 Ruedi Stoop
Ruedi Stoop- Institute of Neuroinformatics, University and ETH of Zürich, Zurich, Switzerland
Hearing is one of the human’s foremost sensors; being able to hear again after suffering from a hearing loss is a great achievement, under all circumstances. However, in the long run, users of present-day hearing aids and cochlear implants are generally only halfway satisfied with what the commercial side offers. We demonstrate here that this is due to the failure of a full integration of these devices into the human physiological circuitry. Important parts of the hearing network that remain unestablished are the efferent connections to the cochlea, which strongly affects the faculty of listening. The latter provides the base for coping with the so-called cocktail party problem, or for a full enjoyment of multi-instrumental musical plays. While nature clearly points at how this could be remedied, to achieve this technologically will require the use of advanced high-precision electrodes and high-precision surgery, as we outline here. Corresponding efforts must be pushed forward by coordinated efforts from the side of science, as the commercial players in the field of hearing aids cannot be expected to have a substantial interest in advancements into this direction.
Introduction
Comparing vision with hearing demonstrates that humans depend as much on auditory as on visual inputs. The compensation of corresponding sensory deficits is, at least in milder cases, much simpler and more successful in the visual domain (glasses and lenses) than in audition.
To improve hearing, in extension of the hollow hand, humans used early on animal horns and hallow bones, cf. Figure 1. Later on, these solutions were succeeded by more efficient ear trumpets, made of metal. All of these remedies worked via the bundling of the arriving sound waves at the level of the outer ear. As is shown by the limited influence of the outer ear on the hearing threshold, see Figure 2, this strategy is able to contribute to speech and sound intelligibility only to a limited extent.
FIGURE 1. Horns used as hearing devices. From (Kircher, 1673).
FIGURE 2. Human hearing threshold. Black dashed vertical lines delimit the proper frequency range of the Hopf cochlea model composed of 30 discretized sections of excitabilities (“Hopf parameters”) μ, centered around decaying center frequencies CF (cf. text references for the model); red vertical lines delimit the area of outer ear influence. Gray curves: data from Zwicker's publication Zwicker and Heinz, 1955, extrapolations thereof dashed. Gray shading: observed human variability. Adapted from (Kanders et al., 2017).
Whereas weakness in visual focusing can be compensated by optical glasses, a convincing idea of how to cope with corresponding problems in the auditory field seems to be still missing. Present outer-ear artificial hearing aids, as well as inner-ear cochlear implants, have not yet made any serious attempt to restore the active processes that are naturally involved in biological hearing. Digital hearing aids use computer chip technology to convert sound waves into digital signals, which opens the road to complex input signal processing. As most hearing aid users value speech intelligibility as their top priority, speech enhancers, directional microphones, and noise and feedback cancellation come standard with top-of-the-line hearing aids, helping their users to hear speech even in loud and noisy environments. Among the biggest achievements presented, they process auditory signals according to input volume: Soft speech is made audible, while loud speech is kept comfortable. These implemented capabilities are mostly helpful if an intrinsically useful signal (e.g., speech) is to be separated from an intrinsically un-useful disturber (e.g., noise). As soon as we deal with several signals of potential similar importance (e.g., two speakers), the task becomes a difficult one. Regarding a separation of individual voices from a mixture of voices (the so-called cocktail problem), as well as regarding the perception of music, the results remain to be rather limited, if compared to the human faculty.
EMOCS at the Heart of Artificial Hearing Aids Problems
The heart of the problem that prohibits hearing aids from making more substantial progress comes from two sides. The most advanced hearing aids boast that, in contrast to competitors, they start to distort by their processing input only above 113 dB SPL “Combining this with a music program that allows as little interaction as possible from the more advanced features in the hearing aid, this higher maximum input level allows musicians to enjoy music even in one of these sophisticated hearing aids” (University of Colorado at, 2017; Croghan et al., 2014). This hints at that digital filter and amplification approaches applied to the input signal are too complicated, and inefficient. For digital implementations of the correctly understood nature of the inner ear (the cochlea), neither this (see Figures 2, 3), nor the reproduction of all salient features of human “psychoacoustic” hearing, are difficult tasks (cf. Kern, 2003; Kern and Stoop, 2003; Stoop and Kern, 2004a; Stoop and Kern, 2004b; Martignoli and Stoop, 2010; Gomez and Stoop, 2014; Kanders et al., 2017).

