 Eunjeong Park
Eunjeong Park Hyuk-jae Chang2
Hyuk-jae Chang2 Hyo Suk Nam
Hyo Suk Nam
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Neurol., 07 September 2018
Sec. Stroke
Volume 9 - 2018 | https://doi.org/10.3389/fneur.2018.00699
This article is part of the Research TopicMachine Learning and Decision Support in StrokeView all 15 articles
Bayesian network is an increasingly popular method in modeling uncertain and complex problems, because its interpretability is often more useful than plain prediction. To satisfy the core requirement in medical research to obtain interpretable prediction with high accuracy, we constructed an inference engine for post-stroke outcomes based on Bayesian network classifiers. The prediction system that was trained on data of 3,605 patients with acute stroke forecasts the functional independence at 3 months and the mortality 1 year after stroke. Feature selection methods were applied to eliminate less relevant and redundant features from 76 risk variables. The Bayesian network classifiers were trained with a hill-climbing searching for the qualified network structure and parameters measured by maximum description length. We evaluated and optimized the proposed system to increase the area under the receiver operating characteristic curve (AUC) while ensuring acceptable sensitivity for the class-imbalanced data. The performance evaluation demonstrated that the Bayesian network with selected features by wrapper-type feature selection can predict 3-month functional independence with an AUC of 0.889 using only 19 risk variables and 1-year mortality with an AUC of 0.893 using 24 variables. The Bayesian network with 50 features filtered by information gain can predict 3-month functional independence with an AUC of 0.875 and 1-year mortality with an AUC of 0.895. We also built an online prediction service, Yonsei Stroke Outcome Inference System, to substantialize the proposed solution for patients with stroke.
A stroke is the second most common cause of death in the world and a leading cause of long-term disability. Patients with stroke have higher mortality than age- and sex-matched subjects who have not experienced a stroke. It is also reported that strokes recur in 6–20% of patients, and approximately two-thirds of stroke survivors continue to have functional deficits that are associated with diminished quality of life (1). Such disability after stroke can be measured by the modified Rankin scale that categorizes functional ability from 0 to 6 (2–4). To discriminate the effect of clinical treatment for patients with ischemic stroke, a score on the modified Rankin scale 0–2 is widely applied for the indication of functional independence after stroke (2).
There are many prognostic models for the functional outcomes and risk of death after stroke. However, an agreed set of guidelines or reporting for the development of prognostic score models are currently unavailable. In a recent systematic review of clinical prediction models, the discriminative performances of models were still unsatisfactory, with the AUC values ranging from 0.60 to 0.72, which are similar to the predictability of experienced clinicians (5).
The prediction of prognosis needs to employ a variety of statistical, probabilistic, and optimization techniques to learn patterns from large, complex, and unbalanced medical data. This complexity challenges researchers to apply machine learning techniques to diagnose and predict the progress of the disease (6, 7). Machine learning has been expected to dramatically improve prognosis, and certain applications have achieved remarkable results (7). These applications have employed various machine learning techniques including a deep neural network (8), support vector machine (8, 9), decision trees (10), and ensemble methods (11, 12) to classify diseases, level of deficits, and morality. Selecting the optimal solution for a decision problem should consider the unique pattern of a data set and the specific characteristics of the problem (13).
The Bayesian network, a machine learning method, predicts and describes classification based on the Bayes theorem (14). Bayesian networks are widely used in medical decision support for their ability to intuitively encapsulate cause and effect relationships between factors that are stored in medical data (15, 16). With these characteristics of conditional probabilities, the Bayesian network can provide interpretable classifiers by logic inherent in a decision support (17, 18). The parameters and their dependences with conditional probabilities of the Bayesian network can be provided either by experts' knowledge (16, 19) or by automatic learning from data (20, 21). In addition, Bayesian networks can be used to query any given node in the network and are therefore substantially more useful in clinics compared with classifiers built based on specific outcome variables (22).
In this study, our aim was to investigate the usefulness of a machine learning method to forecast functional recovery for independent activities and 1-year mortality in patients with acute ischemic stroke. We also introduced an online inference system for predicting functional independence at 3 months and mortality in 1 year of patients with stroke based on the proposed Bayesian network.
Subjects for this study were selected from consecutive patients with acute ischemic stroke who had been registered in the Yonsei Stroke Registry over a 6.5-year period (January 2007 to June 2013). The Yonsei Stroke Registry is a prospective hospital-based registry for patients with acute ischemic stroke or transient ischemic attack within 7 days after symptom onset (23).
During admission, all patients were thoroughly investigated for medical history, clinical manifestations, and the presence of vascular risk factors. Every patient was evaluated with 12-lead electrocardiography, chest x-ray, lipid profiles, and standard blood tests. All registered patients underwent brain imaging studies including brain computed tomography (CT) and/or MRI. Angiographic studies using CT angiography, magnetic resonance angiography, or digital subtraction angiography were included in the standard evaluation. Additional blood tests for coagulopathy or prothrombotic conditions were performed in patients younger than 45 years. Transesophageal echocardiography was included in the standard evaluation, except in patients with decreased consciousness, impending brain herniation, poor systemic condition, inability to accept an esophageal transducer because of swallowing difficulty or tracheal intubation, or lack of informed consent (24). Transthoracic echocardiography, heart CT, and Holter monitoring were also performed in selected patients (25). When a patient was admitted more than twice because of recurrent strokes, only data for the first admission were used for this study. Initial stroke severity was determined by National Institute of Health Stroke Scale (NIHSS) scores and score tertiles were used for the analysis.
Hypertension was defined as resting systolic blood pressure ≥140 mm Hg or diastolic blood pressure ≥90 mm Hg after repeated measurements during hospitalization or currently taking antihypertensive medication. Diabetes mellitus was defined as fasting plasma glucose values ≥7 mmol/L or taking an oral hypoglycemic agent or insulin. Hyperlipidemia was diagnosed as a fasting serum total cholesterol level ≥6.2 mmol/L, low-density lipoprotein cholesterol ≥4.1 mmol/L, or currently taking a lipid-lowering drug after a hyperlipidemia diagnosis. A current smoker was defined as an individual who smoked at the time of stroke or had quit smoking 1 year before treatment (26). The collection of variables during admission including clinical, imaging, and laboratory data were used in statistical analysis and Bayesian network modeling.
Stroke classification was determined during weekly conferences based on the consensus of stroke neurologists. Data including clinical information, risk factors, imaging study findings, laboratory analyses, and other special evaluations were collected. Along with these data, prognosis during hospitalization and long-term outcomes were also determined. Data were entered into a web-based registry. Stroke subtypes were identified according to the Trial of ORG 10172 in Acute Stroke Treatment (TOAST) classification (27).
