
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Med. , 30 June 2022
Sec. Ophthalmology
Volume 9 - 2022 | https://doi.org/10.3389/fmed.2022.794045
This article is part of the Research Topic Clinical Application and Development of Ocular Imaging View all 47 articles
 Jinxin Miao1†
Jinxin Miao1† Jiale Yu2†
Jiale Yu2† Wenjun Zou1,3†
Wenjun Zou1,3† Na Su1Zongyi Peng4
Na Su1Zongyi Peng4 Xinjing Wu1Junlong Huang1
Xinjing Wu1Junlong Huang1 Yuan Fang1
Yuan Fang1 Songtao Yuan1Ping Xie1Kun Huang2Qiang Chen2
Songtao Yuan1Ping Xie1Kun Huang2Qiang Chen2 Zizhong Hu1*
Zizhong Hu1* Qinghuai Liu1*
Qinghuai Liu1*Purpose: To develop artificial intelligence (AI)-based deep learning (DL) models for automatically detecting the ischemia type and the non-perfusion area (NPA) from color fundus photographs (CFPs) of patients with branch retinal vein occlusion (BRVO).
Methods: This was a retrospective analysis of 274 CFPs from patients diagnosed with BRVO. All DL models were trained using a deep convolutional neural network (CNN) based on 45 degree CFPs covering the fovea and the optic disk. We first trained a DL algorithm to identify BRVO patients with or without the necessity of retinal photocoagulation from 219 CFPs and validated the algorithm on 55 CFPs. Next, we trained another DL algorithm to segment NPA from 104 CFPs and validated it on 29 CFPs, in which the NPA was manually delineated by 3 experienced ophthalmologists according to fundus fluorescein angiography. Both DL models have been cross-validated 5-fold. The recall, precision, accuracy, and area under the curve (AUC) were used to evaluate the DL models in comparison with three types of independent ophthalmologists of different seniority.
Results: In the first DL model, the recall, precision, accuracy, and area under the curve (AUC) were 0.75 ± 0.08, 0.80 ± 0.07, 0.79 ± 0.02, and 0.82 ± 0.03, respectively, for predicting the necessity of laser photocoagulation for BRVO CFPs. The second DL model was able to segment NPA in CFPs of BRVO with an AUC of 0.96 ± 0.02. The recall, precision, and accuracy for segmenting NPA was 0.74 ± 0.05, 0.87 ± 0.02, and 0.89 ± 0.02, respectively. The performance of the second DL model was nearly comparable with the senior doctors and significantly better than the residents.
Conclusion: These results indicate that the DL models can directly identify and segment retinal NPA from the CFPs of patients with BRVO, which can further guide laser photocoagulation. Further research is needed to identify NPA of the peripheral retina in BRVO, or other diseases, such as diabetic retinopathy.
Retinal non-perfusion area (NPA) is a vision-threatening condition that is strongly associated with retinal neovascularization (NV) (1), vitreous hemorrhage, and macular edema in retinal diseases, such as diabetic retinopathy (DR) (2) and branch retinal vein occlusion (BRVO) (3, 4). In ophthalmological practice, a standard and early location of NPA is critical for clinical decision-making, such as prompt laser photocoagulation (2, 5).
It is acknowledged that fundus fluorescein angiography (FFA) is the gold standard for circling the NPA. However, FFA might not be acceptable for those with serious liver or kidney dysfunction, or with a drug allergy history (6). Serious complications can occur with FFA, such as an anaphylactic reaction (7). In other circumstances, when patients with undetermined vitreous hemorrhage are receiving diagnostic pars plana vitrectomy, laser photocoagulation is usually performed after the clearance of vitreous hemorrhage, which might not be precise if in the absence of FFA.
Recently, artificial intelligence (AI) has been showing promising potential in assisting the diagnosis and treatment of medical conditions based on medical imaging (8). Deep learning (DL), as a particular form of AI, allows systems to learn predictive features from raw images based on a large dataset of labeled examples without specifying rules or features. In ophthalmology, a number of studies have demonstrated the feasibility of using DL algorithms for the identification of various retinal diseases, such as diabetic retinopathy (DR) (9). In the study of Arcadu F et al. (10), DL was reported to be able to predict key quantitative traditional optical coherence tomography (TD-OCT) measurements related to macular thickening from color fundus photographs (CFPs) and enhance the efficiency of diabetic macular edema (DME) diagnosis in teleophthalmology programs. In a more recent investigation, DL was used to automatically segment the NPA in OCTA images of patients with DR (3, 10), which provides a measure for monitoring peripheral vascular perfusion in eyes with early diabetic disease and the therapeutic response of eyes undergoing treatment for proliferative diabetic retinopathy (PDR) or DME (11–13). In the present study, we stepped forward and employed AI to interpret NPA areas directly from CFP images.
