 Daniel Hölle
Daniel Hölle Sarah Blum
Sarah Blum Sven Kissner4
Sven Kissner4 Stefan Debener
Stefan Debener Martin G. Bleichner
Martin G. Bleichner- 1Neurophysiology of Everyday Life Group, Department of Psychology, University of Oldenburg, Oldenburg, Germany
- 2Neuropsychology Lab, Department of Psychology, University of Oldenburg, Oldenburg, Germany
- 3Cluster of Excellence Hearing4all, Oldenburg, Germany
- 4Institute for Hearing Technology and Audiology, Jade University of Applied Sciences, Oldenburg, Germany
With smartphone-based mobile electroencephalography (EEG), we can investigate sound perception beyond the lab. To understand sound perception in the real world, we need to relate naturally occurring sounds to EEG data. For this, EEG and audio information need to be synchronized precisely, only then it is possible to capture fast and transient evoked neural responses and relate them to individual sounds. We have developed Android applications (AFEx and Record-a) that allow for the concurrent acquisition of EEG data and audio features, i.e., sound onsets, average signal power (RMS), and power spectral density (PSD) on smartphone. In this paper, we evaluate these apps by computing event-related potentials (ERPs) evoked by everyday sounds. One participant listened to piano notes (played live by a pianist) and to a home-office soundscape. Timing tests showed a stable lag and a small jitter (< 3 ms) indicating a high temporal precision of the system. We calculated ERPs to sound onsets and observed the typical P1-N1-P2 complex of auditory processing. Furthermore, we show how to relate information on loudness (RMS) and spectra (PSD) to brain activity. In future studies, we can use this system to study sound processing in everyday life.
1. Introduction
Mobile electroencephalography (EEG) allows to record brain activity beyond the lab while participants go about their everyday life (Debener et al., 2012; De Vos et al., 2014; Hölle et al., 2021; Wascher et al., 2021). It thereby provides unique insights into human cognition that cannot be gained by introspection or by the observation of behavior alone. Importantly, it can help us to understand the coupling of action and cognition (Gramann et al., 2014; Ladouce et al., 2017; Parada, 2018). In everyday life, action and cognition are tightly coupled—the brain has to continuously adapt to changing events in the environment and adjust goal-directed behavior accordingly. For example, we have to react immediately to the honking of a car. By studying the brain in complex naturalistic environments, we can learn more about the dynamics of brain processes over longer time periods (Hölle et al., 2021) and in response to environmental events that are difficult to recreate in the laboratory.
If we want to understand the brain in relation to everyday life events (we will focus here on auditory events), we need to capture both the brain activity and information about the events concurrently with high temporal precision: simply put, to analyze the brains' response to the honking car at the correct moment, we need to know when the honk occurred relative to the EEG data. By relating naturally occurring sounds in everyday life to ongoing EEG activity, we can investigate questions about auditory perception and attention in real world scenarios. There is an increasing number of studies using naturalistic stimuli to study auditory perception (e.g., Perrin et al., 2005; De Lucia et al., 2012; Roye et al., 2013; Scheer et al., 2018; Zuk et al., 2020). However, in this lab-based research, everyday life sounds and contexts are approximated by using artificial stimuli and conditions. With mobile EEG we can record the brain and the acoustic environment throughout the day in everyday live, and start to understand sound processing in real life contexts (Hölle et al., 2021).
Ideally, brain recordings in everyday life should not interfere with natural behavior. The used recording setup should neither be noticeable for the participant nor for outside observers, only then we can expect a natural and therefore representative behavior of the participant. Hence, the optimal setup is maximally transparent, portable, and non-restrictive for a participant (Bleichner and Debener, 2017). Such a transparent EEG solution is smartphone-based, as smartphones have sufficient computational power for EEG recordings and processing, and they can be comfortably carried in a pocket (Debener et al., 2015; Blum et al., 2017, 2019; Piñeyro Salvidegoitia et al., 2019; Hölle et al., 2021).
To investigate sound processing in daily life, we have developed two apps for Android smartphones (Record-a and AFEx) that allow us to record and process naturally occurring sounds and brain data. Record-a is a generic app that uses the LabStreamingLayer (LSL) framework for the simultaneous acquisition and synchronization of different data streams (Blum et al., 2021). The AFEx app dissects raw audio into acoustic features (Power spectral density, PSD; average signal power, RMS; sound onsets) in a privacy-protecting way. These features are broadcast as LSL streams and can be recorded concurrently with EEG data by the Record-a app.
Before studying sound processing in everyday life in a hypothesis-driven manner with this system, each component has to be carefully tested and validated (Scheel et al., 2021). Hence, in this paper, we evaluate this smartphone-based system regarding timing precision and plausibility of the EEG data. We show how we use this system to relate EEG and acoustic features to study ERPs. We use sound onsets to calculate ERPs, spectral information to distinguish tones, and information on loudness to contrast ERPs elicited by loud and soft sounds.
2. Materials and Methods
For the recordings, we used a smartphone running three apps: AFEx computes and streams the acoustic features (sound onsets, PSD, RMS); Smarting (mBrainTrain, Belgrade, Serbia), a commercial app, streams EEG data; and Record-a concurrently records the former two data streams into one xdf-file. We recorded EEG from one person equipped with a mobile EEG cap. In our analyses, we could use the audio onsets provided by AFEx to cut the continuous EEG data and average over these epochs to gain ERPs. See Figure 1 for an illustration of the system components and how they play together.
