 Weiming Hu1
Weiming Hu1 Haoyuan Chen
Haoyuan Chen Xinyu Huang
Xinyu Huang Marcin Grzegorzek
Marcin Grzegorzek Chen Li
Chen Li
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Med., 07 December 2022
Sec. Pathology
Volume 9 - 2022 | https://doi.org/10.3389/fmed.2022.1072109
This article is part of the Research TopicComputational Pathology for Precision Diagnosis, Treatment, and Prognosis of CancerView all 10 articles
Introduction: Gastric cancer is the fifth most common cancer in the world. At the same time, it is also the fourth most deadly cancer. Early detection of cancer exists as a guide for the treatment of gastric cancer. Nowadays, computer technology has advanced rapidly to assist physicians in the diagnosis of pathological pictures of gastric cancer. Ensemble learning is a way to improve the accuracy of algorithms, and finding multiple learning models with complementarity types is the basis of ensemble learning. Therefore, this paper compares the performance of multiple algorithms in anticipation of applying ensemble learning to a practical gastric cancer classification problem.
Methods: The complementarity of sub-size pathology image classifiers when machine performance is insufficient is explored in this experimental platform. We choose seven classical machine learning classifiers and four deep learning classifiers for classification experiments on the GasHisSDB database. Among them, classical machine learning algorithms extract five different image virtual features to match multiple classifier algorithms. For deep learning, we choose three convolutional neural network classifiers. In addition, we also choose a novel Transformer-based classifier.
Results: The experimental platform, in which a large number of classical machine learning and deep learning methods are performed, demonstrates that there are differences in the performance of different classifiers on GasHisSDB. Classical machine learning models exist for classifiers that classify Abnormal categories very well, while classifiers that excel in classifying Normal categories also exist. Deep learning models also exist with multiple models that can be complementarity.
Discussion: Suitable classifiers are selected for ensemble learning, when machine performance is insufficient. This experimental platform demonstrates that multiple classifiers are indeed complementarity and can improve the efficiency of ensemble learning. This can better assist doctors in diagnosis, improve the detection of gastric cancer, and increase the cure rate.
Gastric cancer is a serious threat to human health as a global killer disease. According to the most recent Global Cancer Statistics Report, gastric cancer has become the fifth most common cancer and the fourth leading cause of death (1). Histopathological examination of gastric cancer constitutes the gold standard for the detection of gastric cancer and is a prerequisite for its management (2).
Histopathological examinations begin by staining the sections with Hematoxylin and Eosin (H&E), which are used to visualize the nuclei and cytoplasm of tissue sections, highlighting the fine structure of cells and tissues for physician observation (3). The pathologist finds the diseased area by gross observation of the pathological slides with the naked eye. The pathologist then observes and diagnoses the diseased area of the pathological section using the low-power microscope of the microscope. Pathologists can use high-power microscopes for careful observation and judgment (4). For the entire pathological slice diagnosis process (5), the following problems can be found: slice information is easy to ignore (6). This shows that there is subjectivity throughout the process. The workload of pathologists is huge and the working hours are long, which is highly likely to lead to misdiagnosis (7). Therefore, there is an urgent need to address the issues more intensively.
However, computer-aided diagnosis technology has advanced rapidly in recent years, and the emergence of medical image classification technology in computer vision technology can achieve fast and efficient help for doctors to examine gastric cancer tissue sections (8). Image classification techniques have brought new breakthroughs to discriminate between benign and malignant cancer, distinguish between stages of tumor differentiation and differentiate tumor subtypes, as image classification techniques can provide valid information for pathologists to refer to during the diagnostic process (9). In addition, the development direction of image classification technology is mainly to enhance the accuracy of classification algorithms and improve the anti-interference ability, ensemble learning becomes an effective solution, and it becomes especially important to find multiple efficient classification algorithms with complementarity properties (10). Moreover, there is a lack of computer performance in practical work, and computer-aided medical image analysis often crops full-slice images into sub-size pictures (11). Therefore, we compare the image classification performance of a large number of algorithms on sub-size images in order to expect to find algorithms with complementarity properties for ensemble learning to improve medical image classification performance.
The database used in this study is GasHisSDB (12), containing 245,196 images, of which there are 97,076 abnormal images and 148,120 normal images. GasHisSDB is a database containing three sub-databases, including sub-database A (160 × 160 pixels), Sub-database B (120 × 120 pixels.), Sub-database C (80 × 80 pixels). GasHisSDB provides the ability to distinguish between classical machine learning classifier performance and deep learning classifier performance (13). Details are given in Section 2.1.
Classical machine learning methods still have excellent classification results in the field of image classification (14). Existing methods can extract different features of images and supply different performance of classifiers for image classification (15). Exploring different features using appropriate classifiers to obtain efficient classification results is the basis of using ensemble learning for medical images (16). Therefore, in this study, five different image features including two color features and three texture features are extracted for GasHisSDB. After extracting the features seven different classifiers are used for classification. Details are given in Sections 2.2 and 2.3.
In the field of medical image classification, deep learning algorithms are the most effective algorithms, and Convolutional Neural Network (CNN) is a widely used model for image classification, which can extract information from original medical images and classify normal and abnormal case images (17). Recently, Visual Transformer, which is originally applied to Natural Language Processing tasks, have become popular in computer vision, and Vision Transformer (ViT) have effective classification results when trained on large amounts of data and can significantly reduce the computer hardware and software resources required for training (18). CNN-based deep learning models, this study used VGG6, Inception-V3 and ResNet50. Visual transformer-based deep learning models in this study used VIT. The above four deep learning models use the same parameters with the same database: GasHisSDB. Details are given in Section 2.4.
This study makes the following contributions to the field of sub-size pathology image classification:
• Extensive testing is done and the complementarity of different classification methods is found.
• According to the complementarity, it can provide a basis for future ensemble learning research.
This paper is structured as follows: In Section 2, we detail the dataset used, classical classification methods, and deep learning methods. In Section 3, we show the comparative experimental setup, evaluation metrics and experimental results. In Section 4, we compare the experimental results and analyze them. In Section 5, we summarize the research and suggest future research directions.
The publicly available dataset GasHisSDB is used in this study to compare the performance of various learning models, expecting to discover the complementarity of various models in ensemble learning (12). The database contains three sub-datasets with a total of 245,196 images, and the size and number are shown in Table 1. The database is a sub-size gastric cancer pathology H&E staining image database, which contains two categories of images: normal and abnormal. The abnormal image contains more than 50% of the cancerous area, and the normal image is the image of the normal pathological slice tissue. Some examples of the GasHisSDB database are shown in Figure 1.

Table 1. Dataset scale of GasHisSDB.
