 Yupeng Li1Dong Zhao1*
Yupeng Li1Dong Zhao1* Guangjie Liu1Yi Liu2
Guangjie Liu1Yi Liu2 Yasmeen Bano2Alisherjon Ibrohimov2
Yasmeen Bano2Alisherjon Ibrohimov2 Huiling Chen3*Chengwen Wu3Xumin Chen4*
Huiling Chen3*Chengwen Wu3Xumin Chen4*- 1College of Computer Science and Technology, Changchun Normal University, Changchun, China
- 2Department of Nephrology, The First Affiliated Hospital of Wenzhou Medical University, Wenzhou, China
- 3College of Computer Science and Artificial Intelligence, Wenzhou University, Wenzhou, China
- 4Department of Nephrology, The First Affiliated Hospital of Wenzhou Medical University, Wenzhou University, Wenzhou, China
Intradialytic hypotension (IDH) is an adverse event occurred during hemodialysis (HD) sessions with high morbidity and mortality. The key to preventing IDH is predicting its pre-dialysis and administering a proper ultrafiltration prescription. For this purpose, this paper builds a prediction model (bCOWOA-KELM) to predict IDH using indices of blood routine tests. In the study, the orthogonal learning mechanism is applied to the first half of the WOA to improve the search speed and accuracy. The covariance matrix is applied to the second half of the WOA to enhance the ability to get out of local optimum and convergence accuracy. Combining the above two improvement methods, this paper proposes a novel improvement variant (COWOA) for the first time. More, the core of bCOWOA-KELM is that the binary COWOA is utilized to improve the performance of the KELM. In order to verify the comprehensive performance of the study, the paper sets four types of comparison experiments for COWOA based on 30 benchmark functions and a series of prediction experiments for bCOWOA-KELM based on six public datasets and the HD dataset. Finally, the results of the experiments are analyzed separately in this paper. The results of the comparison experiments prove fully that the COWOA is superior to other famous methods. More importantly, the bCOWOA performs better than its peers in feature selection and its accuracy is 92.41%. In addition, bCOWOA improves the accuracy by 0.32% over the second-ranked bSCA and by 3.63% over the worst-ranked bGWO. Therefore, the proposed model can be used for IDH prediction with future applications.
Introduction
End-stage renal disease (ESRD) threatens tens of millions of lives. Renal replacement therapy includes hemodialysis (HD), peritoneal dialysis (PD), and renal transplantation. Compared with transplantation, dialysis partially replaces renal function. Thus, there are several complications in dialysis patients despite intrinsic complications of ESRD, especially HD. HD is a treatment drawing blood out of patients, diffusing uremic toxins, ultrafiltering extra volume, and transfusion the purified blood back to the patient. The hemodynamics is unstable during HD. Once the patient’s cardiac function or peripheral vascular resistance cannot compensate, intradialytic hypotension (IDH) occurs.
IDH is defined according to different studies or guidelines. Even if systolic pressure (SBP) declines 20 mmHg without any symptoms, there are still target organ injuries and increased mortality (Burton et al., 2009a). Episodes of IDH decease perfusion to the heart, renal, brain, limbs, and mesenterium induces various complications. Examples are ischemic cardiomyopathy (Burton et al., 2009b), cerebral infarction (Naganuma et al., 2005), rapid loss of residual renal function (Jansen et al., 2002), critical limb ischemia (Matsuura et al., 2019), mesenteric ischemia (Ori et al., 2005), and vascular access thrombosis (Chang et al., 2011). The symptoms of IDH range from asymptomatic to loss of consciousness and sudden death. Therefore, managing IDH is an excellent way to avoid HD’s adverse events. When IDH episodes during HD, there are several acute managements, including administering saline, lowering the dialysate temperature and ultrafiltration rate, reducing the dialyzer blood flow, and increasing dialysate sodium concentration. Although physicians combine these treatments, dialysis treatment must be stopped in severe cases. In addition, the long-term benefits are still debated. Some studies reported that reduction of dialysate temperature prevented IDH, but meta-analysis showed the effect was uncertain. Furthermore, as compared to conventional dialysate, it may increase the rate of pain (Tsujimoto et al., 2019).
Schytz et al. (2015) performed a randomized clinical trial (RCT), and the results did not show any consistent trend in blood pressure (BP) changes to a reduction of the dialyzer blood flow. Sherman (2016) summarized the experience in their center; it was a common practice to lower the dialyzer blood flow in patients who developed IDH. However, the consideration did not apply to current dialysis practice. A meta-analysis reported that stepwise sodium profiling rather than linear sodium profiling effectively reduced IDH (Dunne, 2017). The results of sodium profiling were quick, and there was worry that in the long run, sodium profiling might result in a positive sodium balancing, increased thirst, and interdialytic weight increases (IDWG). ARCT showed low dialysate sodium concentration (135 mmol/L) significantly reduced IDWG, while no statistical difference in IDH episodes over 12 months of follow-up (Marshall et al., 2020). Radhakrishnan et al. (2020) showed there were lower IDWG, pre-HD SBP, and incidence of IDH when dialysate sodium concentration was equal to individual serum sodium level instead of high dialysate sodium concentration (140 mmol/L). Administration of saline and limited ultrafiltration rate prevent IDH by increasing relative blood volume, but always result in post-dialysis hypervolemia and heart failure. An inadequate ultrafiltration prescription induces IDH episodes, then nurses have to reducing ultrafiltration rate, leading to ultrafiltration failure in a 4-h dialysis session.
Artificial intelligence (AI), which focuses on modeling human cognition in computing, has achieved significant progress in a broad range of disciplines (Zhang J. et al., 2021; Luo et al., 2022). AI-assisted medical systems have recently gotten attention, making diagnosis systems and medical decision-making more instant, autonomous, and intelligent (Li et al., 2020c,2022; Zhang M. et al., 2021; Liu et al., 2022e). Thus, developing an intelligent early-warning system to predict IDH will greatly assist HD staff in setting optimal dialysate and ultrafiltration parameters (Lin et al., 2019). There are a few studies that focus on the IDH prediction model. Nafisi and Shahabi (2018), Solem et al. (2010), and Sandberg et al. (2014), respectively conducted small sample studies and showed that the finger photoplethysmography (PPG) signal helped predict IDH. However, PPG instruments are not available in all primary hospitals. Huang et al. (2020) integrated five machine learning models (least absolute shrinkage and selection operator, extreme gradient boosting, random forest, support vector regression, and multiple linear regression) to predict BP during HD based on the databaseand found previous BP in the last HD session and first BP reading in the current HD session, which were the most correlated parameters. Lin et al. (2018) developed a prediction model using BP and ultrafiltration records of 667 patients for 30 months. Although these database studies had good accuracy, they ignored the seasonal gradient of BP in HD patients (Duranton et al., 2018). In addition, serum protein levels and blood cells are associated with interdialytic BP. Ozen and Cepken (2020) found that white blood cell (WBC) values were significantly higher in patients developing IDH. The difference between post-dialysis protidemia and pre-dialysis protidemia outperformed BNP (B-natriuretic peptide) and ultrafiltration rate as a predictor for the 30-day risk of IDH (Assayag et al., 2020). Nephrologists still seek a simplified and readily available method, especially in the HD setting, when many patients start treatments while waiting for ultrafiltration prescriptions. Under these circumstances, blood routine test is readily accessible, cost-efficient, and can be of immediate use in any scale HD center. In addition, many scholars have used various machine learning methods to conduct research to explore the relationship between multiple factors and a certain thing.
Liu et al. (2022a) proposed a new chaotic simulated annealing overhaul of the MVO (CSAMVO) and successfully established a hybrid model used for disease diagnosis named CSAMVO-KELM. Liu et al. (2022c) proposed an improved new version of SFLA, that includes a dynamic step size modification method utilizing historical data, a specular reflection learning mechanism, and a simulated annealing process that utilizes chaotic map and levy flight. Moreover, the performance advantages of the method for feature selection were successfully validated in 24 UCI data sets. Shi et al. (2022) combined multiple strategies integrated slime mold algorithm (MSSMA) with KELM technology and successfully proposed a predictive model (MSSMA-KELM) that can be used to predict pulmonary hypertension. El-Kenawy et al. (2020) proposed a feature selection algorithm (SFS-Guided WOA) that combined with well-known classifiers (KNN, SVM, etc.) to achieve a more accurate classification prediction of CT images of covid-19 disease. Elminaam et al. (2021) proposed a new method for dimensionality reduction by combining the Marine Predator Algorithm (MPA) with K-NN and achieved predictions for 18 medical datasets in feature selection. Houssein et al. (2021) proposed a BMO-SVM classification prediction model for more accurate microarray gene expression profiling and cancer classification prediction. Le et al. (2021) used a Gray wolf optimizer (GWO) and the adaptive Particle swarm optimizer (APSO) to optimize the Multilayer perceptron (MLP). They proposed a novel wrapper-based feature selection model for the predictive analysis of early onset in diabetic patients. Senthilkumar et al. (2021) proposed a recursive prediction model based on AI techniques for the prediction of cervical cancer incidence, named the ENSemble classification framework (ENSCF).
In addition, Alagarsamy et al. (2021) introduced a technique that embedded the functionary of the Spatially constricted fish swarm optimization (SCFSO) technique and interval type-II fuzzy logic system (IT2FLS) methodologies, which settled the inaccurate forecasting of anomalies found in various topographical places in brain subjects of magnetic resonance imaging (MRI) modality light. Alshwaheen et al. (2021) proposed a new model based on the long short-term memory-recurrence neural network (LSTM-RNN) combined with the modified Genetic algorithm (GA) to predict the morbidity of ICU patients. Adoko et al. (2013) predicted the rockburst intensity based on a fuzzy inference system (FIS) and adaptive neuro-fuzzy inference system (ANFIS), as well as field measurement data. Cacciola et al. (2013) built a fuzzy ellipsoidal system for environmental pollution prediction using fuzzy rules. Liu et al. (2020) proposed an effective intelligent predictive model (COSCA-SVM) for predicting cervical hyperextension injuries by combining a modified Sine cosine algorithm (SCA) with a support vector machine (SVM). Hu et al. (2022b) proposed a feature selection model (HHOSRL-KELM model) by combining the binary Harris hawk optimization (HHO) algorithm with the specular reflection learning and the kernel extreme learning machine (KELM), which was successfully applied to the severity assessment of covid-19 disease. Therefore, it is feasible to develop a new perspective model based on the swarm intelligence optimization algorithms to predict IDH in this study.
In recent years, a large number of researchers have been exploring ways to combine machine learning techniques with medical diagnostics due to the simplicity of operation, speed of convergence, excellent global convergence performance, and parallelizability of swarm intelligence algorithms. And an increasing number of teams are using swarm intelligence optimization algorithms to optimize the performance of classifiers. For example, there are sine cosine algorithm (SCA) (Mirjalili, 2016), moth-flame optimization (MFO) (Mirjalili, 2015), particle swarm optimization (PSO) (Kennedy and Eberhart, 1995), whale optimization algorithm (WOA) (Mirjalili and Lewis, 2016; Mirjalili et al., 2019), bat-inspired algorithm (BA) (Yang, 2010), gray wolf optimization (GWO) (Mirjalili et al., 2014), grasshopper optimization algorithm (GOA) (Saremi et al., 2017), colony predation algorithm (CPA) (Tu et al., 2021b), slime mould algorithm (SMA) (Li et al., 2020b), hunger games search (HGS) (Yang et al., 2021), weighted mean of vectors (INFO) (Ahmadianfar et al., 2022), Harris hawks optimization (HHO) (Heidari et al., 2019b), Runge Kutta optimizer (RUN) (Ahmadianfar et al., 2021), firefly algorithm (FA) (Yang, 2009), ant colony optimization (ACO) (Dorigo, 1992; Dorigo and Caro, 1999), ant colony optimization based on continuous optimization (ACOR) (Socha and Dorigo, 2008) crow search algorithm (CSA) (Askarzadeh, 2016), and so on. These algorithms have also been successfully applied to several fields, such as optimization of machine learning model (Ling Chen et al., 2014), image segmentation (Hussien et al., 2022; Yu et al., 2022b), medical diagnosis (Xia et al., 2022a,b), economic emission dispatch problem (Dong et al., 2021), plant disease recognition (Yu et al., 2022a), scheduling problems (Gao et al., 2020; Han et al., 2021; Wang et al., 2022), practical engineering problems (Chen et al., 2020; Yu et al., 2022c), multi-objective problem (Hua et al., 2021; Deng et al., 2022b), solar cell parameter Identification (Ye et al., 2021), expensive optimization problems (Li et al., 2020a; Wu et al., 2021a), bankruptcy prediction (Cai et al., 2019; Xu et al., 2019), combination optimization problems (Zhao F. et al., 2021), and feature selection (Hu et al., 2021, 2022a). However, with the development of swarm intelligence and the times, some original heuristic algorithms have gradually revealed their weaknesses in problem optimization, mainly including slow convergence speed, poor convergence accuracy, and easily falling into local optimality in certain problems, etc. Therefore, many scholars have conducted relevant research on original metaheuristic algorithms in the hope that the problem-solving ability of metaheuristic algorithms can be improved. For example, there are chaotic BA (CBA) (Adarsh et al., 2016), boosted GWO (OBLGWO) (Heidari et al., 2019a), modified SCA (mSCA) (Qu et al., 2018), hybrid BA (RCBA) (Liang et al., 2018), hybridizing GWO (HGWO) (Zhu et al., 2015), hybrid SCA and PSO (SCAPSO) (Nenavath et al., 2018), BA based on collaborative and dynamic Learning (CDLOBA) (Yong et al., 2018), and GWO based on cellular automata concept (CAGWO) (Lu et al., 2018).
Inspired by the unique feeding behavior of humpback whales, in 2016, Mirjalili and Lewis (2016) successfully proposed an emerging metaheuristic, named WOA, by imitating the foraging behavior of humpback whales in their natural state, which at the time had a strong ability to find optimal solutions. As the field of the application continues to evolve, the WOA algorithm’s ability to find global optimality in new problem optimization is declining and is prone to fall into local optimality. As a result, a wide range of research has been carried out for WOA, and many improved variants of WOA have been proposed. For example, there are chaotic WOA (CWOA) (Patel et al., 2019), improved WOA (IWOA) (Tubishat et al., 2019), enhanced associative learning-based WOA (BMWOA) (Heidari et al., 2020), A-C parametric WOA (ACWOA) (Elhosseini et al., 2019), lévy flight trajectory-based WOA (LWOA) (Ling et al., 2017), improved opposition-based WOA (OBWOA) (Abd Elaziz and Oliva, 2018), and enhanced WOA (EWOA) (Tu et al., 2021a). Also, many optimized variants of WOA that were proposed by relevant research scholars have been applied to the corresponding areas where they are suitable. For example, Adam et al. (2020) proposed the binary WOA (bWOA) to solve user-base station (BS) association and sub-channel assignment problems. Cao et al. (2021) proposed a hybrid genetic WOA (HGWOA) that optimizes purchased equipment’s production planning and maintenance processes. El-Kenawy et al. (2020) proposed a stochastic fractal search (SFS)-based guided WOA (SFS-Guided WOA) and performed feature classification balancing experiments on it based on COVID-19 images to achieve high accuracy classification prediction of COVID-19 diseases. Ghoneim et al. (2021) proposed an adaptive dynamic polar rose guided WOA (AD-PRS-Guided WOA), which improved the parameters of the classification technique in order to improve the diagnostic accuracy of transformers. Revathi et al. (2020) proposed a genetic WOA by combining a Genetic algorithm (GA) and WOA that successfully overcame the data perturbation problem in cloud computing. Zhao et al. (2022) proposed a hybrid improved WOA and PSO (IWOA-PSO) method and successfully applied it to optimize time jitter path planning to reduce vibration in tandem manipulators and improve robot efficiency.
In the current study, to make WOA better overcome the poor convergence accuracy, easily falling into local optimality and weak stability of WOA for clinical classification prediction, this paper proposes a novel and more excellent variant (COWOA) of WOA for the first time, which introduces the orthogonal learning mechanism and the covariance matrix strategy into the original method to improve its optimization-seeking performance. In COWOA, the orthogonal learning mechanism is first applied to the first half of WOA to increase the population diversity, which is beneficial to the traversal range of the whale population in the solution space and ultimately improves the search ability of the population at that stage. Then, the covariance matrix is applied to the second half of WOA to increase the possibility of each agent jumping out of the local optimum. Eventually, the ability to escape from the local optimum and the convergence accuracy are successfully improved by this method. Finally, the ability of WOA to explore and exploit the global optimum is greatly enhanced by the dual mechanisms. In the process of the COWOA proposal, this paper set up inter-mechanism comparison experiments to verify the algorithm performance of COWOA based on 30 benchmark test functions in IEEE CEC2014. To further enhance the persuasiveness of the COWOA, the paper also compared the COWOA with seven WOA variants, nine original algorithms, and eight optimization variants of other algorithms. Then, this paper combines the binary COWOA (bCOWOA) with the KELM to propose a prediction model for clinical diagnosis and prediction, named the bCOWOA-KELM model. To validate the classification performance of the bCOWOA-KELM model, this paper conducted comparative experiments of the proposed method and other well-known methods based on six public datasets. In addition, to further illustrate the superiority of the bCOWOA-KELM model. a series of classification prediction experiments based on current hospital collected datasets were conducted, including comparison experiments of the different combinations of bCOWOA and six classification methods, comparison experiments of the bCOWOA-KELM model with five well-known classifiers and comparison experiments based on the swarm intelligence optimization algorithm. Moreover, the superiority of the bCOWOA-KELM model was analyzed by four evaluation metrics, including Accuracy, Specificity, Precision, and F-measure. Finally, this paper concluded with a detailed medical discussion of the critical characteristics derived from the experimental results. The main contributions of this study are summarized below.
(1) A higher performance optimization algorithm based on the WOA is proposed, namely COWOA.
(2) A discrete binary algorithm based on the improved COWOA is proposed, named bCOWOA.
(3) A classification prediction model based on bCOWOA and the KELM is proposed, named the bCOWOA-KELM model.
(4) The bCOWOA-KELM model is successfully applied to the classification prediction of IDH.
The rest of the paper is structured as follows. In section “An overview of whale optimization algorithm,” the WOA is introduced, and its basic principles are described. In section “The proposed COWOA,” the improvement process of the COWOA is presented. Section “The proposed bCOWOA-KELM model” shows the proposed process of bCOWOA-KELM. In section “Experiments results and analysis,” we set up comparative experiments to verify the performance of the COWOA and the bCOWOA-KELM model. Section “Discussion” the experimental results and the clinical application of bCOWOA-KELM. Finally, this paper concludes the whole paper and points out future research directions in section “Conclusion and future works.”
An overview of whale optimization algorithm
The WOA mimics the collaborative behavior of humpback whales during hunting in its search for optimal solutions by driving prey and enclosing them. During the whale’s search and catching of prey, the researchers highlight three key phases: the prey encirclement phase, the bubble net attack phase, and the prey finding phase.
In the surrounding prey phase, other search agents try to perform position updates toward the current optimal position to close to the prey. The behavior is represented by Eq. (2).
where X* denotes the optimal search agent explored so far. t is the number of iterations of the current population update. D indicates the distance with the weight between the current best whale position and the current whale position. A and C are the control parameters of the formula, expressed as in Eq. (3) and Eq. (4).
where r denotes a random number in the interval [0,1] and a1 decreases gradually from 2 to 0 as the number of evaluations increases in each iteration. FEs is the current number of evaluations, and MaxFEs is the maximum number of evaluations.
In the bubble net attack phase, also known as the exploitation phase of the WOA, a total of two whale bubble behaviors are involved, including the enveloping contracting behavior and the spiral updating position. It finds the optimum within a specific range by mimicking how humpback whales attack their prey. When |A| < 1, the whales develop a constricting envelope around the prey in the enveloping contracting phase, the essence of the principle is the same as the behavior in the enveloping prey phase, as shown in Eq. (6).
The distance among the whale location and the food location is first computed in the spiral improvement was made, and then a spiral equation is established between the whale and target positions to simulate the spiral motion of the humpback whale, as illustrated in Eq. (7) and Eq. (8).
where D′ indicates the distance between the current best and current whale positions. b is a constant that can determine the shape of the logarithmic spiral in the mathematical model, and it is set to 1 in the experiment. l is a random number between the interval [−2,1] that is used to control the shape of the spiral when the whale attacks the target, as shown in Eq. (9).
where rand is a random number taking values in the interval [0,1], and a2 decreases linearly with the number of evaluations in [−2, −1].
In order to ensure the good performance of the whale algorithm, the two update mechanisms are balanced and controlled in the actual model by artificially introducing a random parameter p on the interval [0,1] so that both location update strategies have a 50% probability of being executed. In summary, the complete development model for the attack phase of the bubble network is shown in Eq. (11).
In the prey finding phase, also known as the exploration phase of the WOA model. In this process, the whale’s position update approach is designed by referring to the position of an arbitrarily selected individual in the whale population. Furthermore, the introduction of random whale individuals increases the diversity of individuals in the population to a certain extent, giving the whales the possibility to jump out of the local optimum to find the optimum. At the same time, parameter A is introduced into the process control phase, whose absolute magnitude controls the selection of the whale’s position in the optimization phase.
When |A| = 1, the whale’s feeding process enters the prey-seeking phase. Based on the working principles described above, the behaviors of the whale searching for prey during this phase can be defined by Eq. (12) and Eq. (13).
where Xrand(t) indicates the position of a random individual in the current population. X(t) Indicates the location of individuals in the current population of whales. D″ denotes the distance of a random individual whale from the current individual whale under the effect of parameter C. C is a random number on the interval [0,2].
Based on the above, the following paper will give the flowchart and the pseudo-code of the traditional WOA, as shown in Figure 1 and Algorithm 1, respectively.
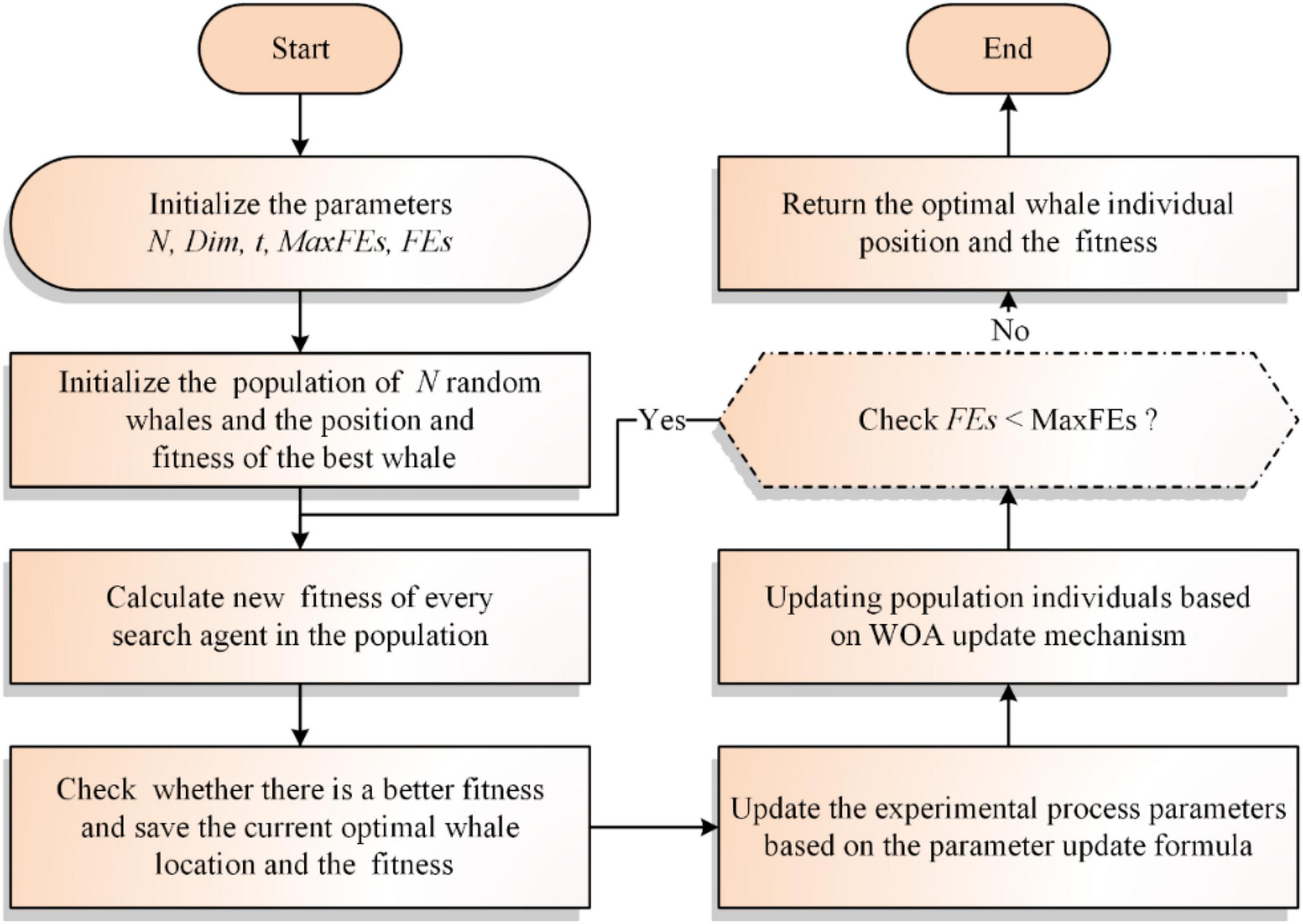
Figure 1. Flowchart of the traditional WOA.
Algorithm 1. Pseudocode for the traditional WOA.
Input: The fitness function F(x),
maximum evaluation number (MaxFEs),
population size (N), dimension (dim)
Output: The best Whale (Leader_pos)
Initialize a population of random
whales X
Initialize position vector and score
for the leader: Leader_pos,Leader_score
Initialize the parameters: FEs, t;
While (FEs < MaxFEs)
For i = 1: size(X,1)
Return back the search agents that
go beyond the boundaries of the search
space
Calculate objective function for
each search agent
FEs = FEs + 1
Update Leader_pos
End for
For i = 1: size(X,1)
Updates the parameters of WOA
Position update of population
individuals using the population update
mechanism of WOA
End for
t=t+1
End while
Return Leader_pos
In summary, it is easy to find that the complexity of the WOA is mainly determined by the initializations, updating the population position, updating the weights, and the fitness value calculation. As the time spent by the algorithm is closely related to the specific problem to be solved, the following analysis will focus on the complexity of the WOA in the following aspects, mainly including initializing the population O(N*D), updating the population position O(N*D*T), updating the weights O(N*T) and calculating the fitness value O(N*T). Therefore, the time complexity of the WOA can be derived as O(((2 + D)*T + D)*N) by combining the above time complexity analysis. T denotes the maximum number of evaluations and can be derived from the maximum number of iterations. N denotes the number of individuals in the whale population, and D denotes the number of dimensions of the individual whales.
