 Brett C. Nelson
Brett C. Nelson- Division of Linguistics, School of Languages, Linguistics, Literatures and Cultures, University of Calgary, Calgary, AB, Canada
Phonological redeployment is the theoretical ability of language learners to utilize non-local phonological knowledge from known languages in the mapping and acquisition of novel contrasts in their target languages. The current paper probes the limits of phonological redeployment in a third language acquisition scenario. The phonological features [Advanced Tongue Root] and [Retracted Tongue Root] capture a range of phonological contrasts and harmony processes in both vowels and consonants of spoken languages across the world, including, but not limited to, vowel tensing and post-velar places of articulation (e.g. uvular). Kaqchikel (cak) exhibits both a tense-lax vocalic contrast in its vowels plus a velar-uvular Place contrast in its eight stop consonant phonemes. English (eng) exhibits a tense-lax vocalic distinction but no velar-uvular distinction among its six stop phonemes. Spanish (spa) exhibits neither of these contrasts in its vowels or among its six stop phonemes. How do multilingual learners of Kaqchikel already familiar with English and Spanish, but who differ in which is their first language (L1), compare in their categorical perception of Kaqchikel stop consonants? Despite English and Spanish having a three-way Place distinction among stops in common, in a phonemic categorization task, L1 English learners of Kaqchikel were better at correctly categorizing audio recordings of Kaqchikel uvular stops than L1 Spanish learners of Kaqchikel. To account for this surprising result, I propose that the L1 English group have easier access than the L1 Spanish group to the feature underlying English's tense-lax distinction. This access allows them to redeploy that phonological feature to accurately map out the novel four-way contrast of Kaqchikel's stop consonants, and the [±RTR] specified velar-uvular distinction in particular. Therefore, phonological redeployment must be considered in models of third language acquisition.
1. Introduction
The phonological tongue root features [Advanced Tongue Root] (or [ATR]) and [Retracted Tongue Root] ([RTR]) capture a range of phonological contrasts and harmony processes in both vowels and consonants of spoken languages across the world (Beltzung et al., 2015). Among these are relatively less common vocalic contrasts such as /e–ɛ/ and /o–ɔ/, which are often involved in harmony processes, particularly among African languages, and the pharyngealization of oral consonants in Semitic and Salish languages (Davis, 1995; Shahin, 2002; Abo-Mokh and Davis, 2020). This relationship between tongue retraction and pharyngeals also implicates [RTR] in phonological contrasts among consonants articulated in and around the pharynx, including uvular, pharyngeal, and other post-velar consonants (Rose, 1996) along with harmony processes associated with those consonants (Sylak Glassman, 2014).
Kaqchikel (ISO 639-3: cak), a Mayan language used mostly by about 400,000 Kaqchikel people in the highlands of Guatemala and in diaspora across North America (Heaton and Xoyón, 2016), exhibits a contrast among its 10 vowels in which a series of 5 tense vowels is not specified for [RTR], while another series of (up to) 5 lax vowels is specified for [RTR]. This contrast is neutralized in unstressed syllables (the feature is lost), so that only tense vowels surface in those positions (Rill, 2013; Bennett, 2016). Among Kaqchikel's stops, there is also a velar–uvular contrast, which may similarly be derived by [RTR] (Shahin, 2002).
English (eng), a Germanic language used by billions of people across the world, similarly exhibits a contrast among its vowels in which two series are contrasted: one tense and one lax. While this contrast is typically attributed to a [tense] feature (Kim and Clements, 2015), Beltzung et al. (2015) notes that [tense] and [ATR] lead to nearly identical outcomes cross-linguistically. Moreover, some analyses have attributed this contrast directly to the feature [RTR] (Brown and Golston, 2006). However, unlike Kaqchikel, English only contrasts three places of articulation (PoA) among its stops: labial, coronal, and velar, each of which may be specified by just a single corresponding Place feature.
Spanish (spa), a Romance language used by hundreds of millions of people across the world, differs from both Kaqchikel and English by exhibiting only a single series of five vowels /i e a o u/, contrasting only on height and backness (Torres-Tamarit, 2019). No [tense] or tongue root feature is present in Spanish, and this can lead to difficulties learning vowel contrasts in other languages which do use those features, as examined in Escudero (2005), among many others. However, Spanish is similar to English in only contrasting three PoA among its stops, again differing from Kaqchikel's four-way contrast.
In this study of third language (L3) acquisition (L3A) of Kaqchikel by learners who already use English and Spanish, listeners were divided into groups based on their first language (L1), in order to investigate the effects of L1 on L3 phonological perception of stop consonant contrasts (Nelson, forthcoming).1 The primary research question of the current study asks whether these learner groups differ in their categorical perception of Kaqchikel stops based on differential access to the [RTR] feature in their known languages.
2. Background
2.1. Acquisition theory
2.1.1. Second vs. third language acquisition
Both subfields of L2A and L3A deal with the process of adding an additional language system to a person's repertoire of linguistic knowledge. Both ask questions about how previous knowledge impacts the implementation of new linguistic knowledge, and vice-versa: how new knowledge affects how previous linguistic knowledge is utilized. Both have various models and hypotheses within them that posit different causes for variable relative difficulty of language learning across different learners of the same language.
The two subfields differ as to which iteration of language acquisition the process is being studied. For L2A, the process being studied is an additional language learned later in life than the first language of that learner, usually after a certain point in the life of said learner. Therefore, a primary difference among learners is that first language. For L3A, on the other hand, the minimum prerequisite for the process being studied is the presence of multiple (minimally two, but, of course, there is the possibility for more) language systems in the linguistic knowledge of the learner. That is to say, for L3A there is additional complexity due to the increased number of potential sources and directions of influence between the multiple existing language systems and the new, target L3 system.
2.1.2. Second language acquisition
2.1.2.1. Basics of second language acquisition
The study of L2A has a relatively long history within modern linguistic inquiry, going back to at least the 1940s. A primary object of study in field of L2A is interlanguage, coined by Selinker (1972) to describe a speaker's L2 competence that was distinct from both that speaker's L1 competence as well as the competence of a native speaker of the target L2, though obviously being influenced by both. It is built upon three main processes: that of L1 transfer, overgeneralization of L2 patterns, and fossilization. According to the original theory of interlanguage, 95% of learners do not acquire native-like competence and thus continue to have an interlanguage after all learning has concluded (VanPatten and Benati, 2010), thus the expected result of L2A, or even L3A, cannot be native-like fluency.
Narrowing our focus, the interlanguage phonology of a given learner is influenced by a variety of factors, including similarities and differences between their known L1 and target L2 (see, e.g., Lado, 1957), markedness of features and structures they are learning (Eckman, 1977), their age (Flege, 1995), and their specific dialectal experience in both L1 and L2 (Best and Tyler, 2007).
2.1.2.2. Phonological segments in L2A
Following decades of L2A investigation, Flege (1995) proposed the Speech Learning Model (SLM)2 finding a correlation between a learner's age of learning (AoL) and their inability to “produce L2 vowels and consonants in a native-like fashion”(237). This segment-specific approach to the L2A of spoken languages' sound systems posits that foreign-accentedness arises from difficulty in learning, which in turn arises from acoustic similarity of L2 segments to known L1 segment categories. That is to say, L2 segments perceptually distinct from L1 segments are actually easier to identify, and therefore learn, than L2 segments perceived as being similar to L1 segments.
