 Felix Fritzen
Felix Fritzen Mauricio Fernández
Mauricio Fernández Fredrik Larsson
Fredrik Larsson- 1EMMA - Efficient Methods for Mechanical Analysis, Institute of Applied Mechanics, University of Stuttgart, Stuttgart, Germany
- 2Material and Computational Mechanics, Department of Industrial and Materials Science, Chalmers University of Technology, Göteborg, Sweden
A multi-fidelity surrogate model for highly nonlinear multiscale problems is proposed. It is based on the introduction of two different surrogate models and an adaptive on-the-fly switching. The two concurrent surrogates are built incrementally starting from a moderate set of evaluations of the full order model. Therefore, a reduced order model (ROM) is generated. Using a hybrid ROM-preconditioned FE solver additional effective stress-strain data is simulated while the number of samples is kept to a moderate level by using a dedicated and physics-guided sampling technique. Machine learning (ML) is subsequently used to build the second surrogate by means of artificial neural networks (ANN). Different ANN architectures are explored and the features used as inputs of the ANN are fine tuned in order to improve the overall quality of the ML model. Additional ML surrogates for the stress errors are generated. Therefore, conservative design guidelines for error surrogates are presented by adapting the loss functions of the ANN training in pure regression or pure classification settings. The error surrogates can be used as quality indicators in order to adaptively select the appropriate—i.e., efficient yet accurate—surrogate. Two strategies for the on-the-fly switching are investigated and a practicable and robust algorithm is proposed that eliminates relevant technical difficulties attributed to model switching. The provided algorithms and ANN design guidelines can easily be adopted for different problem settings and, thereby, they enable generalization of the used machine learning techniques for a wide range of applications. The resulting hybrid surrogate is employed in challenging multilevel FE simulations for a three-phase composite with pseudo-plastic micro-constituents. Numerical examples highlight the performance of the proposed approach.
1. Introduction
In computer-assisted materials design and in the simulation of complex materials with rich microstructure major challenges remain to be solved despite the outstanding advances made in recent years. For example, the discretization of all microstructural features in a monolithic finite element (FE) simulation is unfeasible due to the various length scales involved that range from micrometers up to the meters. These would lead to a ludicrous complexity of the resulting overall model. By accounting for a separation of length scales, the FE2 ansatz (Feyel, 1999; Miehe, 2002) can lead to some savings over the monolithic approach by replacing the heterogeneous material by microscopic FE problems at the macroscopic integration points, leading to a partial decoupling of microscopic and macroscopic degrees of freedom. Still the number of overall unknowns is prohibitive and calls for massively improved computational efficiency in terms of CPU time, memory savings and information compression. Novel strategies contributing to the vision of a fully connected investigation of materials and aspiring the prediction process-structure-property relationships across multiple length and time scales are, thus, much sought-after, see, e.g., Schmitz and Prahl (2016). Due to the rapid growth of available material and simulation data, data-integrated approaches that exploit information from different sources in order to complement or substitute simulations and experiments are experiencing increased attention, see, e.g., Kalidindi and De Graef (2015), Kalidindi (2015), and Ramakrishna et al. (2018).
Due to novel improvements in machine learning and computational resources, a zoo of data-driven methods comprising, e.g., kernel methods, principal component analysis, and artificial neural networks, have developed immense momentum over the last years. The successful implementation of these techniques in materials research is an active field. For instance, in Chupakhin et al. (2017) artificial neural networks and finite element computations have been combined in order to predict the influence of plasticity on the residual stress field measured by hole drilling. Principal component analysis of n-point microstructure statistics have shown excellent performance in order to examine microstructure-property relationships, see, e.g., Çeçen et al. (2014), Gupta et al. (2015), and Altschuh et al. (2017). In Bélisle et al. (2015), several machine learning methods have been considered in the context of molecular dynamics. Liu et al. (2015) show how data mining and machine learning are combined in order to efficiently approximate the elastic localization in voxelized microstructures. Another branch of data-driven materials research exploring the use of convolutional neural networks and deep learning in order to deliver accurate structure-property linkages is currently in heavy development, see, e.g., Çeçen et al. (2018) and Yang et al. (2018).
While data-driven approaches have their appeal, the structure of the underlying physical problem can be accounted for only in parts. For instance, established balanced laws and thermodynamic principles are hard to be incorporated in the aforementioned methods. Reduced order models for the microscopic problem offer an advantageous compromise between physics-informed modeling and computational efficiency. Purely data-driven surrogates lack accuracy (i) if the amount of training data is limited, (ii) if the validity domain is left, or (iii) if the error of the surrogate in respect to the reference solution is to be estimated. In these scenarios, reduced order models following physical principles offer, in general, better accuracy and robustness. For example, in Fritzen and Leuschner (2013) a highly efficient potential based reduced order model has been developed. This ansatz has a natural physical supporting argument, since a reduced basis for the solution field is generated based on snapshot data of FE computations. The approach has been demonstrated to achieve substantial speed-ups and memory savings, see also Fritzen et al. (2014) and Fritzen and Hodapp (2016). Other developments in this field comprise the NTFA (e.g., Michel and Suquet, 2003) and NTFA-TSO (Michel and Suquet, 2016) or hyper-reduced simulations and related schemes (Ryckelynck, 2009; Soldner et al., 2017). In order to improve the incorporation of surrogates obtained from reduced order models a goal-oriented error estimation or quality indication is required. The quantity of interest (QoI) is the effective stress and its accuracy (up to a prescribed tolerance) is essential for reliability of the overall predictions. In Lu et al. (2018), for example, neural networks have been successfully trained to approximate the microscopic nonlinear microscopic electric material law of graphene/polymer nanocomposites, but without error control or model adaptivity in macroscopic simulations. A macroscopic goal-oriented approach combining reduced order modeling and machine learning techniques has been demonstrated in Trehan et al. (2017) for two-dimensional oil-water subsurface flow systems and in Freno and Carlberg (2018) for three-dimensional mechanical problems. The approach considers a reduced order model and an a posteriori correction through machine learning methods. The ansatz shows promising results, but it requires the evaluation of the reduced order model. For twoscale simulations with a macroscopic and a microscopic problem, even the evaluation of a reduced order model for the microscopic problem may not be always viable due to the large number of needed evaluations in the macroscopic problem. It is, therefore, necessary to seek efficient alternatives incorporating a hierarchy of surrogate models of different computational complexity and different accuracy in the QoI. Hereby, one may also take into consideration physics-informed artificial neural networks, as done in Raissi et al. (2018), in order to obtain the field solution of the balance equations for the microscopic physical problem at hand and then computing the QoI for the macroscopic scale. Such approaches are highly attractive, but not suitable for the objectives of twoscale computations, since the surrogate for the microscopic model is only required to return the QoI for the macroscale and additional calibration of the artificial neural networks for the microscopic solution field would only increase the computational costs without any benefits for the convergence of the macroscopic problem.
The present work aims in mechanical multiscale FE simulations at the adaptive combination of the physics-informed reduced order model (ROM) of Fritzen and Kunc (2018), for nonlinear hyperelastic problems (i.e., no history dependency), with artificial neural networks (ANNs), for which feedforward neural networks are considered. Hereby, the ANNs are trained based on FE computation of the full three-dimensional microstructure and material at hand for a set of loading strains (input quantity). The QoI (output quantity) is the effective stress, which the ANNs are trained for. The trained ANNs are then used as a highly efficient constitutive relation surrogate for the nonlinear material at hand. For macroscopic FE computations, the ANN material law surrogate is to be used, if possible, at every integration point for given effective strain. Based on quality indicators, as accuracy or range of validity, the ANN constitutive relation surrogate may be inaccurate or insecure for given strain. The present work, therefore, further considers the error modeling of trained ANNs and discusses guidelines in order to induce conservative properties to the error models, which are calibrated through ANNs in standard regression or classification approaches. Additionally, strategies are proposed for an adaptive ANN-ROM schemes, where the more accurate but expensive ROM is only called at an integration point, if the quality indicator demands it.
The manuscript is organized as follows: In section 2, two concurrent surrogate models for the QoI obtained by reduced order modeling and from purely data-driven ANNs are described. The twoscale mechanical problem is introduced and the challenges in the goal-oriented error estimation of derived quantities of interest remaining in nonlinear reduced order modeling are detailed. Then, the data generation for the training of the ANNs is illustrated, followed by the guidelines for the material law and error approximation. At the end of the section, adaptive twoscale simulation strategies including on-the-fly model switching are presented. Section 3 offers numerical examples for a three-phase pseudo-plastic material: The ANN is used for the direct surrogation of the QoI. This is adaptively complemented by a more robust and reliable reduced order model based on the concept of quality indicators. Multiscale FE simulations comparing the different multiscale simulation techniques are presented. The manuscript ends with a concluding summary of the results in section 4.
