 Hyojin Bae
Hyojin Bae Sanghun Lee2,3
Sanghun Lee2,3 Chang-Eop Kim
Chang-Eop Kim- 1Department of Physiology, Gachon University College of Korean Medicine, Seongnam, South Korea
- 2Korean Medicine Data Division, Korea Institute of Oriental Medicine, Daejeon, South Korea
- 3Department of Korean Convergence Medical Science, University of Science and Technology, Daejeon, South Korea
Pattern identification (PI), a unique diagnostic system of traditional Asian medicine, is the process of inferring the pathological nature or location of lesions based on observed symptoms. Despite its critical role in theory and practice, the information processing principles underlying PI systems are generally unclear. We present a novel framework for comprehending the PI system from a machine learning perspective. After a brief introduction to the dimensionality of the data, we propose that the PI system can be modeled as a dimensionality reduction process and discuss analytical issues that can be addressed using our framework. Our framework promotes a new approach in understanding the underlying mechanisms of the PI process with strong mathematical tools, thereby enriching the explanatory theories of traditional Asian medicine.
Introduction
Pattern identification (PI), a distinctive diagnostic system found in traditional Asian medicine (TAM), is a clinical reasoning process that uses the signs and symptoms of patients to identify diagnostic patterns (1). These patterns convey information about the nature of the disease or the location of lesions and serve as a guide for treatment selection (2) (e.g., drain for a “excess” pattern and tonify for a “deficient” pattern). Notably, patterns in TAM are pragmatic concepts that are widely accepted as a useful treatment target rather than actual pathogens or objectively measurable states (3). It can be said that PI is a strategy chosen to make diagnostic decisions based on naked sense observations and to determine corresponding treatments. Despite their centrality in theory and practice, the information processing principles of PI have remained relatively superficial. Additionally, abstract descriptions make it difficult to objectively describe the PI process, resulting in a low level of consistency between practitioners (4–6).
In recent years, approaches based on machine learning (ML) have demonstrated remarkable performance in a variety of tasks, including image classification, speech processing, and natural language processing, all of which are difficult to solve using knowledge-based approaches (7). Interestingly, this success has spawned approaches in systems neuroscience that use ML to study how the brain works (8–11). The strategy is to use ML algorithms as a computational model of the brain and to benchmark this model in order to gain a better understanding of how the brain represents, learns, and flexibly processes high-dimensional information.
Inspired by the idea that ML models can help capture critical aspects of the brain's computation, we present a novel framework for explaining how information is processed in the PI system and why it is effective. Within our framework, we model the PI system as a dimensionality-reduction algorithm and propose several research questions. By leveraging ML's framework, we can adopt powerful mathematical tools, broaden the scope of inquiry, and enrich explanatory theory in TAM.
Manuscript Formatting
A Brief Introduction to Dimensionality Reduction
In this paper, we view the PI system through the lens of dimensionality reduction process, which reduces high-dimensional data to a low-dimensional representation. To that end, we'll discuss high-dimensional data and dimensionality reduction briefly. Rather than providing strict mathematical definitions, we will explain these concepts with examples to aid intuitive understanding.
The dimensionality of data is defined as the number of features (attributes) that describe the observations in data (Figure 1A) (assuming that the number of rows (observations) exceeds the number of columns (features/attributes) and the data matrix is full-rank, which is easily satisfied in noisy, real-world datasets). A larger number of features leads to a more detailed representation of the observation (i.e., high representational power) (12). Additionally, when compared to low-dimensional space, high-dimensional space makes data classification easier (13). For instance, while classification in a low-dimensional space requires non-linear and complex decision boundaries, data can be made linearly separable by adding additional dimensions (axes) (Figure 1B).
