 Yaofeng Xie
Yaofeng Xie Zhibin Yu
Zhibin Yu Xiao Yu1
Xiao Yu1- 1Sanya Oceanographic Institution, Ocean University of China, Sanya, China
- 2College of Electronic Engineering, Ocean University of China, Qingdao, China
Currently, optical imaging cameras are widely used on underwater vehicles to obtain images and support numerous marine exploration tasks. Many underwater image enhancement algorithms have been proposed in the past few years to suppress backscattering noise and improve the signal-to-noise ratio of underwater images. However, these algorithms are mainly focused on underwater image enhancement tasks in a bright environment. Thus, it is still unclear how these algorithms would perform on images acquired in an underwater scene with low illumination. Images obtained in a dark underwater scene usually include more noise and have very low visual quality, which may easily lead to artifacts during the process of enhancement. To bridge this gap, we thoroughly study the existing underwater image enhancement methods and low illumination image enhancement methods based on deep learning and propose a new underwater image enhancement network to solve the problem of serious degradation of underwater image quality in a low illumination environment. Due to the lack of ready-made datasets for training, we also propose the first dataset for low-light underwater image enhancement to train our model. Our method can be implemented to skillfully and simultaneously address low-light degradation and scattering degradation in low-light underwater images. Experimental results also show that our method is robust against different illumination levels, which greatly expands the applicable scenarios of our method. Compared with previous underwater image enhancement methods and low-light image enhancement methods, outstanding performance is achieved using our method in various low-light underwater scenes.
1 Introduction
Scattering and absorption are two widely discussed causes of image degradation in the field of underwater image enhancement. Low illumination, which is an unavoidable situation in the case of deep-sea exploration, makes underwater image enhancement tasks more challenging. The quality of information from underwater images captured under low illumination conditions is often poor. As a result, it may difficult to complete further application such as underwater environmental monitoring, object recognition, and tracking.
The existing underwater image enhancement methods can be used to improve the color distortion and blur of underwater images affected by backscatter noise under normal illumination to a certain extent, and the existing low-light image enhancement methods can be used to adjust the brightness of low-light images in the air and recover the image degradation caused by insufficient illumination well. However, the problem of low-light underwater image degradation cannot be solved using these methods.
As shown in Figure 1, (A) shows the input image, and (B) shows the enhanced result obtained by successively removing scattering using the underwater image enhancement method Ushape (Peng et al., 2021) and low-light degradation using the low-light image enhancement method KinD (Zhang et al., 2019b); (C) shows the enhanced result obtained by successively removing low-light degradation using the low-light image enhancement method KinD (Zhang et al., 2019b); and scattering using the underwater image enhancement method Ushape (Peng et al., 2021); (D) shows the result of using our method to process the input image. It can be seen from (B) and (C) that good results in terms of removing scattering and low-light degradation in low-light underwater images have not been achieved using the existing methods. Suppose that the scattering is first removed from the low-light underwater image. During the process of removing the scattering, the image texture structure may be changed, which affects the accuracy of the subsequent low-light image restoration. Therefore, (B) appears fuzzy. In addition, most of the current scattering removal methods are based on normal lighting scenes and cannot be directly used for low-light scenes. As a result, some blue fog is visible in subfigure (B), which indicates that the scattering in the image has not been completely removed. Instead, suppose that the image degradation caused by low-light conditions is first removed. In this process, the original backscattering structure of the image may be damaged. As a result, the scattering degradation in the image is not completely removedby the underwater image enhancement method. Therefore, the foggy scattering in subfigure (C) is more pronounced than that in subfigure (B).

Figure 1 Comparison of enhancement effects of different methods on low-light underwater images. The subfigure (A) means the input image, (D) means processing the input image by our method, (B) means processing the input image by underwater image enhancement method and low-light image enhancement method in turn. (C) means processing the input image by low-light image enhancement method and underwater image enhancement method in turn.
Based on the above considerations, we aim to find a method to simultaneously solve the complex degradation of low-light underwater images caused by scattering and insufficient illumination.
However, due to the flow of water and the complexity of shooting underwater images, it is difficult to capture underwater scenes under low-light and normal light conditions. We also lack paired data to describe the image degradation characteristics in the underwater low-light scenes. Influenced by LED-Net (Zhou et al., 2022b), we process the normal underwater scattering image by changing the exposure function of Zero-DCE (Guo et al., 2020) to obtain low-light underwater scattering image sets for pairwise training. We have named this dataset LUIE
By studying the existing underwater image enhancement and low-light image enhancement methods based on deep learning, we propose an effective network LDS-Net to simultaneously solve the problems of scattering and insufficient illumination of low-light underwater images.
In our method, we consider the degradation of underwater images caused by the scattering in water and insufficient illumination as damage to scene reflectance and then let the network learn the transformation of the nondegraded image according to the reflectance map and illumination map of the degraded image obtained by image decomposition. Specifically, inspired by Retinex-Net (Wei et al., 2018) and KinD (Zhang et al., 2019b), o, our model first decomposes the low-light underwater image into an illumination map and a reflectance map through the decomposition network and transmits them to the restoration network. The restoration network takes the normal light underwater image without scattering as a reference, inputs the given illuminance and reflectance maps, and outputs the restoration results.
Based on a large number of experiments, our method works well to address the problem of low-light underwater image degradation and is beneficial in other applications of underwater vision tasks using low-light underwater images.
Overall, our contributions are summarized as follows:
First, for low-light underwater image enhancement, we propose a dataset that is generated by strictly screening 890 image pairs from the UIEB (Li et al., 2020) datasets and 5004 image pairs from the LSUI (Peng et al., 2021) datasets and obtaining low-light image samples through a variant of the Zero-DCE (Guo et al., 2020) network.
Second, we propose the first network for low-light underwater image enhancement LDS-Net, which is composed of Decom-Net and Restor-Net. Combined with Retinex theory and image decomposition technology, LDS-Net regards the impact of scattering degradation and low-light degradation on the image as a new hybrid degradation on scene reflectance obtained by image decomposition. Therefore, it can simultaneously deal with scattering degradation and low-light degradation in low-light underwater images of different sizes.
Third, our method can enhance underwater images with different illumination from low illumination to normal illumination. Different illumination maps and similar reflectance maps will be obtained through image decomposition from underwater images with different illumination of the same scene. Taking different illumination maps as a conditional prior and inputting them together with reflectance maps into the Restor-Net for training can make our network enhance underwater images with different illumination.
2 Related work
2.1 Underwater image enhancement
Based on whether they are data-driven, underwater image enhancement methods can be divided into deep learning methods and non-deep learning methods.
The underwater image enhancement method without deep learning can be roughly divided into the methods that directly change the image pixel value to enhance the image and methods based on priors.
In the former methods, high-quality underwater images are obtained by adjusting the image pixel values by stretching them or by image fusion. For example, Ancuti fused a contrast-enhanced image with a color-corrected image through a multiscale mechanism to generate an enhanced image with better global contrast and richer detail information (Ancuti et al., 2012). Zhou proposed a visual quality enhancement method (Zhou et al., 2022a) for underwater images based on multifeature prior fusion. By applying a gamma correction power function and spatial linear adjustment to enhance the brightness and structural details of the image, the overall quality of the image improved.