2. Reduced Order Modeling and Artificial Neural Networks
2.1. Twoscale Framework
2.1.1. Problem Setting
The simulation of microstructured solids with a sufficient separation of length scales is investigated. More precisely, a macroscopic domain with characteristic length and an attached microstructure with characteristic length are considered. The microstructure is assumed to be ergodic and the existence of a periodic Representative Volume Element (RVE) Ω is assumed. In the following, macroscopic fields are overlined . The twoscale problem consists of the concurrent solution of the macroscopic boundary value problem (BVP)
and, for each macroscopic point , of the solution of the RVE problem
Here denote displacements, are infinitesimal strain tensors and denote the stress fields on the microscopic and macroscopic domain, respectively. The solution of (P) defines the missing constitutive relation for the macroscopic stress via the volume average
The two BVPs are strongly coupled since the solution of defines the boundary condition for (P) via , while the solution of (P) implicitly provides the missing constitutive equation via (3).
A straight-forward yet computationally costly approach to solving the twoscale problem is given in terms of the FE2 method (Feyel, 1999; Miehe, 2002): Here the microscopic problem is solved at each macroscopic integration point and the effective tangent operator is used in order to allow for Newton-Raphson iterations of the nonlinear macroscopic BVP. In the following, the solution of the microscopic BVP using Finite Elements is considered as the reference solution, i.e., it denotes the Full Order Model (FOM). In Figure 1 the macroscopic and microscopic problems are illustrated in the context of FE2.
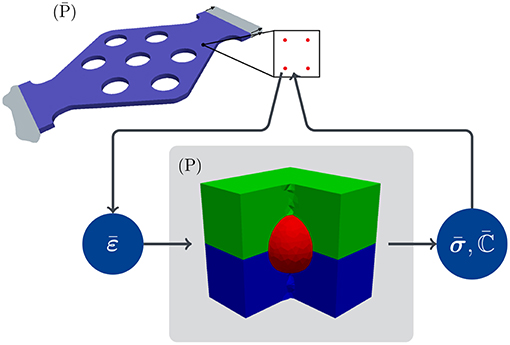
Figure 1. Twoscale mechanical problem in the context of FE2 for a material with a microstructure composed of three material phases: at every integration point of the macroscopic problem the microscopic problem (P) is solved in the FOM through a microscopic FE computation for prescribed , the resulting effective stress , and corresponding gradient are then computed and returned to the macroscopic integration point.
2.1.2. Reduced Order Model (ROM)
Given the massive computational demands of the FE2 technique and the limited availability of computational resources, the use of nowadays established reduced order models (ROM), in order to replace the costly microscopic BVP evaluations, has become an accepted alternative for dissipative and pseudo-plastic hyperelastic materials (Radermacher and Reese, 2016; Fritzen and Kunc, 2018). The reduced basis of dimension N obtained from the snapshot Proper Orthogonal Decomposition (POD, Sirovich, 1987) can be expressed in terms of a matrix , where each column represents a displacement field. The reduced parameterization of the solution is then given in vector notation via (i = 1, …, N)
where refers to the ith column of the corresponding matrix. Here, the matrix and vector notation of the effective strain are used concurrently for convenience. In the following, attention is limited to pseudo-plastic materials, i.e., to strongly nonlinear hyperelastic solids for which the stress σ and the stiffness ℂ are defined as the gradients of a free energy function W(ε) according to
Following Fritzen and Kunc (2018) the reduced problem is to find the coefficients ξ ∈ ℝN solving
While the effective stress is obtained from simple volume averaging of σ, the effective tangent stiffness is computed via
which follows from straight-forward linearization of (6). The accuracy of the ROM depends on the quality and amount of the snapshots and of the reduced dimension N. It shall be noted that the Galerkin ROM inherits the properties of classical Finite Elements, i.e., the solution is Galerkin orthogonal and, thus, energy optimal. It follows the basic physical principle of energy minimization. From a theoretical perspective this motivates the robustness and accuracy of the ROM even beyond the considered parameters used during the generation of the snapshot data, i.e., the ROM can be considered to generalize.
2.2. Goal-Oriented Error Estimation
For the microscopic BVP, using the ROM (or any other approximation of the FOM) naturally introduces an error into the solution of the problem, and into the quantity of interest (QoI). In this work the latter is the effective stress. Hence, in order to enable error control for the macroscopic boundary value problem, it is crucial to estimate the error in the QoI, see, e.g., Larsson and Runesson (2011). For this purpose, we define the error in displacements on the microscale as e(x) = uF(x) − uRN(x), where uF and uRN are the solutions to the microscopic problem (2) using the FOM and N-dimensional ROM, respectively. In view of the reduced kinematics (4), we can parameterize the error in the ROM as
where denotes the (finite element) shape functions pertinent to the FOM and ξe denotes the nodal values of the fully resolved error. The FOM and N-dimensional ROM effective stress functions are referred to for clarity as
while the corresponding error is addressed as
Now, consider the corresponding FOM residual equation analogous to (6) and the error in the QoI given in (11) in terms of the error in the solution defined in (8). Through linearization, we obtain the error equation and the linearization of the macroscopic stress error
respectively. Here rF, , and define the residual, Jacobian and linearized stress error in (6) and (7), with replaced by defining the strains of the finite element shape functions. The, nowadays, standard method of goal-oriented error estimation can be carried out by solving the suitably formulated dual (or adjoint) problem (see, e.g., Oden and Prudhomme, 2001)
Finally, (12) and (13) can be combined to yield the result
We note that the estimator (14) has, in particular, the following properties: (i) It is restricted to estimating the linearized error contribution, (ii) it requires the assembly of the entire FOM residual and Jacobian, and (iii) it requires the solution of the dual problem using the FOM to formally hold. Even if the linearization error is negligible, the high computational cost involved in assembling the full (FOM) Jacobian and residual of the problem makes this technique unalluring for use in conjunction with highly efficient ROM approximations. Possible approximations of (13) pertain to hierarchical approximations. One could, for instance, solve the dual problem using an enriched ROM, rather than the FOM. However, designing a robust hierarchical scheme requires means of guaranteeing that the enriched basis is sufficient. In view of the discussion above, we shall henceforth consider alternative methods to estimating (and controlling) the error in macroscopic stress from each microscopic problem.
2.3. Artificial Neural Networks (ANNs)
2.3.1. Generation of Data
2.3.1.1. Design of input data / loading directions
The present work is concerned with materials based on state dependent models for, e.g., pseudo-plasticity. For such material models, see, e.g., Kunc and Fritzen (2018), the transition zone between elastic and plastic domain is found in the vecinity of the origin in strain space. In this transition zone a pronounced nonlinearity and change of slope not only from the elastic to the plastic domain take place, but also depending on the load direction in the plastic domain, followed by a saturation behavior for increasing load amplitudes. This material behavior motivated the Concentric Sampling (CS) approach proposed by Kunc and Fritzen (2018) for pseudo-plastic materials, which is also used in this work. Based on the CS approach, nd almost uniformly distributed unit vectors / directions d(i) ∈ ℝ6 (i = 1, …, nd) are generated. Samples along the generated directions are considered with an exponentially growing step width from the origin. The primal strain dataset is addressed as
with the primal strain norm discretization Dr and set of directions Dd. The definition (15) corresponds to a tensor decomposition into direction and amplitude. For many materials the volume changes are rather small compared to isochoric deformations. This effect is particularly pronounced for (pseudo-) plastic materials. In order to sample the strain space in a problem specific manner, a rescaling of the strains defined in (15) may be convenient. The present work solely rescales the spherical part (sph) of each primal strain (i.e., the dilatation), while the deviatoric part (dev) remains unchanged. The actual strain dataset is described by
where specifies the rescaling of the spherical part. The number of strain samples #(Dε) is given by the product of number of the directions #(Dd) and the number of amplitudes per direction #(Dr).
2.3.1.2. Generation of output data
For the training of the artificial neural networks (ANNs), training (T), validation (V), and random (Monte Carlo - MC) datasets, referred to as , , and , respectively, are generated. The latter are not obtained using CS, but using a uniformly random set of directions in strain space. They are mainly used for unbiased testing of the surrogate independent of the proximity to the training and validation set. The output of interest in the present work is, primarily, the effective stress, but also some error measures for the derived surrogates, which will be defined in the following sections.
Technically, the process of generating the data samples is challenging. In order to obtain reliable data, the FOM and the ROM must be evaluated thousands of times in order to obtain the needed data. Each sample consists of an effective strain and the related effective stress . In order to boost the performance of the simulations, a ROM-preconditioned solver for the FOM has been developed: First, an accurate (i.e., high-dimensional) ROM is solved for each load path. Then the FEM is accelerated by taking the ROM solution as initial guess for the nodal displacements during the first increment and, during the subsequent load steps, by taking the ROM displacement increment as initial guess for the FEM displacement adjustment. This not only brings the initial guess close to the final solution but it also leads to an accurate global stiffness matrix that can be combined with Quasi-Newton techniques. The ROM-accelerated FE showed a 20% reduction in the number of Newton iterations, despite the use of a Quasi-Newton scheme. This is remarkable in view of the less accurate stiffness matrix of Quasi-Newton scheme and the faster convergence must be attributed to the improved initial guess for the FE displacement vector reconstructed from the ROM solution. Overall, this approach provides significant computational improvements over a naive FE based data generation. Further, it is noteworthy that the high-dimensional ROM solution can be used to derive a hierarchy of lower-dimensional ROM solutions needing virtually no additional Newton-Raphson iterations via linearization. More precisely the trailing entries of a ROM solution can be eliminated by making use of the Schur complement which leads to an adjustment of the remaining reduced coefficients. In our tests this downscaling of high quality ROM solutions to N-dimensional ROMs proved an efficient tool.