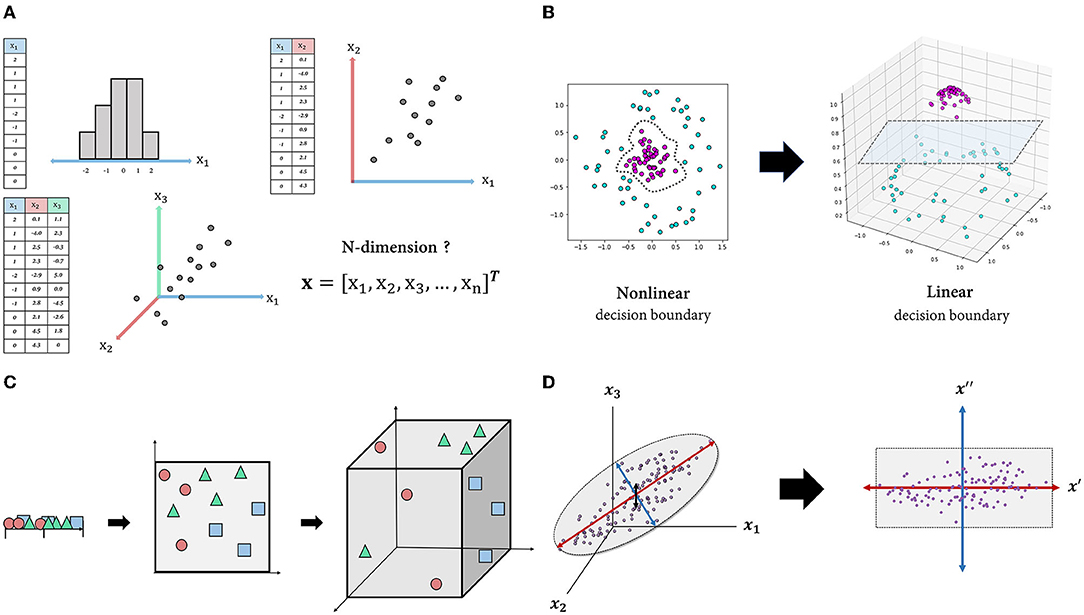
Figure 1. Schematic figures explaining the features of high-dimensional data. (A): Intuitive understanding of multidimensional data. Each observation (row) in each table is described by one or more features (columns) and visualized as a point in one-, two- or three-dimensional space. This representation is easily extended to four-dimensional space or higher, but it cannot be visualized. (B): By transforming the dataset into high-dimensional space, the data can be separated using a linear decision boundary. (C): Curse of dimensionality. As the dimension of the space increases, the volume of the space expands exponentially, and the density of the space becomes increasingly sparse. (D): Projection into an intrinsic-dimensional space. Data laid out in three-dimensional space can be approximated by a two-dimensional plane composed of newly discovered axes that account for majority of the data variability.
However, high-dimensional space does not come without drawbacks. Due to the fact that more than four-dimensional space is beyond human cognition, high-dimensional data are unintuitive, making it difficult to interpret or derive insights. More importantly, as the input dimension increases, the classifier's performance on unseen data typically degrades rather than improves. A common explanation for this is the “curse of dimensionality” (14). As the dimension increases, the volume of space in which data are represented increases exponentially, to the point where available data become sparse (Figure 1C) (15). In this case, the model is likely to miss generalizable patterns in the data. One solution is to increase the size of the training data until the density is sufficient, while another is to reduce the dimensionality of the data, which is usually the more practical option (16).
Apart from these disadvantages of high-dimensional data, the typical motivation for dimensionality reduction is that the genuine dimension (i.e., degree of freedom) of the space may be significantly less than the number of features due to feature dependencies (17). That is, even if the dataset contains hundreds or even millions of features, the majority of variation may be explained by a handful of latent variables. There are numerous dimensionality-reduction algorithms, and which one to use depends on the nature of the data and the research objective. For instance, principal component analysis (PCA), one of the most widely used linear dimensionality-reduction techniques, seeks to identify orthogonal axes [i.e., principal components (PCs)] that best account for the variance of the data via a linear combination of existing axes (18). By projecting the data into a subspace of leading PCs, we can obtain a compact representation of the data, albeit with some information loss (Figure 1D). There are also non-linear techniques such as Isomap (19), t-stochastic neighbor embedding (20), uniform manifold approximation and projection (21) that capture non-linear relations between variables. Overall, the motivations for dimensionality reduction in dealing with high-dimensional data are as follows: first, high-dimensional data are unintuitive; second, they are prone to the curse of dimensionality; and third, a dataset's dimensionality may be artificially high.
