 J. H. Jensha Haennah
J. H. Jensha Haennah C. Seldev Christopher2
C. Seldev Christopher2- 1St. Xavier’s Catholic College of Engineering, Affiliated to Anna University Chennai, Tamil Nadu, India
- 2St. Xavier’s Catholic College of Engineering, Nagercoil, Tamil Nadu, India
- 3Sahrdaya College of Engineering and Technology, Thrissur, Kerala, India
As a result of the COVID-19 (coronavirus) disease due to SARS-CoV2 becoming a pandemic, it has spread over the globe. It takes time to evaluate the results of the laboratory tests because of the rising number of cases each day. Therefore, there are restrictions in terms of both therapy and findings. A clinical decision-making system with predictive algorithms is needed to alleviate the pressure on healthcare systems via Deep Learning (DL) algorithms. With the use of DL and chest scans, this research intends to determine COVID-19 patients by utilizing the Transfer Learning (TL)-based Generative Adversarial Network (Pix 2 Pix-GAN). Moreover, the COVID-19 images are then classified as either positive or negative using a Duffing Equation Tuna Swarm (DETS)-optimized Resnet 101 classifier trained on synthetic and real images from the Kaggle lung CT Covid dataset. Implementation of the proposed technique is done using MATLAB simulations. Besides, is evaluated via accuracy, precision, F1-score, recall, and AUC. Experimental findings show that the proposed prediction model identifies COVID-19 patients with 97.2% accuracy, a recall of 95.9%, and a specificity of 95.5%, which suggests the proposed predictive model can be utilized to forecast COVID-19 infection by medical specialists for clinical prediction research and can be beneficial to them.
1. Introduction
Lung diseases affect a significant number of individuals all over the globe. People are susceptible to a wide range of significant lung disorders, including fibrosis, asthma, pneumonia, and tuberculosis, to name just a few (1). Coronavirus infections often begin in the respiratory system, namely the lungs. Lung problems can be treated more successfully if they are discovered in the early stages (2). Image processing, Machine Learning (ML), and DL models might potentially all play a significant part in this scenario. Since December 2019, the city of Wuhan in China, along with numerous other countries, has been affected by a new coronavirus referred to as SARS-CoV-2 (3). According to Worldometer (4), as of April 18, there were 2 million and more verified patients of the virus and 150,000 and more people died.
Early detection is essential to allow the individual suspected of having the rare COVID-19 illness to be immediately isolated and to minimize infection risks to the general public as a whole because there is neither a therapeutic therapy nor a vaccine available to treat or prevent the illness (5). Chest radiography, also known as X-ray or Computed Tomography (CT) images, is a straightforward and speedy method that is used to make a diagnosis of pneumonia and COVID-19 (6). In the beginning phases of COVID-19, a ground glass pattern appears; however, it is difficult to identify this pattern near the margins of the pulmonary arteries. There have also been reports of asymmetrical, patchy, or widespread opacities of the airways associated with COVID-19. Deciphering changes in the body on such a minute scale requires a group of radiologists with extensive training (7).
Automated ways of finding such elusive abnormalities can aid with diagnosis as well as enhance early detection rates with high accuracy. Given the vast number of suspects and the limited number of radiologists who are adequately trained. DL and Artificial Intelligence (AI)-driven approaches to problem-solving have the potential to be incredibly powerful tools for addressing the problems at hand (8). AI and CT scan imaging both have the potential to provide key biomarkers for COVID-19 sickness (9). Though radiography detects sickness rapidly, several types of research have shown that employing AI and CT images to detect COVID-19-affected people is insignificant owing to a lack of sufficient images of the virus (10). Despite all of its benefits, DL has challenges at every level, from creation to application. The fundamental issue is that actual data, rather than synthetic data, is first required in most health-related systems, and as AI and DL models get more complicated, algorithms become harder to understand. In certain instances, the legal approval of the procedure is dependent on how easily the systems can be understood. There has been much written on “black-box” algorithms; in some situations, Deep Neural Networks (DNN) in particular cannot comprehend the outcome (11, 12). Even though the conclusion that was drawn from the findings of the previous investigations revealed complexities, AI and DL models aid to solve numerous disease classification systems using image processing techniques (13). Because of these reasons, this paper intends to generate synthetic images of the COVID-19 chest by using a TL method named Pix2Pix-GAN. The key contributions of this paper are outlined as follows:
a. TL of the pre-trained Pix2Pix-GAN model for the public chest CT test dataset is used to predict disease.
b. A novel DL approach is designed via Convolutional Neural Network (CNN) with a TSO algorithm.
c. Moreover, the implemented model provides sufficient aid to the medical field and analyzes the disease severity with the help of Tuna Optimized Resnet 101.
d. Based on the labels and images obtained using the openly available public Lung CT image dataset from Kaggle, create a robust prediction model that considers both COVID-19-affected and unaffected scenarios.
e. The processing time is improved by cross-validating the proposed model and verifying it via a comparative study over other existing model.
The remainder of this paper describes the recent research in Section 2, while Sections 3 and 4 illustrate the problem statement and the proposed system methodologies, respectively, and Sections 5 and 6 illustrate the result, discussion, and concept of the conclusion, along with the proposed paper’s future scope.
2. Related works
Babukarthik et al. (14) attempt to differentiate between pneumonia due to COVID-19 and healthy lungs from CXR images (in a normal individual). A genetic DL CNN (GDCNN) and other innovative technologies were among the tools used in the research. To extract features for separating COVID-19 images from other types of images, it was trained from scratch. A new CT image retrieval approach using deep-metric learning was introduced by Zhong et al. (15). The proposed model learned the best embedding space by using multi-similarity loss, a hard-mining sampling method with an attention strategy. Training and validation of the model were carried out using a global multisite COVID-19 dataset from 3 various sources around the world. The proposed model is providing a reliable solution to evaluate CT images and manage patients for COVID-19 based on experimental findings of image retrieval and diagnostic tasks using the COVID-19 virus. COVID-19’s severity, as well as identification, were combined using multitask learning, and the CNN was suggested as a model for this purpose by Goncharov et al. (16). Findings from training a model on a large dataset were encouraging and labels were applied to a 3D chest CT by Han et al. (17). AD3D-MIL was an attention-based deep 3D multiple-instance learning method. After the potential infection area, the AD3D-MIL approach was capable of semantically building deep 3D instances. For the AD3D-MIL algorithm, Cohen’s kappa was 95.7%, Area Under Curve (AUC) was 99.99%, and overall accuracy was 97%, according to some empirical studies. Wang et al. (18) published an approach for quick COVID-19 discovery via 3D chest CT images to connect two 3D ResNets. Using the previously developed prior-attention strategy, this research created a Prior-Attention Residual Learning (PARL) model to expand residual learning. It was possible to train the model end-to-end with multi-task losses by stacking the PARL blocks. The proposed framework has been shown in experiments to considerably enhance the efficiency of screening for COVID-19. Human and machine collaboration was employed in COVID-Net, which was developed as a network designed explicitly to detect COVID-19 patients using CT scans by Wang et al. (19). Gunraj et al. (20) presented a machine-driven design examination process for building the COVIDNet-CT for determining the optimal micro and macro architecture patterns to use when building the Deep Neural Network (DNN) through automated network architectural design research. It provided more flexibility in the designing than human designing and assured the final layer met the specified operational criteria. As a result, a Deep CNN (DCNN) specifically designed for detecting COVID-19 from chest CT scans was developed using the machine-driven design exploration method. Kumar and Mahapatra (21) suggested that fractal characteristics in photographs are used for DNN construction and that lung X-ray images be used for CNN construction. The use of segmentation in conjunction with CNN architecture has been used to find the sick area (tissues) in the lung image. Jin et al. (22) provided a domain adaptation-based self-correction (DASC-Net) system for addressing the difficulties in the current COVID-19 CT images. On CT images, the developed system segmented the COVID-19-infected region. The DASC-Net system comprised of a special Attention and Feature Domain Enhanced Domain Adaptation (AFD-DA) method for addressing domain shifts with a self-correcting learning procedure designed for adaptively combining the learned network and related pseudo-labels to the transmission of associated source and target domain data for reducing overfitting to noise due to pseudo-labels. Hryniewska et al. (23) found an Explainable AI (XAI) and DL method for identifying COVID-19 via CT that depend on confounding variables. Besides, testing a DL strategy on external data was inadequate for ensuring the networks were dependent on therapeutically relevant pathophysiology since the unexpected crosscuts learned using DL frameworks can function well for datasets at new institutions, according to Geirhos et al. (24). These findings revealed that before the clinical adoption of AI systems for medical imaging, explainable DL should be taken into consideration as a need.
