 Alexandra J. Lukasiewicz1
Alexandra J. Lukasiewicz1 Abigail N. Leistra2Lily Hoefner3
Abigail N. Leistra2Lily Hoefner3 Erika Monzon2Cindy J. Gode4Bryan T. Zorn4Kayley H. Janssen5Timothy L. Yahr5,6
Erika Monzon2Cindy J. Gode4Bryan T. Zorn4Kayley H. Janssen5Timothy L. Yahr5,6 Matthew C. Wolfgang4,7
Matthew C. Wolfgang4,7 Lydia M. Contreras2*
Lydia M. Contreras2*- 1Department of Molecular Biosciences, The University of Texas at Austin, Austin, TX, United States
- 2McKetta Department of Chemical Engineering, The University of Texas at Austin, Austin, TX, United States
- 3Department of Biology, The University of Texas at Austin, Austin, TX, United States
- 4Marsico Lung Institute, University of North Carolina at Chapel Hill, Chapel Hill, NC, United States
- 5Department of Microbiology and Immunology, University of Iowa, Iowa, IA, United States
- 6Bellin College, Green Bay, WI, United States
- 7Department of Microbiology and Immunology, University of North Carolina at Chapel Hill, Chapel Hill, NC, United States
Pseudomonas aeruginosa (PA) is a ubiquitous, Gram-negative, bacteria that can attribute its survivability to numerous sensing and signaling pathways; conferring fitness due to speed of response. Post-transcriptional regulation is an energy efficient approach to quickly shift gene expression in response to the environment. The conserved post-transcriptional regulator RsmA is involved in regulating translation of genes involved in pathways that contribute to virulence, metabolism, and antibiotic resistance. Prior high-throughput approaches to map the full regulatory landscape of RsmA have estimated a target pool of approximately 500 genes; however, these approaches have been limited to a narrow range of growth phase, strain, and media conditions. Computational modeling presents a condition-independent approach to generating predictions for binding between the RsmA protein and highest affinity mRNAs. In this study, we improve upon a two-state thermodynamic model to predict the likelihood of RsmA binding to the 5′ UTR sequence of genes present in the PA genome. Our modeling approach predicts 1043 direct RsmA-mRNA binding interactions, including 457 novel mRNA targets. We then perform GO term enrichment tests on our predictions that reveal significant enrichment for DNA binding transcriptional regulators. In addition, quorum sensing, biofilm formation, and two-component signaling pathways were represented in KEGG enrichment analysis. We confirm binding predictions using in vitro binding assays, and regulatory effects using in vivo translational reporters. These reveal RsmA binding and regulation of a broader number of genes not previously reported. An important new observation of this work is the direct regulation of several novel mRNA targets encoding for factors involved in Quorum Sensing and the Type IV Secretion system, such as rsaL and mvaT. Our study demonstrates the utility of thermodynamic modeling for predicting interactions independent of complex and environmentally-sensitive systems, specifically for profiling the post-transcriptional regulator RsmA. Our experimental validation of RsmA binding to novel targets both supports our model and expands upon the pool of characterized target genes in PA. Overall, our findings demonstrate that a modeling approach can differentiate direct from indirect binding interactions and predict specific sites of binding for this global regulatory protein, thus broadening our understanding of the role of RsmA regulation in this relevant pathogen.
1 Introduction
Pseudomonas aeruginosa (PA) is a widespread, opportunistic pathogen that contributes to nosocomial infection and mortality in immunocompromised individuals. Critical to pathogenesis is the ability of PA to rapidly alter gene expression to respond to the environment. The post-transcriptional regulator RsmA, a member of the CsrA family of RNA-binding proteins (RBPs), achieves this rapid response via post-transcriptional regulation. RsmA is a 6.9 kDa homodimeric protein whose regulatory influence is of clinical relevance as it regulates the expression of genes involved in motility, cell adhesion (Brencic and Lory, 2009), biofilm formation (Irie et al., 2010), and secretion of effector proteins (Brencic and Lory, 2009).
The mechanism by which Rsm/Csr family proteins repress translation is by blocking ribosomal pairing to the Ribosome Binding Site (RBS) present in the 5′ untranslated region (UTR) of an mRNA (Liu et al., 1995; Mercante et al., 2009). This can occur through direct binding to and occlusion of the RBS sequence, or through binding in adjacent regions that result in structural rearrangement that reduces (Irie et al., 2010) or increases (Ren et al., 2014) accessibility of the RBS. In PA, the RsmA protein exerts tight control of pathways associated with planktonic colonization and sessile biofilm forming states (Goodman et al., 2004). In addition, PA also encodes for the CsrA paralog RsmF/N (Marden et al., 2013; Morris et al., 2013) which binds and regulates overlapping (Romero et al., 2018) and exclusive (Chihara et al., 2021) genes relative to RsmA. The regulatory activity of RsmA itself is sensitive to control by the GacA/GacS two-component signaling (TCS) pathway, which activates expression of antagonistic sRNA sponges RsmY and RsmZ (Brencic et al., 2009) that sequester the RsmA protein. Upon sequestration by these sRNA sponges, the regulatory effect of RsmA is inhibited and produces an inverse effect on translation of directly bound mRNAs. RsmA binds and regulates genes globally throughout the transcriptome. RsmA knockout results in large phenotypic changes to the cell including decreased infection phenotypes (Irie et al., 2020), impedes active colonization, and promotion of chronic infection states (Mulcahy et al., 2008).
Full characterization of the binding repertoire of a post-transcriptional regulator, such as RsmA, is difficult to adequately capture using a single high throughput approach (Sowa et al., 2017). Wide variety in gene expression and regulatory effects have been observed for Csr/Rsm family proteins due to various stresses or infectious states (Chourashi and Oglesby, 2024; Potts et al., 2019). This is partially due to the fact that the pathways that govern the cellular transition from active colonization to chronic biofilm forming states are complex, deeply interlinked, and sensitive to the experimental contexts they are studied in (Valentini et al., 2018).
Efforts to experimentally map the regulatory influence of RsmA range from broad, high throughput sequencing screens to individual in vitro biochemical assays. Overall, these high throughout approaches have estimated a target pool of approximately 500 genes that are either directly or indirectly regulated by RsmA (Brencic and Lory, 2009; Romero et al., 2018; Chihara et al., 2021; Burrowes et al., 2006; Gebhardt et al., 2020). Direct binding has been biochemically confirmed in vitro for fewer than 2% of this estimated pool of 500 genes. To date, confirmed direct bound mRNA targets of RsmA include tssA1, fha1, magA (Brencic and Lory, 2009), psl (Irie et al., 2010), rahU, algU, pqsR, hxuI (Kulkarni et al., 2014), mucA (Romero et al., 2018), and retS (Corley et al., 2022).
While sequencing approaches have been valuable for understanding the breadth of regulation influenced by the Gac/Rsm pathway, they may not capture potential targets due to low gene expression, strain to strain variation, condition dependent expression, heterogenous expression, sample manipulation, or high limits of detection. For example, microarray, RNA-seq, and proteomic screens fall short when assessing whether post-transcriptional regulation is occurring in a direct (i.e., direct binding of RBP to transcript) or indirect (i.e., network) manner. RNA-seq based approaches can also lose detection of transcripts that are not always degraded when bound by a post-transcriptional regulator, which convolute differential expression-based analyses; thus, missing potential targets of the protein (Baker et al., 2007). In contrast, cross-linking immunoprecipitation (CLIP) and RNA immunoprecipitation (RIP) sequencing approaches can identify more direct binding interactions; however, data resulting from these techniques lose positional resolution for mRNA binding sites for small proteins like RsmA. In addition, cross-linking can introduce false positives due to nonspecific linkages between the protein of interest and nearby RNA. Finally, many available high throughput datasets are limited to a narrow range of growth phase, strain, and media conditions that do not capture the full diversity of conditions the organism experiences natively. This presents a bottleneck in discovery, as gene expression varies widely across experimental conditions (Rajput et al., 2022) and can be influenced by extensive strain diversity (Lebreton et al., 2021; Trouillon et al., 2021).
Computational modeling offers a condition-independent method for predicting binding partners of globally binding proteins. Thermodynamic models of protein-RNA interactions have demonstrated high predictive capabilities, such as that for the PUF4 protein interactions in Saccharomyces cerevisiae (Sadée et al., 2022). Similarly, thermodynamic models to predict binding and translation rates for ribosomes (Salis, 2011; Espah Borujeni et al., 2014) have been used for both prediction of native translation and forward design of effective RBS sequences (Salis et al., 2009). Although the small handful of confirmed, direct RsmA targets limits the ability to generate accurate models of binding using learning algorithms, much more data of direct targets has been collected for its closely related protein CsrA as genome wide screens have been performed to predict binding sites of the CsrA protein. In 2014, a sequence-based model was crafted for the Csr/Rsm family proteins to identify potential targets within transcriptomes of Escherichia coli, P. aeruginosa, L. pneumatophilia, and S. enterocolitica (Kulkarni et al., 2014). In this work, we improve upon this approach by applying a biophysical model of interaction built upon additional molecular features that influence binding which yields an energetic prediction for the probability of an interaction between RsmA and an mRNA in P. aeruginosa.
The Escherichia coli CsrA protein has been shown to be well suited for construction of a biophysical model of protein-RNA binding with characterized, empirically-derived, parameters (Leistra et al., 2018), as core elements of binding mechanism that governs its post-transcriptional regulatory effect have been biochemically assessed. These principal rules of interaction include (1) the clear definition of a core ANGGA binding motif (Dubey et al., 2005), (2) the energetic contribution of individual nucleotides within the core motif, (3) establishing a minimal distance between binding sites to reduce steric hindrance within the homodimer (Mercante et al., 2009), and (4) position of binding within stem loop structures of the bound RNA (Dubey et al., 2005; Figures 1A–E; Supplementary Figure S1). Previously, these core rules were leveraged to craft a biophysical model to observe binding patterns of the CsrA protein in E. coli (Leistra et al., 2018) which yielded insights in the various molecular features that influence CsrA binding to 236 mRNAs (Leistra et al., 2018).
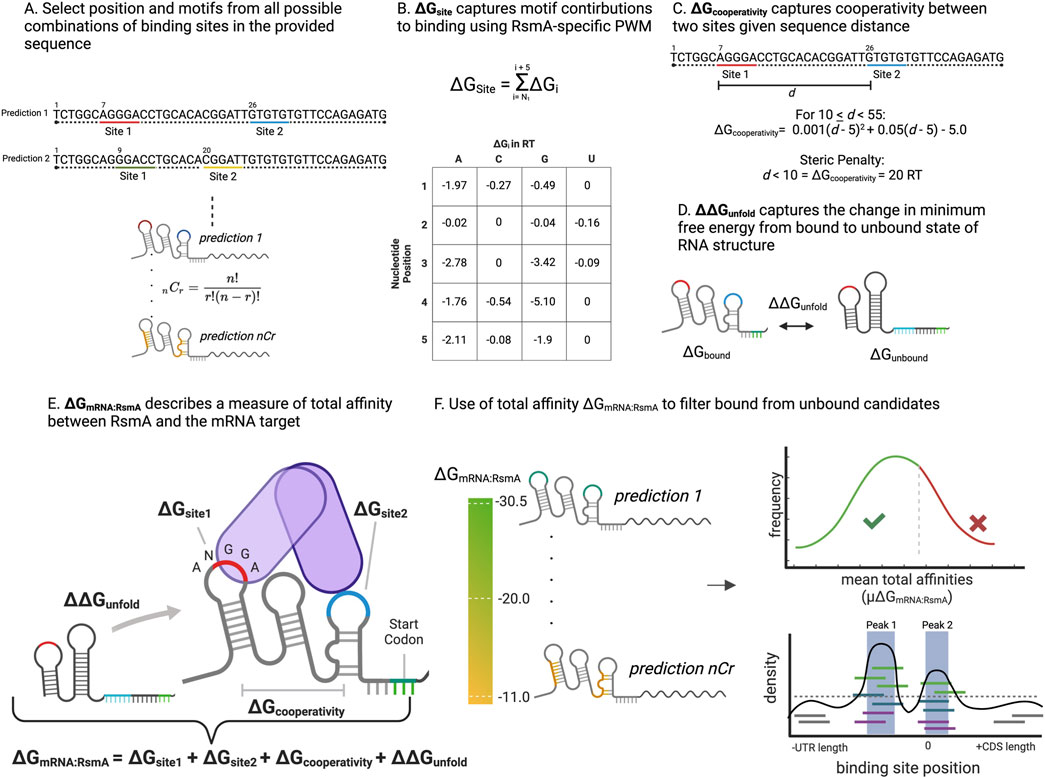
Figure 1. Overview of energy parameters and procedure of the RsmA biophysical model. (A) The modeling procedure begins as described in (Leistra et al., 2018) by selecting the positions of all possible combinations of two Csr/Rsm binding sites along a provided sequence. This allows for the exploration of dimeric binding to thousands of possible conformations per gene. (B) A 5-nucleotide window is selected from each site and scored given the positional energies of binding. In this work, we update the prior model to include contributions from non-canonical nucleotides present in the core motif, and use the scaffold of a Pseudomonas-specific Rsm protein, RsmE. The sum within this 5 nt window makes up the ∆GsiteN variable. (C) For each prediction a parameter describing the optimal distance between binding sites of the homo-dimeric form of the protein, ∆Gcooperativity is calculated given the distance, d, between the 3′ end of site 1 and the 5′ end of site 2. Sites that are too close receive a penalty of 20 RT units, making those conformations highly unfavorable. Sites equal to 55 receive an energy contribution of 0, with more positive penalties incurred with increasing distance. (D) The change in minimum free energy between the unbound and bound mRNA structures are calculated using the RNAfold tool within ViennaRNA, with folding constraints to reflect Csr/Rsm bound regions in the sequence. This change in free energy makes up the ∆∆Gunfold. (E) Each of the terms defined in B-D are summed to generate a measure of total affinity, ∆GmRNA:RsmA per prediction in the full ensemble of predictions per gene. (F) In an update from the model described in (Leistra et al., 2018), the ∆GmRNA:RsmA is used to filter predicted candidates as bound or unbound. This takes into account the distribution of affinities predicted per gene, and is tuned given the distribution of affinities present transcriptome wide. The pool of targets is then filtered by the mean ∆GmRNA:RsmA and the peak height of predicted binding regions. These filtered genes are then forwarded to the OSTIR translation initiation rate calculator to measure translational effect of binding.
Given this established prior framework, we hypothesized that we could employ the core parameters of this model to capture binding and regulation by the CsrA homolog RsmA in P. aeruginosa. Homologs of CsrA are found widely across the γ-proteobacteria (Sobrero and Valverde, 2020; Vakulskas et al., 2015). Within the Pseudomonas genus, homologs such as RsmA and RsmE share high sequence and structural similarity with CsrA (Schubert et al., 2007); the protein sequence of P. aeruginosa RsmA is 85% identical to its ortholog CsrA in E coli (Camacho et al., 2009). Furthermore, similar binding mechanisms. SELEX studies have also shown that the RsmA protein shares high affinity for the same binding motif ANGGA (Schulmeyer et al., 2016), and NMR structural studies of the Pseudomonas protegens homolog RsmE also recapitulated affinity for this core motif (Schubert et al., 2007). In addition, the crystal structures of Csr/Rsm family proteins in complex with RNA are available in the Protein Data Bank for CsrA in E. coli [1Y00], CsrA in Yersinia enterocolitica [2BTI], RsmE in Pseudomonas protegens pf-5 [2MFO and 2JPP], and RsmA in Pseudomonas aeruginosa [7YR7]. In tandem with models that leverage data from protein structures (Kappel and Das, 2019) these data can be used to computationally predict changes in free energy for a given motif.
