 Gan Wang
Gan Wang Moran Cerf
Moran Cerf- 1School of Mechanical and Electrical Engineering, Soochow University, Suchow, China
- 2Interdepartmental Neuroscience Program, Northwestern University, Evanston, IL, United States
Brain-Computer Interfaces (BCIs) are increasingly useful for control. Such BCIs can be used to assist individuals who lost mobility or control over their limbs, for recreational purposes such as gaming or semi-autonomous driving, or as an interface toward man-machine integration. Thus far, the performance of algorithms used for thought decoding has been limited. We show that by extracting temporal and spectral features from electroencephalography (EEG) signals and, following, using deep learning neural network to classify those features, one can significantly improve the performance of BCIs in predicting which motor action was imagined by a subject. Our movement prediction algorithm uses Sequential Backward Selection technique to jointly choose temporal and spectral features and a radial basis function neural network for the classification. The method shows an average performance increase of 3.50% compared to state-of-the-art benchmark algorithms. Using two popular public datasets our algorithm reaches 90.08% accuracy (compared to an average benchmark of 79.99%) on the first dataset and 88.74% (average benchmark: 82.01%) on the second dataset. Given the high variability within- and across-subjects in EEG-based action decoding, we suggest that using features from multiple modalities along with neural network classification protocol is likely to increase the performance of BCIs across various tasks.
Introduction
Brain-Computer Interfaces (BCIs) act as a link between neural activity and machine operations. The BCI extracts data from electrodes or sensors acquiring neural signals and translates those data into digital code (Bulárka and Gontean, 2016). Applications of BCI include those focused on improved health outcomes (i.e., rehabilitation of impaired motor function; Courtine et al., 2013), restoration of sensory functions (Hochberg et al., 2012), interpreting thoughts from individuals who cannot otherwise communicate them (Cerf et al., 2010), enhanced control of devices (i.e., operating heavy machinery, flying drones, or driving; Chiuzbaian et al., 2019, Nader et al., 2021), or recreational uses (i.e., gaming; Cerf and Garcia-Garcia, 2017). Invasive BCIs, such as ones built on single-neuron recordings, have recently shown high accuracy in interpreting human/animal intentions, actions, and imagery (Cerf et al., 2010; Hochberg et al., 2012). Non-invasive tools such as ones using electroencephalography (EEG) data have demonstrated high performance in interpreting thoughts and actions. For example, interpreting imagined motor action–a commonly used task for evaluating BCIs–has shown decoding accuracies ranging between 70 and 85% in recent works (Gordleeva et al., 2017).
Notably, BCIs based on motor imagination (MI) tasks, where subjects imagine an action (i.e., clenching of the fist) and the BCI aims to identify the action imagined, have shown remarkable improvement in recent years. In a typical MI task, the BCI derives neural signatures (i.e., power changes in the alpha and beta rhythms extracted from sensory-motor regions) that accurately predict the action intent following a training period. Given that non-invasive signals generated by EEG are often contaminated by artifacts derived from eye movement or muscle movement, a typical EEG-based BCI requires larger training data and isolated trials to increase the action identification accuracy. The repeated trials enable the averaging of the event-related signals and the extraction of a synchronized clean input. Variance across individual subjects, electrode montages, experimental sessions, and trial types add difficulty to the interpretation of the signals.
Given the challenges in EEG-based BCI development using noisy inputs, numerous methods have been proposed to improve the decoders performance (Lebedev and Nicolelis, 2006; Lotte et al., 2007; Prashant et al., 2015; Abiri et al., 2019; Andersen et al., 2019). The suggested methods often focus on the isolation of temporal or spectral components in the signal. Algorithms based on spectral feature selection are more prominent in the BCI arsenal since the time courses of event-related synchronization (or de-synchronization) vary heavily among subjects during motor tasks (Hochberg et al., 2012; Andersen et al., 2019).
Within the feature selection BCIs signal toolkit arsenal, common spatial patterns (CSPs) algorithms are dominant (Bhatti et al., 2019). These algorithms seek to find an optimal spatial filter that distinguishes one brain state from another. In EEG, the performance of CSPs is highly sensitive to the choice of frequency bands, making the decision on which filter to use heavily dependent on the recording configuration. To afford some generalization, variants of CSP were proposed as ways to improve the signal processing. Those variants often use narrower frequency bands (termed: sub-band CSP; SBCSP; Novi et al., 2007) and Filter Banks (FBCSP; Ang et al., 2008) and show increased performance for action decoding, yet are still scarce.
In addition to the extended frequency bands and filters improvements, recent attempts to include temporal signals in BCIs emerged in the form of Temporally Constrained Group Spatial Pattern (TSGSP) algorithms (Zhang et al., 2018). TSGSP optimally select the CSP features by considering different temporal windows for signal extraction derived from multi-task learnings. That is, instead of collapsing all the trials within one MI class (i.e., all left-hand movement trials) various MI tasks are combined to suggest the ideal CSP for a specific individual subject. The TSGSP algorithms use Support Vector Machines (SVM) for the classification of new trials to their corresponding action class. This inclusion of temporal data was recently shown to improve the performance of CSP-based BCIs (Sakhavi et al., 2018; Zhang et al., 2018; Deng et al., 2021).
Neural network based classifiers that frequently show superiority in data-rich non-linear clustering tasks such as MI decoding were recently suggested as a potential improvement for the CSP algorithms (Bhatti et al., 2019). Specifically, the usage of Sequential Backward Floating Selection method along with a radial basis function neural network (RBFNN) for optimal CSP features selection was suggested as a potential superior algorithm for BCIs (Bhatti et al., 2019).
Here we implement and test a combination of the suggested improvements for MI decoding and show the tuning curves of key parameters driving the performance increase. Namely, we introduce a number of additions to the BCI motor classification algorithms arsenal. First, we incorporate both temporal and spectral features in the MI BCI. Second, we use sub-bands rather than typical frequency bands for the BCI inputs. Third, we combine the successful Sequential Backward Selection (SBS) method with CSP features for the temporal-spectral feature selection. Fourth, we separate the feature selection process from the following feature classification process. Finally, we incorporate the suggested RBFNN (rather than SVM) in the motor classification. We demonstrate the effectiveness of our method using popular public datasets and compare our performance to the current state-of-the-art BCI benchmark algorithms.
This work contributes to the BCI literature by showing that the combination of a SBS and temporal-spectral EEG signals with RBFNN significantly outperforms other methods. This is the first work to test the combination of all previously suggested improvements to existing algorithms in a single implementation (see Sakhavi et al., 2018; Zhang et al., 2018; Deng et al., 2021; for discussions of the improvements implemented here).
Materials and methods
Data
Two popular BCI datasets were used for the algorithm testing:
Dataset 1
Brain-computer interface competition IV, dataset 2a, which contains 22-channel EEG data recorded from 9 healthy subjects (A01–A09) participating in different MI tasks. In each task, subjects were asked to imagine movement of the left hand, right hand, feet, and tongue. The experiment consisted of two sessions. In each session, there were 72 trials for each of the four classes of movement. The EEG signals were sampled at 250 Hz and bandpass filtered between 0.5 and 100 Hz with a 50 Hz notch filter. We used the data from the left- and right-hand imagery tasks alone to align with the second dataset and some of the benchmark algorithms that focused solely on those movement classes.
Dataset 2
Brain-computer interface competition IV, dataset 2b, which contains 3-channel EEG data recorded from 9 different subjects (B01–B09) participating in two MI tasks. The experimental protocol was nearly identical to dataset 1 other than the fact that subjects only imagined movements of the left-hand and right-hand, and that instead of two sessions there were five session. For each subject, separate training and testing sets were available. The EEG signals were sampled at 250 Hz and bandpass filtered between 0.5 and 100 Hz with a 50 Hz notch filter.
See Leeb et al. (2008) for additional details on the two datasets.
Feature extraction
Pre-processing
Raw EEG signals were filtered between 4 and 40 Hz with fifth-order Butterworth filter. For each trial, we used samples between 500 and 4,500 ms from the trial onset in the analyses. The first 500 ms were excluded, in alignment with the instructions of the BCI IV competition winners, because of response times deviations across trials.
Feature selection
The neural signals were divided to five overlapping 2-s windows with a step size of 500 ms. This ensured temporal generalizability within a trial. Following, the data were filtered along 17 overlapping frequency bands ranging from 4 to 40 Hz with a 2 Hz step. Finally, a common spatial filter (Bhatti et al., 2019) was identified such that it maximized the variance within a single class (i.e., across all left-hand trials) and minimized the variance across classes (i.e., between left-hand and right-hand trials).
The data for a single trial were represented as a matrix, X ∈ RN⋅T (with N reflecting the number of channels, and T the time) whose normalized covariance matrix, C, is:
Averaging across all trials within a class yielded a matrix, Ct (t indicating the class type).
The spatial covariance was calculated by averaging all covariance matrices:
The Cc matrix was white transformed:
with UC the eigenvector matrix and λC the eigenvectors.
Defining P as:
the individual class matrices were transformed to:
such that the St matrices have the same eigenvectors.
Given that St could be represented as BλtBT with B the eigenvectors matrix and λt the eigenvalues:
the projection matrix, W, was derived:
Thus, the EEG data were projected to a matrix, Z:
where the columns of Z corresponded to the data’s spatial source distribution vectors. The vectors maximized the variance across classes and corresponded to the maximum eigenvalues (λleft–hand and λright−hand).
Finally, the classification features were represented by:
where Zp are the CSPs (p = 1..N).
A subset of Z (first and last m rows) were used in further analyses.
An SBS (Pasyuk et al., 2019) was used to reduce the initial 85-feature set (17 frequency bands × 5 time-windows) from each individual trial. According to the SBS criteria, in every iteration of the algorithm the feature yielding the lowest accuracy was discarded. That is, if the initial performance with all 85 features was, say, 87%, the performance using 84 features was computed next, leaving one feature out in each iteration (f1 = 78%, f2 = 82%, f3 = 77%, …). Comparing all 85 leave-one-out iterations, the feature whose contribution to the performance was lowest (i.e., one without whom the performance drops least; f2 in the particular example) was discarded. Following, the performance of the remaining 84 features was set as the anchor performance and the evaluation was repeated with 83 features. Each run led to a drop of a single feature. The optimal performance across all 3,655 iterations (85+84+…) was regarded the network’s accuracy, with the feature set yielding the highest performance being the preferred set.
Neural network
An RBFNN was used for the classification. The network consisted of two layers: an input layer and a hidden layer. The output of the hidden layer was summed proportionally to the input features to yield the output classification. Formally, this is represented as:
where wi are the weights, fi the Gaussian radial basis functions, ci the center values of the Gaussian radial function, b the bias, and k the number of neurons in the hidden layer.
With fi formally computed as:
where σi is the standard deviation.
In each iteration of the RBFNN implementation the extracted input features are scaled and used to train the network, followed by a testing. The network was implemented using Matlab’s newrbe function default hyperparameters, with the spread of the radial basis functions set to 16.
Implementation
The implementation of the method–pre-processing, feature selection, and neural network classification are available online at https://www.morancerf.com/publications.
Analyses
We compared our algorithm’s performance to that of all state-of-the-art methods which: (a) were published in the last 5 years, (b) used the same datasets as ours, and (c) were implemented on both the left- and right-hand MI data. We used one implementation of each method to avoid focusing on coding variations but rather on conceptual differences in the protocol. Altogether, 38 methods were compared to our algorithms, and 19 were not included in our analyses because they did not satisfy the inclusion criteria (namely, those algorithms used different movement classes outside of the ones we tested).
