 Chengye Li
Chengye Li Lingxian Hou2
Lingxian Hou2 Huiling Chen
Huiling Chen- 1Department of Pulmonary and Critical Care Medicine, The First Affiliated Hospital of Wenzhou Medical University, Wenzhou, China
- 2Department of Rehabilitation, Wenzhou Hospital of Integrated Traditional Chinese and Western Medicine, Wenzhou, China
- 3Key Laboratory of Intelligent Treatment and Life Support for Critical Diseases of Zhejiang Province, Wenzhou, Zhejiang, China
- 4Collaborative Innovation Center for Intelligence Medical Education, Wenzhou, Zhejiang, China
- 5Zhejiang Engineering Research Center for Hospital Emergency and Process Digitization, Wenzhou, Zhejiang, China
- 6Department of Intensive Care Unit, The First Affiliated Hospital of Wenzhou Medical University, Wenzhou, Zhejiang, China
- 7College of Computer Science and Artificial Intelligence, Wenzhou University, Wenzhou, Zhejiang, China
- 8Department of Pulmonary and Critical Care Medicine, The First Affiliated Hospital of Wenzhou Medical University, Wenzhou, Zhejiang, China
- 9Department of Information Technology, Wenzhou Polytechnic, Wenzhou, China
Introduction: Although tuberculous pleural effusion (TBPE) is simply an inflammatory response of the pleura caused by tuberculosis infection, it can lead to pleural adhesions and cause sequelae of pleural thickening, which may severely affect the mobility of the chest cavity.
Methods: In this study, we propose bGACO-SVM, a model with good diagnostic power, for the adjunctive diagnosis of TBPE. The model is based on an enhanced continuous ant colony optimization (ACOR) with grade-based search technique (GACO) and support vector machine (SVM) for wrapped feature selection. In GACO, grade-based search greatly improves the convergence performance of the algorithm and the ability to avoid getting trapped in local optimization, which improves the classification capability of bGACO-SVM.
Results: To test the performance of GACO, this work conducts comparative experiments between GACO and nine basic algorithms and nine state-of-the-art variants as well. Although the proposed GACO does not offer much advantage in terms of time complexity, the experimental results strongly demonstrate the core advantages of GACO. The accuracy of bGACO-predictive SVM was evaluated using existing datasets from the UCI and TBPE datasets.
Discussion: In the TBPE dataset trial, 147 TBPE patients were evaluated using the created bGACO-SVM model, showing that the bGACO-SVM method is an effective technique for accurately predicting TBPE.
1 Introduction
According to WHO Global tuberculosis report 2016, there was an approximately 10.4 million new cases of TB and 1.4 million deaths caused by TB. Six countries with the most severe cases of TB were China, South Africa, India, Indonesia, Nigeria, and Pakistan (Pan, 2012). Besides, the most common pulmonary tuberculosis, there is tuberculous pleurisy and so on. One of the most common causes of pleural effusion is tuberculous pleurisy. Tuberculous pleurisy is often manifested as non-productive cough, fever, chest pain, dyspnea, etc. Those patients suspected of tuberculous pleurisy need rapid and accurate diagnosis and prompt treatment, otherwise it will develop into tuberculous empyema, thoracic malformations and other serious consequences, and even death.
Diagnosis of tuberculous pleurisy relies on sputum, pleural effusion, pleural biopsy specimen culture, or molecular linear probe assay to detect Mycobacterium tuberculosis (World Health Organization, [WHO], 2010). The patient often presents with a non-productive cough and less bacteria in pleural fluid so the culture has low sensitivity. With long incubation, timely diagnosis is almost impossible (Gopi et al., 2007; von Groote-Bidlingmaier et al., 2013). Pleural biopsy for invasive examination includes blind biopsy and Thoracoscopic pleural biopsy. Blind biopsy has low sensitivity and it can easily cause pneumothorax. Thoracoscopic examination requires higher infrastructure and technical skills, difficult to access in regions with poor economy and higher incidence of TB. Other common examinations, such as acid-fast Mycobacterium tuberculosis smear, Xert MTB/RIF detection on samples, IFN-r assay, pleural fluid cell count, and biochemical detection etc. exist but have moderate sensitivity, low specificity, and high cost (Seibert et al., 1991; Conde et al., 2003; Jiang et al., 2007; Udwadia and Sen, 2010; Porcel et al., 2013; Lee et al., 2014). In the areas with high prevalence of tuberculosis, the most frequent cases of tuberculous pleurisy were inferred from a predominantly lymphocytic exudate combined with high adenosine deaminase (ADA), which is comparatively better but there was still a false negative or false positive, especially in early tuberculous pleurisy (Lee et al., 2014).
Others diagnose tuberculous pleurisy using diagnostic models. In addition, artificial general intelligence methods (Yang S. et al., 2021; Yang et al., 2022a,b,c) are critical studies in the field of brain-inspired intelligence to realize high-level intelligence, high accuracy, high robustness, and low power consumption in comparison with the state-of-the-art artificial intelligence works. Seixas et al. (2013) employ artificial neural networks (ANN), the non-invasive prediction model established for the pleural effusion smear, culture, ADA, serology, and nucleic acid amplification (NAA) test results in HIV-infected patients, and the detection accuracy was > 90%. Shu et al. (2015) use logistic regression analysis in patients with predominantly lymphocytic pleural effusion to analyze the inflammatory cytokines, anti-inflammatory cytokines and T lymphocyte effector molecules, including total protein, cell and classification counts, culture of bacteria, lactate dehydrogenase (LDH), fungi, and chemokines [monocyte chemo-attractant protein (MCP)-1, cytology, cytokines interleukin (IL)-1β, IL-2, IL-6, IL-10, IL-12, IL-13, TNF-α, and IFN-γ, mycobacteria, macrophage inflammatory protein (MIP)-1α, regulated on activation, normal T cell expressed and secreted, and IP-10], soluble tumor necrosis factor receptor TNF-sR1 and TNF-sR2, vascular endothelial growth factor (VEGF) and establish the diagnostic model. The results showed ADA ≥ 40 IU/mL, IFN-γ ≥ 75 pg/mL, DcR3 ≥ 9.3 ng/mL, and soluble tumor necrosis factor receptor 1 (TNF-sR1) ≥ 3.2 ng/mL which were independent factors associated with tuberculous pleurisy. Based on the prediction probability of four predictors, the area under ROC curve was 0.920, and the specificity and sensitivity were 86.7 and 82.9%, respectively (Shu et al., 2015). Klimiuk et al. (2015) used ROC analysis and multiple regression analysis to construct the prediction model of tuberculous pleurisy. According to the patient’s clinical data and multiple pleural effusion biomarkers (ADA, IFN-γ, IL-2, IL-2sRα, IL-12p40, IL-18, IL-23, IP-10, Fas-ligand, MDC, and TNF-α), the diagnostic accuracy (AUC) of tuberculous pleurisy was higher than 0.95 (Klimiuk et al., 2015). Demirer used unrestricted logistic regression method to distinguish tuberculous pleural effusion (TBPE) from the non-TBPE, which only relies on the general condition of a patient with pleural effusion, imaging studies, results of pleural effusion routine test. Results showed that specificity and sensitivity were 83.0 and 60.5% and AUC was 0.719 when only the age was less than 47 and the pleural fluid ADA more than 35 or pleural fluid protein serum protein ratio was higher than 0.71 (Demirer et al., 2012). Some of these models need to detect unusual molecular markers, which are expensive. Since some models rely on pleural fluid detection, it’s difficult to use the model when the fluid is difficult to obtain, such as inadequate fluid, a scapular posterior pleural effusion, patient has severe pleural reaction, and so on.
In computer-aided diagnosis technology, machine learning methods play an important role, and the classification and prediction ability of support vector machine (SVM) has been fully validated not only in the medical field, but also by many scholars in various other fields, and many researches on SVM have been conducted for this purpose. For example, in medical diagnosis fields, Zhou et al. (2022) developed a SVM-based discriminating model to extract a set of candidate biomarkers for malignant brain gliomas. Gao et al. (2022) proposed a novel kernel-free ν-fuzzy reduced kernel-free quadratic surface SVM model and applied it to Alzheimer’s Disease prodromal detection. Badr et al. (2022) applied a recent gray wolf optimizer to improve the performance of SVM for breast cancer diagnosis with efficient scaling techniques. Vidya and Gait (2021) presented a gait classification based decision support system using multi-class SVM to assist the clinicians to diagnose the Parkinson’s disease and rate the severity level. Chen B. et al. (2021) implemented an extended kalman filter with SVM for automated brain tumor detection. Viloria et al. (2020) applied a SVM to predict the diagnosis of diabetes according to the above factors in patients. Akinnuwesi et al. (2020) adopted the hybrid of principal component analysis (PCA) and SVM to establish breast cancer risk assessment and early diagnosis model which can accurately establish the early diagnosis model of breast cancer. In other fields, Devi Thangavel et al. (2023) used fuzzy logic and multi-class SVM techniques to properly set and monitor model parameters such as suitable temperature, humidity, and soil moisture for greenhouse farms located near Modaculic Erosion. Zhao Z. et al. (2022) proposed a new residual-type combined Gray Model-Least Squares Support Vector Machine (LSSVM) forecasting model by extracting the load characteristics of components. Zhang J. et al. (2022) proposed a two-stage intelligent fault diagnosis methodology for rotating machinery based on optimized support vector data description to optimize SVM. Wang S. et al. (2022) proposed a novel optimization method named synergy adaptive moving window algorithm based on the immune SVM to select wavelength variables or preprocessing methods in near-infrared spectroscopy. Pathivada and Vedagiri (2022) evaluated the dilemma frontier under mixed traffic levels using SVM, contributing to better understand the dilemma frontier in developing countries under mixed traffic conditions, such as India.
Based on the above research on SVM, it is easy to find that SVM has powerful classification and prediction ability, and has been widely used in many fields, among which the contribution in the field of medical diagnosis is indelible. In previous study, we used the SVM method in the machine learning algorithm to diagnose TBPEs. The general clinical condition, blood biochemical parameters and routine pleural fluid analysis had very good diagnostic accuracy of 94.3%, sensitivity and specificity were 93.6 and 94.1%. We envisage the ability to diagnose tuberculous pleural fluid that is difficult to obtain by pleural effusion by detecting the blood of our patients. In the end we employed the bGACO-SVM method, a swarm intelligence algorithm to establish the diagnosis of tuberculous pleurisy model, only based on patient general condition and routine blood test results. The diagnostic accuracy of ACC reached 96.57%, Matthew correlation coefficient (MCC) was 0.9366, with F-measure and specificity 96.65 and 96.91%, respectively.
In this study, the ACOR is first reviewed, and then an in-depth study is conducted to propose an ant colony optimizer with a grade-based search, called grade-based search technique (GACO), focusing on the aspects of ACOR in terms of the convergence accuracy and avoiding falling into local optimum. In GACO, a grade-based search mechanism with strong convergence properties is mainly introduced into the original ACOR, which effectively improves the convergence accuracy of GACO and further enhances the ability to avoid falling into local optima. In order to prove the performance of GACO, a comparative simulation was conducted between GACO and nine basic algorithms and nine similar variant optimization algorithms, and the Wilcoxon signed-rank test (García et al., 2010) and Friedman test (Derrac et al., 2011) were utilized to evaluate the experimental results, which effectively proved that GACO has a strong convergence ability and the ability to avoid being trapped in a local optimum. Finally, to achieve diagnostic prediction of TBPE, the GACO was first transformed into a binary version, called bGACO, and subsequently an SVM classifier with both feature selection functions, called bGACO-SVM, was proposed based on bGACO. For the proposed bGACO-SVM, it is not only validated on some very common public datasets, but also applied to the TBPE prediction problem. bGACO-SVM is effectively demonstrated to have strong classification prediction capability and can be successfully used for TBPE diagnosis and prediction through experimental simulation results.
To summarize, the important contributions and innovations of this paper are as follows.
➢ A novel swarm intelligence optimization algorithm, called GACO, is proposed by introducing a grade-based search method to ACO.
➢ The grade-based search greatly improves the convergence performance of GACO and the ability to avoid getting trapped in local optimization, thus improving the classification capability of bGACO-SVM.
➢ Both GACO and nine basic algorithms and nine state-of-the-art variants are compared with each other, providing strong evidence of GACO’s core strengths.
➢ The prediction accuracy of bGACO-SVM was evaluated using existing datasets from the UCI and TBPE datasets, showing that the bGACO-SVM method can accurately predict TBPE.
The follow-up of the paper is organized as follows. Section II describes the data acquisition of TBPE and other related contents. The review of ACOR and the proposed GACO are given in Section 3. The construction process of bGACO-SVM model is given in Section 4. Section 5 first validates the performance of GACO by way of experiments and then simulates the diagnosis prediction of TBPE using bGACO-SVM. Section 6 discusses all the research work in this paper. Section 7 summarizes the whole paper and discusses future works.
2 Data analysis
2.1 Patient information
The research was prospectively conducted on the 147 patients with pleural effusion that were admitted to the First Affiliated Hospital Wenzhou Medical University from October 2015 to May 2016, with an age greater than 15 years and no HIV infection. This research was carried out in accordance with the declaration of Helsinki and approved by the Medical Ethics Committee of The First Affiliated Hospital Wenzhou Medical University.
The results of growth of mycobacterium tuberculosis in biopsy specimens or pleural fluid culture were utilized as the gold standard for the diagnosis of tuberculous pleuritis (World Health Organization, [WHO], 2010). The pathogenesis of pleural effusion was determined by means of thoracic puncture, closed pleural blindness, internal medicine thoracoscopy, bone marrow puncture, blood test, pleural effusion and pleural tissue culture, and pathological examination. Results 73 patients were diagnosed with tuberculous pleurisy. There are 67 patients with non- TBPE, including transudate (Light et al., 1972) (postrenal transplantation, heart failure), malignant tumor, infectious disease, connective tissue disease, and hematopathy. 7 patients were not included in the research because the cause could not be determined see Table 1.
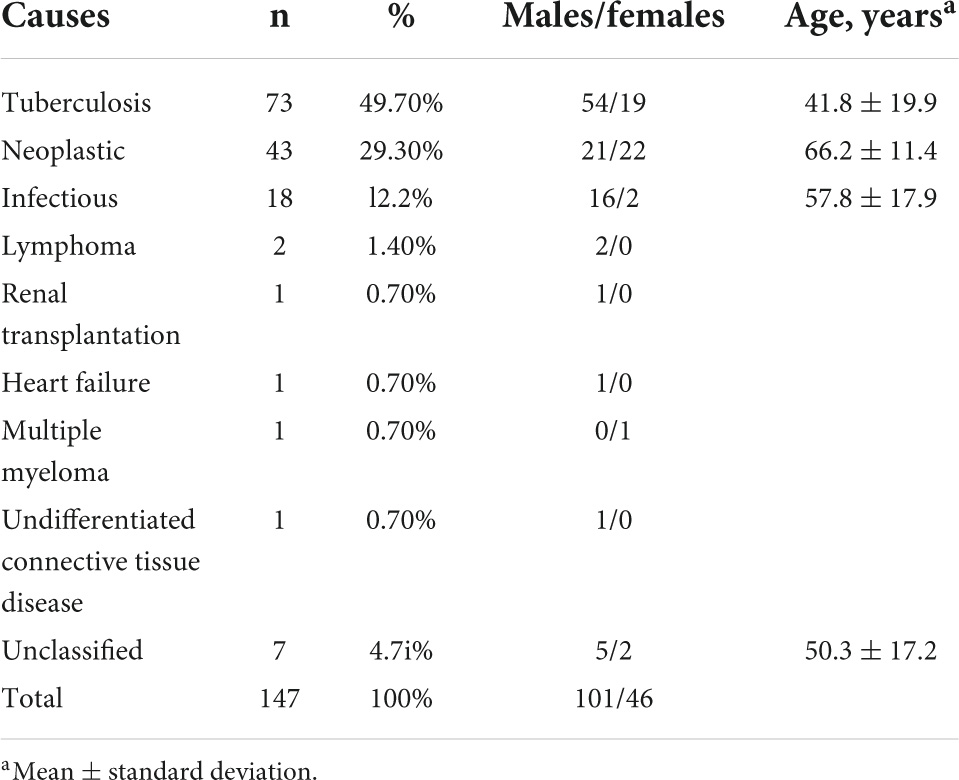
Table 1. The features at diagnosis of PE.
2.2 Statistical analysis
With medical history and physical examination, general clinical data were collected including body mass index, sex, age, body temperature, and diabetes status. The fasting venous blood was collected from all subjects using a vacuum blood collection vessel (Becton Dickinson, Medical Devices Co., Ltd., NC, USA). The Hospital Inspection Center used Japan’s sysmex XE—2100 automatic blood cell analyzer (Sysemx Corporation, Kobe, Japan) to conduct 24 routine blood indices. See Table 2 for a detailed description.

Table 2. The whole features utilized in this research and their descriptions.
SPSS 19 was used for statistical analysis. Using analysis of ANOVA and chi square test, the general clinical data and blood routine test of both patients of TBPE and non-TBPE were analyzed to find out the statistical differences. In all analyses, a p-value of less than 0.05 (5% significant level) was considered significant. The detailed statistics are shown in Tables 3, 4.

Table 3. The clinical features of TPE patients and Non-TPE patients.
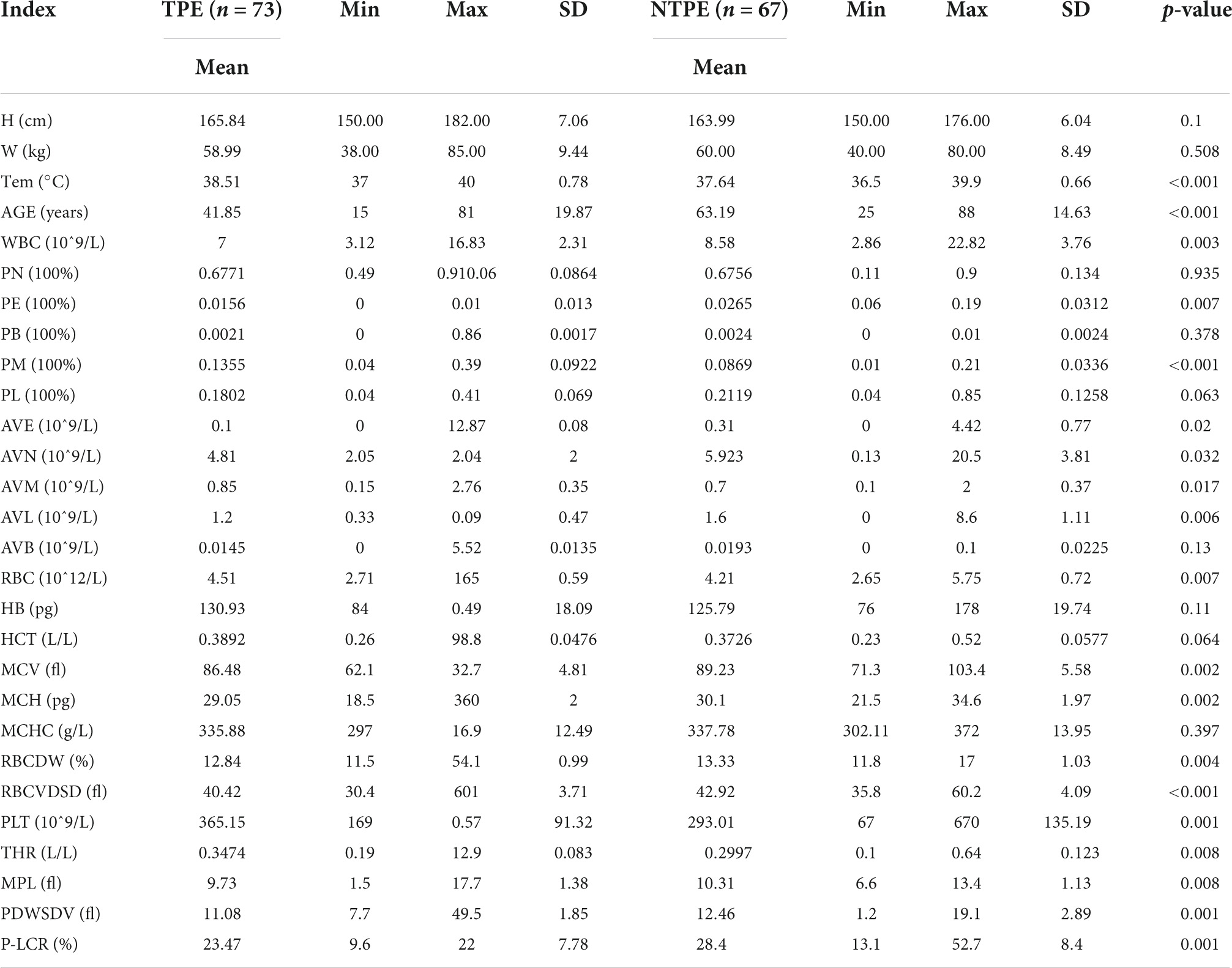
Table 4. Biochemical and clinical parameters in TPE patient and Non-TPE patient.
