 Xingguo Wang1,2†
Xingguo Wang1,2† Yanyan Zhang3†
Yanyan Zhang3† Yuhui Ma2
Yuhui Ma2 William Robert Kwapong4Jianing Ying5
William Robert Kwapong4Jianing Ying5 Jiayi Lu1,2Shaodong Ma2Qifeng Yan2
Jiayi Lu1,2Shaodong Ma2Qifeng Yan2 Quanyong Yi3*
Quanyong Yi3* Yitian Zhao1,2*
Yitian Zhao1,2*- 1Cixi Biomedical Research Institute, Wenzhou Medical University, Ningbo, China
- 2Institute of Biomedical Engineering, Ningbo Institute of Materials Technology and Engineering, Chinese Academy of Sciences, Ningbo, China
- 3The Affiliated Ningbo Eye Hospital of Wenzhou Medical University, Ningbo, China
- 4Department of Neurology, West China Hospital, Sichuan University, Chengdu, China
- 5Health Science Center, Ningbo University, Ningbo, China
Purpose: Fast and automated reconstruction of retinal hyperreflective foci (HRF) is of great importance for many eye-related disease understanding. In this paper, we introduced a new automated framework, driven by recent advances in deep learning to automatically extract 12 three-dimensional parameters from the segmented hyperreflective foci in optical coherence tomography (OCT).
Methods: Unlike traditional convolutional neural networks, which struggle with long-range feature correlations, we introduce a spatial and channel attention module within the bottleneck layer, integrated into the nnU-Net architecture. Spatial Attention Block aggregates features across spatial locations to capture related features, while Channel Attention Block heightens channel feature contrasts. The proposed model was trained and tested on 162 retinal OCT volumes of patients with diabetic macular edema (DME), yielding robust segmentation outcomes. We further investigate HRF’s potential as a biomarker of DME.
Results: Results unveil notable discrepancies in the amount and volume of HRF subtypes. In the whole retinal layer (WR), the mean distance from HRF to the retinal pigmented epithelium was significantly reduced after treatment. In WR, the improvement in central macular thickness resulting from intravitreal injection treatment was positively correlated with the mean distance from HRF subtypes to the fovea.
Conclusion: Our study demonstrates the applicability of OCT for automated quantification of retinal HRF in DME patients, offering an objective, quantitative approach for clinical and research applications.
1. Introduction
Diabetic retinopathy (DR) is one of the most common complications of diabetes (1). With about 1 in every 10 diabetic patients developing visual impairment due to DR (2). One of the leading causes of visual impairment in DR patients is diabetic macular edema (DME) (3). It is suggested that in DR patients, disruption of the blood-retina barrier leads to increased fluid leakage within the retina, resulting in the development of DME (4) ultimately resulting in visual loss.
In recent decades, advances in high-resolution fundus imaging techniques have led to the discovery of specific imaging features of retinal diseases, which may serve as diagnostic, predictive, and prognostic biomarkers for this disease (5). Optical coherence tomography (OCT) is an imaging tool that can help in the visualization of the intra-retinal layers. Due to its non-invasiveness, affordability and high resolution, this imaging tool is suggested as the gold standard for the diagnosis and monitoring of DME (6). ‘Hyperreflective foci’ (HRF) is a term denoting any hyperreflective lesion, focal or dotted appearance, seen at any retinal layer on OCT images (7). Reports suggest that HRF is associated with lipid extravasation (7), microglia cells (8), migrating retinal pigment epithelium (RPE) cells (9), degenerated photoreceptor cells, and visual prognosis (10), increasing its clinical significance. In the last decade, it was shown that the presence of HRF was associated with DME, and several more recent studies have indicated that HRF could serve as a promising biomarker for investigating DME, due to its association with the soluble cluster of differentiation 14 (CD14) pro-inflammatory cytokine expressed by glial cells, monocytes, and macrophages (8, 11).
However, manual annotation of HRF in OCT is time-consuming, and sometimes excessively subjective. With the rapid development of computer science, there is great potential for automatic segmentation and quantification of HRF in OCT images, with benefits for clinical practice. The segmentation algorithms for HRF can be categorized into two primary groups: traditional segmentation algorithms and deep learning-based segmentation methods. Traditional HRF segmentation approaches usually require manual parameter tuning and extensive prior knowledge. Okuwobi et al. (12) employed an automated grow-cut algorithm for HRF segmentation. It is difficult for traditional automated methods to perform accurate HRF segmentation due to boundary blurring and speckle noise within HRF images. Okuwobi et al. (13) introduced another component tree-based method to segment HRF by extracting the extreme regions from the connected areas. Still, the method is complicated and relies on handcrafted features. Deep learning techniques have achieved significant success in medical image segmentation. Yu et al. (14) modified GoogLeNet for HRF segmentation in DR using pixel-level predictions of small image patches. However, this method partially addresses the class imbalance issue, leading to the mis-segmentation of large blood vessels or low-contrast backgrounds as HRF. Xie et al. (15) modified 3D-UNet for HRF segmentation, introducing denoised and enhanced OCT images as a dual-channel input and dilation convolution in the final layer of the encoder to expand the receptive field. Nevertheless, this approach overlooks false positive outcomes caused by high-frequency noise in the NFL/GCL and IS/OS layers. Yao et al. (16) modified U-Net for HRF segmentation, enhancing gradient propagation by replacing ordinary convolution blocks with dual residual modules and integrating adaptive modules within the bottleneck layer to fuse local features and global dependencies. However, this network ignores the inappropriateness of employing deformable convolutions for the segmentation of HRF due to its small size and lack of shape information. Wei et al. (17) preprocessed images using Non-local means (NLM) filters and adopted a patch-based segmentation approach, employing a lightweight network for automated HRF segmentation. This network relies on the patch-based method, which further diminishes the limited semantic information inherent in HRF.
In this study, we presented a deep learning-based framework for the quantitative analysis of HRF in OCT images. Specifically, the main contributions of our article can be summarized as follows:
• We achieve excellent HRF segmentation performance by combining nnU-Net (18) adaptability with the advanced long-range feature-capturing abilities of channel and spatial attention modules.
• Using the proposed method, we extracted 12 parameters to characterize HRF morphology and distribution, showing significant differences in volume and amount among the three HRF sub-types in retinal OCT images.
• Using the extracted 12 HRF parameters, we evaluated changes in HRF before and after treatment and their correlation with central macular thickness (CMT) improvement.
2. Materials and methods
This is a retrospective, longitudinal study conducted at the Affiliated Ningbo Eye Hospital of Wenzhou Medical University (Ningbo, China) from November 2020 to July 2022. This study was approved by the ethics committee of the Affiliated Ningbo Eye Hospital of Wenzhou Medical University (ID: 20210327A), and informed written consent was obtained from each participant involved in our study according to the Declaration of Helsinki.
2.1. DME participants
Type 2 diabetes mellitus (DM) patients were recruited and diagnosed by an endocrine specialist. Demographic and clinical information from all patients such as age, gender, duration of DM, and systolic/diastolic blood pressure were recorded. All patients had an extensive ophthalmic examination, involving slit-lamp biomicroscopy, and assessment of intraocular pressure, axial length, and visual acuity. The inclusion criteria of our patients are as follows: 1. Diagnosed with type 2 DM; 2. Age > 18 years; 3. Macular edema, defined clinically and by a retinal thickness of >250 μm in the central subfield (19); 4. Could cooperate with OCT imaging. Exclusion criteria were as follows: 1. Myopia; 2. Presence of media opacities; 3. Inability to cooperate with OCT imaging.
2.2. OCT image acquisition
3D retinal imaging was performed using the OCT tool (Spectralis HRA + OCT; Heidelberg Engineering, Heidelberg, Germany, software version V6.16.2). This imaging equipment has a scanning protocol of 40,000 A-scans/s (20), with an axial resolution of 3.9 μm and a lateral resolution of 11.4 μm in high-speed mode. We acquired OCT images covering fovea-centered regions of 4.5 × 4.5 mm2, with 384 B-scans, and 6 × 6 mm2, with 512 B-scans. OCT images showing retinal abnormalities such as age macular degeneration (AMD), severe cataract, and glaucoma; images with signal quality less than 7; or with OCT artifacts present, were excluded. OCT data displayed in our study followed the OSCAR-IB quality criteria (21) and APOSTEL recommendation (22). Patients were excluded if their CMT did not increase after treatment with anti-vascular endothelial growth factor (anti-VEGF).
2.3. HRF and retinal layers segmentation
We introduced an automatic tool for HRF analysis in OCT images. A deep learning-based approach was employed for precise segmentation of HRF, boundaries of inner retina (IR) and outer retina (OR) in OCT images. The resulting segmentations are then used to calculate HRF parameters.
2.3.1. Hyperreflective foci segmentation
HRF was defined as discrete and well-defined lesions distributed between the in-ternal limiting membrane (ILM) and retinal pigmented epithelium (RPE), with similar reflectivity to the RPE layer (8). Considering that the most HRFs cross 2–4 B-scans (15), we randomly selected 8 consecutive B-scans from each OCT volume for manual annotations of HRF. Two senior ophthalmologists made manual annotations of HRF on 140 OCT volumes, and their consensus was defined as the ground-truth. 112 OCT volumes were randomly selected for training: the rest were used for validation. The best-performing model during training was then used for the evaluation of HRF segmentation in intact OCT data from all participants, across 22 OCT volumes from 11 eyes and a total of 9,216 B-scans. Figure 1A shows the automated segmentation results indicating HRF. Section 2.4 gives a detailed description of the proposed approach.