Branch retinal vein occlusion refers to the obstruction of a branch of the retinal vein at an arteriovenous crossing, which has become the second most common retinal vascular disease after diabetic retinopathy. Studies have found the risk of BRVO to be 1.6–1.8%. The compression of the vein is thought to cause turbulent blood flow that leads to thrombus formation, and the thrombosis can result in engorged veins frequently accompanied by variable amounts of retinal non-perfusion. Branch retinal vein occlusion may present with a sudden onset of painless vision loss or visual field defect correlating to the area of perfusion of the obstructed vessels. The complete dilated fundus examination can help diagnose early BRVO (14, 15). As reported, retinal NV developed in 9% within 12 months from onset and in 15% within 36 months from onset, and optic disc NV developed in 8.3% within 12 months from onset and in 10.4% within 30 months from onset (16). Thus, scatter argon laser photocoagulation is promising for use in the involved sector in major BRVO, especially when NV exists (17). Given that BRVO is relatively uniform in clinic and is characterized by blockage of the branch retinal vein and non-perfusion status where laser therapy is needed, here, we first tried the DL methods in BRVO (18).
The study was conducted in accordance with the Declaration of Helsinki, and the study protocol was approved by the Ethics Committee of the First Affiliated Hospital of Nanjing Medical University (2021-SR-330).
The dataset used in this study included CFPs and FFA images from patients diagnosed with BRVO from March 2018 to October 2020 in the First Affiliated Hospital of Nanjing Medical University. CFPs were captured with a digital retinal camera (Canon INC, CR-2 AF, Japan) and FFA was performed with the Spectralis HRA2 (Heidelberg Engineering, Heidelberg, Germany). The inclusion criteria were as follows: (1) patients with the diagnosis of BRVO after FFA examination. (2) patients with simultaneous CFPs and FFA images; and (3) high quality CFPs and FFA images. The fair-quality images were defined as photographs with partial visibility of distinct retinal vessels, optic nerve, and retinal backgrounds. Photographs with blurred retinal components that abnormal lesions could not be distinguished were defined as poor-quality images. We used Matlab software (MATLAB 8.3 R2014a, The MathWorks, Natick, Massachusetts) to manually register the CFPs and FFA images and then scaled them to the size of 1,024 pixels × 1,024 pixels.
Figure 1 shows the main research strategies of the work. The CFPs and FFA images of diagnosed BRVO cases were reviewed by three experienced ophthalmologists. In the first step, the BRVO cases were divided into two groups, with or without the need for prompt laser photocoagulation. In the former cases, scatter laser therapy was performed on the involved sector of BRVO and was done only if there were neovascular vessels. The latter cases were defined as those with fresh retinal hemorrhage, low-quality CFPs, and FFA images, or with no NPA. The first DL model was trained to differentiate the two BRVO statuses. Next, we removed the CFPs and FFA images with no need for prompt laser photocoagulation. We then registered the CFP images with the FFA through the superposition of the blood vessels. The NPA in the FFA images were then labeled in the CFP for the second DL training (Figure 2). Finally, the segmentation ability of the second DL model is compared with that of three doctors.
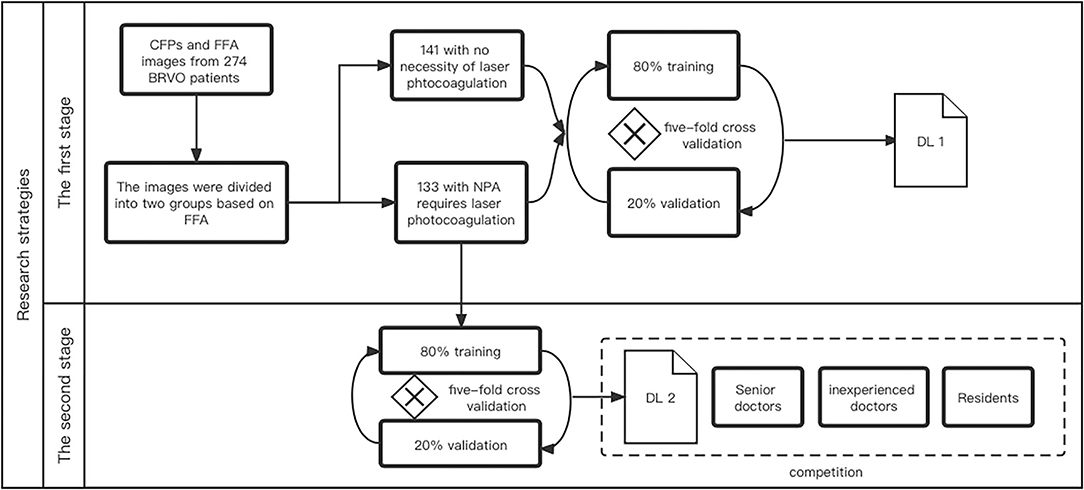
Figure 1. The research strategy of this study.
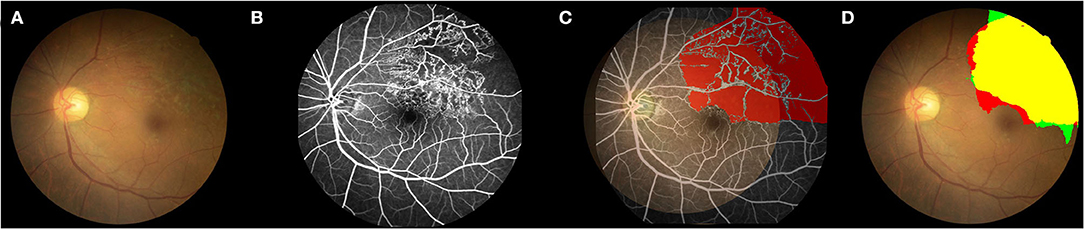
Figure 2. Example of the comparison between the second DL model and FFA in detecting the non-perfusion area. (A) Color fundus photograph (CFP). (B) FFA image shows the superior-temporal non-perfusion area. (C) Labeling the NPA in the CFP according to the FFA images. The CFP image was registered with the corresponding FFA image through the superposition of the blood vessels. The NPA in the FFA image was then labeled in the CFP for the following DL training. (D) TP, True positive; yellow region; TN, true negative, colorless region; FP, false positive, green region; and FN, false negative, red region. Green plus yellow shows the NPA indicated by the DL model; red plus yellow shows the true NPA indicated by FFA. DL, deep learning; CFP, color fundus photograph; FFA, fundus fluorescein angiography; NPA, non-perfusion area.
