 Danlei Ru
Danlei Ru Jinchen Li
Jinchen Li Ouyi Xie1
Ouyi Xie1 Hong Jiang
Hong Jiang
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Neuroinform., 30 August 2022
Volume 16 - 2022 | https://doi.org/10.3389/fninf.2022.978630
Existing treatments can only delay the progression of spinocerebellar ataxia type 3/Machado-Joseph disease (SCA3/MJD) after onset, so the prediction of the age at onset (AAO) can facilitate early intervention and follow-up to improve treatment efficacy. The objective of this study was to develop an explainable artificial intelligence (XAI) based on feature optimization to provide an interpretable and more accurate AAO prediction. A total of 1,008 affected SCA3/MJD subjects from mainland China were analyzed. The expanded cytosine-adenine-guanine (CAG) trinucleotide repeats of 10 polyQ-related genes were genotyped and included in related models as potential AAO modifiers. The performance of 4 feature optimization methods and 10 machine learning (ML) algorithms were compared, followed by building the XAI based on the SHapley Additive exPlanations (SHAP). The model constructed with an artificial neural network (ANN) and feature optimization of Crossing-Correlation-StepSVM performed best and achieved a coefficient of determination (R2) of 0.653 and mean absolute error (MAE), root mean square error (RMSE), and median absolute error (MedianAE) of 4.544, 6.090, and 3.236 years, respectively. The XAI explained the predicted results, which suggests that the factors affecting the AAO were complex and associated with gene interactions. An XAI based on feature optimization can improve the accuracy of AAO prediction and provide interpretable and personalized prediction.
Spinocerebellar ataxia type 3 (SCA3), also called Machado–Joseph disease (MJD), is a common polyglutamine (polyQ) disease. PolyQ diseases are neurodegenerative disorders, and include Huntington's disease (HD), spinal bulbar muscular atrophy (SBMA), dentatorubral pallidoluysian atrophy (DRPLA), and spinocerebellar ataxia (SCA) types 1, 2, 3, 6, 7, and 17. The age at onset (AAO) of polyQ diseases is usually at middle age, and after that, the condition progressively worsens for 10–30 years until death (Ross, 1997; Fan et al., 2014). Although many studies have focused on the treatment of polyQ disease, there is no effective clinical treatment (Esteves et al., 2017; Paulson et al., 2017; Coarelli et al., 2018; Brooker et al., 2021; Costa and Maciel, 2022). Current treatments can only alleviate the symptoms and delay the progression of the disease after onset, and the treatment goals are to improve the motor performance and the quality of life (Ashizawa et al., 2018; Rodríguez-Díaz et al., 2018; Klockgether et al., 2019; Lanza et al., 2020). However, patients with mild symptoms are more likely to benefit from treatment (Miyai et al., 2012). Animal experiments also show that some potential treatments may prevent or reverse the progression of the disease, but they are more suitable for the early stage (Ashizawa et al., 2018; Friedrich et al., 2018). Therefore, AAO prediction contributes to early initiation to slow the progression and helps health care and social security agencies provide follow-up visits to improve the treatment efficacy (Jacobi et al., 2015; Paulson et al., 2017).
PolyQ diseases are caused by expanded cytosine-adenine-guanine (CAG) trinucleotide repeats. The relationship between the expanded CAG repeat (CAGexp) length and the AAO of polyQ diseases has been proven, and the AAO decreased with increasing CAGexp length (Collin et al., 1993; Gusella and Macdonald, 2000; Tang et al., 2000; Chattopadhyay et al., 2003; França Jr et al., 2012; Tezenas Du Montcel et al., 2014). However, the relationship between the AAO and modified genes is complex. The CAG repeat length of the expanded ATXN3 is the major AAO factor of SCA3/MJD, but other polyQ-related genes (CACNA1A, TBP, KCN3, RAI1, HTT, ATN 1, ATXN1, 2, and 7) and gene interactions also have modifying effects on the AAO (Andresen et al., 2007; Tezenas Du Montcel et al., 2014; Chen et al., 2016a). Other polyQ diseases, such as SCA1 (Wang et al., 2019), SCA2 (Hayes et al., 2000; Li et al., 2021), HD (Hmida-Ben Brahim et al., 2014), also have similar relationships.
Models including the maximum likelihood estimation model (França Jr et al., 2012), least-squares linear regression (Collin et al., 1993; Aylward et al., 1996; Peng et al., 2014; Bettencourt et al., 2016), linear regression based on the log-transformed AAO (Andrew et al., 1993; Lucotte et al., 1995; Chattopadhyay et al., 2003), piecewise regression (Andresen et al., 2007), quadratic regression (Tezenas Du Montcel et al., 2014; Chen et al., 2016a), survival models (Brinkman et al., 1997; Langbehn et al., 2004, 2010; Almaguer-Mederos et al., 2010; Du Montcel et al., 2014; De Mattos et al., 2019; Peng et al., 2021b), and machine learning (ML) models (Peng et al., 2021a) have been used for AAO fitting. Most statistical models attempt to investigate the relationship between the AAO and a few modifiers, but only a few studies have focused on AAO prediction, and the prediction accuracy still needs to be improved. For example, previous ML models of AAO prediction found that ML can improve model performance by comparing the performances of linear regression and 6 other ML models, but its overall prediction performance is still limited (Peng et al., 2021a).
The complex relationship between modifiers and the AAO is one reason for inaccurate prediction. Because of the complexity of gene interactions, this study proposes a feature optimization method to better fit non-linear relationships. We tried to use feature crosses to represent gene interactions and then selected the most important features to ensure the efficiency of the models.
Compared with statistical models, ML models address more variables and improve the accuracy, but ML models are black boxes, and it is difficult to explain the prediction results, which limits the application of ML models. Applying explainable artificial intelligence (XAI) in medicine is very important because the lack of interpretability is the reason ML-based clinical decisions are hard to trust and far from clinical practice (Gilpin et al., 2018; Vellido, 2020; Antoniadi et al., 2021; Banegas-Luna et al., 2021). SHapley Additive exPlanations (SHAP) (Lundberg and Lee, 2017) is based on game theory and can provide an interpretation for the output of ML models. We combined SHAP and ML algorithms to build an XAI for AAO prediction.
In this study, we reanalyzed the data from the literature (Peng et al., 2021a), including the largest cohort of Chinese mainland SCA3/MJD populations. This study aims to compare the performance of feature optimization methods and ML algorithms and proposes an XAI for AAO prediction.
A total of 1,008 subjects with SCA3/MJD from the Chinese Clinical Research Cooperative Group for Spinocerebellar Ataxias were included in the study. All clinical data of participants were derived from a previous study by Peng et al. (2021a). The AAO was defined as the age at which the first neurological symptoms appeared. This study was approved by the ethics committee of Xiangya Hospital, Central South University, and written informed consent was obtained from all study participants.
Genomic DNA (gDNA) was extracted from peripheral blood leucocytes using a standard protocol. The CAG repeat sequences of polyQ-related genes (ATXN3, ATXN1, ATXN2, CACNA1, ATXN7, TBP, HTT, ATN1, KCNN3, and RAI1) were genotyped by polymerase chain reaction and capillary electrophoresis. The sizes of the shorter alleles (A1) and the longer alleles (A2) were considered as different variables, respectively. The relationships between the length of two alleles are also defined as variables, including the mean (M) of the length of two alleles, and the difference (D) of the length of two alleles. In this way, genetic variables about these 10 polyQ-related genes were described as A1, A2, M and D. Candidate predictors included 40 genetic variables. The Pearson correlation coefficient was calculated to evaluate the correlation between the predictors and the AAO.
We filtered out subjects with ATXN3 CAGexp repeat lengths less than 60 or higher than 80 because the number of individuals was too small and scattered. Data were randomly divided into a training set and testing set at a ratio of 8:2 based on non-repetitive random sampling. For comparison with the piecewise model proposed in the literature (Peng et al., 2021a), the total testing set was further split into two subsets according to CAGexp repeat length at ATXN3.
The original feature set included all candidate predictors, including 40 genetic variables. We used 4 different methods to optimize the original feature set.
Optimized feature set 1 was selected by a less strict p-value (p < 0.1) of the Pearson correlation coefficient referring to the methods in the literature (Sun et al., 1996; Hongyue et al., 2017; Angraal et al., 2020; Peng et al., 2021a).
Optimized feature set 2 was optimized by two steps: feature crossing and feature selection based on the Pearson correlation coefficient. Feature crosses were formed by multiplying two features in the original genetic features. After crossing, feature set 2 is then selected by the p-value (p < 0.01) and r value (|r| > 0.2) of the Pearson correlation coefficient.
Recursive feature elimination (RFE) is a backward feature selection algorithm that removes the least important features from the feature set recursively by training models with different feature sets. Optimized feature set 3 was a subset of feature set 2. After crossing and correlation-based selection, features were selected using an SVM-RFE with 10-fold cross-validation, and the coefficient of determination (R2) was used to evaluate the best feature set.
Optimized feature set 4 was also a subset of feature set 2. After crossing and correlation-based selection, features were selected using a StepSVM (Guo and Chou, 2020) with 10-fold cross-validation, and the R2 score was used to evaluate the best feature set. A StepSVM is a stepwise method for feature selection based on an SVM. A StepSVM tries every possible subset, including two features, and the subset with the highest accuracy is chosen as the initial feature set. Then, the features were added to the set recursively to achieve a higher accuracy until the accuracy no longer increased or the maximum number of features allowed was reached.
