
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Med. , 17 January 2022
Sec. Intensive Care Medicine and Anesthesiology
Volume 8 - 2021 | https://doi.org/10.3389/fmed.2021.728521
This article is part of the Research Topic Clinical Application of Artificial Intelligence in Emergency and Critical Care Medicine, Volume II View all 19 articles
 Jinzhang Li1,2,3
Jinzhang Li1,2,3 Ming Gong2,3*
Ming Gong2,3* Yashutosh Joshi4Lizhong Sun2Lianjun Huang5
Yashutosh Joshi4Lizhong Sun2Lianjun Huang5 Ruixin Fan6Tianxiang Gu7Zonggang Zhang8Chengwei Zou9Guowei Zhang10Ximing Qian11Chenhui Qiao12Yu Chen13
Ruixin Fan6Tianxiang Gu7Zonggang Zhang8Chengwei Zou9Guowei Zhang10Ximing Qian11Chenhui Qiao12Yu Chen13 Wenjian Jiang2,3,4*
Wenjian Jiang2,3,4* Hongjia Zhang1,2,3*
Hongjia Zhang1,2,3*Background: Acute renal failure (ARF) is the most common major complication following cardiac surgery for acute aortic syndrome (AAS) and worsens the postoperative prognosis. Our aim was to establish a machine learning prediction model for ARF occurrence in AAS patients.
Methods: We included AAS patient data from nine medical centers (n = 1,637) and analyzed the incidence of ARF and the risk factors for postoperative ARF. We used data from six medical centers to compare the performance of four machine learning models and performed internal validation to identify AAS patients who developed postoperative ARF. The area under the curve (AUC) of the receiver operating characteristic (ROC) curve was used to compare the performance of the predictive models. We compared the performance of the optimal machine learning prediction model with that of traditional prediction models. Data from three medical centers were used for external validation.
Results: The eXtreme Gradient Boosting (XGBoost) algorithm performed best in the internal validation process (AUC = 0.82), which was better than both the logistic regression (LR) prediction model (AUC = 0.77, p < 0.001) and the traditional scoring systems. Upon external validation, the XGBoost prediction model (AUC =0.81) also performed better than both the LR prediction model (AUC = 0.75, p = 0.03) and the traditional scoring systems. We created an online application based on the XGBoost prediction model.
Conclusions: We have developed a machine learning model that has better predictive performance than traditional LR prediction models as well as other existing risk scoring systems for postoperative ARF. This model can be utilized to provide early warnings when high-risk patients are found, enabling clinicians to take prompt measures.
Acute aortic syndrome (AAS) is a serious and life-threatening disease process involving the ascending aorta and aortic arch. Traditionally, surgical intervention is the best way to treat AAS (1). Acute renal failure (ARF) is an important complication affecting the prognosis of AAS patients after surgery. This complication indicates that the patient has a poor prognosis, and it can increase postoperative mortality and morbidity (2). While renal replacement therapy (RRT) is a feasible treatment modality, it is arguably more important to identify the risk factors for postoperative ARF and identify potential patients with a higher likelihood of developing ARF in the postoperative setting. Some scoring systems already exist for predicting ARF after cardiac surgery (3–6), but they are usually employed for coronary artery bypass graft or heart valve surgery. Whether these scoring systems can be used in AAS-related surgery is unclear.
In recent years, machine learning has become increasingly widely used in medicine; it can help us process large amounts of data and find potential data relationships. Multiple excellent algorithms have been developed in the field of machine learning so that we can use them to build predictive models.
The main purpose of this study was to establish a predictive model for the occurrence of ARF in AAS patients after surgery through machine learning, thereby helping to identify potential patients who may develop ARF, and compare it with a traditional logistic regression (LR) prediction model and other scoring systems. This study followed the recommendations of the Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis statement (7).
A total of 1,637 AAS patients undergoing surgery and treatment at nine medical centers in China from January 1, 2015, to December 31, 2019 were recruited for this study. The ethics committee of Beijing Anzhen Hospital approved this retrospective cohort study (No. 2018015; Date: 2018-10-18). Patients' written informed consent was waived due to the retrospective nature of the study. We collected demographic, surgical, and clinical data with a potential relationship to the renal function of patients from admission through discharge. Patients who had renal failure before surgery, incomplete surgical data, or surgery involving the abdominal aorta and below were excluded. All patients were diagnosed with Stanford type-A AAS through aortic computed tomography angiography (CTA) by experienced imaging specialists and cardiovascular surgeons. The diagnosis of ARF was established according to the Kidney Disease: Improving Global Outcomes guidelines (8). Postoperative ARF was defined as an increase of >3 times or an increase of >4.0 mg/dL (353.6 μmol/L) in postoperative serum creatinine (Scr) or the initiation of RRT compared to baseline. The estimated glomerular filtration rate (eGFR) was calculated using the Chronic Kidney Disease Epidemiology Collaboration formula (CKD-EPI) (9). Surgery was performed by the surgical team of the medical center at the time of the patient's admission.
Anesthesia was maintained by either total intravenous anesthetics (propofol and sufentanil) or an inhalational agent (sevoflurane) with vecuronium bromide. Tranexamic acid was used for coagulation support. Cardiopulmonary bypass (CPB) was routinely instituted at 2.2 to 2.5 L/min/m2. When the lesion involved the aortic arch, arterial cannulation was performed in the right axillary and/or femoral artery and/or ascending aorta; venous cannulations were bicaval. Cold blood cardioplegia for myocardial protection was perfused through the left and right coronary arteries. If the distal aorta or aortic arch needed reconstruction, this process was performed under deep or moderate hypothermia and circulatory arrest. Once the distal reconstruction was complete, the aortic graft was clamped proximally. Selective anterograde perfusion was most often instituted through the innominate arteries. During core cooling, accompanying cardiac procedures, including aortic valve repair or replacement, sinus reconstruction, and root replacement, were performed if necessary. If the lesion involved only the ascending aorta, arterial cannulation was performed in the ascending aorta; venous cannulations were bicaval. Subsequently, reconstruction of the ascending aorta was performed.
For missing data, we used the k-nearest neighbors approach to fill in missing values (10). By calculating the Euclidean distance between each case, the missing value was imputed using the mean value from the five nearest neighbors. When the data were in the range of 0 to 1, most machine learning algorithms had excellent performance. To improve the performance of machine learning, we used the method provided by the MinMaxScaler function to scale the data during data pre-processing.
The description of the data and basic statistical analysis were performed using IBM SPSS Statistics for Windows Version 25.0. Continuous variables are expressed as the median (along with the first and third quartile values). Categorical variables are expressed as frequencies (n) with percentages (%). Statistical analysis of continuous variables was performed using the Mann–Whitney U test, while categorical variables were analyzed using the chi-squared test and Fisher's exact test. The area under the curve (AUC) of the receiver operating characteristic (ROC) curve was compared with the machine learning prediction model. DeLong's test (11) was used to calculate the P value. A P < 0.05 was considered statistically significant, and all statistical tests were two-sided.
We used Python for programming and used the scikit-learn 0.22.1 package to build machine learning classifiers (12). The concise process of establishing and evaluating the prediction model is shown in Supplementary Figure 1.