Here, we modify, tune, validate, and improve upon a prior model constructed for the E. coli CsrA protein (Leistra et al., 2018) to accurately predict breadth of binding and regulation by the RsmA protein across the entire Pseudomonas aeruginosa PA14 transcriptome. This approach allows us to probe the entire sequence space computationally, thus lifting the constraints presented by prior experimental approaches. In an improvement upon our prior model, we consider alternative motifs given the generation of a crystal-structure derived, RsmA-specific, position weight matrix. Unlike GGA motif-based screens, our model also yields predictions regarding the mechanism of binding to a given target including: the approximation of binding strength, diversity of binding peak frequencies, and predicting the effect binding has on translation. We also leverage several publicly available high throughput sequencing datasets to statistically verify the accuracy of our predictions. In doing so, we establish effective filtering cutoffs that differentiate between bound and unbound targets. This yields a pool of 1043 genes predicted to be bound by RsmA, which includes 457 genes with no prior binding evidence. Our pool of filtered predictions is enriched in transcriptional regulators and virulence associated pathways. An important resulting observation of this work is the experimental characterization of two novel transcriptional regulators rsaL and mvaT, mRNA encoding for factors involved in Quorum Sensing and the Type IV Secretion System, among others. In this work, we use model predictions to confirm binding, binding site pockets, and regulation of these mRNAs in vitro and in vivo. This characterization both validates the predictive capabilities of the model and expand upon our understanding of RsmA regulation. Overall, our updated model opens up new avenues for differentiating direct from indirect targets of RsmA and aids in generating hypotheses for the varying regulatory mechanisms governing complex signaling networks in PA.
2 Materials and methods
2.1 Construction of model and definition of energy terms
A free energy model constructed for describing binding by the CsrA protein from E. coli was described in (Leistra et al., 2018). This prior model was applied to a limited number of genes in the E. coli transcriptome, and was crafted using empirically derived parameters for the CsrA protein. In our current approach, we improve upon model throughput to capture interactions transcriptome-wide in a new organism, and craft an updated motif search that considers the nucleotide contributions of bases other than the core ANGGA. This was also tuned to capture RsmA-mRNA interactions using the structure of the Pseudomonas fluorescens RsmE in complex with hcnA [PDB: 2JPP (Schubert et al., 2007)]. The thermodynamic model relies upon the sum of energetic contributions of 3 key parameters: 1) the position weight matrix of individual nucleotide contributions to binding (∆Gsite1 and ∆Gsite2), 2) the change in free energy from the unbound to bound state of the mRNA (∆∆Gunfold), 3) the distance between binding sites to reflect steric effects of dimer binding (∆Gcooperativity) (Figures 1A–E). Total affinity ∆GmRNA:RsmA is calculated using the following two-state thermodynamic equation, previously defined in (Leistra et al., 2018) and summarized in Supplementary Figure S1:
Modeling interrogates all possible combinations of two binding sites across the provided sequence space and generates a measure of the ∆GmRNA:RsmA for each combination, per gene. These are then sorted from highest (most negative) to lowest affinity, with the highest affinity reflecting the most likely conformation of bound regions along the sequence (Figure 1F).
After sorting the summed ∆GmRNA:RsmA values for each pair of binding sites across the sequence space (Figure 1F) and the position of binding sites for the top 15, highest affinity, prediction positions were converted into dot-parens structural constraints and evaluated using the open source translation rate calculator, OSTIR (Figure 1F; Roots et al., 2021). This yielded a measure of the translation initiation rate for the bound (TIRRsmA bound i) and unbound (TIRunbound) states for each prediction of binding positions. Effects of binding on translation were calculated as follows:
TIR ratios were used to predict the effect that RsmA binding would have on translation, and binned into three categories: repressed (Ri > 1.2), activated (Ri < 0.8), or no impact (0.8 < Ri < 1.2) based on boundaries defined in (Leistra et al., 2018).
2.2 Calculation of the per-nucleotide contributions to binding
The protein sequence of P. aeruginosa RsmA is 85% identical to its ortholog CsrA in E coli. Key residues for RNA recognition, such as the arginine present at position 44 are conserved. To update the prior model to effectively capture energetics of RsmA binding we utilize a computational energy-based modeling tool. The Rosetta-Vienna RNP ∆∆G tool (Kappel and Das, 2019) was used to measure the relative change in binding affinities between a wild-type hcnA sequence GGGCUUCACGGAUGAAGCCC (motif in bold) and all possible mutants within the 5-nt binding motif at positions 8–12. The solution NMR structure of the CsrA and RsmA homolog present in Pseudomonas fluorescens, RsmE, in complex with the hcnA mRNA (Duss et al., 2014) (PDB: 2JPP) was used as the scaffold of the model due to the conservation of key residues that are involved in RNA binding (Schubert et al., 2007).The RNP ∆∆G approach incorporates the RNAfold command within the Vienna RNA package 2.0 (Lorenz et al., 2011) to calculate the minimum free energy of each unbound mutant (Supplementary Figure S1A). The position weight matrix of per-nucleotide contributions to binding was then calculated as follows:
Wherein i is the position of the nucleotide within the 5 nt binding motif and nt is the specific nucleotide mutation (ATGU) at that position. To generate an energetic measure of the individual nucleotide contribution, each ∆G value was subtracted from the maximum affinity found across all four nucleotides at a given position. The ∆Gnt,i was then converted from kcal/mol to RT units given the product of the gas constant and the temperature at 37°C (RT = 0.616).
2.3 Generation and modeling of UTR sequences from the PA14 genome
The 5′ Untranslated Region (UTR) of an mRNA transcript is the primary region where the Csr/Rsm family proteins enact their regulatory function by influencing ribosome binding. We selected the 5′ UTR plus the first 100 bases of coding sequence (CDS) to generate predictions via modeling. Prior RNA sequencing in (Wurtzel et al., 2012) defined the transcription start sites (TSS) across the P. aeruginosa PA14 transcriptome at 28°C and 37°C. Where the primary TSS was defined, we selected nucleotides from the TSS site to 100 bases into the CDS. If no TSS was known, we selected −100 bases from the start site to encompass the RBS region. Sequences were extracted from the Pseudomonas aeruginosa UCBPP-PA14 reference genome assembly GCF_000014625.1. This yielded 5285 UTR sequences which are summarized in Supplementary Table S2. Predictions of all combinations of 2 binding sites were performed for each of the modeled 4861 sequences in parallel on the Stampede2 compute cluster at the Texas Advanced Computing Center (TACC) at The University of Texas at Austin. Associated python scripts used to run the model on the Stampede2 compute cluster can be found at https://github.com/ajlukasiewicz/rsm_biophysical_model.
2.4 Ensemble analysis of predicted binding sites and peak calling
For each gene evaluated by the model, all possible combinations of binding pairs are evaluated across the entire sequence space, and sorted by affinity (∆GmRNA:RsmA). This yields an ensemble of predictions per gene with varying free energies. We then transform each affinity score, ∆GmRNA:RsmA, in the ensemble into a measure of the likelihood of binding via the Boltzmann probability distribution:
Wherein the probability of a particular binding conformation (p(α)) is a function of the ∆GmRNA:RsmA for an individual prediction (α) given the distribution of the top 300 conformations predicted for a gene. The cutoff of 300 predictions was derived from the inflection point of observed ∆GmRNA:RsmA values generated for each gene in the prior model (Supplementary Figure S2A). β, originally defined as 0.45, is a scaling factor based on thermodynamic predictions of RNA-RNA interactions (Leistra et al., 2018). Here we update this prior scaling factor β using select predicted energy and affinity values from our prior CsrA model (Leistra et al., 2018) fit to affinities derived from literature. To generate a measure of overall affinity for a given gene, or μ∆GmRNA:RsmA, we apply the following equation:
Where the average affinity (μ∆GmRNA:RsmA) is calculated based on the weighted sum of the ∆GmRNA:RsmA of the top 300 sorted confοrmations. The total affinity for each conformation (∆GmRNA:RsmA;α) is multiplied by its respective Boltzmann probability of binding (p(α)) calculated using Equation 4.
The model-predicted μ∆GmRNA:RsmA values for characterized CsrA targets csrA, glgC, nhaR, cstA, pgaA, and rpoE were calculated given a range of β scaling factors. These were then compared to literature-derived binding affinities which were converted into free energy using the following equation: ∆(G) = - RT ln(kD). Dissociation constants were found via prior EMSA experiments for CsrA binding to glgC, nhaR, cstA, pgaA, and rpoE (Baker et al., 2002; Pannuri et al., 2012; Dubey et al., 2003; Wang et al., 2005; Yakhnin et al., 2017). The Boltzmann probability was used to weigh predicted ∆GmRNA:RsmA affinity scores in calculating an overall average (μ∆GmRNA:RsmA) as described in Equation 5. We selected a range of β values from 0.35 to 0.45, in which β = 0.4 was determined to generate the highest linear correlation between the predicted ∆G value and the measured affinity (adjusted R2 = 0.98, p-value = 0.0009527, Supplementary Figure S2B). Linear regression tests were performed in R.
Out of all predictions per gene, the 300 top predictions were used to calculate the Boltzmann probability given the inflection point of energy predictions observed in positive control genes extracted from modeling data in (Leistra et al., 2018; Equation 4; Supplementary Figure S2B, C). The frequency of binding site position predictions was calculated as a function of the Boltzmann probability of binding to that position (Supplementary Figure S2D). These frequencies were then used to generate densities of binding interactions across the UTR itself, yielding peaks which we interpret as footprints or binding sites of RsmA. Using the lolB sequence (Figure 2B; Supplementary Table S3) as a negative control, we established the peak height threshold for binding to be the maximum height for lolB binding site frequencies, 0.0064.
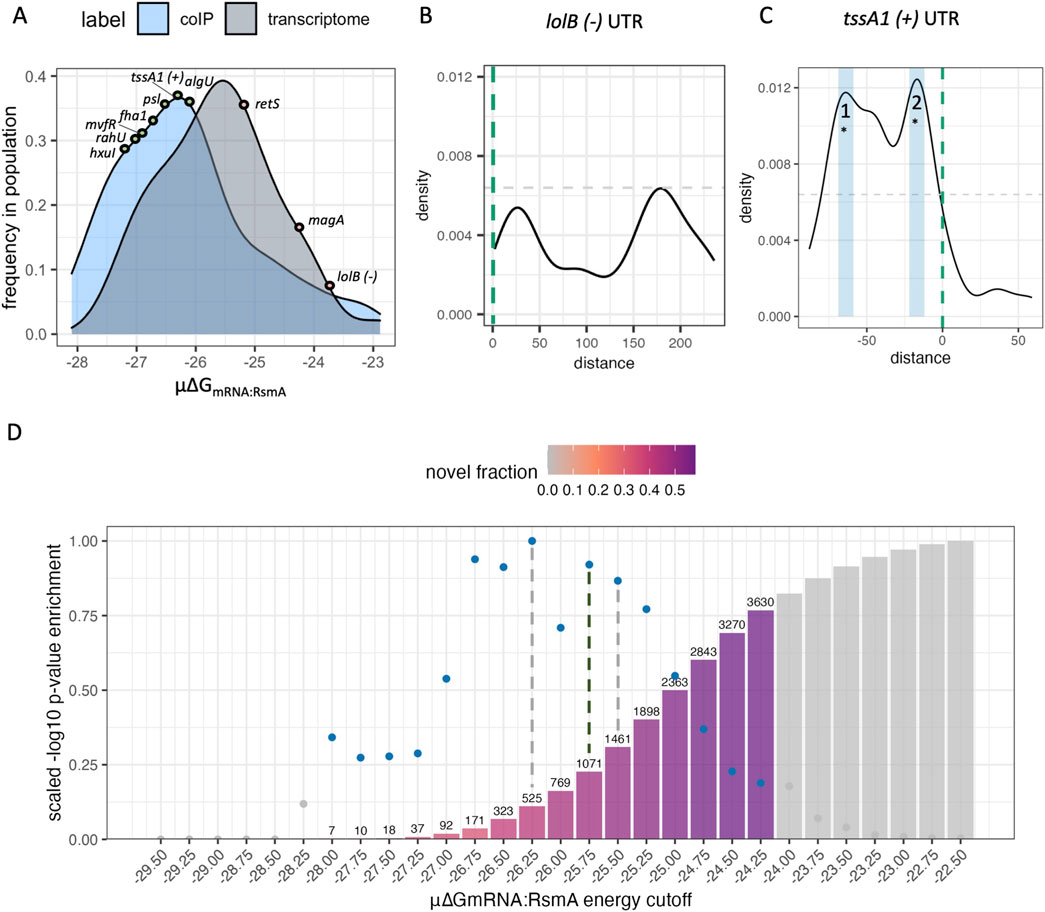
Figure 2. Model parameters are refined and validated using experimental datasets. (A) Overall affinity scores (μ∆GmRNA:RsmA) from genes identified to be bound by RsmA in prior RNA immunoprecipitation studies (coIP) are a distinct population relative to a random sample from the rest of the transcriptome. Positive and negative control RNA tssA1 and lolB fall at opposite sites in these populations wherein more negative μ∆GmRNA:RsmA values represent higher affinity scores. (B) Frequency of binding site predictions along the lolB mRNA sequence. Predictions along the sequence space of this gene are very disperse and have low affinity, and the most frequent peak hight informs our cutoff point for filtering targets (grey dashed line) (C) Frequency of binding site predictions across the tssA1 UTR sequence, with detected peak regions defined by blue boxes. The start codon is indicated by the vertical green dashed line. Binding site frequencies across the space of this sequence pass our threshold at three main sites. *Two of which were confirmed binding sites of RsmA given past mutational studies (Schulmeyer et al., 2016). (D) Distribution of genes that pass each energetic cutoff evaluated using hypergeometric enrichment testing. Blue dots reflect the -log10 (p-value) of enrichment for known targets that pass the significance threshold, and grey dots and bars are shown that do not pass the threshold. Bars are colored by the fraction of predictions that are novel in each pool of filtered targets, and bar height reflects the total number of predictions that pass the filtering cutoff. Enrichment testing reveals that the peak energy cutoff that enriches for known targets of RsmA falls at −26.25, and the threshold that excludes non-targets is −25.50 (grey dashed lines). To move forward with filtering we selected a value with the highest -log10(p-value) between these cutoffs, −25.75 kcal/mol (black line), as the cutoff for our model. The number of predictions that pass this filter are shown in text, and the % of novel predictions are shown in color. At the energy cutoff of −25.75, 457 out of the 1071 filtered targets are novel. Non-colored bars and points represent energy thresholds where predicted targets were not significantly enriched (p-value >0.05) relative to random chance.