The proposed COWOA
WOA is one of the more popular population-based metaheuristic optimization algorithms that has been used to solve continuity problems and has achieved significant results in real-world problems. However, the convergence accuracy and convergence speed of the original WOA are not satisfactory, and it tends to fall into local optima. Due to the above two shortcomings of the original WOA, this paper applies the covariance matrix strategy (CMS) and orthogonal learning mechanism (OLM) to WOA, which not only improves the convergence speed and convergence accuracy of the WOA but also enhances its ability to escape from local optima. In this section, we will go into more detail about the optimization process of the COWOA and the two optimization methods of CMS and OLM.
Covariance matrix strategy
In the original WOA, its guidance of individuals of the whale population in the search for the best focuses on the local area near the best individuals. However, it ignores the possibility of whales finding the best solution near those random individuals, resulting in the original WOA being very susceptible to falling into local optimization. Similarly, when the stochastic parameter p < 0.5, the attenuation parameter a1 controls the exploration and exploitation of the whale population by influencing the absolute value of the key factor A. If |A| = 1, the algorithm enters the exploration phase. However, as the number of evaluations increases, a1 decreases linearly from 2 to 0, while the absolute value of |A|also gradually decays non-linearly and randomly from 2 to 0. After the number of evaluations increases to a certain level, there is no longer a possibility that |A| is greater than 1, so the original WOA cannot find the global optimum at the late stage of each exploration phase. Therefore, this study addresses these shortcomings by introducing a covariance matrix strategy (CMS) (Beyer and Schwefel, 2002; Hu et al., 2021) into the original WOA, allowing WOA to escape from local optima. It works in three main phases, including the sampling phase, the selection and reorganization phase, and the location update phase. Each of them will be described below.
In the sampling phase, the CMS selects a random individual in the whale population and then uses a normal distribution to generate a new population in its vicinity centered on that individual. The process works as shown in Eq. (14).
where X(t + 1) denotes the new population generated based on the random solution, and t denotes the number of iterations of the population in the evolutionary process. m denotes the random solution selected in the whale population during the iteration and is the central individual that generates the next generation population. σ represents the step size of each move. N denotes the multinomial normal distribution, and C denotes the covariance matrix applied in this operation, as shown in Eq. (16).
In the selection and recombination phase, some representative individuals will be selected from the optimal set of the best individuals obtained after each update and the selected individuals will be recombined to generate a subpopulation relative to the overall population. The formula is shown in Eq. (15).
where m(t + 1) denotes the central individual of the new population generated for the next iteration, whose position is progressively closer to the optimal solution of the population. Xi denotes the ith population individual selected during the iteration. μ denotes the size of the subpopulation. ωidenotes the adaptive weights of the corresponding population individuals, and ω1 + ω1 + ω3 + ⋯ + ωμ=1.
In the position update phase, this process involves two main update methods, named the Rank−u−update update model and the Rank−1−update update model, respectively, which guide the individuals of the entire population in the global level search for superiority by updating the covariance matrix of the population. As shown, respectively, in Eq. (16), Eq. (17) and Eq. (18).
In the above equation, R1 denotes the Rank−1−update update mode, Ru denotes the Rank−u−update update mode, and c1 and cμ denote the learning rates of the two update modes, respectively, which are calculated as shown in Eq. (20) and Eq. (21).
where μeff represents a choice set subject to variance, whose mathematical model is shown in Eq. (22)
During the work of the mechanism, Pc represents how the matrix evolves when the CMS mechanism functions in the search for an advantage, and its update process is shown in Eq. (23).
In the above equation, cc denotes the learning rate of Pc; σ is the step parameter in matrix evolution. The initial value of σ is Sbest/S in which Sbest is the variance of the global best individual in each dimension relative to the population mean position and S is the sum of the variances of each individual in the population in each dimension relative to the population mean position. Its updating process is shown in Eq. (24).
where E(⋅) is the mathematical expectation function; I is a unit matrix used to calculate the step size. cσ is the learning rate of σ; dσ is the way of the step size that is updated for the damping coefficient. The initial value of Pσ is equal to 0 and is an evolutionary way of the step size, whose mathematical model is shown in Eq. (25).
Orthogonal learning mechanism
Under the experimental conditions set by the original WOA, the optimal whale search agent in the population was prone to fall into a local optimum (LO) in guiding other group members in the process of finding and apprehending prey, which greatly affected the ability of the whale population to explore and exploit the global optimum (GO). In this paper, an orthogonal learning mechanism (OLM)(Kadavy et al., 2020; Hu et al., 2021) is used to guide the population in a direction closer to the optimal solution by constructing a bootstrap vector after the original whale optimization mechanism, which to some extent improves the convergence speed and the ability of the WOA to explore the optimal solution in the early stages throughout the experiment. The OLM utilized in this experiment is described in the section below.
First, we will locate a guided individual. To better apply the advantages of OLM to the renewal process of whale populations, this study used three randomly selected whale individuals from the original whale population to locate a theoretically relatively better superior whale for the OLM to update the whale population. The expression is shown in Eq. (26).
where Xleader represents the guide whale positioned by random individuals Xk1, Xk2 and Xk3 represent the three selected random whales, respectively.
Then, this study introduces the OLM to the WOA and combines it with the acquisition of individual guided whales for guided updating of whale populations. At the same time, to better exploit the advantages of the OLM for exploring whale populations, this study carried out random grouping and hierarchical construction of whale populations and individuals, respectively. We will describe the OLM below; the details can be found in Ref. (Hu et al., 2021).
In order to make full use of each dimension in the individual whale and to better exploit its strengths, this experiment constructed Q levels for each dimension. The working model is shown in Eq. (27).
where q denotes the level at which the corresponding dimension is located in the hierarchy construction process.
In each round of experiments, we will obtain the corresponding candidate solutions and then compare each candidate solution’s evaluated values, allowing us to select the best experimental combination solution among many candidates as the current best prediction solution. As shown in Eq. (28).
where fitidenotes the evaluation value corresponding to each orthogonal combination solution generated by OLM; △i,j is the average evaluation value obtained for each influence factor at each level; Z denotes the prediction solution obtained; M denotes the number of prediction solutions. Finally, we select the experimental combination solution having the lowest average evaluation value as the best prediction solution by comparing the evaluation value of each candidate solution at different dimensions and levels.
Implementation of COWOA
In this section, the optimization process of COWOA is given based on the above two optimization strategies for the first time. As shown in Algorithm 2, this table describes the overall framework of the COWOA proposed in this paper with pseudo-code. As shown in Figure 2, this chart shows the overall workflow of the COWOA with flowcharts. The COWOA proposed in this paper largely compensates for the shortcomings of exploring and exploiting better solutions for the original WOA. In the first half of the whole experimental process, the exploration ability of the original algorithm is increased by introducing the OLM, which improves the convergence ability of WOA in the early part of the experiment to a certain extent. In the second half of the experimental process, the CMS was introduced to make the original WOA more likely to jump out of the local optimum, greatly improving the population’s search ability and convergence accuracy.

Figure 2. Flowchart of the COWOA.
Based on the improvement process and overall workflow of the COWOA, we can find that the initializations mainly determine the complexity of the COWOA, population position update, fitness value calculation, sorting, and the introduction of the OLM and the CMS in WOA together. As the time spent by the algorithm is closely related to the specific problem to be solved, the following analysis will focus on the complexity of COWOA in the following aspects, mainly including initializing the population O(N*D), updating the weights O(N*T), sorting O(N*logN*T), whale position update O(N*D*T/2), CMS update O(N*T/2) and OLM update O(N*(M*D + M*K)T/2). Therefore, the time complexity of the COWOA can be derived as O(N*T*(logN + (M*D + M*K) + 2) + N*D) by combining the above time complexity analysis. T denotes the maximum number of evaluations and can be derived from the maximum number of iterations. N denotes the number of individuals in the whale population, and D denotes the number of dimensions of the individual whales.
The proposed bCOWOA-KELM model
Binary transformation method
It is well known that the WOA is an excellent algorithm proposed for solving continuous problems. Similarly, the COWOA, an improved variant of the WOA proposed in this paper, is also oriented toward continuous problems. However, the core experiments in this paper require a discrete classification technique for feature selection, so the COWOA cannot be applied directly to the feature selection experiments. Therefore, a discrete binary version of the COWOA is proposed, named bCOWOA. The discrete process of the COWOA is described below.
Algorithm 2. The pseudocode for the COWOA.
Input: The fitness function F(x),
maximum evaluation number (MaxFEs),
population size (N), dimension (dim)
Output: The best Whale (Leader_pos)
Initialize a population of random
whales X
Initialize position vector and score
for the leader: Leader_pos, Leader_score
Initialize the parameters FEs, t, Q, F,
flag, alpha_no
While (FEs < MaxFEs)
For i = 1: size(X,1)
Return back the search agents that
go beyond the boundaries of the search
space
Calculate the objective function for
each search agent
FEs = FEs + 1
Update Leader_pos
Update parameters: flag, alpha_no
End for
If (FEs < MaxFEs/2)
Updating the optimization parameters
of the WOA
For i = 1: size(X,1)
Updating the optimization parameters
of the WOA
Updating individual whale
populations based on the original WOA
update mechanism and calculate the
assessment value of each individual
Locating an individual based on
three random individuals
Obtain variant individuals using the
OLM
End for
Else
Updating the population of
individuals using the CMS
End if
t=t+ 1
End while
Return Leader_pos
1) Based on the knowledge of discretization techniques, we can quickly determine that the solution domain of a discretization problem is [0,1].
2) As shown in Eq. (29), the bCOWOA is required to convert the searched solution to 0 or 1 by means of the S-shaped transformation function during the experiment.
where r is a random number in the interval [0,1]. Xd(t + 1)denotes a new solution obtained after the binary solution update. 1 indicates that the feature is selected, and 0 indicates that the feature is not selected. And the sigmoid(⋅) denotes the S-type transformation function used for the Xd(t)position update, as shown in Eq. (30).
where x denotes the solution generated during the process of the COWOA.
Kernel extreme learning machine
The KELM (Tian et al., 2019; Zhang et al., 2020; Zou et al., 2020; Chen H. et al., 2021; Wang and Wang, 2021) is an improved technology based on the Extreme Learning Machine (ELM) combined with a kernel function, which improves the predictive performance of the model while retaining the benefits of the ELM and is a single hidden feedforward neural network with a three-layer independent layer structure, including the input layer, the output layer, and the implicit layer. For a training set with N samples: S=(xj,tj) ∈ Rn×Rm, its target learning function model F(x) can be expressed in Eq. (31).
where xj denotes the jth input vector. ωi denotes the ith random input weight of the input vector. β denotes the ith output weight. f(ωixj + bi)denotes the activation function of the model. tj denotes the corresponding output expectation. Following the requirement of scientific research on the principle of simplicity and rigorousness of formulas, Eq. (31) can be rewritten as Eq. (32).
In the above equation, TN = [t1,t2,t3,…,tN]T, βN = [β1,β2,β3,…,βN]T, HN is a pre-feedback network matrix consisting of *Nf(⋅). According to the above equation, the functional model of the output weights can be represented by Eq. (33).
A regularization factor C and a unit matrix I can be incorporated to boost the neural network’s reliability, and the least squares result for the final weights is presented in Eq. (34).
Based on the ELM, the kernel function model is introduced to obtain the KELM whose function model is shown in Eq. (35).
where ΩELM denotes a kernel matrix consisting of kernel functions. K(xi,xj) denotes the kernel functions introduced in the ELM. where xi and xj denote the input vectors of the sample training set and γ is the parameter in the kernel function.
Implementation of the bCOWOA-KELM model
This section proposes a novel and efficient model based on the bCOWOA and the KELM for feature selection experiments, named the bCOWOA-KELM model. The model is mainly used to select key features from the dataset. The core model construction method is the optimal solution found by the bCOWOA, and then the optimal solution is extracted by the KELM classifier for secondary classification to improve the classification efficiency and accuracy of the model. In this model, we evaluate the quality of the solution vectors obtained by the bCOWOA through Eq. (38) (Chen et al., 2012, 2013; Hu et al., 2022b,c; Yang et al., 2022a), and use this evaluation as the basis for selecting the optimal solution vector, which is also a key step in the whole feature selection experiment.
where error is the error rate of the classifier model. D is the dimensionality of the dataset and also represents the number of attributes of the datasets. Rrepresents the number of attributes in the subset obtained from the experiment. α is a key parameter used to evaluate the classification and represents the weight for calculating the importance of the error rate. β denotes the length of the selected features. In this paper, α = 0.99 and β = 0.01.
In summary, we can obtain the bCOWOA-KELM model by combining the proposed bCOWOA with the KELM in this paper, and its workflow is shown in Figure 3.
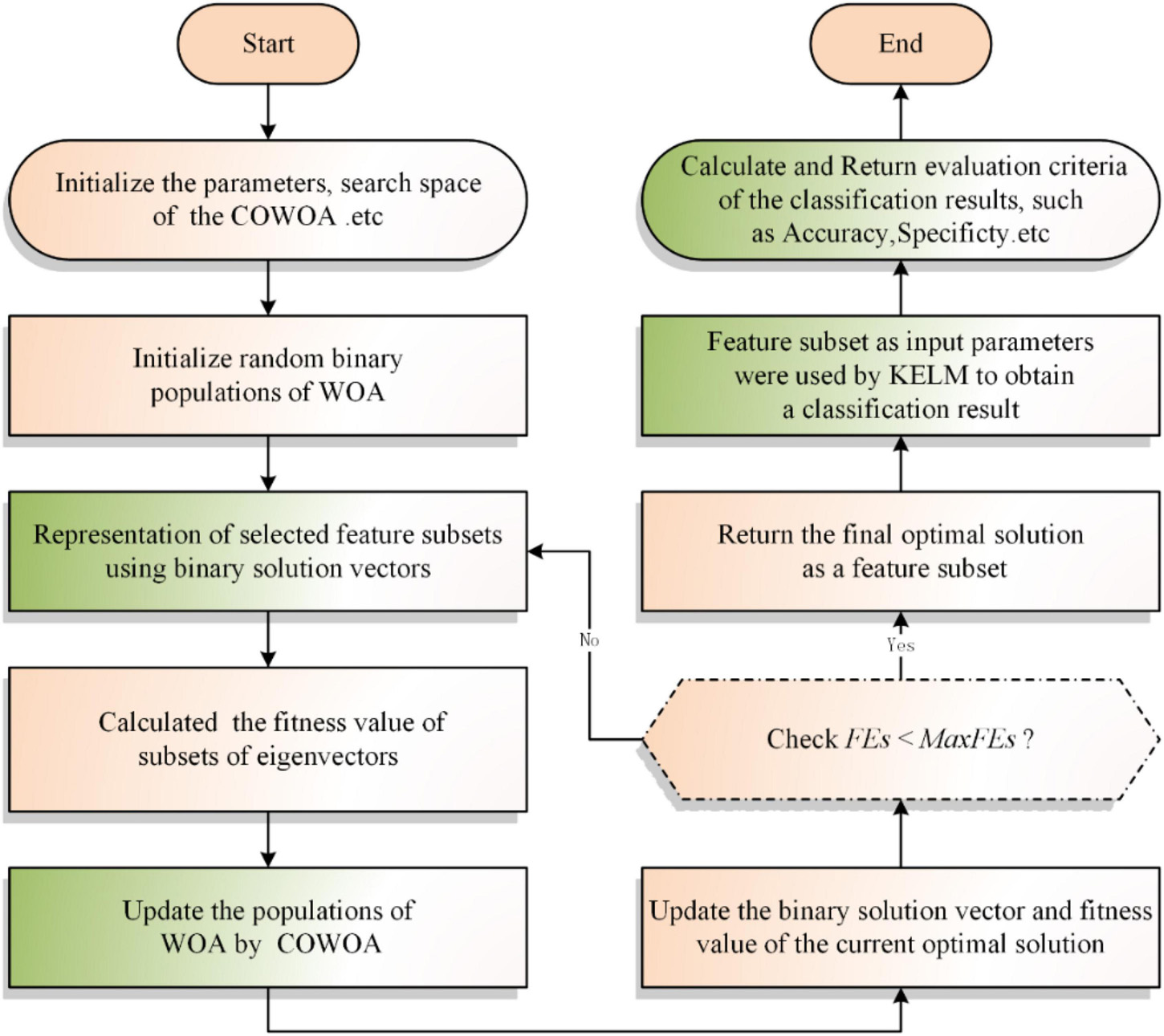
Figure 3. Flowchart of the bCOWOA-KELM model.
Experiment results and analysis
The purpose of setting up this section is to verify the comprehensive performance of the COWOA and to enhance the persuasiveness of the method proposed in this paper through the analysis results of the experimental data, which mainly include the comparison experiments of the benchmark functions and the classification prediction experiments of the dataset, with two main categories of experimental content. Assessment of computational tasks is a decisive stage that needs benchmarks, available data, and suitable metrics for a valid comparison (Cao Z. et al., 2022; Liu et al., 2022b,d). The evaluation criteria involved include the average value and variance of the relevant experimental data and Accuracy, Specificity, F-measure, and Precision used in the classification prediction experiments. In the benchmark experiment section, the COWOA is compared with the two single-strategy WOA variants and the original WOA, respectively, to demonstrate the better convergence performance of WOA under the dual-strategy effect. To further test the convergence performance of the COWOA, this section also sets up three comparison experiments based on the 30 functions of IEEE CEC2014 so that the COWOA is experimentally compared with seven WOA variants, nine original algorithms, and eight optimized variants of other algorithms, respectively. In the feature selection section, to validate the classification predictive power of the bCOWOA-KELM model and its effectiveness and scalability, the experiments are conducted based on six UCI public datasets and one medical dataset (HD dataset), respectively. Please see below for details of the experiments.
Benchmark function validation
This section mainly aims to verify the experimental performance of the COWOA proposed in this paper from several aspects, thus providing the basis for the next step of validating the bCOWOA-KELM classification prediction model proposed in this paper.
Experiment setup
This section focuses on the basic performance testing of the COWOA proposed in this paper in four aspects, including the comparison between the COWOA optimization mechanisms, the comparison between the COWOA and nine original algorithms, the comparison between the COWOA and seven WOA optimization variants, and the comparison between the COWOA and eight optimization variants of other algorithms. Specific details of the 30 benchmarking functions of IEEE CEC2014 are given in Table 1. The parameters of the involved algorithm are as shown in Table 2 in all function experiments (Table 3).
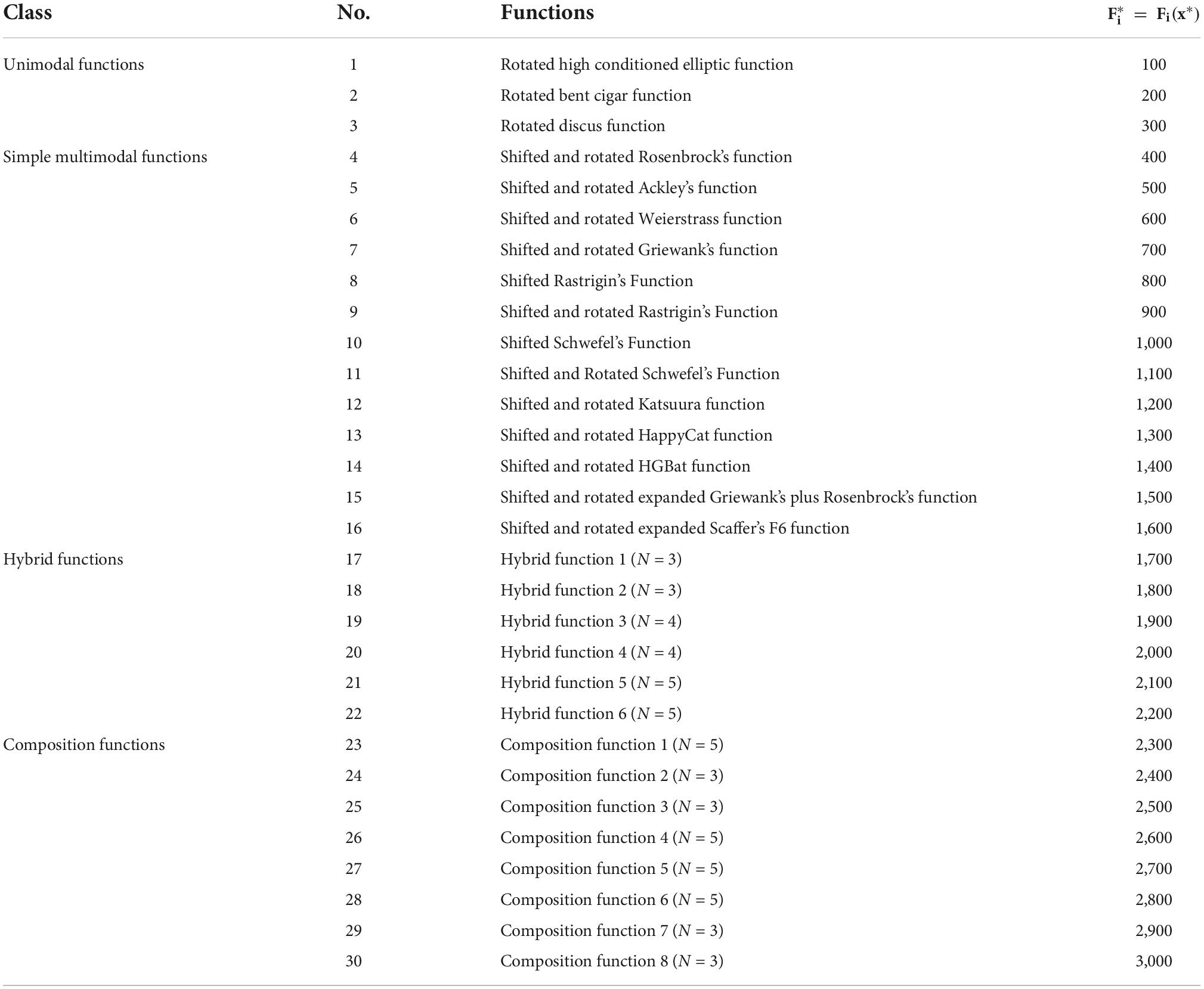
Table 1. Description of the 30 benchmark functions.
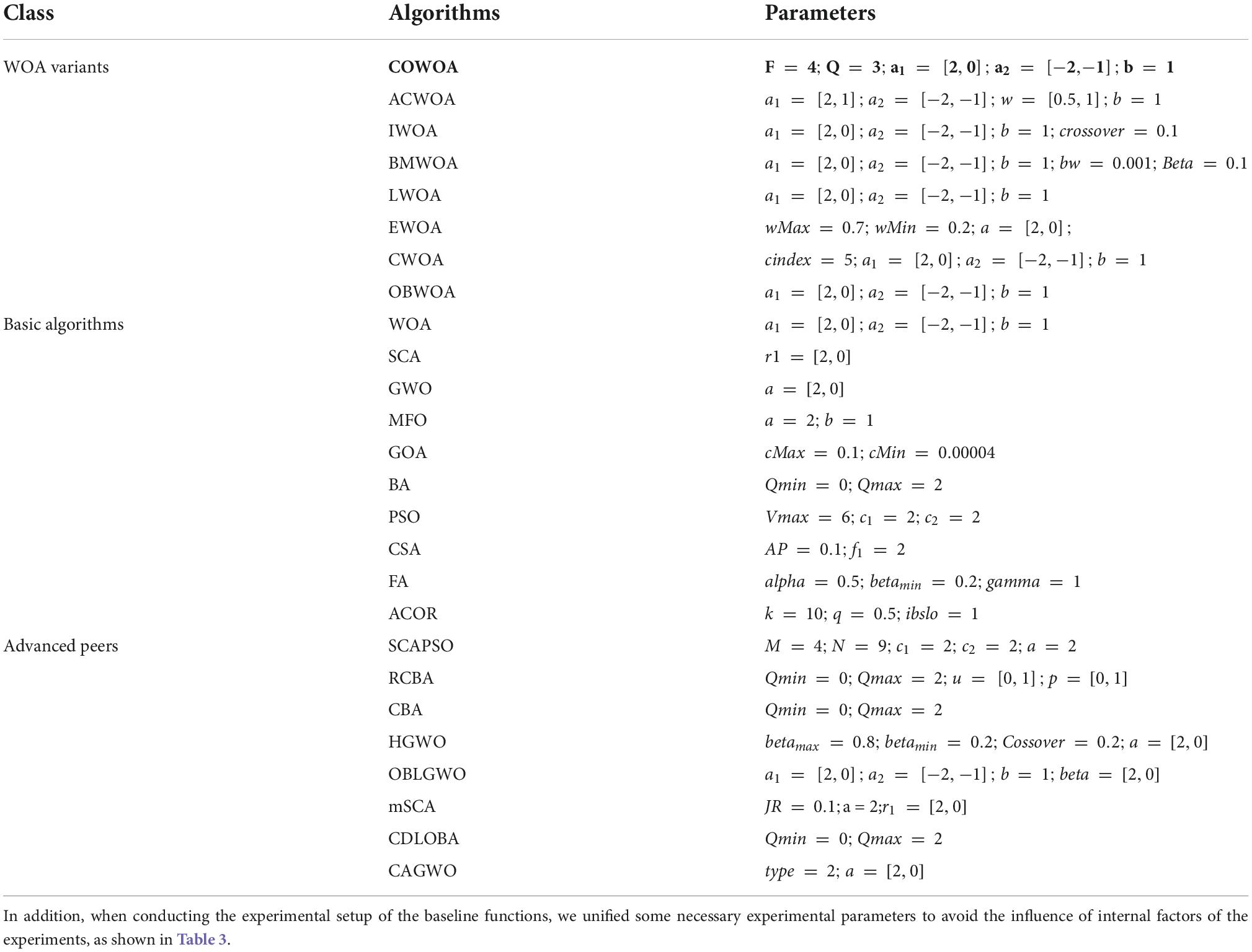
Table 2. Description of the parameters in involved algorithms.

Table 3. Parameter setting of the experiment.