The machine learning prediction model used data from 1,637 patients from nine medical centers in China. Among them, 1,318 patient data points from six medical centers in Beijing, Zhejiang, Shandong, Liaoning and Henan provinces were used for machine learning training and internal validation. Training and validation data were divided by ten-fold cross-validation, each time 90% of the data was used as training data, and 10% of the data was used as validation data. And 319 patient data points from three medical centers in Heilongjiang and Guangdong provinces and Xinjiang Uygur Autonomous Region were used for external validation of the prediction model. The division of internal validation and external validation data was determined by the geographic location of the medical centers. The six medical centers used for machine learning training and internal validation were located in central China, and the three medical centers used for external validation were located in northern, southern and western China. This division method was suitable for evaluating the generalization ability of predictive models.
For the selection of machine learning algorithms, we chose the support vector machine classifier (SVC) linear kernel and Nu-SVC with the radial basis function kernel in the SVC algorithm. These are two classic algorithms that use the classifier with the largest interval in the feature space for classification, and can perform data classification after linear-range or high-dimensional mapping. It is still valid when the feature has a high-dimensional relationship. Among them, SVC uses a linear algorithm, while Nu-SVC uses a radial basis function. At the same time, we chose the AdaBoost algorithm (13) and the eXtreme Gradient Boosting (XGBoost) algorithm (14) in the ensemble methods, which are popular algorithms in machine learning classifiers and can combine the predictions of several base estimators so that they have excellent performance. AdaBoost integrates multiple basic decision trees, uses misclassified data points to identify problems, and improves the model by adjusting the weights of misclassified data points. XGBoost uses negative gradients to identify problems, and calculates negative gradients to improve the model. In addition, we also tested the combination of two algorithms. This combination uses two independent algorithms to build prediction models separately, and uses the results of the two prediction models as features to retrain the new prediction model, which is also called a stacking algorithm. We tested the combination of XGBoost + random forest algorithm and XGBoost + decision tree algorithm.
To make the prediction model more accurate, we selected all demographic characteristics and preoperative clinical data as the features for machine learning. At the beginning of model training, all 134 features were used (Supplementary Table 3), and Shapley additive explanations (SHAP) was used to judge the importance of each feature. In the machine learning prediction model, SHAP can analyse the impact of each feature of each patient on the prediction result (15). Finally, the features that were considered important in all prediction models were used as the final features of the machine learning model.
Ten-fold cross-validation is considered a reliable method for model evaluation and performance improvement (16), and it was used for parameter adjustment and algorithm comparison. Since machine learning algorithms usually cannot use training data as test data, 10-fold cross-validation is generally used to evaluate machine learning algorithms. Ten-fold cross-validation can divide the data into 10 parts. The classifier used nine of them for training, and the remaining part was used for testing. Ten repetitions constituted a 10-fold cross-validation (Supplementary Figure 2). The average of 10 test results was used to evaluate the predictive ability of machine learning algorithms and parameters.
Each classifier algorithm had many parameter settings, and the choice of parameters had a great impact on the results of the classifier. We used the grid-search algorithm and internal validation data to determine the best parameters for each classifier algorithm.
The grid-search algorithm used 10-fold cross-validation to select the parameters of the machine learning algorithm. We told the grid search algorithm the potential optimal parameter range of the classifier, and the grid search algorithm used 10-fold cross validation to calculate the predictive ability of each set of parameters. After the grid-search algorithm calculated each set of parameter combinations, it told us the optimal parameter combination. After constantly changing the parameter range used by the grid search algorithm, the optimal parameter combination of this machine learning algorithm was finally obtained.
Similarly, 10-fold cross-validation was used to compare classifier algorithms. The ROC curve and AUC were calculated at each validation, and the mean and standard deviation of each AUC were compared to obtain the optimal classifier algorithm.
To compare the machine learning prediction model with the traditional prediction model, we used multivariable LR analysis to establish an LR prediction model with ARF as the end point. In addition, the Cleveland scoring system (3), the simplified renal index (SRI) scoring system (5) and the Leicester scoring system (6) were selected as representatives of the traditional prediction model. The endpoints of these three classic scoring systems were renal failure and RRT, and they were also scored for complex surgery. To evaluate the prediction model, we compared the machine learning prediction model with the four traditional prediction models. The ROC curve and AUC of the prediction model were calculated using internal validation data. The machine learning prediction model used 10-fold cross-validation to calculate the mean ROC curve and the AUC. In the external validation, the machine learning predictive model was trained using internal validation data. Then, we used the parametric approach based on Platt's logistic model to calibrate the probability of the machine learning model (17) and evaluated the discrimination and calibration of the model by calculating the Brier score. The trained machine learning prediction model was compared with the traditional prediction models using external validation data to evaluate the generalization ability of the prediction model.
A total of 1,637 patients were enrolled in the study, with 1,318 of these cases being used for machine learning training and internal validation. The main characteristics of patients in the internal validation group are presented in Table 1. The median age of the patients was 50.0 (42.0–57.0) years; 301 (22.8%) patients were female.
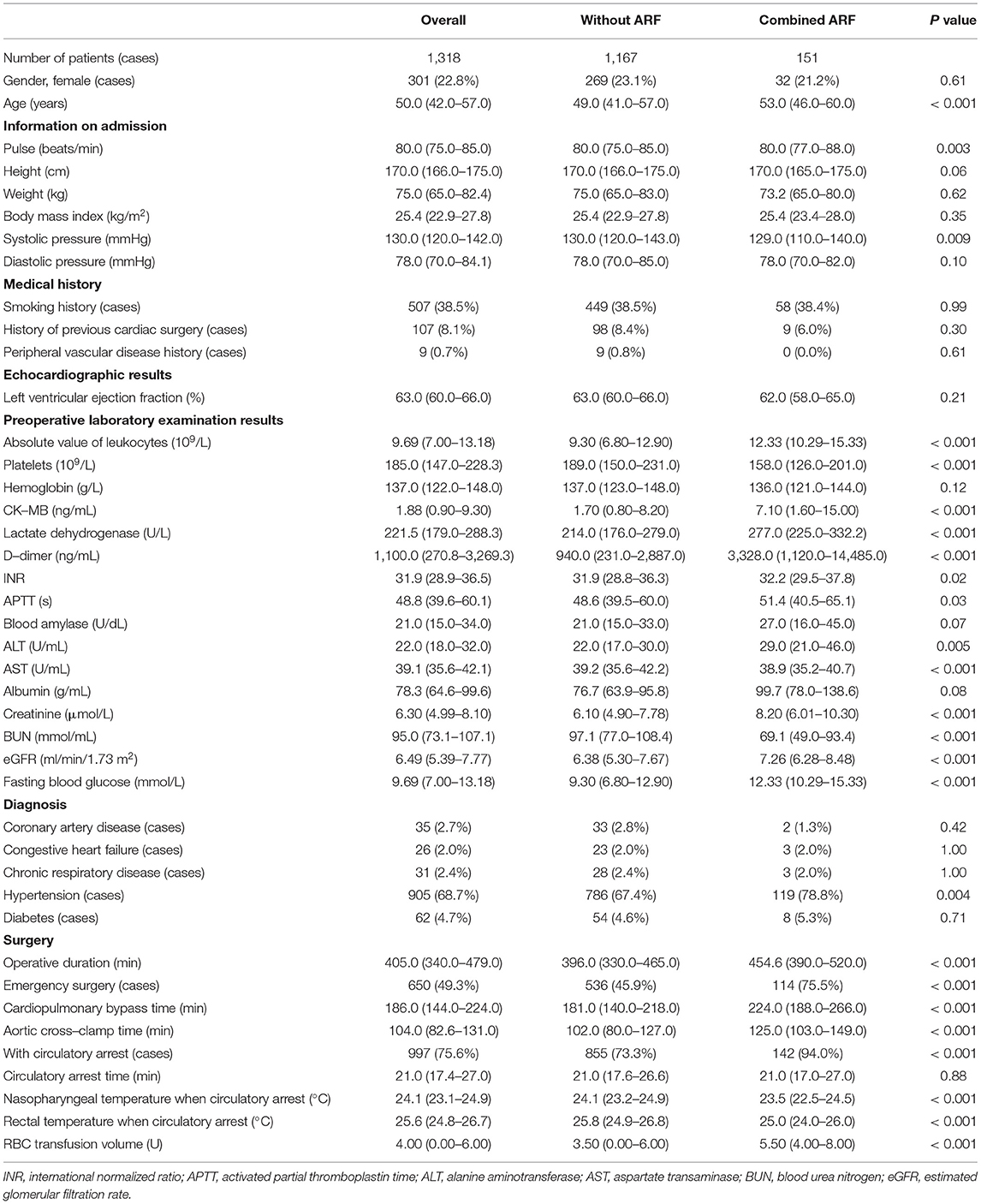
Table 1. Main characteristics of patients in the internal validation groups.