In the latter methods, the image degradation process is mostly reversed according to key parameters of the physical model, which are deduced by priors to restore the image. For example, Wang proposed an adaptive attenuation curve a priori (Wang et al., 2017), which compensates for the transmission by estimating the attenuation factor, to achieve the effect of image restoration. Drew proposed a method based on the physical model of light propagation (Drews et al., 2016), in which the effects of absorption and scattering on image degradation were comprehensively considered, and statistical priors were used to restore the visual quality of the images acquired in typical underwater scenarios.
Image enhancement methods based on deep learning can be roughly divided into network-based GAN (Goodfellow et al., 2014) models, such as UWGAN (Wang et al., 2019), WaterGAN (Li et al., 2018), MyCycleGAN (Lu et al., 2019), and UGAN (Fabbri et al., 2018), and network-based CNN models, such as UIR-Net (Cao et al., 2018), URCNN (Hou et al., 2018), and Ucolor (Li et al., 2021). WaterGAN (Li et al., 2018), which is a representative GAN (Goodfellow et al., 2014) network model, solves the problem that there is a lack of real and reliable paired training data of underwater images by using the GAN network to synthesize degraded/normal image pairs and generate underwater images with good perceptual quality through loss function constraints.
The authors who proposed Water-Net (Li et al., 2020), facing the problem that there is a lack of paired data for underwater image training, manually selected good results through different enhancements of underwater scattering images as nonscattered reference standards and constructed the paired training dataset UIEB (Li et al., 2020), which contains corresponding scattered underwater images. Most of the subsequent underwater image enhancement networks based on CNNs are also trained based on this dataset. In the CNN network model Ucolor (Li et al., 2021), the common scattering problem in underwater images is solved by integrating the underwater imaging model into their network.
However, these existing underwater image enhancement methods cannot be applied to low-light scenes. Therefore, we aim to find a method to process both normal illumination underwater images and low-light underwater images.
2.2 low-light image enhancement based on deep learning
After the development of the first low-light image enhancement method LLNet (Lore et al., 2017), which was based on deep learning, an increasing number of low-light image enhancement methods based on deep learning, such as MBLLEN (Feifan Lv et al., 2018), EXCNet (Zhang et al., 2019a) and EnlightenGAN (Jiang et al., 2021), were proposed. In Retinex-Net (Wei et al., 2018), KinD (Zhang et al., 2019b) and RRDNet (Zhu et al., 2020), different subnetworks were designed by combining Retinex theory as guidance to estimate the components of the Retinex model. EnlightGAN (Jiang et al., 2021), which was introduced to solve the problem of the poor generalization ability of models trained with paired data, uses GAN (Goodfellow et al., 2014) to generate normal illumination images according to the low-light images. Yan also proposed a low-light image enhancement method (Yan et al., 2021) based on the enhanced network module optimized generative adversarial network (Goodfellow et al., 2014). Compared with traditional image enhancement methods, this method has better overall perception quality.
Facing the problem that supervised learning and unsupervised learning have poor generalization ability or unstable training, ExCNet (Zhang et al., 2019a) was proposed as a zero-shot low-light image enhancement method, in which learning and enhancement come from only the test image. The input image is decomposed into a base layer and detail layer, and the image is enhanced by adjusting the base layer through the estimated S-curve. For a low-light image, simply adjusting the brightness of the image inevitably amplifies the image noise. Faced with this problem, AGLL (Lv et al., 2021) was proposed, in which a synthetic dataset was constructed carefully designed with low-light simulation strategies. Then, a novel end-to-end attention-guided method was proposed based on a multibranch convolutional neural network trained with the new dataset to enhance low-light images. Facing the problem that no paired data are available to characterize the coexistence of low-light and blur, Zhou introduced a novel data synthesis pipeline (Zhou et al., 2022b) that models realistic low-light blurring degradation. An effective network (Zhou et al., 2022b) named LED-Net was proposed to perform joint low-light enhancement and deblurring.
Inspired by LED-Net (Zhou et al., 2022b), we also synthesize a low-light image dataset for joint low-light enhancement and scattering removal by modifying the Zero-DCE (Guo et al., 2020) network. However, our modification to the Zero-DCE (Guo et al., 2020) network makes it different from the original.
In this method, we also decompose the image into reflectance and illumination according to Retinex theory and then enhance the image by learning the mapping from the obtained reflectance map and illumination map to the nondegraded underwater image.
Unlike KinD (Zhang et al., 2019b) and Retinex-Net (Wei et al., 2018), which restore the illuminance map and reflectance map, respectively, for image enhancement, we input the decomposed illumination map and reflectance map into the restoration network at the same time and the generation of the enhanced image is directly learned according to the ground truth. In addition, given that in KinD (Zhang et al., 2019b), the image degradation caused by low-light is considered as pollution in the image scene reflectance map, we further explore the feasibility of treating the image degradation caused by low-light and scattering as pollution related to image reflectance.
3 LUIE dataset
3.1 Motivation
Due to the fluidity of water and the difficulty of underwater shooting, it is difficult to capture underwater low-light images and underwater normal light images with consistent scenes. Therefore, we consider synthesizing appropriate underwater images with low-light degradation and scattering according to the existing datasets for network training.
We choose to synthesize underwater images with low-light degradation and scattering by using underwater images under normal light conditions with scattering in the UIEB (Li et al., 2020) and LSUI (Peng et al., 2021) datasets and take the normal light images without scattering in the original datasets as the ground truth. Because the data results synthesized by GAN (Goodfellow et al., 2014) often contain artifacts, adding low-light degradation to the original scattering underwater image through the GAN (Goodfellow et al., 2014) may change the original scattering degradation of the image. Therefore, we consider a method to synthesize underwater images with low-light degradation and scattering without damaging the inherent scattering degradation in the image as much as possible. Inspired by LED-Net (Zhou et al., 2022b), we also modify Zero-DCE (Guo et al., 2020) from a low-light image enhancement model to a normal light image darkening model to add low-light degradation to the image. However, our modification to the Zero-DCE (Guo et al., 2020) network is different from previous approaches. We reduce the exposure loss function of the original network from 0.6 to (0.24, 0.25, 0.26, 0.27, 0.28, 0.29) to obtain six variants of the Zero-DCE (Guo et al., 2020) network and add different degrees of low-light degradation to the normal illumination images.
3.2 Data synthesis pipeline
Our data generation process can be roughly divided into four stages
First, we collected the UIEB (Li et al., 2020) and LSUI (Peng et al., 2021) datasets, selected paired images of the appropriate size and removed 600 × 400 blocks from these images for subsequent data generation.
In the second step, we noted that the quality of the paired images was uneven, and some reference images had problems such as red color deviation and blur. Therefore, we preliminarily screened the datasets to remove the data pairs with poor quality, such as those with color deviation and blur.
Next, we changed the exposure loss function weight of the Zero-DCE (Guo et al., 2020) network to obtain six network models for adding different degrees of low-light degradation to normal light. Then, we performed six different degrees of light degradation on the scattered images under normal light conditions, which were obtained in the previous stage, and took the normal light images without scattering, which were obtained in the previous stage, as the reference standard for the degraded images.