Peaks in binding site density data were called using the signal function within SciPy 1.0 (Chihara et al., 2021) with the following parameters: the peak width was set from 5 to 15 to represent the range between the minimum base pairing footprint and the maximum number of possible predictions for a single site. The minimum height for a peak was set at 0.0064, which was determined to be the maximum height for a negative control UTR, lolB (Figure 2B). The script for parsing and calling peaks can be found in the rsm_biophysical_model GitHub repository as peak_calling.py. Analysis and generation of footprint density plots was performed in R (Version 4.3.1).
2.5 RNA Co-immunoprecipitation
Strain PA14ΔrsmAF carrying an empty vector control (pJN105), pRsmAHis6, pRsmFHis6, or the RNA binding mutant expressing plasmids pRsmA(R44A)His6 and pRsmF(R62A)His6 were grown at 37C with shaking at 300 RPM in 200 mL Tryptic Soy Broth (TSB) supplemented with 20 mM MgCl2, 5 mM EGTA, 15 μg/mL gentamicin, and 0.1% arabinose to mid-log phase, and pelleted at 4C. Cells pellets were immediately resuspended and lysed in Qiagen native purification lysis buffer (50 mM NaH2PO4, 300 mM NaCl, 10 mM imidazole, pH 8.0) supplemented with 2.5 mM vanadyl ribonucleoside complex (NEB) (to inhibit RNase activity), 1 mg/mL lysozyme, and 0.1% Triton X-100. Lysis was completed by three freeze-thaw cycles. Lysates were treated with 10 μL RQ-1 RNase-free DNase and cleared by centrifugation. An aliquot was removed from the cleared lysate for total RNA isolation and preserved in TRIzol (Thermo Fisher), and the remaining lysate was incubated with nickel-nitrilotriacetic acid (Ni-NTA)–agarose at 4°C for 1 h under nondenaturing binding conditions. Ni-NTA–agarose was then loaded into a column and washed 3 times with nondenaturing binding buffer containing 10 mM imidazole. Protein and associated RNAs were eluted in four fractions with 250 mM imidazole and four fractions with 500 mM imidazole. An aliquot of each fraction was analyzed by Western blot, and fractions containing RsmAHis6, RsmFHis6 or the respective RNA binding mutant version of the proteins were individually pooled as were the equivalent fractions from the vector control strain. Each pool was treated with TRIzol and RNA was extracted according to the manufacturer’s protocol. RNA was treated with RQ1 RNase-free DNase and concentrated using RNA Clean and Concentrator kit (Zymo).
2.6 Library preparation and next-generation sequencing analysis
Purified total RNA and co-IP enriched RNA was treated with Ribo-Zero (Illumina) according to the manufacture and purified and concentrated with Zymo Clean and Concentrator 5. First strand cDNA was generated using Superscript II RT (Invitrogen) and Random Primer 9 (NEB) and converted to double stranded cDNA using Second Strand cDNA Synthesis Kit (NEB) according to the manufacturer’s protocols. cDNA was purified using Zymo RNA Clean and Concentrator Kit modified for cDNA recovery. Libraries were prepared using the Nextera XT DNA Library Kit (Illumina, San Diego, CA) according to the manufacture’s protocol including tagment of cDNA, amplicons indexation/barcoding through PCR amplification using Nextera master mix, clean-up, and pooling. Finally, pooled and barcoded amplicons were single end sequenced on an Illumina NextSeq500 System. Sequencing reads were trimmed using Trimmomatic to remove library adapters. Trimmed reads were aligned to a Pseudomonas aeruginosa PA14 reference genome using bowtie2 (Langmead and Salzberg, 2012). Aligned reads were then transformed into binary alignment maps (BAM files) using samtools (Li et al., 2009). Finally, files were analyzed in Geneious software to obtain count tables containing transcripts per million read counts for each gene. Raw sequencing outputs were uploaded to the publicly available Sequence Read Archive (SRA) under the Bioproject ID PRJNA1131461.
Analysis of gene expression was performed using the DEseq2 package (Love et al., 2014) in R. To determine enriched genes, we first calculated the differential expression between the total RNA and the overexpressed RsmA-his pulldown genes. Genes with L2FC > 1 and p adj < 0.005 were considered enriched in our dataset (Supplementary Table S6).
2.7 Proteomic sample preparation and analysis
Overnight cultures of WT P. aeruginosa PA103 and ∆rsmA, ∆rsmF, and ∆rsmAF mutants were diluted to an optical density of 0.1 at 600 nm (OD600) in tryptic soy broth supplemented with 1% glycerol, 100 mM monosodium glutamate, and 2 mM EGTA. Cultures were incubated at 37°C with shaking until the OD600 reached 1.0. Cells (1 mL) were harvested by centrifugation (10 min, 4°C, 12,500 x g). Cell pellets were washed with 1 mL PBS and then stored at −80°C. Proteomic sample preparation and analyses were performed by the VIB Proteomics Core, Gent, Belgium. Differentially expressed proteins were identified using the DEseq2 package (Love et al., 2014) in R. Proteins with L2FC > 1 and p adj < 0.005 were considered differentially expressed in our dataset (Supplementary Table S7).
2.8 Filter binding assay for testing binding interactions in vitro
Assessment of binding interactions between RsmA and several candidate genes were evaluated using an in vitro nitrocellulose filter binding assay. Sequences generated with efficient T7 promoter design and synthesized (IDT). Sequences for these targets can be found in Supplementary Table S3. RNA was produced via in vitro transcription (Thermo T7 megascript kit) with supplemented 3.75 mM guanosine for efficient radiolabeling. P32 labeled ATP was integrated to the 5′ end of purified RNA with PNK and cleaned up using silica filter spin column extraction (NEB Monarch).
His-tagged RsmA was purified using nickel chromatography. Briefly, BL21 E. coli cells were transformed with an arabinose-inducible, his-tagged RsmA encoding plasmid. These were grown in overnight cultures and seeded into large shaker flasks until reaching exponential phase (OD600 = 0.6).
Binding strengths between purified RsmA and various radiolabeled RNA sequences were assessed using nitrocellulose filter binding. Serially diluted RsmA was incubated with 0.5 nM p32 radiolabeled RNA in an optimized binding buffer (10 mM Tris-HCl pH 7.5, 100 mM KCl, 10 mM MgCl2, 10 mM DTT, 10 ug/mL heparin, Murine RNase inhibitor) at 37 C for 30 min. Following incubation, reactions were loaded into the Bio-Dot microfiltration apparatus (Bio-Rad) and light suction was applied to pass the reactions through sandwiched 0.45 mM nitrocellulose and N+ (Cytiva Amersham™ Hybond™-N+) membranes. Signal intensities were captured via phosphorimaging on the Amersham Typhoon 5, and measured using Bio-Rad Image Lab software. Dissociation constants were calculated using the modified hill equation described in (Ryder et al., 2008) with a Hill Constant of two to reflect cooperative binding of the homodimeric form of the RsmA protein.
2.9 Construction of translational reporters for assessing effects on regulation in PA103
The effects of RsmA binding on translation were assayed using a translational GFP reporter system. The E. coli and P. aeruginosa compatible plasmid, pJN105, encodes for a arabinose inducible RsmA expression and was modified as follows: The constitutive lacUV5 promoter upstream of the 5′ UTR of our gene of interest was inserted into pJN105 along with the first 99 bases of coding sequence. This leader was fused to the GFPmut3 sequence with a trailing SRA degradation tag (M0051, sequence from IGEM database). Sequences for our genes of interest, along with positive and negative controls were amplified with compatible primers and inserted through Gibson assembly (NEB HiFi Gibson assembly kit). pJN105 was encoded with an inducible RsmA region via the pBAD promoter and constitutive araC expression. All plasmids and primers used in this study can be found in Supplementary Table S3.
Following assembly, plasmids were transformed using heat shock into chemically competent DH5α E. coli and plated on 15 ug/mL Gentamycin supplemented (Sigma-Aldrich) LB plates. Plasmids were extracted from overnight cultures using the Zymo zippy miniprep kit and submitted to Plasmidsaurus for sequence confirmation. Following extraction, plasmids were then transformed into chemically competent PA103 ∆RsmA/RsmF strains and plated on LB- agar media supplemented with 80 ug/mL Gentamycin antibiotic. Transformed strains were grown overnight in LB broth supplemented with 80 ug/mL Gentamycin (Sigma) and then seeded into 30 mL of supplemented LB culture at a 1:100 dilution. Upon reaching OD 0.02, cultures were split into two flasks and half were induced with 0.5% L-arabinose. Induced and uninduced cultures were monitored for fluorescence intensity on the Cytation3 plate reader at 484 and 513 excitation and emission wavelengths. Fluorescence and OD600 measurements were taken at 0, 1, 2, 4, and 6 h post induction. Fluorescence values were normalized by OD600 measurement and analyzed in R.
2.10 Generating mutations for rsaL and mvaT
Mutations were made for all combinations of predicted binding sites on rsaL and mvaT while minimizing the change to overall structure for the folded mRNA. Minimum Free Energy calculations were performed using ViennaRNA RNAfold secondary structure prediction tool (version 2.4.18). All scripts were written and executed in Python 3.7. For binding sites within the coding region, mutations were made to exclude stop codons while still maintaining overall structure. Motif mutations were generated using all combinations of low scoring residues present in our prior PWM. The full list of mutant sequences can be found in Supplementary Table S3.
3 Results
3.1 Using the RsmE-mRNA binding structure to generate a biophysical framework that captures different energetic contributions of various RNA sequences to binding
The P. aeruginosa RsmA and E. coli CsrA protein sequences share 85% amino acid identity (BLAST alignment: Camacho et al., 2009) however, slight differences in the primary and secondary binding motifs have been reported for the Csr/Rsm family across organisms (Kulkarni et al., 2014; Lapouge et al., 2007). To construct an energetic matrix that captures interactions between RsmA and specific motifs in P. aeruginosa, we selected the scaffold structure of RsmE-hcnA available in the Protein Data Bank (PDB: 2JPP) as representative of the overall protein structure in complex with mRNA. RsmE is a homolog of both CsrA and RsmA that is found in P. protegens, as well as in other members of the Pseudomonas genus. This protein was selected as the modeling scaffold because this entry contained structural data for both the protein and mRNA structures in complex with one another (Schubert et al., 2007).Changes in free energy due to single positional mutations were captured using the Rosetta-Vienna RNP ∆∆G tool (Kappel and Das, 2019) as described in (Methods, Equations 1–3, and Supplementary Figure S1). This generated a Position Weight Matrix (PWM) of per-nucleotide contributions of binding based on their position within a 5-nucleotide window (Table 1).
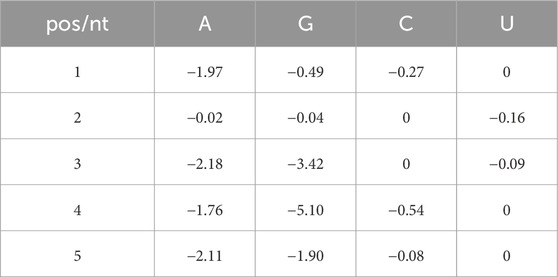
Table 1. Rosetta modeling derived Position Weight Matrix of the free energy contributions for each nucleotide present in a 5 nt window. An example of this calculation would be as follows: high affinity motifs such as AUGGA would contribute the maximum possible score to the overall free energy calculation, whereas low affinity sequences such as UCCUU would not contribute to the overall score.
The highest affinity motif produced by a 5-nt window using this crafted PWM (Table 1) would therefore be AUGGA, which is consistent with the binding motif observed for RsmA (Schubert et al., 2007). Prior models crafted for the E. coli CsrA protein confer the highest energetic contribution when a strict AAGGA motif is found (Leistra et al., 2018). A comparison of the two matrices can be found in Supplementary Table S1. The Rosetta-crafted PWM presented here confers an additional benefit to the model, wherein non-canonical motifs may contribute to the overall energy calculation and thus considers alternative sequences that RsmA can bind. Using this PWM we can then calculate the free energy contributions of a motif within sliding 5 nt windows (∆Gsite1 and ∆Gsite2), which we sum with additional biophysical parameters (Equation 1) to generate a prediction of overall affinity, or the change in free energy (∆GmRNA:RsmA) due to RsmA binding in a specific conformation to an mRNA of interest (Figures 1A–E).
To briefly summarize the contributions of this PWM to our two-step thermodynamic equation, we calculate the ∆GmRNA:RsmA as the change in free energy from the unbound to a bound state for one conformation of binding sites. These biophysical parameters are defined as follows: The energies of the bound state are calculated given the matrix-derived free energy of each motif bound by the homodimeric form of RsmA (∆Gsite1 and ∆Gsite2) and added to a penalty for steric hindrance for binding sites in close proximity (∆Gcooperativity) and the minimum free energy of RNA folding given bound folding constraints (∆∆Gunfold) (Figures 1A–E; Equation 1). These calculations are performed for all possible combinations of binding sites along each transcript modeled (Figure 1F) and the positions are sorted by the predicted highest affinity. Predictions of translational effect are calculated as summarized in Leistra et al. (2018) and in Equation 2. Given the empirically-derived nature of these energy terms, we hypothesize that the in silico predictions of high energetic affinity (∆GmRNA:RsmA) can be used to predict binding interactions in-vivo.
3.2 Genes enriched in RNA co-immunoprecipitation and proteomics establish positive control population for model tuning
To tune model filtering terms, we established a positive control population using RNA co-immunoprecipitation sequencing (RIP-seq) and proteomics. For the RIP-seq experiments Total RNA and pulled down fractions were sequenced in PA14 ∆rsmAF carrying plasmids encoding His-tagged RsmA, RsmF, the respective inactive mutants (RsmA R44A, RsmF R62A) or an empty vector control (pJN105). PCA analysis (Supplementary Figure S5A) of RNA sequencing performed for the pulldown study suggests that the difference in RNA in total and enriched fractions contributed to 33% of the observed variance in the dataset. 18% of the variance could be attributed to an inactivating mutation present in the overexpressed RsmF protein. Conditions lacking vector expressing RsmA/RsmF and the presence of empty vector encoding no protein both clustered closely and therefore the presence of the plasmid did not alter gene expression.
358 genes were identified to be significantly enriched (L2FC > 1 and p-adj < 0.005; Supplementary Figure S5B; Supplementary Table S6) in RsmA pulldown relative to the total RNA. These targets were considered to have a high likelihood of being bound partners of RsmA and were used to define the positive control population to tune the cutoff term for our model. This enriched population included positive controls such as algU, rahU, and magA, however, other well characterized direct targets of RsmA (“positive control genes”) such as tssA1 were not enriched in the RsmA pulldown pool. Interestingly, more genes were significantly enriched in the RsmF pulldown relative to RsmA (Supplementary Figure S5B). This pool of 565 mRNAs included positive control genes such as tssA1, fha1, rahU, and mucA. 228/565 genes overlap with the pool of enriched mRNAs pulled down by RsmA.
The proteomics experiments identified additional 261 proteins (Supplementary Table S7) that were found to be significantly differentially expressed (L2FC > 1, p-adj < 0.005) in PA103 ∆rsmA strain relative to WT (interpreted as repressed in native conditions).