The incidence of ARF after aortic surgery was 11.5% (151 in 1,318). The prognostic characteristics of the patients are presented in Supplementary Table 1. Patients with postoperative ARF had a poor prognosis and had longer ICU stays (204.0 (104.5–308.2) h vs. 43.0 (20.0–112.5) h, P < 0.001) as well as longer ventilator use times (114.0 (62.0–179.0) h vs. 20.0 (15.0–48.0) h, P < 0.001). Postoperative ARF may be related to the use of more blood products and drug infusions. Furthermore, patients with postoperative ARF had more postoperative complications (74.8 vs. 34.5%, P < 0.001). Most importantly, there were significant differences in mortality between patients with and without ARF (12.6 vs. 0.8%, respectively, P < 0.001).
As a comparison with machine learning models, we used traditional statistical methods to analyse all preoperative and intraoperative factors that either had significant differences or were clinically believed to be related to ARF and calculated the risk factors for postoperative ARF. A multivariable binary LR with the “Forward: LR” method was conducted to determine the risk factors for postoperative ARF (Table 2). The results showed that, among the preoperative factors, older age, a higher pulse rate, emergency surgery, and an increased absolute value of leukocytes in the preoperative setting were all risk factors. It was also noted that an increased estimated glomerular filtration rate (eGFR) and platelet count were protective factors against postoperative ARF. In the combined analysis of preoperative and intraoperative factors, in addition to the aforementioned preoperative factors, longer cardiopulmonary bypass time, lower rectal temperature when circulatory arrest, and surgery with circulatory arrest were risk factors for postoperative ARF. We used preoperative factors to establish an LR prediction model for the predictive model to have the ability to predict postoperative ARF of patients before surgery (Table 2).
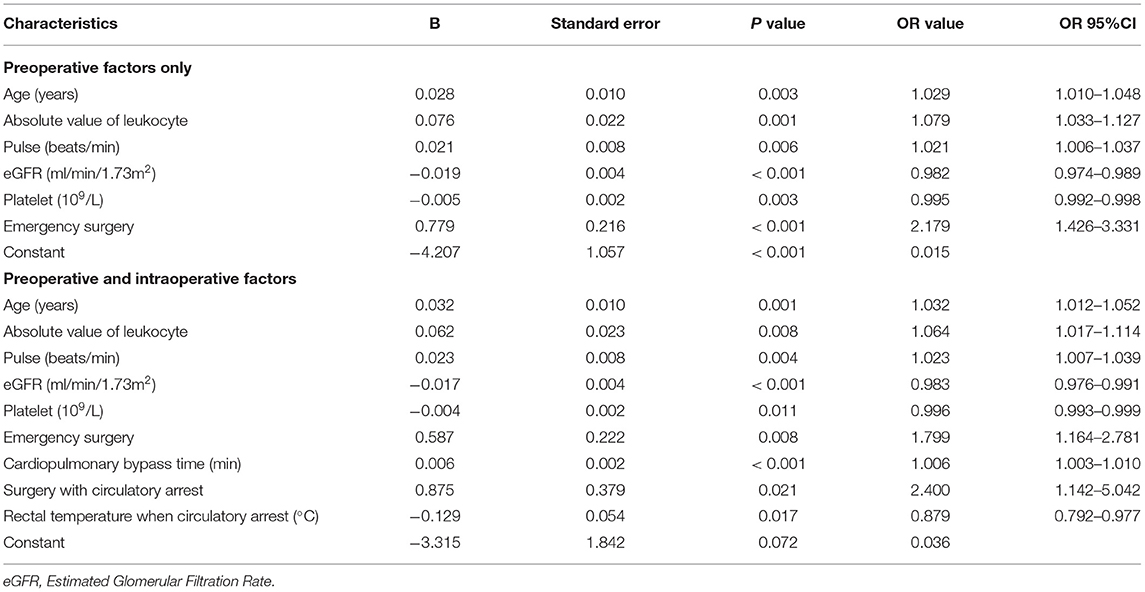
Table 2. Multivariable binary logistic regression results.
In the initial stage, we built machine learning models using all the preoperative features and unoptimized parameters. We analyzed the feature importance of these machine learning models through SHAP (15) and finally selected 15 features for building machine learning prediction models (Table 3).
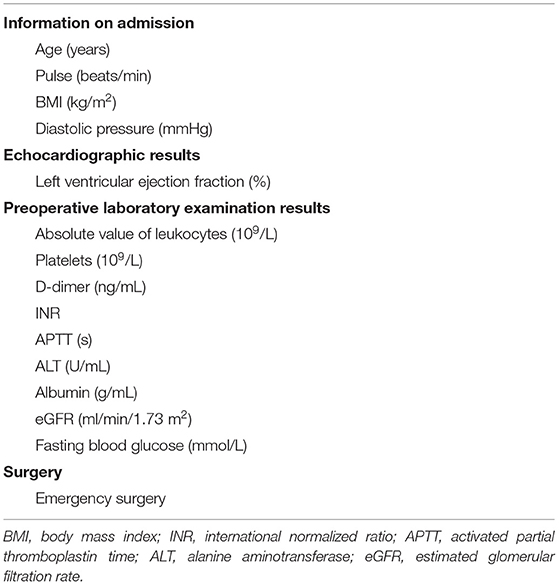
Table 3. Features used to build machine learning prediction model.