For dataset 1 we compared our performance to the following methods (see results in Table 1):
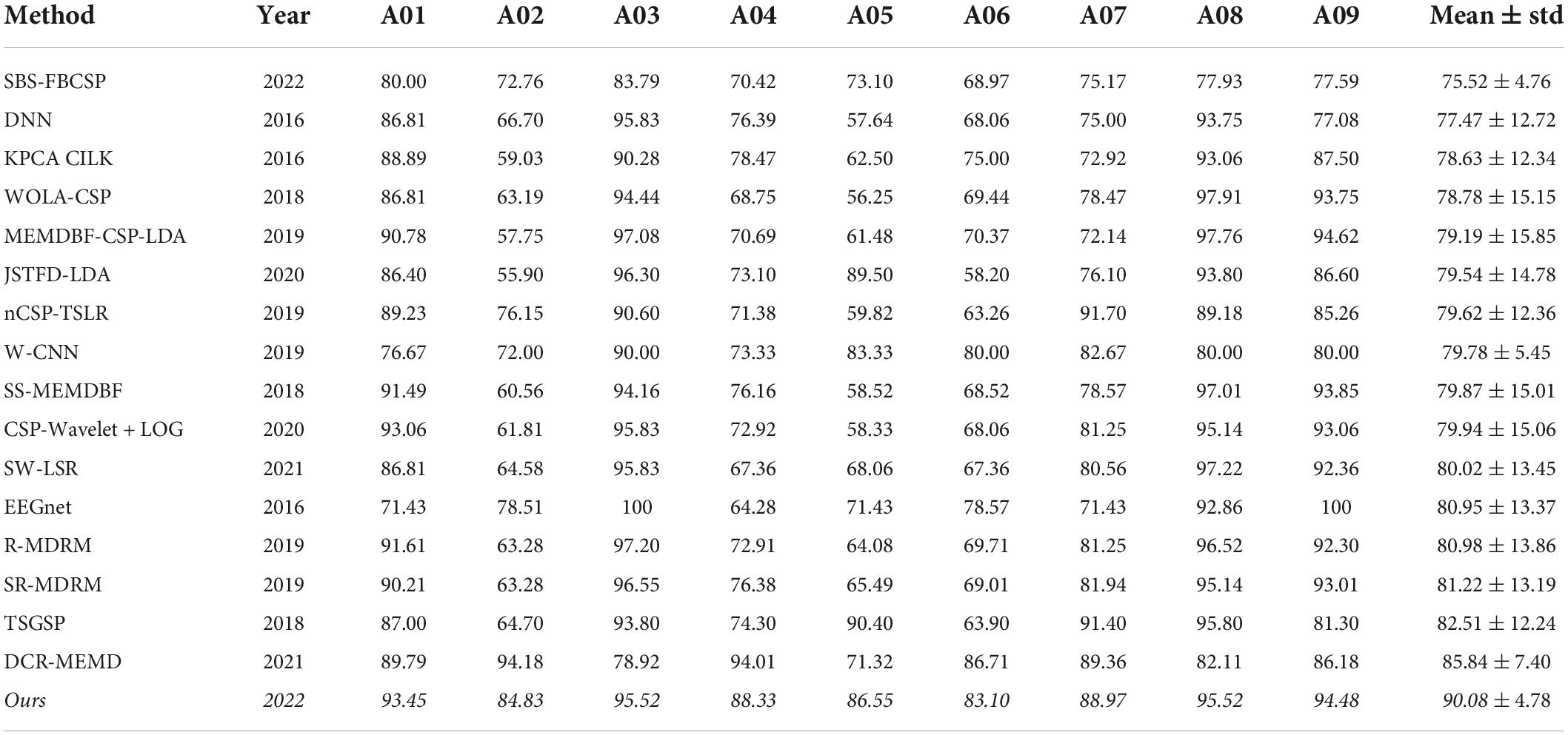
Table 1. Performance comparison for dataset 1, sorted by accuracy.
(1) Deep Neural Network (DNN) (Kumar et al., 2016)
(2) Kernel Principal Component Analysis using Conformal-Isometric Linearizing Kernel (KPCA-CILK) (Sadatnejad and Ghidary, 2016)
(3) Weighted Overlap Add Common Spatial Patterns (WOLA-CSP) (Belwafi et al., 2018)
(4) Multivariate Empirical Mode Decomposition Based Filtering-Common Spatial Pattern-Linear Discriminant Analysis (MEMDBF-CSP-LDA) (Gaur et al., 2019)
(5) Joint Spatio-temporal Filter Design Linear Discriminant Analysis (JSTFD-LDA) (Jiang et al., 2020)
(6) Normalized Common Spatial Pattern Tangent Space Logistic Regression (nCSP-TSLR) (Olias et al., 2019)
(7) Wavelet Convolutional Neural Network (W-CNN) (Xu et al., 2018)
(8) Subject Specific Multivariate Empirical Mode Decomposition Based Filtering (SS-MEMDBF) (Gaur et al., 2018)
(9) Common Spatial Pattern-Filter Bank-Log (CSP-FB-LOG) (Zhang S. et al., 2020)
(10) Sliding Window-Longest Consecutive Repetition (SW-LSR) (Gaur et al., 2021)
(11) EEG Network (EEGnet) (Lawhern et al., 2018)
(12) Regularized Minimum Distance to Riemannian Mean (R-MDRM) (Singh et al., 2019)
(13) Spatial Regularized Minimum Distance to Riemannian Mean (SR-MDRM) (Singh et al., 2019)
(14) Temporally Constrained Sparse Group Spatial Patterns (TSGSP) (Zhang et al., 2018)
(15) Dynamic Channel Relevance-Multivariate Empirical Mode Decomposition (DCR-MEMD) (Song and Sepulveda, 2018)
For dataset 2 we compared our results to the following methods (see results in Table 2):
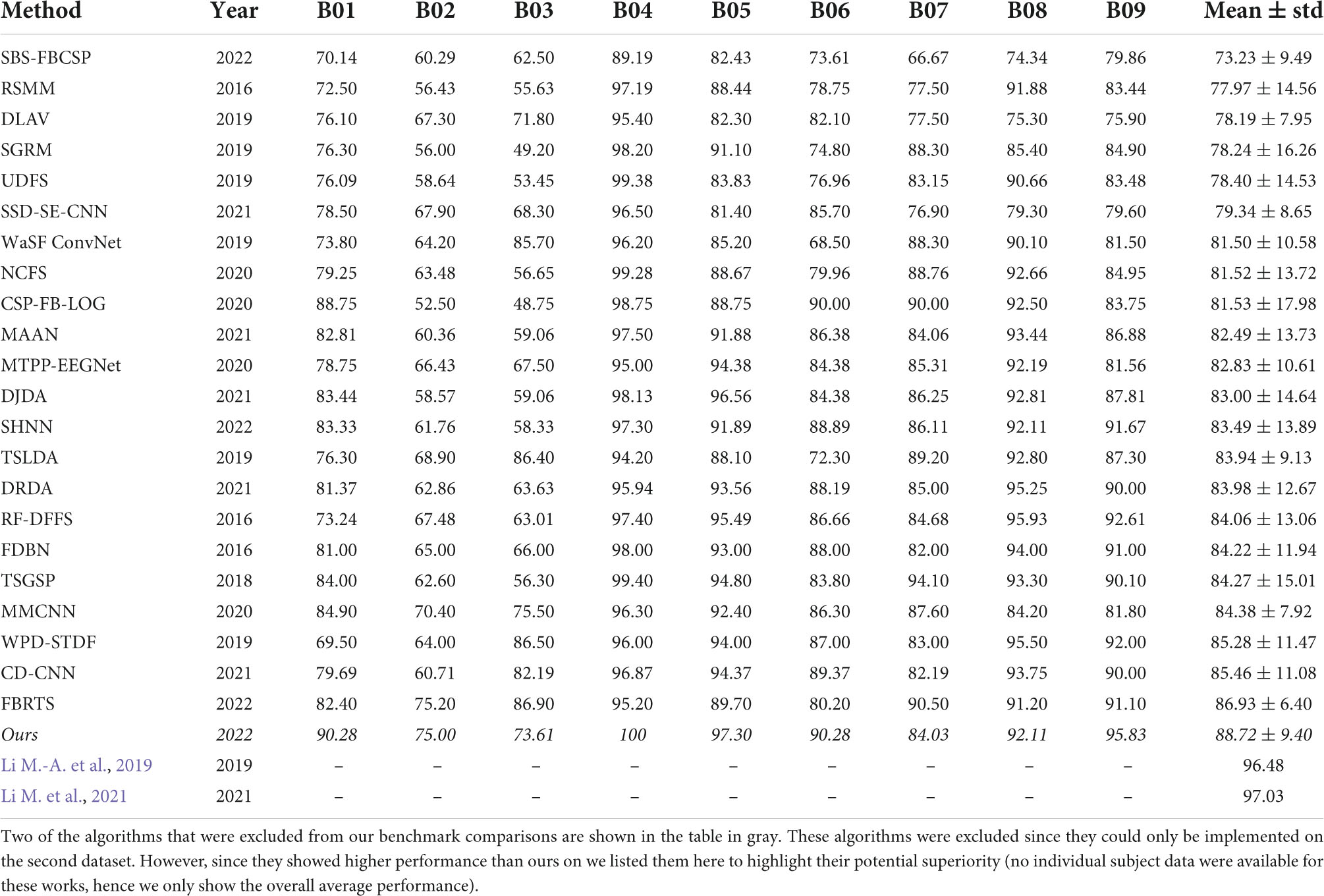
Table 2. Performance comparison for dataset 1, sorted by accuracy.
(1) Robust Support Matrix Machine (RSMM) (Zheng et al., 2018)
(2) Deep Learning with Variational Autoencoder (DLVA) (Dai et al., 2019)
(3) Sparse Group Representation Model (SGRM) (Jiao et al., 2018)
(4) Unsupervised Discriminative Feature Selection (UDFS) (Al Shiam et al., 2019)
(5) Sparse Spectro-temporal Decomposition Squeeze-and-Excitation Convolutional Neural Network (SSD-SE-CNN) (Sun et al., 2020)
(6) Wavelet Spatial Filter Convolution Network (WaSF ConvNet) (Dy et al., 2019; Fang et al., 2022)
(7) Neighborhood Component analysis based Feature Selection (NCFS) (Molla et al., 2020)
(8) Common Spatial Pattern-Wavelet-Log (CSP-Wavelet-LOG) (Zhang S. et al., 2020)
(9) Multi-Attention Adaptation Network (MAAN) (Chen et al., 2021)
(10) Multilayer Temporal Pyramid Pooling EEG Network (MTPP-EEGNet) (Ha and Jeong, 2020)
(11) Dynamic Joint Domain Adaptation (DJDA) (Hong et al., 2021)
(12) SincNet-based Hybrid Neural Network (SHNN) (Liu et al., 2022)
(13) Tangent Space Linear Discriminant Analysis (TSLDA) (Ai et al., 2019; Fang et al., 2022)
(14) Deep Representation-based Domain Adaptation (DRDA) (Zhao et al., 2020)
(15) Random Forest Dynamic Frequency Feature Selection (RF-DFFS) (Luo et al., 2016)
(16) Frequential Deep Belief Network (FDBN) (Lu et al., 2016)
(17) Temporally constrained Sparse Group Spatial Patterns (TSGSP) (Zhang et al., 2018)
(18) Multi-branch Multi-scale Convolutional Neural Network (MMCNN) (Jia et al., 2020)
(19) Wavelet Package Decomposition Spatio-Temporal Discrepancy Feature (WPD-STDF) (Luo et al., 2019)
(20) Central Distance Loss Convolutional Neural Network (CD-CNN) (Yang et al., 2021)
(21) Filter Banks and Riemannian Tangent Space (FBRTS) (Fang et al., 2022)
Additionally, we implemented a version of the Sequential Backward Selection Filter Bank Common Spatial Patterns (SBS-FBCSP) algorithm, which is an adaptation of the Sub-Band Common Spatial Patterns with Sequential Backward Floating Selection (SBCSP-SBFS) proposed by Bhatti et al. (2019). The original SBCSP-SBFS algorithm did not use temporal features and was limited to 12 overlapping frequency bands (4–30 Hz). Conceptually, the SBS-FBCSP algorithm resembled our method in that it, too, used sub-bands and CSPs feature selection. SBS-FBCSP differed from our method in that it used the full trial as temporal dimension.
For dataset 1, we varied the parameter m from 1 to 7 (with 2m options yielding up to 14 features in each trial) since the parameter selection impacts the performance. To calculate the accuracy, we used 5-fold cross validation with all the trials from the first dataset (combining the first and second sessions onto one data set).
For dataset 2 we varied m from 1 to 3 yielding up to six features. To calculate the accuracy, we combined all sessions data in random order and used 80% of the trials for training and the remaining 20% for testing sessions as training set and the remaining two for testing, with five-fold cross validation (see Luo et al., 2016).