3 The proposed GACO
In this subsection, a review of ACOR is presented, followed by an introduction of the Grade-based search strategy, and finally a detailed description of the process and significance of GACO proposal.
3.1 An overview of ACOR
In recent years, swarm intelligence optimization algorithms have been widely applied to various fields, and therefore have been developed rapidly, and many excellent algorithms have sprung up. For example, there are some basic optimization algorithms including gray wolf optimization (GWO) (Mirjalili et al., 2014), Harris hawks optimization (HHO) (Heidari et al., 2019), moth-flame optimization (MFO) (Mirjalili, 2015), particle swarm optimization (PSO) (Kennedy and Eberhart, 1995), whale optimizer (WOA) (Mirjalili and Lewis, 2016), Runge Kutta optimizer (RUN) (Ahmadianfar et al., 2021), hunger games search (HGS) (Yang Y. et al., 2021), weighted mean of vectors (INFO) (Ahmadianfar et al., 2022), colony predation algorithm (CPA) (Tu et al., 2021), slime mold algorithm (SMA) (Li S. et al., 2020), JAYA optimization algorithm (Rao, 2016), firefly algorithm (FA) (Yang, 2009), stochastic fractal search (SFS) (Salimi, 2015), and ant colony optimization for continuous domains (ACOR) (Socha and Dorigo, 2008). In addition, there are some advanced variant algorithms, such as fruit fly optimizer with multi-population outpost mechanism (MOFOA) (Chen et al., 2020), bat algorithm based on collaborative and dynamic learning of opposite population (CDLOBA) (Yong et al., 2018), hybridizing gray wolf optimization (HGWO) (Zhu et al., 2015), opposition-based sine cosine algorithm (OBSCA) (Abd Elaziz et al., 2017), Moth-flame optimizer with sine cosine (SMFO) (Chen C. et al., 2021), Cauchy and Gaussian sine cosine algorithm (CGSCA) (Kumar et al., 2017), modified SCA (m_SCA) (Qu et al., 2018), double adaptive random spare reinforced whale optimization algorithm (RDWOA) (Chen et al., 2019), and associative learning-based exploratory whale optimizer (BMWOA) (Heidari et al., 2020). Furthermore, they are already making their impact in many fields, such as train scheduling (Song et al., 2023), image segmentation (Hussien et al., 2022; Yu et al., 2022), feature selection (Liu Y. et al., 2022), complex optimization problem (Deng et al., 2022a), bankruptcy prediction (Zhang et al., 2021), gate resource allocation (Deng et al., 2020; Wu D. et al., 2020), multi-objective problem (Hua et al., 2021; Deng et al., 2022d), expensive optimization problems (Li J.-Y. et al., 2020; Wu S.-H. et al., 2021), robust optimization (He et al., 2019, 2020), airport taxiway planning (Deng et al., 2022c), scheduling problems (Gao et al., 2020; Han et al., 2021; Wang G.-G. et al., 2022), medical diagnosis (Chen et al., 2016; Wang et al., 2017), and resource allocation (Deng et al., 2022b).
Besides, no single algorithm is one-size-fits-all and can solve every issue, as stated in the notion of no free lunch (Wolpert and Macready, 1997). Therefore, we designed a novel feature selection method based on continuous ant colony optimization (ACOR) (Socha and Dorigo, 2008). The proposed feature selection method has also been successfully applied to TBPE prediction. ACOR is proposed firstly by Socha and Dorigo (2008), which has been applied to a wide variety of realistic scenarios with relatively unexpected success, such as image segmentation (Liu et al., 2021; Zhao et al., 2021a,b), engineering optimization design (Chen and Wang, 2014; Zhao D. et al., 2022), path planning (Liu J. et al., 2022), image registration (Wu et al., 2019), energy optimization (Fetanat and Khorasaninejad, 2015), and maintenance scheduling problem (Fetanat and Shafipour, 2011). As far as we know, few studies have used this approach to address this TBPE prediction problem.
In the design and implementation of ACOR, the core idea is the archive theory shown in Figure 1, which stores the ant individuals, the individual fitness values, and the individual weight.
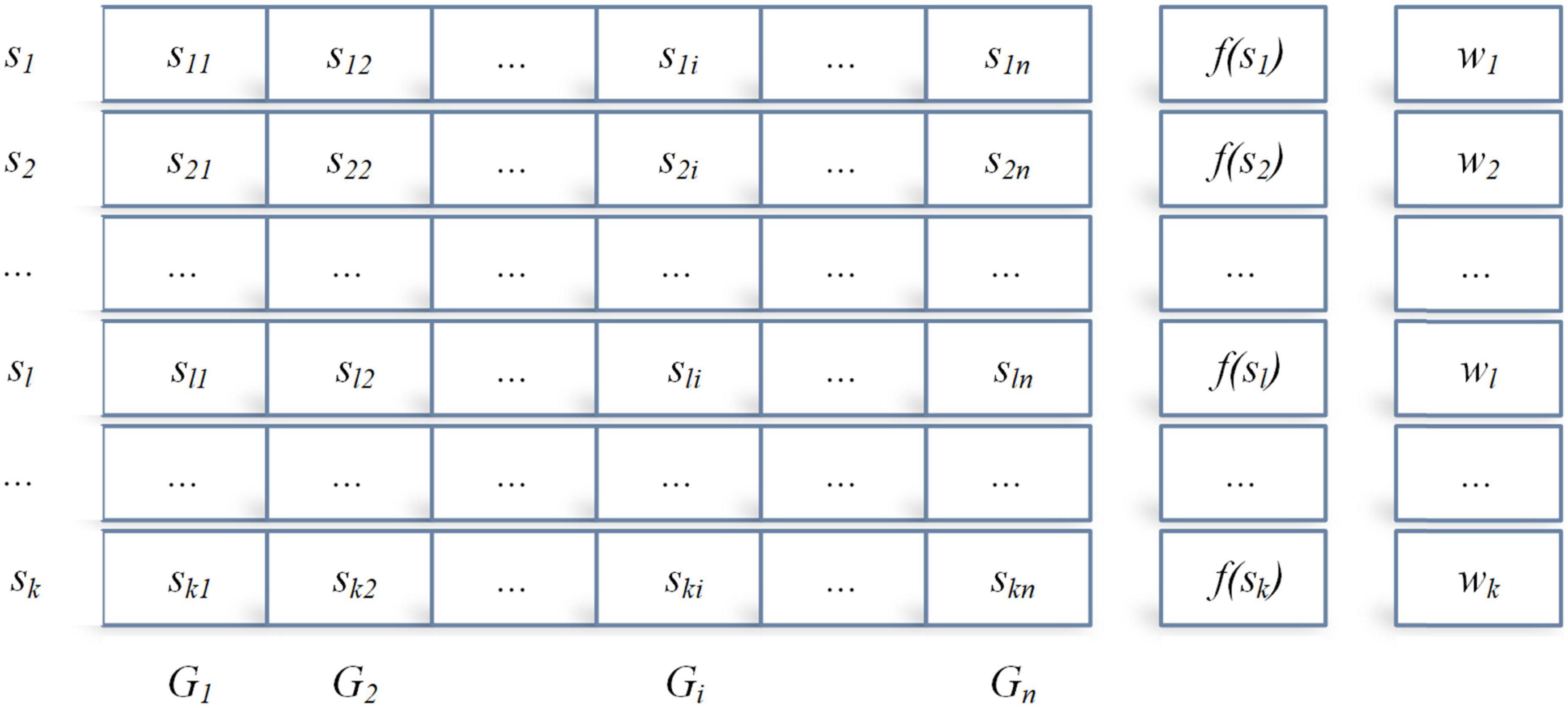
Figure 1. The archive of solutions in AOCR.
where sl = {sl1,…,sln} denotes an ant individual l, and f(sl) and wl denote the corresponding fitness value and weight value of individual l, respectively. Between f(sl) and wl, if f(s1)≤…f(sl)≤…f(sk), then the foot w1≥…wl≥…wk.
The continuous probability density function is the core of ACOR. Among the common probability density functions, the Gaussian function, although easy to sample, has only one peak for a single Gaussian function, and when there are two or more peaks, the Gaussian function cannot be handled well. Therefore, ACOR uses the Gaussian kernel function Gi(x) as the probability density function, and it is actually a weighted sum of several one-dimensional Gaussian functions, as shown in Eq. (1).
where k is the number of individual ants composing the archive bag, is the mean vector in the Gaussian function Gi(sli), and is the standard deviation vector related to Gi(sli) in a single dimension.
In the actual implementation, firstly, the guide individual sl is selected by roulette based on the weight w. The greater the weight of the guide individual, the higher the chance of being selected, and then new ant individuals are generated by exploring around the guide individual sl. The exploration process mainly relies on the constructed Gaussian function. Finally, the m ant individuals generated and the k individuals in the archive are merged, and the m poorer individuals are removed from the merged archive, which is also the process of pheromone update of ant individuals.
3.2 Grade-based search strategy
The grade-based search strategy (GS) is a mechanism abstracted from GWO, where the core is mainly to simulate the hierarchy of gray wolves. As a swarm intelligence optimization algorithm proposed by Mirjalili et al. (2014) in 2014, GWO is characterized by few parameters, strong convergence performance and easy implementation. Therefore, based on the inspiration of the above ideas, GS is introduced into this paper to improve the convergence performance of ACOR.
In the GS, ant individuals are also classified into four classes: α, β, δ, and ω. There are the α, β, and δ leaders in the population, representing the current optimal candidate solution, second best solution, and third best solution, independently. Other individual ants are called ω, which follow α, β, and δ to search for food. Therefore, ant individuals searching for food can be represented by the following mathematical model.
where t represents the number of current iterations, and are coefficient vectors, indicates the position vector of food, and is the location vector of ant individual. and can be obtained according to the following Eqs. 4, 5.
where decreases linearly from 2 to 0 as the iteration. and are all random number vectors between [0, 1].
Furthermore, the ant individual takes the current location as the optimal food position when | A | < 1. In contrast, the ant moved away from the food when | A | > 1 and searched for other food. The central position of α, β, and δ is taken as the optimal solution since the position of the optimal food is unknown. Other ant individuals update their positions according to these three optimal ant individuals with the following Eqs. (6–8).
3.3 The proposed GACO
By reviewing the key elements of ACOR in section “3.1 An overview of ACOR,” it can be seen that ACOR relies mainly on the constant updating of individuals in the archive to obtain the optimal solution. Therefore, since each iteration removes the inferior solutions and retains the superior ones, this allows the ant individuals to continuously move closer to the optimal ones, but this also leads to the same problem of reduced diversity of ant individuals, poor convergence and easy to fall into local optimum. To make up for these shortcomings as much as possible, this paper introduces the GS strategy in ACOR to form a new continuous ant colony optimizer, called GACO. The GS strategy mainly simulates the wolf pack hierarchy and group hunting behavior in GWO, and it mainly acts on the population as a whole after merging the ant individuals in the archive and the newly generated ant individuals. Since the first half of wolf foraging emphasizes more on the global performance in optimization and the second half emphasizes more on the local performance, the introduction of GS strategy then makes ACOR have better convergence performance and stronger ability to jump out of the local optimum. See Algorithm 1 for the pseudo-code of the proposed GACO.
Algorithm 1. Pseudo-code of GACO.
Input: The fitness function f(s),
maximum evaluation number (MaxFEs),
the parameter q, archive size(k),
population size (m), dimension (n),
pheromone evaporation rate(ξ)
Output: The best ant (bestAnt)
Initialize the parameters
MaxFEs,q,k,m,ξ;
Initialize the population of k ants in
archive;
s = ∅;
For l = 1 to k
sl = rand(UL);
s = s∪sl;
fl = f(sl);
End For
s = sorting(s);
;
;
BestAnt = x1;
While (FEs ≤ MaxFEs)
Generate the empty population of m
ants;
For i = 1 to m
Choose a solution sc according to
probability pc where c ∈ [1,k];
For j = 1 to n
μij = scj;
;
xij = 𝒩(μij, σij);
End For
fk + i = f(xi);
x = s ∪ xi;
End For
x = sorting(x);
For l = 1 to k + m
Form by simulating GS strategy;
;
If
;
End If
End For
x = sorting(x);
x = x − sm;
bestAnt = x1;
End While
Return bestAnt
4 The proposed bGACO-sVM model
4.1 Binary transformation method
Feature selection technique is regarded as a binary optimization problem. In order to solve the feature selection issue, an enhanced binary version based on the GACO algorithm is put forward. In this study, the solution is represented as a d dimension vector, where d is the number of attributes of the dataset. The original update method of the GACO algorithm is useless when handling binary optimization issues because these solutions do not only have the “0” and “1” values. In order to settle the problem, it discretizes the position vector of individual ants into a binary value. The updated formula is defined as following.
where rand denotes a random number obeying a uniform distribution between [0,1]⋅Xd(t + 1) is an iteration of t using binary position update. the specific expression of sigmoid is shown below.
In this way, the original continuous problem is transformed into a discrete problem. In addition, in order to further evaluate the importance of the selected features, machine learning methods are added to the evaluation of the fitness values to further select the most effective features.
4.2 Support vector machine
SVM has been applied to many practical issues such as breast cancer diagnosis (Huang et al., 2019), TBPE diagnosis (Li et al., 2018), analysis of patients with paraquat poisoning (Hu et al., 2017), prognosis of patients with paraquat poisoning (Chen et al., 2017), prediction of electricity price (Weron, 2014), prediction of electricity spot-prices (Cincotti et al., 2014), and prediction of Parkinson’s disease (Cai et al., 2017). The mechanism of SVM is to find an optimal plane that can maximally separate different data. The support-vector is the data point closest to the boundary. In data processing, SVM is often used as a supervised learning method to decide the optimal hyperplane which distinguish positive and negative samples accurately. The hyperplane is defined as follows, giving the dataset G = (xi,yi),i = 1,…,N,x ∈ Rd,y ∈ {±1}.
Minimization in terms of geometric comprehension of the hyperplane equals to the maximization of geometric spacing equals minimization. In the presence of a small number of outliers, the “soft interval” idea is added, and the slack variable ξi > 0 is utilized. The discipline factor c represents the ability to accept outliers and is one of the main factors affecting the effectiveness of SVM classification. The standard SVM model is shown in the figure below.
where ω denotes the weight of inertia, b represents a constant.
This method transforms low-dimensional data i into high-dimensional data and combines the multivariate linear techniques to partition the optimal classification surface. At the same time, SVM changes the set of linearly indivisible samples Φ:Rd→H non-linearly. In order to ensure that the computational outcomes of the high-dimensional part are the same as the low-dimensional part, an appropriate kernel function k(xi,xj) is constructed, with αi indicating the Lagrange multiplier and Eq. (3) being transformed as follows:
In this paper, the generalized radial basis kernel function is adopted, and its expression is as follows.
where γ is another factor that is very important for the classification performance of SVM and denotes a kernel parameter that specifies the interaction width of the kernel function.
4.3 The proposed bGACO-SVM model
This section proposes a novel and efficient model based on the bGACO and the SVM for feature selection experiments, named bGACO-SVM model. The model is mainly used to select key features from the dataset. The fitness of the selected feature subset for each individual ant is evaluated during the feature selection process. The specific fitness values are calculated as follows.
where er denotes the SVM classification error rate, |D| represents the number of features in the dataset. |R| denotes the number of features of the selected feature subset. α is a weight that measure the importance of the classification error rate and β is a weight that measure the length of the selected features, respectively. In our research, α = 0.99 and β = 0.01 are set, and both are commonly used in many works.
In summary, we can obtain the bGACO-SVM model by combining the proposed bGACO with the SVM in this paper, and its workflow is shown in Figure 2.
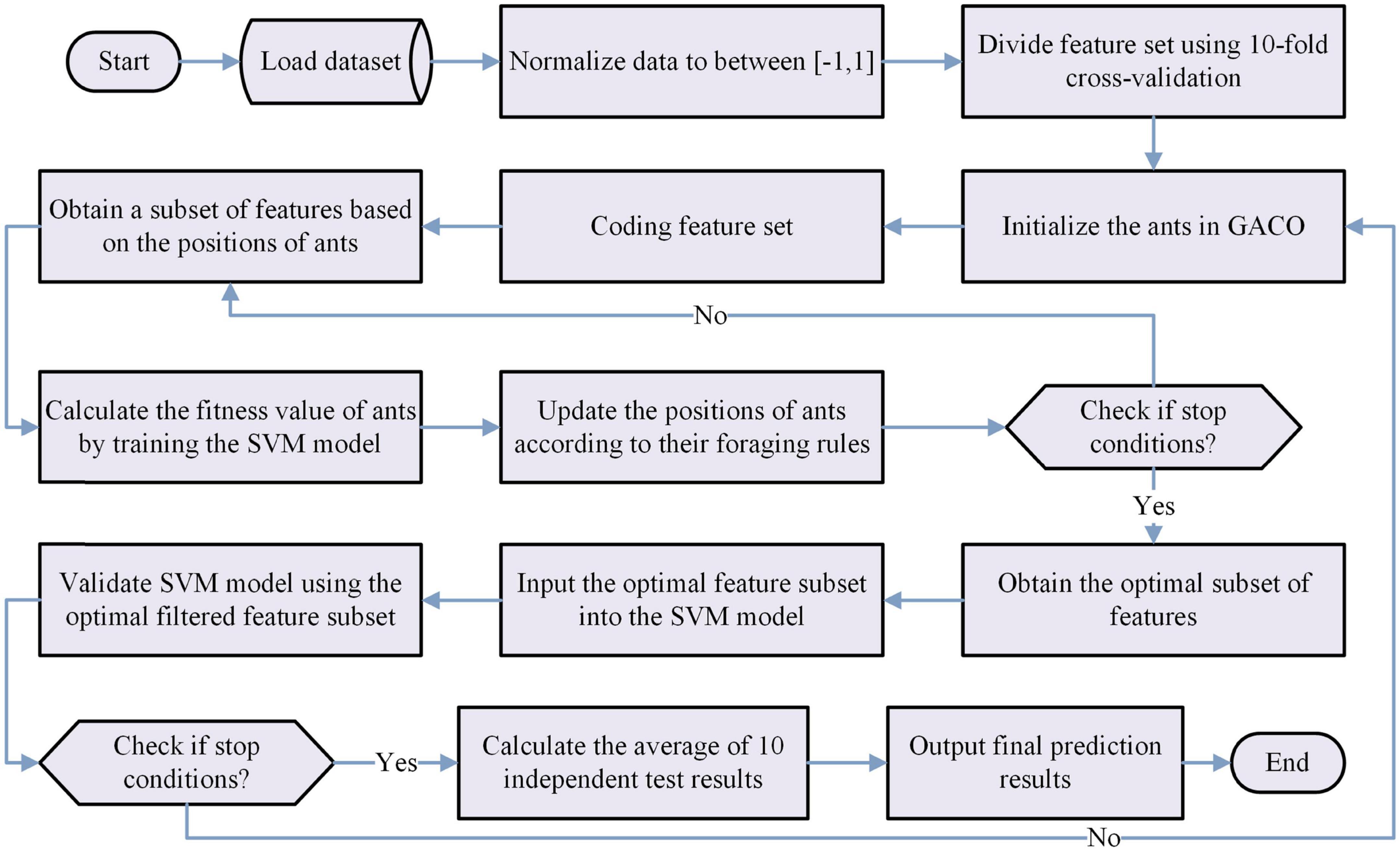
Figure 2. Flow chart of the bGACO-SVM model.
