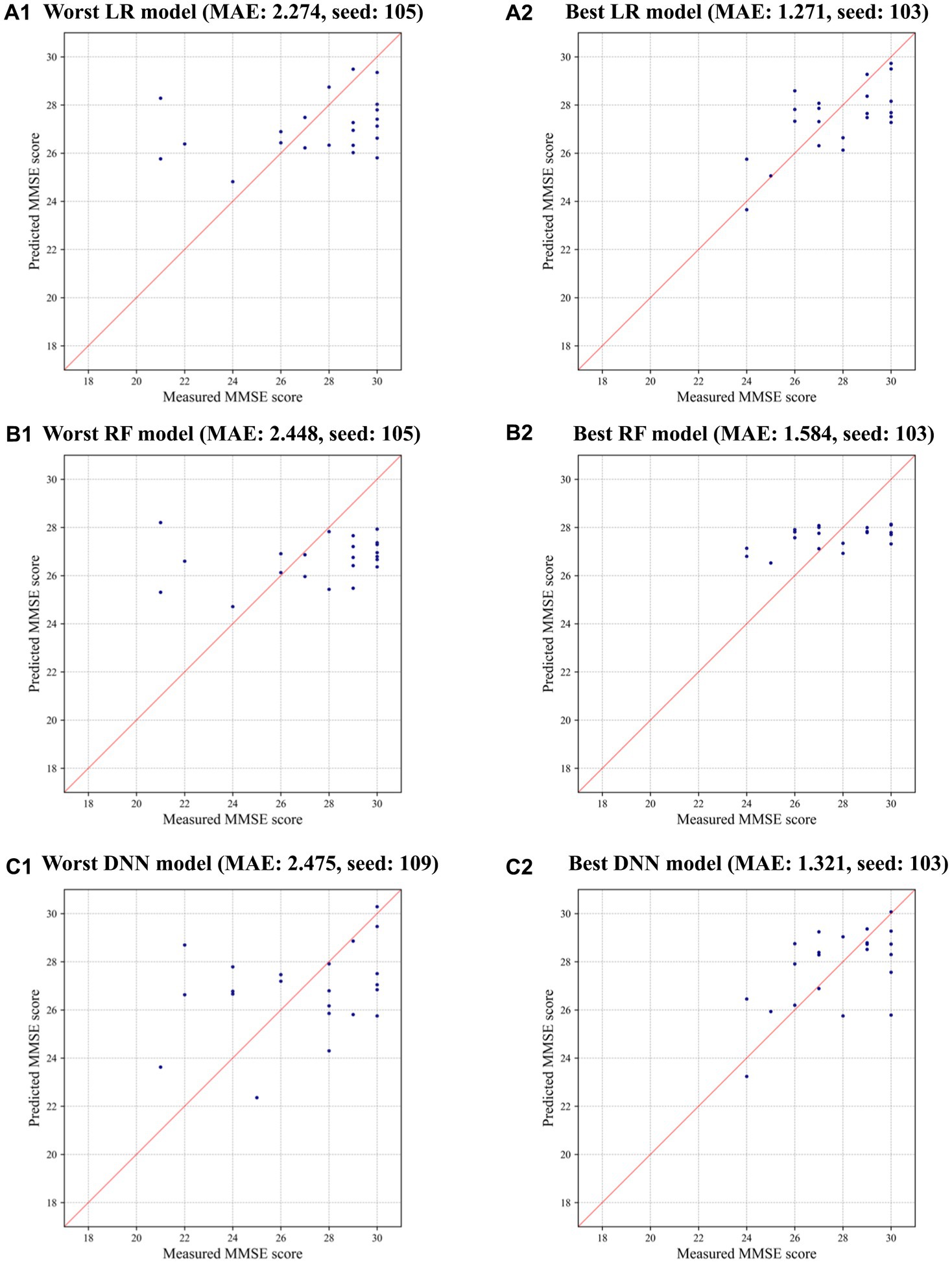
Figure 3. Measured and predicted scores in the worst and best models using CTGAN-synthesized data: (A) LR, (B) RF, and (C) DNN.
Next, the mean ± SD of standard coefficients in the LR models were assessed to understand the variable importance of periodontal examination items (Table 4). While PESA originally showed higher importance with the measured data, its importance diminished when CTGAN-synthesized data were included. Instead, the average PD level became relatively important while the number of remaining teeth is known to be a good biomarker. To assess the dependency on age, we further analyzed the models by excluding this variable as listed in Table 4. BUN, Height, Weight, and PESA especially emerged as more influential variables in the LR models without Age.