Among the 15 features used to establish these models, we collected complete demographic and renal function data. However, as AAS patients may require emergency surgery, occasionally, the blood test results were partially missing. We used the k-nearest neighbors approach to fill in missing values. Supplementary Table 2 shows the details of missing values.
Machine learning models were trained using internal validation data, and the performance of the machine learning models was evaluated using 10-fold cross-validation. The results showed the mean ROC curve and AUC of each machine learning model after 10-fold cross-validation (Figure 1). We found that among the prediction models established by a single algorithm, the XGBoost machine learning model performed best (AUC = 0.82, 95% confidence interval (CI): 0.79–0.85), and the combination of XGBoost and other algorithms did not improve performance (Supplementary Figure 3); thus, we chose the XGBoost model as the final machine learning model to evaluate its performance. This model had 750 gradient boosted trees, the maximum tree depth was eight, the learning rate was 0.01, the subsample ratio of columns when constructing each tree was 0.75, and the subsample ratio of the training instance was 0.68.
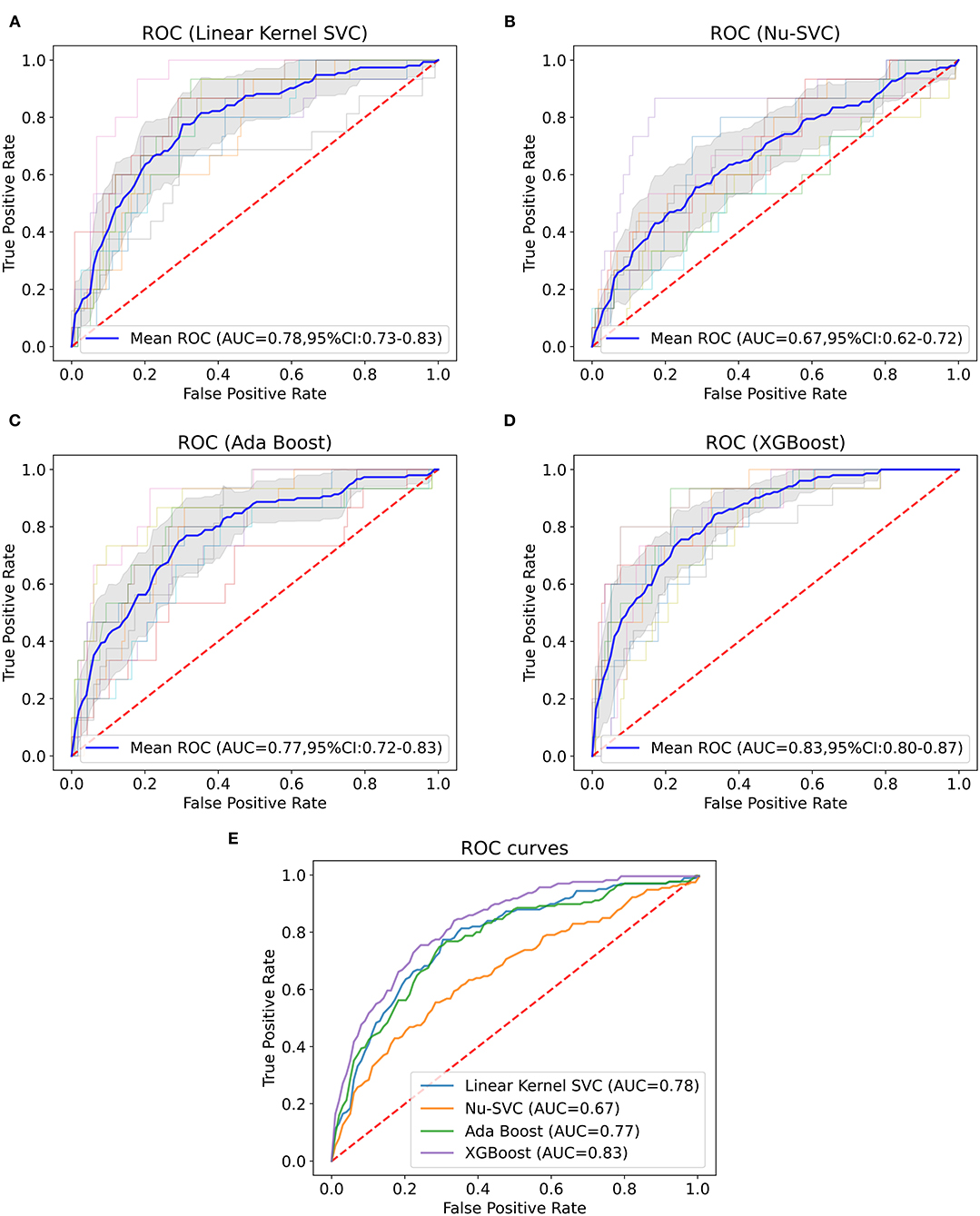
Figure 1. Mean ROC curve and AUC of machine learning models. This figure depicts the mean ROC curve and AUC of the linear kernel SVC (A), Nu-SVC (B), AdaBoost (C) and XGBoost (D) using internal validation data (n = 1,318). The blue line represents the mean of each ROC curve after 10-fold cross-validation. The shaded area is the 95% confidence interval of the mean ROC curve. The other translucent lines are ROC curves for each cross-validation. (E) Comparison of the mean ROC curves for each algorithm.
Subsequently, the importance of each feature of the XGBoost model was analyzed by the SHAP method. Figure 2 shows the results of the feature importance analysis, with more important features distributed on the top and relatively unimportant features on the bottom. Most of the characteristics, either positively or negatively, correlated with the prediction results; however, activated partial thromboplastin time (APTT), fasting blood glucose, body mass index (BMI), international normalized ratio (INR), and alanine aminotransferase (ALT) that were either too high or too low increased the risk of ARF. At the same time, we also analyzed the feature importance based on the fitted trees of the XGBoost model (Supplementary Figure 4), and the result is similar to the result of SHAP.
