 Antonio Benítez-Burraco
Antonio Benítez-Burraco Sihan Chen
Sihan Chen David Gil
David Gil
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
BRIEF RESEARCH REPORT article
Front. Lang. Sci., 19 January 2024
Sec. Psycholinguistics
Volume 3 - 2024 | https://doi.org/10.3389/flang.2024.1340493
This article is part of the Research TopicThe Adaptive Value of Languages: Non-Linguistic Causes of Language Diversity (Volume II)View all 10 articles
The hypothesis that all languages are equally complex often invokes a trade-off principle, according to which if a language is more complex in one particular domain, it will be simpler in another different domain. In this paper, we use data from WALS to test the existence of a trade-off between two specific domains: morphology and syntax. Contrary to widespread views, we did not find a negative correlation between these two language domains, but in fact a positive correlation. At the same time, this positive correlation seems to be driven by some language families, and it disappears when one considers purely morphological and purely syntactic features only. We discuss these findings in relation to ongoing research about language complexity, and in particular, the effects of factors external to language on linguistic structure.
Over the years, most linguists have assumed that all human languages are roughly equivalent with respect to their fundamental components, basic structure, and specifically, overall complexity (see Dixon, 1997 or Fromkin et al., 2011 for general views). This equi-complexity hypothesis has furthermore been thought to involve a trade-off principle, according to which if a language is more complex in one particular domain, it will be simpler in some other different domain. This view can be traced back to Hockett (1958), and has been recently reexamined by several authors (e.g., Miestamo, 2017). Still, as noted by Fenk-Oczlon and Fenk (2014), Sinnemäki (2014), and Bentz et al. (2022), such trade-offs, within specific domains or across diverse domains, do not necessarily entail equal overall complexity. In fact, in their statistical approach to this issue, using written texts from 80 typologically-diverse languages, Bentz et al. found ample support for the equi-complexity hypothesis, but only partial support for the trade-off principle. In his recent review of the literature about language complexity, Coloma (2017) concluded that trade-off effects could be more abundant and stronger within specific language domains but less common and weaker when comparisons are made across different domains.
In this Brief Research Paper, we aim to check the possibility that there exists a trade-off effect specifically between morphological and syntactic complexity. Although this has been one of the most recurrent claims by adherents of the trade-off principle (including Hockett himself), more empirical research, using large databases and robust statistical methods, is needed to properly support this view. In their research, Bentz et al. found, specifically, several negative correlations between morphological and syntactic measures. In our approach, we aim to expand this research. Accordingly, we have relied on the typological data in the World Atlas of Language Structures (WALS; Dryer and Haspelmath, 2013). WALS has been used in the past for testing different potential trade-offs within specific language domains, including phonology (Maddieson, 2007; Moran and Blasi, 2014) and grammar (Sinnemäki, 2008). In his paper, Coloma (2017) used 60 features and 100 languages from WALS to look for possible complexity trade-offs within and across language domains, with a focus on phonology. In our paper, we examine the whole set of morphological and syntactic features as compiled in WALS, and consider all the languages for which data are available.
There are 144 grammatical features listed in WALS (see Dryer and Haspelmath, 2013 for details). Among them, we identified 44 features pertaining to morphological complexity and 39 features pertaining to syntactic complexity. In some cases, assigning a grammatical feature to either morphology or syntax can be tricky, and can depend on background theoretical assumptions about the nature of grammar (and even language). For instance, Feature 49A provides data from 261 languages on the number of cases. Inflecting a word for case can be regarded as a morphological feature, as it modifies the word form, but case also marks the syntactic function of the word within a sentence, so it could be also assigned to syntax. Accordingly, we have conducted two separate analyses. In the first analysis, we followed the simplest criterion possible: if a grammatical feature pertains to rules within a word, it was considered as a morphological feature, whereas if it pertains to rules between words, it was considered as a syntactic feature. However, since it has always been an issue in linguistics regarding which features fall into the purview of morphology or syntax (see Baker, 1985; Aronoff, 1994; Holmberg and Roberts, 2013; Harley, 2015 among many others), in the second analysis, we focused on the subset of features that can be assigned unambiguously to either morphology or syntax (see Supplementary data 1 for details).