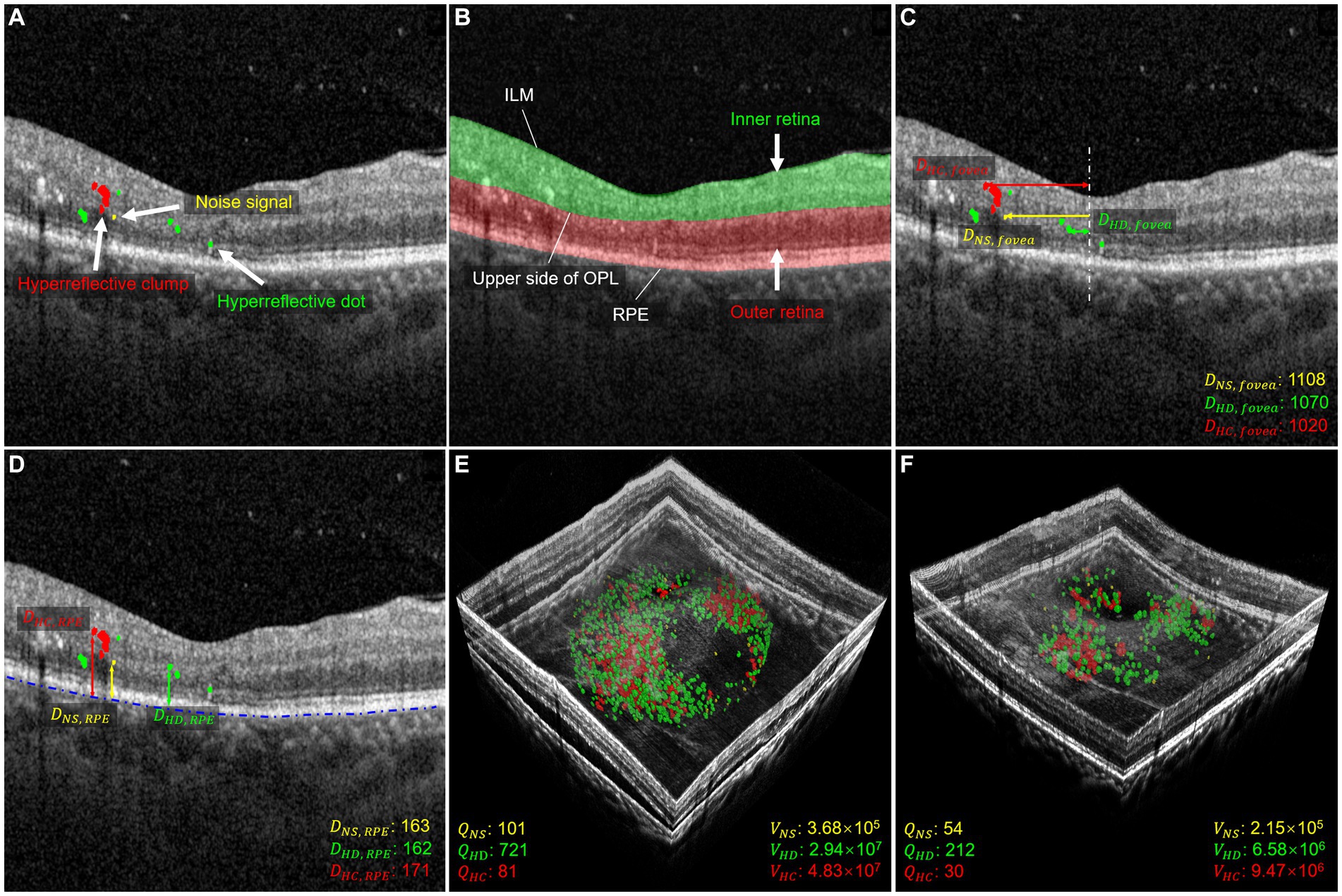
Figure 1. Morphology and distribution-related parameters used in quantitative measurements. (A) Shows the segmentation of HRF with NS in yellow, HD in green, and HC in red. (B) Shows the segmentation of the retina, with the inner layer in green and the outer layer in red. (C) Shows the distance parameter for the foveal direction of HRF. The distance between NS and fovea is shown in yellow, the distance between HD and fovea is shown in green, and the distance between HC and fovea is shown in red. The distance is measured in μm. (D) Shows the distance parameters between HRF and RPE. The distance between NS and RPE is shown in yellow, the distance between HD and RPE is shown in green, and the distance between HC and RPE is shown in red. The distance is measured in μm. (E,F) illustrate three-dimensional volume-rendered optical coherence tomography at the initial visit and six months after the initial visit, with NS in yellow, HD in green, and HC in red. For this case, the number parameters (, , ), and volume parameters (, , and ) decreased.
2.3.2. Inner and outer retinal layers segmentation
The distribution of HRF in the IR and OR, and their downward shift, have been previously studied (23). The IR region is defined as the region between the upper boundary of the ILM and the upper boundary of the outer plexiform layer (OPL), while the OR region is defined as the region between the upper boundary of the OPL and the lower boundary of the RPE (24). The whole retinal layer (WR) region is then defined as including both IR and OR. When HRF cross the upper boundary of OPL, they are considered located in the OR region. The IR and OR boundaries of 1,120 OCT images randomly selected from the training and validation dataset in section 2.3.1 were manually annotated by a senior ophthalmologist (Y.Y.Z). We used 896 images for training and the rest for validation. The evaluation dataset is also the same as in section 2.3.1. Figure 1B illustrates an example of IR and OR segmentation in OCT images.
2.4. Methods
2.4.1. Network architecture
In this research, we modified the nnU-Net, to, respectively, perform two segmentation tasks: hyperreflective foci segmentation and retinal layer segmentation. The framework comprises a basic U-Net architecture library that includes 2D and 3D version.
For the retinal layer segmentation task, we modified the 2D version of nnU-Net as the underlying network topology. The network architecture is shown in Figure 2. The network consists of six symmetric encoder-decoder layers with skip connections, which provides detailed features from the encoder to the decoder. A 384 × 384 patch with 3 channels is first input to one 3 × 3 convolution with stride 1 to obtain the low-level feature map with 32 channels. In the encoder, each layer contains two 3 × 3 convolutions with stride 1 followed by one 3 × 3 down-convolution with stride 2. In the decoder, each layer contains a 2 × 2 up-convolution with stride 2 followed by two 3 × 3 convolutions with stride 1. Finally, the feature map of the last decoder layer is fed into one 1 × 1 convolution with stride 1 to output the segmentation map.
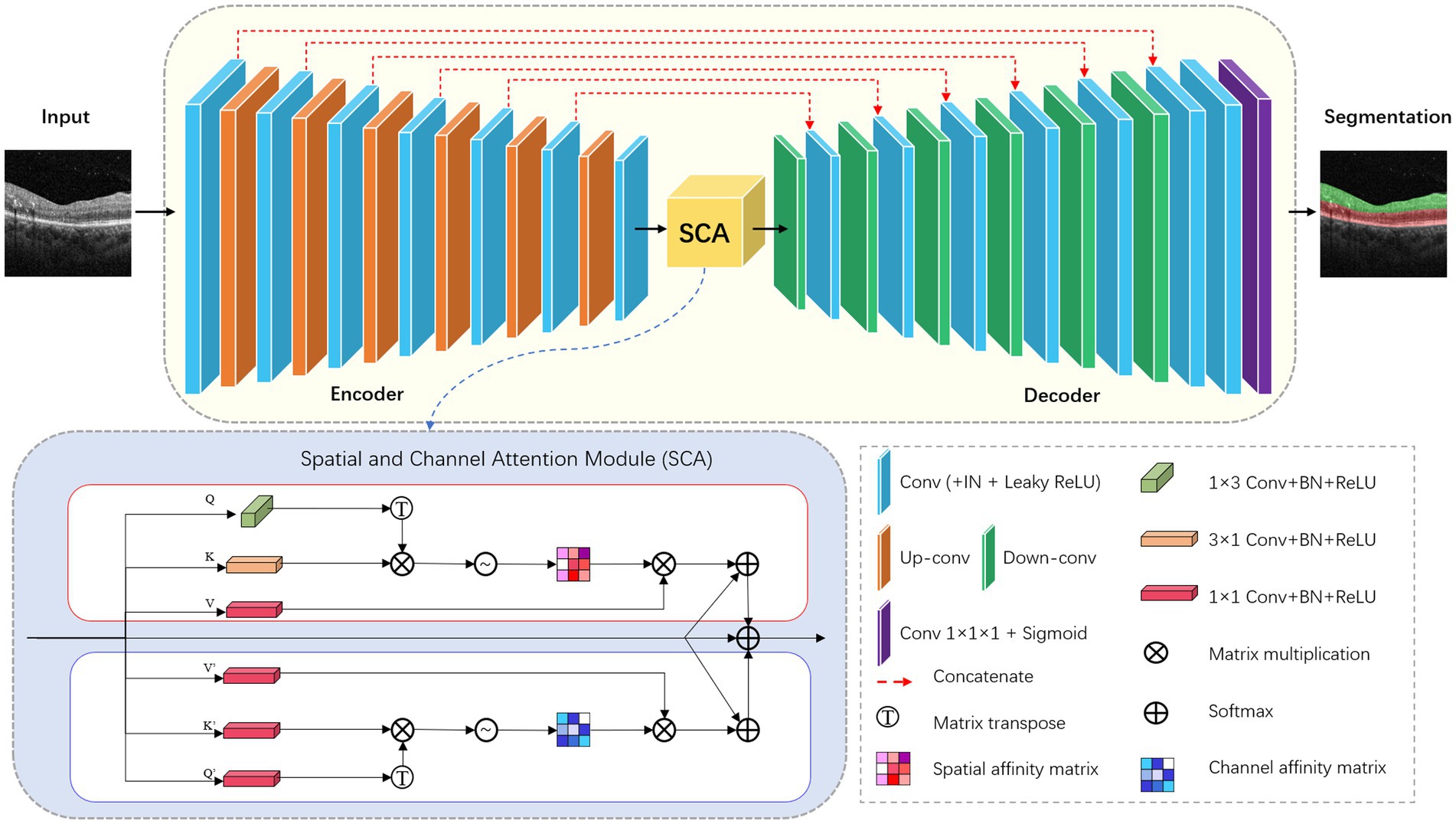
Figure 2. Architecture of modified nnU-Net (2D version).