FIGURE 3. Close-to-biology small signal amplifier implementation, including subcritical tuning and influence of cochlear fluid (endolymph). Hopf cochlea covering 14.08–0.44 kHz with 20 sections; output at Section 5 (CF = 6.79 kHz), stimulation by pure tones. Numbers denote input levels in dB; CF: section’s central frequency. (A) Response in dB, (B) gain in dB; a difference of 33 dB in peak gain for two input levels differing by 70 dB corresponds to observations in chinchilla (between 20 and 90 dB SPL curves, 32.5 + dB (Ruggero et al., 1997)). (C) Tuning curves for fixed output levels. Numbers denote input levels in dB; CF: section’s central frequency.
As such a sensor can easily be combined with present-day cochlear implant stimulation electrodes, the real challenge to be solved is the cocktail-party problem. In current hearing aid technology, directional microphones are still the top-notch solution for this problem, although in the meantime methods that use the properties of the sources have been demonstrated to work extremely well (but come with some computational demand). In one of these approaches (Kern and Stoop, 2011), a speaker’s main sound properties are extracted using wavelet-like filters and adapted to changing speech by the “matching pursuit approach”. The work showed that deterministic signal features can be exploited for signal separation of several voices under quite general conditions, which reaches far beyond the noise-speech issue handled by current-day hearing aids (Author Anonyms, 2022).
The core of this approach was borrowed from how mammalian (and to a large extent more general: animal) hearing is embedded into feedback loops telling the hearing sensor what to listen to. The lack of an appropriate embedding of the hearing aids into the natural sensory network physiology is the main obstacle against arriving at better hearing aids. The cochlea, the mammalian hearing sensor, hosts in the case of humans at birth, on the order of 3,500 inner hair cells and 12,000 outer hair cells. Outer hair cells amplify the shallow fluid surface waves into which the hearing sensor has converted arial sounds after their arrival at the cochlea (Kern, 2003; Kern and Stoop, 2003). Unfortunately, ageing and inflammatory processes strongly affect—almost exclusively—the outer hair cells in an irreversible manner; the inner hair cells that pick up the amplified wave signals and relay them onwards to the cortex, remain generally unaffected. Biological studies have established that hearing is additionally embedded into several neural loops. In the past, this has been described to great physiological details in the works of Spoendlin (Spoendlin, 1966a; Spoendlin, 1966b), see Figure 4. Most of the current-day’s drawings of the cochlear innervation details are based, often without mentioning, on that work.
FIGURE 4. Mammalian listening circuit. Adapted from (Spoendlin, 1966b).
From these and ensuing physiological studies on, the purpose of the eminent innervation of the organ of Corti by means of efferent, almost exclusively inhibitory, connections has remained an open problem. The general belief was that they could play a role in the coding of the sound towards neural signals, cf. (Spoendlin, 1966b). The main argument for the particular innervation by efferent cochlear neurons appears to have been that (quotes from Ref. (Spoendlin, 1966b)) “a great number of even small inputs could generate and action potential at the initial segment,” “the role of the efferent fibres for the coding of the acoustic message at the level of the organ of Corti is not yet entirely understood. The only directly demonstrated action is an inhibitory effect on the afferent nerve impulses. This inhibition is, however, not very strong and it is hard to believe that such ab extensive efferent innervation system in the cochlear receptor would have only such a limited function. It is more likely that the efferent fibres have a much more complex function than this relatively restricted inhibition which can be measured. They might influence the afferent impulses in a more qualitative than quantitative fashion,” “Many different phenomena of the auditory physiology might depend on the efferent innervation of the cochlea. However, only a few have been directly demonstrated hitherto as for the adaptation phenomenon,” “As long as these coding mechanisms can not be simulated, an artificial cochlea will only provide a very rudimentary function”. After Spoendlin, this view persisted, in essence, until today.
