 Tinashe M. Tapera1,2
Tinashe M. Tapera1,2 Matthew Cieslak1,2
Matthew Cieslak1,2 Max Bertolero1,2
Max Bertolero1,2 Azeez Adebimpe1,2Geoffrey K. Aguirre3Ellyn R. Butler1,2Philip A. Cook4Diego Davila1,2Mark A. Elliott4Sophia Linguiti1,2Kristin Murtha1,2
Azeez Adebimpe1,2Geoffrey K. Aguirre3Ellyn R. Butler1,2Philip A. Cook4Diego Davila1,2Mark A. Elliott4Sophia Linguiti1,2Kristin Murtha1,2 William Tackett3John A. Detre3
William Tackett3John A. Detre3 Theodore D. Satterthwaite1,2*
Theodore D. Satterthwaite1,2*- 1Penn Lifespan Informatics & Neuroimaging Center, University of Pennsylvania, Philadelphia, PA, United States
- 2Department of Psychiatry, University of Pennsylvania, Philadelphia, PA, United States
- 3Department of Neurology, Perelman School of Medicine, University of Pennsylvania, Philadelphia, PA, United States
- 4Department of Radiology, University of Pennsylvania, Philadelphia, PA, United States
The recent and growing focus on reproducibility in neuroimaging studies has led many major academic centers to use cloud-based imaging databases for storing, analyzing, and sharing complex imaging data. Flywheel is one such database platform that offers easily accessible, large-scale data management, along with a framework for reproducible analyses through containerized pipelines. The Brain Imaging Data Structure (BIDS) is the de facto standard for neuroimaging data, but curating neuroimaging data into BIDS can be a challenging and time-consuming task. In particular, standard solutions for BIDS curation are limited on Flywheel. To address these challenges, we developed “FlywheelTools,” a software toolbox for reproducible data curation and manipulation on Flywheel. FlywheelTools includes two elements: fw-heudiconv, for heuristic-driven curation of data into BIDS, and flaudit, which audits and inventories projects on Flywheel. Together, these tools accelerate reproducible neuroscience research on the widely used Flywheel platform.
Introduction
Many fields in science are grappling with failures of scientific reproducibility (Botvinik-Nezer et al., 2020). Given the high dimensionality of the data, the need for complex image processing, and a plethora of analytic techniques, this crisis is particularly acute for neuroimaging research. As such, major academic centers and large consortia have increasingly adopted platforms that leverage database technologies that have become standard in other fields. In addition to providing functionality for searching and categorizing complex source data, imaging databases enhance reproducible research by providing a clear audit trail of image processing applied to the data and its results, including both derived images and other data. Widely used imaging databases include Collaborative Informatics Neuroimaging Suite (COINS) (Landis et al., 2016), eXtensible Neuroimaging Archive Toolkit (XNAT) (Herrick et al., 2016), Longitudinal Online Research and Imaging System (LORIS) (Vaccarino et al., 2018), and others (Helmer et al., 2011; Sherif et al., 2014; Book et al., 2016; Poldrack and Gorgolewski, 2017; Rogovin et al., 2020). More recently, the commercial platform Flywheel has become widely used due to its modern technology, ease of use, and scalability.
Many neuroimaging databases now leverage the Brain Imaging Data Structure (BIDS) (Gorgolewski et al., 2016). BIDS is an open-source standard for neuroimaging data organization that specifies how files should be named, how directories should be organized, and how metadata should be structured. As such, BIDS provides users with a well-documented structure to understand both imaging data and metadata. Importantly, as BIDS provides transparent format for recording imaging parameters and key aspects of the experimental design, it enhances both data accessibility and data sharing. BIDS has rapidly evolved to become the standard in the neuroimaging community for data organization. Importantly, BIDS is supported by a large community that contributes to its development and adoption. Further, proposals for BIDS schema pass through a rigorous testing process before being adopted.
Notably, BIDS allows users to leverage BIDS-apps – image processing pipelines (e.g., fMRIPrep, C-PAC, and QSIprep) that read the metadata defined by BIDS (Craddock et al., 2013; Esteban et al., 2019; Cieslak et al., 2020). As BIDS-apps can auto-configure to ensure that analytic parameters are appropriate for the input data provided, they dramatically reduce barriers to implementing best practices in image processing. Importantly, containerized BIDS-apps encompass all software dependencies, further enhancing reproducibility.
On a filesystem, conversion of raw DICOM images to NIfTIs that conform to BIDS can be accomplished with a variety of tools including HeuDiConv, dcm2bids, and others (Halchenko et al., 2018). However, this crucial step, a process typically called “BIDS curation,” is incompletely implemented on Flywheel. While Flywheel provides automated BIDS curation, flexibility is limited. As BIDS curation is one of the very first steps performed on the data, flexibility in curation is essential. Here, we introduce FlywheelTools: software that provides flexible and reproducible methods for BIDS curation on the Flywheel platform. Documentation and code can be found online at: https://fw-heudiconv.readthedocs.io/en/latest/.
Materials and Methods
The FlywheelTools toolkit allows users to follow a reproducible workflow for BIDS curation and auditing of their data. This workflow typically includes inspection of sequences collected during a study, design of a curation schema, implementation of that curation schema, and auditing the curated data.
Programming Languages and Technologies
FlywheelTools is built primarily in Python 3.6 (Van Rossum and Drake, 2009) to leverage Flywheel’s highly accessible Software Development Kit (SDK). Additionally, R 3.4.1 (R Core Team, 2019) is used for HTML report generation. For reproducibility and workflow management, the modules of FlywheelTools are packaged as Docker container images (Merkel, 2014). It should be noted that FlywheelTools relies on users adopting BIDS as their data standard.
Flywheel
Flywheel is a data management and analysis platform that is tailored for neuroimaging research. The platform focuses heavily on collaborative and reproducible science. User-facing components of the platform itself are the web User Interface (UI), the Command Line Interface (CLI), the Flywheel SDK, and the Application Programming Interface (API).
Flywheel Web UI
The web UI is accessible through any modern web browser. Through this point-and-click interface, users are able to upload, view, download, and analyze data with ease. However, accomplishing tasks with many repetitive steps or over a large number of participants/sessions can be tiresome and error-prone. In addition to interactions via web GUI, many users also make use of the API and SDK to manipulate and analyze data programmatically.