2.3.2. Surrogate Model for the Effective Stress
2.3.2.1. Feature design
For the successful training of ANNs the normalization of the input and output data and the design of appropriate inputs (usually referred to as features) through linear or nonlinear transformations is essential. Compared to image data and convolutional neural networks, which usually take advantage of the intrinsic connection of image data and convolution, the present input data (strain data) is low-dimensional and necessarily requires sensible mechanical guidance during feature design. From a pure data-driven perspective, general batch normalization can greatly improve the prediction quality of a network. But in the present problem setting the input and output data have a clear physical nature. Therefore, based on mechanical reasoning, the consideration of the dependency of the material law on the spherical () and deviatoric () degrees of freedom of the strain offers a material theoretic starting point. This linear transformation is addressed as
Additionally, the deviatoric part of the strain can be split into its norm and direction
After either of these transformations, a corresponding normalization is performed in order to prepare the strain features for the subsequent evaluation through the ANN: For Tsd1, each component of the vector Tsd1 is shifted and then divided by its corresponding mean and standard deviation over the training dataset , i.e., component-wise shifting and scaling are applied. For Tsd2, the first component (i.e., the volumetric strain) is scaled according to the standard procedure while the deviatoric strain amplitude is divided by its peak value and the deviatoric direction remains unchanged. In the following the shifted and scaled inputs are referred to as x[0] ∈ ℝD, D = 6, 7.
2.3.2.2. Architecture of the artificial neural network
In the present work, feedforward neural networks are used. This choice within the plethora of available artificial neural networks is driven by the fact that a function is to be calibrated that depends exclusively on the current state : the effective stress of the FOM . It should be remarked that for problems with history dependency, e.g., path-dependent plasticity or damage in cyclic loading, feedforward neural networks could, in principle, be considered, but recurrent neural networks offer much better alternatives. They are specially designed for time series and they feed back outputs of the model into the prediction of the subsequent cycle. Generally, the training costs of recurrent neural networks are immensely higher than that of feedforward neural networks, since a large number of input paths is required, instead of points in the input space. For the problem at hand recurrent neural networks offer no advantages. Hence, we choose feedforward neural networks for the rest of the present work. Hereby, networks consisting of L > 1 layers are taken into account. For each layer l = 1, …, L consisting of n[l] neurons the inputs x[l−1] ∈ ℝn[l−1] and outputs x[l] ∈ ℝn[l] are related by weights , biases b[l] and activation functions a[l] via the recursion
complemented by n[0] = D. The weights and biases of the ANN are parameters, which need to be calibrated with training data by solving an unconstrained optimization problem. The choice of activation functions is an abstract parameter that can heavily influence the quality of the surrogate. Its selection depends on the intuition of the user, complemented by thorough testing in terms of architecture sweeps. In the present context, the differentiability of the stress surrogate is aspired, as it allows for a computation of the tangent stiffness at low computational expense through automatic differentiation. This requirement naturally favors smooth activation functions. Our ANN implementation is based on Python3 (v3.4.3) using Google's TensorFlow library (v1.12.0), which offers automatic differentiation capabilities. For architecture tests the following activation functions have been used:
• the identity function (Id) a(x) = x,
• the rectified linear unit (RELU) a(x) = max(x, 0),
• the softplus function (SP) a(x) = log(1 + exp(x))
• and the hyperbolic tangent (TANH) a(x) = tanh(x).
The identity function (Id) allows to pass unaltered input, such that a linear combination of the activation functions of the previous layer is returned. This is particularly desired in the last layer, in order to obtained an optimized linear combination of nonlinear functions as final output y = x[L] of the ANN. The evaluation of a single input strain through the whole ANN is addressed by the composition of all layers
2.3.2.3. Loss function
The training of the ANN requires an objective function that provides an error respecting the nature of the outputs. In the context of ANNs, the objective function is referred to as loss function. Similar to the inputs, the outputs, the effective stress of the FOM defined in (9), should also be scaled using an invertible transformation
Here, the same transformations Tsd1 and Tsd2 as for the inputs are considered for Tσ during architecture testing. The evaluation of the ANN is analogously abbreviated as
In this work, the mean squared error (MSE) is chosen as the loss function
The MSE (23) is then optimized with respect to the ANN parameters, i.e., the weights and biases are identified starting from a random initialization. The ANN output is then obtained through an inverse transformation
It should be remarked that, from the perspective of physics-informed artificial neural networks, one may also consider the incorporation of the norm of the non-symmetric part of the gradient in the loss function. This would help to calibrate the network, such that its gradient is likely to be close to symmetric. But since this can not be assured for arbitrary input , number of layers, neurons and activation functions, the present work prefers to solely consider (23) for the loss function, calibrate as good as possible and simply symmetrize the resulting gradient . Hereby, it should be stressed that a symmetric gradient is essential for the hyperelastic/pseudo-plastic material considered in this work, since the assembled system matrix of the macroscopic problems is symmetric by the corresponding material theory. A non-symmetric system matrix in the macroscopic problem would also increase the computational costs, due to the thereby induced necessity for solvers for non-symmetric matrices.
The quality of the ANN during training is checked, not with respect to the training dataset, but with the validation dataset via the mean relative norm error (MRNE)
In addition to that, the mean coefficient of determination of the effective stress is evaluated
The coefficient of determination is bounded by one which is attained if and only if the surrogate coincides with the reference for all queries.
2.3.3. Surrogate Model for the Error in the Quantity of Interest
2.3.3.1. Error regression and classification
In this section, we are interested in the calibration of ANNs taking strain data as input and delivering quantitative and qualitative error estimates for the stress. On the one hand, for a given strain, it might be of interest to predict the error of stress surrogate against the FOM stress. On the other hand, it might not be of particular interest to know the exact error value, but rather to know if the error is acceptable, i.e., if it is smaller than a prescribed tolerance. The quantitative error prediction leads to a classical regression problem, whereas the binarized response gives rise to an ordinary classification problem.
In the error regression problem, for a given model of the effective stress, we are interested in the absolute and relative norm errors
For the error classification problem, we consider the indicator function
with prescribed absolute and relatives tolerances τa and τr, respectively. The outcome of χM is particularly useful in order to decide on the subsequent treatment: For χM = 1, the error is considered acceptable and the surrogate can be used, while χM = 0 should trigger an adaptive refinement. For instance, the classifier χM can decide if the stress surrogate at a macroscopic integration point is acceptable or whether a more dedicated surrogate is needed.
For error regression and classification, the fully connected feed forward ANNs as described by (19) and the same activation functions as in section 2.3.2.2 are used. For the binary classification the final ANN layer is regarded as a log-probability with a single neuron. This setup is usually referred to as logits in binary classification.
2.3.3.2. Loss function
One of the desired properties, considering possible safety requirements in the error regression and classification, is to obtain if not accurate, then at least conservative results. In order to achieve a conservative behavior, for the error regression problem we consider the function
which changes the slope for negative input values to α. The function ϕα can be used to penalize underestimation of the error (for α > 1) when applied to the scalar argument of the MSE for the true error eM (representing the absolute error or the relative error of the model M ∈ {RN, ANN}) and its ANN surrogate ẽM
The MSEα is considered as the loss function for error regression, where α acts as a penalty parameter. The corresponding R2 value and the relative conservative amount (RCA) over the validation dataset
are used to assess the quality of the prediction.
For the error classification of model M∈{RN, ANN}, due to the binary nature of (28), the last layer of the ANN is defined as the composition of a standard sigmoid function and a shifted step function, i.e.,
The loss function for classification chosen in this work is the weighted binary cross entropy
Herein, false positive predictions dominate the cross entropy for w > 1, while 0 < w < 1 puts the focus on false negative classification. We define the overall accuracy of the classifier as the expectation of finding the same response in the true indicator χM and in the surrogate :
Further, the accuracy within the bin b ∈ {0, 1} is defined as the conditional probability
The reader should note, that ACC0 is more relevant when seeking conservative estimates. Only if ACC0 and ACC1 are close to unity, then the overall classification is robust, while for seemingly good ACC (e.g., around 0.98) the critical ACC0 could be inappropriate. This effect is particularly important if the surrogate has only few outliers requiring further processing.
2.4. Hybrid ANN/ROM Multi-Level Finite Element Simulation
2.4.1. General Hybrid Approach
In order to build a twoscale simulation model relying on the finite element method on the larger scale, the material model must be replaced by the homogenized response of the heterogeneous solid. In sections 2.1.2 and 2.3.2 the use of ROM and ANN serving as surrogates for the effective stress tensor and the effective tangent stiffness are described in detail. Both surrogates can be combined by introducing an indicator function which adaptively selects between the rapid and purely data-driven (but less physical) ANN if χ = 1 and the physics-driven ROM for χ = 0. The indicator function represents the binarized confidence in the accuracy of the ANN surrogate.