Differing from the literature (Guo and Chou, 2020), the StepSVM used in this study started with a feature subset including only one feature. Because (1) there were too many features in the set, the cost of trying every pair of two features is too high; (2) it was confirmed that the CAGexp repeat length is an important feature for AAO prediction. The flowchart of the StepSVM is shown in Figure 1. In this study, the minimum expected R2 improvement was set to 0.001, and the maximum number of features selected was set to 30.
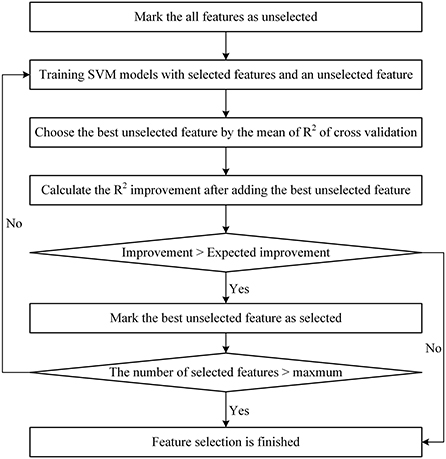
Figure 1. Flowchart of the StepSVM.
We chose 10 ML algorithms for prediction, including linear regression (LR), ridge regression (RR), Lasso, elastic net (EN), Huber regression (HR), K-nearest neighbor (KNN), support vector machine (SVM), random forest (RF), extreme gradient boosting (XGBoost), and artificial neural network (ANN).
We used 4 optimized feature sets and 10 ML algorithms to construct 40 regression models. All models were implemented in Python 3.8 using the scikit-learn (Pedregosa et al., 2011) and XGBoost (Chen and Guestrin, 2016) packages. The parameters of the models were determined by a cross-validated grid search.
LR is a simple multiple regression linear regression model. Usually, the LR coefficient is estimated using the ordinary least squares method, and the objective function of LR is:
RR is a modified ordinary least squares equal estimate. It gives up the unbiasedness of the least squares and makes the regression process more realistic at the cost of partial accuracy. It can prevent the model from overfitting by adding the L2-norm. The RR objective function is:
Lasso is a linear model that estimates sparse coefficients. Similar to RR, it consists of a linear model and an additional regularization term, but Lasso regression improves the ordinary least squares by adding the L1-norm. The Lasso regression objective function is:
EN is a linear regression model applying L1 and L2 regularization. It can not only remove invalid features as Lasso does but also has the stability of RR. The EN objective function is:
HR is a kind of robust estimation theory. It reduces the weight of outliers to reduce the impact of outliers on regression results. Its loss combines the advantages of the mean square error (MSE) and the mean absolute error (MAE).
where θ is the scale transformation coefficient; δ is a threshold, and a smaller δ leads to a solution closer to the MSE, while a larger δ leads to a solution closer to the MAE; and S is the residual error between the predicted value and the true value.
KNN predicts the label by finding K training samples closest in distance to the new point, and the Euclidean distance is the most common method of distance calculation in KNN. An appropriate value of K is very important for KNN. When K is too small, the prediction result is too sensitive to the nearest point, and when K is too large, distances that are far from the input will also work on the prediction.
A SVM performs regression by finding the optimal hyperplane, which divides the data by applying the maximum margin. The maximum margin improves the generalization of the SVM. It has been widely used in disease prediction and has achieved good performance (Chekol and Hagras, 2018; Asha and Vijaya, 2019; Kibtia et al., 2020; Byeon, 2021). The SVM regression function is:
where the coefficients ω and b are estimated by minimizing the regularized risk function:
where is the empirical error (risk); is the regularization term; Lε(y, f(x)) is the ε-insensitive loss function; and C is a constant regularization parameter, and it is the determinant of the trade-off between deviation and regularization. This indicates tolerance for errors. When C is too large, it may cause overfitting; otherwise, it may cause overgeneralization.
An RF is an important ensemble model based on bagging. It resamples a dataset by bootstrapping and trains a decision tree on each dataset. The RF prediction result is the combination of the results of the decision trees.
XGBoost is a tree-based ensemble model constructed by boosting. It is an improvement of the gradient boosting decision tree (GBDT) algorithm. It sums up the results of many decision trees as the final prediction.
where t is the number of decision trees; is a loss function; and Ω(fk) is the sum of the regularization items of the trees.
An ANN is also called a multi-layer perceptron (MLP). In an ANN, there are multiple hidden layers between the input and output layers. The layers are fully connected by neurons with a non-linear activation function, and the input to each layer is the weighted sum of the output of the previous layer.
In this study, we use a rectified linear unit (ReLU) as an activation function, and it is a piecewise linear function:
The limited-memory Broyden-Fletcher-Goldfarb-Shanno (L-BFGS) algorithm is used to optimize the ANN, which ensures that the network can be optimized quickly and approach the global optimal solution to the greatest extent. The L-BFGS algorithm is an efficient optimization algorithm that can converge faster and perform better on small datasets.
To evaluate the prediction accuracy and performance of each model, a set of evaluation metrics was used, including the R2, mean absolute error (MAE), root mean square error (RMSE), median absolute error (MedianAE), proportion of the samples that |AAOactual−AAOpredicted| < 5 (Proportion < 5), and proportion of the samples that |AAOactual−AAOpredicted| > 10 (Proportion > 10).
SHAP (Lundberg and Lee, 2017) is based on game theory and uses Shapley values to explain ML models. We chose the AAO prediction model with the best performance and used SHAP as the XAI method to explain the best AAO prediction model on the training set. The explanations provided by XAI include the importance of the features, the impact of features on the model output, and the personalized prediction of each sample.
The flowchart of the process is shown in Figure 2.
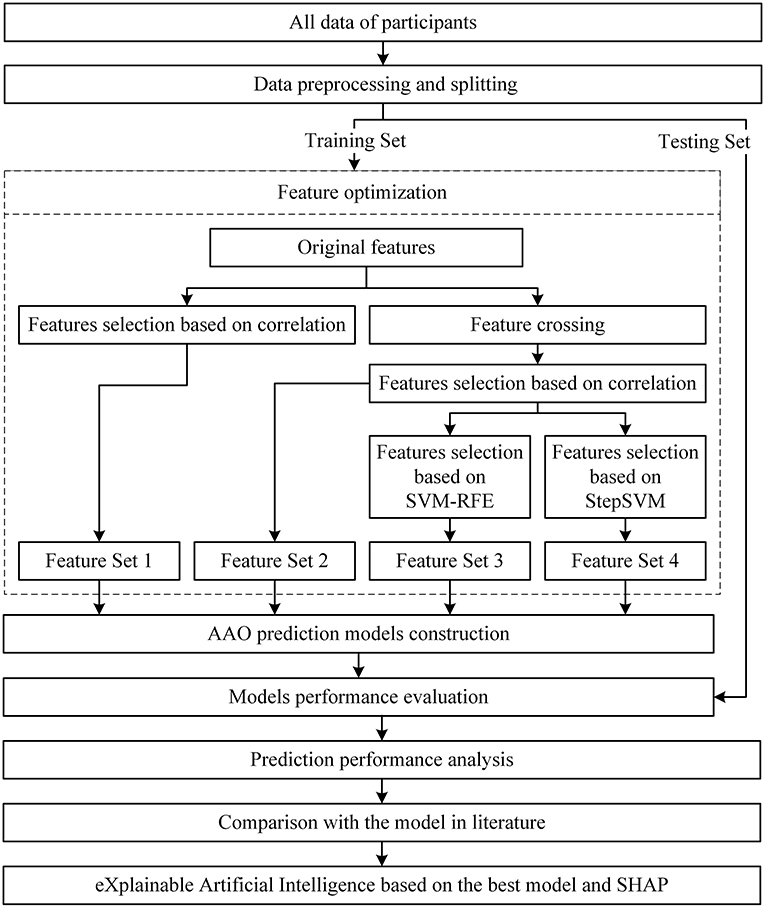
Figure 2. Flowchart of the study.
Among the 1,008 subjects with SCA3/MJD, 549 were male (54.5%), 385 were maternally transmitted, 36 were sporadically transmitted, and 258 were transmission unknown. The mean AAO of all subjects was 35.0 ± 10.2 years, and the mean repeat length of the expanded ATXN3 allele was 71.8 ± 3.6.
Among the 1,008 subjects, 11 subjects with ATXN3 CAGexp repeat lengths less than 60 or higher than 80 were filtered out. A total of 997 subjects with ATXN3 repeat lengths between 60 and 80 were used for model construction. There were 797 individuals in the training set and 200 in the testing set. The total testing set was split into two subsets for comparison with the piecewise model proposed in the literature (Peng et al., 2021a). There were 24 individuals in testing subset 1 (ATXN3 CAGexp ≤ 68) and 176 in testing subset 2 (ATXN3 CAGexp > 68).
The details of the descriptive statistical analysis are shown in Table 1.