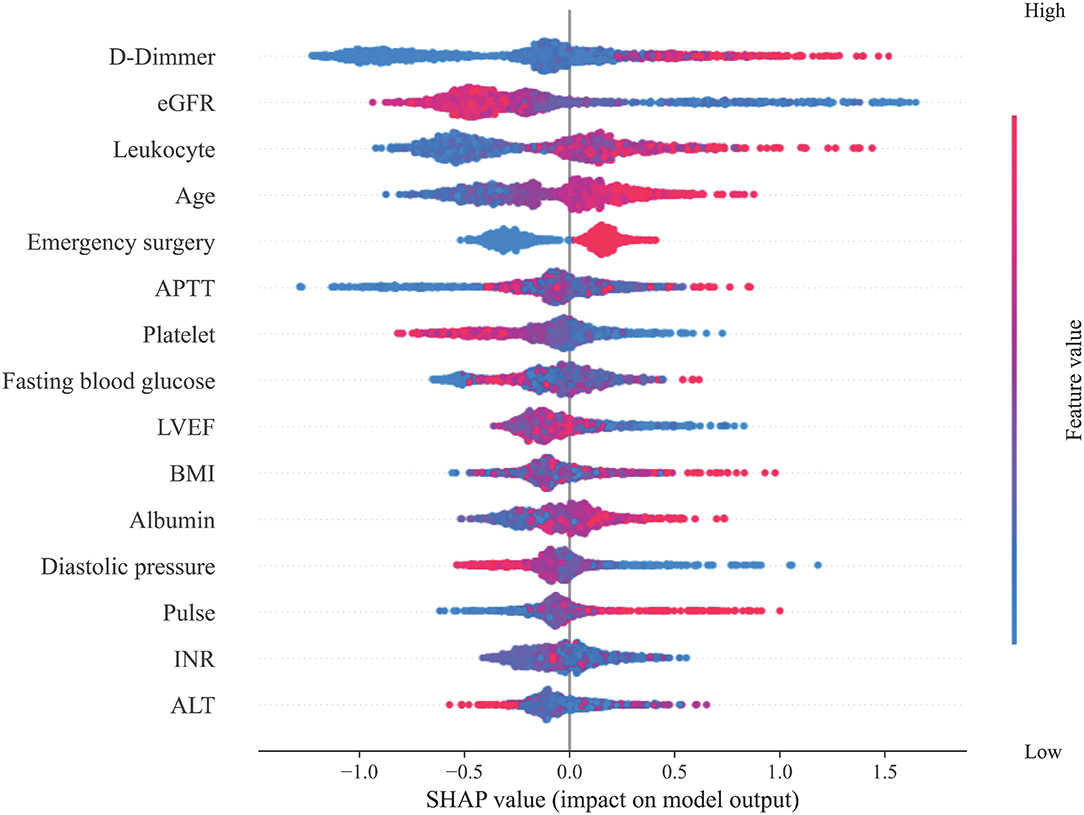
Figure 2. Feature importance analysis. This figure shows the results of the analysis on the importance of the features in the XGBoost model through the SHAP method. Each feature value of each patient is marked as a dot on the graph. The color of the dot represents the degree of deviation of the feature value from the overall value according to the ordinate, and purple represents that the feature of the patient is close to the mean of the feature of the overall patient value. The SHAP value of the dot indicates the influence of the feature on the prediction result. A negative SHAP value indicates that the patient's risk of ARF is reduced, while a positive SHAP value indicates that the patient's risk of ARF is increased.
We used internal validation data to calculate the ROC curve and the AUC of the four traditional prediction models (Figure 3) and found that the XGBoost model (AUC = 0.82, 95% CI: 0.79–0.85) performed better than the LR prediction model (AUC = 0.77, 95% CI: 0.73–0.81, P <0.001), the Cleveland scoring system (AUC = 0.73, 95% CI: 0.69–0.77, P <0.001), the SRI scoring system (AUC = 0.72, 95% CI: 0.68–0.76, P <0.001), and the Leicester scoring system (AUC = 0.72, 95% CI: 0.68–0.77, P < 0.001) (Table 4).
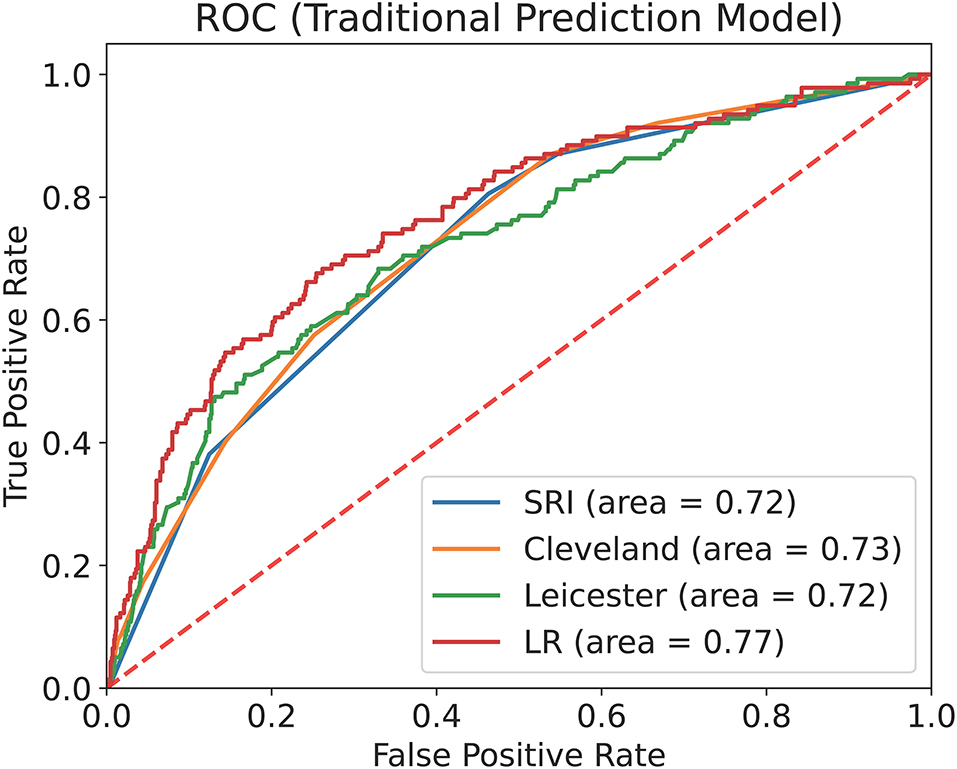
Figure 3. ROC curve and AUC of the traditional prediction models with internal validation data. This figure describes the ROC curve and the AUC of the Cleveland scoring system, the SRI scoring system, the Leicester scoring system and the LR prediction model with internal validation data (n = 1,318).
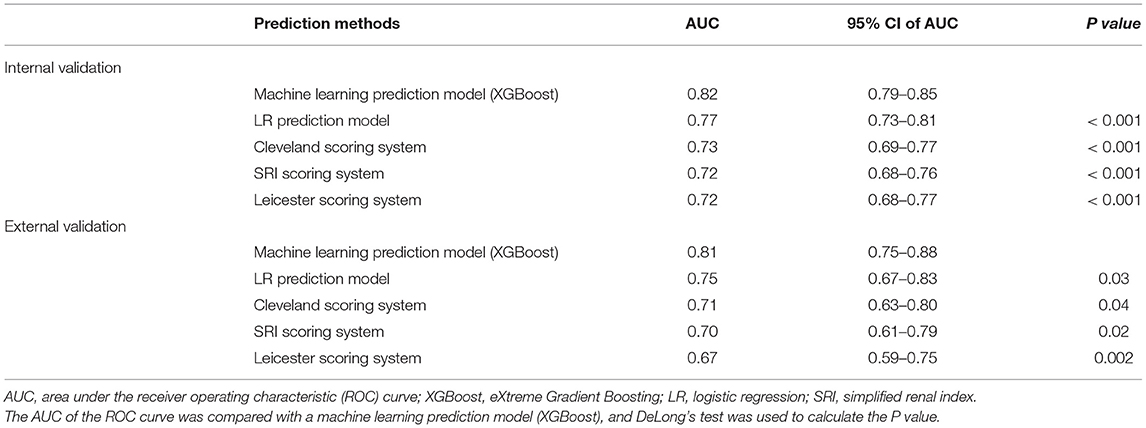
Table 4. Performance of machine learning prediction model and scoring system.