Each WALS feature assigns a value to a language based on available data in the literature (see Supplementary data 2). For instance, Feature 22A provides data from 145 languages on the number of morphological categories per word. Languages are assigned values between 1 (0–1 category per word) and 7 (12–13 categories per word). Here we constructed grammatical classifications from these features, by grouping the WALS feature values in different ways. While in some cases our grammatical classification is identical to the original value assignment (e.g., Feature 22A), in other cases we grouped together several values. For example, Feature 81A shows the order of subject, object, and verb in 1381 languages. There are seven values in this feature, with 1–7 representing six different permutations of subject, verb, and object, along with no dominant word order. A question pertaining to syntactic complexity arising from this feature is whether a language has a dominant word order. In this case, we grouped values 1–6 together as “having a dominant word order” and value 7 alone as “not having a dominant word order”. In the resulting grammatical classification, we assigned value 1 to not having a dominant word order, and 2 to having a dominant word order, with the latter being more complex than the former. We denoted this classification as 7 < 1/2/3/4/5/6, where 7 is assigned the new value 1, and 1–6 the new value 2 (the classifications for the set of WALS features considered in our analyses can be checked in the Supplementary data 1).
As noted, in assigning new values in our grammatical classifications, we followed a formulation of descriptive complexity: if a grammatical rule requires more description than some other rule, it is considered as more complex (e.g., Li and Vitányi, 2008; Sinnemäki, 2011). Having a dominant word order requires a description of what the order is, and therefore is more complex than not having a dominant word order.
In some cases, we have formulated more than one grammatical classification from a single WALS feature. For example, Feature 30A includes the number of grammatical genders in 257 languages, with values 1–5 representing no gender, two genders, three genders, four genders, and five or more genders. One classification is concerned with whether a language has a grammatical gender system, contrasting value 1 (no gender) with others (having two or more genders, hence 1 < 2/3/4/5). A second classification pertains to the number of grammatical genders a language has, contrasting languages of values 2–5 with each other (i.e., 2 < 3 < 4 < 5). For our first analysis, we formulated a total of 100 grammatical classifications based on 83 feature values pertaining to morphology and syntax. For our second analysis, we considered only the 12 grammatical classifications that can be regarded as purely morphological, as they pertain exclusively to word forms. One example is WALS Chapter 79, on suppletion in tense or aspect. In our classification, we consider having suppletion as being morphologically more complex than having no suppletion. Having an unpredictable pattern in tense and/or aspect conjugations seems to only result in more form distinctions, not meaning distinctions as might be caused by classifications that have both syntactic and morphological flavors. On the other hand, 35 classifications can be considered purely syntactic, such as the existence of a dominant word order (Chapter 81).
We normalized the grammatical classification values in order for them to be comparable across grammatical classifications, using the formula (value – minimal value)/(maximal value – minimal value). As a result, if a value is the lowest in a classification, it was normalized to 0 according to the formula, whereas if a value is the highest in a classification, it was normalized to 1.
Up to this point, each language had a series of values between 0 and 1, with each value corresponding to a normalized complexity score with respect to a grammatical classification. To assign each language morphological and syntactic complexity scores, we averaged the normalized values across features pertaining to morphology and syntax, respectively. However, due to the limited data availability in WALS, languages vary dramatically in terms of feature coverage (see Supplementary data 2). For example, some languages have entries in almost all features, whereas others only have entries in a few. As a consequence, languages in WALS also vary greatly in terms of the resulting grammatical classifications. Therefore, we excluded languages with fewer than 5 morphological grammatical classifications, along with those with fewer than five syntactic grammatical classifications. Finally, for our first analysis, we obtained a list of 591 languages, each with a morphological complexity score and a syntactic complexity score, whereas for our second analysis we obtained a list of only 180 languages, since there are very few features that are purely morphological.
In addition to these general analyses in which we considered all the languages together, we conducted analyses by macro-families, aimed to determine whether different language groups behave differently with respect to these potential trade-offs between morphology and syntax.