In the fourth step, we further screened the dataset to remove the synthetic low-light images with poor quality. For example, some synthetic images have contain color deviation, blur, and artifacts. Therefore, we removed them from the dataset.
Finally, we used 362 images of underwater scenarios to synthesize 2524 pairs of 600 × 400 size data as the training dataset, and 14 images underwater scenarios were used as the test set. It should be noted that in the 2524 pairs of experimental data in the training dataset, data of the same scene have the same reference standard of normal illumination without scattering and consistent scattering degradation, and only the degree of illumination degradation differs.
4 Method
4.1 Research background
As mentioned in our previous analysis of the results shown in Figure 1, when dealing with the dual degradation of a low-light underwater image caused by scattering and low-light, whether the scattering degradation or low-light degradation is removed first, there will be a change to the image degradation remaining in the image while removing the current kind of image degradation, resulting in difficulty during subsequent image processing.
Therefore, we aim to find an effective method to simultaneously address the dual degradation caused by low-light and scattering. Inspired by the KinD (Zhang et al., 2019b) method, the image degradation caused by low-light is regarded as the degradation of the inherent reflectance of the image. We consider whether the image degradation caused by scattering can also be regarded as having an impact on the inherent reflectance of the image. After analysis, we believe that this assumption is reasonable to some extent.
According to the image imaging model commonly used in underwater scenes (Tan, 2008), without considering the influence of forwarding scattering on underwater imaging, the underwater image can be expressed as:
where J represents the underwater image without scattering degradation, A represents the ambient light, and t represents the transmittance. According to Retinex theory, the restored underwater image J can be expressed as:
where R represents the reflectance of image J, and L1 represents the illumination of image J. Then, Equation 1 can be expressed as:
Referring to the representation of the low-light image in air in KinD (Zhang et al., 2019b), in which the low-light degradation of the image is considered light pollution P1, the low-light underwater image I2 can be expressed as:
where L2 represents the illumination of image I2. It should be noted that the effect of low-light degradation on the image is not only based on simply changing the image illumination from L1 to L2 but also introducing blur, noise, and other negative effects to the image. Therefore, P1 is used to express these negative effects. We regard the backscattering effect of atmospheric light on the image as another kind of light pollution P2.
Then I2 can be expressed as:
If we regard the influence of low-light pollution P1 and atmospheric light pollution P2 on image I2 as the influence p1 and p2 on the image reflectance R, Equation 6 will become:
Meanwhile, we regard the image degradation caused by the scattering rate t as reduction in the inherent reflectance of the image. Because of the existence of medium scattering, the light reflected by the object will be reduced by a certain proportion, which is equivalent to the reduction in the inherent reflectance of the object by a certain proportion under the assumption that there is no medium scattering.
Then, the reflectance of the degraded image can be expressed as Rp, and
For the nondegraded image J, the degraded image I2 can be expressed as:
Then, according to Equations 2 and 9, the image degradation caused by low-light and scattering is equivalent to degrading the inherent reflectance of the image from R to Rp and the illumination of the image from L1 to L2.
Similar to the KinD (Zhang et al., 2019b) and Retinex-Net (Wei et al., 2018) methods, we decompose the low-light image I2 and normal light image J into illumination maps L1 and L2, respectively, and reflectance maps Rp and R, respectively, and then restore the image according to the decomposed illumination map and reflectance map. However, in KinD (Zhang et al., 2019b) and other methods, images are restored by learning the mapping from Rp to R and the mapping from L2 to L1. We choose to directly learn the mapping of generating the real image J according to the Rp and L2 of the low-light image. Because image decomposition is an ill-posed problem, the decomposed Rp, R, L1 and L2 are approximate results. For example, in theory, J = RL. However, there may be a certain gap between the approximate result RL1 and the real ground truth J. Instead of letting Rp and L2 learn the approximate R and L1, respectively, to complete image restoration, we choose to let Rp and L2 learn the real ground truth J to complete image restoration.
It should be noted that we do not need to obtain a reflectance and illumination decomposition as accurate as the eigen image decomposition methods TSSD (Cheng et al., 2018) and ULID (Liu et al., 2020). Instead, we utilize the scene consistency between low-light images and normal light images to obtain an approximate representation of scene reflectance to facilitate subsequent image restoration. Meanwhile, we also believe that through the process of image decomposition, we can increase the amount of image information input into the restoration network and reduce the overall difficulty of image restoration. Obviously, compared with one single input image I2 for restoration, a combination between reflectance map Rp and illumination map L2 can make the network (Restor-Net) easier to converge (Figure 2). Equation 9 also provides an additional constraint to reconstruct I2 and guide the training process of Decom-Net.
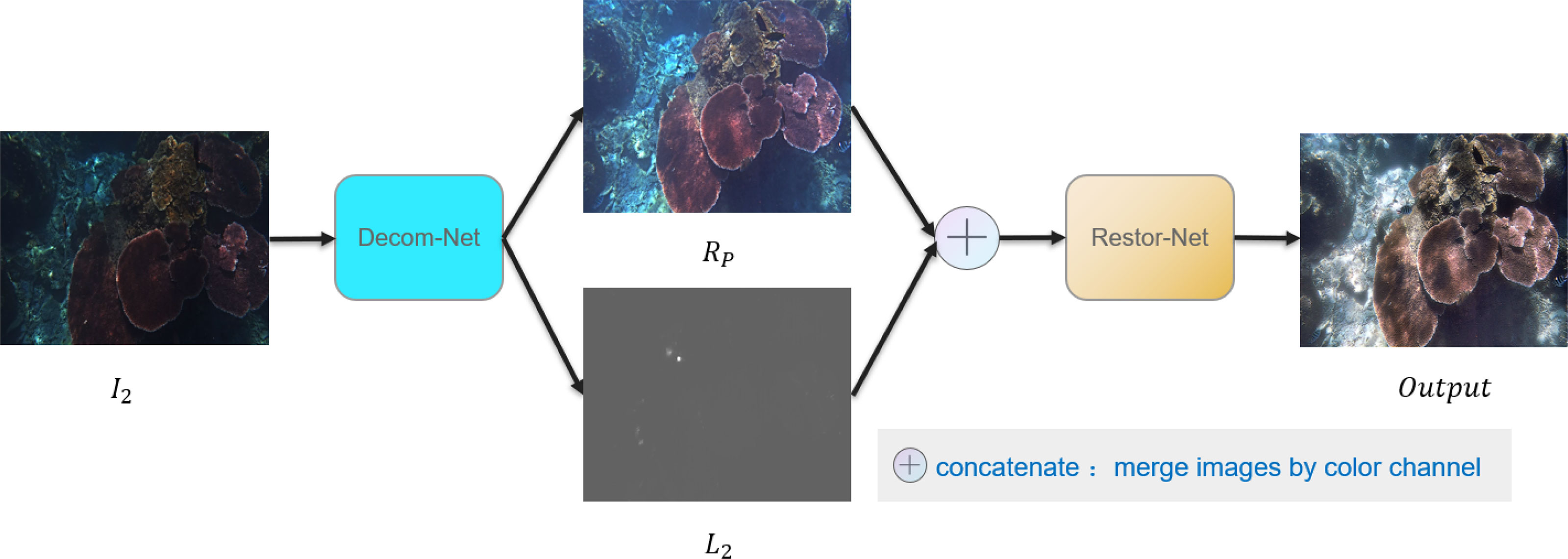
Figure 2 Overview of the LDS-Net.