Convolutional neural networks with U-Net structure have higher inductive bias, but lack the ability to capture long-distance dependent features. Inspired by CS2-Net (25), we embed a spatial and channel attention (SCA) module integrating channel attention and spatial attention mechanisms at the bottleneck layer. Specifically, the features output by the encoder are fed into two sub-modules of SCA in parallel. Spatial Attention Block (SAB) aggregates features at each spatial location to correlate similar features, while Channel Attention Block (CAB) enhances the contrast of each channel feature. The spatial attention matrix models the spatial relationship between pixel features. The acquisition of intra-class spatial association can be expressed as follows:
where represents the influence of the y position on the x position. N represents the number of features. T denotes matrix transposition. and represent two new feature maps generated from input features, representing the vertical and horizontal directions of structural features. The channel attention matrix enhances similar channel features and reduces different channel features, which can be expressed as follows:
where represents the association between the features of the x-channel and y-channel. C denotes the number of channels. T represents matrix transpose. and represent the original input features.
For the HRF segmentation task, we have extended the modified nnU-Net from 2D to 3D. To achieve this, we have replaced all the 2D operations in both the encoder and decoder modules with 3D ones. Additionally, we have incorporated the 3D version of the SCA module into the bottleneck layer of the network. The detailed network architecture is illustrated in Figure 3.
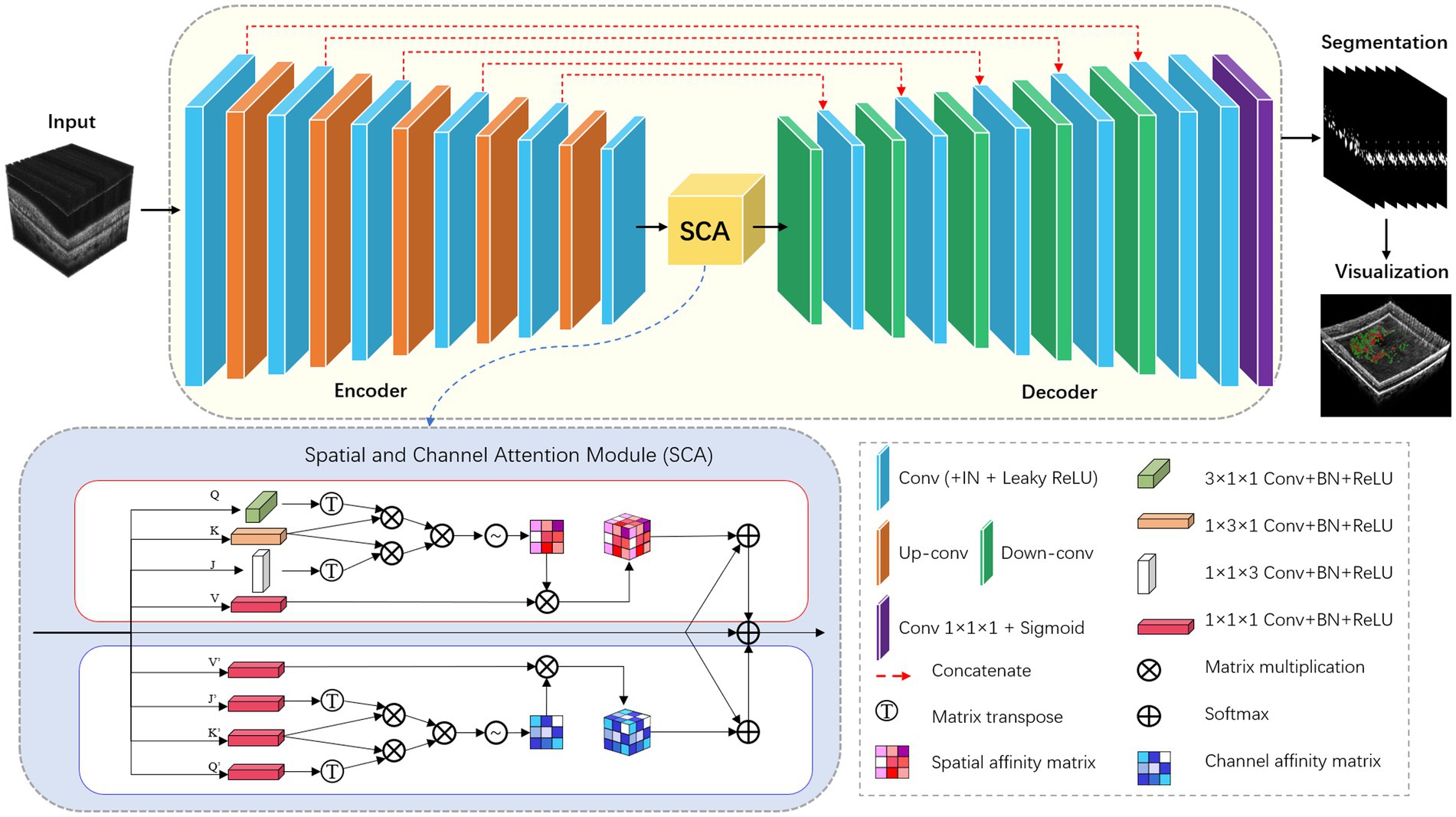
Figure 3. Architecture of modified nnU-Net (3D version).
All convolutions in the encoder and decoder adopt the form of Convolution-InstanceNorm-LeakyReLU, which are different from that in the vanilla architecture. Specifically, LeakyReLU (negative slope = 0.01) is used instead of ReLU, and instance normalization (26) is used instead of batch normalization (27). To train the network, the framework adopts a combination of dice coefficient loss and cross-entropy loss:
The dice loss formula used here is a variant of that used in Drozdzal et al. (28), and it is implemented as follows:
where u ∈ RI × K denotes the softmax output of the network, v ∈ RI × K denotes the one-hot encoding of the ground truth, I represent the number of pixels in a training batch and K represents the number of categories.
2.5. Definitions of quantitative parameters
In this study, we analyzed changes in HRF’s morphology and distribution in OCT images before and after IVI treatment. A previous study limited the maximum diameter range of HRF to 20–50 μm, which excludes the other two signals (8), refers to HRF <20 μm and > 50 μm, respectively. These signals were considered small noise signals (NS) in OCT images, and as hyperreflective clumps (HC) that appear as hard exudates in fundus images, respectively. By contrast, our study included all three types of these HRFs, allowing us to comprehensively investigate their differences in terms of number, volume, and spatial distribution. To this end, we first divided HRF into three types: NS, hyperreflective dots (HD), and HC, which are, respectively, defined as simply connected regions with a diameter range 0–20 μm, 20–50 μm, and greater than 50 μm. We then focused on 12 parameters that describe the distribution and morphological characteristics of these HRF in the retinal regions to be analyzed, as depicted in Figures 1C–F. Figures 1E,F demonstrate a 3D volume reconstruction case before and after IVI treatment. Following previous studies (8, 29), we selected a circular range of 3 mm in diameter, centered on the central macular region, for assessment of horizontal B-scans across the macular region. This region was used for analysis to ensure consistency in the region of interest across all participants.
2.5.1. Morphology-related parameters
- Noise Signal Quantity (): Number of NS within the analyzed region.
- Hyperreflective Dots Quantity (): Number of HD within the analyzed region.
- Hyperreflective Clumps Quantity (): Number of HC within the analyzed region.
- Noise Signal Volume (): Volume of NS within the analyzed region in μm3.
- Hyperreflective Dots Volume (): Volume of HD within the analyzed region in μm3.
- Hyperreflective Clumps Volume (): Volume of HC within the analyzed region in μm3.
2.5.2. Distribution-related parameters
- Distance between noise signal and fovea (): Distance between NS and fovea, indicating average distance of NS pixels from the foveal center in μm.
- Distance between hyperreflective dots and fovea (): Distance between HD and fovea, indicating average distance of HD pixels from the foveal center in μm.
- Distance between hyperreflective clumps and fovea (): Distance between HC and fovea, indicating average distance of HC pixels from the foveal center in μm.
- Distance between noise signal and RPE (): Distance between NS and RPE, indicating average distance of NS pixels from RPE in μm.
- Distance between hyperreflective dots and RPE (): Distance between HD and RPE, indicating average distance of HD pixels from RPE in μm.
- Distance between hyperreflective clumps and RPE (): Distance between HC and RPE, indicating average distance of HC pixels from RPE in μm.