To automatically figure out the status of BRVO in the first step, we employed a convolutional neural network (CNN) with a (VGG)1 (19) architecture, which was typically designed for the image classification tasks. To automatically segment out the NPA regions in the second step, we employed another CNN with a modified U-Net (20) architecture. The U-Net architectures were widely used in the medical image segmentation tasks (21, 22).
Both two DL models are trained in an end-to-end manner, which means that we can get the classification and the segmentation results without any subsequent processing.
We used a VGG network consisting of 13 convolutional layers, 3 fully connected layers, and one extra adaptive averaging pooling layer between convolutional layers and fully connected layers. The first 13 convolutional layers extract sematic features from CFPs from 3 channels to 512 channels and process 5 times max-pooling as spatial downsampling. For enhancing the feature extraction ability, we used per-trained parameters in ImageNet (23) as the initial parameters of the convolutional layers. After extracting the features of 512 dimensions by the last convolutional layer, the adaptive averaging pooling layer was used to resize the special size of feature to 1 × 1, which led to the feature being a vector of 512 dimension. Finally, three fully connected layers map the features from 512 to 4,096, from 4,096 to 4,096, and from 4,096 to 2, respectively. Thus, we get the probabilities of two states of the BRVO.
The U-Net network we used is an encoder-decoder architecture with skip-connections to concatenate features with the same resolution of the encoder and the decoder. Thus, it can retain pixel-level detail information at different resolutions, which is important for pixel-wise segmentation. The detail of the network is shown in Figure 3.
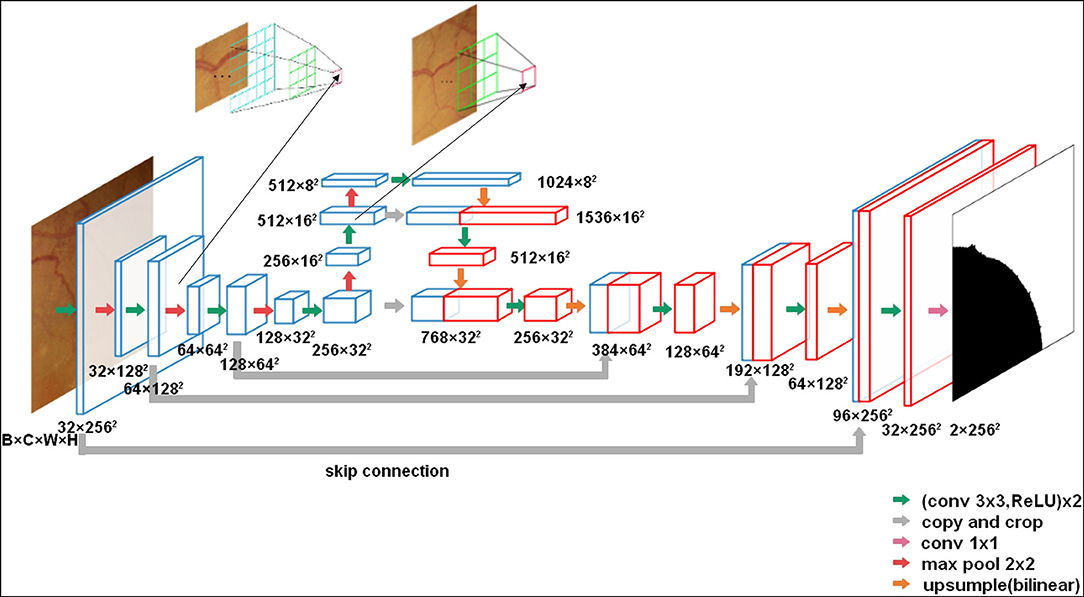
Figure 3. The U-net architecture (3 × 256 × 256 input, for instance). Each green arrow corresponds to two 3 × 3 convolutions each followed by a rectified linear unit (ReLU). Red arrows correspond to a 2 × 2 max pooling operation with stride 2 for downsampling. The orange arrows indicate upsampling with bilinear interpolation. The gray arrows indicate the skip-connection in the U-Net. A 1 × 1 convolution is represented by a purple arrow at the end of the model.
In comparison with the original U-Net architecture, we increased the network depth to achieve a large enough receptive field. Meanwhile, to reduce the parameters, the number of convolutional filters was increased from 32 to 1,024 in the encoder. Moreover, to obtain the same output size as the input CFPs, we used a 3 × 3 convolution kernel size with padding 1. In total, the network has 23 convolutional layers.