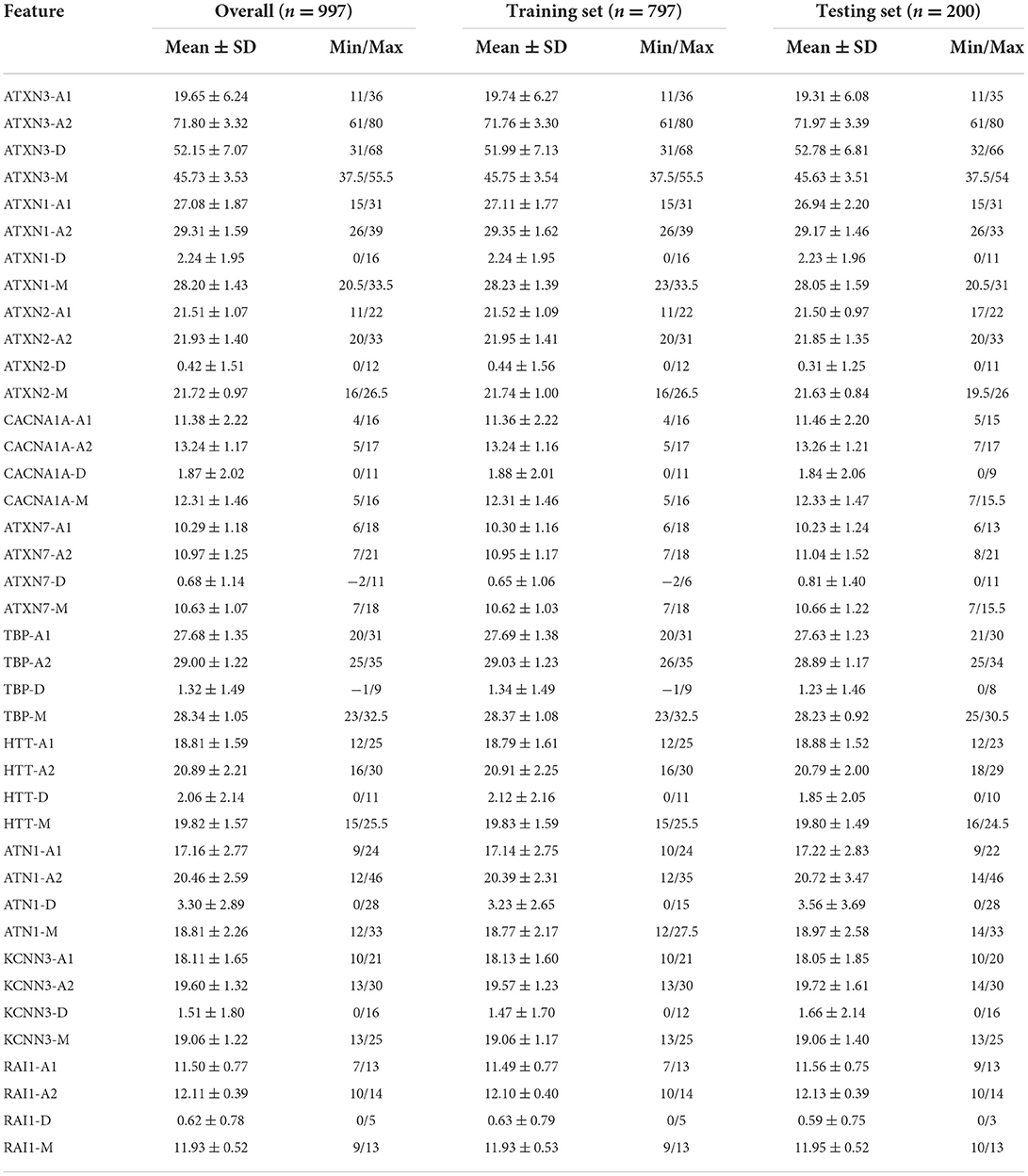
Table 1. Results of the descriptive statistical analysis.
The results of the Pearson correlation coefficient (Table 2) showed that there were 6 features correlated with the AAO (p < 0.05). Because a less strict p-value (p < 0.1) was applied for feature selection, 8 features were selected for optimized feature set 1, including ATXN3-A2, ATXN3-D, ATXN3-M, TBP-A1, TBP-M, ATXN1-A2, ATXN2-A1, and KCNN3-D.
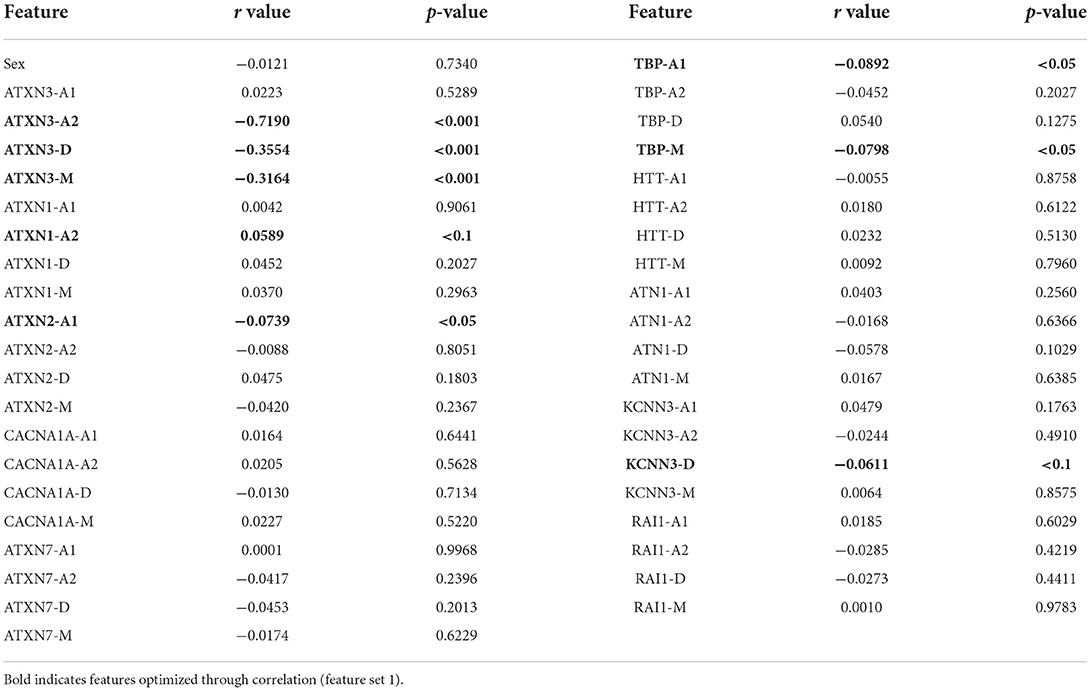
Table 2. Result of the Pearson correlation coefficient.
After feature crossing, 820 features (780 feature crosses and 40 original features) were used for feature selection. Finally, 75 features were considered to be correlated with the AAO (p < 0.01, |r| > 0.2) and included in the optimized feature set 2, which is shown in Table 3.
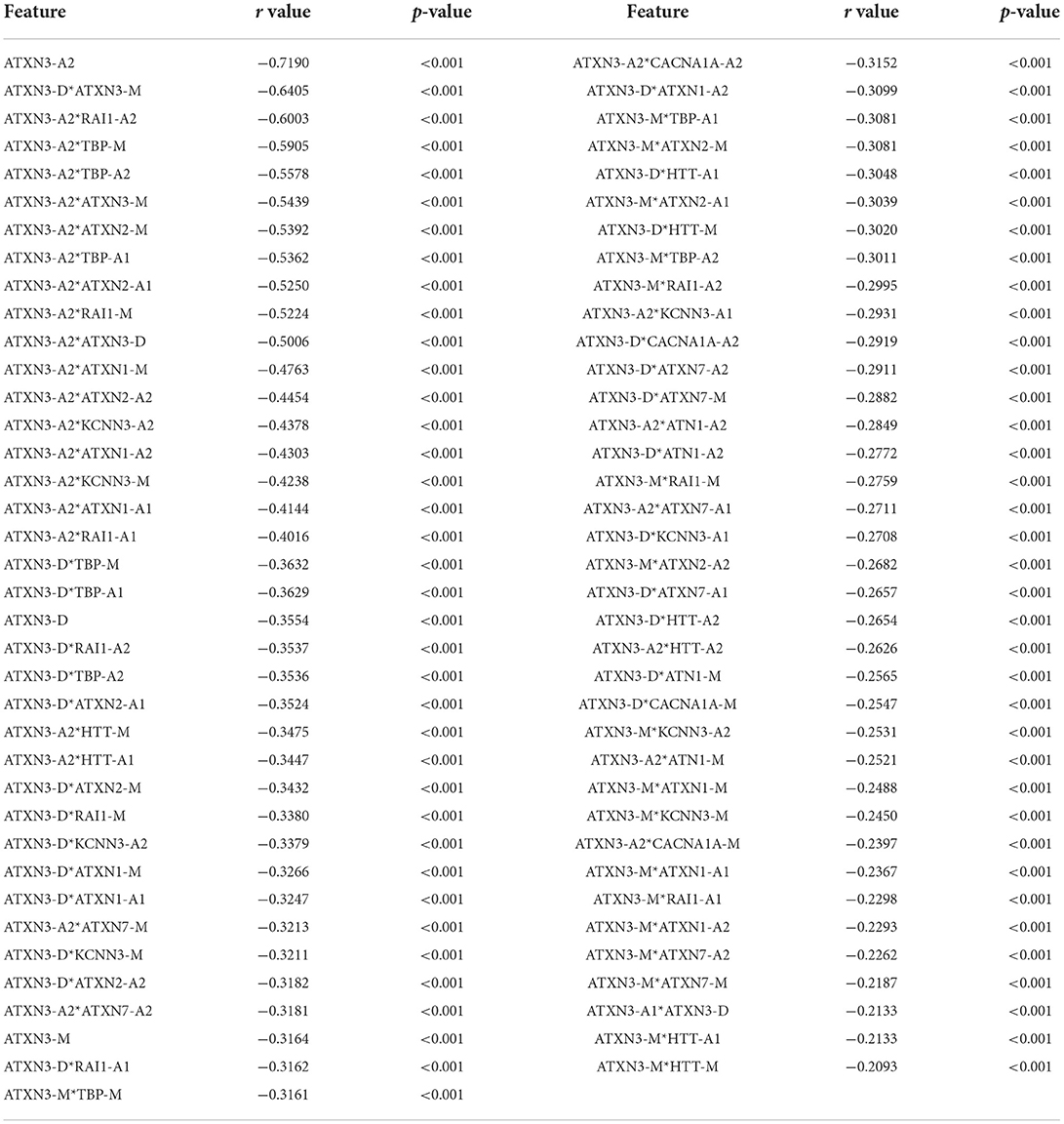
Table 3. Result of feature optimization by cross-correlation (feature set 2).