3.3 Predicted mean total affinity can be used to differentiate bound from unbound targets
The predicted mean affinity score, μ∆GmRNA:RsmA, can be interpreted as a probability for binding occurring when RsmA and the target mRNA are present. To evaluate the predictive capabilities of the model, we sought to determine whether the mean total affinity score, μ∆GmRNA:RsmA, could be used as a metric to differentiate direct binding interactions from indirect or unbound gene targets.
Predictions were generated for 5861 UTR sequences extracted from the PA14-UCBB transcriptome (NCBI:txid 208,963, Supplementary Table S4). As of this publication, PA14 has a total of 5,893 identified genes but we were unable to generate predictions for all due to their lack of inclusion in prior TSS profiling (Wurtzel et al., 2012). To evaluate our predictions, we sought to compare the model predictions to experimental results. A combination of prior RNA co-immunoprecipitation sequencing (Romero et al., 2018) and the RNA co-immunoprecipitation and proteomics performed in this work were used to experimentally identify 780 genes potentially regulated by RsmA. This pool of genes was used to define a positive control population for binding. A random selection of 780 additional UTR sequences were collected from the rest of the modeled PA14 transcriptome to generate a control population. For each gene within the positive and background populations, the μ∆GmRNA:RsmA affinity score was calculated given the 300 most favorable predicted energies in the ensemble (μ∆GmRNA:RsmA, Equation 5). These first 300 predictions represent the most probable conformations of binding between RsmA and the RNA target. When assessed using a nonparametric Wilcoxon rank-sum test, we observed a significant difference (p < 0.05) between the mean total affinity scores (μ∆GmRNA:RsmA) of 780 randomly selected sequences and those from Co-IP enriched genes (Figure 2A). We identified several control genes to validate our results. The tssA1 (positive) and lolB, (negative) genes are outlined (Figure 2A) due to their extensive binding characterization. These fall at expected values within each population. The mean total affinity score for tssA1 was determined to be highly favorable (μ∆GmRNA:RsmA: −27.75 RT), and fell within the energy range for our positive control population (Figure 2A). The mean total affinity for the negative control, lolB, was calculated to be −23.80 RT which fell within the population range for our randomly selected “non-targets” population. This indicated to us that we could use the μ∆GmRNA:RsmA metric as a cutoff for filtering true from false targets in our pool of predictions.
To further refine the exact μ∆GmRNA:RsmA cutoff that differentiates direct bound targets from indirect non-targets, we performed hypergeometric enrichment testing for the pool of predictions that would enrich for genes pulled down in prior RIP-seq studies, while also minimizing those included by random chance. We evaluated cutoff values within a μ∆GmRNA:RsmA range of −27.50 RT to −24.0 RT (Figure 2D). The cutoff value that conferred the highest significant enrichment for immunoprecipitated genes was found at a μ∆GmRNA:RsmA threshold of −26.25 (p = 7.08e-08), and the second highest at μ∆GmRNA:RsmA −25.75 (p = 2.61e-07). In addition, genes with no prior evidence of binding by RsmA were selected to performed exclusion testing of non-targets for each energy cutoff. This determined that the depletion of non-targets reached its maximum at the cutoff value of −25.50 (p = 6.36e-07). Given these results, the optimal cutoff used was −25.75 which yielded 1071 predictions of putative targets for RsmA. This observation validated that the μ∆GmRNA:RsmA can be used as a predictor of overall affinity.
3.4 Peak analysis of predicted binding sites for enriched targets validate the predictive capabilities of the model
In addition to predicting a measure of overall affinity, our updated application of the model also has the capability to determine the position of RsmA binding sites along the modeled mRNA leader sequence. The Boltzmann probability of binding was calculated given the ∆GmRNA:RsmA per prediction presented in Equation 4, and described in Methods and in Supplementary Figure S2D. This is a novel transformation of the binding peak data. Our previous version of the model weighed each of the top 15 predictions equally. In an improvement on this approach, we weigh the occurrence of predicted sites as a function of their likelihood in a pool of conformations, and expand from only considering the top 15. Calculation of the frequency of binding interactions at a specific site was extrapolated from the Boltzmann probability and used to weigh highest affinity predictions relative to the expanded set of those per gene. This allowed each predicted binding site to be visualized on a density plot (Supplementary Figure S2D). Then, peak calling was performed on all genes with a baseline cutoff established from the negative control sequence of the lolB mRNA leader sequence (Methods). The application of this cutoff filtered our list of predictions to 1043 possible targets of RsmA, 457 of which are genes for which no prior experimental evidence was found.
The specific binding sites of P. aeruginosa RsmA on its established targetome has been experimentally validated on tssA1 (Schulmeyer et al., 2016). To evaluate the capabilities of the model for predicting bound regions, we compared peak predictions on the 5′ UTR of tssA1 which has been experimentally verified binding sites that fall at −15 and −67 nt from the start codon (Schulmeyer et al., 2016). Predicted binding site peaks not only fall within those two regions (Figure 2C), but also identify a third region where RsmA may potentially bind to repress translation of tssA1. Confirmation of more than two binding sites that confer flexible binding of the protein to a given mRNA target has been identified for CsrA (Rojano-Nisimura et al., 2024). Due to the lack of footprinting data available for other mRNAs within PA, binding site predictions were also performed on experimentally footprinted targets of Rsm/Csr family proteins in closely related organisms, such as E. coli (CsrA-glgC) and P. fluorescens (RsmE-hcnA). Binding site predictions coincided with experimentally characterized sites of Rsm/Csr binding (Supplementary Figure S4). Peak predictions for all modeled genes can be found in the accompanying Data Sheet 2 file. Overall, the capturing multiple experimentally characterized binding site across a range of well-studied RsmA/CsrA targets that we selected provided confidence in the ability of the model to identify RsmA binding sites across different potential mRNA targets.
3.5 Enrichment of quorum sensing and biofilm pathway transcription factors in predicted RsmA targets
Given our pool of 1043 predicted targets, we next sought to determine whether new pathways that were regulated by RsmA (but not yet identified) were enriched in our filtered pool. Encouragingly, pathways with prior experimental evidence of regulation by the GacA/S TCS pathway were identified in our analyses. GO term and KEGG pathway enrichment analyses of our pool of 1,043 putative mRNA targets show significant (EASE score <0.1) representation of genes involved in key virulence pathways (Figures 3A, B). Molecular features enriched in our predicted targets include those with DNA-binding transcriptional activator (GO:0001216), metal ion binding (GO: 0046872) and cytochrome-c oxidase (GO:0004129) activities (Figure 3A). Roughly 60 transcriptional regulators were predicted to be bound by RsmA in our model, including key QS regulators LasR, MvfR, and the orphan regulator, QscR.
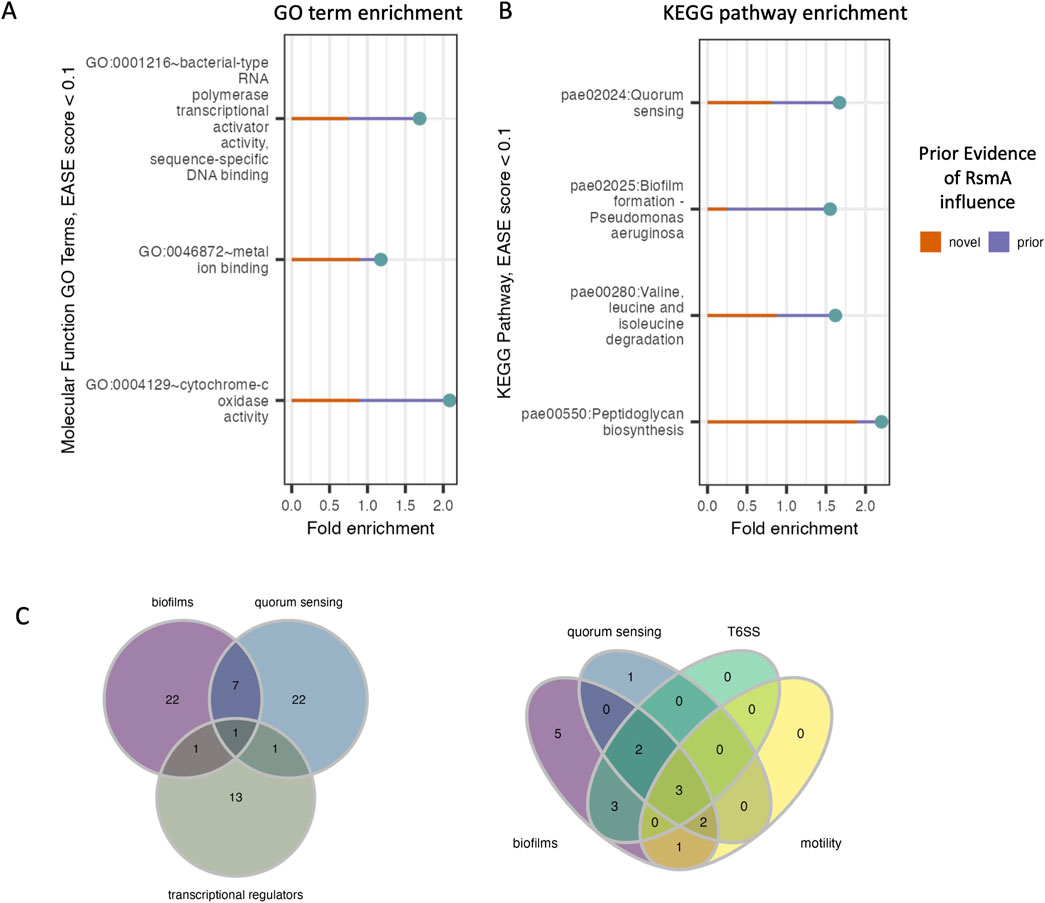
Figure 3. Distribution of enriched molecular functions and pathways in pool of predicted targets of RsmA. (A, B) DAVID enrichment analysis for molecular function GO terms and KEGG pathways, sorted by increasing p-value (<0.1). Along with the reported fold change of enrichment, the lines display the proportion of genes within each category that are novel predictions yielded by the model (red line) and the proportion of genes with some prior evidence of association with RsmA (purple line). (C) Predictions that fall within key virulence pathways such as quorum sensing and biofilm formation also have shared transcription factor regulation. Left: one transcriptional regulator, LasR (PA14_45960) is associated with both quorum sensing and biofilms. Right: Model predictions identify several newly profiled transcription factors (Wang et al., 2021) that are also associated with virulence pathways. Three transcriptional regulators associated with all four processes include PA1437, a two-component response regulator, PA4184, SouR regulator of Phezanine biosynthesis, and PA1431, RsaL, a novel target and regulator involved in quorum sensing.
Key pathways enriched by our predictions include quorum sensing (pae02024), biofilm formation (pae02025), valine, leucine, and isoleucine degradation (pae00280), and peptidoglycan biosynthesis (pae00550) (Figure 3B). Although many of these processes have already been shown to be regulated by the Gac/Rsm pathway (Pessi et al., 2001; Parkins et al., 2001), several novel predictions were generated within each feature (Figures 3A, B). This suggests modeling allows us to expand upon the total number of genes that RsmA may regulate across complex and condition-sensitive pathways.
The full profiling of transcriptional regulatory network in PA is yet incomplete, but recent efforts to characterize binding specificities in vitro (Wang et al., 2021) has expanded upon our understanding of transcription factor interactions with known, key virulence pathways. Transcriptional regulators were significantly enriched in our predicted pool of genes bound by RsmA (Figure 3A); therefore, we sought to identify which of these transcriptional regulators were associated with KEGG enriched pathways. Of note is the identification of lasR (PA14_45960) is shared by both QS and biofilm forming processes (Figure 3C). Out of 86 total transcription factors mapped to biofilm, quorum sensing, the Type 6 Secretion System (T6SS) and motility pathways in (Wang et al., 2021), 17 were identified by our model to be bound by RsmA. Of these 17, 3 were found to be associated with all four pathways (Figure 3C), which were identified as PA1431 (rsaL), PA4184 (souR), and PA1437, a two-component response regulator. Only PA1437 was previously predicted to be a potential target via a prior motif search approach (Kulkarni et al., 2014), whereas PA1431 (rsaL) and PA4184 (souR) are entirely novel mRNA predictions.
3.6 Meta-analysis of aggregated RNA-seq datasets reveal that novel targets identified in our model are lowly expressed in standard media types used for binding/pulldown studies
The influence of RsmA on regulating the aforementioned pathways has been well demonstrated by prior studies (Pessi et al., 2001; Parkins et al., 2001). Therefore, we sought to determine how many of our predicted genes were also found in other high-throughput characterizations of RsmA regulation in P. aeruginosa. We compared predictions to all those found in previous modeling (Kulkarni et al., 2014), microarray analysis (Burrowes et al., 2006), RNA-seq studies (Brencic and Lory, 2009; Gebhardt et al., 2020), RIP-seq studies (Romero et al., 2018), CLIP-seq studies (Chihara et al., 2021), and recent nascent chain profling methods such as ChiPPar-seq (Gebhardt et al., 2020). Comparisons across these studies revealed that 586 of our predictions had some level of prior evidence of binding or direct/indirect regulation by RsmA, and 457 were entirely novel predictions.
Prior experimental approaches have estimated RsmA has some regulatory effect (including direct and indirect) on approximately 500 genes, yet our number of predictions (1043) is double that estimate. In an effort to understand why our pool of predictions is larger than prior approximations, we hypothesized that many predictions were dependent on conditions not tested in prior experimental screens. To investigate this hypothesis we leveraged the aggregated, publicly available, RNA sequencing data from a meta-analysis of gene expression across various conditions in P. aeruginosa (Rajput et al., 2022). This dataset included values of normalized gene expression in transcripts per million (log TPM) from 411 sequencing datasets, including data from a RsmA pulldown study (Romero et al., 2018). These datasets measure gene expression in a wide variety of experimental conditions including various strain types, growth phases, media, antibiotic supplementation, clinical isolates, and lifestyles and demonstrates that gene expression is highly variable and condition-specific (Rajput et al., 2022). In our analysis, we interpreted a gene to be expressed if the log TPM value was greater than 0. The expression data was filtered and subsequently binned into 10 ranges and then labeled given their prior evidence for regulation by RsmA. Overall, genes with some prior experimental evidence of binding to RsmA were more represented in higher expression bins, whereas those that had no evidence, or were novel predictions by our model, aggregated towards lower expression bins (Figure 4A). This observation suggests that the novel predictions generated by the model were not identified as RsmA targets in prior experimental screens due to low expression levels in the conditions tested.