5 Experiments results and analysis
The proposed method is validated and applied using experiments from two aspects. First, a series of benchmark function experiments are conducted to validate the performance of GACO, and second, bGACO-SVM is applied to some classification prediction problems on feature selection, which effectively illustrates that bGACO-SVM has strong classification prediction capability.
5.1 Benchmark function validation
In this subsection, IEEE CEC2017 is used as the basis for benchmark function experiments, and the core advantages of GACO with strong convergence performance and less susceptibility to local optima are fully illustrated by comparing experiments not only between GACO and nine basic algorithms, but also between GACO and nine advanced variant algorithms.
5.1.1 Experiment setup
In the benchmark function experiments, 30 benchmark functions in IEEE CEC2017 are used as the basis of the experiments, which are illustrated in Table 5. In the process of the experiments, the basic algorithm comparative experiments and advanced variant algorithm comparative experiments were conducted. In the basic algorithm comparative experiments, the algorithms involved in the simulation are ACOR (Socha and Dorigo, 2008), GWO (Mirjalili et al., 2014), HHO (Heidari et al., 2019), MFO (Mirjalili, 2015), PSO (Kennedy and Eberhart, 1995), WOA (Mirjalili and Lewis, 2016), JAYA (Rao, 2016), FA (Yang, 2009), and SFS (Salimi, 2015), whose superior performance has been well demonstrated in some previous original studies, so much so that the comparison with their comparative results are also convincing. It is also necessary to compare with some advanced variant algorithms since GACO actually belongs to one variant algorithm, where MOFOA (Chen et al., 2020), CDLOBA (Yong et al., 2018), HGWO (Zhu et al., 2015), OBSCA (Abd Elaziz et al., 2017), SMFO (Chen C. et al., 2021), CGSCA (Chen C. et al., 2021), RDWOA (Chen et al., 2019), m_SCA (Qu et al., 2018), and BMWOA (Heidari et al., 2020) participate in the comparative study. These variant algorithms involved in the comparison not only have a performance due to but also have been successfully applied to several fields.

Table 5. The detailed 30 benchmark functions of CEC2017.
Furthermore, to ensure fairness of the experimental process and the accuracy of the experimental results, all the algorithms participating in the comparison are carried out under the same conditions, where the population size is set to 30 and the maximum number of evaluations is uniformly set to 300,000. In addition, the values of the key parameters of all the algorithms involved in the comparison are kept consistent with the values of the parameters in the original literature. Besides, all algorithms are independently tested 30 times to reduce the effect of random conditions. Mean, standard deviation, the Wilcoxon signed-rank test and the Friedman test are used for detailed statistics and analysis of all experimental results obtained on the benchmark functions.
5.1.2 Comparison with basic algorithms
In this subsection, GACO and nine basic algorithms are compared in experiments at IEEE CEC2017, and the algorithms involved in the comparison are ACOR (Socha and Dorigo, 2008), GWO (Mirjalili et al., 2014), HHO (Heidari et al., 2019), MFO (Mirjalili, 2015), PSO (Kennedy and Eberhart, 1995), WOA (Mirjalili and Lewis, 2016), JAYA (Rao, 2016), FA (Yang, 2009), and SFS (Salimi, 2015). Table 6 gives their average values and standard deviations obtained during the experiment, where “AVG” denotes the average value and “STD” denotes the standard deviation. The best results are bolded in each column. By observing the average and standard deviation, it can be found that GACO obtained the minimum average value on 20 functions, PSO on 6 functions and GWO on 4 functions. Based on the observation of the average values, it is evident that GACO performs the best on two-thirds of the functions, which effectively shows that GACO has a strong optimization capability to obtain high-quality solutions. Similarly, GACO also performs well in terms of standard deviation, indicating that it has good stability.
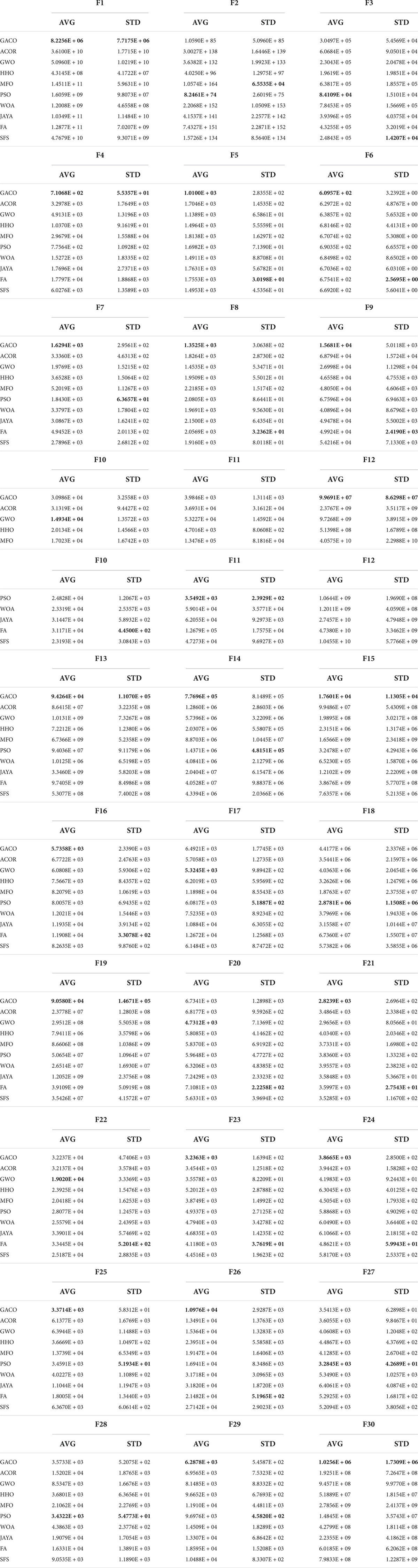
Table 6. The average values and the standard deviations obtained by GACO and basic algorithms.
Further, Table 7 gives the performance ranking of all algorithms on each benchmark function, as well as the overall ranking on the 30 benchmark functions. The observation shows that GACO not only performs as No. 1 on every function category in IEEE CEC2017, but it also ranks No. 1 overall on 30 functions, which provides sufficient proof of GACO’s performance. In addition, for a more reliable analysis of the experimental results, the results of the Wilcoxon signed-rank test are presented in Table 7, where “+” indicates that GACO outperforms the comparison algorithm, “-” indicates that GACO outperforms the comparison algorithm, and “=” indicates that the performance of GACO and the comparison algorithm are comparable. Based on the observation of the analysis results, GACO outperforms the other algorithms on 20 out of 30 functions, which provides sufficient evidence to prove the performance of GACO.
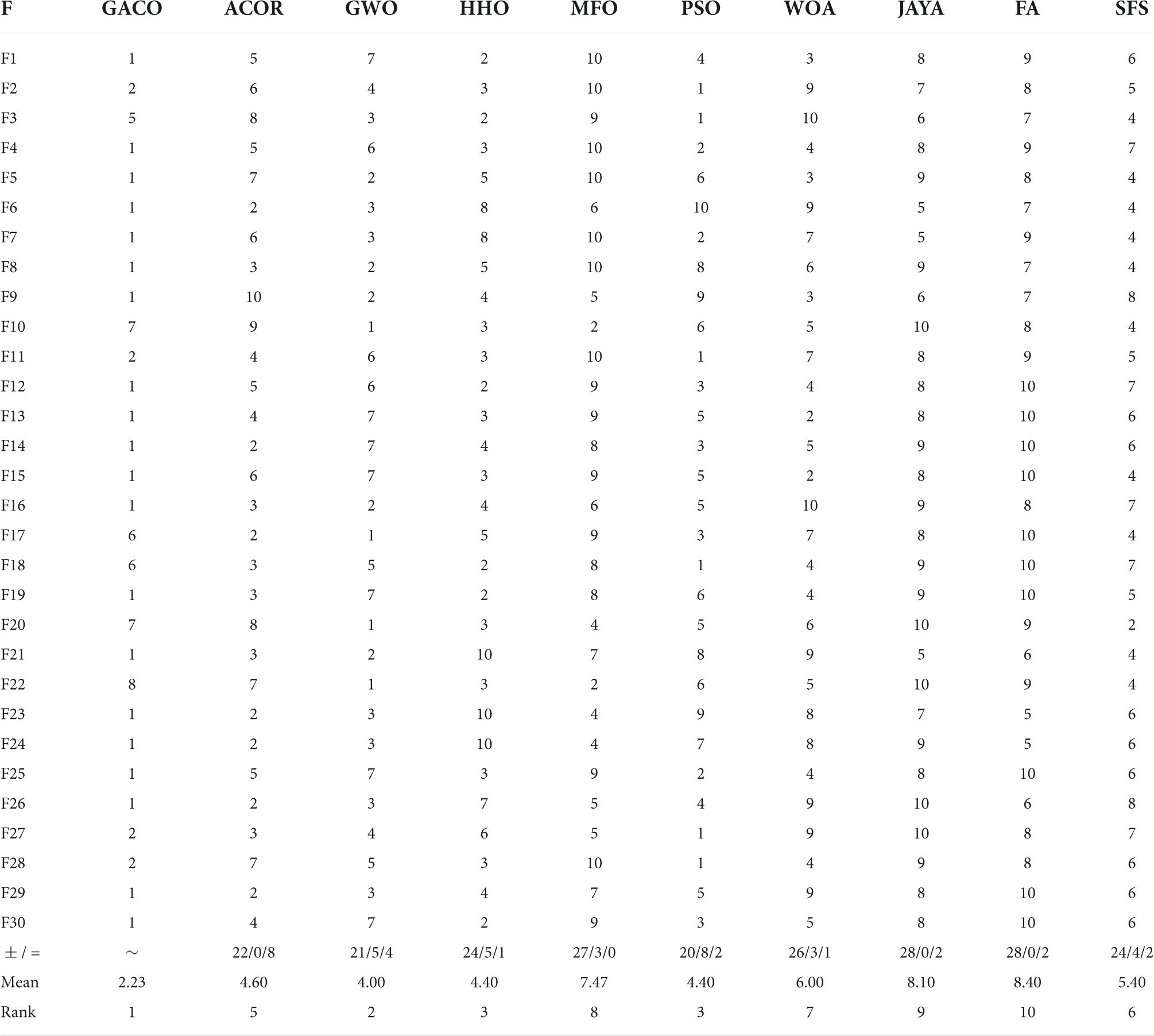
Table 7. The performance ranking of all algorithms and the results of the Wilcoxon signed-rank test.
After the Wilcoxon signed-rank test analysis, Figure 3 gives the results of the Friedman test analysis, where GACO is No. 1 with 2.46 and GWO is No. 2 with 4.04. Therefore, the analysis shows that GACO has a greater advantage over GWO, which is ranked No. 2, and this also shows that GACO has an advantage over other algorithms. Finally, to illustrate the convergence performance of GACO, the convergence curves on some functions are given in Figure 4, where F6, F9, F14, F15, and F19 demonstrate that the convergence performance of GACO is better than other basic algorithms, and F1, F12, F13, and F20 reflect the strong ability of avoiding falling into local optimum that GACO has.
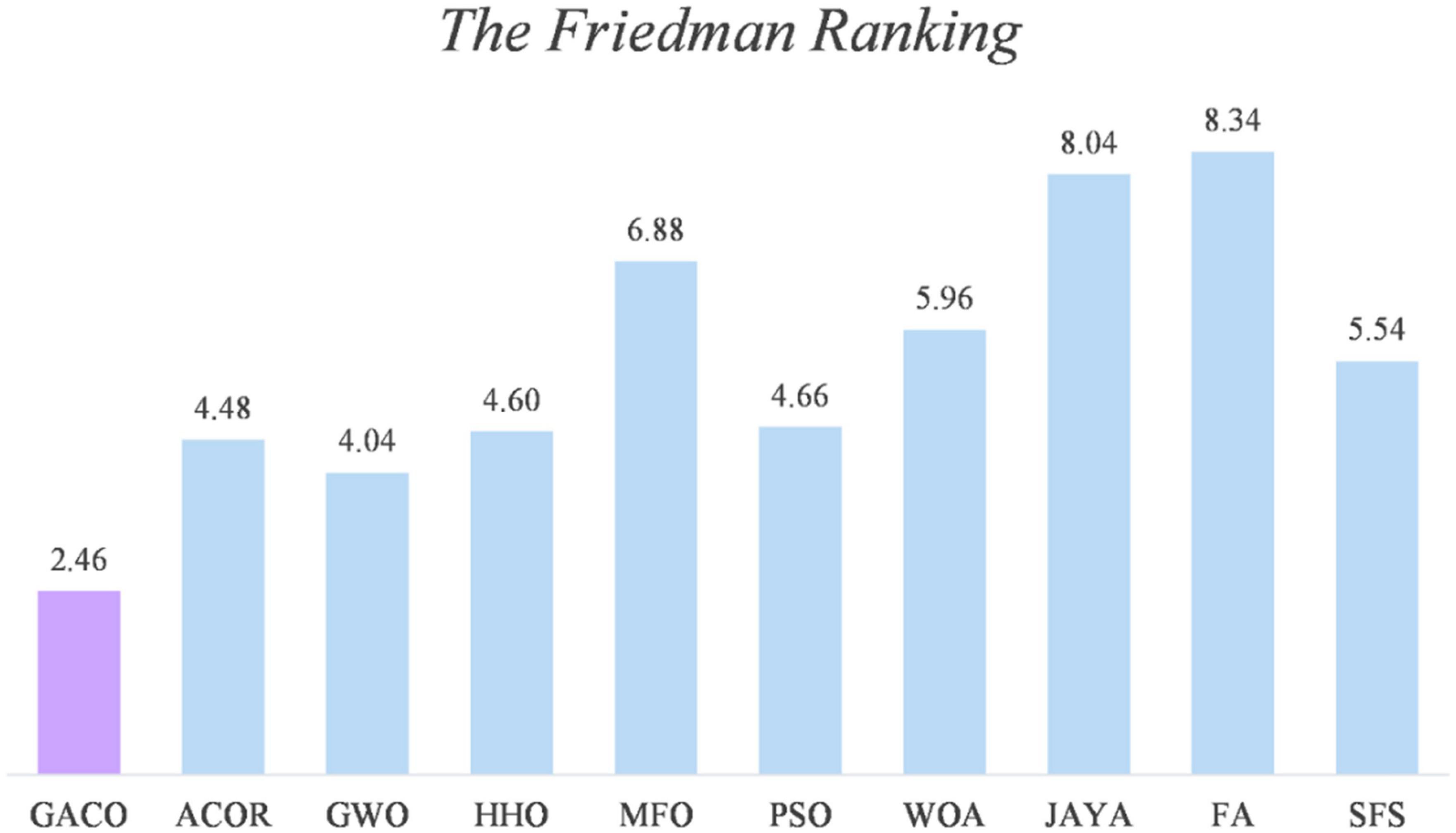
Figure 3. The results of the Friedman test analysis.
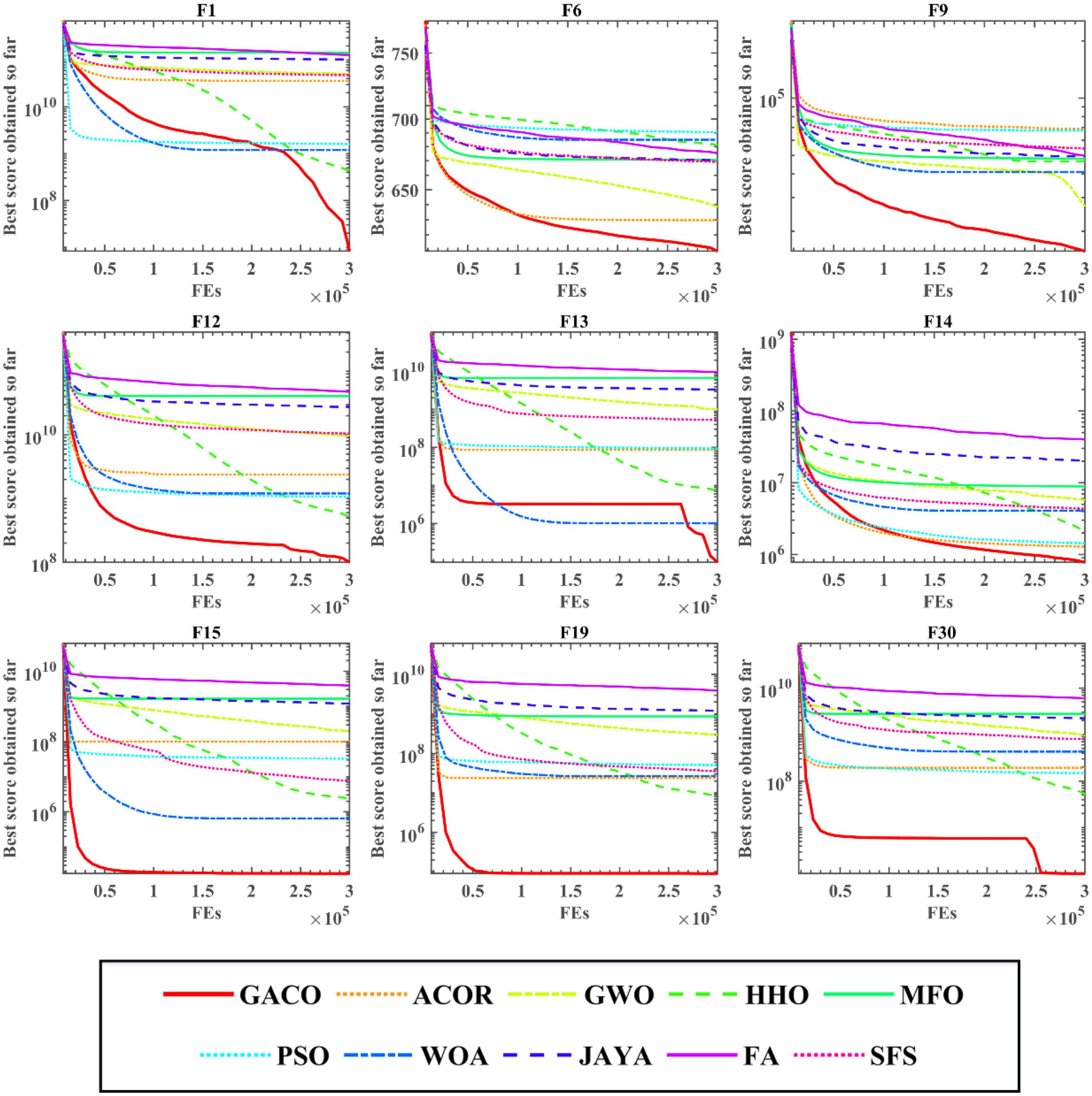
Figure 4. The convergence curves of GACO and basic algorithms on some functions.