The excluded methods were:
(1) Distance Preservation to Local Mean (Davoudi et al., 2017)
(2) Neighborhood Rough Set Classifier (Udhaya Kumar and Hannah Inbarani, 2017)
(3) Channel-wise Convolution with Channel Mixing (Sakhavi et al., 2018)
(4) Gated Recurrent Unit Recurrent Neural Network Long-Short Term Memory-Recurrent Neural Network (Luo et al., 2018)
(5) Deep Recurrent Spatial-Temporal Neural Network (Ko et al., 2018)
(6) Long-Short Term Memory network (Wang et al., 2018)
(7) Dempster-Shafer Theory (Razi et al., 2019)
(8) Densely Feature Fusion convolutional neural Network (Li D. et al., 2019)
(9) Convolutional Neural Network Long-term Short-term Memory Network (Zhang R. et al., 2019)
(10) Multi-branch 3D Convolutional Neural Network (Zhao et al., 2019)
(11) Channel-Projection Mixed-scale convolutional neural Network (Li Y. et al., 2019)
(12) Convolutional Recurrent Attention Model (Zhang D. et al., 2019)
(13) Weight-based Feature Fusion Convolutional Neural Network (Amin et al., 2019)
(14) Multi-Scale Fusion Convolution Neural Network (Li D. et al., 2020)
(15) Multiple Kernel Stein Spatial Patterns (Galindo-Noreña et al., 2020)
(16) Graph-based Convolutional Recurrent Attention Model (Zhang D. et al., 2020)
(17) Temporal-Spatial Convolutional Neural Network (Chen et al., 2020)
(18) Temporal-Spectral-based Squeeze-and-Excitation Feature Fusion Network (Li Y. et al., 2021)
(19) Shallow Convolution Neural Network and Bidirectional Long-Short Term Memory (Lian et al., 2021)
(20) Temporal Convolutional Networks-Fusion (Musallam et al., 2021)
(21) EEG-Inception-Temporal Network (Salami et al., 2022)
Results
Performance
Our algorithm, which we term Sequential Backward Selection with Temporal Filter Bank Common Spatial Patterns (SBS-TFBCSP), significantly outperformed the average performance (79.99% ± 2.23; mean ± std) of all other algorithms. By 12.61% (T(8) = 5.057, p < 0.001; t-test; Table 1) and outperformed each of those algorithms individually. The algorithm outperformed the contender leading algorithm (DCR-MEMD) by 4.94%, yet this was not significant (T(8) = 1.322, p = 0.223, t-test). While conceptually similar, the SBS-FBCSP yielded the lowest score among the methods compared.
Using the second dataset, our algorithm significantly outperformed the average (82.01% ± 3.25) of all other algorithms by 8.18% (T(8) = 5.697, p < 0.001; t-test) and each of those algorithms individually (Table 2). Comparing our algorithm’s performance to the leading state-of-the-art contender algorithm (FBRTS), we see a non-significant 2.06% increase in performance favoring our method (T(8) = 0.707, p = 0.499, t-test). The SBS-FBCSP again yielded the lowest performance among the methods compared.
Noting that the performance of SBS-FBCSP is lower across datasets while the key difference between our algorithm and the SBS-FBCSP is the features selected, we suggest that the inclusion of temporal features in the CSPs is likely driving the performance increase (Figure 1). The expansion of the frequency range implemented in our algorithm increases the feature selection granularity, and in turn the performance. As an intuition for the advantage of the method with respect to the feature selection, we show examples (subjects A01, A02; chosen arbitrarily; Figure 1) where the feature-subsets selected by the algorithms are highlighted. In both subjects, a larger proportion of the selected features were drawn from the last 2 s (which SBS-FBCSP would ignore since it averages across the entire 4-s window). Additionally, a number of the selected features were drawn from frequency bands above 30 Hz which would be excluded in the standard SBCSP-SBFS implementations (Bhatti et al., 2019) because they correspond to frequencies not typically associated with MI.
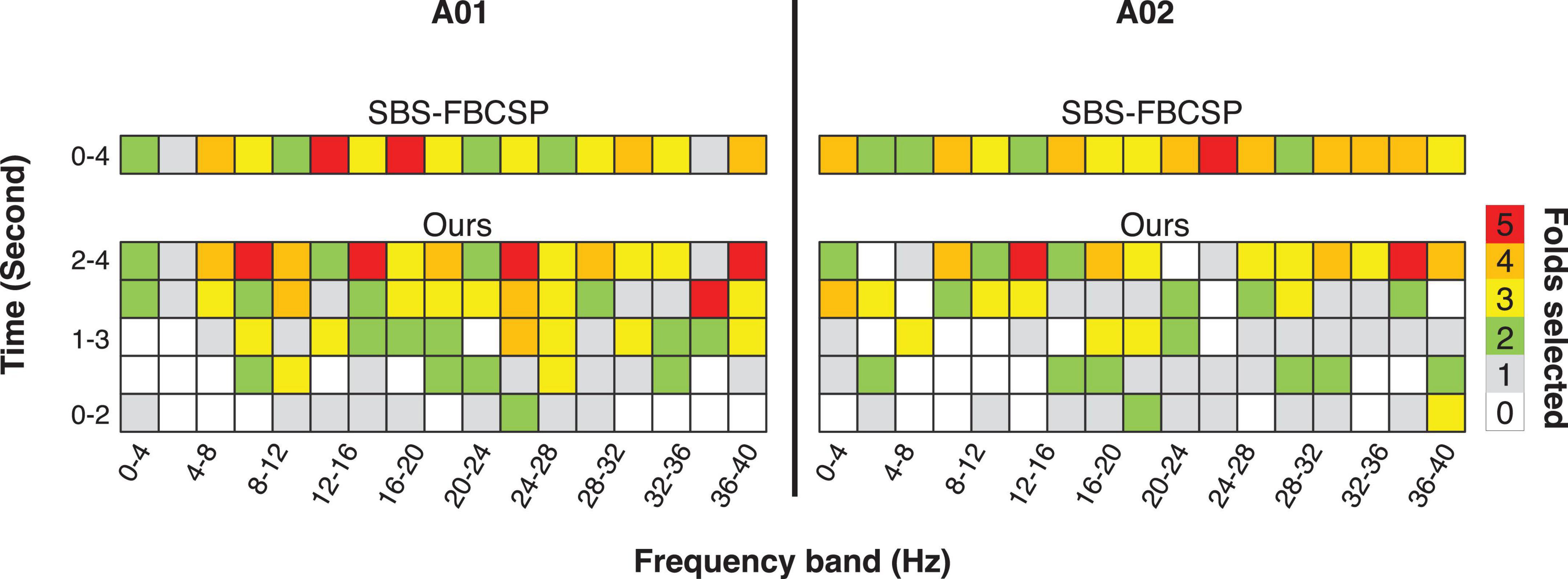
Figure 1. Illustration of the results of the 5-fold feature selection comparing a contender algorithm (SBS-FBCSP) and our algorithm, which namely differ in the breakdown of temporal features. The colors (taken from subject A01, A02; chosen arbitrarily) denote the number of times a feature-subset was selected during the 5-fold cross validation.
To further investigate the difference between our work and similar methods we highlight two additional algorithms that share various features with ours. The Sparse Filter Bank Common Spatial Pattern (SFBCSP) and the Multiple Windows SFBCSP (SFBCSP-MT) both used a feature selection to choose the CSP features from multiple filter banks (SFBCSP) and 5 (dataset 1) or 6 (dataset 2) time windows (SFBCSP-MT). However, the contender algorithms did not use SBS. Our method outperformed the SFBCSP contender algorithm among eight of the nine subjects using both dataset 1 and 2, and among seven (dataset 1) and eight (dataset 2) of the nine subjects with the SFBCSP-MT contender algorithm (Tables 3, 4).

Table 3. Performance comparisons of our method and two similar ones, for dataset 1.

Table 4. Performance comparisons of our method and two similar ones, for dataset 2.
Taken together, our results suggest that the performance increase is driven by broader choice of inputs, and the feature selection process.
Results of other performance measure
To further evaluate the performance of our algorithm we used additional standard accuracy metrics. Namely, we estimated the Positive Precision Value (PPV, ), Negative Precision Value (NPV, ), sensitivity (True Positive Rate, ), specificity (True Negative Rate, ), and Kappa value (), where TP represents the number of testing samples whose real value aligned with the model prediction (True Positive), TN represents the number of testing samples whose real value and model predicted values were both negative (True Negative), FP represents the number of testing samples whose real value is negative while their model predicted value is positive (False Positive), and FN represents the number of testing samples whose real value is positive while their model predicted value is negative (False Negative). Po is the proportion of observed agreement, and Pe probability that the agreement is at chance. In both dataset 1 (Table 5) and dataset 2 (Table 6) our algorithm proved superior compared to the SBS-FBCSP using those metrics.
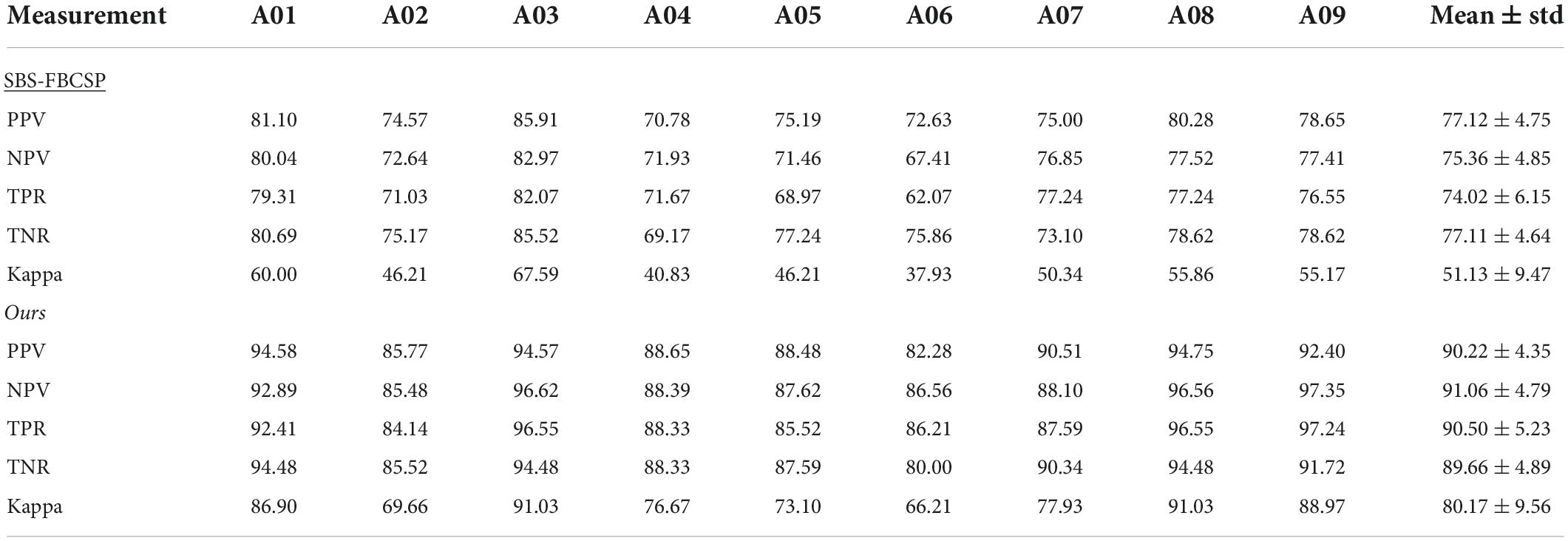
Table 5. Performance comparison between SBS-FBCSP and our method, using dataset 1.
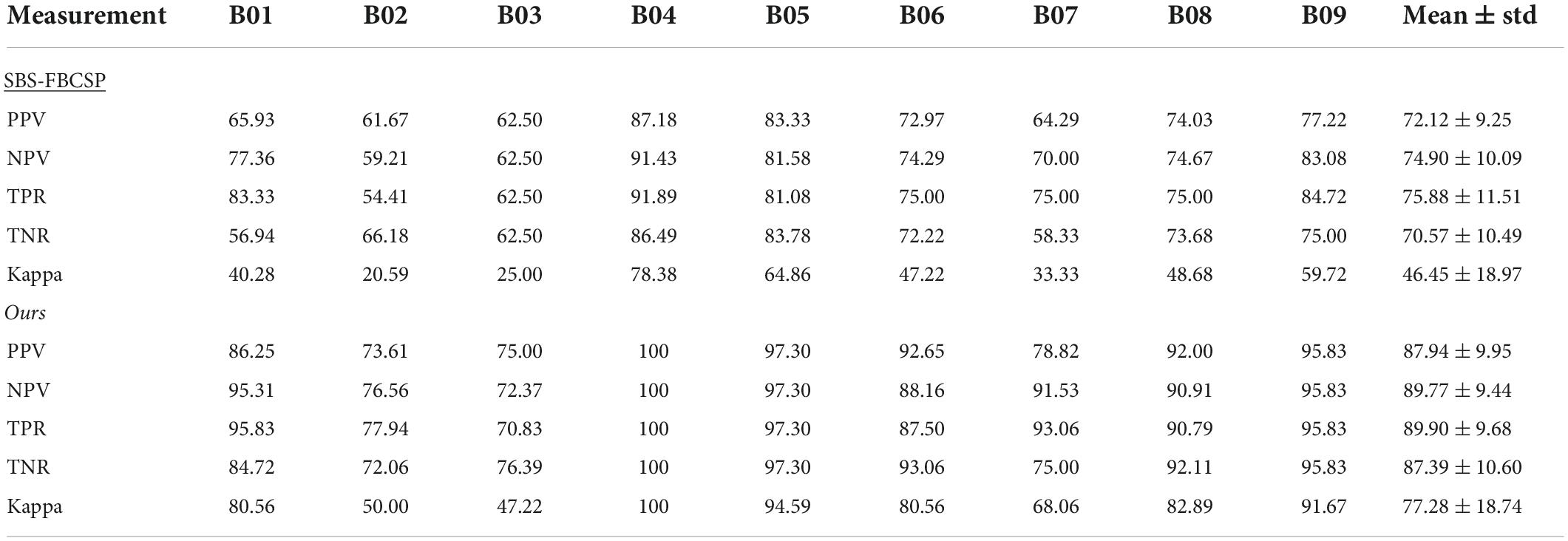
Table 6. Performance comparison between SBS-FBCSP and our method, using dataset 2.