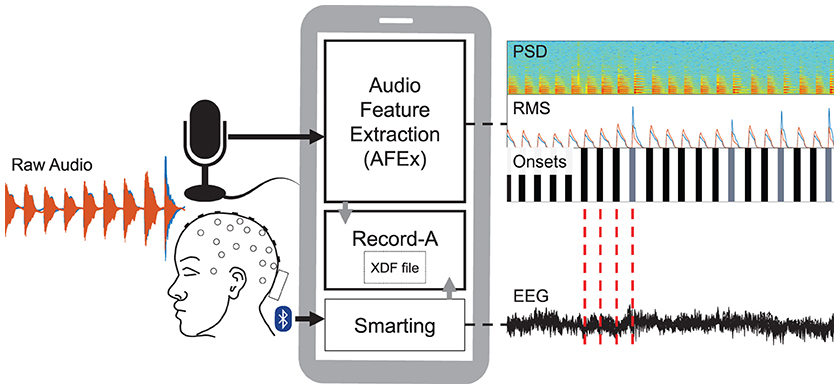
Figure 1. Schematic of recording setup. The participant was equipped with a mobile EEG and listened to audio. An EEG data stream was generated by the Smarting app that received the data from the amplifier via Bluetooth. The sound features (PSD, RMS, onsets) were computed by the AFEx app which received the audio data via a microphone connected to the smartphone. Audio feature and EEG data streams were recorded with the Record-a app and written in an xdf-file. With the sound onsets, we can epoch the EEG data (red lines) and compute ERPs.
2.1. Software
2.1.1. Smarting
For streaming EEG data, we used a Smarting (mBrainTrain, Belgrade, Serbia) system. The ongoing EEG signal was provided as an LSL stream by the Smarting android app (Version 1.6.0). Note that any EEG system that provides the EEG data as LSL stream can be used.
2.1.2. AFEx
AFEx is an Android app that calculates acoustic features (https://doi.org/10.5281/zenodo.5814670). It implements a framework that allows to concatenate various stages such as audio capture, signal filtering, and signal transformation to produce the desired metrics. The produced data is pushed to the LSL in chunks equivalent to the block sizes specified below. Figure 2 shows the signal path.
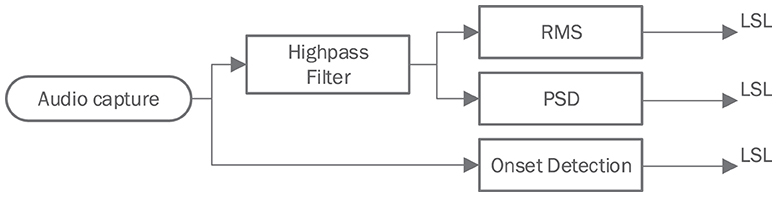
Figure 2. Signal path through the different stages of the Audio Feature Extraction Framework AFEx.
The different metrics are calculated and parameterized as follows:
2.1.2.1. Audio Capture
A stereo microphone signal is captured at a sampling rate of 16 kHz, buffered and transferred to subsequent stages in chunks of 250 ms. Each stage is rebuffering data to provide the blocksizes (incl. overlaps) requested by succeeding processing stages. Note that the properties of the signal are depending on the recording setup. A signal being recorded using an Android's device internal microphone or input via the headphone/mic jack will usually result in two identical, i.e., duplicated, mono channels. Stereo signals can be recorded using external USB devices.
2.1.2.2. Highpass Filter
The second order biquad filter has a cutoff frequency of 250 Hz to suppress low frequency noise. The signal is filtered in blocks of 25 ms.
2.1.2.3. Signal Power (RMS)
The RMS is calculated with a blocklength of 25 ms and an overlap of 50%, resulting in a sampling rate of 80 Hz.
2.1.2.4. Spectra (PSD)
The power spectral density is calculated for blocks of 125 ms with an overlap of 50%, resulting in a sampling rate of 8 Hz. The resulting spectra are exponentially smoothed and averaged, with one spectrum being produced every 125 ms. This method prevents reconstruction of the time domain signal to protect a person's privacy.
2.1.2.5. Acoustic Onset Detection
To detect acoustic onsets, a variable state filter produces low-, band-, and highpass filtered signals (2nd order, fg, fc = 800 Hz, ). Those are then smoothed with both, slow and fast time constants, tuned to different values per band (Table 1). If the faster signal emerges from the slower in any band, an onset is triggered.

Table 1. Smoothing time constants for the low-, band-, and highpass-filtered signals used for acoustic onset detection.
All calculations are performed on the smartphone and the results are written to LSL. The audio signal does not need to be stored or cached on the device's permanent storage. Additionally, the parameters have been chosen in such a way as to prevent reconstruction of semantic content or information, i.e., from PSDs, thus ensuring a participant's privacy (Kissner et al., 2015; Bitzer et al., 2016). Note that modified parameters or new features would require a re-validation of said privacy.
AFEx has been tested with Android OS up to version 10. Permissions to access storage and the microphone are explicitly required. Processing runs as foreground service, giving it some precedency over other apps. There are, however, no additional mechanisms in place to prevent interaction with the app. The Android OS may, for instance, decide to end AFEx based on a lack of available storage space or low battery level. Moreover, the app is not hardened against end-users: there is no kiosk mode to prevent a user from performing actions that might cause a processing lag (e.g., open another app) or any GUI that might guide an end-user and prevent incorrect usage. Note that a processing lag would not lead to lost or inaccurate data, the audio data would only be processed later. For optimal recordings, we recommend to ensure that the phone has enough storage space and battery, and that not needed apps or services are disabled.
2.1.3. Record-a
The Record-a app allows to record LSL data streams in the network into one xdf-file. With the LSL framework, different data streams with different sampling rates can be recorded simultaneously. Each data stream has its own time information in reference to a master clock and upon import, they are time corrected and thereby synchronized. This app is described in detail in Blum et al. (2021). The app is available at: https://github.com/s4rify/Pocketable-Labs.
2.2. Hardware
2.2.1. EEG System
We used a 24-channel cap (easycap GmbH, Germany) connected to a mobile 24-channel Smarting mobi amplifier with 24 bit resolution (mBrainTrain, Belgrade, Serbia). We recorded the EEG data with a sampling rate of 250 Hz. The amplifier transmitted the data to the smartphone via bluetooth.