Therefore, based on the above experimental analysis, the convergence performance of GACO, as well as the stronger ability to avoid local optima, are well demonstrated in the comparison experiments of the basic algorithms.
5.1.3 Comparison with state-of-art variants
This subsection compares GACO with nine advanced variants since GACO is one variant by introducing the GS strategy into ACOR. Their average values and standard deviations obtained for each function are given in Table 8, where the best results are bolded in each column, GACO obtains the best average value on 23 functions, CDLOBA obtains the best average value on 5 functions, and m_SCA has a better performance on 2 two functions. Based on the observation of the mean performance, it is clear that GACO has a very obvious advantage over other algorithms. In addition, its performance on STD is also very good, which also reflects that GACO has some stability.
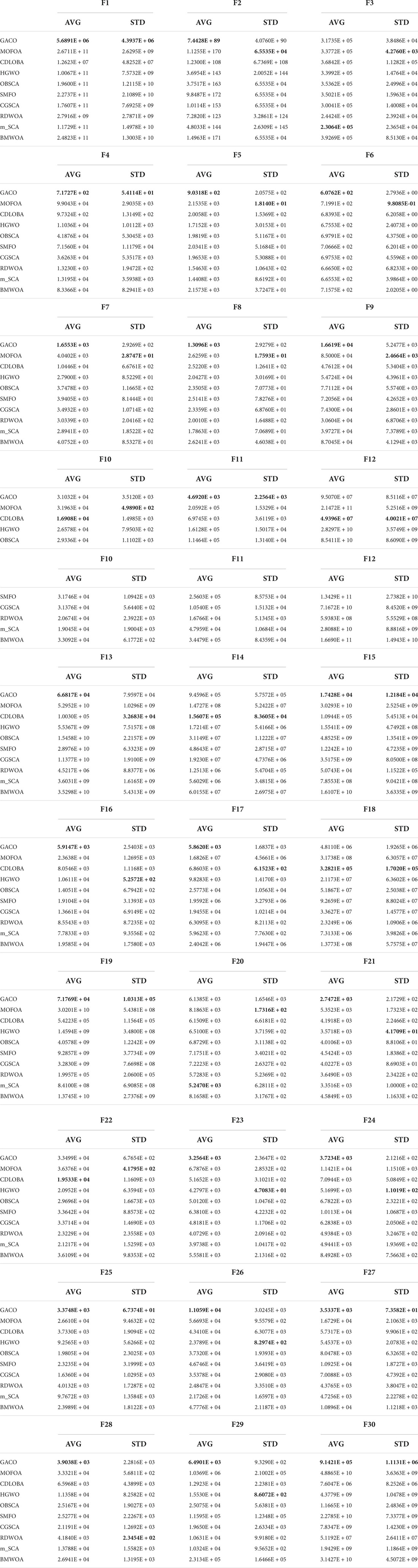
Table 8. The average values and standard deviations of GACO and nine advanced variants.
In order to further analyze the performance of GACO on 30 benchmark functions, the ranking of all algorithms on each function is given in Table 9, where the advantage of GACO is clearly demonstrated, both on individual functions and overall performance is far better than other similar algorithms. The advanced performance of GACO is further verified by the Wilcoxon signed-rank test, which shows that GACO outperforms other algorithms on at least 23 benchmark functions.
Table 9. The ranking of all algorithms on each function and the Wilcoxon signed-rank test result.
Next, the Friedman test analysis was further used to analyze the performance of the algorithms, and Figure 5 gives the Friedman ranking results for each algorithm. By observing the ranking results, it can be found that GACO ranks No. 1 with 1.94, followed by RDWOA in second place with 2.76, which effectively shows that GACO outperforms RDWOA, and likewise shows that GACO is better than other similar algorithms. Finally, the convergence curves of all algorithms on some functions are given in Figure 6, which clearly shows that GACO has a greater advantage in convergence performance than other similar variants of the algorithm.
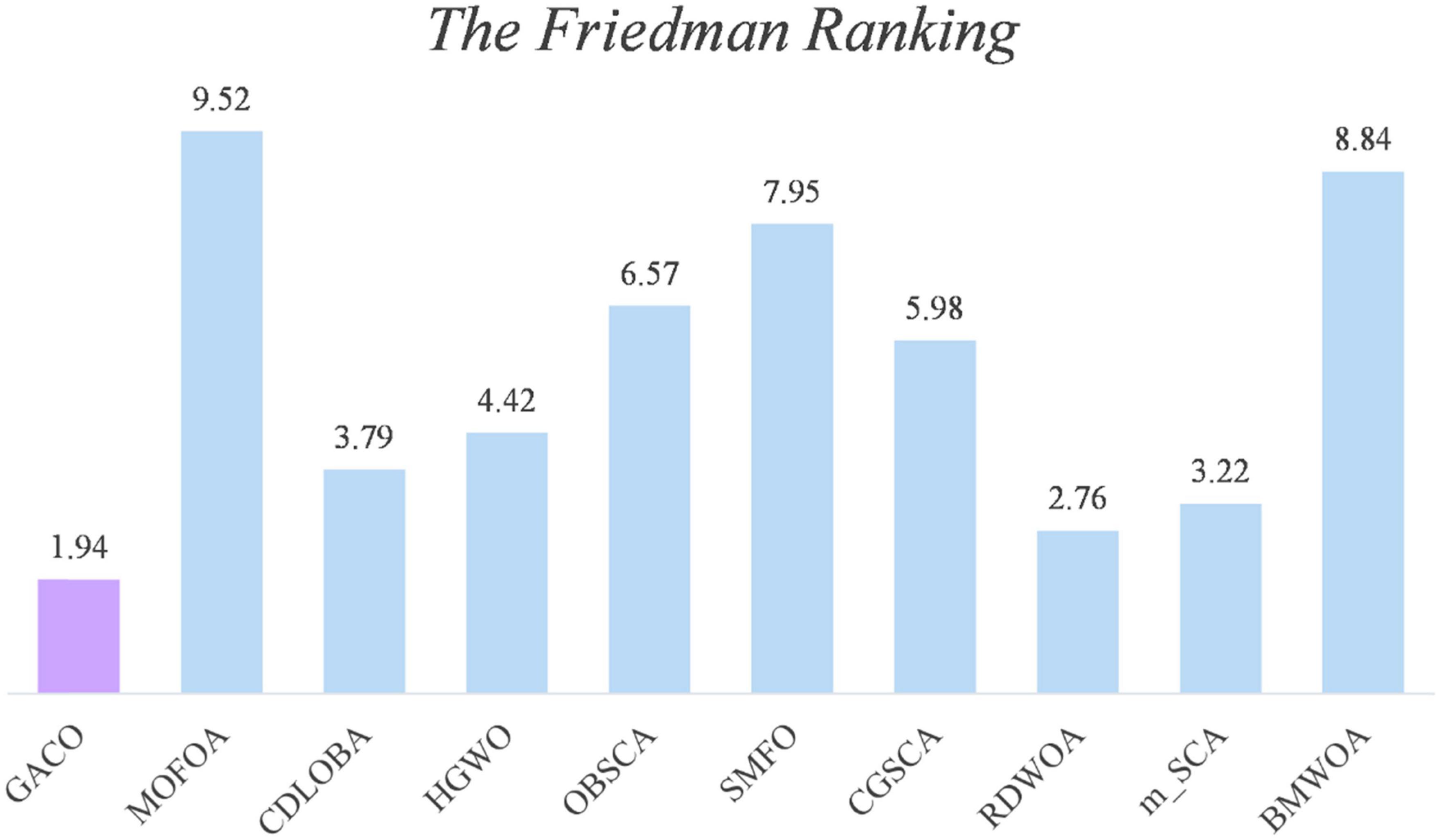
Figure 5. The Friedman ranking results for each algorithm.
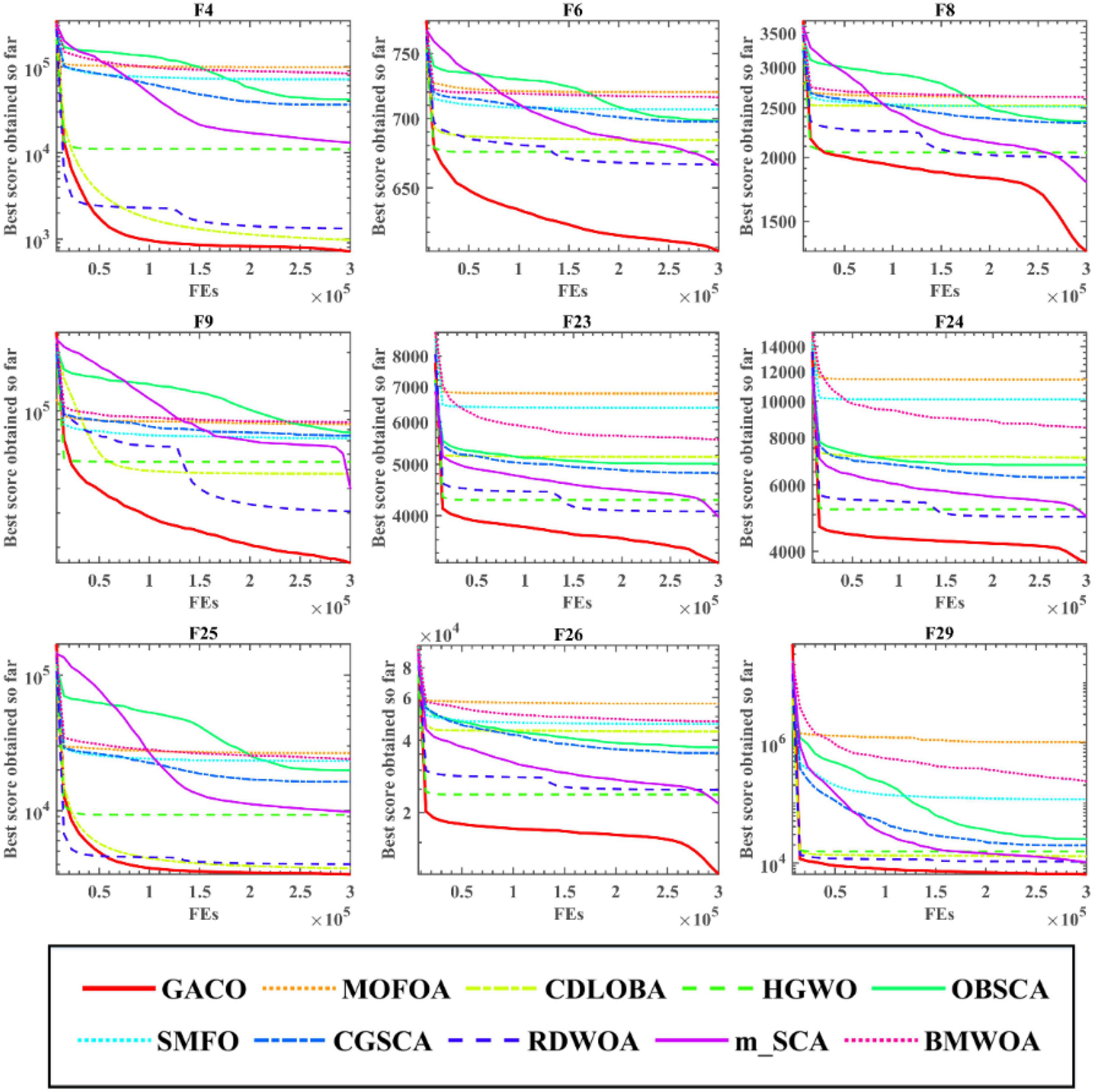
Figure 6. The convergence curves of all algorithms on some functions.
Therefore, the core performance of GACO is further demonstrated by the comparison experiments between GACO and advanced variant algorithms, effectively showing that GACO is an excellent swarm optimization algorithm so that it can applied more fields, such as recommender system (Li et al., 2014, 2017), information retrieval services (Wu Z. et al., 2020; Wu et al., 2021), microgrids planning (Cao et al., 2021), clustering of cancer attributed networks (Gao et al., 2021; Wu and Ma, 2022), drug discovery (Zhu et al., 2018; Li Y. et al., 2020), disease identification and diagnosis (Su et al., 2019; Tian et al., 2020), image denoising (Zhang et al., 2020), tensor completion (Wang W. et al., 2022), colorectal polyp region extraction (Hu et al., 2022), drug repositioning (Cai et al., 2021), smart contract vulnerability detection (Zhang L. et al., 2022), human activity recognition (Qiu et al., 2022), structured sparsity optimization (Zhang X. et al., 2022), and medical data processing (Guo et al., 2022).
5.2 Feature selection experiments
In this subsection, the proposed bGACO-SVM is mainly applied to a variety of feature selection problems, mainly including tests on the public dataset, and tests on the TBPE dataset, as a way to show that it has good application capabilities.
5.2.1 Experimental setup
In this subsection, firstly, bGACO is experimented with some similar methods on 11 public datasets, where the specific datasets involved are shown in Table 10. Then, bGACO is similarly compared with similar algorithms on the TBPE dataset, where the relevant description of the data is given in section “2 Data analysis.” In order to effectively illustrate the role of bGACO on TBPE, experiments comparing GACO with five very common machine learning algorithms are also performed. In order to ensure the reliability of the experiments, all experiments were conducted in the same environment as the benchmark function experiments, where some important parameters of the algorithms involved in the comparison are set using their settings in the original studies.
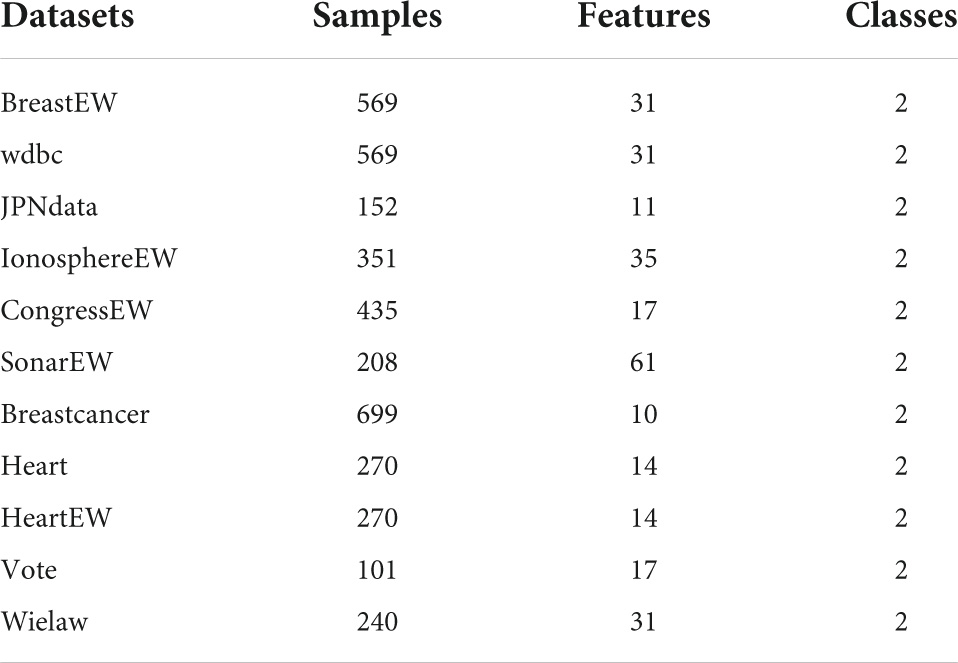
Table 10. Description of UCI datasets.
Accuracy, specificity, precision, the Mathews correlation coefficient (MCC), and the F-measure are the metrics that are used in order to assess how well the model performs in response to the outcomes of the experiments that were carried out. Accuracy refers to the proportion of cases correctly classified by the model, both in terms of true positives and true negatives. When the accuracy rate is higher, it suggests that a greater percentage of the samples have been accurately predicted. The term “specificity” refers to the percentage of “positive negatives” that are correctly classified by the model in “negative occurrences.” A lower rate of incorrect categorization is associated with a better specificity. The term “precision” refers to the likelihood that a given sample is positive out of the total number of samples for which a positive result is anticipated. When the precision is greater, it means that the forecast of affirmative instances is more precise. The MCC score provides insight into the model’s dependability. A more accurate forecast of the topic is indicated by an MCC that is closer to the value 1. A classifier may be evaluated in its entirety using the F-measure. When the F-measure is greater, it implies that the results of the classification are more in line with predictions. The definitions of the evaluation metrics may be found in Eqs (16)–(20).
where TP represents the number of occurrences of a true positive, TN represents the number of instances of a true negative, FN represents the number of instances of a false negative, and FP represents the number of instances of a false positive.
5.2.2 Public dataset experiment
The overall predictive potential of the bGACO-SVM is illustrated in this portion of the article. On various datasets from the University of California, Irvine (UCI),1 which is an open-source dataset suitable for the direction of pattern recognition and machine learning, and many scholars choose to use the dataset on UCI to verify the correctness of their proposed algorithms. The bGACO-SVM feature selection framework is put up against 12 different standard approaches, which include bACOR, bCSO, bWOA, bGWO, bHHO, bJAYA, bPSO, bSCA, bSMA, bSSA, bDE, and bFA.
Table 11 compares the accuracy of 13 different algorithms applied to various datasets from the University of California, Irvine, and finds that the bGACO-based technique achieves the highest average accuracy over 20 separate tests, where the best results are bolded in each column. The bGACO-based technique has an accuracy of 99.48, 99.83, 99.33, 100.00, 99.77, 100.00, 99.43, 97.04, 95.93, 100.00, and 92.10%, respectively, for each of the nine datasets. Only the technique that was based on bSMA had a standard deviation that was significantly lower than the others in the BreastEW dataset. In the Breastcancer dataset, only the bJAYA-based technique had a standard deviation that was significantly lower than the others. Only the approach that was based on bHHO had a standard deviation that was much lower than the others in the heart dataset. In addition, the experimental outcomes of the bGACO-based technique are more consistent when applied to different datasets. According to the findings of the aforementioned investigation, the bGACO-SVM feature selection approach exceeds any and all other methods with regard to the accuracy and consistency of its predictions.