Specifically, with respect to dataset 1, our algorithm significantly outperformed the PPV of the SBS-FBSP (77.12% ± 4.75) by 16.99% (T(8) = 13.653, p < 10–7; t-test), the NPV of the SBS-FBSP (75.36% ± 4.85) by 20.83% (T(8) = 14.704, p < 10–7; t-test), the TPR of the SBS-FBSP (74.02% ± 6.15) by 22.26% (T(8) = 11.469, p < 10–6; t-test), the TNR of the SBS-FBSP (77.11% ± 4.64) by 16.28% (T(8) = 8.125, p < 10–5; t-test), and the Kappa of the SBS-FBSP (51.13% ± 9.47) by 56.80% (T(8) = 18.318, p < 10–8; t-test).
In dataset 2, our algorithm again significantly outperformed the PPV of the SBS-FBSP (72.12% ± 9.25) by 21.94% (T(8) = 14.33, p < 10–7; t-test), the NPV of the SBS-FBSP (74.90% ± 10.09) by 19.85% (T(8) = 10.952, p < 10–6; t-test), the TPR of the SBS-FBSP (75.88% ± 11.51) by 18.48% (T(8) = 8.514, p < 10–5; t-test), the TNR of the SBS-FBSP (70.57% ± 10.49) by 23.83% (T(8) = 8.169, p < 10–5; t-test), the Kappa of the SBS-FBSP (46.45% ± 18.97) by 66.37% (T(8) = 15.479, p < 10–7; t-test).
Parameters sensitivity
Given that the performance of our proposed method heavily depends on the selection of the m parameter we tested the robustness of our results by enumerating over all m values possible in dataset 1 (Table 7) and dataset 2 (Table 8). While, indeed, the choice of m impacts the algorithm performance across subjects, the average difference in performance for dataset 1 was 2.23% ± 0.85 and average difference in performance for dataset 2 of 0.99% ± 0.67 (with the highest drop in performance yielding 83.94% accuracy). The lowest performance was aligned with the accuracy of the DCR-MEMD algorithm, but better than all other methods. The highest performance drop yielded an accuracy of 86.79%. which was on par with the FBRTS method but better than all other methods. Combined, these results suggest that the method is robust to perturbations of its single free parameter and maintains its efficiency irrespective of the parameter choice.
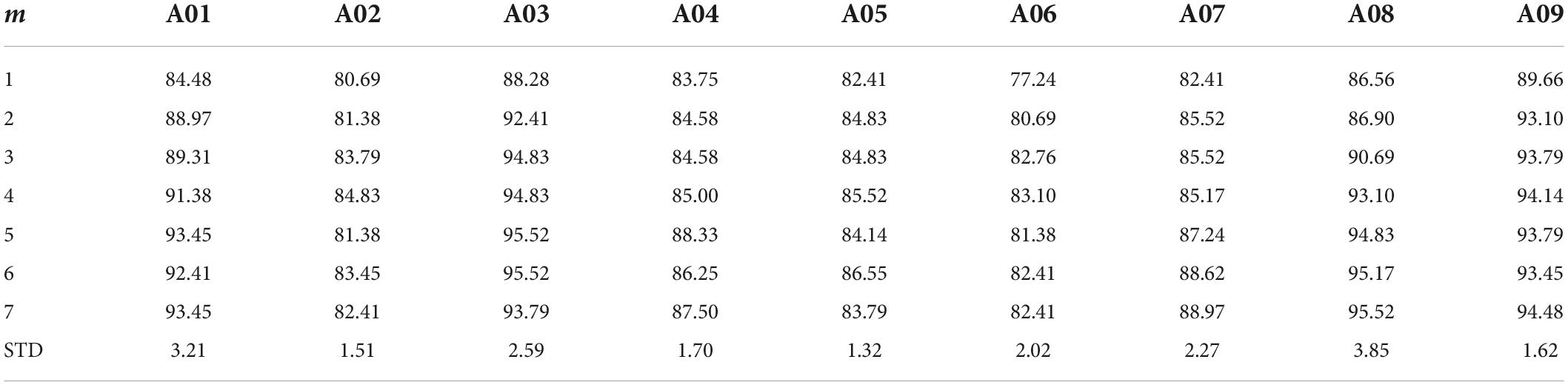
Table 7. Performance comparison of different values of m for our method, using dataset 1.

Table 8. Performance comparison of different values of m for our method, using dataset 2.
Additionally, as our algorithm used temporal windows similar to those suggested in previous work (Zhang et al., 2018), yet the selection of number of windows in both ours and the previous work was arbitrary, we estimated the sensitivity of the algorithm to the selection of window sizes. We altered the number of temporal windows used from 4 to 6 to see the impact of this change on the accuracy. We used this range under the assumption that keeping the number of windows proportional to the number of frequency bands would align with existing works and the theoretical reasoning that they suggest for the bin sizes (Zhang et al., 2018). Testing the algorithm with varying window sizes shows that the range of perturbations yields a performance change of ±1.74%, proportional to the number of windows used. While manipulating the window size impacted the performance, the change was not significant. That is, the impact of ±1 window size usage had a marginal difference in performance (±1.29% on average for dataset 1, and ±0.87% for dataset 2). This non-significant change in performance along with the fact that a change from a single window (SBS-FBCSP) to 5 bins (ours) yields a notable difference suggest that there is a plateau in the performance increment after four bins.
Ablation study
To further investigate the validity of the proposed algorithm we conducted a series of tests where we hindered the algorithm’s inputs and evaluated the performance change. As one key difference between our algorithm and existing ones is the inclusion of both temporal and spectral bands, we varied both input features. In a series of ablation studies, we decreased the range of spectral features from 17 (our algorithm) to 12 (as is done in contender algorithms) and the range of temporal features from five (our algorithm) to one (as is done in contender algorithms, namely SBS-FBCSP). Across all tests, the feature selection (Sequential Backward Selection) and the classifications parameters were held constant. Across all ablation tests, the performance drop ranged from −4.62% to −2.05% for dataset 1, and −7.33% to −1.61% for dataset 2. Our algorithm remained on par with the state-of-the-art benchmarks despite the drop in performance. The algorithm maintained its superiority for dataset 1, and ranked 15th (out of 21) for dataset 2 at its most hindered state, when the number of frequency bands used was lowest. That is, the selection of time windows and frequency bands that led to our algorithm’s performance seem to be mostly sensitive to the number of frequency bands used as inputs (Figure 2). Importantly, the drop in frequency bands to a lower number puts our algorithm in line with the contender ones, suggesting that some of the improvement is contingent on this input feature broadening.
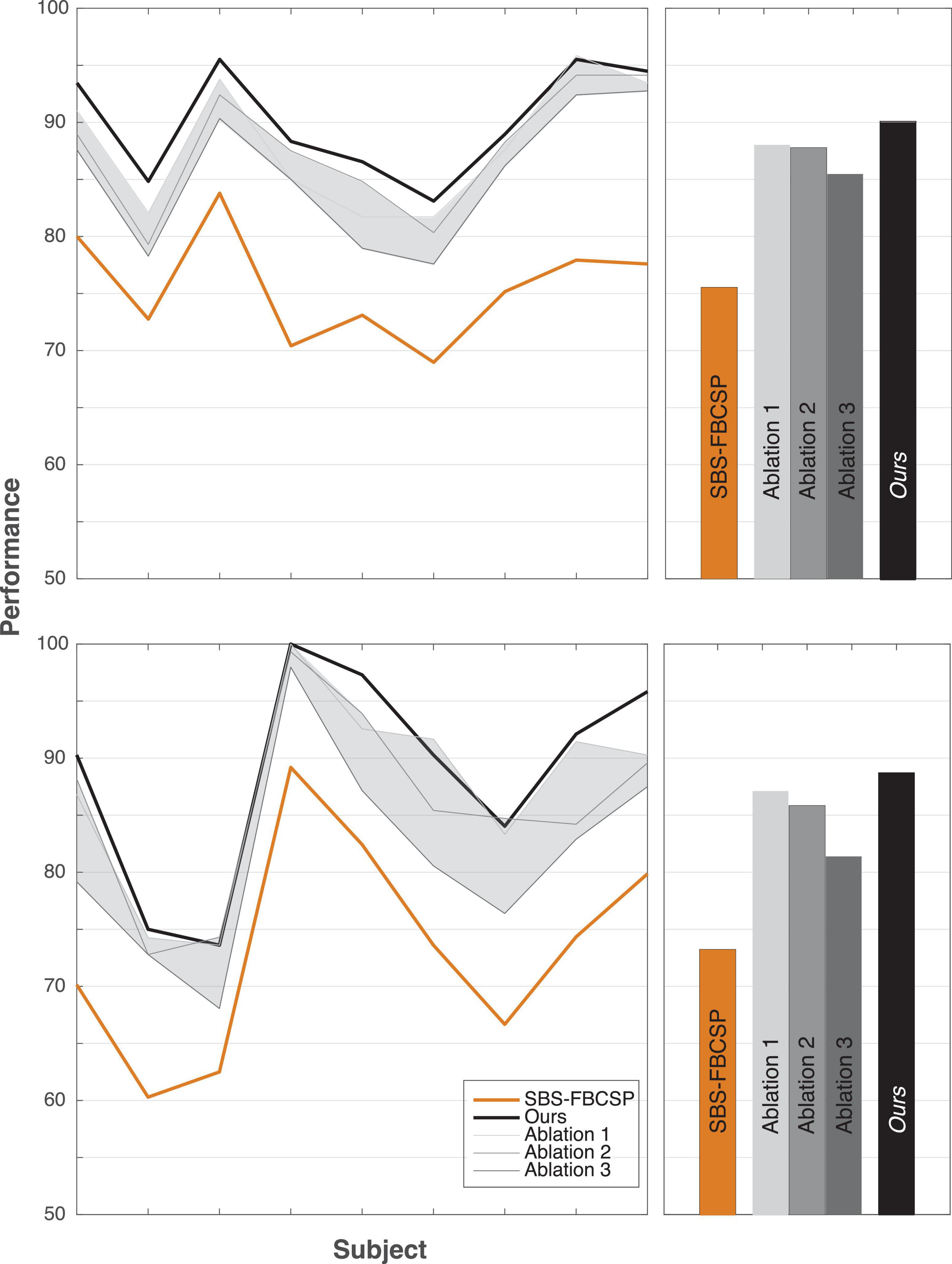
Figure 2. Ablation tests. Reducing the number of features as ablation tests for dataset 1 (top row) and dataset 2 (bottom row). The shaded areas depict the range of performance for all nine subjects across all ablation tests, with the three tests showing the extremal performance highlighted individually as “Ablation #.” Right panels show the average performance across all subjects. “Ablation 1” corresponds to a test that included all five time windows (500–4,500 ms range, with 2 s windows size, and 500 ms step size) and 12 frequency bands (4–30 Hz range, with 4 Hz window size, and 2 Hz step size) for a total of 60 input features (12 bands × 5 time windows) reduced gradually to 10 features through the selection. “Ablation 2” corresponds to a test with three time windows (500–3,500 ms range, with 2 s windows size, and 500 ms step size) and 17 frequency bands (4–40 Hz range, with 4 Hz window size, and 2 Hz step size) for a total of 51 input features (17 bands × 3 time windows) reduced gradually to 10 features through the selection. “Ablation 3” corresponds to a test with three time windows (500–3,500 ms range, with 2 s windows size, and 500 ms step size) and 12 frequency bands (4–30 Hz range, with 4 Hz window size, and 2 Hz step size) for a total of 36 input features (12 bands × 3 time windows) reduced gradually to 10 features through the selection.