For the experimental data, we use the experimentally derived average value (AVG) to reflect the performance of the corresponding algorithm, and the lower the mean value indicates, the more outstanding performance of the algorithm; we use the variance (STG) to reflect the stability of the algorithm, and the lower the variance indicates the relatively more stable performance of the algorithm. Also, in order to further discuss the comprehensive performance of all the algorithms participating in the comparison experiments, the Wilcoxon signed-rank test (García et al., 2010) and Friedman test (García et al., 2010) were also used to analyze the experimental results, and in the paper, respectively, are given in the form of tables and bar charts. In the results of the Wilcoxon signed rank test, “+” in the corresponding table given below indicates that COWOA performs better overall than the other algorithms, “ = ” indicates that it performs almost exactly the same as the other algorithms, and “-” indicates that it performs relatively worse than the other algorithms. Finally, in order to visually discuss the convergence ability of the algorithms and the ability to escape local optima, the partial convergence images of the algorithms are also given in the paper.
We have recommendations in other papers for fair empirical comparison between two or more optimization methods, which demand assigning the same computational resources per approach (Li et al., 2017; Chen J. et al., 2021; Liu K. et al., 2021; Zheng et al., 2022). To ensure the fairness of the external factors, we unified all the experiments based on functions in this section in the same environment, with the parameters of the specific experimental environment, as shown in Table 4.

Table 4. Description of the experimental environment.
Impacts of components
This section discusses the proposed process of COWOA, with the main purpose of providing a minimum practical basis for the COWOA proposed in this paper; it also explores the impact of the CMS and the OLM on the WOA during the experimental process and the advantages that the COWOA exhibits in the experiments, such as the superior convergence speed compared to the WOA. Therefore, this subsection sets up a comparison experiment between the COWOA and the CMS-based WOA variant (CMWOA), the OLM-based WOA variant (OWOA), and the original WOA based on the 30 benchmark test functions in IEEE CEC2014.
According to Supplementary Table 1, it is easy to see that among the 30 benchmark function test experiments, the COWOA is relatively more prominent in terms of the number of times it has a smaller mean and variance performance compared to the other three algorithms. Among them, the more the mean value of COWOA, it means that COWOA has more vital exploration and exploitation ability on the optimal problem and also means that it is easier to get a better solution; the more the number of times to get smaller mean value means that COWOA is more adaptable on the optimization problem. In addition, we can see that the variance of the COWOA is relatively small, and the number of performances is relatively high, which indicates that the COWOA proposed in this paper is relatively more stable on the preliminary benchmark function test. Therefore, we can conclude that the comprehensive performance of the COWOA is better when the benchmark functions are optimized using COWOA, CMWOA, OWOA, and WOA, which also tentatively indicates that the COWOA has the prerequisites to be proposed.
To further demonstrate the performance of the COWOA and to enhance the persuasiveness of the COWOA proposed in this paper, two more intuitive statistical methods, the Wilcoxon signed-rank test, and the Freedman test, are used below to analyze and evaluate the experimental data. Table 5 shows the results of the Wilcoxon signed-rank test, where the second column of Table 5 gives the comparative details of the experiments, from which we can see that the COWOA proposed in this paper is superior to the original WOA in as many as 25 out of 30 basis functions, with one having similar performance and only four being relatively poor, which also shows that there is still room for improvement in the COWOA, but does not negate the fact that the COWOA is superior to the original WOA. Similarly, we can see that the COWOA also outperforms the CMWOA and OWOA. Also, the table gives the Wilcoxon ranking, and COWOA is ranked first in the comparison.
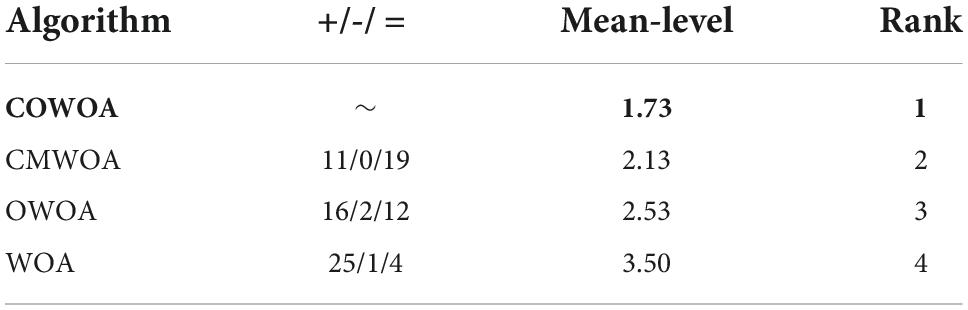
Table 5. Results of Wilcoxon signed-rank test.
Table 6 gives the P-values obtained for this experiment based on the Wilcoxon signed-rank test, and the bolded parts in the table represent the results of experiments with P-values less than 0.05. By looking at the P-values, it can be seen that only a few values are greater than 0.05, which indicates that the COWOA exhibits much better performance than the single mechanism improvement variant and the original WOA in this comparison experiment.
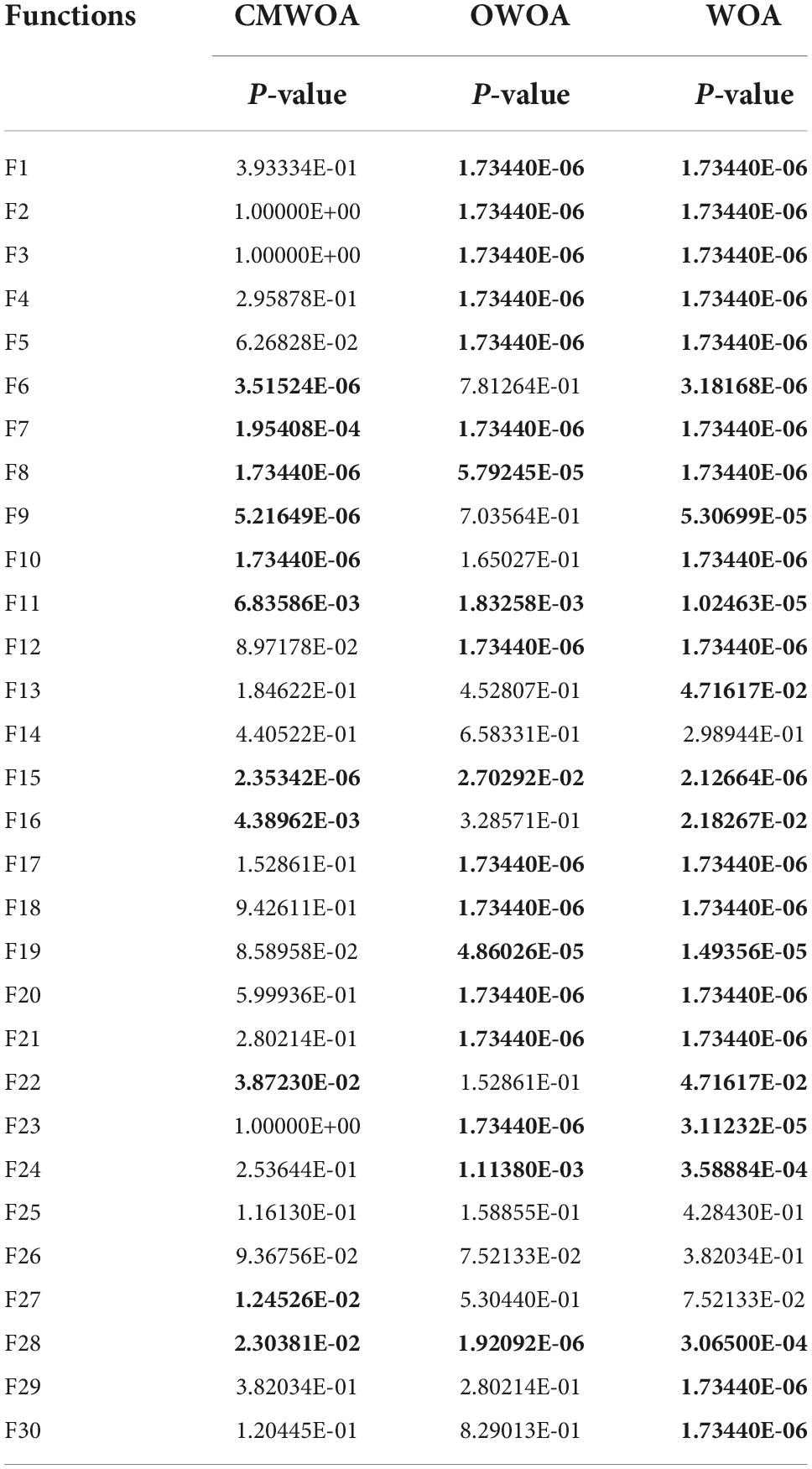
Table 6. P-values of COWOA on the Wilcoxon test.
Figure 4 Shows the Friedman ranking results of this improvement experiment, from which it can be more intuitively seen that the COWOA can obtain a smaller Friedman average than the other three comparative algorithms in the improvement process under the dual effect of CMS and OLM, which indicates that the COWOA is ranked first in this test method. Therefore, we can tentatively determine that the performance of the COWOA is optimal in this improvement experiment.
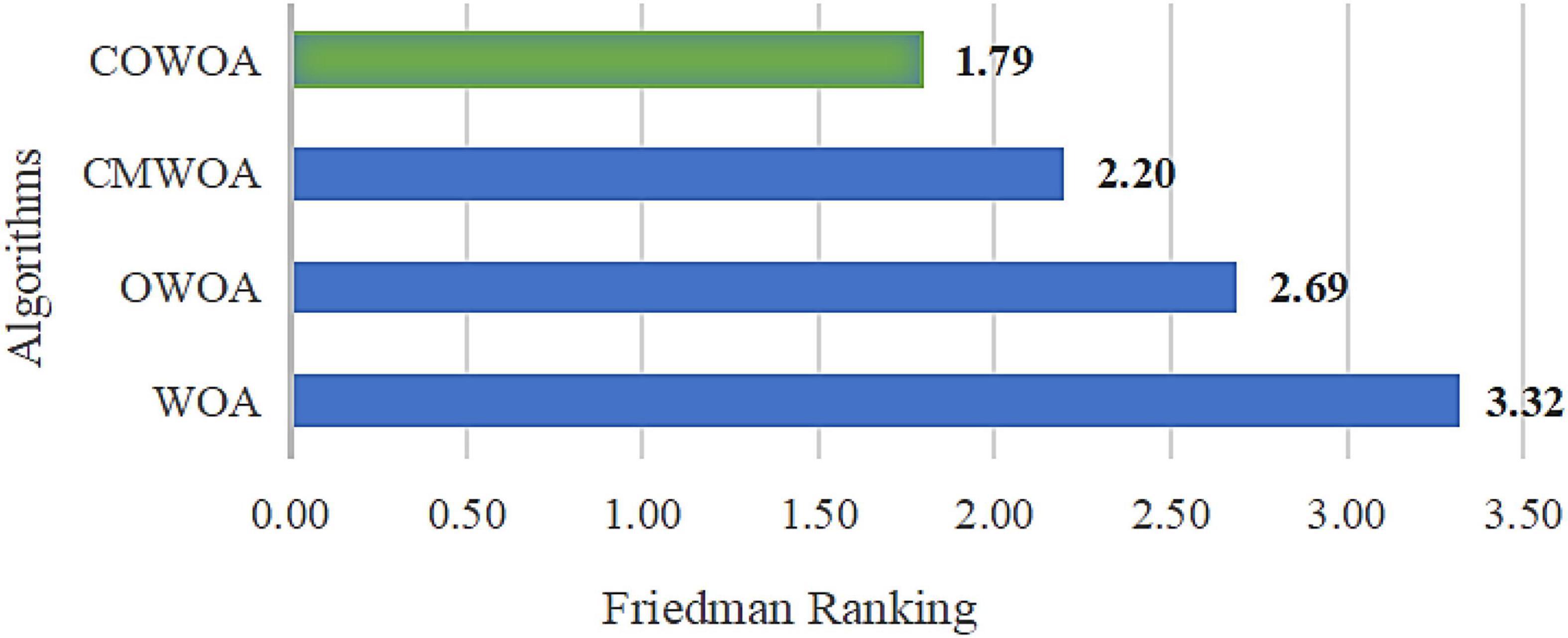
Figure 4. Results of Friedman ranking between the COWOA optimization mechanisms.
Figure 5 gives some of the convergence curves of the four algorithms in the process of finding the optimal solution. The 30 benchmark test functions used in the experiments are divided into four categories: unimodal, simple multimodal, hybrid, and combinatorial functions. Therefore, in order to highlight the performance of the COWOA, we selected the convergence plots so that Figure 5 covers these four categories. It is relatively intuitive to see from the plots that the convergence ability of COWOA on functions F10, F11, and F16 performs very well relative to the other three algorithms. Their convergence curves explore the relatively optimal solutions early in the pre-convergence period, indicating that the COWOA also runs the risk of being unable to escape from the local optimum in some problems. However, the convergence ability it possesses in this experiment is also unmatched by the WOA and cannot be compared. On functions F1, F2, F12, and F17, the shapes of the convergence curves of the COWOA and the CMWOA are extremely similar, but in terms of the final convergence accuracy, except for the equal convergence accuracy on function F2, COWOA is superior; in addition, we can also see that the convergence curve of COWOA reaches a relatively better time earlier than that of CMWOA, which indicates that the COWOA has been strengthened after the introduction of the OLM based on the CMWOA. Not only the convergence accuracy has been improved, but also the convergence speed has been significantly enhanced. The convergence curves of COWOA on functions F1, F2, F11, F12, F16, and F17 all have inflection points in the middle and early stages of the whole experiment, which indicates that the optimization algorithm can escape the local optimum at that stage. In summary, through the comparative experiments and analysis of COWOA with CMWOA, OWOA, and WOA, we can conclude that COWOA is an excellent optimized swarm intelligence algorithm among the improved WOA variants under different combinations of the two optimization methods.
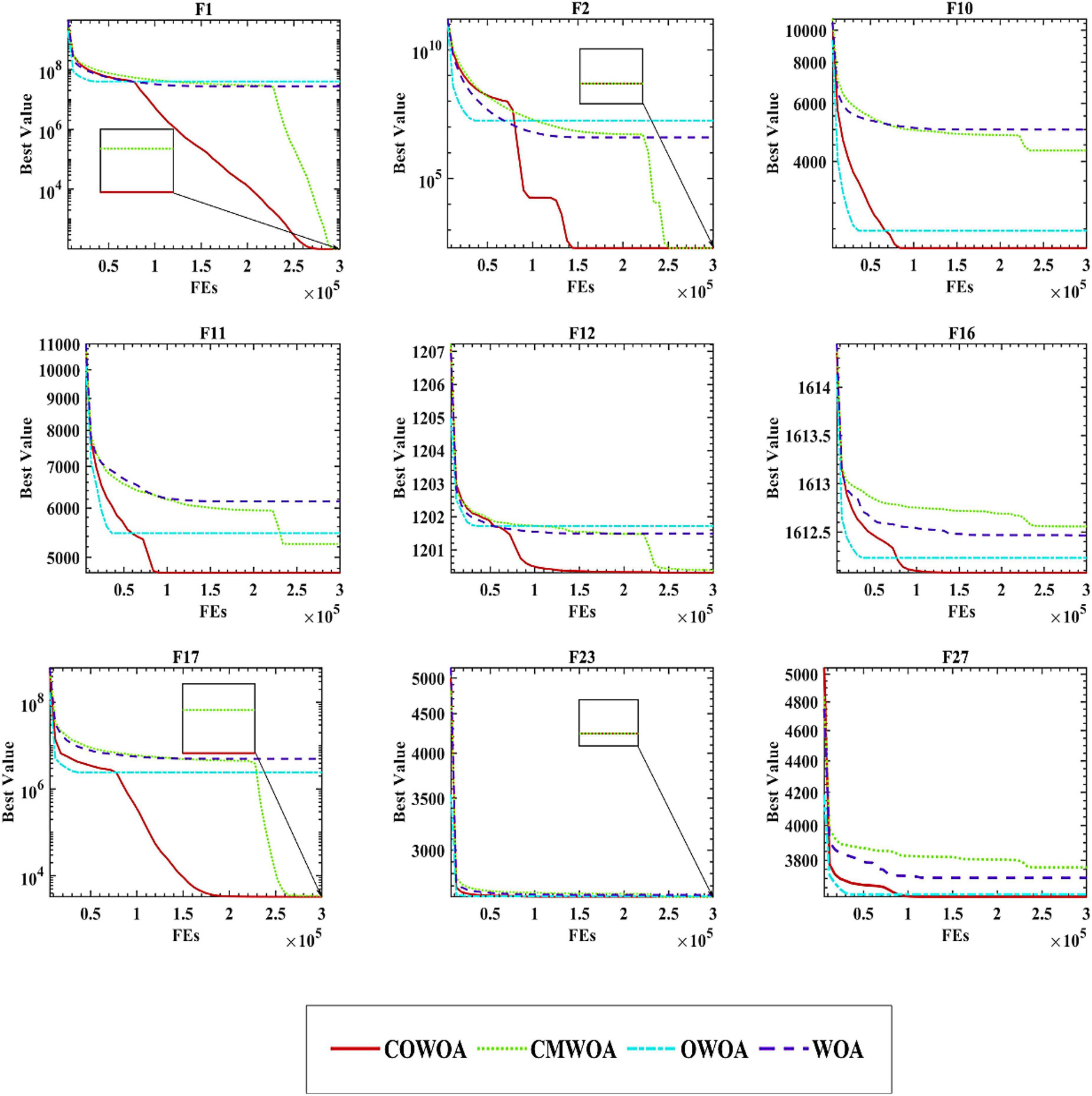
Figure 5. Convergence curves of COWOA performance tests.
Balance analysis experiment
The balance analysis results are given in Figure 6 based on partial benchmark functions. The balance analysis results of COWOA are shown in Figure 6A. The balance analysis results of CMWOA are shown in Figure 6B. The balance analysis results of OWOA are shown in Figure 6C. The balance analysis results of WOA are shown in Figure 6D. Finally, Figure 6E gives the convergence curves obtained by the above four algorithms for the corresponding benchmark function experiments. According to the equilibrium analysis results shown in Figure 6, it can be seen from the functions F6, F12, F17, and F19 that the CMS can enhance the exploration ability of WOA to a certain extent. The OLM improves the development ability of WOA. Combining the results of the equilibrium analysis and the corresponding convergence curves, it can be easily seen that the combination of CMS and OLM can make COWOA reach a better balance point in exploration and exploitation, so that COWOA can obtain better convergence accuracy and convergence speed than CMWOA, OWOA, and WOA in the benchmark function experiments.

Figure 6. The balance analysis results of COWOA, CMWOA, OWOA, and WOA.
Comparison with whale optimization algorithm variants
In this subsection, to demonstrate that the COWOA still has outstanding optimization performance in the improved WOA variants and to further enhance the persuasiveness of the COWOA proposed in this paper, seven optimization variants of WOA were purposely selected for comparative experiments and results analysis on 30 benchmark functions. There are CWOA (Patel et al., 2019), IWOA (Tubishat et al., 2019), BMWOA (Heidari et al., 2020), ACWOA (Elhosseini et al., 2019), LWOA (Ling et al., 2017), OBWOA (Abd Elaziz and Oliva, 2018), and EWOA (Tu et al., 2021a). In Supplementary Table 2 shows the AVG and STD of the eight improvement variants of the WOA, including the COWOA, obtained in this experiment. By looking at the table, we can see that the COWOA obtains not only the relatively smallest mean value but also the variance on 13 of the 30 benchmark functions, such as functions F1, F2, F3, F4, F5, F7, F17, F18, F19, F20, F21, F29, and F30. This indicates that the COWOA is able to obtain not only relatively optimal solutions, but also possesses a stability that is difficult to match with the other seven WOA optimization variants. Based on the table of 30 benchmark functions in the experimental setup section, we can find that the 13 listed optimization problems cover the four categories of benchmark functions in the table, which indicates that the COWOA is still more adaptable among the participating WOA variants. In summary, we can conclude that the COWOA is an improved variant of WOA that performs well.
In order to further verify the excellent performance of the COWOA, two test results that are statistically significant are presented next, which are the results of the Wilcoxon signed-rank test and the results of Friedman ranking, as shown in Table 7 and Figure 7, respectively. As can be seen from Table 7, the COWOA has a significant average ranking advantage and the final Wilcoxon signed-rank test ranks first among the algorithms involved in the comparison; the second column of Table 7 gives the strengths and weaknesses of the COWOA relative to the other WOA variants in the Wilcoxon signed-rank test. Although the relative strengths and weaknesses are mixed, the final results show that the COWOA is relatively the best.
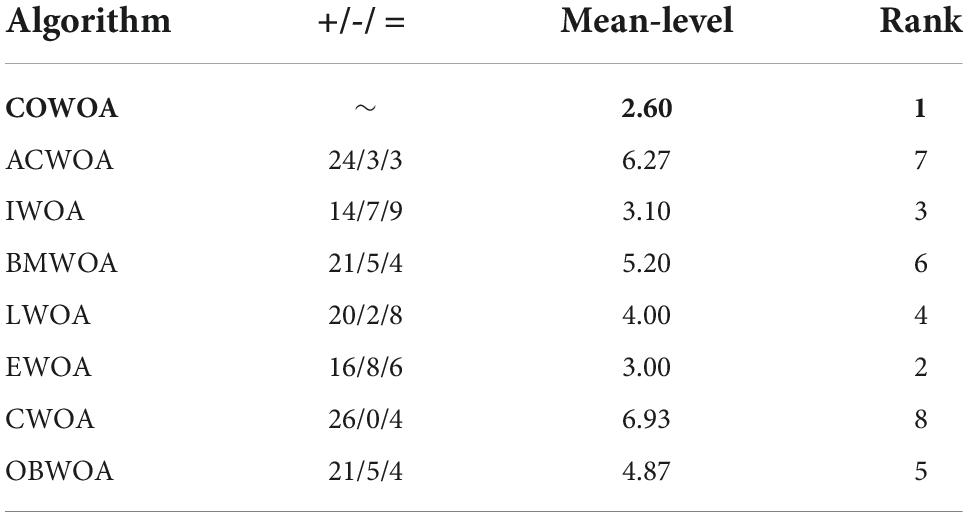
Table 7. Results of Wilcoxon signed-rank test.
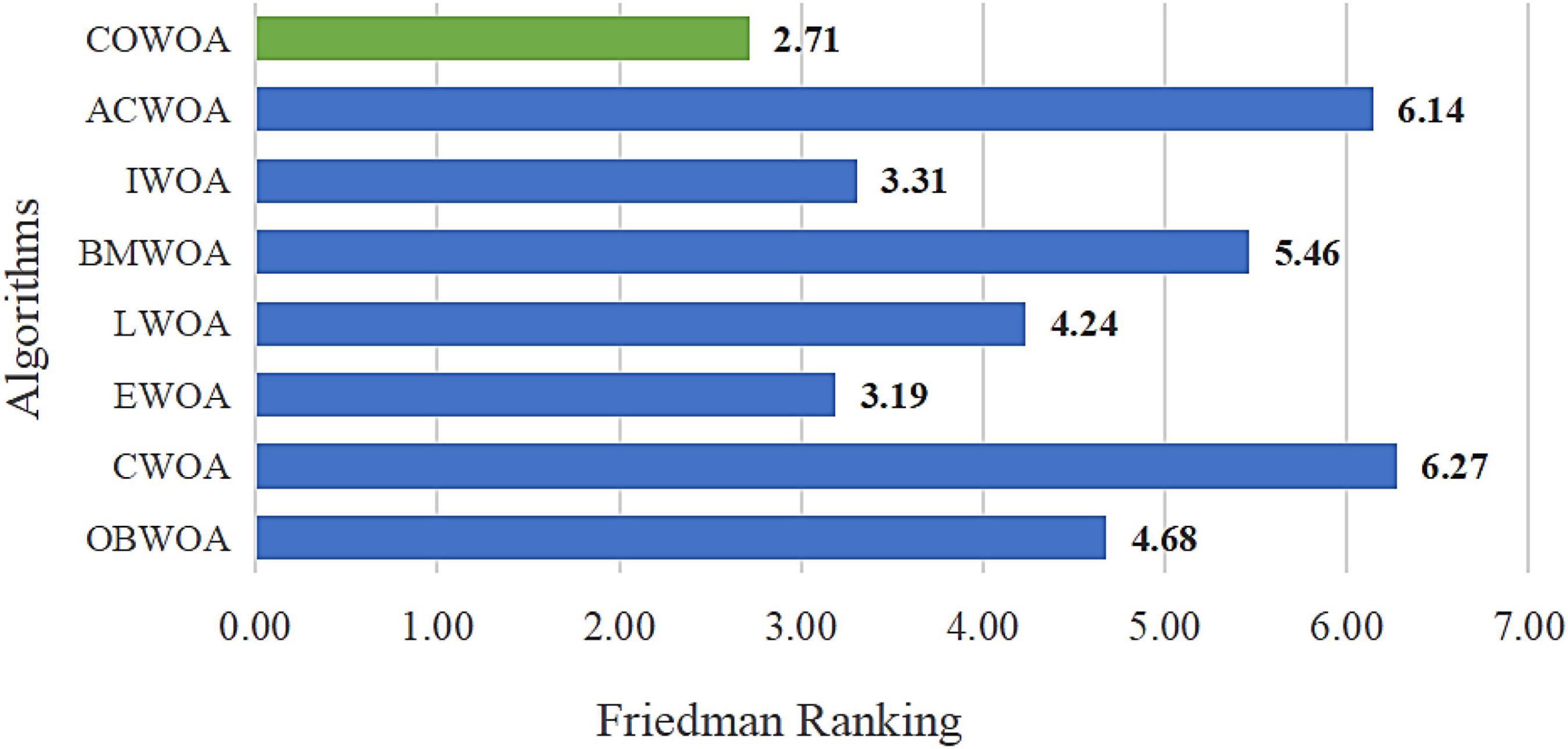
Figure 7. Result of Friedman ranking between the COWOA and the well-known WOA variant algorithms.
Table 8 gives the P-values obtained for this experiment based on the Wilcoxon signed-rank test, and the bolded parts of the table represent the results of experiments with P-values greater than 0.05. According to the results in the table, the number of P-values greater than 0.05 is a much smaller proportion of the overall results than the proportion less than 0.05, which indicates that the COWOA is superior to the other 7 well-known WOA variants in this evaluation method.