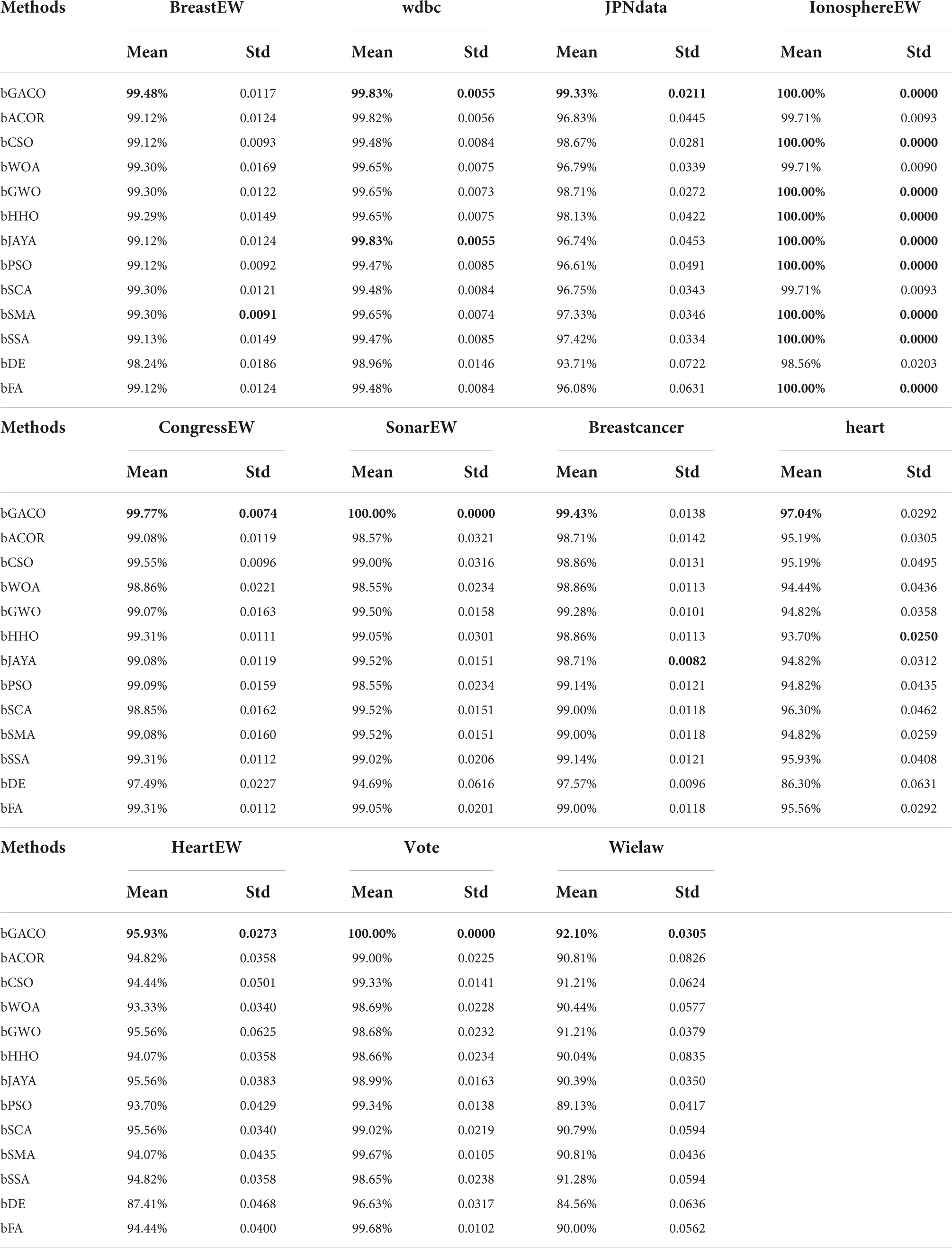
Table 11. Accuracy value on UCI datasets.
The specificity ratings for each of the 10 algorithms are shown in Table 12. The best results are bolded in each column. It is clear from looking at the table that the bGACO-based technique yields mean values that are all equal to No 1. The typical results of Bgaco’s Specificity test may achieve values as high as 98.62, 100.00, 98.57, 100.00, 100.00, 100.00, 100.00, 100.00, 100.00, 100.00, 95.00, 95.00, 100.00, and 92.95%, respectively. Only for the BreastEW, JPNdata, heart, and HeartEW do the results of the standard deviation not show the greatest performance, but the prediction results of bGACO are similarly stable in all other cases. As a result, the bGACO-SVM has a smaller classification error in these comparing methodologies’ species.
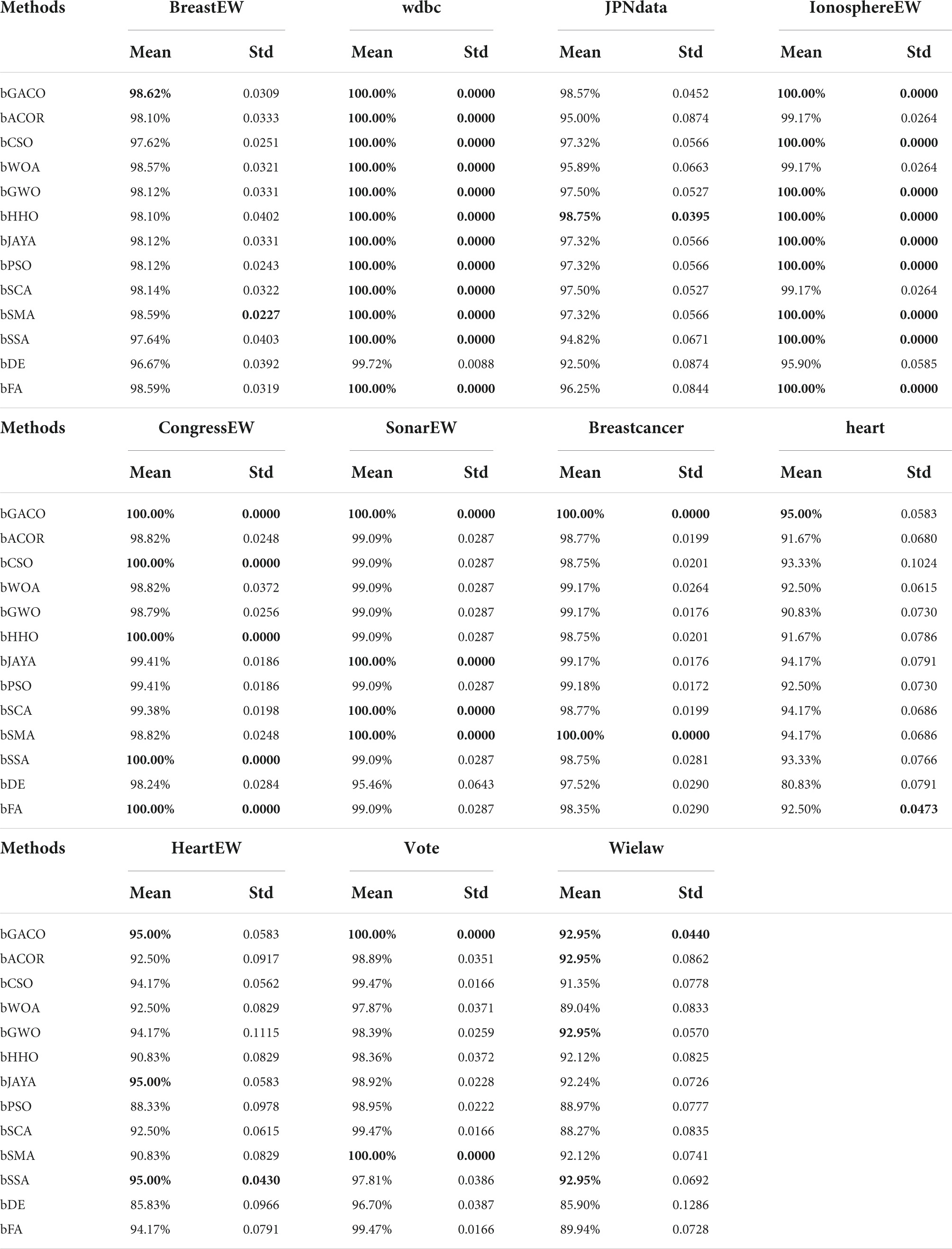
Table 12. Specificity value on UCI datasets.
The mean as well as the standard deviation of the accuracy findings are shown in Table 13. The best results are bolded in each column. The bGACO-based technique achieved average outcomes of 99.20, 100.00, 98.89, 100.00, 100.00, 100.00, 100.00, 96.28, 96.28, 100.00, and 92.20%, respectively, when applied to all 11 datasets. Table 13 shows that the bGACO-based technique delivers the greatest and most consistent Precision results overall. These findings are based on an average of the measurements. Therefore, when compared to other techniques of prediction, bGACO-SVM has a higher level of accuracy when it comes to forecasting positive cases.
Table 13. Precision value on UCI datasets.
The mean and standard deviation of the MCC are shown in Table 14. The best results are bolded in each column. The approach that was suggested in this article achieved mean outcomes of 0.9891, 0.9963, 0.9873, 1.0000, 0.9953, 1.0000, 0.9880, 0.9417, 0.9207, 1.0000, and 0.8439, respectively, in the MCC. The comparative findings are shown in Table 14, and they reveal that the bGACO-based technique is capable of demonstrating superior performance and more reliable outcomes, where the best results are bolded in each column. As a result, the bGACO-SVM that was presented is an improved method for making predictions using the target dataset.
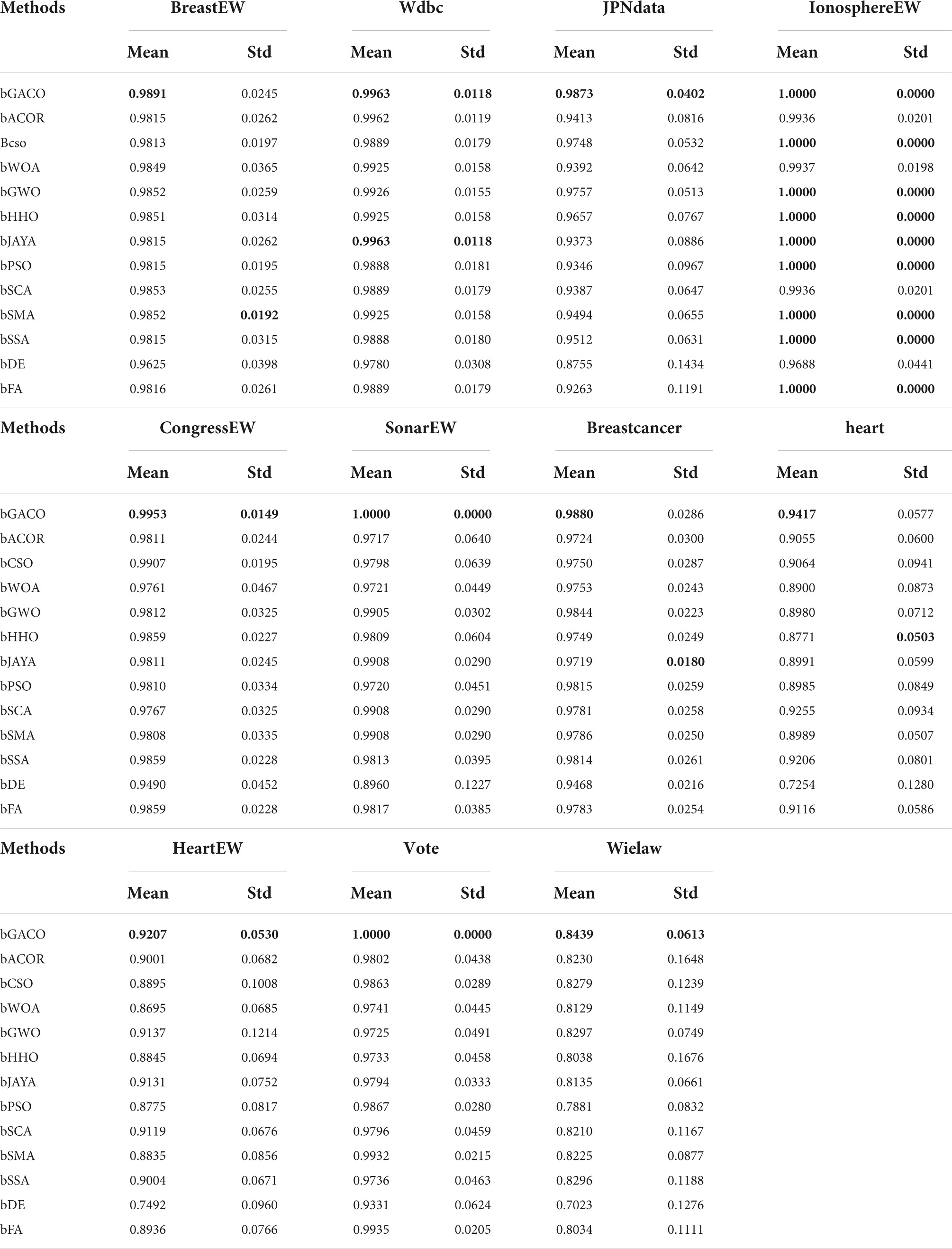
Table 14. MCC value on UCI datasets.
Table 15 displays the mean and standard deviation of the F-measure. The best results are bolded in each column. It can be seen that the mean standards of bGACO-based method reached 99.59, 99.76, 99.41, 100.00, 99.80, 100.00, 99.55, 97.40, 96.34, 100.00, and 91.49%, respectively. The bGACO-based method is the most stable among the experimental results of wdbc, JPNdata, IonosphereEW, CongressEW, SonarEW, HeartEW, Vote, and Wielaw. According to the analysis of Table 15, the experimental data shows that the bGACO-SVM technique is a more effective classification method than the others.
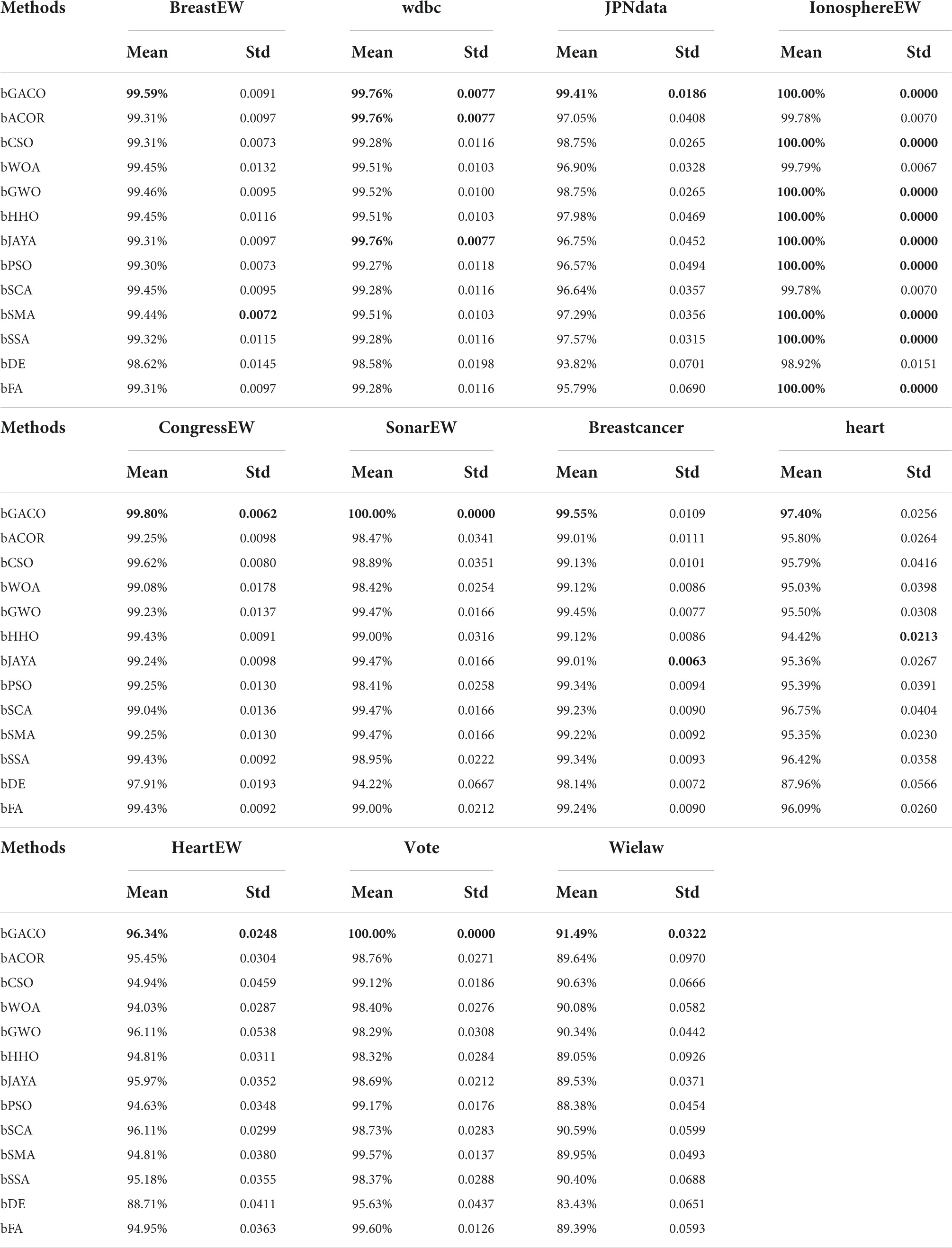
Table 15. F-measure value on UCI datasets.
In this part, comparison experiments are conducted using the UCI dataset. Based on the results of these tests, it is clear that bGACO-SVM has dependable and outstanding prediction performance. Based on the results of the experiments including accuracy, specificity, precision, MCC, and F-measure, it would seem that bGACO-SVM is successful in achieving the target it was intended for.
5.2.3 TBPE dataset experiment
Comparisons are made between bGACO-SVM and 13 other comparable techniques, also including bACOR, bCSO, bWOA, bGWO, bHHO, bJAYA, bMFO, bPSO, bSCA, bSMA, bSSA, bDE, and bFA. This is done to prove that bGACO-SVM is extremely competitive when compared to other methods of a similar kind.
The findings of the six assessment criteria are broken down and averaged in Table 16. It is clear to observe that the bGACO-SVM has an accuracy of 96.57%, specificity of 96.91%, precision of 97.64%, MCC of 0.9366, and an F-measure of 96.65%, respectively. Despite the fact that the bGACO-SVM algorithm requires a considerable amount of time. Along with the large gain in classification accuracy, a certain amount of additional time consumption is unavoidable; nevertheless, we have the ability to make up for this shortfall by using methods for parallel computing or boosting the computational capacity of computing equipment. The 10 iterations of the boxplot for the 10 different algorithms are shown in Figure 7. The maximum, median, and lowest values shown in the figure demonstrate that the experimental results of bGACO-SVM are both outstanding and consistent. The good classification results that bGACO-SVM produces are not the product of a few lucky tests; rather, they are the consequence of the system’s consistency and its outstanding classification performance.