Modeling the PI as a Dimensionality-Reduction Process From the Symptom Space
One of the most distinctive characteristics of TAM in clinical practice is the use of patterns to identify and treat the patient. TAM physicians evaluate patient's clinical symptoms and signs and classify them according to specific pattern groups (4). The identified patterns provide basis for prescribing treatments including herbal formula (22). Each patient can be thought of as a point in a multidimensional symptom space, with each dimension corresponding to a distinct symptom. If the total number of symptoms is p, the patient is represented as a p-dimensional vector whose elements are the coordinate values on each symptom axis. Similarly, the herbal space can be defined in the same way, with each dimension representing an individual herb. If the total number of herbs is q, a herbal prescription (a mixture of herbs) is represented as a q-dimensional vector whose elements are the coordinate values for each herbal axis. Following that, treatment selection can be formulated as a mapping from the symptom space to the herbal space (To keep the discussion concise, treatment is limited to herbal prescriptions). From the doctor's perspective, there are several motivations to reduce the dimension of the input data to perform this task successfully. Assuming the symptom and herbal space have dimensions of p and q, respectively, the number of theoretically possible mappings is qp. Even if each p and q are on a tens-scale, they are already beyond the cognitive capacity of any single human memory. In this case, shrinking the input space's dimension can exponentially reduce the number of available alternatives (Figure 2A).
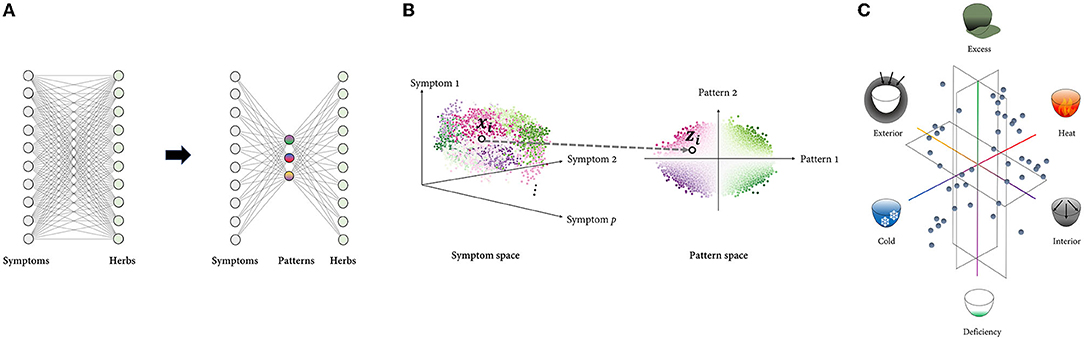
Figure 2. Framework modeling the PI with dimensionality reduction. (A): Rather than mapping high-dimensional spaces directly, the number of cases can be reduced exponentially by first projecting the input space to low-dimensional space composed of multiple latent variables and then mapping it to the output space. (B): Representing the data using a few underlying patterns reveals the intrinsic structure of the data, which is difficult to capture in a high-dimensional space where distinct factors of variations are highly entangled. Each point represents sample data, and the points denoted by a black circle represent the ith sample, which is represented in both the symptom space () and the pattern space (). The points are color-coded according to the identified patterns. (C): TAM's low-dimensional pattern space is constructed from metaphorical concepts that are embodied in everyday life. The pattern space in eight-principle PI, the most comprehensive type of PI, is visualized as an example. Six of eight principle patterns are composed of the exterior, interior, cold, heat, deficiency, and excess, while the other two are Yin and Yang, which are higher concepts that encompass the other six patterns. Six principle patterns are grouped in pairs of mutually opposing properties: exterior-interior, cold-heat, and deficiency and excess. These three pairs represent the extent to which external pathogens penetrate the body, the nature of the disease, and the relative superiority of the body's resistance to pathogenic factors and the pathogenic qi, respectively. These concepts' familiar and abstract characteristics enable robust inference of the pathological pattern from a myriad of symptom phenotypes.
Additionally, there is frequently a high degree of correlation and redundancy among individual symptoms, limiting possible patterns of variation (e.g., fever may have a positive correlation with thirst and a negative correlation with a pale face). In other words, a small number of independent patterns can effectively describe the system's behavior, resulting in symptom data that may span only a constrained, low-dimensional subset of the entire space. In this case, the overall structure of the symptom data, which may not be visible at the individual symptom level, may be more important for treatment selection. Disentangling the data based on latent patterns may aid in revealing the data's intrinsic structure (Figure 2B).
Given this perspective, the PI system can be modeled as the process of representing high-dimensional symptom data in a low-dimensional space defined by a few latent patterns. Assuming that the patient records contain p symptom variables and are represented by r pattern variables, PI process can be described as follows: Given a set of n patient vectors [i.e., the ith training sample is a vector , where xij is jth feature of ith sample], the aim is to transform each vector into a new vector where r≪p. The mapping function f:X ⊂Rp→Z⊂Rrcan be estimated differently depending on the specific forms of the objective function.