2.6. Statistical analysis
All statistical analysis was performed using version 18.0 of SPSS software (SPSS, Inc., Chicago, IL, USA). Continuous variables were expressed as mean ± standard deviation (SD) for normal data; and median and interquartile ranges (IQR) for skewed data. Categorical variables were presented as frequencies. To compare the differences among different subtypes of HRF and the differences in HRF parameters before and after treatment, the Wilcoxon signed-rank test was used, and the results were expressed as the median (IQR). To investigate the correlation between the improvement in CMT and given parameters of HRF, Spearman’s rank correlation coefficients were calculated using a non-parametric test for linear correlation. A significance level of p < 0.05 (two-sided test) was adopted to express statistical significance.
3. Results
3.1. Experimental results
3.1.1. Implementation details
The proposed model was implemented in PyTorch using an NVIDIA GeForce 3,090 GPU with 24GB memory. The training process involved 500 epochs, and employed the following settings: Adam optimization, with an initial learning rate of 0.01; a batch size of 2 for HRF segmentation; and a batch size of 1 for retinal layer segmentation. To enhance training stability, we adopted a poly learning rate policy, with a momentum of 0.9.
3.1.2. Evaluation metrics
To quantitatively assess the proposed network’s segmentation performance, we employ the following metrics. The Dice Similarity Coefficient (DSC) quantifies the agreement between HRF manually annotated by expert ophthalmologists and those automatically segmented by the proposed network, which can be defined as:
We also assess our method using Intersection over Union (IOU), precision, recall, and F1-Score, defined as:
where TP indicates true positives, FP indicates false positives, TN indicates true negatives, and FN indicates false negatives.
3.1.3. Comparison of different segmentation methods
In order to evaluate the effectiveness of the proposed network, we selected several state-of-the-art neural networks for comparison, including FCN (30), U-Net (31), U-Net++ (32), Res U-Net (33), 3D U-Net (34), SW-3DUNet (15), SANet (16), DBR-Net (17). The evaluation metrics utilized include the DSC, IOU, precision, recall, and F1 Score, as detailed in Table 1. We show that the proposed network outperforms other methods regarding DSC, IOU, and precision. Although the proposed method has a slightly lower recall rate than U-Net, when we consider both precision and recall comprehensively, the proposed method outperforms in terms of the F1 Score.
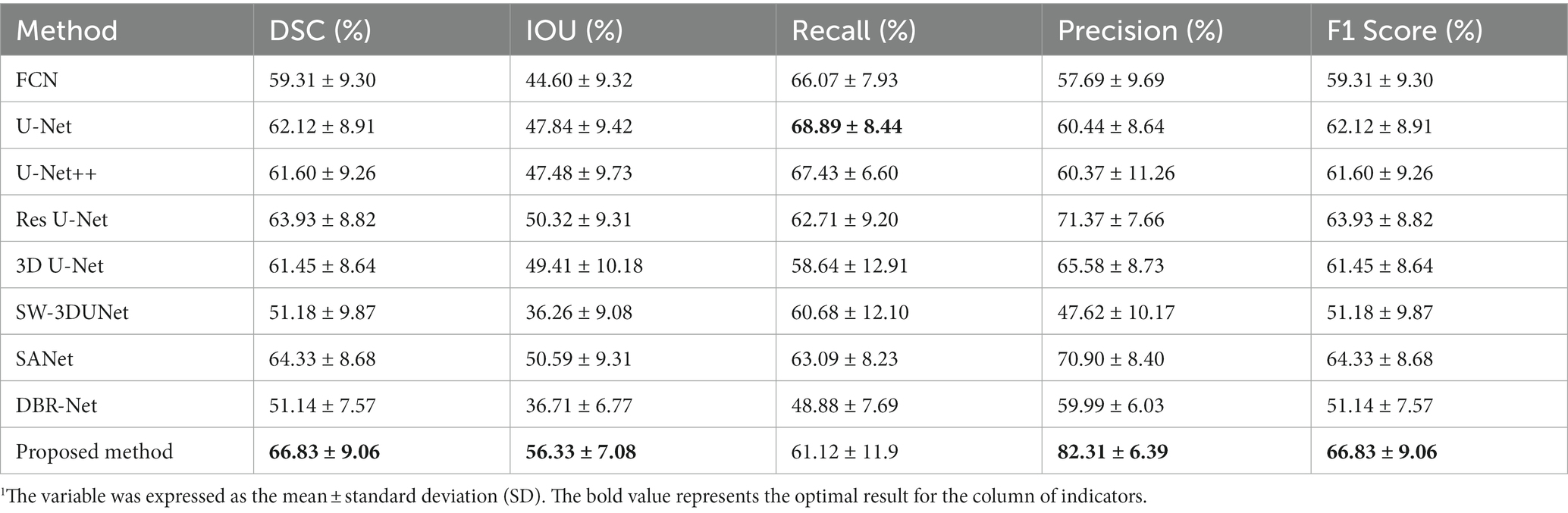
Table 1. Comparison of different segmentation methods.
As seen in Figure 4, our proposed network outperforms at identifying complete HRF regions and avoiding errors in segmentation when compared to other methods in the task of HRF segmentation for DME diseases. This indicates that the proposed network can effectively extract detailed HRF features and analyze them, by combining robust pre-processing capabilities from the baseline network and embedding spatial and channel attention modules. As a result, there is a notable improvement in segmentation effectiveness.

Figure 4. Comparison between the proposed SW-3DUNet and other methods. Yellow and green arrows represent the regions of over-segmentation and under-segmentation. B-scans in the second column are taken from fovea-centered regions of 6 × 6 mm2, while B-scans in the other columns are taken from fovea-centered regions of 4.5 × 4.5 mm2.
3.1.4. Ablation experiment
To demonstrate the effectiveness of the channel attention and spatial attention modules, we compared our proposed method with the baseline method and two variants.
• Baseline + SAB: We removed the CAB from this variant to assess its contribution.
• Baseline + CAB: We removed the SAB from this variant to assess its contribution.
• Baseline: We removed both SAB and CAB to evaluate their combined contribution.
Table 2 presents the experimental results for our proposed method, the baseline, and its two variants. Compared to the results of our proposed method, the variant without SAB exhibited reductions of 0.31% in DSC, 4.29% in IOU, 0.7% in recall, 0.4% in precision, and 0.31% in F1 Score. The variant without CAB showed reductions of 1.15% in DSC, 5% in IOU, 0.55% in recall, 0.75% in precision, and 1.55% in F1 Score. Removing both SAB and CAB resulted in reductions of 1.7% in DSC, 5.65% in IOU, and 2.91% in recall. Although there was a slight increase of 0.41% in precision, there was a decrease of 1.7% in F1 Score. The experimental results above demonstrate the rationality and effectiveness of embedding spatial and channel attention modules in the bottleneck layer of the baseline model.
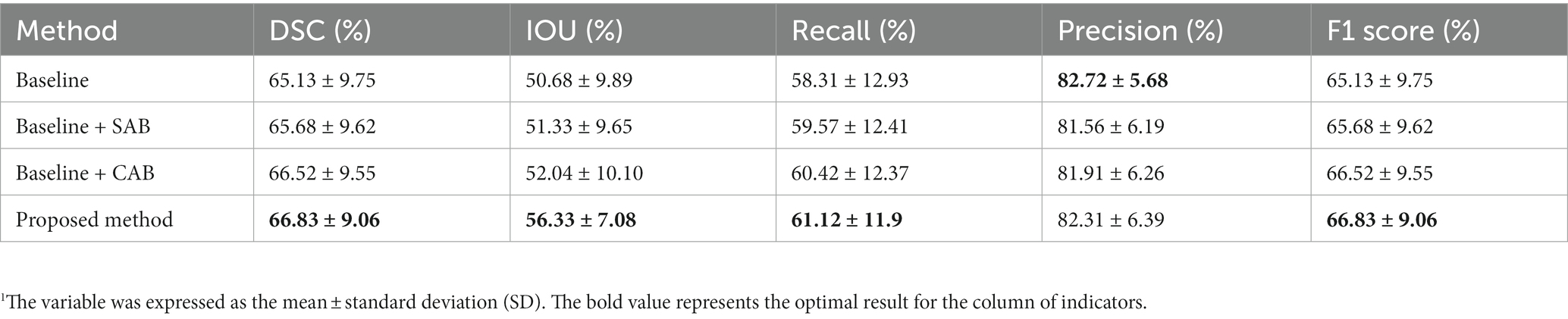
Table 2. Ablation experiment.
3.2. Quantitative parameter evaluation
We enrolled 47 eyes from 26 patients with DME, acquired with OCT (Spectralis HRA + OCT), and a total of 11 eyes from 8 patients were included in this study. We excluded 36 eyes from 18 patients from the analysis. One eye of one patient was excluded due to poor OCT image quality (motion artifacts on OCT images): 22 eyes of 11 patients were excluded due to lack of follow-up records; and 13 eyes from 7 patients were excluded due to no improvement in CMT after anti-VEGF or dexamethasone IVI treatment. The characteristics and clinical information of our study participants are displayed in Table 3. Two sets of OCT data were included for each eye, one at baseline, and one at follow-up, for a total of 9,472 OCT B-scans included in the study.
