
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Med. , 28 June 2021
Sec. Intensive Care Medicine and Anesthesiology
Volume 8 - 2021 | https://doi.org/10.3389/fmed.2021.664966
This article is part of the Research Topic Clinical Application of Artificial Intelligence in Emergency and Critical Care Medicine, Volume I View all 20 articles
 Longxiang Su1†
Longxiang Su1† Zheng Xu2†
Zheng Xu2† Fengxiang Chang2†Yingying Ma2
Fengxiang Chang2†Yingying Ma2 Shengjun Liu1
Shengjun Liu1 Huizhen Jiang3Hao Wang1Dongkai Li1Huan Chen1
Huizhen Jiang3Hao Wang1Dongkai Li1Huan Chen1 Xiang Zhou1
Xiang Zhou1 Na Hong2*
Na Hong2* Weiguo Zhu3,4*
Weiguo Zhu3,4* Yun Long1*
Yun Long1*Background: Early prediction of the clinical outcome of patients with sepsis is of great significance and can guide treatment and reduce the mortality of patients. However, it is clinically difficult for clinicians.
Methods: A total of 2,224 patients with sepsis were involved over a 3-year period (2016–2018) in the intensive care unit (ICU) of Peking Union Medical College Hospital. With all the key medical data from the first 6 h in the ICU, three machine learning models, logistic regression, random forest, and XGBoost, were used to predict mortality, severity (sepsis/septic shock), and length of ICU stay (LOS) (>6 days, ≤ 6 days). Missing data imputation and oversampling were completed on the dataset before introduction into the models.
Results: Compared to the mortality and LOS predictions, the severity prediction achieved the best classification results, based on the area under the operating receiver characteristics (AUC), with the random forest classifier (sensitivity = 0.65, specificity = 0.73, F1 score = 0.72, AUC = 0.79). The random forest model also showed the best overall performance (mortality prediction: sensitivity = 0.50, specificity = 0.84, F1 score = 0.66, AUC = 0.74; LOS prediction: sensitivity = 0.79, specificity = 0.66, F1 score = 0.69, AUC = 0.76) among the three models. The predictive ability of the SOFA score itself was inferior to that of the above three models.
Conclusions: Using the random forest classifier in the first 6 h of ICU admission can provide a comprehensive early warning of sepsis, which will contribute to the formulation and management of clinical decisions and the allocation and management of resources.
With high morbidity and mortality, sepsis seriously endangers human health and causes a heavy medical burden (1, 2). The understanding of sepsis has evolved from an inflammatory response syndrome caused by infection (sepsis 1.0) to an inflammatory response syndrome with organ dysfunction (sepsis 2.0) to a life-threatening organ disorder caused by the body's uncontrolled response to infection (sepsis 3.0) (3). Employed as the core indicator in sepsis 3.0 diagnosis, the SOFA score was proven to be an accurate and feasible method in the prognosis assessment with its ability to judge the degree of organ failure and assess the severity of patients with sepsis (4, 5). With the establishment of and improvement in critical illness databases and the continuous advancement of machine learning methods, an ever-increasing number of new models are being proposed by researchers. Compared with the SOFA, the Oxford Acute Severity of Illness Score (OASIS) is a scoring system that was constructed by Johnson et al. through machine learning algorithms (6). It contains only 10 variables and no laboratory measure whose diagnostic efficiency is high. Kim et al. (7) also proposed a deep model-based, data-driven early warning score tool, PROMPT, that can predict mortality in critically ill children. With regard to machine learning techniques, Pirracchio et al. proposed that ensemble and neural network models would demonstrate better performance in predicting mortality (8). However, differences exist among the current machine learning models for diagnosis, such as parameter composition, the source population for model construction, and the scope of clinical use. The conclusions obtained by different clinical studies have even been contradictory. This study intends to examine data from the Chinese sepsis patient population under the Chinese medical system and environment using machine learning algorithms to explore a model for predicting the prognosis of sepsis patients, the severity of the disease, and the potential duration of ICU treatment (LOS), which may contribute to understanding sepsis and treating sepsis in the ICU.
This study was conducted in the ICU of Peking Union Medical College Hospital. All electronic medical data from patients diagnosed with sepsis based on sepsis 3.0 were retrospectively gathered from 2016 to 2018 and securely stored in the Peking Union Medical College Hospital Intensive Care Medical Information System and Database (PICMISD). The data consisted of demographic information, ICU length of stay (LOS), medications, and vital signs of the respiratory, cardiovascular, hepatic, coagulation, renal, and neurological systems. As one of the commonly used methods for tracking patient status in the ICU and estimating the risk of mortality due to sepsis, a sequential organ failure assessment (SOFA) was introduced as one of the inclusion criteria and a baseline prediction tool. It was computed from the key measurements from multiple-organ systems.