For target variables in classification, we collected the outcome variables for patients who were followed in the outpatient clinic or by a structured telephone interview at 3 months and every year after discharge. Short-term functional outcomes at 3 months were determined based on the modified Rankin scale. Major disability was defined as a score on the modified Rankin scale of 3–6, as a poor outcome at 3 months after stroke. Deaths among subjects from January 2001 to December 31, 2013, were confirmed by matching the information in the death records and identification numbers assigned to the subjects at birth (5). We obtained data for the date and causes of death from the Korean National Statistical Office, which were identified based on death certificates (28, 29). The institutional review board of Severance Hospital, Yonsei University Health System, approved this study and waived the patients' informed consent because of a retrospective design and observational nature of this study.
The collected data set was used to construct Bayesian networks for predicting post-stroke outcomes. We extracted a total of 76 random variables of each instance for patient data. A Bayesian network consists of a directed acyclic graph whose nodes represent random variables and links express dependences between nodes. Suppose random variables Vi ∈ V(1 ≤ i ≤ n). A Bayesian network is described as a directed acyclic graph G = (V, A, P) with links A ⊆ V × V and P a joint probability distribution. P, a joint probability over V, is described as
where π(Vi) is the set of parent nodes of Vi.
Training Bayesian network classifiers is the process of parameter learning to find optimal Bayesian structures estimating parameter set of P that best represents given data set with labeled instances (13). Given a data set D with variable Vi, the observed distribution PD is described as a joint probability distribution over D. The learning process now measures and compares the quality of Bayesian networks to evaluate how well the represented distribution explains the given data set. The log-likelihood is the basic common value used for measuring the quality of a Bayesian network as follows:
where is the Bayesian network over D and |πB(Vi) is parent nodes of Vi in (13, 30).
Diverse quality measurement methods have been investigated (31). The algorithm searched the best Bayesian network based on the Bayesian information criterion (32), Bayesian Dirichlet equivalence score (19), Akaike information criterion (AIC) (33), and the maximum description length (MDL) scores (30, 34). In this study, we used the MDL score to evaluate the quality of a Bayesian network. The MDL score is described as
where N is the number of instances in D, and is the number of parameters in . The smaller the MDL score, the better the network. The search algorithm, greedy hill-climbing algorithm (35) in our study, selects the best Bayesian network by calculating MDL scores of candidate networks. For the type of Bayesian network structure, we constructed tree-augmented network (TAN) structures that restrict the number of parents to two nodes (36).
The entire process of a Bayesian network-based prediction system is shown in Figure 1. A total of 76 features were extracted from the Yonsei Stroke Registry and data preparation process filtered records with missing outcome variables and exclusion criteria. For feasible prediction service in clinical environment, we performed two different feature selection methods.
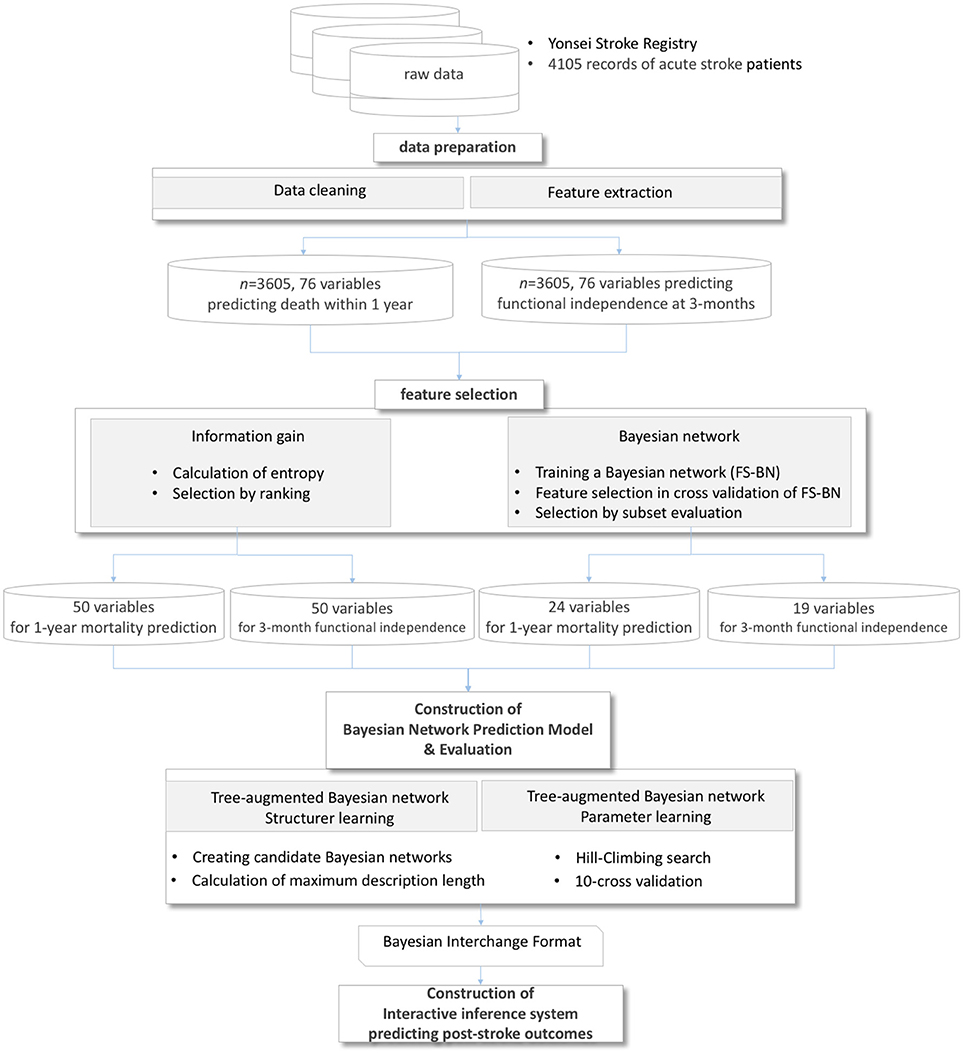
Figure 1. Process of a prediction system for post-stroke outcomes.
Feature selection or dimension reduction is the process of reducing the number of random variables under consideration by obtaining a set of principal variables (37, 38). Feature selection improves the overfitting problem caused by irrelevant or redundant variables that may strongly bias the performance of the classifier. The definition of feature selection in formal expression is described in Drugan and Wiering (30) and Hruschka et al. (39). In many studies, feature selection methods are categorized into filters, wrappers, or embedded methods that are applied to the data set in advance of the training learning algorithm, or to embed feature selection in the learning process (37, 40). Filter methods select features based on a performance measure regardless of the employed data modeling algorithm. The filter approach selects random variables based on information gain score, ReliefF, or correlation-based method by ranking variables or searching subset of variables. Information gain measures the amount of entropy as a measure of uncertainty reduced by knowing a feature (41–43); ReliefF evaluates the worth of an attribute by repeatedly sampling an instance and considering the value of the given attribute for the nearest instance of the same and the different class (44, 45); and correlation evaluates the worth of a subset of attributes by considering the individual predictive ability of each feature along with the degree of redundancy between them (46, 47). Unlike the filter approach, wrapper methods measure the usefulness of a subset of features by actually training a model on it. We evaluated the performance of Bayesian networks with a reduced variable set selected by information gain and Bayesian network algorithms that are popular in filter and wrapper methods (42, 48, 49).