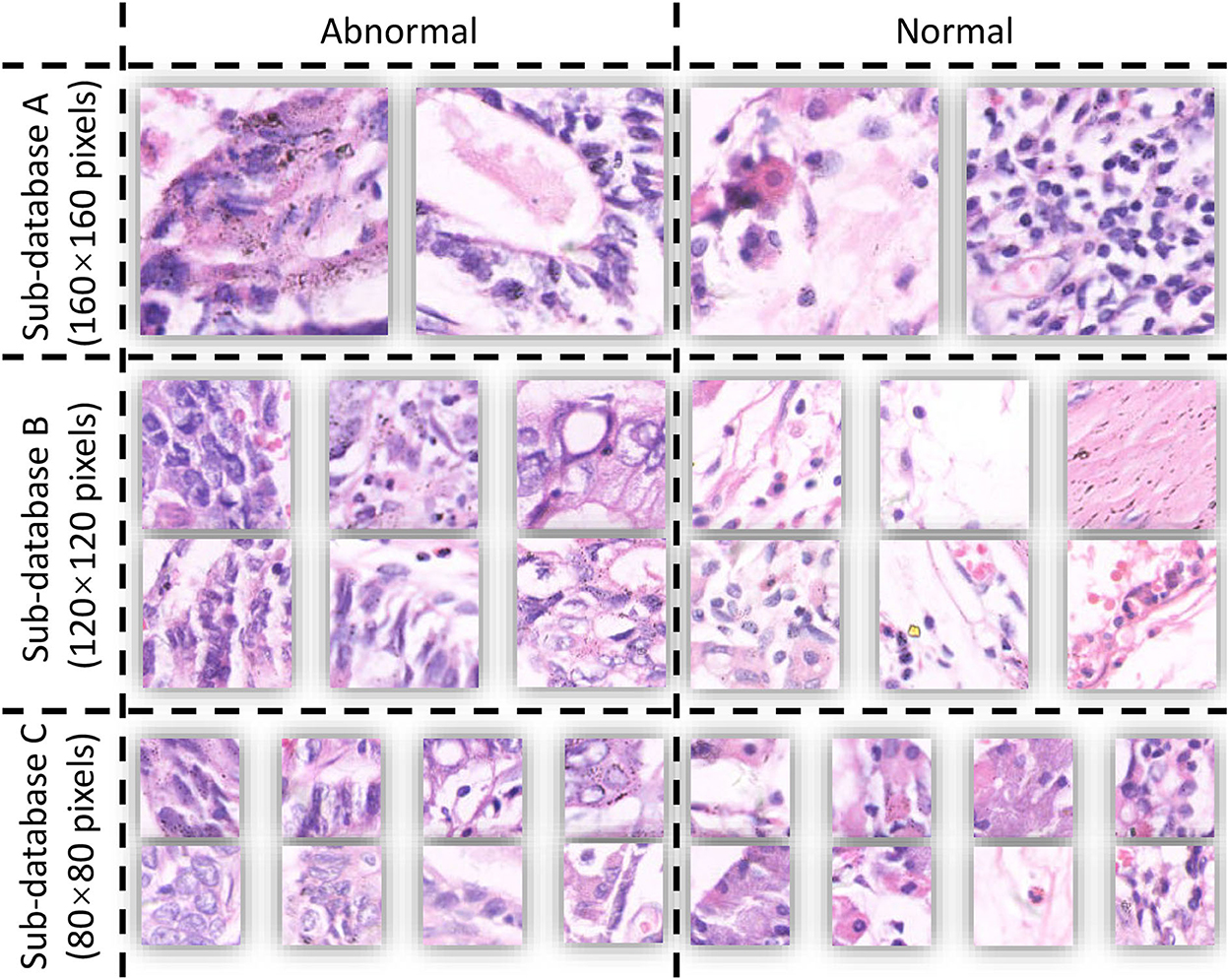
Figure 1. Example of GasHisSDB.
GasHisSDB contains images in png format acquired using electron microscopy. GasHisSDB contains two categories and the details of the two categories are shown below:
• Normal: each normal image does not contain cancerous regions. Each cell is almost free of anisotropy. In addition, the nuclei of the cells in the images have almost no mitosis and are arranged in a regular layer. Therefore, when observed under the light microscope, if no elimination of any cells and tissues is observed and the characteristics of a normal image are met, it can be judged as a normal image (19).
• Abnormal: Each abnormal image contains more than 50% of gastric cancer images. The general morphology of gastric cancer is mostly ulcerative. As the disease progresses, the cancer nest infiltrates from the mucosal layer to the muscular layer and plasma layer. The texture is hard and the cross-section is often grayish white. Under microscopic observation, the cancer cells can be arranged in nest-like, glandular vesicle-like, tubular or cord-like, and the boundary with the interstitium is usually clear. However, when cancer cells infiltrate the stroma, the borders between them are not clear. Based on these facts, abnormal pathological images can be judged when cells are observed to form unevenly sized, irregularly shaped, and irregularly arranged glandular or adenoid structures (19).
To extract a variety of virtual features of GasHisSDB is a prerequisite for classification using classical machine learning classifiers. In the comparison experiments, five methods are used to extract visual features from the database, including Color histogram, Luminance histogram, Histogram of Oriented Gradient (HOG), Local Binary Patterns (LBP), and Gray-level Co-occurrence Matrix (GLCM).
Among the different methods of feature extraction, the most common method to describe the color features of an image is the color histogram. The color histogram clearly represents the color spread in the image. The color histogram has the characteristic of being unaffected by image rotation and shift changes and by further normalization of image scale changes. It is especially applicable to describe images that are resistant to automatic segmentation and images that do not require consideration of the spatial location of subjects. However, the color histogram does not characterize the partial spread of colors in an image, the spatial location of each color, and specific objects. In this experiment, the luminance histogram is used as the luminance feature. The luminance feature is expressed as a histogram of the average of the three color components.
The texture is a visual feature that reflects homogeneous phenomena in an image (20). That reflects the structure and arrangements of the surface structures on the surface of an object with slow or periodic changes (21). A texture feature is not a pixel-based feature. It requires statistical computation of regions containing multiple pixels, such as the grayscale distribution of pixels and their surrounding spatial neighbors, and local texture information. In addition, the global texture information is reflected as the repetition degree of local texture information. In this experiment, three texture features are extracted, which are HOG, LBP, and GLCM.
HOG is a feature descriptor commonly used in image processing for object detection. Features are constructed by computing a histogram of the gradient direction of local regions of an image. HOG has the property of operating on the local units of the image. So it has the advantage of maintaining excellent invariance in terms of geometric and optical distortion of the image. LBP has advantages such as gray invariance and rotation invariance, and the features are easy to compute. GLCM is defined by the joint probability density of pixels at two locations and is a second-order statistical feature about the variation of image brightness. It not only reflects the distribution of luminance. It also reflects the distribution of positions between pixels with the same or similar luminance. The main statistical values are: Contrast, Correlation, Energy, and Homogeneity.
After the feature extraction step, complementarity comparison tests for image classification are performed using seven classical machine learning methods, including Linear Regression, k-Nearest Neighbor (kNN), naive Bayesian classifier, Random Forest (RF), linear Support Vector Machine (linear SVM), non-linear Support Vector Machine (non-linear SVM), and Artificial Neural Network (ANN).
Classical machine learning methods perform image classification by using virtual features. Linear Regression is a method to get a linear model as much as possible to accurately predict the real value output label. In Linear regression, the least square function is used to establish the relationship between one or more independent variables (22). An easy and commonly used supervised learning method is kNN. The main idea of kNN is to first find the nearest k samples based on the distance and then vote for the prediction result (23). The naive Bayesian classifier based on Bayesian decision theory in probability theory (24). RF is a parallel integrated learning method based on a decision tree learner. RF adds random attribute selection to the training process of decision trees (25). SVMs are divided into linear and non-linear. The difference between the two is mainly that the kernel functions of both are different (26). Linear SVM maps training examples to points in space to maximize the gap between the two categories. Then, the new examples are mapped to the same space and predicted to belong to a category based on which side of the gap they fall on. In addition to performing linear classification, SVM can also use a kernel function to perform non-linear classification effectively, thereby implicitly mapping its input to a high-dimensional feature space. The ANN is a classification algorithm composed of a structure that simulates human brain neurons and is trained through a propagation algorithm (27).