First, a simple ansatz for χ is chosen by setting χ to one if the current strain at the macroscopic position falls within the region covered by samples during the training of the ANN. In the present study this is equivalent to the kinematic indicator
Here, is the peak amplitude used during Concentric Sampling and ∥·∥W denotes a weighted norm that transforms elements of Dε defined via (16) back into normalized directions:
The use of the ROM outside of the training domain is motivated by its reluctance to energy minimization, i.e., by preserving the key physical characteristics of the full order model while restricted to a relevant subspace of the solution manifold.
A second indicator can be obtained by evaluating the accuracy of the ANN. Therefore, a binary classifier is employed following the procedure outlined in section 2.3.3. The indicator function is then replaced by the classifier: .
2.4.2. Technical Issues Related to on-the-fly Model Switching
At first, the concept of the indicator function χ marking the confidence region for the ANN and employing the ROM elsewhere sounds straight-forward. However, this simple approach does not work in practice as the two concurrent surrogates do not provide continuous approximations of the stresses. This can be illustrated by letting denote the confidence region of the ANN in strain space. It should be noted, that may contain several holes depending on the chosen quality indicator determining a point or region in strain space as admissible or not. On the boundary of the confidence region there is a hard transition between the two surrogates which induces a stress jump, leading to a non-smooth material response. When switching between ANN and ROM on-the-fly, i.e., when deciding for each query adaptively which surrogate should be evaluated, convergence of the macroscopic problem is disrupted, rendering the straight-forward implementation of a quality indicator guided adaptive procedure infeasible. One may try to solve this problem with multi-fidelity approaches, see, e.g., Meng and Karniadakis (2019), where multiple nested surrogates (e.g., artificial neural networks) based on data groups of different accuracy/fidelity and amounts are trained. Unfortunately, such multi-fidelity data approaches are not applicable for the problem at hand. In order to motivate this more clearly, consider again Figure 1 and the strategy illustrated in Figure 2 for a macroscopic boundary value problem solved with FE and calling for an on-the-fly model switching at the integration points for the computation of for prescribed .
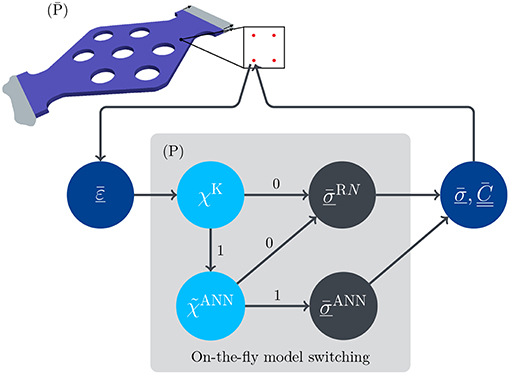
Figure 2. Macroscopic FE boundary value problem with on-the-fly model switching at integration points for the computation of the effective microscopic stress for prescribed microscopic effective strain for the microscopic problem (P): first, χK checks if is in the training region of the ANN surrogate for ; if the quality of ANN is acceptable based on , then is evaluated and passed to the macroscopic FE problem; but if either is outside of the ANN training range or the ANN surrogate is not accurate enough, then a previously selected accurate ROM of corresponding dimension N is evaluated and then passed to the macroscopic problem.
In the context of twoscale simulations, the problem is not the accuracy/fidelity of the training data of the microscopic problem, but (1) the usage of a surrogate outside of its training range (based on χK for the ANN stress surrogate) and (2) the point-wise quality of the surrogate with respect to prescribed tolerances ( for the ANN effective stress surrogate), which define the boundary of the confidence region and trigger the model switching. Both events can occur in twoscale simulations, since the input field at the macroscopic scale (i.e., ) is not known for arbitrary macroscopic geometry and boundary conditions, such that point-wise at the macroscopic scale the ANN microscopic surrogate for the effective stress may be evaluated far outside of its training range or may be inaccurate. If the ANN effective stress surrogate is inaccurate, then, e.g, a fixed ROM of sufficient accuracy can be initiated, as depicted in Figure 2. Naturally, in order to lower the number of ROM evaluations, one could simply enhance the existing networks and during the online computation by re-training using additional samples. However, there is no methodology available that can a priori guaranty accuracy gains without the need of extensive architecture sweeps and substantial sampling of extended and/or refined regions in the input space. Therefore, such an online re-training is not a viable option at the moment and alternatives need to be investigated. Contrary to the inherent properties of ANNs and the related training, (i) the ROM solution is obtained in a physically guided procedure, (ii) the errors of the ROMs drop with increasing dimension, and (iii) the ROM has no intrinsic validity domain limitation in strain space. This motivates the use of a ROM of sufficient dimension outside of the validity domain of the ANN stress surrogate. Approaches for the algorithmic realization of the dynamic switching between concurrent surrogates are described in the sequel.
2.4.2.1. Staggered hybrid ANN/ROM algorithm
The first approach consists of a staggered procedure, where the ANN is used as the only stress surrogate in a first run of the twoscale simulation (see Algorithm 1). Thereby, a first overall response is gathered. This is followed by a second run, in which the subset of all integration points having seen a zero quality indicator during any of the load steps of the first run are enforced to use the ROM surrogate. This set is then kept constant, i.e., switching from ANN to ROM is one way. This procedure enables the use of the ANN solution as an initial guess for the subsequent hybrid run which leads to low iteration counts and improved performance. During the second run, the difference of the ANN and the ROM can be evaluated to provide valuable post-processing data in order to better understand the quantitative impact of the model modifications, see also examples in section 3.3.2. Two major disadvantages of this approach are (i) the irreversibility of the ROM activation which can lead to substantial computational costs and (ii) the possible failure during the first run, if the ANN surrogate becomes non-convergent. The latter can, e.g., occur if the local magnitude of on the macroscale falls way outside of range of the training data.

Algorithm 1. Staggered hybrid ANN/ROM twoscale simulation algorithm.
2.4.2.2. Adaptive on-the-fly ANN/ROM algorithm
A second on-the-fly model selection procedure, solving both of the aforementioned issues, is described in Algorithm 2: It re-initializes the quality indicator in favor of the ANN at the beginning of each load increment. During the subsequent non-linear Newton-Raphson iterations of the same increment, the indicator is updated in a monotonic way, i.e., switching from ANN to ROM is allowed but not vice verse (see line 11 in Algorithm 2). The computational efficiency can be improved by substituting only part of the equilibrium iteration by the ROM.

Algorithm 2. Adaptive on-the-fly ANN/ROM twoscale simulation algorithm.
3. Numerical Examples
3.1. Underlying Material Model
An artificial heterogeneous solid consisting of three phases is investigated. It consists of a laminate structure of two pseudo-plastic materials where the two layers share the same elastic parameters (E1 = E2 = 75 GPa, ν1 = ν2 = 0.3) but have different yield strength and hardening behavior: The first layer has a yield stress of 100 MPa and a linear hardening slope of 2,000 MPa, whereas the second layer has a yield stress of 115 MPa in the absence of hardening. The third phase is represented by a spherical inclusion that is centered on the interface of the two phases. The inclusion is assumed linear elastic with properties mimicking a ceramic inclusion made of SiC (E = 400 GPa, ν = 0.2), see Figure 3. The volume fractions of the two plastic layers are 46.73% each and the one of the inclusion is 6.54%. The material was designed to induce a directional dependency of the effective material behavior (see right plot in Figure 3 for an example). This feature makes the identification of the unknown homogenized response more challenging and, thereby, a benchmark problem for the developed methodology is designed.
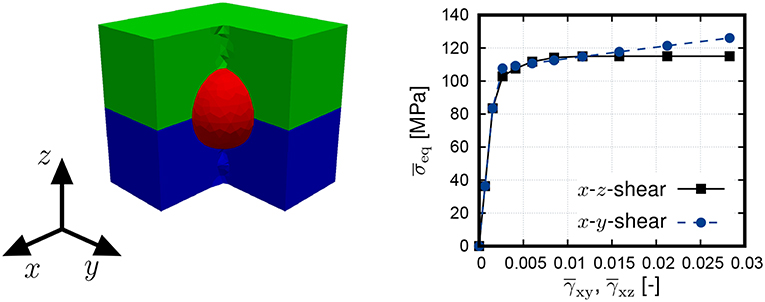
Figure 3. (Left) Periodic representative volume element (RVE) of the triphasic material: layer 1 (blue; pseudo-plastic with hardening), layer 2 (green; pseudo-plastic, no hardening), and inclusion (red; linear elastic); (Right) Directional dependency of the material response.
3.2. Quantitative Comparison of ROM and ANN Surrogate Models
3.2.1. Effective Stress Surrogate
The strain space is sampled as described in section 2.3.1 for an effective strain amplitude discretization Dr = {0.0005, 0.002, 0.0035, 0.005, 0.0075, 0.01, 0.015, 0.025, 0.04}. The spherical / volumetric part of the primal strain dataset is rescaled with . Then, 1152 training, 288 validation and 512 Monte Carlo directions are generated, yielding 10368 training, 2592 validation and 4608 Monte Carlo effective strain points in ℝ6.