How EMOCS Work
In our view, these loops, however, foster the biological need of mammals to identify a large spectrum of pre-defined relevant signals as follows. Mathematically, the properties of the outer hair-cells can be represented by dynamical systems that are close to a Hopf bifurcation and act as small-signal amplifiers (Derighetti et al., 1985; Wiesenfeld and McNamara, 1985; Wiesenfeld and McNamara, 1986; Camalet et al., 2000; Eguíluz et al., 2000; Duke and Jülicher, 2003; Kern, 2003; Kern and Stoop, 2003; Magnasco, 2003). Systems close to a Hopf bifurcation not only depend on the input strength and frequency of the stimulating signal, but also on how close the system actually is to the Hopf bifurcation (whereas in the concurrent approach of Refs. (Eguíluz et al., 2000; Magnasco, 2003), this point was left open, in Refs. (Camalet et al., 2000; Duke and Jülicher, 2003), systems were required to be poised exactly at the bifurcation point). The distance to the bifurcation point is the main element that rules the amplifier’s specificity, see Figure 5. Moreover, this feature provides the access point for the embedding of the sensor into the physiological network.
FIGURE 5. Single Hopf amplifier response (Kern, 2003; Kern and Stoop, 2003), describing the behaviour of outer hair cells with a preferred frequency CF embedded into the basilar membrane. Frequency selectivity regarding different distances μ ∈ { − 0.05, − 0.1, − 0.2, − 0.4, − 0.8} from bifurcation point (showing slightly more asymmetry if compared to Figure 3).
There is strong biological evidence that EMOCS (efferent medial olivocochlear stimulations) regulate the Hopf elements’ distances to the bifurcation point, see Figure 6, most likely in a stronger manner than originally anticipated by Spoendlin. Activated EMOCS drive the system away from the bifurcation point, exerting in this way an inhibitory effect on the targeted Hopf amplifiers, see Figure 7. Changed individual amplification entrains striking effects at the level of the whole sensory organ. A recent work (Stoop and Gomez, 2016) focused on the excitation network from the nonlinear interaction of excited amplifiers generating combination tones. It was shown that under absence of EMOCS, signals of two complex tones of random amplitude and frequency, generated “activation networks” with the size s of links being distributed according the typical critical branching network paradigm (exponent a = 3/2, at − 60 dB input, the typical strength of human speech). Stronger input ( − 50 dB) yields distributions that are typical for supercritical states, whereas upon EMOC activation, the distributions change into a subcritical shape. This reveals that at the most relevant working condition, the system’s information-receiving predisposition is at criticality, whereas listening (implemented by means of EMOCS) is characterized by subcritical states (Lorimer et al., 2015).
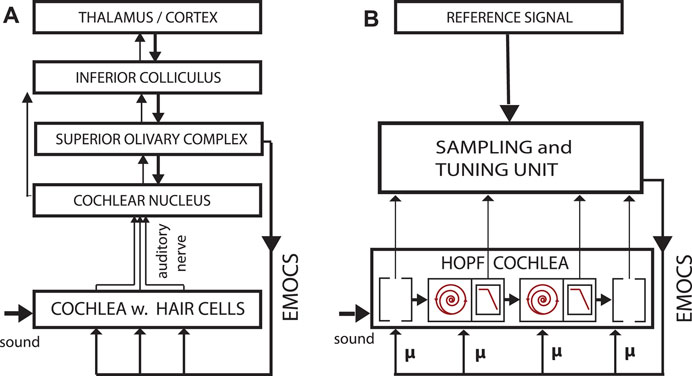
FIGURE 6. (A) Biological vs. (B) artificial implementation of the hearing—listening circuit. Listening is a dedicated activity that requests and represents a particular computational effort, involving “EMOCS” (efferent medial olivocochlear stimulations), adapted from (Kern and Stoop, 2011).