The Perceptual Assimilation Model-L2 (PAM-L2) of Best and Tyler (2007) contrasts with SLM, holding that perception of languages other than L1 is done within L1 categories, as opposed to the comparison of L2 segments to L1 segments in SLM. As such, according to PAM-L2, learners form their interlanguage by assimilating L2 segments into L1 categories, which may cause interference in the development of contrasts between L2 segments.
Best and Tyler (2007) predicted four possible cases of L1 assimilation for a set of contrasting segments in L2 (28–29):
1. Two-Category (TC): Only one L2 category is perceived as equivalent to a given L1 category.
2. Category Goodness (CG): Multiple L2 categories perceived as equivalent to the same L1 category, but one is a better fit than other(s).
3. Single Category (SC): Multiple L2 categories are perceived as equivalent to the same L1 category, but as equally good instances of it.
4. Uncategorized: No L1-L2 assimilation.
Best and Tyler (2007) ordered these in increasing order of difficulty, with TC Assimilations being easier to learn than CG Assimilations, which should be easier than SC Assimilations. Uncategorized contrasts, however, are subject to more variation, depending on the perceptual distance from each L2 category to known L1 categories. Long-term learning outcomes for the SC and unassimilated L2 segments would also depend upon lexical-functional differences among them.
Escudero (2005) proposed a model similar to PAM-L2 with L2 Linguistic Perception (L2LP), under which phonological L2A is initiated using L1 categories. However, mappings are made via auditory perception. L2LP predicts three scenario types, new, subset, and similar, and these scenarios range in the level of difficulty they present the learner from high to low, based on the nature of categorical remapping each requires. Thus, in both PAM-L2 and L2LP, the conflict that arises when L2 segments are categorized based on L1 categories using L1 cues is the primary contributor to interference in phonological L2A.
The SLM, PAM-L2, and L2LP were put to the test in the scenario of L1 English learners of Q'eqchi', a Mayan language related to Kaqchikel (the target language of the current study), in Wagner and Baker-Smemoe (2013), who compared L1 English to L1 Q'eqchi' participants in both perception and production of Q'eqchi' plain and ejective stops. They found that while none of the three models were perfect in their predictions of stop production based on perception results, they each “to some extent, predicted learning accuracy” (466).
According to Wagner and Baker-Smemoe (2013), SLM accurately predicted that L1 English learners would differ more from L1 Q'eqchi' speakers in their production of plain stops, relative to glottalized stops, but failed to predict their better ability in producing native-like cues for velars compared to other PoAs. PAM-L2 predicted the Laryngeal distinction at both velar and uvular PoAs to each be difficult to acquire SC categorizations, but the learners did not show difficulty with these pairs. PAM-L2 predicted ease of learning in the CG categorizations of the velar–uvular Place distinction, but Wagner and Baker-Smemoe (2013) found that this place distinction was more difficult than the laryngeal distinction. Similarly, L2LP made similar incorrect predictions as PAM-L2 regarding the relative difficulty of learning the Laryngeal distinction compared to the velar–uvular place distinction.
Wagner and Baker-Smemoe (2013) provide a possible explanation for the surprising results of the ease of learning distinctions among the velar and uvular stops in that the mapping of four categories onto a single L1 category forced learners to focus more intently on those contrasts, leading to better than expected learning outcomes for the velar and uvular stops of Q'eqchi' by L1 English learners. These results bear on the current study, as Kaqchikel, like Q'eqchi', contrasts uvular stops with velar stops. These outcomes should be replicated in the L3A scenarios of the current study.
2.1.2.3. Phonological features in L2A
Other models of L2A posit a filter effect that prevents some learners from developing adequate phonological mapping in their target language. This filter is caused by the supposed unlearnability of underlying features, the bundles of information that specify phonological contrasts of human language in theories of generative phonology (Chomsky and Halle, 1968). Building upon this, Clements (1985) and others developed an extension of feature theory called Feature Geometry, which holds that the underlying features exist in a hierarchical relationship to one another. Much of the work reviewed in the remainder of this background section depends on Feature Geometry, and I assume this theory for the current study as well.
Brown (1997, 1998, 2000) analyzes the relative difficulty of learning the English liquid contrast /l~r/ by L1 Japanese learners compared to L1 Mandarin Chinese3 learners. Brown claims that Japanese and Korean feature geometries lack the [Coronal] feature necessary to specify the distinction between the English liquids, while Mandarin does use this feature, so L1 Mandarin learners of English are able to use this feature in acquiring /l~r/, leading to differences in outcomes between learners differing in L1 language background (Brown, 2000).
LaCharité and Prévost (1999) hypothesized a weaker filter, in which only some features are unlearnable in L2A: those at intermediate, articulator nodes in the feature geometry. Terminal nodes projecting no dependent nodes, on the other hand, are learnable. Thus, it is unsurprising to observe that L1 Japanese learners of English seem unable to acquire the [Coronal] node in learning liquids, but L1 French learners of English more easily acquire English /θ/ compared to /h/ because /θ/ requires the addition of a terminal [distributed] node, while /h/ requires the addition of articulator [Pharyngeal] node. Moreover, LaCharité and Prévost (1999) predicted the acquisition of /ŋ/ by these same learners to be even easier than both /θ/ and /h/, as no new features need to be added to the feature geometry to specify /ŋ/.
Mah (2003) found the attribution of [Pharyngeal] to English /h/ to be unfounded as it “does not involve any constriction of the pharyngeal cavity”(24). Additionally, there is evidence that a [Pharyngeal] feature is in fact utilized in French, specifying its rhotic // (Mah, 2003). Instead, Mah (2011) followed Iverson and Salmons (1995) in specifying English /h/ with a Laryngeal node projecting the terminal node [spread glottis], which further problematizes the predictions and findings of LaCharité and Prévost (1999), as French stops use the Laryngeal node in representing voiceless and voiced obstruents. Thus, only the terminal node of the feature [spread glottis] would need to be added when francophones learn English /h/. Brown (2000) would predict this as impossible, but LaCharité and Prévost (1999) would predict this as possible but not as easy as other scenarios. Yet, Mah (2011) and Mah et al. (2016) again found that francophone learners of English are unable to perceive English /h/, despite being able to detect its acoustic cues in non-linguistic conditions. Therefore, Mah (2011) concluded that the learning problem arises due to francophones' inability to form a phonological representation for English /h/ in their interlanguage, missing the key feature [spread glottis], as Brown (2000) would predict.
2.1.2.4. Phonological redeployment in L2A
The filter hypotheses predict impossibility of learning based on what they assume to be irreconcilable disparities between underlying feature geometries. To account for the remarkable ability of some language learners to learn patterns and contrasts that these hypotheses and other theories of L2A predict as difficult, Archibald (2005) proposed that learners may dynamically redeploy previous linguistic knowledge to remedy their lack of the specific linguistic knowledge that L1 users of their target L2 have, including, but not limited to, phonological features.
González Poot (2011, 2014) offered redeployment as a potential facilitator in L2A of glottalized stops in Yukatek, another Mayan language distantly related to Kaqchikel. González Poot (2011) noted the differential use of the feature [constricted glottis] among Yukatek, English, and Spanish. In Yukatek, [constricted glottis] is distinctive, underlying the contrast between plain and glottalized stops. However, in Spanish, [constricted glottis] has no status whatsoever, while in English it may be used in word-final allophonic ejectives. González Poot (2011, 2014) did not investigate English learners of Yukatek, leaving open the possibility of redeployment of non-contrastive features, like [constricted glottis] in English, for future research. Nevertheless, González Poot (2011, 2014) found that the L1 Spanish L2 learners of Yukatek acquired its Laryngeal contrast, which González Poot (2014) credits to the ejectives' strong acoustic cues.