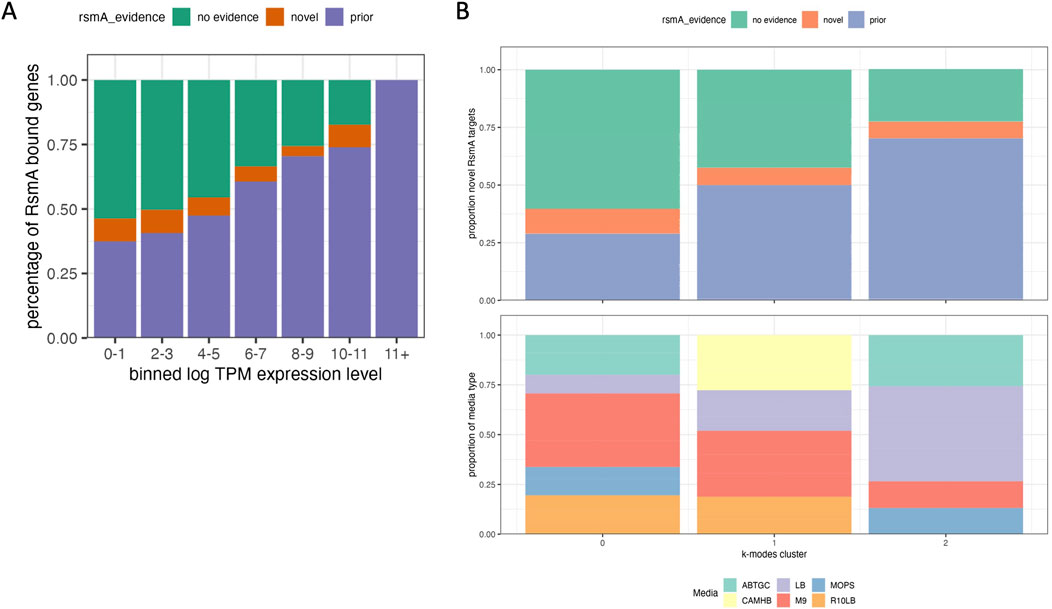
Figure 4. Comparison of results with transcriptomic data suggests novel transcripts are found at lower concentrations. 483 genes were predicted by the model that are not represented in any prior modeling, microarray, RNA-seq or pulldown studies of RsmA. A recent publication aggregated 411 expression datasets for Pseudomonas aeruginosa grown in various experimental conditions. (A) Bar chart of the proportion of predictions with no evidence of RNA binding, prior evidence of binding, and entirely novel predictions, binned by log TPM expression level in that experiment. The proportion of genes with prior evidence increases as the log TPM levels of expression increases, suggesting that expression influences detection. (B) K-modal clustering of all categories in the aggregated experimental conditions from 411 expression datasets (KO, media, growth phase, stress) to observe whether the presence of novel or predicted targets cluster within specific conditions, knockouts, or media types, overlaid with the proportion of genes that fall within each cluster. Predictably, most of the genes that have some prior association with RsmA are expressed in conditions cultured in LB media, whereas more novel targets were expressed in minimal media such as M9 or ABTHC.
To assess where novel predictions were clustering across these varied conditions, we used k-modal clustering of experimental condition categories as described in Methods. Overall, a higher proportion of genes with some prior evidence of RsmA interaction were found in experiments performed in LB media (cluster 3), whereas nutrient-limited media types like M9 and ABTGT exhibited a higher proportion of novel predictions and genes with no RsmA regulatory evidence (Figure 4B, cluster 1). This recapitulates observations that media type has a large impact on gene expression, and therefore the availability of certain genes for high throughput profiling. As example of note is rsaL, a novel target encoding for a quorum sensing transcriptional regulator, that we identify to be bound by RsmA computationally but, when assessed across datasets, appears rarely expressed. We define high expression in this case as a log TPM value greater than that of the rimM housekeeping gene (average log TPM = 1.95). RsaL reaches a log TPM expression level above 1.95 in only 3 of the 411 RNA-seq experiments (SRA accession numbers SRS605141, SRR6018047, and ERS530377) aggregated in (Rajput et al., 2022); indicating that sufficient levels of rsaL expression may only occur in certain experimental conditions.
3.7 RsmA binds and regulates several predicted mRNA targets encoding for key transcriptional regulators as assessed by in vitro binding and in vivo translational reporter assays
Given the concordance of our computational predictions with previously published experimental results, we sought to test RsmA binding to our novel predictions in vitro (Chua et al., 2014). Therefore, we selected 8 genes that were representative of the core quorum sensing regulatory cascade (Figure 5A; Supplementary Table S3) to assess binding in vitro. These were quorum sensing regulatory genes lasR/lasI, rhlR/rhlI, mvfR, and a novel prediction rsaL. Secretion system regulators included the mvaT and aprD leader sequences. These targets have varied support in the literature for RsmA interactions, the majority lacking evidence of either in vitro binding or regulatory impact. Finally, the tssA1 and loB sequences were included as positive and negative controls. Filter binding assays were performed with the [α-32P] ATP radiolabeled mRNA and purified RsmA protein. aprD binding was evaluated via Electrophoretic Mobility Shift Assay (EMSA) (Supplementary Figure S6). Each of these genes had varying degrees of prior RsmA regulatory characterization as summarized in Figure 5A. Importantly, we observed strong in vitro binding interactions between RsmA and mvaT, lasR, rhlI and tssA1 leader sequences. These observations are consistent with the predicted overall affinity (μ∆GmRNA:RsmA) scores for each gene, which were predicted to be −26.29, −26.54, −26.37, and −26.34 respectively (Figure 5A). Weaker interactions were seen for rsaL, mvfR, and lasI. These each had average predicted affinities (μ∆GmRNA:RsmA) of −25.82, −26.55, and −24.79 (Figure 5A). Disassociation constants (kDs) from this biochemical characterization correlate well with the predicted mean total affinities (R2 = 0.92, Figure 5B). It is worth noting that although we initially excluded genes such as rhlR from our true target predictions (in accordance with the −25.75 energy threshold), we tested them experimentally for binding given the observation that we predicted two other mRNA targets (lasR and lasI) in our final candidate pool that encode for two closely functionally related proteins to RhlR in the quorum sensing pathway. We did not observe binding between RsmA and rhlR in our in vitro filter binding assays (Figure 5A) or via EMSA (Supplementary Figure S6) experiments, which recapitulates the negative result from the model. Finally, we did not observe binding between RsmA and the lolB negative control. Overall, these results indicate that RsmA does bind to targets predicted by the model, and that relative binding affinity predicted via the μ∆GmRNA:RsmA affinity score is correlated with affinities measured in vitro.
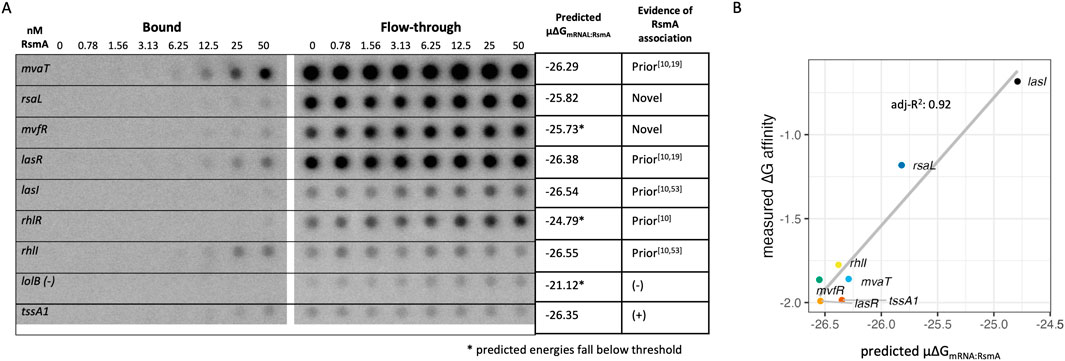
Figure 5. in vitro filter binding assay demonstrates binding interactions between RsmA and predicted targets (A) Phosphoscreen of bound and unbound radiolabeled intensities with an accompanying summary table of the model predicted energy and degree of novelty. (B) A linear correlation exists between predicted and measured affinities generated via fitting filter binding assay.
As a post-transcriptional regulator, RsmA is able to repress or activate gene expression by blocking or enhancing ribosomal binding to the 5′ UTR region of an mRNA. To evaluate the effects of binding on translation, we performed plasmid-based in vivo translational reporter assays (summarized in Figure 6A). Sequences from the same pool of 8 genes selected for in vitro characterization were fused to the GFPmut3 coding sequence, and fluorescence values were measured following RsmA induction in a PA103 ∆RsmA/RsmF strain (Supplementary Table S3). lolB was not used in these assays due to the observation that the established sequence used in prior mobility shift experiments (Brencic and Lory, 2009) is not the leader sequence, but falls within a portion of the coding region and therefore does not contain a ribosome binding site (see Supplementary Table S3). Specifically, BLAST search revealed the lolB sequence used in prior experiments falls between nucleotides 5236896 and 5237178 in the PA01 genome. Given the lack of binding observed between RsmA and rhlR in our in vitro binding assays (Figure 5A; Supplementary Figure S6) we selected this target to use as a suitable negative control for this assay. No significant difference in fluorescence is observed for rhlR (Figure 6B). The tssA1 5′ UTR was used as a positive control for repression and showed a significant (p < 0.05) reduction in normalized fluorescence values following induction of RsmA. We also observed significant reduction of fluorescent signal for the HSL synthetase genes lasI and rhlI (p < 0.001, and p < 0.05, respectively) (Figure 6B). Given results for our positive and negative regulatory controls, we then performed the assay on mvaT, lasR and rsaL. Each of these genes have some lacking prior evidence of direct RsmA binding and/or regulation from the literature (Figure 5A). These targets yielded reduced fluorescent values following RsmA induction (Figure 6B) and we interpret these results to suggest these genes are repressed by RsmA in vivo.
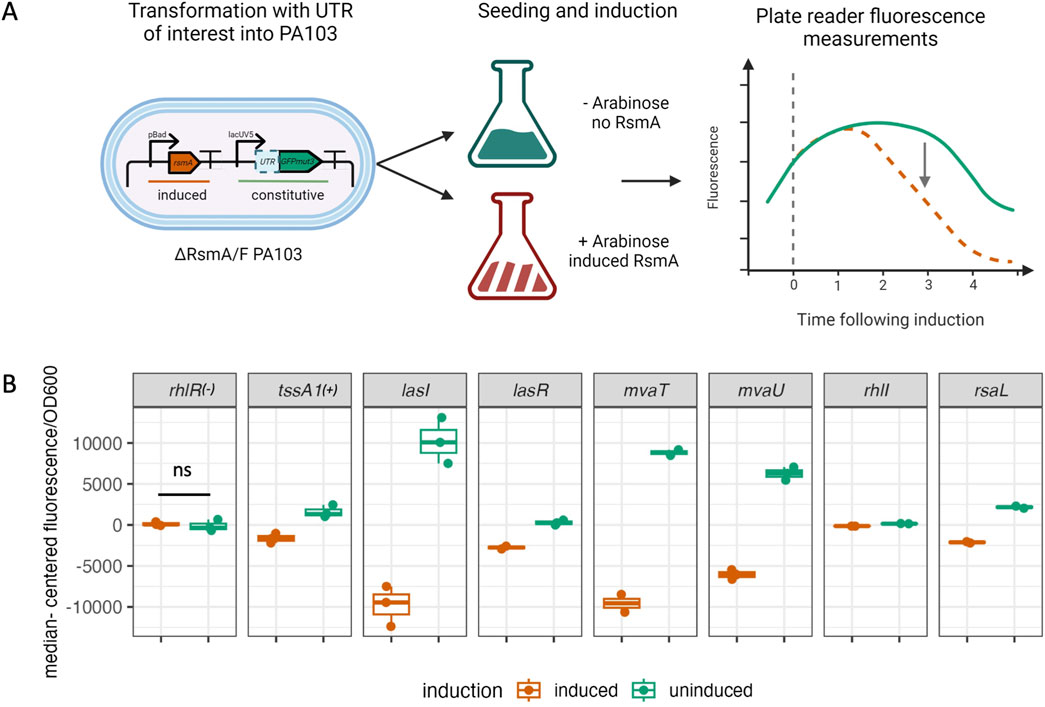
Figure 6. in vivo repression assay. (A) Experimental overview of in vivo translational repression assay. UTRs were fused to GFPmut3 and expressed off of the lacUV5 constitutive promoter. Plasmids were transformed into PA103 ∆RsmA/RsmF strains and seeded into ± 0.5% arabinose LB media. Fluorescence was monitored up to 6 h following induction, during which fluorescent changes were assessed between uninduced (green) and induced (orange dashed line) conditions. (B) rhlR and tssA1 UTR sequences were used as negative and positive controls for our assay. No significant change in fluorescence was measured for rhlR, which is consistent with our prediction and in vitro experimental results. A significant reduction in fluorescence values was observed for the positive control tssA1. A significant reduction in fluorescence was also detected for our pool of additional tested genes, including lasI and rhlI. Fluorescence values are plotted median centered to account for changes in translation rates due to the native RBS encoded in each individual UTR.
3.8 RsmA binds to model-predicted binding sites in novel targets rsaL and mvaT in vitro
The model identifies several binding sites along the sequence space of each gene. Given our observation that two novel targets rsaL and mvaT were bound by RsmA in vitro, we sought to assess binding to the specific predicted locations produced by the model. The top three binding sites for each gene (Figures 7A–F) were mutated individually, and for all combinations of two binding sites along the sequence. Binding to each mutant was evaluated via in vitro filter binding assay.

Figure 7. Mutational evaluation of predicted RsmA binding sites on rsaL and mvaT (A) Density plot of predicted binding pockets along the modeled region of the rsaL leader sequence +100 bases of CDS. Blue boxes represent the highest frequency regions for the ensemble of predictions along the sequence space. Light grey dashed line represents the minimum peak threshold for considering a binding pocket. Green dashed line is the start codon. (B) Structural diagram of the rsaL leader sequence with labeled binding pockets (brown, green, and purple) as well as key functional regions such as the start codon (green) and predicted RBS (pink). (C) Filter binding generated binding curves for RsmA in complex with WT rsaL (pink) and individual mutations (orange through brown) or mutations in combination (grey through red). (D) Density plot of predicted binding pockets along the modeled region of the mvaT leader sequence +100 bases of CDS. Blue boxes represent the highest frequency regions for the ensemble of predictions along the sequence space. Light grey dashed line represents the minimum peak threshold for considering a binding pocket. Green dashed line is the start codon. (E) Structural diagram of the mvaT leader sequence with labeled binding pockets (green, and purple) as well as key functional regions such as the start codon (green) and predicted RBS (pink). (F) Filter binding generated binding curves for RsmA in complex with WT mvaT (grey) and individual site mutations (brown through red) or mutations in combination (green through pink).
The three predicted binding sites (termed BS1, BS2, and BS3) on the rsaL transcript fall within the coding region at +12, +67, and +76 nt from the start codon (Figure 7A, BS1, BS2, and BS3), with the highest frequency of binding predictions falling peaks 67 and 76 nt (Figure 7A). Guided by the strict peaks (i.e., specific binding sites) predicted by the model in this case, we selected these three specific binding sites to test. Evaluating these mutations via in vitro binding reveals that mutation of BS3 significantly reduces binding affinity of RsmA to the rsaL transcript (Figure 7C). Mutating BS1 and BS2 individually did not alter affinity to the transcript however, tandem mutations at sites BS1 and BS2 as well as sites BS2 and BS3 hinder binding interactions from occurring. Overall these results suggest that BS3 is the main anchor of binding interactions with the transcript, with BS2 as the site with second highest affinity. Mutation of BS1, which falls below our peak threshold, did not impact binding as strongly and is therefore a less likely site for RsmA-rsaL interactions.