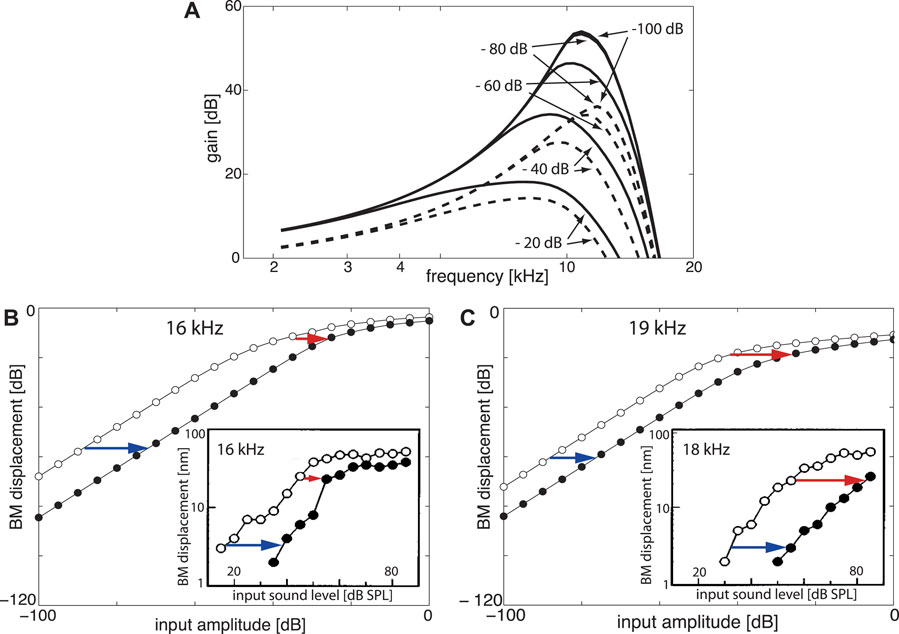
FIGURE 7. EMOCS effects: (A) Gain isointensity curves at Section 5 (fch = 1.42 kHz) without (solid lines) and with (dashed lines) EMOC input. From flat tuning (μ = −0.1 for all sections, EMOC stimulation is implemented by shifting to μ5 = −1.0 ( − 80 and − 100 dB lines collapse). (B) Upon 16 and (C) 19 kHz pure tone EMOCS, implemented by a shift from a flat tuned cochlea from μ2 = −0.05 to μ2 = −0.5, BM levels at Section 2 (fch = 16.99 kHz) shift from open circles to full circles. Insets: Corresponding animal experiments (Russell and Murugasu, 1997).
Listening to Sounds
In the following we demonstrate how EMOCS represent the faculty of listening at the biological level. For this, we reinterpret earlier results (Gomez et al., 2014) on sound separation from mixtures of sounds, see Figure 8.
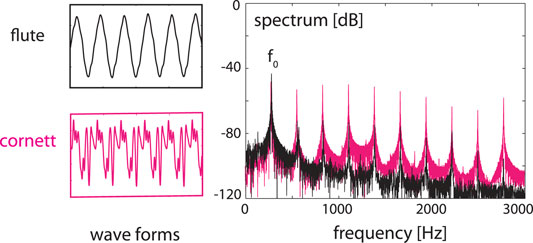
FIGURE 8. Sounds of a cornett and a flute (left) at the same fundamental frequency f0, superimposed (right), static case.
To achieve separation, the listening process fosters a previously identified subset of amplifiers, disposing amplifiers that are not associated with the desired signal. This process is implemented in biology with the help of information from the brain, mediated by means of EMOCS: Nerves leading from the brain to the cochlea via medial olivocochlear stimulation suppress the efficacy of the targeted cochlea sections by, technically speaking, pushing corresponding Hopf amplifiers further away from their point of bifurcation, cf. Figure 4. The correctness of this translation from biology to the model has, we re-iterate, been fully corroborated by the available data from the biological effects by EMOCS in Figure 7.