First, we tested the Bayesian network classifier with features chosen by information gain based on entropy of each feature. The other feature selection method, considering the characteristics of Bayesian network classifiers, reduces the variable set by evaluating the performance of the Bayesian network classifier in cross-validation in which a search algorithm extracts a subset of attributes to maximize AUC in prediction (Figure 1). The optimization for AUC is to solve the imbalance between the number of survival and mortal subjects.
Using the reduced variables by feature selection, the system constructed a Bayesian network prediction model to search optimal Bayesian network structures and parameters. We evaluated the performance of prediction algorithms using (1) a basic tree-augmented Bayesian network, (2) a tree-augmented Bayesian network with features filtered by information gain, and (3) a tree-augmented Bayesian network with features filtered by the wrapper of a Bayesian network. The performances of all Bayesian networks and predictive models were evaluated based on the AUC, specificity, and sensitivity of 10-fold cross-validations (50). We also implemented an online prediction system for post-stroke outcomes embedding the trained classifiers. In the validation process, we bound the minimum sensitivity as 0.50 to utilize the trained classifiers in real-world applications with imbalanced data.
During the study period, 4,105 consecutive patients with acute ischemic stroke or transient ischemic attack were registered to the Yonsei Stroke Registry. Exclusion criteria of this study were patients with the stroke subtypes other than cryptogenic stroke including transient ischemic attack (n = 326), foreigner (n = 48), missing data (n = 29), follow-up loss (n = 97). After exclusion, a total of 3,605 patients were finally enrolled for this study. The mean age was 65.9 ± 12.6 years, and 60.7% were men. A comparison of demographic characteristics between the outcome at 3 months and death within 1 year is shown at Table 1. Patients with poor outcome were older, more likely to be women, not a current smoker, frequently had old stroke, hypertension, atrial fibrillation, congestive heart failure, peripheral artery obstructive disease, or anemia. Thrombolysis or endovascular mechanical thrombectomy, symptomatic intracranial hemorrhage, and herniation are frequent in patients with poor outcome. Laboratory data showed that patients with poor outcome showed lower hemoglobin, hematocrit, albumin, prealbumin, body weight and higher ESR, fibrinogen, hsCRP, and D-dimer level. The differences of demographics of patients between survival and death within 1 year were similar with functional outcome at 3 months. D-dimer levels were significantly higher in patients who died within 1 year compared with survivors (3079.8 ± 9723.3 vs. 464.5 ± 1759.3, p < 0.001).
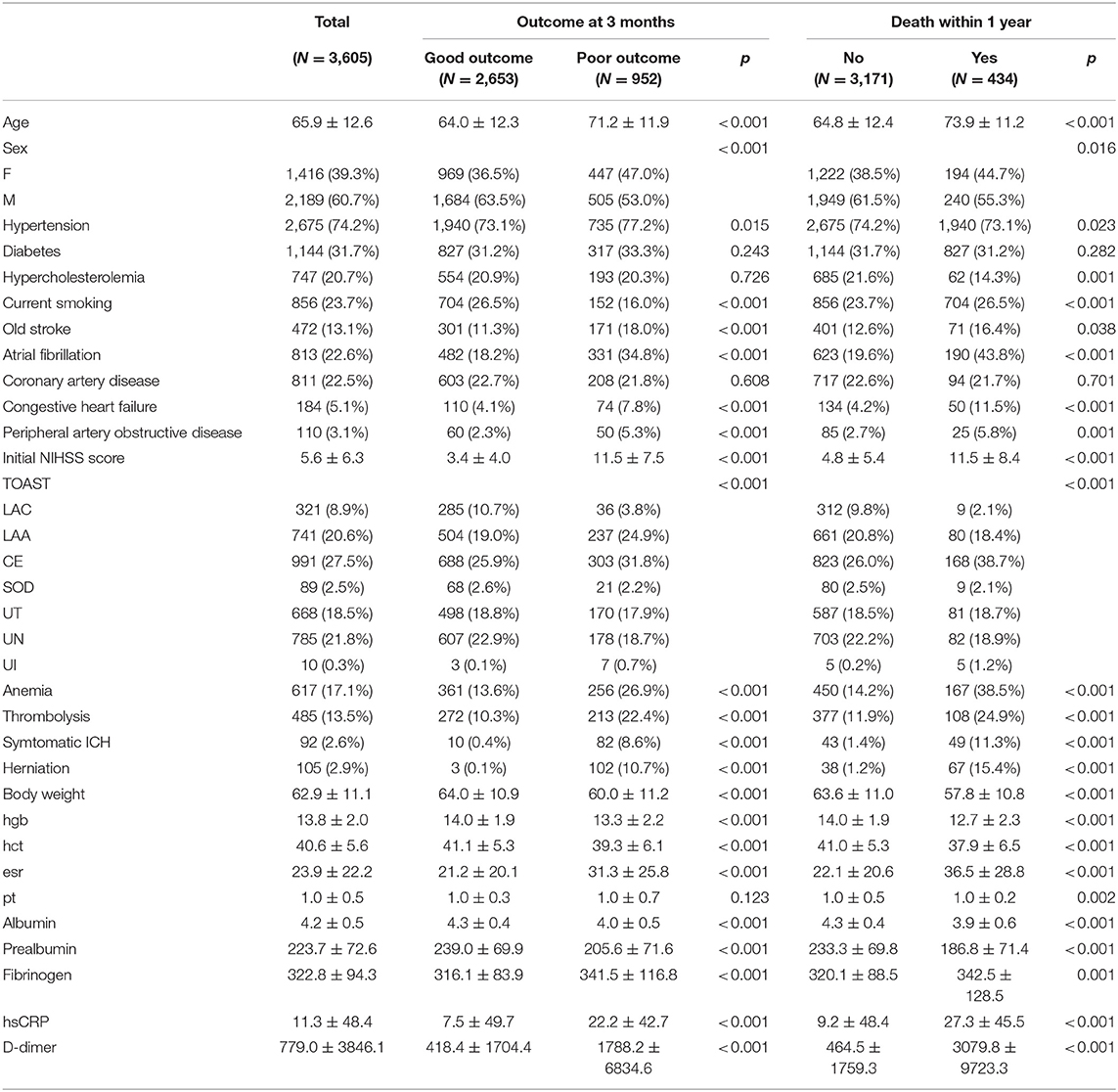
Table 1. Demographic characteristics and comparison of outcome at 3 months and death within 1 year.