The R2 scores of different numbers of features selected by the SVM-RFE are shown in Figure 3. When the SVM-RFE selected 23 features, the SVM had the highest R2 score.
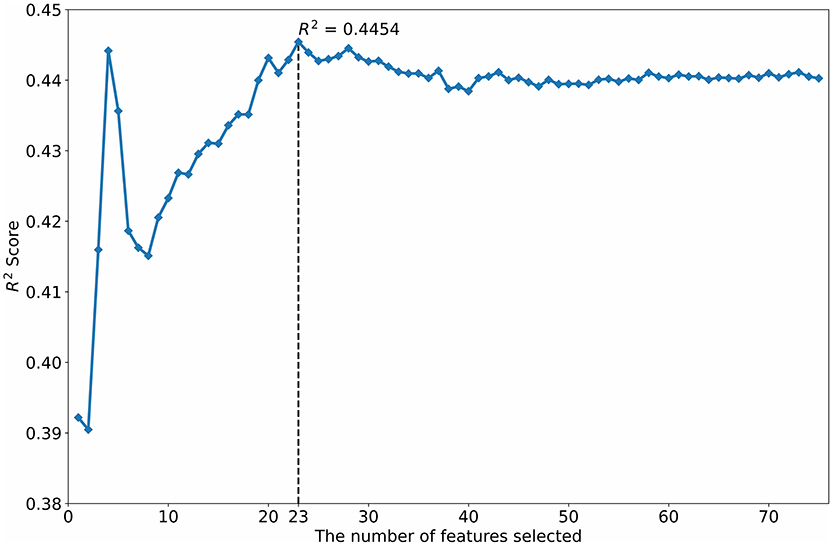
Figure 3. Feature selection using the SVM-RFE.
The R2 scores of the numbers of features selected by the StepSVM are shown in Figure 4. When the number of features selected is greater than 16, the R2 improvement is lower than the expected improvement of 0.001.
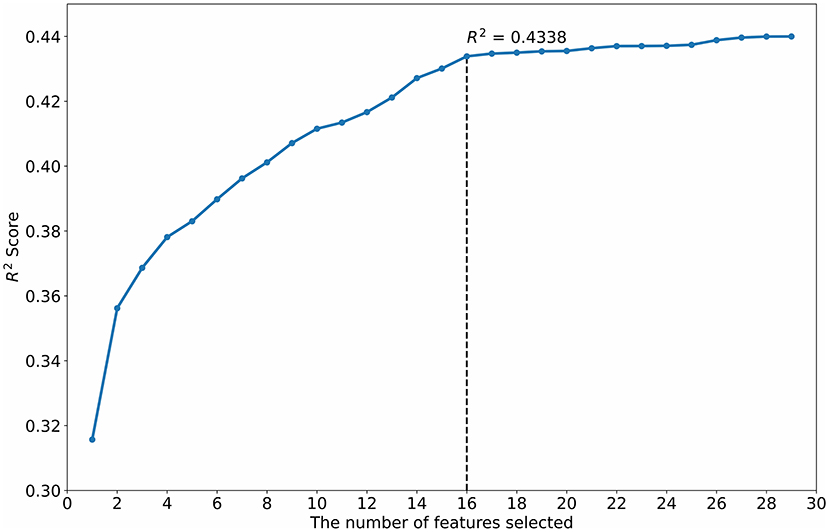
Figure 4. Feature selection using the StepSVM.
The performance of models constructed with the 4 optimized feature sets and 10 ML methods is shown in Table 4.
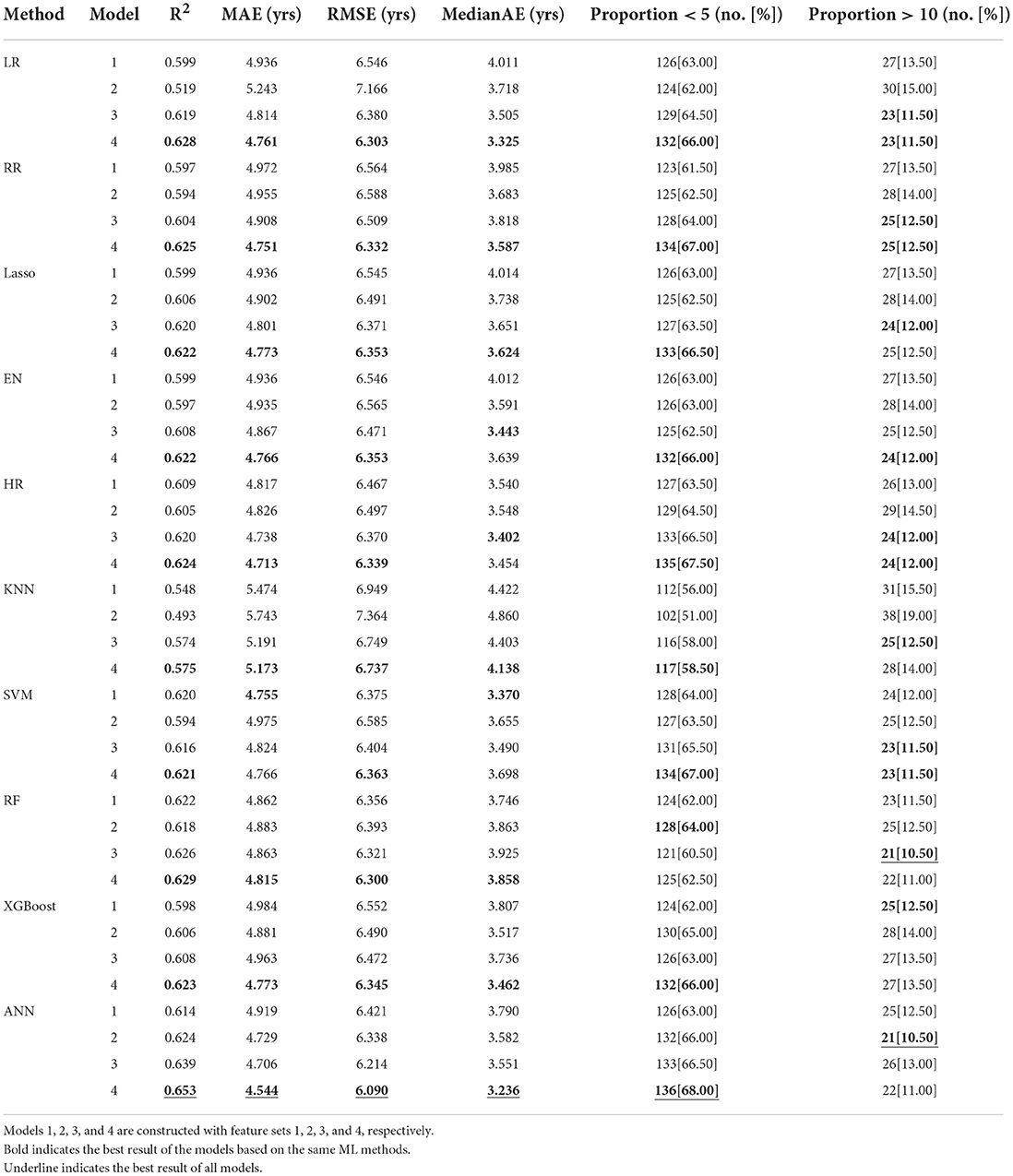
Table 4. Performances of models constructed with different feature sets and ML methods.
Among the models using different feature sets, the performance of feature set 1 was the worst, which suggests that crossing can improve the prediction accuracy. Models based on optimized feature set 4 have achieved the best prediction, which suggests that the Crossing-Correlation-StepSVM is the best feature optimization method for AAO prediction.
Among the models using different ML methods, models constructed with an ANN perform best. The models constructed with HR also achieve good prediction results.
Among all models, the ANN constructed with feature set 4 (Crossing-Correlation-StepSVM) performs best and achieves the best R2 (0.653), MAE (4.544), RMSE (6.090), MedianAE (3.236), and Proportion < 5 (136[68.00]) on the testing set.
The AAO prediction performances on two testing subsets are shown in Table 5. It shows the results of the models constructed with the optimized feature set 4 and results declared in the literature (Peng et al., 2021a).