Supervised learning with neural networks usually requires a large number of image-label pairs. The data of BRVO were relatively small for training DL models and were hard to expand because of the strict inclusion criteria. To mitigate the data requirements of DL models, we used several data augmentation strategies.
We randomly rotated, resized, and flipped the CFPs for both tasks, which can teach models about rotation invariance, scale invariance, and inversion invariance. In addition, we performed experiments that retained other parameters from the experiments and added random modifications to the brightness, saturation, and contrast of the input images in the data augmentation to determine whether these factors have an impact on the performance of models. Additionally, we randomly clipped them to the size of 256 × 256 for the second task, which allows a larger batch size to improve the efficiency of training. During training, we selected one or more of the above strategies to dynamically augment the data. The data augmentation improves the robustness of the models effectively.
We used the Cross-Entropy Loss as the loss function for both two tasks. In the first task, it is defined as:
where yi taken from 0 and 1 represents the two BRVO statuses and pi represents the probability that the CFP is predicted to be with NPA by the classification model.
In the second task, it is defined as:
where yx,y taken from 0 and 1 indicates whether the pixel behaves as NPA and px,y represents the probability according to the segmentation model.
In both tasks, we performed one 5-fold cross-validation test to train our models for performance evaluation and comparison. In the first task, 133 CFPs with NPA and 141CFPs without NPA were split into five parts separately. For every part, we randomly took 20% of CFPs with NPA and 20% of CFPs without NPA without repetition so that the proportion of positive and negative samples in the training set and verification set is equal. Furthermore, in the second task, 133 CFPs with NPA were split into five groups. In our experiments, 4 groups were used for training and 1 group was used for testing. Then, we executed this process 5 times in a loop until each group was used as the training and testing objects.
Through trial and error, we finally set the hyper parameters as shown in Table 1 for the first task and in Table 2 for the second task. To make the model converge, we adjusted the learning rate as the training went on. In the first task, we set the initial learning rate to 0.0001 and reduced it after every epoch. In the second task, we set the initial learning rate to 0.001 and linearly decreased it to 0.0005 in the last thousand groups of epochs. We used an Adam optimizer (24) to update the model parameters for efficient stochastic optimization with little memory requirement.

Table 1. Hyper-parameters of the first task.
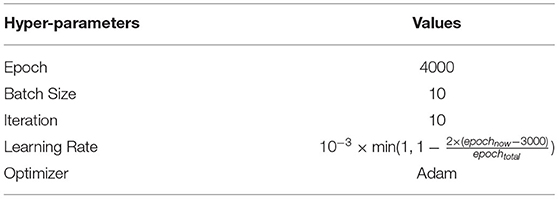
Table 2. Hyper-parameters of the second task.
Table 3 illustrates the confusion matrix using binary classification. In the result, we figured out the number of true positive (TP), true negative (TN), false positive (FP), and false negative (FN). TP represents the number that was correctly classified as positive, FP represents the number that was incorrectly classified as positive, FN represents the number that was incorrectly classified as negative, and TN represents the number that was correctly classified as negative.

Table 3. Confusion matrix.
In the classification task, cases with the NPA needing prompt laser photocoagulation were defined as positive, and the other cases were defined as negative. In the segmentation task, we defined the pixels of the NPA region in CFPs as positive, and the other pixels as negative.
To increase the accuracy of the evaluation indicators, we did not include the black edge around the circular fundus image. In addition, we calculated the model accuracy, precision, recall rate, F1, receiver operating characteristic (ROC), and area under the curve (AUC).
Accuracy describes the proportion of correct predictions defined as:
Precision (also called positive predictive value) describes the proportion of all predicted positive cases that are correctly predicted positive, which is defined as:
Recall or sensitivity (as it is called in psychology) describes the proportion of real positive cases that are correctly predicted positive, which is defined as:
In the segmentation task, our proportion of positive and negative samples approached 1:2. At this time, accuracy may yield misleading results. Thus, more attention needs to be paid to precision and recall (25).
F1 score was used to calculate the harmonic mean of the precision rate and the recall rate.
The ROC curve shows the FP rate on the x-axis and the true positive rate on the y-axis when the positive identification threshold is different. In addition, the AUC is the area under the value ROC curve. The higher the value of AUC, the better the performance of the model.
In addition, we compared the performance among the AI and three groups (number of each group = 3) of ophthalmologists with different experiences. The senior group had doctors with over 10 years of clinical training. The inexperienced group comprised doctors with <3 years of experience and the resident group had doctors with an experience of <1 year. All of the doctors were blind to all the cases and were guided to use the method to label the areas they considered to be NPA on the CFPs as mentioned above (Figure 4).