In Figure 9 we report the result of our biomorphic implementation of the listening process, where in subpanel a) we show how the tuning of the amplifiers changes, as the target object, the musical organ, increases its fundamental frequency in time. To assess how close we arrive to the target, we use our tuning error measure TE that has the expression
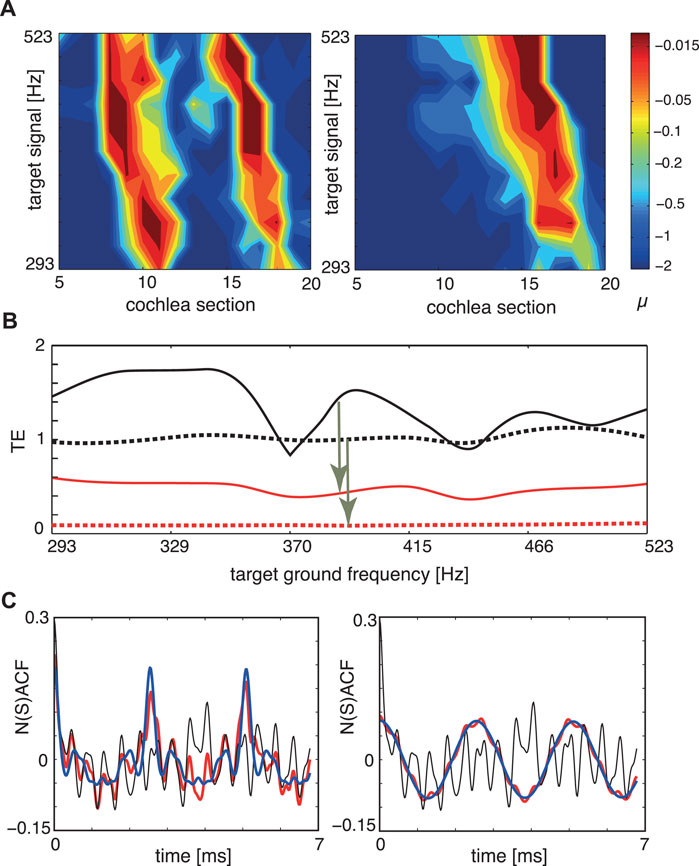
FIGURE 9. Sound separation, dynamic case, where the target instrument changes the height of the generated tone: (A) Tuning patterns, dynamical case. Colors indicate the Hopf parameter values of the sections. Left: Cornett vs. flute (disturber). Right: Flute vs. cornett (disturber). (B) TE for the two target signals of (A). Flat tuning: black; μ-tuning: red. Full: cornett target, dashed: flute target. Arrows indicate improvements by EMOCS. (C) NSACF, NACF for the two target signals of (A,B) at a chosen target ground frequency. Flat tuning: black, μ-tuning: red, target signal: blue. Targets at 392 Hz, disturbers at 2,216 Hz. After Ref. (Gomez et al., 2014).
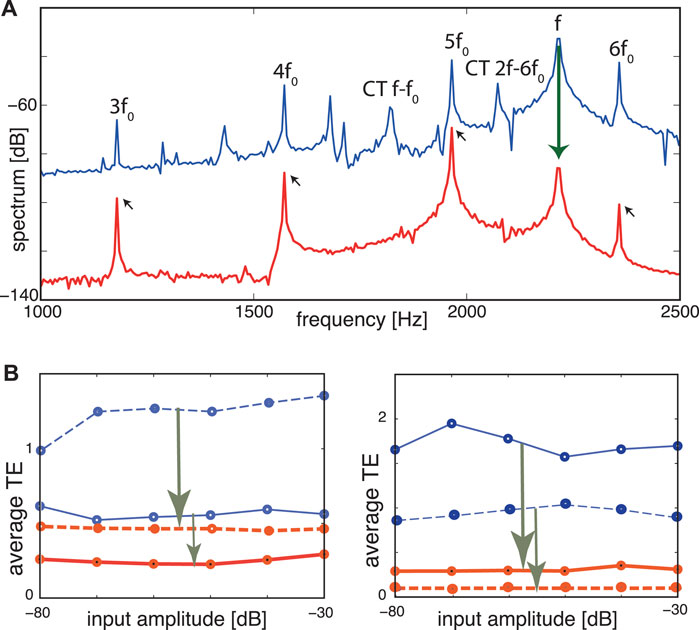
FIGURE 10. TE improvement by μ-tuning, static case. (A) Frequency spectrum at Section 8 (CF = 1964 Hz). Blue: Flat tuning (−80 dB, target cornett f0 = 392 Hz, disturber flute f = 2,216 Hz). Cross-combination tones (CT, two explicitly labeled) between the flute’s fundamental f and higher harmonics of the cornett are clearly visible. Red: Optimized tuning. f (flute) and cross-combination frequencies are suppressed, leaving a harmonic series of the target (small arrows). (B) Averaged TE over 13 different fundamental target frequencies (steps of 1 semitone) demonstrates input amplitude independence. Blue lines: flat tuning. Red lines: optimized μ-tuning. Left panel: (full lines) target sound cornett (277–554 Hz), disturbing sound flute (at 277 Hz); (dashed lines) same target but flute at 2,216 Hz. Right panel: same experiment with target and disturber interchanged. TE improvements: arrows in (B). From (Gomez et al., 2014).