Yau et al. (25) examined the uses of imaging ultrasound, and their sonographic findings for COVID-19 cases compiled the most recent information and advice and discussed the possible application of POCUS in the detection, monitoring, and risk-based classification of COVID-19 cases. Xue et al. (26) created a new DL system named Dual-level Supervised Multiple Instance Learning (DSA-MIL) modules for COVID-19 patient severity rating based on Lung Ultrasound (LUS) with clinical data and exposed considerable outcomes. COVID-19 has received additional reviews for ultrasonic imaging applications. According to Saha et al. (27), the GraphCovidNet framework was a graph-isomorphic network-based framework to detect COVID-19 in chest CT images and X-rays of people with cancer. Image data were preprocessed using the GraphCovidNet model, which created an undirected graph from them and only considered their edges rather than the whole picture. The GraphCovidNet framework was capable of exactly identifying all the COVID-19 scans in a binary classification challenge. Liu and Ji (28) published a multistage Attentive TL (ATTNs) paradigm to improvise COVID-19 findings via CT scans. Moreover, the proposed model used a three-phase approach that draws on a variety of tasks and data sources. A new self-supervised learning technique that gathers semantic data from the entire lung and emphasizes the functioning of each lung area to build multiscale representations of lung CT images was developed. Finally, the method was incorporated into a TL framework so that complex patterns discovered in CT scans can be reused. The researchers found that architectures having self-attention improved efficacy more than networks without self-attention when subjected to TL. Iwendi et al. (29) addressed a Random Forest (RF) method enhanced using the AdaBoost approach to predict COVID-19. For this reason, the COVID-19 case’s geographic, as well as demographic data were utilized for the network to forecast the severity with the possibility of cure or death. The framework attained 94% accuracy and an F1 Score of 86%. Wang et al. (8) employed a GoogleNet Inception v3 CNN model to detect COVID-19.1065 CT images of people with pathogen-confirmed COVID-19 pneumonia and those who had previously been identified as having normal viral pneumonia data were gathered. To create the method, the inception TL model was changed. In 2023, Bharati et al. (30) addressed the XAI methods in healthcare. The study examined the current XAI trends and outlined the main moving directions of the field. What, why, and when of using these XAI models, as well as their effects were explained. Also, a thorough analysis of XAI approaches and a justification for how an accurate AI may be created by defining AI models for healthcare areas was provided. In 2022, Munnangi et al. (31) established a Nonlinear Cosine-based Time series Learning (NCTL) approach for COVID-19 diagnosis in India. Initially, the relevant features were selected using the nonlinear least squares regressive feature selection (NLS-RFS) model, which considers both active situations while having a lower prediction error. The cosine-based neighborhood filter technique was then used to choose the most pertinent characteristics with the shortest prediction time. Finally, the number of COVID-19 instances registered was predicted using a cosine neighborhood-based LSTM. In 2023, Podder et al. (32) developed DenseNet-169 and DenseNet-201 for Covid-19 detection by adjusting the hyperparameters via the Nadam optimization algorithm to enhance the model’s performance. 3312 CXR images were used. In 2021, Mondal et al. (33) proposed optimized InceptionResNetV2 for COVID-19 (CO-IRv2) based on the ideas of InceptionNet and ResNet with hyperparameter adjustment, global average pools, batch normalization, dense layer, and dropouts.
Table 1 summarizes the features and achievements of previous COVID-19 detection models using various AI algorithms. Several covid-prediction technologies are being developed by researchers. Although each has its drawbacks. Computational time and classification errors are major problems that still limit performance. Besides, CXR images and chest CT images were widely used in the research. Also, limited data was used in the existing research. For this reason, this paper aims to develop a novel COVID-19 disease prediction model with enhanced efficiency. Here, Lung CT images are utilized with synthetically generated data. Additionally, the performance of the classifier is enhanced by tuning the hyperparameters by optimization concepts to ensure better accuracy with minimum testing time.
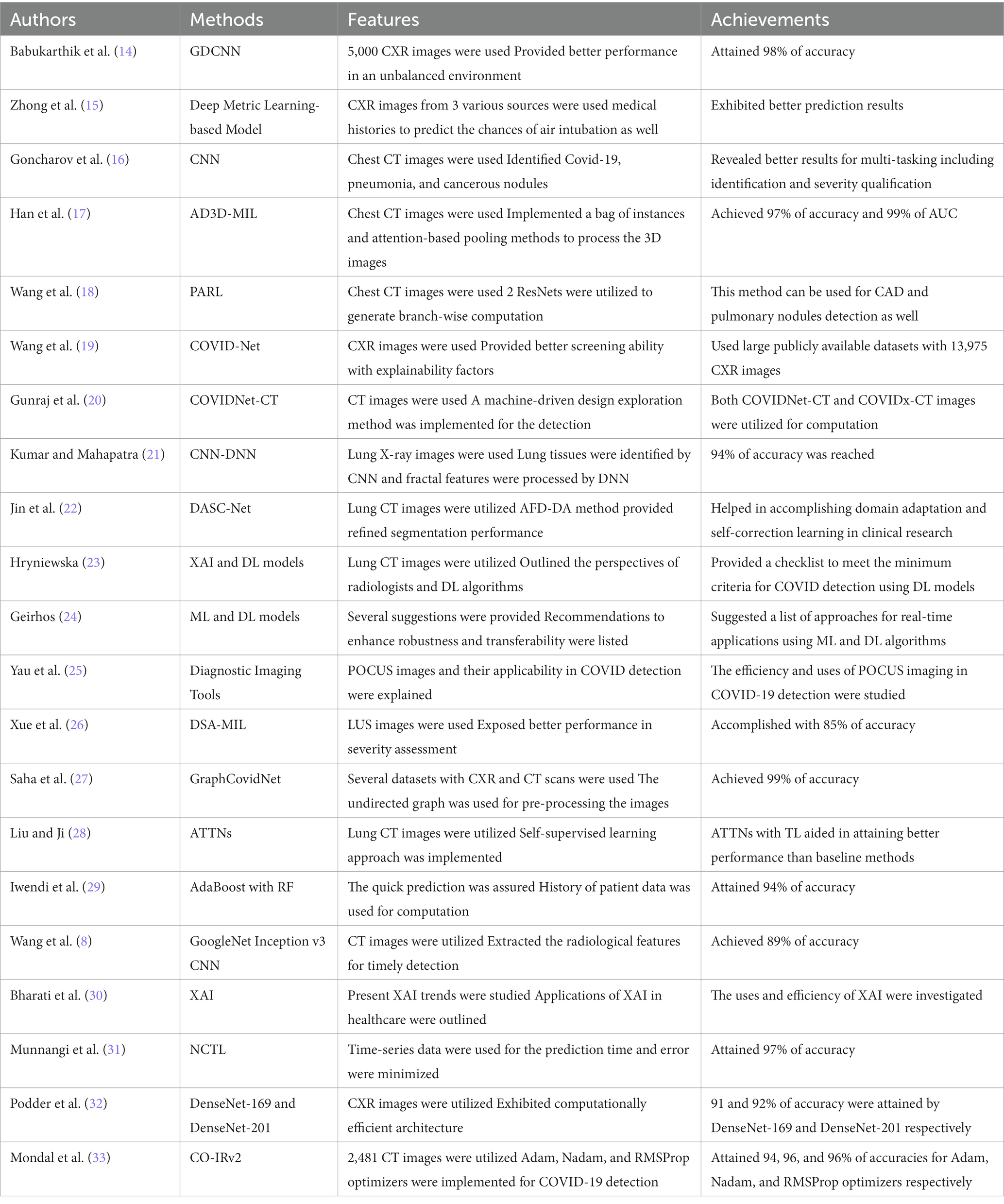
Table 1. Features and achievements of existing COVID-19 detection systems using AI algorithms.
3. Problem statement
COVID-19, viral and bacterial pneumonia have recently been detected and classified using DL models mostly based on CNN. In the absence of adequate studies on scalable datasets, it remains a tough scientific topic to distinguish COVID-19-based pneumonia from viral and bacterial pneumonia. Recent ways of detecting COVID-19 and pneumonia illnesses using CT scans have several research holes, which is why this new approach was developed. Usually, CNN-related approaches fail to address the difficulties of improving picture quality. As a result, during the automated CNN feature extraction, contaminated parts of pictures were not appropriately detected as being infected at all.
In previous CNN-based studies that used the entire lung image to automatically extract features, only characteristics of affected lung areas were significant to diagnosis. To classify chest pictures, high-dimensional and irrelevant features are extracted due to the absence of ROI estimates in the images. The absence of ROI-specific traits makes it difficult to assess the degree of illness. Early lung disease diagnosis is hampered by the computationally inefficient solution provided by CNN’s lengthy training requirements. On tiny X-ray samples, COVID-19 and pneumonia detection techniques employing DL have been examined for testing, training, and validation on 10–15% of samples. Such models need a higher ratio of training to testing if they are to be considered efficient and reliable. It was necessary to train CNN models for lung disease prediction, utilizing irrelevant datasets to automatically extract feature information. A paucity of clinical data in CNN’s pre-trained networks resulted in incorrect feature extraction since COVID-19-induced pneumonia is so new. This necessitates the development of effective strategies to address the current challenges.
4. A novel COVID prediction scheme
The developed model provides a significant way to analyze COVID disease using the DL technique for accurate prediction. The developed model addresses the production of synthetic lung CT images, which is based on the TL-based Pix2Pix GAN.
4.1. Dataset
The dataset for the COVID-19 photos was found on several different platforms. In addition, a collection of lung-imaging CT scans is used and utilized data from the Kaggle repository for testing and validation purposes in the link SARS-COV-2 Ct-Scan Dataset | Kaggle [Access Date 08-12-2022). There are two types of data in this set. Data on people infected with COVID-19 is presented first, followed by data on people who aren’t infected with COVID-19, or “normal” people. Classification and identification of COVID-19 infection are all possible uses for this information. There are 2,482 photos in the dataset, 1,252 of which are of patients with COVID-19, and 1,230 of which are not. From these real images, the pix 2 pix GAN is used to generate synthetic data which employs the data augmentation process to eliminate the overfitting issues in Resnet 101 classifier. Here, the images are loaded, rescaled, and converted to grayscale format by variating the Loss function L1. Now, the augmented dataset consists of 7,446 images, The process of pix 2 pix GAN in this research is explained in Section 4.2. Figure 1 portrays the architecture of the suggested COVID-19 prediction model using the DL algorithm.