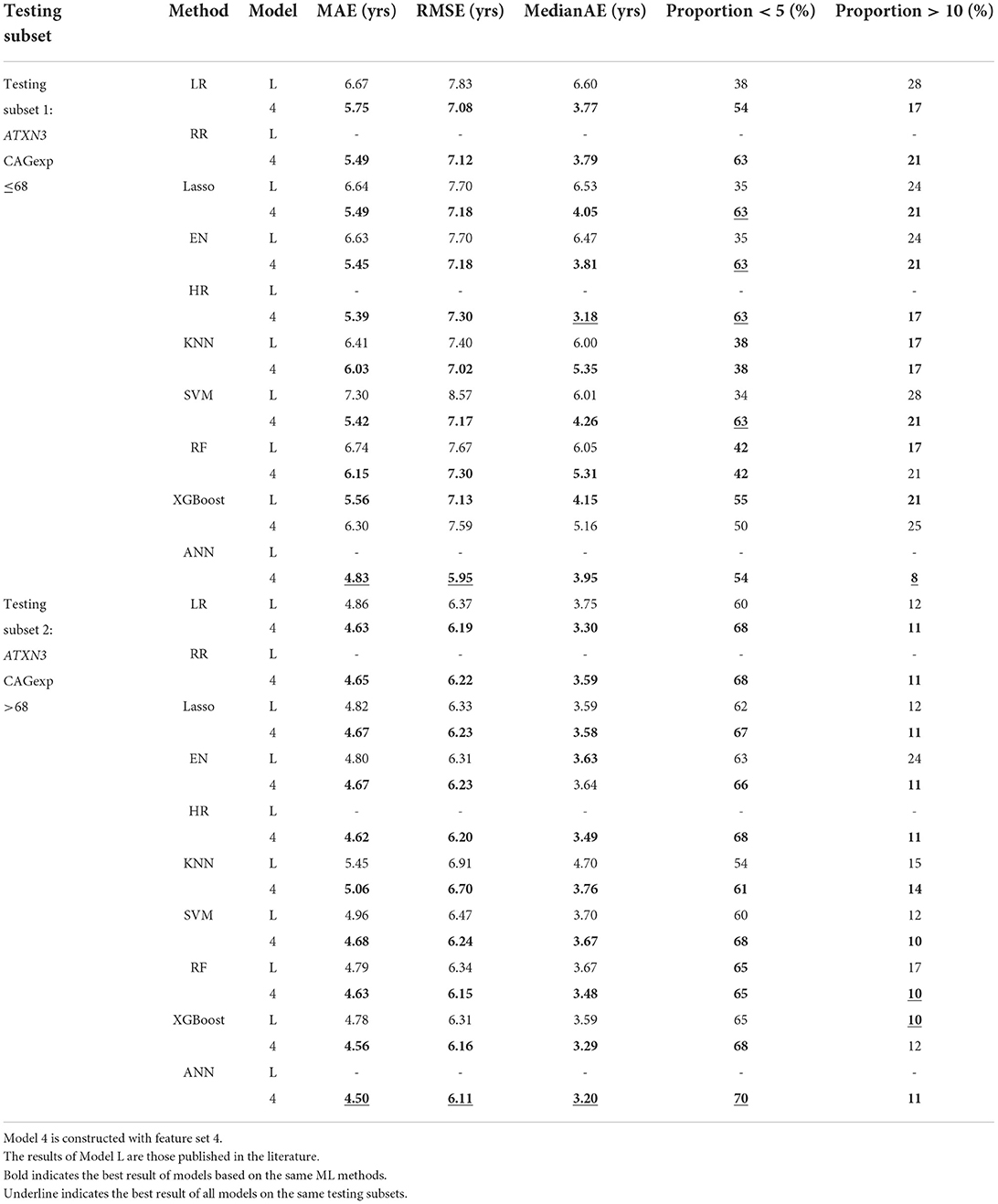
Table 5. Performance on different testing subsets.
In testing subset 1 (ATXN3 CAGexp ≤ 68), several models achieved a higher proportion < 5 (63%) than the best model, XGBoost, in the literature (55%). HR, as one of the models with the highest proportion < 5 (63%), also achieved the lowest MedianAE (3.18). Additionally, the ANN achieved the lowest MAE (4.83), RMSE (5.95), and proportion > 10 (8%), which showed obvious superiority in prediction accuracy over XGBoost in the literature (MAE: 5.56, RMSE: 7.13, proportion > 10: 21%), but its proportion < 5 (54%) was slightly lower than that of the reported XGBoost model (55%).
In testing subset 2 (ATXN3 CAGexp > 68), the ANN was the best AAO prediction model, and the evaluated results were MAE (4.50), RMSE (6.11), MedianAE (3.20), Proportion < 5 (70%), which was considerably superior to other models and the previous XGBoost (MAE: 4.78, RMSE: 6.31, MedianAE 3.59: proportion < 5: 65%).
Overall, the results of models constructed with the optimized feature set 4 are better than the results reported in the literature, and the performance of the ANN is the best, followed by HR.
We used the SHAP explainer on the best model (the ANN constructed with the optimized feature set 4) to build the XAI. In the SHAP result, the higher the SHAP value of a feature is, the higher the AAO prediction will be.
The importance of each feature is measured by the mean of the absolute SHAP value. The importance ranking of the 16 features according to their SHAP values is shown in Figure 5.
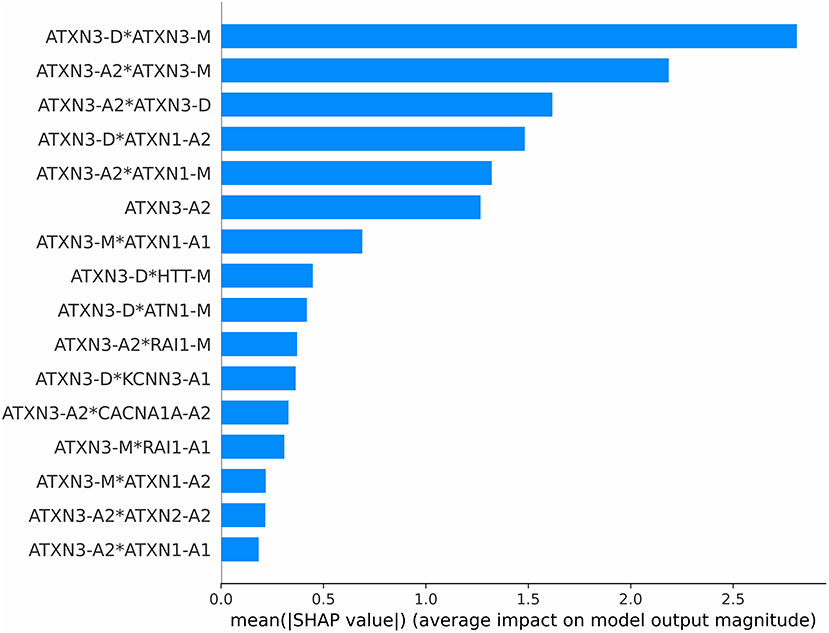
Figure 5. Importance ranking according to SHAP value.
The ATXN3-related features have the greatest impact on the model, which suggests that ATXN3-related features have the greatest impact on the model. The ATXN-A2 is not the most important feature, but the three most important features are only associated with the ATXN3 gene. It suggests that the in addition to the CAG repeat length of ATXN, the relationships between the expanded allele and normal allele of ATXN cannot be ignored. In addition, the combination of ATXN3 and ATXN1 is also very important for AAO prediction.
The impact on the model output of all features is shown in Figure 6. The red color represents a higher feature value, while the blue color represents a lower feature value. A positive SHAP value means that the feature results in an increase in the AAO prediction value, and a negative SHAP value means that it leads to a decline. For example, a higher value of the first 3 features will lead to a lower predicted AAO.
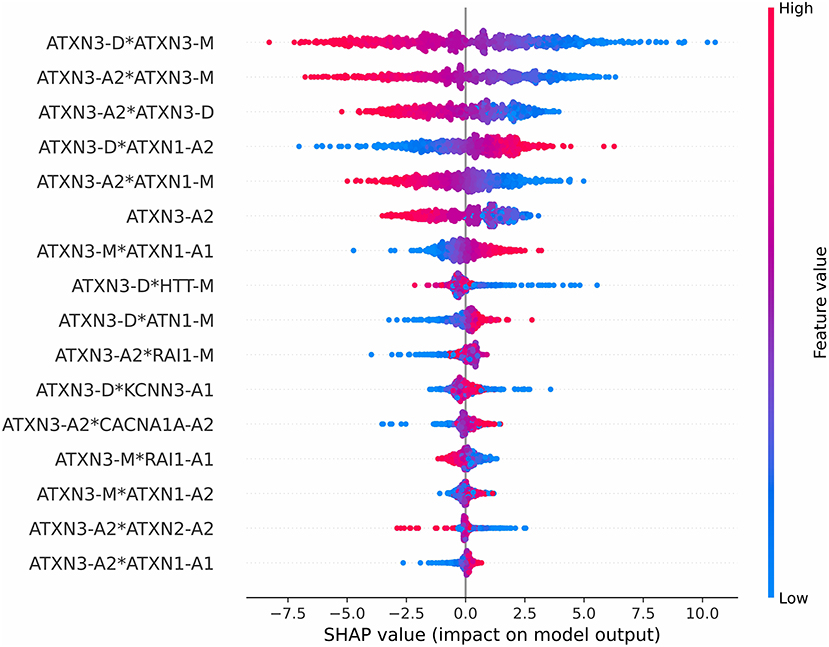
Figure 6. Impact on the model output of all features.
We used the SHAP value to analyze the impact of ATXN3-A2 on AAO output because ATXN3-A2 is the only original feature, and it is the most relevant feature to the AAO (r = −0.7190, p < 0.001). The relationship between the SHAP value of ATXN3-A2 and ATXN3-A2 before normalization (ATXN3 CAGexp) is shown in Figure 7. With the increase in the length of ATXN3 CAGexp, the SHAP value first decreased and then increased, and the segmentation point was at ATXN3 CAGexp = 68, which is similar to the results of a previous study (Chen et al., 2016b).