From 2016 to 2018, a total of 11,512 critically ill patients were admitted and treated in the ICU of Peking Union Medical College Hospital. A total of 2,436 patients with sepsis meeting the following criteria were included in the dataset: SOFA score ≥ 2; high possibility of infection (pathogenic microbiology examinations obtained) and usage/update of antibiotics; age ≥ 18 years. After a thorough examination of the dataset, several constraints were added on some variables to ensure the reliability of the medical data: 0 < P(v-a)CO2/C(a-v)O2 < 5; 0 < P(v-a)CO2 < 15; 0 < SO2 ≤ 100; 0 < oxygenation index ≤ 1,000; white blood cell ( ×108/L) > 100; oxygen concentration (%) ≥21; and breath rate (bpm) > 0. The number of patients decreased to 2,224 with the extra constraints in place. With reference to the lactic acid values, all patients were labeled as having one of two categories of severity level: sepsis (<2 mmol/L; 1,122 patients) and septic shock (≥2 mmol/L; 1,102 patients). All key measurements of the organs were recorded during the first 6 h after ICU admission. Unlike regular methods of using at least 24 h of measurement in the ICU (9–11), data recorded in the first 6 h can also be sufficiently accurate to assist clinicians in performing early prediction. Informed consent was obtained from all the participants in compliance with the requirements of the Ethics Committee of Peking Union Medical College Hospital.
Regarding the predictor classes, the mortality (survivor, non-survivor) and severity (sepsis, septic shock) predictions depended on the classification model, while patient LOS in the ICU was labeled by dividing patients into two groups: > 6 days and ≤ 6 days. The 6-day cut-off point was derived from the quartile values (first quartile: 3 days, second quartile: 6 days, third quartile: 13 days) from the overall patient distribution. The classification model incorporated the following methods: logistic regression (12), random forest (RF) (13), and XGBoost. To select the most relevant features, the least absolute shrinkage and selection operator (LASSO) was applied. All the features were normalized before being introduced into the classification models. The training and testing datasets were randomly split by 70 and 30% of all patients.
K-nearest neighbor (KNN) imputation (14) was utilized to handle the partial missing data. Each entry of missing data was imputed with the average of its five nearest neighbors. The value k = 5 in the KNN algorithm was chosen because it achieves the best classification results as supported by validation.
As the dataset is enormously biased toward the survivors, a method of over-sampling [specifically, the synthetic minority oversampling technique (SMOTE) (15)] on the minority class was applied in the training dataset for mortality prediction.
The classification models were assessed with the area under the receiver operating characteristic (AUC) curve, sensitivity (also known as recall), specificity, and F1 score. The foundation of these assessment variables comes from the four possible outcomes (TP = true positive, TN = true negative, FP = false positive, FN = false negative) of the binary classifier. Computed by plotting sensitivity as a function of (1-specificity), the area under the ROC curve is widely used as a performance measurement for classification problems at various threshold settings. A higher AUC value indicates a better model for distinguishing between classes. In this study, false positives (e.g., a survivor is predicted as a non-survivor) may be overmedicated, while false negatives (e.g., a non-survivor is predicted as a survivor) may not receive any extra actions for early prevention. Both cases should be avoided here. The F1 score, as the harmonic mean of precision and recall, is a better metric for imbalanced classes. Meanwhile, a five-fold cross validation method was applied for all the models in three classification problems to avoid overfitting during the model training.
All continuous variables in the clinical data are presented as the mean value ± standard deviation (SD). The distribution of LOS in the ICU was evaluated through quartile values, and then the second quartile value was chosen as the cut-off point for prediction labeling. T-tests with a threshold p < 0.05 were performed to determine significant differences between subgroups in each prediction problem. Regarding the mortality prediction, the SOFA score, as a baseline prediction tool, was used to generate an ROC curve for comparison with other machine learning models. The sensitivity and specificity of the SOFA score were estimated on the basis of a preset threshold. All statistical analyses were performed in Python 3.6.
A total of 2,224 patients were included in the analysis. Their average of LOS in the ICU was 10.32 ± 11.84 days. The whole group included 1,292 males and 932 females aged 58.96 ± 16.62 years. Approximately 415 (18.7%) patients with sepsis did not survive in the ICU. A summary of the patients' clinical data for each prediction is presented in Tables 1A–C.