An initial architecture testing phase is conducted. The activation functions and transformations illustrated in section 2.3.2 are considered, together with varying number of layers and neurons. The architecture test with L ∈ {3, …, 6} and number of neurons per hidden layer n[l] ∈ {16, 32, 64, 128}, l ∈ {1, …, L − 1}, yields that none of the activation functions (RELU, SP, TANH) show a remarkable advantage over the other, even for as large number of epochs as 10,000 with whole batch training for a learning rate of 0.001 using an ADAM optimizer. However, the feature design of input (effective strain) and output data (effective stress of the FOM) has a major influence. Hereby, the most successful combination is identified to be the use of the spherical-deviatoric transformation Tsd1 for the input as well as for the output. The transformation Tsd2 did not show major advantages in the final objective function values.
Based on the initial architecture testing, the softplus function (SP) has been chosen to power further investigations, due to its monotonic and differentiability properties in regard of an expected monotonic stress behavior and need for tangent operators for future FE multiscale computations. In Table 1, different architectures are tabulated, showing the performance of each ANN. Based on the MRNE and values for the validation dataset (and the corresponding values MRNEMC and evaluating the MC dataset), the ANN1 comprised of six layers with five softplus hidden layers and 128 neurons per hidden layer is chosen for the final evaluation. In Figure 4 the prediction of ANN1 for the von Mises effective stress is depicted for the three in Table 2 tabulated directions of the training (dirT12, dirT23, and dirTmixed) and validation datasets (dirV12, dirV23, and dirVmixed), showing a good agreement with the FOM data. It should be noted that the directions dirT/V12 have a (12) dominant component, meaning that the hardening material shown in Figure 3 is activated, while dirT/V23 have a (23) dominant component allowing for a localization of the deformation in the non-hardening material, see Figure 4. The effective strain directions dirT/Vmixed show some examples for combined loading and corresponding material response, see Figure 4. The reader should take into account, that the ANNs have been trained with strain data up to a norm of 0.04 in the primal strain set (corresponding to the last data point for each loading direction in Figure 4). The behavior of the ANN1 beyond this norm value was expected to tend to keep increasing due to the properties of the softplus function. However, due to the tendency of the ANN to increasingly overestimate the stresses and the artificial stiffening at load amplitudes beyond the training data, ANN1 is not expected to deliver accurate results beyond an effective strain norm of approximately 0.04 in respect to the primal strain set . Finally, in addition to the a posteriori symmetrization of the gradient , numerical tests were carried out to verify that (i) the gradient obtained via automatic differentiation is almost symmetric (with an average error lower than 1%) and (ii) that the difference of the symmetrized gradient to the algorithmic tangent of the ROM with 96 modes was matched up to relative errors around 1.5%. These two checks approved the chosen approach. For a better transparency of these results, the authors offer Supplemental Data, see section Supplementary Material, containing the FOM data, the trained ANN1 and commands for the reproduction of all corresponding results.

Table 1. ANNs for the effective stress surrogate with corresponding choice of input features, network architecture, intermediate transformation of stress data Tσ, measures MRNE and for the validation dataset, and MRNEMC and for the MC dataset.
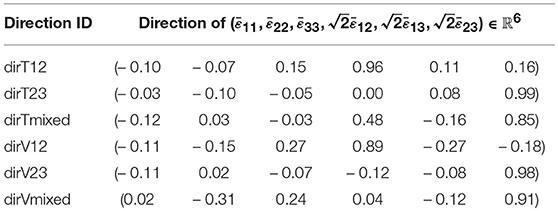
Table 2. Effective strain load directions for the inspection of the effective von Mises stress in the evaluation of ANN1.
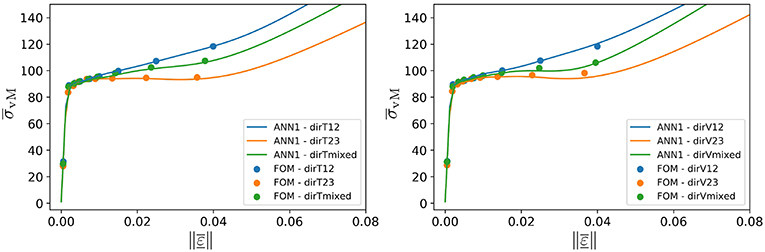
Figure 4. Von Mises effective stress vs. effective strain norm for ANN1 for the 3 loading directions of the training dataset (Left) and 3 loading directions of the validation dataset (Right) tabulated in Table 2.
3.2.2. Error Surrogates
For the error regression and classification, it is first necessary to gain an overview regarding the quality of the N-dimensional ROMs and of the best of the trained ANN effective stress surrogates of the previous section.
In Figure 5 the cumulative distribution function of the absolute norm error (ANE) and of the relative norm error (RNE) for the validation set are shown for ROMs of different dimensions N and for . It is clearly visible that for increasing ROM dimension, the accuracy of the ROM improves for both, the ANE and RNE. This is expected, since the higher the ROM dimension, the richer the underlying function space, i.e., the distance to the solution manifold of the full order model decreases. It should be noted that the ANN effective stress model performs well against ROM16 and ROM24. The ROM32 yields a mean ANE of 1.019 MPa and a mean RNE of 0.007. It is from now on assumed that the accuracy of the ROM32 suffices for future multiscale FE simulations, i.e., an a priori quality assessment is made.
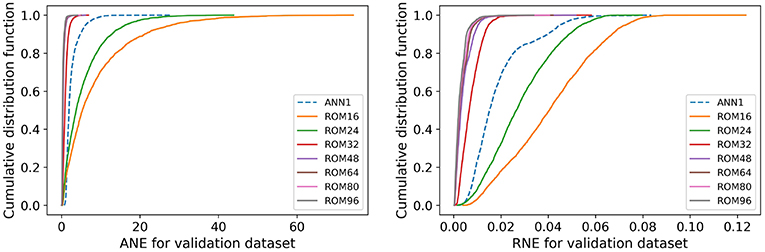
Figure 5. Cumulative distribution function of the errors of ANN and ROMs of dimensions 16 to 96: distribution of ANE (Left); distribution of RNE (Right).
We first demonstrate the error regression in terms solely of the N-dimensional ROMs for the corresponding ANE and RNE. These error measures could be used for an adaptive selection of a ROM after having access to its estimated errors. An architecture test for ANNs with number of layers L ∈ {3, …, 6}, neurons per hidden layer n[l] ∈ {16, 32, 64}, up to 10,000 epochs and whole batch training is performed. A selection of the trained ANNs is tabulated in Table 3.
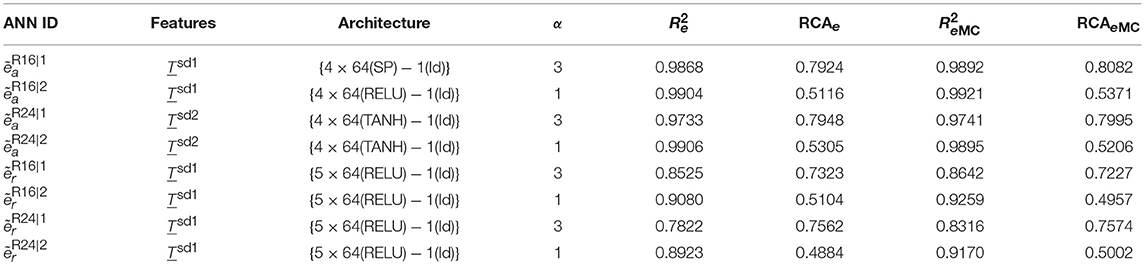
Table 3. ANNs for error regression with corresponding choice of input feature, network architecture, penalty parameter α, corresponding quality indicators and RCAe for the validation dataset and and RCAeMC for the MC dataset.
The ANNs , tabulated in Table 3, are depicted in Figure 6. The influence of the penalty parameter α, introduced in (29), can be seen in Figure 6 (left plot), where it becomes visible that the larger amount of points are found on the upper side of the diagonal, i.e., the predicted error is larger than the error in the validation set. This is reflected in the relative conservative amount (RCA), see Table 3. The usual trade-off is that increasing α yields conservative behavior (i.e., a higher RCA), but reduces the accuracy in terms of . Analog behavior is observed for er, as tabulated in Table 3 (bottom half). Large values of α yield reduced values, due to the dilemma of balancing a reduction of the loss function, while preserving conservative behavior.
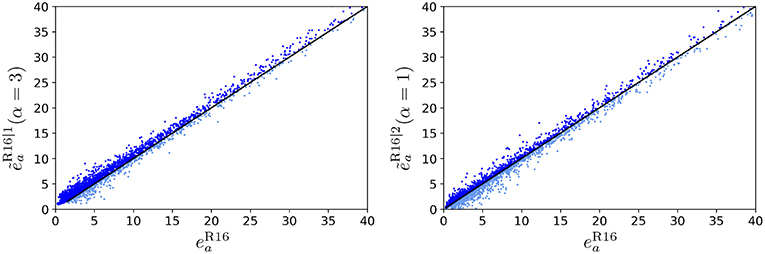
Figure 6. Correlation plots for the ROM16 ANE and corresponding error regression ANNs in the range [0,40] MPa: with penalization of error underestimation parameter α = 3 (Left) and with α = 1 (Right).