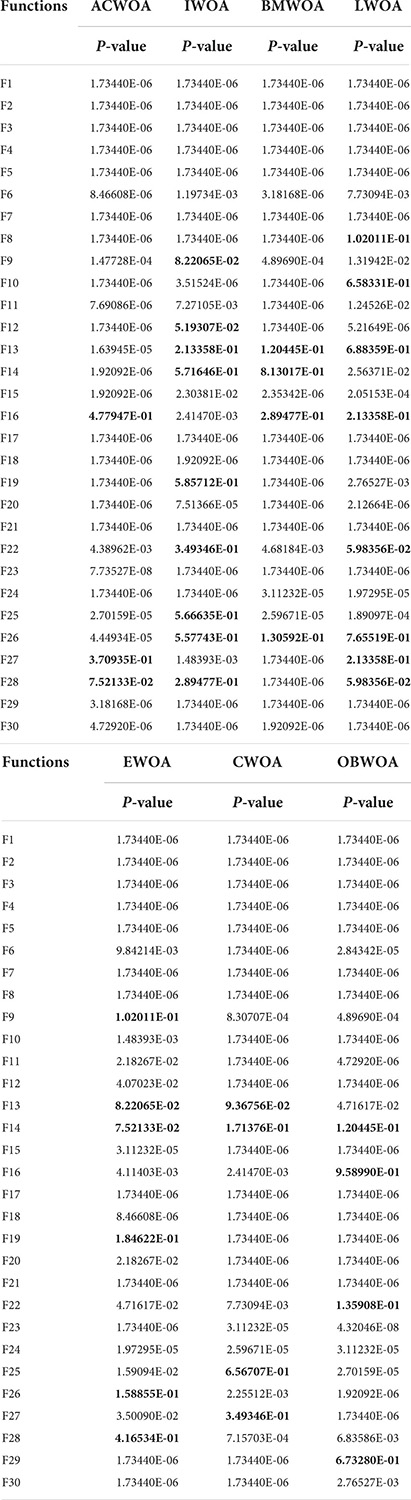
Table 8. P-values of COWOA vs. well-known WOA variants on the Wilcoxon test.
As seen in Figure 7, the COWOA obtained a Friedman mean of 2.71 and the smallest compared to the seven well-known WOA improvement variants, indicating that the COWOA ranks first under this test method. For the other seven compared algorithms, the mean value obtained by COWOA is 0.48 smaller than the second-ranked EWOA and 3.56 smaller than the poorly ranked CWOA. In summary, we can prove through this experiment that the COWOA is an excellent new variant of WOA improvement.
To confirm the superiority of the COWOA, we next took the convergence curves obtained throughout the experiment and selected images of the optimization process for nine functions according to the principle of including four classes of benchmark functions, as shown in Figure 8. The convergence curves of the COWOA on the listed functions are significantly better than those of the other seven WOA variants, except for F9, which shows that the COWOA is relatively the strongest in these optimization problems. On functions F1, F2, F12, F17, F21, F29, and F30, the other seven WOA variants’ convergence curves are relatively smooth. In contrast, the convergence curves of the COWOA have one or two inflection points in the middle and early stages of the experiment, which indicates that the COWOA can escape the local optimum early in the process of finding the optimal solution and that the convergence achieved in the end is the accuracy is also relatively optimal. In summary, in the comparative experiments set up in this paper, the convergence ability of the COWOA proposed can achieve relatively better than the seven WOA variants of the algorithm. Therefore, this experiment proves that the COWOA is an excellent WOA variant.
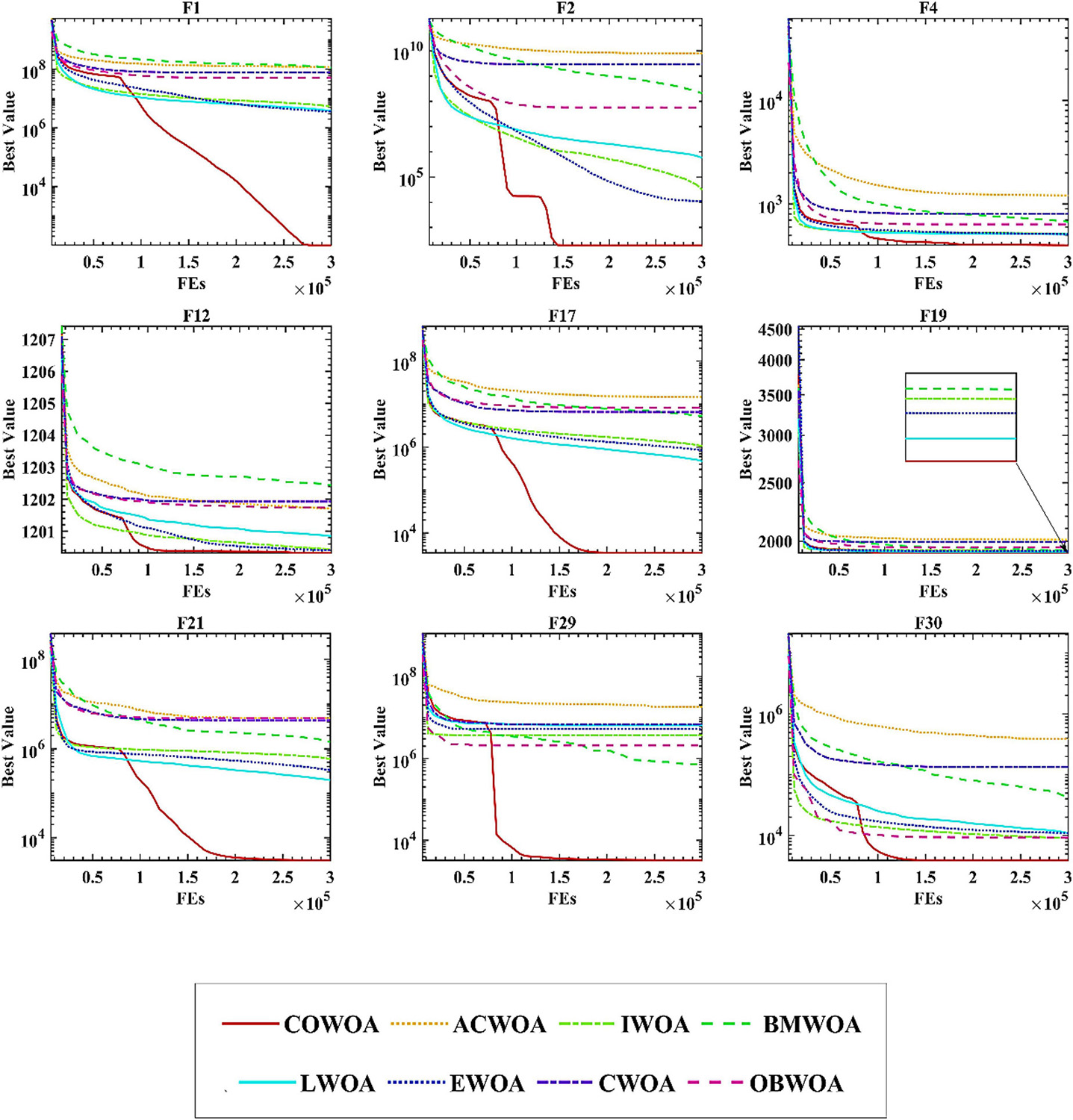
Figure 8. Convergence curves of COWOA with the WOA variants.
The results of the experiments that compare the computational costs of COWOA and the 7 WOA variants are shown in Figure 9. To ensure the experiment’s fairness, the experiment uniformly uses the same experimental setup as the benchmark function validation experiments. In addition, the results of this experiment are counted in seconds. As seen in Figure 9, COWOA, IWOA, EWOA, and CWOA have similar time costs in optimizing the 30 basic problems, and all have relatively higher complexity than ACWOA, BMWOA, LWOA, and OBWOA. This is due to the different complexity of the optimization methods introduced in the WOA variants. For COWOA, the CMS and the OLM bring more computational overhead to it. The comprehensive analysis of the experimental results presented in this section concludes that COWOA is computationally acceptable in terms of the time cost spent.
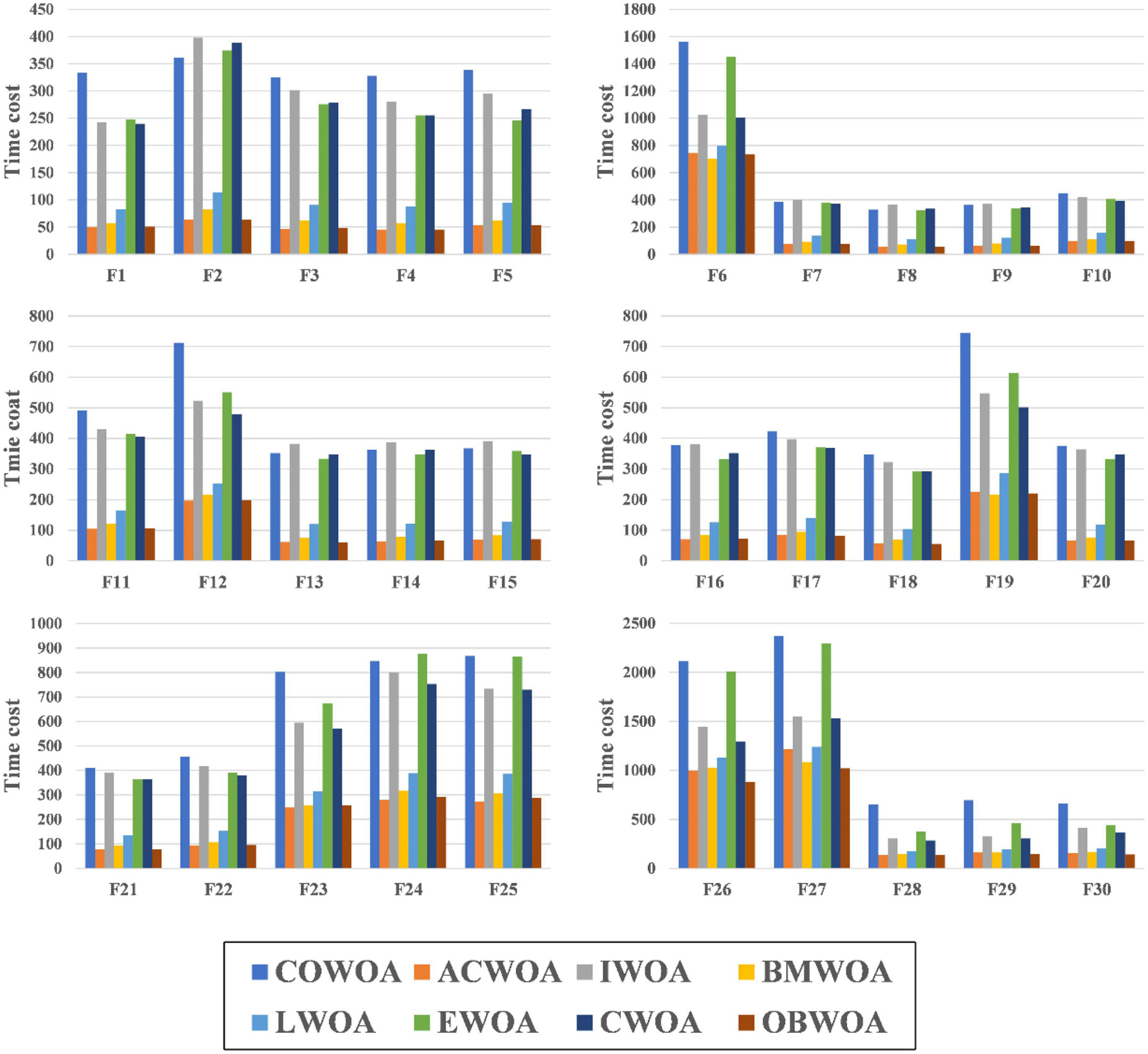
Figure 9. The computational cost of COWOA with the WOA variants.
Comparison with basic algorithms
In this subsection, we set up a comparison experiment between the COWOA and the well-known original algorithms of today, and there are SCA, MFO, PSO, WOA, BA, GWO, GOA, FA, ACOR, and CSA. The main purpose of this section is to provide a practical basis for the COWOA proposed in this paper and to further demonstrate that the COWOA also has relatively outstanding convergence capabilities among other original algorithms.
Supplementary Table 3 presents the corresponding experimental results in the form of AVG and STG in Supplementary Table. By comparing and looking at the mean values; we can see that the COWOA exhibits the smallest mean values for functions F1, F2, F3, F4, F7, F10, F12, F17, F18, F19, F20, F21, F23, F29, and F30 out of the 30 is benchmark functions. The COWOA excelled in this area with 15 benchmark functions compared to other algorithms, a capability that other algorithms participating in the comparison experiments did not have. In addition, the COWOA showed the smallest variance in functions F1, F2, F3, F4, F7, F12, F17, F18, F20, F21, F23, F29, and F30, indicating that the COWOA is relatively more stable in its optimization of these benchmark functions. In summary, the COWOA is not only highly adaptive to the optimization problem, but also achieves relatively better solutions in comparison with the nine well-known original algorithms; the relatively small variance of the optimal solution for most of the problems demonstrates that the COWOA is more stable most of the time. Therefore, the overall capability of the COWOA is worthy of recognition, and the COWOA is a very good improvement algorithm.
To make the experimental results more scientific, the Wilkerson signed-rank test was used to evaluate the experimental results below, as shown in Table 9. According to Table 9, we can see that the COWOA ranks first in the overall ranking of the comparison experiments in this setup. The two columns Mean-level and Rank give the final ranking data more intuitively. In addition, the second column of the table shows the details of the experimental results based on 30 benchmark functions, from which it is easy to see that the original algorithm performs better on at least 17 optimization problems and at most 28 optimization problems for the different original algorithms. Although the performance on some problems is not as outstanding as the other original algorithms, this does not affect the overall performance of the COWOA, which is relatively the best among them, but only shows that the COWOA still has much room for optimization in the future.
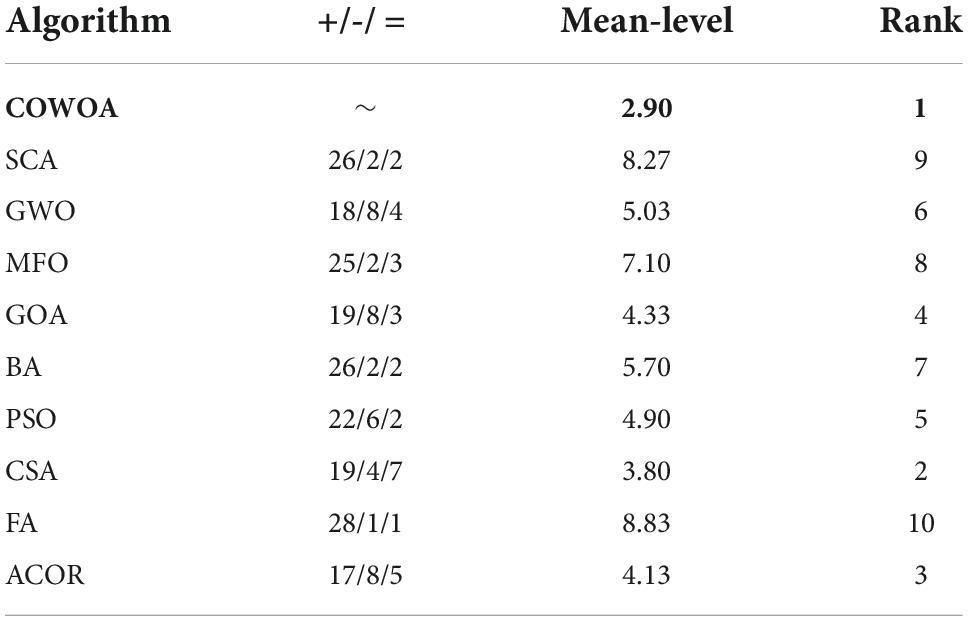
Table 9. Results of Wilcoxon signed-rank test.
Further validation of the Wilcoxon signed-rank test is given in Table 10, where the bold data indicates a p-value greater than 0.05. The number of p-values greater than 0.05 in the overall results of the COWOA against the 9 well-known original algorithms is very small, which proves that the COWOA still performs very well in comparison with the well-known WOA variants.
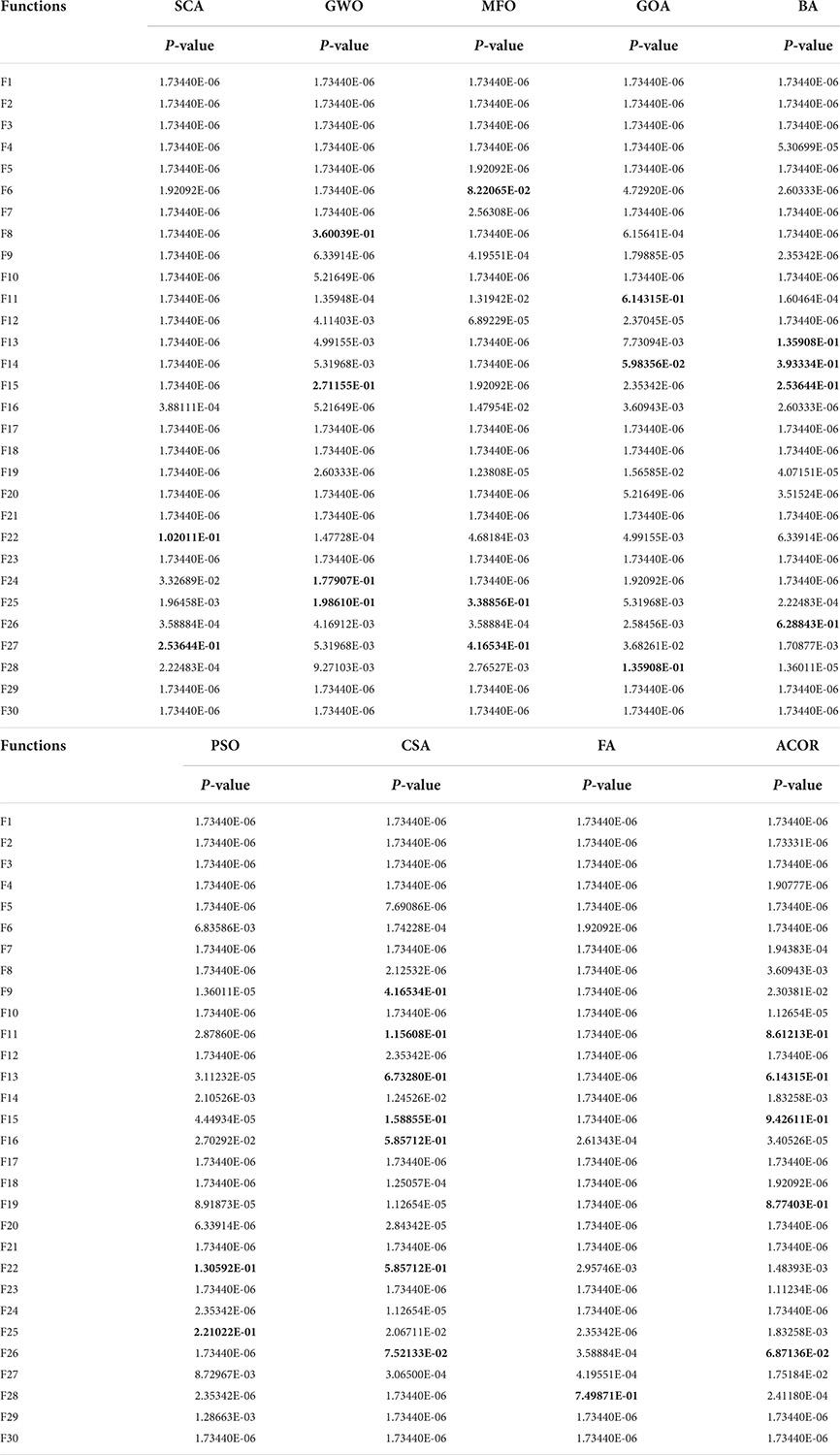
Table 10. P-values of COWOA vs. the well-known original algorithms on the Wilcoxon test.
The results of the Friedman test are given in Figure 10, from which it can be seen that the COWOA has the smallest mean value of the Friedman compared with the nine well-known original algorithms, which indicates that the COWOA is ranked first in this basis function experiment. If the difference between the second-ranked ACOR and the COWOA is defined as △, then the absolute value of △ is greater than 1, |△| > 1. As a result, it can be proven that the COWOA still has an obvious advantage under this evaluation method.
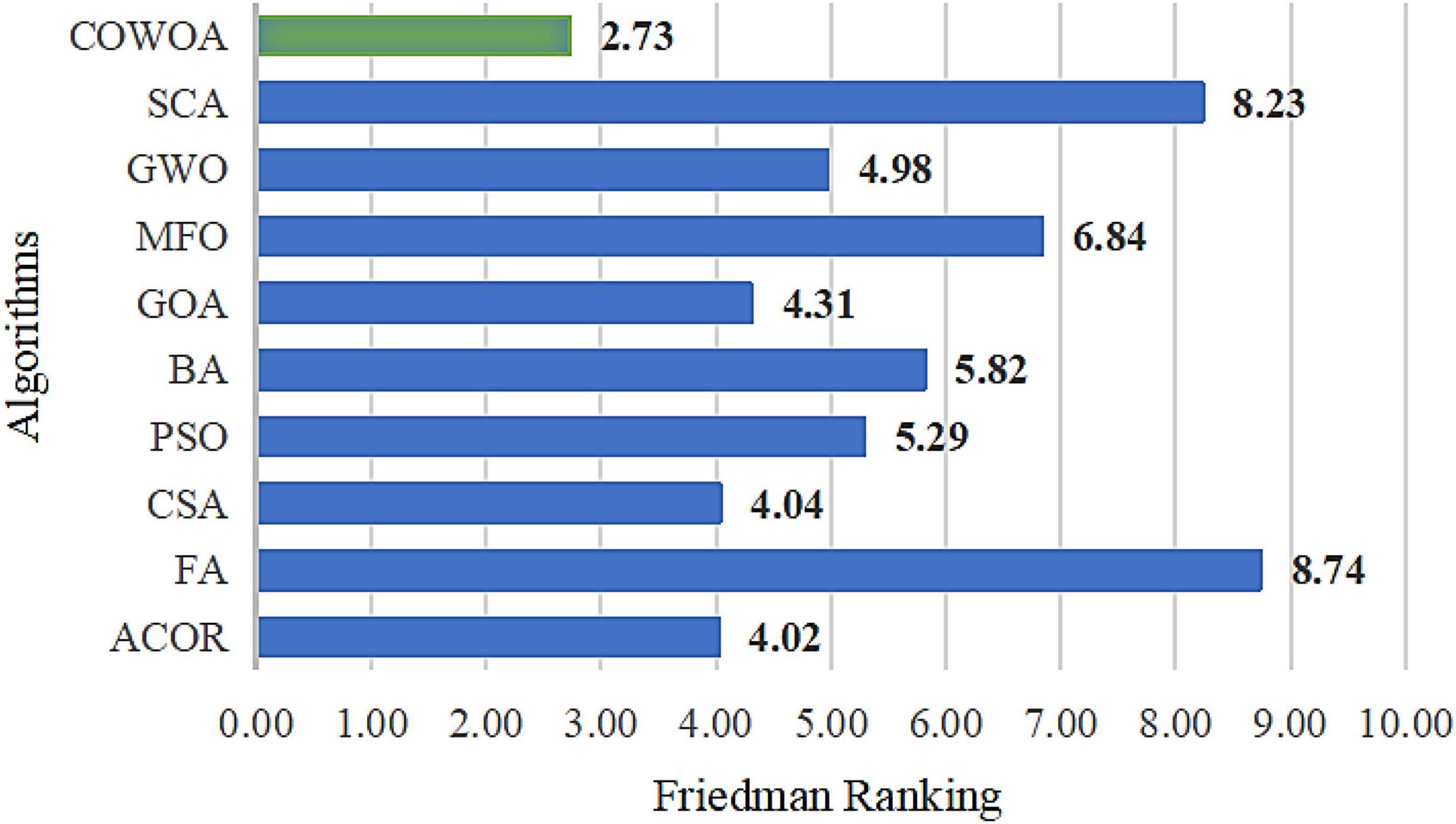
Figure 10. Result of Friedman ranking between the COWOA and the well-known original algorithm.
To further demonstrate the benefits of COWOA, this subsection also uses the same experimental structure set up in the performance testing section of COWOA to give convergence curves for the entire iterative process and the convergence curves for the nine functions selected by the four classes of benchmark functions, as shown in Figure 11. It can be seen from the convergence plots that the convergence speed of COWOA has an undeniable advantage over the entire iterative process. The ability to develop a global optimum is relatively the best relative to the nine original algorithms. In addition, the convergence curves of the COWOA on functions F1, F2, F17, F21, F29, and F30 all have obvious inflection points, and the inflection points are relatively forward, which indicates that the optimization algorithm has an undeniable ability to escape the local optimum in the early stage of finding the optimal solution, which is a convergence performance that the other nine original algorithms do not have. In summary, through the analysis of the comparative experiments in this setup, we can conclude that the COWOA proposed in this paper is an excellent variant of WOA.