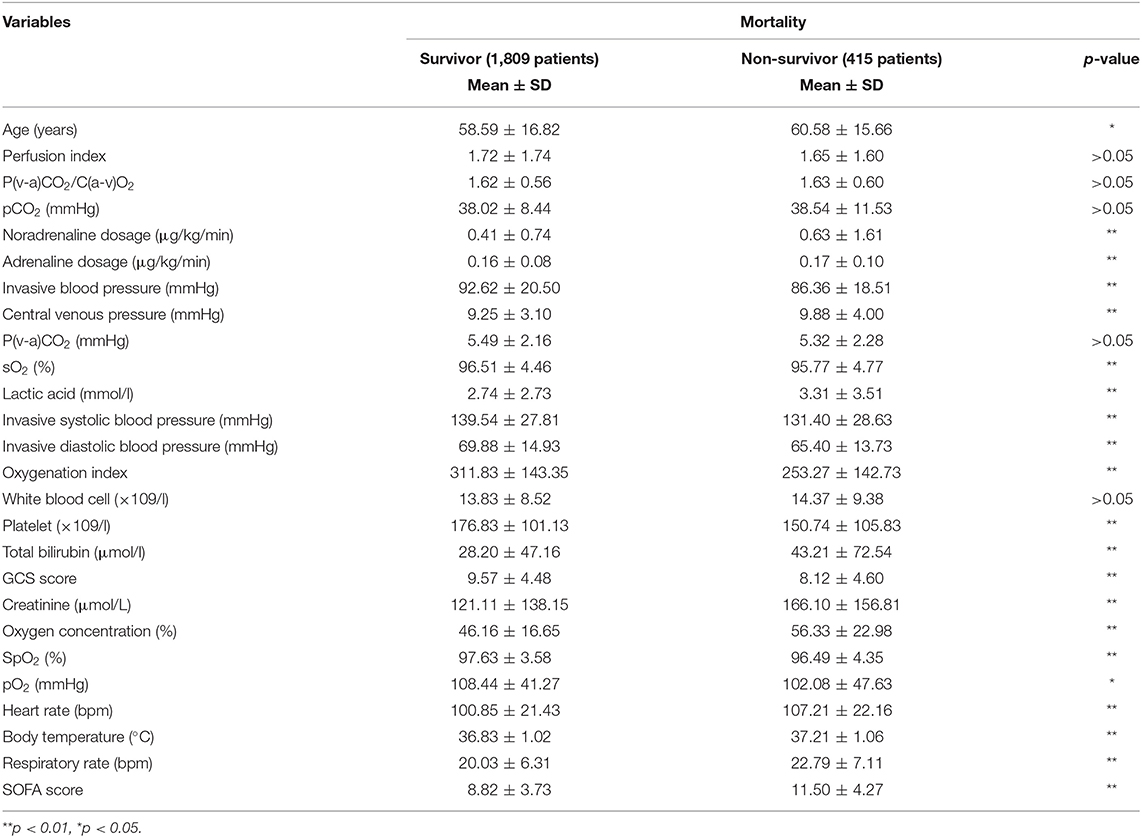
Table 1A. Subgroups of patients' clinical data for the mortality prediction.
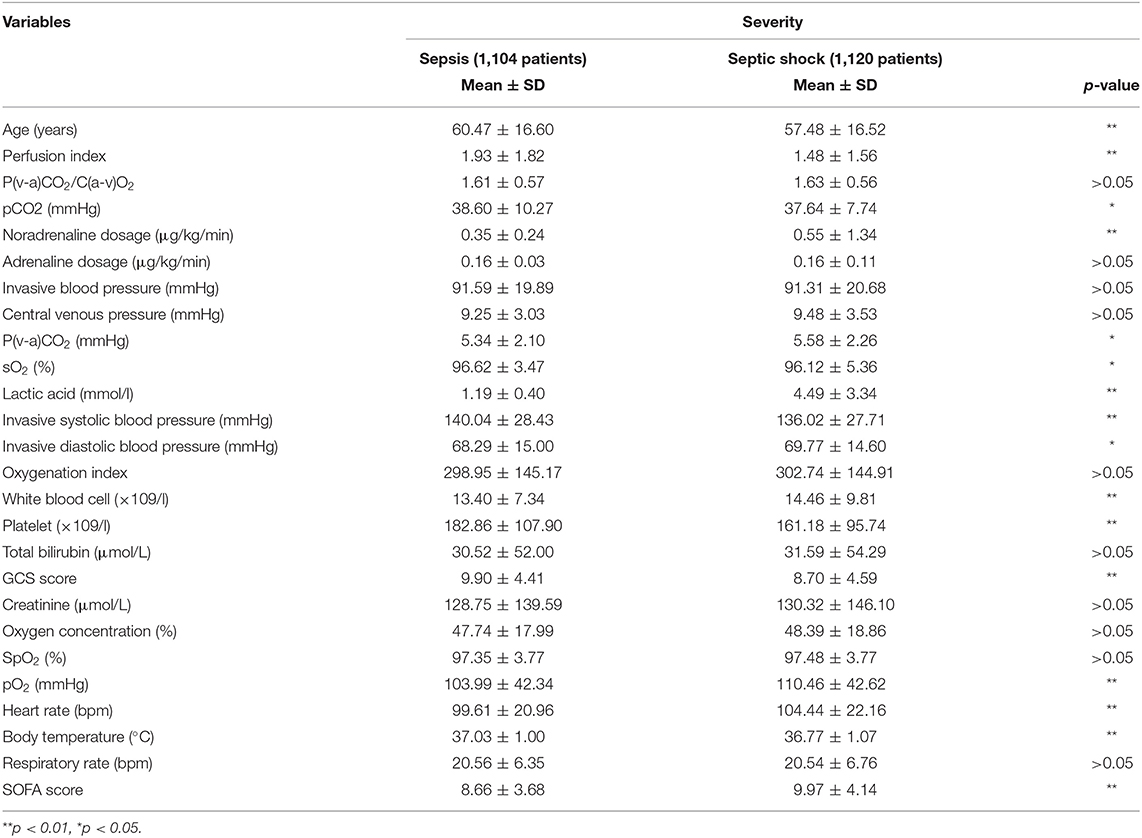
Table 1B. Subgroups of patients' clinical data for the severity prediction.