In order to further prove the significance of the image decomposition process, we conduct an ablation study in Figure 3. Without Decom-Net for image decomposition, the images are enhanced with serious color deviation and artifacts as shown in the middle column of Figure 3. In the right column, the images enhanced with Decom-Net has better structured information, and higher quality.

Figure 3 Ablation study of the decomposition process. The subfigure (A) means the input images, (B) means the images enhanced without Decom-Net, and (C) means the images enhanced with Decom-Net.
4.2 LDS-Net
The general structure of our network is shown in Figure 2. As seen from Figure 2, our LDS-Net is composed of Decom-Net and Restor-Net. A low-light underwater image is first decomposed into an illumination map and reflectance map through the Decom-Net network. Then the illumination map and reflectance map are concentrated and passed to the Restor-Net network to obtain the restoration results.
4.2.1 Decom-Net
Our Decom-Net structure is shown in Figure 4. For simplicity, Decom-Net uses the same network structure as KinD (Zhang et al., 2019b). It contains two branches that correspond to reflectance and illumination. The reflectance branch adopts a simplified U-Net [24], and the illumination branch has a convolutional layer on concatenated feature maps from the reflectance branch to exclude scene textures from illumination.
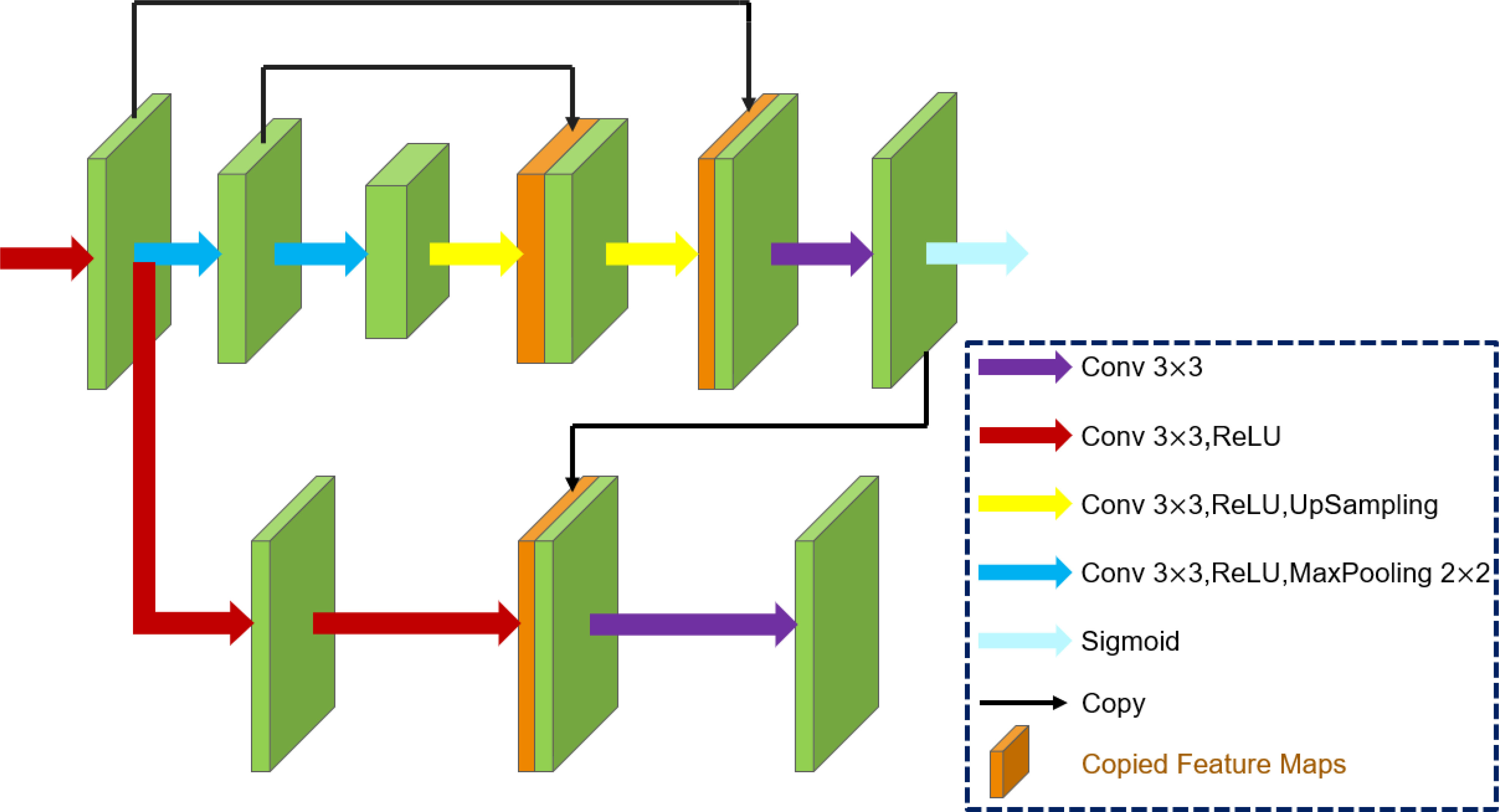
Figure 4 The network structure of Decom-Net.
Recovering two components from an image is a highly ill-posed problem. Without the information based on the ground truth as guidance, we cannot guide the network to directly learn the accurate decomposition results. We can only guide the network to approach the correct decomposition direction through the constraint of the loss function.
Theoretically, the reflectance of a scene should be shared among different images. Therefore, the image reflectance R and Rp obtained by decomposition of low-light scattering underwater image I2 and normal light underwater image J without scattering are similar. Ideally, if there is no degradation, the image reflectance in both images should be the same.
Therefore, we define the reflectance similarity loss Lr to restrict the similarity of the reflectance decomposition results:
where ‖·‖2 means the ℓ2 norm.
In addition, the illumination in natural images is generally smooth, so the decomposed illumination map should be smooth. We define the light smoothness loss Li to constrain the smoothness of the illumination map:
where ∇ represents the first-order derivative operator containing ∇x (horizontal) and ∇y (vertical) directions. In addition, ϵ is a small positive constant (0.01 in this study) that is utilized to prevent a zero denominator, and ‖·‖1 represents the ℓ1 norm.
Meanwhile, for the low-light underwater scattering image I2 and the normal light scattering underwater image J, if they share the same reflectance, the ratio of the two illumination maps should be I2 / J. Specifically, according to Equations 2 and 9, if Rp = R (ideally, if there is no degradation, they should be the same because I2 and J have the same scene), then we have I2 /J = L2 / L1 and , where and represent the means of I2 and L2, respectively.
Therefore, we define the Lc loss to constrain the accuracy of the decomposed illumination map:
where | · | is the absolute value operator.
Finally, the decomposition result should be able to reproduce the input, so we use the reconstruction loss Lrec to limit the error of reconstructing the input from the decomposition result:
The total loss function of the training decomposition network can be expressed as:
where w1 = 0.009, w2 = 0.05, w3 = 0.1.