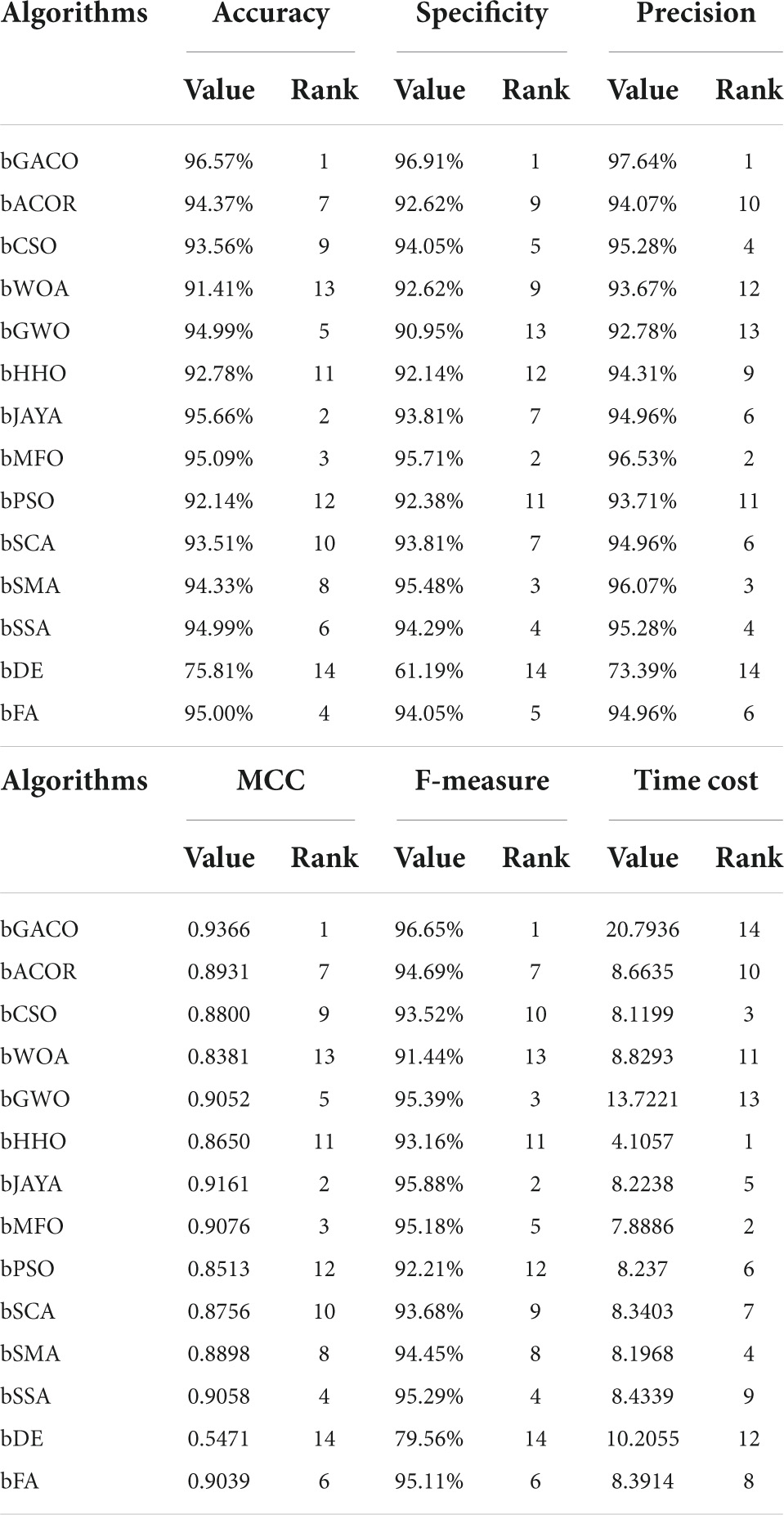
Table 16. Average values of 10 methods in the six metrics.
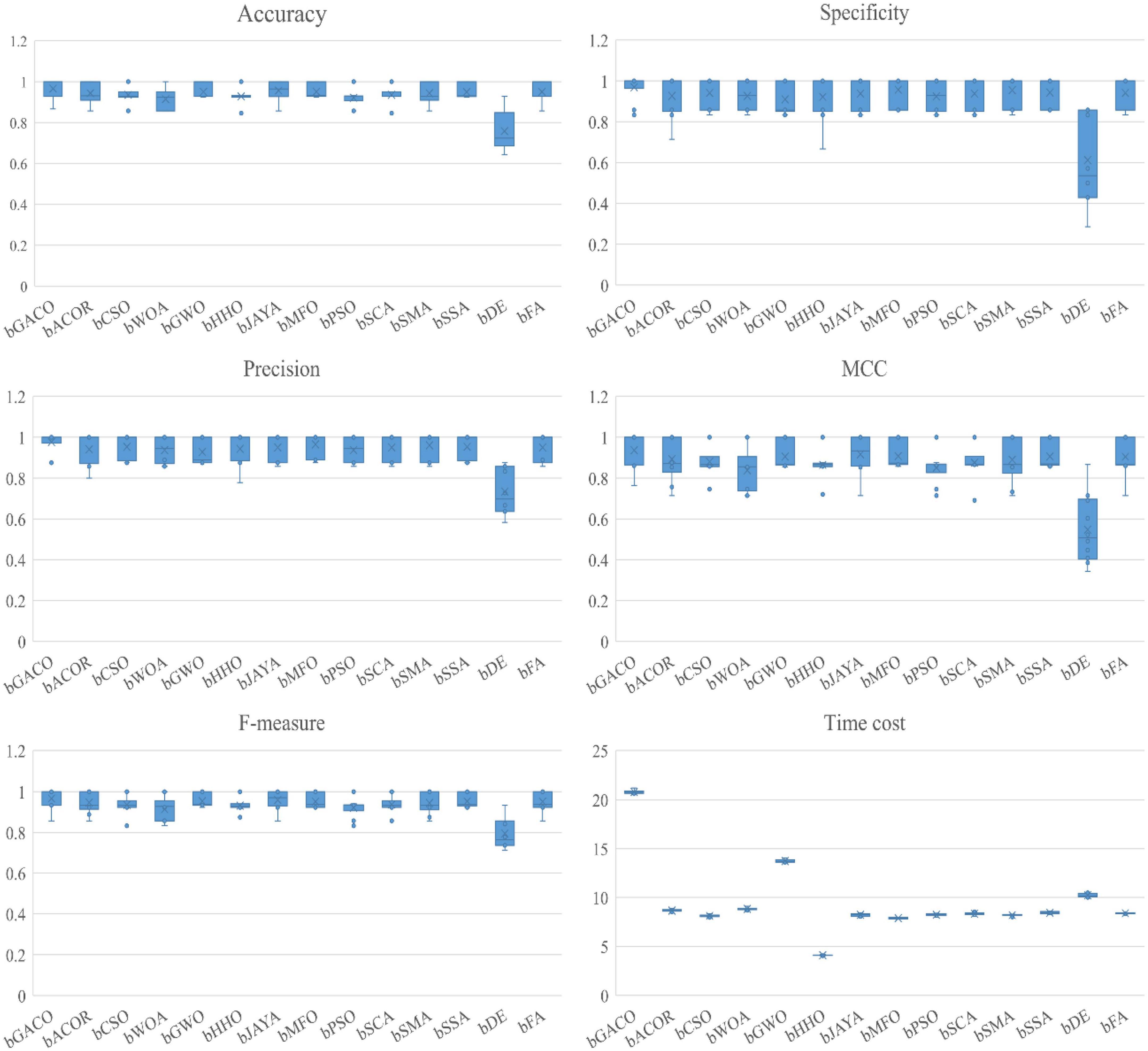
Figure 7. Boxplot of the performance of 10 methods in six metrics.
In this part, the bGACO-SVM algorithm is evaluated with a number of other well-known classifiers. It is clear from looking at Figure 8 that the classification approach that performs the best out of the six options is the bGACO-SVM, followed by the BP neural network. The results of the Extreme Learning Machine (ELM) for forecasting TBPE are disappointing. This suggests that classification models based on bGACO and SVM can make up for the deficiency of single classifier in classification and provide classification results with a greater level of accuracy.
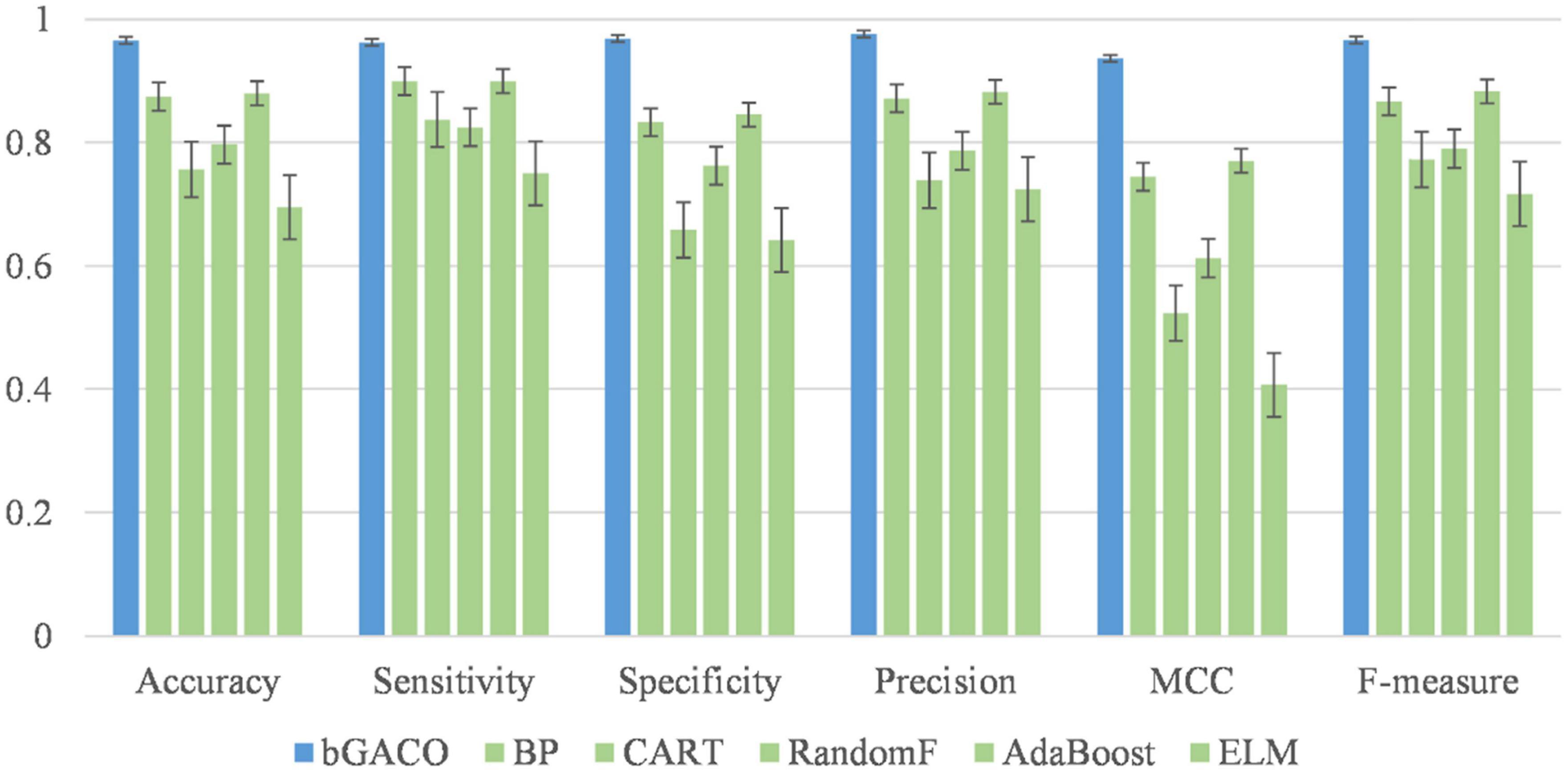
Figure 8. Comparison of bGACO-SVM with well-known classifiers.
The above experimental study allows us to draw the conclusion that bGACO-SVM has the potential to produce a feature subset for the TBPE dataset that has superior outcomes. We increased the number of runs to a hundred so that we could assess whether or not the best feature subset that was chosen is relevant for medical diagnosis. The frequency with which each characteristic occurred served as a reliable indicator of the significance of those characteristics in terms of clinical diagnosis. Figure 9 shows the number of occurrences of the overall features. The main characteristics that affect TEPB are temperature, age, white blood cell, percentage of monocyte, absolute value of eosinophils, mean corpuscular hemoglobin, where age (ID6) is selected 63 times, absolute value of eosinophils (ID13) is selected 62 times, mean corpuscular hemoglobin (ID22) is selected 61 times, serum temperature (ID4) is selected 59 times, percentage of monocyte (ID11) is selected 55 times, and white blood cell (ID7) is selected 54 times. These features are not negligible in the TEPB forecast.
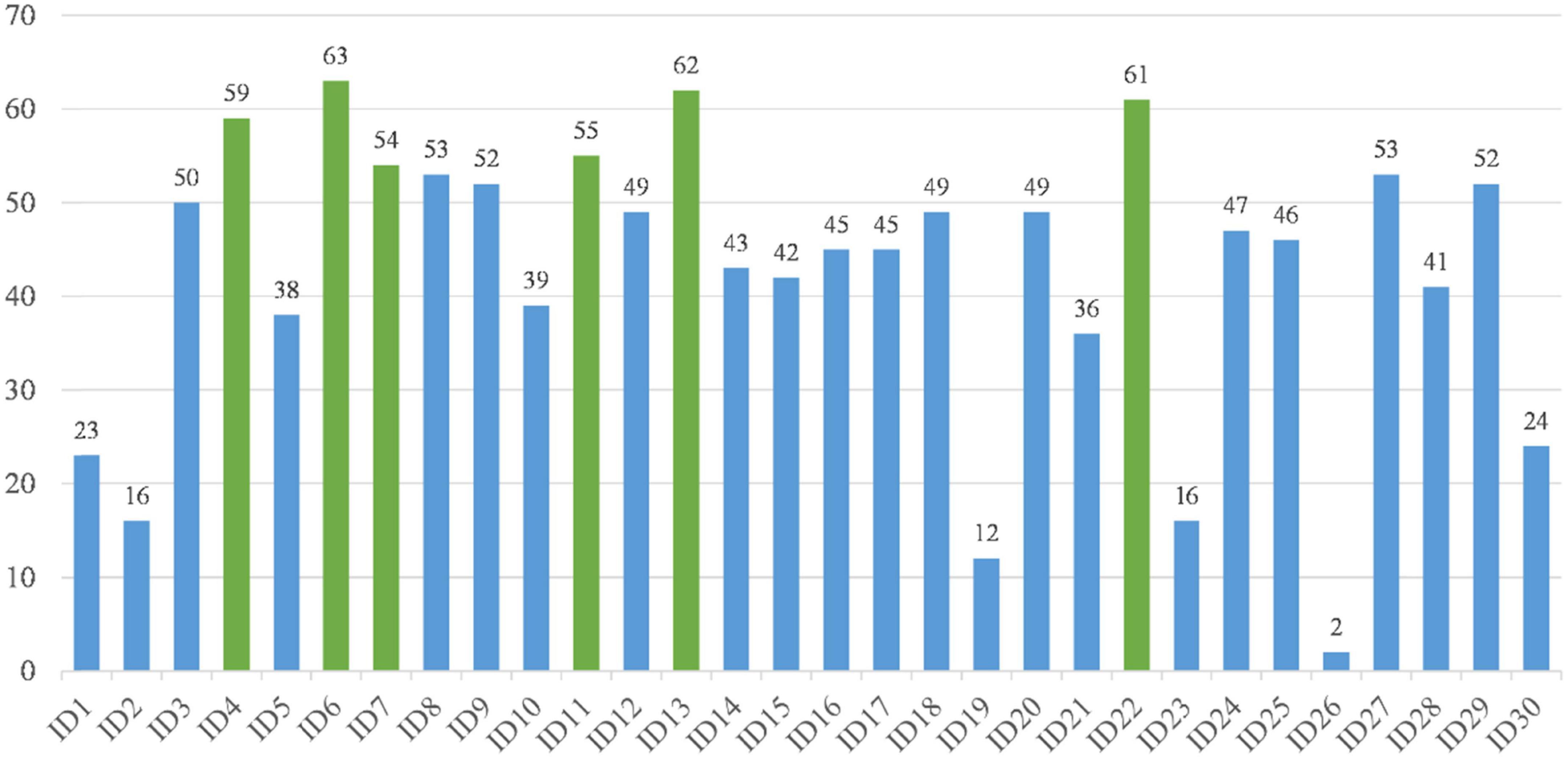
Figure 9. The number of times each feature was selected in 100 experiments.
6 Discussion
It is suspected that patients with TBPE need rapid accurate diagnosis and immediate treatment, otherwise it can cause tuberculous abscess, thickening of pleural membrane, thoracic malformations, and other adverse consequences. This study by the method of GACO, only used the patients’ general clinical condition and routine blood test results, set up effective diagnosis model to distinguish the TBPE and non-TBPE. The model diagnosis accuracy ACC reached 96.57%, MCC was 0.9366, F-measure and specificity of 96.65 and 96.91%, respectively.
In this experiment, we acquired a relatively high diagnostic accuracy with the methods of combination. We also carried out the statistics and found several of the characteristics had relatively high frequency, which is consistent with the actual situation of clinical medicine. Among the high frequency characteristics were body temperature, WBC count, absolute value of eosinophils, age, percentage of monocytes, and mean corpuscular hemoglobin (MCH). These six characteristics play an important role in the identification of TBPE and non-TBPE. Fever is a common clinical manifestation of tuberculous pleurisy (Kimura et al., 2002). Non-TBPE such as malignant tumors, transudate, blood disease, connective tissue disease often has no fever, but infectious pleural effusion can also be expressed as fever. Peripheral white blood cell count is increased in non-TBPE, may be related to pleural effusion of pneumonia in non-TBPE. This is the research results of Carrion-Valero and Perpina-Tordera (2001) and Neves et al. (2007), and the these two regard the peripheral white blood cell count as an important feature of distinguishing TBPE and non-TBPE models. The absolute value of eosinophils is increased in non-TBPE and may be related to lung cancer, lymphoma and multiple myeloma. In this study, the average age of TBPE was 41.85 years old, and age was selected as an important distinguishing feature, which may be related to China’s high prevalence of tuberculosis (Pan, 2012). In countries with high incidence of tuberculosis, tuberculous pleurisy is slightly in the younger, with an average age of 32–35 years (Valdes et al., 1998; Mihmanli et al., 2004; Ibrahim et al., 2005; Porcel et al., 2008). Whereas the average age of patients with tuberculous pleurisy in industrial countries is high. A study from the United States, from 1993 to 2003, showed 7,549 patients with tuberculous pleurisy had an average age of 45 years (Baumann et al., 2007). Monocytes are often increased in tuberculosis (Viloria et al., 2020) but are reduced in acute and chronic lymphocytic leukemia and all-bone marrow dysfunction diseases. Using the bGACO-SVM method, we selected the mean corpuscular hemoglobin as an important feature, with currently no similar study. The average amount of hemoglobin may be a potential predictor of TBPE.
In some diagnostic models, such as the artificial neural network model (ANN) of Seixas et al. (2013), the multivariate regression prediction model of Klimiuk et al. (2015) and the multi-factor prediction model of Shu et al. (2015) mentioned in the introduction section, need high requirements, or to detect some clinically not commonly used predictors. These predictors have not yet been routinely applied clinically, and the reagents are difficult to obtain and costly. In some underdeveloped regions and poor laboratory conditions, it’s difficult to carry out.
There are also some diagnostic models, such as Sales et al. (2009) which established two digital scoring models to distinguish TBPE and tumor pleural effusion. Diagnostic tuberculosis model 1, including characteristic variables ADA, globulin, and tumor cells with accuracy, sensitivity, specificity 97, 94.5, and 99.5%, respectively. Diagnostic tuberculosis model 2, including the characteristic variables ADA, globulin, and pleural effusion appearance with accuracy, sensitivity, specificity of 95.8, 95.5, and 96.1%, respectively. Porcel and Vives (2003) established a scoring system to identify TBPEs and tumor-related pleural effusions through multivariate analysis. Model 1 includes variable ADA, age, body temperature, pleural effusion RBC count, and the area under the ROC curve is 0.987, and sensitivity and specificity are 95 and 97%, respectively. Model 2 includes no tumor history, age, body temperature, chest water red cell count, pleural effusion LDH and serum LDH ratio, pleural effusion protein, and ROC curve of 0.982, with a sensitivity and specificity of 97 and 91%, respectively. Although these models are simple, diagnostic accuracy is high, but doesn’t include the various causes of pleural effusion in other patients, so only suitable for identifying cancerous pleural effusion and TBPE.