Flywheel API and SDK
Flywheel’s database uses MongoDB for data storage and access, meaning that all Flywheel data are represented by hierarchical relationships between document objects. This allows users to create and store complex structures with ease, and query data rapidly (Banker, 2011). To access these data, Flywheel uses a RESTful API (REpresentational State Transfer) (Biehl, 2016), making each document or data object accessible through a specific URL that a web browser or SDK can access by requesting the data and waiting for a response from the server. The Flywheel Python SDK1 provides a powerful interface for inspecting and manipulating data through this API. By standardizing this underlying data model into Pythonic objects, the Flywheel SDK is effectively an object relationship mapper, similar to the popular SQLAlchemy software.
Flywheel Data Model
Objects in Flywheel’s data model follow a specific hierarchical structure – at the top level is a Flywheel instance, a process that serves the API to an organization (e.g., a neuroimaging center). Within the Flywheel instance, there are multiple groups, which are typically labs or research units that collaborate on one or more projects. Each project object can have one or many subjects (i.e., participants), and each subject can have one or many sessions (i.e., scanning visits). Within a session, there may be one or many acquisition objects which represent the scanning sequences collected during a particular scan or examination (e.g., sMRI, rs-fMRI, and dMRI). Finally, the data files associated with the sequence (e.g., NIfTIs or DICOMs) are attached to each acquisition. Note that a file can additionally be attached to any object type, and each object can have metadata associated with it. Hence, a “subject” object may have metadata associated with that participant (such as demographic information) and may also have a text file attached to it (such as clinical data). A notable exception to this hierarchical structure is the analysis object, which behaves in much the same way as others but can be a child object of any other object, allowing researchers to create analyses of entire projects, for example, each with their own associated metadata and files.
Abstracting this data model in Python results in simple hierarchical objects, each with methods for handling metadata and files, and methods for accomplishing object-specific tasks like traversing the hierarchical structure or running analyses. The modules of FlywheelTools make use of this data model to accomplish a wide range of tasks.
Flywheel Gears
Flywheel encourages the use of pre-packaged computational workflows, called “gears.” Gears are run by virtual machines using Docker; as such, they are version-controlled and can be executed on any platform supporting Docker. Gears can accomplish tasks such as data manipulation, pre-processing, and analysis. In addition to the existing gears available on the platform, users are able to package their own software in a gear and use it for running analysis workflows on their Flywheel data via the web UI or SDK. The complexity and frequency of the task help to guide if a task should be accomplished using the web UI, programmatically using the SDK, or by wrapping a workflow into a gear. Gear developers are able to construct configurable options and necessary inputs for their gear in a standardized manifest file, written as a JSON. These configurations appear as clickable options in the GUI, can be set programmatically using the SDK, or specified using the CLI. Once a gear is launched, the gear queries Flywheel for the specified input data (such as images or file attachments) and runs the pipeline. Once a workflow has completed running, Flywheel collects any files remaining in the pre-defined output directory of the container and attaches them to a resulting analysis object. The output of a gear (such as an HTML report or tabulated data) can be viewed on the Flywheel UI, downloaded to disk for further sharing or analysis, or used as input to a subsequent gear.
Results
FlywheelTools is implemented using the Flywheel SDK to enable easy inspection, curation, validation, and audit of Flywheel data through a handful of user-friendly gears and command-line interfaces. The first module of the package is fw-heudiconv, a toolbox for reproducible curation of neuroimaging data into BIDS on Flywheel. The second module, flaudit, is a tool for auditing a Flywheel project, giving users an overview of the key elements of their dataset.
FW-HEUDICONV
The first tool, fw-heudiconv2, is a multi-purpose command-line interface and Flywheel gear designed for BIDS curation on Flywheel (Figure 1). It is designed to be intuitive, flexible, and reproducible. Users of the Flywheel gear have used it to successfully run 27,251 jobs at the time of this writing.
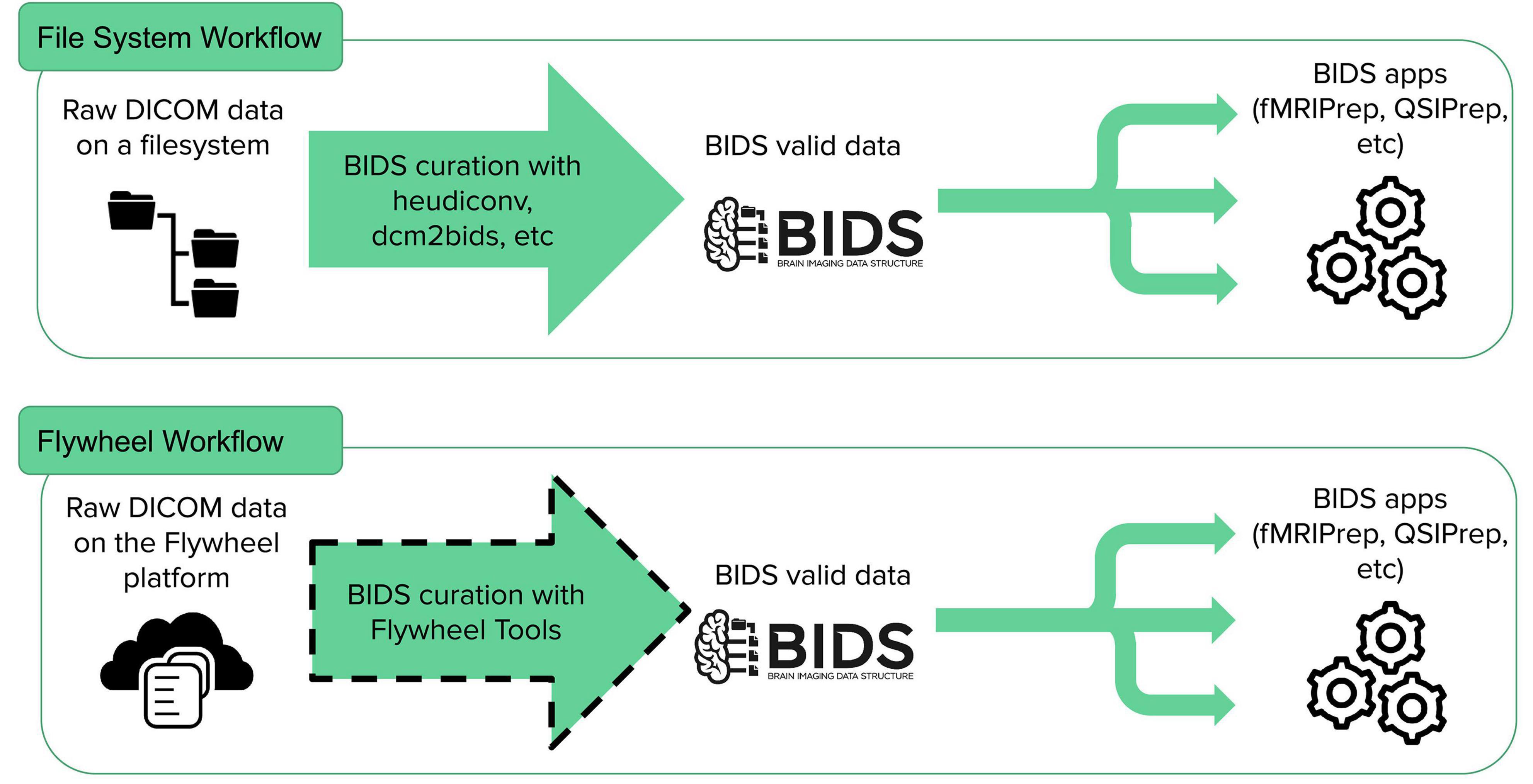
Figure 1. Brain Imaging Data Structure-app workflow. BIDS curation on file systems is a common task that can be accomplished by existing tools (heudiconv, dcm2bids, etc.) or manually, but mechanisms for BIDS curation on many cloud databases have yet to be developed. FlywheelTools provides this functionality for the Flywheel platform.