The external validation group included 319 patients. The comparison of the internal and external validation group characteristics is presented in Table 5. The median of the average age of patients in the external validation group was 50.0 (16.0) years. The incidence of ARF after aortic surgery was similar to that in the internal validation group (11.0 vs. 11.5%, P = 0.807).
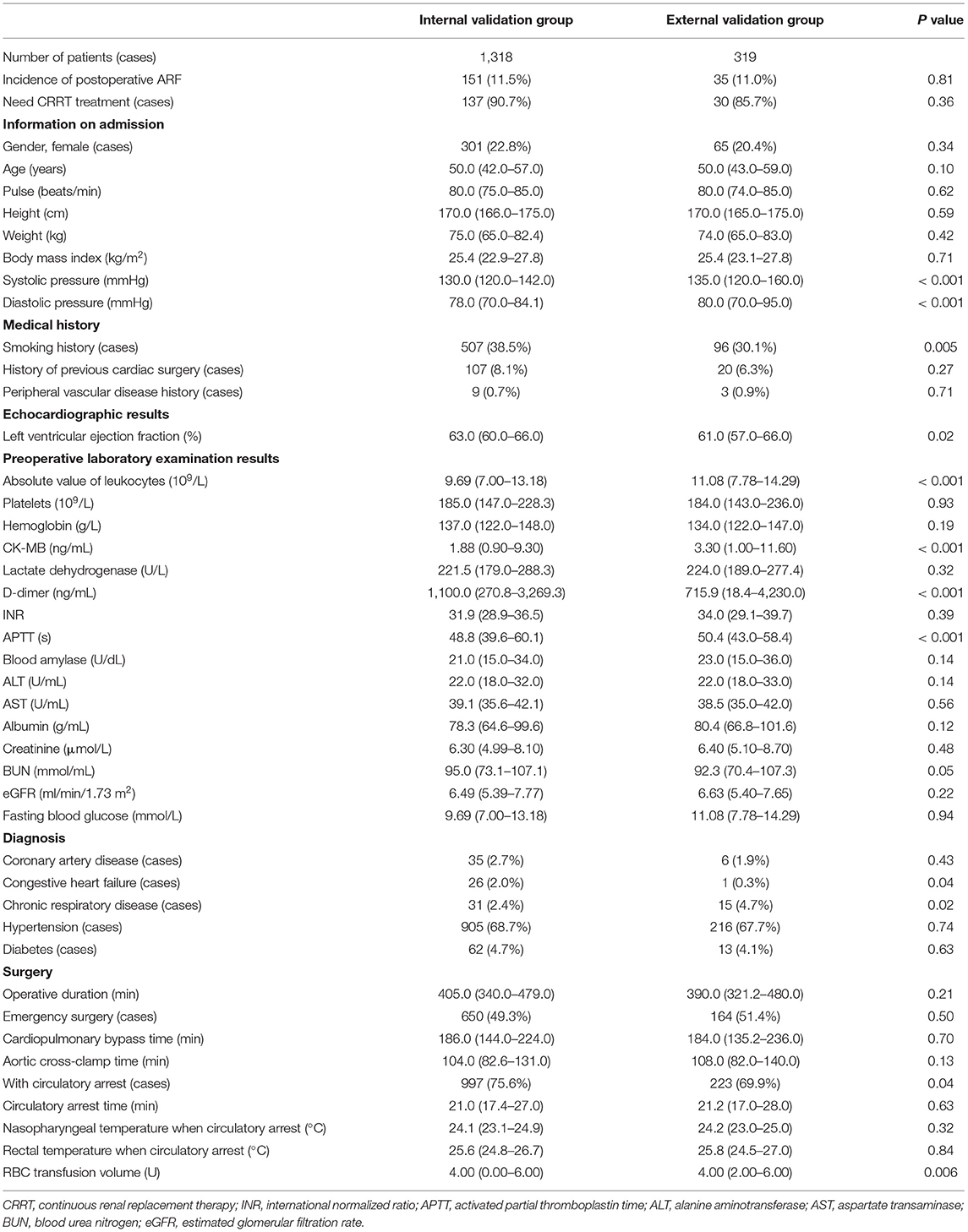
Table 5. Comparison of characteristics in the internal and external validation groups.
After probability calibration, the Brier score of the machine learning prediction model using the external validation data was 0.087, which showed that the prediction model had good discrimination and calibration. Using external validation data for evaluation, we found that the XGBoost model after probability calibration (AUC = 0.81, 95% CI: 0.75–0.88) performed better than the LR prediction model (AUC = 0.75, 95% CI: 0.67–0.83, P = 0.03), the Cleveland scoring system (AUC = 0.71, 95% CI: 0.63–0.80, P = 0.04), the SRI scoring system (AUC = 0.70, 95% CI: 0.61–0.79, P = 0.02), and the Leicester scoring system (AUC = 0.67, 95% CI: 0.59–0.75, P = 0.002) (Table 4).
Finally, to make the XGBoost prediction model easy to use, we developed an application (https://ljzyal.github.io/ARF/) for clinical use. The application used a probability-calibrated XGBoost prediction model, which had the same performance as the prediction model in external validation. We set the cut-off value based on the results of external validation. The prediction model had a sensitivity of 82.9% and a specificity of 67.6%. The risk calculated by the application increased with the possibility of postoperative ARF.
ARF is the end stage of acute kidney injury, and it is the most common major complication following cardiac surgery (18). ARF can lead to poor patient prognosis and is independently associated with increased morbidity and mortality after cardiac surgery (19). In this study, the incidence of postoperative ARF in AAS patients reached 11.5%, and patients with ARF had a longer ICU length of stay, longer ventilator use time and a worse prognosis.
The mechanism of ARF after cardiac surgery remains to be elucidated, and its pathogenesis is currently thought to be related to renal hypoperfusion, tissue ischaemia-reperfusion injury and the inflammatory response (20). Previous studies have shown that risk factors for ARF include female sex, advanced age, previous heart surgery, chronic obstructive pulmonary disease, diabetes, complex heart surgery, prolonged cardiopulmonary bypass, rapid heart rate, emergency surgery, and intraoperative infusion of 2 or more packed red blood cell (RBC) units (21–23). In this study, we found that patients with AAS have more complex risk factors for postoperative ARF. In addition to the above factors, we found that postoperative ARF was also related to preoperative leukocyte and platelet counts, which may be because the occurrence of ARF is related to the inflammatory response (20). The higher preoperative leukocyte count may indicate that the inflammatory response caused by AAS is more serious. This effect may continue to play a role after surgery, making postoperative ARF more likely to occur. Furthermore, abnormal blood coagulation is another potential mechanism of ARF (24). Lower preoperative platelets may be a manifestation of a hypercoagulable state and intravascular coagulation, which makes AAS patients with higher preoperative platelet counts less prone to postoperative ARF.