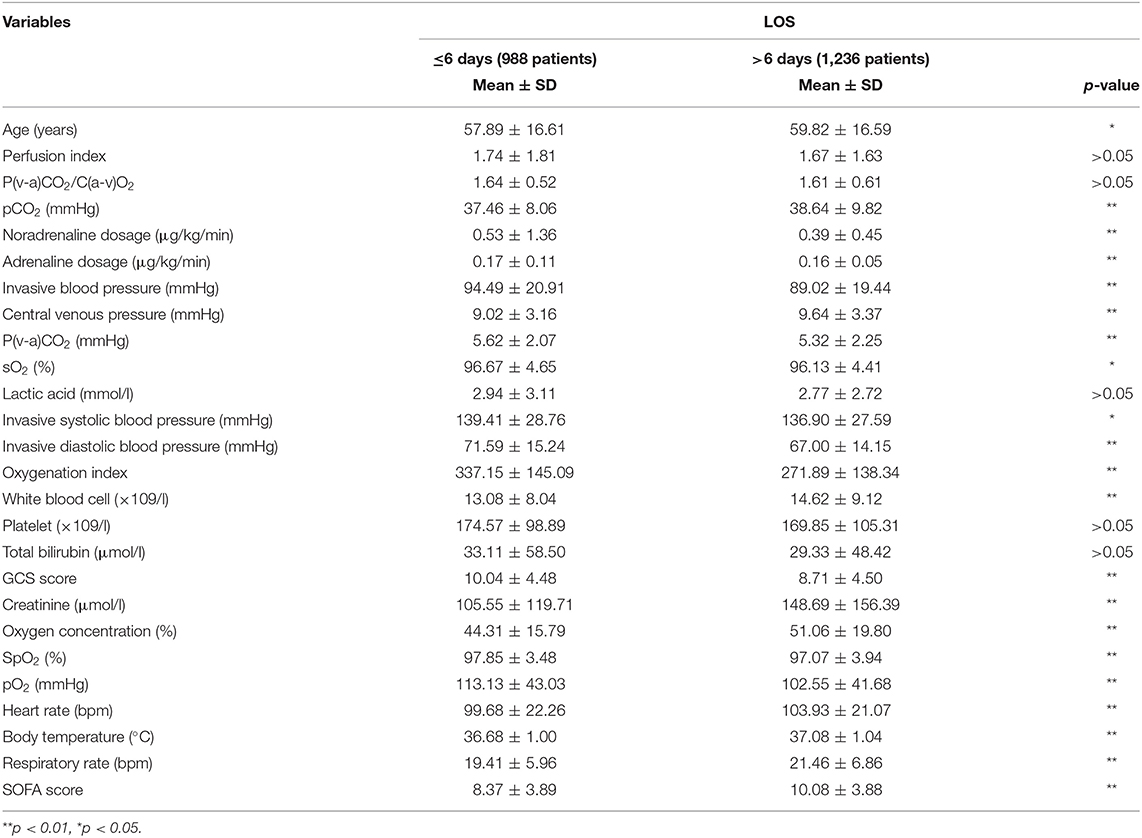
Table 1C. Subgroups of patients' clinical data for the LOS prediction.
In the dataset, the number of non-survivors (415 patients) was approximately a quarter of the number of survivors (1,809 patients). The non-survivor group was slightly older than the survivor group. Among the 25 variables in Table 1A, only five variables, including perfusion index, P(v-a)CO2/C(a-v)O2, pCO2, P(v-a)CO2, and white blood cell count, showed no significant difference between the two groups, while the remaining variables did. With regular statistical methods, the SOFA score was used to produce ROC curves individually instead of being included as a feature in the model. It is reasonable that the average SOFA score for the survivor group was significantly lower than that for the non-survivor group.
As presented Figure 1, the SMOTE method significantly improved the sensitivity rate (without SMOTE: mean sensitivity = 0.13; with SMOTE: mean sensitivity = 0.49) in all models. Nonetheless, specificity, together with AUC, from all three models was considerably reduced after applying the SMOTE method. RF presented the best classification results (without SMOTE: AUC = 0.77; with SMOTE: AUC = 0.74), regardless of the application of the SMOTE method. All machine learning models demonstrated better prediction results than the SOFA score (AUC = 0.70).