2.2.2. Smartphone and Microphone
We used a Google Pixel 3a smartphone (Android Version: 10). To record stereo sound with this phone, we used customized ear microphones comprising two omni-directional EK-23024 microphones (Knowles Electronics, Illinois, USA) placed into behind-the-ear shells. The ear-microphones were connected to the phone via the USB-C port with a sound adapter (Andrea Pure Audio USB-MA, Andrea Electronics, Bohemia, USA). Naturally, the microphones process sounds differently than human ears: they may pick up on sounds not perceptible to human ears, but they may also miss sounds that the ear would perceive. However, the microphone clearly detects the onset sounds that are essential to our analyses.
2.3. System Validation
To relate EEG data and audio onsets reliably, both data streams need to be stable over time and have sufficient temporal precision in the millisecond domain. As the audio signal is buffered and then processed, there is a lag between the actual audio onset and the recorded audio onsets (onset marker) as they occurred in the real world. In the system validation, we conducted timing tests to quantify this lag. Furthermore, we also checked whether this lag remains stable over time (jitter).
We conducted five short (~45 min) and one long (~180 min) timing tests. The smartphone was restarted between timing tests. For these timing tests we used wav-files that were generated with Matlab (Version: 9.6.0.1335978; The Mathworks Inc., Natick, MA, USA). The wav-files contained square wave impulses that were presented at 1 sec intervals at a sampling rate of 44,100 Hz. We used square waves as they produce a sharp response in the EEG amplifier. The square wave impulse had a duration of 50 ms. For the short timing test, the wav-file consisted of a 10 s silence at the beginning followed by 2,500 impulses. The wav-file of the long-term timing test consisted of four times the wav-file for the short timing test for a total of 10,000 impulses. These sound files were presented via PC on external speakers (Wavemaster 1520, Bremen, Germany) in a soundproof cabin and simultaneously fed into the EEG amplifier via a customized adapter.
Hence, with this procedure, an impulse produced both a response in the data recorded with the EEG amplifier and an audio onset as detected by the AFEx app. We can then cut the sound signal recorded with the EEG amplifier based on the audio onsets and calculate lag and jitter. The AFEx app detected onsets for all impulses plus a few extra sounds (experimenter leaving the room, nearby construction work). In our analysis (also in Matlab), we deleted these additional onsets.
We then epoched the data from −1 to 0.1 s (baseline correction −1 to −0.9) relative to the detected sound onsets. To quantify the delay between audio onset and onset marker, we identified the time point when the audio onset in the EEG reached its half maximum (same time point for all recordings) and then calculated the time difference between this maximum and the onset marker for every epoch.
2.4. Participant
We recorded one volunteer (male, age between 25 and 35, ambidextrous) who had previous experience with EEG recordings. He provided written informed consent prior to participation. We deemed neural data from one participant sufficient to demonstrate the functionality of the technical setup.
2.5. Procedure
For the EEG recordings we had three conditions that increase in stimulus complexity. In the first two conditions, the participant listened to piano notes played live by a pianist. In the third condition, the participant listened to an home-office soundscape. In Figure 3, we show the average ERPs to all detected audio onsets for the three conditions.
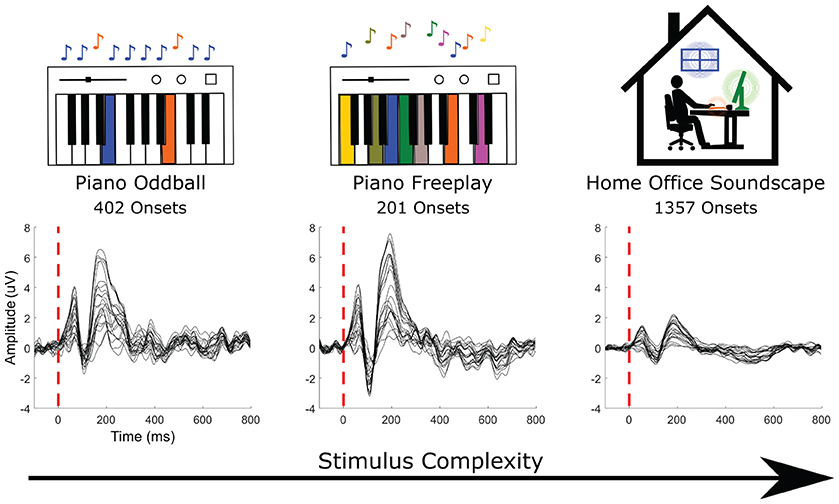
Figure 3. Grand average event-related potentials (ERPs) of all channels in the EEG recorded in response to the random sequence of two tones (piano oddball, 402 onsets), the random sequences of multiple tones (piano freeplay, 201), and to home-office soundscape events (1,357).
Before the participant was fit with the EEG cap, his skin was cleaned with alcohol and electrolyte gel (Abralyt HiCl, easycap GmbH, Germany). All impedance was kept below 10 kOhm. The ear microphones were plugged into the smartphone and placed on the participant's ear. The smartphone was always placed on a table adjacent to the participant. For condition one and two, the participant sat in a chair approximately at a distance of 1 m to the piano (Yahama Digital Piano P-35, Hamamatsu, Japan; set to 75% volume, LAeq ≈62 dB at participant's location), fixating his gaze on a fixation cross on a wall. The participants sat with his back to the piano; hence, he could neither see the pianist nor the experimenter. In the third condition, the participant sat in a soundproof cabin looking at a fixation cross on a computer screen while listening to a soundscape that was presented free-field (two Sirocco S30 loudspeakers, Cambridge Audio, London, United Kingdom) at a participant-comfortable volume (LAeq ≈63 dB). For all conditions, the participant was instructed to move as little as possible.