Interestingly, human-inferred latent patterns may not always be the optimal solution in terms of information loss minimization, which is the primary goal of dimensionality-reduction algorithms such as PCA. This is because, given human expert's inductive reasoning, reduced representations must not only deliver compact information but also be cognitively efficient. Indeed, the patterns in TAM, such as heat, cold, deficiency, and excess, are primarily intuitive and metaphorical concepts that are embodied in daily life (Figure 2C). Inferring patterns from experiences or observations of the physical world and explaining the physiological and pathological phenomena of the human body in terms of these conceptual patterns are key characteristics of TAM theory (23). While this approach may appear crude and ideological in comparison to pathogen-based diagnosis, it provides an intuitive foundation for inductive reasoning (24, 25).
Research Questions in PI Systems That Can Be Addressed Using Mathematical Metrics Developed in ML
In this section, we raise several research questions that can be addressed by utilizing our novel framework that models the PI system in terms of the ML perspective. In particular, we focus on the topics for specifying the dimensionality reduction properties of the PI system.
Is PI a Linear or Non-linear Process?
Dimensionality-reduction algorithms can be classified mathematically as linear or non-linear, which is critical for implementation. Linear techniques such as PCA, multidimensional scaling, and factor analysis are widely used in a variety of fields. They employ straightforward linear algebraic techniques that are easy to implement and provide clear geometric interpretations (26). In the real world, however, data may form a highly non-linear manifold. Low-dimensional embeddings obtained via methods assuming a linear submanifold may be unsatisfactory in this case (27).
Whether to use a linear or non-linear technique should be determined by the nature of the data being analyzed, as well as the nature of the problem being solved. The PI process should compress the symptom space while retaining the information required for treatment selection, but its linear or non-linear nature has not been investigated. For instance, the probability of being identified as a particular pattern can increase supra-linearly when a particular symptom pair appears concurrently, whereas the probability may be negligible in the absence of a single symptom.
Numerous techniques exist for quantifying non-linearity in operations (28–30). Quantifying non-linearity may allow for the assessment of the adequacy of currently developed tools supporting clinical PI. For example, a questionnaire based on linear regression may be ineffective for a disease in which significant non-linear associations exist between symptoms and patterns.
How and to What Extent the PI Abstracts Information
The core characteristic of human intelligence is to learn from small samples to deal with previously unknown situations, which are often linked with the critical challenges raised in ML (31). For the brain to learn efficiently within its limited resources, it is necessary to draw general conclusions from individual experiences rather than memorize them all (32). Abstraction and hierarchical information processing are critical capabilities that contribute to the human brain's remarkable capacity for generalization (7, 33).
Given that PI is the process of representing patients' clinical symptoms as metaphorical patterns, it is fundamentally an abstraction process. Abstract representations may aid physicians in robustly inferring pathological patterns from a wide variety of symptom combinations, thereby simplifying patient classification. It is critical to investigate how and at what level abstractions are made and how they contribute to patient classification and/or treatment selection in order to gain a better understanding of information processing in PI.
Obtaining abstract (high-level) representations while ignoring irrelevant details is also critical in artificial intelligence (AI). Deep neural networks, in particular, such as convolutional neural networks and autoencoders are thought to learn abstract representations, and abstraction in representations can be quantified in various ways, for example, the degree of dichotomy or the capacity for generalization (34–38). Similarly, abstractions in PI can be explicitly quantified using the PI model's representation. Whether or not TAM concepts with varying levels of abstraction are hierarchically encoded in the system, or whether the level of abstraction varies between different types of PI that employ distinct conceptual patterns, such as Qi and blood, viscera and bowels (zangfu), or the five phases, could be specific research topics. This would enable us to assess the appropriate level of abstraction as well as its advantages and disadvantages.
What Is the Objective Function of the PI System?
The objective function specifies how a model's performance/cost is calculated, and a model is trained to maximize or minimize it. In other words, the objective function represents the model's learning goal, which is a critical component that must be specified in ML practice along with the learning rule and the architecture (39). Similarly, we can consider the PI system's objective function. Investigating the objective function that led the development of TAM's clinical decision-making model into its current form will give insight on the information processing strategy of PI system.