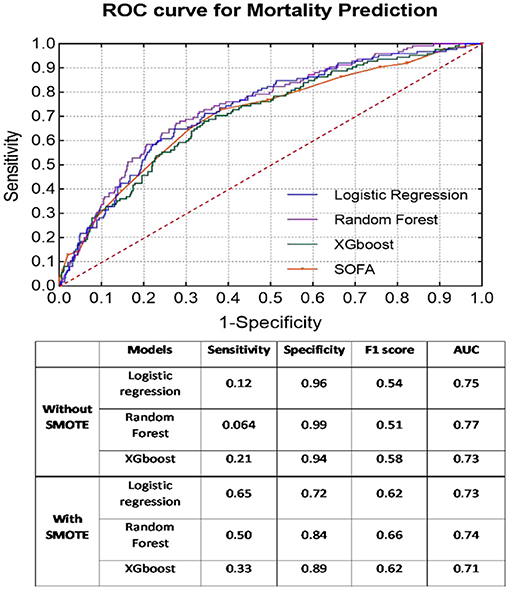
Figure 1. ROC curves of each classifier with SMOTE for mortality prediction. Classification results before and after SMOTE are presented in the embedded table.
The dataset consisted of 1,104 patients with sepsis and 1,120 patients with septic shock. The subgroup with high severity (age: 57.48 ± 16.52 years) was significantly younger than the other subgroup (age: 60.47 ± 16.60 years). As seen in Table 1B, 10 variables related to respiratory [P(v-a)CO2/C(a-v)O2, oxygenation index, oxygen concentration, SpO2], renal (creatinine, adrenaline dosage) and coagulation (invasive blood pressure, central venous pressure, total bilirubin) systems showed no significant differences between the two classes. Among all classifiers, the RF classifier provided the best prediction results for severity (sensitivity = 0.65, specificity = 0.73, F1 score = 0.72, AUC = 0.79) and presented enhanced results compared to the baseline SOFA score (AUC = 0.59) (see Figure 2).
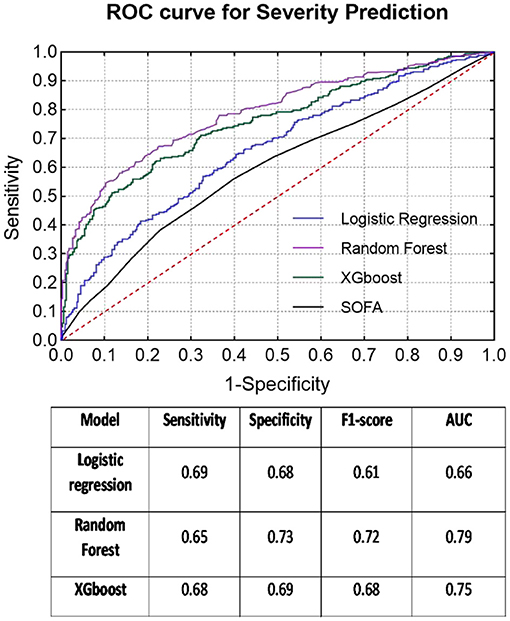
Figure 2. ROC curves of each classifier for severity prediction and classification results in the table below.
The second quartile (6 days) of all LOS data almost equally divided the group into two classes (≤ 6 days: 1,127 cases, >6 days: 1,097 cases). The patients with longer ICU stays (>6 days) were older (59.82 ± 16.59 years) than the other patients (age: 57.89 ± 16.61 years). Similar to the previous mortality classes, only five variables [perfusion index, P(v-a)CO2/C(a-v)O2, lactic acid, platelets, and total bilirubin] indicated no significant differences between the LOS subgroups. Meanwhile, the RF model again exhibited the best prediction results for LOS (sensitivity = 0.79, specificity = 0.66, F1 score = 0.69, AUC = 0.76), which was much better than the SOFA score (AUC = 0.62) (see Figure 3).
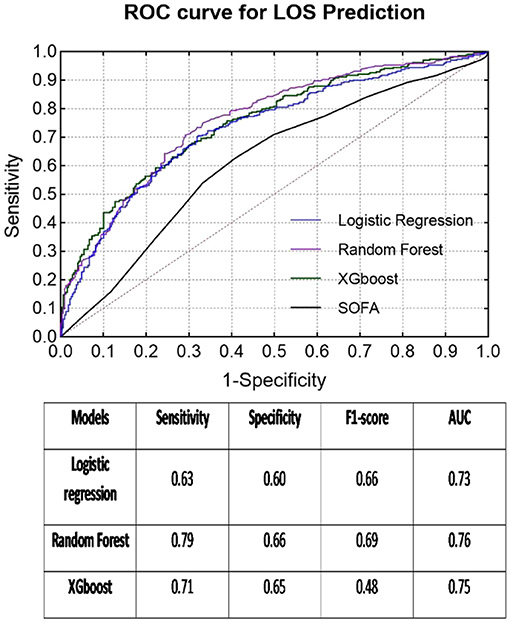
Figure 3. ROC curves of each classifier for LOS prediction and classification results in the table below.