Architecture and Design
To curate data into BIDS format, fw-heudiconv first considers DICOM data to be the “ground truth” and builds its curation approach using data in the DICOM headers. DICOMs are added to the Flywheel database, either through manual upload or automatically from a linked scanner. The DICOMs are then automatically converted into NIfTI files by Flywheel’s automated gears. The result is an acquisition object with both DICOMs and one or more NIfTIs. Ultimately, fw-heudiconv only has permission to manipulate metadata associated with a NIfTI file. By not manipulating DICOMs or their associated metadata, BIDS curation can safely be reproduced from ground truth data.
fw-heudiconv can be downloaded as a command-line tool from the Python Package Index using pip or can be run from the Flywheel GUI as a gear. Running fw-heudiconv as a gear has the added advantage of containerization, allowing gear configuration and all changes to the data to be tracked. There are a number of commands available in fw-heudiconv, and each of them starts by querying data from Flywheel. Users can filter their queries to operate on an entire Flywheel project, a subset of subjects, or a subset of sessions. Notably, with the – dry-run option, each command has the ability to test and evaluate its effects without actually manipulating metadata in the Flywheel database or writing data to disk. Below, we consider each of the five available commands.
fw-heudiconv-tabulate
The tabulate tool is used to parse and extract DICOM header information in a project (or within a filtered subset of that project) and compile these data into a table for the user to examine. By collecting DICOM header information into a tabular format, the tabulate tool gives users a comprehensive overview of the different scanning sequences that have been collected in the query, including the sequence parameters. Additionally, users have the option to limit the tabulation to a unique combination of common DICOM header fields, which significantly decreases the complexity of the table. When used at the command line, the table produced by this command is written to a local disk. When used as a gear on Flywheel, once the workflow has completed running, Flywheel collects any files remaining in the pre-defined output directory of the container and attaches them to the resulting analysis object.
fw-heudiconv-curate
The curate tool is used to curate a dataset on Flywheel into BIDS format. Much like HeuDiConv, curation is accomplished through the use of a heuristic: a Python file that programmatically defines the templates for a range of BIDS-valid filenames, and defines the Boolean logic that would assign a given scanning sequence to each template. This logic is usually based on the sequence information users find in the tabulation of sequences, but all fields available in the DICOM header can be used to determine which template a particular file can be assigned to. Additionally, the curate tool can be used to manipulate BIDS metadata that may need to be added to the dataset. The process of curation only manipulates the BIDS metadata of NIfTI files, and hence can be repeated or updated at any time at the user’s discretion. In addition to hardcoding metadata, users can also use the heuristic to create and upload additional BIDS files (e.g., a README, participants TSV, or events TSV). If the required dataset description does not already exist in the project, it is auto-populated by fw-heudiconv with the minimum required fields. The curate tool ensures that these files are tracked as BIDS files by hardcoding their relative BIDS paths into the file’s Flywheel metadata.
fw-heudiconv-export
The export tool is used to export a BIDS dataset on Flywheel to disk. It can also be used by other gears or scripts to easily extract their BIDS data into the workspace of an analysis pipeline. Importantly, the export tool downloads all additional files created by the curate tool by ensuring they have been created with BIDS-valid paths in their metadata.
fw-heudiconv-validate
The validate tool is a wrapper around the popular BIDS Validator package and is used to check if the applied curation results in a BIDS-valid dataset (Gorgolewski et al., 2020). After exporting a dataset with fw-heudiconv-export, the validate tool runs the BIDS Validator on the dataset and returns the verbose output of the errors and warnings given by the BIDS Validator. Additionally, the results of the validator can be tabulated for easy inspection. On the Flywheel GUI, fw-heudiconv-validate also displays a green check mark in the analysis tab for a successful validation, and a red check mark otherwise, allowing for quick visual inspection of BIDS curation status for each session.
fw-heudiconv-clear
The clear tool is used to clear BIDS information cleanly and safely from the project or subjects and sessions queried. This can be useful when a user wants to rerun the curation. The previously created persistent fields can be removed by running fw-heudiconv-clear before re-curating.
The Heuristic File
The heuristic file is a Python file used as input to the fw-heudiconv-curate command. The file instructs fw-heudiconv on how to programmatically sort and parse through each acquisition object in Flywheel and assign it to a valid BIDS naming template. This is done by checking the attributes of a list of seqInfo objects – which are generated from each DICOM’s header information – against user-defined Boolean rules. For example, if a T1-weighted image is present in a dataset, the user may define a string with a BIDS-valid naming template for this type of file, such as:
t1w = ‘sub-{SubjectLabel}_ses
-{SessionLabel}_T1w.nii.gz’
where the SubjectLabel and SessionLabel portions are expected to be automatically generated for each subject and session in the dataset. After the DICOM SeriesDescription field is added to the SeriesDescription attribute of seqInfo, the user can create a simple Boolean expression to check if the string ‘T1w’ is in the SeriesDescription. If such a rule is met, this acquisition and its NIfTI file will be assigned to the T1-weighted image naming template. The NIfTI file will ultimately have this BIDS naming added to its metadata and be named correctly when exported to a filesystem. In more complex naming scenarios, fw-heudiconv can flexibly use Boolean expressions involving any number of seqInfo attributes, which the user can access in the output of fw-heudiconv-tabulate.