We can start with a common objective function of ML to determine that of the PI system. In supervised learning, the most widely used objective function is as follows:
denotes the function space of f, and the function is found by the minimization of the cost (inside the square bracket), which is composed of the loss function L(yi, f(xi)) and the regularization function J(f) with its associated regularization weight λ. yi and f(xi) denotes the ground-truth treatment and model prediction for the ith-sample xi, respectively. To minimize the loss, the model should fit the training data as closely as possible. However, the complexity of the model is constrained by the penalty imposed by the regularization term. The strategy of having two conflicting components in the objective function enables the designer to consider a reasonable bias-variance trade-off (i.e., enhancing the model's reliability in the face of unseen data at the expense of greater bias) (40). In other words, the objective function formulation expresses explicitly which characteristics the system values and penalizes.
It will be important to investigate which type of performance or penalty should be assessed by the loss and regularization functions in order to induce the current PI system. For example, when describing the long-term evolution of a PI system, the regularization function may be used to constrain the agent's cognitive and/or computational load rather than to prevent overfitting (In the long run, variance shrinks because where σ2 denotes the model variance).
Discussion
Earlier research on developing an AI-based diagnostic system for TAM was primarily focused on developing an expert system that makes use of expertise and ontology (41–45), whereas in recent years, a bottom-up approach that generates knowledge from the data has become more prevalent. The majority of recent PI studies utilizing ML have attempted to develop predictive models capable of reproducing a physician's diagnosis (46–48). While these studies explored the clinical applicability of ML algorithms based on their predictive performance, there were also studies examining the PI theory itself. One study validated TAM pattern types statistically by demonstrating that patient clusters in the data set correspond well to theoretical pattern types (49, 50), and another used a decision tree algorithm to extract a collection of symptoms indicative of a pattern in a particular disease (51) [For a more comprehensive and systematic review of the application of quantitative models in traditional medicine, see (52, 53)]. Our study is unique in that it presents a broader framework for explaining and analyzing PI system's information processing strategy from a ML perspective. Additionally, while we explained the PI process as dimensionality reduction, it is not exclusive to other ML algorithms such as clustering.
When dimensionality reduction is used to extract latent features, the process is comparable to that of theorization or modeling. Both involve deriving fundamental principles or patterns from massive and disordered data at the expense of detailed information. A model that fully describes all data samples is merely an enumeration of facts and is incapable of conveying generalized knowledge. Instead, we require a simple explanation to make sense of the data despite the presence of residuals that the model cannot account for. This aspect of dimensionality reduction is consistent with TAM's distinctive way of thinking, which seeks to interpret changes of the patient's symptoms and discomfort using abstract concepts that describe the dynamic nature of the micro-environment of the human body (54). By grasping the generalizable principles underlying individual observations, we can explain, predict, and manipulate the observed system's behavior beyond the scope of our experience.
According to cognitive psychology, humans frequently employ heuristic strategies that arrive at satisfactory solutions with a modest amount of computation to make decisions within their cognitive capacity and time constraints (55–57). Numerous models have been proposed to explain the strategies employed by the human brain, and dimensionality-reduction model in this paper is in line with such models. However, the constraint on computing resources in the dimensionality reduction of ML is not severe, resulting in differences between the human and machine computation. Additionally, it is expected that extensive feature selection will occur prior to dimensionality reduction in the actual PI process, based on cues such as the patient's chief complaint. This procedure would be based on the physician's prior knowledge, which correspond to the Bayesian prior. It is also noteworthy that reduced representations in PI systems must be interpretable because they are the product of conscious reasoning, unlike many ML algorithms, including PCA.
We combine the ingredients of systems neuroscience and ML to propose a conceptual framework for investigating the PI system, based on TAM domain knowledge. The introduction of a new perspective leads to the emergence of novel research questions and methodologies, opening a novel field of investigation. By implementing mathematical tools developed in ML, we will be able to verify a variety of hypotheses to which qualitative approaches have been applied primarily and contribute to the development of shareable explicit knowledge. This may help overcome one of TAM theory's primary flaws, namely that it is subjective and difficult to articulate. While this framework leaves room for elaboration, we believe it will serve as the foundation for developing interpretable AI for the medical domain.
Data Availability Statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author Contributions
C-EK, C-yL, and SL: conceptualization. HB and C-EK: investigation. HB: writing—original draft. C-EK and SL: writing—review and editing and funding acquisition. All authors contributed to the article and approved the submitted version.