Relative to the distinct peaks observed on rsaL, binding site predictions on the mvaT leader sequence fall in a wider range, as evidenced by a single peak in the within the coding sequence of the gene (Figure 7D). Predicted binding sites on the mvaT leader sequence were mutated at positions +26, +41, and +68 nt from the start codon (Figures 7D, E, BS1, BS2, and BS3). Given the lack of distinct peaks, and therefore a broader selection of potential binding sites, RsmA-mvaT binding interactions were not disrupted as expected. Specifically, in our in vitro binding assays, no change in affinity was observed by mutating BS1, BS2, or BS3 individually. A slight decrease in affinity was observed when mutating BS1 and BS2, or BS1 and BS3 in tandem (Figure 7F). It is interesting to note that predicted RsmA binding sites along the mvaT sequence cluster in a wide region within the CDS (Figure 7D), suggesting that there may be a multitude of conformations by which RsmA binds to this transcript.
4 Discussion
In this work, we expand beyond motif-based screens to computationally profile binding and regulation by the RsmA protein across the entire P. aeruginosa transcriptome. Modeling and subsequent filtering yielded 1043 potential targets, of which 457 were not identified in prior experimental screens. We deem these as novel putative targets of RsmA. These putative novel targets were found to have variable media and condition-specific expression when investigated in context of publicly available sequencing data, which we posit explains earlier inability to detect them. Within each prediction we identify key molecular features that influence binding, and used these to effectively differentiate direct from indirect binding. Overall, this effort demonstrates the utility in using empirically derived binding parameters to computationally interrogate expansive sequence spaces.
4.1 Metrics such as the energy terms and binding sites correlate with experimental evidence, which demonstrate utility of model in predicting true vs. false targets of RsmA
Given empirically derived binding parameters, our free energy model of RsmA binding was able to differentiate direct from indirect or unbound targets. Our predictions of overall affinity (μ∆GmRNA:RsmA) and the position of binding sites were identified as the key parameters that allowed us to interrogate binding to mRNA leader sequences across the transcriptome. Molecular features on the RNA sequence are key for enabling regulatory function, and also provide information on the mechanism by which RsmA is able to bind. In comparing our model predictions to publicly available pulldown sequencing data, we demonstrate that the calculation of the overall affinity term μ∆GmRNA:RsmA can be used as a metric to differentiate true from false targets of RsmA (Figure 2) which allowed us to effectively filter predictions made across the entire transcriptome. This was facilitated by improvements made to tailor our model for the P. aeruginosa RsmA protein. One such improvement was the generation of a RsmA-specific PWM (Table 1). This PWM allows for the contribution of non-canonical bases to the overall energy score, and prioritizes an AUGGA motif. Although not drastically different from the canonical A(N)GGA CsrA consensus, the AUGGA motif was independently observed in prior crystal structure (Schubert et al., 2007), SELEX (Schulmeyer et al., 2016), and CLIP-seq (Chihara et al., 2021) studies to be favored by RsmA. This also demonstrates the utility in using solved crystal structures to generate models of protein-RNA interactions. Overall, considering slight changes in the protein sequence allowed for our approach to be better tailored for assessing interactions occurring within P aeruginosa.
Our model appears to be able to accurately capture binding interactions between RsmA and candidate targets, as evidenced by the correlation between the measured in vitro binding affinities and the predicted μ∆GmRNA:RsmA values that we performed in a small selection of predicted mRNA targets (Figure 5B). More qualitatively, genes that did not pass our energetic threshold (such as rhlR) were not observed to bind in vitro (Figure 5A), and showed no significant change in translation in vivo (Figure 6B). This suggests that the model has the ability to predict relative binding affinity and can aid in further exploration of network regulation, particularly as it relates to lowly expressed or condition-dependent genes. Interestingly, of the 1043 genes predicted to be bound by RsmA, several previously characterized genes did not pass our energy cutoff. These included magA, and mucA, for which binding was previously experimentally confirmed in vitro (Brencic and Lory, 2009; Romero et al., 2018). Each of these predictions yielded less favorable μ∆GmRNA:RsmA scores, with only a handful of the suite of binding conformations scoring with high favorability. It is possible then, that other sequences that exhibit strict site ranges may have been lost to filtering. Other genes that did not pass our energetic cutoff included those regulated in tandem with other post-transcriptional regulators, or require multiple copies of RsmA. This is possible as it has been demonstrated that RsmA is not always the sole repressor and can bind genes in tandem with other regulatory factors; this has been shown to occur with two transcriptional regulators, AmrZ and Vfr, wherein RsmA is only able to bind these transcripts in the presence of an additional global post-transcriptional regulator Hfq (Irie et al., 2020; Gebhardt et al., 2020). Neither amrZ nor vfr were predicted to be bound by RsmA in our model, therefore our pool of predicted targets is limited to those regulated by RsmA alone.
Future iterations of our model can improve upon capturing the influence of multimerization on binding. RsmA binding can cause structural changes along an RNA transcript and promote multimerization via subsequent folding of higher affinity sites. This phenomenon has been best demonstrated via loading of multiple copies of RsmE on the RsmZ sRNA sponge (Duss et al., 2014). Our model only considers binding interactions between a single RsmA protein and transcript; therefore, the structural influence of multiple proteins is missed by the model. To address these limitations, future improvements could include structural constraints due to partner binding, however, the footprint and position of the cooperative partner must be known. In addition, changes can be made to have RNA sequences “inherit” structural constraints from a primary iteration of predictions, and measure changes in total affinity due to the addition of secondary or tertiary elements. This can also prove useful in modeling RsmA-mRNA interactions in other Pseudomonas species that encode multiple paralogs of RsmA, such as RsmA and RsmE in Pseudomonas putida and Pseudomonas syringae (Sobrero and Valverde, 2020).
Global trends in our binding site predictions agree with patterns observed in prior high throughput screens. Distances between the top binding sites and the start codon were plotted for all genes that passed our mean total affinity and peak filtering (Supplementary Figure S4D). Overall, binding sites for RsmA were localized to three main regions: RBS region (between −30 and 0 relative to the start codon), the start codon, and a broad distribution of sites within the first 100 bases of the coding sequence. This is consistent with binding site frequencies observed in CLIP-seq studies of RsmA in P. aeruginosa (Chihara et al., 2021) and CsrA in E. coli (Potts et al., 2017). These observations suggest that, in addition to predicting an overall affinity score, our model can also predict specific binding sites on the mRNA which provides additional information on the exact mechanism by which the protein interacts with its target.
More globally, binding site distributions vary across transcripts. To investigate this, we used custom peak calling scripts with parameters defined in Methods. A peak is therefore a region with a sufficiently high frequency of predicted sites that passes some minimum threshold set by negative controls. Approximately 30% of genes modeled have wide, overlapping, pockets of binding sites that span 30 + nucleobases across of the mRNA. An example of this is shown in predictions on the mvaT transcript (Figure 7D). 70% contain narrower, distinct, peaks that are less than 30 nucleotides wide, which is also seen for predictions across rsaL (Figure 7A). Analysis of peak count distributions for our predictions (shown in Supplementary Figure S4D) reveals that the majority of genes have an average number of 1.25 peaks in their distribution of binding site peaks, and a smaller population of genes contain an average of 2.5 peaks where RsmA is predicted to bind. This indicates that the majority of genes contain one to two distinct binding peaks, whereas a smaller population contain 2 or more distinct peaks. This recapitulates prior observations that Rsm/Csr proteins facultatively interact with targets at a single binding site, or at double binding sites (Mercante et al., 2009; Morris et al., 2013). The divergent patterns of binding also suggest “anchoring” at single high affinity site along the gene, prior to binding to lower affinity positions. This phenomenon was recently characterized for CsrA-acnA and evgA sequences in E. coli (Rojano-Nisimura et al., 2024).
Further, the location of predicted binding peaks appeared to correlate well with in vitro experimental evidence. Our initial observation was the concordance of predicted peak location on the well-studied RsmA binding partner tssA1. These predictions fell within characterized binding sites on the mRNA sequence (Figure 2C; Schulmeyer et al., 2016). The model also accurately predicted high affinity binding sites on the rsaL mRNA sequence which had no prior binding or foot-printing evidence. Using in vitro filter binding, we experimentally confirmed these predictions by disrupting interactions via mutation of the highest affinity motif (BS3) (Figure 7C), and a further disruption of binding strength was observed upon mutating the second strongest motif (BS2) in tandem with BS3 (Figure 7C). This is consistent with the theory that Csr/Rsm family proteins may anchor to lower affinity sites on the nascent transcript (Gebhardt et al., 2020), before binding more strongly to downstream high affinity sites (Leistra et al., 2018). In contrast, mutating predicted sites along the mvaT leader sequence did not result in a change in affinity (Figure 7F). Predicted RsmA binding sites along the mvaT sequence cluster in a wide region within the CDS (Figure 7D), and suggest that there may be a multitude of conformations by which RsmA binds to this transcript. This mechanism of binding has been theorized previously (Leistra et al., 2018) as a strategy CsrA to ensure binding to a dynamic structured RNA.
4.2 Loss of target discovery can be attributed to widely varying expression profiles across study conditions
Perhaps the most exciting element of the model results is demonstrating the ability of computational predictions to capture interactions for mRNAs that are expressed transiently or in a condition-dependent manner. Our evaluation of target predictions across 411 gene expression datasets revealed that the majority of novel genes predicted by our model are lowly expressed (Figure 4A) or condition specific (Figure 4B). Indeed, K-modal clustering showed a higher ratio of these novel genes to cluster with nonstandard media types like ABTGT or M9 minimal media (Figure 4B). This highlights the importance of considering multiple approaches to profile the effects of a post-transcriptional regulator, as condition dependent gene expression can cause a bottleneck in discovery. This is the case for sRNA discovery, especially, as many are expressed in specific nutrient (Mihailovic et al., 2021) or infection contexts (Cao et al., 2023).
4.3 Model identifies that RsmA exerts regulatory control of quorum sensing and biofilm forming pathways through binding and regulation of redundant transcription factor nodes
RsmA is a major global regulator of a variety of pathways that contribute to survival and pathogenicity of P. aeruginosa. These include indirect activation of pathways critical for epithelial colonization such as the Type 3 Secretion System (T3SS) (Stevens, 2018), Type IV Pili, and flagellar biosynthesis processes (Brencic and Lory, 2009). RsmA also has been shown to directly repress pathways that contribute to chronic infection states, such as the formation of biofilms, Quorum Sensing (QS) (Pessi et al., 2001), and the Type 6 Secretion System (T6SS) (Goodman et al., 2004). Tight control of these processes is advantageous for fitness and survival of PA as it responds to rapid changes in the environment. Direct forms of post-transcriptional regulation typically have a stronger and more immediate effect on gene expression. It is therefore important to effectively differentiate between indirect and direct forms of regulation by RsmA to better understand the influence on dynamic signaling networks. In this study, we used our tuned model to predict the likelihood of a direct interaction occurring between RsmA and an mRNA leader sequence, and found predictions to be enriched for transcriptional regulators and core virulence pathways (Figure 3A). Here, we discuss noteworthy predictions generated for genes in quorum sensing and biofilm forming pathways.
Quorum Sensing (QS) in PA are complex, interconnected, context-dependent signaling cascades that facilitate group control and survival. Gene expression in these pathways is stochastic and sensitive to environmental conditions including fluctuations in nutrients, pH, and cellular density (Schuster and Greenberg, 2007; Papenfort and Bassler, 2016). QS expression can also vary from cell to cell in a population, and it is thought that this heterogeneity is a survival strategy that ensures proper division of labor and resource conservations within biofilms (Bettenworth et al., 2019). It has also been observed that post-transcriptional regulation by sRNAs and RBPs allows for fine tuning of signal production (Valverde and Haas, 2008). These factors present challenges in fully characterizing how these pathways are regulated experimentally, and efforts have been made to understand dynamics using computational modeling (Goryachev, 2009).
The activation of the hierarchical and interconnected quorum sensing pathways in PA has been shown to directly influence the lifestyle switch towards sessile biofilm forming states. The Gac/Rsm regulatory pathway has been identified as a key influencer of the QS cascade (Pessi et al., 2001). Our model identified several transcriptional regulators in the QS pathway as potential regulatory targets of RsmA (Figures 3A, C). This included lasR and mvfR transcriptional activators as well as the lasI and rhlI homo-serine lactone synthetases. The hierarchical cascade of QS signaling is initiated when transcriptional activator, LasR, is becomes active upon sensing 3-oxo-C12-HSL. This event sets off a signaling cascade and activates expression of subsequent transcriptional regulators RhlR, and MvfR [Figure 8; (Lee and Zhang, 2015)]. There exists an interplay between the RhlR and MvfR, wherein RhlR represses MvfR expression (Cao et al., 2001). Interestingly, RsmA binding to rhlR was neither predicted nor observed (Figures 5A, 6B; Supplementary Figure S6) which, given the repressive effect RhlR has on mvfR transcription, suggests a redundant mechanism by which RsmA regulates expression of this pathway along multiple nodes. Additional QS associated regulators were also evaluated in vitro given results of our model, including transcriptional repressors rsaL and mvaT. Both rsaL and mvaT repress elements of the LasR/I QS cascade (Figure 8). mvaT has been observed to repress additional transcription factors including mvfR (Diggle et al., 2002) and represses rsaL in P. fluorescens (Yu et al., 2022).
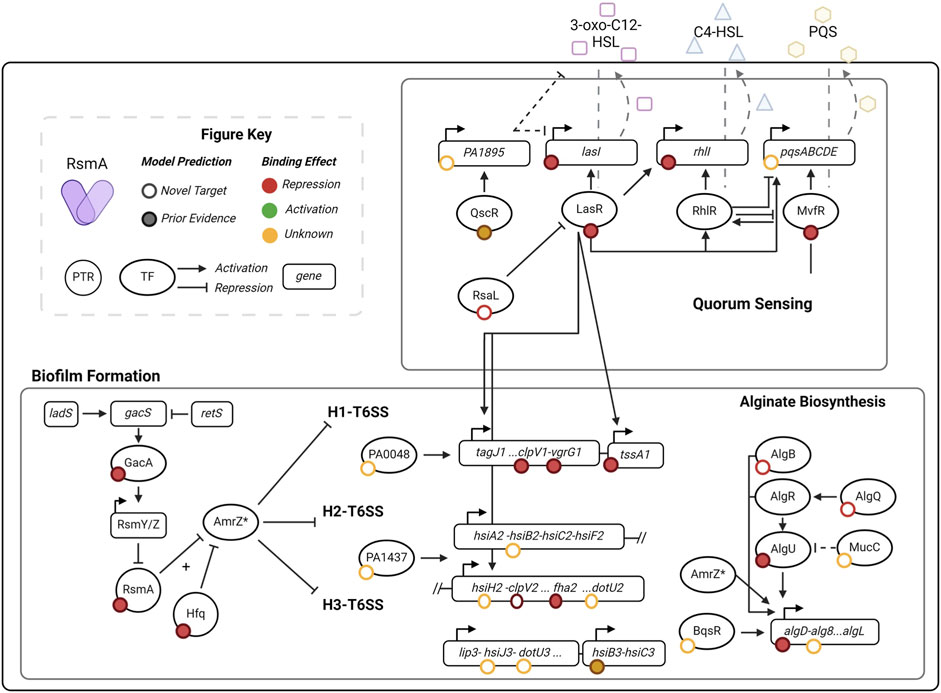
Figure 8. Virulence associated pathways enriched in target predictions included key regulatory transcription factors. Pathway diagrams shown here represent RsmA targets identified by our model in context of their cellular contribution to virulence. Circles represent predictions that passed our filter and are shown in solid or hollow based on whether there is prior experimental evidence of direct or indirect regulation of that gene. In addition, these circles are colored by their predicted regulatory effect: repression (red), activation (green), or an unknown effect (yellow). Genes are shown as boxes, and key transcriptional regulators are present as ovals. Finally post transcriptional regulators such as RsmA and Hfq are shown as circles. As shown in the box describing Quorum Sensing, several key transcription factor regulators are targeted by RsmA, as well as their cognate synthetases that contribute to the autoregulatory feedback loop. Key transcription factors such as LasR are also directly involved in influencing biofilms, and here we illustrate the activation effect on several pathogenicity islands that make up the T6SS in PA. * Our model did not identify AmrZ as a potential direct target, and this is likely due to the cooperative effect that Hfq binding has on loading RsmA to this gene. We also show predictions for several transcriptional regulators present in the Alginate biosynthesis pathway, providing further clarity on the level of control over this pathway.