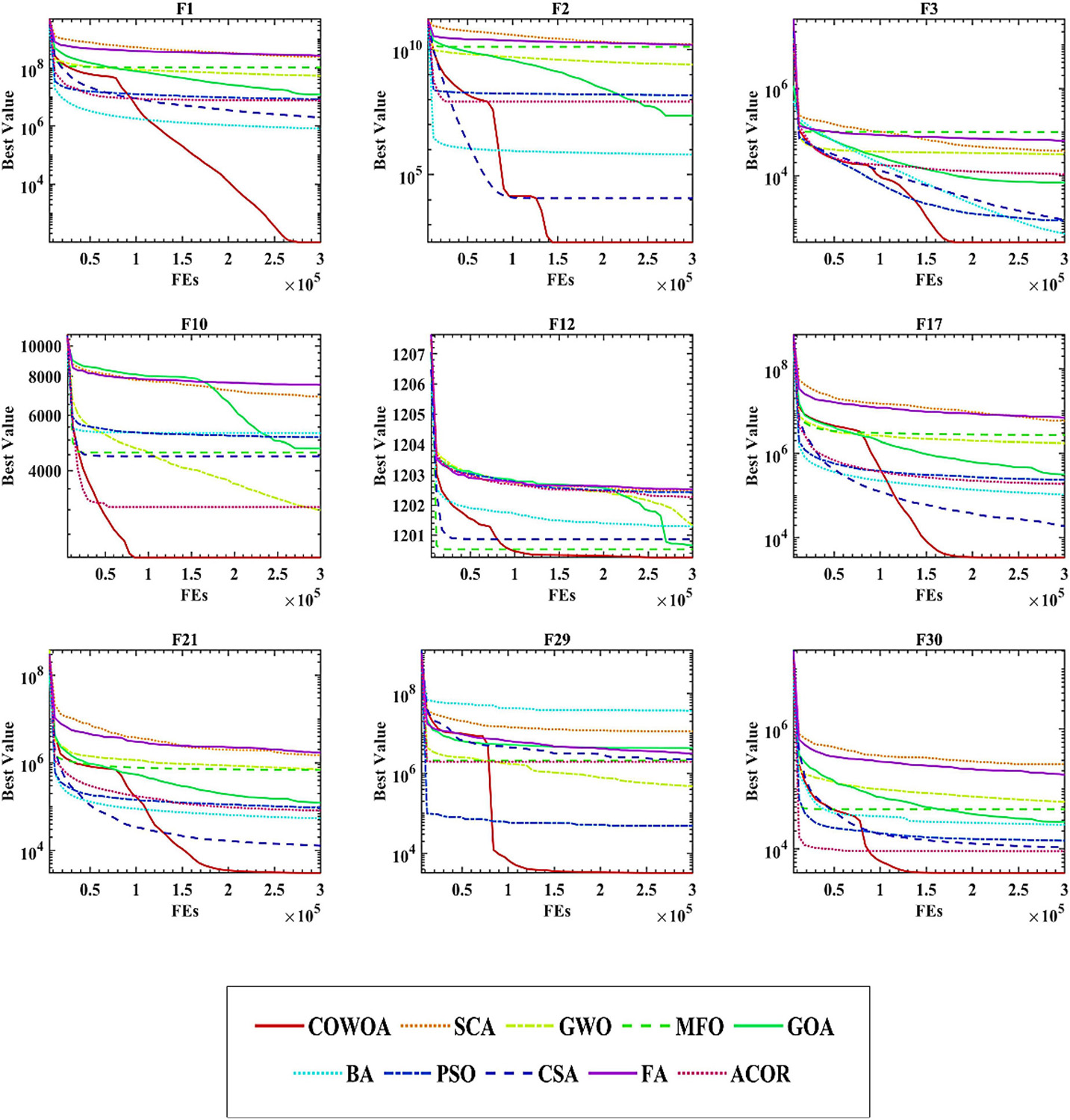
Figure 11. Convergence curves of COWOA with the well-known original algorithms.
Comparison with advanced peers
In this section, we make a comparative experiment and analysis of COWOA with eight optimization variants of other algorithms, which will be the most powerful interpretation of COWOA performance in the experimental part of this paper on basis functions. They are CBA (Adarsh et al., 2016), OBLGWO (Heidari et al., 2019a), mSCA (Qu et al., 2018), RCBA (Liang et al., 2018), HGWO (Zhu et al., 2015), SCAPSO (Nenavath et al., 2018), CDLOB (Yong et al., 2018), and CAGWO (Lu et al., 2018). Supplementary Table 4 shows the AVG and STG of the benchmark experimental results of COWOA against the eight improved algorithms. By comparing and looking at the average values, we find that for most of the benchmark functions, COWOA has the smallest average value. This indicates that the COWOA has a relatively higher quality optimization capability in this experiment. Furthermore, the relatively smallest variance of the optimal solutions obtained is a strong indication of the better stability of the COWOA’s optimization capability on these benchmark functions. Therefore, we can tentatively conclude that the COWOA is a novel and excellent improvement algorithm.
Table 11 shows the final analysis and evaluation details of the Wilkerson signed-rank test, from which it can be seen that the mean of the COWOA has a significant advantage in this set-up of the comparison experiment and is ranked first among the compared algorithms. In addition, the second column of the table gives the degree of superiority of the COWOA compared to the other eight algorithms, from which we can see that the COWOA exhibits relatively more outstanding optimization capabilities for most of the optimization problems, which not only demonstrates the greater performance of the COWOA but also proves that it has better adaptability to many optimization problems.
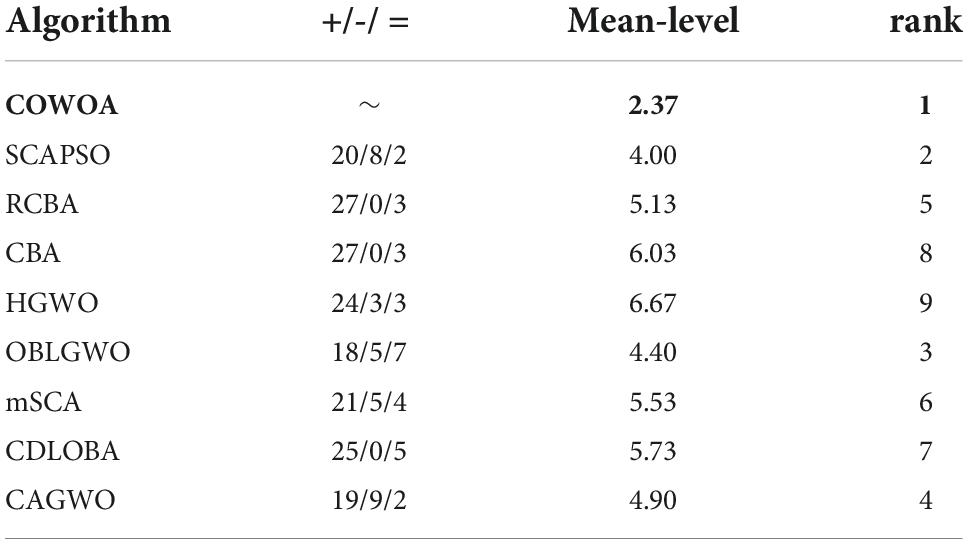
Table 11. Results of Wilcoxon signed-rank test.
Table 12 shows the p-values of the COWOA for the eight well-known variants, where the bolded data indicate p-values greater than 0.05. According to the table, the number of data less than 0.05 occupies the majority of the overall portion, indicating that the COWOA performs better than the well-known variant algorithms.
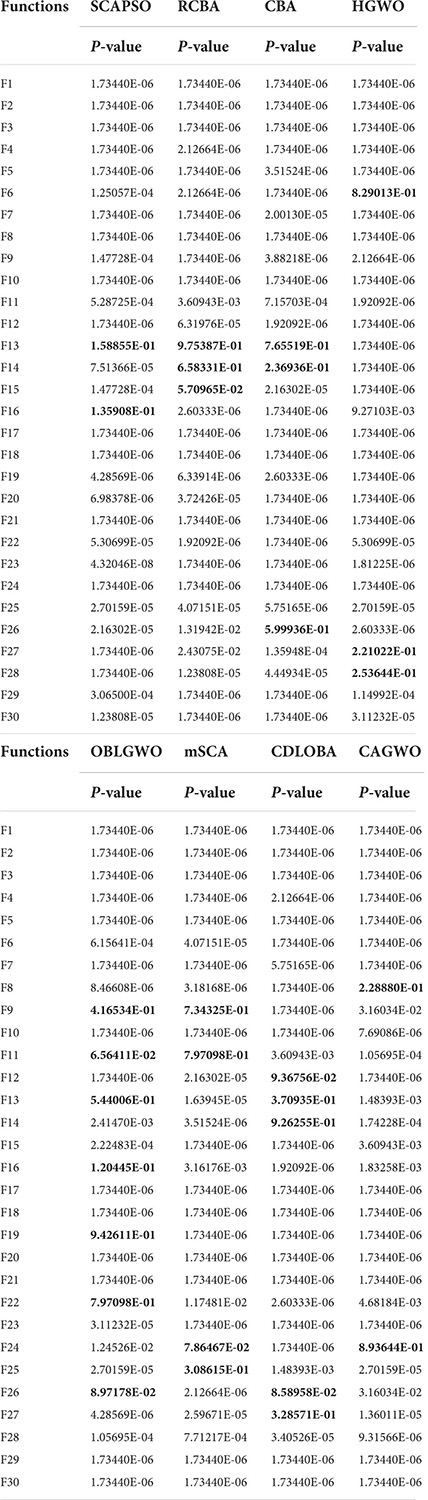
Table 12. The p-values of COWOA vs. well-known algorithms on the Wilcoxon test.
Figure 12 shows the result of the Friedman ranking, from which it can be seen that the COWOA has the smallest average, which indicates that it still has a very strong advantage under this testing method. Therefore, COWOA is still a relatively better swarm intelligence optimization algorithm for the experiments in this setup.
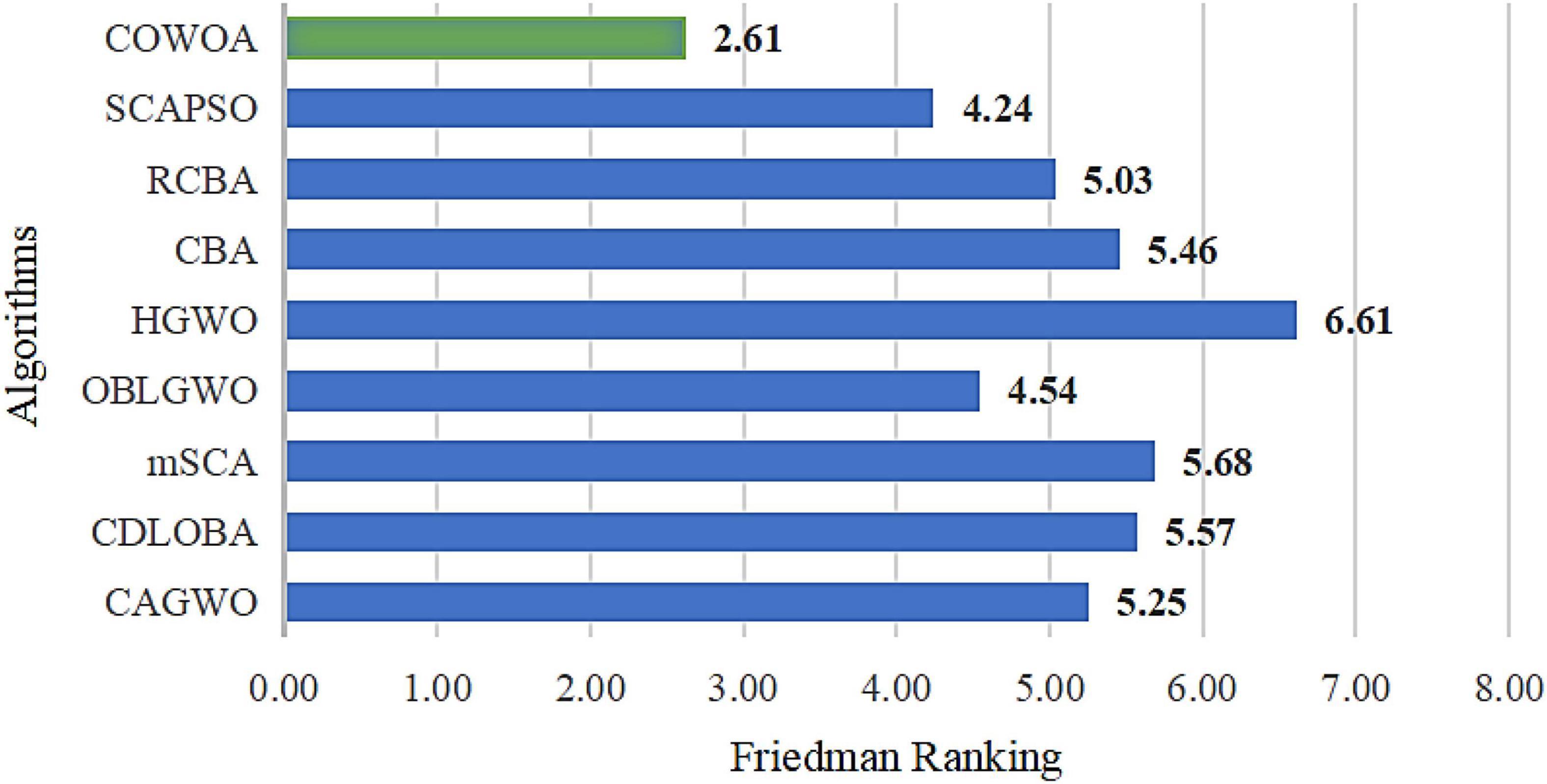
Figure 12. Result of Friedman ranking between the COWOA and the well-known variant algorithms.
In order to enhance the conviction that the optimization capability of the COWOA is relatively better in the comparison experiments, nine convergence curves obtained during the experiments are given below, as shown in Figure 13. The convergence curves of the COWOA have a convergence advantage over the other eight algorithms, except for the optimization F26, which finally achieves a relatively optimal convergence accuracy. In addition, the convergence curves of the eight compared algorithms are relatively smooth throughout the convergence process. In contrast, the convergence curves of the COWOA have different numbers of inflection points, and there is a very obvious drop in the curve after the inflection point, which indicates that the COWOA not only jumps out of the local optimum but also has a faster convergence speed. In summary, we can conclude that the convergence ability of the COWOA proposed in this paper is relatively more excellent compared to the eight excellent variants of other algorithms. Therefore, this experiment proves that the COWOA is an excellent swarm intelligence algorithm.
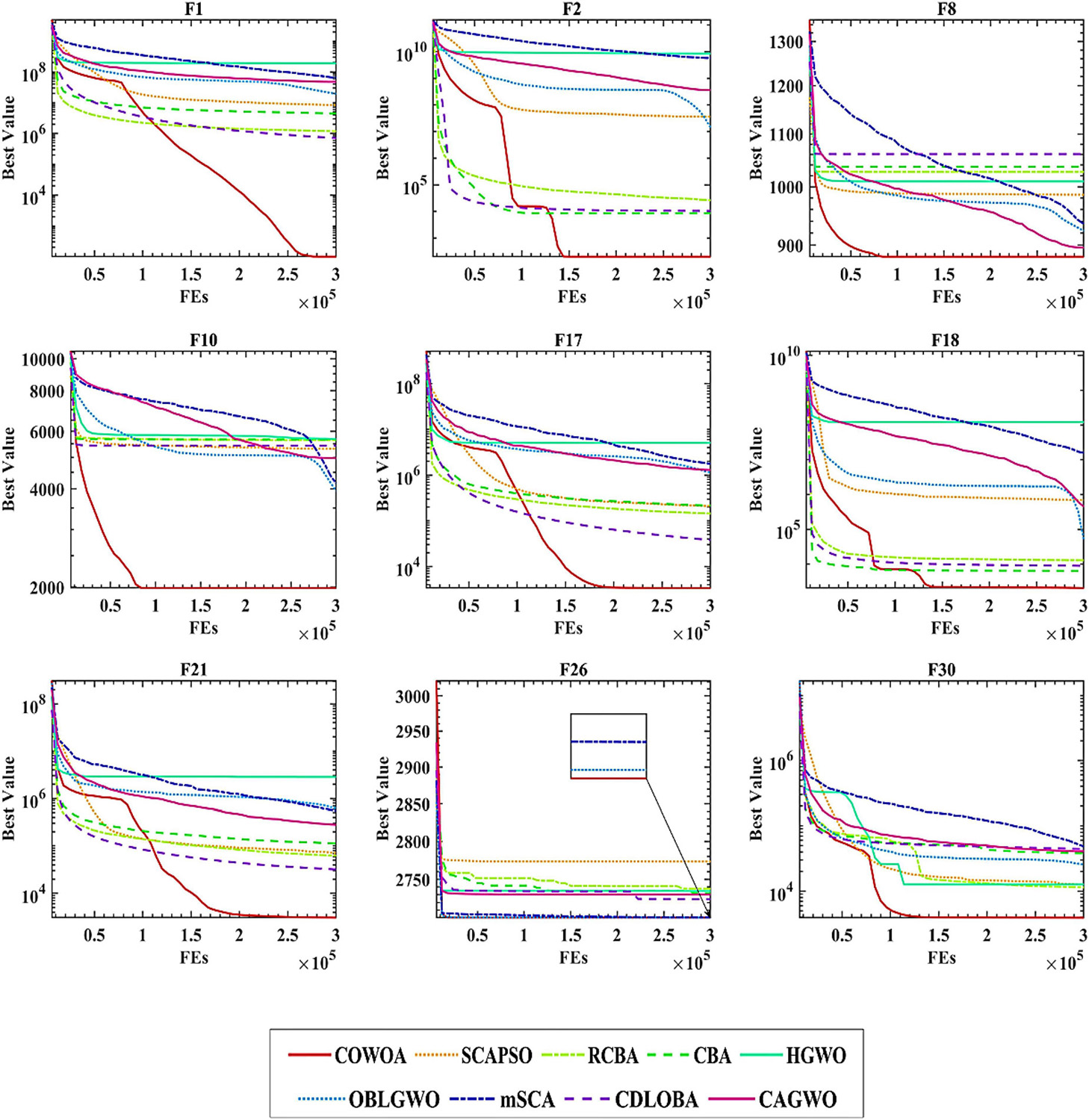
Figure 13. Convergence curves of COWOA with the well-known variant algorithms.
Feature selection experiments
Experimental setup
To confirm the performance of the bCOWOA-KELM model in the direction of feature selection, this section conducts feature selection experiments based on six public datasets in the UCI and a medical dataset (HD) collected at the moment, respectively. To enhance the persuasiveness of the experimental results, this paper also uses nine binary swarm intelligence optimization algorithms in the feature selection experiments for comparison experiments with the bCOWOA, including bWOA, bGWO, bHHO, bMFO, bSCA, bSMA, bSSA, bCSO, and BBA. The experimental parameters of the corresponding algorithms are given in Table 13.

Table 13. Key parameters of the algorithms.
In the experimental section of the public datasets, we set up comparison experiments based on six public datasets from the UCI repository, which are used to validate the performance of the bCOWOA-KELM model on the feature selection problem. Since the medical data problem addressed in this paper is binary in nature, the public datasets selected for this section are all of the binary type. Details of the parameters of these six public datasets are presented in Table 14.
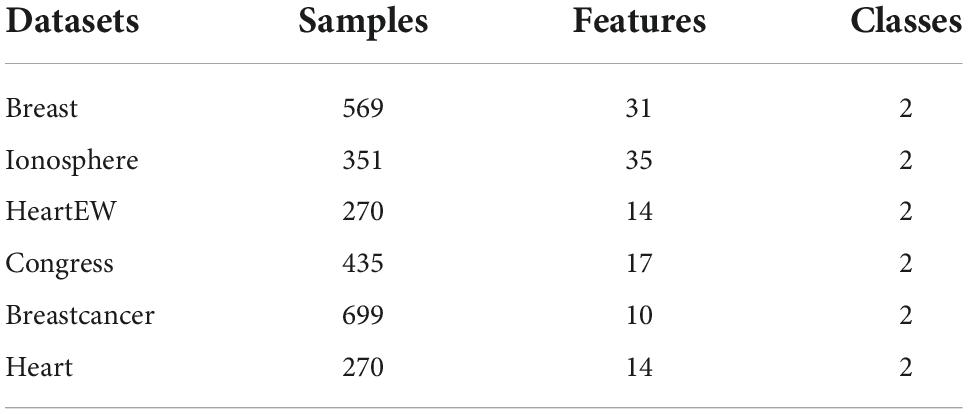
Table 14. Description of public datasets.
In the experimental section of the HD dataset, HD sessions were recorded from April 1, 2020, to April 18, 2020, in an outpatient HD unit at First Affiliated Hospital of Wenzhou Medical University. The inclusion criteria are as follows: (1) age ≥ 18 years; (2) maintenance HD ≥ 3 months; (3) the frequency of the treatment was three times per week, and the duration of the treatment was 4 hours. The exclusion criteria are as follows: (1) HD sessions with missing data; (2) HD therapy without using of heparin or low molecular heparin. A total of 156 patients with 1239 HD sessions were included. The dialysate temperature was 37°C, sodium concentration was 140 mmol/L, and calcium concentration was 1.5 mmol/L at the beginning of the sessions. Patients were detected blood routine once a month. The fast serological specimens were collected from a peripheral vein in a sitting position before dialysis on April 1st or April 2nd (mid-week therapy). BP was measured five times in each treatment session: At 0-h, 1 h, 2 h, 3 h after drawing blood and at reinfusion. Extra measurements of BP were carried out when patients suffered discomforts. IDH was defined as a drop of SBP ≥ 20 mmHg or a drop of (mean arterial pressure) MAP ≥ 10 mmHg from pre-dialysis to nadir intradialytic levels plus ≥ 2 repetitive measures (K/Doqi Workgroup, 2005). The description of this dataset’s details is given below, as shown in Table 15.

Table 15. Description of attributes screened by the classifiers.
IDH denotes intradialytic hypotension and IQR denotes interquartile range.
In addition, this paper analyses and compares the average value (Avg) and standard deviation (Std) of the experimental results and evaluates the comprehensive performance of each binary classification model by ranking them, thus demonstrating more intuitively that the bCOWOA-KELM model has relatively better feature selection performance.
Finally, to ensure the fairness of the experimental process of feature selection, we set the overall size of each algorithm population to 20 and the number of iterations to 100 times uniformly; to ensure the consistency of the experimental environment and to avoid the influence of environmental factors on the experimental results, the running environment of all experiments in this section is consistent with the experimental part of the basic function.
Performance evaluation metrics
In this subsection, we present some of the analytical evaluation methods used to analyze the results of the feature selection experiments (Hu et al., 2022a,b; Liu et al., 2022a,c; Shan et al., 2022; Shi et al., 2022; Xia et al., 2022a; Yang et al., 2022b; Ye et al., 2022). The aim is to provide a valid theoretical basis for demonstrating that the bCOWOA-KELM model performs better in feature selection than other comparative models. In the following, each of the mentioned evaluation methods is described.
In experiments, we usually classify the truth of the data as true (T) and false (F). We would then predict and classify them by machine learning, and the resulting positive predictions are defined as Positive (P) and the negative results are defined as Native (N). Thus, throughout the feature classification experiments, we typically derive four performance evaluation metrics that are used to assess the performance of the binary classifier model, as shown in Table 16.
Table 16. Description of classification details.
The following is a detailed description of Table 16.
(1) TP (True Positive): indicates a positive class prediction, where the classifier predicts the same data sample situation as the true one.
(2) FP (False Positive): The classifier misrepresents the negative class prediction as a positive class prediction, where the classifier discriminates the data sample situation as the opposite of the true situation and misidentifies the negative result as a positive result.
(3) TN (True Negative): indicates a negative class prediction and the classifier correctly identifies the negative class prediction.
(4) FN (False Negative): Positive class prediction is treated as a negative class prediction, resulting in the classifier missing the positive class prediction.
In addition, in order to better facilitate the evaluation of the feature extraction capability and classification capability of the bCOWOA-KELM model and to enhance the persuasiveness of the model proposed in this paper, this paper uses four categories of evaluation criteria commonly used in the fields of machine learning and information retrieval, and there are Accuracy, Specificity, Precision, and F-measure. The following section describes the details of the 4 evaluation criteria for the classifier experiments are described as follows:
(1) Accuracy indicates the number of samples successfully classified by the classifier as a proportion of all samples. In general, a larger accuracy rate indicates better performance of the classifier.
(2) Specificity indicates the proportion of all negative cases that are successfully classified, and measures the classifier’s ability to identify negative cases.
(3) Precision indicates the proportion of true positive prediction instances among all instances discriminated by the classifier as positive prediction outcomes.
(4) F-measure (F) is a special comprehensive evaluation criterion among the several types of evaluation criteria mentioned in this section, and is used to evaluate the overall performance of the binary model in the same way as error rate and accuracy. Its evaluation value is the weighted average of precision (P) and recall (R).
where α generally takes a value of 1; P denotes Precision as mentioned above; and R denotes Recall, which is an assessment criterion covering the range ability and describes the underreporting of positive class predictions and the degree of recall of positive class results.
Public dataset experiment
In this section, we set up comparative experiments based on six public datasets from the UCI repository to verify that the comprehensive performance of the bCOWOA-KELM model is relatively optimal in this experiment and also demonstrate that the bCOWOA-KELM model is more adaptive. For the experimental analysis, three evaluation methods were selected. The results were analyzed and validated by the Avg and Std design in each evaluation method and the average ranking of the algorithms involved in the comparison experiment on the six public datasets. The experimental analysis is presented below.
The experimental results of the classification accuracy of the bCOWOA-KELM model compared with other feature selection methods are given in Supplementary Table 5. The table shows the average classification of the bCOWOA-KELM model on the Breast, Ionosphere, HeartEW, Congress, Breastcancer, and heart datasets. The accuracy was always the largest, and their average classification accuracies were all above 94.81%, indicating that the bCOWOA-KELM model has relatively optimal classification ability. To further enhance the convincing power, the average ranking of each algorithm on the six public datasets was counted in this experiment, as shown in Table 17. It can be seen that bCOWOA ranks first in terms of average classification accuracy, which indicates that bCOWOA has outstanding adaptability to different datasets; BBA has the worst average ranking, which indicates that BBA has the relatively worst adaptability.

Table 17. Average classification accuracy ranking.
The results of this experiment describing the precision are given in Supplementary Table 6. As seen from the table, the average of bCOWOA on the six public datasets is always relatively the largest and its average precision is above 93.36%, which indicates that the bCOWOA-KELM model has the relatively best rate of correct classification among the compared methods. In addition, we also present the average ranking of each algorithm on the six datasets, as shown in Table 18. In particular, the bCOWOA-KELM model ranked first in terms of accuracy, bSMA ranked second, and bSCA ranked last.

Table 18. Average classification precision ranking.
Supplementary Table 7 shows the mean F-measure and variance of the bCOWOA-KELM model and the nine comparison models participating in the experiment on six public datasets. The F-measure is known to be a comprehensive criterion for assessing the classification performance of an algorithm, and it provides a more comprehensive assessment of the classification capability of bCOWOA. As can be seen from the table, the average F-measure values of bCOWOA are consistently the largest and their average accuracy is above 95.39%. As shown in Table 19, we also give the average ranking of each classification method on the six datasets. It can be seen that the bCOWOA-KELM model ranks first on average in terms of F-measure.

Table 19. Average ranking of F-measure.