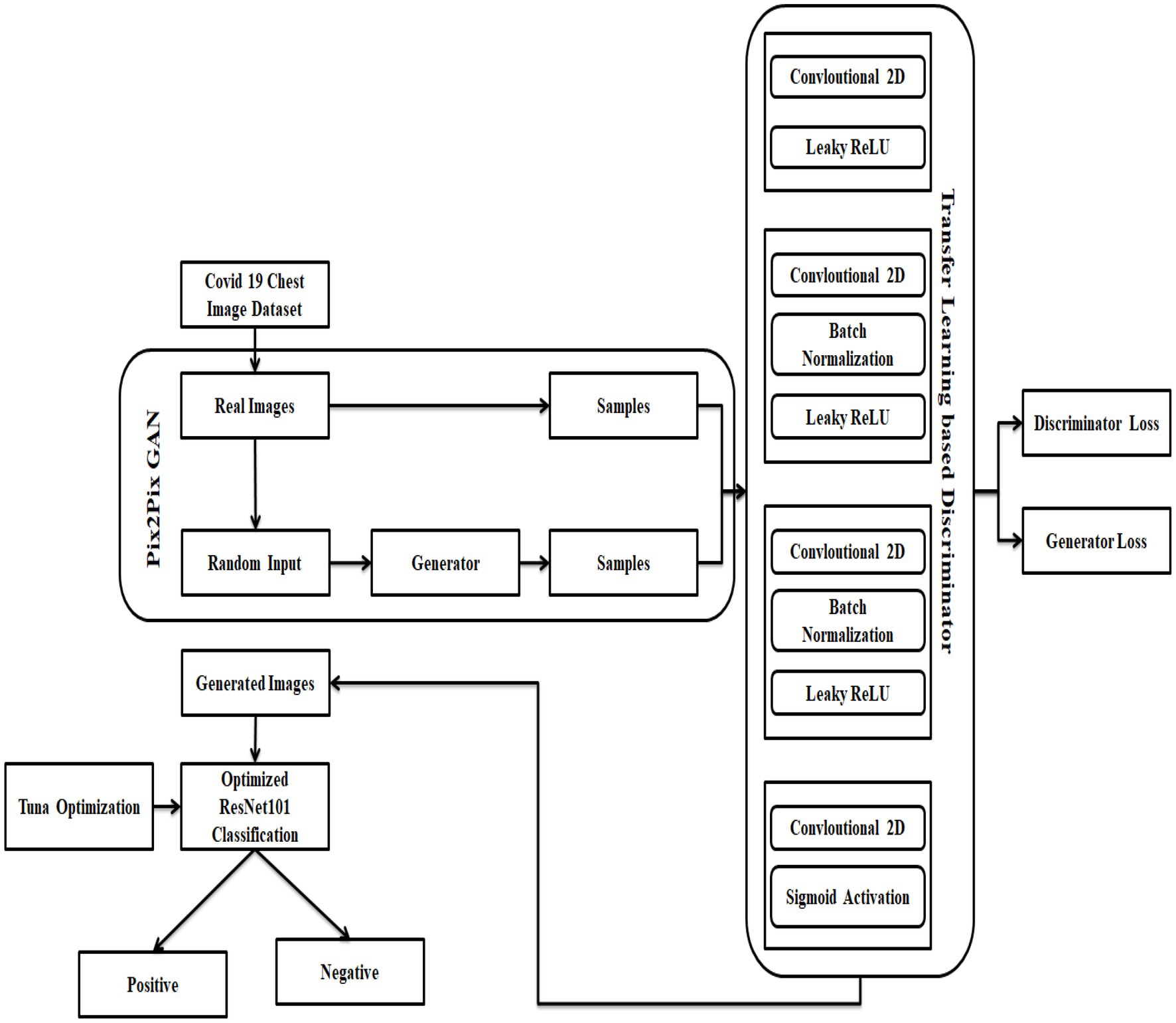
Figure 1. Architecture of the suggested COVID prediction model.
4.2. Transfer learning-based pix 2 pix GAN
The corona disease prediction process is considered as a mapping of input corona data to its matching illness prediction data through a mapping function as and it is non-invertible in the ideal case, meaning that the original image cannot be recovered from the de-identification image. To produce images with a specified pattern of distribution, researchers often use GANs. This study’s goal is to generate chest images by meeting a series of requirements; therefore, a GAN-based architecture seems like an obvious choice for learning the mapping function . Generating input data is the first step of GAN, and it is followed by a discriminator network that determines whether or not an input image belongs to the original data distribution or one learned by the generator network; this is the simplest kind of GAN to understand and implement (i.e., fake data). To achieve both the identity code and its phases using this GAN’s fundamental structure, however, is not conceivable. Conditional GANs seem to be the best solution if a collection of secondary features is used for input data distribution learning. Loss functions for each auxiliary piece of information are generated via conventional metrics/Neural Networks (NNs). Also, the aggregate loss of each of the secondary models and metrics is collectively reduced with the loss function for the discriminator.
As a starting point, build the Optimized ResNet 101 using two independent deep networks, a pix-2-pix GAN, and TL, and design loss functions. There must be no traces of the input image in the produced image, and it must also retain the qualities of that data to be considered accurate. In Figure 1, a generator and a discriminator are combined to form one unit. The generator creates an image. Also, the discriminator returns a score (GAN loss) showing whether the created image falls inside the gallery set’s probability distribution. Both contrastive and cross-entropy loss are calculated by the verifier networks to reflect how similar or different an image produced from an input image is from the original image. Losses from a specific epoch are sent back to build a better corona image based on the weighted combination of these data later. The combination is more appropriate for the various constraints or situations.
Reconstruction of the under-sampled chest CT data was achieved via TL using a pre-trained Pix2Pix-GAN model (34). Repurposing an already-trained model for another task is known as TL. To build a model from scratch for uncommon or developing illnesses, TL is most beneficial when there are not enough training examples available. Using TL, the model parameters are already excellent and just require a few minor tweaks that are best suited to the new functions at hand, making the process much easier. It is possible to employ a pre-trained network for new tasks in one of two ways. When a pre-trained model is used to extract features instead of being used to classify, then there is no change in the pre-trained model’s internal weights to fit the new tasks. Another option is to fine-tune the whole network, or a part of it, for the new purpose. A trained model is used as a starting point and modified throughout training. With the help of the GAN-based TL technique, the suggested model can combine domain adaptation and feature learning in one training phase. The generator ( ) and the discriminator ( ) are the only two components of a GAN model that are straightforward. When a multi-layer mapping function is used to generate the feature vectors, the raw sampling points are used as the source domain, and be defined as , where Od is the probability that comes from the target rather than the source domain and is the discriminator parameter. While in training mode, the discriminator tries to optimize such that the produced feature from a target, a domain can be discriminated from the generated feature from the source. Contrary to this, the generator’s goal is not to increase the , but rather to deceive the discriminator by generating bogus samples with a distribution that closely resembles that of the original domain. The generator’s strategy function is expressed as given in Equation (1) are captured by the GAN model as the minimax model progresses.
Equation (1) can be rewritten as stated in Equation (2),
For the first time in the history of corona disease prediction, this paper concentrates on creating more realistic images with unique morphological traits and obvious borders. To help with the model training, this discriminator’s last layer calculates the loss function. Using the noise distribution provided by Om, the generator fed using an arbitrary noise vector (assume ). is likewise assumed to be a distribution of input data and is a distribution of output data learned via a generator at a given iteration Using the training sample, the generator produces a mapping , in which and . Multiple epochs are used to train the GAN, and the training procedure is stopped once the 2 distributions as well as are comparable.
The value function is used by the discriminator and generator in a min-max process . To minimize its reward , the discriminator tries to diminish its reward, while the generator tries to maximize its loss. To develop high-resolution images with synthetic images, the generator must be close to the deeper network. More convolution layers and time spent training for up-sampling are required for a deeper network. Initially, input the original image data and scaled it to before using the GPU for training. To match the generator’s pixel values, the image was resized to . The activation function is why it was issued. Fake samples are generated by feeding a noise vector into the generating network. High-quality synthetic images were created using four convolution layers and ReLU activation. It is the generator’s goal to decrease the next loss function, whereas the discriminator’s goal is to increase it. With the original input data and random noise variable added, the generator creates samples . Over the data distribution , is the discriminator’s estimate of how likely it is that the actual instance is real. The discriminator’s estimate of the likelihood that a false instance is genuine is . To deceive the discriminator, the generator attempts to produce almost flawless images. Contrast this with an algorithm that attempts in vain to discriminate between actual and false data samples until the generator’s created data cannot be separated from real data samples.
To accurately categorize a given image into one of two categories: genuine or false from the distributions and correspond to the two classes. Assume the ground truth labels for and are and respectively. A generator that has completed its training phase can generate pictures that are quite close to the source data in terms of appearance. A CNN with four layers serves as the discriminator model. The activation function of the Leaky ReLU is employed in the first and second convolutional layers of this model. The generator encoder block’s network topology is carried through to the third to sixth levels. Finally, a convolutional layer with a stride of 1 is applied as the last step. The encoder’s primary goal is to learn the representation feature, whereas the discriminator’s primary goal is to identify the discriminating feature as shown in Equation (3).
where the discriminator’s feature map is , the function processes , and the decoder’s function reflects processing on sample from real images . The rectangular portion of the original picture is first resized. A picture feature map is extracted from the major component of the discriminator, and the decoder can build a good reconstruction from this data Here, an adversarial loss for GAN is proposed, taking into account both real and false samples that fall inside the margins. In the generator training step, artificial samples outside of the bounds that include misleading local patterns are disregarded as demonstrated in Equation (4).
The training pattern is called which represents the input picture for the discriminator at this specific epoch. If falls inside or ’s probability distribution or , the discriminator differentiates between the two. The generator-discriminator network’s mini-max loss function can be expressed as stated in Equation (6).
In this case, stands for the expectation operator. Also, training the GAN using the loss function of Equation (6) failed to adequately retain the structure. Rendering images might seem precise. Adding a structural similarity loss term ( ), together with the loss function, allows us to maintain the non-biometric characteristics mentioned above while still generating an appealing corona disease prediction picture at high resolution. The similarity, in contrast, brightness, and structure between and is used to calculate this loss term, which is a composite measure of all three. The Structural Similarity Index (SSIM) among 2 input pictures Z and is formally stated as portrayed in Equation (7).
where, the parameters and are defined as given in Equations (8)–(10) respectively.