As we described in Figure 1, two different feature selection techniques were performed in our experiment: variables selected by information gain with ranking or variables selected by a wrapper embedding Bayesian network with greedy stepwise subset selection in cross-validation. The top-ranked variables in the filter by information gain and the wrapper of the Bayesian network in forecasting functional independence at 3 months are shown in Figures 2A,B, and variables for predicting 1-year mortality are shown in Figures 2C,D. The most affective factor for functional recovery prediction was Initial NIHSS, while D-dimer ranked top in 1-year mortality prediction. The common variables for predicting post-stroke outcomes were Initial NIHSS, D-dimer, hsCPR, and Age. However, the subset-searching algorithm selects a method differently from the ranking method that evaluates the individual variables separately; thus, certain variables were excluded from the selected subset even though their ranks are high in individual evaluation.
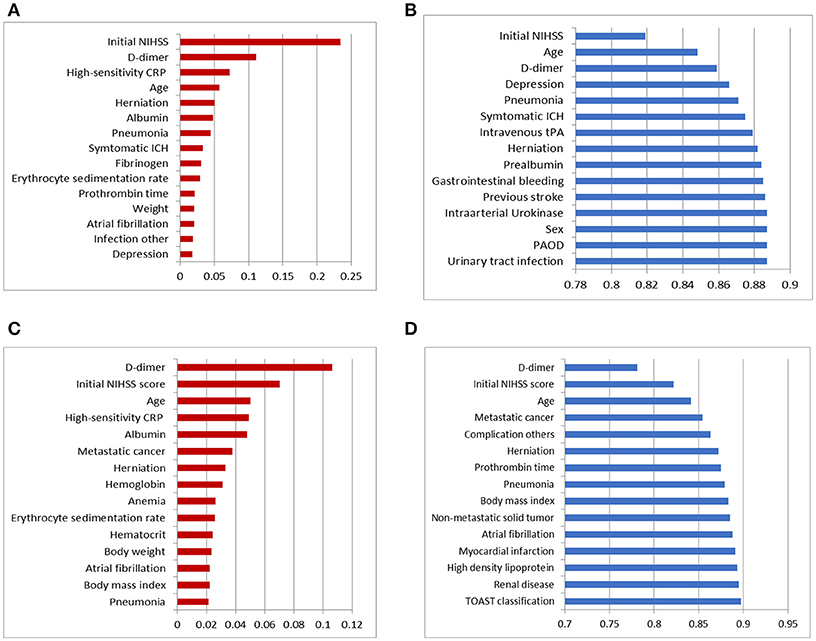
Figure 2. Top 15 variables in dimension reduction for post-stroke outcome prediction: (A) variables filtered by ranks of information gain for predicting functional independence at 3 months, (B) variables selected by the wrapper of the Bayesian network classifier with greedy subset selection for predicting functional independence at 3 months, (C) variables filtered by ranks of information gain for predicting 1-year mortality, and (D) variables selected by the wrapper of the Bayesian network classifier with greedy subset selection for predicting 1-year mortality.
Using the result of feature selection, we trained three tree-augmented Bayesian network classifiers; (1) Tree-augmented Bayesian network with the entire dataset, (2) tree-augmented Bayesian network with features filtered by ranking of information gain, and (3) tree-augmented Bayesian network with features filtered by the wrapper of the Bayesian network classifier (see Figure 3). The predictive performance for 3-month outcomes is shown in Figure 3A. The classifier trained with features chosen by the Bayesian network's subset evaluation performs in prediction of 3-month functional recovery with the specificity of 0.931, accuracy of 0.643, and AUC of 0.889 (95% CI, 0.879–0.899) although the sensitivity (0.643) is slightly lower than other algorithms. The tree-augmented Bayesian network without feature selection achieved the AUC of 0.875 (95% CI, 0.864–0.886), but the highest sensitivity of 0.684; and the Bayesian network with features by ranking of information gain obtained the AUC of 0.875 (95% CI, 0.864–0.886) and mid-level performance between two other algorithms. The Bayesian network classifier with feature selection achieved best performance in most metrics except sensitivity, although it reduced the variable set from 76 variables to 19 variables, resulting in a great reduction in model construction time.
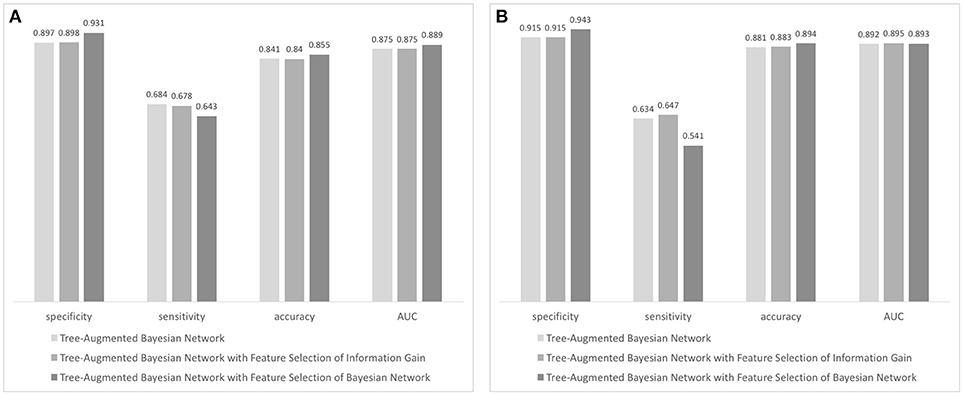
Figure 3. Performance evaluation of Bayesian network-based classifiers: (A) performance of classifiers forecasting 90-day functional independence and (B) performance of classifiers for 1-year mortality prediction.
In prediction of 1-year mortality, AUCs of three algorithms were not significantly different (0.892 with 95% CI, 0.872–0.912; 0.895 with CI, 0.875–0.915; and 0.893 with CI, 0.873–0.913). All algorithms achieved higher specificities in predicting 1-year mortality than those for the prediction of functional independence (0.915 vs. 0.897 with a basic Bayesian network, 0.915 vs. 0.898 with a Bayesian network with features filtered by information gain, and 0.943 vs. 0.931 with a Bayesian network with features chosen by the wrapper of the Bayesian network classifier). The Bayesian network algorithm with feature selection for 1-year mortality cuts out the entire variable set to 24 variables that curtail network construction time. The final Bayesian networks predicting functional recovery and 1-year mortality are shown in Figures 4, 5, respectively.