4.2.2 Restor-Net
The structure of our Restor-Net is shown in Figure 5. It adopts almost the same network structure as that of U-Net (Ronneberger et al., 2015). The illuminance map and reflectance map of the low-light image decomposed by the decomposition network are taken as input, and the underwater image without scattering normal light is taken as the reference to learn low-light image restoration. Inspired by ESRGAN (Wang et al., 2018), we do not add a BN layer behind the network volume layer. Similar to Real-ESRGAN (Wang et al., 2021) and Ucolor (Li et al., 2021), we choose to use the perceptual loss function as the training loss. However, different from these approaches, we only use the perceptual loss function for training.
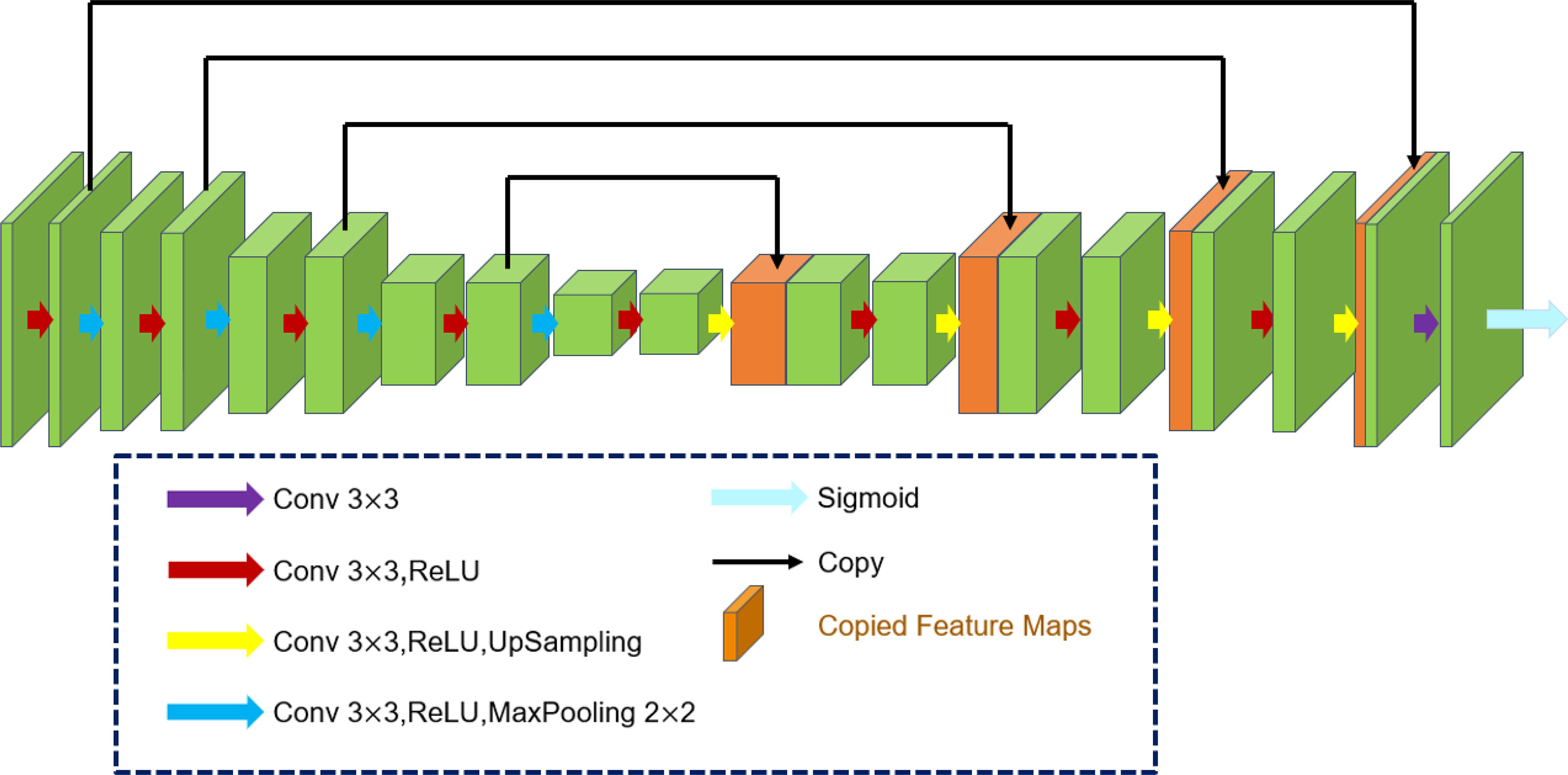
Figure 5 The network structure of Restor-Net.
The perceptual loss is computed based on the VGG-19 net-work (Simonyan and Zisserman, 2014), which is pre-trained on the ImageNet dataset (Deng et al., 2009).
Specifically, we calculate the total perceptual loss with weight (0.1, 0.1, 1, 1, 1) on the (conv12, conv22, conv32, conv42, conv54) feature layer of the VGG-19 network (Simonyan and Zisserman, 2014), where convij indicates the features obtained by the jth convolutional layer in the ith block.
5 Experiment
In this section, we first describe the implementation details and introduce the experimental settings. Then, we compare our method with representative low-light image enhancement methods and underwater image enhancement methods. Then, we show the enhancement effect of LDS-Net on underwater images with different brightness. In the ablation experiment, we verify the necessity of each part of the loss function in Decom-Net. Finally, we show the enhancement effect of our method on underwater images with different illumination.
5.1 Implementation details
We choose to train our network with our synthesized LUIE dataset. Meanwhile, to enable our network to process the underwater images with normal illumination, we also add the original normal scattering underwater images used to synthesize the LUIE dataset for training. We use Adam for network optimization. When training Decom-Net, the learning rate is initialized to 0.0008, the batch size is set to 32, and the patch size is set to 48 × 48. When training Restor-Net, the learning rate is initialized to 0.001, the batch size is set to 64, and the patch size is set to 384 × 384. The entire network is trained on an Nvidia GTX 3090 GPU using the PyTorch framework. Our method can process 13 pictures of 600 × 400 size and more than 30 pictures of 256 × 256 size per second.
5.2 Experiment settings
To test the enhancement effect of our method on low-light underwater images, we use 14 images of underwater scenarios with normal illumination, which were reserved for testing. These images are used to synthesize low-light underwater images using the modified Zero-DCE (Guo et al., 2020) network; this collection of images is referred to as test set A. Additionally, we collect some real low-light underwater images from the Great Barrier Reef documentary with David Attenborough; this collection of images is referred to as test set B. We use the unreferenced underwater image quality evaluation standards UIQM (Panetta et al., 2016) and UCIQE (Yang and Sowmya, 2015) and the referenced image quality evaluation standard PSNR to evaluate image quality.