Figure 1 shows the results of our first analysis, in which we assigned WALS features to either morphology or syntax. The figure shows the syntactic complexity score of the 591 languages plotted against the morphological complexity score. A linear regression gives a significant, positive slope estimate (β = 0.151, p < 0.001***), indicating that for each 0.1 point increase in the morphological complexity score, there is expected to be a 0.015 point increase in the syntactic complexity score. However, a linear regression does not address Galton's problem (Roberts and Winters, 2013), namely that this relation might have been driven solely by languages coming from the same family or those coming from the same linguistic area. To preliminarily address this issue, we adopted a mixed-effects linear regression using the lme4 package (Bates et al., 2014) in R (R Core Team, 2013). We coded the morphological complexity score as a fixed effect and included random intercept for language family and random intercept of geographical area, taken from a database in Donohue et al. (2013). The model also shows a positive relation between morphology and syntax (β = 0.175, p < 0.001***).
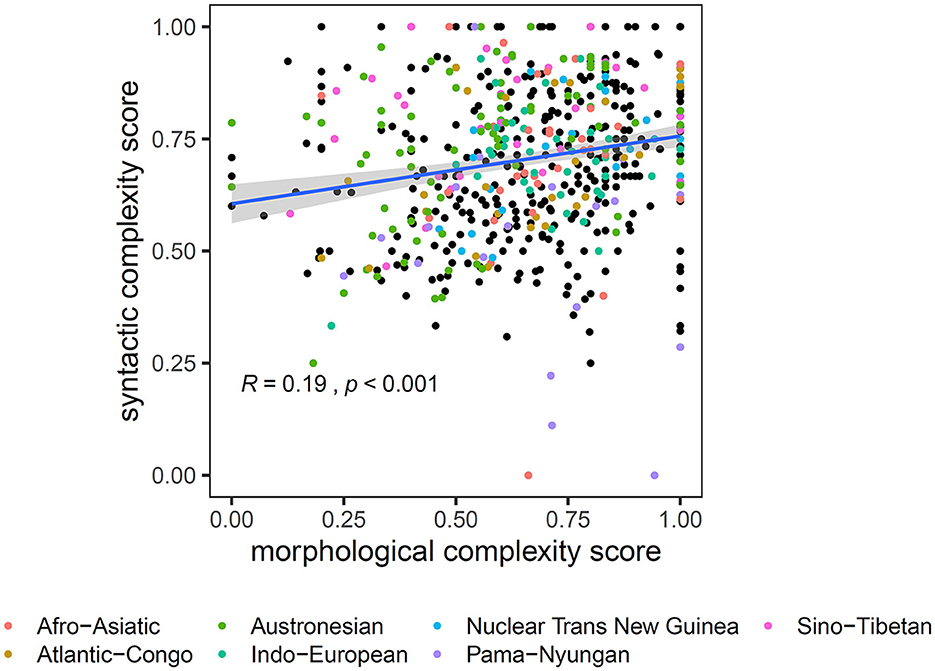
Figure 1. The morphological complexity score (x-axis) and the syntactic complexity score (y-axis) for 591 languages. Languages from families containing more than 200 languages are highlighted in colors. The blue line represents a linear fit of the two complexity scores, and the gray shade represents the 95% confidence interval for the slope.
Figure 2 shows the results of our second analysis, in which we only considered the WALS features that can be assigned unambiguously to either morphology or syntax. As in Figure 1, this figure shows the syntactic complexity score (this time of 180 languages only) plotted against the morphological complexity score. There is no evidence for a trade-off between the two complexity scores (Pearson correlation coefficient ρ = −0.042, p = 0.578). We then loosened the inclusion threshold from five classifications to three classifications, which increased the number of languages from 180 to 243. The results (see Supplementary Figure S1) still exhibit no evidence for a trade-off (Pearson correlation coefficient ρ = 0.027, p = 0.673).