Funding
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korean government (MSIT) (No. 2020R1F1A107317912) and the Collection of Clinical Big Data and Construction of Service Platform for Developing Korean Medicine Doctor with Artificial Intelligence research project (KSN2021110).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Birch S, Alraek T. Traditional East Asian medicine: how to understand and approach diagnostic findings and patterns in a modern scientific framework? Chin J Integ Med. (2014) 20:336–40. doi: 10.1007/s11655-014-1809-3
2. Textbook Compilation Committee of Pathology in Korean Medicine. Pathology in Korean Medicine. Seoul: Hanuimunhwasa (2010).
3. Birch S, Alraek T, Bovey M, Lee MS, Lee JA, Zaslawsk C, et al. Overview on pattern identification – history, nature and strategies for treating patients: a narrative review. Eur J Integ Med. (2020) 35:101101. doi: 10.1016/j.eujim.2020.101101
4. Zhang GG, Lee W, Bausell B, Lao L, Handwerger B, Berman B. Variability in the traditional Chinese medicine (TCM) diagnoses and herbal prescriptions provided by three TCM practitioners for 40 patients with rheumatoid arthritis. J Altern Compl Med. (2005) 11:415–21. doi: 10.1089/acm.2005.11.415
5. Berle CA, Cobbin D, Smith N, Zaslawski C. A novel approach to evaluate traditional chinese medicine treatment outcomes using pattern identification. J Altern Compl Med. (2010) 16:357–67. doi: 10.1089/acm.2009.0367
6. Zhou X, Li Y, Peng Y, Hu J, Zhang R, He L, et al. Clinical phenotype network: the underlying mechanism for personalized diagnosis and treatment of traditional Chinese medicine. Front Med. (2014) 8:337–46. doi: 10.1007/s11684-014-0349-8
7. Saxe A, Nelli S, Summerfield C. If deep learning is the answer, what is the question?. Nat Rev Neurosci. (2021) 22:55–67. doi: 10.1038/s41583-020-00395-8
8. Glaser JI, Benjamin AS, Farhoodi R, Kording KP. The roles of supervised machine learning in systems neuroscience. Prog Neurobiol. (2019) 175:126–37. doi: 10.1016/j.pneurobio.2019.01.008
9. Williamson RC, Doiron B, Smith MA, Yu BM. Bridging large-scale neuronal recordings and large-scale network models using dimensionality reduction. Curr Opin Neurobiol. (2019) 55:40–7. doi: 10.1016/j.conb.2018.12.009
10. Marblestone AH, Wayne G, Kording KP. Toward an integration of deep learning and neuroscience. Front Comput Neurosci. (2016) 10:94. doi: 10.3389/fncom.2016.00094
11. Stevenson IH, Kording KP. How advances in neural recording affect data analysis. Nat Neurosci. (2011) 14:139. doi: 10.1038/nn.2731
12. Bengio Y, Delalleau O. On the Expressive Power of Deep Architectures, International Conference on Algorithmic Learning Theory. Heidelberg: Springer (2011). p. 18–36.
13. Tarca AL, Carey VJ, Chen X-w, Romero R, Drăghici S. Machine learning and its applications to biology. PLoS Comput Biol. (2007) 3:e116. doi: 10.1371/journal.pcbi.0030116
14. Friedman JH. On bias, variance, 0/1—loss, the curse-of-dimensionality. Data Min Knowl Dis. (1997) 1:55–77. doi: 10.1023/A:1009778005914
15. Altman N, Krzywinski M. The curse (s) of dimensionality. Nat Methods. (2018) 15:399–400. doi: 10.1038/s41592-018-0019-x
16. Verleysen M, François D. The curse of dimensionality in data mining and time series prediction. In: Cabestany J, Prieto A, Sandoval F, editors. Computational Intelligence and Bioinspired Systems. Berlin: Springer Berlin Heidelberg (2005). p. 758–70.