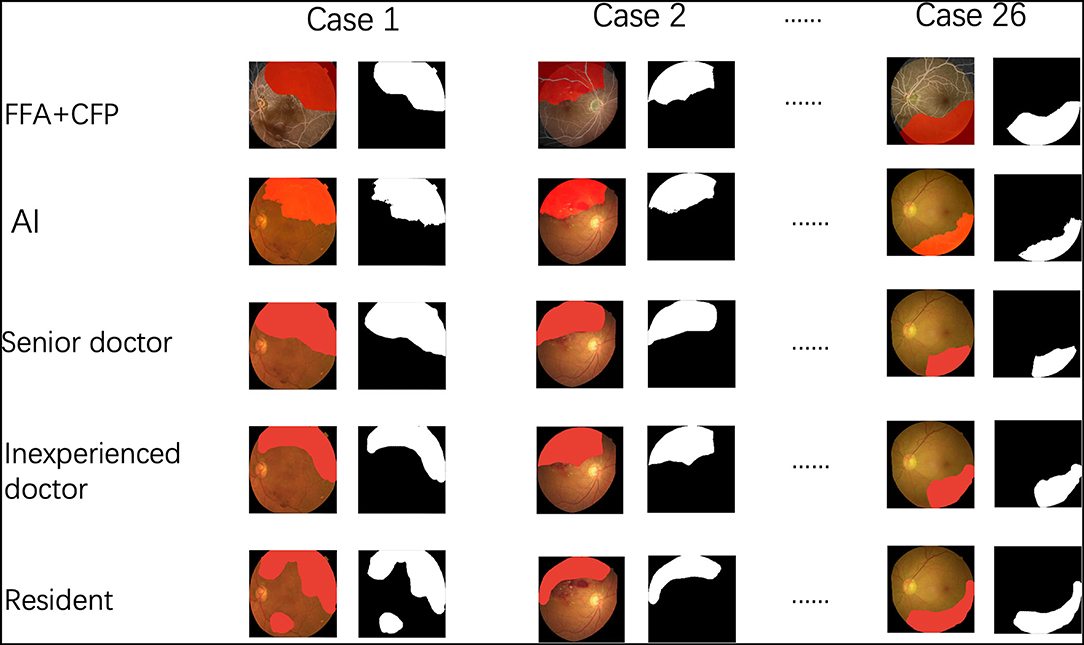
Figure 4. The procedure of the comparison among the artificial intelligence (AI) and three groups of ophthalmologists.
The TP, TN, FP, and FN of each CFP were averaged among three doctors and were compared with those in AI using an independent T-test. Data were expressed as mean ± standard deviation (SD). A p-value < 0.05 was considered statistically significant.
In total, 274 BRVO images from 274 patients (mean age: 66.3 ± 10.6 years; 141 men and 133 women; 139 left eyes and 135 right eyes) were analyzed.
In the first DL model, the recall, precision, accuracy, and AUC were 0.75 ± 0.08, 0.80 ± 0.07, 0.79 ± 0.02, and 0.82 ± 0.03, respectively, for predicting the necessity of laser photocoagulation for BRVO CFPs.
The standard NPA was annotated by senior doctors based on FFA images (Figure 2). With regard to the second DL model for predicting NPA of BRVO, the recall was 0.74 ± 0.05, the precision was 0.87 ± 0.02, and the accuracy was 0.89 ± 0.02. The ROC of an average 5-fold cross validation is shown in Figure 5, and the value of AUC obtained was 0.96 ± 0.02 (Table 4). In addition, the prediction ability of models that data augmented with brightness, saturation, and contrast did not show a significant difference (Supplementary Table 1).
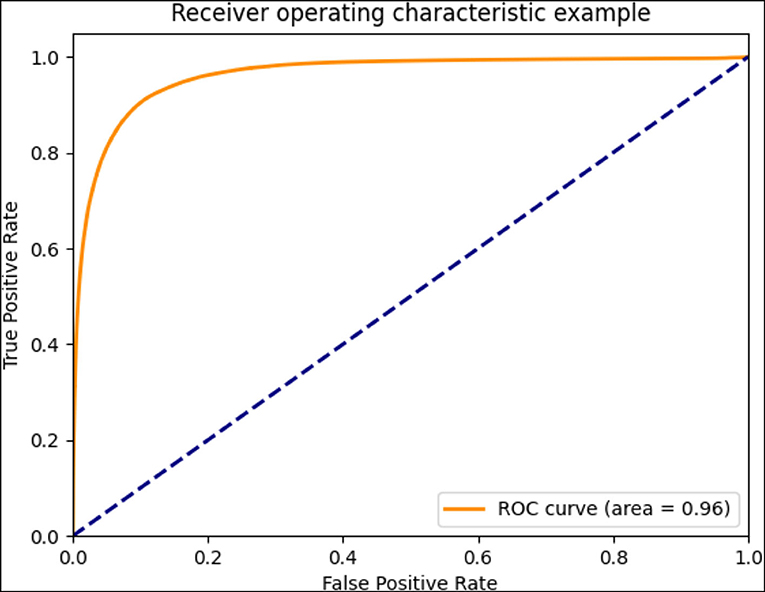
Figure 5. The receiver operating characteristic (ROC) curve of averaged 5-fold cross-validation.
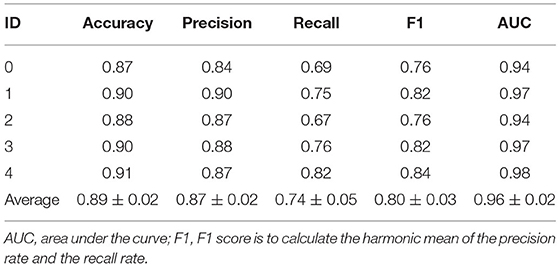
Table 4. Evaluation indicators obtained by a 5-fold cross-validation.