2.5.1. Piano Oddball
The participant listened to live played notes on the piano. The pianist alternated between playing middle c (~264 Hz, 159 in total, standards) and middle g (~392 Hz, 39 in total, targets) on the keyboard. The sequence of tones was predefined and provided on a paper sheet. We recorded this oddball twice with a different predefined sequence in the second run. The participants task was to count the target tones. To check whether the pianist played exactly the notes from the sheet, we also recorded the MIDI file of the oddball. Each oddball took 3 min. For later analysis, we merged both oddball datasets.
2.5.2. Piano Freeplay
The participant listened to the pianist playing a monophonic sequence of random tones with variable loudness and tempo for 6 min. The exact sequence of sounds was recorded as a MIDI file.
2.5.3. Home-Office Soundscape
In this condition, the participant listened to a soundscape of a home-office environment for 27 min. This soundscape (wav-file) included typical home-office activities such as operating a computer (clicking with the mouse, typing on the keyboard, notification sounds), walking around, using a hole puncher, or unloading the dishwasher. It did not contain music or speech. Due to technical interference in this recording, we recorded the sound onsets again in an empty room and mapped them onto the EEG recording.
2.6. Data Analysis
Data were analyzed offline with Matlab (Version: 9.6.0.1335978; The Mathworks Inc., Natick, MA, USA) and EEGLAB (Version: v2019.0; Delorme and Makeig, 2004) using custom scripts (available at https://osf.io/bcfm3/). Filters were used as implemented in EEGLAB (zero-phase Hamming windowed sync finite impulse response).
2.6.1. Preprocessing
The EEG data were re-referenced to linked mastoids, low-pass filtered at 25 Hz (Order 134) and high-pass filtered at 0.1 Hz (Order 8,250). To account for the previously determined time lag, the recorded markers for sound onsets were shifted by −248 ms (−62 samples; see system validation results). We deleted some markers at the beginning and the end of each recording (14 in total) as these onsets were due to the starting and stopping of the recording. We used artifact subspace reconstruction (ASR) to clean the data. For ASR, we used the EEGLAB-plugin clean_rawdata (Version: 1.0; parameters: flatline criterion = 60, high-pass = [0.25 0.75], channel criterion = off, line noise criterion = off, burst criterion = 20, window criterion = off). We epoched the data from −0.1 to 0.8 s relative to each sound onset (baseline correction −0.1 to 0 s).
2.6.1.1. Piano Oddball
Based on the recorded PSD data, we identified target and standard tones. First, we visually identified the first target tone in the spectrum. Second, we created a template based on this target tone. We then correlated this template with every tone in the spectrum. This procedure allowed us to automatically identify target tones when the correlation was higher than 0.9.
2.6.1.2. Piano Freeplay and Home-Office Soundscape
In both conditions, for each audio onset, we computed an average RMS based on the mean of five samples (62.5 ms) after the audio onset of both audio channels to gain a corresponding RMS value for each sound onset.
2.6.2. Data Quality Measures
To obtain an estimation for the reliability of the ERPs, we calculated an amplitude threshold based on ERPs extracted from random events for each condition. Data within this threshold can be considered as noise. For 1,000 permutations, we inserted 500 markers at random time points in the data, epoched with these markers, and computed the ERP over all channels. We then determined the maximum and minimum amplitude of the mean over all permutations plus two times the standard deviation. This value corresponds to ~95% of the amplitude distribution. Additionally, for all ERP components used in statistical comparisons, we report the standardized measurement error (SME) as a data quality measure (Luck et al., 2021).
3. Results
3.1. System Validation
Table 2 shows the results of the timing tests. We identified a mean lag of 247.23 ms (62 samples at 250 Hz). When shifting the recorded sound onset markers by this number, they align with the actual onset of the sound.
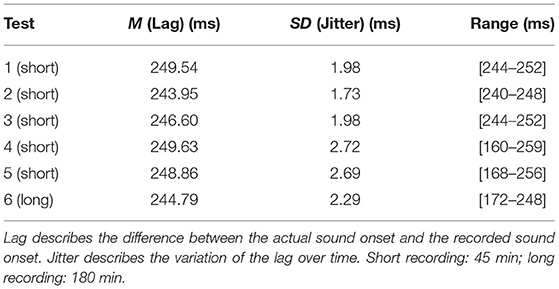
Table 2. Timing test results.
3.2. EEG Recordings
Apart from timing tests, we also recorded neural data to validate the system. The participant listened to three different auditory inputs (a random sequence of two tones, a random sequence of multiple tones, and a home-office soundscape). In Figure 3, we show the average ERPs to all detected audio onsets for the three conditions. These conditions are analyzed in more detail below.
3.2.1. Piano Oddball
In this condition, the participant listened to two tones that were played live by a pianist in the same room. One note was played frequently and the other infrequently. The participant had to count the infrequent tone (target). The participant correctly counted all targets. On average, the AFEx app detected a tone every 0.99 s (SD = 0.24 s, Range = [0.25–1.42 s]). AFEx detected all tones played by the pianist. Figure 4A shows the results of the piano oddball, split into target and standard tones based on the PSD data. The automatic identification of targets and standards corresponded exactly to the actual notes played as recorded by a MIDI file (ground truth). For both tones, auditory evoked potentials (P1,N1,P2) can be observed. Compared to the standard tone, the target tone also shows a P3 response. A two-sample t-test based on the mean single trial amplitudes at electrode Cz (Polich, 2007) from 368 to 392 ms (see topoplots) confirmed that this difference is significant [t(393) = −5.11, p = < 0.001, SMEstandard = 0.36, SMEtarget = 0.97].