18. Jolliffe IT, Cadima J. Principal component analysis: a review and recent developments. Philos Trans Royal Soc A Mathe Phys Eng Sci. (2016) 374:20150202. doi: 10.1098/rsta.2015.0202
19. Tenenbaum JB, Silva Vd, Langford JC. A global geometric framework for nonlinear dimensionality reduction. Science. (2000) 290:2319. doi: 10.1126/science.290.5500.2319
21. McInnes L, Healy J, Melville J. Umap: Uniform manifold approximation and projection for dimension reduction. arXiv. (2018) 03426: doi: 10.21105/joss.00861
22. Wang J, Cai C, Kong C, Cao Z, Chen Y. A computer method for validating traditional Chinese medicine herbal prescriptions. Am J Chin Med. (2005) 33:281–97. doi: 10.1142/S0192415X05002825
23. Lee CY. Discussion on the issues of the modernization of the fundamental theories and terms in korean medicine. J Physiol Pathol Korean Med. (2013) 27:540–52.
24. Overholser JC. Elements of the socratic method: II. Inductive reasoning. Psychoth Theory Res Prac Train. (1993) 30:75. doi: 10.1037/0033-3204.30.1.75
25. Heit E. Properties of inductive reasoning. Psychonomic Bull Rev. (2000) 7:569–92. doi: 10.3758/BF03212996
26. Cunningham JP, Ghahramani Z. Linear dimensionality reduction: survey, insights, and generalizations. J Mach Learn Res. (2015) 16:2859–900.
27. Lee JA, Verleysen M. Nonlinear Dimensionality Reduction. New York, NY: Springer Science & Business Media (2007).
28. Emancipator K, Kroll MH. A quantitative measure of nonlinearity. Clin Chem. (1993) 39:766–72. doi: 10.1093/clinchem/39.5.766
29. Weilin H, Yin H. Linear and Nonlinear Dimensionality Reduction for Face Recognition, 2009 16th IEEE International Conference on Image Processing (ICIP) (Piscataway, NY). (2009). p. 3337–40.
30. Nagamine T, Seltzer ML, Mesgarani N. On the Role of Nonlinear Transformations in Deep Neural Network Acoustic Models, Interspeech. Rhineland-Palatinate: dblp computer science bibliography (2016). p. 803–7.
31. Cortese A, De Martino B, Kawato M. The neural and cognitive architecture for learning from a small sample. Curr Opin Neurobiol. (2019) 55:133–41. doi: 10.1016/j.conb.2019.02.011
33. Tenenbaum JB, Kemp C, Griffiths TL, Goodman ND. How to grow a mind: statistics, structure, and abstraction. Science. (2011) 331:1279. doi: 10.1126/science.1192788
34. Saitta L, Zucker J-D. Abstraction in Artificial Intelligence and Complex Systems. New York, NY: Springer (2013).
35. Zucker J-D. A grounded theory of abstraction in artificial intelligence. Philos Trans Royal Soc London Series B Biol Sci. (2003) 358:1293–309. doi: 10.1098/rstb.2003.1308
36. Wutz A, Loonis R, Roy JE, Donoghue JA, Miller EK. Different levels of category abstraction by different dynamics in different prefrontal areas. Neuron. (2018) 97:716–26.e8. doi: 10.1016/j.neuron.2018.01.009
37. Saez A, Rigotti M, Ostojic S, Fusi S, Salzman CD. Abstract context representations in primate amygdala and prefrontal cortex. Neuron. (2015) 87:869–81. doi: 10.1016/j.neuron.2015.07.024
38. Bernardi S, Benna MK, Rigotti M, Munuera J, Fusi S, Daniel Salzman C. The geometry of abstraction in the hippocampus and prefrontal cortex. Cell. (2020) 183:954–67. doi: 10.1016/j.cell.2020.09.031
39. Richards BA, Lillicrap TP, Beaudoin P, Bengio Y, Bogacz R, Christensen A, et al. A deep learning framework for neuroscience. Nat Neurosci. (2019) 22:1761–70. doi: 10.1038/s41593-019-0520-2
40. Zhang C, Bengio S, Hardt M, Recht B, Vinyals O. Understanding deep learning requires rethinking generalization. arXiv. (2016) 03530.
41. Lukman S, He Y, Hui S-C. Computational methods for traditional Chinese medicine: a survey. Comp Meth Prog Biomed. (2007) 88:283–94. doi: 10.1016/j.cmpb.2007.09.008
42. Huang M-J, Chen M-Y. Integrated design of the intelligent web-based Chinese medical diagnostic system (CMDS)–Systematic development for digestive health. Exp Syst Appl. (2007) 32:658–73. doi: 10.1016/j.eswa.2006.01.037
43. Xiao S, Peng C, Wang Z, Wang F, Zhiwei N. Using the algebraic sum method in medical expert systems. IEEE Eng Med Biol Mag. (1996) 15:80–2. doi: 10.1109/51.499763
44. Gu P, Chen H, Yu T. Ontology-oriented diagnostic system for traditional Chinese medicine based on relation refinement. Comp Mathemat Meth Med. (2013). doi: 10.1155/2013/317803
45. Wang X-w, Qu H-b, Liu X-s, CHENG Y-y. Bayesian network approach to knowledge discovery in traditional Chinese medicine. J Zhej Univ Eng Sci. (2005) 39:948.