Complementarity comparison experiments use deep learning models for the classification of gastric cancer pathology images (28). First, the model is trained using training and validation sets generated from three sub-datasets of GasHisSDB. The test set is used in this experiment to evaluate the models' performance (29). Comparative analysis of multiple classification results is performed using the obtained evaluation metrics to determine if the classifiers would be complementarity in Ensemble learning (30). This experiment uses four deep learning models. Three of the models are based on CNNs, including VGG16, Inception-V3, and ResNet50. One more model corresponds to VT, which is ViT (31).
VGG is a convolutional neural network (CNN) improved by AlexNet, developed by Visual Geometry Group and Google DeepMind in 2014, and the most commonly used one in image classification is VGG16 (32). In 2014, Google's InceptionNet made its debut at the ILSVRC competition. Several versions of InceptionNet have been developed, with Inception-V3 being one of the more representative versions of this large family (33). He et al. proposed ResNet to address the difficulty of training deep networks due to gradient disappearance. The most commonly used in the field of image classification is ResNet50 (34). In recent years, Dosovitskiy et al. have proposed the ViT model using transformer. This model is not only very effective in the field of natural language processing, but also provides good results in the field of image classification. Effectively reduces the dependence of computer vision on CNN (35).
The main process of complementarity experiments is divided into two parallel parts: The classification results of classical models and deep learning models are both analyzed and evaluated. The experimental flow is shown in Figure 2.
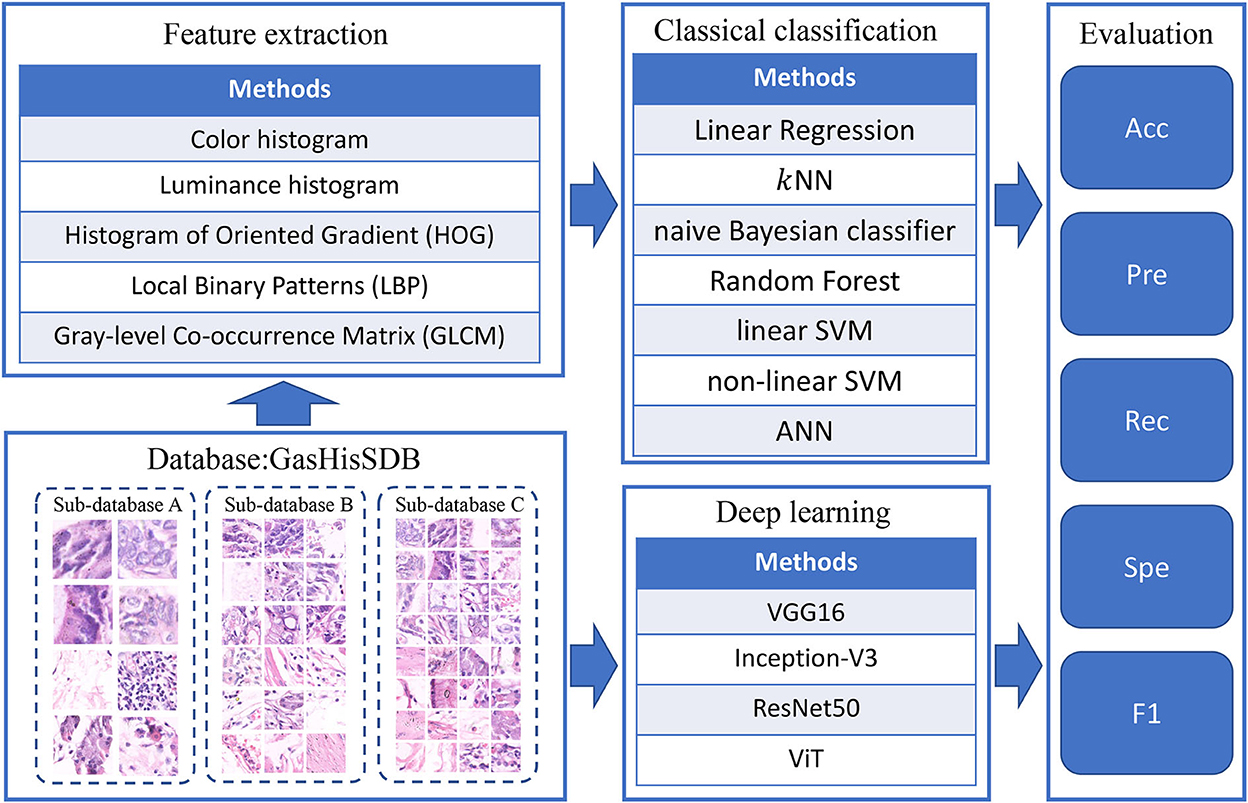
Figure 2. Workflow of the complementarity comparison experiment.
The various settings of the experimental platform are as follows:
1. Hardware configuration: The complementarity comparison experiment is conducted on a local computer with the Win10 operating system. The computer has 32 GB of running memory and is equipped with an 8 GB NVIDIA Quadro RTX 4000.
2. Data set partitioning: In this experiment, the training set, validation set and test set are divided in the ratio of 4:4:2.
3. Classical machine learning software configuration: The classical programming software use for machine learning is Matlab R2020a (9.8.0.132 350 2).
4. Deep learning software configuration: The Pytorch version 1.7.1 framework in Deep Learning Python 3.6 is very mature, and the code for this part of the experiment is done using them.
5. Classical machine learning parameter settings: The same parameters are used for all classification comparison experiments. In kNN, k is set to 9. The number of trees in RF is set to 10. The kernel function of the non-linear SVM is a Gaussian kernel. The ANN uses a 2-layer network with 10 nodes in the first layer and 3 nodes in the second layer. The number of epochs for ANN training is set to 500, the learning rate is set to 0.01, and the expected loss is set to 0.01.
6. Deep learning parameter settings: This part of the experiment focuses on classifying GasHisSDB using four deep learning methods to observe model complementarity. A learning rate of 0.00002 is used for each model, and the batch size is set to 32. One hundred epochs of experiments are performed to observe the classification results of this database on different models.
The selection of evaluation indicators is important in complementarity comparison papers. In the experiments of this thesis, Accuracy (Acc) is the most significant metric, but also Precision (Pre), Recall (Rec), Specificity (Spe), and F1-score (F1) are selected. These selected metrics are very commonly used in comparison papers to analyze classifiers and thus better identify their complementarities to enhance and improve ensemble learning (36).
In the case of positive-negative binary classification, true positives (TP) correspond to the number of positive samples that are accurately predicted. The number of negative samples predicted to be positive is called false positive (FP). The number of positive samples predicted to be negative samples is called false negative (FN). True Negative (TN) is the number of negative samples predicted accurately (37).
The five evaluation indicators are described below and the formulas are shown in Table 2.
1. Acc: Accuracy is the ratio of the number of correct predictions to the total number of samples.
2. Pre: Precision is a measure of accuracy, indicating the proportion of examples classified as positive that are actually positive.
3. Recl: Recall is a measure of coverage, a measure of the number of positive examples classified as positive examples, indicating the proportion of all positive examples classified as pairs, which measures the ability of the classifier to identify positive examples.
4. Spe: Specificity indicates the proportion of all negative cases that were scored correctly, and measures the classifier's ability to identify negative cases.
5. F1: F1-Score combines Precision and Recall. Accuracy is the ratio of the number of correct predictions to the total number of samples.

Table 2. Evaluation metrics.
We set up an experimental platform to conduct various classification experiments on three sub-databases of the GasHisSDB. A large amount of experimental data is obtained for our experiments in order to investigate the complementarity of different methods (38).
The comparative results of classical machine learning methods are shown in Tables 3–5.