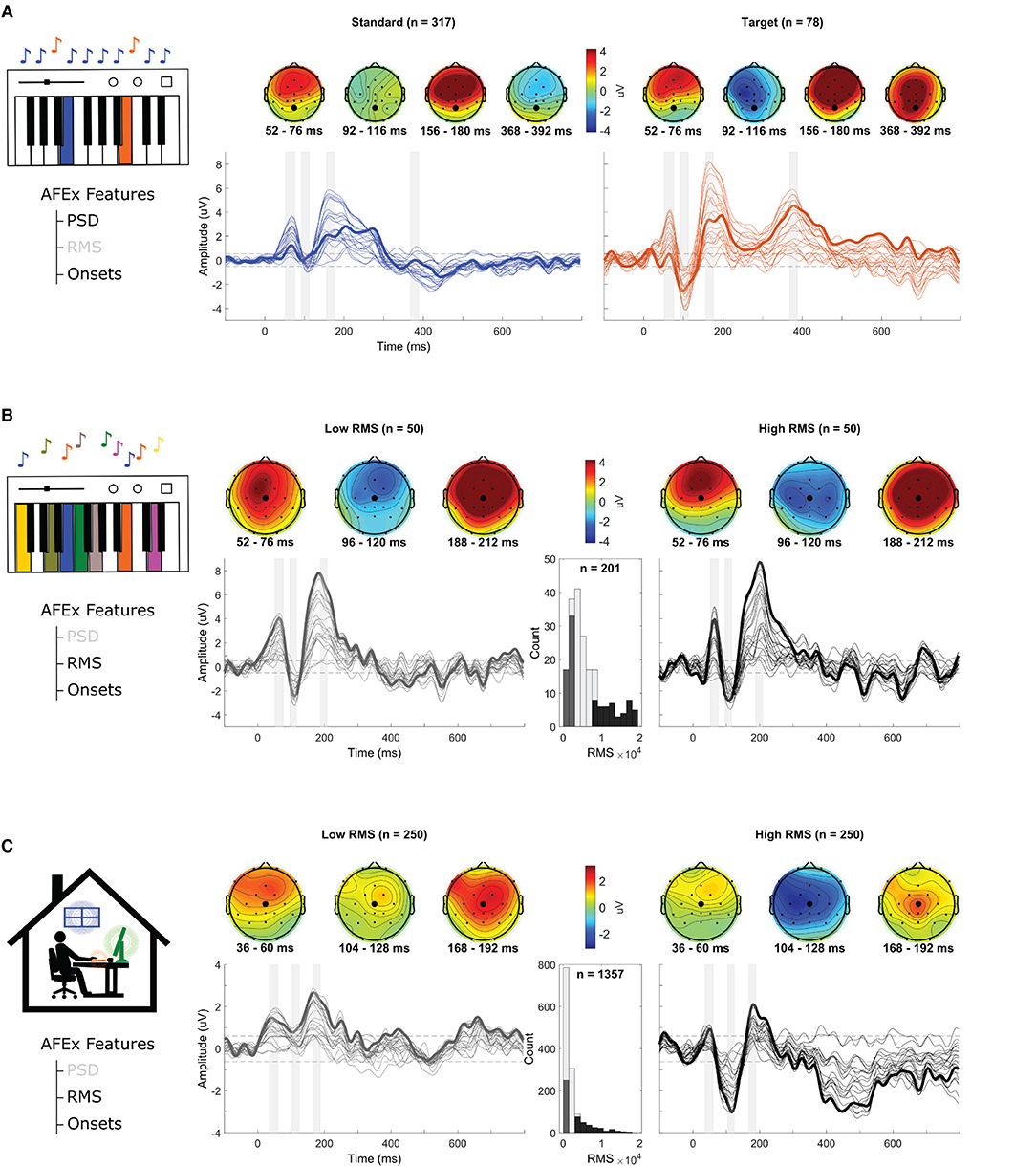
Figure 4. Grand average ERPs per condition. (A) Average ERP to piano oddball, divided into standard (frequent, n = 317 blue) and target (infrequent, n = 78, orange) tones based on the PSD information. (B) Average ERP in the piano freeplay. RMS information was used to sort audio onsets from lowest to highest RMS. The ERP is shown in response to the 50 softest (left) and 50 loudest sounds (right). The histogram shows the distribution of the RMS values (n = 201) and the color coding indicates which value range was used for the plots. (C) Average ERP in response to detected sounds in the home-office soundscape (left: 250 softest sounds; right: 250 loudest sounds). The histogram shows the distribution of the RMS values (n = 1,357) and the color coding indicates which value range was used for the plots. Each line represents a channel. The gray shaded arrays correspond to the time windows of the topographies. The dotted black lines represent the amplitude threshold for a signal deviation that is significantly different from baseline. Data below this threshold was considered as noise. The bold lines show electrode Cz (Piano, Office) or electrode Pz (Oddball). The corresponding electrodes are also highlighted in the topoplot (larger circle).
3.2.2. Piano Freeplay
The participant passively listened to the free playing of individual tones by the pianist. The pianist varied the speed and the loudness at which he played the tones. He played 329 tones (6 min) of which the AFEx app detected 201 (61.09%) including one false event. On average, AFEx detected a tone every 1.82 s (SD = 1.28 s, Range = [0.39–9.83 s]). Figure 4B shows the average ERPs for the 50 events with the highest RMS and for the 50 events with the lowest RMS (RMS distribution: M = 6488.40, SD = 5262.06, Range = [37.17–25924.36]). Again, a P1-N1-P2 complex is clearly visible (cf. Figure 3 for the grand average of all tones). A paired t-test based on the mean single trial amplitudes at electrode Pz (Woods, 1995) from 96 to 120 ms (see topoplots) indicates that there is no difference in the N1 component between both RMS conditions [t(49) = −0.5, p = 0.62, SMElowRMS = 0.62, SMEhighRMS=0.57].