More recently, Yang et al. (2022) found that L1 Mandarin learners of Russian perceived Russian voiced stops as being highly similar to Mandarin voiceless unaspirated stops, which the SLM would predict would lead to difficulty in their L2A of Russian stops. Surely enough, in their productions of Russian-like nonce words, the learners did not produce a voice onset time (VOT) distinction between the phonemically voiced and voiceless stops, producing them both as short-lag stops, as if they all belonged to a single category of voiceless, unaspirated stops. They had no representation of the voicing distinction of Russian stops. Yang et al. (2022) interpreted these results as a refutation of redeployment theory. In their view of redeployment, the learners ought to have been able to redeploy [±voice] from Mandarin fricatives /ʂ/ and /ʑ/ in specifying Russian stops.4
In reviewing Yang et al. (2022) and Archibald (2023) clarified key points about redeployment. First, that redeployment is not phonetic, but rather phonological; it is embedded within learners' phonological systems. Second, that relatively robust cues to contrasts in the target language allow learners to better notice those contrasts, while contrasts with weaker cues may not get noticed. However, Archibald (2023) principal point was that noticing phonetic differences across languages is not the outcome of successful phonological learning. Instead it is an important preliminary step to phonological learning, which may be aided by redeployment of previous phonological knowledge and which may involve re-weighting of acoustic cues to account for the new contrasts they have begun to notice.
2.1.3. Third language acquisition
2.1.3.1. Basics of third language acquisition
Third language acquisition, when compared to L2A, is a younger field of study. While L2A has many decades of research behind it, L3A only has two or three decades of specific research, as it only arose out of the field of L2A in the 1990s. In addition to the L2A concept of interlanguage, an additional object of study in L3A is the concept of cross-linguistic influence: how the multiple different systems interact in the mind of the multilingual language user/learner (Hammarberg, 2001). Logically, any of a learner's language systems may interact and have cross-linguistic influence on any of their other language systems. However, theories differ as to the nature and amount of cross-linguistic influence possible in each direction of a given L3A scenario.
2.1.3.2. Phonological effects in L3A
As briefly discussed in §2.1.2, Mah (2003) investigated the filter effects proposed for phonological L2A. However, Mah (2003) did not find any differences in the perception of French vs. Spanish trills (// and /r/, respectively) by L1 English learners, concluding that these learners were unable to construct appropriate phonological representation for either. Mah (2003) also noted that L2 exposure to non-L1 segments may only affect processing of the segment in L3 only when that exposure was in a childhood L2 and sufficient enough to learn the features necessary for representing the segment, implicating the AoL effect in L2A on subsequent L3A.
Cabrelli Amaro and Rothman (2010), noting similar age-related effects of L2A on L3A, offered the Phonological Permeability Hypothesis (PPH) of L3A. Later expanded upon in Cabrelli Amaro (2013b, 2017), the premise of PPH lies in the AoL effect, that there exists a critical/sensitive period of phonological learning in pre-pubescence, and that languages learned during this period are fundamentally different than languages learned after it. Thus, PPH predicts similarities among languages learned in childhood, and a separate set of similarities among languages learned in adulthood. Evidence for PPH comes in the form of relative susceptibility to regressive transfer from L3 during L3A: L2 is more permeable to this cross-linguistic influence than L1 is (Cabrelli Amaro, 2017). This implicates the conceptual similarity between L2 and L3 being greater than that between L1 and L3, as well as the higher degree of phonological fossilization present in systems learned in childhood as compared to systems learned in adulthood. In short, languages learned during childhood are more entrenched in a person's greater phonological system than subsequently learned languages.
Wrembel et al. (2019), noting previous studies showed that L2A enhances auditory awareness in L3A, offered an extension of PAM to the domain of phonological L3A. In their study of the acquisition of Polish by teenagers who were multilingual in other European languages, Wrembel et al. (2019) found that learners did operate under the assumptions of PAM, and that pairs of L3 and L2 sounds (including both consonants and vowels) were assimilated more often than pairs of L3 and L1 sounds. Therefore the models of phonological L2A do seem to have some predictive power in L3A in that comparisons of L3 categories are made to known categories, but learner do prefer assimilating L3 categories into L2 categories rather than those of L1.
2.1.3.3. Selective transfer in phonological L3A
Most recently, Archibald (2022) analyzed the L3A of English by L1 Arabic, L2 French learners in Algeria and Tunisia (as presented by Benrabah, 1991 and Ghazali and Bouchhioua, 2003), arguing that phonological transfer in L3A comes from both/all known languages on a property-by-property basis (as opposed to wholesale) along the lines of the Linguistic Proximity Model (Westergaard et al., 2017). Specifically, the learners of L3 English were found to transfer the vocalic system from French, but their consonants, including pharyngealized stops, from Arabic. Furthermore, the Tunisian novice-level English learners in Ghazali and Bouchhioua (2003) seemed to transfer sentence-level prominences from French, but word-level stress rules from Arabic.
Archibald (2022) used the Contrastive Hierarchy of Dresher (2009) and Feature Geometry to show that learners select different sources for their phonological L3A transfer on a property-by-property basis. Learners do this based on the evidence available to them in their learning environments, the knowledge from the integrated I-grammar of their known languages, and the general constraints provided by Universal Grammar. In the end, learners tend to make the decision to transfer the phonological subsystem which most optimally accounts for the L3 contrasts they can observe. Note, however, that they still must be able to observe or notice the contrasts, as per Archibald (2023), before they begin to integrate them into their I-grammar's phonology.
As theories of phonological learning, especially those allowing for redeployment, depend on underlying specification of segments, the following subsection makes clear the featural specifications that I assume for each of the three languages of the current study.
2.2. Phonological background
2.2.1. Kaqchikel phonology
2.2.1.1. Kaqchikel vocalic phonology
Kaqchikel's vocalic phonology is typical of Mayan languages in its basis as a five-vowel inventory. However, it is atypical of Mayan languages in that it does not contrast these five base vowels for length, instead exhibiting a tense–lax contrast. The maximal ten-vowel inventory of Standard Kaqchikel is shown in Figure 1A. The tense–lax contrast of Kaqchikel vowels only surfaces in stressed syllables. Outside of stressed syllables, only tense vowels surface (Rill, 2013). In practice, due to the location of stress in Kaqchikel being fixed to the final syllable of the word, lax vowels may only surface in the final syllable of words (Brown et al., 2006).
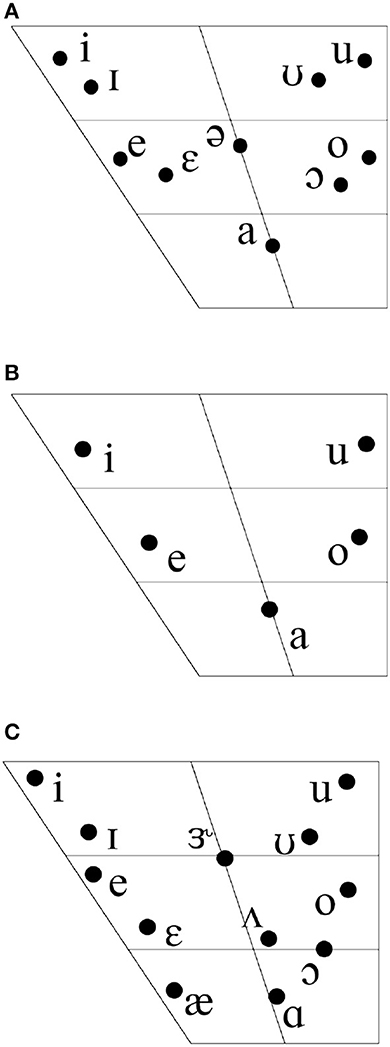
Figure 1. Monophthong vowel inventories: (A) Standard Kaqchikel vowel monophthong phonemes. (B) Guatemalan Spanish vowel monophthong phonemes. (C) Typical US American English vowel monophthong phonemes.