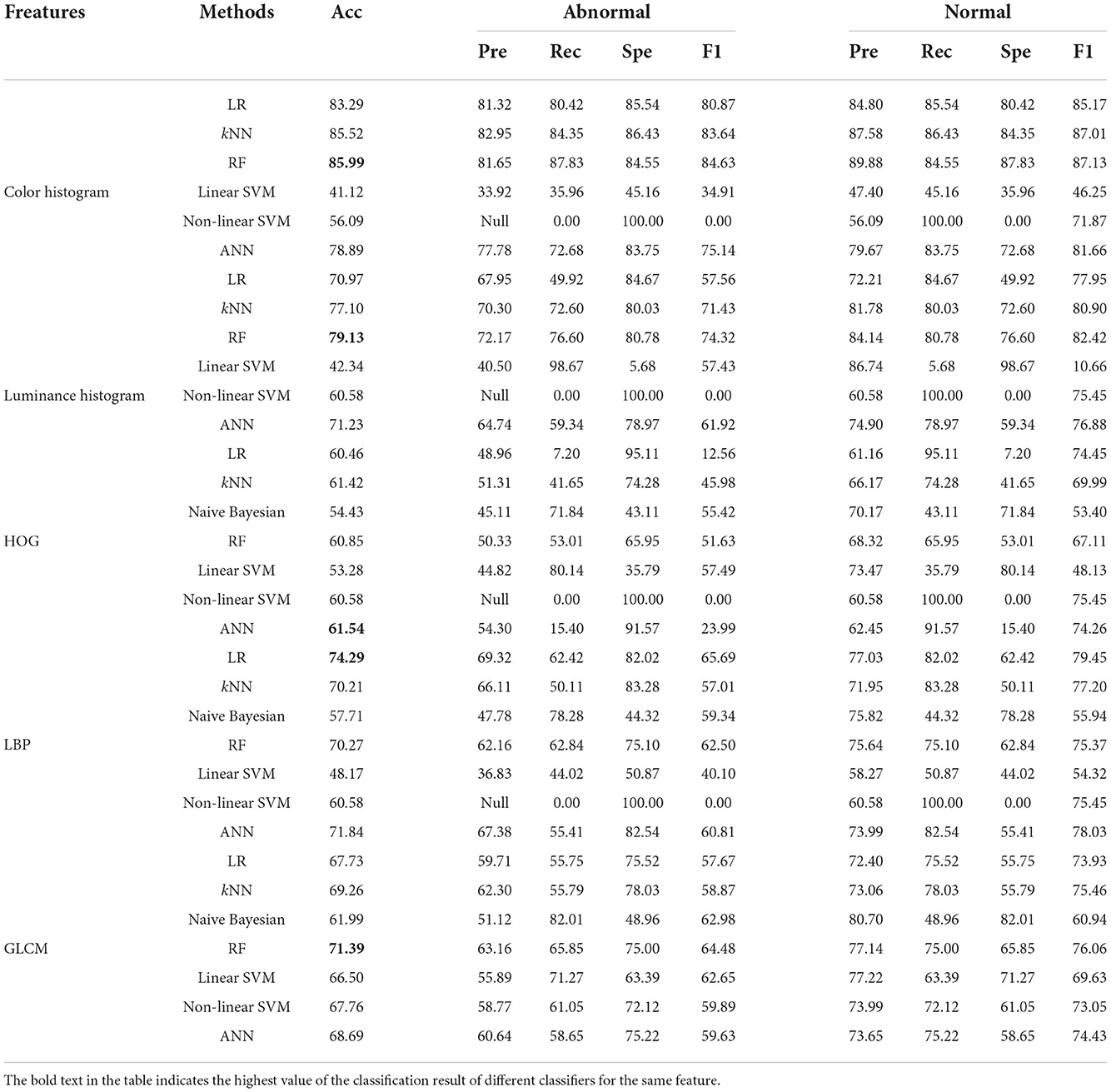
Table 3. Classification results of five image features using different classifiers in the 160 × 160 pixels sub-database of GasHisSDB [In (%)].
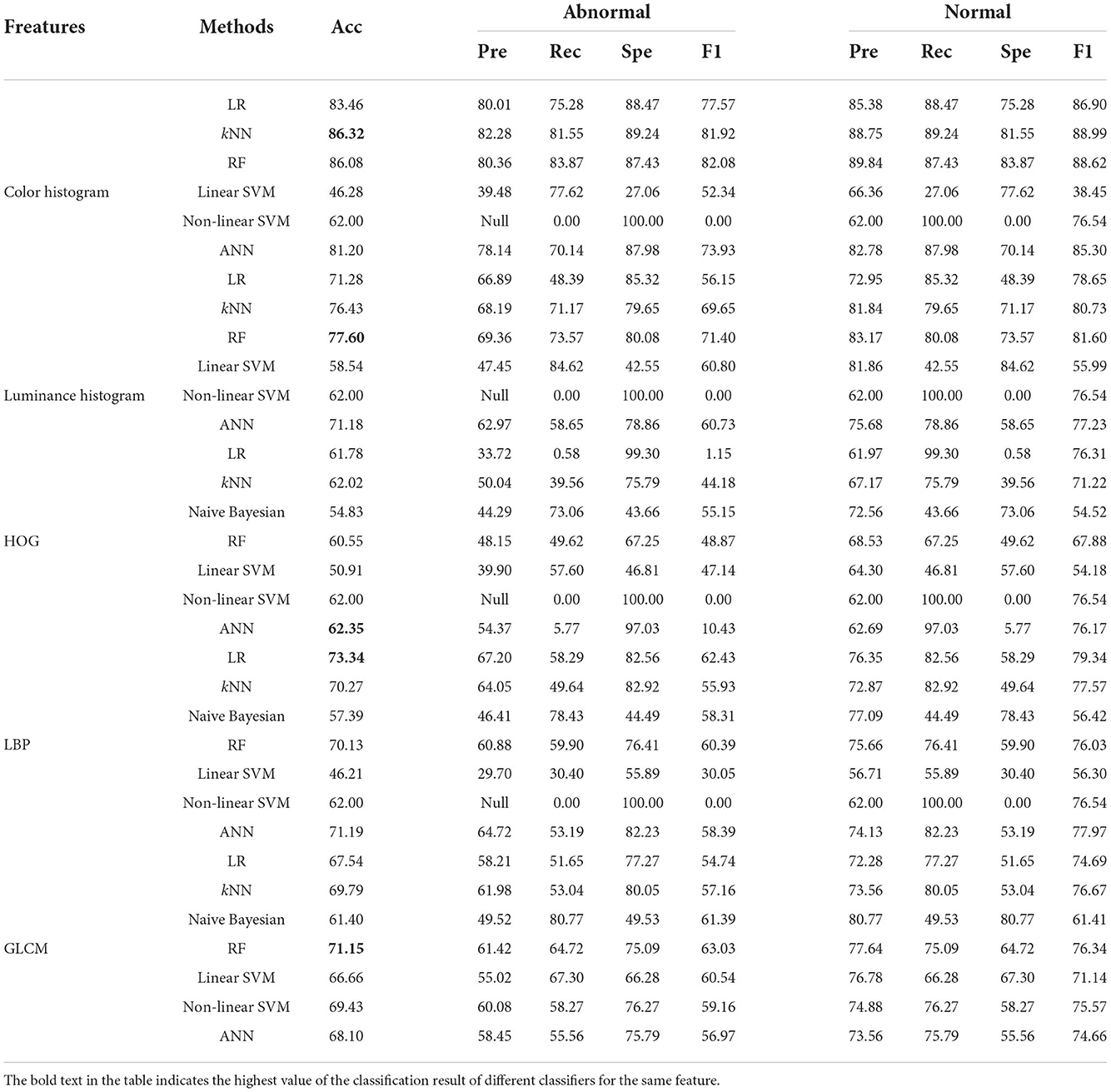
Table 4. Classification results of five image features using different classifiers in the 120 × 120 pixels sub-database of GasHisSDB [In (%)].