A second principle that comes to the aid of the EMOCS is the particular efferent innervation within the cochlea, see Figure 11. The particular arrangement of the innervation of out hair cells expresses a feedforward signal-coupling scheme that has been analyzed in Ref. (Gomez et al., 2016), with the result that such an arrangement fosters a collective signal-sharping, as is demonstrated in Figure 12. Such a signal sharpening may explain the surprising frequency discrimination (Spoendlin, 1966b) of the mammalian hearing sensor. To exhibit this, we consider two frequency-rescaled unforced Hopf systems that interact via their output signals (i.e., perform a “signal-coupling”), which yields

FIGURE 11. Cochlear hair-cells innervation.
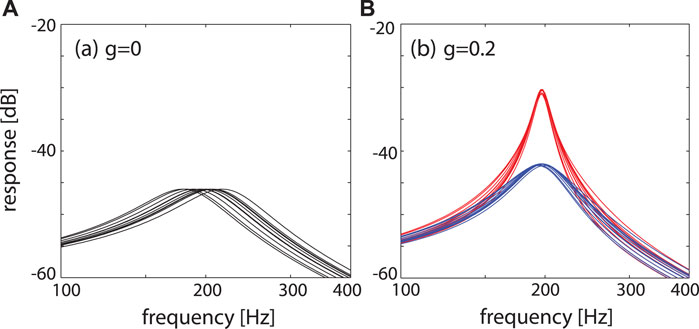
FIGURE 12. Effects of signal coupling. Response of N = 10 systems, characteristic frequencies distributed around 200 Hz, to a test signal of amplitude − 60 dB. (A) Uncoupled, μ = −0.2, (B) signal-coupled (blue: μ = −0.3, red: μ = −0.2), exhibiting a coherent and sharply tuned response around fc ≃ 200 Hz. From (Gomez et al., 2016).
A Program for Solving the Listening Problem
For the implementation of the full physiological hearing circuitry, we propose to use a recording array for the efferent signals to the cochlea, that will serve to tune the Hopf cochlea away from the “normally” distributed μ's (that decay slowly along the cochlea, see (Gomez and Stoop, 2014; Kanders et al., 2017)), reflecting in this way the will of the listener to focus on the remaining signal part. In the recording unit, the efferent nerves are grouped according to the intrinsic biological resolution modulo the available micro-surgical possibilities. The grouped signal then modifies the Hopf cochlear amplification such that the input signal to the cochlea is selectively amplified in the described manner, whereupon it is sent towards the stimulation electrodes of the inner hair cells, see Figure 13. With such a setting—that we hope to be feasible in the near future—hearing could become fully restored, reconciling the limitations of present-day hearing aids.
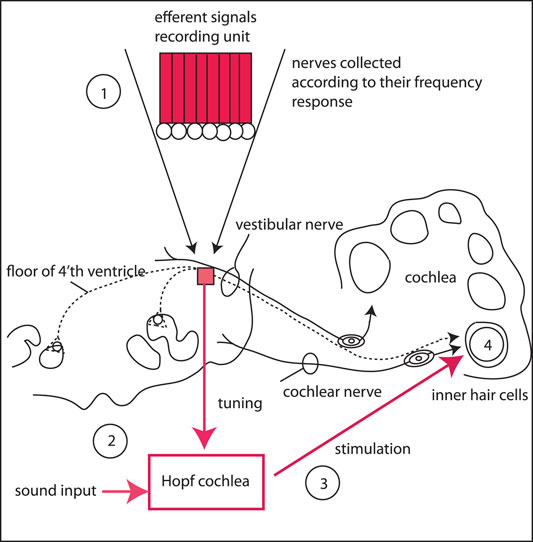
FIGURE 13. Proposed solution of the listening problem: Using a recording array for the efferent signals to the cochlea (1), the Hopf cochlea (2) is tuned away from the “flat” (i.e., normally distributed μ's) according to the will of the listener. The tuned amplified signal is then sent to the stimulation electrodes (3) of inner hair cells (4). In the recording unit (1), the efferent nerves are grouped according to their frequency response and subject to the micro-surgical limitations.