Hither, and indicate the input’s and mean intensities, signifies the variances of intensities of and and indicates and covariance. Constants , and are defined as expressed in Equations (11)–(13) respectively.
Here, points to pixel values’ dynamic range. Besides, Equation (14) is used to calculate .
If portrays generators and discriminator’s loss function to be minimized without applying any condition, then is stated as specified in Equation (15).
where indicates a positive constant in the interval . The value must be carefully set for attaining a better balance between successful de-identification and preservation of structural similarities. The ideal equilibrium is achieved at 0.25 to acquire accurate images.
4.3. Optimized Resnet 101 classification
Here, the classifier parameter is tuned using the improved Tuna Swarm Optimization (TSO) method (35), which is based on the tuna’s foraging behavior and offers excellent global searchability. Tuna has a streamlined physique in tropical and subtropical warm seas because they are marine fish. After seeing the target, the tuna swarm circles the prey in a bionic manner, searching for prey in groups of individuals and populations that are randomly swimming in the water. Finally, the tuna will progressively shrink the surrounding range, which is dominated by spiral and parabolic patterns. Swim rapidly to grab prey like mackerel after you have found a good spot.
Initialization: Here, tuna is arbitrarily dispersed concerning their current position as given in Equation (16).
in which specifies the initial location of the tuna, and points to search range of tuna, refers to tuna fish population count, and signifies an arbitrary vector uniformly distributed among .
1. Spiral Foraging: When immature fish swarms confront predators, the fish school creates a thick shape, continually altering its swimming direction, making it impossible for the predator to secure its location as defined in Equation (17).
1. The tuna swam in a helical formation, encircling and engulfing their victim. The tuna can change places at any moment and pursue the prey. A meta-heuristic algorithm like the tuna swarm performs a global search in the early stages before progressively shifting its focus to a local search as described in Equations (18)–(22).
1. The spiral foraging procedure is stated in Equation (23).
1. Parabolic Foraging: At times, tuna would hunt their food in the parabolic shape, using a school of larval fish as their point of reference. It is common for one section of the swarm to adopt a spiral shape, while the other part adopts a parabolic shape. The mathematical model of the parabolic shape assumes that the chance of selecting the two hunted and released is 50% as expressed in Equations (24), (25).
R represents the Iteration, , and are the weight control parameters; refers to the constant, is the arbitrary number among , signifies the spiral equation; denotes the spiral equation parameter, is the current iteration number. There are four possible positions for the iteration of the population: random, O (rand), and optimum. O (rand) represents the iteration of the population’s random location, while O best represents the ideal position for the population’s iteration. A random integer between zero and one between and is used to determine how many times to repeat the process
Generally, the traditional TSO is efficient in solving complex optimization problems and engineering problems. However, the traditional TSO performance is limited due to complexities in deciding the behavior from an individual tuna’s perspective. Often tends to premature convergence and local optima issues due to the neighborhood search pattern of tuna. Intending to solve these issues, the traditional update expression given in Equation (18) is replaced by the Duffing equation concepts. Since Duffing equation is better at solving nonlinear and chaotic problems, the concepts are used to update the tuna’s position update to evade the local optimal and low convergence issues as shown in Equation (26).
Here, indicates the tuna at iteration , denotes the first order of , points to the second order derivative of , the constants used in Equation (26) have the default values as , , , , and . moreover, indicates the tuna at iteration , denotes the first order of , points to the second-order derivative of , the variables used in Equation (26) are estimated based on Equations (27)–(29) respectively.
Now, the key parameters of the Resnet 101 classifier are optimized with the improved DETS optimizer. The 1st hidden layer nodes count , the 2nd hidden layer nodes count , the iterations count , and the learning rate all had a significant influence on classification outcomes in the Resnet 101 network (36). The DETS optimizer is used to optimize key variables of the Resnet 101 network. Nodes in one layer are linked to nodes in the next, but nodes inside a layer are not connected at all. When the unit vector of the visible layer and hidden layer is noted, the joint state energy function among every neuron’s pair of visible and hidden layers of Resnet 101 can be expressed as stated in Equation (30).
Where, indicates visible layer bias, refers to hidden layer bias, denotes the weight matrix to connect visible and hidden layers, and portrays Resnet 101 network’s parameter. The distribution function of the visible and concealed components can be calculated using the energy function as shown in Equations (31) and (32).
where is a normalizing partition function.
The following logical function is used to represent conditional probability in Resnet 101, which is derived from the Bayesian formula’s premise as portrayed in Equations (33)–(35).
in which σ point to the Logistic function.
The first step is to initialize the layer which is visible to the user. The hidden neuron’s conditional probability is then determined using the visible layer’s value and the conditional probability equation. The guidelines for updating relevant parameters as a result of repeatedly doing this procedure are demonstrated in Equations (36)–(38).
where 𝜀 is the feature learning rate and represent the model is a representation of the data, and the model’s anticipated values reflect the data. Using this criterion, an appropriate weight is found; the same process can be followed until all Resnet 101 weights have been adjusted using this criterion. The following are the steps taken by the DETS optimizer to improve the parameter calculations for Resnet 101.
Step 1: After preprocessing, dimensionality reduction, and normalization, the actual data are imported and separated into training as well as testing samples.
Step 2: The Resnet 101 network topology was created by the sample data requirements.
Step 3: After the settings of the Resnet 101 were initialized, as well as the DETS optimizer parameters, comprising the tuna population and samples are set.
Step 4: As the tuna fish continued to operate, the fitness value and the position were updated in real-time using formulae (30), (31), and (32); within the iteration range. If the new site was superior, the old one would have been demolished and rebuilt.
Step 5: The value of the appropriate combination of Resnet 101 parameters was stored based on the optimum fitness value.
Step 6: Resnet 101 was trained and the appropriate parameters were stored based on the ideal parameter combination .
Because of step 6, Resnet 101 was able to generate the categorization results. Finally, the covid positive and non-covid images can be classified. Figure 2 depicts the flowchart of the proposed model. Algorithm 1 and 2 shows the pseudocode of the DETS optimizer and the proposed optimized Resnet 101 model.
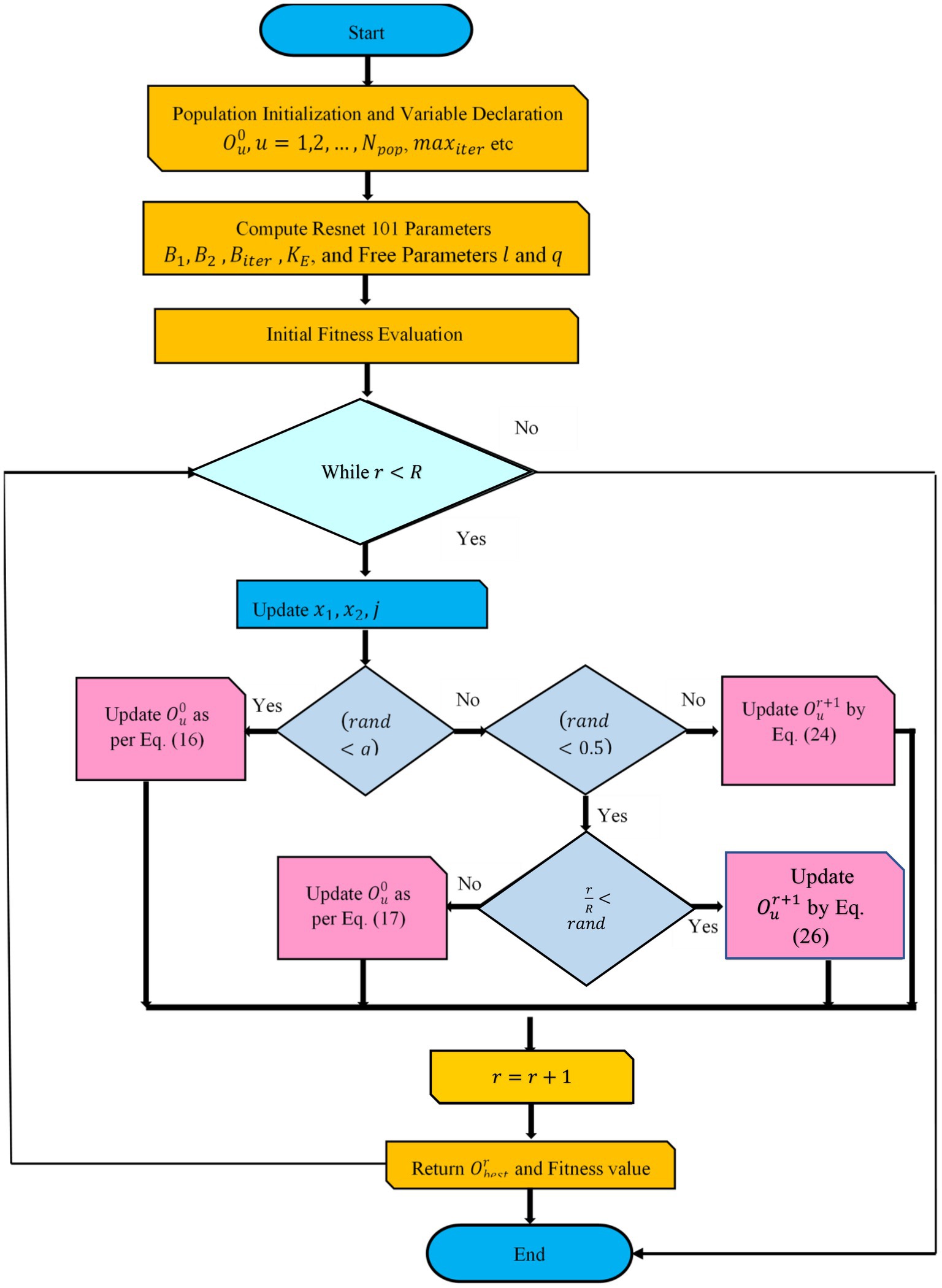
Figure 2. Flowchart of proposed optimized Resnet 101 using DETS optimizer.