3.2.3. Home-Office Soundscape
The participant passively listened to a pre-recorded soundscape. AFEx detected 1357 onsets. On average, it detected a sound every 1.17 s (SD = 1.52 s, Range = [0.16–21.49 s]). Figure 4C shows the average ERPs for the 250 events with the highest RMS and for the 250 events with the lowest RMS (RMS distribution: M = 2449.57, SD = 2746.32, Range = [805.07–21970.01]). Again, a P1-N1-P2 complex is clearly visible. A higher amplitude of the N1 component (at around 100 ms) in the high-RMS condition compared to the low-RMS one can also be observed. A paired t-test based on the mean single trial amplitudes at electrode Pz from 104 to 128 ms (see topoplots) indicates that this difference is statistically significant [t(249) = 4.23, p < 0.001, SMElowRMS=0.33, SMEhighRMS = 0.39].
4. Discussion
We presented a system incorporating two Android apps that allow to relate acoustic features of the soundscape to continuous EEG data. Our goal was to evaluate the timing precision and EEG data plausibility of this system. In the timing tests, we showed that the temporal precision of the system is sufficient to compute ERPs. We identified a constant lag (due to signal buffering of AFEx), that can be easily accounted for by shifting the recorded onset marker, and a negligible jitter. For the EEG recordings, we presented sounds with increasing stimulus complexity from single piano tones to complex office sounds. In all experimental conditions, we found clear auditory evoked potentials in response to sound onsets.
Furthermore, we showed how acoustic features in addition to sound onsets can be used to analyse EEG data. In the piano oddball condition, we used PSD to distinguish target from standard tones. The resulting ERPs show the expected P3 response for target tones only (Polich, 2007). Advancing from this simple validation task to everyday life settings, PSD information could be used to differentiate between different sound sources (e.g., Fahim et al., 2018). For example, in a two speaker scenario, PSD can be used to identify which speaker (low vs. high voice) is currently talking.
In the piano freeplay and home-office soundscape condition, we contrasted high-RMS sounds with low-RMS sounds. In line with literature (May and Tiitinen, 2010), we observed a significantly higher N1 response for high-RMS onsets compared to low-RMS ones in the home-office soundscape. We did not observe this difference in the piano freeplay, which may be due to the lower number of onsets and thus lower variance of RMS values. Note that ERP amplitudes in the home-office condition were lower than in the other conditions, which is most visible in the grand average of all sound onsets. This finding can be explained by the higher number of low-RMS onsets (see histogram) in this recording, resulting in lower amplitudes overall.
To calculate these ERPs, we relied on sound onsets. Importantly, there are many different methods of defining sound onsets (e.g., Thoshkahna and Ramakrishnan, 2008; Böck et al., 2012); for example, some methods are specifically geared for detecting onsets in music (Bello et al., 2005; Haumann et al., 2021). For the online detection of onsets, we optimized the parameters to detect clear, isolated sound onsets in the presence of background noise. Consequently, not all onsets that humans perceive as onsets are picked up by the detector. For example, in the freeplay condition, 120 notes were missed by the detector. Thus, the onsets that were detected are a subset of all onsets a person perceives. Depending on the use case, the parameter settings can be adapted and optimized to detect fewer or more sound onsets. It is important to note that missing onsets could distort the ERP, for instance, when a missed sound overlaps with a detected sound. Moreover, false alarms could decrease the average ERP amplitude; however, we observed only one false alarm.
Obviously, the acoustic features that are provided by AFEx only provide limited information about the soundscape. The app does not provide information about many aspects that are known to be relevant for sound perception; for example, whether a sound was self-generated or generated by another sound source (e.g., Sanmiguel et al., 2013), whether the sound was relevant or irrelevant (e.g., Scheer et al., 2018; Dehais et al., 2019; Holtze et al., 2021), or expected or unexpected for a person (e.g., Dalton and Fraenkel, 2012; Koreimann et al., 2014). How to assess these factors remains a challenge. Some of these factors could be assessed by asking the person about subjective experience of the soundscape on a regular basis using momentary ambulatory assessment (Trull and Ebner-Priemer, 2013), but this will interrupt the person in their normal activity. An alternative is to use additional microphones that provide more information about the origin of a sound, or sensors that provide context information. However, it is unlikely that we will be able to capture the full complexity of the participants environment in the near future.
To sum up, we demonstrated that the presented technical setup reliably combines EEG and acoustic features and thereby allows to measure event related potential in response to everyday sounds. This smartphone-based setup can be used fast and easily. It allows us to study brain activity everywhere: We could record EEG next to a construction site, while driving through the city, or in the classroom. These contexts are already of interest to researchers (e.g., Ko et al., 2017; Getzmann et al., 2018; Ke et al., 2021). In these everyday contexts, we can also investigate individual differences in sound processing: Why do some individuals notice some sounds that other people miss? How does their brain response to sounds differ? Which sounds are distracting or even annoying to an office worker on the neural level? As evident from these various examples, the AFEx app in combination with Record-a and a commercial EEG app facilitate new research of auditory processing in everyday life, which was henceforth typically only assessed with surveys (e.g., Banbury and Berry, 2005; Oseland and Hodsman, 2018).
Data Availability Statement
The EEG datasets are available from the corresponding author on request. The code used for the analyses, the stimuli used, and the datasets from the timing test are available at: https://osf.io/bcfm3/. The code for the AFEx can be found at: https://doi.org/10.5281/zenodo.5128051. The Record-a app can be found at: https://github.com/s4rify/Pocketable-Labs.
Ethics Statement
The studies involving human participants were reviewed and approved by Ethics Committee of the University of Oldenburg. The patients/participants provided their written informed consent to participate in this study.
Author Contributions
DH and MB conceived the experiments with the help of SB and SD. DH carried out the data collection and analyses. DH wrote the manuscript with the input of MB, SD, SB, and SK. SB lead the development of the Record-a app. MB designed the AFEx functionality. SK developed the AFEx app. All authors contributed to the article and approved the submitted version.