Conclusion
Our work opens a perspective towards the development of more adequate cochlear implant hearing aids, responding to the listener’s desire for the selection of particular sounds. This is of importance for the cocktail party problem as well as for listening to many-instrumental music. With the recognition of the physiological network that hearing is embedded in, and with the proper re-embedding of the biomorphic Hopf cochlea (Stoop et al., 2008) into this physiological network, we can reach far beyond of what is presently achievable by present-day hearing sensor technology. The task to achieving this in the near future should, however, preferentially not be delegated the hearing-aid industry, as the latter cannot be too much interested in the corresponding shift from digital engineering to high-precision micro-surgery, required for the embedding of the sensor into the physiological network of hearing.
Data Availability Statement
The original contributions presented in the study are included in the article, further inquiries can be directed to the corresponding author.
Author Contributions
The author confirms being the sole contributor of this work and has approved it for publication.
Conflict of Interest
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Author Anonyms, , Stoop, R., and Gomez, F. (2022). Even the Perception of Harmonic vs. Non-harmonic Sounds Can Be Derived from the Physics of the Hopf Cochlea. (manuscript in preparation 2022).
Camalet, S., Duke, T., Jülicher, F., and Prost, J. (2000). Auditory Sensitivity provided by Self-Tuned Critical Oscillations of Hair Cells. Proc. Natl. Acad. Sci. U.S.A. 97, 3183–3188. doi:10.1073/pnas.97.7.3183
Croghan, N. B., Arehart, K. H., and Kates, J. M. (2014). Music Preferences with Hearing Aids: Effects of Signal Properties, Compression Settings, and Listener Characteristics. Ear Hear 35, e170–84. doi:10.1097/AUD.0000000000000056
Derighetti, B., Ravani, M., Stoop, R., Meier, P. F., Brun, E., and Badii, R. (1985). Period-doubling Lasers as Small-Signal Detectors. Phys. Rev. Lett. 55, 1746–1748. doi:10.1103/physrevlett.55.1746
Duke, T., and Jülicher, F. (2003). Active Traveling Wave in the Cochlea. Phys. Rev. Lett. 90, 158101–158104. doi:10.1103/physrevlett.90.158101
Eguíluz, V. M., Ospeck, M., Choe, Y., Hudspeth, A. J., and Magnasco, M. O. (2000). Essential Nonlinearities in Hearing. Phys. Rev. Lett. 84, 5232–5235. doi:10.1103/physrevlett.84.5232
Fastl, H., and Zwicker, E. (2007). Psychoacoustics - Facts and Models. 3rd edition. Berlin): Springer-Verlag.
Gomez, F., Lorimer, T., and Stoop, R. (2016). Signal-coupled Subthreshold Hopf-type Systems Show a Sharpened Collective Response. Phys. Rev. Lett. 116, 108101. doi:10.1103/physrevlett.116.108101
Gomez, F., Saase, V., Buchheim, N., and Stoop, R. (2014). How the Ear Tunes in to Sounds: A Physics Approach. Phys. Rev. Appl. 1, 014003. doi:10.1103/physrevapplied.1.014003
Gomez, F., and Stoop, R. (2014). Mammalian Pitch Sensation Shaped by the Cochlear Fluid. Nat. Phys 10, 530–536. doi:10.1038/nphys2975
Kanders, K., Lorimer, T., Gomez, F., and Stoop, R. (2017). Frequency Sensitivity in Mammalian Hearing from a Fundamental Nonlinear Physics Model of the Inner Ear. Sci. Rep. 7, 9931–9938. doi:10.1038/s41598-017-09854-2
Kern, A. (2003). A Nonlinear Biomorphic Hopf-Amplifier Model of the Cochlea. PhD Thesis ETH No. 14915 (Zürich, Switzerland: ETH Zurich).