46. Xu Q, Tang W, Teng F, Peng W, Zhang Y, Li W, et al. Intelligent syndrome differentiation of traditional chinese medicine by ann: a case study of chronic obstructive pulmonary disease. IEEE Access. (2019) 7:76167–75. doi: 10.1109/ACCESS.2019.2921318
47. Liu G-P, Yan J-J, Wang Y-Q, Zheng W, Zhong T, Lu X, et al. Deep learning based syndrome diagnosis of chronic gastritis. Comp Mathemat Meth Med. (2014) 2014:8. doi: 10.1155/2014/938350
48. Zhang Q, Zhang W-T, Wei J-J, Wang X-B, Liu P. Combined use of factor analysis and cluster analysis in classification of traditional Chinese medical syndromes in patients with posthepatitic cirrhosis. J Chin Integ Med. (2005) 3:14–18. doi: 10.3736/jcim20050105
49. Zhang NL, Yuan S, Chen T, Wang Y. Latent tree models and diagnosis in traditional Chinese medicine. Art Intell Med. (2008) 42:229–45. doi: 10.1016/j.artmed.2007.10.004
50. Zhang NL, Fu C, Liu TF, Chen B-x, Poon KM, Chen PX, et al. A data-driven method for syndrome type identification and classification in traditional Chinese medicine. J Integ Med. (2017) 15:110–23. doi: 10.1016/S2095-4964(17)60328-5
51. Wang Y, Ma L, Liao X, Liu P. Decision tree method to extract syndrome differentiation rules of posthepatitic cirrhosis in traditional Chinese medicine. In: 2008 IEEE International Symposium on IT in Medicine and Education (IEEE). (2008). p. 744–8. doi: 10.1109/ITME.2008.4743965
52. Arji G, Safdari R, Rezaeizadeh H, Abbassian A, Mokhtaran M, Hossein Ayati M. A systematic literature review and classification of knowledge discovery in traditional medicine. Comp Meth Prog Biomed. (2019) 168:39–57. doi: 10.1016/j.cmpb.2018.10.017
53. Chu X, Sun B, Huang Q, Peng S, Zhou Y, Zhang Y. Quantitative knowledge presentation models of traditional Chinese medicine (TCM): a review. Art Intell Med. (2020) 103:101810. doi: 10.1016/j.artmed.2020.101810
54. Lee C-Y. Investigating 'model-dependent realism' from the viewpoint of the traditional medical theories research. J Physiol Pathol Korean Med. (2015) 29:353–60. doi: 10.15188/kjopp.2015.10.29.5.353
55. Shah AK, Oppenheimer DM. Heuristics made easy: an effort-reduction framework. Psychol Bull. (2008) 134:207. doi: 10.1037/0033-2909.134.2.207
56. Lieder F, Griffiths TL, Huys QJ, Goodman ND. The anchoring bias reflects rational use of cognitive resources. Psychon Bull Rev. (2018) 25:322–49. doi: 10.3758/s13423-017-1286-8
Keywords: pattern identification, machine learning, dimensionality reduction, diagnostic system, traditional Asian medicine, traditional Chinese medicine, syndrome differentiation
Citation: Bae H, Lee S, Lee C-y and Kim C-E (2022) A Novel Framework for Understanding the Pattern Identification of Traditional Asian Medicine From the Machine Learning Perspective. Front. Med. 8:763533. doi: 10.3389/fmed.2021.763533
Received: 24 August 2021; Accepted: 23 December 2021;
Published: 03 February 2022.
Edited by:
Michele Mario Ciulla, University of Milan, ItalyReviewed by:
Young-Bae Park, Nubebe Mibyeong Research Institu, South KoreaWonmo Jung, Hamkkekiugi Inc., South Korea
Copyright © 2022 Bae, Lee, Lee and Kim. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Chang-Eop Kim, ZW9wY2hhbmdAZ2FjaG9uLmFjLmty