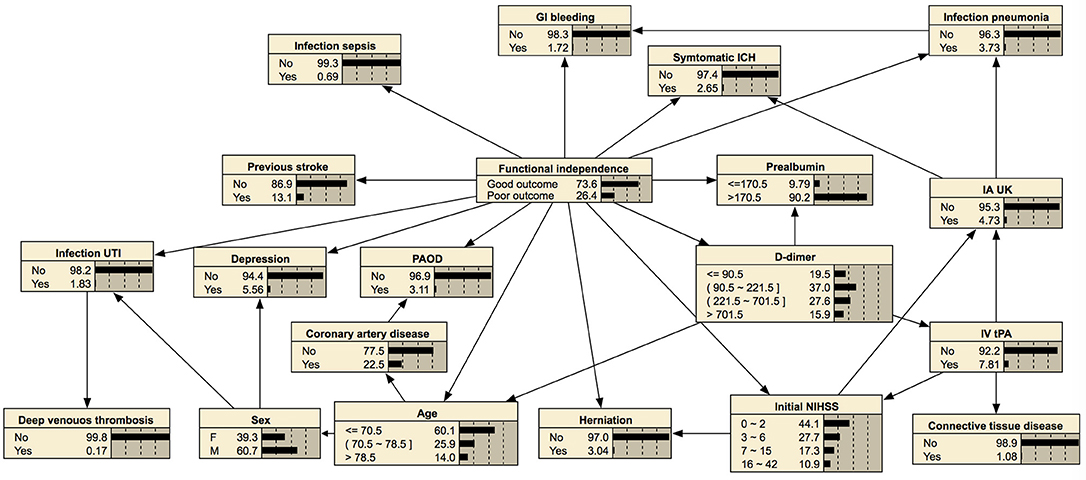
Figure 4. Bayesian network for predicting functional independence at 3 months. The tree-augmented Bayesian network used 19 variables selected by the wrapper of the Bayesian network for prediction.
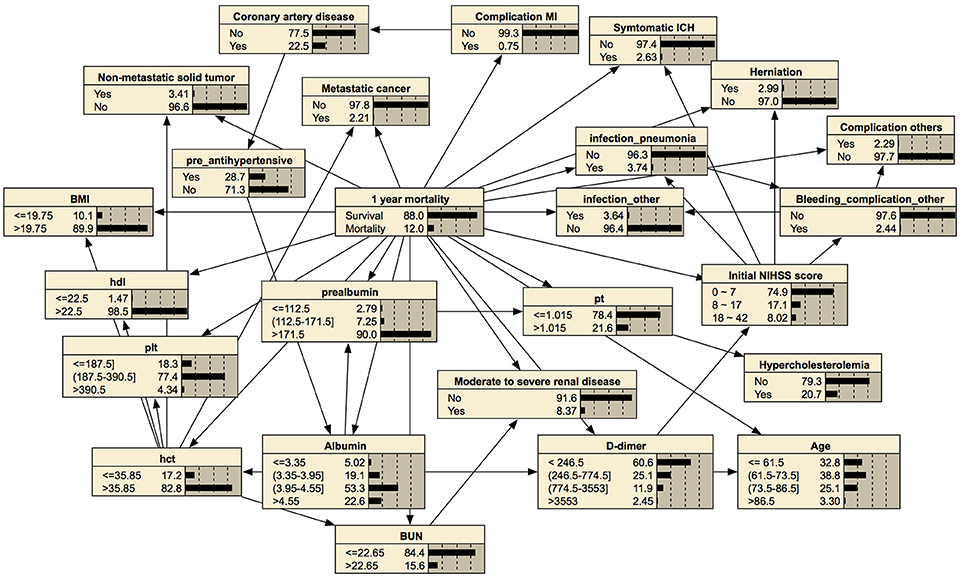
Figure 5. Bayesian network for predicting 1-year mortality. The tree-augmented Bayesian network used 24 variables selected by the wrapper of the Bayesian network for prediction.
To realize decision support using Bayesian network classifiers, we embedded our final Bayesian networks into an online inference system, Y-SOIS (Yonsei-Stroke Outcome Inference System, https://www.hed.cc/?a=Yonsei_SOIS), that enables answering post-stroke outcomes when users provide available risk variables. Figure 6 shows the screenshots of Y-SOIS.
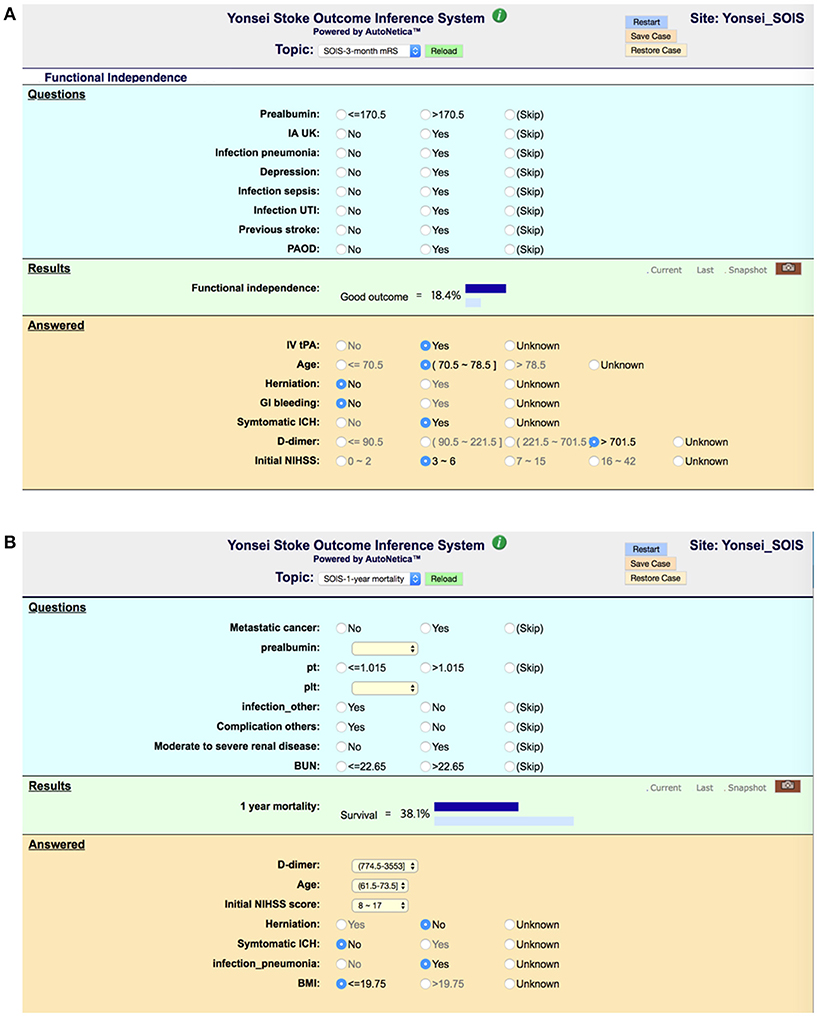
Figure 6. Screenshots of an online prediction system, Y-SOIS (Yonsei Stroke Outcome Inference System). (A) Y-SOIS forecasts the functional independence at 3 months and (B) Y-SOIS forecasting the 1-year mortality.