In addition to setting naming templates, the heuristic file can also be used to hard-code and assign metadata in BIDS. These data are hard-coded into the metadata of the file object on Flywheel and are assigned by using specially reserved functions and keywords in fw-heudiconv. For example, the heuristic file can be used to point fieldmap scans to their intended sequences using a list:
IntendedFor = {
fieldmap1: [’sub-{SubjectLabel}_ses
-{SessionLabel}_task-rest_bold.nii.gz’] }
By reserving select keywords for functions and metadata, heuristic files become versatile tools for defining and manipulating a wide array of metadata in Flywheel BIDS curation. For example, users can make use of the keywords ReplaceSubject() or ReplaceSession() to create functions that dynamically and programmatically manipulate subject or session labels shown in BIDS. The MetadataExtras keyword is used for hardcoding metadata fields found in JSON sidecars, and the AttachToProject() and AttachToSession() keywords can be used to dynamically attach BIDS files to Flywheel objects.
Importantly, because this heuristic file is plain text Python code, users are able to version control their files using Git and share these files via Github. Finally, when run on Flywheel as a gear, the heuristic file is automatically attached as an input to the analysis object created by fw-heudiconv-curate, allowing users to easily access the version history of their curation.
Curation Workflow
For most users, the curation workflow follows the sequence detailed above (Figure 2). After DICOMs have been converted to NIfTIs, users can then begin by running fw-heudiconv-tabulate to gather the information stored in the DICOM headers necessary for creating a heuristic. Once the tabulation has been completed, the output file can be opened by any program that can read tabular data. At this stage, users can begin creating a heuristic file and running fw-heudiconv-curate, using the – dry-run flag to test the heuristic changes incrementally with informative logging. When satisfied, users can simply remove the – dry-run flag to apply the changes. The user can then use fw-heudiconv-validate to run the BIDS validator on the dataset or start over by removing all BIDS metadata with fw-heudiconv-clear.
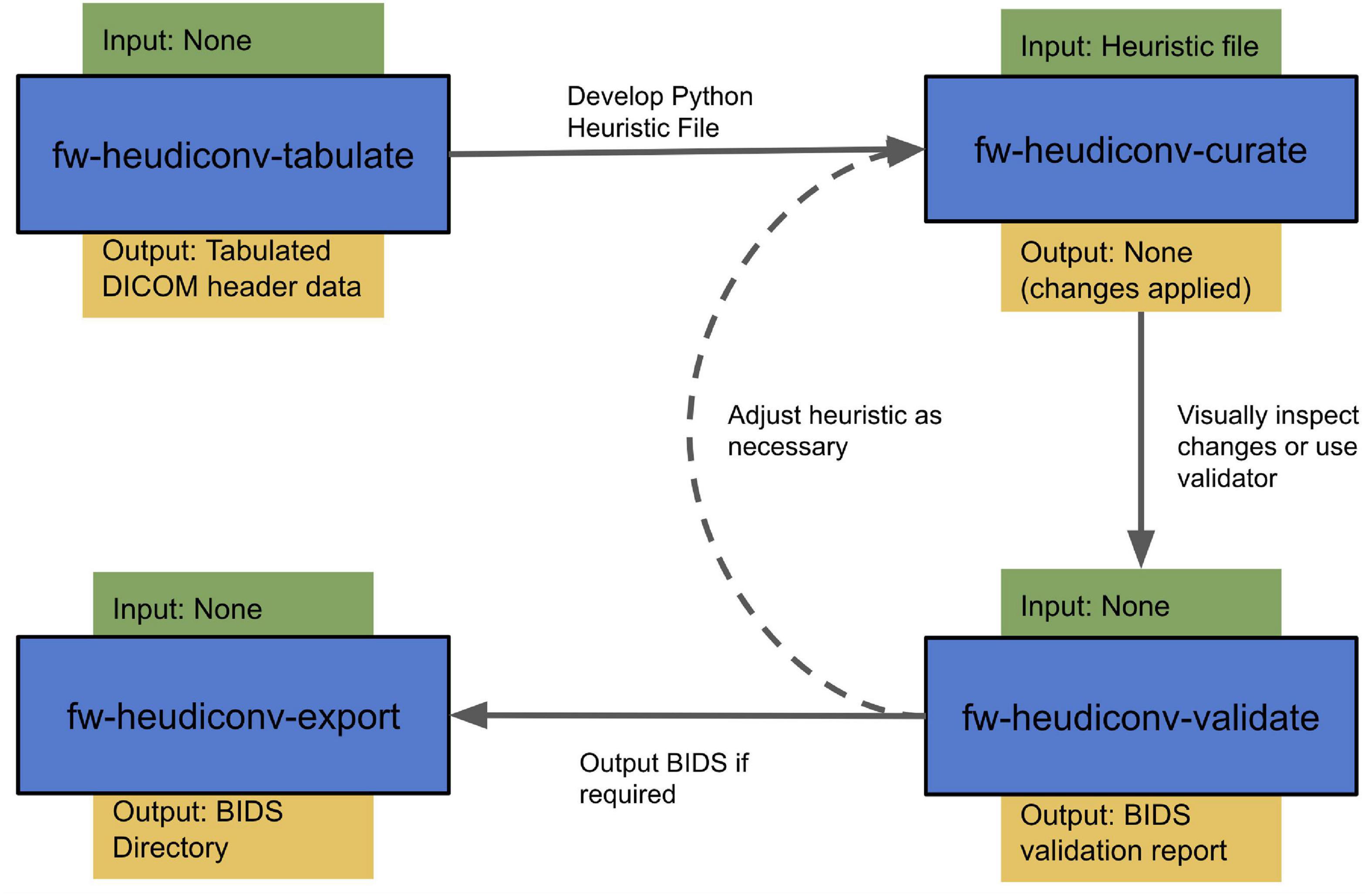
Figure 2. FlywheelTools workflow. Users first use the tabulate tool to extract sequence information from their data, which they use to develop a heuristic that delineates how sequences are mapped into BIDS. After this, they use the curate tool to convert their data into BIDS, and the validate tool to assess their curation. The export tool can be used to export their BIDS data as necessary.