5.3 Comparison of underwater image enhancement methods and low-light image enhancement methods
Since underwater image enhancement methods are mostly applied to underwater images taken under normal lighting conditions, an ideal enhancement effect cannot be achieved when applying these methods to low-light underwater images. As shown in Figure 6, even if we apply the latest two underwater image enhancement methods, DeepWave-Net (Sharma et al., 2021) and Ushape (Peng et al., 2021) to process low-light underwater images, there is no obvious quality improvement in the enhanced results. Therefore, in situations in which the underwater image enhancement methods under normal illumination have no enhancement effect when applied to the low-light underwater image, we only compare our method with low-light image enhancement methods based on deep learning, which are state-of-the-art methods, and a traditional method LUWE [21], which focuses on low-light underwater image restoration. First, we qualitatively and quantitatively compare our method with KinD (Zhang et al., 2019b), Zero-DCE (Guo et al., 2020), MBLLEN (Feifan Lv et al., 2018), RUAS (Liu et al., 2021), HEP (Zhang et al., 2021), HWMNet (Fan et al., 2022), and LUWE (Porto Marques and Branzan Albu, 2020) on the test set A. The results are shown in Figure 7 and Table 1. Due to the limited space, we only show the qualitative comparison results of some representative methods in Figure 7.

Figure 6 Comparison with representative underwater image enhancement methods. The subfigure (A) means the input images, (B, C) mean the images enhanced with the latest two underwater image enhancement methods DeepWave-Net and Ushape, and (D) means the images enhanced with our method.

Figure 7 Enhancement results of different methods on test set A. (A) means the input images, (B, C) mean the images enhanced with the representative low-light image enhancement methods KinD and Zero-DCE, (D) means the images enhanced with our method, and (E) means the groundtruth of the input images.
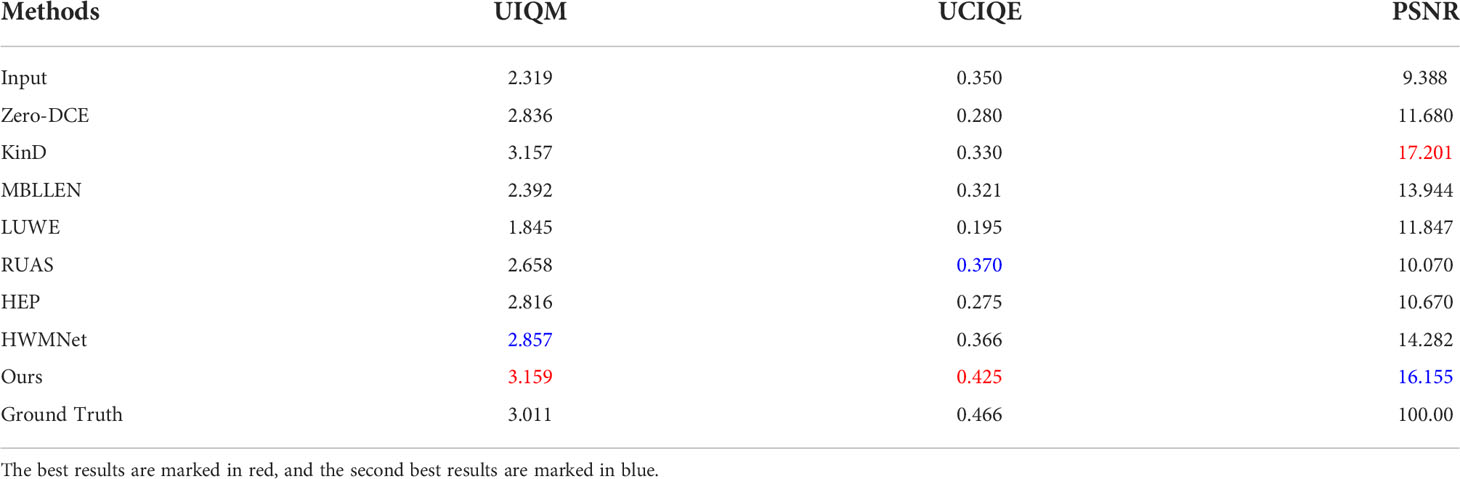
Table 1 Using UIQM, UCIQE and PSNR to evaluate the results of different methods on test set A, the higher the score, the better the enhancement effect.
As seen from Figure 7, compared with other methods, our method has a better effect on image detail restoration and higher image quality. In addition, it can be seen from the restoration results that when low-light degradation is removed from the low-light underwater images using Zero-DCE (Guo et al., 2020) and KinD (Zhang et al., 2019b) the scattering degradation in the images cannot be removed. As a result, the restoration results appear foggy, especially in subfigure (C).
From the results of test set A in Table 1, we can see that the best results using the UIQM (Panetta et al., 2016) and UCIQE (Yang and Sowmya, 2015) evaluation standards and the second-best results using the PSNR evaluation standards are achieved using our method. Overall, our method has a better image restoration effect.
Then we qualitatively and quantitatively compare our method with KinD (Zhang et al., 2019b), Zero-DCE (Guo et al., 2020), MBLLEN (Feifan Lv et al., 2018), RUAS (Liu et al., 2021), HEP (Zhang et al., 2021), HWMNet (Fan et al., 2022), and LUWE (Porto Marques and Branzan Albu, 2020) on test set B. The results are shown in Figure 8 and Table 2.

Figure 8 Enhancement results of different methods on test set B. The subfigure (A) means the input images, (B, C) mean the images enhanced with the representative low-light image enhancement methods KinD and Zero-DCE, and (D) means the images enhanced with our method.
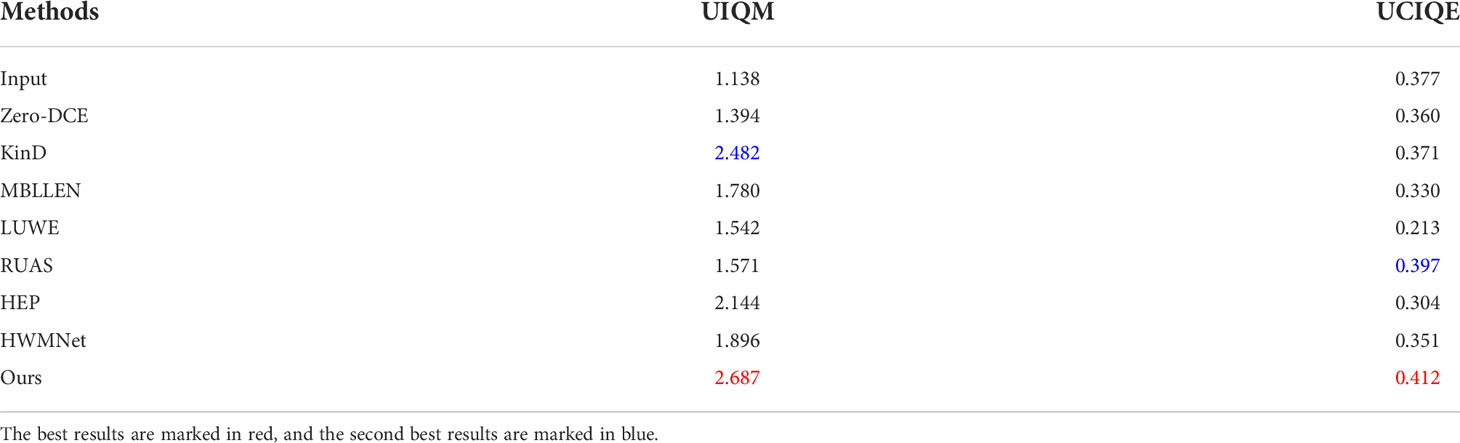
Table 2 Using UIQM and UCIQE to evaluate the results of different methods on test set B, the higher the score, the better the enhancement effect.