Most varieties of Kaqchikel, however, do not mark the tense–lax contrast for all five vowel archiphonemes, and exhibit mergers of the tense–lax distinction in some or even all vowels. However, this is subject to much community-based variation. The standardized orthography of Kaqchikel marks the tense–lax distinction for all five vowels, and the textbooks used at Oxlajuj Aj, the language school where the learners in the current study had enrolled, use the standardized orthography (Brown et al., 2006; Maxwell and Little, 2006). Furthermore, though the teachers at Oxlajuj Aj come from various Kaqchikel communities, they all accommodate to the standard in their teaching. Thus, the target language of all students is taken to be Standard Kaqchikel and its 10 vowel inventory, with the tense–lax distinction realized for all five vowel archiphonemes.
The featural specification for Standard Kaqchikel is as follows: There are four distinctive features that specify Kaqchikel's ten vowels: [±high], [±back], [±round], and [RTR]. The [+high] vowels are /i ɪ ʊ u/, while all other vowels /e ɛ a ə ɔ o/ are [−high]. The [+back] vowels are /u ʊ o ɔ/, while all other vowels /i ɪ e ɛ ə a/ are [−back]. The [+round] vowels include all [+back] vowels plus central vowels /a ə/5, leaving the front, unrounded vowels /i ɪ e ɛ/ as [−round]. Finally, the [+RTR] vowels are the lax vowels /ɪ ɛ ə ɔ ʊ/, while tense vowels /i e a o u/ are [−RTR].
2.2.1.2. Kaqchikel consonantal phonology
The consonantal inventory of Kaqchikel appears at the top of Table 1. Due to space constraints and the scope of the current study, I discuss only the phonology of this inventory's stops here. Broader consideration of the consonantal inventory is given in Nelson (forthcoming). All stops in Kaqchikel (and also Spanish and English) are [+consonantal], [−sonorant], [−continuant], and [−strident], differing from each other only in Place and Laryngeal specification.
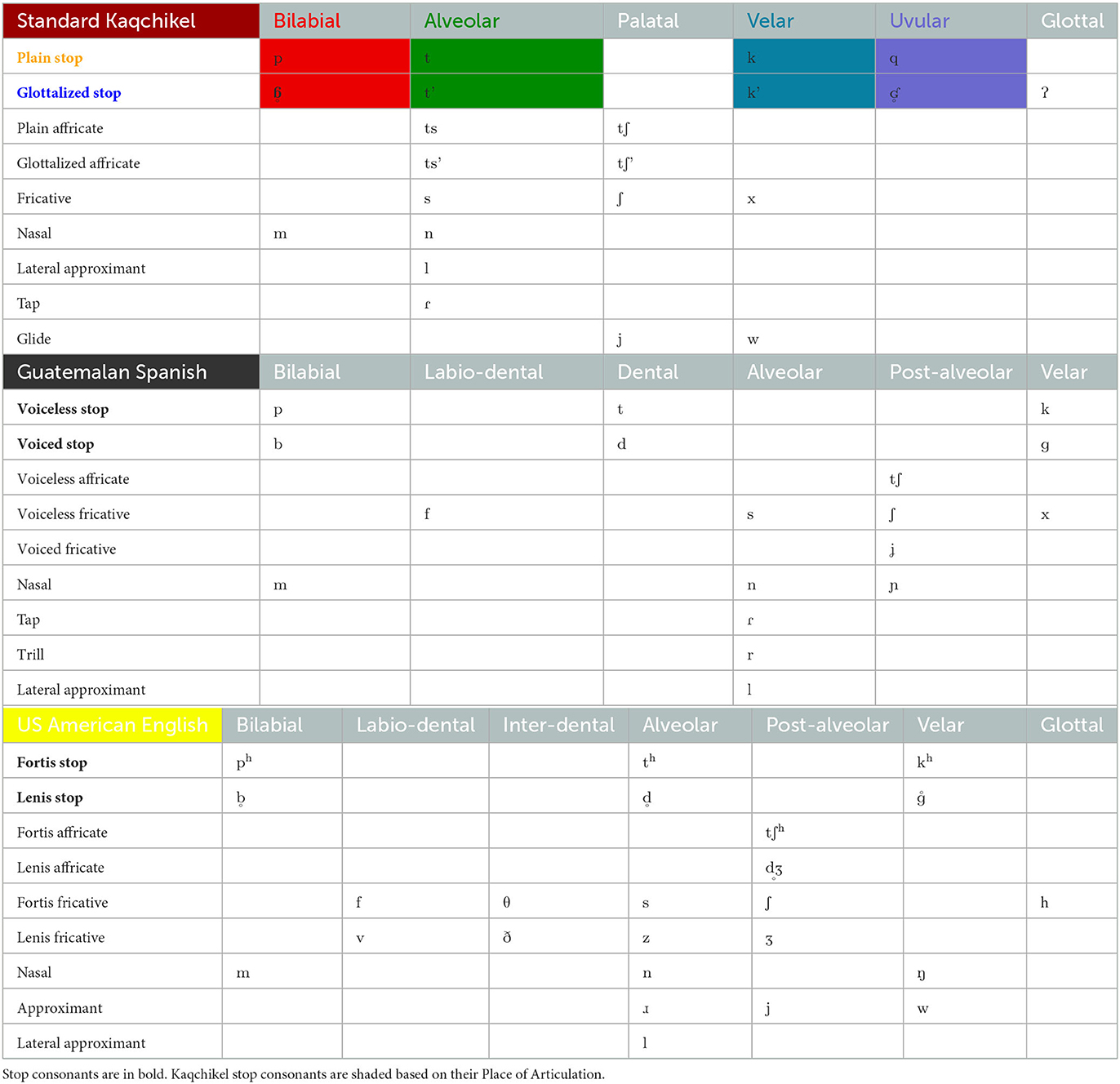
Table 1. Consonant phoneme inventories of Kaqchikel, Spanish, and English.
Kaqchikel stops exhibit a four-way place contrast. These four PoAs are, in order from the front of the mouth backwards: bilabial, alveolar, velar, and uvular. The distinction between the first three is usually specified under Feature Theory with a single Place feature for each: Labial for bilabials, Coronal for alveolars, and Dorsal for velars. However, the uvular distinction is less commonly made. Therefore, phonological systems that do contrast uvulars and/or other sounds articulated beyond the velum require more featural complexity to derive their Place contrasts.
Both of Kaqchikel's Labials /p ɓ ° / are specified for the Place feature [Labial], with no further Labial features/nodes necessary. Similarly, the Coronals /t t'/ are specified for the Place feature [Coronal]. However, Kaqchikel distinguishes between anterior and posterior coronal consonants. Therefore, these two anterior stops are specified [−posterior].