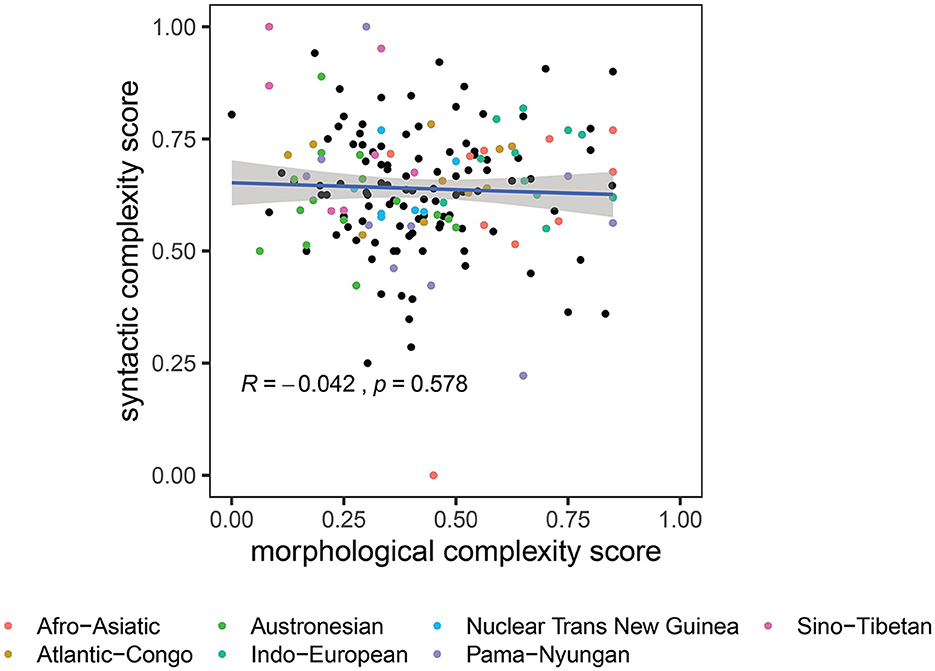
Figure 2. The morphological complexity score (x-axis) and the syntactic complexity score (y-axis), calculated from grammatical features that are considered purely morphological and purely syntactic, for 180 languages. Languages from families containing more than 200 languages are highlighted in colors. The blue line represents a linear fit of the two complexity scores, and the gray shade represents the 95% confidence interval for the slope.
Figure 3 shows the result of a by-family reanalysis of our first analysis. Linear regressions for individual macrofamilies (families with more than 200 languages according to Glottolog) are now displayed. We found a positive correlation between morphology and syntax for most, but not all macrofamilies: Atlantic-Congo, Austronesian, Indo-European, and Nuclear Trans New Guinea. By contrast, the positive correlation was not significant for Sino-Tibetan (p = 0.129). Likewise, the correlations are not significant within the two families where a trade-off seems to take place (Afro-Asiatic, p = 0.701; Pama-Nyungan, p = 0.239). We also looked at smaller language families (between 50 and 200 languages according to Glottolog) and found only one significant, positive correlation (Mande, ρ = 0.98, p = 0.004). The rest was not significant but generally heading toward a positive correlation (see Supplementary Figure S2). We could not compute a reliable correlation for families smaller than 50 languages, as there were too few samples in the 591 languages.
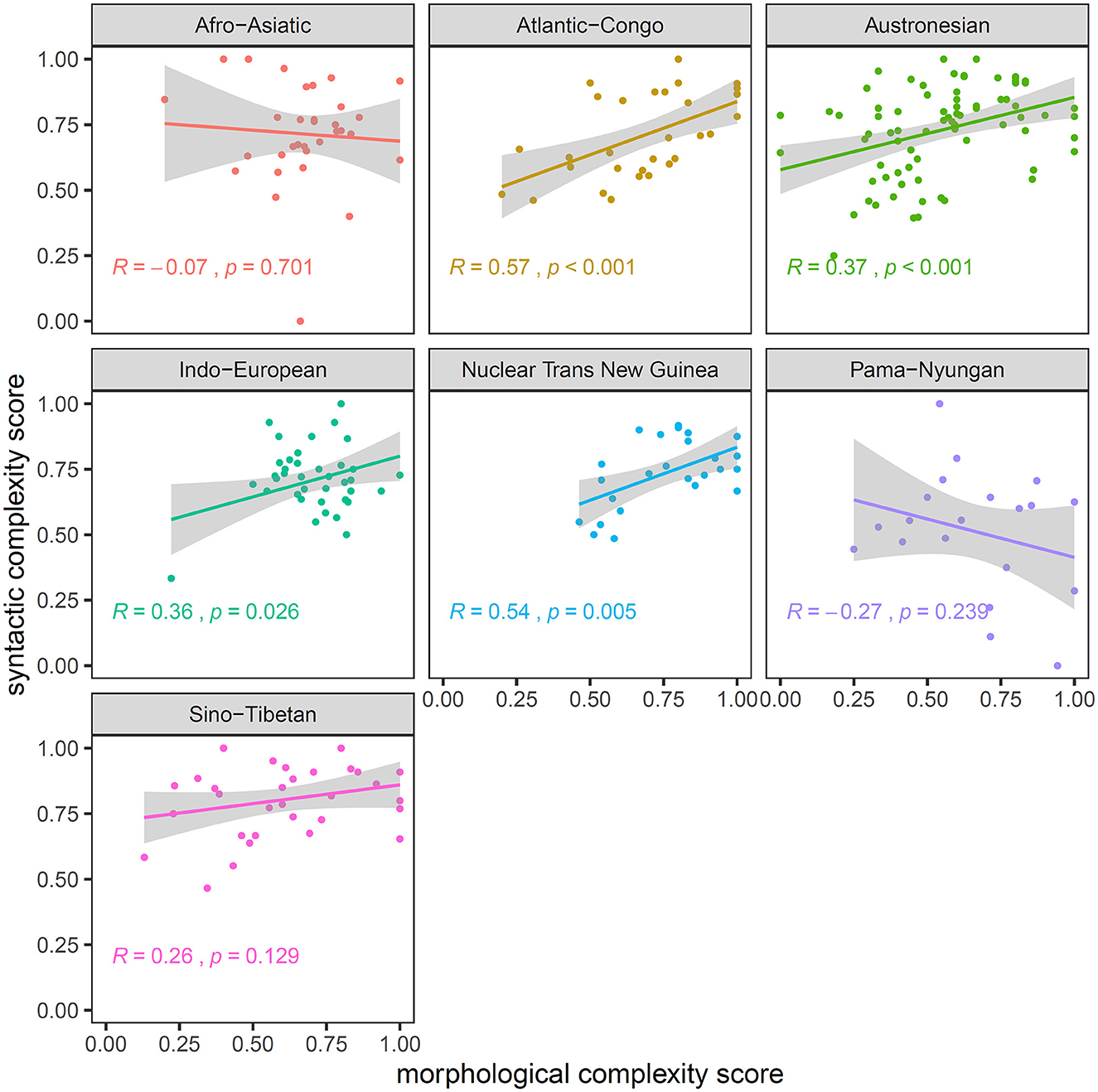
Figure 3. The morphological complexity score (x-axis) and the syntactic complexity score (y-axis) for languages from families with size between 50 and 150, according to Glottolog. The results are faceted by language family. The blue line represents a linear fit of the two complexity scores, and the gray shade represents the 95% confidence interval for the slope.
As shown above, WALS data calls into question the widespread assumption that there is a trade-off between morphological and syntactic complexity, with greater morphological complexity being offset by lesser syntactic complexity, or, conversely, lesser morphological complexity being compensated for by greater syntactic complexity. On the contrary, our findings suggest that there is, if anything, a positive correlation between the two, with morphological and syntactic complexity going hand in hand. At the same time, this positive correlation on the global scale might be driven by just a few major language families. Overall, our results call for a more detailed analysis of the complex relationships that seem to exist between morphological