The error classification is conducted for the absolute and relative tolerances τa = 2MPa and τr = 0.02, respectively. Architecture testing for L ∈ {3, …, 6} and n[l] ∈ {16, 32, 64} for the hidden layers yield varying quality of results depending on the weight w on the false positive. Depending on the number of positive and negative outcomes, the weights should be adapted. For the architecture testing of this work, the ratio
is considered. If the number of negative outcomes in the training data is higher than the positives, then w0 > 1 holds. The consideration of w = w0 in the binary cross entropy partly equilibrates the influence of the false positive (i.e., classified accurate but violating the tolerance) and false negative (i.e., classified inaccurate but within tolerance). But it may also overly bias the cross entropy during training, yielding poor accuracy in one bin. Therefore, w is sampled between unity and w0 in four evenly spaced steps during architecture testing. A selection of trained ANNs is tabulated in Table 4.

Table 4. ANNs for error classification for and of previous section with tolerances τa = 2MPa and τr = 0.02.
Classification ANNs with acceptable accuracy with respect to the validation dataset are obtained for the 16-, 24-, and even for the 32-dimensional ROM. These ANNs, denoted as in Table 4, offer, in principle, the opportunity for an adaptive ROM scheme, in which for a given effective strain the lowest-dimensional but still acceptable ROM can be automatically identified for the chosen tolerances. In addition to the error classification of different ROMs, an attempt to classify the quality of the ANN labeled in Table 1 is made for the same tolerances with , see last row in Table 4. The surrogate has already intrinsic information of the training dataset, due to its optimization in respect to this dataset. In order to avoid an over-calibration, the training, validation and Monte Carlo datasets have been concatenated, randomly reordered and split into new training and validation datasets containing 90% and 10% of the data, respectively. The classifier for is trained on these new datasests. An extensive architecture test is performed with the same parameters as for the ROMs. The classifier for , denoted as in Table 4, reaches acceptable accuracy, but notably lower than the ones achieved for the ROM classifiers. In retrospective, a justification for the lower performance of the classifier is found in the higher regularity of the ROM solution that is matching the behavior of the full order model. This is explained by the ROM inheriting the mathematical structure and the physical principles of the FOM. The classifiers of this section allow for an on-the-fly model switching, as illustrated in Figure 2, to be exemplified in the following section. Hereby, the ROM32 is considered for Algorithm 1 and Algorithm 2 due to its sufficient accuracy, see Figure 5.
3.3. Multiscale Simulation Based on Adaptive ANN-ROM-Scheme
3.3.1. Twoscale Problem
The presented hybrid methods introduced in Algorithms 1 and 2 are used in actual three-dimensional twoscale simulations. The results are compared to FE2R simulations (in the spirit of Fritzen and Hodapp, 2016) in which the reduced order model is used as a stress surrogate in all points of a macroscopic structure which is considered as a reference based on the high accuracy of the ROM with 32 modes (see Figure 5, section 3.2.2).
The macroscopic problem depicted in Figure 1 is borrowed from Fritzen and Hodapp (2016), while the microstructure is described through the material of section 3.1. Three different 3-dimensional mesh densities are considered on the macroscopic level: M1 (1,734 elements/13,872 int. points), M2 (6,318 elements/50,512 int. points) and M3 (53,790 elements/430,320 int. points). All three models consist of trilinear hexahedral elements with selectively reduced integration (i.e., B-bar elements are used). The loading in terms of a 2% stretch of the macroscopic specimen is applied in 10 equally spaced increments up to 0.2% followed by nine increments of 0.2% amplitude each in order to better cover the transition between elastic and elasto-plastic behavior for Algorithm 2.
3.3.2. Staggered Adaptive Procedure cf. Algorithm 1
First the staggered procedure introduced in Algorithm 1 is used. It is found that the first run that is relying on the ANN surrogate only achieves excellent runtimes when evaluating the ANN on graphics cards (here: one Nvidia GTX Titan Black), leading to runtimes of approximately 15 s for one evaluation of the surrogate at each of the 430,320 integration points of the finest mesh M3. It shall be noted that this includes a major execution overhead1.
A general dilemma of twoscale simulations that was observed for the FE2R method by Fritzen and Hodapp (2016) is also present here: Local outliers of the strain field attain magnitudes that quickly exceed the range of the inputs used during training of the ANN stress surrogate. The number of outliers becomes more relevant for the finer discretizations. This reveals a major short-coming of Algorithm 1: While the simulation for mesh level M1 terminated cleanly in roughly 3 h wall-clock time with most of the computing time being spent during the hybrid ANN/ROM phase, M2 did not converge for loadings larger than 1.2% due to locally excessive strains that lead to spurious stress response of the ANN. The finer mesh M3 fails to converge beyond 0.8% of overall stretch. Additionally, the ANN version failed to improve the accuracy beyond a certain limit, i.e., it failed to achieve quadratic convergence starting beyond a critical load amplitude. In Figure 7 a comparison of the tension force of the ANN-only run (lines) and of the subsequent hybrid run (symbols) is shown. During the hybrid run the number of integration points evaluating the ROM are determined from the quality indicator at the end of the last load step of the first run. For M1 this amounts to 960 out of 13,872 integration points (6.92%)2. These numbers illustrate that the ROM must be evaluated approximately 42,000 times for M1 (44 Newton iterations were needed in total) which leads to a substantial computational effort. Surprisingly, the ANN-only run and the hybrid run are hard to distinguish from the overall force-stretch plots, i.e., the ANN appears to yield good accuracy for this test. This is supported by the rather small absolute errors in the effective stress tensor, see Figure 7 (right) for the final load and mesh M1. In summary, the staggered procedure can exclusively be used if the peak strain in the macroscopic problem is sufficiently low due to the aforementioned convergence issues. Then the solution can be expected to give accurate predictions.
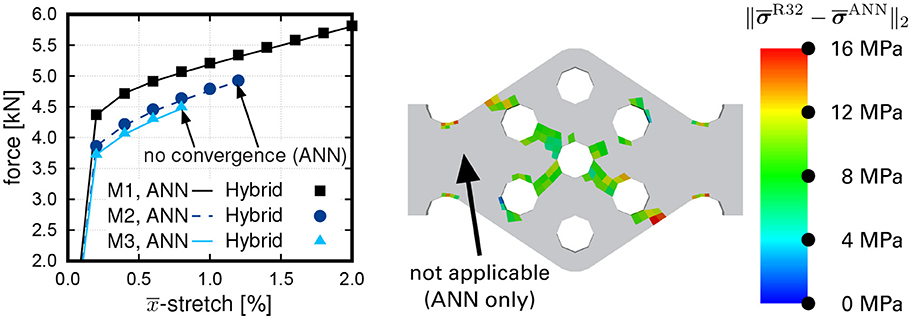
Figure 7. (Left) Comparison of the force of the ANN-only run (lines) and of the subsequent hybrid ANN/ROM run (symbols) for M1 (1734 elements), M2 (6318 elements), and M3 (53790 elements); (Right) Absolute error in the stress at the end of the hybrid run for M1.
In view of the number of quadrature points marked for use of the more reliable ROM, the adaptive scheme shows a steady increase when using the kinematic indicator χK marking points outside of the training range as not trustworthy for the ANN.
3.3.3. Single Pass on-the-Fly Adaptive Algorithm cf. Algorithm 2
The crucial ingredient of the on-the-fly adaptive scheme, described in Algorithm 2, is the irreversible update of the quality indicator during each load increment. Thereby, alternating model selection is prevented. All three macroscopic models, M1, M2, and M3, converged without any issues. The resulting macroscopic tension force of all three is compared in Figure 8, where the hybrid curve from Figure 7 and the FE2R curve for the ROM featuring 32 modes are also shown for M1. It is observed from Figure 8 (right) that all algorithms yield virtually identical results. Closer inspection reveals, however, that the FE2R and adaptive algorithm have nearly indistinguishable slopes (despite a negligible shift), whereas the ANN model is slightly curved, i.e., it shows a qualitative difference toward the reference solution which gets more pronounced at increasing load amplitude.
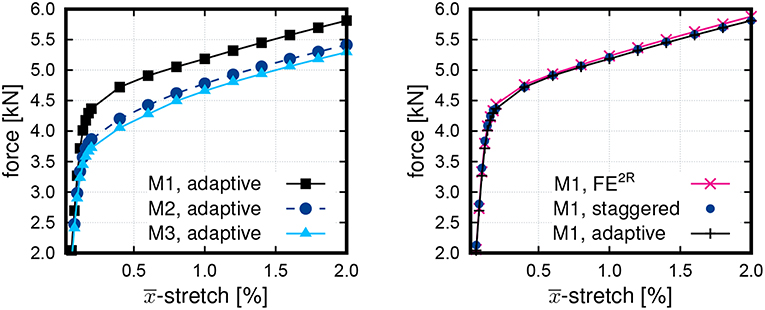
Figure 8. (Left) Comparison of the macroscopic stretch-force relation for the on-the-fly adaptive algorithm for meshes M1–M3; (Right) Comparison for M1: on-the-fly adaptive vs. staggered vs. FE2R with 32 modes.