ALGORITHM 1 Pseudocode of Proposed DETS Optimizer
Input: and
Output: Optimal
Declare initial population
Free parameters and , where
While
Fitness estimation
Update
For every do
Update
If then
Update as per Eq. (16)
Else if then
If then
If then
Update by Eq. (18)
If then
Update by Eq. (17)
Else if then
Update as per Eq. (26)
End for
End while
Return and fitness value
End
ALGORITHM 2 Pseudocode of Optimized Resnet 101
Input: Generated image
Output: Classified output
for char do and char binary image char (char)
end for
for do
optimization
end for
return
attach (tuning parameter)
end
5. Experimental setup
The presented COVID-19 disease diagnosis approach via the optimized ResNet model was implemented in MATLAB on Intel core® core i3 processor 7,020 U@2.3 GHz, 8 GB RAM, 64-bit operating system. Lung CT images are used for implementation. For experimentation, the proposed scheme employed a holdout of 70:30 training-to-testing data ratio of Optimized Resnet 101 to categorize covid-19 photos. The efficacy of the proposed COVID-19 detection scheme is achieved using simulation results. Here, the existing models like Fractal Features-based Deep Neural Network (FFDNN) (21), CCN (21), Resnet 101 (36), and traditional TSO-based Resnet are compared with the proposed model
5.1. Performance analysis
Statistical research evaluates the effectiveness of the suggested model in identifying defective covid lungs based on a range of performance parameters. Sample lung images are shown in Figure 3. Here, Figure 3A depicts the 2D axial views, and Figure 3B shows covid-19 severity classes. Red signifies instances of life-threatening severity, whereas pink denotes COVID early stages cases, orange denotes patients in the mid-stage of covid, yellow represents patients who have recovered from covid, and green specifies healthy non-covid individuals. Even if the suggested method is successful, it is still feasible to discriminate between covid and non-covid cases using this method. Figures 3C,D demonstrate the original image and the corresponding synthetic images generated using pix2pix GAN. As seen in Figure 4, there exists a considerable rise in loss values when the training begins and a significant reduction in loss values when the training ends. Due to the low number of COVID-19 cases compared to the other two classes (Pneumonia and No-Findings), this dramatic spike and decline are mostly due to this class. It is possible to lessen these high and low points in the training by examining all CT images repeatedly for each epoch of training.
• True negative (TN): Normal lung image is properly identified.
• True positive (TP): The case is correctly distinguished.
• False negative (FN): The case is incorrectly identified.
• False positive (FP): The normal lung image is incorrectly diagnosed.
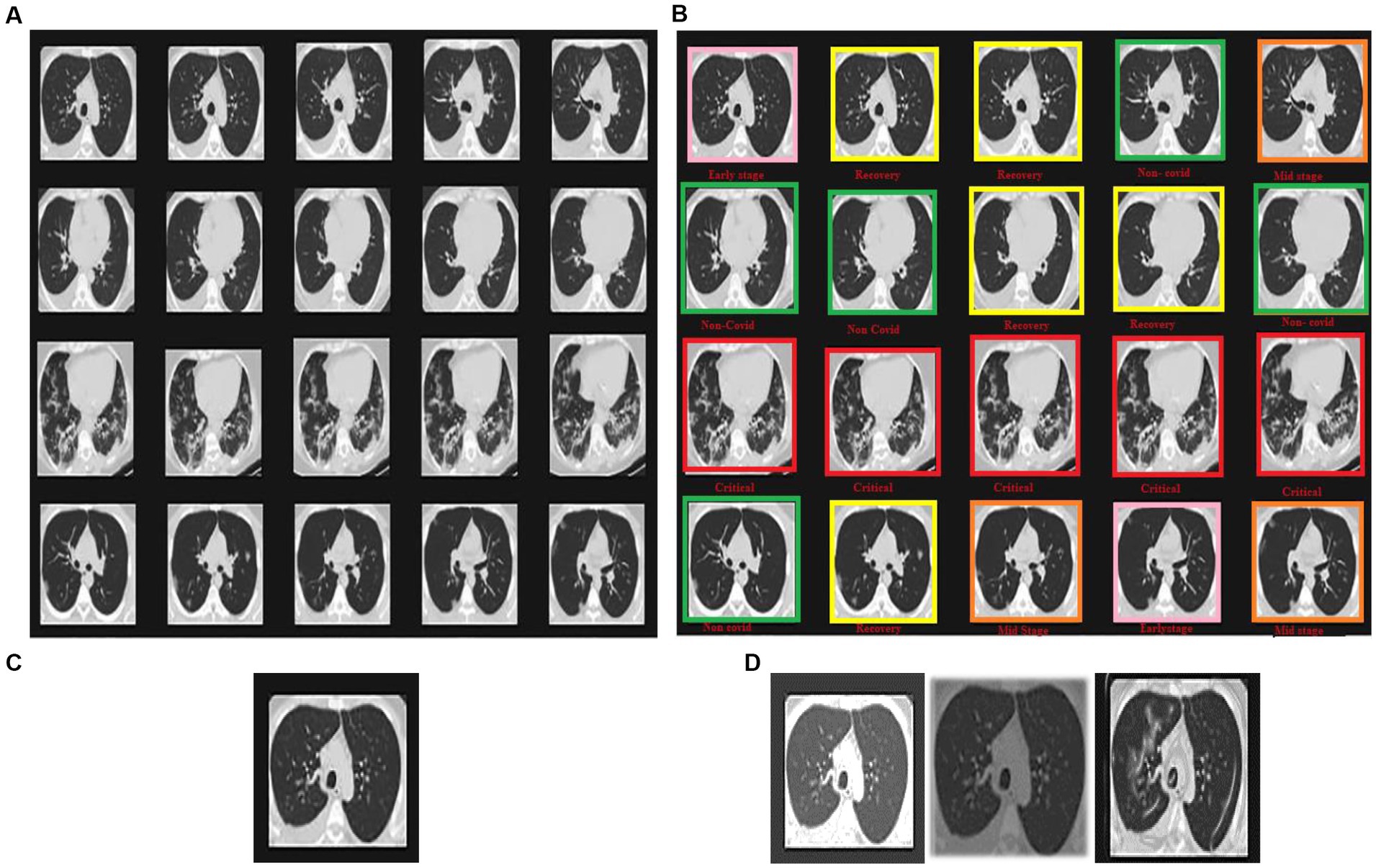
Figure 3. Sample images displaying lung CT images classification in terms of (A) 2D axial views, (B) COVID-19 severity classes, (C) original image, and (D) synthetic images of loaded, rescaled, and grayscale.
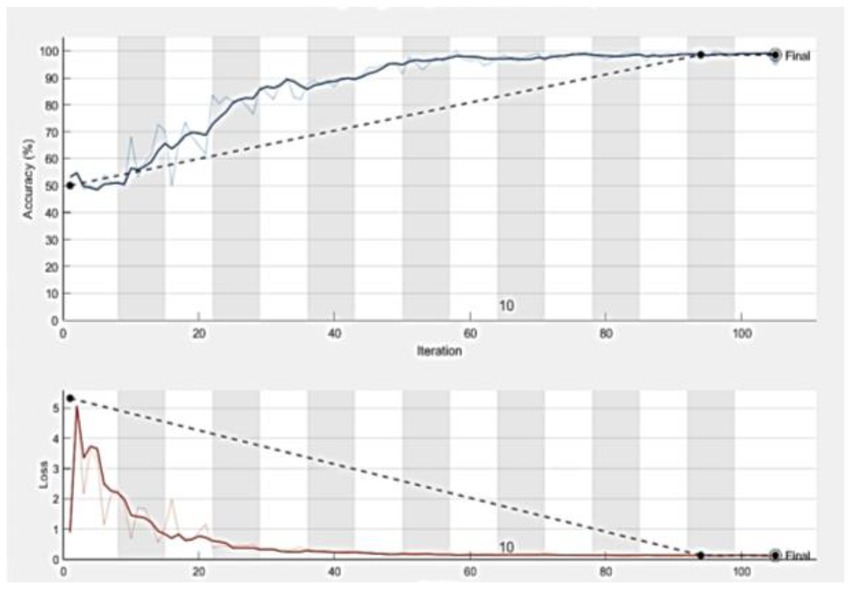
Figure 4. The accuracy and loss curves which tend to be stable after descending, signify that the training process converges.
5.2. Accuracy
The percentage of accurate findings based on the total number of data points is called image quality. It is displayed in percentages how accurate and precise the recall is as shown in Equation (39).
5.3. Specificity
Specificity refers to arbitrary errors to calculate algebraic variability as portrayed in Equation (40).
5.4. Recall
The positive data percentage is appropriately identified as the “true optimistic rate and is estimated as illustrated in Equation (41).
5.5. Precision
Precision portrays the conditional probabilities of the actual class and the predicted class. Equation (42) shows the expression for precision.
Figure 5 shows the significance of the proposed DETS-optimized Resnet 101 classifier over traditional methods. Here, Figure 5A shows the convergence of the proposed DETS-optimized Resnet over traditional TSO and accomplished better accuracy which is 2.25% improved than traditional TSO-Resnet.