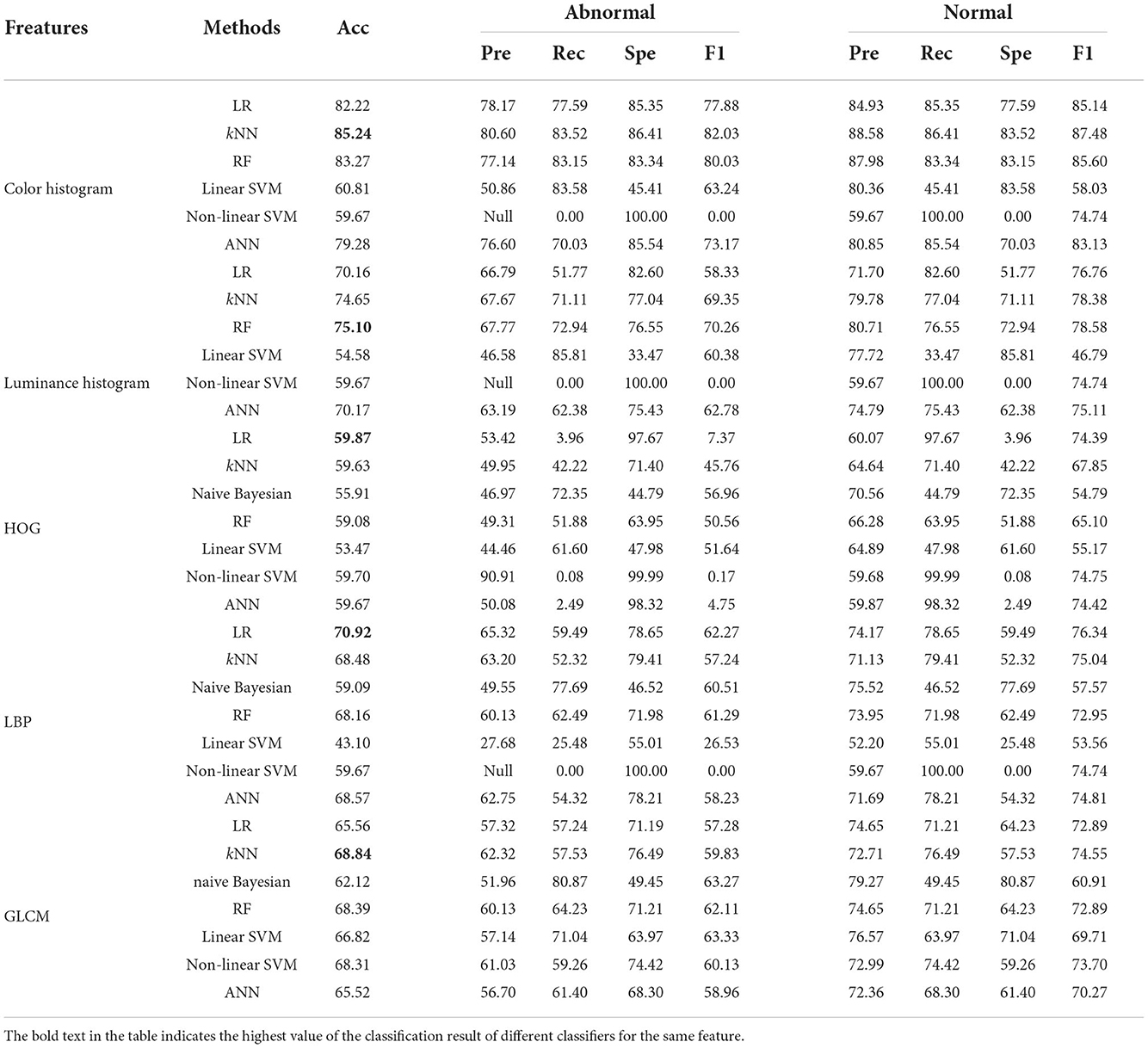
Table 5. Classification results of five image features using different classifiers in the 80 × 80 pixels sub-database of GasHisSDB [In (%)].
Table 6 show the comparison results of the deep learning methods.
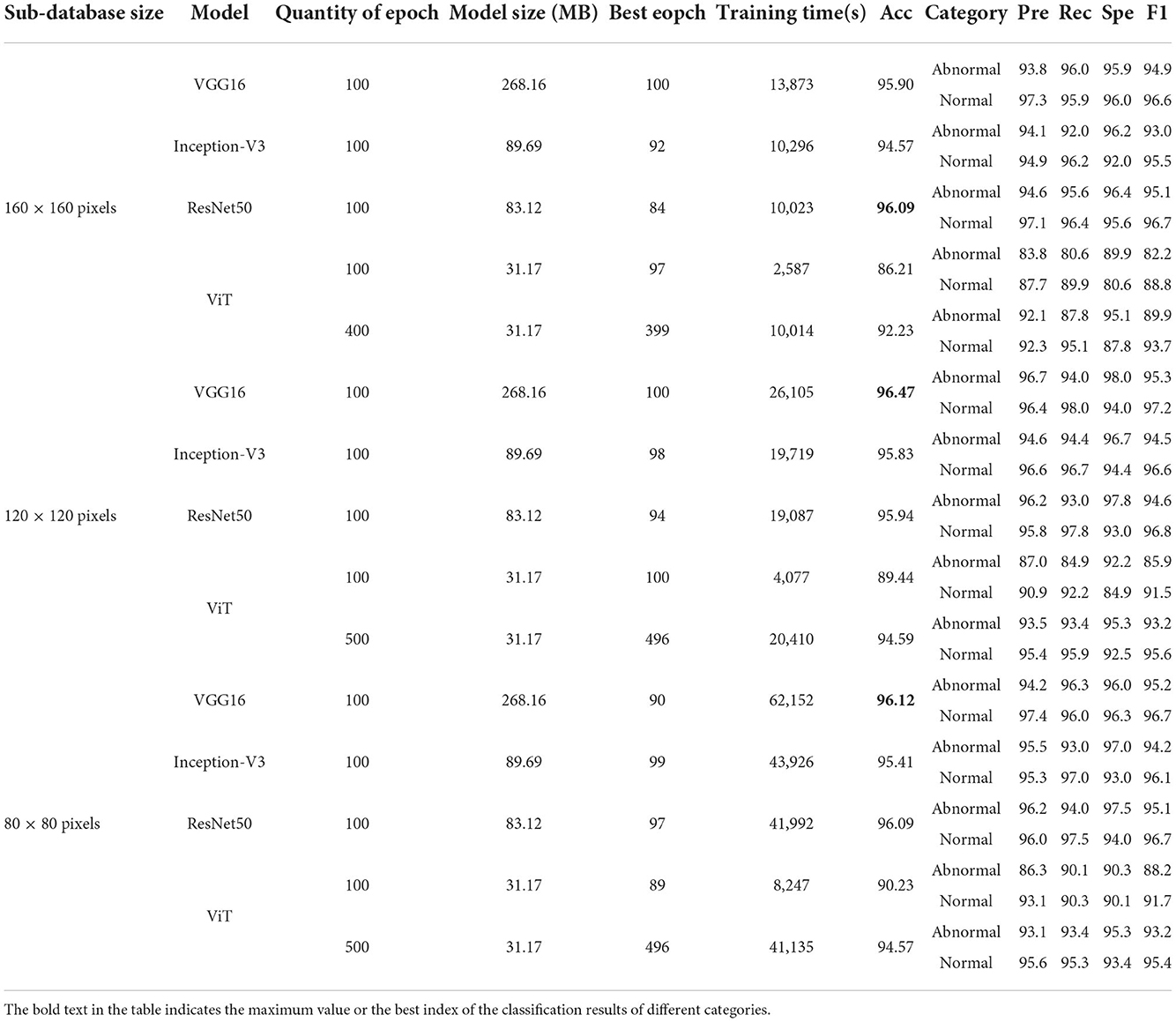
Table 6. Classification results of four deep learning classifiers on GasHisSDB [In (%)].