The adaptive algorithm has the advantage that the number of macroscopic integration points that require evaluation of the ROM depends only on the current state. For the considered proportional loading, and when using the kinematic indicator χK, the relative amount of integration points grows monotonically with increasing load, cf. Figure 9.
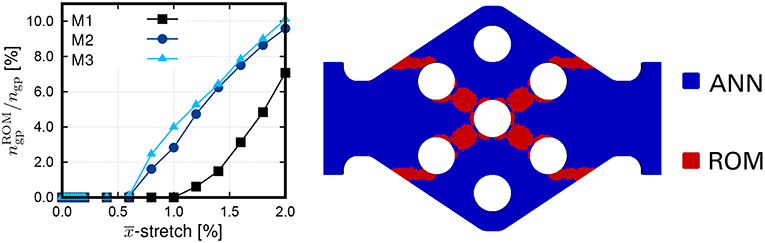
Figure 9. (Left) Relative amount of integration points with active ROM during the adaptive twoscale simulation; (Right) Quality indicator χK at the end of the adaptive twoscale simulation using mesh M3.
In order to investigate the practical usefulness of the ANN classifier, a comparison of the on-the-fly adaptive simulation using the kinematic quality indicator and the same simulation supplemented by the ANN classifier discussed in section 3.2.2 is considered. As expected, the solid yet not overly satisfying accuracy of the ANN classifier (see Table 4) induces a large number of additional ROM evaluations, thereby increasing the computation time considerably (approx. by a factor of 7), see Figure 10. Notably, the ANN classifier adds a considerable amount of points at the left and right constriction and close to the holes. In order to assess the relevance of these additional points, the macroscopic tensile force was investigated: It varies less than 0.3%, except in the very first load step with a difference around 0.6%.
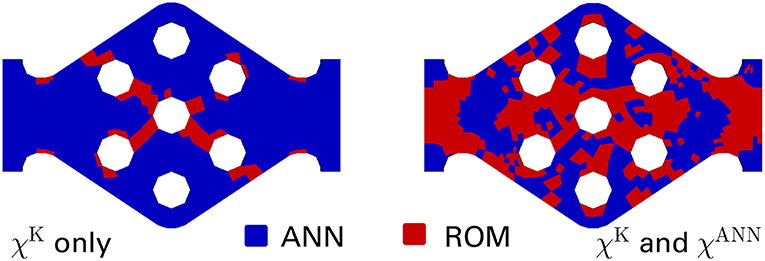
Figure 10. Comparison of the final quality indicators at the end of the adaptive simulation for mesh M1: kinematic classifier only (Left) vs. hybrid classifier accounting for the ANN accuracy cf. section 3.2.2 (Right).
4. Concluding Summary
A multi-fidelity approach for generating surrogate models of the effective stress tensor for the use in twoscale simulations is developed in section 2.1. At first, a ROM is derived from data gathered during full field simulations. The estimation of the error in the effective stress tensor (representing the QoI) of the ROM is discussed from a theoretical perspective in section 2.2. The mathematical structure of the error estimate reveals, that the ROM error estimation produces computational cost that is almost equivalent or even beyond that needed to solve a more dedicated ROM, thereby making it hard to justify such estimates when in the need for computational efficiency.
In our view this dilemma can only be resolved by finding alternative surrogates with low computational complexity but moderate to good accuracy complemented by adaptive strategies for local model refinement that employ costly computational methods only when needed. In this regard, ANNs are seen as promising candidates for the calibration of surrogate models for the effective stress and for classification that can trigger adaptive refinement. In section 2.3, the layout and the theoretical background of ANNs are discussed, together with different feature designs for the inputs and outputs based on the mechanical nature of the strain and stress. For the calibration of the stress surrogate, the mean squared error is used as loss function, while the quality of the trained ANN is checked on the validation dataset with the mean coefficient of determination and the mean relative norm error. In the case of error regression, a penalized mean squared error is proposed, which allows the conservative calibration of trained ANNs. For the error classification based on prescribed tolerances, the weighted cross entropy is used in order to allow for a better focus on the more important warning case, if the warning case density is low. Based on the proposed models, the core contribution of the present work constitutes two model-adaptive algorithms which encompass convergence issues encountered in the naive implementation of on-the-fly adaptive surrogate selection, see section 2.4. The first staggered algorithm is based on a two run approach, in which the first run is conducted solely with the ANN effective stress surrogate and flags points evaluated outside of the strain training region, such that only these points are evaluated with the high-accuracy ROM in a second run. The second algorithm offers a more flexible on-the-fly model-adaptive approach by allowing the re-initialization of the ANN at the beginning of each load increment.
Numerical examples of the illustrated approaches are presented in section 3 for a three-phase pseudo-plastic material with microstructure. First, ANNs are trained in order to approximate the effective stress. The surrogate of choice, , achieved a mean relative norm error of 0.0189 and a mean coefficient of determination of 0.9995 and yields an accurate tangent stiffness, due to its formulation on the automatic differentiation capabilities of the TensorFlow library. The accuracy of the ANN stress surrogate is found to range between ROMs of dimension 24 and 32, respectively (see section 3.2). The ansatz for error regression of ROMs of different dimension is presented, showing the possibilities for a calibration of a conservative ROM error estimator. In view of subsequent twoscale simulations with adaptive model selection, error classification is carried out for ROMs of different dimension and for the trained ANN stress surrogate. The achieved accuracy of the ROMs are higher than for the ANN stress surrogate, which indicates that the physics-informed ROM still shows a clearer pattern than the trained ANN stress surrogate, due to its inherited mathematical structure and underlying physical principles.
The trained ANNs are then used in twoscale mechanical FE simulations, based on the two developed algorithms of section 2.4. The staggered algorithm produces sensible results but has two limitations: First, the number of macroscopic quadrature points marked for correction grows irreversibly. Second, the ANN surrogate must be sufficiently robust and of—at least—moderate accuracy in a prohibitive part of the strain space. This requirement stems from the fact that local strain outliers lead to queries that are way outside of the usual training range of the ANN. This effect is found to be more pronounced when the macroscopic mesh density is increased which further complicates the robust surrogate construction using purely data-driven methods in general, see section 3.3.2. The second algorithm offers a true on-the-fly adaptivity in which the ANN surrogate can be recovered, e.g., during unloading. It is observed in section 3.3.3 that this second algorithm offers the fastest convergence among the considered twoscale simulations being approximately 3–10 times faster than the staggered algorithm and around 20 times in comparison to the fully coupled FE2R algorithm using the ROM with 32 modes for all stress predictions. The adaptive on-the-fly model of the second algorithm offers, therefore, an attractive approach which combines a low number of ROM evaluations with good convergence.
The final test using the additional error classifier for the ANN stress surrogate introduced a high number of additional negative outcomes (i.e., ANN error greater than tolerances), considerably increasing the number of integration points requiring the ROM. This was expected due to the low accuracy achieved during the training of the classifier, more specifically, due to the low accuracy for the positive outcome ACC1 and corresponding high amount of positive outcomes reflected by w0, see Table 4. On the one hand, this last approach offers a conservative twoscale scheme relying on the robust ROM. On the other hand, the approach loses computational efficiency, which leaves the error classification for rapid multiscale problems still an open issue. Future improvements should, therefore, focus on further theoretical or hybrid error estimators and an improved error classification for the effective stress. The latter could benefit from datasets spanning larger portions of the strain space. The authors are convinced that the ambitious goal of reliable twoscale simulations can only be achieved by fusing data-driven methods together with dedicated theories. For example, the reader should consider that at least two quality indicators are indeed necessary for a reliable model-adaptive ansatz. One quality indicator should address the trained ANN stress surrogate over the sampled strain (input) space and one quality indicator should definitely return a warning if the input leaves the training region. This is quintessential, since the range of macroscopic strain is not a priori known and the behavior of the purely data-driven ANN outside the training region may endanger the convergence and quality of the multiscale simulation. The results of the present work support the usability of ANNs in computational materials science, although further research ideally addressing the combination of theory and data is urgently required.
Author Contributions
FF conducted the finite element and reduced order model computations on the microscale and the twoscale simulations based on his self-developed code and wrote the corresponding sections. MF implemented, trained the artificial neural networks, and wrote the corresponding sections. FL conducted together with FF preliminary work on theoretical error estimates solely based on the reduced order model, which yielded the theoretical insights for the computational expenses and the necessity for alternative approaches. FL wrote the corresponding section for the theoretical error estimation.