In comparison with three independent doctors, our DL model was nearly comparable with the senior doctors in segmenting the NPA and was significantly better than the inexperienced doctors and residents (Table 5).
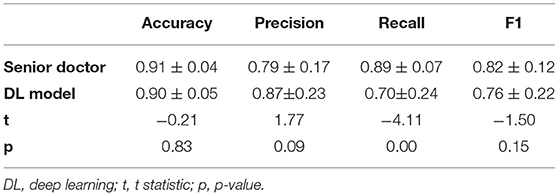
Table 5. Performance of DL model and senior doctor in identifying non-perfusion area (NPA).
In this study, the DL model identifying and segmenting the NPA from CFPs of eyes with BRVO showed high recall, precision, accuracy, and good performance of AUC. The DL model might facilitate the clinical decision for oculists in the treatment of BRVO with no need for invasive FFAs.
At present, with the rapid development of DL models, such as deep CNNs (26, 27), DL models have been intensively applied in ophthalmology (14), such as in detecting diabetic retinopathy (28), age-related macular degeneration (29), RVO (18, 30), and vitreous-retinal interface disorder (31) with CFPs or OCT images. Recently, studies have shown the application of AI for identifying microaneurysms (10, 32, 33) and NPA in DR based on FFA images (28, 34). However, FFA is an invasive method and is seldom used during surgery. As for the OCTA, a non-invasive method, it can identify the NPA (18) but with a relatively limited field. Here, our results show the possibility of detection of NPA using DL models with non-invasive CFPs. The results further demonstrated that the performance of the DL model may be close to an experienced ophthalmologist, which means that the algorithm can assist junior doctors to identify the NPA directly from the CFPs. DL models were compared with individual doctors, which has also been reported in previous studies (12, 13).
In some recent studies, DL has been reported to automatically identify NPA areas, especially in patients with diabetic retinopathy (DR) complicated by DME and retinal NV.
However, these identification models were almost achieved based on FFA images, or occasionally on wide-angle OCTA, which is still in their infancy, expensive, and not widely used. Although FFA is the gold standard to identify NPA, there are some limitations of FFA as described above. Notably, the FFA examination is invasive, and the quality of images may be influenced by eye movement, the poor focus of the camera, or uneven illumination due to the prolonged examination time. These studies also did not achieve automatic registration of FFA images and CFPs.
Our study creatively proposed to identify and segment NPAs only based on CFPs without the need for FFA and validate it for the first time in patients with BRVO. The performance reached by our DL models was similar to that obtained by previous models and human grader agreement. This convenient and inexpensive model can greatly aid those patients with contraindication of sodium fluorescein, as well as relieve the pressures of the exponential increase in clinical appointments. Our models can also facilitate ophthalmology clinicians, especially enabling junior doctors to make laser treatment decisions. The combination of the DL model and CFPs might also facilitate telemedicine. This approach may be particularly useful in areas with a shortage of FFA instruments or experienced examiners. With a clear CFP, patients with BRVO can immediately receive a precise segmentation of NPA and be guided with further laser photocoagulation (35). This study is an in-depth study from computer-aided diagnosis to treatment, and the potential use of this DL algorithm will be an outcome measure in clinical trials and a decision tool in clinical practice, which will be the theoretical basis for the application of intelligent guided laser (34, 36).
The present study also had some limitations. First, we compared only CFP images of BRVO eyes and did not include CFP images of normal eyes or other retinal diseases, which means that the FP possibility was not evaluated. Second, the scan area of CFPs was not large enough to detect the entire NPA in the montage FFA images, which calls for further training of peripheral CFPs or wide-field CFPs. Third, the sample size included was relatively small, and further studies using larger samples and involving other retinal diseases, such as DR, are required to evaluate the performance and versatility of DL for the detection of NPA.
In conclusion, our study proposed a conception of detecting the NPA directly from a CFP in the absence of FFA. Here, we first tried in the eyes with BRVO and demonstrated the DL model with a high level of accuracy. This model can also potentially be developed for the identification of NPA of the peripheral retina and other diseases, such as DR in the future.
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author/s.
The study was conducted in accordance with the Declaration of Helsinki, and the study protocol was approved by the Ethics Committee of First Affiliated Hospital of Nanjing Medical University (2021-SR-330).
The research project was designed by ZH and QL and organized by JM, ZH, and QL. Data collection and labeling were performed by JM, WZ, NS, XW, ZP, and JH. DL modeled the design and training was performed by JY, KH, and QC. Statistical analysis was conducted by JM, JY, and YF. The test of the DL model was performed by YF, JH, PX, and SY. The first draft of the manuscript was written by JM and ZH, and the manuscript was reviewed and critiqued by ZH and QL. All authors contributed to the article and approved the submitted version.
This study was supported by the National Natural Science Foundation of China (81900875 and 12027808 to ZH 81970821 and 81770973 to QL); the Key Research and Development Program of Jiangsu Province (BE2018131 to SY); and the Natural Science Foundation of Jiangsu Province (BK20191059 to ZH). The funders had no role in the study design, data collection, and analysis, decision to publish, or preparation of the manuscript.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The authors thank those who provide thoughtful suggestions and were not listed as the co-authors.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fmed.2022.794045/full#supplementary-material
1. ^VGG Net is the name of a convolutional neural network (CNN) invented by Simonyan and Zisserman from Visual Geometry Group (VGG) at University of Oxford in 2014.