This section focuses on the classification results of classical machine learning methods for the 160 × 160 sub-database.
The color histogram has the highest number of items among all features. According to Table 3, the classical machine learning classifier on the color histogram, the best performer is RF with an accuracy of 85.99%. In addition, in color histogram, the classification accuracy of the three classifiers reached around 80%, which are LR, kNN, and ANN. All SVM classifiers perform poorly on color histogram features. However, color histogram on GasHisSDB, the naive Bayesian classifier, cannot get the classification effect because of the existence of a large number of low luminance statistics with zero values in the three color channels.
The luminance is the average of the colors. Its histogram does not yield better classification accuracy as a feature. Because of this, luminance histogram also has the above problem on the naive Bayesian classifier. The classification results of the naive Bayesian classifier for these two color features are therefore not presented in the Table 3. RF shows robustness in two features and obtains the highest accuracy rate of 79.13% using luminance histogram for classification. However, the LR, kNN, and ANN classifiers that perform better on color histogram significantly drop on luminance histogram.
The classification effect of HOG on all classifiers is not very effective and the accuracy is very close. The difference is not much distributed between 53 and 62%.
On the contrary, the distribution of LBP image classification accuracy is particularly scattered, with the highest Linear Regression classifier reaching 74.29%, followed by ANN reaching 71.84%. The lowest linear SVM classification effect is < 50%.
The classification effect of the four statistic values of GLCM is 71.39% only for RF, and other classifiers are also above 60%. It is worth noting that the accuracy of non-linear SVM with other features except color histogram and GLCM has not changed at all, which is 60.58%. The accuracy of non-linear SVM classifier with color histogram is 56.09% and the accuracy of GLCM's non-linear SVM classifier is 67.76%.
Here, we focus on the comparison of the experimental results of the 120 × 120 pixels sub-database. The experimental results are shown in Table 3. In general, compared with 160 × 160 pixels sub-database classification results, 120 × 120 pixels sub-database classification results except for color histogram, the rest of the best classifiers remain unchanged.
The four better-performing classifiers on color histogram feature still perform better, and the accuracy rate fluctuates slightly, resulting in the kNN classifier reaching the best accuracy rate of 86.32%. The classification performance of the two SVM classifiers on the features of color histogram is still not ideal. Naive Bayesian classifier is still not suitable for color histogram and luminance histogram features. The linear SVM effect of luminance histogram classifier has been greatly improved in the classification of the 120 × 120 pixels sub-database. The accuracy of other classifiers on the features of luminance histogram has little change. The HOG feature still does not perform well in every classifier. The highest accuracy rate is only 62.35% of ANN. The classification results of LBP and GLCM features are similar to the classification effect on the 160 × 160 pixels sub-database. The best accuracy rate on LBP is a linear regression with a precision rate of 73.34%. The best accuracy rate on GLCM is that the RF reaches 71.15%. Similarly, the non-linear SVM of 120 × 120 pixels sub-database also has the problem of constant accuracy of multiple features.
The classification results of the 80 × 80 pixels sub-database are shown in Table 4. The overall best classifier on each feature remains the same as that of the best classifier for each feature corresponding to the 120 × 120 pixels sub-database except for HOG features that have a small gap between each classifier.
Compared with the classification results of the other two sub-databases, the classification effect of each classifier on color histogram and luminance histogram has no particularly large fluctuations. It confirms the consistency of the three databases of GasHisSDB.
The classification accuracy of color histogram is still polarized. The four excellent classifiers reach about 80%, and the other two are about 60%. The RF still showed robustness in the luminance histogram classification task. RF was the best classifier with an accuracy of 75.10%. The classification accuracy distribution of HOG features is denser than that of the other two sub-databases. The highest is only 59.87%. Due to the reduced sample size, each classifier has different degrees of accuracy reduction in addition to the naive Bayesian classifier for LBP features and GLCM features. The best classifier for LBP feature is still linear regression which reaches 70.92%. The highest accuracy rate of LBP feature has become 68.84% of kNN. In the classification results of the 80 × 80 pixels sub-database, the naive Bayesian classifier of color histogram and luminance histogram is not applicable, and, except for the GLCM feature, the problem that the accuracy of the non-linear SVM classifier does not change still exists.
According to Table 5, on 160 × 160 pixels sub-database, all deep learning models have better classification results than classical machine learning methods. The VGG model with the longest training time and the largest model size has an accuracy above 95%. Inception-V3 and ResNet50 have better model size and training time than VGG16. However, Inception-V3 has lower accuracy than VGG16, and ResNet50 has the highest accuracy of 96.09%, which is the highest among all models. ViT is a Transformer-based classifier with an accuracy of 86.21%. However, it is still higher than the classification accuracy of all traditional machine learning methods on this sub-database. Significantly, ViT achieves such accuracy with only 1/4 of the training time and 1/3 of the model size compared to ResNet. Also, the accuracy curve is still trending upward and the loss function is still not fully converged.
According to the Table 5, the classification results are excellent on the sub-database of 120 × 120 pixels. Due to a large number of training samples, VGG16 is the classifier with the highest accuracy of 96.47% on this sub-database. However, the training time is doubled compared to that on the 160 × 160 sub-database. The accuracies of 95.83 and 95.94% are obtained for Inception-V3 and ResNet50, respectively. Due to the increase in the amount of training data, ViT also gained an accuracy improvement, rising to 89.44%.
According to Table 5, the classification results of the 80 × 80 subdatabase can be seen. It is the sub-database with the largest number of samples, and the accuracy of the four classifiers only changes slightly. VGG16 performs stably with an accuracy of 96.12%, which is the classification model with the highest accuracy. The lowest accuracy is still the ViT model with the least training time, at 90.23. It is worth noting that the training time of ViT is 13.26% of that of the highest accurate VGG16 on this sub-database.
As stated in Section 4.2.1, ViT did not converge completely within 100 epochs. Experiments are added in this section to explore the performance of ViT, and the results are reflected in the last row of each sub-database in Table 5. The same parameter conditions were maintained for all additional experiments. In the additional experiments for the 160 × 160 sub-database, the control training time was similar to that of Inception-V3 and ResNet running 100 epochs. ViT runs 400 epochs and the accuracy reaches 92.23%. In the other two sub-databases with larger amount of data, again when controlling for the same training time as Inception-V3 and RseNet50. At this time, the accuracy of ViT models for the 120 × 120 pixel sub-database and the 80 × 80 pixel sub-database improves to 94.59 and 94.57%, respectively. The model size of ViT has a great advantage. Moreover, these image classification results reach the general level of medical image classification.
To explore the possibility of ensemble learning between deep learning classifiers, we conducted a TSNE analysis of the top performing deep learning classifiers. the t-SNE method analysis was performed using the 160 × 160 pixels sub-database as an example and the results are shown in Figure 3.

Figure 3. Plot of results from t-SNE analysis of four deep learning classification models.