Interpretability is a core requirement for machine learning models in medicine, because both patients and physicians need to understand the reason behind a prediction (51). This study presents an evaluation of Bayesian networks in providing post-stroke outcomes estimates based on the collected demographic data, lab result, and initial neurological assessment. The stroke-specific variables were selected from a large stroke registry, and our experiment filtered those variables into the Bayesian network-suitable reduced set. The trained Bayesian networks were embedded in our online prediction system.
Research on stroke outcomes is essential for both clinical care and policy development, because approximately two-thirds of stroke survivors continue to experience functional deficits and approximately 1 of 10 patients died within 1 year (5). The prediction of post-stroke outcomes thus requires high accuracy in classification along with the understandable result that can be explained to patients. A Bayesian network can intuitively make connections between variables in medical data and provide interpretable determination in medical decision (17, 18). Therefore, Bayesian networks are well suited for representing uncertainty and causality in prediction for patients with stroke. In recent machine learning studies, a Bayesian neural network is focused on a state of the art method which estimates predictive uncertainty (52). In Kendall and Gal (53), a Bayesian deep learning framework combines input-dependent aleatoric uncertainty together with epistemic uncertainty, to solve the black-box problem in deep learning. Constructing Bayesian networks enables medical diagnosis or prediction with incomplete and partially correct statistics, because it determines causes and effects based on the conditional probability between variables (54).
Often real-world data sets are predominately composed of normal instances with only a small percentage of interesting instances; therefore, class imbalance is one of the most important challenges (55). Our study also has heavily unbalanced classes in mortality prediction (3,171:434). Suppose entire positive instances were classified into negative class; then the accuracy is 0.880 in 1-year mortality prediction, although mortality is not predicted at all. Most machine learning algorithms train classifiers mainly searching for higher accuracy; therefore, the minority class is less considered in the training process. To challenge this imbalanced classification, a number of techniques have been proposed (56): oversampling approaches create minority instances by simple duplication or synthetic-minority oversampling technique (SMOTE) (57–59); certain classifiers with undersampling beat oversampling (60); cost-sensitive methods weigh higher penalty on misclassification of the minority class (61); and bagging, boosting, and hybrid approaches utilize feedback from misclassification in previous stages of learning (62).
In addition to the capability of interpretable prediction and reduced uncertainty, a Bayesian network is strong machine learning in classifying an imbalanced data set as investigated in Drummond and Holte (60) and Monsalve-Torra et al. (63). In Monsalve-Torra et al. (63), the Bayesian network outperformed radial basis function and multilayer perceptron in sensitivity. In our experiment, the learning process searched the best Bayesian network structure and parameters for the highest AUC while it guarantees at least 0.5 in sensitivity. A more computation-expensive searching algorithm such as repeated hill climbing might be helpful to increase sensitivity in classification.
Bayesian networks can also provide a visual graph structure. We constructed a tree-augmented Bayesian network structure that shows an association between nodes. This visualization of conditional probability might be helpful for clinical reasoning. For example, a Bayesian network can provide the association among symptomatic intracranial hemorrhage, higher initial NIHSS score, or higher 1-year mortality with conditional probability, as shown in Figure 5. Therefore, our prediction model of post-stroke outcomes differs from the black-box concept of other machine learning methods (54).
The reduction of dimension is also helpful to visualize inference of prediction. The results demonstrated that the Bayesian network classifier with a reduced variable set can adapt the size of a network for better interpretability with a minimal or better impact on other performance.
In this study, the information gain analysis showed that “D-dimer” was the highest feature in predicting 1-year mortality. We previously reported that a high D-dimer level by itself appeared to be associated with an increased risk of mortality (64). D-dimer can be found to be elevated in various thrombotic and inflammatory conditions, including ischemic heart disease, infection, or malignancy. These conditions are frequently found in patients with stroke and can increase the risk of mortality (65). However, patients with comorbid diseases were frequently excluded from the clinical trials, so there are no guidelines and evidence whether to treat or not patients with serious comorbid diseases in real clinical practice. In this respect, providing information of the impact of the comorbid condition with a Bayesian network might be helpful to predict the outcomes.
This study was conducted in a single university hospital and focused on those of East Asian descent. To provide generalizability on our prediction system, we will include various cohorts including different ethnics or patients who received thrombolysis or endovascular thrombectomy. We have plan to apply the interpretable prediction for the SECRET (SElection CRiteria in Endovascular thrombectomy and Thrombolytic therapy) study, which is a nationwide registry for hyperacute stroke. Consecutive patients who received intravenous thrombolysis and/or endovascular thrombectomy were registered (Clinical Trial Registration: NCT02964052). Bayesian network analysis of this specific condition can be used to predict outcome in patients with hyperacute stroke. We will also enlarge our training data including data of various populations by applying the proposed solution to global data archives. Additive risk predictors might be selected as determinant features in a Bayesian network, and it makes the prediction system more applicable in a global clinical environment.
HN designed the study; EP analyzed the data and wrote the manuscript; and H-jC and HN contributed to data interpretation and revising the manuscript.
This research was supported by the Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (NRF-2017R1D1A1B03029014) and grant funded by the Korea government (MSIP) (2016R1C1B2016028) and the National Fire Agency, Republic of Korea (MPSS-2015-70).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
1. Ko Y, Park JH, Kim WJ, Yang MH, Kwon OK, Oh CW, et al. The long-term incidence of recurrent stroke: single hospital-based cohort study. J Korean Neurol Assoc. (2009) 27:110–5.