1. Falavarjani KG, Mirshahi R, Riazi-Esfahani H, Anvari P, Habibi A, Ashraf Khorasani M, et al. Spatial distribution of diabetic capillary non-perfusion. Microcirculation. (2021) 28:e12719. doi: 10.1111/micc.12719
2. Jung EE, Lin M, Ryu C, Moysidis SN, Burkemper B, Murgai R, et al. Association of the pattern of retinal capillary non-perfusion and vascular leakage with retinal neovascularization in proliferative diabetic retinopathy. J Curr Ophthalmol. (2021) 33:56–61. doi: 10.4103/JOCO.JOCO_234_20
3. Tan B, Sim YC, Chua J, Yusufi D, Wong D, Yow AP, et al. Developing a normative database for retinal perfusion using optical coherence tomography angiography. Biomed Opt Express. (2021) 12:4032–45. doi: 10.1364/BOE.423469
4. Qian Z, Xie X, Yang J, Ye H, Wang Z, Chen J, et al. Detection of shallow anterior chamber depth from two-dimensional anterior segment photographs using deep learning. BMC Ophthalmol. (2021) 21:341. doi: 10.1186/s12886-021-02104-0
5. Krásný J, Magera L, Pluhovský P, Celedová J, Holubová L. Pre-retinopathy of type 1 diabetes in the context of functional, structural and microcirculatory changes in the macular area. Cesk Slov Oftalmol. (2021) 77:170–82. doi: 10.31348/2021/20
6. Su Z, Ye P, Teng Y, Zhang L, Shu X. Adverse reaction in patients with drug allergy history after simultaneous intravenous fundus fluorescein angiography and indocyanine green angiography. J Ocul Pharmacol Ther. (2012) 28:410–3. doi: 10.1089/jop.2011.0221
7. Bouman AC, de Kruijf D, Emmen JMA, Rettig TCD, Groot MJCK, Faes MC. Systemic reaction to and interference with urine protein measurements after intravenous fluorescein injection. BMC Ophthalmol. (2019) 19:261. doi: 10.1186/s12886-019-1276-x
8. Ting DSW, Pasquale LR, Peng L, Campbell JP, Lee AY, Raman R, et al. Artificial intelligence and deep learning in ophthalmology. Br J Ophthalmol. (2019) 103:167–75. doi: 10.1136/bjophthalmol-2018-313173
9. Sayres R, Taly A, Rahimy E, Blumer K, Coz D, Hammel N, et al. Using a deep learning algorithm and integrated gradients explanation to assist grading for diabetic retinopathy. Ophthalmology. (2019) 126:552–64. doi: 10.1016/j.ophtha.2018.11.016
10. Arcadu F, Benmansour F, Maunz A, Michon J, Haskova ZD, McClintock AP, et al. Deep learning predicts OCT measures of diabetic macular thickening from color fundus photographs invest. Ophthalmol Vis Sci. (2019) 60:852–7. doi: 10.1167/iovs.18-25634
11. Wu JH, Liu TYA, Hsu WT, Ho JH, Lee CC. Performance and limitation of machine learning algorithms for diabetic retinopathy screening: meta-analysis. J Med Internet Res. (2021) 23:e23863. doi: 10.2196/23863
12. Wongchaisuwat N, Trinavarat A, Rodanant N, Thoongsuwan S, Phasukkijwatana N, Prakhunhungsit S, et al. In-Person verification of deep learning algorithm for diabetic retinopathy screening using different techniques across fundus image devices. Transl Vis Sci Technol. (2021) 10:17. doi: 10.1167/tvst.10.13.17
13. Li F, Liu Z, Chen H, Jiang M, Zhang X, Wu Z. Automatic detection of diabetic retinopathy in retinal fundus photographs based on deep learning algorithm. Transl Vis Sci Technol. (2019) 8:4. doi: 10.1167/tvst.8.6.4
14. Lam C, Yu C, Huang L, Rubin D. Retinal lesion detection with deep learning using image patches. Invest Ophthalmol Vis Sci. (2018) 59:590–6. doi: 10.1167/iovs.17-22721
15. Karia N. Retinal vein occlusion: pathophysiology and treatment options. Clin Ophthalmol. (2010) 4:809–16. doi: 10.2147/OPTH.S7631
16. Hayreh SS, Zimmerman MB. Fundus changes in branch retinal vein occlusion. Retina. (2015) 35:1016–27. doi: 10.1097/IAE.0000000000000418
17. Hayreh SS, Rubenstein L, Podhajsky P. Argon laser scatter photocoagulation in treatment of branch retinal vein occlusion a prospective clinical trial. Ophthalmologica. (1993) 206:1–14. doi: 10.1159/000310354
18. Nagasato D, Tabuchi H, Masumoto H, Enno H, Ishitobi N, Kameoka M, et al. Automated detection of a nonperfusion area caused by retinal vein occlusion in optical coherence tomography angiography images using deep learning. PLoS ONE. (2019) 14:e0223965. doi: 10.1371/journal.pone.0223965
19. Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. In: Bengio Y, LeCun Y, editors. 3rd International Conference on Learning Representations. San Diego, CA: ICLR (2015). Available online at: http://arxiv.org/abs/1409.1556
20. Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer (2015). p. 234–41. doi: 10.1007/978-3-319-24574-4_28
21. Imran AAZ, Terzopoulos D. Progressive adversarial semantic segmentation. In: 25th International Conference on Pattern Recognition. Milan: IEEE (2020). p. 4910–7. doi: 10.1109/ICPR48806.2021.9412530
22. Lian C, Zhang J, Liu M, Zong X, Hung SC, Lin W, et al. Multi-channel multi-scale fully convolutional network for 3D perivascular spaces segmentation in 7T MR images. Med Image Anal. (2018) 46:106–117. doi: 10.1016/j.media.02.009
23. Deng J, Dong W, Socher R, Li LJ, Li K, Fei-Fei L. Imagenet: a large-scale hierarchical image database. In: IEEE Conference on Computer Vision and Pattern Recognition. IEEE (2009). p. 248–55. doi: 10.1109/CVPR.2009.5206848
24. Kinga D. A Methodforstochasticoptimization. Anon. Internationalconferenceon Learning Representations. SanDego, CA: ICLR (2015).