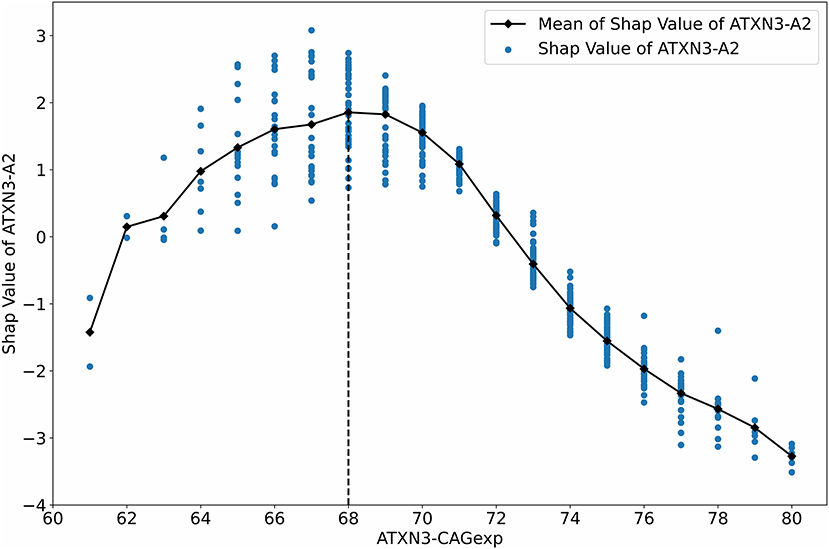
Figure 7. Relationship between the SHAP value and ATXN3 CAGexp.
The dataset was divided into two parts according to ATXN3 CAGexp = 68 and the importance of each feature was checked. The ranking of feature importance and the impact of features are different in the two parts of the data is shown in Figure 8. The importance and impact of the features were different in different part of samples. Compared with cases of ATXN3 CAGexp > 68, the importance of ATXN3-related features decreased in cases of ATXN3 CAGexp ≤ 68.
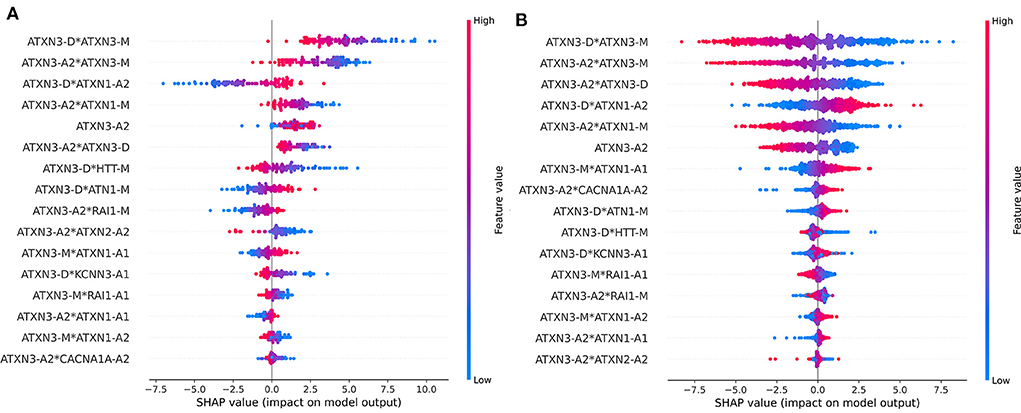
Figure 8. Impact on model output of all features in the two parts of the data: (A) ATXN3 CAGexp ≤ 68, (B) ATXN3 CAGexp > 68.
The SHAP can provide personalized predictions for each sample. Two samples with the largest and smallest predicted AAO were selected as examples of personalized prediction. The relationship between the predicted AAO and features is shown in Figure 9. It explains how the value of each variable leads to the final prediction. The red color represents the increase of AAO prediction, while the blue color represents a decrease of AAO prediction.
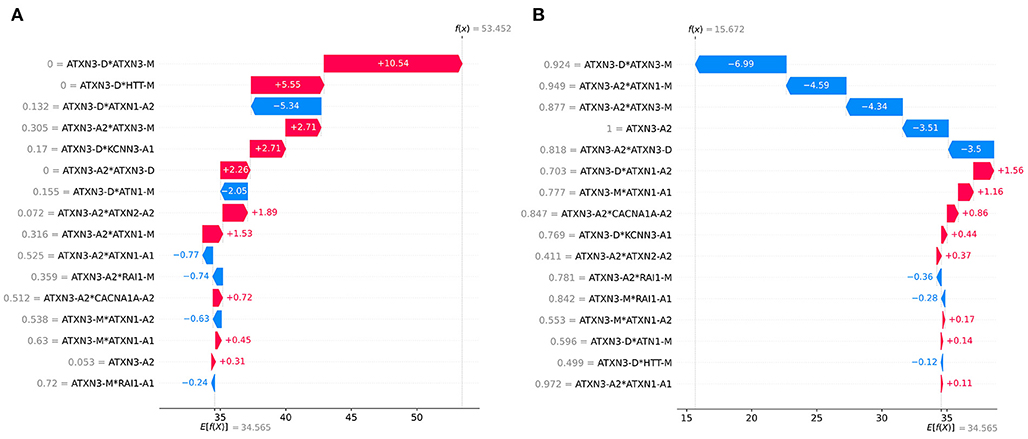
Figure 9. Examples of personalized prediction: (A) sample with the largest predicted AAO, (B) sample with the smallest predicted AAO. f (x) is the predicted AAO and E[f (x)] is the expectation of the predicted AAO of all samples.
To our knowledge, this is the first study attempting to apply XAI to the AAO prediction of SCA3/MJD. This study proposed an XAI model based on feature optimization, which achieved a better AAO prediction accuracy than previous studies (Peng et al., 2021a,b) and can explain the impact of features and provide a personalized prediction.
The relationship between polyQ-related genes and the AAO may be non-linear because of the complex gene interaction. We used feature optimization to model the non-linear relationship between genes and the AAO and compared different feature optimization methods. The best feature optimization method (Crossing-Correlation-StepSVM) can improve the performance of different ML methods. For future research, the feature optimization method can be used for other polyQ diseases because the relationships between the AAO and genetic modifiers are similar in polyQ diseases, such as SCA1 (Wang et al., 2019), SCA2 (Hayes et al., 2000; Li et al., 2021), and HD (Hmida-Ben Brahim et al., 2014).
We compared the performance of 10 ML algorithms for AAO prediction, including LR, RR, Lasso, EN, HR, KNN, SVM, RF, XGBoost, and ANN, and models constructed with the ANN achieved the best accuracy. Additionally, although we chose an ANN to build the XAI model for the final prediction, HR also achieved good results. Combined with feature optimization, HR can provide an effective prediction but requires only a few parameters, which may have more potential in clinical practice.
The XAI proposed in this study performs better in comparison with the results from the literature, and it achieved better R2 (0.653), MAE (4.544), RMSE (6.090), MedianAE (3.236), and proportion < 5 (136[68.00]) values. The previous piecewise XGBoost model for AAO prediction of SCA3/MJD patients achieves metrics of MAE (5.56 and 4.78), RMSE (7.13 and 6.31), MedianAE (4.15 and 3.59), and proportion < 5 (55% and 65%) for CAGexp ≤ 68 and CAGexp > 68, respectively (Peng et al., 2021a). Another survival analysis study proposed a parametric survival analysis method to predict the AAO with a reported R2 of 0.54 (Peng et al., 2021b).
The interpretability of the XAI model was provided by the result of feature optimization and the SHAP (Figure 5). All optimized features were of the ATXN3 gene. The most important feature is not ATXN3-A2 (the length of ATXN3 CAGexp) but the combination of ATXN3-D (the difference in the length of the two alleles of ATXN3) and ATXN3-M (the mean length of the two alleles of ATXN3). In addition, optimized features include crosses related to ATXN1, HTT, ATN1, RAI1, KCNN3, CACNA1A, and ATXN2. The feature crosses related to ATXN1 are considered of high importance. This suggests that the ATXN3 gene is the most important AAO modifier, but the relationship between AAO and ATXN3 is not simply linear, and the factors affecting the AAO are more complex and associated with more modifiers and gene interactions. The proposed XAI also helps to achieve a personalized prediction, which can provide the impact of each feature on the final prediction output in a specific sample (Figure 9). Personalized prediction makes the prediction results of the ML model easier to understand and trust, which may contribute to clinical decisions in the future. For abnormal samples with inaccurate prediction, personalized interpretability can also be combined with medical record analysis, which may also help to discover more AAO modifiers and further improve the prediction model.
This study has some limitations. First, the study reanalyzed data from previous research to provide an XAI model with more accurate prediction but only included data with a small number of subjects from a single center. Second, piecewise models may be more suitable for AAO prediction because the strong negative correlation between the AAO and ATXN3 CAGexp only exists in cases with ATXN3 CAG repeats > 68 (Chen et al., 2016b). Our SHAP analysis also supports this segmentation point (Figure 7). However, there are too few cases with ATXN3 CAG repeats ≤ 68, so we did not use piecewise models as in the literature (Peng et al., 2021a). Third, there are 11 subjects with ATXN3 CAGexp repeat lengths less than 60 or higher than 80 were excluded from our study, while the model in previous literature (Peng et al., 2021a) included all subjects. Comparing with the correlation coefficient reported in the literature, the correlation of ATXN3-A2 increased (r1 = −0.708, r2 = −0.7190) and that of ATXN3-D (r1 = −0.378, r2 = −0.3554) and ATXN3-M (r1= −0.336, r2 = −0.3164) decreased (r1 is the Pearson coefficient reported in the literature, r2 is the Pearson coefficient in this study). Although the correlation changes are small, there is still the possibility of causing differences in the prediction effect. At last, the improvement of accuracy is still limited, especially for the cases with ATXN3 CAG repeats ≤ 68. This result suggests a more complex set of AAO modifying factors. There may be other related genes that have not been tested, and environmental influences are difficult to quantify and consider.