Additionally, we replicated the accuracy metrics tests with the ablated inputs to evaluate the impact of the input on performance in an additional manner (Table 9). We attempted various implementations of the model with input features ranging from 12 to 17 frequency bands and 3–5 temporal windows. Our algorithm significantly outperformed a variety of contender algorithms with ablated input. Highlighting three of the ablation studies (“Ablation 1” with 60 input features, “Ablation 2” with 51 input features, and “Ablation 3” with 36 input features), our algorithm maintained its performance improvement. Specifically, for ablation test “1” our algorithm outperformed the non-ablated input by over 2% (T(8) = 4.143, p = 0.003; t-test) using dataset 1, and by over 1.5% using dataset 2 (T(8) = 2.024, p = 0.078; t-test). Similarly, in ablation test “2,” dataset 1 (T(8) = 3.869, p = 0.005; t-test), dataset 2 (T(8) = 2.883, p = 0.020; t-test) as well as in ablation test “3,” dataset 1 (T(8) = 7.051, p < 10–4; t-test) and dataset 2 (T(8) = 6.553, p < 10–4; t-test) the performance was consistency significantly higher for the non-ablated implementation.
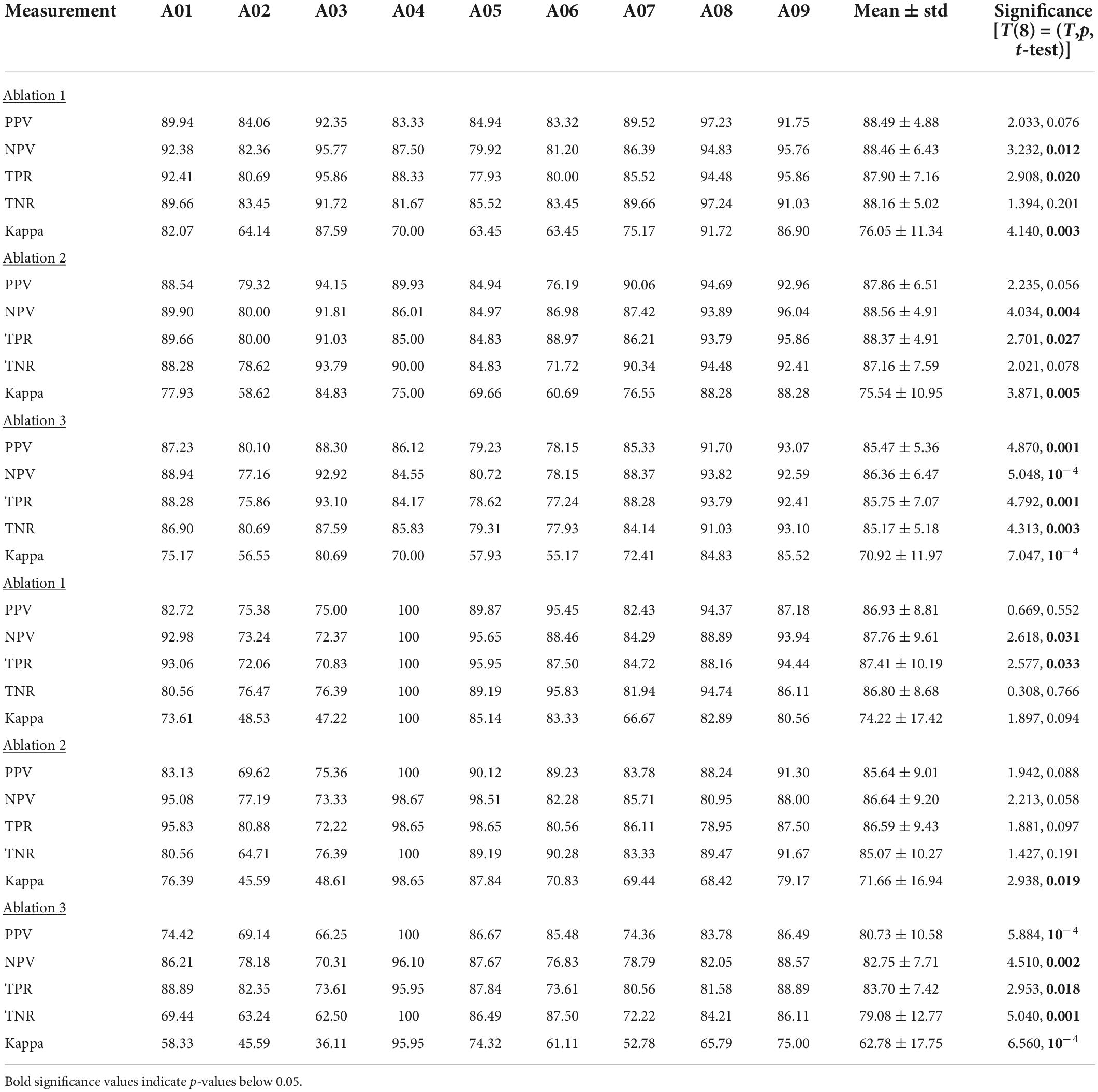
Table 9. Details of three ablation tests using our algorithm in dataset 1 and 2.
Comparison of computational time
Finally, to demonstrate that the new method is useful for BCI applications, we tested its computational efficiency. As BCIs require not only high decoding accuracy but also relatively fast parsing of the intended motion, a speedy classification is important. We used a 2.67 GHz i5-M480 processor with 4 Gb RAM to analyze the classification speed.
Runtime profiling of the algorithm took 366.91 ± 51.29 s for the entire assessment. While this is nearly 2.8 orders of magnitude longer than the similar contender algorithm (SBS-FBCSP) which took only 8.05 ± 3.02 s) this test compared both the feature selection/validation and classification. As the feature selection is only required for the model training, a comparison of the online classification alone showed that our algorithm is on par with competing algorithms that report their computational efficiency (Zhang et al., 2018). Namely, it is within 3 s from the SBS-FBCSP algorithm (n.s.). Together with the improved classification accuracy, we argue, the sacrifice in computational efficiency still renders our method ideal for BCI applications, and comparable to leading benchmark algorithms.
Discussion
We evaluated the performance of a novel neural decoding algorithm, which used both temporal and spectral EEG signals, in predicting a motor action planned by subjects. Our algorithm showed increased accuracy of 2.06–4.94% above benchmark algorithms using two different standard dataset (Tables 1, 2).
The main differences between our method and the state-of-the-art algorithms tested were the inclusion of both temporal and spectral signals as inputs, and the extended features selection process. We suggest that these changes are key drivers of the performance improvement. Namely, we propose that the combined feature sets capture information that amplifies the variance within trials of a single individual and therefore increase the performance. To explore this hypothesis, we performed an ablation study where we hindered the inputs by altering the set of features included in the analyses and showed that the decoding accuracy decreased by an average of 3.88%. Even with the drop in accuracy, our algorithm was on par with state-of-the-art algorithms. As a sanity check, our results show that a decrease of the number of temporal features to a single feature yielded performance that was parallel to that of contender methods which only used spectral features.
Given that our method relies on the choice of a free parameter, m, we also tested the algorithm’s robustness to the parameter selection and showed that the results remain consistent (Tables 7, 8). Further, given that the choice of temporal window size was done arbitrarily in previous works, we tested a range of windows as well as a numbers of frequency bands permutations and showed that the results remain within ±1.49% for dataset 1 and ±1.74% for dataset 2, indicating that the decision is valid and reasonable.
In dataset 2, two algorithms outperformed our implementation. Both algorithms used an approach that deviated from traditional feature extraction methods. One algorithm used multi-scale CNN as a mechanism for the feature selection and the other used montage irregularities. These algorithms’ average performance increase was 8.03% (0.85 standard deviations) above our method. Given that both our algorithm and the contender ones show an effective deviation from traditional feature extraction methods, we suggest that a focus on improving this part of the MI classification process may be key to the success of novel methods.
Contribution
In addition to proposing a new algorithm that implements various suggestions from a large corpus of prior works and yielding an improved performance, we also demonstrate the robustness of the method in multiple ways. We estimate the algorithm on two different datasets (allowing for generalizability of the implementation) and identify dominant parameters driving the performance. We situate the work in the context of existing algorithms and suggest that the process of feature extraction followed by independent classification maximizes the performance yield. Using inputs that are not traditionally considered for MI the expansion of classification set affords the algorithm a richer idiosyncratic noise minimization and tuning option. We show that the algorithm is offering an improvement without considerable hyperparameters tuning. Finally, we show that expanding the input set and the processing steps does not come at a significant cost with respect to decoding speed. The proposed algorithm can show generalized improvement in near real-time on consumer-grade computation tools, making it a viable method for future implementations by practitioners (Massaro et al., 2020) as well as academics (Cerf et al., 2007).
Prior works
Our method is not the first to consider the multi-modal structure of EEG signals along with a dedicated classification tool during MI. For example, previous work (Deng et al., 2021) has combined temporally constrained group LASSO with CNN to interpret the underlying mechanisms driving the successful EEGNet decoding (Lawhern et al., 2018). Similarly, a framework for time frequency CSP smoothing was recently implemented to improve EEG decoding performance through ensemble learning (Miao et al., 2021). Both those methods focused on selecting CSP features by ranked weight. Conversely, our method incorporated the temporal features selection using a neural network. The neural networks classifiers were previously suggested as an extension of the establish body of works for MI tasks (Bhatti et al., 2019), yet were not implemented. Our work suggest that the non-linear feature selection provided by the network yields notable performance increase.
Focusing on the neural network implementation, it is noteworthy that a number of classifiers were proposed as variations on the method we used. Due to the recent developments in deep learning algorithms a majority of the methods proposed focused on CNN for the motor classification (Lawhern et al., 2018; Xu et al., 2018; Amin et al., 2019; Dy et al., 2019; Zhang D. et al., 2019; Zhang R. et al., 2019; Zhao et al., 2019; Chen et al., 2020; Ha and Jeong, 2020; Jia et al., 2020; Lian et al., 2021; Musallam et al., 2021). Specifically, Sakhavi et al. (2018) utilized CNN with temporal data, spectral data, and combination of these data to show a notable improvement in the classification performance compared to benchmark methods. Similarly, Dai et al. (2019) and Sun et al. (2020) showed that adoption of Squeeze-and-Excitation networks (Hu et al., 2018) in the CNN architecture improved the classification further because they accounted for the inter-dependencies among the EEG channels in the calibration of the spectral responses. In parallel, Zhang D. et al. (2019; 2020) and Chen et al. (2021) have implemented attentional mechanisms within the neural network architecture to benefit from the temporal dynamics of subject-specific signal properties. In line with these methods, Zhang D. et al. (2019) and Jia et al. (2020) deployed a multi-branch strategy that benefited from the idiosyncratic temporal-properties of different subjects by utilizing complementary networks. Applying the same logic to spatial-temporal signals, Li Y. et al. (2019) used CNN to capture mixed-scale temporal information and improve the decoding accuracy. In addition to improving the input signal features selection, novel methods have focused on bettering the feature discrimination and selection strategies (Yang et al., 2021) and the data augmentation tools (Li Y. et al., 2019; Yang et al., 2021). Specifically, investigating the input features further, Jin et al. (2021) have introduced time filter to a task-related component analyses method that enhanced the signal detection. The works used singular value decomposition to suppresses the general noise and increase the classification accuracy. The method was implemented on steady-state visual evoked potential based BCIs which are different than our data, but it is likely that the method will be useful for our data as well because of the similarity in decoding performance. Beyond similarity in noise reduction, previous works have also improved the feature selection optimization as we did. Jin et al. (2020) implemented feature selection based on the Dempster-Shafer theory which considers the distribution of the features and found the optimal combination of CSPs that minimized the influence of non-stationarity in the signal. Similar to our implementation, this method took into account the inherent defects of CSPs. Further, the work proposed an investigation of the temporal-spectral feature binning for the BCIs similar to the way bins were integrated into the sequential backward feature selection process in our work. Additionally, Jin et al. (2019) have proposed a correlation-based channel selection combined with regularized CSP (RCSP) as a way to improve the classification accuracy. The method seems to align with ours in its performance despite the fact that the RCSP does not consider both the temporal and spectral properties of the MI. The inclusion of both temporal and spectral feature types is suggested in the work as a future endeavor to be investigated. Completing the previous work, Li et al. (2018) have reported that using multiple modality inputs (in their work, both audio and visual signals) to enhance the representation of incoming signals yield increased accuracy in action decoding task (in their case: decoding “crying” vs. “laughing”). The work suggests that in addition to richer signal, the multi-modal inputs afford comprehensive data that benefits from the internal correlation among features. Besides being analogous to our work in their approach to the decoding, these works suggest that rich (or even superfluous or noisy) data inputs can prove useful in classification improvement. While the data in some of the listed works are different (i.e., fMRI data, or different tasks data) we intuit that the methods could be used to improve our work toward an even greater accuracy in the MI decoding. Finally, the network architecture itself was optimized in several works. For example, LSTM and RNN were incorporated in the CNN with the intent to capture additional properties of the EEG signal segments (Ko et al., 2018; Zhang D. et al., 2019; Zhang R. et al., 2019; Lian et al., 2021). Together, all these methods have demonstrated the benefit of incorporating subject-specific temporal properties in the neural network and the advantages these data have in improving the decoding performance.