As seen from Figure 8, compared with other methods, better image details, lower image blur, and higher image quality are observed from using our method. From the test results of test set B in Table 2, we can see that higher scores for the e UIQM (Panetta et al., 2016) and UCIQE (Yang and Sowmya, 2015) evaluation standards are obtained using our method than other methods, and our method has a better image restoration effect.
5.4 Experiments on underwater images with different illumination using LDS-Net
In this section, we show the enhancement effect of our method on underwater images of different scenes under different illumination conditions. Due to the limited space, we only show the comparative experimental results of two scenes. For example, subfigure (A) in Figure 9 shows the underwater images of Scene 1 under three different illumination conditions, and subfigure (B) shows the corresponding enhancement results. As seen from subfigure (B) and subfigure (D), our method can achieve a good enhancement effect for underwater images with different illumination. In addition, from the last column results of subfigure (B) and subfigure (D), we can see that our method has a good effect on scattering removal for underwater images under normal illumination.

Figure 9 Enhancement results of underwater images with different illumination with LDS-Net. The subfigure (A, C) mean the input images in one Scene with different illumination. (B, D) mean the corresponding enhancement results with our method.
5.5 Ablation experiment
We conduct detailed ablation experiments to analyze the importance of each component of the loss function of Decom-Net. Decom-Net decomposes the input low-light image into two parts: an illumination map and a reflectance map.
To make the contrast effect of the ablation experiment more obvious, we choose to use different illumination maps obtained by Decom-Net trained with different loss functions for comparison.
Figure 10 is the result of the ablation experiment, where w/o Lr loss means that Decom-Net is trained without Lr loss, w/o Li loss means that Decom-Net is trained without Li loss, w/o Lc loss means that Decom- Net is trained without Lc loss, w/o Lrec loss means that Decom-Net is trained without Lrec loss, w / Lt loss means that Decom-Net is trained with Lt loss and Lt loss is the total loss function used when we train Decom-Net.

Figure 10 Ablation study for the loss function of Decom-Net. The subfigure (A) means the input images, and (B-F) mean the illumination maps obtained by the Decom-Net trained with different loss function.
Since the illumination of the image in the real scene is generally smooth and independent of the objects in the scene, the illumination map obtained from the image input in Decom-Net should also be smooth and reflect the illumination characteristics of the input image. In Figure 10, subfigure (A) is an input image, and the other subfigures are different illumination maps obtained by Decom-Net trained with different loss functions. Comparing the subfigures (B) and (C) in Figure 10, it can be seen that the decomposition result of the illumination map obtained with Lr loss is smoother and more accurate. The illumination map in subfigure (D) is the same as the input image. The illumination maps in subfigures (E) and (F) are a pure white image and a pure black image, respectively. As seen from these three subfigures, the use of Li, Lc and Lrec is crucial. Without them, the training effect of Decom-Net is far from the results obtained under ideal conditions in subfigure (B).
6 Conclusion
In this paper, we propose a dataset LUIE for low-light underwater images, which provides a basis for the further exploration of low illumination underwater image enhancement. In addition, we propose a low-light underwater image enhancement method LDS-Net based on deep learning. This method can remove the influence of low-light degradation and scattering degradation on the low-light underwater images at the same time. Through experimental verification, our method can be applied to underwater images with different illumination. Our method can also provide a baseline for follow-up low-light underwater image research. In future work, we will attempt to find a way to combine the two subnetworks Decom-Net and Restor-Net of our LDS-Net into one network so that network training can be completed in one step. We will also try to combine our method with the target detection/classification algorithm to improve the accuracy of the object detection/classification.
Data availability statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: https://github.com/yuxiao17/LDS-Net.
Author contributions
YX completed most of the work in this paper. XY completed the synthesis of the datasets and the typesetting of the paper. ZY and BZ provided guidance and funding for this research. All authors contributed to the article and approved the submitted version.
Funding
This work was supported by the National Natural Science Foundation of China (Grant No. 62171419), the Project of Sanya Yazhou Bay Science and Technology City (Grant No. SCKJ-JYRC-2022-102), and National Natural Science Foundation of China (Grant Numbers 62171419).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Ancuti C., Ancuti C. O., Haber T., Bekaert P. (2012). “Enhancing underwater images and videos by fusion,” in 2012 IEEE conference on computer vision and pattern recognition (New York, USA: IEEE), 81–88.
Cao K., Peng Y.-T., Cosman P. C. (2018). Underwater image restoration using deep networks to estimate background light and scene depth. in. 2018 IEEE Southw. Sympos. Imag. Anal. Interpret. (SSIAI). 1–4. doi: 10.1109/SSIAI.2018.84703478470347
Cheng L., Zhang C., Liao Z. (2018). “Intrinsic image transformation via scale space decomposition,” in 2018 IEEE/CVF conference on computer vision and pattern recognition (New York, USA: IEEE), 656–665. doi: 10.1109/CVPR.2018.000758578173
Deng J., Dong W., Socher R., Li L.-J., Li K., Fei-Fei L. (2009). “Imagenet: A large-scale hierarchical image database,” in 2009 IEEE conference on computer vision and pattern recognition (New York, USA: IEEE). doi: 10.1109/CVPR.2009.52068485206848
Drews P. L., Nascimento E. R., Botelho S. S., Campos M. F. M. (2016). Underwater depth estimation and image restoration based on single images. IEEE Comput. Graphics Appl. 36, 24–35. doi: 10.1109/MCG.2016.26
Fabbri C., Islam M. J., Sattar J. (2018). “Enhancing underwater imagery using generative adversarial networks,” in 2018 IEEE international conference on robotics and automation (ICRA), 7159–7165. doi: 10.1109/ICRA.2018.84605528460552
Fan C.-M., Liu T.-J., Liu K.-H. (2022). “Half wavelet attention on m-net+ for low-light image enhancement,” in arXiv preprint arXiv:2203.01296.
Feifan Lv J. W., Feng Lu, Lim C. (2018). Mbllen: Low-light image/video enhancement using cnns. Br. Mach. Vision Conf. 220:4.