Our model has the advantages of simplicity, rapid prediction and low cost compared with the previous model, and the diagnostic accuracy is 90%. This model doesn’t require thoracocentesis; very suitable for diagnosing TBPE in patients with high difficulty obtaining pleural fluid such as less pleural fluid, a posterior scapular pleural effusion, encapsulated pleural effusion, etc. For non-invasive diagnosis, it is possible to avoid invasive pleural biopsy or thoracoscopy, which is more suitable for patients with severe pleural reaction or advanced age. The model is low cost and easy to detect, and it can be used in the economically underdeveloped areas and the high TB prevalence regions. It can be made as a phone or tablet app that requires no Internet connection to make it easier for clinicians to use it anywhere.
Our model also has some flaws. Sample size is small but the it can be expanded by continuous collection of pleural effusion cases, and the model can be optimized to improve the diagnostic accuracy. China is a highly epidemic country with tuberculosis, and the age of TB patients is significantly lower than that of tuberculosis low prevalence countries. Therefore, the model needs to be further validated in the low epidemic area of tuberculosis. We take into account the economic burden, didn’t join the blood gamma interferon release test or sputum NAA detection. These tests in economically underdeveloped areas are difficult to carry out. Including these detections or other biological indicators may improve the diagnostic accuracy.
7 Conclusion and future directions
In order to develop a study on the assisted diagnosis of TBPE, a high-performance classification prediction model, called bGACO-SVM, is proposed in this paper for the assisted diagnosis of TBPE from the perspective of swarm intelligence optimization and machine learning. bGACO-SVM consists of a classification prediction model combining a newly proposed swarm intelligence optimization algorithm GACO and a machine learning method SVM, where SVM is mainly used as a cost function of GACO to select the optimal subset of features. GACO, the core of bGACO-SVM, is an improved ant colony optimizer formed by introducing the grade-based search strategy into ACOR, which effectively compensates for the shortcomings of ACOR in terms of convergence performance and avoidance of local optima, and further enhances the performance of the bGACO-SVM model. In order to investigate the performance of GACO, this paper conducts basic algorithm comparison experiments and advanced variant algorithm comparison experiments using 30 benchmark functions in IEEE CEC2017 as the experimental basis. For the obtained experimental results, the Wilcoxon signed-rank test (García et al., 2010) and the Friedman test (Derrac et al., 2011) are mainly used to analyze the experimental results, which effectively prove that GACO has strong convergence ability and the ability to avoid falling into local optimum.
To investigate the classification prediction ability of bGACO-SVM for TBPE, we first validated it on the public dataset and then applied it to the TBPE prediction problem. During the experiments, bGACO-SVM was first compared with some similar algorithms on public datasets, and then, on the TBPE dataset, bGACO-SVM was compared not only with some similar algorithms, but also with five very classical machine learning methods. Five metrics, including accuracy, specificity, precision, MCC, and F-measure, are analyzed on the experimental simulation results from several perspectives, effectively demonstrating that bGACO-SVM has a strong classification prediction capability and can be successfully used for TBPE diagnosis prediction. However, the work in this paper also has some limitations. For example, by introducing grade-based search strategy into ACOR, the complexity of the algorithm is increased. However, these problems will be ready to be solved in the future by concurrency control of computers and future computer performance improvements. In conclusion, we have established a simple diagnostic model for predicting TBPE by the bGACO-SVM method of swarm intelligence algorithm, which achieves better diagnostic accuracy, sensitivity, and specificity by testing blood routine only. The low cost, fast diagnosis, non-invasive, and low equipment and technical requirements make it suitable for wide clinical application. Although the proposed GACO achieves very good performance on the benchmark functions, and the bGACO-SVM also shows some advantages on the classification prediction of TBPE, the introduction of the grade-based search strategy makes GACO have a large limitation in time complexity.
In the future, it is one of the most important works to overcome the time limitation of the proposed method by using high performance computing techniques. In addition, bGACO-SVM can be used for more disease diagnosis, and GACO can be applied to more optimization problems, such as: recommender system, image dehazing, medical image augmentation, and location-based services.
Data availability statement
The original contributions presented in this study are included in the article/supplementary material, further inquiries can be directed to the corresponding author/s.
Ethics statement
This research was carried out in accordance with the declaration of Helsinki and approved by the Medical Ethics Committee of The First Affiliated Hospital Wenzhou Medical University.
Author contributions
CL, LH, JP, and GL: writing—original draft, writing—review and editing, software, visualization, and investigation. HC and XC: conceptualization, methodology, formal analysis, investigation, writing—review and editing, funding acquisition, and supervision. All authors contributed to the article and approved the submitted version.
Funding
This work was supported in part by the Natural Science Foundation of Zhejiang Province (LZ22F020005), the Science and Technology Plan Project of Wenzhou, China (Y2020252), and the National Natural Science Foundation of China (62076185 and U1809209).
Acknowledgments
We acknowledge the comments of the reviewers.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Footnotes
References
Abd Elaziz, M., Oliva, D., and Xiong, S. (2017). An improved Opposition-Based Sine Cosine Algorithm for global optimization. Expert Syst. Appl. 90, 484–500. doi: 10.1016/j.eswa.2017.07.043
Ahmadianfar, I., Asghar Heidari, A., Gandomi, A. H., Chu, X., and Chen, H. (2021). RUN Beyond the Metaphor: An Efficient Optimization Algorithm Based on Runge Kutta Method. Expert Syst. Appl. 181:115079. doi: 10.1016/j.eswa.2021.115079
Ahmadianfar, I., Asghar Heidari, A., Noshadian, S., Chen, H., and Gandomi, A. H. (2022). INFO: An Efficient Optimization Algorithm based on Weighted Mean of Vectors. Expert Syst. Appl. 195:116516. doi: 10.1016/j.eswa.2022.116516
Akinnuwesi, B. A., Macaulay, B. O., and Aribisala, B. S. (2020). Breast cancer risk assessment and early diagnosis using Principal Component Analysis and support vector machine techniques. Inform. Med. Unlocked 21:100459. doi: 10.1016/j.imu.2020.100459
Badr, E., Almotairi, S., Abdul Salam, M., and Ahmed, H. (2022). New Sequential and Parallel Support Vector Machine with Grey Wolf Optimizer for Breast Cancer Diagnosis. Alex. Eng. J. 61, 2520–2534. doi: 10.1016/j.aej.2021.07.024
Baumann, M. H., Nolan, R., Petrini, M., Lee, Y. C., Light, R. W., Schneider, E., et al. (2007). Pleural tuberculosis in the United States: Incidence and drug resistance. Chest 131, 1125–1132. doi: 10.1378/chest.06-2352
Cai, L., Lu, C., Xu, J., Meng, Y., Wang, P., Fu, X., et al. (2021). Drug repositioning based on the heterogeneous information fusion graph convolutional network. Brief. Bioinform. 22:bbab319. doi: 10.1093/bib/bbab319
Cai, Z., Gu, J., and Chen, H. (2017). A New Hybrid Intelligent Framework for Predicting Parkinson’s Disease. IEEE Access 5, 17188–17200. doi: 10.1109/ACCESS.2017.2741521
Cao, X., Sun, X., Xu, Z., Zeng, B., and Guan, Z. (2021). “Hydrogen-Based Networked Microgrids Planning Through Two-Stage Stochastic Programming With Mixed-Integer Conic Recourse,” in IEEE Transactions on Automation Science and Engineering, (New York, NY: IEEE), 1–14.
Carrion-Valero, F., and Perpina-Tordera, M. (2001). Screening of tuberculous pleural effusion by discriminant analysis. Int. J. Tuberc. Lung Dis. 5, 673–679.
Chen, B., Chen, B., Zhang, L., Chen, H., Liang, K., and Chen, X. (2021). A novel extended Kalman filter with support vector machine based method for the automatic diagnosis and segmentation of brain tumors. Comput. Methods Programs Biomed. 200:105797. doi: 10.1016/j.cmpb.2020.105797
Chen, C., Wang, X., Yu, H., Wang, M., and Chen, H. (2021). Dealing with multi-modality using synthesis of Moth-flame optimizer with sine cosine mechanisms. Math. Comput. Simul. 188, 291–318. doi: 10.1016/j.matcom.2021.04.006
Chen, H., Hu, L., Li, H., Hong, G., Zhang, T., Ma, J., et al. (2017). An Effective Machine Learning Approach for Prognosis of Paraquat Poisoning Patients Using Blood Routine Indexes. Basic Clin. Pharmacol. Toxicol. 120, 86–96. doi: 10.1111/bcpt.12638
Chen, H., Li, S., Asghar Heidari, A., Wang, P., Li, J., Yang, Y., et al. (2020). Efficient multi-population outpost fruit fly-driven optimizers: Framework and advances in support vector machines. Expert Syst. Appl. 142:112999. doi: 10.1016/j.eswa.2019.112999
Chen, H., Yang, C., Asghar Heidari, A., and Zhao, X. (2019). An efficient double adaptive random spare reinforced whale optimization algorithm. Expert Syst. Appl. 154:113018. doi: 10.1016/j.eswa.2019.113018
Chen, H.-L., Wang, G., Ma, C., Cai, Z.-N., Liu, W.-B., and Wang, S.-J. (2016). An efficient hybrid kernel extreme learning machine approach for early diagnosis of Parkinson×s disease. Neurocomputing 184, 131–144. doi: 10.1016/j.neucom.2015.07.138
Chen, Z., and Wang, C. (2014). Modeling RFID signal distribution based on neural network combined with continuous ant colony optimization. Neurocomputing 123, 354–361. doi: 10.1016/j.neucom.2013.07.032
Cincotti, S., Ponta, L., Raberto, M., and Gallo, G. (2014). Modeling and forecasting of electricity spot-prices: Computational intelligence vs classical econometrics. AI Commun. 27, 301–314. doi: 10.3233/AIC-140599
Conde, M. B., Loivos, A. C., Rezende, V. M., Soares, S. L., Mello, F. C., Reingold, A. L., et al. (2003). Yield of sputum induction in the diagnosis of pleural tuberculosis. Am. J. Respir. Crit. Care Med. 167, 723–725. doi: 10.1164/rccm.2111019
Demirer, E., Miller, A. C., Kunter, E., Kartaloglu, Z., Barnett, S. D., and Elamin, E. M. (2012). Predictive Models for Tuberculous Pleural Effusions in a High Tuberculosis Prevalence Region. Lung 190, 239–248. doi: 10.1007/s00408-011-9342-z
Deng, W., Ni, H., Liu, Y., Chen, H., and Zhao, H. (2022b). An adaptive differential evolution algorithm based on belief space and generalized opposition-based learning for resource allocation. Appl. Soft Comput. 127:109419. doi: 10.1016/j.asoc.2022.109419
Deng, W., Xu, J., Gao, X.-Z., and Zhao, H. (2022a). An Enhanced MSIQDE Algorithm With Novel Multiple Strategies for Global Optimization Problems. IEEE Trans. Syst. Man Cybern. Syst. 52, 1578–1587. doi: 10.1109/TSMC.2020.3030792
Deng, W., Xu, J., Zhao, H., and Song, Y. (2020). A Novel Gate Resource Allocation Method Using Improved PSO-Based QEA. IEEE Trans. Syst. Man Cybern. Syst. 23, 1737–1745. doi: 10.1109/TITS.2020.3025796
Deng, W., Zhang, L., Zhou, X., Zhou, Y., Sun, Y., Zhu, W., et al. (2022c). Multi-strategy particle swarm and ant colony hybrid optimization for airport taxiway planning problem. Inf. Sci. 612, 576–593. doi: 10.1016/j.ins.2022.08.115
Deng, W., Zhang, X., Zhou, Y., Liu, Y., Zhou, X., Chen, H., et al. (2022d). An enhanced fast non-dominated solution sorting genetic algorithm for multi-objective problems. Inf. Sci. 585, 441–453. doi: 10.1016/j.ins.2021.11.052
Derrac, J., García, S., Molina, D., and Herrera, F. (2011). A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm Evol. Comput. 1, 3–18. doi: 10.1016/j.swevo.2011.02.002
Devi Thangavel, K., Seerengasamy, U., Palaniappan, S., and Sekar, R. (2023). Prediction of factors for Controlling of Green House Farming with Fuzzy based multiclass Support Vector Machine. Alex. Eng. J. 62, 279–289. doi: 10.1016/j.aej.2022.07.016
Fetanat, A., and Khorasaninejad, E. (2015). Size optimization for hybrid photovoltaic–wind energy system using ant colony optimization for continuous domains based integer programming. Appl. Soft Comput. 31, 196–209. doi: 10.1016/j.asoc.2015.02.047
Fetanat, A., and Shafipour, G. (2011). Generation maintenance scheduling in power systems using ant colony optimization for continuous domains based 0–1 integer programming. Expert Syst. Appl. 38, 9729–9735. doi: 10.1016/j.eswa.2011.02.027
Gao, D., Wang, G.-G., and Pedrycz, W. (2020). Solving fuzzy job-shop scheduling problem using DE algorithm improved by a selection mechanism. IEEE Trans. Fuzzy Syst. 28, 3265–3275. doi: 10.1109/TFUZZ.2020.3003506
Gao, X., Ma, X., Zhang, W., Huang, J., Li, H., and Li, Y. (2021). “Multi-view Clustering with Self-representation and Structural Constraint,” in IEEE Transactions on Big Data, (New York, NY: IEEE), 882–893. doi: 10.1109/TBDATA.2021.3128906
Gao, Z., Wang, Y., Huang, M., Luo, J., and Tang, S. (2022). A kernel-free fuzzy reduced quadratic surface ν-support vector machine with applications. Appl. Soft Comput. 127:109390. doi: 10.1016/j.asoc.2022.109390
García, S., Fernández, A., Luengo, J., and Herrera, F. (2010). Advanced nonparametric tests for multiple comparisons in the design of experiments in computational intelligence and data mining: Experimental analysis of power. Inf. Sci. 180, 2044–2064. doi: 10.1016/j.ins.2009.12.010
Gopi, A., Madhavan, S. M., Sharma, S. K., and Sahn, S. A. (2007). Diagnosis and treatment of tuberculous pleural effusion in 2006. Chest 131, 880–889. doi: 10.1378/chest.06-2063
Guo, K., Chen, T., Ren, S., Li, N., Hu, M., Kang, J., et al. (2022). Federated Learning Empowered Real-Time Medical Data Processing Method for Smart Healthcare. IEEE/ACM Trans. Comput. Biol. Bioinform. [Epub ahead of print]. doi: 10.1109/TCBB.2022.3185395
Han, X., Han, Y., Chen, Q., Li, J., Sang, H., Liu, Y., et al. (2021). Distributed Flow Shop Scheduling with Sequence-Dependent Setup Times Using an Improved Iterated Greedy Algorithm. Complex Adapt. Syst. Model. 1, 198–217. doi: 10.23919/CSMS.2021.0018
He, Z., Yen, G. G., and Ding, J. (2020). Knee-based decision making and visualization in many-objective optimization. IEEE Trans. Evol. Comput. 25, 292–306. doi: 10.1109/TEVC.2020.3027620
He, Z., Yen, G. G., and Lv, J. (2019). Evolutionary multiobjective optimization with robustness enhancement. IEEE Trans. Evol. Comput. 24, 494–507. doi: 10.1109/TEVC.2019.2933444
Heidari, A. A., Aljarah, I., Faris, H., Chen, H., Luo, J., Mirjalili, S., et al. (2020). An enhanced associative learning-based exploratory whale optimizer for global optimization. Neural Comput. Appl. 32, 5185–5211. doi: 10.1007/s00521-019-04015-0
Heidari, A. A., Mirjalili, S., Faris, H., Aljarah, I., Mafarja, M., Chen, H., et al. (2019). Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 97, 849–872. doi: 10.1016/j.future.2019.02.028
Hu, K., Zhao, L., Feng, S., Zhang, S., Zhou, Q. J., Gao, X., et al. (2022). Colorectal polyp region extraction using saliency detection network with neutrosophic enhancement. Comput. Biol. Med. 147:105760. doi: 10.1016/j.compbiomed.2022.105760
Hu, L., Lin, F., Li, H., Tong, C., Pan, Z., Li, J., et al. (2017). An intelligent prognostic system for analyzing patients with paraquat poisoning using arterial blood gas indexes. J. Pharmacol. Toxicol. Methods 84, 78–85. doi: 10.1016/j.vascn.2016.11.004
Hua, Y., Liu, Q., Hao, K., and Jin, Y. (2021). A Survey of Evolutionary Algorithms for Multi-Objective Optimization Problems With Irregular Pareto Fronts. IEEE/CAA J. Autom. Sin. 8, 303–318. doi: 10.1109/JAS.2021.1003817
Huang, H., Feng, X., Zhou, S., Jiang, J., Chen, H., Li, Y., et al. (2019). A new fruit fly optimization algorithm enhanced support vector machine for diagnosis of breast cancer based on high-level features. BMC Bioinformatics 20:290. doi: 10.1186/s12859-019-2771-z
Hussien, A. G., Heidari, A. A., Ye, X., Liang, G., Chen, H., Pan, Z., et al. (2022). Boosting whale optimization with evolution strategy and Gaussian random walks: An image segmentation method. Eng. Comput.. doi: 10.1007/s00366-021-01542-0
Ibrahim, W. H., Ghadban, W., Khinji, A., Yasin, R., Soub, H., Al-Khal, A. L., et al. (2005). Does pleural tuberculosis disease pattern differ among developed and developing countries. Res. Med. 99, 1038–1045. doi: 10.1016/j.rmed.2004.12.012
Jiang, J., Shi, H. Z., Liang, Q. L., Qin, S. M., and Qin, X. J. (2007). Diagnostic value of interferon-gamma in tuberculous pleurisy: A metaanalysis. Chest 131, 1133–1141. doi: 10.1378/chest.06-2273
Kennedy, J., and Eberhart, R. (1995). Particle swarm optimization. Proc. ICNN’95 Int. Conference Neural Netw. 4, 1942–1948.