Since our method implements feature selection and subject-idiosyncratic inputs in the training, as well as further granular features breakdown along the one discussed here, we suggest that our proposed method benefits from the collection of previous advantages. Namely, as our method separated the feature selection process from the following classification task, we suggest that the two-stage process, which enabled the reduction of features number, is one of the significant drivers of the performance increase.
Comparison to leading contender algorithms
Comparing our method to an algorithm that uses similar routines (SBS-FBCSP) showed average increased performance of 20.22% (19.28% for dataset 1, and 21.15% for dataset 2). Similarly, a comparison to two other algorithms that share key characteristics with ours, albeit with less direct alignment in the protocol (SFBCSP and SFBCSP-MT) showed an incremental performance increase for our proposed method.
While the SBS-FBCSP was the algorithm conceptually closest to ours and, therefore, the subject of the main comparison, it is useful to highlight some of the similarities and differences between our method and other popular classification protocols.
Examining the notable similarities and differences between our method and 15 methods tested with dataset 1 (Table 10) or 21 tested with dataset 2 (Table 11) we note the main difference being the type of features selected as inputs, and the separation of the feature selection and generation steps.
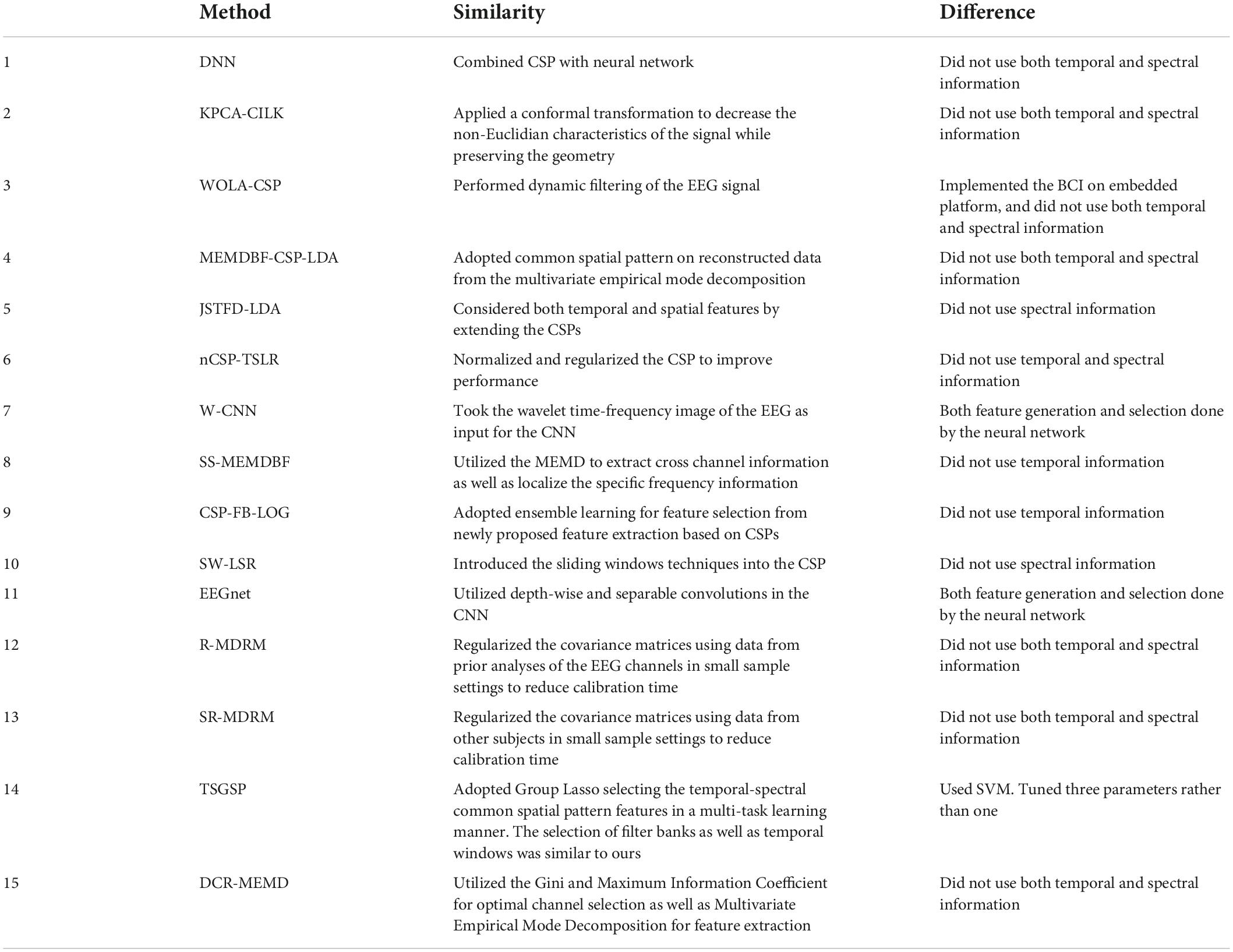
Table 10. Comparison of contender algorithm implemented with dataset 1.
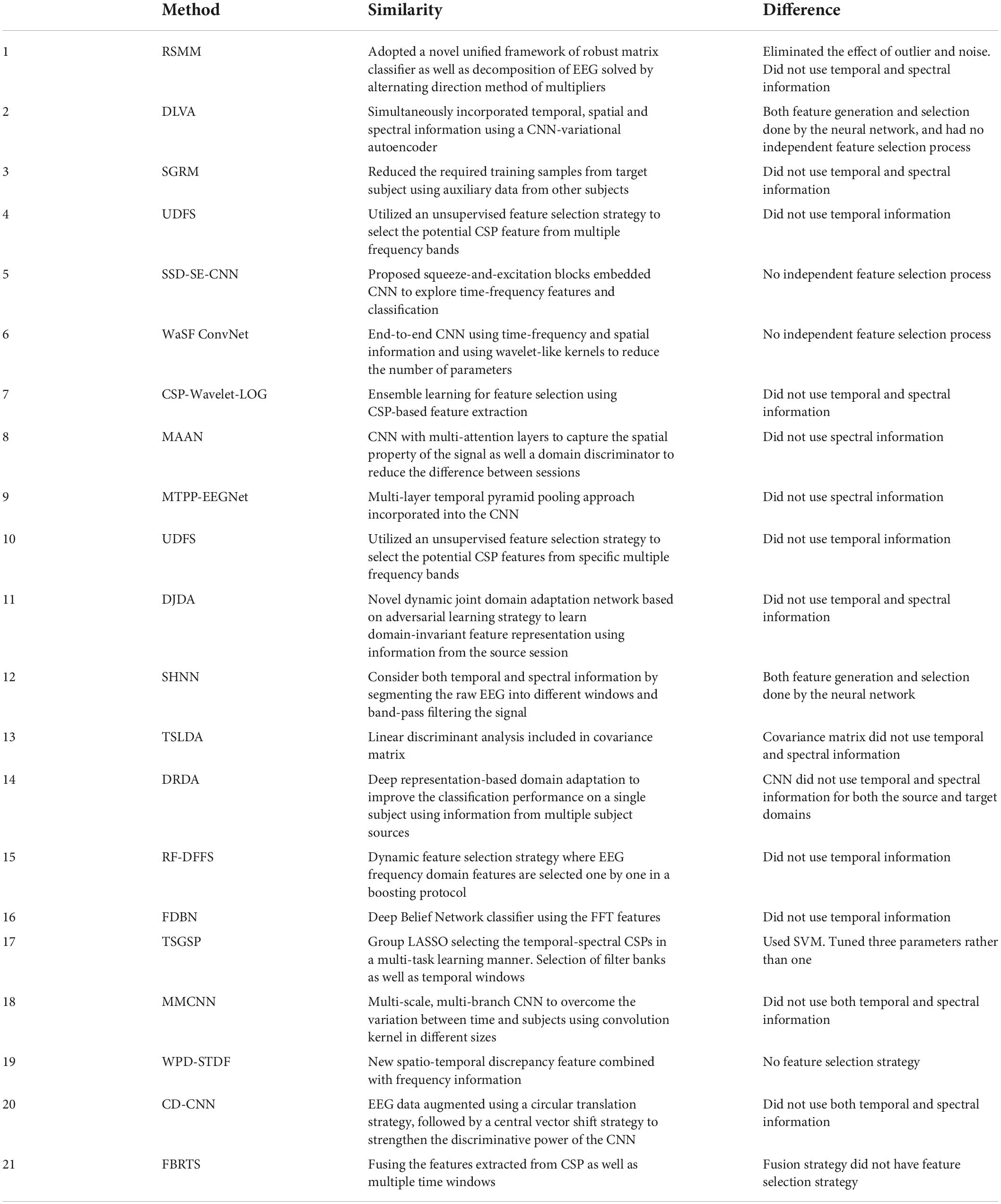
Table 11. Comparison of contender algorithm implemented with dataset 2.
Limitations
The proposed decoding method suffers from a number of limitations that are driven by the extension of the temporal components. First, the method requires a priori intuition about the data in order to accurately choose the temporal segments. To prove the method’s superiority in datasets where no prior knowledge is available it would be useful to test either arbitrary datasets, or randomly selected temporal windows. If the method proves superior even with those selections, it will be regarded more robust.
Second, the algorithm has additional degrees of freedom that could be optimized with regards to the selection of hyperparameters. We elected to use the default ones operationalized by the Matlab implementation (Matlab version 2018a) without any additional tuning, but recognize that future work could focus solely on tuning those hyperparameters. Given the lack of theoretical justification for any alternative choice and given that the contender algorithms also used the default hyperparameters without additional emphasis on tuning, we did not deviate from this norm. Ideally, future work will yield theoretical reasoning for some of the tuning alternatives and thereby improve the algorithm’s performance as well as its usefulness for varying test cases outside of the MI implemented here.
Third, our method could be orders of magnitude slower in its initial computation training time than other methods. This means that usage of the method for BCIs that continuously update the feature set would either be challenging or require extensive computational resources. To overcome this challenge, one should investigate whether smaller time-window sizes (presumably yielding faster processing) could produce higher performance. Shorter time-window that maintain the high performance would elevate the usefulness of the algorithm.
Fourth, it is not clear whether the method would easily generalize to BCI tasks outside of MI. Specifically, because MI tasks are less likely to show the types of noise that pollutes active motor actions, the fact that our method shows superiority in one domain does not guarantee its success in others. We focused on implementing the method on MI tasks as these are the ones mostly implemented thus far and because of their ecological validity in the context of therapy and rehabilitation (Sokol et al., 2019). Implementing the method in other domains (i.e., language decoding) would validate the usefulness of the method further, or highlight the differences in the BCI uses.
Future directions
Two research venues that directly extend our work are: i) the enhancement of the features selection granularity (while attempting to maintain the feature-classification performance), and ii) the generalization of the temporal features classification process. Specifically, as EEG and other biological signals are heavily dependent on combined temporal and spectral dynamics, usage of feature selection process with tools such as the recently proposed attention guided neural networks (Sun et al., 2019) may improve the ability to extract the appropriate features without a priori knowledge on the data. This would make the algorithm generalizable to other BCI inputs.
Further, as the majority of the benchmark algorithms we compared use neural networks for the full classification process (thereby effectively using all the available features without pre-selection) we suggest that amending the benchmark algorithms to focusing on the deep learning ones incorporating the two-step selection-classification process may increase the performance of all the benchmark methods.