Our study found that this machine learning method using data within the first 6 h of ICU admission can predict sepsis patients' prognosis, the severity of sepsis (i.e., whether there is septic shock), and the length of stay in the ICU (i.e., whether it was longer than 6 days). Furthermore, the RF classifier had stronger diagnostic power for the three predictions, with areas under the ROC curve of 0.74, 0.79, and 0.76, respectively. After the validation set was verified, its effect was significantly better than that of the traditional SOFA score. This implies that the use of RF predictions in the early stages of ICU admission will enable us to know the possibility of ICU patient outcomes earlier, appropriately allocate medical resources, and optimize treatment behavior.
At present, the diagnosis of sepsis is more specific and clearer with the definition of sepsis 3.0 than the previous two versions. More emphasis should be placed on how we can more accurately predict ICU outcomes after the diagnosis of sepsis (16). As mentioned above, the current treatments for sepsis are still not ideal. Early recognition and correct treatment are closely related to improving prognosis (17). Since sepsis is essentially an out-of-control regulation of the systemic immune response, it is not caused by a single factor. The pathophysiological process is complicated, which leads to large differences in clinical manifestations and disease processes across patients (18). A single diagnostic index is obviously difficult to perform. The sepsis scoring system represented by the SOFA score is used in the diagnosis and treatment of sepsis, which is constantly strengthened by an increasing amount of evidence (19). However, it is difficult to balance the massive data and the complexity of the disease in the ICU treatment of sepsis. With the emergence of large electronic databases and the development of advanced algorithms such as machine learning and data mining, new scoring systems will continue to emerge. Our study identified a relatively good machine learning result, suggesting that the RF method can better predict the 28-day prognosis of patients in the first 6 h after ICU admission. Overall, accurate prediction of the prognosis of ICU patients with sepsis is of great clinical significance. It depends on an appropriate prognostic scoring system. However, how to define and select the “appropriate” scoring system requires the comprehensive judgment of multiple studies and multiple evaluation indicators. In the future, with continuous input of multimodal parameters, more machine learning methods are needed to aggregate data and information from all parties and obtain more accurate conclusions to guide clinical practice.
Compared with the previous two versions of the sepsis guidelines, the largest change was the definition of septic shock (3). At present, septic shock is defined as an inability to maintain blood pressure and the need for vasoactive drugs to maintain circulation after sufficient fluid resuscitation; at this time, lactic acid is >2 mmol/L. For this definition, it may be more necessary to understand the patient's situation and have information from multiple dimensions such as whether this patient is sepsis, what the SOFA score is, whether the patient has undergone fluid resuscitation, what the blood pressure is, whether blood pressure medications are currently being used, and what the lactic acid level is. This makes it even more necessary to use computers as an aid to identify and provide an early alert to ICU staff about this severe sepsis situation. This confirmed that the use of clinical information to define septic shock outperformed models developed based on only administrative data (20). Kim et al. (21) demonstrated that ML classifiers significantly outperformed clinical scores in screening septic shock at ED triage. Combined with machine learning methods, we can see that the RF method can accurately predict patients with septic shock for the first time and determine which patients are more severe. This is of great significance for clinical treatment. Another study also supported our conclusion using a RF classifier to predict sepsis and septic shock (13). In addition, we can also predict which sepsis patients needed longer ICU support through the RF method, and the limited ICU resources can be configured and more efficiently better used. Staziaki et al. (22) reported that SVM and ANN models combining CT findings and clinical parameters improved the prediction of length of stay and ICU admission in torso trauma. Castineira et al. (23) added continuous vital sign information to static clinical data to improve the prediction of length of stay after intubation. Even ELM has been used to determine whether the patient can be discharged within 10 days (24). The use of machine learning algorithms is of great significance to patients with sepsis, and it is better than the traditional SOFA score, which is relatively monotonous in the systematic assessment of organ damage.
The algorithms also played an important role in this study. Before inputting data into the model, imputation of the missing data was necessary. In the future, other imputation methods, such as stochastic regression and tree-based models, can be assessed to compete with the only method, “KNN imputation,” used in this study. The oversampling method “SMOTE” successfully solved the problem of imbalanced datasets, which often leads to a highly biased prediction result, as the model will place more weight on the majority class. In the meantime, some other methods of oversampling can also be tested to improve the classification results. Certainly, as the core of the prediction problem, choosing the best machine learning model is the most important aspect. Therefore, some additional models from the deep learning field, such as artificial neural networks (ANNs) and convolutional neural networks (CNNs), may be applied in future investigations.