2. Albers GW, Marks MP, Kemp S, Christensen S, Tsai JP, Ortega-Gutierrez S, et al. Thrombectomy for stroke at 6 to 16 hours with selection by perfusion imaging. New Engl J Med. (2018) 378:708–18. doi: 10.1056/NEJMoa1713973
3. Anderson CS, Woodward M, Chalmers J. More on low-dose versus standard-dose intravenous alteplase in acute ischemic stroke. New Engl J Med. (2018) 378:1465–6. doi: 10.1056/NEJMc1801548
4. Banks JL, Marotta CA. Outcomes validity and reliability of the modified Rankin scale: implications for stroke clinical trials: a literature review and synthesis. Stroke (2007) 38:1091–6. doi: 10.1161/01.STR.0000258355.23810.c6
5. Nam HS, Kim HC, Kim YD, Lee HS, Kim J, Lee DH, et al. Long-term mortality in patients with stroke of undetermined etiology. Stroke (2012) 43:2948–56. doi: 10.1161/STROKEAHA.112.661074
6. Cruz JA, Wishart DS. Applications of machine learning in cancer prediction and prognosis. Cancer Inf. (2006) 2:117693510600200030. doi: 10.1177/117693510600200030
7. Obermeyer Z, Emanuel EJ. Predicting the future—big data, machine learning, and clinical medicine. New Engl J Med. (2016) 375:1216. doi: 10.1056/NEJMp1606181
8. Asadi H, Dowling R, Yan B, Mitchell P. Machine learning for outcome prediction of acute ischemic stroke post intra-arterial therapy. PLoS ONE (2014) 9:e88225. doi: 10.1371/journal.pone.0088225
9. Magnin B, Mesrob L, Kinkingnéhun S, Pélégrini-Issac M, Colliot O, Sarazin M, et al. Support vector machine-based classification of Alzheimer's disease from whole-brain anatomical MRI. Neuroradiology (2009) 51:73–83. doi: 10.1007/s00234-008-0463-x
10. Tjortjis C, Saraee M, Theodoulidis B, Keane J. Using T3, an improved decision tree classifier, for mining stroke-related medical data. Methods Inf Med. (2007) 46:523–9. doi: 10.1160/ME0317
11. Ward MM, Pajevic S, Dreyfuss J, Malley JD. Short-term prediction of mortality in patients with systemic lupus erythematosus: classification of outcomes using random forests. Arthritis Care Res. (2006) 55:74–80. doi: 10.1002/art.21695
12. Statnikov A, Wang L, Aliferis CF. A comprehensive comparison of random forests and support vector machines for microarray-based cancer classification. BMC Bioinform. (2008) 9:319. doi: 10.1186/1471-2105-9-319
13. Witten IH, Frank E, Hall MA, Pal CJ. Data Mining: Practical Machine Learning Tools and Techniques. Burlington, MA: Morgan Kaufmann (2016).
14. Friedman N, Geiger D, Goldszmidt M. Bayesian network classifiers. Mach Learn. (1997) 29:131–63. doi: 10.1023/A:1007465528199
15. Lucas PJ, Van der Gaag LC, Abu-Hanna A. Bayesian networks in biomedicine and health-care. Artif Intell Med. (2004) 30:201–14. doi: 10.1016/j.artmed.2003.11.001
16. Nikovski D. Constructing Bayesian networks for medical diagnosis from incomplete and partially correct statistics. IEEE Trans Knowl Data Eng. (2000) 12:509–16. doi: 10.1109/69.868904
17. Letham B, Rudin C, McCormick TH, Madigan D. Interpretable classifiers using rules and bayesian analysis: building a better stroke prediction model. Ann Appl Stat. (2015) 9:1350–71. doi: 10.1214/15-AOAS848
18. Jansen R, Yu H, Greenbaum D, Kluger Y, Krogan NJ, Chung S, et al. A Bayesian networks approach for predicting protein-protein interactions from genomic data. Science (2003) 302:449–53. doi: 10.1126/science.1087361
19. Heckerman D, Geiger D, Chickering DM. Learning bayesian networks: the combination of knowledge and statistical data. Mach Learn. (1995) 20:197–243. doi: 10.1007/BF00994016
20. Uusitalo L. Advantages and challenges of Bayesian networks in environmental modelling. Ecol Model. (2007) 203:312–8. doi: 10.1016/j.ecolmodel.2006.11.033
21. Kononenko I. Machine learning for medical diagnosis: history, state of the art and perspective. Artif Intell Med. (2001) 23:89–109. doi: 10.1016/S0933-3657(01)00077-X
22. Sesen MB, Nicholson AE, Banares-Alcantara R, Kadir T, Brady M. Bayesian networks for clinical decision support in lung cancer care. PLoS ONE (2013) 8:e82349. doi: 10.1371/journal.pone.0082349
23. Lee BI, Nam HS, Heo JH, Kim DI. Yonsei stroke registry. Cerebrovasc Dis. (2001) 12:145–51. doi: 10.1159/000047697
24. Cho HJ, Choi HY, Kim YD, Nam HS, Han SW, Ha JW, et al. Transoesophageal echocardiography in patients with acute stroke with sinus rhythm and no cardiac disease history. J Neurol Neurosurg Psychiatry (2010) 81:412–5. doi: 10.1136/jnnp.2009.190322
25. Yoo J, Yang JH, Choi BW, Kim YD, Nam HS, Choi HY, et al. The frequency and risk of preclinical coronary artery disease detected using multichannel cardiac computed tomography in patients with ischemic stroke. Cerebrovasc Dis. (2012) 33:286–94. doi: 10.1159/000334980
26. Song TJ, Kim J, Lee HS, Nam CM, Nam HS, Kim YD, et al. Distribution of cerebral microbleeds determines their association with impaired kidney function. J Clin Neurol. (2014) 10:222–8. doi: 10.3988/jcn.2014.10.3.222
27. Adams HPJr, Bendixen BH, Kappelle LJ, Biller J, Love BB, Gordon DL, et al. Classification of subtype of acute ischemic stroke. Definitions for use in a multicenter clinical trial. TOAST. Trial of Org 10172 in Acute Stroke Treatment. Stroke (1993) 24:35–41. doi: 10.1161/01.STR.24.1.35
28. Khang Y-H, Lynch JW, Kaplan GA. Health inequalities in Korea: age-and sex-specific educational differences in the 10 leading causes of death. Int J Epidemiol. (2004) 33:299–308. doi: 10.1093/ije/dyg244
29. Kim HC, Choi DP, Ahn SV, Nam CM, Suh I. Six-year survival and causes of death among stroke patients in Korea. Neuroepidemiology (2009) 32:94–100. doi: 10.1159/000177034
30. Drugan MM, Wiering MA. Feature selection for Bayesian network classifiers using the MDL-FS score. Int J Approx Reason. (2010) 51:695–717. doi: 10.1016/j.ijar.2010.02.001
31. Liu Z, Malone B, Yuan C. Empirical evaluation of scoring functions for Bayesian network model selection. BMC Bioinformatics (2012) 13(Suppl. 15):S14. doi: 10.1186/1471-2105-13-S15-S14
32. Schwarz G. Estimating the dimension of a model. Ann Stat. (1978) 6:461–4. doi: 10.1214/aos/1176344136
33. Vrieze SI. Model selection and psychological theory: a discussion of the differences between the Akaike information criterion (AIC) and the Bayesian information criterion (BIC). Psychol Methods (2012) 17:228. doi: 10.1037/a0027127
34. Lam W, Bacchus F. Learning Bayesian belief networks: an approach based on the MDL principle. Comput Intell. (1994) 10:269–93. doi: 10.1111/j.1467-8640.1994.tb00166.x
35. Tsamardinos I, Brown LE, Aliferis CF. The max-min hill-climbing Bayesian network structure learning algorithm. Mach Learn. (2006) 65:31–78. doi: 10.1007/s10994-006-6889-7
36. Chinnasamy A, Sung W-K, Mittal A. Protein structure and fold prediction using tree-augmented naive Bayesian classifier. J Bioinform Comput Biol. (2005) 3:803–19. doi: 10.1142/S0219720005001302