This study proposed an XAI based on feature optimization for AAO prediction in the largest cohort of patients with SCA3/MJD in mainland China. We compared the performance of 4 feature optimization methods and 10 ML algorithms, and the model constructed with the ANN and the feature optimization method of Crossing-Correlation-StepSVM performed best. Then, we built an XAI based on the best model and the SHAP to provide an interpretable and personalized prediction. We hope this study can provide a reference for clinical treatment and help with genetic counseling.
The data analyzed in this study is subject to the following licenses/restrictions: datasets analyzed in this study are not publicly available. Further information about the datasets is available to researchers upon reasonable request to the author (HJ). Requests to access these datasets should be directed to HJ, jianghong73868@126.com.
The studies involving human participants were reviewed and approved by the Ethics Committee of Xiangya Hospital, Central South University. The patients/participants provided their written informed consent to participate in this study.
RQ and DR conceived and designed the study. DR and OX did the implementation of the method, conducted the experiments, and generated the results. HJ and LP provided resources and data curation. DR wrote the manuscript. JL, LP, and RQ provided suggestions in writing the manuscript. All authors contributed to the article and approved the submitted version.
This study was funded by the National Key Research and Development Program of China (No. 2021YFA0805200 to HJ), the National Natural Science Foundation of China (Nos. 81771231, 81974176, and 82171254 to HJ), the Innovation Research Group Project of Natural Science Foundation of Hunan Province (No. 2020JJ1008 to HJ), the Science and Technology Innovation Group of Hunan Province (No. 2020RC4043 to HJ), the Scientific Research Foundation of Health Commission of Hunan Province (No. B2019183 to HJ), the Key Research and Development Program of Hunan Province (Nos. 2020SK2064 and 2018SK2092 to HJ), the Innovative Research and Development Program of Development and Reform Commission of Hunan Province to HJ, and the Project Program of National Clinical Research Center for Geriatric Disorders (Xiangya Hospital, Nos. 2020LNJJ12 and XYYYJSTG-05 to HJ).
We thank all the participating patients for their involvement in this study.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fninf.2022.978630/full#supplementary-material
Almaguer-Mederos, L., Falcón, N., Almira, Y., Zaldivar, Y., Almarales, D. C., Góngora, E., et al. (2010). Estimation of the age at onset in spinocerebellar ataxia type 2 Cuban patients by survival analysis. Clin. Genet. 78, 169–174. doi: 10.1111/j.1399-0004.2009.01358.x
Andresen, J. M., Gayán, J., Djoussé, L., Roberts, S., Brocklebank, D., Cherny, S. S., et al. (2007). The relationship between CAG repeat length and age of onset differs for Huntington's disease patients with juvenile onset or adult onset. Ann. Hum. Genet. 71, 295–301. doi: 10.1111/j.1469-1809.2006.00335.x
Andrew, S. E., Goldberg, Y. P., Kremer, B., Telenius, H., Theilmann, J., Adam, S., et al. (1993). The relationship between trinucleotide (CAG) repeat length and clinical features of Huntington's disease. Nat. Genet. 4, 398–403. doi: 10.1038/ng0893-398
Angraal, S., Mortazavi, B. J., Gupta, A., Khera, R., Ahmad, T., Desai, N. R., et al. (2020). Machine learning prediction of mortality and hospitalization in heart failure with preserved ejection fraction. JACC: Heart Fail. 8, 12–21. doi: 10.1016/j.jchf.2019.06.013
Antoniadi, A. M., Du, Y., Guendouz, Y., Wei, L., Mazo, C., Becker, B. A., et al. (2021). Current challenges and future opportunities for XAI in machine learning-based clinical decision support systems: a systematic review. Appl. Sci. 11, 5088. doi: 10.3390/app11115088
Asha, P., and Vijaya, M. (2019). “Support vector regression for predicting binding affinity in spinocerebellar ataxia,” in Integrated Intelligent Computing, Communication and Security, eds A. N. Krishna, K. C. Srikantaiah, and C. Naveena (Singapore: Springer), 173–184. doi: 10.1007/978-981-10-8797-4_19
Ashizawa, T., Öz, G., and Paulson, H. L. (2018). Spinocerebellar ataxias: prospects and challenges for therapy development. Nat. Rev. Neurol. 14, 590–605. doi: 10.1038/s41582-018-0051-6
Aylward, E. H., Codori, A.-M., Barta, P. E., Pearlson, G. D., Harris, G. J., Brandt, J., et al. (1996). Basal ganglia volume and proximity to onset in presymptomatic Huntington disease. Arch. Neurol. 53, 1293–1296. doi: 10.1001/archneur.1996.00550120105023
Banegas-Luna, A. J., Peña-García, J., Iftene, A., Guadagni, F., Ferroni, P., Scarpato, N., et al. (2021). Towards the interpretability of machine learning predictions for medical applications targeting personalised therapies: a cancer case survey. Int. J. Mol. Sci. 22, 4394. doi: 10.3390/ijms22094394
Bettencourt, C., Hensman-Moss, D., Flower, M., Wiethoff, S., Brice, A., Goizet, C., et al. (2016). DNA repair pathways underlie a common genetic mechanism modulating onset in polyglutamine diseases. Ann. Neurol. 79, 983–990. doi: 10.1002/ana.24656
Brinkman, R., Mezei, M., Theilmann, J., Almqvist, E., and Hayden, M. (1997). The likelihood of being affected with Huntington disease by a particular age, for a specific CAG size. Am. J. Hum. Genet. 60, 1202.
Brooker, S. M., Edamakanti, C. R., Akasha, S. M., Kuo, S. H., and Opal, P. (2021). Spinocerebellar ataxia clinical trials: opportunities and challenges. Ann. Clinic. Trans. Neurol. 8, 1543–1556. doi: 10.1002/acn3.51370
Byeon, H. (2021). Predicting the severity of Parkinson's disease dementia by assessing the neuropsychiatric symptoms with an SVM regression model. Int. J. Environ. Res. Public Health 18, 2551. doi: 10.3390/ijerph18052551
Chattopadhyay, B., Ghosh, S., Gangopadhyay, P. K., Das, S. K., Roy, T., Sinha, K. K., et al. (2003). Modulation of age at onset in Huntington's disease and spinocerebellar ataxia type 2 patients originated from eastern India. Neurosci. Lett. 345, 93–96. doi: 10.1016/S0304-3940(03)00436-1
Chekol, B. E., and Hagras, H. (2018). “Employing machine learning techniques for the malaria epidemic prediction in Ethiopia,” in 2018 10th Computer Science and Electronic Engineering (CEEC) (University of Essex, UK: IEEE), 89–94. doi: 10.1109/CEEC.2018.8674210
Chen, T., and Guestrin, C. (2016). “Xgboost: a scalable tree boosting system,” in Proceedings of the 22nd acm sigkdd International Conference on Knowledge Discovery and Data Mining (New York, NY, USA: Association for Computing Machinery), 785–794.
Chen, Z., Zheng, C., Long, Z., Cao, L., Li, X., Shang, H., et al. (2016a). (CAG) n loci as genetic modifiers of age-at-onset in patients with Machado-Joseph disease from mainland China. Brain 139, e41–e41. doi: 10.1093/brain/aww087
Chen, Z., Zheng, C., Long, Z., Cao, L., Li, X., Shang, H., et al. (2016b). (CAG) n loci as genetic modifiers of age-at-onset in patients with Machado-Joseph disease from mainland China. Brain 139, e41–e41.