Importantly, when running at the command line, all fw-heudiconv tools run on the entire Flywheel project by default, but all come with optional – subject and – session flags to allow the user to specify operations. The recommended workflow at the command line is to first develop and test the heuristic file on a single subject’s session. Often, it is most useful to conduct testing on the session with the most complete data. When testing is complete and curation works as intended, this heuristic can be applied to the full project. When using the Flywheel GUI, gears by default run at the session level. In this case, users can similarly develop and test their heuristic on a single session using the GUI. When satisfied with that session’s curation, the gear can be run from the project level to curate all the available data. This option is beneficial for data provenance, as all of a gear’s commands and inputs, as well as outputs and logs, are stored and attached to each gear run.
FLAUDIT
The second module of FlywheelTools is a Flywheel project auditor, named flaudit3. The module is intended to give Flywheel users a broad understanding of their entire Flywheel project, by summarizing the available data and illustrating analysis workflows. The output of this module, a portable HTML report, presents this information using a number of visualizations built in R Markdown using HTML, Javascript, and ggplot2, in two main sections: project overview and project completeness.
Architecture and Design
Using internal machinery similar to fw-heudiconv-tabulate, flaudit loops over existing data in a project and tabulates information about scanning sequences, BIDS metadata, and gear analyses that have been run. These three tables are saved internally and then passed as input to an R markdown script that generates an interactive HTML report. The data are also saved as output for the user to further access and analyze in their software of choice.
Flaudit: Project Overview
The overview section of the flaudit report provides a numerical overview of sequences, BIDS data, gear runs, and gear runtimes.
The first visualization uses the sequence data input to create a bar chart visualizing the names of the different sequences acquired across the entire Flywheel dataset. This chart is accompanied by an interactive table that users can search to compare values (Figure 3).
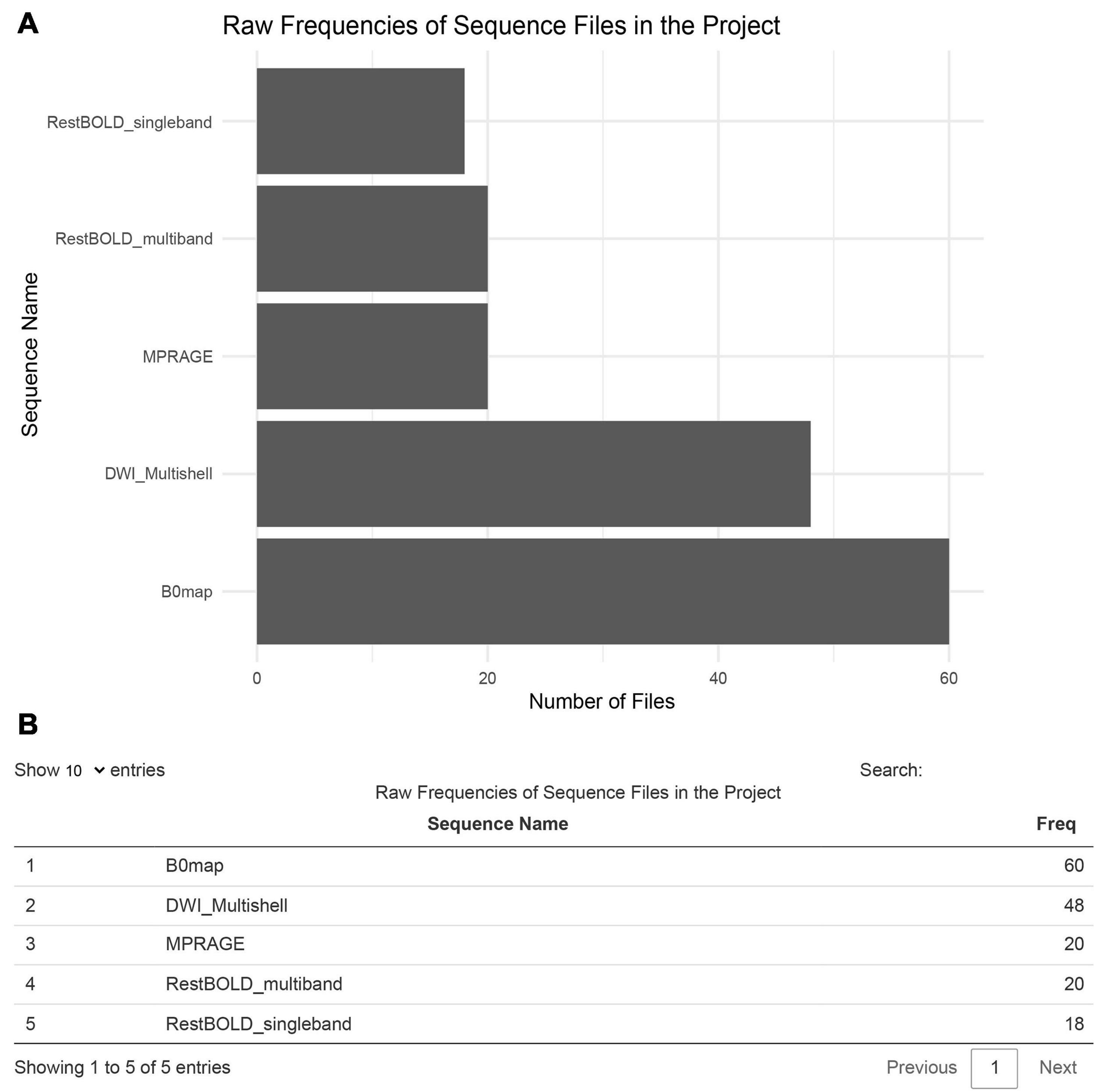
Figure 3. Enumeration of available sequences in a flywheel project. Panel (A) plots the count of files in each collected sequence; in this example, there are 60 files collected for the B0map sequence, as there are 20 subjects and 3 B0map sequences. Panel (B) shows the accompanying interactive table.
Next, using the BIDS metadata input, the report provides an interactive tree viewer to examine BIDS curation. In the tree, the nodes branch out from the project to show each sequence acquisition. For each acquisition, if the data has been curated into BIDS, the node itself can also branch out to show a BIDS name template, demonstrating what BIDS name that sequence has been given. Hovering over the BIDS name will display the number of subjects whose data have been named as such (Figure 4).