Early identification of patients with a higher ARF risk can help clinicians strengthen patient monitoring and take measures to prevent ARF. Many studies have used risk factors or novel biomarkers to build prediction models for ARF (3–6, 25). Novel biomarker-related prediction methods, however, are usually cumbersome, and no new biomarker has been widely accepted (25). Currently, the best-performing large-sample model is poor at predicting ARF after complex surgery (6). Aortic surgery usually results in a higher incidence of postoperative ARF; therefore, postoperative ARF prediction methods for complex heart and aortic surgeries are necessary.
According to the results of this study, we recommend the following measures to reduce the occurrence of ARF. Once the model is used to predict the postoperative risk of ARF, for those with a low predicted risk, it is recommended to perform surgery in a timely fashion once the patient is surgically prepared.
For patients with a higher predicted risk of ARF, it is recommended to attempt to ameliorate the modifiable risk factors that are included in the prediction model. This could be achieved by improving preoperative preparations, such as administering antimicrobials, considering platelet transfusion, controlling blood glucose levels, maintaining adequate diastolic blood pressure, and controlling heart rate. In addition, during the operation, it is recommended to pay more attention to renal function and to maintain renal perfusion by taking measures to maintain circulatory stability. In addition to the aforementioned modifications, intraoperative innovations in surgical methods should be adopted, which can help reduce the operative and CPB time.
Additionally, for patients noted to be at a higher risk of ARF, it is also recommended to use stricter monitoring and more favorable preventive and treatment measures in perioperative management, which could include minimizing the use of nephrotoxic drugs and administering treatment for renal injury as soon as possible to prevent patients from progressing to ARF.
Risk prediction plays an important role in cardiovascular disease research. As the most commonly used traditional predictive model, LR sometimes cannot handle complex clinical data and thus cannot obtain an ideal predictive model. Conversely, machine learning can handle complex clinical data and thus potentially has more advantages (26). In this study, by selecting AAS as a disease process for focused research, we found that the performance of machine learning predictive models is better than that of traditional predictive models. This suggests that machine learning algorithms are more suitable for building clinical prediction models and have a higher performance than LR.
In this study, we found that the XGBoost algorithm has the best prediction performance and still has excellent performance in external validation. XGBoost is a machine learning algorithm that uses classification and regression trees as weak classifiers (14). Compared with other algorithms, the XGBoost algorithm allows easy adjustment of parameters and can deal with nonlinear features. It usually has higher sensitivity and specificity when overfitting is avoided. In most cases, XGBoost has higher prediction performance than other algorithms (27, 28).
Machine learning algorithms are also suitable for the construction of other predictive models, which have excellent performance and can be continuously trained with new data to have greater potential. After the prediction model is established, the newly collected data can be used to continue training, thereby enhancing the generalization ability of the prediction model.
Machine learning algorithms have been considered a black box in the past, which is the main disadvantage compared to LR. However, the SHAP method can explain the machine learning prediction model. We used the SHAP method to analyse the importance of particular features in the prediction model. This method can analyse the impact of each variable on each patient so the prediction model is interpretable. We found that the SHAP method is effective in determining the importance of particular individual features.
To compare with LR, all features included in an LR are also considered important features in machine learning prediction models. Concurrently, however, the SHAP method also judges other features, those that are not considered statistically significant in the LR, as important features. This possibly results in LR not including certain relevant features, whereas the SHAP method does not exclude such features. According to the results of the feature importance analysis, we can also judge the impact of each variable on the results to determine the patient's treatment direction to prevent postoperative ARF.
First, all data for this study were sourced from China. Due to ethnic differences, the performance of our predictive model in other countries may decrease. However, our research method is innovative, and it is feasible to establish such a model in other countries through this investigational method. Second, machine learning algorithms are more complex than LR, and model representation is also very complicated (29). Our predictive model cannot be similar to LR, and it does not provide a scoring system for clinicians. We have therefore developed an online application for convenience. Third, our machine learning prediction model needs more extensive data for verification. Finally, although the performance of our prediction model was better than that of LR, some data were not involved in the initial data collection, such as detailed laboratory test results, detailed medical history and detailed documentation of the use of nephrotoxic drugs. Supervised machine learning can improve the model after supplementing these data, and consequently, our predictive model has the potential to improve.
In summary, our findings suggest that machine learning prediction models can provide better prediction performance than traditional LR prediction models and other existing risk scoring systems for AAS and complex cardiac and aortic surgeries. This predictive model is helpful for the early detection of patients with high ARF risk, thus enabling clinicians to take early measures to prevent and treat ARF.
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
The studies involving human participants were reviewed and approved by the Ethics Committee of Beijing Anzhen Hospital. Written informed consent for participation was not required for this study in accordance with the national legislation and the institutional requirements.
HZ and WJ designed the research. JL and MG analyzed the data and wrote the paper. YJ analyzed the data and revised the manuscript. LS, LH, RF, TG, ZZ, CZ, GZ, XQ, CQ, and YC were responsible for the data collection. All authors read and approved the final manuscript.
This study was supported by the National Key Research and Development Program of China (2017YFC1308000), Capital Health Development Research Project (2018-2-2066 and 2018-4-2068), National Science Foundation of China (81600362 and 81800404), Beijing Lab for Cardiovascular Precision Medicine (PXM2017_014226_000037), Beijing Advanced Innovation Center for Big Data-based Precision Medicine (PXM2021_014226_000026), Beijing Municipal Administration of Hospitals' Youth Program (QML20180601), and Foundation of Beijing Outstanding Young Talent Training Program (2017000021469G254). The funders did not have a role in the study design, collection, analysis or reporting of data, preparation of the manuscript or decision to submit for publication.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fmed.2021.728521/full#supplementary-material
1. Erbel R, Aboyans V, Boileau C, Bossone E, Bartolomeo RD, Eggebrecht H, et al. 2014 ESC Guidelines on the diagnosis and treatment of aortic diseases: Document covering acute and chronic aortic diseases of the thoracic and abdominal aorta of the adult. The Task Force for the Diagnosis and Treatment of Aortic Diseases of the European Society of Cardiology (ESC). Eur Heart J. (2014) 35:2873–926. doi: 10.1093/eurheartj/ehu281
2. Englberger L, Suri RM, Greason KL, Burkhart HM, Sundt TM. 3rd, Daly RC, et al. Deep hypothermic circulatory arrest is not a risk factor for acute kidney injury in thoracic aortic surgery. J Thorac Cardiovasc Surg. (2011) 141:552–8. doi: 10.1016/j.jtcvs.2010.02.045
3. Thakar CV, Arrigain S, Worley S, Yared JP, Paganini EP, A. clinical score to predict acute renal failure after cardiac surgery. J Am Soc Nephrol. (2005) 16:162–8. doi: 10.1681/ASN.2004040331
4. Mehta RH, Grab JD, O'Brien SM, Bridges CR, Gammie JS, Haan CK, et al. Bedside tool for predicting the risk of postoperative dialysis in patients undergoing cardiac surgery. Circulation. (2006) 114:2208–16. doi: 10.1161/CIRCULATIONAHA.106.635573
5. Wijeysundera DN, Karkouti K, Dupuis JY, Rao V, Chan CT, Granton JT, et al. Derivation and validation of a simplified predictive index for renal replacement therapy after cardiac surgery. JAMA. (2007) 297:1801–9. doi: 10.1001/jama.297.16.1801
6. Birnie K, Verheyden V, Pagano D, Bhabra M, Tilling K, Sterne JA, et al. Predictive models for kidney disease: improving global outcomes (KDIGO) defined acute kidney injury in UK cardiac surgery. Crit Care. (2014) 18:606. doi: 10.1186/s13054-014-0606-x
7. Collins GS, Reitsma JB, Altman DG, Moons KG, Group T. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): the TRIPOD statement. The TRIPOD group. Circulation. (2015) 131:211–9. doi: 10.1161/CIRCULATIONAHA.114.014508
8. Kellum JA, Lameire N, Group KAGW. Diagnosis, evaluation, and management of acute kidney injury: a KDIGO summary (Part 1). Crit Care. (2013) 17:204. doi: 10.1186/cc11454
9. Levey AS, Stevens LA, Schmid CH, Zhang YL, Castro AF. 3rd, Feldman HI, et al. A new equation to estimate glomerular filtration rate. Ann Intern Med. (2009) 150:604–12. doi: 10.7326/0003-4819-150-9-200905050-00006
10. Troyanskaya O, Cantor M, Sherlock G, Brown P, Hastie T, Tibshirani R, et al. Missing value estimation methods for DNA microarrays. Bioinformatics. (2001) 17:520–5. doi: 10.1093/bioinformatics/17.6.520
11. DeLong ER, DeLong DM, Clarke-Pearson DL. Comparing the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach. Biometrics. (1988) 44:837–45. doi: 10.2307/2531595
12. Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, et al. Scikit-learn: machine learning in Python. J Mach Learn Res. (2011) 12:2825–30.