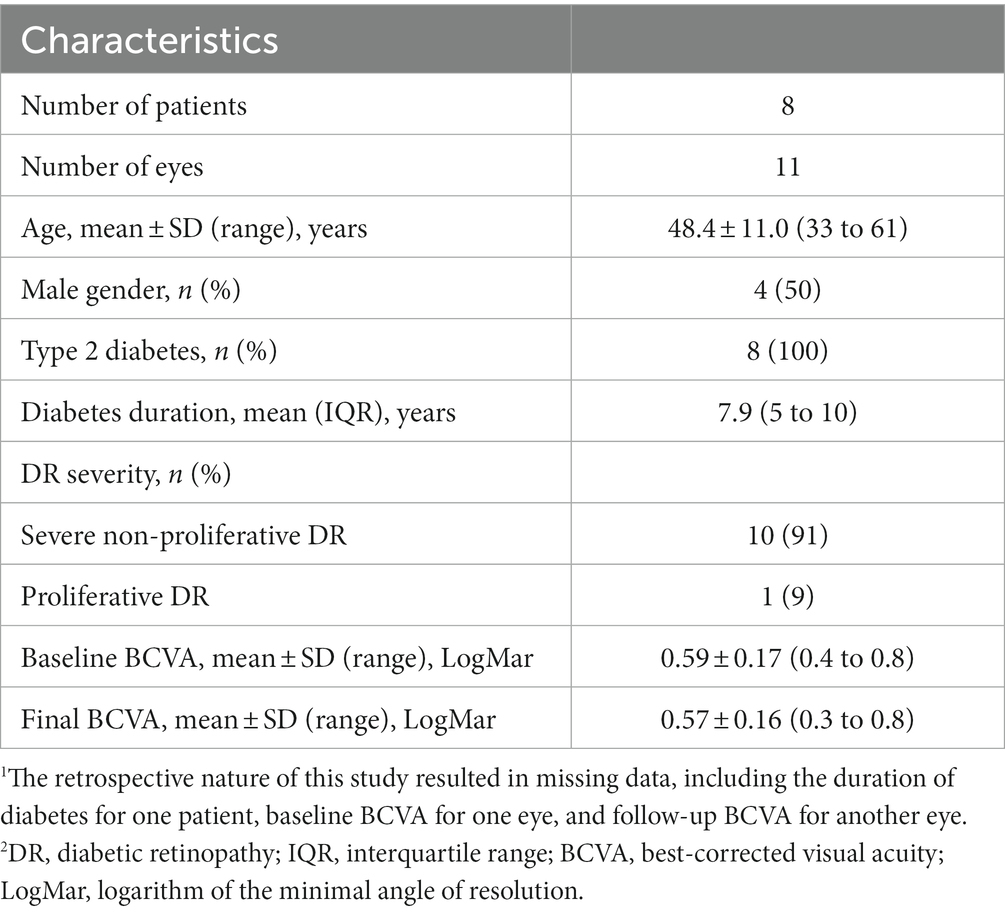
Table 3. Demographics.
3.2.1. Parametric comparison of baseline hyperreflective foci
Table 4 compares 12 quantitative parameters of HRF, classified by different diameter sizes in WR at baseline. Among the morphology-related parameters, significant differences were observed between and , and , and , and , and and (all p = 0.003). No significant differences were found between and (p = 0.131). Among the distance-related parameters, the results showed no significant differences between the HRF classified according to their diameter size.
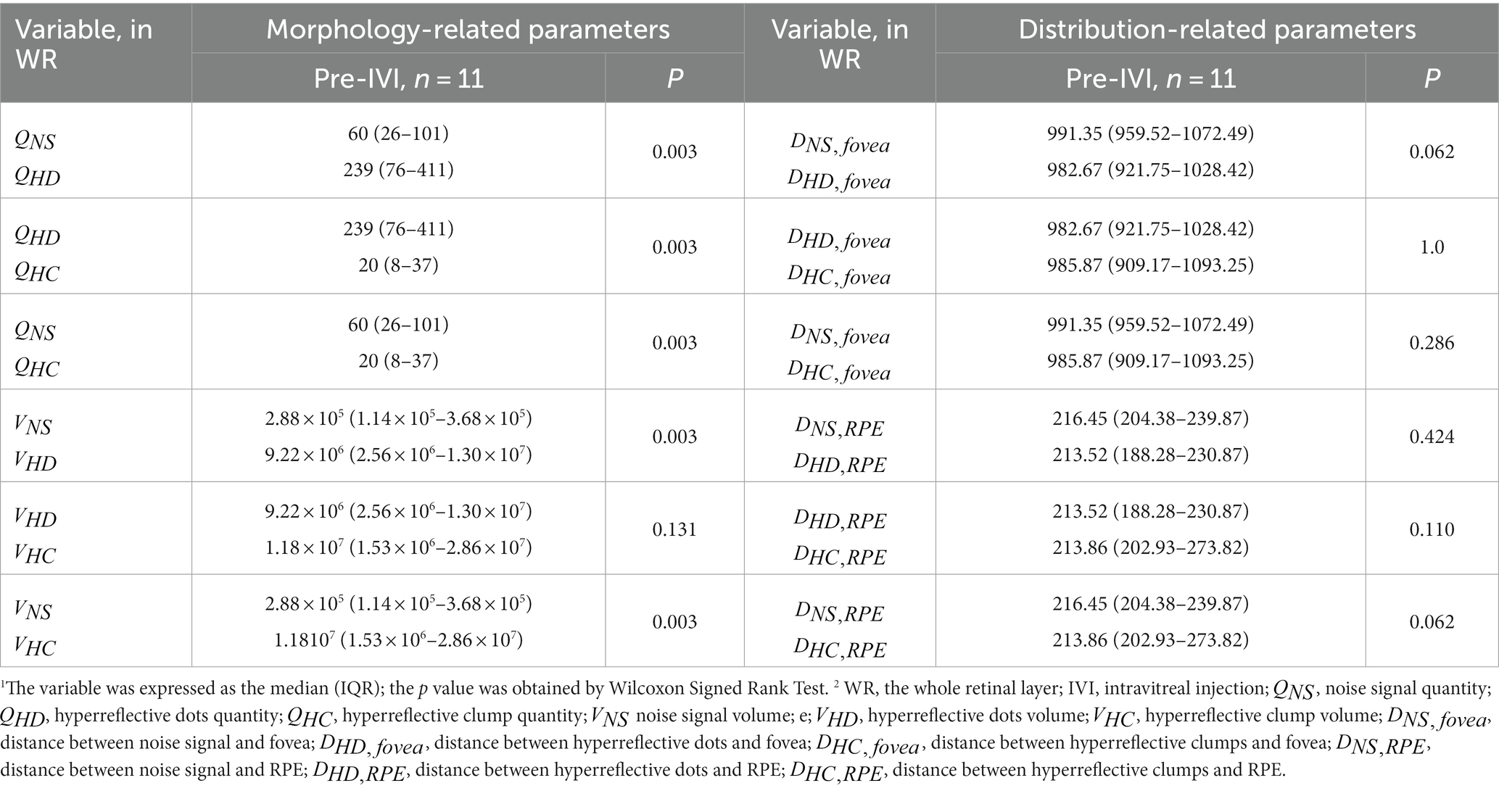
Table 4. Parametric comparisons of hyperreflective foci of different diameters.
3.2.2. Parametric comparison of follow-up hyperreflective foci
Due to the retrospective design of the study, OCT examinations were not performed at regular intervals. To avoid bias related to the duration of follow-up, only two consecutive follow-up visits with improvement in CMT were selected for each eye. The longitudinal study included 11 eyes from 8 patients, with a follow-up of 1.9 ± 1.6 months (range 1 to 6, median 1). During study period, all eyes were treated with intravitreal injections: 91% (10/11) of eyes received anti-VEGF injections and 9% (1/11) of eyes received dexamethasone injections. The number of intravitreal injections was 1.4 ± 0.7 (range 1 to 3, median 1).
We assessed whether changes in HRF were significant at two consecutive follow-up visits in the presence of improved CMT. Table 5 showed the comparison of the 12 quantitative parameters of HRF in WR, IR, and OR between the pre-IVI and post-IVI stages. In WR, , , , , , and CMT were significantly reduced in post-IVI compared with pre-IVI (p = 0.003, p = 0.033, p = 0.003, p = 0.026, p = 0.008, p = 0.004, p = 0.003, respectively). There were no significant changes in the other six quantitative parameters between the two phases. In IR, and were significantly reduced in post-IVI compared with pre-IVI (p = 0.016, p = 0.016, respectively). There were no significant changes in the other 10 quantitative parameters between the two phases. In OR, , , , , were significantly reduced in post-IVI compared to pre-IVI (p = 0.006, p = 0.047, p = 0.006, p = 0.004, p = 0.004, respectively). There were no significant changes in the other seven quantitative parameters between the two phases.