Several genes predicted by our model are part of the extensive biofilm formation pathway. Our observation that our model and experimental results confirm binding and repression of LasR led us to further investigate whether RsmA also regulated additional targets of LasR activated genes involved in the T6SS. Inter-operonic binding was observed for genes in the H1, H2, and H3-T6SS (Figure 8). The GacA/S TCS has been observed to regulate key genes in the H1-T6SS and H3-TCSS, including the well-characterized target tssA1. In PA14, the H2-T6SS is more essential than H1 (Allsopp et al., 2017), and is activated by the QS transcriptional regulator MvfR (Maura et al., 2016). The prediction that RsmA regulates several genes within this locus (Figure 8), as well as repressing mvfR, reflects a shift towards redundant regulatory control of that crucial region. Overall, this outlines the utility of the model in capturing inter-operonic binding events that regulate the assembly of large, multi-component structures in PA.
In our study we further evaluated the strength and regulatory nature of binding between RsmA and the rsaL and mvaT transcriptional regulators. RsaL was identified as a regulator of four major virulence-associated pathways, including QS [Figure 3, (Wang et al., 2021)], exhibits low levels of expression across an aggregate of publicly available sequencing data (Rajput et al., 2022), and is an entirely novel prediction generated by our model. In this study, we demonstrate that RsmA binds to this mRNA in vitro (Figure 5A) at positions +67 and +76 nucleotides from the start codon (Figure 7). Binding results in repression of translation of this protein (Figure 6). We also theorize that this gene evaded prior high throughput screens because of low (Figure 4A), or context-dependent (Supplementary Figure S7) expression during planktonic growth phase. The observation that RsmA represses translation of rsaL suggests a surprising mechanism of indirect activation, as RsaL negatively regulates lasI expression by blocking LasR transcriptional activation (Rampioni et al., 2007). Perhaps this is a mechanism by which RsmA can initiate the autoregulatory feedback loop for the LasR/I signaling cascade at intermediate points during the motile–sessile lifestyle switch.
The second transcript we characterized further was that encoding the MvaT transcriptional repressor. There exists prior evidence of RsmA causing changes in expression (Gebhardt et al., 2020) or binding directly to this transcript (Chihara et al., 2021), however no prior evidence exists of direct binding in vitro or repression in vivo. Interestingly, MvaT has also been shown to regulate the Gac/Rsm regulatory pathway through repression of the RsmY and RsmZ sRNA sponges (Mcmackin et al., 2019). MvaT is also a regulator of QS, and its influence the system is thought to be through repression of mvfR and rsaL. In this study, we find that RsmA binds mvaT within the coding sequence (Figure 7F) and represses expression of mvaT as well as its paralog mvaU (Figure 6). Although mutations at model-predicted binding sites did not result in full loss of binding, the width of predicted binding sites on this transcript (Figure 7D) suggests that RsmA may bind in multiple conformations.
In this study, we confirm RsmA binds and represses translation of lasR, lasI, rhlI, mvfR, rsaL and mvaT (Figures 5–7). We hypothesize that this mechanism of redundant regulatory control across quorum sensing and biofilm formation allows for tight regulation of energetically costly pathways that can become rapidly de-repressed upon sequestration by the RsmY and RsmZ small RNAs, and could also fine tune production of signaling molecules at intermediate steps along the planktonic to biofilm forming lifestyle switch.
5 Conclusion
In this work, we demonstrate the utility in using thermodynamic modeling for differentiating direct from indirect regulatory interactions between the RsmA protein and the entirety of the P. aeruginosa transcriptome. We adapt a previously published model for a selection of CsrA-mRNA interactions in E. coli to capture novel mRNA- RsmA interactions in. P. aeruginosa. Applying this newly adapted model in a manner that differentiates bound from unbound mRNAs reveals widespread, redundant regulation of key virulence pathways, such as quorum sensing and biofilm formation. Specifically, our further biochemical characterization of RsmA binding to two transcriptional regulatory targets mvaT and rsaL reveal that RsmA has a far more extensive influence on quorum sensing pathways, at least in P. aeruginosa. We anticipate that the predictions presented in this dataset will aid in further characterization of RsmA regulatory influence upon the complex and interconnected networks within this widespread pathogen. It is worth noting that this approach yielded novel genes not yet reported to be bound or regulated by the RsmA, likely due to lack of expression in standard laboratory growth conditions. The ability to explore the entire sequence space in silico allows identification of regulatory interactions with genes that would only be observed experimentally under specific conditions that favors expression of those specific genes. Lastly, this work opens up further questions regarding the conserved nature of binding in other members of the gammaproteobacteria, as the model can be applied more broadly to Csr/Rsm harboring bacteria. We expect that application of computational modeling approaches to other organisms can reveal new paradigms regarding the diversity of post-transcriptional regulation.
Data availability statement
Scripts and associated files can be found at https://github.com/ajlukasiewicz/rsm_biophysical_model. Raw sequencing data for the RNA Co-Immunoprecipitation Sequencing experiments can be found in the Sequence Read Archive (SRA) under the Bioproject ID PRJNA1131461.
Author contributions
AJL: Conceptualization, Data curation, Formal Analysis, Funding acquisition, Investigation, Methodology, Software, Validation, Visualization, Writing–original draft, Writing–review and editing. ANL: Conceptualization, Methodology, Writing–review and editing. LH: Data curation, Methodology, Writing–review and editing. EM: Data curation, Writing–review and editing. CG: Data curation, Writing–review and editing. BZ: Writing–review and editing. KJ: Writing–review and editing. TY: Writing–review and editing. MW: Writing–review and editing. LC: Conceptualization, Funding acquisition, Supervision, Writing–original draft, Writing–review and editing.
Funding
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. AJL, ANL, LH, EM, and LMC were supported by the National Institutes of Health (Project # 5R01GM135495-05) and the National Science Foundation (DGE-1610403). LMC was supported by the Welch foundation (F-1756). AJL and ANL were supported through the National Science Foundation Graduate Research Fellowship Program (DGE-1610403). MCW, TLY, and BTZ were supported by a grant from the National Institute of Allergy and Infectious Diseases (AI097264). CJG was supported by a Postdoctoral Fellowship from the Cystic Fibrosis Foundation (POTRAT14F0).
Acknowledgments
We would like to thank Ryan Buchser, Kobe Grismore, Trevor Simmons, and Philip Sweet for their feedback on the manuscript. Figures were generated for this work using Biorender (BioRender.com).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The author(s) declared that they were an editorial board member of Frontiers, at the time of submission. This had no impact on the peer review process and the final decision.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fmolb.2025.1493891/full#supplementary-material
References
Allsopp, L. P., Wood, T. E., Howard, S. A., Maggiorelli, F., Nolan, L. M., Wettstadt, S., et al. (2017). RsmA and AmrZ orchestrate the assembly of all three type VI secretion systems in Pseudomonas aeruginosa. Proc. Natl. Acad. Sci. U. S. A. 114, 7707–7712. doi:10.1073/pnas.1700286114
Baker, C. S., Eöry, L. A., Yakhnin, H., Mercante, J., Romeo, T., and Babitzke, P. (2007). CsrA inhibits translation initiation of Escherichia coli hfq by binding to a single site overlapping the Shine-Dalgarno sequence. J. Bacteriol. 189, 5472–5481. doi:10.1128/JB.00529-07
Baker, C. S., Morozov, I., Suzuki, K., Romeo, T., and Babitzke, P. (2002). CsrA regulates glycogen biosynthesis by preventing translation of glgC in Escherichia coli. Mol. Microbiol. 44, 1599–1610. doi:10.1046/j.1365-2958.2002.02982.x
Bettenworth, V., Steinfeld, B., Duin, H., Petersen, K., Streit, W. R., Bischofs, I., et al. (2019). Phenotypic heterogeneity in bacterial quorum sensing systems. J. Mol. Biol. 431, 4530–4546. doi:10.1016/j.jmb.2019.04.036
Brencic, A., and Lory, S. (2009). Determination of the regulon and identification of novel mRNA targets of Pseudomonas aeruginosa RsmA. Mol. Microbiol. 72, 612–632. doi:10.1111/j.1365-2958.2009.06670.x
Brencic, A., McFarland, K. A., McManus, H. R., Castang, S., Mogno, I., Dove, S. L., et al. (2009). The GacS/GacA signal transduction system of Pseudomonas aeruginosa acts exclusively through its control over the transcription of the RsmY and RsmZ regulatory small RNAs. Mol. Microbiol. 73, 434–445. doi:10.1111/j.1365-2958.2009.06782.x
Burrowes, E., Baysse, C., Adams, C., and O’Gara, F. (2006). Influence of the regulatory protein RsmA on cellular functions in Pseudomonas aeruginosa PAO1, as revealed by transcriptome analysis. Microbiol. (N Y) 152, 405–418. doi:10.1099/mic.0.28324-0
Camacho, C., Coulouris, G., Avagyan, V., Ma, N., Papadopoulos, J., Bealer, K., et al. (2009). BLAST+: architecture and applications. BMC Bioinforma. 10, 421. doi:10.1186/1471-2105-10-421
Cao, H., Krishnan, G., Goumnerov, B., Tsongalis, J., Tompkins, R., and Rahme, L. G. (2001). A quorum sensing-associated virulence gene of Pseudomonas aeruginosa encodes a LysR-like transcription regulator with a unique self-regulatory mechanism. Proc Natl Acad Sci U S A. 98 (25), 14613–8. doi:10.1073/pnas.251465298
Cao, P., Fleming, D., Moustafa, D. A., Dolan, S. K., Szymanik, K. H., Redman, W. K., et al. (2023). A Pseudomonas aeruginosa small RNA regulates chronic and acute infection. Nature 618, 358–364. doi:10.1038/s41586-023-06111-7
Chihara, K., Barquist, L., Takasugi, K., Noda, N., and Tsuneda, S. (2021). Global identification of RsmA/N binding sites in Pseudomonas aeruginosa by in vivo UV CLIP-seq. RNA Biol. 18, 2401–2416. doi:10.1080/15476286.2021.1917184
Chourashi, R., and Oglesby, A. G. (2024). Iron starvation increases the production of the Pseudomonas aeruginosa RsmY and RsmZ sRNAs in static conditions. J. Bacteriol. 206, e0027823. doi:10.1128/jb.00278-23
Chua, S. L., Liu, Y., Yam, J. K. H., Chen, Y., Vejborg, R. M., Tan, B. G. C., et al. (2014). Dispersed cells represent a distinct stage in the transition from bacterial biofilm to planktonic lifestyles. Nat. Commun. 5, 4462. doi:10.1038/ncomms5462
Corley, J. M., Intile, P., and Yahr, T. L. (2022). Direct inhibition of RetS synthesis by RsmA contributes to homeostasis of the Pseudomonas aeruginosa gac/rsm signaling system. J. Bacteriol. 204, e0058021. doi:10.1128/jb.00580-21
Diggle, S. P., Winzer, K., Lazdunski, A., Williams, P., and Cámara, M. (2002). Advancing the quorum in Pseudomonas aeruginosa: MvaT and the regulation of N-acylhomoserine lactone production and virulence gene expression. J. Bacteriol. 184, 2576–2586. doi:10.1128/jb.184.10.2576-2586.2002
Dubey, A. K., Baker, C. S., Romeo, T., and Babitzke, P. (2005). RNA sequence and secondary structure participate in high-affinity CsrA-RNA interaction. Rna 11, 1579–1587. doi:10.1261/rna.2990205
Dubey, A. K., Baker, C. S., Suzuki, K., Jones, A. D., Pandit, P., Romeo, T., et al. (2003). CsrA regulates translation of the Escherichia coli carbon starvation gene, cstA, by blocking ribosome access to the cstA transcript. J. Bacteriol. 185, 4450–4460. doi:10.1128/jb.185.15.4450-4460.2003
Duss, O., Michel, E., Yulikov, M., Schubert, M., Jeschke, G., and Allain, F. H. T. (2014). Structural basis of the non-coding RNA RsmZ acting as a protein sponge. Nature 509, 588–592. doi:10.1038/nature13271
Espah Borujeni, A., Channarasappa, A. S., and Salis, H. M. (2014). Translation rate is controlled by coupled trade-offs between site accessibility, selective RNA unfolding and sliding at upstream standby sites. Nucleic Acids Res. 42, 2646–2659. doi:10.1093/nar/gkt1139
Gebhardt, M. J., Kambara, T. K., Ramsey, K. M., and Dove, S. L. (2020). Widespread targeting of nascent transcripts by RsmA in Pseudomonas aeruginosa. Proc. Natl. Acad. Sci. U. S. A. 117, 10520–10529. doi:10.1073/pnas.1917587117
Goodman, A. L., Kulasekara, B., Rietsch, A., Boyd, D., Smith, R. S., and Lory, S. (2004). A signaling network reciprocally regulates genes associated with acute infection and chronic persistence in Pseudomonas aeruginosa. Dev. Cell 7, 745–754. doi:10.1016/j.devcel.2004.08.020