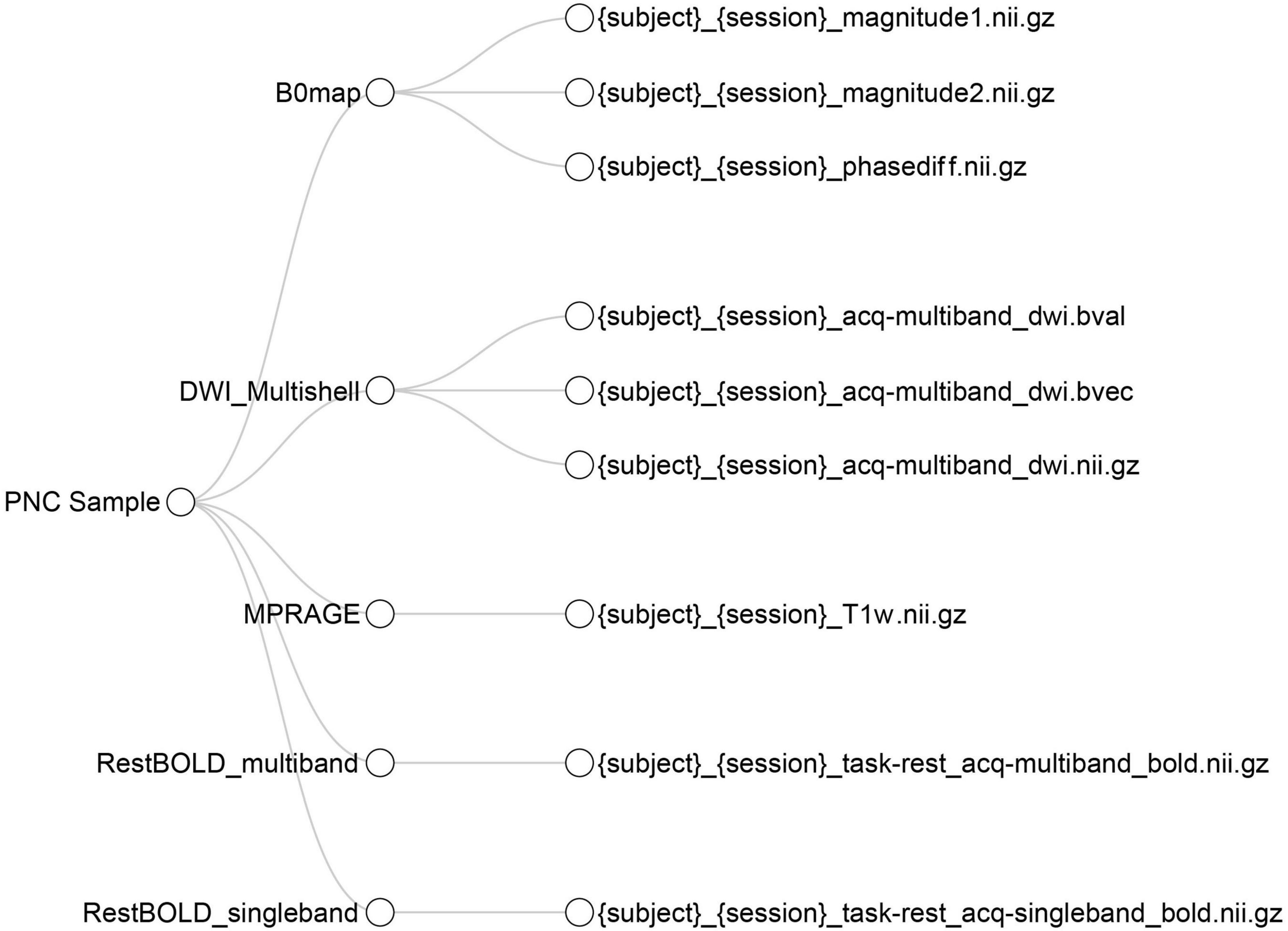
Figure 4. Interactive tree diagram illustrating BIDS curation. The tree shows how each sequence has been curated into BIDS format; users can hover their mouse over each leaf to show how many files have been curated into each BIDS filename template.
Finally, using the gear analysis data as input, the last section of the overview enumerates the gear analyses that have been run successfully on any session within the project, and enumerates the runtimes for these processes. The results are visualized in a bar chart (Figure 5).
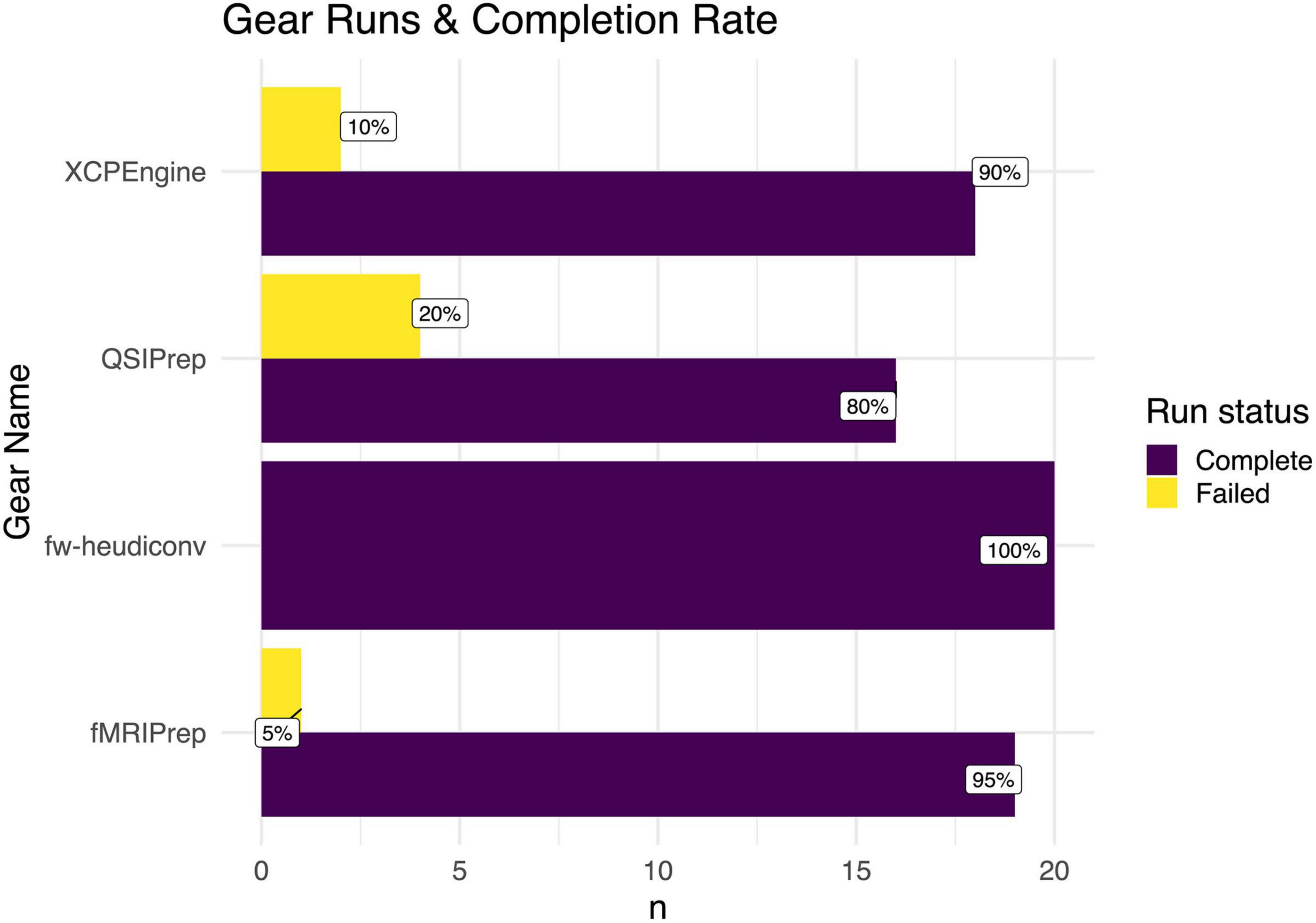
Figure 5. Enumeration of gear runs in a Flywheel project. The number of gear runs is shown for various gears. For each gear, the percent of completed versus failed runs is shown. For example, 95 percent of the subjects (n = 19) were successfully run through fMRI-prep.