The four remaining Kaqchikel stops are all specified for the Place feature [Dorsal]. However, the velars /k k'/ must be distinguished from the uvulars /q ʛ ° /. Previous analyses of languages with velars and post-velars offer various features and specifications in order to derive these contrasts. Sylak Glassman (2014) provided a detailed history of the featural representation of velars, uvulars, and other post-velars, including [flat] (Jakobson, 1962), [±high] (Chomsky and Halle, 1968), tongue body features (Ladefoged, 1971), [guttural] (Hayward and Hayward, 1989), [pharyngeal] (McCarthy, 1994), and [RTR] (Rose, 1996). This final feature [RTR] is of primary interest to the current study, as it is already utilized for the tense–lax distinction of Kaqchikel vowels. Variably placed within Feature Geometry as a dependent of Pharyngeal, Dorsal, and Tongue Root (TR), I follow Davis (1995) and Shahin (2002) in assuming that post-velars are distinguished from velars via the feature [±RTR], projecting from a TR node, in turn projecting from the Dorsal node held in common between velars and uvulars (76: (45a) vs. (45c)). Acoustic evidence for these specifications of [±RTR, including lowering and backing of front vowels preceding uvulars, is forthcoming in Nelson (forthcoming).
Thus, I assume that Kaqchikel velars contain a Dorsal node, projecting TR, which in turn projects [−RTR] (Figure 2A), while Kaqchikel uvulars contain the same Dorsal and TR nodes, but with [+RTR] as the terminal projection (Figure 2B). In consideration of space, I assume all [±RTR] features are dependent of the articulator node TR, and thus omit the TR node from feature geometry diagrams in the current paper.
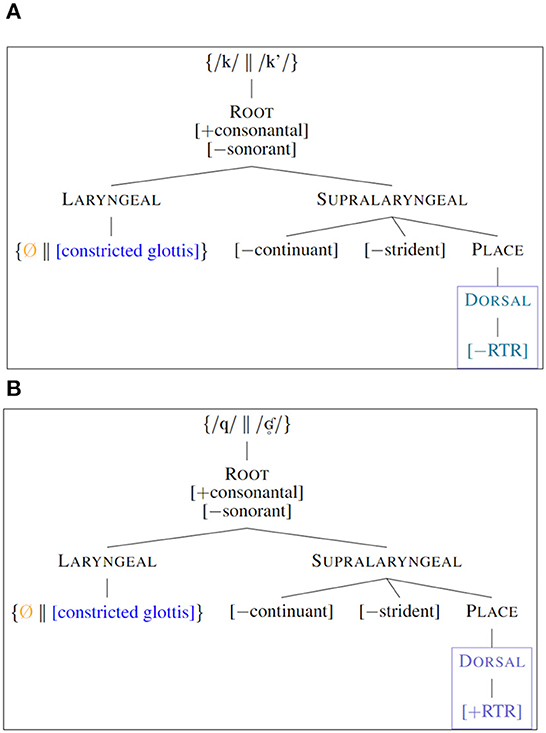
Figure 2. Feature geometry for Kaqchikel Dorsal stops: (A) velars /k/ and /k'/, (B) uvulars /q/ and /ʛ ° /.
Kaqchikel stops6 show an additional contrast that other sound classes in the language do not: a Laryngeal contrast in which one series is glottalized via a closure/restriction of the glottis in addition to the closure made in the mouth at the stop's PoA. This typically results in an ejective, in which the glottal closure releases and forces the high pressure air upward and outward through the mouth. However, Kaqchikel glottalized labial and uvular stops are often realized as voiceless implosives (Bennett, 2016, p. 485), when, in addition to the oral closure, the vocal folds that form the glottis are closed and move downward without vibrating (Ladefoged and Johnson, 2015, p. 165). Regardless of their phonetic realizations, the glottalized stops contrast with plain, non-glottalized stops at each PoA. The plain stops are realized as voiceless, unaspirated stops in syllable- and word-initial positions (i.e., onset), but as voiceless, aspirated stops in syllable- and word- final positions (i.e., in coda).7
The contrast between plain stops and glottalized stops can be uncontroversially derived via specification of [constricted glottis]. The members of the glottalized series /ɓ ° t' k' ʛ ° / are specified as having [constricted glottis], while members of the plain series /p t k q/ are specified with an absence of the feature (represented by the null set symbol Ø). The underspecification of a Laryngeal feature for Kaqchikel plain stops allows them to take on the feature [spread glottis] in final positions, thereby surfacing as voiceless, aspirated stops (Nelson, 2023).
2.2.2. Spanish phonology
2.2.2.1. Spanish vocalic phonology
The five vowel inventory of Spanish is shown as Figure 1B. Following Barrios et al. (2016), these five vowels, /i e a o u/, can be specified by just three features, [±back], [±high], and [±low]. The vowels /u o a/ are specified [+back], while the two front vowels are [−back]. The high vowels /i u/ are [+high], leaving the remaining three non-high vowels as [−high]. The only vowel specified [+low] is /a/, while all other vowels are [−low].
2.2.2.2. Spanish consonantal phonology
The center of Table 1 shows the consonantal inventory of Guatemalan Spanish, which includes some phonemes not typically found in other Spanishes, such as /ʃ/. Our focus remains on the stops however, of which there are six phonemes in Guatemalan Spanish, /p t k b d ɡ/, divided among three PoAs and two Laryngeal series.
I assume Spanish stops to be specified for Place based on a feature geometry with three Place features (Clements and Hume, 1995; Halle et al., 2000; Padgett, 2002), a node for each of Labial, Coronal, and Dorsal place. The bilabials /p b/ have Labial Place. The dentals /t d/ have Coronal Place, and, with both stops being dental while post-alveolar coronals are distinguished in Spanish, the projection of terminal node for [−posterior] is necessary. Finally, the velars /k ɡ/ have Dorsal Place, with no further features projected from the Dorsal node. The feature geometry diagrams for the two Spanish velars are shown as Figure 3A.
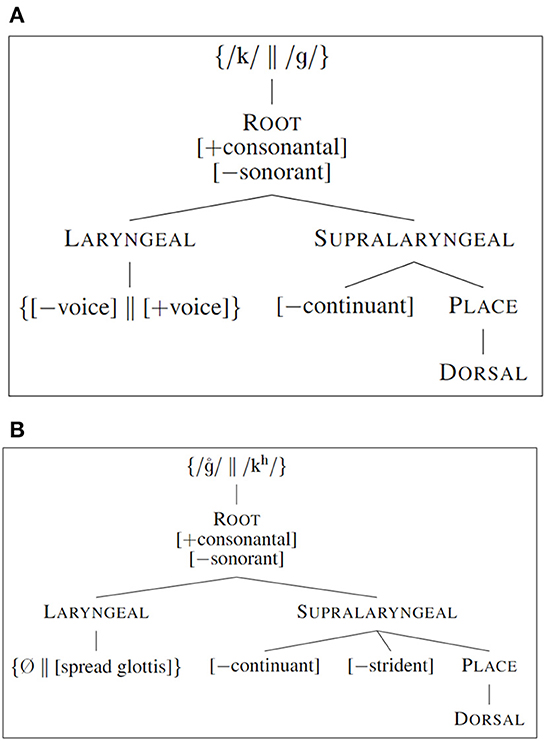
Figure 3. Feature geometry for Spanish and English Dorsal stops: (A) Spanish velars /k/ and /ɡ/, (B) English velars /°ɡ / and /kh/.
I follow Torres-Tamarit (2019) in assuming that, like other Romance languages, the two-way Laryngeal contrast in Spanish is derived by the feature [±voice]. Evidence for this feature lies in the acoustic cues associated with each series. The series /p t k/ exhibits positive, but short VOT in onset position, while the series /b d ɡ/ has negative VOT. Thus, I assume that the first series is a voiceless series specified as [−voice], while the second is a voiced series specified as [+voice].