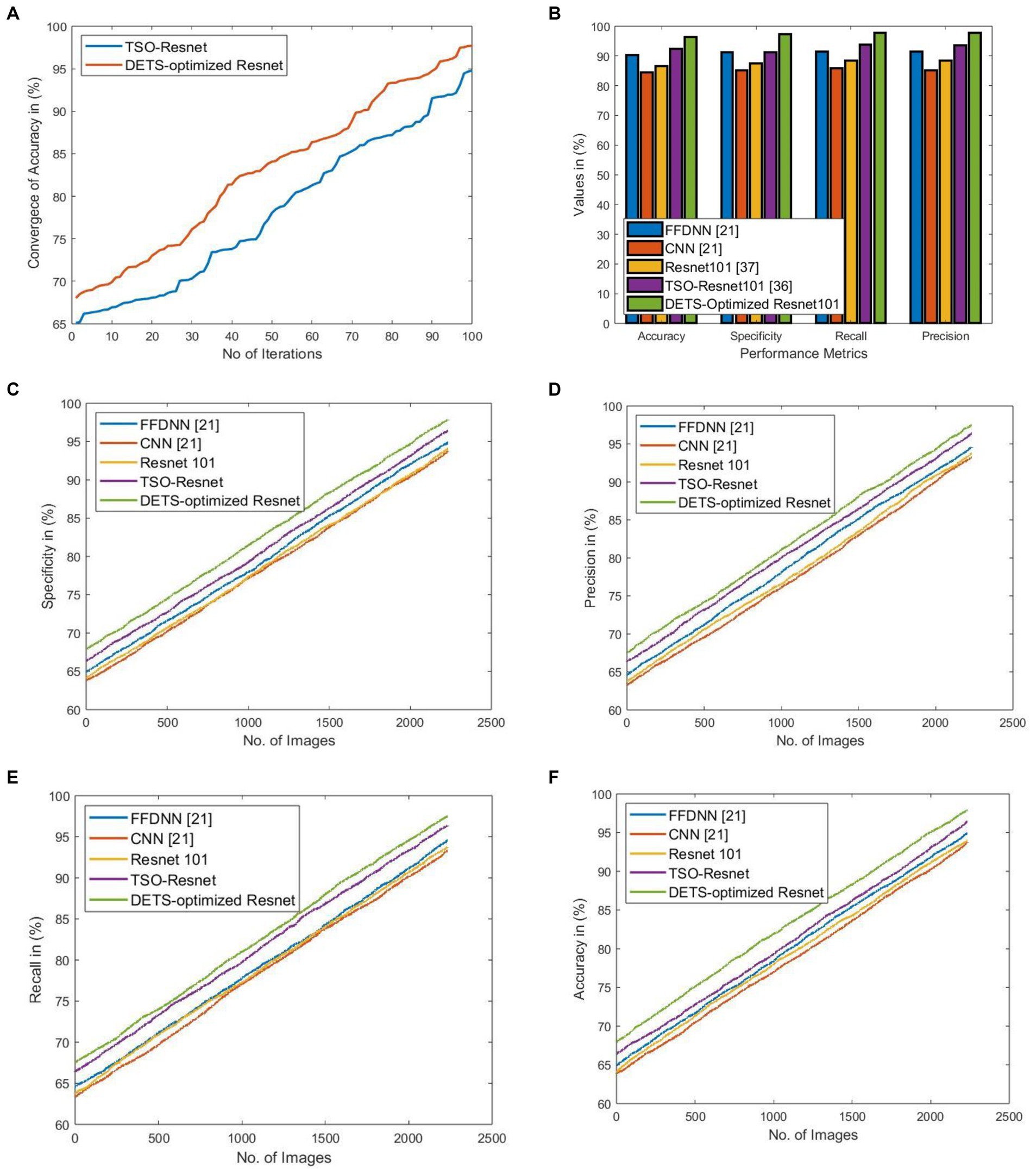
Figure 5. Significance of implemented DETS-optimized Resnet concerning (A) convergence of accuracy over TSO-Resnet, (B) performance over other methods, (C) specificity, (D) precision, (E) recall, and (F) Accuracy.
Figure 5B shows the performance of the proposed DETS-Optimized Resnet 101 classifier over other methods using holdout as 70% of training data and 30% of testing data. For accuracy, the implemented DETS-optimized Resnet 101 model attained 6.32, 12.42, 8.29, and 3.83% better than FFDNN, CNN, Resnet 101, and TSO-based Resnet, respectively. Similarly, for specificity, recall, and precision, the proposed DETS-Optimized Resent 101 classifier performed well than other methods. Besides, Figures 5C–F portray the specificity, precision, recall, and accuracy, respectively, of the proposed DETS-Optimized Resnet over other methods. Herein, 30% of testing data is employed that is 744 images with 378 COVID-19+ and 366 COVID-19 negative people. This investigation demonstrates that the proposed COVID-19 classification system using lung images via DL models performed well and outruns the other models.
Using specific CT images, the model produced 0.95 and 0.89 AUC for internal and external validations, respectively, as shown in Figure 6. Additionally, Table 2 represents the internal and external validations of the proposed DL algorithm where the accuracy is 97.2 and 95.4% for internal and external validations, respectively. Similarly, specificity is 95.5 and 94.62%, precision is 96.7 and 94.25%, and recall is 95.9, and 93.95% for internal and external validations, respectively. Besides, Positive Predictive Value (PPV), and Negative Predictive Value (NPV) are also evaluated to estimate the disease-positive and disease-negative data. Kappa values are estimated to find the interrater reliability among the data which is measured using the proposed DL classification results and clinical results. Also, ROC and Youden index is employed to measure the optimal cutoff between sensitivity and specificity which yielded 0.84 and 0.78 for internal and external validations, respectively. Table 3 summarizes the performance of the proposed DL over skilled radiologists. Around 730 images are given to determine the COVID-19 disease by 2 expert radiologists (R1 and R2). Here, Radiologist 1 (R1) attained 54.89% accuracy whereas Radiologist 2 (R2) achieved 56.21% of accuracy. Also, the specificity precision, recall, F1-score, NPV, and PPV values are low when compared with the proposed DL model. It indicates that the classification of COVID-19 using bare eyes is insignificant when compared with DL algorithms. Table 4 shows the 5-fold cross-validation results of the proposed DETS-ResNet model. Hither, the cross-validation approach is used to distinguish between the training and testing images in the dataset and assess the proposed algorithm’s performance. The entire number of images is divided into five sets. The data from set 1 are utilized for testing and the images from other sets are used for training the first fold. The classification accuracy and other metrics were determined for the first fold taking this into account. For the second fold, the data from set 2 are utilized for testing, while other sets are used for training. The remaining data are utilized as training images for the third fold, fourth fold, and fifth fold metrics, from sets 3, 4, and 5 for testing, respectively. To arrive at the overall results, the metrics acquired for folds 1–5 were averaged. From this assessment, fold 3 attained better results with Adam’s optimizer. The overall performance of the proposed model reached 96.7% accuracy, 96.87% specificity, 97.27% precision, 97% recall, 87.67% NPV, 89.07% PPV, and 96.9% F1-score.
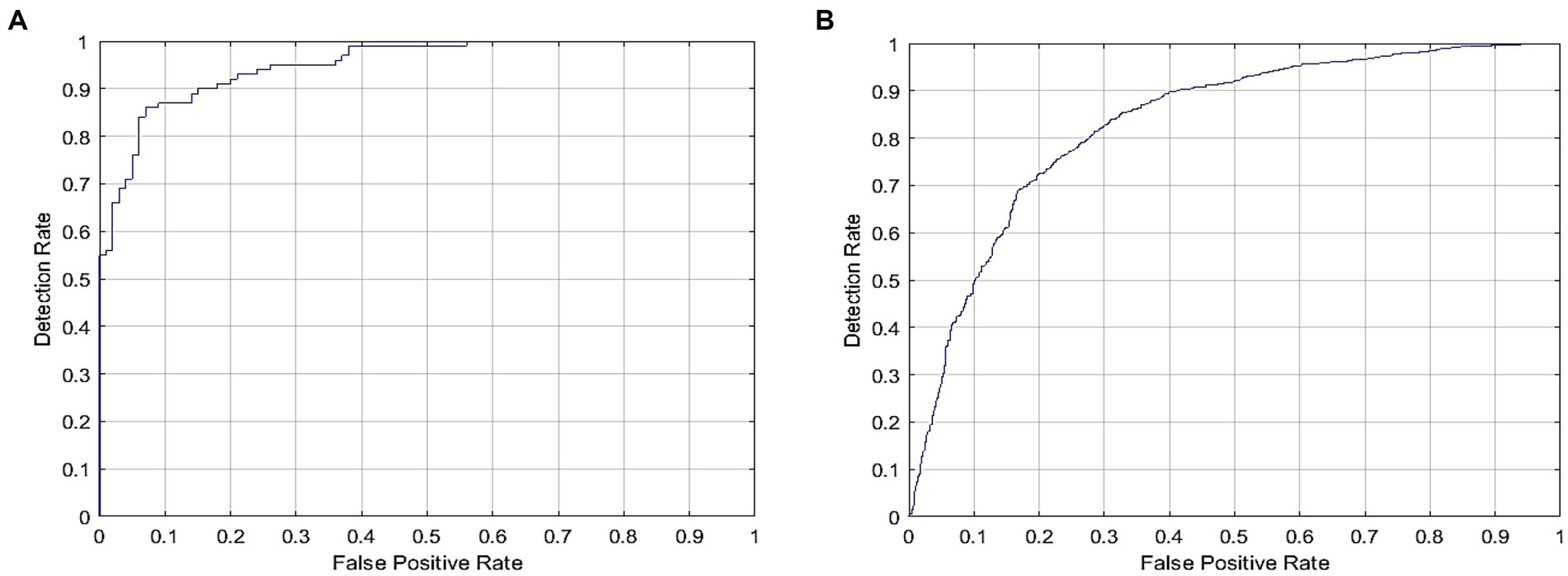
Figure 6. ROC for COVID-19 detection for DL model signifying (A) Internal and (B) external validation.