13. Freund Y, Schapire RE, editors. A desicion-theoretic generalization of on-line learning and an application to boosting. European conference on computational learning theory. Springer. (1995) doi: 10.1007/3-540-59119-2_166
14. Chen T, Guestrin C. XGBoost: A Scalable Tree Boosting System. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco, California, USA: Association for Computing Machinery (2016). p. 785–94. doi: 10.1145/2939672.2939785
15. Lundberg SM, Lee S-I, A. Unified Approach to Interpreting Model Predictions. Adv Neural Inf Process Syst. (2017) 30:4765–74.
16. Motwani M, Dey D, Berman DS, Germano G, Achenbach S, Al-Mallah MH, et al. Machine learning for prediction of all-cause mortality in patients with suspected coronary artery disease: a 5-year multicentre prospective registry analysis. Eur Heart J. (2017) 38:500–7. doi: 10.1093/eurheartj/ehw188
17. Platt JC. Probabilistic Outputs for Support Vector Machines and Comparisons to Regularized Likelihood Methods. Advances in Large Margin Classifiers. (1999).
18. Bove T, Monaco F, Covello RD, Zangrillo A. Acute renal failure and cardiac surgery. HSR Proc Intensive Care Cardiovasc Anesth. (2009) 1:13–21.
19. Ortega-Loubon C, Fernandez-Molina M, Carrascal-Hinojal Y, Fulquet-Carreras E. Cardiac surgery-associated acute kidney injury. Ann Card Anaesth. (2016) 19:687–98. doi: 10.4103/0971-9784.191578
20. Chew STH, Hwang NC. Acute Kidney Injury After Cardiac Surgery: A Narrative Review of the Literature. J Cardiothorac Vasc Anesth. (2019) 33:1122–38. doi: 10.1053/j.jvca.2018.08.003
21. Pacini D, Pantaleo A, Di Marco L, Leone A, Barberio G, Parolari A, et al. Risk factors for acute kidney injury after surgery of the thoracic aorta using antegrade selective cerebral perfusion and moderate hypothermia. J Thorac Cardiovasc Surg. (2015) 150:127–33 e1. doi: 10.1016/j.jtcvs.2015.04.008
22. Khan UA, Coca SG, Hong K, Koyner JL, Garg AX, Passik CS, et al. Blood transfusions are associated with urinary biomarkers of kidney injury in cardiac surgery. J Thorac Cardiovasc Surg. (2014) 148:726–32. doi: 10.1016/j.jtcvs.2013.09.080
23. Shiao CC, Huang YT, Lai TS, Huang TM, Wang JJ, Huang CT, et al. Perioperative body weight change is associated with in-hospital mortality in cardiac surgical patients with postoperative acute kidney injury. PLoS ONE. (2017) 12:e0187280. doi: 10.1371/journal.pone.0187280
24. Nguyen TC, Cruz MA, Carcillo JA. Thrombocytopenia-associated multiple organ failure and acute kidney injury. Crit Care Clin. (2015) 31:661–74. doi: 10.1016/j.ccc.2015.06.004
25. Wang Y, Bellomo R. Cardiac surgery-associated acute kidney injury: risk factors, pathophysiology and treatment. Nat Rev Nephrol. (2017) 13:697–711. doi: 10.1038/nrneph.2017.119
26. Hamet P, Tremblay J. Artificial intelligence in medicine. Metabolism. (2017) 69S:S36–S40. doi: 10.1016/j.metabol.2017.01.011
27. Ruan Y, Bellot A, Moysova Z, Tan GD, Lumb A, Davies J, et al. Predicting the risk of inpatient hypoglycemia with machine learning using electronic health records. Diabetes Care. (2020) 43:1504–11. doi: 10.2337/dc19-1743
28. Leung WK, Cheung KS Li B, Law SYK, Lui TKL. Applications of machine learning models in the prediction of gastric cancer risk in patients after Helicobacter pylori eradication. Aliment Pharmacol Ther. (2021) 53:864–72. doi: 10.1111/apt.16272
Keywords: machine learning, acute renal failure, acute aortic syndrome, prediction model, eXtreme Gradient Boosting
Citation: Li J, Gong M, Joshi Y, Sun L, Huang L, Fan R, Gu T, Zhang Z, Zou C, Zhang G, Qian X, Qiao C, Chen Y, Jiang W and Zhang H (2022) Machine Learning Prediction Model for Acute Renal Failure After Acute Aortic Syndrome Surgery. Front. Med. 8:728521. doi: 10.3389/fmed.2021.728521
Received: 21 June 2021; Accepted: 24 December 2021;
Published: 17 January 2022.
Edited by:
Zhongheng Zhang, Sir Run Run Shaw Hospital, ChinaCopyright © 2022 Li, Gong, Joshi, Sun, Huang, Fan, Gu, Zhang, Zou, Zhang, Qian, Qiao, Chen, Jiang and Zhang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Hongjia Zhang, emhhbmdob25namlhNzIyQGNjbXUuZWR1LmNu; Wenjian Jiang, amlhbmd3ZW5qaWFuQGNjbXUuZWR1LmNu; Ming Gong, Z29uZ21hc3RlckAxMjYuY29t
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.