2.2.3. English phonology
2.2.3.1. English vocalic phonology
Figure 1C shows the comparatively dense vowel inventory of English. Even within a single country, like the United States where all L1 English learners of Kaqchikel who participated in the current study were born and raised, there is considerable variation in the language's vowel inventory. Thus, my description of the inventory is general in that it consists of around 12 vowels.
English distinguishes these many vowels on dimensions of height, backness, rounding, and tenseness. To account for these many distinctions, more vocalic features are necessary than for the previous two languages. These features are: [±back], [±high], [±low], [±round], and [±tense]. I take all vowels to be specified for all features. The [+back] vowels are /u ʊ o ɔ ʌ ɑ/. The [+high] vowels are /i ɪ u ʊ/. The [+low] vowels are /æɑ/. The [+round] vowels are /ɝɔ o ʊ u/. Finally, the [+tense] vowels are /i e o u/ (Kim and Clements, 2015), though, as mentioned previously, Brown and Golston (2006) proposed that one of [ATR] or [RTR] capture this distinction (advanced or retracted in their model).
2.2.3.2. English consonantal phonology
The consonantal inventory of United States American English is shown at the bottom of Table 1. In English, there are six stop phonemes, just as in Spanish, with three PoAs on two Laryngeal series.
I take English to use the same specifications for Place as Spanish: the bilabials /ph b ° / are specified for [Labial], the coronal stops /th d ° / (which in English are alveolar) are specified for Coronal with a terminal node of [−posterior] projecting from it, and the velars /kh °ɡ / are specified for [Dorsal]. The feature geometry for English Dorsal stops is shown as Figure 3B.
Based on Laryngeal Realism (Honeybone, 2001), I take the operative Laryngeal feature in English to be [spread glottis] (Iverson and Salmons, 1995). The fortis (or aspirated) stops /ph th kh/ are marked in this respect, and thus bear the Laryngeal feature [spread glottis], while the lenis (unaspirated) stops /b ° d ° °ɡ / are unmarked and do not bear the feature. The lenis series being unmarked for a Laryngeal feature in turn makes them susceptible to intervocalic (passive) voicing in some environments, while in other environments, the [spread glottis] feature is suppressed so that fortis stops may surface as unaspirated (e.g., in sC- onset cluster).
Additionally, in multiple English varieties, word-final stops increasingly surface as ejectives, with at least 26% of such stops being realized as ejective in a corpus analysis by Price et al. (2020). However, MRI analysis in Price et al. (2022) showed that many English ejectives are produced without an elevated larynx, implicating an airstream mechanism distinct from the laryngeal egressive airstream typically ascribed to ejective production in languages like Kaqchikel. Could experience with these emerging allophonic glottalized stops provide learners of Kaqchikel with knowledge transferable to their acquisition of the Kaqchikel laryngeal contrast?
2.3. Learning problem
With these differences in stop phonology among these three languages in hand, we can now formulate the learning problem encountered by learners of Kaqchikel who have already learned and use both Spanish and English. Spanish contrasts voiced stops from voiceless stops, based on the Laryngeal feature [±voice], while English contrasts aspirated stops from unaspirated stops with the Laryngeal feature [spread glottis]. These contrasts, underlying features, and associated cues are neither equivalent to each other, nor equivalent to the Laryngeal contrast of Kaqchikel, a glottalization contrast between glottalized stops and plain stops based instead on [constricted glottis]. How can these learners use their knowledge of Laryngeal contrasts in Spanish and English to learn the new glottalization contrast of Kaqchikel? Adding to this learning problem of Laryngeal specification, Spanish and English both contrast their respective stop consonants at three PoAs: labials, coronals, and velars. Kaqchikel, on the other hand, adds uvulars to these three. Thus, learning the glottalization contrast cannot simply be an extension of the Laryngeal contrasts already known, as new cues must be learned for the uvulars and the contrast between them as well.
2.4. Research questions
The current paper investigates how learners manage to solve the learning problem presented by the new categories and contrasts among Kaqchikel stops by asking the following research questions.
1. Do Spanish-English multilingual learners differ in their perception of Kaqchikel stop consonants based on their L1 (i.e., their L1 Group)?
2. If so, which language is privileged in this regard?
3. Is any such privilege present across the whole stop subsystem, or restricted to individual parts, namely the Laryngeal contrast on one hand and Place contrasts on the other hand(s)?
4. Is there a difference in stop perception based on its Position within its word?
I hypothesize, based on the phonological differences between Spanish and English, that there will be differences between these two groups. These differences should arise in the groups' perception of the Laryngeal contrast of Kaqchikel, but not the place contrasts. English phonology offers a Laryngeal contrast based on [spread glottis], which is a better match than Spanish's [voice] for Kaqchikel's system based on [constricted glottis]. Therefore, based on the L2 Status Factor Model (Bardel and Falk, 2007) and the findings of Wrembel et al. (2019) that PAM in L3 prefers mappings of L3 on L2, the L2 English group (NSS) should outperform the L2 Spanish group (NES) in perception of Kaqchikel's stop contrasts.
On the other hand, if both groups select optimal mappings, as is predicted under redeployment models, no inter-group differences should emerge among the learners, as they should make similar mappings based on their shared knowledge of both Spanish and English. In this case, it may be more beneficial to consider individual cases of L3A of Kaqchikel rather than group-wise comparisons based on learners' L1s.
As there is no difference in Place phonology between English and Spanish stops, the decision to transfer the phonological structure from one language over that of another should not impact their perception. Therefore, I do not predict group differences based on PoA. Instead, the findings of Wagner and Baker-Smemoe (2013) lead me to predict relatively good uvular categorization by both learner groups.
However, I do hypothesize that there is an effect of stop's position that could interact with the potential Group effects, or overall effects of Laryngeal and Place contrasts on categorical perception of Kaqchikel stops. English stops regularly appear in a variety of syllabic positions, including at the beginnings of words and syllables and at the ends of words and syllables. Spanish stops do not regularly appear in domain-final positions. However, Spanish voiceless stops in initial position do map more closely to Kaqchikel plain stops in initial position, in both having unmarked phonological specification and in the acoustic cues associated with them. Therefore, based on property-by-property transfer (Westergaard et al., 2017; Archibald, 2022), knowledge of Spanish domain-initial voiceless stops could be transferred to account for Kaqchikel initial plain stops, while English domain-final stops could be transferred to account for Kaqchikel final stops.
3. Materials and methods
3.1. Participants
In order to investigate the stated research questions, I recruited 18 multilingual Kaqchikel–Spanish–English users to perform various tasks in those three languages. The first group were L1 users of Kaqchikel (heretofore labeled as “Native Kaqchikel SpeakersNKS), while the two other groups were L3 learners of Kaqchikel. The learner groups were divided according to the L1 of each participant, with 6 learners being L1 Spanish (receiving the identifier “Native Spanish Speakers”, NSS) and 7 learners being L1 English (“Native English Speakers”, NES), in a mirror-image design (Ortin and Fernandez-Florez, 2019).
One NES learner's (NES7) results were excluded due to their insufficient Spanish experience relative to other NES participants. This left 5 NKS, 6 NSS, and 6 NES. Each participant also gave a self-assessment of their Kaqchikel, Spanish, and English skill levels in listening and speaking using a three-point rating scale (1=“beginner”, 2=“intermediate”, and 3=“fluent”). The descriptive statistics for the groups' ages and their age of learning and self-assessments for each language appear in Table 2.