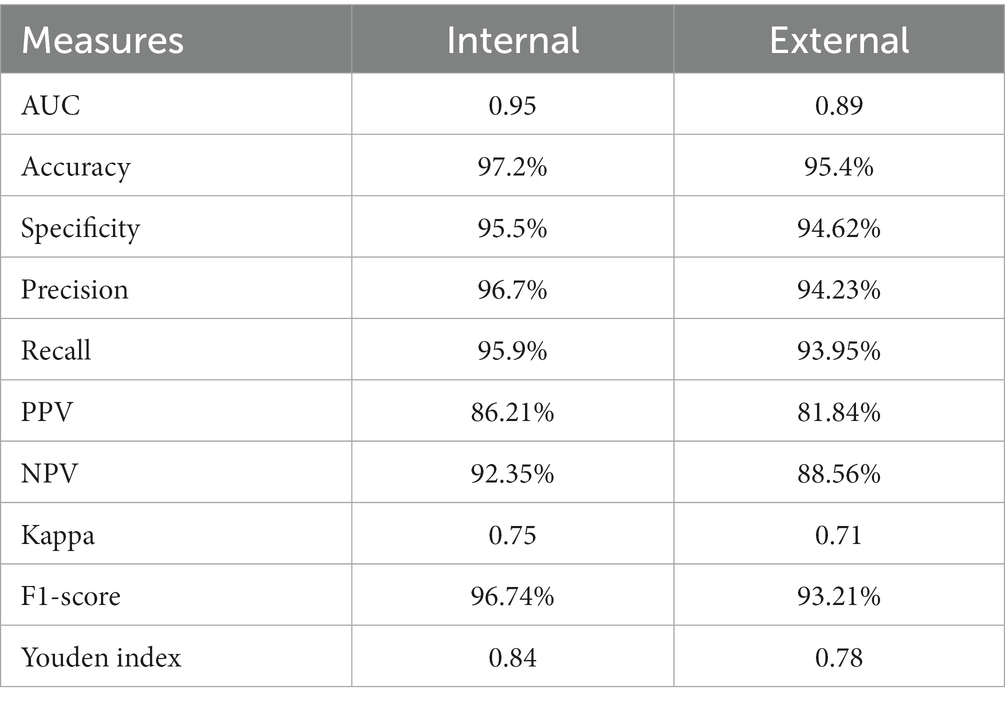
Table 2. Performance of proposed DL model.
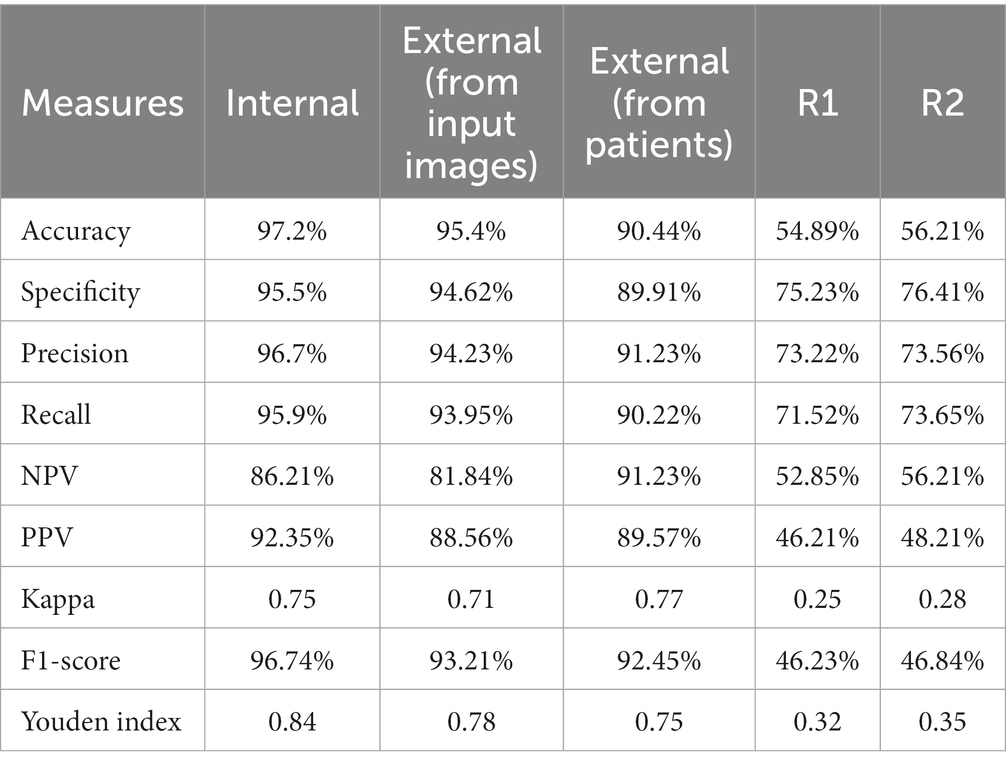
Table 3. Performance measures for proposed DL model over skilled radiologists.
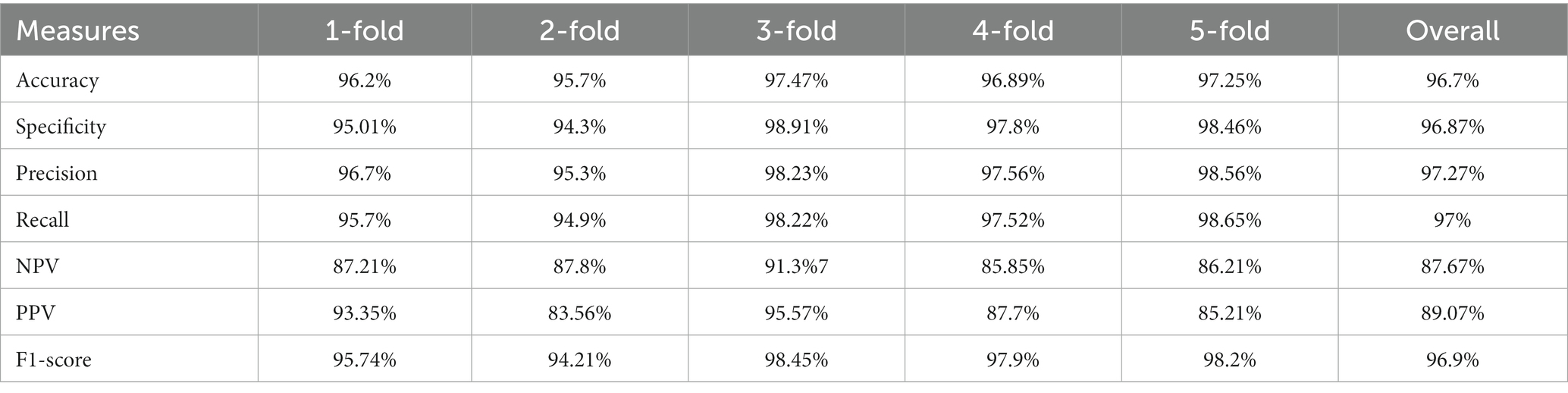
Table 4. Performance measures for proposed DL model using 5-fold cross validation.
5.6. Discussion
There has been a pressing need for quicker alternatives that front-line healthcare workers may employ for reliably and swiftly detecting the condition due to the limits of manual tests. In this work, a DL algorithm is proposed for the analysis of sample CT scans. Using the developed DETS-optimized Resnet, which has a 97.2% overall accuracy. More significantly, the developed framework obtained a reasonably high sensitivity of 95.9 and 93.95% on internal and exterior CT images, correspondingly, making it an effective screening approach. Notably, although both COVID-19 and other common viral pneumonia have many radiological features, the proposed model was able to differentiate between them. Therefore, the DETS-optimized Resnet model has the potential as an effective tool for COVID-19 screening during the present worldwide COVID-19 epidemic. There is no segmentation procedure used in this work. In fact, segmentation helps to enhance classification performance. Also, the data used in the experimentation is gathered from a single source which is synthetically augmented. In the future, data from various sources will be gathered and utilized for COVID-19 detection with multi-Modality.
6. Conclusion
Using an optimized Resnet 101 model, the chest CT scans were classified between an infected patient and a healthy one. In this investigation, CT scans were used since they reveal the polluted areas of the lungs and were practically universally accessible in hospitals. Other germs, such as pneumonia and flu, become more virulent in frigid temperatures, making it difficult for physicians to determine the severity of an illness. The study’s second goal was to build a collection of exact images using a Pix 2 Pix GAN network based on TL. Stages include early, mid, recovery, critical, and non-covid in the CT pictures of the chest. DETS Optimizer technique and DL-based Resnet 101 approaches were part of the suggested strategy. The accurate pictures were obtained by the application of image reconstruction algorithms. TL-based GAN was applied to a picture that has been randomly generated in both height and width. The suggested model was put to the test in a variety of ways. COVID-19 CT image categorization with five classifications was tested. Based on many assessment factors such as Accuracy, Precision, Recall, and Specificity, the enhanced Resnet 101 was assessed. Four courses yielded the best outcomes. CNN and DNN models were used for the comparison. In all classes, the improved Resnet 101 surpasses CNN and DNN. In the future, image segmentation will be done using a variety of color saturation algorithms to enhance the classification performance. Besides, Hemodialysis patients in Alsaffar (37), can use the proposed model instead of statistical data. Image datasets can be used with the effectiveness of Deep Learning algorithms to identify more precisely. Moreover, it can reduce the highly time-consuming process of manual diagnosis. For this process, the proposed optimized Resnet 101 can be employed to reduce the manual workload and can help in early detection.
Data availability statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found at: https://www.kaggle.com/datasets/plameneduardo/sarscov2-ctscan-datase0074.
Ethics statement
Ethical approval was not required for the study involving humans in accordance with the local legislation and institutional requirements. Written informed consent to participate in this study was not required from the participants or the participants’ legal guardians/next of kin in accordance with the national legislation and the institutional requirements.