There were also some limitations. Firstly, the research subjects came from a single ICU, and there may be bias caused by regional factors. Whether the research conclusions can be extended to other regions needs further research and testing. Secondly, it is necessary to verify that the next step is to implement forward-looking research based on the current research results to further verify the validity and scalability of the model constructed in this study and provide further improvements. In our study, only three subjects have breath rate below 5 bpm, which is only 0.1% of the whole population. It will not lead to high risk of biased dataset according to the inclusion criteria of breath rate > 0 bpm. In the clinical decision-making, the general cut-off point of LOS is 4–5 days while 6 days was chosen here based on the distribution of LOS.
Machine learning models using the first 6 h of medical data can decently predict mortality, severity, and LOS in the ICU. The overall results demonstrated that the RF model was the best model of classification for all three prediction problems (AUC for all RF models > 0.70) compared to logistic regression and XGBoost models. The prospects of applying machine learning in the ICU are broad, but BCT research is still needed to study the stability of the model and clarify the potential limitations.
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethical review and approval was not required for the study on human participants in accordance with the local legislation and institutional requirements. The patients/participants provided their written informed consent to participate in this study.
YL, WZ, and NH take responsibility for the integrity of the work as a whole, from the inception to the published article. LS, ZX, and FC are responsible for study design and conception. YM, SL, HJ, HW, DL, HC, and XZ are responsible for the data management and statistical analysis. LS drafted the manuscript. All authors revised the manuscript for important intellectual content.
The study was supported by the Chinese National Key R&D Program (2018YFC0116900), the Beijing Nova Program from Beijing Municipal Science and Technology Commission (Grant no. Z201100006820126) project for the undergraduate teaching reform of Peking Union Medical College Hospital (Grant no. 2020zlgc0109), the China Health Information and Health Care Big Data Association Severe Infection Analgesia and Sedation Big Data Special Fund (Grant no. Z-2019-1-001), and China International Medical Exchange Foundation Special Fund for Young and Middle-aged Medical Research (Grant no. Z-2018-35-1902).
ZX, FC, YM, and NH were employed by the DHC Software Co. Ltd.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
1. Dellinger RP, Levy MM, Rhodes A, Annane D, Gerlach H, Opal SM, et al. Surviving sepsis campaign: international guidelines for management of severe sepsis and septic shock: 2012. Crit Care Med. (2013) 41:580–637. doi: 10.1097/CCM.0b013e31827e83af
2. Paoli CJ, Reynolds MA, Sinha M, Gitlin M, Crouser E. Epidemiology and costs of sepsis in the United States-an analysis based on timing of diagnosis and severity level. Crit Care Med. (2018) 46:1889–97. doi: 10.1097/CCM.0000000000003342
3. Singer M, Deutschman CS, Seymour CW, Shankar-Hari M, Annane D, Bauer M, et al. The third international consensus definitions for sepsis and septic shock (sepsis-3). JAMA. (2016) 315:801–10. doi: 10.1001/jama.2016.0287
4. Vincent JL, Moreno R, Takala J, Willatts S, De Mendonca A, Bruining H, et al. The SOFA (sepsis-related organ failure assessment) score to describe organ dysfunction/failure. On behalf of the Working Group on Sepsis-Related Problems of the European Society of Intensive Care Medicine. Intensive Care Med. (1996) 22:707–10. doi: 10.1007/BF01709751
5. Vincent JL, de Mendonca A, Cantraine F, Moreno R, Takala J, Suter PM, et al. Use of the SOFA score to assess the incidence of organ dysfunction/failure in intensive care units: results of a multicenter, prospective study. Working group on “sepsis-related problems” of the European Society of Intensive Care Medicine. Crit Care Med. (1998) 26:1793–800. doi: 10.1097/00003246-199811000-00016
6. Johnson AE, Kramer AA, Clifford GD. A new severity of illness scale using a subset of acute physiology and chronic health evaluation data elements shows comparable predictive accuracy. Crit Care Med. (2013) 41:1711–8. doi: 10.1097/CCM.0b013e31828a24fe
7. Kim SY, Kim S, Cho J, Kim YS, Sol IS, Sung Y. A deep learning model for real-time mortality prediction in critically ill children. Crit Care. (2019) 23:279. doi: 10.1186/s13054-019-2561-z