Table 2. Descriptive statistics of each group's ages (in years) at time of study plus their ages of learning (AoL, also in years) and listening and speaking self-assessment scores (out of 3) for each language. Group means (with standard deviations in parentheses).
3.2. Categorization task
3.2.1. Materials
3.2.1.1. Stimuli
Stimuli for the categorization task were audio recordings of 160 Kaqchikel, Spanish, and English words as spoken by a female L1 Kaqchikel L2 Spanish, L3 English speaker. This speaker was born and raised in Guatemala, but had resided elsewhere at various points in her life, including the United States and Spain. As a Kaqchikel language researcher and teacher, she was able to produce the stimuli in a Standard Kaqchikel variety.
She recorded the stimuli into a Zoom H4N Handy Recorder equipped with a Sony ECM-44B condenser microphone attached to the her lapel, by reading aloud from wordlists with each target word placed within a carrier sentence that matched the language of the word. For Kaqchikel, this carrier sentence was Xinb'ij [word] la q'ij la' “I said [word] that day)”. For Spanish it was Dijo [word] la semana pasada “I said [word] last week”. For English words the carrier sentence was I said [word] last week. She also read from an additional Kaqchikel wordlist, recordings of which formed part of the category labels for the categorization task. She read each wordlist two times, with half of stimuli selected for presentation in the task coming from the first readings and half coming from the second readings. Recordings were trimmed down to just the target word using speech analysis and modification software, Praat.
In order to test for any differences in categorization based on the stops' positions within their respective words, the stimuli featured each of the three languages' six or eight stops in both initial/onset and final/coda positions. Additionally, each stop phone for all three languages appeared before each of the four vowels /i e o u/ in the initial condition and after each of the four vowels /i e o u/ in the final condition. Each stimulus word was presented twice giving a total of 320 trials for each participant. Of the 320 trials, only 128 presented Kaqchikel words; the remaining 192 presented Spanish or English words. For the purpose of the current study's analysis, the 192 Spanish and English trials were distractors that kept the listener in a trilingual mode of perception throughout testing. They would be cross-linguistically categorizing Spanish and English stops into Kaqchikel categories, but cis-linguistically categorizing Kaqchikel stops into Kaqchikel categories. The use of stimuli from three languages is based on the bilingual categorization task of Wagner and Baker-Smemoe (2013), in which English and Q'eqchi' stops were categorized into English categories. The list of Kaqchikel stimuli words presented to listeners is shown in Tables 3, 4.
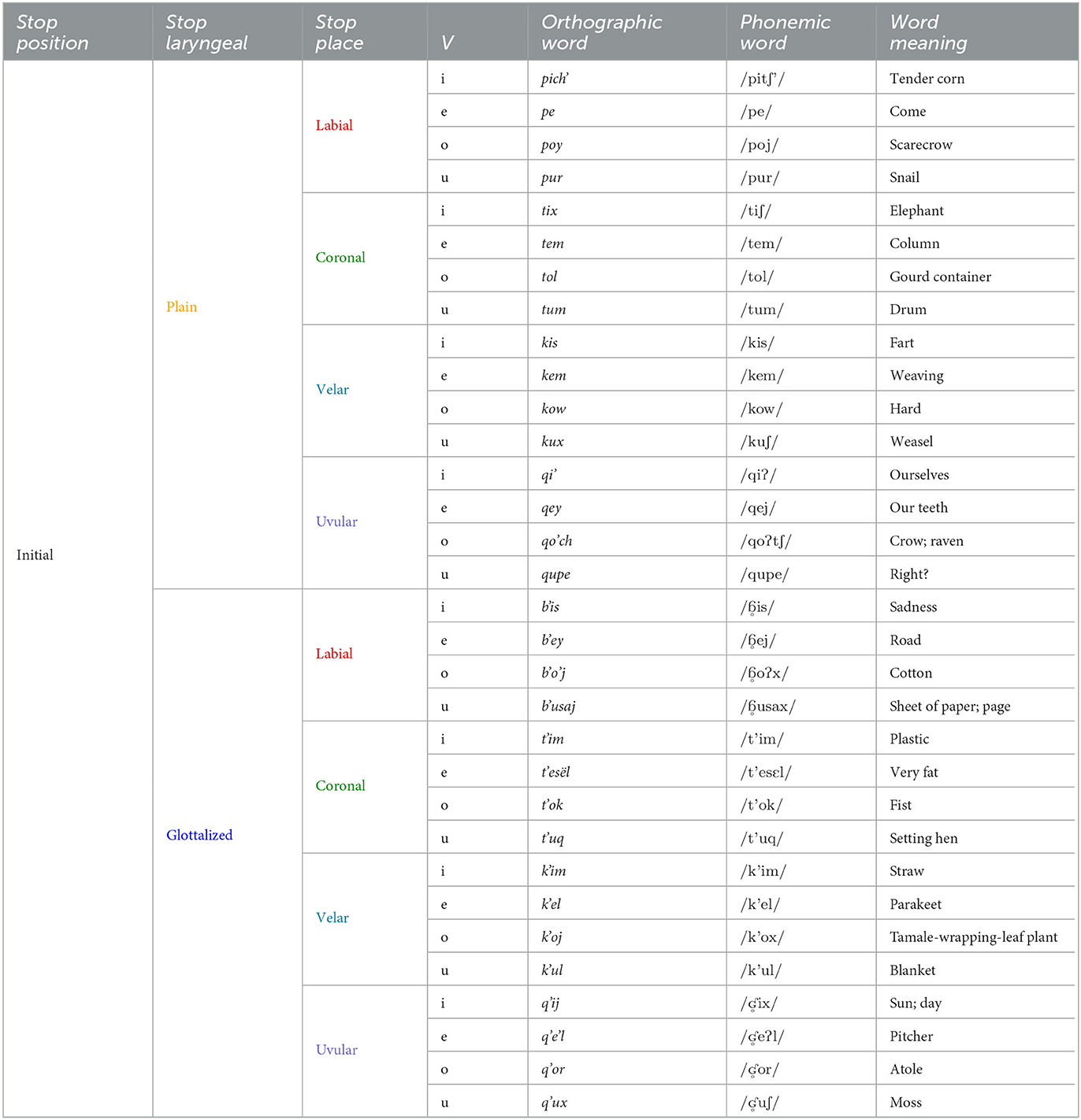
Table 3. Categorization task stimulus words: Kaqchikel, initial stops only.