It has not escaped our notice that as SVMs were previously shown to be superior with respect to feature classification (whereas deep learning networks were shown to be superior in BCI feature selection; Li Y. et al., 2019; Deng et al., 2021; Tiwari and Chaturvedi, 2021) a combination of both methods might improve our algorithm further and allow it to generalize to tasks outside of MI or motor control (i.e., non-verbal communication, language decoding, or parsing of thoughts).
Conclusion
In this work we have shown that an algorithm which incorporates both temporal and spectral EEG inputs can yield high performance in recognizing which action was imagined by a subject. The algorithm uses SBS technique to reduce the number of inputs and to identify which inputs are less likely to be idiosyncratic across subjects. Once the input features are selected, a RBFNN is used for the classification of the action. We suggest that the method yields performance improvements compared to existing protocols primarily because the inclusion of the large subset of features reduces the individual noise idiosyncrasies within subjects. The suggested algorithm incorporates many of the benefits of the current corpus of state-of-the art BCI protocols and implements the improvements suggestion offered by numerous prior works. In line with these prior suggestion, the method could be applicable for other neural classification problems, modalities, and domains outside of the ones tested herein.
Data availability statement
Publicly available datasets were analyzed in this study. These datasets can be found here: Leeb et al. (2008).
Author contributions
GW conducted the analyses. Both authors wrote the manuscript and generated the final output.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Abiri, R., Borhani, S., Sellers, E. W., Jiang, Y., and Zhao, X. (2019). A comprehensive review of EEG-based brain–computer interface paradigms. J. Neural Eng. 16:11001. doi: 10.1088/1741-2552/aaf12e
Ai, Q., Chen, A., Chen, K., Liu, Q., Zhou, T., Xin, S., et al. (2019). Feature extraction of four-class motor imagery EEG signals based on functional brain network. J. Neural Eng. 16:026032. doi: 10.1088/1741-2552/ab0328
Al Shiam, A., Islam, M. R., Tanaka, T., and Molla, M. K. I. (2019). “Electroencephalography based motor imagery classification using unsupervised feature selection,” in Proceedings of the 2019 international conference on cyberworlds (CW), Kyoto, 239–246. doi: 10.1109/CW.2019.00047
Amin, S. U., Alsulaiman, M., Muhammad, G., Bencherif, M. A., and Hossain, M. S. (2019). Multilevel weighted feature fusion using convolutional neural networks for EEG motor imagery classification. IEEE Access 7, 18940–18950. doi: 10.1109/ACCESS.2019.2895688
Andersen, R. A., Aflalo, T., and Kellis, S. (2019). From thought to action: The brain–machine interface in posterior parietal cortex. Proc. Natl. Acad. Sci. U.S.A. 116, 26274–26279. doi: 10.1073/pnas.1902276116
Ang, K. K., Chin, Z. Y., Zhang, H., and Guan, C. (2008). “Filter bank common spatial pattern (FBCSP) in brain-computer interface,” in Proceedings of the 2008 IEEE international joint conference on neural networks (IEEE World congress on computational intelligence), (Hong Kong: IEEE), 2390–2397.
Belwafi, K., Romain, O., Gannouni, S., Ghaffari, F., Djemal, R., and Ouni, B. (2018). An embedded implementation based on adaptive filter bank for brain–computer interface systems. J. Neurosci. Methods 305, 1–16. doi: 10.1016/j.jneumeth.2018.04.013
Bhatti, M. H., Khan, J., Khan, M. U. G., Iqbal, R., Aloqaily, M., Jararweh, Y., et al. (2019). Soft computing-based EEG classification by optimal feature selection and neural networks. IEEE Trans. Industr. Inform. 15, 5747–5754. doi: 10.1109/TII.2019.2925624
Bulárka, S., and Gontean, A. (2016). “Brain-computer interface review,” in Proceedings of the 2016 12th IEEE international symposium on electronics and telecommunications (ISETC), (Timisoara: IEEE), 219–222. doi: 10.1109/ISETC.2016.7781096
Cerf, M., Cleary, D. R., Peters, R. J., Einhäuser, W., and Koch, C. (2007). Observers are consistent when rating image conspicuity. Vision Res. 47, 3052–3060. doi: 10.1016/j.visres.2007.06.025
Cerf, M., Thiruvengadam, N., Mormann, F., Kraskov, A., Quiroga, R. Q., Koch, C., et al. (2010). On-line, voluntary control of human temporal lobe neurons. Nature 467, 1104–1108. doi: 10.1038/nature09510
Chen, J., Yu, Z., Gu, Z., and Li, Y. (2020). Deep temporal-spatial feature learning for motor imagery-based brain–computer interfaces. IEEE Trans. Neural Syst. Rehabil. Eng. 28, 2356–2366. doi: 10.1109/TNSRE.2020.3023417
Chen, P., Gao, Z., Yin, M., Wu, J., Ma, K., and Grebogi, C. (2021). Multiattention adaptation network for motor imagery recognition. IEEE Trans. Syst. Man Cybernet. Syst. 52, 5127–5139. doi: 10.1109/TSMC.2021.3114145
Chiuzbaian, A., Jakobsen, J., and Puthusserypady, S. (2019). “Mind controlled drone: An innovative multiclass SSVEP based brain computer interface,” in Proceedings of the 2019 7th international winter conference on brain-computer interface (BCI), Gangwon, 1–5. doi: 10.1109/IWW-BCI.2019.8737327
Courtine, G., Micera, S., DiGiovanna, J., del, R., and Millán, J. (2013). Brain–machine interface: Closer to therapeutic reality? Lancet 381, 515–517. doi: 10.1016/S0140-6736(12)62164-3
Dai, M., Zheng, D., Na, R., Wang, S., and Zhang, S. (2019). EEG classification of motor imagery using a novel deep learning framework. Sensors 19:551. doi: 10.3390/s19030551
Davoudi, A., Ghidary, S. S., and Sadatnejad, K. (2017). Dimensionality reduction based on distance preservation to local mean for symmetric positive definite matrices and its application in brain–computer interfaces. J. Neural Eng. 14:036019. doi: 10.1088/1741-2552/aa61bb
Deng, X., Zhang, B., Yu, N., Liu, K., and Sun, K. (2021). Advanced TSGL-EEGNet for motor imagery EEG-based brain-computer interfaces. IEEE Access 9, 25118–25130. doi: 10.1109/ACCESS.2021.3056088
Dy, Z., Fz, T., and Bl, S. (2019). Learning joint space–time–frequency features for EEG decoding on small labeled data. Neural Netw. 114, 67–77. doi: 10.1016/j.neunet.2019.02.009
Fang, H., Jin, J., Daly, I., and Wang, X. (2022). Feature extraction method based on filter banks and Riemannian tangent space in motor-imagery BCI. IEEE J. Biomed. Health Inform. 26, 2504–2514. doi: 10.1109/JBHI.2022.3146274
Galindo-Noreña, S., Cárdenas-Peña, D., and Orozco-Gutierrez, Á (2020). Multiple kernel stein spatial patterns for the multiclass discrimination of motor imagery tasks. Appl. Sci. 10:8628. doi: 10.3390/app10238628
Gaur, P., Gupta, H., Chowdhury, A., McCreadie, K., Pachori, R. B., and Wang, H. (2021). A sliding window common spatial pattern for enhancing motor imagery classification in EEG-BCI. IEEE Trans. Instrum. Meas. 70, 1–9. doi: 10.1109/TIM.2021.3051996
Gaur, P., Pachori, R. B., Wang, H., and Prasad, G. (2018). A multi-class EEG-based BCI classification using multivariate empirical mode decomposition based filtering and Riemannian geometry. Expert Syst. Appl. 95, 201–211. doi: 10.1016/j.eswa.2017.11.007
Gaur, P., Pachori, R. B., Wang, H., and Prasad, G. (2019). An automatic subject specific intrinsic mode function selection for enhancing two-class EEG-based motor imagery-brain computer interface. IEEE Sens. J. 19, 6938–6947. doi: 10.1109/JSEN.2019.2912790
Gordleeva, S. Y., Lukoyanov, M. V., Mineev, S. A., Khoruzhko, M. A., Mironov, V. I., Kaplan, A. Y., et al. (2017). Exoskeleton control system based on motor-imaginary brain–computer interface. Mod. Technol. Med. 9:31. doi: 10.17691/stm2017.9.3.04
Ha, K.-W., and Jeong, J.-W. (2020). Temporal pyramid pooling for decoding motor-imagery EEG signals. IEEE Access 9, 3112–3125. doi: 10.1109/ACCESS.2020.3047678
Hochberg, L. R., Bacher, D., Jarosiewicz, B., Masse, N. Y., Simeral, J. D., Vogel, J., et al. (2012). Reach and grasp by people with tetraplegia using a neurally controlled robotic arm. Nature 485, 372–375. doi: 10.1038/nature11076
Hong, X., Zheng, Q., Liu, L., Chen, P., Ma, K., Gao, Z., et al. (2021). Dynamic joint domain adaptation network for motor imagery classification. IEEE Trans. Neural Syst. Rehabil. Eng. 29, 556–565. doi: 10.1109/TNSRE.2021.3059166
Hu, J., Shen, L., and Sun, G. (2018). “Squeeze-and-excitation networks,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, (Salt Lake City, UT: IEEE), 7132–7141. doi: 10.1109/CVPR.2018.00745
Jia, Z., Lin, Y., Wang, J., Yang, K., Liu, T., and Zhang, X. (2020). “MMCNN: A multi-branch multi-scale convolutional neural network for motor imagery classification,” in Proceedings of the joint European conference on machine learning and knowledge discovery in databases, eds F. Hutter, K. Kersting, J. Lijffijt, and I. Valera (Cham: Springer), 736–751. doi: 10.1007/978-3-030-67664-3_44
Jiang, A., Shang, J., Liu, X., Tang, Y., Kwan, H. K., and Zhu, Y. (2020). Efficient CSP algorithm with spatio-temporal filtering for motor imagery classification. IEEE Trans. Neural Syst. Rehabil. Eng. 28, 1006–1016. doi: 10.1109/TNSRE.2020.2979464
Jiao, Y., Zhang, Y., Chen, X., Yin, E., Jin, J., Wang, X., et al. (2018). Sparse group representation model for motor imagery EEG classification. IEEE J. Biomed. Health Inform. 23, 631–641. doi: 10.1109/JBHI.2018.2832538
Jin, J., Miao, Y., Daly, I., Zuo, C., Hu, D., and Cichocki, A. (2019). Correlation-based channel selection and regularized feature optimization for MI-based BCI. Neural Netw. 118, 262–270. doi: 10.1016/j.neunet.2019.07.008
Jin, J., Wang, Z., Xu, R., Liu, C., Wang, X., and Cichocki, A. (2021). Robust similarity measurement based on a novel time filter for SSVEPs detection. IEEE Trans. Neural Netw. Learn. Syst. doi: 10.1109/TNNLS.2021.3118468 [Epub ahead of print].
Jin, J., Xiao, R., Daly, I., Miao, Y., Wang, X., and Cichocki, A. (2020). Internal feature selection method of CSP based on L1-norm and Dempster–Shafer theory. IEEE Trans. Neural Netw. Learn. Syst. 32, 4814–4825. doi: 10.1109/TNNLS.2020.3015505
Ko, W., Yoon, J., Kang, E., Jun, E., Choi, J.-S., and Suk, H.-I. (2018). “Deep recurrent spatio-temporal neural network for motor imagery based BCI,” in Proceedings of the 2018 6th international conference on brain-computer interface (BCI), (Gangwon: IEEE), 1–3. doi: 10.1109/IWW-BCI.2018.8311535
Kumar, S., Sharma, A., Mamun, K., and Tsunoda, T. (2016). “A deep learning approach for motor imagery EEG signal classification,” in Proceedings of the 2016 3rd Asia-Pacific world congress on computer science and engineering (APWC on CSE), (Nadi: IEEE), 34–39. doi: 10.1109/APWC-on-CSE.2016.017
Lawhern, V. J., Solon, A. J., Waytowich, N. R., Gordon, S. M., Hung, C. P., and Lance, B. J. (2018). EEGNet: A compact convolutional neural network for EEG-based brain–computer interfaces. J. Neural Eng. 15:56013. doi: 10.1088/1741-2552/aace8c
Lebedev, M. A., and Nicolelis, M. A. L. (2006). Brain–machine interfaces: Past, present and future. Trends Neurosci. 29, 536–546. doi: 10.1016/j.tins.2006.07.004
Leeb, R., Brunner, C., Müller-Putz, G., Schlögl, A., and Pfurtscheller, G. (2008). BCI competition 2008–Graz data set B. Graz: Graz University of Technology, 1–6.