Funding
The contributions of MF and FF are funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) – FR2702/6 – within the scope of the Emmy Noether Group EMMA – Efficient Methods for Mechanical Analysis. The contributions of FL are funded by the Swedish Research Council (VR) under grant no. 2015-05422.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
Vivid discussions within the scope of Cluster of Excellence SimTech (DFG EXC310 and EXC2075) regarding machine learning and data-driven model surrogation are highly appreciated. FF and MF further acknowledge the valuable discussions with Steffen Freitag (Ruhr-Universität-Bochum) on the topic of ANN-based regression and classification.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fmats.2019.00075/full#supplementary-material
Supplemental Data. Supplementary material is provided in the form of three HDF5 datasets (containing all FEM and ROM results used for the ANN training). Further, the stress surrogate and the quality indicator for this ANN are provided including a Python interface for accessing the file.
Footnotes
1. ^For simplicity each evaluation launches a new Python instance, reloads the model from a file and returns the results to the FE code through another file.
2. ^The numbers for M2 and M3 are not representative as the final load was not achieved.
References
Altschuh, P., Yabansu, Y. C., Hötzer, J., Selzer, M., Nestler, B., and Kalidindi, S. R. (2017). Data science approaches for microstructure quantification and feature identification in porous membranes. J. Membr. Sci. 540, 88–97. doi: 10.1016/j.memsci.2017.06.020
Bélisle, E., Huang, Z., Le Digabel, S., and Gheribi, A. E. (2015). Evaluation of machine learning interpolation techniques for prediction of physical properties. Comput. Mater. Sci. 98, 170–177. doi: 10.1016/j.commatsci.2014.10.032
Çeçen, A., Dai, H., Yabansu, Y. C., Kalidindi, S. R., and Song, L. (2018). Material structure-property linkages using three-dimensional convolutional neural networks. Acta Mater. 146, 76–84. doi: 10.1016/j.actamat.2017.11.053
Çeçen, A., Fast, T., Kumbur, E., and Kalidindi, S. (2014). A data-driven approach to establishing microstructure-property relationships in porous transport layers of polymer electrolyte fuel cells. J. Power Sources 245, 144–153. doi: 10.1016/j.jpowsour.2013.06.100
Chupakhin, S., Kashaev, N., Klusemann, B., and Huber, N. (2017). Artificial neural network for correction of effects of plasticity in equibiaxial residual stress profiles measured by hole drilling. J. Strain Anal. Eng. Design 52, 137–151. doi: 10.1177/0309324717696400
Feyel, F. (1999). Multiscale FE2 elastoviscoplastic analysis of composite structures. Comput. Mater. Sci. 16, 344–354. doi: 10.1016/S0927-0256(99)00077-4
Freno, B. A., and Carlberg, K. T. (2018). Machine-learning error models for approximate solutions to parameterized systems of nonlinear equations. Comput. Methods Appl. Mech. Eng. 348, 250–296. doi: 10.1016/j.cma.2019.01.024
Fritzen, F., and Hodapp, M. (2016). The finite element square reduced (FE 2R) method with GPU acceleration: towards three-dimensional two-scale simulations. Int. J. Numer. Methods Eng. 107, 853–881. doi: 10.1002/nme.5188
Fritzen, F., Hodapp, M., and Leuschner, M. (2014). GPU accelerated computational homogenization based on a variational approach in a reduced basis framework. Comput. Methods Appl. Mech. Eng. 278, 186–217. doi: 10.1016/j.cma.2014.05.006
Fritzen, F., and Kunc, O. (2018). Two-stage data-driven homogenization for nonlinear solids using a reduced order model. Eur. J. Mech. A Solids 69, 201–220. doi: 10.1016/j.euromechsol.2017.11.007
Fritzen, F., and Leuschner, M. (2013). Reduced basis hybrid computational homogenization based on a mixed incremental formulation. Comput. Methods Appl. Mech. Eng. 260, 143–154. doi: 10.1016/j.cma.2013.03.007
Gupta, A., Cecen, A., Goyal, S., Singh, A. K., and Kalidindi, S. R. (2015). Structure-property linkages using a data science approach: application to a non-metallic inclusion/steel composite system. Acta Mater. 91, 239–254. doi: 10.1016/j.actamat.2015.02.045
Kalidindi, S. R. (2015). Data science and cyberinfrastructure: critical enablers for accelerated development of hierarchical materials. Int. Mater. Rev. 60, 150–168. doi: 10.1179/1743280414Y.0000000043
Kalidindi, S. R., and De Graef, M. (2015). Materials data science: current status and future outlook. Annu. Rev. Mater. Res. 45, 171–193. doi: 10.1146/annurev-matsci-070214-020844
Kunc, O., and Fritzen, F. (2018). Generation of energy-minimizing point sets on spheres and their application in mesh-free interpolation and differentiation. Adv. Comput. Math. (submitted)
Larsson, F., and Runesson, K. (2011). On two-scale adaptive fe analysis of micro-heterogeneous media with seamless scale-bridging. Comput. Methods Appl. Mech. Eng. 200, 2662–2674. doi: 10.1016/j.cma.2010.10.012
Liu, R., Yabansu, Y. C., Agrawal, A., Kalidindi, S. R., and Choudhary, A. N. (2015). Machine learning approaches for elastic localization linkages in high-contrast composite materials. Integr. Mater. Manufact. Innov. 4:13. doi: 10.1186/s40192-015-0042-z
Lu, X., Giovanis, D. G., Yvonnet, J., Papadopoulos, V., Detrez, F., and Bai, J. (2018). A data-driven computational homogenization method based on neural networks for the nonlinear anisotropic electrical response of graphene/polymer nanocomposites. Comput. Mech. 1–15. doi: 10.1007/s00466-018-1643-0
Meng, X., and Karniadakis, G. E. (2019). A composite neural network that learns from multi-fidelity data: application to function approximation and inverse PDE problems. Available online at: https://arxiv.org/abs/1903.00104
Michel, J., and Suquet, P. (2003). Nonuniform transformation field analysis. Int. J. Solids Struct. 40, 6937–6955. doi: 10.1016/S0020-7683(03)00346-9
Michel, J. C., and Suquet, P. (2016). A model-reduction approach to the micromechanical analysis of polycrystalline materials. Comput. Mech. 57, 483–508. doi: 10.1007/s00466-015-1248-9
Miehe, C. (2002). Strain-driven homogenization of inelastic microstructures and composites based on an incremental variational formulation. Int. J. Numer. Methods Eng. 55, 1285–1322. doi: 10.1002/nme.515
Oden, J., and Prudhomme, S. (2001). Goal-oriented error estimation and adaptivity for the finite element method. Comput. Math. Appl. 41, 735–756. doi: 10.1016/S0898-1221(00)00317-5
Radermacher, A., and Reese, S. (2016). POD-based model reduction with empirical interpolation applied to nonlinear elasticity. Int. J. Numer. Methods Eng. 107, 477–495. doi: 10.1002/nme.5177
Raissi, M., Yazdani, A., and Karniadakis, G. E. (2018). Hidden fluid mechanics: a navier-stokes informed deep learning framework for assimilating flow visualization data. Available online at: https://arxiv.org/abs/1808.04327
Ramakrishna, S., Zhang, T.-Y., Lu, W.-C., Qian, Q., Low, J. S. C., Yune, J. H. R., et al. (2018). Materials informatics. J. Intell. Manufact. 1–20. doi: 10.1007/s10845-018-1392-0
Ryckelynck, D. (2009). Hyper-reduction of mechanical models involving internal variables. Int. J. Numer. Methods Eng. 77, 75–89. doi: 10.1002/nme.2406
Schmitz, G. J., and Prahl, U. (2016). Handbook of Software Solutions for ICME. (Weinheim: Wiley-VCH). doi: 10.1002/9783527693566
Sirovich, L. (1987). Turbulence and the dynamics of coherent structures. Part 1: coherent structures. Q. Appl. Math. 45, 561–571.
Soldner, D., Brands, B., Zabihyan, R., Steinmann, P., and Mergheim, J. (2017). A numerical study of different projection-based model reduction techniques applied to computational homogenisation. Comput. Mech. 60, 613–625. doi: 10.1007/s00466-017-1428-x
Trehan, S., Carlberg, K. T., and Durlofsky, L. J. (2017). Error modeling for surrogates of dynamical systems using machine learning. Int. J. Numer. Methods Eng. 112, 1801–1827. doi: 10.1002/nme.5583
Keywords: reduced order modeling (ROM), machine learning, artificial neural networks (ANN), surrogate modeling, error control, on-the-fly model adaptivity, multiscale simulations
Citation: Fritzen F, Fernández M and Larsson F (2019) On-the-Fly Adaptivity for Nonlinear Twoscale Simulations Using Artificial Neural Networks and Reduced Order Modeling. Front. Mater. 6:75. doi: 10.3389/fmats.2019.00075
Received: 04 February 2019; Accepted: 05 April 2019;
Published: 03 May 2019.
Edited by:
Christian Johannes Cyron, Hamburg University of Technology, GermanyReviewed by:
Alireza Yazdani, Brown University, United StatesErcan Gürses, Middle East Technical University, Turkey
Copyright © 2019 Fritzen, Fernández and Larsson. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Felix Fritzen, ZnJpdHplbkBtZWNoYmF1LnVuaS1zdHV0dGdhcnQuZGU=