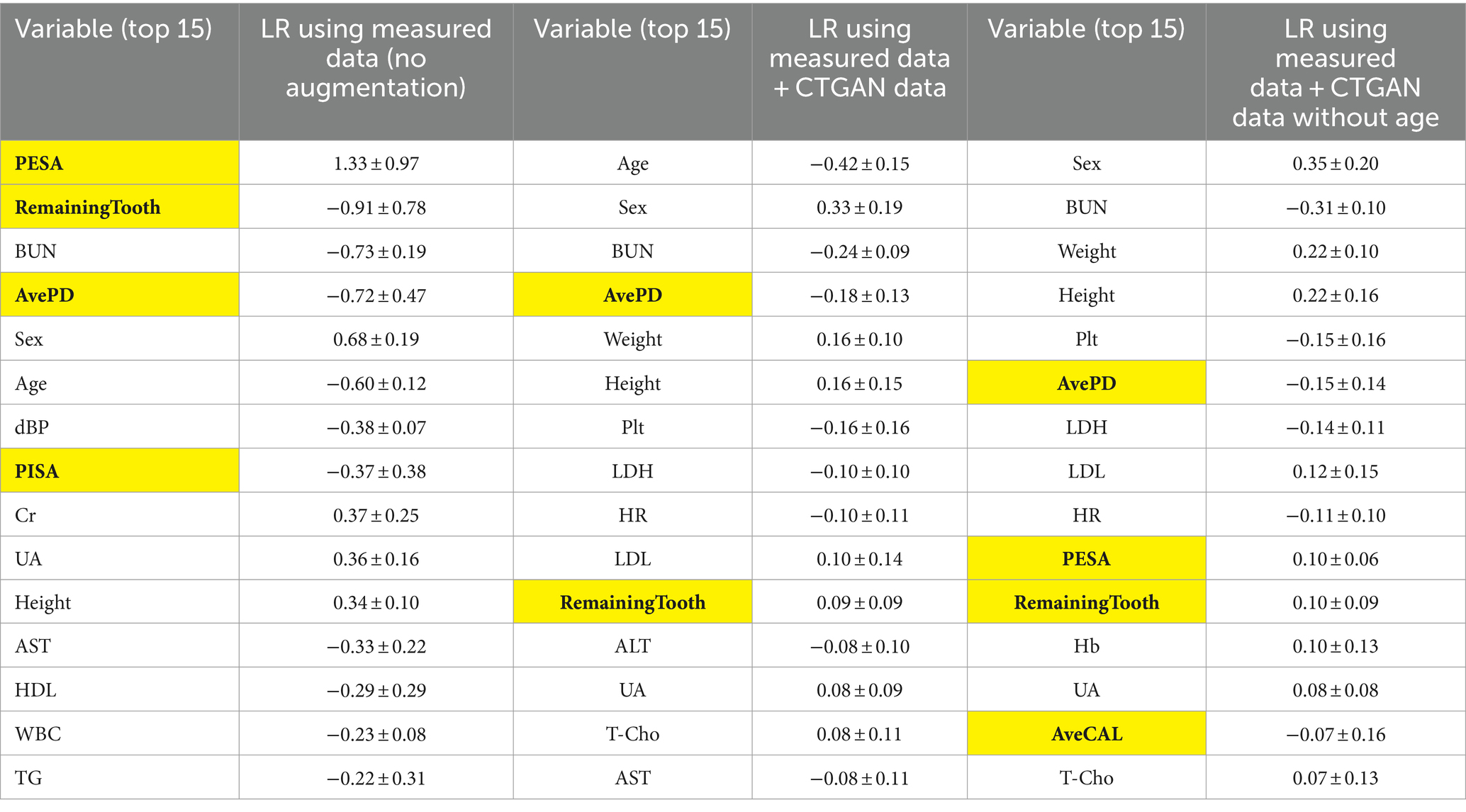
Table 4. Standard coefficients in the LR models for comparison between measured data only (N = 108) and measured data + CTGAN-synthesized data (N = 108 + 500) in repeated hold-out validation: periodontal examination items are highlighted.
3.4 Robustness experiments
To evaluate model robustness against the insertion of anomalous data, validation tests were conducted with the input Age set to “0,” where Age is the important variable both for both original and synthesized models. In these cases, the models trained with measured data exhibited a significant increase in prediction errors. Specifically, LR, as a linear model, showed heightened sensitivity to anomalous values in both the measured and synthesized datasets. By contrast, the GAN-and CTGAN-synthesized models demonstrated stable MAEs as detailed in Table 5. These results suggest that handling diverseness in the data distribution during the augmentation process may be key to addressing challenges prevalent in medical datasets, such as imbalanced data and missing values.

Table 5. Prediction errors in repeated hold-out validation with the anomalous inputs by replacing test data: age = 0.