Flaudit: Project Completeness
As an optional input, flaudit allows users to specify a template subject – a subject from the Flywheel project who serves as an exemplar for other subjects to be compared against. This subject should be chosen based on the fact that they have both complete input data and analyses. This allows flaudit to determine if other subjects in the project have equally complete data or are missing specific raw data or analytic output. The project completion section of the flaudit report consists of three interactive tables.
In the first table, it’s assumed that the template subject has acquired a complete set of imaging sequences. These sequences are listed as columns in the table. Each subsequent row is a subject in the project, and each value in the table is a Boolean (complete or incomplete) indicating if that subject has each sequence. The table is searchable, meaning that users can simply filter each column for “incomplete” to learn which subjects do not have the same data as the template (Figure 6A). Likewise, the second table illustrates the completeness of BIDS data for other subjects in comparison to the template (Figure 6B). In this case, rows indicate subjects while columns delineate the specified BIDS naming template. Lastly, the third table illustrates completeness of analytic gear runs. Researchers can use this table to compare the analytic output of all other subjects in the project to the analysis pipelines run for the template subject. To ensure uniform versions of pipeline software, the version of a pipeline that was used for each subject must match that of the template subject (Figure 6C).

Figure 6. Project completeness tables compared to the template participant in a Flywheel project. Panel (A) compares the sequences available for each participant to the template subject and identifies missing sequences. For example, this table illustrates that subjects cec4ba54 and f53cd86f did not have DWI sequences collected. Panel (B) similarly shows completeness of BIDS curation. As expected, the two participants who did not have DWI sequences [in panel (A)] did not have diffusion data curated into BIDS. Panel (C) shows gear run completion; here, flaudit reports that the same two participants that lacked DWI data did not have a successful run of QSIPrep. Finally, the report notes that participant f53cd86f did not yet complete fMRIPrep or XCPEngine successfully.
Discussion
FlywheelTools provides new capabilities for the popular and powerful Flywheel platform, allowing researchers to maximize reproducibility and enhance scalability. Specifically, fw-heudiconv provides users a flexible and reproducible way of curating data into BIDS on Flywheel. Complementary function is provided by flaudit, which provides intuitive visual reports of raw, curated, and processed data.
Flywheel has been rapidly adopted by major imaging centers due to its ease of use, extensive functionality, scalability, and emphasis on reproducible research. Despite these strengths, at present there have been limited options for conversion of imaging data to BIDS format on Flywheel. This step is absolutely critical, as BIDS provides a standardized format for important imaging metadata. Notably, initial curation to BIDS has frequently been an important gap in workflows for reproducible research.
Accordingly, fw-heudiconv provides critical functionality for reproducible and flexible BIDS curation on Flywheel. The combination of containerized code and heuristics that are version controlled with git maximizes reproducibility, ensuring that all curation steps have a clear audit trail. Furthermore, the flexible architecture employed by fw-heudiconv allows workflows to be updated to accommodate both new scanning protocols and the evolving specifications of the BIDS standard.
Once data are curated with fw-heudiconv, flaudit allows users to audit the data in a Flywheel project. Specifically, flaudit provides intuitive summaries at each stage of a typical workflow, concisely visualizing raw data, curated data in BIDS, and data processed by containerized analytic gears. These accessible reports allow users to rapidly assess the overall organizational state of a project, while interactive tables allow for more granular inspection of data. This approach facilitates understanding the diverse data types typically collected in multi-modal imaging studies.
There are of course limitations of FlywheelTools. First, it should be acknowledged that FlywheelTools is built for the Flywheel platform, and as such does not generalize to other imaging databases that are in use. However, given the rapid adoption of this platform by the imaging community, we anticipate that this toolkit will fill an important need for the many large research institutions that rely upon Flywheel. Second, some understanding of Python is necessary to build the heuristic for fw-heudiconv. We attempt to minimize this issue by providing both extensive documentation and heuristic templates for various uses of fw-heudiconv4, but usage is ultimately a programming task.
A significant improvement to FlywheelTools would be automated curation of BIDS data similar to that implemented by ReproNim’s ReproIn workflow5, In the ReproIn workflow, researchers adhere to specific naming conventions when scans are acquired, resulting in DICOMs that can be automatically converted by HeuDiConv with the use of a turnkey heuristic that comes with the software. At present, fw-heudiconv includes a prototype ReproIn heuristic that we plan to expand and further evaluate moving forward.
FlywheelTools provides essential functionality to the Flywheel platform. The flexible toolkit allows for curation and description of complex imaging studies. Taken together, the toolkit is designed to accelerate reproducible imaging research at scale.