Funding
This work was funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under the Emmy-Noether program—BL 1591/1-1—Project ID 411333557.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
We thank Arnd Meiser for the fruitful discussions. We thank Inga Holube and Jörg Bitzer for their help in starting the development of the AFEx app. We thank the cluster of excellence Hearing4all for some seed funding from the innovation pitch competition.
References
Banbury, S. P., and Berry, D. C. (2005). Office noise and employee concentration: Identifying causes of disruption and potential improvements. Ergonomics 48, 25–37. doi: 10.1080/00140130412331311390
Bello, J. P., Daudet, L., Abdallah, S., Duxbury, C., Davies, M., and Sandler, M. B. (2005). A tutorial on onset detection in music signals. IEEE Trans. Speech Audio Process. 13, 1035–1046. doi: 10.1109/TSA.2005.851998
Bitzer, J., Kissner, S., and Holube, I. (2016). Privacy-aware acoustic assessments of everyday life. J. Audio Eng. Soc. 64, 395–404. doi: 10.17743/jaes.2016.0020
Bleichner, M. G., and Debener, S. (2017). Concealed, unobtrusive ear-centered EEG acquisition: cEEGrids for transparent EEG. Front. Hum. Neurosci. 11:163. doi: 10.3389/fnhum.2017.00163
Blum, S., Debener, S., Emkes, R., Volkening, N., Fudickar, S., and Bleichner, M. G. (2017). EEG recording and online signal processing on android: a multiapp framework for brain-computer interfaces on smartphone. BioMed Res. Int. 2017:3072870. doi: 10.1155/2017/3072870
Blum, S., Hölle, D., Bleichner, M. G., and Debener, S. (2021). Pocketable labs for everyone: synchronized multi-sensor data streaming and recording on smartphones with the lab streaming layer. Sensors 21:8135. doi: 10.3390/s21238135
Blum, S., Jacobsen, N. S. J., Bleichner, M. G., and Debener, S. (2019). A Riemannian modification of artifact subspace reconstruction for EEG artifact handling. Front. Hum. Neurosci. 13:141. doi: 10.3389/fnhum.2019.00141
Böck, S., Krebs, F., and Schedl, M. (2012). “Evaluating the online capabilities of onset detection methods,” in Proceedings of the 13th International Society for Music Information Retrieval Conference, ISMIR 2012 (Porto), 49–54.
Dalton, P., and Fraenkel, N. (2012). Gorillas we have missed: Sustained inattentional deafness for dynamic events. Cognition 124, 367–372. doi: 10.1016/j.cognition.2012.05.012
De Lucia, M., Tzovara, A., Bernasconi, F., Spierer, L., and Murray, M. M. (2012). Auditory perceptual decision-making based on semantic categorization of environmental sounds. NeuroImage 60, 1704–1715. doi: 10.1016/j.neuroimage.2012.01.131
De Vos, M., Gandras, K., and Debener, S. (2014). Towards a truly mobile auditory brain-computer interface: exploring the P300 to take away. Int. J. Psychophysiol. 91, 46–53. doi: 10.1016/j.ijpsycho.2013.08.010
Debener, S., Emkes, R., De Vos, M., and Bleichner, M. (2015). Unobtrusive ambulatory EEG using a smartphone and flexible printed electrodes around the ear. Sci. Rep. 5, 1–11. doi: 10.1038/srep16743
Debener, S., Minow, F., Emkes, R., Gandras, K., and de Vos, M. (2012). How about taking a low-cost, small, and wireless EEG for a walk? Psychophysiology 49, 1617–1621. doi: 10.1111/j.1469-8986.2012.01471.x
Dehais, F., Roy, R. N., and Scannella, S. (2019). Inattentional deafness to auditory alarms: inter-individual differences, electrophysiological signature and single trial classification. Behav. Brain Res. 360, 51–59. doi: 10.1016/j.bbr.2018.11.045
Delorme, A., and Makeig, S. (2004). EEGLAB: an open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J. Neurosci. Methods 134, 9–21. doi: 10.1016/j.jneumeth.2003.10.009
Fahim, A., Samarasinghe, P. N., and Abhayapala, T. D. (2018). PSD estimation and source separation in a noisy reverberant environment using a spherical microphone array. IEEE/ACM Trans. Audio Speech Lang. Process. 26, 1594–1607. doi: 10.1109/TASLP.2018.2835723
Getzmann, S., Arnau, S., Karthaus, M., Reiser, J. E., and Wascher, E. (2018). Age-related differences in pro-active driving behavior revealed by EEG measures. Front. Hum. Neurosci. 12:321. doi: 10.3389/fnhum.2018.00321
Gramann, K., Ferris, D. P., Gwin, J., and Makeig, S. (2014). Imaging natural cognition in action. Int. J. Psychophysiol. 91, 22–29. doi: 10.1016/j.ijpsycho.2013.09.003
Haumann, N. T., Lumaca, M., Kliuchko, M., Santacruz, J. L., Vuust, P., and Brattico, E. (2021). Extracting human cortical responses to sound onsets and acoustic feature changes in real music, and their relation to event rate. Brain Res. 1754:147248. doi: 10.1016/j.brainres.2020.147248
Hölle, D., Meekes, J., and Bleichner, M. G. (2021). Mobile ear-EEG to study auditory attention in everyday life. Behav. Res. Methods. 53, 2025–2036. doi: 10.1101/2020.09.09.287490
Holtze, B., Jaeger, M., Debener, S., Adiloğlu, K., and Mirkovic, B. (2021). Are they calling my name? Attention capture is reflected in the neural tracking of attended and ignored speech. Front. Neurosci. 15:643705. doi: 10.3389/fnins.2021.643705
Ke, J., Du, J., and Luo, X. (2021). The effect of noise content and level on cognitive performance measured by electroencephalography (EEG). Autom. Constr. 130:103836. doi: 10.1016/j.autcon.2021.103836
Kissner, S., Holube, I., Bitzer, J., Technology, H., and Sciences, A. (2015). “A smartphone-based, privacy-aware recording system for the assessment of everyday listening situations,” in Proceedings of the International Symposium on Auditory and Audiological Research (Nyborg), 445–452.