25. Powers DM. Evaluation: from precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv preprint arXiv. (2020) 2010:16061.
26. De Fauw J, Ledsam JR, Romera-Paredes B, Nikolov S, Tomasev N, Blackwell S, et al. Clinically applicable deep learning for diagnosis and referral in retinal disease. Nat Med. (2018) 24:1342–50. doi: 10.1038/s41591-018-0107-6
27. Phene S, Dunn RC, Hammel N, Liu Y, Krause J, Kitade N, et al. Deep learning and glaucoma specialists: the relative importance of optic disc features to predict glaucoma referral in fundus photographs. Ophthalmology. (2019) 126:1627–39. doi: 10.1016/j.ophtha.2019.07.024
28. Li X, Xie J, Zhang L, Cui Y, Zhang G, Wang J, et al. Differential distribution of manifest lesions in diabetic retinopathy by fundus fluorescein angiography and fundus photography. BMC Ophthalmol. (2020) 20:471. doi: 10.1186/s12886-020-01740-2
29. Romond K, Alam M, Kravets S, Sisternes L, Leng T, Lim JI, et al. Imaging and artificial intelligence for progression of age-related macular degeneration. Exp Biol Med (Maywood). (2021) 246:2159–69. doi: 10.1177./15353702211031547
30. Nagasato D, Tabuchi H, Ohsugi H, Masumoto H, Enno H, Ishitobi N, et al. Deep-learning classifier with ultrawide-field fundus ophthalmoscopy for detecting branch retinal vein occlusion. Int J Ophthalmol. (2019) 12:94–9. doi: 10.18240/ijo.2019.01.15
31. Lo YC, Lin KH, Bair H, Sheu WH, Chang CS, Shen YC, et al. Epiretinal membrane detection at the ophthalmologist level using deep learning of optical coherence tomography. Sci Rep. (2020) 10:8424. doi: 10.1038/s41598-020-65405-2
32. D Ting DSW, Cheung CY, Lim G, Tan GSW, Quang ND, Gan A, et al. Development and validation of a deep learning system for diabetic retinopathy and related eye diseases using retinal images from multiethnic populations with diabetes. JAMA. (2017) 318:2211–23. doi: 10.1001/jama.2017.18152
33. Gulshan V, Peng L, Coram M, Stumpe MC, Wu D, Narayanaswamy A, et al. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA. (2016) 316:2402–10. doi: 10.1001/jama.2016.17216
34. Jin K, Pan X, You K, Wu J, Liu Z, Cao J, et al. Automatic detection of non-perfusion areas in diabetic macular edema from fundus fluorescein angiography for decision making using deep learning. Sci Rep. (2020) 10:15138. doi: 10.1038/s41598-020-71622-6
35. Gao Q, Amason J, Cousins S, Pajic M, Hadziahmetovic M. Automated Identification of Referable Retinal Pathology in Teleophthalmology Setting. Transl Vis Sci Technol. (2021) 10:30. doi: 10.1167/tvst.10.6.30
Keywords: deep learning, non-perfusion area, color fundus photograph, branch retinal vein occlusion, artificial intelligence, automatic segmentation
Citation: Miao J, Yu J, Zou W, Su N, Peng Z, Wu X, Huang J, Fang Y, Yuan S, Xie P, Huang K, Chen Q, Hu Z and Liu Q (2022) Deep Learning Models for Segmenting Non-perfusion Area of Color Fundus Photographs in Patients With Branch Retinal Vein Occlusion. Front. Med. 9:794045. doi: 10.3389/fmed.2022.794045
Received: 13 October 2021; Accepted: 30 May 2022;
Published: 30 June 2022.
Edited by:
Feng Wen, Sun Yat-Sen University, ChinaReviewed by:
Jiayan Wang, Marshall University, United StatesCopyright © 2022 Miao, Yu, Zou, Su, Peng, Wu, Huang, Fang, Yuan, Xie, Huang, Chen, Hu and Liu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Qinghuai Liu, bGl1cWhAbmptdS5lZHUuY24=; Zizhong Hu, aHV6aXpob25nQG5qbXUuZWR1LmNu
†These authors have contributed equally to this work and share first authorship
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.