and syntactic complexity. This entails not only looking at each language family and linguistic area, but also considering cross-cultural differences between speakers of languages within specific families and areas. More importantly (and we acknowledge this as a limitation of our approach), future studies aimed to clarify this issue should move from the consideration of databases like WALS or even the recently-released Skirgård et al. (2023), which treat morphological or syntactic features as binary traits (present/absent), or as simple scales, to the consideration of the relative frequency of data of interest as resulting from the examination of large corpora of naturalistic speech, which makes possible a truly quantitative approach through the consideration of the relative frequency of relevant phenomena.
How might one account for such facts? Potentially, explanations may be sought in a variety of different directions; we offer here just one speculative way of approaching our findings. Often, proponents of a trade-off between morphological and syntactic complexity put forward a functional motivation: all languages, it is suggested, must be able to express a similar range of meanings. So if a language can accomplish this with its morphology, it does not need to do so, once again, with its syntax. Whereas, if a language lacks the requisite morphological tools, it must have recourse to its syntax. One of the most celebrated applications of this way of looking at things comes from the historical study of Romance languages. All languages, supposedly, must distinguish between thematic roles such as agent and patient. In Latin, such thematic roles were distinguished by means of morphological case marking such as nominative and accusative. In contrast, in the development of the modern Romance languages such as Spanish, French and Italian, these morphological markers were lost, and this was compensated for by the introduction of syntactic devices such as fixed word order. Our results suggest that this case could be an exception and not the norm. Even the assumption that all languages are endowed with roughly equivalent expressive power has been called into question by a number of recent studies. For example, in the domain of thematic roles, it has been shown that languages may vary substantially with regard to the degree to which such roles are grammaticalized; in particular, in some languages there is neither case marking nor fixed word order, as a result of which thematic roles may remain unexpressed; see, for example, the work summarized in Gil and Shen (2019). By contrast, in many others thematic roles are marked both morphologically and syntactically.