3.5 External validity
We also evaluated the prediction errors using the external validation test dataset (Table 6). CTGAN-synthesized LR exhibited a significant decrease in MAEs, to 1.55 ± 0.27 (18.8% improvements). Despite of the limited 14 common items, we confirmed that reasonable prediction error results are obtained using CTGAN-synthesized data.

Table 6. Prediction errors for the external validation test data (N = 41) using the 10 sets of measured and synthesized data: most improved MAEs are highlighted.
4 Discussion
4.1 Validity of periodontal examination and blood test data for dementia risk screening
The integration of periodontal examination and blood test data showed slight improvements. However, the average probing depth (PD) and the number of remaining teeth were identified as valuable biomarkers. This confirms the importance of tooth counts as a modifiable dementia risk factor (12) and the potential role of PD levels in dementia risk screening.
PESA can be useful for dementia risk screening; however, it is highly dependent on Age. PESA is calculated by summing the product of the remaining teeth and the probing depth (PD) level for each tooth, meaning the number of remaining teeth significantly affects the results. This suggests that further stratified analysis based on Age and the number of teeth may contribute to a better understanding of the importance of periodontal examination items if PESA is considered.
While the relationship between periodontitis and dementia is well established, other blood test items related to oxygen transport and nutrition did not show the expected variations with MMSE scores in our dataset. This could be attributed to the demographic characteristics of our participants, who were primarily patients undergoing oral health assessments and were less likely to exhibit symptoms typically associated with dementia, such as anemia, metabolic syndrome, and chronic inflammation.
Further research is needed to explore the interrelations between blood test results and periodontal disease. Although salivary levels of BUN and AST are known to be useful biomarkers for screening periodontal disease (13), whether blood test results are significantly influenced by periodontal disease remains unclear.
4.2 Effectiveness of synthesized medical tabular data for model performance
The synthesized data generated using GAN and CTGAN showed promising results, especially for improving the performance of the LR models. Interestingly, the inclusion of CTGAN-synthesized data (N = 500) significantly enhanced the predictive accuracy of the LR models more than RF and DNN models. This suggests that LR models are better suited for application of synthesized data in predicting dementia risk.
The findings also indicate that synthesized data can help handle the issue of limited sample sizes in medical research. Not only addition of CTGAN-synthesized data preserves the statistical properties of the original dataset, synthesized data are effective to improve the robustness and generalizability of machine learning models. This will be particularly important in the context of dementia risk prediction, where obtaining large and diverse datasets can be challenging.
We conclude that the potential of combining blood test results, periodontal examination data with synthesized data to improve dementia risk screening, and boot-strapping of synthesized data will be the key for successful models of dementia risk screening where data collection may be limited or expensive, on the other hand, it may always take some time to find the best result and some degree of automation is necessary for practical use.
4.3 Implications for dementia risk screening and limitations
The application of artificial intelligence (AI) and machine learning in health care, particularly in dementia research, represents a significant technological advancement. However, this comes with ethical responsibilities, including the protection of data privacy, informed patient consent, and the reliability of predictions. Collaborative efforts among data scientists, clinicians, and health-care professionals are more vital to ensure the responsible use of AI in medical practice than ever.
This study did have some limitations, including the initial dataset size and its representativeness. Previous studies have identified other crucial blood test components, such as Plt, glycated hemoglobin, albumin, and electrolytes (3, 14); however, we could not examine these components in the present study. Further research considering these elements could provide a more comprehensive understanding of dementia risk factors. Moreover, while the correlation between periodontitis and dementia is more evident, the causal relationships remain to be fully explained. In this sense, longitudinal data analysis to track changes over time and identify potential causal pathways can give good solutions.
This study also acknowledges that the training process for both GAN and CTGAN can be time-intensive and highly sensitive to learning parameters. Recent advancements in the field of GAN training may result in methodologies that can mitigate these challenges. The success of GANs in this study warrants their exploration in other health-care domains where data limitations are a significant barrier to innovation.