Ko, L. W., Komarov, O., Hairston, W. D., Jung, T. P., and Lin, C. T. (2017). Sustained attention in real classroom settings: an EEG study. Front. Hum. Neurosci. 11:388. doi: 10.3389/fnhum.2017.00388
Koreimann, S., Gula, B., and Vitouch, O. (2014). Inattentional deafness in music. Psychol. Res. 78, 304–312. doi: 10.1007/s00426-014-0552-x
Ladouce, S., Donaldson, D. I., Dudchenko, P. A., and Ietswaart, M. (2017). Understanding minds in real-world environments: toward a mobile cognition approach. Front. Hum. Neurosci. 10:694. doi: 10.3389/fnhum.2016.00694
Luck, S. J., Stewart, A. X., Simmons, A. M., and Rhemtulla, M. (2021). Standardized measurement error: a universal metric of data quality for averaged event-related potentials. Psychophysiology 58, 1–15. doi: 10.1111/psyp.13793
May, P. J., and Tiitinen, H. (2010). Mismatch negativity (MMN), the deviance-elicited auditory deflection, explained. Psychophysiology 47, 66–122. doi: 10.1111/j.1469-8986.2009.00856.x
Oseland, N., and Hodsman, P. (2018). A psychoacoustical approach to resolving office noise distraction. J. Corp. Real Estate 20, 260–280. doi: 10.1108/JCRE-08-2017-0021
Parada, F. J. (2018). Understanding natural cognition in everyday settings: 3 pressing challenges. Front. Hum. Neurosci. 12:386. doi: 10.3389/fnhum.2018.00386
Perrin, F., Maquet, P., Peigneux, P., Ruby, P., Degueldre, C., Balteau, E., et al. (2005). Neural mechanisms involved in the detection of our first name: a combined ERPs and PET study. Neuropsychologia 43, 12–19. doi: 10.1016/j.neuropsychologia.2004.07.002
Pi neyro Salvidegoitia, M., Jacobsen, N., Bauer, A. K. R., Griffiths, B., Hanslmayr, S., and Debener, S. (2019). Out and about: Subsequent memory effect captured in a natural outdoor environment with smartphone EEG. Psychophysiology 56, 1–15. doi: 10.1111/psyp.13331
Polich, J. (2007). Updating P300: an integrative theory of P3a and P3b. Clin. Neurophysiol. 118, 2128–2148. doi: 10.1016/j.clinph.2007.04.019
Roye, A., Jacobsen, T., and Schröger, E. (2013). Discrimination of personally significant from nonsignificant sounds: a training study. Cogn. Affect. Behav. Neurosci. 13, 930–943. doi: 10.3758/s13415-013-0173-7
Sanmiguel, I., Todd, J., and Schröger, E. (2013). Sensory suppression effects to self-initiated sounds reflect the attenuation of the unspecific N1 component of the auditory ERP. Psychophysiology 50, 334–343. doi: 10.1111/psyp.12024
Scheel, A. M., Tiokhin, L., Isager, P. M., and Lakens, D. (2021). why hypothesis testers should spend less time testing hypotheses. Perspect. Psychol. Sci. 16, 744–755. doi: 10.31234/osf.io/vekpu
Scheer, M., Bülthoff, H. H., and Chuang, L. L. (2018). Auditory task irrelevance: a basis for inattentional deafness. Hum. Factors 60, 428–440. doi: 10.1177/0018720818760919
Thoshkahna, B., and Ramakrishnan, K. R. (2008). “A psychoacoustics based sound onset detection algorithm for polyphonic audio,” in International Conference on Signal Processing Proceedings, ICSP, Vol. 20 (Beijing), 1424–1427. doi: 10.1109/ICOSP.2008.4697399
Trull, T. J., and Ebner-Priemer, U. (2013). Ambulatory assessment. Annu. Rev. Clin. Psychol. 9, 151–176. doi: 10.1146/annurev-clinpsy-050212-185510
Wascher, E., Reiser, J., Rinkenauer, G., Larrá, M., Dreger, F. A., Schneider, D., et al. (2021). Neuroergonomics on the go: an evaluation of the potential of mobile eeg for workplace assessment and design. Hum. Factors doi: 10.1177/00187208211007707
Woods, D. L. (1995). The component structure of the N1 wave of the human auditory evoked potential. Electroencephalogr. Clin. Neurophysiol. 44, 102–109.
Keywords: mobile EEG, smartphone-based experimentation, auditory perception, ERP, android applications
Citation: Hölle D, Blum S, Kissner S, Debener S and Bleichner MG (2022) Real-Time Audio Processing of Real-Life Soundscapes for EEG Analysis: ERPs Based on Natural Sound Onsets. Front. Neuroergon. 3:793061. doi: 10.3389/fnrgo.2022.793061
Received: 11 October 2021; Accepted: 03 January 2021;
Published: 04 February 2022.
Edited by:
Raphaëlle N. Roy, Institut Supérieur de l'Aéronautique et de l'Espace (ISAE-SUPAERO), FranceReviewed by:
Mehdi Senoussi, Ghent University, BelgiumDaniel M. Roberts, Proactive Life, Inc., United States
Copyright © 2022 Hölle, Blum, Kissner, Debener and Bleichner. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Daniel Hölle, ZGFuaWVsLmhvZWxsZUB1b2wuZGU=