Author contributions
All authors listed have made a substantial, direct, and intellectual contribution to the work and approved it for publication.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Allwood, BW, Byrne, A, Meghji, J, Rachow, A, Van Der Zalm, MM, and Schoch, O (2021). D: post-tuberculosis lung disease: clinical review of an under-recognised global challenge. Respiration 100:751–63. doi: 10.1159/000512531
2. Cascella, M, Rajnik, M, Aleem, A, Dulebohn, SC, and Napoli, RD. Features, evaluation, and treatment of coronavirus (COVID-19) [updated 2022 Jun 30]. In: StatPearls [internet]. Treasure Island, FL: StatPearls Publishing (2022) Available at: https://www.ncbi.nlm.nih.gov/books/NBK554776/
3. Bhattacharya, S, Reddy Maddikunta, PK, Pham, QV, Gadekallu, TR, Krishnan, SSR, Chowdhary, CL, et al. (2021). Deep learning and medical image processing for coronavirus (COVID-19) pandemic: a survey. Sustain Cities Soc 65:102589. doi: 10.1016/j.scs.2020.102589
4. Worldometer. Available at: https://www.worldometers.info/coronavirus/.
5. Mali, SN, Pratap, AP, and Thorat, BR (2020). The rise of new coronavirus infection-(COVID-19): a recent update. Eur J Med Oncol (EJMO) 4:35–41. doi: 10.14744/ejmo.2020.22222
6. Churruca, M, Martínez-Besteiro, E, Couñago, F, and Landete, P (2021). COVID-19 pneumonia: a review of typical radiological characteristics. World J Radiol 13:327–43. doi: 10.4329/wjr.v13.i10.327
7. Harapan, H, Itoh, N, Yufika, A, Winardi, W, Keam, S, Te, H, et al. (2020). Coronavirus disease 2019 (COVID-19): a literature review. J Infect Public Health 13:667–73. doi: 10.1016/j.jiph.2020.03.019
8. Wang, S, Kang, B, Ma, J, Zeng, X, Xiao, M, Guo, J, et al. (2021). A deep learning algorithm using CT images to screen for Corona virus disease (COVID-19). Eur Radiol 31:6096–104. doi: 10.1007/s00330-021-07715-1
9. Subasi, A, Qureshi, SA, Brahimi, T, and Serireti, A. Chapter 14 - COVID-19 detection from X-ray images using artificial intelligence, in Next gen Tech Driven Personalized med&Smart Healthcare. In: Artificial intelligence and big data analytics for smart healthcare (2021). 209–24.
10. Kaheel, H, Hussein, A, and Chehab, A (2021). AI-based image processing for COVID-19 detection in chest CT scan images. Fron Commun Netw 2:645040. doi: 10.3389/frcmn.2021.645040
11. Kızrak, MA, Müftüoğlu, Z, and Yıldırım, T. Limitations and challenges on the diagnosis of COVID-19 using radiology images and deep learning In: Data Science for COVID-19 (2021). p. 91–115.
12. Došilović, FK, Brčić, M, and Hlupić, N (2020). “Explainable artificial intelligence: a survey”, in 2018 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO). Opatija, Croatia, 182–91. doi: 10.23919/MIPRO.2018.8400040
13. Manapure, P, Likhar, K, and Kosare, H (2020). Detecting COVID-19 in X-ray images with keras, tensor flow, and deep learning. Assessment, Vol. 2.
14. Babukarthik, R, Adiga, VAK, Sambasivam, G, Chandramohan, D, and Amudhavel, J (2020). Prediction of COVID-19 using genetic deep learning convolutional neural network (GDCNN). IEEE Access 8:177647–66. doi: 10.1109/ACCESS.2020.3025164
15. Zhong, A, Li, X, Wu, D, Ren, H, Kim, K, Kim, Y, et al. (2021). Deep metric learning-based image retrieval system for chest radiograph and its clinical applications in COVID-19. Med Image Anal 70:101993. doi: 10.1016/j.media.2021.101993
16. Goncharov, M, Pisov, M, Shevtsov, A, Shirokikh, B, Kurmukov, A, Blokhin, I, et al. (2021). CT-based COVID-19 triage: deep multitask learning improves joint identification and severity quantification. Med Image Anal 71:102054. doi: 10.1016/j.media.2021.102054
17. Han, Z, Wei, B, Hong, Y, Li, T, Cong, J, Zhu, X, et al. (2020). Accurate screening of COVID-19 using attention-based deep 3D multiple instance learning. IEEE Trans Med Imaging 39:2584–94. doi: 10.1109/TMI.2020.2996256
18. Wang, J, Bao, Y, Wen, Y, Lu, H, Luo, H, Xiang, Y, et al. (2020). Prior-attention residual learning for more discriminative COVID-19 screening in CT images. IEEE Trans Med Imaging 39:2572–83. doi: 10.1109/TMI.2020.2994908
19. Wang, L, Lin, Z, and Wong, A (2020). COVID-net: a tailored deep convolutional neural network design for detection of COVID-19 cases from chest X-ray images. Sci Rep 10:19549. doi: 10.1038/s41598-020-76550-z
20. Gunraj, H, Wang, L, and Wong, A (2020). Covidnet-ct: a tailored deep convolutional neural network design for detection of covid-19 cases from chest CT images. Front Med 7:608525. doi: 10.3389/fmed.2020.608525
21. Kumar, A, and Mahapatra, RP (2022). Detection and diagnosis of COVID-19 infection in lungs images using deep learning techniques. Int J Imaging Syst Technol 32:462–75. doi: 10.1002/ima.22697
22. Jin, Q, Cui, H, Sun, C, Meng, Z, Wei, L, and Su, R (2021). Domain adaptation ased self-correction model for COVID-19 infection segmentation in CT images. Expert Syst Appl 176:114848. doi: 10.1016/j.eswa.2021.114848
23. Hryniewska, W, Bombiński, P, Szatkowski, P, Tomaszewska, P, Przelaskowski, A, and Biecek, P (2021). Checklist for responsible deep learning modeling of medical images based on COVID-19 detection studies. Pattern Recogn 118:108035. doi: 10.1016/j.patcog.2021.108035
24. Geirhos, R, Jacobsen, J-H, Michaelis, C, Zemel, R, Brendel, W, Bethge, M, et al. (2020). Shortcut learning in deep neural networks. Nat Mach Intell 2:665–73. doi: 10.1038/s42256-020-00257-z
25. Yau, O, Gin, K, Luong, C, Jue, J, Abolmaesumi, P, Tsang, M, et al. (2021). Point-of-care ultrasound in the COVID-19 era: a scoping review. Echocardiography 38:329–42. doi: 10.1111/echo.14951
26. Xue, W, Cao, C, Liu, J, Duan, Y, Cao, H, Wang, J, et al. (2021). Modality alignment contrastive learning for severity assessment of COVID-19 from lung ultrasound and clinical information. Med Image Anal 69:101975. doi: 10.1016/j.media.2021.101975
27. Saha, P, Mukherjee, D, Singh, PK, Ahmadian, A, Ferrara, M, and Sarkar, R (2021). GraphCovidNet: a graph neural network based model for detecting COVID-19 from CT scans and X-rays of chest. Sci Rep 11:1–16. doi: 10.1038/s41598-021-02469-8
28. Liu, Y, and Ji, S (2021). A multi-stage attentive transfer learning framework for improving covid-19 diagnosis. arXiv preprint arXiv:2101.05410
29. Iwendi, C, Bashir, AK, Peshkar, A, Sujatha, R, Chatterjee, JM, and Pasupuleti, S (2020). COVID-19 patient health prediction using boosted random forest algorithm. Front Public Health 8:357. doi: 10.3389/fpubh.2020.00357
30. Bharati, S, Mondal, MRH, and Podder, P (2023). A review on explainable artificial intelligence for healthcare: why, how, and when? IEEE Trans Artif Intell :1–15. doi: 10.1109/TAI.2023.3266418
31. Munnangi, AK, Sekaran, R, Rajeyyagari, S, Ramachandran, M, Kannan, S, and Bharati, S (2022). Nonlinear cosine neighborhood time series-based deep learning for the prediction and analysis of COVID-19 in India. Wirel Commun Mob Comput 2022:1–11. doi: 10.1155/2022/3180742
32. Podder, P, Alam, FB, Mondal, MRH, Hasan, MJ, Rohan, A, and Bharati, S (2023). Rethinking densely connected convolutional networks for diagnosing infectious diseases. Computers 12:95. doi: 10.3390/computers12050095
33. Mondal, MRH, Bharati, S, and Podder, P (2021). CO-IRv2: optimized InceptionResNetV2 for COVID-19 detection from chest CT images. PLoS One 16:e0259179. doi: 10.1371/journal.pone.0259179
34. Huang, C-M, Wijanto, E, and Cheng, H-C (2021). Applying a Pix2Pix generative adversarial network to a Fourier-domain optical coherence tomography system for artifact elimination. IEEE Access 9:103311–24. doi: 10.1109/ACCESS.2021.3098865
35. Xie, L, Han, T, Zhou, H, Zhang, ZR, Han, B, and Tang, A (2021). Tuna swarm optimization: a novel swarm-based metaheuristic algorithm for global optimization. Comput Intell Neurosci 2021:1–22. doi: 10.1155/2021/9210050
36. RDS, D, Negara, BS, Negara, SS, and Satria, E (2021). COVID-19 classification for chest X-ray images using deep learning and Resnet-101. 2021 International Congress of Advanced Technology and Engineering (ICOTEN) :1–4.
Keywords: COVID-19, transfer learning, generative adversarial network, Tuna Swarm Optimization, Resnet 101
Citation: Haennah JHJ, Christopher CS and King GRG (2023) Prediction of the COVID disease using lung CT images by Deep Learning algorithm: DETS-optimized Resnet 101 classifier. Front. Med. 10:1157000. doi: 10.3389/fmed.2023.1157000
Edited by:
Surapaneni Krishna Mohan, Panimalar Medical College Hospital and Research Institute, IndiaReviewed by:
Javad Hassannataj Joloudari, University of Birjand, IranSubrato Bharati, Bangladesh University of Engineering and Technology, Bangladesh
Copyright © 2023 Haennah, Christopher and King. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: J. H. Jensha Haennah, amVuc2hhaGFlbm5haEBnbWFpbC5jb20=