Coarelli, G., Brice, A., and Durr, A. (2018). Recent advances in understanding dominant spinocerebellar ataxias from clinical and genetic points of view. F1000Research 7. doi: 10.12688/f1000research.15788.1
Collin, S. O., Nicole, P., Franz, M. L., Abbott, M. H., Folstein, S. E., Ross, C. A., et al. (1993). Correlation between the onset age of Huntington's disease and length of the trinucleotide repeat in IT-15. Hum. Mol. Genet. 1547–1549. doi: 10.1093/hmg/2.10.1547
Costa, M. D., and Maciel, P. (2022). Modifier pathways in polyglutamine (PolyQ) diseases: from genetic screens to drug targets. Cell. Mol. Life Sci. 79, 1–31. doi: 10.1007/s00018-022-04280-8
De Mattos, E. P., Leotti, V. B., Soong, B. W., Raposo, M., Lima, M., Vasconcelos, J., et al. (2019). Age at onset prediction in spinocerebellar ataxia type 3 changes according to population of origin. Eur. J. Neurol. 26, 113–120. doi: 10.1111/ene.13779
Du Montcel, S. T., Durr, A., Rakowicz, M., Nanetti, L., Charles, P., Sulek, A., et al. (2014). Prediction of the age at onset in spinocerebellar ataxia type 1, 2, 3 and 6. J. Med. Genet. 51, 479–486. doi: 10.1136/jmedgenet-2013-102200
Esteves, S., Duarte-Silva, S., and Maciel, P. (2017). Discovery of therapeutic approaches for polyglutamine diseases: a summary of recent efforts. Med. Res. Rev. 37, 860–906. doi: 10.1002/med.21425
Fan, H.-C., Ho, L.-I., Chi, C.-S., Chen, S.-J., Peng, G.-S., Chan, T.-M., et al. (2014). Polyglutamine (PolyQ) diseases: genetics to treatments. Cell Transplant. 23, 441–458. doi: 10.3727/096368914X678454
França Jr, M. C., Emmel, V. E., D'abreu, A., Maurer-Morelli, C. V., Secolin, R., Bonadia, L. C., et al. (2012). Normal ATXN3 allele but not CHIP polymorphisms modulates age at onset in Machado–Joseph disease. Front. Neurol. 3, 164. doi: 10.3389/fneur.2012.00164
Friedrich, J., Kordasiewicz, H. B., O'callaghan, B., Handler, H. P., Wagener, C., Duvick, L., et al. (2018). Antisense oligonucleotide–mediated ataxin-1 reduction prolongs survival in SCA1 mice and reveals disease-associated transcriptome profiles. JCI Insight 3, e123193. doi: 10.1172/jci.insight.123193
Gilpin, L. H., Bau, D., Yuan, B. Z., Bajwa, A., Specter, M., Kagal, L., et al. (2018). “Explaining explanations: An overview of interpretability of machine learning,” in 2018 IEEE 5th International Conference on data science and advanced analytics (DSAA): IEEE (Turin, Italy), 80–89. doi: 10.1109/DSAA.2018.00018
Guo, C.-Y., and Chou, Y.-C. (2020). A novel machine learning strategy for model selections-Stepwise Support Vector Machine (StepSVM). PLoS ONE 15, e0238384. doi: 10.1371/journal.pone.0238384
Gusella, J. F., and Macdonald, M. E. (2000). Molecular genetics: unmasking polyglutamine triggers in neurodegenerative disease. Nat. Rev. Neurosci. 1, 109–115. doi: 10.1038/35039051
Hayes, S., Turecki, G., Brisebois, K., Lopes-Cendes, I., Gaspar, C., Riess, O., et al. (2000). CAG repeat length in RAI1 is associated with age at onset variability in spinocerebellar ataxia type 2 (SCA2). Hum. Mol. Genet. 9, 1753–1758. doi: 10.1093/hmg/9.12.1753
Hmida-Ben Brahim, D., Chourabi, M., Ben Amor, S., Harrabi, I., Trabelsi, S., Haddaji-Mastouri, M., et al. (2014). Modulation at age of onset in tunisian Huntington disease patients: implication of new modifier genes. Genet. Res. Int. 2014, 210418. doi: 10.1155/2014/210418
Hongyue, W., Jing, P., Bokai, W., Xiang, L., Julia, Z. Z., Kejia, W., et al. (2017). Inconsistency between univariate and multiple logistic regressions. Shanghai Arch. Psychiatry 29, 124. doi: 10.11919/j.issn.1002-0829.217031
Jacobi, H., Du Montcel, S. T., Bauer, P., Giunti, P., Cook, A., Labrum, R., et al. (2015). Long-term disease progression in spinocerebellar ataxia types 1, 2, 3, and 6: a longitudinal cohort study. Lancet Neurol. 14, 1101–1108. doi: 10.1016/S1474-4422(15)00202-1
Kibtia, H., Abdullah, S., and Bustamam, A. (2020). “Comparison of random forest and support vector machine for prediction of cognitive impairment in Parkinson's disease,” in AIP Conference Proceedings (Surakarta, Indonesia: AIP Publishing LLC), 020093.
Klockgether, T., Mariotti, C., and Paulson, H. L. (2019). Spinocerebellar ataxia. Nat. Rev. Dis. Primers 5, 1–21. doi: 10.1038/s41572-019-0074-3
Langbehn, D. R., Brinkman, R. R., Falush, D., Paulsen, J. S., Hayden, M., Group A.I.H.S.D.C., et al. (2004). A new model for prediction of the age of onset and penetrance for Huntington's disease based on CAG length. Clin. Genet. 65, 267–277. doi: 10.1111/j.1399-0004.2004.00241.x
Langbehn, D. R., Hayden, M. R., Paulsen, J. S., and Group, P.H.I.O.T.H.S. (2010). CAG-repeat length and the age of onset in Huntington disease (HD): a review and validation study of statistical approaches. Am. J. Med. Genet. B: Neuropsychiatr. Genet. 153, 397–408. doi: 10.1002/ajmg.b.30992
Lanza, G., Casabona, J. A., Bellomo, M., Cantone, M., Fisicaro, F., Bella, R., et al. (2020). Update on intensive motor training in spinocerebellar ataxia: time to move a step forward? J. Int. Med. Res. 48, 0300060519854626. doi: 10.1177/0300060519854626
Li, Y., Liu, Z., Hou, X., Chen, Z., Shen, L., Xia, K., et al. (2021). Effect of CAG repeats on the age at onset of patients with spinocerebellar ataxia type 2 in China. Zhong nan da xue xue bao. Yi xue ban= Journal of Central South University. Medical Sciences 46, 793–799. doi: 10.11817/j.issn.1672-7347.2021.210230
Lucotte, G., Turpin, J., Riess, O., Epplen, J., Siedlaczk, I., Loirat, F., et al. (1995). Confidence intervals for predicted age of onset, given the size of (CAG) n repeat, in Huntington's disease. Hum. Genet. 95, 231–232. doi: 10.1007/BF00209410
Lundberg, S. M., and Lee, S.-I. (2017). “A unified approach to interpreting model predictions”, in Proceedings of the 31st International Conference on Neural Information Processing Systems (Long Beach, California, USA: Curran Associates Inc.).
Miyai, I., Ito, M., Hattori, N., Mihara, M., Hatakenaka, M., Yagura, H., et al. (2012). Cerebellar ataxia rehabilitation trial in degenerative cerebellar diseases. Neurorehabil. Neural Repair 26, 515–522. doi: 10.1177/1545968311425918
Paulson, H. L., Shakkottai, V. G., Clark, H. B., and Orr, H. T. (2017). Polyglutamine spinocerebellar ataxias—from genes to potential treatments. Nat. Rev. Neurosci. 18, 613–626. doi: 10.1038/nrn.2017.92
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., et al. (2011). Scikit-learn: machine learning in Python. J. Machine Learn. Res. 12, 2825–2830. doi: 10.5555/1953048.2078195
Peng, H., Wang, C., Chen, Z., Sun, Z., Jiao, B., Li, K., et al. (2014). The APOE ε2 allele may decrease the age at onset in patients with spinocerebellar ataxia type 3 or Machado-Joseph disease from the Chinese Han population. Neurobiol. Aging 35, e2115-2179. doi: 10.1016/j.neurobiolaging.2014.03.020
Peng, L., Chen, Z., Chen, T., Lei, L., Long, Z., Liu, M., et al. (2021a). Prediction of the age at onset of spinocerebellar ataxia type 3 with machine learning. Mov. Disord. 36, 216–224. doi: 10.1002/mds.28311
Peng, L., Chen, Z., Long, Z., Liu, M., Lei, L., Wang, C., et al. (2021b). New model for estimation of the age at onset in spinocerebellar ataxia type 3. Neurology 96, e2885–e2895. doi: 10.1212/WNL.0000000000012068
Rodríguez-Díaz, J. C., Velázquez-Pérez, L., Rodríguez Labrada, R., Aguilera Rodríguez, R., Laffita Pérez, D., Canales Ochoa, N., et al. (2018). Neurorehabilitation therapy in spinocerebellar ataxia type 2: a 24-week, rater-blinded, randomized, controlled trial. Mov. Disord. 33, 1481–1487. doi: 10.1002/mds.27437
Ross, C. A. (1997). Intranuclear neuronal inclusions: a common pathogenic mechanism for glutamine-repeat neurodegenerative diseases? Neuron 19, 1147–1150. doi: 10.1016/S0896-6273(00)80405-5
Sun, G.-W., Shook, T. L., and Kay, G. L. (1996). Inappropriate use of bivariable analysis to screen risk factors for use in multivariable analysis. J. Clin. Epidemiol. 49, 907–916. doi: 10.1016/0895-4356(96)00025-X
Tang, B., Liu, C., Shen, L., Dai, H., Pan, Q., Jing, L., et al. (2000). Frequency of SCA1, SCA2, SCA3/MJD, SCA6, SCA7, and DRPLA CAG trinucleotide repeat expansion in patients with hereditary spinocerebellar ataxia from Chinese kindreds. Arch. Neurol. 57, 540–544. doi: 10.1001/archneur.57.4.540
Tezenas Du Montcel, S., Durr, A., Bauer, P., Figueroa, K. P., Ichikawa, Y., Brussino, A., et al. (2014). Modulation of the age at onset in spinocerebellar ataxia by CAG tracts in various genes. Brain 137, 2444–2455. doi: 10.1093/brain/awu174
Vellido, A. (2020). The importance of interpretability and visualization in machine learning for applications in medicine and health care. Neural Comput. Appl. 32, 18069–18083. doi: 10.1007/s00521-019-04051-w
Keywords: spinocerebellar ataxia type 3, CAG repeats, age at onset, machine learning, feature optimization, explainable artificial intelligence (XAI)
Citation: Ru D, Li J, Xie O, Peng L, Jiang H and Qiu R (2022) Explainable artificial intelligence based on feature optimization for age at onset prediction of spinocerebellar ataxia type 3. Front. Neuroinform. 16:978630. doi: 10.3389/fninf.2022.978630
Received: 26 June 2022; Accepted: 09 August 2022;
Published: 30 August 2022.
Edited by:
Alexandros Tzallas, University of Ioannina, GreeceReviewed by:
Xia-an Bi, Hunan Normal University, ChinaCopyright © 2022 Ru, Li, Xie, Peng, Jiang and Qiu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Rong Qiu, cWl1cm9uZ3JvbmdAMTI2LmNvbQ==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.