The positive correlation between morphological and syntactic complexity we have observed could thus be a reflection of cross-linguistic variation with respect to the range of meanings that a language is called upon to convey. But such variation is presumably due less to purely functional constraints than it is to sociolinguistic concerns. In particular, languages required to express a wider range of meanings for sociological/cultural reasons will be associated with greater complexity in both morphological and syntactic domains. Although this assumption may be disputed, many have argued that speakers communicate the same amount of information in all languages, but in some cases they rely more on grammatical devices for that, whereas in others a great deal of the information is conveyed via implicatures because of a richer common ground (see Wray and Grace, 2007 for discussion). The possibility that sociopolitical and cultural factors ultimately explain how and why some languages are required to (verbally) express more meanings than other languages is supported by increasing empirical evidence. For instance, in her recent study using online language corpora in thirty languages, Levshina (2021) found no evidence of trade-offs between linguistic variables that reflect different cues to linguistic meanings, including, specifically, case marking and fixed word order. She concludes that the relationships between these variables can be explained predominantly by sociolinguistic factors, but not by any principle of communicative efficiency. Likewise, Chen et al. (2023) have found that close-knit societies, with reduced population sizes and limited cultural contacts, tend to speak languages with more complex morphologies. Finally, some authors have suggested that the adoption of writing might have inhibited the purported trade-offs between morphology and syntax, increasing the overall syntactic complexity of languages, given that writing heavily relies on complex syntactic features like recursion (see e.g., Karlsson, 2009).
The original contributions presented in the study are publicly available. This data can be found here: https://osf.io/dfq7j/ and in Supplementary material.
AB-B: Conceptualization, Funding acquisition, Investigation, Project administration, Writing – original draft, Writing – review & editing. SC: Formal analysis, Investigation, Methodology, Writing – original draft, Writing – review & editing. DG: Conceptualization, Writing – original draft, Writing – review & editing.
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This research was supported by grant PID2020-114516GB-I00 funded by MCIN/AEI/10.13039/501100011033 (to AB-B).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The author(s) declared that they were an editorial board member of Frontiers, at the time of submission. This had no impact on the peer review process and the final decision.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/flang.2024.1340493/full#supplementary-material
Baker, M. C. (1985). The mirror principle and morphosyntactic explanation. Linguist. Inq. 16, 373–416.
Bates, D., Mächler, M., Bolker, B., and Walker, S. (2014). Fitting linear mixed-effects models using lme4. arXiv. [preprint] arXiv:1406.5823. doi: 10.18637/jss.v067.i01
Bentz, C., Gutierrez-Vasques, X., Sozinova, O., and Samardžić, T. (2022). Complexity trade-offs and equi-complexity in natural languages: a meta-analysis. Linguist. Vang. doi: 10.1515/lingvan-2021-0054
Chen, S., Gil, D., Gaponov, S., Reifegerste, J., Yuditha, T., and Tatarinova, T. V. (2023). Linguistic and memory correlates of societal variation: a quantitative analysis. doi: 10.31234/osf.io/bnz2s
Coloma, G. (2017). Complexity trade-offs in the 100-language WALS sample. Lang. Sci. 59, 148–158. doi: 10.1016/j.langsci.2016.10.006
Donohue, M., Hetherington, R., McElvenny, J., and Dawson, V. (2013). World Phonotactics Database. Department of Linguistics, Camberra, ACT: The Australian National University.
Dryer, M. S., and Haspelmath, M, . (eds.). (2013). WALS Online (v2020.3) [Data set]. Zenodo. Available online at: https://wals.info (accessed December 19, 2023).