Data Availability Statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: https://fw-heudiconv.readthedocs.io/en/latest/.
Author Contributions
TT and MC contributed to the design and implementation of the code and software. TS, MB, and MC supervised writing of the manuscript. AA, MC, EB, DD, and WT provided substantial software use-cases, software feature requests, test data, and critical bug reports. KM and SL assisted with the software documentation. ME, GA, PC, JD, and TS were involved in the proposing, planning, and supervising all the work. All authors contributed to the article and approved the submitted version.
Funding
This work was support provided by R01MH120482, R01MH112847, R01MH113550, and RF1MH116920.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fninf.2021.678403/full#supplementary-material
Footnotes
- ^ Flywheel also provides a MATLAB SDK, however, we use the term SDK in this work to refer to the Python SDK, which we use exclusively in FlywheelTools.
- ^ https://github.com/PennLINC/fw-heudiconv
- ^ https://github.com/PennLINC/flaudit
- ^ https://fw-heudiconv.readthedocs.io/en/latest/index.html
- ^ https://www.repronim.org/do.html
References
Book, G. A., Stevens, M. C., Assaf, M., Glahn, D. C., and Pearlson, G. D. (2016). Neuroimaging data sharing on the neuroinformatics database platform. Neuroimage 124(Pt. 8), 1089–1092. doi: 10.1016/j.neuroimage.2015.04.022
Botvinik-Nezer, R., Holzmeister, F., Camerer, C. F., Dreber, A., Huber, J., Johannesson, M., et al. (2020). Variability in the analysis of a single neuroimaging dataset by many teams. Nature 582, 84–88.
Cieslak, M., Cook, P. A., He, X., Yeh, F.-C., Dhollander, T., Adebimpe, A., et al. (2020). QSIPrep: an integrative platform for preprocessing and reconstructing diffusion mri. bioRxiv[Preprint]. doi: 10.1101/2020.09.04.282269
Craddock, C., Sikka, S., Cheung, B., Khanuja, R., Ghosh, S. S., Yan, C., et al. (2013). Towards automated analysis of connectomes: the configurable pipeline for the analysis of connectomes (c-Pac). Front. Neuroinform. 42, 10–3389. doi: 10.3389/conf.fninf.2013.09.00042
Esteban, O., Markiewicz, C. J., Blair, R. W., Moodie, C. A., Isik, A. I., Erramuzpe, A., et al. (2019). fMRIPrep: a robust preprocessing pipeline for functional mri. Nat. Methods 16, 111–116. doi: 10.1038/s41592-018-0235-4
Gorgolewski, C., Hardcastle, N., Hobson-Lowther, T., Nishikawa, D., Blair, R., Appelhoff, S., et al. (2020). Bids-standard/bids-validator: 1. 4. 3 (1.4.3) [Computer software].Geneva: Zenodo
Gorgolewski, K. J., Auer, T., Calhoun, V. D., Craddock, R. C., Das, S., Duff, E. P., et al. (2016). The brain imaging data structure, a format for organizing and describing outputs of neuroimaging experiments. Sci. Data 3:160044.
Halchenko, Y., Goncalves, M., Castello, M. V. O., Ghosh, S., Hanke, M., Brett, M., et al. (2018). Nipy/Heudiconv: Heudiconv V0.5.1 (version v0.5.1). Geneva: Zenodo.
Helmer, K. G., Ambite, J. L., Ames, J., Ananthakrishnan, R., Burns, G., Chervenak, A. L., et al. (2011). Enabling collaborative research using the biomedical informatics research network (Birn). J. Am. Med. Inform. Assoc. 18, 416–422.
Herrick, R., Horton, W., Olsen, T., McKay, M., Archie, K. A., and Marcus, D. S. (2016). XNAT central: open sourcing imaging research data. NeuroImage 124, 1093–1096.
Landis, D., Courtney, W., Dieringer, C., Kelly, R., King, M., Miller, B., et al. (2016). COINS data exchange: an open platform for compiling, curating, and disseminating neuroimaging data. NeuroImage 124, 1084–1088.
Merkel, D. (2014). Docker: lightweight linux containers for consistent development and deployment. Linux J. 239.
Poldrack, R. A., and Gorgolewski, K. J. (2017). OpenfMRI: open sharing of task fMRI data. Neuroimage 144, 259–261.
R Core Team (2019). R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing.
Rogovin, O., Zhao, Y., Chen, S., Wang, Z., Papaemmanouil, O., and Van Hooser, S. D. (2020). NDI: a platform-independent data interface and database for neuroscience physiology and imaging experiments. BioRxiv[Preprint]. doi: 10.1101/2020.05.13.093542
Sherif, T., Rioux, P., Rousseau, M. E., Kassis, N., Beck, N., Adalat, R., et al. (2014). CBRAIN: a web-based, distributed computing platform for collaborative neuroimaging research. Front. Neuroinform. 8:54. doi: 10.3389/fninf.2014.00054
Vaccarino, A. L., Dharsee, M., Strother, S., Aldridge, D., Arnott, S. R., Behan, C., et al. (2018). Brain-Code: a secure neuroinformatics platform for management, federation, sharing and analysis of multi-dimensional neuroscience data. Front. Neuroinform. 12:28. doi: 10.3389/fninf.2018.00028
Keywords: neuroimaging, neuroinformatics, BIDS, curation, Flywheel
Citation: Tapera TM, Cieslak M, Bertolero M, Adebimpe A, Aguirre GK, Butler ER, Cook PA, Davila D, Elliott MA, Linguiti S, Murtha K, Tackett W, Detre JA and Satterthwaite TD (2021) FlywheelTools: Data Curation and Manipulation on the Flywheel Platform. Front. Neuroinform. 15:678403. doi: 10.3389/fninf.2021.678403
Received: 09 March 2021; Accepted: 18 May 2021;
Published: 22 June 2021.
Edited by:
Xi-Nian Zuo, Beijing Normal University, ChinaReviewed by:
Yaroslav O. Halchenko, Dartmouth College, United StatesXindi Wang, Montreal University, Canada
Copyright © 2021 Tapera, Cieslak, Bertolero, Adebimpe, Aguirre, Butler, Cook, Davila, Elliott, Linguiti, Murtha, Tackett, Detre and Satterthwaite. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Theodore D. Satterthwaite, c2F0dGVydHRAcGVubm1lZGljaW5lLnVwZW5uLmVkdQ==