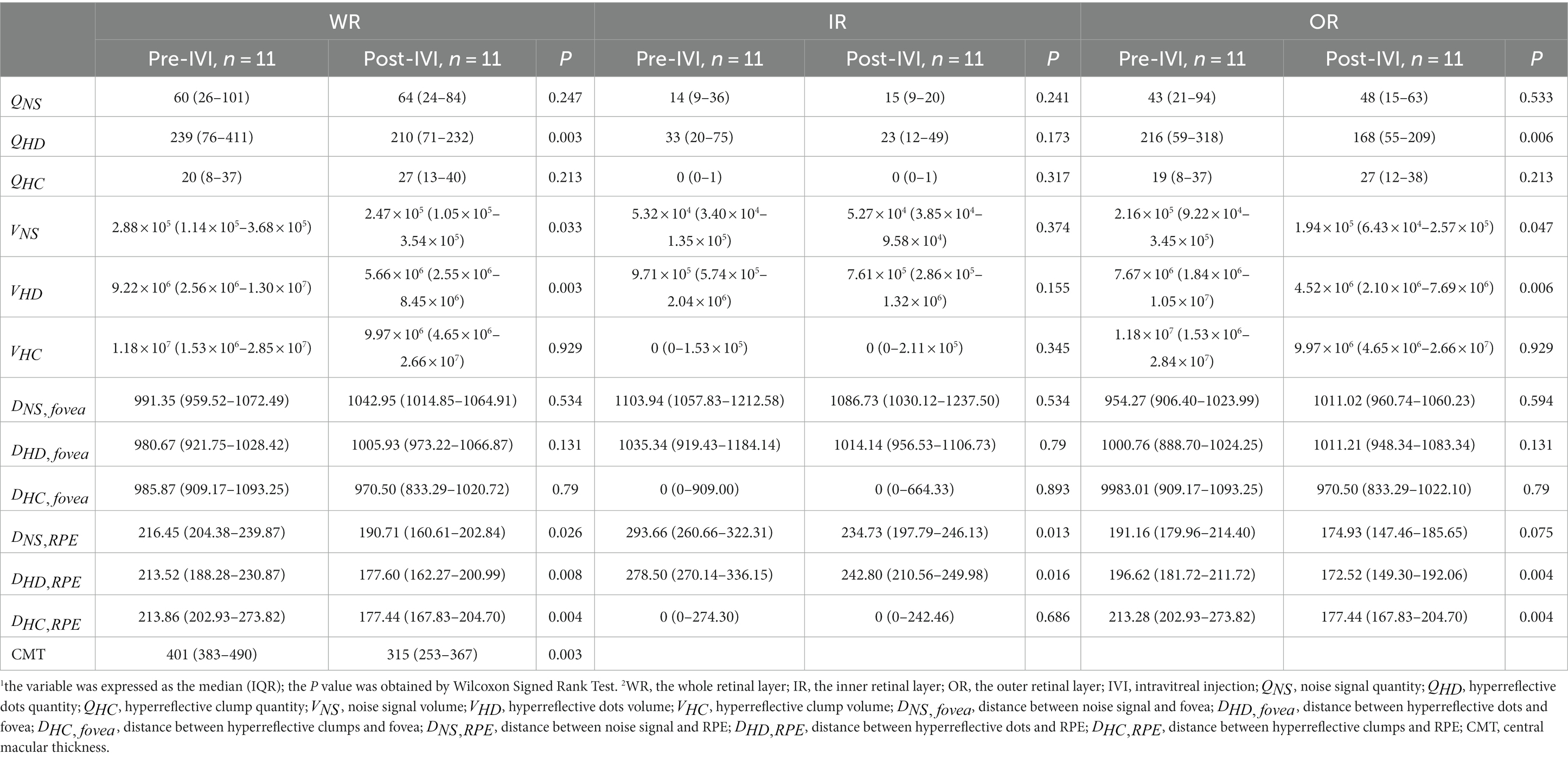
Table 5. Comparison of parameters between pre-IVI and post-IVI.
3.2.3. Correlation between follow-up CMT changes and baseline hyperreflective foci
We assessed whether there was a significant correlation between improvement in CMT at two consecutive follow-up visits and baseline HRF. Table 6 shows the correlation between the 12 quantitative parameters of baseline HRF in WR, IR, OR, and the percentage of CMT improvement (). In WR, significant positive correlations were shown between baseline , , , and (p = 0.015, p = 0.016, p < 0.001, respectively). There was no significant correlation between the other nine baseline quantitative parameters and . In OR, significant positive correlations were shown between baseline , , , and (p = 0.006, p = 0.019, p < 0.001, respectively). There was no significant correlation between the other nine baseline quantitative parameters and . In IR, there was no significant correlation between all 12 baseline quantitative parameters and .
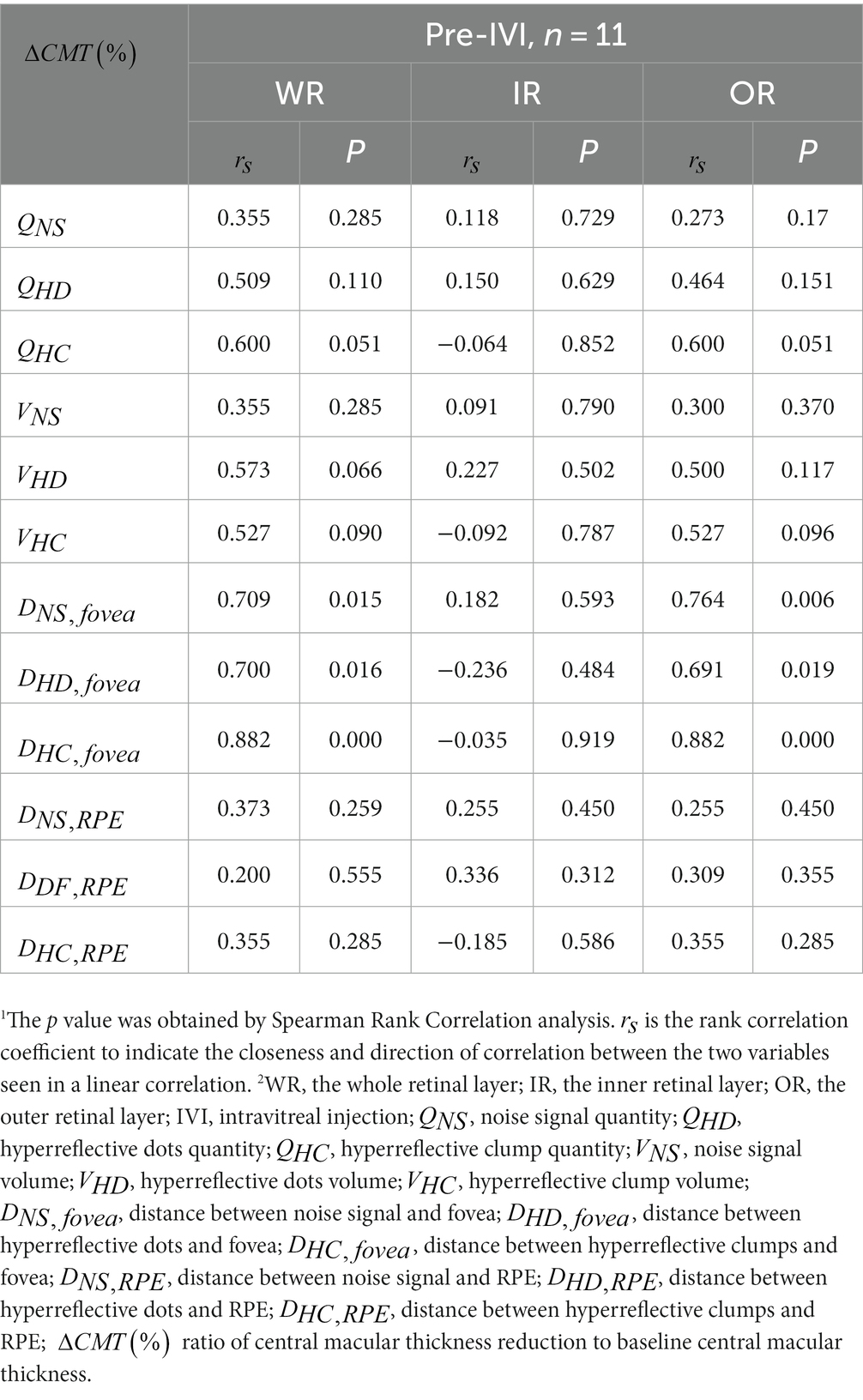
Table 6. Results of spearman correlation analysis.
4. Discussion
The given study aims to quantify HRF in OCT images as part of a retrospective study on patients with DME at baseline and follow-up. Previous studies relied on manual counting methods to quantify HRF, which is time-consuming and less reliable. In examining HRF as a potential biomarker, the existing body of literature has been inconsistent (23, 35–42), which may be due to variations in the OCT tool used, image quality, and manual segmentation of HRF. To address these challenges, our study employed artificial intelligence techniques for quantifying HRF, thereby overcoming some limitations of previous studies. With artificial intelligence, retinal images can be analyzed in a completely new way. We showed that the three subtypes of HRF were significantly different in volume and number on retinal OCT images, with HC pre-dominating in volume and HD in number. We also showed that the mean distance from HRF to RPE was reduced after IVI treatment compared to before IVI treatment. In addition, we showed that eyes with less HRF in the center of the macula showed greater reduction in macular edema after IVI treatment. These findings validate previous findings and suggest new insights, emphasizing the potential of deep learning as a powerful tool for analyzing baseline and follow-up HRF in DME patients.
4.1. Differences between baseline HRF parameters
Statistical analysis indicated significant disparities in both the number and volume parameters of baseline HRF subtypes. Our study validated HRF discrimination based on diameter range by analyzing baseline HRF morphological parameters. A previous study used 20 μm and 50 μm diameters to differentiate HRF subtypes (8), found a positive correlation between the number of HRF subtypes in the 20–50 μm range and the levels of CD14, without discussing the other two subtypes. Our study revealed significant differences among the three subtypes. Our findings corroborated previous studies showing that smaller HRFs merge into larger HRF (7), and show differential treatment responses (23). Furthermore, our study observed different responses to IVI treatment in the number and volume of the smallest HRF subtype, which may include microglia cells, whose activation decreased with treatment (43).