Fenk-Oczlon, G., and Fenk, A. (2014). Complexity trade-offs do not prove the equal complexity hypothesis. Poznań Stud. Contemp. Linguist. 50, 145–155. doi: 10.1515/psicl-2014-0010
Fromkin, V., Rodman, R., and Hyams, N. (2011). An Introduction to Language, 9th Edn. Boston, MA: Wadsworth, Cengage Learning.
Gil, D., and Shen, Y. (2019). How grammar introduces asymmetry into cognitive structures: compositional semantics, metaphors and schematological hybrids. Front. Psychol. Lang. Sci. 10, e02275. doi: 10.3389/fpsyg.2019.02275
Harley, H. (2015). “The syntax/morphology interface,” in Syntax, Theory and Analysis: An International Handbook, Vol II, eds A. Alexiadou, and T. Kiss (Berlin: de Gruyter), 1128–1154.
Holmberg, A., and Roberts, I. (2013). The syntax–morphology relation. Lingua 130, 111–131. doi: 10.1016/j.lingua.2012.10.006
Karlsson, F. (2009). “Origin and maintenance of clausal embedding complexity,” in Language Complexity as an Evolving Variable, eds G. Sampson, D. Gil, and P. Trudgill (Oxford: Oxford University Press), 192–202.
Levshina, N. (2021). Cross-linguistic trade-offs and causal relationships between cues to grammatical subject and object, and the problem of efficiency-related explanations. Front. Psychol. 12:648200. doi: 10.3389/fpsyg.2021.648200
Li, M., and Vitányi, P. (2008). An Introduction to Kolmogorov Complexity and Its Applications, Vol. 3. New York, NY: Springer, 11.
Maddieson, I. (2007). “Issues of phonological complexity: statistical analysis of the relationship between syllable structures, segment inventories and tone contrasts,” in Experimental Approaches to Phonology, eds M. Solé, P. Beddor, and M. Ohala (New York, NY: Oxford University Press), 93–103.
Miestamo, M. (2017). Linguistic diversity and complexity. Lingue Linguaggio 16, 227–254. doi: 10.1418/88241
Moran, S., and Blasi, D. (2014). “Cross-linguistic comparison of complexity measures in phonological systems,” in Measuring Grammatical Complexity, eds F. J. Newmeyer and L. Preston (Oxford: Oxford University Press), 217–240.
R Core Team (2013). R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing. Available online at: http://www.R-project.org/ (accessed December 19, 2023).
Roberts, S., and Winters, J. (2013). Linguistic diversity and traffic accidents: Lessons from statistical studies of cultural traits. PLoS ONE 8:e70902. doi: 10.1371/journal.pone.0070902
Sinnemäki, K. (2008). “Complexity trade-offs in core argument marking,” in Language Complexity: Typology, Contact and Change, eds M. Miestamo, K. Sinnem?ki, F. Karlsson (Amsterdam: John Benjamins), 67–88.
Sinnemäki, K. (2011). Language universals and linguistic complexity: Three case studies in core argument marking (Ph.D. dissertation), University of Helsinki, Helsinki, Finland.
Sinnemäki, K. (2014). Global optimization and complexity trade-offs. Poznan Stud. Contemp. Linguist. 50, 179–195. doi: 10.1515/psicl-2014-0013
Skirgård, H., Haynie, H. J., Blasi, D. E., Hammarström, H., Collins, J., Latarche, J. J., et al. (2023). Grambank reveals the importance of genealogical constraints on linguistic diversity and highlights the impact of language loss. Sci. Adv. 9, eadg6175. doi: 10.1126/sciadv.adg6175
Keywords: morphological complexity, trade-offs, WALS, syntactic complexity, typology
Citation: Benítez-Burraco A, Chen S and Gil D (2024) The absence of a trade-off between morphological and syntactic complexity. Front. Lang. Sci. 3:1340493. doi: 10.3389/flang.2024.1340493
Received: 27 November 2023; Accepted: 03 January 2024;
Published: 19 January 2024.
Edited by:
Pedro Guijarro-Fuentes, University of the Balearic Islands, SpainReviewed by:
Caleb Everett, University of Miami, United StatesCopyright © 2024 Benítez-Burraco, Chen and Gil. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Antonio Benítez-Burraco, YWJlbml0ZXo4QHVzLmVz
†ORCID: Antonio Benítez-Burraco orcid.org/0000-0003-4574-5666
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.