37. Guyon I, Elisseeff A. An introduction to variable and feature selection. J Mach Learn Res. (2003) 3:1157–82.
38. Roweis ST, Saul LK. Nonlinear dimensionality reduction by locally linear embedding. science. (2000) 290:2323–6. doi: 10.1126/science.290.5500.2323
39. Hruschka ER, Hruschka ER, Ebecken NF. Feature selection by Bayesian networks. In: Conference of the Canadian Society for Computational Studies of Intelligence. London, ON: Springer (2004).
40. Jović A, Brkić K, Bogunović N. A review of feature selection methods with applications. In: 2015 38th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO) Opatija (2015).
41. Lee C, Lee GG. Information gain and divergence-based feature selection for machine learning-based text categorization. Informat Proc Manag. (2006) 42:155–65. doi: 10.1016/j.ipm.2004.08.006
42. Motwani M, Dey D, Berman DS, Germano G, Achenbach S, Al-Mallah MH, et al. Machine learning for prediction of all-cause mortality in patients with suspected coronary artery disease: a 5-year multicentre prospective registry analysis. Eur Heart J. (2016) 38:500–7. doi: 10.1093/eurheartj/ehw188
43. Lei S. A feature selection method based on information gain and genetic algorithm. In: Computer Science and Electronics Engineering (ICCSEE), 2012 International Conference on Hangzhou: IEEE (2012).
44. Kononenko I. Estimating attributes: analysis and extensions of RELIEF. In: European Conference on Machine Learning. Catania: Springer (1994).
45. Robnik-Šikonja M, Kononenko I. An adaptation of Relief for attribute estimation in regression. In: Proceedings of the 14th International Conference on Machine Learning (ICML). San Francisco, CA (1997).
46. Hall MA. Correlation-based feature selection of discrete and numeric class machine learning. In: ICML '00 Proceedings of the Seventeenth International Conference on Machine Learning. San Francisco, CA (2000).
47. Yu L, Liu H. Feature selection for high-dimensional data: a fast correlation-based filter solution. In: Proceedings of the 20th International Conference on Machine Learning (ICML). Washington, DC (2003).
48. Bermejo P, Gamez JA, Puerta JM. Improving incremental wrapper-based subset selection via replacement and early stopping. Int J Pattern Recogn Artif Intell. (2011) 25:605–25. doi: 10.1142/S0218001411008804
49. Kohavi R, John GH. Wrappers for feature subset selection. Artif Intell. (1997) 97:273–324. doi: 10.1016/S0004-3702(97)00043-X
50. Arlot S, Celisse A. A survey of cross-validation procedures for model selection. Stat Surv. (2010) 4:40–79. doi: 10.1214/09-SS054
51. Valdes G, Luna JM, Eaton E, Simone II CB, Ungar LH, Solberg TD. MediBoost: a patient stratification tool for interpretable decision making in the era of precision medicine. Sci Rep. (2016) 6:37854. doi: 10.1038/srep37854
52. Lakshminarayanan B, Pritzel A, Blundell C. Simple and scalable predictive uncertainty estimation using deep ensembles. In: Advances in Neural Information Processing Systems. Long Beach, CA (2017).
53. Kendall A, Gal Y. What uncertainties do we need in bayesian deep learning for computer vision? In: Advances in Neural Information Processing Systems. Long Beach, CA (2017).
55. Maldonado S, Weber R, Famili F. Feature selection for high-dimensional class-imbalanced data sets using Support Vector Machines. Inf Sci. (2014) 286:228–46. doi: 10.1016/j.ins.2014.07.015
56. Fernández A, García S, Herrera F. Addressing the classification with imbalanced data: open problems and new challenges on class distribution. In: International Conference on Hybrid Artificial Intelligence Systems. Wroclaw: Springer (2011).
57. Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP. SMOTE: synthetic minority over-sampling technique. J Artif Intell Res. (2002) 16:321–57. doi: 10.1613/jair.953
58. Han H, Wang W-Y, Mao B-H. Borderline-SMOTE: a new over-sampling method in imbalanced data sets learning. In: International Conference on Intelligent Computing. Hefei: Springer (2005).
59. Ho KC, Speier W, El-Saden S, Liebeskind DS, Saver JL, Bui AA, et al. Predicting discharge mortality after acute ischemic stroke using balanced data. In: AMIA Annual Symposium Proceedings, American Medical Informatics Association. Washington DC (2014).
60. Drummond C, Holte RC. C4. 5, class imbalance, and cost sensitivity: why under-sampling beats over-sampling. In: Workshop on Learning from Imbalanced Datasets II. Washington DC: Citeseer (2003).
61. Weiss GM, McCarthy K, Zabar B. Cost-sensitive learning vs. sampling: which is best for handling unbalanced classes with unequal error costs? In: IEEE International Conference on Data Mining (2007) p. 35–41.
63. Monsalve-Torra A, Ruiz-Fernandez D, Marin-Alonso O, Soriano-Payá A, Camacho-Mackenzie J, Carreño-Jaimes M. Using machine learning methods for predicting inhospital mortality in patients undergoing open repair of abdominal aortic aneurysm. J Biomed Inf. (2016) 62:195–201. doi: 10.1016/j.jbi.2016.07.007
64. Kim YD, Song D, Nam HS, Lee K, Yoo J, Hong G-R, et al. D-dimer for prediction of long-term outcome in cryptogenic stroke patients with patent foramen ovale. Thromb Haemost. (2015) 114:614–22. doi: 10.1160/TH14-12-1040
Keywords: stroke, bayesian network, prognostic model, machine learning classification, decision support techniques, imbalanced data
Citation: Park E, Chang H-j and Nam HS (2018) A Bayesian Network Model for Predicting Post-stroke Outcomes With Available Risk Factors. Front. Neurol. 9:699. doi: 10.3389/fneur.2018.00699
Received: 30 May 2018; Accepted: 02 August 2018;
Published: 07 September 2018.
Edited by:
Fabien Scalzo, University of California, Los Angeles, United StatesReviewed by:
Jens Fiehler, Universitätsklinikum Hamburg-Eppendorf, GermanyCopyright © 2018 Park, Chang and Nam. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Hyo Suk Nam, aHNuYW1AeXVocy5hYw==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.