Li, D., Wang, J., Xu, J., and Fang, X. (2019). Densely feature fusion based on convolutional neural networks for motor imagery EEG classification. IEEE Access 7, 132720–132730. doi: 10.1109/ACCESS.2019.2941867
Li, D., Xu, J., Wang, J., Fang, X., and Ji, Y. (2020). A multi-scale fusion convolutional neural network based on attention mechanism for the visualization analysis of EEG signals decoding. IEEE Trans. Neural Syst. Rehabil. Eng. 28, 2615–2626. doi: 10.1109/TNSRE.2020.3037326
Li, M., Han, J., and Yang, J. (2021). Automatic feature extraction and fusion recognition of motor imagery EEG using multilevel multiscale CNN. Med. Biol. Eng. Comput. 59, 2037–2050. doi: 10.1007/s11517-021-02396-w
Li, M.-A., Han, J.-F., and Duan, L.-J. (2019). A novel MI-EEG imaging with the location information of electrodes. IEEE Access 8, 3197–3211. doi: 10.1109/ACCESS.2019.2962740
Li, Y., Guo, L., Liu, Y., Liu, J., and Meng, F. (2021). A temporal-spectral-based squeeze-and-excitation feature fusion network for motor imagery EEG decoding. IEEE Trans. Neural Syst. Rehabil. Eng. 29, 1534–1545. doi: 10.1109/TNSRE.2021.3099908
Li, Y., Wang, F., Chen, Y., Cichocki, A., and Sejnowski, T. (2018). The effects of audiovisual inputs on solving the cocktail party problem in the human brain: An fMRI study. Cereb. Cortex 28, 3623–3637. doi: 10.1093/cercor/bhx235
Li, Y., Zhang, X.-R., Zhang, B., Lei, M.-Y., Cui, W.-G., and Guo, Y.-Z. (2019). A channel-projection mixed-scale convolutional neural network for motor imagery EEG decoding. IEEE Trans. Neural Syst. Rehabil. Eng. 27, 1170–1180. doi: 10.1109/TNSRE.2019.2915621
Lian, S., Xu, J., Zuo, G., Wei, X., and Zhou, H. (2021). A novel time-incremental end-to-end shared neural network with attention-based feature fusion for multiclass motor imagery recognition. Comput. Intell. Neurosci. 2021:6613105. doi: 10.1155/2021/6613105
Liu, C., Jin, J., Daly, I., Li, S., Sun, H., Huang, Y., et al. (2022). SincNet-based hybrid neural network for motor imagery EEG decoding. IEEE Trans. Neural Syst. Rehabil. Eng. 30, 540–549. doi: 10.1109/TNSRE.2022.3156076
Lotte, F., Congedo, M., Lécuyer, A., Lamarche, F., and Arnaldi, B. (2007). A review of classification algorithms for EEG-based brain–computer interfaces. J. Neural Eng. 4, R1–R13. doi: 10.1088/1741-2560/4/2/R01
Lu, N., Li, T., Ren, X., and Miao, H. (2016). A deep learning scheme for motor imagery classification based on restricted Boltzmann machines. IEEE Trans. Neural Syst. Rehabil. Eng. 25, 566–576. doi: 10.1109/TNSRE.2016.2601240
Luo, J., Feng, Z., and Lu, N. (2019). Spatio-temporal discrepancy feature for classification of motor imageries. Biomed. Signal Process. Control 47, 137–144. doi: 10.1016/j.bspc.2018.07.003
Luo, J., Feng, Z., Zhang, J., and Lu, N. (2016). Dynamic frequency feature selection based approach for classification of motor imageries. Comput. Biol. Med. 75, 45–53. doi: 10.1016/j.compbiomed.2016.03.004
Luo, T., Zhou, C., and Chao, F. (2018). Exploring spatial-frequency-sequential relationships for motor imagery classification with recurrent neural network. BMC Bioinformatics 19:344. doi: 10.1186/s12859-018-2365-1
Massaro, S., Drover, W., Cerf, M., and Hmieleski, K. M. (2020). Using functional neuroimaging to advance entrepreneurial cognition research. J. Small Bus. Manag. 1–29. doi: 10.1080/00472778.2020.1824527
Miao, Y., Jin, J., Daly, I., Zuo, C., Wang, X., Cichocki, A., et al. (2021). Learning common time-frequency-spatial patterns for motor imagery classification. IEEE Trans. Neural Syst. Rehabil. Eng. 29, 699–707. doi: 10.1109/TNSRE.2021.3071140
Molla, M. K. I., Al Shiam, A., Islam, M. R., and Tanaka, T. (2020). Discriminative feature selection-based motor imagery classification using EEG signal. IEEE Access 8, 98255–98265. doi: 10.1109/ACCESS.2020.2996685
Musallam, Y. K., AlFassam, N. I., Muhammad, G., Amin, S. U., Alsulaiman, M., Abdul, W., et al. (2021). Electroencephalography-based motor imagery classification using temporal convolutional network fusion. Biomed. Signal Process. Control 69:102826. doi: 10.1016/j.bspc.2021.102826
Nader, M., Jacyna-Golda, I., Nader, S., and Nehring, K. (2021). Using BCI and EEG to process and analyze driver’s brain activity signals during VR simulation. Transport 60, 137–153. doi: 10.5604/01.3001.0015.6305
Novi, Q., Guan, C., Dat, T. H., and Xue, P. (2007). “Sub-band common spatial pattern (SBCSP) for brain-computer interface,” in Proceedings of the 2007 3rd international IEEE/EMBS conference on neural engineering, (Kohala Coast, HI: IEEE), 204–207. doi: 10.1109/CNE.2007.369647
Olias, J., Martín-Clemente, R., Sarmiento-Vega, M. A., and Cruces, S. (2019). EEG signal processing in MI-BCI applications with improved covariance matrix estimators. IEEE Trans. Neural Syst. Rehabil. Eng. 27, 895–904. doi: 10.1109/TNSRE.2019.2905894
Pasyuk, A., Semenov, E., and Tyuhtyaev, D. (2019). “Feature selection in the classification of network traffic flows,” in Proceedings of the 2019 international multi-conference on industrial engineering and modern technologies (FarEastCon), (Vladivostok: IEEE), 1–5. doi: 10.1109/FarEastCon.2019.8934169
Prashant, P., Joshi, A., and Gandhi, V. (2015). “Brain computer interface: A review,” in Proceedings of the 2015 5th Nirma University international conference on engineering (NUiCONE), (Ahmedabad: IEEE), 1–6. doi: 10.1109/NUICONE.2015.7449615
Razi, S., Mollaei, M. R. K., and Ghasemi, J. (2019). A novel method for classification of BCI multi-class motor imagery task based on Dempster–Shafer theory. Inform. Sci. 484, 14–26. doi: 10.1016/j.ins.2019.01.053
Sadatnejad, K., and Ghidary, S. S. (2016). Kernel learning over the manifold of symmetric positive definite matrices for dimensionality reduction in a BCI application. Neurocomputing 179, 152–160. doi: 10.1016/j.neucom.2015.11.065
Sakhavi, S., Guan, C., and Yan, S. (2018). Learning temporal information for brain-computer interface using convolutional neural networks. IEEE Trans. Neural Netw. Learn. Syst. 29, 5619–5629. doi: 10.1109/TNNLS.2018.2789927
Salami, A., Andreu-Perez, J., and Gillmeister, H. (2022). EEG-ITNet: An explainable inception temporal convolutional network for motor imagery classification. IEEE Access 10, 36672–36685. doi: 10.1109/ACCESS.2022.3161489
Singh, A., Lal, S., and Guesgen, H. W. (2019). Small sample motor imaginery classification using regularized riemannian features. IEEE Access 7, 46858–46869.
Sokol, L. L., Young, M. J., Paparian, J., Kluger, B. M., Lum, H. D., Besbris, J., et al. (2019). Advance care planning in Parkinson’s disease: Ethical challenges and future directions. NPJ Parkinsons Dis. 5:24. doi: 10.1038/s41531-019-0098-0
Song, Y., and Sepulveda, F. (2018). A novel technique for selecting EMG-contaminated EEG channels in self-paced brain–computer Interface task onset. IEEE Trans. Neural Syst. Rehabil. Eng. 26, 1353–1362. doi: 10.1109/TNSRE.2018.2847316
Sun, B., Zhao, X., Zhang, H., Bai, R., and Li, T. (2020). EEG motor imagery classification with sparse spectrotemporal decomposition and deep learning. IEEE Trans. Autom. Sci. Eng. 18, 541–551. doi: 10.1109/TASE.2020.3021456
Sun, L., Shao, W., Zhang, D., and Liu, M. (2019). Anatomical attention guided deep networks for ROI segmentation of brain MR images. IEEE Trans. Med. Imaging 39, 2000–2012. doi: 10.1109/TMI.2019.2962792
Tiwari, A., and Chaturvedi, A. (2021). A novel channel selection method for BCI classification using dynamic channel relevance. IEEE Access 9, 126698–126716. doi: 10.1109/ACCESS.2021.3110882
Udhaya Kumar, S., and Hannah Inbarani, H. (2017). PSO-based feature selection and neighborhood rough set-based classification for BCI multiclass motor imagery task. Neural Comput. Appl. 28, 3239–3258. doi: 10.1007/s00521-016-2236-5
Wang, P., Jiang, A., Liu, X., Shang, J., and Zhang, L. (2018). LSTM-based EEG classification in motor imagery tasks. IEEE Trans. Neural Syst. Rehabil. Eng. 26, 2086–2095. doi: 10.1109/TNSRE.2018.2876129
Xu, B., Zhang, L., Song, A., Wu, C., Li, W., Zhang, D., et al. (2018). Wavelet transform time-frequency image and convolutional network-based motor imagery EEG classification. IEEE Access 7, 6084–6093. doi: 10.1109/ACCESS.2018.2889093
Yang, L., Song, Y., Ma, K., and Xie, L. (2021). Motor imagery EEG decoding method based on a discriminative feature learning strategy. IEEE Trans. Neural Syst. Rehabil. Eng. 29, 368–379. doi: 10.1109/TNSRE.2021.3051958
Zhang, D., Chen, K., Jian, D., and Yao, L. (2020). Motor imagery classification via temporal attention cues of graph embedded EEG signals. IEEE J. Biomed. Health Inform. 24, 2570–2579. doi: 10.1109/JBHI.2020.2967128
Zhang, D., Yao, L., Chen, K., and Monaghan, J. (2019). A convolutional recurrent attention model for subject-independent EEG signal analysis. IEEE Signal Process. Lett. 26, 715–719. doi: 10.1109/LSP.2019.2906824
Zhang, R., Zong, Q., Dou, L., and Zhao, X. (2019). A novel hybrid deep learning scheme for four-class motor imagery classification. J. Neural Eng. 16:066004. doi: 10.1088/1741-2552/ab3471
Zhang, S., Zhu, Z., Zhang, B., Feng, B., Yu, T., and Li, Z. (2020). The CSP-based new features plus non-convex log sparse feature selection for motor imagery EEG classification. Sensors 20:4749.
Zhang, Y., Nam, C. S., Zhou, G., Jin, J., Wang, X., and Cichocki, A. (2018). Temporally constrained sparse group spatial patterns for motor imagery BCI. IEEE Trans. Cybernet. 49, 3322–3332. doi: 10.1109/TCYB.2018.2841847
Zhao, H., Zheng, Q., Ma, K., Li, H., and Zheng, Y. (2020). Deep representation-based domain adaptation for nonstationary EEG classification. IEEE Trans. Neural Netw. Learn. Syst. 32, 535–545. doi: 10.1109/TNNLS.2020.3010780
Zhao, X., Zhang, H., Zhu, G., You, F., Kuang, S., and Sun, L. (2019). A multi-branch 3D convolutional neural network for EEG-based motor imagery classification. IEEE Trans. Neural Syst. Rehabil. Eng. 27, 2164–2177. doi: 10.1109/TNSRE.2019.2938295
Keywords: Brain-Computer Interfaces, motor, EEG, neural networks, deep learning
Citation: Wang G and Cerf M (2022) Brain-Computer Interface using neural network and temporal-spectral features. Front. Neuroinform. 16:952474. doi: 10.3389/fninf.2022.952474
Received: 25 May 2022; Accepted: 24 August 2022;
Published: 05 October 2022.
Edited by:
Jiayang Guo, Xiamen University, ChinaReviewed by:
Jing Jin, East China University of Science and Technology, ChinaJipeng Wu, Shenzhen Institute of Advanced Technology (CAS), China
Copyright © 2022 Wang and Cerf. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Moran Cerf, bW9yYW5AbW9yYW5jZXJmLmNvbQ==