4.2. Follow-up findings
We showed the mean distance from HRF to RPE was significantly reduced after IVI treatment. By studying the distribution parameters of HRF in a longitudinal analysis of two consecutive follow-ups, our study indicated the tendency of HRF to migrate from the inner retina to the outer retina after IVI treatment; similar to our findings, Pemp et al. showed that DME uptake triggered the downward migration of HRF (44) into the outer retina. Notably, despite the lack of response to IVI treatment, the largest diameter HRF subtype exhibited a significant reduction in mean distance to the RPE in both OR and WR. This finding was consistent with Marmor’s mechanistic model of retinal fluid movement (45), which postulated fluid flowed across the retina due to intraocular pressure, choroidal osmolarity, and active fluid uptake by the RPE. The migration of partial HRF was impeded by narrow channels on the ELM, composed of zonular adhesions between Müller cells and photoreceptor inner segments. Consequently, this fraction of HRF aggregated in front of the ELM, forming the HRF isoform with the largest diameter, supporting the study conducted by Bolz et al. (7). However, no evidence was found to indicate migration of HRF toward or away from the fovea after IVI treatment, suggesting that IVI treatment did not significantly impact the distribution of HRF in the direction of the fovea. Further studies are required to confirm this conjecture.
4.3. Correlations between HRF parameters and CMT improvement
We also showed that improvement in CMT resulting from IVI treatment was positively correlated with the mean distance from HRF to the fovea in OR and WR, and not significantly correlated with other parameters. We explored the correlation between the therapeutic effect of IVI on foveal edema and the quantitative parameters of HRF at baseline by examining the quantitative parameters of HRF at baseline and the percentage improvement in CMT at two consecutive follow-up visits. A previous study (46) performed two-dimensional quantification of hard exudates in OCT enface images, and found that the area of hard exudates in the fovea at baseline was inversely correlated with BCVA at the 12th month. Similar to the aforementioned report, we showed that in both OR and WR, the percentage of IVI treatment-induced improvement in CMT was inversely correlated with the concentration of HRF in the fovea at baseline, but independent of other quantified parameters. Notably, the concentration of the largest-diameter HRF subtype in the fovea was inversely correlated with the reduction in CMT (=0.882, p < 0.001), which could explain why there was no correlation between the concentration of baseline HRF in the fovea in IR and the reduction in CMT, since the convergence of smaller HRF subtypes to larger HRF subtypes mainly occurs in OR according to the discussion above. We speculate that future studies on the differential distribution of HRF aggregated in the fovea may be able to verify whether it produces some physiological changes that affect the outcome of IVI treatment.
4.4. Limitations
Our study has certain limitations. Firstly, all participants were Chinese, and enrolled from a single medical center: larger and more various samples would be an advantage. More multi-center studies should therefore be conducted on larger cohorts to confirm the reproducibility of analysis on these parameters of HRF. Secondly, the enrollment criteria for this study only included cases with a positive response to injection therapy, rather than including refractory cases. It would be more convincing to recruit subjects with definitive treatment and make a long-term follow-up comparison. Thirdly, the study design lacked untreated blank controls to derive reasons for changes in parameters before and after treatment, while the small sample size and high homogeneity made the study findings more indicative of a pilot.
5. Conclusion
We introduced a deep learning-based approach to quantify hyperreflective foci in OCT images of DME patients. Our retrospective analysis of 11 eyes using this method showed that it effectively quantified baseline and follow-up changes in hyperreflective foci by extracting relevant geometric parameters. In this study, we were able to validate certain findings reported in prior research and uncover novel insights: for instance, our investigation revealed that the concentration of HRF in the fovea region may influence the efficacy of IVI treatment. We believe that accurate quantification and follow-up of HRF in OCT images at baseline and during treatment may enable clinicians to monitor DME disease progression, assess treatment response and identify patients who may benefit from a personalized approach to treatment.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics statement
The studies involving humans were approved by the ethics committee of the Affiliated Ningbo Eye Hospital of Wenzhou Medical University (ID: 20210327A). The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
Author contributions
XW: Conceptualization, Methodology, Software, Writing – original draft, Writing – review & editing, Formal analysis. YaZ: Conceptualization, Formal analysis, Resources, Writing – review & editing. YM: Writing – review & editing. WK: Conceptualization, Formal analysis, Writing – review & editing. JY: Investigation, Writing – review & editing. JL: Software, Writing – review & editing. SM: Conceptualization, Writing – review & editing. QiY: Conceptualization, Validation, Writing – review & editing. QuY: Conceptualization, Resources, Writing – review & editing. YiZ: Conceptualization, Data curation, Funding acquisition, Investigation, Methodology, Resources, Software, Supervision, Visualization, Writing – original draft, Writing – review & editing.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work was supported in part by the National Natural Science Foundation of China (62272444); Zhejiang Provincial Natural Science Foundation (LR22F020008); Youth Innovation Promotion Association CAS (2021298). National Science Foundation Program of China (62302488); Zhejiang Provincial Natural Science Foundation of China (LQ23F010007).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The author(s) declared that they were an editorial board member of Frontiers, at the time of submission. This had no impact on the peer review process and the final decision.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Cheung, N, Mitchell, P, and Wong, TY. Diabetic retinopathy. Lancet. (2010) 376:124–36. doi: 10.1016/S0140-6736(09)62124-3
2. Yau, JW, Rogers, SL, Kawasaki, R, Lamoureux, EL, Kowalski, JW, Bek, T, et al. Global prevalence and major risk factors of diabetic retinopathy. Diabetes Care. (2012) 35:556–64. doi: 10.2337/dc11-1909
3. Jampol, LM, Glassman, AR, and Sun, JK. Evaluation and Care of Patients with diabetic retinopathy. N Engl J Med. (2020) 382:1629–37. doi: 10.1056/NEJMra1909637
4. Klein, R, Lee, KE, Danforth, L, Tsai, MY, Gangnon, RE, Meuer, SE, et al. The relationship of retinal vessel geometric characteristics to the incidence and progression of diabetic retinopathy. Ophthalmology. (2018) 125:1784–92. doi: 10.1016/j.ophtha.2018.04.023
5. Suciu, CI, Suciu, VI, and Nicoara, SD. Optical coherence tomography (angiography) biomarkers in the assessment and monitoring of diabetic macular edema. J Diabetes Res. (2020) 2020:6655021–10. doi: 10.1155/2020/6655021
6. Olson, J, Sharp, P, Goatman, K, Prescott, G, Scotland, G, Fleming, A, et al. Improving the economic value of photographic screening for optical coherence tomography-detectable macular oedema: a prospective, multicentre, UK study. Health Technol Assess. (2013) 17:1–142. doi: 10.3310/hta17510
7. Bolz, M, Schmidt-Erfurth, U, Deak, G, Mylonas, G, Kriechbaum, K, and Scholda, C. Optical coherence tomographic hyperreflective foci: a morphologic sign of lipid extravasation in diabetic macular edema. Ophthalmology. (2009) 116:914–20. doi: 10.1016/j.ophtha.2008.12.039
8. Lee, H, Jang, H, Choi, YA, Kim, HC, and Chung, H. Association between soluble CD14 in the aqueous humor and Hyperreflective foci on optical coherence tomography in patients with diabetic macular edema. Invest Ophthalmol Vis Sci. (2018) 59:715–21. doi: 10.1167/iovs.17-23042
9. Curcio, CA, Zanzottera, EC, Ach, T, Balaratnasingam, C, and Freund, KB. Activated retinal pigment epithelium, an optical coherence tomography biomarker for progression in age-related macular degeneration. Invest Ophthalmol Vis Sci. (2017) 58:BIO211–26. doi: 10.1167/iovs.17-21872
10. Uji, A, Murakami, T, Nishijima, K, Akagi, T, Horii, T, Arakawa, N, et al. Association between hyperreflective foci in the outer retina, status of photoreceptor layer, and visual acuity in diabetic macular edema. Am J Ophthalmol. (2012) 153:710–717.e1. doi: 10.1016/j.ajo.2011.08.041
11. Fragiotta, S, Abdolrahimzadeh, S, Dolz-Marco, R, Sakurada, Y, Gal-Or, O, and Scuderi, G. Significance of Hyperreflective foci as an optical coherence tomography biomarker in retinal diseases: characterization and clinical implications. J Ophthalmol. (2021) 2021:1–10. doi: 10.1155/2021/6096017