Kern, A., and Stoop, R. (2003). Essential Role of Couplings between Hearing Nonlinearities. Phys. Rev. Lett. 91, 128101. doi:10.1103/physrevlett.91.128101
Kern, A., and Stoop, R. (2011). Principles and Typical Computational Limitations of Sparse Speaker Separation Based on Deterministic Speech Features. Neural Comput. 23, 2358–2389. doi:10.1162/neco_a_00165
Kircher, A. (1673). Phonurgia nova Sive Conjugium Mechanico-Physicum Artis & Naturae Paranympha Phonosophia Concinnatum (R. Dreherr, Kempten).
Lorimer, T., Gomez, F., and Stoop, R. (2015). Two Universal Physical Principles Shape the Power-Law Statistics of Real-World Networks. Sci. Rep. 5, 12353. –8. doi:10.1038/srep12353
Magnasco, M. O. (2003). A Wave Traveling over a Hopf Instability Shapes the Cochlear Tuning Curve. Phys. Rev. Lett. 90, 058101058104. doi:10.1103/PhysRevLett.90.058101
Martignoli, S., and Stoop, R. (2010). Local Cochlear Correlations of Perceived Pitch. Phys. Rev. Lett. 105, 048101. doi:10.1103/PhysRevLett.105.048101
Ruggero, M. A., Rich, N. C., Recio, A., Narayan, S. S., and Robles, L. (1997). Basilar-membrane Responses to Tones at the Base of the chinchilla Cochlea. The J. Acoust. Soc. America 101, 2151–2163. doi:10.1121/1.418265
Russell, I. J., and Murugasu, E. (1997). Medial Efferent Inhibition Suppresses Basilar Membrane Responses to Near Characteristic Frequency Tones of Moderate to High Intensities. J. Acoust. Soc. America 102, 1734–1738. doi:10.1121/1.420083
Spoendlin, H. (1966). “The Innervation of the Organ of Corti,” in Symposium on Electron Microscopy (London: Inst. of Laryngology and Otology), 717–738.
Spoendlin, H. (1966). The Organization of the Cochlear Receptor. Fortschr Hals Nasen Ohrenheilkd 13, 1-227.
Stoop, R., and Gomez, F. (2016). Auditory Power-Law Activation Avalanches Exhibit a Fundamental Computational Ground State. Phys. Rev. Lett. 117, 038102. doi:10.1103/PhysRevLett.117.038102
Stoop, R., and Kern, A. (2004). Two-tone Suppression and Combination Tone Generation as Computations Performed by the Hopf Cochlea. Phys. Rev. Lett. 93, 268103. doi:10.1103/PhysRevLett.93.268103
Stoop, R., and Kern, A. (2004). Essential Auditory Contrast-Sharpening Is Preneuronal. Proc. Natl. Acad. Sci. U.S.A. 101, 9179–9181. doi:10.1073/pnas.0308446101
Stoop, R., Kern, A., and Vyver, V. D. J. P. (2008). Sound Analyzer Based on a Biomorphic Design. US Patent US20080197833A1 (Zürich, Switzerland: Universitaet Zuerich).
University of Colorado at Boulder (2017). When Hearing Aid Users Listen to Music, Less Is More. ScienceDaily 27. www.sciencedaily.com/releases/2014/10/141027145056.
Wiesenfeld, K., and McNamara, B. (1985). Period-doubling Systems as Small-Signal Amplifiers. Phys. Rev. Lett. 55, 13–16. doi:10.1103/physrevlett.55.13
Wiesenfeld, K., and McNamara, B. (1986). Small-signal Amplification in Bifurcating Dynamical Systems. Phys. Rev. A. 33, 629–642. doi:10.1103/physreva.33.629
Keywords: hearing network physiology, hearing aids, listening process, source separation, cochlear embedding, hair cells innervation
Citation: Stoop R (2022) Why Hearing Aids Fail and How to Solve This. Front. Netw. Physiol. 2:868470. doi: 10.3389/fnetp.2022.868470
Received: 02 February 2022; Accepted: 14 March 2022;
Published: 25 April 2022.
Edited by:
Plamen Ch. Ivanov, Boston University, United StatesReviewed by:
Sebastiano Stramaglia, University of Bari Aldo Moro, ItalyGiorgio Mantica, University of Insubria, Italy
Copyright © 2022 Stoop. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ruedi Stoop, cnVlZGlAaW5pLnBoeXMuZXRoei5jaA==