This experimental platform use the t-SNE method to downscale the features extracted by the four deep learning methods into two-dimensional scatters displayed in the image. Representative images from the test set are selected in the figure, where the abnormal image suffers from misclassification in ViT, and its points after feature downscaling fall in the image normal population. This image performs well in the other three classifiers, and its feature-descended points fall in the image abnormal population. However, it can be observed that the selected normal image it performs well in Inception-V3, ResNet50, ViT, with the reduced points falling in the normal population, but performs poorly in VGG16.
This chapter compares the classification results of different classifiers from the Linear Regression to Visual Transformer on the 160 × 160, 120 × 120, and 80 × 80 pixels sub-databases of the GasHisSDB. The classification performance of each method on GasHisSDB reflects complementarity.
Classical machine learning methods have a rigorous theoretical foundation. Their simplified ideas can show good classification results on some specific features and algorithms (39).
This experimental platform shows that seven classifiers for GLCM classification on three sub-databases with little difference in accuracy, where the naive Bayesian classifier has significantly higher Rec than Spe for the abnormal category, and the linear SVM has slightly higher Rec than Spe. It shows that these two classifiers are better in classifying the abnormal category. However, the Spe of the other classification models are higher than the Rec, indicating that they are more effective in classifying the normal category. The same phenomenon occurs for every feature of every sub-database. There exist classifiers with high Rec values or high Spe values in the same condition. Such a result can be a powerful indication of the existence of this complementarity of these classifiers.
However, deep learning methods are still far ahead of classical machine learning methods in terms of image classification accuracy and experiment workload (40).
By analyzing the deep learning methods using the t-SNE method, there is a clear classification performance for their feature extraction. In Figure 3 it can also be seen that there is an aggregation of normal and abnormal images in the four classifiers. However, there is still inconsistency in the classification results and it can be understood that these methods can exist to some extent in a complementary manner (41).
The evaluation metrics for deep learning models are generally high, but complementarity in the field of machine learning also occurs in the field of deep learning (42). For example, the Spe of Inception-V3 and ResNet50 on sub-database C for abnormal category classification is high, but the high Rec of VGG16 can be well performed to the complementarity of the above two models.
The selection of suitable classifiers is the primary problem of ensemble learning, and after relevant experiments in the complementarity comparison experimental platform, it can be observed that these classifiers exhibit different performances (43). The complementarity possessed by these classifiers can adequately meet the needs of ensemble learning (44).
In practice, machine performance often limits model training for large-size images, and finding multiple classification models with complementarity types is the basis for ensemble learning. For sub-sized images, this experiment tries a large number of classification models to find their complementarity and thus improve the efficiency of ensemble learning.
The experimental results show that complementarity in machine learning does exist for different classifiers of the same feature. Different classifiers for the same feature include classifiers that classify the abnormal category well and classifiers that classify the normal category well. This is a powerful indication of the complementarity among classifiers.
The evaluation metrics of the deep learning models are both very excellent. There are models that are less effective in classifying the abnormal category than the normal category. In this case, selecting the appropriate model that performs well for the abnormal category can contribute to ensemble learning. Complementarity can also be demonstrated in this situation.
There are still many excellent methods that have not been added to the experimental platform. Moreover, the recently popular ViT excels in the field of image processing, but ViT does not show significant experimental results on sub-size images. In the future, we will add more models to explore the complementarity nature of ensemble learning on sub-size images to improve the efficiency of ensemble learning.
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
WH: method, experiment, and writing. HC and WL: experiment. XL and HS: medical knowledge. XH and MG: method. CL: method, writing, and funding. All authors contributed to the article and approved the submitted version.
This work was supported by the National Natural Science Foundation of China (No. 82220108007) and Beijing Xisike Clinical Oncology Research Foundation (No. Y-tongshu2021/1n-0379).
We would like to thank Miss. Zixian Li and Mr. Guoxian Li for their important discussion in this work.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
1. Sung H, Ferlay J, Siegel RL, Laversanne M, Soerjomataram I, Jemal A, et al. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J Clin. (2021) 71:209–49. doi: 10.3322/caac.21660
2. Wang FH, Shen L, Li J, Zhou ZW, Liang H, Zhang XT, et al. The Chinese society of clinical oncology (CSCO): clinical guidelines for the diagnosis and treatment of gastric cancer. Cancer Commun. (2019) 39:10. doi: 10.1186/s40880-019-0349-9
3. Cheng J, Han Z, Mehra R, Shao W, Cheng M, Feng Q, et al. Computational analysis of pathological images enables a better diagnosis of TFE3 Xp11. 2 translocation renal cell carcinoma. Nat Commun. (2020) 11:1778. doi: 10.1038/s41467-020-15671-5
4. Liang J, Yang X, Huang Y, Li H, He S, Hu X, et al. Sketch guided and progressive growing GAN for realistic and editable ultrasound image synthesis. Med Image Anal. (2022) 79:102461. doi: 10.1016/j.media.2022.102461
5. Tahiliani HT, Purohit AP, Desai SC, Jarwani PB. Retrospective analysis of histopathological spectrum of premalignant and malignant colorectal lesions. Cancer Res Stat Treat. (2021) 4:472–8. doi: 10.4103/crst.crst_87_21
6. Zhao P, Li C, Rahaman MM, Xu H, Yang H, Sun H, et al. A comparative study of deep learning classification methods on a small environmental microorganism image dataset (EMDS-6): from convolutional neural networks to visual transformers. Front Microbiol. (2022) 13:792166. doi: 10.3389/fmicb.2022.792166
7. Xue D, Zhou X, Li C, Yao Y, Rahaman MM, Zhang J, et al. An application of transfer learning and ensemble learning techniques for cervical histopathology image classification. IEEE Access. (2020) 8:104603–18. doi: 10.1109/ACCESS.2020.2999816
8. Nazarian S, Glover B, Ashrafian H, Darzi A, Teare J. Diagnostic accuracy of artificial intelligence and computer-aided diagnosis for the detection and characterization of colorectal polyps: systematic review and meta-analysis. J Med Internet Res. (2021) 23:e27370. doi: 10.2196/27370
9. Schmarje L, Santarossa M, Schroder SM, Koch R. A survey on semi-, self-and unsupervised learning for image classification. IEEE Access. (2021) 9:82146–68. doi: 10.1109/ACCESS.2021.3084358
10. Shinde PP, Shah S. A review of machine learning and deep learning applications. In: 2018 Fourth International Conference on Computing Communication Control and Automation (ICCUBEA). Pune: IEEE (2018). p. 1–6. doi: 10.1109/ICCUBEA.2018.8697857