Goodfellow I., Pouget-Abadie J., Mirza M., Xu B., Warde-Farley D., Ozair S., et al. (2014). Generative adversarial nets. Adv. Neural Inf. Process. Syst. 27:2672–2680. doi: 10.5555/2969033.2969125
Guo C., Li C., Guo J., Loy C. C., Hou J., Kwong S., et al. (2020). Zero-reference deep curve estimation for low-light image enhancement. in. 2020. IEEE/CVF. Conf. Comput. Vision Pattern Recog. (CVPR)., 1777–1786. doi: 10.1109/CVPR42600.2020.00185
Hou M., Liu R., Fan X., Luo Z. (2018). “Joint residual learning for underwater image enhancement,” in 2018 25th IEEE international conference on image processing (ICIP), (New York, USA: IEEE) 4043–4047. doi: 10.1109/ICIP.2018.8451209
Jiang Y., Gong X., Liu D., Cheng Y., Fang C., Shen X., et al. (2021). Enlightengan: Deep light enhancement without paired supervision. IEEE Trans. Imag. Process. 30, 2340–2349. doi: 10.1109/TIP.2021.3051462
Li C., Anwar S., Hou J., Cong R., Guo C., Ren W. (2021). Underwater image enhancement via medium transmission-guided multi-color space embedding. IEEE Trans. Imag. Process. 30:4985–5000. doi: 10.1109/TIP.2021
Li C., Guo C., Ren W., Cong R., Hou J., Kwong S., et al. (2020). An underwater image enhancement benchmark dataset and beyond. IEEE Trans. Imag. Process. 29, 4376–4389. doi: 10.1109/TIP.2019.2955241
Li J., Skinner K. A., Eustice R. M., Johnson-Roberson M. (2018). Watergan: Unsupervised generative network to enable real-time color correction of monocular underwater images. IEEE Robot. Autom. Lett. 3, 387–394. doi: 10.1109/LRA.2017.2730363
Liu Y., Li Y., You S., Lu F. (2020). “Unsupervised learning for intrinsic image decomposition from a single image,” in 2020 IEEE/CVF conference on computer vision and pattern recognition (CVPR), (New York, USA: IEEE) 3245–3254. doi: 10.1109/CVPR42600.2020.00331
Liu R., Ma L., Zhang J., Fan X., Luo Z. (2021). Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhancement. in. Proc. IEEE/CVF. Conf. Comput. Vision Pattern Recognit., 10561–10570. doi: 10.1109/CVPR46437.2021.01042
Lore K. G., Akintayo A., Sarkar S. (2017). Llnet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recog. 61, 650–662. doi: 10.1016/j.patcog.2016.06.008
Lu J., Li N., Zhang S., Yu Z., Zheng H., Zheng B. (2019). Multi-scale adversarial network for underwater image restoration. Optic. Laser. Technol. 110, 105–113. doi: 10.1016/j.optlastec.2018.05.048
Lv F., Li Y., Lu F. (2021). Attention guided low-light image enhancement with a large scale low-light simulation dataset. Int. J. Comput. Vision 129, 2175–2193. doi: 10.1007/s11263-021-01466-8
Panetta K., Gao C., Agaian S. (2016). Human-visual-system-inspired underwater image quality measures. IEEE J. Ocean. Eng. 41, 541–551. doi: 10.1109/JOE.2015.2469915
Peng L., Zhu C., Bian L. (2021). U-Shape transformer for underwater image enhancement. ArXiv. Prepr. arXiv:2111.11843.
Porto Marques T., Branzan Albu A. (2020). “L2uwe: A framework for the efficient enhancement of low-light underwater images using local contrast and multi-scale fusion,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops (New York, USA: IEEE), 538–539.
Ronneberger O., Fischer P., Brox T. (2015). “U-Net: Convolutional networks for biomedical image segmentation,” in Medical image computing and computer-assisted intervention – MICCAI 2015 (Cham: Springer International Publishing), 234–241.
Sharma P. K., Bisht I., Sur A. (2021). Wavelength-based attributed deep neural network for underwater image restoration. ArXiv. Prepr. arXiv:2106.07910.
Simonyan K., Zisserman A. (2015). Very deep convolutional networks for large-scale image recognition. in 2015 IEEE international conference on Learning Representations (ICLR), 1–14.
Tan R. T. (2008). Visibility in bad weather from a single image. in. 2008 IEEE Conf. Comput. Vision Pattern Recognit., 1–8. doi: 10.1109/CVPR.2008.45876434587643
Wang Y., Liu H., Chau L.-P. (2017). Single underwater image restoration using adaptive attenuation-curve prior. IEEE Trans. Circuit. Syst. I.: Reg. Paper. 65, 992–1002 28wang. doi: 10.1109/TCSI.2017.2751671
Wang X., Xie L., Dong C., Shan Y. (2021). “Real-esrgan: Training real-world blind super-resolution with pure synthetic data,” in Proceedings of the IEEE/CVF international conference on computer vision, (New York, USA: IEEE) 1905–1914.
Wang X., Yu K., Wu S., Gu J., Liu Y., Dong C., et al. (2018). “Esrgan: Enhanced super-resolution generative adversarial networks,” in Proceedings of the European conference on computer vision (ECCV) workshops.
Wang N., Zhou Y., Han F., Zhu H., Yao J. (2019). Uwgan: Underwater gan for real-world underwater color restoration and dehazing. ArXiv. Prepr. arXiv:1912.10269.
Wei C., Wang W., Yang W., Liu J. (2018). Deep retinex decomposition for low-light enhancement. Br. Mach. Vision Conf. Avialable at: https://arxiv.org/abs/1808.04560
Yan L., Fu J., Wang C., Ye Z., Chen H., Ling H. (2021). Enhanced network optimized generative adversarial network for image enhancement. Multimed. Tools Appl. 80, 14363–14381. doi: 10.1007/s11042-020-10310-z
Yang M., Sowmya A. (2015). An underwater color image quality evaluation metric. IEEE Trans. Imag. Process. 24, 6062–6071. doi: 10.1109/TIP.2015.24910207300447
Zhang F., Shao Y., Sun Y., Zhu K., Gao C., Sang N. (2021). Unsupervised low-light image enhancement via histogram equalization prior. ArXiv. Prepr. arXiv:2112.01766.
Zhang L., Zhang L., Liu X., Shen Y., Zhang S., Zhao S. (2019a). Zero-shot restoration of back-lit images using deep internal learning. Proc. 27th. ACM Int. Conf. Multimed.
Zhang Y., Zhang J., Guo X. (2019b). “Kindling the darkness: A practical low-light image enhancer,” in Proceedings of the 27th ACM international conference on multimedia, vol. 19. (New York, NY, USA: ACM), 1632–1640. doi: 10.1145/3343031.3350926zhang2019kindling
Zhou J., Zhang D., Zhang W. (2022a). Underwater image enhancement method via multi-feature prior fusion. Appl. Intell., 1–23. doi: 10.1007/s10489-022-03275-z
Zhou S., Li C., Loy C. C. (2022b). Lednet: Joint low-light enhancement and deblurring in the dark. ArXiv. Prepr. arXiv:2202.03373.
Keywords: underwater image enhancement, low-light image enhancement, deep learning, scattering removal, image decomposition
Citation: Xie Y, Yu Z, Yu X and Zheng B (2022) Lighting the darkness in the sea: A deep learning model for underwater image enhancement. Front. Mar. Sci. 9:921492. doi: 10.3389/fmars.2022.921492
Received: 19 April 2022; Accepted: 19 July 2022;
Published: 18 August 2022.
Edited by:
Ahmad Salman, National University of Sciences and Technology (NUST), PakistanReviewed by:
Lingyu Yan, Hubei University of Technology, ChinaKhawar Khurshid, National University of Sciences and Technology (NUST), Pakistan
Copyright © 2022 Xie, Yu, Yu and Zheng. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Zhibin Yu, eXV6aGliaW5Ab3VjLmVkdS5jbg==; Bing Zheng, YmluZ3poQG91Yy5lZHUuY24=