Hemodialysis dataset experiment
In this section, in order to verify whether the bCOWOA-KELM model is effective, we collected information such as the clinical features, dialysis parameters and indexes of blood routine test from the dataset. We conducted prediction IDH comparison experiments on the bCOWOA-KELM model proposed in this paper. To analytically validate the performance of the proposed bCOWOA-KELM model, four different classifier evaluation metrics were used to assess the comprehensive performance of the model as far as possible, including Accuracy, Specificity, Precision and F-measure. To demonstrate that the bCOWOA-KELM model is superior, we compare bCOWOA-KELM with combinations of bCOWOA and four other classical classifiers, including bCOWOA-FKNN, bCOWOA -KNN, bCOWOA-MLP, and bCOWOA -SVM. To further compare the performance differences between the categorical prediction model based on swarm intelligence optimization algorithm and classical machine learning algorithms such as RandomF, AdaBoost, and CART, we set up a comparison experiment between the bCOWOA-KELM model and these methods. Furthermore, to demonstrate that the predictive performance of the combination of bCOWOA-KLEM in the swarm intelligence optimization algorithms is also relatively better, we selected nine well-known swarm intelligence algorithms to set up a comparison experiment of with bCOWOA in this section, such as bGWO, bHHO, bSMA and so on. Finally, in order to demonstrate that the bCOWOA-KELM model has practical application value in the prediction of IDH and to reduce the effect of random factors on the experiment, we set up a 10-fold cross-validation (CV) analysis experiment on it.
In general, the same binary algorithm combined with different classifier methods often produces different classification results. The comparison experiment of the bCOWOA-KELM model with four other classifier combinations, including bCOWOA-FKNN, bCOWOA -KNN, bCOWOA-MLP, and bCOWOA -SVM, the analysis of the results for the four evaluation methods is given in a box plot in Figure 14. The graph shows that the values of the four evaluation criteria for the bCOWOA-KELM model are relatively more concentrated and have the relatively highest mean values. This indicates that the combined approach has the relatively best classification prediction ability and the most stable classification performance. bCOWOA-MLP model is the worst in the four aspects. The bCOWOA-FKNN model and the bCOWOA-KELM model perform similarly. However, looking closely at the box diagram, it is not difficult to find that the bCOWOA-KELM classification combination model has better means on all evaluation criteria, and the evaluation data generated by the experiment is relatively more concentrated. This shows that the bCOWOA-KELM is not only better at the end result but also proves that it has stronger stability. Therefore, we can conclude that the bCOWOA-KELM model is the best classification prediction model among the five combined approaches.
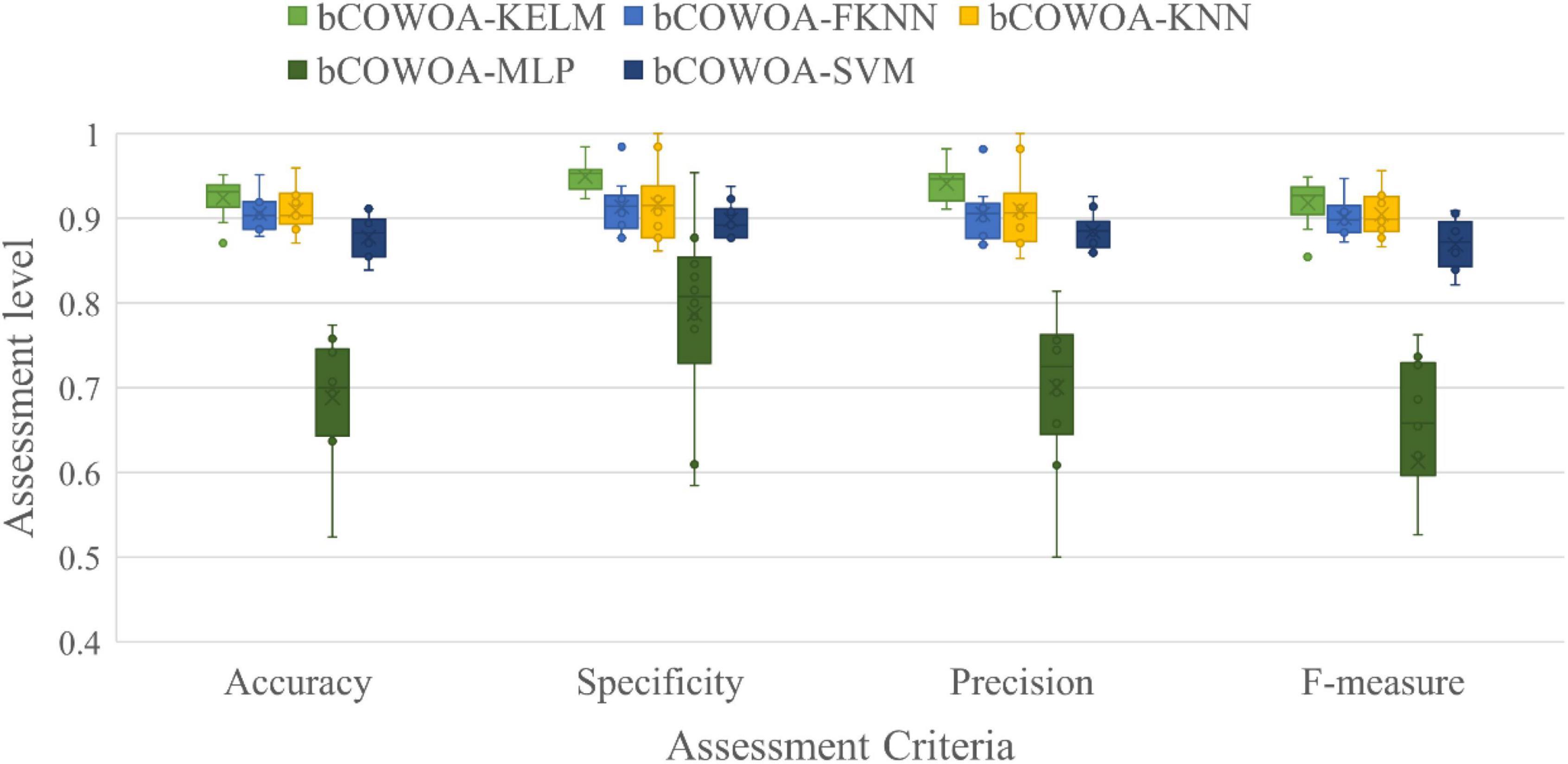
Figure 14. Comparison results of the five bonding methods.
In order to examine the effect of the swarm intelligence optimization algorithm on the classification performance of the classifier in terms of feature selection experiments, we compared the bCOWOA-KELM model with five machine learning methods that did not incorporate the bCOWOA, and the comparison results are shown in Figure 15. Compared with BP, the proposed bCOWOA-KELM model has better stability than BP, although it is less optimal. Compared with the other four classification methods, the proposed bCOWOA-KELM model is better in terms of Accuracy and specificity and has a more stable performance. In summary, the comprehensive performance of the bCOWOA-KELM model proposed in this paper is better than the original classification method without the swarm intelligence algorithm.
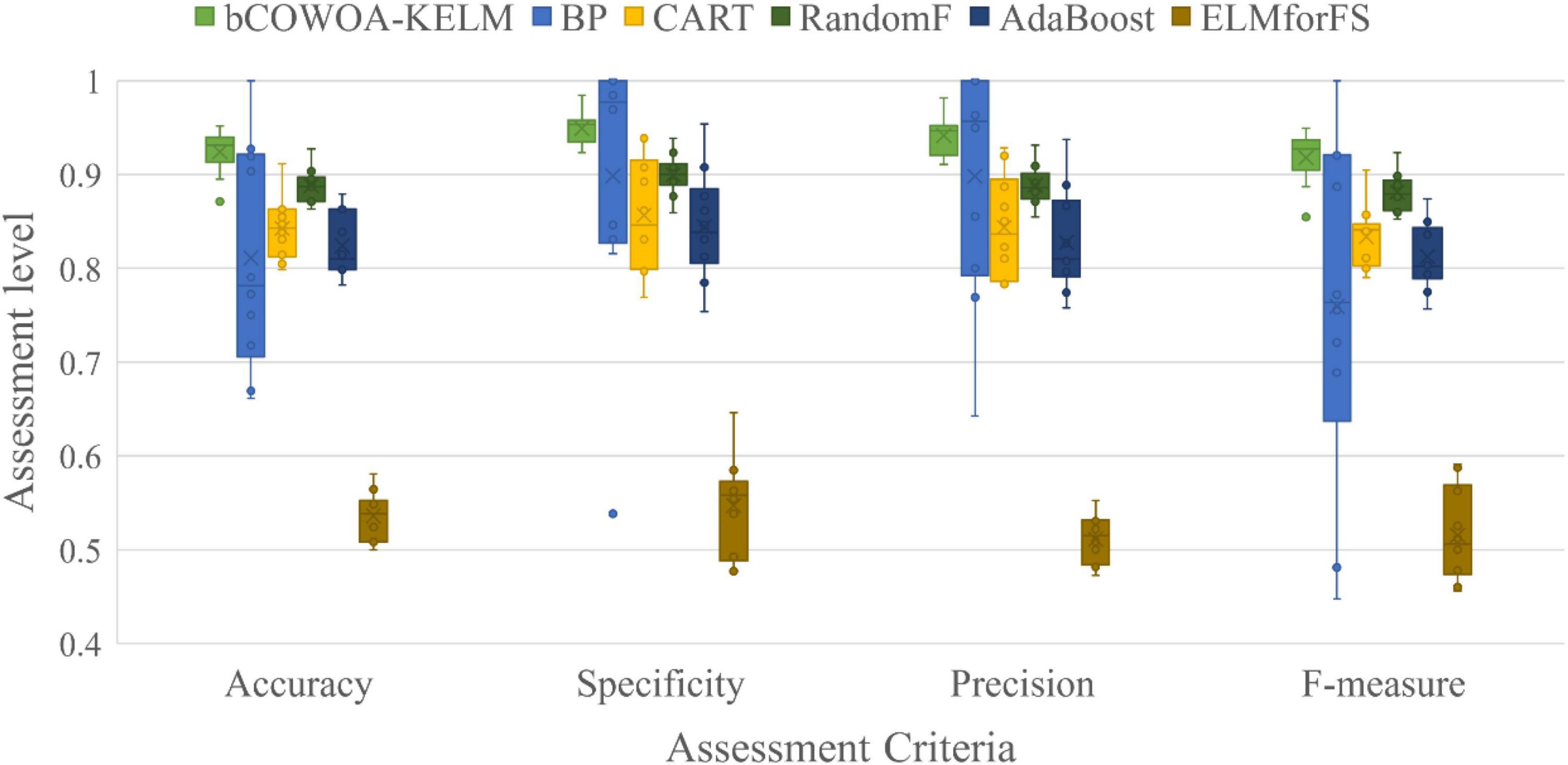
Figure 15. Comparison results of the bCOWOA-KELM with five classifiers.
To demonstrate the practical relevance of the prediction model and to further verify that the performance of the bCOWOA-KELM model is relatively optimal on the IDH dataset, the proposed bCOWOA was compared with nine binary algorithms based on the KELM classification technique, including bWOA, bGWO, bHHO, bMFO, bSCA, bSMA, bSSA, Bcso, and BBA. Then, all combinations of the above binary algorithms and KELM were analyzed and evaluated in terms of six aspects: Accuracy, Specificity, Precision, F-measure, Error, and time spent.
The statistical results of this experiment on the HD dataset are given in Figure 16. According to the results, the combination of bCOWOA and KELM on the first five evaluation criteria have a relatively concentrated box plot distribution compared to the combination of the other nine algorithms, indicating that the bCOWOA-KELM model has very considerable stability compared to the other algorithms. Meanwhile, bCOWOA also has the highest average value, indicating that bCOWOA has better classification capability than all the algorithms compared. However, the bCOWOA’s average value is the highest in terms of time spent, which is one of the drawbacks that should be of concern for the future of the algorithm. In conclusion, this part of the experiment demonstrates that the bCOWOA-KELM model has the relatively best classification ability for the HD dataset.
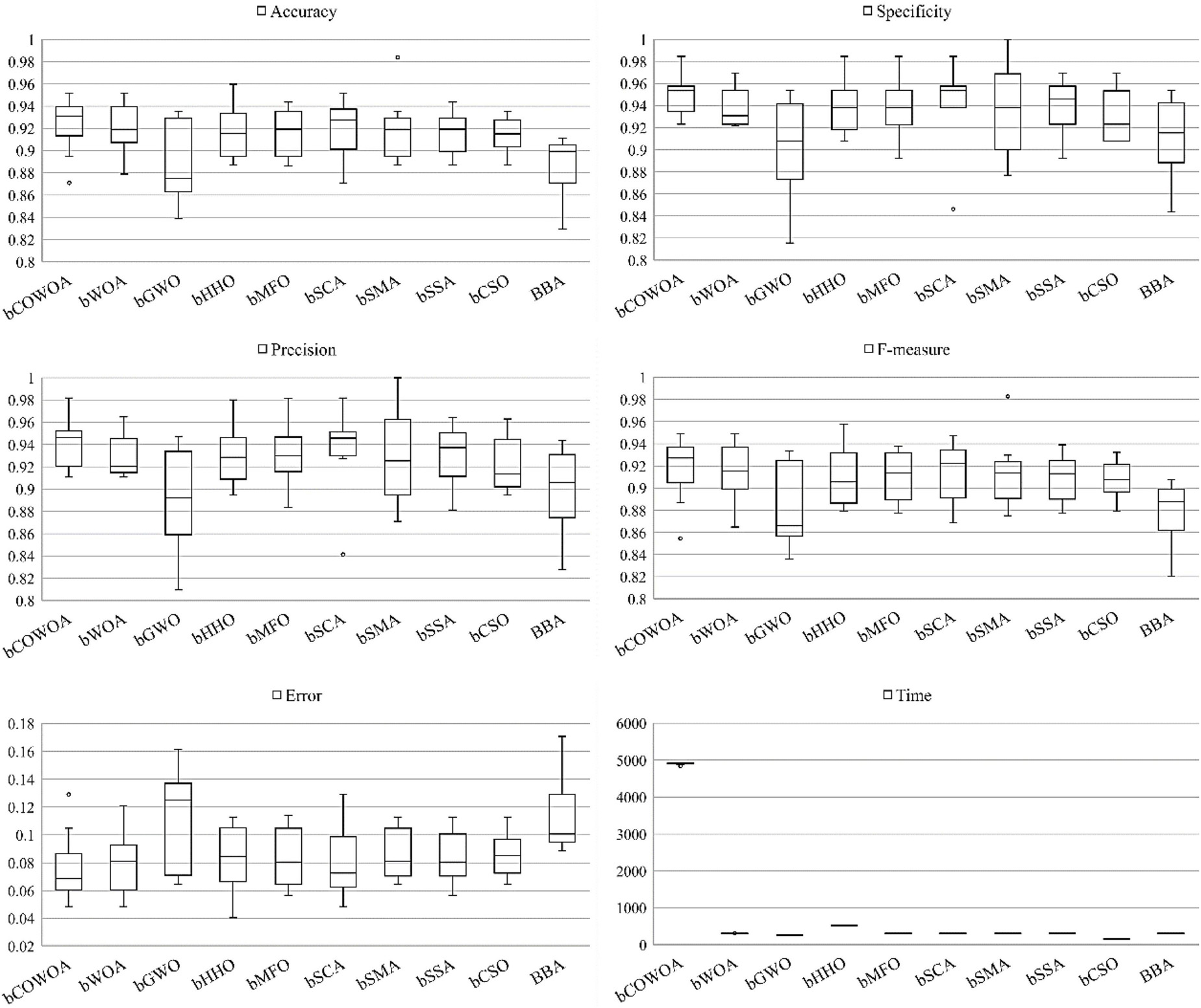
Figure 16. Comparison results of bCOWOA with other binary algorithms.
Table 20 analyses the results of the bCOWOA-KELM model after completing 10 feature selection experiments. In rows 2–11 of Table 20, the Fold column indicates the number of experiments, the second column indicates the number of features selected in each feature selection experiment, the remaining four columns indicate the Accuracy, Specificity, Precision and F-measure obtained, and the last two rows of Table 20 give the average value and variance corresponding to the four evaluation criteria, respectively. As can be seen from the table, the average classification accuracy value of the bCOWOA-KELM is 0.9241, the average specificity value is 0.9492, the average accuracy value is 0.9415 and the average F-measure is 0.9180. According to Table 21, it is easy to find that bCOWOA obtains the better scores on the four metrics In addition, bCOWOA improves 0.32% in accuracy, 0.62% in specificity, 0.54% in Precision, and 0.29% in F-measure over the second-ranked bSCA. bCOWOA improved 3.63% in accuracy, 4.62% in specificity, 4.94% in Precision, and 3.70% in F-measure over the worst-ranked bGWO.
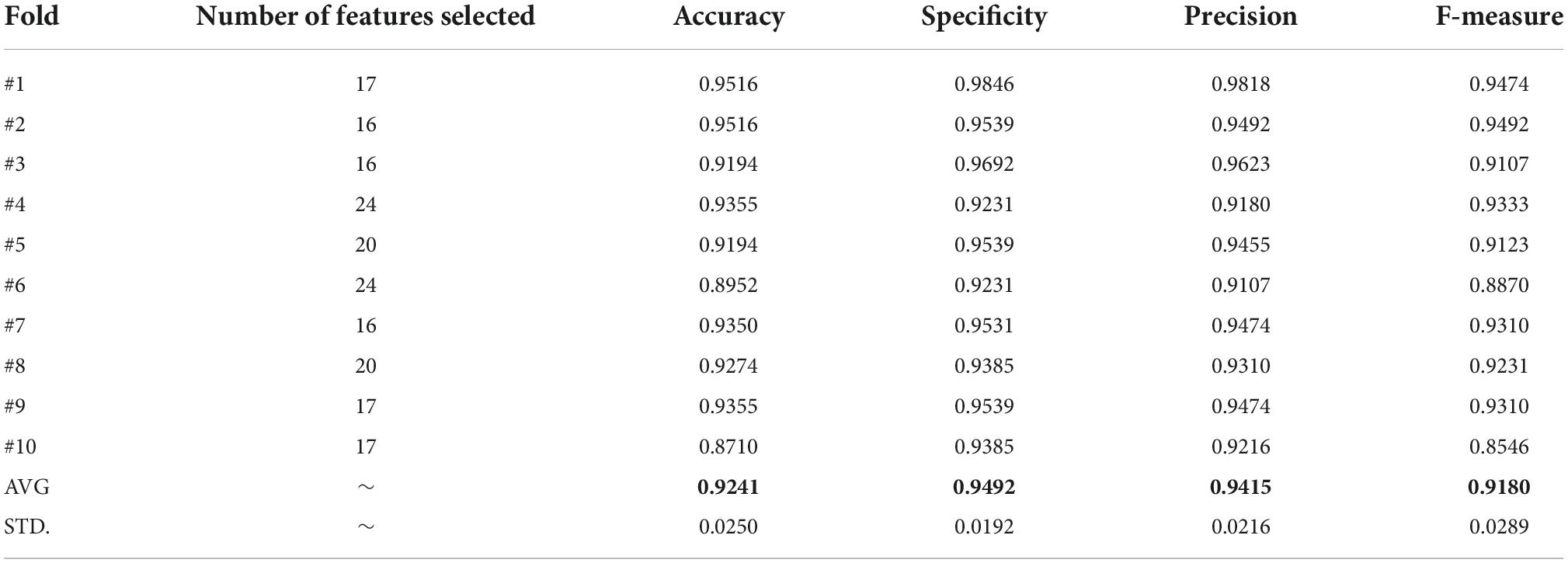
Table 20. Results of the bCOWOA-KELM model.
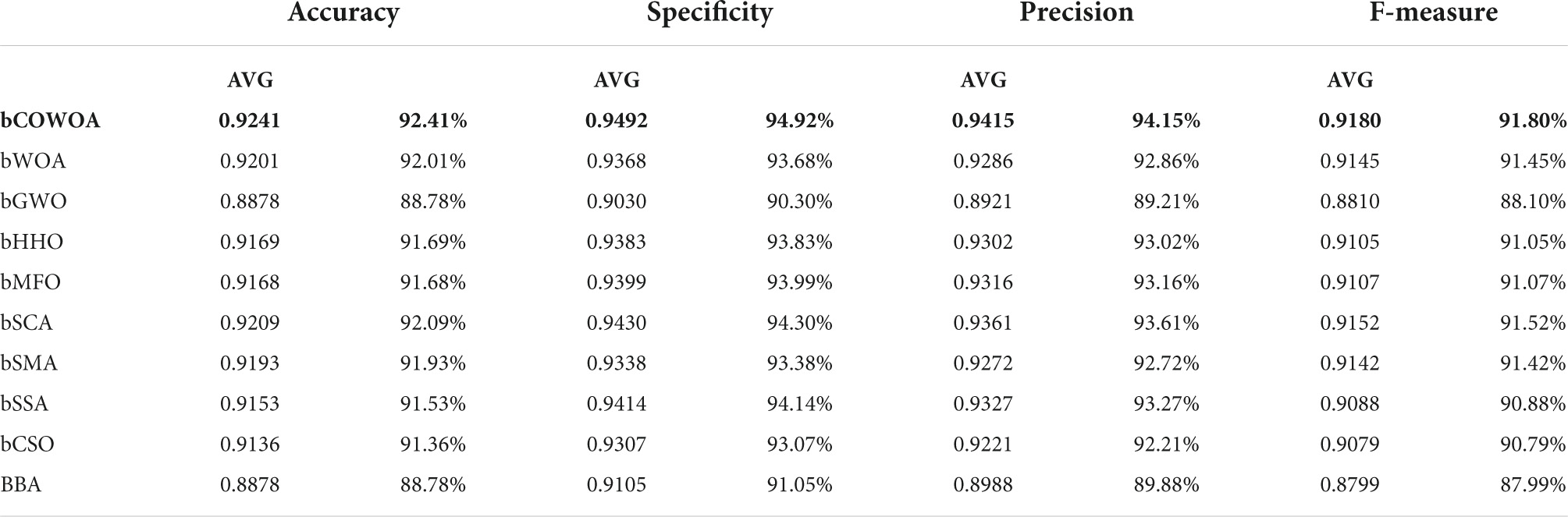
Table 21. The average of bCOWOA and well-known binary algorithms.
To further verify the predictive performance of the bCOWOA-KELM model, we conducted a 10 times 10-fold crossover experiments based on the HD dataset. To facilitate the selection of features and the analysis of experimental results, we present 36 features and their selection through a histogram, as shown in Figure 17. What’s more, the features selected by bCOWOA-KELM to predict IDH are illustrated in Table 22.
Figure 17. Results of 10 times 10-fold cross-validation analysis.

Table 22. Clinical features selected by in IDH and Non-IDH groups.
In Figure 17, the vertical axis represents the code name of the feature that appeared in this experiment and the abscissa axis represents the number of times each feature was selected in 100 experiments. The characteristics of the green color in the figure are the key features selected in this experiment, including F22, F11, F14, F13, F3, F1, F21, and F23. They, respectively, represent platelet to lymphocyte ratio (PLR), MAP, white blood cells (WBCs), gender, ultrafiltration volume, dialysis vintage, monocyte to lymphocyte ratio (MLR) and neutrophil to monocyte ratio (NMR). Finally, we concluded that the eight key features selected by the bCOWOA-KELM model in this experiment are in line with clinical practice. Therefore, we have once again demonstrated the effectiveness of the bCOWOA-KELM model in combination with the clinical experience of IDH.
Discussion
Comparison with previous studies and summary
Although the definition of IDH was different in various studies, even in recent studies, IDH was defined as an SBP below to 90 mmHg, to build an early warning system, IDH was defined according to guidelines of the National Kidney Foundation Kidney Disease Quality Outcomes Initiative (K/DOQI) (K/Doqi Workgroup, 2005). To predict IDH episodes, previous studies analyzed pre-dialysis BP, demographic characteristics and ultrafiltration parameters. Liu et al. (2022e) study applied the least absolute shrinkage and selection operator (LASSO) to select features from dialysis parameters and patients’ characteristics. The sensitivity and specificity were below 90%. Some of them also included serum biomarkers in the analysis to improve accuracy. Assayag et al. (2020) analyzed B-natriuretic peptide using a logistic mixed model to predict the 30-day risk of IDH. The accuracy was still not satisfactory. Our previous study got good accuracy from an artificial neural network (ANN) model utilizing chronic kidney disease-mineral and bone disorders (CKD-MBD) biomarkers. The biomarkers mentioned above are associated with volume or vasoactivity, which are determinants of BP. Compared with these biomarkers, blood routine test is generally carried out in basic hospitals and are inexpensive, though does not have a direct correlation with BP. The prediction models are divided into logistic regression models and ANN models. As we know, the events are not linearly dependent on features in clinical practice. Various ANN models are apt to deal with non-linear relationships.
To predict IDH, our team built different models to screen various factors. Yang et al. (2022a) proposed an IDH prediction model (BSWEGWO-KELM) based on improved GWO and KELM. And this method successfully screened four key features that affect the incidence of IDH, including dialysis vintage, MAP, alkaline phosphatase (ALP), and intact parathyroid hormone (iPTH). Hu et al. (2022c) proposed a promising model (MQGWO-FKNN) using the Fuzzy K-Nearest Neighbor (FKNN) based on the mutation quantum GWO, and the method enabled the prediction of serum albumin increases and decreases to assist in the diagnosis of IDH. Also, the key features selected by the MQGWO-FKNN model were analyzed with physiological significance, including age, dialysis vintage, diabetes, and baseline albumin. It is worth noting that although the methods mentioned above compensate for the performance shortcomings of a single technique by enabling the combination of swarm intelligence optimization algorithms with classical classification techniques and achieve prediction of the influencing factors of IDH, it is not difficult to find crossover and complementarity between the classification results of the above two methods, which shows that the factors that affect IDH are not a single subset of features and also illustrates the real and non-linear relationship between clinical features and IDH.
Therefore, in order to further explore those clinical features that are more relevant to IDH morbidity, this paper proposes another novel classification approach (bCOWOA-KELM) to predict IDH. And unlike the former, the dataset collected this time has been adjusted in terms of features and number of features. Finally, the experimental results show that the proposed method successfully predicts eight key characteristics affecting IDH. Compared with the former two, the features predicted by the bCOWOA-KELM model are more abundant, which once again supplements the experimental basis to predict IDH and expands the direction of related research in the future. At the same time, this paper once again verifies that the clinical characteristics and IDH incidence are not linear, which is also one of the important practical medical significances of this paper. In addition, the features screed by bCOWOA-KELM are contain indices of blood routine test. Compared with the former study, blood routine test is easier to use and more cost-efficient biomarkers than CKD-MBD.