11. Li Y, Wu X, Li C, Li X, Chen H, Sun C, et al. A hierarchical conditional random field-based attention mechanism approach for gastric histopathology image classification. Appl Intell. (2022) 1–22. doi: 10.1007/s10489-021-02886-2
12. Hu W, Li C, Li X, Rahaman MM, Ma J, Zhang Y, et al. GasHisSDB: a new gastric histopathology image dataset for computer aided diagnosis of gastric cancer. Comput Biol Med. (2022) 142:105207. doi: 10.1016/j.compbiomed.2021.105207
13. Fu B, Zhang M, He J, Cao Y, Guo Y, Wang R. StoHisNet: a hybrid multi-classification model with CNN and transformer for gastric pathology images. Comput Methods Programs Biomed. (2022) 221:106924. doi: 10.1016/j.cmpb.2022.106924
14. Wang P, Fan E, Wang P. Comparative analysis of image classification algorithms based on traditional machine learning and deep learning. Pattern Recogn Lett. (2021) 141:61–7. doi: 10.1016/j.patrec.2020.07.042
15. Ma P, Li C, Rahaman MM, Yao Y, Zhang J, Zou S, et al. A state-of-the-art survey of object detection techniques in microorganism image analysis: from classical methods to deep learning approaches. Artif Intell Rev. (2022) 1–72. doi: 10.1007/s10462-022-10209-1
16. Sun C, Li C, Zhang J, Rahaman MM, Ai S, Chen H, et al. Gastric histopathology image segmentation using a hierarchical conditional random field. Biocybern Biomed Eng. (2020) 40:1535–55. doi: 10.1016/j.bbe.2020.09.008
17. Zheng X, Wang R, Zhang X, Sun Y, Zhang H, Zhao Z, et al. A deep learning model and human-machine fusion for prediction of EBV-associated gastric cancer from histopathology. Nat Commun. (2022) 13:2970. doi: 10.1038/s41467-022-30459-5
18. Dai Y, Gao Y, Liu F. Transmed: transformers advance multi-modal medical image classification. Diagnostics. (2021) 11:1384. doi: 10.3390/diagnostics11081384
19. Japanese Gastric Cancer Association. Japanese classification of gastric carcinoma: 3rd English edition. Gastric Cancer. (2011) 14:101–12. doi: 10.1007/s10120-011-0041-5
20. Humeau-Heurtier A. Texture feature extraction methods: a survey. IEEE Access. (2019) 7:8975–9000. doi: 10.1109/ACCESS.2018.2890743
21. Kulwa F, Li C, Grzegorzek M, Rahaman MM, Shirahama K, Kosov S. Segmentation of weakly visible environmental microorganism images using pair-wise deep learning features. Biomed Signal Process Control. (2023) 79:104168. doi: 10.1016/j.bspc.2022.104168
22. Hope TM. Linear regression. In: Machine Learning. London: Elsevier (2020). p. 67–81. doi: 10.1016/B978-0-12-815739-8.00004-3
23. Guo G, Wang H, Bell D, Bi Y, Greer K. KNN model-based approach in classification. In: OTM Confederated International Conferences on the Move to Meaningful Internet Systems.” Catania: Springer (2003). p. 986–96. doi: 10.1007/978-3-540-39964-3_62
24. Yang FJ. An implementation of naive bayes classifier. In: 2018 International Conference on Computational Science and Computational Intelligence (CSCI). Las Vegas, NV: IEEE (2018). p. 301–6. doi: 10.1109/CSCI46756.2018.00065
25. Shi T, Horvath S. Unsupervised learning with random forest predictors. J Comput Graph Stat. (2006) 15:118–38. doi: 10.1198/106186006X94072
26. Suthaharan S. Support vector machine. In: Machine Learning Models and Algorithms for Big Data Classification. Boston, MA: Springer (2016). p. 207–35. doi: 10.1007/978-1-4899-7641-3_9
27. Hopfield JJ. Artificial neural networks. IEEE Circ Dev Mag. (1988) 4:3–10. doi: 10.1109/101.8118
28. Zhang J, Li C, Kosov S, Grzegorzek M, Shirahama K, Jiang T, et al. LCU-Net: a novel low-cost U-Net for environmental microorganism image segmentation. Patt Recogn. (2021) 115:107885. doi: 10.1016/j.patcog.2021.107885
29. Zhang J, Ma P, Jiang T, Zhao X, Tan W, Zhang J, et al. SEM-RCNN: a squeeze-and-excitation-based mask region convolutional neural network for multi-class environmental microorganism detection. Appl Sci. (2022) 12:9902. doi: 10.3390/app12199902
30. Chen H, Li C, Wang G, Li X, Rahaman MM, Sun H, et al. GasHis-Transformer: a multi-scale visual transformer approach for gastric histopathological image detection. Patt Recogn. (2022) 130:108827. doi: 10.1016/j.patcog.2022.108827
31. Yang H, Zhao X, Jiang T, Zhang J, Zhao P, Chen A, et al. Comparative study for patch-level and pixel-level segmentation of deep learning methods on transparent images of environmental microorganisms: from convolutional neural networks to visual transformers. Appl Sci. (2022) 12:9321. doi: 10.3390/app12189321
32. Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv Preprint. (2014) arXiv:14091556.
33. Szegedy C, Vanhoucke V, Ioffe S, Shlens J, Wojna Z. Rethinking the inception architecture for computer vision. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV (2016). p. 2818–26. doi: 10.1109/CVPR.2016.308
34. He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV (2016). p. 770–8. doi: 10.1109/CVPR.2016.90
35. Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv Preprint. (2020) arXiv:201011929.
36. Liu W, Li C, Rahaman MM, Jiang T, Sun H, Wu X, et al. Is the aspect ratio of cells important in deep learning? A robust comparison of deep learning methods for multi-scale cytopathology cell image classification: from convolutional neural networks to visual transformers. Comput Biol Med. (2022) 141:105026. doi: 10.1016/j.compbiomed.2021.105026
37. Liu W, Li C, Xu N, Jiang T, Rahaman MM, Sun H, et al. CVM-Cervix: a hybrid cervical pap-smear image classification framework using CNN, visual transformer and multilayer perceptron. Patt Recogn. (2022) 130:108829. doi: 10.1016/j.patcog.2022.108829
38. Zhou X, Li C, Rahaman MM, Yao Y, Ai S, Sun C, et al. A comprehensive review for breast histopathology image analysis using classical and deep neural networks. IEEE Access. (2020) 8:90931–56. doi: 10.1109/ACCESS.2020.2993788
39. Chen A, Li C, Zou S, Rahaman MM, Yao Y, Chen H, et al. SVIA dataset: a new dataset of microscopic videos and images for computer-aided sperm analysis. Biocybern Biomed Eng. (2022) 42:204–14. doi: 10.1016/j.bbe.2021.12.010
40. Shi Z, Zhu C, Zhang Y, Wang Y, Hou W, Li X, et al. Deep learning for automatic diagnosis of gastric dysplasia using whole-slide histopathology images in endoscopic specimens. Gastric Cancer. (2022) 25:751–60. doi: 10.1007/s10120-022-01294-w
41. Tsuneki M, Ichihara S, Kanavati F. Weakly supervised learning for poorly differentiated adenocarcinoma classification in gastric endoscopic submucosal dissection whole slide images. medRxiv. (2022). p. 1–15. doi: 10.1101/2022.05.28.22275729
42. Zhang J, Zhao X, Jiang T, Rahaman MM, Yao Y, Lin YH, et al. An application of pixel interval down-sampling (PID) for dense tiny microorganism counting on environmental microorganism images. Appl Sci. (2022) 12:7314. doi: 10.3390/app12147314
43. Li X, Li C, Rahaman MM, Sun H, Li X, Wu J, et al. A comprehensive review of computer-aided whole-slide image analysis: from datasets to feature extraction, segmentation, classification and detection approaches. Art Intell Rev. (2022) 55:4809–78. doi: 10.1007/s10462-021-10121-0
Keywords: gastric histopathology, sub-size image, robustness comparison, algorithmic complementarity, image classification
Citation: Hu W, Chen H, Liu W, Li X, Sun H, Huang X, Grzegorzek M and Li C (2022) A comparative study of gastric histopathology sub-size image classification: From linear regression to visual transformer. Front. Med. 9:1072109. doi: 10.3389/fmed.2022.1072109
Received: 17 October 2022; Accepted: 18 November 2022;
Published: 07 December 2022.
Edited by:
Jun Cheng, Shenzhen University, ChinaReviewed by:
Gang Yin, Sichuan Cancer Hospital, ChinaCopyright © 2022 Hu, Chen, Liu, Li, Sun, Huang, Grzegorzek and Li. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Chen Li, bGljaGVuQGJtaWUubmV1LmVkdS5jbg==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.