Kimura, K., Koga, H., Kohno, S., Matsuda, H., Yoshitomi, Y., Miyazaki, Y., et al. (2002). A clinical study of tuberculous pleurisy. Kansenshogaku Zasshi 76, 18–22. doi: 10.11150/kansenshogakuzasshi1970.76.18
Klimiuk, J., Safianowska, A., Chazan, R., Korczyński, P., and Krenke, R. (2015). Development and Evaluation of the New Predictive Models in Tuberculous Pleuritis. Adv. Exp. Med. Biol. 873, 53–63. doi: 10.1007/5584_2015_156
Kumar, N., Hussain, I., Singh, B., and Ketan Panigrahi, B. (2017). Single Sensor-Based MPPT of Partially Shaded PV System for Battery Charging by Using Cauchy and Gaussian Sine Cosine Optimization. IEEE Trans. Energy Convers. 32, 983–992. doi: 10.1109/TEC.2017.2669518
Lee, S. J., Lee, S. J., Kim, H. S., Lee, S. H., Lee, T. W., Lee, H. R., et al. (2014). Factors influencing pleural adenosine deaminase level in patients with tuberculous pleurisy. Am. J. Med. Sci. 348, 362–365. doi: 10.1097/MAJ.0000000000000260
Li, C., Hou, L., Sharma, B. Y., Li, H., Chen, C., Li, Y., et al. (2018). Developing a new intelligent system for the diagnosis of tuberculous pleural effusion. Comput. Methods Programs Biomed. 153, 211–225. doi: 10.1016/j.cmpb.2017.10.022
Li, J., Chen, C., Chen, H., and Tong, C. (2017). Towards Context-aware Social Recommendation via Individual Trust. Knowl. Based Syst. 127, 58–66. doi: 10.1016/j.knosys.2017.02.032
Li, J., Zheng, X. L., Chen, S. T., Song, W. W., and Chen, D. (2014). An efficient and reliable approach for quality-of-service-aware service composition. Inf. Sci. 269, 238–254. doi: 10.1016/j.ins.2013.12.015
Li, J.-Y., Zhan, Z. H., Wang, C., Jin, H., and Zhang, J. (2020). Boosting data-driven evolutionary algorithm with localized data generation. IEEE Trans. Evol. Comput. 24, 923–937. doi: 10.1109/TEVC.2020.2979740
Li, S., Chen, H., Wang, M., Heidari, A. A., and Mirjalili, S. (2020). Slime mould algorithm: A new method for stochastic optimization. Future Gener. Comput. Syst. 111, 300–323. doi: 10.1016/j.future.2020.03.055
Li, Y., Li, Y. H., Li, X. X., Hong, J. J., Wang, Y. X., Fu, J. B., et al. (2020). Clinical trials, progression-speed differentiating features and swiftness rule of the innovative targets of first-in-class drugs. Brief Bioinform. 21, 649–662. doi: 10.1093/bib/bby130
Light, R. W., Macgregor, M. I., Luchsinger, P. C., and Ball, W. C. Jr. (1972). Pleural effusions: The diagnostic separation of transudates and exudates. Ann. Intern. Med. 77, 507–513. doi: 10.7326/0003-4819-77-4-507
Liu, J., Anavatti, S., Garratt, M., and Abbass, H. A. (2022). Modified continuous Ant Colony Optimisation for multiple Unmanned Ground Vehicle path planning. Expert Syst. Appl. 196:116605. doi: 10.1016/j.eswa.2022.116605
Liu, L., Zhao, D., Liu, L., Yu, F., Heidari, A. A., Li, C., et al. (2021). Ant colony optimization with Cauchy and greedy Levy mutations for multilevel COVID 19 X-ray image segmentation. Comput. Biol. Med. 136:104609. doi: 10.1016/j.compbiomed.2021.104609
Liu, Y., Asghar Heidari, A., Cai, N. N., Liang, G., Chen, H., Pan, Z., et al. (2022). Simulated annealing-based dynamic step shuffled frog leaping algorithm: Optimal performance design and feature selection. Neurocomputing 503, 325–362. doi: 10.1016/j.neucom.2022.06.075
Mihmanli, A., Ozşeker, F., Baran, A., Küçüker, F., Atik, S., Akkaya, E., et al. (2004). [Evaluation of 105 cases with tuberculous pleurisy]. Tuberk Toraks 52, 137–144.
Mirjalili, S. (2015). Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm. Knowl. Based Syst. 89, 228–249. doi: 10.1016/j.knosys.2015.07.006
Mirjalili, S. S., Mirjalili, M., and Lewis, A. (2014). Grey Wolf Optimizer. Adv. Eng. Softw. 69, 46–61. doi: 10.1016/j.advengsoft.2013.12.007
Mirjalili, S., and Lewis, A. (2016). The Whale Optimization Algorithm. Adv. Eng. Softw. 95, 51–67. doi: 10.1016/j.advengsoft.2016.01.008
Neves, D. D., Dias, R. M., and Cunha, A. J. (2007). Predictive model for the diagnosis of tuberculous pleural effusion. Braz. J. Infect. Dis. 11, 83–88. doi: 10.1590/S1413-86702007000100019
Pan, W. T. (2012). A new Fruit Fly Optimization Algorithm: Taking the financial distress model as an example. Knowl. Based Syst. 26, 69–74. doi: 10.1016/j.knosys.2011.07.001
Pathivada, B. K., and Vedagiri, P. (2022). Investigating dilemma zone boundaries for mixed traffic conditions using support vector machines. Transp. Lett. 14, 378–384. doi: 10.1080/19427867.2020.1870307
Porcel, J. M., Alemán, C., Bielsa, S., Sarrapio, J., Fernández de Sevilla, T., Esquerda, A., et al. (2008). A decision tree for differentiating tuberculous from malignant pleural effusions. Respir. Med. 102, 1159–1164. doi: 10.1016/j.rmed.2008.03.001
Porcel, J. M., and Vives, M. (2003). Differentiating tuberculous from malignant pleural effusions: A scoring model. Med. Sci. Monit. 9, CR175–CR180.
Porcel, J. M., Palma, R., Valdés, L., Bielsa, S., San-José, E., Esquerda, A., et al. (2013). Xpert(R) MTB/RIF in pleural fluid for the diagnosis of tuberculosis. Int. J. Tuberc. Lung Dis. 17, 1217–1219. doi: 10.5588/ijtld.13.0178
Qiu, S., Zhao, H., Jiang, N., Wang, Z., Liu, L., An, Y., et al. (2022). Multi-sensor information fusion based on machine learning for real applications in human activity recognition: State-of-the-art and research challenges. Inf. Fusion 80, 241–265. doi: 10.1016/j.inffus.2021.11.006
Qu, C., Zeng, Z., Dai, J., Yi, Z., and He, W. (2018). A Modified Sine-Cosine Algorithm Based on Neighborhood Search and Greedy Levy Mutation. Comput. Intel. Neurosci. 2018, 4231647–4231647. doi: 10.1155/2018/4231647
Rao, R. V. (2016). Jaya: A simple and new optimization algorithm for solving constrained and unconstrained optimization problems. Int. J. Ind. Eng. 7, 19–34. doi: 10.5267/j.ijiec.2015.8.004
Sales, R. K., Vargas, F. S., Capelozzi, V. L., Seiscento, M., Genofre, E. H., Teixeira, L. R., et al. (2009). Predictive models for diagnosis of pleural effusions secondary to tuberculosis or cancer. Respirology 14, 1128–1133. doi: 10.1111/j.1440-1843.2009.01621.x
Salimi, H. (2015). Stochastic Fractal Search: A powerful metaheuristic algorithm. Knowl. Based Syst. 75, 1–18. doi: 10.1016/j.knosys.2014.07.025
Seibert, A. F., Haynes, J. Jr., Middleton, R., and Bass, J. B. Jr. (1991). Tuberculous pleural effusion Twenty-year experience. Chest 99, 883–886. doi: 10.1378/chest.99.4.883
Seixas, J. M., Faria, J., Souza Filho, J. B., Vieira, A. F., Kritski, A., Trajman, A., et al. (2013). Artificial neural network models to support the diagnosis of pleural tuberculosis in adult patients. Int. J. Tuberc. Lung Dis. 17, 682–686. doi: 10.5588/ijtld.12.0829
Shu, C. C., Wang, J. Y., Hsu, C. L., Keng, L. T., Tsui, K., Lin, J. F., et al. (2015). Diagnostic role of inflammatory and anti-inflammatory cytokines and effector molecules of cytotoxic T lymphocytes in tuberculous pleural effusion. Respirology 20, 147–154. doi: 10.1111/resp.12414
Socha, K., and Dorigo, M. (2008). Ant colony optimization for continuous domains. Eur. J. Oper. Res. 185, 1155–1173. doi: 10.1016/j.ejor.2006.06.046
Song, Y., Cai, X., Zhou, X., Zhang, B., Chen, H., Li, H., et al. (2023). Dynamic hybrid mechanism-based differential evolution algorithm and its application. Expert Syst. Appl. 213:118834. doi: 10.1016/j.eswa.2022.118834
Su, Y., Li, S., Zheng, C., and Zheng, X. (2019). A heuristic algorithm for identifying molecular signatures in cancer. IEEE Trans. Nanobioscience 19, 132–141. doi: 10.1109/TNB.2019.2930647
Tian, Y., Su, X., Su, X., and Zhang, X. (2020). EMODMI: A multi-objective optimization based method to identify disease modules. IEEE Trans. Emerg. Top. Comput. Intell. 5, 570–582. doi: 10.1109/TETCI.2020.3014923
Tu, J., Chen, H., Wang, M., and Gandomi, A. H. (2021). The Colony Predation Algorithm. J. Bionic. Eng. 18, 674–710. doi: 10.1007/s42235-021-0050-y
Udwadia, Z. F., and Sen, T. (2010). Pleural tuberculosis: An update. Curr. Opin. Pulm. Med. 16, 399–406. doi: 10.1097/MCP.0b013e328339cf6e
Valdes, L., Alvarez, D., San José, E., Penela, P., Valle, J. M., García-Pazos, J. M., et al. (1998). Tuberculous pleurisy: A study of 254 patients. Arch. Intern. Med. 158, 2017–2021. doi: 10.1001/archinte.158.18.2017
Vidya, B., and Gait, S. P. (2021). based Parkinson’s disease diagnosis and severity rating using multi-class support vector machine. Appl. Soft Comput. 113:107939. doi: 10.1016/j.asoc.2021.107939
Viloria, A., Herazo-Beltran, Y., Cabrera, D., and Bonerge Pineda, O. (2020). Diabetes Diagnostic Prediction Using Vector Support Machines. Procedia Comput. Sci. 170, 376–381. doi: 10.1016/j.procs.2020.03.065
von Groote-Bidlingmaier, F., Koegelenberg, C. F., Bolliger, C. T., Chung, P. K., Rautenbach, C., Wasserman, E., et al. (2013). The yield of different pleural fluid volumes for Mycobacterium tuberculosis culture. Thorax 68, 290–291. doi: 10.1136/thoraxjnl-2012-202338
Wang, G.-G., Gao, D., and Pedrycz, W. (2022). Solving multi-objective fuzzy job-shop scheduling problem by a hybrid adaptive differential evolution algorithm. IEEE Trans. Industr. Inform. 18, 8519–8528. doi: 10.1109/TII.2022.3165636
Wang, M., Chen, H., Yang, B., Zhao, X., Hu, L., Cai, Z., et al. (2017). Toward an optimal kernel extreme learning machine using a chaotic moth-flame optimization strategy with applications in medical diagnoses. Neurocomputing 267, 69–84. doi: 10.1016/j.neucom.2017.04.060
Wang, S., Zhang, P., Chang, J., Fang, Z., Yang, Y., and Meng, Y. (2022). A powerful tool for near-infrared spectroscopy: Synergy adaptive moving window algorithm based on the immune support vector machine. Spectrochim. Acta Part A: Mol. Bio. Spectros. 282:121631. doi: 10.1016/j.saa.2022.121631
Wang, W., Zheng, J., Zhao, L., Chen, H., Zhang, X., et al. (2022). A Non-Local Tensor Completion Algorithm Based on Weighted Tensor Nuclear Norm. Electronics 11:3250. doi: 10.3390/electronics11193250
Weron, R. (2014). Electricity price forecasting: A review of the state-of-the-art with a look into the future. Int. J. Forecast 30, 1030–1081. doi: 10.1016/j.ijforecast.2014.08.008
World Health Organization, [WHO] (2010). Guidelines Approved by the Guidelines Review Committee, in Treatment of Tuberculosis: Guidelines. Geneva: World Health Organization.
Wolpert, D. H., and Macready, W. G. (1997). No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1, 67–82. doi: 10.1109/4235.585893
Wu, D., Xu, J., Song, Y., and Zhao, H. (2020). An Effective Improved Co-evolution Ant Colony Optimization Algorithm with Multi-Strategies and Its Application. Int. J. Bio-Inspired Comput. 16, 158–170. doi: 10.1504/IJBIC.2020.111267
Wu, S.-H., Zhan, Z.-H., and Zhang, J. (2021). SAFE: Scale-adaptive fitness evaluation method for expensive optimization problems. IEEE Trans. Evol. Comput. 25, 478–491. doi: 10.1109/TEVC.2021.3051608
Wu, W., and Ma, X. (2022). “Network-based Structural Learning Nonnegative Matrix Factorization Algorithm for Clustering of scRNA-seq Data,” in IEEE/ACM Transactions on Computational Biology and Bioinformatics, (New York, NY: IEEE). doi: 10.1109/TCBB.2022.3161131
Wu, Y., Ma, W., Miao, Q., and Wang, S. (2019). Multimodal continuous ant colony optimization for multisensor remote sensing image registration with local search. Swarm Evol. Comput. 47, 89–95. doi: 10.1016/j.swevo.2017.07.004
Wu, Z., Shen, S., Zhou, H., Li, H., Lu, C., Zou, D., et al. (2021). An effective approach for the protection of user commodity viewing privacy in e-commerce website. Knowl. Based Syst. 220:106952. doi: 10.1016/j.knosys.2021.106952
Wu, Z., Zhou, Z., Li, R., and Guo, J. (2020). A user sensitive subject protection approach for book search service. J. Assoc. Inf. Sci. Technol. 71, 183–195. doi: 10.1002/asi.24227
Yang, S., Gao, T., Wang, J., Deng, B., Azghadi, M. R., Lei, T., et al. (2022a). SAM: A Unified Self-Adaptive Multicompartmental Spiking Neuron Model for Learning With Working Memory. Front. Neurosci. 16:850945. doi: 10.3389/fnins.2022.850945
Yang, S., Linares-Barranco, B., and Chen, B. (2022b). Heterogeneous Ensemble-Based Spike-Driven Few-Shot Online Learning. Front. Neurosci. 16:850932. doi: 10.3389/fnins.2022.850932
Yang, S., Tan, J., and Chen, B. (2022c). Robust spike-based continual meta-learning improved by restricted minimum error entropy criterion. Entropy 24:455. doi: 10.3390/e24040455
Yang, S., Wang, J., deng, B., and Linares-Barranco, B. (2021). “Neuromorphic Context-Dependent Learning Framework With Fault-Tolerant Spike Routing,” in IEEE Transactions on Neural Networks and Learning Systems, (New York, NY: IEEE), 1–15.
Yang, X.-S. (2009). Firefly Algorithms for Multimodal Optimization. Berlin: Springer. doi: 10.1007/978-3-642-04944-6_14
Yang, Y., Chen, H., Asghar Heidari, A., and Gandomi, A. H. (2021). Hunger games search: Visions, conception, implementation, deep analysis, perspectives, and towards performance shifts. Expert Syst. Appl. 177:114864. doi: 10.1016/j.eswa.2021.114864
Yong, J., He, F., Li, H., and Zhou, W. (2018). “A Novel Bat Algorithm based on Collaborative and Dynamic Learning of Opposite Population,” in 2018 IEEE 22nd International Conference on Computer Supported Cooperative Work in Design, (NewYork, NY: IEEE). doi: 10.1109/CSCWD.2018.8464759
Yu, H., Song, J., Chen, C., Asghar Heidari, A., Liu, J., Chen, H., et al. (2022). Image segmentation of Leaf Spot Diseases on Maize using multi-stage Cauchy-enabled grey wolf algorithm. Eng. Appl. Artif. 109:104653. doi: 10.1016/j.engappai.2021.104653
Zhang, J., Zhang, Q., Qin, X., and Sun, Y. (2022). A two-stage fault diagnosis methodology for rotating machinery combining optimized support vector data description and optimized support vector machine. Measurement 200:111651. doi: 10.1016/j.measurement.2022.111651
Zhang, L., Wang, J., Wang, W., Jin, Z., Su, Y., Chen, H., et al. (2022). Smart contract vulnerability detection combined with multi-objective detection. Comput. Netw. 217:109289. doi: 10.1016/j.comnet.2022.109289
Zhang, X., Zheng, J., Wang, D. F., Tang, G., Zhou, Z., Lin, Z., et al. (2022). Structured Sparsity Optimization with Non-Convex Surrogates of l2,0-Norm: A Unified Algorithmic Framework. IEEE Trans. Pattern Anal. Mach. Intell. [Epub ahead of print]. doi: 10.1109/TPAMI.2022.3213716
Zhang, X., Zheng, J., Wang, D., and Zhao, L. (2020). Exemplar-Based Denoising: A Unified Low-Rank Recovery Framework. IEEE Trans. Circuits Syst. Video Technol. 30, 2538–2549. doi: 10.1109/TCSVT.2019.2927603
Zhang, Y., Liu, R., Asghar Heidari, A., Wang, X., Chen, Y., Wang, M., et al. (2021). Towards augmented kernel extreme learning models for bankruptcy prediction: Algorithmic behavior and comprehensive analysis. Neurocomputing 430, 185–212. doi: 10.1016/j.neucom.2020.10.038
Zhao, D., Liu, L., Yu, F., Heidari, A. A., Wang, M., Oliva, D., et al. (2021b). Ant colony optimization with horizontal and vertical crossover search: Fundamental visions for multi-threshold image segmentation. Expert Syst. Appl. 167:114122. doi: 10.1016/j.eswa.2020.114122
Zhao, D., Liu, L., Yu, F., Heidari, A. A., Wang, M., Chen, H., et al. (2022). Opposition-based ant colony optimization with all-dimension neighborhood search for engineering design. J. Comput. Dec. Eng. 9, 1007–1044. doi: 10.1093/jcde/qwac038
Zhao, D., Liu, L., Yu, F., Heidari, A. A., Wang, M., Liang, G., et al. (2021a). Chaotic random spare ant colony optimization for multi-threshold image segmentation of 2D Kapur entropy. Knowl. Based Syst. 216:106510. doi: 10.1016/j.knosys.2020.106510
Zhao, Z., Zhang, Y., Yang, Y., and Yuan, S. (2022). Load forecasting via Grey Model-Least Squares Support Vector Machine model and spatial-temporal distribution of electric consumption intensity. Energy 255:124468. doi: 10.1016/j.energy.2022.124468
Zhou, J., Ji, N., Wang, G., Zhang, Y., Song, H. C., Yuan, Y. J., et al. (2022). Metabolic detection of malignant brain gliomas through plasma lipidomic analysis and support vector machine-based machine learning. eBioMedicine 81:104097. doi: 10.1016/j.ebiom.2022.104097
Zhu, A., Xu, C., Li, Z., Wu, J., and Liu, Z. (2015). Hybridizing grey wolf optimization with differential evolution for global optimization and test scheduling for 3D stacked SoC. J. Syst. Eng. Electron. 26, 317–328. doi: 10.1109/JSEE.2015.00037
Keywords: tuberculous pleural effusion, swarm intelligence, machine learning, feature selection, support vector machine
Citation: Li C, Hou L, Pan J, Chen H, Cai X and Liang G (2022) Tuberculous pleural effusion prediction using ant colony optimizer with grade-based search assisted support vector machine. Front. Neuroinform. 16:1078685. doi: 10.3389/fninf.2022.1078685
Received: 24 October 2022; Accepted: 28 November 2022;
Published: 19 December 2022.
Edited by:
Fernando De La Prieta, University of Salamanca, SpainReviewed by:
Shuangming Yang, Tianjin University, ChinaEssam Halim Houssein, Minia University, Egypt
Kunjie Yu, Zhengzhou University, China
Wu Deng, Civil Aviation University of China, China
Copyright © 2022 Li, Hou, Pan, Chen, Cai and Liang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Huiling Chen, Y2hlbmh1aWxpbmcuamx1QGdtYWlsLmNvbQ==; Xueding Cai, eHVlZGluZzUxNEAxMjYuY29t