Physiological significance of the selected features
In this study, COWOA is first built, which is a verified excellent swarm intelligence algorithm. This class of methods can be applied many fields, such as dynamic module detection (Ma et al., 2020; Li et al., 2021), power flow optimization (Cao X. et al., 2022), information retrieval services (Wu et al., 2020a,b, 2021c), human activity recognition (Qiu et al., 2022), location-based services (Wu et al., 2020c,2021b), disease identification and diagnosis (Su et al., 2019; Tian et al., 2020), pharmacoinformatic data mining (Zhu et al., 2012; Yin et al., 2020), autism spectrum disorder classification (Hu et al., 2022d), endoscope imaging (Zhang Z. et al., 2022), and image-to-image translation (Zhang X. et al., 2022). Then, bCOWOA-KELM based on COWOA was also established. The critical features selected by bCOWOA-KELM were PLR, MAP, WBC, gender, ultrafiltration volume, dialysis vintage, MLR, and NMR.
Female gender is a risk factor of IDH assessed by logistic regression in previous studies (Sands et al., 2014; Halle et al., 2020). Females always have smaller body sizes than males; thus, even if the IDWG is the same in males and females, the percentage of IDWG and the ultrafiltration rates are higher in females than males. To get a good clinical outcome and avoid IDH, the suggested percentage of IDWG is below 4% (Wong et al., 2017), and the ultrafiltration rates is below 10 mL/h/kg (Flythe et al., 2011). The comorbidities and complications of CKD damage peripheral vascular resistance with dialysis vintage. First, baroreceptor variability is impaired by uremia toxins. Second, CKD-MBD and diabetes induce vascular calcification and aggravate atherosclerosis and arterial stiffness. Third, ß2 microglobulin amyloid deposits in cardiac myocytes and blood vessel wall (Takayama et al., 2001), impairs cardiac output and peripheral resistance. Cardiac output and peripheral resistance compensate for BP when blood volume is reduced during dialysis.
High MAP is equal to high BP. High BP causes cardiovascular injury. High BP is associated with coronary artery disease (Yeo et al., 2020), cardiac systolic dysfunction, and left ventricular hypertrophy (Chao et al., 2015). There are cause-and-effect relationships between these factors and IDH. High BP also induces endothelial dysfunction and arterial stiffness. In a clinical trial, both of them are independent risk factors of IDH (Dubin et al., 2011). The ultrafiltration volume is associated with IDH, especially after the first 90 min session (Keane et al., 2021).
PLR, WBC, MLR, and NMR represent inflammation and predict prognosis of cancer (Kumarasamy et al., 2021), infective (Palladino, 2021) and inflammatory diseases (Gasparyan et al., 2019). There are also relationships between these hematological indices and cardiac abnormalities. For example, increased MLR is an independent risk factor of death in patients with hypertension (Boos et al., 2021) or heart failure (Delcea et al., 2021). Our study demonstrated the hematological indices and IDH for the first time. Platelets, monocytes, and neutrophils are classified as pro-inflammatory cells, while lymphocytes are anti-inflammatory. These cells interact with each other. Since the parameters contain leukocyted, neutrophils, monocytes, lymphocytes, and platelets, we hypothesize the cytokines derived from these blood cells play roles in regulating BP. Yu et al. (2021) found the levels of serum tumor necrosis factor-α (TNF-α) and interleukin-1β (IL-1β) were higher in the IDH group. TNF-α and IL-1β are pro-inflammatory cytokines secreted by myeloid cells and able to activate platelet. These blood cells and cytokines regulate BP through cross-talk with renal renin-angiotensin system, sympathetic system, and oxidative stress (Zhang R. M. et al., 2021).
Conclusion and future works
The main contributions of the present study are as follows: (1) a novel WOA-based swarm intelligence optimization algorithm was proposed, named COWOA, (2) a new IDH disease early warning model by combining the binary COWOA and the KELM was proposed, named bCOWOA-KELM, (3) the classification potential of KELM was successfully tapped based on the improved WOA and (4) the key features influencing the incidence of IDH are accurately identified using the bCOWOA-KELM model. PLR, WBC, MLR, and NMR are readily available, easy to use, and cost-efficient biomarkers, especially for those basic HD centers.
In COWOA, we successfully improved the search capability and the ability to escape local optima of the original WOA by introducing the OLM and the CMS into the WOA. To verify its performance, we set up four comparison experiments based on 30 benchmark test functions successively, including the comparison experiments between WOA and two mechanisms under different combinations, the comparison experiments between COWOA and seven excellent variants of WOA, the comparison experiments between COWOA and nine other original algorithms and the comparison experiments between COWOA and eight excellent variants of other algorithms. Based on the results of the above comparison experiments, the convergence ability of the COWOA is relatively the best compared to the other comparison algorithms. Therefore, The COWOA is an improved validated variant of WOA.
In bCOWOA-KELM, it is used for clinical prediction. First, to validate the performance of the bCOWOA-KELM model and its effectiveness, we set up two types of classification prediction experiments, including comparison experiments based on six public datasets and comparison experiments based on the HD dataset, and validated the classification results with Accuracy, Specificity, Precision and F- measure as the evaluation criteria to validate the comprehensive performance of the bCOWOA-KELM model. Second, we selected eight features based on the feature selection results of the HD dataset. Finally, the clinical significance of the eight characteristics is discussed in detail. The value of the bCOWOA-KELM model in disease prediction was further confirmed by all the features selected by it were comprehensible for nephrologist.
However, there are still a few limitations in our study, mainly including the COWOA itself and the HD dataset. For the COWOA, since the method proposed in this paper is based on the improved WOA, the introduction of CMS and OLM optimization methods greatly improves the performance of WOA, but it also affects the complexity of the proposed model, which results in it needing to spend more time cost to exert its stronger performance. For the HD dataset, its shortcomings are mainly manifested in three aspects, including: (1) the sample size was small, (2) the blood routine was only detected once to predict a half-month risk of IDH, and (3) IDH was divided into two groups without an order of severity or time-dependent. Therefore, we will further improve this design from the above aspects in the future.
In the future, we will solve the complexity of the COWOA, for example, (1) starting from the complex, under the premise of ensuring its performance, we continue to improve the COWOA, and (2) distributed computing, high-performance computing, and other advanced technologies should be applied in the process of disease prediction. Moreover, the IDH prediction model will be more available. Furthermore, an intelligent HD management system will be built based on an improved algorithm. In addition, we will also explore other application areas of COWOA, such as image segmentation (Liu L. et al., 2021; Zhao D. et al., 2021), engineering optimization (Qi et al., 2022; Qiao et al., 2022), resource allocation (Deng et al., 2022a).
Data availability statement
The original contributions presented in the study are included in the article/Supplementary material, further inquiries can be directed to the corresponding author/s.
Author contributions
YPL, GL, YL, YB, AI, and CW: writing—original draft, writing—review and editing, software, visualization, and investigation. DZ, HC, and XC: conceptualization, methodology, formal analysis, investigation, writing—review and editing, funding acquisition, and supervision. All authors contributed to the article and approved the submitted version.
Funding
This work was supported in part by the Natural Science Foundation of Zhejiang Province (LZ22F020005 and LQ21H050008) and the National Natural Science Foundation of China (62076185 and U1809209). It was also supported by the New Technologies and Products Projects of Zhejiang Health Committee (2021PY054), and the Basic Scientific Research Projects of Wenzhou Science and Technology Bureau (Y2020026).
Acknowledgments
We acknowledge the comments of the reviewers.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fninf.2022.956423/full#supplementary-material
References
Abd Elaziz, M., and Oliva, D. (2018). Parameter estimation of solar cells diode models by an improved opposition-based whale optimization algorithm. Energy Convers. Manag. 171, 1843–1859. doi: 10.1016/j.enconman.2018.05.062
Adam, A. B. M., Wan, X., and Wang, Z. (2020). Energy efficiency maximization in downlink multi-cell multi-carrier NOMA networks with hardware impairments. IEEE Access 8, 210054–210065. doi: 10.1109/ACCESS.2020.3039242
Adarsh, B. R., Raghunathan, T., Jayabarathi, T., and Yang, X.-S. (2016). Economic dispatch using chaotic bat algorithm. Energy 96, 666–675. doi: 10.1016/j.energy.2015.12.096
Adoko, A. C., Gokceoglu, C., Wu, L., and Zuo, Q. J. (2013). Knowledge-based and data-driven fuzzy modeling for rockburst prediction. Int. J. Rock Mech. Mining Sci. 61, 86–95. doi: 10.1016/j.ijrmms.2013.02.010
Ahmadianfar, I., Asghar Heidari, A., Gandomi, A. H., Chu, X., and Chen, H. (2021). RUN beyond the metaphor: An efficient optimization algorithm based on Runge Kutta method. Expert Syst. Applic. 181:115079. doi: 10.1016/j.eswa.2021.115079
Ahmadianfar, I., Asghar Heidari, A., Noshadian, S., Chen, H., and Gandomi, A. H. (2022). INFO: An efficient optimization algorithm based on weighted mean of vectors. Expert Syst. Applic. 195:116516. doi: 10.1016/j.eswa.2022.116516
Alagarsamy, S., Zhang, Y. D., Govindaraj, V., Rajasekaran, M. P., and Sankaran, S. (2021). Smart identification of topographically variant anomalies in brain magnetic resonance imaging using a fish school-based fuzzy clustering approach. IEEE Transac. Fuzzy Syst. 29, 3165–3177. doi: 10.1109/TFUZZ.2020.3015591
Alshwaheen, T. I., Hau, Y. W., Ass’Ad, N., and Abualsamen, M. M. A. (2021). Novel and reliable framework of patient deterioration prediction in intensive care unit based on long short-term memory-recurrent neural network. IEEE Access 9, 3894–3918. doi: 10.1109/ACCESS.2020.3047186
Askarzadeh, A. (2016). A novel metaheuristic method for solving constrained engineering optimization problems: Crow search algorithm. Comput. Struct. 169, 1–12. doi: 10.1016/j.compstruc.2016.03.001
Assayag, M., Levy, D., Seris, P., Maheas, C., Langlois, A. L., Moubakir, K., et al. (2020). Relative change of protidemia level predicts intradialytic hypotension. J. Am. Heart Assoc. 9:e014264. doi: 10.1161/JAHA.119.014264
Beyer, H.-G., and Schwefel, H.-P. (2002). Evolution strategies – A comprehensive introduction. Natural Computing. 1, 3–52. doi: 10.1023/A:1015059928466
Boos, C. J., Toon, L. T., and Almahdi, H. (2021). The relationship between ambulatory arterial stiffness, inflammation, blood pressure dipping and cardiovascular outcomes. BMC Cardiovasc. Disord. 21:139. doi: 10.1186/s12872-021-01946-2
Burton, J. O., Jefferies, H. J., Selby, N. M., and McIntyre, C. W. (2009a). Hemodialysis-induced cardiac injury: Determinants and associated outcomes. Clin. J. Am. Soc. Nephrol. 4, 914–920. doi: 10.2215/CJN.03900808
Burton, J. O., Jefferies, H. J., Selby, N. M., and McIntyre, C. W. (2009b). Hemodialysis-induced repetitive myocardial injury results in global and segmental reduction in systolic cardiac function. Clin. J. Am. Soc. Nephrol. 4, 1925–1931. doi: 10.2215/CJN.04470709
Cacciola, M., Pellicanò, D., Megali, G., Lay-Ekuakille, A., Versaci, M., and Morabito, F. C. (eds) (2013). “Aspects about air pollution prediction on urban environment,” in Proceedings of the 4th IMEKO TC19 Symposium on Environmental Instrumentation and Measurements 2013, (Lecce), 15–20.
Cai, Z., Gu, J., Luo, J., Zhang, Q., Chen, H., Pan, Z., et al. (2019). Evolving an optimal kernel extreme learning machine by using an enhanced grey wolf optimization strategy. Expert Syst. Applic. 138:112814. doi: 10.1016/j.eswa.2019.07.031
Cao, X., Li, P., and Duan, Y. (2021). Joint decision-making model for production planning and maintenance of fully mechanized mining equipment. IEEE Access 9, 46960–46974. doi: 10.1109/ACCESS.2021.3067696
Cao, X., Wang, J., and Zeng, B. A. (2022). Study on the strong duality of second-order conic relaxation of AC optimal power flow in radial networks. IEEE Transac. Power Syst. 37, 443–455. doi: 10.1109/TPWRS.2021.3087639
Cao, Z., Wang, Y., Zheng, W., Yin, L., Tang, Y., Miao, W., et al. (2022). The algorithm of stereo vision and shape from shading based on endoscope imaging. Biomed. Signal Process. Control 76:103658. doi: 10.1016/j.bspc.2022.103658
Chang, T. I., Paik, J., Greene, T., Desai, M., Bech, F., Cheung, A. K., et al. (2011). Intradialytic hypotension and vascular access thrombosis. J. Am. Soc. Nephrol. 22, 1526–1533. doi: 10.1681/ASN.2010101119
Chao, C. T., Huang, J. W., and Yen, C. J. (2015). Intradialytic hypotension and cardiac remodeling: A vicious cycle. Biomed Res Int. 2015, 724147. doi: 10.1155/2015/724147
Chen, H., Miao, F., Chen, Y., Xiong, Y., and Chen, T. A. (2021). Hyperspectral image classification method using multifeature vectors and optimized KELM. IEEE J. Selected Top. Appl. Earth Observ. Remote Sens. 14, 2781–2795. doi: 10.1109/JSTARS.2021.3059451
Chen, H., Wang, M., and Zhao, X. (2020). A multi-strategy enhanced sine cosine algorithm for global optimization and constrained practical engineering problems. Appl. Math. Comput. 369:124872. doi: 10.1016/j.amc.2019.124872
Chen, H.-L., Huang, C.-C., Yu, X.-G., Xu, X., Sun, X., Wang, G., et al. (2013). An efficient diagnosis system for detection of Parkinson’s disease using fuzzy k-nearest neighbor approach. Expert Syst. Applic. 40, 263–271. doi: 10.1016/j.eswa.2012.07.014
Chen, H.-L., Yang, B., Wang, G., Wang, S.-J., Liu, J., and Liu, D.-Y. (2012). Support vector machine based diagnostic system for breast cancer using swarm intelligence. J. Med. Syst. 36, 2505–2519. doi: 10.1007/s10916-011-9723-0
Chen, J., Du, L., and Guo, Y. (2021). Label constrained convolutional factor analysis for classification with limited training samples. Inf. Sci. 544, 372–394. doi: 10.1016/j.ins.2020.08.048
Delcea, C., Buzea, C. A., Vijan, A., Draghici, A., Stoichitoiu, L. E., and Dan, G. A. (2021). Comparative role of hematological indices for the assessment of in-hospital outcome of heart failure patients. Scand. Cardiovasc. J. 55, 227–236. doi: 10.1080/14017431.2021.1900595
Deng, W., Ni, H., Liu, Y., Chen, H., and Zhao, H. (2022a). An adaptive differential evolution algorithm based on belief space and generalized opposition-based learning for resource allocation. Appl. Soft Comput. 127:109419. doi: 10.1016/j.asoc.2022.109419
Deng, W., Zhang, X., Zhou, Y., Liu, Y., Zhou, X., Chen, H., et al. (2022b). An enhanced fast non-dominated solution sorting genetic algorithm for multi-objective problems. Inf. Sci. 585, 441–453. doi: 10.1016/j.ins.2021.11.052
Dong, R., Chen, H., Heidari, A. A., Turabieh, H., Mafarja, M., and Wang, S. (2021). Boosted kernel search: Framework, analysis and case studies on the economic emission dispatch problem. Knowl. Based Syst. 233:107529. doi: 10.1016/j.knosys.2021.107529
Dorigo, M. (1992). Optimization, learning and natural algorithms. Ph.D. Thesis. Milan: Politecnico di Milano.
Dorigo, M., and Caro, G. D. (1999). The ant colony optimization meta-heuristic. New ideas in optimization. New York, NY: McGraw-Hill Ltd, 11–32. doi: 10.1109/CEC.1999.782657
Dubin, R., Owens, C., Gasper, W., Ganz, P., and Johansen, K. (2011). Associations of endothelial dysfunction and arterial stiffness with intradialytic hypotension and hypertension. Hemodial Int. 15, 350–358. doi: 10.1111/j.1542-4758.2011.00560.x
Dunne, N. (2017). A meta-analysis of sodium profiling techniques and the impact on intradialytic hypotension. Hemodial Int. 21, 312–322. doi: 10.1111/hdi.12488
Duranton, F., Kramer, A., Szwarc, I., Bieber, B., Gayrard, N., Jover, B., et al. (2018). Geographical variations in blood pressure level and seasonality in hemodialysis patients. Hypertension 71, 289–296. doi: 10.1161/HYPERTENSIONAHA.117.10274
Elhosseini, M. A., Haikal, A. Y., Badawy, M., and Khashan, N. (2019). Biped robot stability based on an A–C parametric Whale Optimization Algorithm. J. Comput. Sci. 31, 17–32. doi: 10.1016/j.jocs.2018.12.005
El-Kenawy, E. S. M., Ibrahim, A., Mirjalili, S., Eid, M. M., and Hussein, S. E. (2020). Novel feature selection and voting classifier algorithms for COVID-19 classification in CT images. IEEE Access 8, 179317–179335. doi: 10.1109/ACCESS.2020.3028012
Elminaam, D. S. A., Nabil, A., Ibraheem, S. A., and Houssein, E. H. (2021). An efficient marine predators algorithm for feature selection. IEEE Access 9, 60136–60153. doi: 10.1109/ACCESS.2021.3073261
Flythe, J. E., Kimmel, S. E., and Brunelli, S. M. (2011). Rapid fluid removal during dialysis is associated with cardiovascular morbidity and mortality. Kidney Int. 79, 250–257. doi: 10.1038/ki.2010.383
Gao, D., Wang, G.-G., and Pedrycz, W. (2020). Solving fuzzy job-shop scheduling problem using DE algorithm improved by a selection mechanism. IEEE Trans. Fuzzy Syst. 28, 3265–3275. doi: 10.1109/TFUZZ.2020.3003506
García, S., Fernández, A., Luengo, J., and Herrera, F. (2010). Advanced nonparametric tests for multiple comparisons in the design of experiments in computational intelligence and data mining: Experimental analysis of power. Inf. Sci. 180, 2044–2064. doi: 10.1016/j.ins.2009.12.010
Gasparyan, A. Y., Ayvazyan, L., Mukanova, U., Yessirkepov, M., and Kitas, G. D. (2019). The Platelet-to-Lymphocyte ratio as an inflammatory marker in rheumatic diseases. Ann. Lab. Med. 39, 345–357. doi: 10.3343/alm.2019.39.4.345
Ghoneim, S. S. M., Farrag, T. A., Rashed, A. A., El-Kenawy, E. S. M., and Ibrahim, A. (2021). Adaptive dynamic meta-heuristics for feature selection and classification in diagnostic accuracy of transformer faults. IEEE Access 9, 78324–78340. doi: 10.1109/ACCESS.2021.3083593
Halle, M. P., Hilaire, D., Francois, K. F., Denis, T., Hermine, F., and Gloria, A. E. (2020). Intradialytic hypotension and associated factors among patients on maintenance hemodialysis: A single-center study in cameroon. Saudi J. Kidney Dis. Transpl. 31, 215–223. doi: 10.4103/1319-2442.279944
Han, X., Han, Y., Chen, Q., Li, J., Sang, H., Liu, Y., et al. (2021). Distributed flow shop scheduling with sequence-dependent setup times using an improved iterated greedy algorithm. Complex Syst. Model. Simul. 1, 198–217. doi: 10.23919/CSMS.2021.0018
Heidari, A. A., Ali Abbaspour, R., and Chen, H. (2019a). Efficient boosted grey wolf optimizers for global search and kernel extreme learning machine training. Appl. Soft Comput. 81:105521. doi: 10.1016/j.asoc.2019.105521
Heidari, A. A., Aljarah, I., Faris, H., Chen, H., Luo, J., and Mirjalili, S. (2020). An enhanced associative learning-based exploratory whale optimizer for global optimization. Neural Comput. Applic. 32, 5185–5211. doi: 10.1007/s00521-019-04015-0
Heidari, A. A., Mirjalili, S., Faris, H., Aljarah, I., Mafarja, M., and Chen, H. (2019b). Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 97, 849–872. doi: 10.1016/j.future.2019.02.028
Houssein, E. H., Abdelminaam, D. S., Hassan, H. N., Al-Sayed, M. M., and Nabil, E. A. (2021). Hybrid barnacles mating optimizer algorithm with support vector machines for gene selection of microarray cancer classification. IEEE Access 9, 64895–64905. doi: 10.1109/ACCESS.2021.3075942
Hu, J., Chen, H., Heidari, A. A., Wang, M., Zhang, X., Chen, Y., et al. (2021). Orthogonal learning covariance matrix for defects of grey wolf optimizer: Insights, balance, diversity, and feature selection. Knowl. Based Syst. 213:106684. doi: 10.1016/j.knosys.2020.106684
Hu, J., Gui, W., Heidari, A. A., Cai, Z., Liang, G., Chen, H., et al. (2022a). Dispersed foraging slime mould algorithm: Continuous and binary variants for global optimization and wrapper-based feature selection. Knowl. Based Syst. 237:107761. doi: 10.1016/j.knosys.2021.107761
Hu, J., Han, Z., Heidari, A. A., Shou, Y., Ye, H., Wang, L., et al. (2022b). Detection of COVID-19 severity using blood gas analysis parameters and Harris hawks optimized extreme learning machine. Comput. Biol. Med. 142:105166. doi: 10.1016/j.compbiomed.2021.105166
Hu, J., Liu, Y., Heidari, A. A., Bano, Y., Ibrohimov, A., Liang, G., et al. (2022c). An effective model for predicting serum albumin level in hemodialysis patients. Comput. Biol. Med. 140:105054. doi: 10.1016/j.compbiomed.2021.105054
Hu, Z., Wang, J., Zhang, C., Luo, Z., Luo, X., Xiao, L., et al. (2022d). Uncertainty modeling for multicenter autism spectrum disorder classification using takagi–sugeno–kang fuzzy systems. IEEE Trans. Cogn. Dev. Syst. 14, 730–739. doi: 10.1109/TCDS.2021.3073368
Hua, Y., Liu, Q., Hao, K., and Jin, Y. A. (2021). Survey of evolutionary algorithms for multi-objective optimization problems with irregular pareto fronts. IEEE/CAA J. Autom. Sin. 8, 303–318. doi: 10.1109/JAS.2021.1003817
Huang, J. C., Tsai, Y. C., Wu, P. Y., Lien, Y. H., Chien, C. Y., Kuo, C. F., et al. (2020). Predictive modeling of blood pressure during hemodialysis: A comparison of linear model, random forest, support vector regression, XGBoost, LASSO regression and ensemble method. Comput. Methods Programs Biomed. 195:105536. doi: 10.1016/j.cmpb.2020.105536
Hussien, A. G., Heidari, A. A., Ye, X., Liang, G., Chen, H., and Pan, Z. (2022). Boosting whale optimization with evolution strategy and Gaussian random walks: An image segmentation method. Eng. Comput. doi: 10.1007/s00366-021-01542-0
Jansen, M. A., Hart, A. A., Korevaar, J. C., Dekker, F. W., Boeschoten, E. W., and Krediet, R. T. (2002). Predictors of the rate of decline of residual renal function in incident dialysis patients. Kidney Int. 62, 1046–1053. doi: 10.1046/j.1523-1755.2002.00505.x
K/Doqi Workgroup (2005). K/DOQI clinical practice guidelines for cardiovascular disease in dialysis patients. Am J Kidney Dis. 45(4 Suppl. 3), S1–S153. doi: 10.1053/j.ajkd.2005.01.019
Kadavy, T., Senkerik, R., Pluhacek, M., and Viktorin, A. (2020). Orthogonal learning firefly algorithm. Logic J. IGPL 29, 167–179. doi: 10.1093/jigpal/jzaa044
Keane, D. F., Raimann, J. G., Zhang, H., Willetts, J., Thijssen, S., and Kotanko, P. (2021). The time of onset of intradialytic hypotension during a hemodialysis session associates with clinical parameters and mortality. Kidney Int. 99, 1408–1417. doi: 10.1016/j.kint.2021.01.018
Kennedy, J., and Eberhart, R. (eds) (1995). “Particle swarm optimization,” in Proceedings of ICNN’95 - International Conference on Neural Networks. Perth, WA.