Goryachev, A. B. (2009). Design principles of the bacterial quorum sensing gene networks. Inc. WIREs Syst. Biol. Med. 1, 45–60. doi:10.1002/wsbm.27
Irie, Y., La Mensa, A., Murina, V., Hauryliuk, V., Tenson, T., and Shingler, V. (2020). Hfq-assisted RsmA regulation is central to Pseudomonas aeruginosa biofilm polysaccharide PEL expression. Front. Microbiol. 11, 482585. doi:10.3389/fmicb.2020.482585
Irie, Y., Starkey, M., Edwards, A. N., Wozniak, D. J., Romeo, T., and Parsek, M. R. (2010). Pseudomonas aeruginosa biofilm matrix polysaccharide Psl is regulated transcriptionally by RpoS and post-transcriptionally by RsmA. Mol. Microbiol. 78, 158–172. doi:10.1111/j.1365-2958.2010.07320.x
Kappel, K., and Das, R. (2019). Sampling native-like structures of RNA-protein complexes through Rosetta folding and docking. Structure 27, 140–151. doi:10.1016/j.str.2018.10.001
Kulkarni, P. R., Jia, T., Kuehne, S. A., Kerkering, T. M., Morris, E. R., Searle, M. S., et al. (2014). A sequence-based approach for prediction of CsrA/RsmA targets in bacteria with experimental validation in Pseudomonas aeruginosa. Nucleic Acids Res. 42, 6811–6825. doi:10.1093/nar/gku309
Langmead, B., and Salzberg, S. L. (2012). Fast gapped-read alignment with Bowtie 2. Nat. Methods 9, 357–359. doi:10.1038/nmeth.1923
Lapouge, K., Sineva, E., Lindell, M., Starke, K., Baker, C. S., Babitzke, P., et al. (2007). Mechanism of hcnA mRNA recognition in the Gac/Rsm signal transduction pathway of Pseudomonas fluorescens. Mol. Microbiol. 66, 341–356. doi:10.1111/j.1365-2958.2007.05909.x
Lebreton, F., Snesrud, E., Hall, L., Mills, E., Galac, M., Stam, J., et al. (2021). A panel of diverse Pseudomonas aeruginosa clinical isolates for research and development. JAC Antimicrob Resist 3 (4), dlab179. doi:10.1093/jacamr/dlab179
Lee, J., and Zhang, L. (2015). The hierarchy quorum sensing network in Pseudomonas aeruginosa. Protein Cell 6, 26–41. doi:10.1007/s13238-014-0100-x
Leistra, A. N., Gelderman, G., Sowa, S. W., Moon-Walker, A., Salis, H. M., and Contreras, L. M. (2018). A canonical biophysical model of the CsrA global regulator suggests flexible regulator-target interactions. Sci. Rep. 8, 9892. doi:10.1038/s41598-018-27474-2
Li, H., Handsaker, B., Wysoker, A., Fennell, T., Ruan, J., Homer, N., et al. (2009). The sequence alignment/map format and SAMtools. Bioinformatics 25, 2078–2079. doi:10.1093/bioinformatics/btp352
Liu, M. Y., Yang, H., and Romeo, T. (1995). The product of the pleiotropic Escherichia coli gene csrA modulates glycogen biosynthesis via effects on mRNA stability. J. Bacteriol. 177, 2663–2672. doi:10.1128/jb.177.10.2663-2672.1995
Lorenz, R., Bernhart, S. H., Honer zu Siederdissen, C., Tafer, H., Flamm, C., Stadler, P. F., et al. (2011). ViennaRNA package 2.0. Algorithms Model. Biol. 6, 26–14. doi:10.1186/1748-7188-6-26
Love, M. I., Huber, W., and Anders, S. (2014). Moderated estimation of fold change and dispersion for RNA-seq data with DESeq2. Genome Biol. 15, 550–621. doi:10.1186/s13059-014-0550-8
Marden, J. N., Diaz, M. R., Walton, W. G., Gode, C. J., Betts, L., Urbanowski, M. L., et al. (2013). An unusual CsrA family member operates in series with RsmA to amplify posttranscriptional responses in Pseudomonas aeruginosa. Proc. Natl. Acad. Sci. U. S. A. 110, 15055–15060. doi:10.1073/pnas.1307217110
Maura, D., Hazan, R., Kitao, T., Ballok, A. E., and Rahme, L. G. (2016). Evidence for direct control of virulence and defense gene circuits by the pseudomonas aeruginosa quorum sensing regulator, MvfR. Sci. Rep. 6, 34083. doi:10.1038/srep34083
Mcmackin, E. A. W., Marsden, A. E., and Yahr, T. L. (2019). H-NS family members MvaT and MvaU regulate the Pseudomonas aeruginosa type III secretion system. J. Bacteriol. 201, e00054. doi:10.1128/JB.00054-19
Mercante, J., Edwards, A. N., Dubey, A. K., Babitzke, P., and Romeo, T. (2009). Molecular geometry of CsrA (RsmA) binding to RNA and its implications for regulated expression. J. Mol. Biol. 392, 511–528. doi:10.1016/j.jmb.2009.07.034
Mihailovic, M. K., Ekdahl, A. M., Chen, A., Leistra, A. N., Li, B., González Martínez, J., et al. (2021). Uncovering transcriptional regulators and targets of sRNAs using an integrative data-mining approach: H-NS-Regulated RseX as a case study. Front. Cell Infect. Microbiol. 11, 696533. doi:10.3389/fcimb.2021.696533
Morris, E. R., Hall, G., Li, C., Heeb, S., Kulkarni, R. V., Lovelock, L., et al. (2013). Structural rearrangement in an RsmA/CsrA ortholog of Pseudomonas aeruginosa creates a dimeric RNA-binding protein, RsmN. RsmN. Struct. 21, 1659–1671. doi:10.1016/j.str.2013.07.007
Mulcahy, H., O’Callaghan, J., O’Grady, E. P., Maciá, M. D., Borrell, N., Gómez, C., et al. (2008). Pseudomonas aeruginosa RsmA plays an important role during murine infection by influencing colonization, virulence, persistence, and pulmonary inflammation. Infect. Immun. 76, 632–638. doi:10.1128/IAI.01132-07
Pannuri, A., Yakhnin, H., Vakulskas, C. A., Edwards, A. N., Babitzke, P., and Romeo, T. (2012). Translational repression of NhaR, a novel pathway for multi-tier regulation of biofilm circuitry by CsrA. J. Bacteriol. 194, 79–89. doi:10.1128/JB.06209-11
Papenfort, K., and Bassler, B. L. (2016). Quorum sensing signal-response systems in Gram-negative bacteria. Nat. Rev. Microbiol. 14, 576–588. doi:10.1038/nrmicro.2016.89
Parkins, M. D., Ceri, H., and Storey, D. G. (2001). Pseudomonas aeruginosa GacA, a factor in multihost virulence, is also essential for biofilm formation. Mol. Microbiol. 40, 1215–1226. doi:10.1046/j.1365-2958.2001.02469.x
Pessi, G., Williams, F., Hindle, Z., Heurlier, K., Holden, M. T. G., Cámara, M., et al. (2001). The global posttranscriptional regulator RsmA modulates production of virulence determinants and N- acylhomoserine lactones in Pseudomonas aeruginosa. J. Bacteriol. 183, 6676–6683. doi:10.1128/JB.183.22.6676-6683.2001
Potts, A. H., Guo, Y., Ahmer, B. M. M., and Romeo, T. (2019). Role of CsrA in stress responses and metabolism important for Salmonella virulence revealed by integrated transcriptomics. PLoS One 14, e0211430. doi:10.1371/journal.pone.0211430
Potts, A. H., Vakulskas, C. A., Pannuri, A., Yakhnin, H., Babitzke, P., and Romeo, T. (2017). Global role of the bacterial post-transcriptional regulator CsrA revealed by integrated transcriptomics. Nat. Commun. 8, 1596. doi:10.1038/s41467-017-01613-1
Rajput, A., Tsunemoto, H., Sastry, A. V., Szubin, R., Rychel, K., Sugie, J., et al. (2022). Machine learning from Pseudomonas aeruginosa transcriptomes identifies independently modulated sets of genes associated with known transcriptional regulators. Nucleic Acids Res. 50, 3658–3672. doi:10.1093/nar/gkac187
Rampioni, G., Schuster, M., Greenberg, E. P., Bertani, I., Grasso, M., Venturi, V., et al. (2007). RsaL provides quorum sensing homeostasis and functions as a global regulator of gene expression in Pseudomonas aeruginosa. Mol. Microbiol. 66, 1557–1565. doi:10.1111/j.1365-2958.2007.06029.x
Ren, B., Shen, H., Lu, Z. J., Liu, H., and Xu, Y. (2014). The phzA2-G2 transcript exhibits direct RsmA-mediated activation in Pseudomonas aeruginosa M18. PLoS One 9, e89653. doi:10.1371/journal.pone.0089653
Rojano-Nisimura, A. M., Grismore, K. B., Ruzek, J. S., Avila, J. L., and Contreras, L. M. (2024). The post-transcriptional regulatory protein CsrA amplifies its targetome through direct interactions with stress-response regulatory hubs: the EvgA and AcnA cases. Microorganisms 12, 636. doi:10.3390/microorganisms12040636
Romero, M., Silistre, H., Lovelock, L., Wright, V. J., Chan, K. G., Hong, K. W., et al. (2018). Genome-wide mapping of the RNA targets of the Pseudomonas aeruginosa riboregulatory protein RsmN. Nucleic Acids Res. 46, 6823–6840. doi:10.1093/nar/gky324
Roots, C., Lukasiewicz, A., and Barrick, J. (2021). OSTIR: open source translation initiation rate prediction. J. Open Source Softw. 6, 3362. doi:10.21105/joss.03362
Ryder, S. P., Recht, M. I., and Williamson, J. R. (2008). Quantitative analysis of protein-RNA interactions by gel mobility shift. Methods Mol. Biol. 488, 99–115. doi:10.1007/978-1-60327-475-3_7
Sadée, C., Hagler, L. D., Becker, W. R., Jarmoskaite, I., Vaidyanathan, P. P., Denny, S. K., et al. (2022). A comprehensive thermodynamic model for RNA binding by the Saccharomyces cerevisiae Pumilio protein PUF4. Nat. Commun. 13, 4522. doi:10.1038/s41467-022-31968-z
Salis, H. M. (2011). The ribosome binding site calculator. Methods Enzymol. 498, 19–42. doi:10.1016/B978-0-12-385120-8.00002-4
Salis, H. M., Mirsky, E. A., and Voigt, C. A. (2009). Automated design of synthetic ribosome binding sites to control protein expression. Nat. Biotechnol. 27, 946–950. doi:10.1038/nbt.1568
Schubert, M., Lapouge, K., Duss, O., Oberstrass, F. C., Jelesarov, I., Haas, D., et al. (2007). Molecular basis of messenger RNA recognition by the specific bacterial repressing clamp RsmA/CsrA. Nat. Struct. Mol. Biol. 14, 807–813. doi:10.1038/nsmb1285
Schulmeyer, K. H., Diaz, M. R., Bair, T. B., Sanders, W., Gode, C. J., Laederach, A., et al. (2016). Primary and secondary sequence structure requirements for recognition and discrimination of target RNAs by Pseudomonas aeruginosa RsmA and RsmF. J. Bacteriol. 198, 2458–2469. doi:10.1128/JB.00343-16
Schuster, M., and Greenberg, E. P. (2007). Early activation of quorum sensing in Pseudomonas aeruginosa reveals the architecture of a complex regulon. BMC Genomics 8, 287. doi:10.1186/1471-2164-8-287
Sobrero, P. M., and Valverde, C. (2020). Comparative genomics and evolutionary analysis of RNA-binding proteins of the CsrA family in the genus Pseudomonas. Front. Mol. Biosci. 7, 127–222. doi:10.3389/fmolb.2020.00127
Sowa, S. W., Gelderman, G., Leistra, A. N., Buvanendiran, A., Lipp, S., Pitaktong, A., et al. (2017). Integrative FourD omics approach profiles the target network of the carbon storage regulatory system. Nucleic Acids Res. 45, 1673–1686. doi:10.1093/nar/gkx048
Stevens, A. M. (2018). Mechanistic studies of the roles of the transcriptional activator ExsA and anti-activator protein ExsD in the regulation of the type three secretion system in Pseudomonas aeruginosa manisha shrestha.
Trouillon, J., Imbert, L., Villard, A. M., Vernet, T., Attrée, I., and Elsen, S. (2021). Determination of the two-component systems regulatory network reveals core and accessory regulations across Pseudomonas aeruginosa lineages. Nucleic Acids Res. 49, 11476–11490. doi:10.1093/nar/gkab928
Vakulskas, C. A., Potts, A. H., Babitzke, P., Ahmer, B. M. M., and Romeo, T. (2015). Regulation of bacterial virulence by Csr (rsm) systems. Microbiol. Mol. Biol. Rev. 79, 193–224. doi:10.1128/MMBR.00052-14
Valentini, M., Gonzalez, D., Mavridou, D. A., and Filloux, A. (2018). Lifestyle transitions and adaptive pathogenesis of Pseudomonas aeruginosa. Curr. Opin. Microbiol. 41, 15–20. doi:10.1016/j.mib.2017.11.006
Valverde, C., and Haas, D. (2008). Small RNAs controlled by two-component systems. Adv. Exp. Med. Biol. 631, 54–79. doi:10.1007/978-0-387-78885-2_5
Wang, T., Sun, W., Fan, L., Hua, C., Wu, N., Fan, S., et al. (2021). An atlas of the binding specificities of transcription factors in pseudomonas aeruginosa directs prediction of novel regulators in virulence. Elife 10, 618855–e61925. doi:10.7554/eLife.61885
Wang, X., Dubey, A. K., Suzuki, K., Baker, C. S., Babitzke, P., and Romeo, T. (2005). CsrA post-transcriptionally represses pgaABCD, responsible for synthesis of a biofilm polysaccharide adhesin of Escherichia coli. Mol. Microbiol. 56, 1648–1663. doi:10.1111/j.1365-2958.2005.04648.x
Wurtzel, O., Yoder-Himes, D. R., Han, K., Dandekar, A. A., Edelheit, S., Greenberg, E. P., et al. (2012). The single-nucleotide resolution transcriptome of Pseudomonas aeruginosa grown in body temperature. PLoS Pathog. 8, e1002945. doi:10.1371/journal.ppat.1002945
Yakhnin, H., Aichele, R., Ades, S. E., Romeo, T., and Babitzke, P. (2017). Circuitry linking the global Csr- and σ E -dependent cell envelope stress response systems. J. Bacteriol. 199, e00484. doi:10.1128/JB.00484-17
Keywords: post-transcriptional regulation, computational modeling, RNA-binding proteins, regulatory networks, systems biology, RNA-protein interactions, RNA secondary structure, Pseudomonas aeruginosa
Citation: Lukasiewicz AJ, Leistra AN, Hoefner L, Monzon E, Gode CJ, Zorn BT, Janssen KH, Yahr TL, Wolfgang MC and Contreras LM (2025) Thermodynamic modeling of RsmA - mRNA interactions capture novel direct binding across the Pseudomonas aeruginosa transcriptome. Front. Mol. Biosci. 12:1493891. doi: 10.3389/fmolb.2025.1493891
Received: 09 September 2024; Accepted: 27 January 2025;
Published: 20 February 2025.
Edited by:
Giovanni Bertoni, University of Milan, ItalyReviewed by:
Sven Findeiß, Leipzig University, GermanyMohammad Imran K. Khan, Columbia University, United States
Copyright © 2025 Lukasiewicz, Leistra, Hoefner, Monzon, Gode, Zorn, Janssen, Yahr, Wolfgang and Contreras. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Lydia M. Contreras, bGNvbnRyZXJAY2hlLnV0ZXhhcy5lZHU=