12. Okuwobi, IP, Fan, W, Yu, C, Yuan, S, Liu, Q, Zhang, Y, et al. Automated segmentation of hyperreflective foci in spectral domain optical coherence tomography with diabetic retinopathy. J Med Imag. (2018) 5:014002:1. doi: 10.1117/1.JMI.5.1.014002
13. Okuwobi, IP, Ji, Z, Fan, W, Yuan, S, Bekalo, L, and Chen, Q. Automated quantification of hyperreflective foci in SD-OCT with diabetic retinopathy. IEEE J Biomed Health Inform. (2019) 24:1125–36. doi: 10.1109/JBHI.2019.2929842
14. Yu, C, Xie, S, Niu, S, Ji, Z, Fan, W, Yuan, S, et al. Hyper-reflective foci segmentation in SD-OCT retinal images with diabetic retinopathy using deep convolutional neural networks. Med Phys. (2019) 46:4502–19. doi: 10.1002/mp.13728
15. Xie, S, Okuwobi, IP, Li, M, Zhang, Y, Yuan, S, and Chen, Q. Fast and automated hyperreflective foci segmentation based on image enhancement and improved 3D U-net in SD-OCT volumes with diabetic retinopathy. Transl Vis Sci Technol. (2020) 9:21. doi: 10.1167/tvst.9.2.21
16. Yao, C, Zhu, W, Wang, M, Zhu, L, Huang, H, Chen, H, et al. SANet: a self-adaptive network for hyperreflective foci segmentation in retinal OCT images. Med Imag. (2021) 11596:809–15. doi: 10.1117/12.2580699
17. Wei, J, Yu, S, Du, Y, Liu, K, Xu, Y, and Xu, X. Automatic segmentation of Hyperreflective foci in OCT images based on lightweight DBR network. J Digit Imaging. (2023) 36:1148–57. doi: 10.1007/s10278-023-00786-0
18. Isensee, F, Jaeger, PF, Kohl, SAA, Petersen, J, and Maier-Hein, KH. nnU-net: a self-configuring method for deep learning-based biomedical image segmentation. Nat Methods. (2021) 18:203–11. doi: 10.1038/s41592-020-01008-z
19. Zur, D, Iglicki, M, Busch, C, Invernizzi, A, Mariussi, M, Loewenstein, A, et al. OCT biomarkers as functional outcome predictors in diabetic macular edema treated with dexamethasone implant. Ophthalmology. (2018) 125:267–75. doi: 10.1016/j.ophtha.2017.08.031
20. Bosche, F, Andresen, J, Li, D, Holz, F, and Brinkmann, C. Spectralis OCT1 versus OCT2: time efficiency and image quality of retinal nerve Fiber layer thickness and Bruch’s membrane opening analysis for Glaucoma patients. J Curr Glaucoma Pract. (2019) 13:16–20. doi: 10.5005/jp-journals-10078-1244
21. Tewarie, P, Balk, L, Costello, F, Green, A, Martin, R, Schippling, S, et al. The OSCAR-IB consensus criteria for retinal OCT quality assessment. PLoS One. (2012) 7:e34823. doi: 10.1371/journal.pone.0034823
22. Aytulun, A, Cruz-Herranz, A, Aktas, O, Balcer, LJ, Balk, L, Barboni, P, et al. APOSTEL 2.0 recommendations for reporting quantitative optical coherence tomography studies. Neurology. (2021) 97:68–79. doi: 10.1212/WNL.0000000000012125
23. Rübsam, A, Wernecke, L, Rau, S, Pohlmann, D, Müller, B, Zeitz, O, et al. Behavior of SD-OCT detectable hyperreflective foci in diabetic macular edema patients after therapy with anti-VEGF agents and dexamethasone implants. J Diabetes Res. (2021) 2021:1–13. doi: 10.1155/2021/8820216
24. de Moura, J, Samagaio, G, Novo, J, Almuina, P, Fernández, MI, and Ortega, M. Joint diabetic macular edema segmentation and characterization in OCT images. J Digit Imaging. (2020) 33:1335–51. doi: 10.1007/s10278-020-00360-y
25. Mou, L, Zhao, Y, Fu, H, Liu, Y, Cheng, J, Zheng, Y, et al. CS2-net: deep learning segmentation of curvilinear structures in medical imaging. Med Image Anal. (2021) 67:101874. doi: 10.1016/j.media.2020.101874
26. Ulyanov, D, Vedaldi, A, and Lempitsky, V. (2016). Instance normalization: The missing ingredient for fast stylization. Available at: https://arxiv.org/abs/1607.08022
27. Ioffe, S, and Szegedy, C. Batch normalization: accelerating deep network training by reducing internal covariate shift. ICML. (2015) 37:448–56.
28. Drozdzal, M, Vorontsov, E, Chartrand, G, Kadoury, S, and Pal, C. The importance of skip connections in biomedical image segmentation[C]//international workshop on deep learning in medical image analysis In: International workshop on large-scale annotation of biomedical data and expert label synthesis. Eds. G Carneiro, D Mateus, L Peter, A Bradley, J Manuel, and R. Tavares, et al. Cham: Springer (2016). 179–87.
29. Szeto, SK, Hui, VW, Tang, FY, Yang, D, Han Sun, Z, Mohamed, S, et al. OCT-based biomarkers for predicting treatment response in eyes with Centre-involved diabetic macular oedema treated with anti-VEGF injections: a real-life retina clinic-based study. Br J Ophthalmol. (2023) 107:525–33. doi: 10.1136/bjophthalmol-2021-319587
30. Shelhamer, E, Long, J, and Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans Pattern Anal Mach Intell. (2017) 39:640–51. doi: 10.1109/TPAMI.2016.2572683
31. Ronneberger, O, Fischer, P, and Brox, T. U-net: convolutional networks for biomedical image segmentation. MICCAI. (2015) 9351:234–41. doi: 10.1007/978-3-319-24574-4_28
32. Zhou, Z, Rahman Siddiquee, MM, Tajbakhsh, N, and Liang, J. Unet++: a nested u-net architecture for medical image segmentation. Deep learn med image anal multimodal learn Clin Decis support. PRO. (2018) 4:3–11. doi: 10.1007/978-3-030-00889-5_1
33. Schlegl, T, Bogunovic, H, Klimscha, S, Seeboeck, P, Sadeghipour, A, Gerendas, BS, et al. (2018). Fully automated segmentation of hyperreflective foci in optical coherence tomography images. Available at: https://arxiv.org/abs/1805.03278
34. Çiçek, Ö, Abdulkadir, A, Lienkamp, SS, Brox, T, and Ronneberger, O. 3D U-net: learning dense volumetric segmentation from sparse annotation. MICCAI. (2016) 9901:424–32. doi: 10.1007/978-3-319-46723-8_49
35. Framme, C, Schweizer, P, Imesch, M, Wolf, S, and Wolf-Schnurrbusch, U. Behavior of SD-OCT-detected hyperreflective foci in the retina of anti-VEGF-treated patients with diabetic macular edema. Invest Ophthalmol Vis Sci. (2012) 53:5814–8. doi: 10.1167/iovs.12-9950
36. Vujosevic, S, Torresin, T, Bini, S, Convento, E, Pilotto, E, Parrozzani, R, et al. Imaging retinal inflammatory biomarkers after intravitreal steroid and anti-VEGF treatment in diabetic macular oedema. Acta Ophthalmol. (2017) 95:464–71. doi: 10.1111/aos.13294
37. Liu, S, Wang, D, Chen, F, and Zhang, X. Hyperreflective foci in OCT image as a biomarker of poor prognosis in diabetic macular edema patients treating with Conbercept in China. BMC Ophthalmol. (2019) 19:157. doi: 10.1186/s12886-019-1168-0
38. Kang, JW, Chung, H, and Chan, KH. Correlation of optical coherence tomographic Hyperreflective foci with visual outcomes in different patterns of diabetic macular edema. Retina. (2016) 36:1630–9. doi: 10.1097/IAE.0000000000000995
39. Ceravolo, I, Oliverio, GW, Alibrandi, A, Bhatti, A, Trombetta, L, Rejdak, R, et al. The application of structural retinal biomarkers to evaluate the effect of intravitreal Ranibizumab and dexamethasone intravitreal implant on treatment of diabetic macular edema. Diagnostics (Basel). (2020) 10:413. doi: 10.3390/diagnostics10060413
40. Schreur, V, Altay, L, van Asten, F, Groenewoud, JM, Fauser, S, Klevering, BJ, et al. Hyperreflective foci on optical coherence tomography associate with treatment outcome for anti-VEGF in patients with diabetic macular edema. PLoS One. (2018) 13:e0206482. doi: 10.1371/journal.pone.0206482
41. Narnaware, SH, Bawankule, PK, and Raje, D. Short-term outcomes of intravitreal dexamethasone in relation to biomarkers in diabetic macular edema. Eur J Ophthalmol. (2021) 31:1185–91. doi: 10.1177/1120672120925788
42. Vujosevic, S, Berton, M, Bini, S, Casciano, M, Cavarzeran, F, and Midena, E. Hyperreflective retinal spots and visual function after anti-vascular endothelial growth factor treatment in center-involving diabetic macular edema. Retina. (2016) 36:1298–308. doi: 10.1097/IAE.0000000000000912
43. Grigsby, JG, Cardona, SM, Pouw, CE, Muniz, A, Mendiola, AS, Tsin, AT, et al. The role of microglia in diabetic retinopathy. J Ophthalmol. (2014) 2014:1–15. doi: 10.1155/2014/705783
44. Pemp, B, Deák, G, Prager, S, Mitsch, C, Lammer, J, Schmidinger, G, et al. Distribution of intraretinal exudates in diabetic macular edema during anti-vascular endothelial growth factor therapy observed by spectral domain optical coherence tomography and fundus photography. Retina. (2014) 34:2407–15. doi: 10.1097/IAE.0000000000000250
45. Marmor, MF. Mechanisms of fluid accumulation in retinal edema. Doc Ophthalmol. (1999) 97:239–49. doi: 10.1023/a:1002192829817
Keywords: diabetic macular edema, hyperreflective foci, optical coherence tomography, artificial intelligence, deep learning
Citation: Wang X, Zhang Y, Ma Y, Kwapong WR, Ying J, Lu J, Ma S, Yan Q, Yi Q and Zhao Y (2023) Automated evaluation of retinal hyperreflective foci changes in diabetic macular edema patients before and after intravitreal injection. Front. Med. 10:1280714. doi: 10.3389/fmed.2023.1280714
Edited by:
Meng Wang, Agency for Science, Technology and Research (A*STAR), SingaporeCopyright © 2023 Wang, Zhang, Ma, Kwapong, Ying, Lu, Ma, Yan, Yi and Zhao. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yitian Zhao, eWl0aWFuLnpoYW9AbmltdGUuYWMuY24=; Quanyong Yi, cXVhbnlvbmdfX3lpQDE2My5jb20=
†These authors have contributed equally to this work