Kumarasamy, C., Tiwary, V., Sunil, K., Suresh, D., Shetty, S., Muthukaliannan, G. K., et al. (2021). Prognostic utility of platelet-lymphocyte ratio, neutrophil-lymphocyte ratio and monocyte-lymphocyte ratio in head and neck cancers: A detailed PRISMA compliant systematic review and meta-analysis. Cancers 13:4166. doi: 10.3390/cancers13164166
Le, T. M., Vo, T. M., Pham, T. N., and Dao, S. V. T. (2021). A Novel wrapper–based feature selection for early diabetes prediction enhanced with a metaheuristic. IEEE Access 9, 7869–7884. doi: 10.1109/ACCESS.2020.3047942
Li, C., Dong, M., Li, J., Xu, G., Chen, X. B., Liu, W., et al. (2022). Efficient medical big data management with keyword-searchable encryption in healthchain. IEEE Syst. J. 1–12. doi: 10.1109/JSYST.2022.3173538
Li, D., Zhang, S., and Ma, X. (2021). Dynamic module detection in temporal attributed networks of cancers. IEEE/ACM Transac. Comput. Biol. Bioinform. 19, 2219–2230. doi: 10.1109/TCBB.2021.3069441
Li, J., Xu, K., Chaudhuri, S., Yumer, E., Zhang, H., and Guibas, L. (2017). Grass: Generative recursive autoencoders for shape structures. ACM Transac. Graphics 36, 1–14. doi: 10.1145/3072959.3073637
Li, J.-Y., Zhan, Z.-H., Wang, C., Jin, H., and Zhang, J. (2020a). Boosting data-driven evolutionary algorithm with localized data generation. IEEE Transac. Evolut. Comput. 24, 923–937. doi: 10.1109/TEVC.2020.2979740
Li, S., Chen, H., Wang, M., Heidari, A. A., and Mirjalili, S. (2020b). Slime mould algorithm: A new method for stochastic optimization. Future Gener. Comput. Syst. 111, 300–323. doi: 10.1016/j.future.2020.03.055
Li, S., Liu, C. H., Lin, Q., Wen, Q., Su, L., Huang, G., et al. (2020c). Deep residual correction network for partial domain adaptation. IEEE Transac. Pattern Anal. Mach. Intell. 43, 2329–2344. doi: 10.1109/TPAMI.2020.2964173 doi: 10.1109/TPAMI.2020.2964173 doi: 10.1109/TPAMI.2020.2964173
PubMed Abstract | CrossRef Full Text | CrossRef Full Text | Google Scholar
Liang, H., Liu, Y., Shen, Y., Li, F., and Man, Y. A. (2018). Hybrid bat algorithm for economic dispatch with random wind power. IEEE Transac. Power Syst. 33, 5052–5061. doi: 10.1109/TPWRS.2018.2812711
Lin, C. J., Chen, C. Y., Wu, P. C., Pan, C. F., Shih, H. M., Huang, M. Y., et al. (2018). Intelligent system to predict intradialytic hypotension in chronic hemodialysis. J. Formos Med. Assoc. 117, 888–893. doi: 10.1016/j.jfma.2018.05.023
Lin, C. J., Chen, Y. Y., Pan, C. F., Wu, V., and Wu, C. J. (2019). Dataset supporting blood pressure prediction for the management of chronic hemodialysis. Sci .Data 6:313. doi: 10.1038/s41597-019-0319-8
Ling Chen, H., Yang, B., Jing Wang, S., Wang, G., Zhong Li, H., and Bin Liu, W. (2014). Towards an optimal support vector machine classifier using a parallel particle swarm optimization strategy. Appl. Math. Comput. 239, 180–197. doi: 10.1016/j.amc.2014.04.039
Ling, Y., Zhou, Y., and Luo, Q. L. (2017). évy Flight trajectory-based whale optimization algorithm for global optimization. IEEE Access 5, 6168–6186. doi: 10.1109/ACCESS.2017.2695498
Liu, G., Jia, W., Wang, M., Heidari, A. A., Chen, H., Luo, Y., et al. (2020). Predicting cervical hyperextension injury: A covariance guided sine cosine support vector machine. IEEE Access. 8, 46895–46908. doi: 10.1109/ACCESS.2020.2978102
Liu, J., Wei, J., Heidari, A. A., Kuang, F., Zhang, S., Gui, W., et al. (2022a). Chaotic simulated annealing multi-verse optimization enhanced kernel extreme learning machine for medical diagnosis. Comput. Biol. Med. 144:105356. doi: 10.1016/j.compbiomed.2022.105356
Liu, K., Ke, F., Huang, X., Yu, R., Lin, F., Wu, Y., et al. (2021). DeepBAN: A temporal convolution-based communication framework for dynamic WBANs. IEEE Transac. Commun. 69, 6675–6690. doi: 10.1109/TCOMM.2021.3094581
Liu, L., Zhao, D., Yu, F., Heidari, A. A., Li, C., Ouyang, J., et al. (2021). Ant colony optimization with Cauchy and greedy Levy mutations for multilevel COVID 19 X-ray image segmentation. Comput. Biol. Med. 136:104609. doi: 10.1016/j.compbiomed.2021.104609
Liu, S., Yang, B., Wang, Y., Tian, J., Yin, L., and Zheng, W. (2022b). 2D/3D multimode medical image registration based on normalized cross-correlation. Appl. Sci. 12:2828. doi: 10.3390/app12062828
Liu, Y., Heidari, A. A., Cai, Z., Liang, G., Chen, H., Pan, Z., et al. (2022c). Simulated annealing-based dynamic step shuffled frog leaping algorithm: Optimal performance design and feature selection. Neurocomputing 503, 325–362. doi: 10.1016/j.neucom.2022.06.075
Liu, Y., Tian, J., Hu, R., Yang, B., Liu, S., Yin, L., et al. (2022d). Improved feature point pair purification algorithm based on SIFT during endoscope image stitching. Front. Neurorobot. 16:840594. doi: 10.3389/fnbot.2022.840594
Liu, Z., Su, W., Ao, J., Wang, M., Jiang, Q., He, J., et al. (2022e). Instant diagnosis of gastroscopic biopsy via deep-learned single-shot femtosecond stimulated Raman histology. Nat. Commun. 13:4050. doi: 10.1038/s41467-022-31339-8
Lu, C., Gao, L., and Yi, J. (2018). Grey wolf optimizer with cellular topological structure. Expert Syst. Applic. 107, 89–114. doi: 10.1016/j.eswa.2018.04.012
Luo, G., Yuan, Q., Li, J., Wang, S., and Yang, F. (2022). Artificial intelligence powered mobile networks: From cognition to decision. IEEE Network. 36, 136–144. doi: 10.1109/MNET.013.2100087
Ma, X., Sun, P. G., and Gong, M. (2020). An integrative framework of heterogeneous genomic data for cancer dynamic modules based on matrix decomposition. IEEE/ACM Transac. Comput. Biol. Bioinform. 19, 305–316. doi: 10.1109/TCBB.2020.3004808
Marshall, M. R., Vandal, A. C., de Zoysa, J. R., Gabriel, R. S., Haloob, I. A., Hood, C. J., et al. (2020). Effect of low-sodium versus conventional sodium dialysate on left ventricular mass in home and self-care satellite facility hemodialysis patients: A randomized clinical trial. J. Am. Soc. Nephrol. 31, 1078–1091. doi: 10.1681/ASN.2019090877
Matsuura, R., Hidaka, S., Ohtake, T., Mochida, Y., Ishioka, K., Maesato, K., et al. (2019). Intradialytic hypotension is an important risk factor for critical limb ischemia in patients on hemodialysis. BMC Nephrol. 20:473. doi: 10.1186/s12882-019-1662-x
Mirjalili, S. (2015). Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm. Knowl. Based Syst. 89, 228–249. doi: 10.1016/j.knosys.2015.07.006
Mirjalili, S. (2016). SCA: A sine cosine algorithm for solving optimization problems. Knowl. Based Syst. 96, 120–133. doi: 10.1016/j.knosys.2015.12.022
Mirjalili, S., and Lewis, A. (2016). The whale optimization algorithm. Adv. Eng. Softw. 95, 51–67. doi: 10.1016/j.advengsoft.2016.01.008
Mirjalili, S., Dong, J. S., and Lewis, A. (2019). Nature-inspired optimizers: theories, literature reviews and applications. Berlin: Springer. doi: 10.1007/978-3-030-12127-3
Mirjalili, S., Mirjalili, S. M., and Lewis, A. (2014). Grey wolf optimizer. Adv. Eng. Softw. 69, 46–61. doi: 10.1016/j.advengsoft.2013.12.007
Nafisi, V. R., and Shahabi, M. (2018). Intradialytic hypotension related episodes identification based on the most effective features of photoplethysmography signal. Comput. Methods Programs Biomed. 157, 1–9. doi: 10.1016/j.cmpb.2018.01.012
Naganuma, T., Uchida, J., Tsuchida, K., Takemoto, Y., Tatsumi, S., Sugimura, K., et al. (2005). Silent cerebral infarction predicts vascular events in hemodialysis patients. Kidney Int. 67, 2434–2439. doi: 10.1111/j.1523-1755.2005.00351.x
Nenavath, H., Kumar Jatoth, D. R., and Das, D. S. (2018). A synergy of the sine-cosine algorithm and particle swarm optimizer for improved global optimization and object tracking. Swarm Evol. Comput. 43, 1–30. doi: 10.1016/j.swevo.2018.02.011
Ori, Y., Chagnac, A., Schwartz, A., Herman, M., Weinstein, T., Zevin, D., et al. (2005). Non-occlusive mesenteric ischemia in chronically dialyzed patients: A disease with multiple risk factors. Nephron Clin. Pract. 101, c87–c93. doi: 10.1159/000086346
Ozen, N., and Cepken, T. (2020). Intradialytic hypotension prevalence, influencing factors, and nursing interventions: Prospective results of 744 hemodialysis sessions. Iran J. Med. Sci. 189, 1471–1476. doi: 10.1007/s11845-020-02249-9
Palladino, M. (2021). Complete blood count alterations in COVID-19 patients: A narrative review. Biochem. Med. 31:030501. doi: 10.11613/BM.2021.030501
Patel, P., Kumari, G., and Saxena, P. (eds) (2019). “Array pattern correction in presence of antenna failures using metaheuristic optimization algorithms,” in 2019 International Conference on Communication and Signal Processing (ICCSP), (Chennai). doi: 10.1109/ICCSP.2019.8697942
Qi, A., Zhao, D., Yu, F., Heidari, A. A., Chen, H., and Xiao, L. (2022). Directional mutation and crossover for immature performance of whale algorithm with application to engineering optimization. J. Comput. Design Eng. 9, 519–563. doi: 10.1093/jcde/qwac014
Qiao, S., Yu, H., Heidari, A. A., El-Saleh, A. A., Cai, Z., Xu, X., et al. (2022). Individual disturbance and neighborhood mutation search enhanced whale optimization: Performance design for engineering problems. J. Comput. Design Eng. 9, 1817–1851. doi: 10.1093/jcde/qwac081
Qiu, S., Zhao, H., Jiang, N., Wang, Z., Liu, L., An, Y., et al. (2022). Multi-sensor information fusion based on machine learning for real applications in human activity recognition: State-of-the-art and research challenges. Inf. Fusion 80, 241–265. doi: 10.1016/j.inffus.2021.11.006
Qu, C., Zeng, Z., Dai, J., Yi, Z., and He, W. (2018). A modified sine-cosine algorithm based on neighborhood search and greedy levy mutation. Comput. Intell. Neurosci. 2018:4231647. doi: 10.1155/2018/4231647
Radhakrishnan, R. C., Varughese, S., Chandran, A., Jacob, S., David, V. G., Alexander, S., et al. (2020). Effects of individualized dialysate sodium prescription in hemodialysis - results from a prospective interventional trial. Indian J. Nephrol. 30, 3–7. doi: 10.4103/ijn.IJN_391_18
Revathi, S. T., Ramaraj, N., and Chithra, S. (2020). Tracy–singh product and genetic whale optimization algorithm for retrievable data perturbation for privacy preserved data publishing in cloud computing. Comput. J. 63, 239–253. doi: 10.1093/comjnl/bxz101
Sandberg, F., Bailón, R., Hernando, D., Laguna, P., Martínez, J. P., Solem, K., et al. (2014). Prediction of hypotension in hemodialysis patients. Physiol. Meas. 35, 1885–1898. doi: 10.1088/0967-3334/35/9/1885
Sands, J. J., Usvyat, L. A., Sullivan, T., Segal, J. H., Zabetakis, P., Kotanko, P., et al. (2014). Intradialytic hypotension: Frequency, sources of variation and correlation with clinical outcome. Hemodial Int. 18, 415–422. doi: 10.1111/hdi.12138
Saremi, S., Mirjalili, S., and Lewis, A. (2017). Grasshopper optimisation algorithm: Theory and application. Adv. Eng. Softw. 105, 30–47. doi: 10.1016/j.advengsoft.2017.01.004
Schytz, P. A., Mace, M. L., Soja, A. M., Nilsson, B., Karamperis, N., Kristensen, B., et al. (2015). Impact of extracorporeal blood flow rate on blood pressure, pulse rate and cardiac output during haemodialysis. Nephrol Dial Transplant. 30, 2075–2079. doi: 10.1093/ndt/gfv316
Senthilkumar, G., Ramakrishnan, J., Frnda, J., Ramachandran, M., Gupta, D., Tiwari, P., et al. (2021). Incorporating artificial fish swarm in ensemble classification framework for recurrence prediction of cervical cancer. IEEE Access 9, 83876–83886. doi: 10.1109/ACCESS.2021.3087022
Shan, W., Qiao, Z., Heidari, A. A., Gui, W., Chen, H., Teng, Y., et al. (2022). An efficient rotational direction heap-based optimization with orthogonal structure for medical diagnosis. Comput. Biol. Med. 146:105563. doi: 10.1016/j.compbiomed.2022.105563
Sherman, R. A. (2016). We lower blood flow for intradialytic hypotension. Semin. Dial 29, 295–296. doi: 10.1111/sdi.12486
Shi, B., Zhou, T., Lv, S., Wang, M., Chen, S., Heidari, A. A., et al. (2022). An evolutionary machine learning for pulmonary hypertension animal model from arterial blood gas analysis. Comput. Biol. Med. 146:105529. doi: 10.1016/j.compbiomed.2022.105529
Socha, K., and Dorigo, M. (2008). Ant colony optimization for continuous domains. Eur. J. Operat. Res. 185, 1155–1173. doi: 10.1016/j.ejor.2006.06.046
Solem, K., Olde, B., and Sörnmo, L. (2010). Prediction of intradialytic hypotension using photoplethysmography. IEEE Trans. Biomed. Eng. 57, 1611–1619. doi: 10.1109/TBME.2010.2042170
Su, Y., Li, S., Zheng, C., and Zhang, X. (2019). A heuristic algorithm for identifying molecular signatures in cancer. IEEE Transac. Nanobiosci. 19, 132–141. doi: 10.1109/TNB.2019.2930647
Takayama, F., Miyazaki, S., Morita, T., Hirasawa, Y., and Niwa, T. (2001). Dialysis-related amyloidosis of the heart in long-term hemodialysis patients. Kidney Int. Suppl. 78, S172–S176. doi: 10.1046/j.1523-1755.2001.07835.x
Tian, Y., Su, X., Su, Y., and Zhang, X. (2020). EMODMI: A multi-objective optimization based method to identify disease modules. IEEE Transac. Emerg. Top. Comput. Intell. 5, 570–582. doi: 10.1109/TETCI.2020.3014923
Tian, Y., Zhang, J., Chen, L., Geng, Y., and Wang, X. (2019). Single wearable accelerometer-based human activity recognition via kernel discriminant analysis and QPSO-KELM classifier. IEEE Access 7, 109216–109227. doi: 10.1109/ACCESS.2019.2933852
Tsujimoto, Y., Tsujimoto, H., Nakata, Y., Kataoka, Y., Kimachi, M., Shimizu, S., et al. (2019). Dialysate temperature reduction for intradialytic hypotension for people with chronic kidney disease requiring haemodialysis. Cochrane Database Syst. Rev. 7:Cd012598. doi: 10.1002/14651858.CD012598.pub2
Tu, J., Chen, H., Liu, J., Heidari, A. A., Zhang, X., Wang, M., et al. (2021a). Evolutionary biogeography-based whale optimization methods with communication structure: Towards measuring the balance. Knowl. Based Syst. 212:106642. doi: 10.1016/j.knosys.2020.106642
Tu, J., Chen, H., Wang, M., and Gandomi, A. H. (2021b). The colony predation algorithm. J. Bionic Eng. 18, 674–710. doi: 10.1007/s42235-021-0050-y
Tubishat, M., Abushariah, M. A. M., Idris, N., and Aljarah, I. (2019). Improved whale optimization algorithm for feature selection in Arabic sentiment analysis. Appl. Intell. 49, 1688–1707. doi: 10.1007/s10489-018-1334-8
Wang, G.-G., Gao, D., and Pedrycz, W. (2022). Solving multi-objective fuzzy job-shop scheduling problem by a hybrid adaptive differential evolution algorithm. IEEE Transac. Industr. Inform. 18, 8519–8528. doi: 10.1109/TII.2022.3165636
Wang, Y., and Wang, S. (2021). Soft sensor for VFA concentration in anaerobic digestion process for treating kitchen waste based on SSAE-KELM. IEEE Access 9, 36466–36474. doi: 10.1109/ACCESS.2021.3063231
Wong, M. M., McCullough, K. P., Bieber, B. A., Bommer, J., Hecking, M., Levin, N. W., et al. (2017). Interdialytic weight gain: Trends, predictors, and associated outcomes in the international dialysis outcomes and practice patterns study (DOPPS). Am. J. Kidney Dis. 69, 367–379. doi: 10.1053/j.ajkd.2016.08.030
Wu, S.-H., Zhan, Z.-H., and Zhang, J. (2021a). SAFE: Scale-adaptive fitness evaluation method for expensive optimization problems. IEEE Transac. Evol. Comput. 25, 478–491. doi: 10.1109/TEVC.2021.3051608
Wu, Z., Li, G., Shen, S., Cui, Z., Lian, X., and Xu, G. (2021b). Constructing dummy query sequences to protect location privacy and query privacy in location-based services. World Wide Web. 24, 25–49. doi: 10.1007/s11280-020-00830-x
Wu, Z., Li, R., Xie, J., Zhou, Z., Guo, J., and Xu, X. (2020a). A user sensitive subject protection approach for book search service. J. Assoc. Inf. Sci. Technol. 71, 183–195. doi: 10.1002/asi.24227
Wu, Z., Shen, S., Lian, X., Su, X., and Chen, E. (2020b). A dummy-based user privacy protection approach for text information retrieval. Knowl. Based Syst. 195:105679. doi: 10.1016/j.knosys.2020.105679
Wu, Z., Shen, S., Zhou, H., Li, H., Lu, C., and Zou, D. (2021c). An effective approach for the protection of user commodity viewing privacy in e-commerce website. Knowl. Based Syst. 220:106952. doi: 10.1016/j.knosys.2021.106952
Wu, Z., Wang, R., Li, Q., Lian, X., and Xu, G. (2020c). A location privacy-preserving system based on query range cover-up for location-based services. IEEE Transac. Vehicular Technol. 69, 5244–5254. doi: 10.1109/TVT.2020.2981633
Xia, J., Wang, Z., Yang, D., Li, R., Liang, G., Chen, H., et al. (2022a). Performance optimization of support vector machine with oppositional grasshopper optimization for acute appendicitis diagnosis. Comput. Biol. Med. 143:105206. doi: 10.1016/j.compbiomed.2021.105206
Xia, J., Yang, D., Zhou, H., Chen, Y., Zhang, H., Liu, T., et al. (2022b). Evolving kernel extreme learning machine for medical diagnosis via a disperse foraging sine cosine algorithm. Comput. Biol. Med. 141:105137. doi: 10.1016/j.compbiomed.2021.105137
Xu, Y., Chen, H., Heidari, A. A., Luo, J., Zhang, Q., Zhao, X., et al. (2019). An efficient chaotic mutative moth-flame-inspired optimizer for global optimization tasks. Expert Syst. Applic. 129, 135–155. doi: 10.1016/j.eswa.2019.03.043
Yang, X., Zhao, D., Yu, F., Heidari, A. A., Bano, Y., Ibrohimov, A., et al. (2022a). An optimized machine learning framework for predicting intradialytic hypotension using indexes of chronic kidney disease-mineral and bone disorders. Comput. Biol. Med. 145:105510. doi: 10.1016/j.compbiomed.2022.105510
Yang, X., Zhao, D., Yu, F., Heidari, A. A., Bano, Y., Ibrohimov, A., et al. (2022b). Boosted machine learning model for predicting intradialytic hypotension using serum biomarkers of nutrition. Comput. Biol. Med. 147:105752. doi: 10.1016/j.compbiomed.2022.105752
Yang, X.-S. (2010). “A new metaheuristic bat-inspired algorithm,” in Nature inspired cooperative strategies for optimization (NICSO 2010), eds J. R. González, D. A. Pelta, C. Cruz, G. Terrazas, and N. Krasnogor (Berlin: Springer), 65–74. doi: 10.1007/978-3-642-12538-6_6
Yang, X.-S. (2009). Firefly algorithms for multimodal optimization. Berlin: Springer. doi: 10.1007/978-3-642-04944-6_14
Yang, Y., Chen, H., Heidari, A. A., and Gandomi, A. H. (2021). Hunger games search: Visions, conception, implementation, deep analysis, perspectives, and towards performance shifts. Expert Syst. Applic. 177:114864. doi: 10.1016/j.eswa.2021.114864
Ye, X., Cai, Z., Lu, C., Chen, H., and Pan, Z. (2022). Boosted sine cosine algorithm with application to medical diagnosis. Comput. Math. Methods Med. 2022:6215574. doi: 10.1155/2022/6215574
Ye, X., Liu, W., Li, H., Wang, M., Chi, C., Liang, G., et al. (2021). Modified whale optimization algorithm for solar cell and PV module parameter identification. Complexity 2021:8878686. doi: 10.1155/2021/8878686
Yeo, S., Moon, J. I., Shin, J., Hwang, J. H., Cho, I., and Kim, S. H. (2020). Impacts of coronary artery calcification on intradialytic blood pressure patterns in patients receiving maintenance hemodialysis. Chonnam. Med. J. 56, 27–35. doi: 10.4068/cmj.2020.56.1.27
Yin, J., Sun, W., Li, F., Hong, J., Li, X., Zhou, Y., et al. (2020). VARIDT 1.0: Variability of drug transporter database. Nucleic Acids Res. 48, D1042–D1050. doi: 10.1093/nar/gkz779
Yong, J., He, F., Li, H., and Zhou, W. (eds) (2018). “A novel bat algorithm based on collaborative and dynamic learning of opposite population,” in 2018 IEEE 22nd International Conference on Computer Supported Cooperative Work in Design ((CSCWD)), (Nanjing). doi: 10.1109/CSCWD.2018.8464759
Yu, H., Cheng, X., Chen, C., Heidari, A. A., Liu, J., Cai, Z., et al. (2022a). Apple leaf disease recognition method with improved residual network. Multimed. Tools Applic. 81, 7759–7782. doi: 10.1007/s11042-022-11915-2
Yu, H., Qiao, S., Heidari, A. A., Bi, C., and Chen, H. (2022c). Individual disturbance and attraction repulsion strategy enhanced seagull optimization for engineering design. Mathematics 10:276. doi: 10.3390/math10020276
Yu, H., Song, J., Chen, C., Heidari, A. A., Liu, J., Chen, H., et al. (2022b). Image segmentation of Leaf Spot Diseases on Maize using multi-stage Cauchy-enabled grey wolf algorithm. Eng. Applic. Artif. Intell. 109:104653. doi: 10.1016/j.engappai.2021.104653
Yu, J., Chen, X., Li, Y., Wang, Y., Cao, X., Liu, Z., et al. (2021). Pro-inflammatory cytokines as potential predictors for intradialytic hypotension. Ren. Fail. 43, 198–205. doi: 10.1080/0886022X.2021.1871921
Zhang, J., Zhu, C., Zheng, L., and Xu, K. (2021). ROSEFusion: Random optimization for online dense reconstruction under fast camera motion. ACM Transac. Graphics 40, 1–17. doi: 10.1145/3478513.3480500
Zhang, M., Chen, Y., and Lin, J. (2021). A privacy-preserving optimization of neighborhood-based recommendation for medical-aided diagnosis and treatment. IEEE Internet Things J. 8, 10830–10842. doi: 10.1109/JIOT.2021.3051060
Zhang, M., Zhang, X., Wang, H., Xiong, G., and Cheng, W. (2020). Features fusion exaction and KELM with modified grey wolf optimizer for mixture control chart patterns recognition. IEEE Access 8, 42469–42480. doi: 10.1109/ACCESS.2020.2976795
Zhang, R. M., McNerney, K. P., Riek, A. E., and Bernal-Mizrachi, C. (2021). Immunity and hypertension. Acta Physiol. 231:e13487. doi: 10.1111/apha.13487
Zhang, X., Fan, C., Xiao, Z., Zhao, L., Chen, H., and Chang, X. (2022). Random reconstructed unpaired image-to-image translation. IEEE Transac. Industr. Inform. 1–1. doi: 10.1109/TII.2022.3160705
Zhang, Z., Wang, L., Zheng, W., Yin, L., Hu, R., and Yang, B. (2022). Endoscope image mosaic based on pyramid ORB. Biomed. Signal Process. Control 71:103261. doi: 10.1016/j.bspc.2021.103261
Zhao, D., Liu, L., Yu, F., Heidari, A. A., Wang, M., Liang, G., et al. (2021). Chaotic random spare ant colony optimization for multi-threshold image segmentation of 2D Kapur entropy. Knowl. Based Syst. 216:106510. doi: 10.1016/j.knosys.2020.106510
Zhao, F., Di, S., Cao, J., and Tang, J. (2021). A novel cooperative multi-stage hyper-heuristic for combination optimization problems. Complex Syst. Model. Simul. 1, 91–108. doi: 10.23919/CSMS.2021.0010
Zhao, J., Zhu, X., and Song, T. (2022). Serial manipulator time-jerk optimal trajectory planning based on hybrid IWOA-PSO algorithm. IEEE Access 10, 6592–6604. doi: 10.1109/ACCESS.2022.3141448
Zheng, W., Cheng, J., Wu, X., Sun, R., Wang, X., and Sun, X. (2022). Domain knowledge-based security bug reports prediction. Knowl. Based Syst. 241:108293. doi: 10.1016/j.knosys.2022.108293
Zhu, A., Xu, C., Li, Z., Wu, J., and Liu, Z. (2015). Hybridizing grey wolf optimization with differential evolution for global optimization and test scheduling for 3D stacked SoC. J. Syst. Eng. Electron. 26, 317–328. doi: 10.1109/JSEE.2015.00037
Zhu, F., Shi, Z., Qin, C., Tao, L., Liu, X., Xu, F., et al. (2012). Therapeutic target database update 2012: A resource for facilitating target-oriented drug discovery. Nucleic Acids Res. 40, D1128–D1136. doi: 10.1093/nar/gkr797
Keywords: medical diagnosis, machine learning, swarm intelligence, feature selection, intradialytic hypotension
Citation: Li Y, Zhao D, Liu G, Liu Y, Bano Y, Ibrohimov A, Chen H, Wu C and Chen X (2022) Intradialytic hypotension prediction using covariance matrix-driven whale optimizer with orthogonal structure-assisted extreme learning machine. Front. Neuroinform. 16:956423. doi: 10.3389/fninf.2022.956423
Received: 30 May 2022; Accepted: 28 September 2022;
Published: 31 October 2022.
Edited by:
Essam Halim Houssein, Minia University, EgyptReviewed by:
Mario Versaci, Mediterranea University of Reggio Calabria, ItalyIman Ahmadianfar, Rajamangala University of Technology Rattanakosin, Thailand
Copyright © 2022 Li, Zhao, Liu, Liu, Bano, Ibrohimov, Chen, Wu and Chen. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Dong Zhao, emQtaHlAMTYzLmNvbQ==; Huiling Chen, Y2hlbmh1aWxpbmcuamx1QGdtYWlsLmNvbQ==; Xumin Chen, Y3htQHd6aG9zcGl0YWwuY24=