8. Pirracchio R, Petersen ML, Carone M, Rigon MR, Chevret S, van Mendonca MJ. Mortality prediction in intensive care units with the Super ICU Learner Algorithm (SICULA): a population-based study. Lancet Respir Med. (2015) 3:42–52. doi: 10.1016/S2213-2600(14)70239-5
9. Kramer AA, Zimmerman JE. A predictive model for the early identification of patients at risk for a prolonged intensive care unit length of stay. BMC Med Inform Decis Mak. (2010) 10:27. doi: 10.1186/1472-6947-10-27
10. Meadows K, Gibbens R, Gerrard C, Vuylsteke A. Prediction of patient length of stay on the intensive care unit following cardiac surgery: a logistic regression analysis based on the cardiac operative mortality risk calculator, EuroSCORE. J Cardiothorac Vasc Anesth. (2018) 32:2676–82. doi: 10.1053/j.jvca.2018.03.007
11. Nielsen AB, Thorsen-Meyer HC, Belling K, Nielsen AP, Thomas CE, Chmura PJ, et al. Survival prediction in intensive-care units based on aggregation of long-term disease history and acute physiology: a retrospective study of the Danish National Patient Registry and electronic patient records. Lancet Digit Health. (2019) 1:e78–e89. doi: 10.1016/S2589-7500(19)30024-X
12. Tolles J, Meurer WJ. Logistic regression: relating patient characteristics to outcomes. JAMA. (2016) 316:533–4. doi: 10.1001/jama.2016.7653
13. Giannini HM, Ginestra JC, Chivers C, Draugelis M, Hanish A, Schweickert WD, et al. A machine learning algorithm to predict severe sepsis and septic shock: development, implementation, and impact on clinical practice. Crit Care Med. (2019) 47:1485–92. doi: 10.1097/CCM.0000000000003891
14. Troyanskaya O, Cantor M, Sherlock G, Brown P, Hastie T, Tibshirani R, et al. Missing value estimation methods for DNA microarrays. Bioinformatics. (2001) 17:520–5. doi: 10.1093/bioinformatics/17.6.520
15. Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP. SMOTE: synthetic minority over-sampling technique. J Artif Intellig Res. (2002) 16:321–57. doi: 10.1613/jair.953
16. Power GS, Harrison DA. Why try to predict ICU outcomes? Curr Opin Crit Care. (2014) 20:544–9. doi: 10.1097/MCC.0000000000000136
17. Seymour CW, Gesten F, Prescott HC, Friedrich ME, Iwashyna TJ, Phillips GS, et al. Time to treatment and mortality during mandated emergency care for sepsis. N Engl J Med. (2017) 376:2235–44. doi: 10.1056/NEJMoa1703058
18. Gotts JE, Matthay MA. Sepsis: pathophysiology and clinical management. BMJ. (2016) 353:i1585. doi: 10.1136/bmj.i1585
19. Seymour CW, Liu VX, Iwashyna TJ, Brunkhorst FM, Rea TD, Scherag A, et al. Assessment of clinical criteria for sepsis: for the third international consensus definitions for sepsis and septic shock (sepsis-3). JAMA. (2016) 315:762–774. doi: 10.1001/jama.2016.0288
20. Misra D, Avula V, Wolk DM, Farag HA, Li J, Mehta YB, et al. Early detection of septic shock onset using interpretable machine learners. J Clin Med. (2021) 10:301. doi: 10.3390/jcm10020301
21. Kim J, Chang H, Kim D, Jang DH, Park I, Kim K. Machine learning for prediction of septic shock at initial triage in emergency department. J Crit Care. (2020) 55:163–70. doi: 10.1016/j.jcrc.2019.09.024
22. Staziaki PV, Wu D, Rayan JC, Santo IDO, Nan F, Maybury A, et al. Machine learning combining CT findings and clinical parameters improves prediction of length of stay and ICU admission in torso trauma. Eur Radiol. (2021). doi: 10.1007/s00330-020-07534-w. [Epub ahead of print].
23. Castineira D, Schlosser KR, Geva A, Rahmani AR, Fiore G, Walsh BK, et al. Adding continuous vital sign information to static clinical data improves the prediction of length of stay after intubation: a data-driven machine learning approach. Respir Care. (2020) 65:1367–77. doi: 10.4187/respcare.07561
Keywords: sepsis, prediction, machine learning, outcome, sequential (sepsis-related) organ failure assessment
Citation: Su L, Xu Z, Chang F, Ma Y, Liu S, Jiang H, Wang H, Li D, Chen H, Zhou X, Hong N, Zhu W and Long Y (2021) Early Prediction of Mortality, Severity, and Length of Stay in the Intensive Care Unit of Sepsis Patients Based on Sepsis 3.0 by Machine Learning Models. Front. Med. 8:664966. doi: 10.3389/fmed.2021.664966
Received: 06 February 2021; Accepted: 20 May 2021;
Published: 28 June 2021.
Edited by:
Borna Relja, Otto von Guericke University, GermanyReviewed by:
Michel Van Genderen, Erasmus Medical Center, NetherlandsCopyright © 2021 Su, Xu, Chang, Ma, Liu, Jiang, Wang, Li, Chen, Zhou, Hong, Zhu and Long. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yun Long, bHlfaWN1QGFsaXl1bi5jb20=; Weiguo Zhu, emh1d2dAcHVtY2guY24=; Na Hong, aG9uZ25hQGRjaGVhbHRoLmNvbQ==
†These authors have contributed equally to this work
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.