5 Conclusion
The results of this study confirm the potential of GANs in enhancing dementia risk prediction, particularly in settings with data limitations. The GAN- and CTGAN-synthesized models were able to maintain robustness against anomalies and outperform models trained with limited data. Future advancements in GAN methodologies could further revolutionize health-care technology and patient care in dementia and beyond.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics statement
The studies involving humans were approved by Nihon University Hospitals’ Joint Institutional Review Board. The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
Author contributions
KO: Conceptualization, Formal analysis, Funding acquisition, Investigation, Methodology, Project administration, Resources, Software, Supervision, Validation, Visualization, Writing – original draft, Writing – review & editing. TI: Data curation, Investigation, Writing – original draft. YN: Data curation, Funding acquisition, Investigation, Project administration, Writing – review & editing. RK: Data curation, Investigation, Writing – review & editing. DK: Data curation, Writing – review & editing. KK: Formal analysis, Writing – review & editing. KS: Supervision, Writing – review & editing.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work was supported in part by a JSPS Grant-in-Aid for Scientific Research (B) grant number JP23K25233 and Nihon University Research Grants for 2020.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fneur.2024.1379916/full#supplementary-material
References
1. Long, S, Benoist, C, and Weidner, W. World Alzheimer report 2023: reducing dementia risk: never too early, never too late. Alzheimer’s Dis Int. (2023)
2. Murayama, Y, Sato, Y, Hu, L, Brugnera, A, Compare, A, and Sakatani, K. Relation between cognitive function and baseline concentrations of hemoglobin in prefrontal cortex of elderly people measured by time-resolved near-infrared spectroscopy. Adv Exp Med Biol. (2017) 977:269–76. doi: 10.1007/978-3-319-55231-6_37
3. Sakatani, K, Oyama, K, and Hu, L. Deep learning-based screening test for cognitive impairment using basic blood test data for health examination. Front Neurol. (2020) 11:588140. doi: 10.3389/fneur.2020.588140
4. Karako, K, Chen, Y, Oyama, K, Hu, L, and Sakatani, K. Relationship between cognitive function, Oral conditions and systemic metabolic function in the elderly. Adv Exp Med Biol. (2022) 1438:27–31. doi: 10.1007/978-3-031-42003-0_5
5. Ali, H, Biswas, MR, Mohsen, F, Shah, U, Alamgir, A, Mousa, O, et al. The role of generative adversarial networks in brain MRI: a scoping review. Insights Imaging. (2022) 13:98. doi: 10.1186/s13244-022-01237-0
6. Zhang, Y, Wang, Z, Zhang, Z, Liu, J, Feng, Y, Wee, L, et al. GAN-based one dimensional medical data augmentation. Soft Comput. (2023) 27:10481–91. doi: 10.1007/s00500-023-08345-z
7. Branco, P, Torgo, L, and Ribeiro, R. SMOGN: a pre-processing approach for imbalanced regression. Proc Mach Learn Res. (2017) 74:36–50.
8. Goodfellow, I, Pouget-Abadie, J, Mirza, M, Xu, B, Warde-Farley, D, Ozair, S, et al. Generative adversarial nets. Adv Neural Inf Proces Syst. (2014) 27:2672–80.
9. Xu, L, Skoularidou, M, Cuesta-Infante, A, and Veeramachaneni, K. Modeling Tabular data using Conditional GAN. Adv Neural Inf Proces Syst. (2019) 32:1–11.
10. Sarica, A, Cerasa, A, and Quattrone, A. Random Forest algorithm for the classification of neuroimaging data in Alzheimer's disease: a systematic review. Front Aging Neurosci. (2017) 9:329. doi: 10.3389/fnagi.2017.00329
11. Tombaugh, TN, and McIntyre, NJ. The mini-mental state examination: a comprehensive review. J Am Geriatr Soc. (1992) 40:922–35. doi: 10.1111/j.1532-5415.1992.tb01992.x
12. Kato, H, Takahashi, Y, Iseki, C, Igari, R, Sato, H, Sato, H, et al. Tooth loss-associated cognitive impairment in the elderly: a community-based study in Japan. Intern Med. (2019) 58:1411–6. doi: 10.2169/internalmedicine.1896-18
13. Nomura, Y, Tamaki, Y, Tanaka, T, Arakawa, H, Tsurumoto, A, Kirimura, K, et al. Screening of periodontitis with salivary enzyme tests. J Oral Sci. (2006) 48:177–83. doi: 10.2334/josnusd.48.177
Keywords: blood test, periodontal examination, deep learning, generative adversarial networks, cognitive function
Citation: Oyama K, Isogai T, Nakayama Y, Kobayashi R, Kitano D, Karako K and Sakatani K (2024) Enhancing dementia risk screening with GAN-synthesized periodontal examination and general blood test data. Front. Neurol. 15:1379916. doi: 10.3389/fneur.2024.1379916
Edited by:
Shang-Ming Zhou, University of Plymouth, United KingdomReviewed by:
Johann Faouzi, National School of Statistics and Information Analysis, FranceAtsuhiro Tsubaki, Niigata University of Health and Welfare, Japan
Copyright © 2024 Oyama, Isogai, Nakayama, Kobayashi, Kitano, Karako and Sakatani. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Katsunori Oyama, b3lhbWEua2F0c3Vub3JpQG5paG9uLXUuYWMuanA=