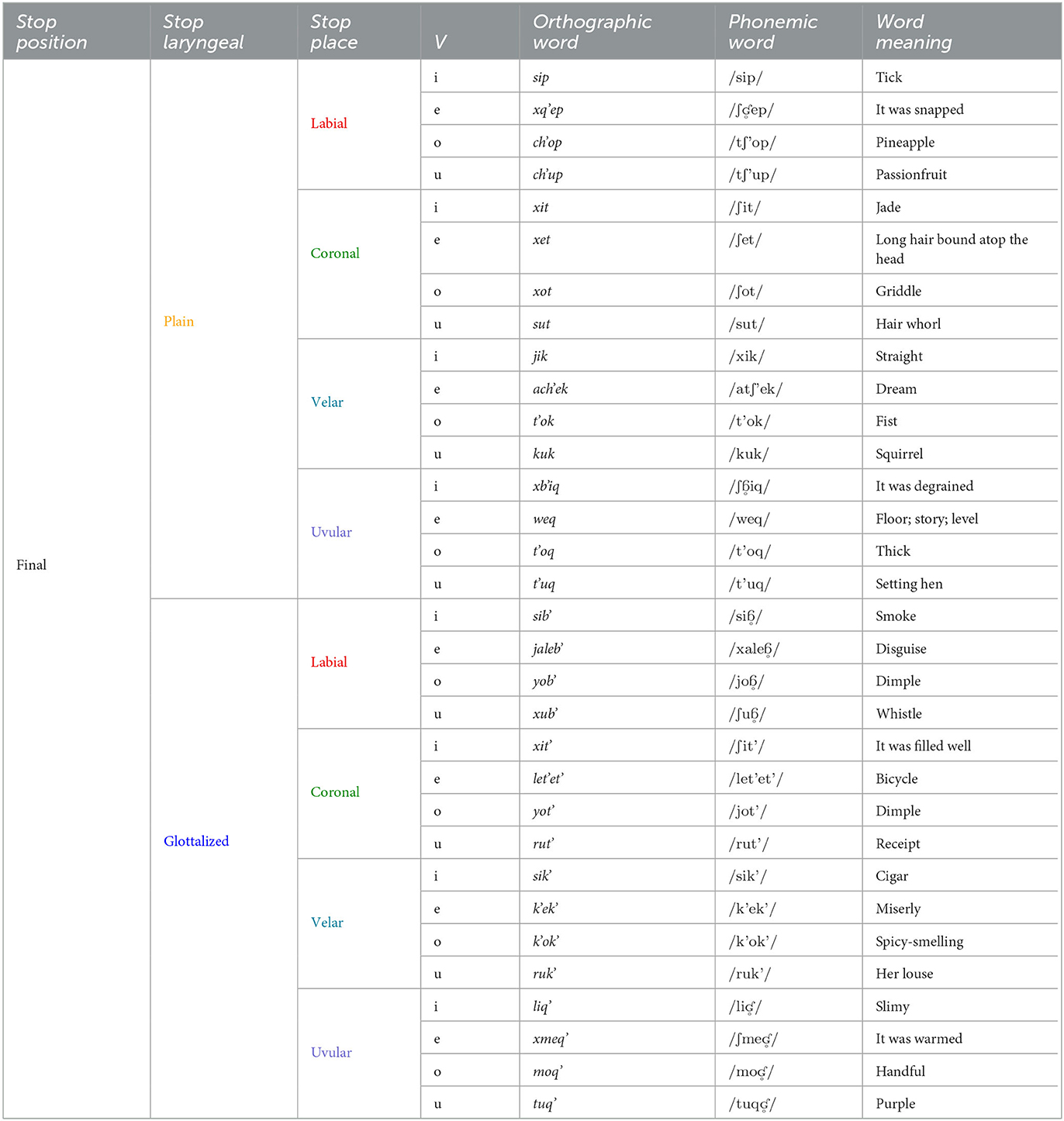
Table 4. Categorization task stimulus words: Kaqchikel, final stops only.
The categories that participants would be asked to sort each word into were the eight phonemic oral stops of Kaqchikel. These categories were represented visually by an icon that corresponded to a word which began with the stop phoneme it was serving as a label for. I give these eight category label words in Table 5.

Table 5. Categorization task category label word associations.
In addition to categorizing words based on their initial and final stop consonants, participants also rated the goodness of each categorization. This rating was made on a scale with 5 discrete points. Ratings could be indicated by clicking a point on the scale or by pressing the corresponding number on the keyboard.
3.2.1.2. Equipment
The experiment was run on the same Dell Inspiron 13 7370 laptop computer for all participants. Participants listened to the stimuli at maximum volume through a pair of Sony MDRZX110 over-the-ear headphones wired to the laptop. The category and rating interface appeared on the laptop's display, allowing participants to indicate their responses using the laptop's track-pad or a wireless mouse connected to the laptop via Universal Serial Bus (USB) adapter. All equipment was wiped with rubbing alcohol before each participant used it.
3.2.2. Methods
The trilingual categorization and rating task was designed and blocked out using the PsychoPy software, which generated and ran Python code that presented stimuli to participants and recorded their responses in spreadsheet format. All participants completed the task during the summer of 2019, prior to the COVID-19 pandemic and any potential adjustments to methods that it would have forced.
Prior to any practice or testing trials, each participant was given unlimited time to familiarize themself with the experimental interface and category labels via a PowerPoint slide matching the interface they would see in test trials. This slide included clickable icons, each of which played an audio recording of the word associated with that icon. Each icon was a monochrome depiction of the meaning of its associated word. This training was necessary as the audio for each category label would not be playable during categorization trials. Therefore, participants would have to associate the initial stop of each category label word with the icons on the screen during this time.
The experiment was divided into two blocks, with 160 trials testing initial stops randomized within the first block, and 160 trials testing final stops randomized within the second block. Prior to each testing block, a screen displayed instructions for the task in both English and Spanish. Once participants read this screen and indicated they were ready, practice trials began. After completing four practice trials, which included a word from each of the three languages being studied, another screen reminding participants of their instructions was shown. Again, once participants read this screen and indicated they were ready, testing trials began.
For each trial an audio file of a word in either Kaqchikel, Spanish, or English played a single time. The categorization interface displayed eight black icons corresponding to the Kaqchikel stop category labels learned from the PowerPoint slide prior to the task. Once the participant clicked any of the icons, the screen would switch to the rating interface, where the participant would indicate how good of a match that word's stop was to the category they selected. There was no reminder of which categorization the participant made. Once the rating was confirmed, the next trial began. This repeated for all 160 test trials in the block. Between blocks there was a break. Once the participant indicated they were ready to continue, they saw a screen showing the instructions for the “Final” block, and the process was repeated focusing on the final stop of stimuli words. After they completed all trials, a final screen thanked the participant for their time. BN then debriefed the participant compensated for their time.
3.2.3. Measures
For each trial, every participant's response was recorded using the PsychoPy software. This included the Kaqchikel stop category selected as the best match for the played word's stop consonant (i.e., the categorization), the amount of time elapsed between the playing of the audio and the participant's categorization (Response Time, RT), the participant's rating of their categorization, and the amount of time elapsed between the initiation of the rating interface and the selection of the rating.
For the current analysis, rates of correct categorizations can also be calculated. These rates (or accuracy scores) could then be used to assess the accuracy of a participant's or group of participants' categorical perception of a given division of Kaqchikel's stop consonants: by Place feature, by Laryngeal feature, by word Position, or any combination of any of these three factors. Alternatively, for a logistic regression analysis, as is to be performed here, each response is coded as either correct (with a binary value of 1) or incorrect (0).
The category with the most selections for a given division of the sample (i.e., a listener, a language group, or the sample as a whole) for a given stimulus specification (i.e., a Kaqchikel stop phoneme with or without regard to its position in its word) was determined to be the modal categorization for that division for that stimulus specification. In the event that multiple categorizations are tied as a modal categorization, the categorization with the highest mean rating was determined to be the modal categorization. Modal categorizations can be used to compare different participants' or participant groups' performance on this task to each other.
When the categorization is done cross-linguistically, ratings show what types of assimilation or categorization scenario are occurring. Higher ratings indicate high category goodness, while lower ratings indicate low category goodness. Thus, even in the case where a learner selects the same category phoneme for multiple stimulus phones, relative goodness among their categorizations can be determined. Cross-language rating tasks of this type have been used in previous multilingual studies to show how multilinguals perceive sounds from both their known and target languages at different levels of similarity to sounds in one of those languages [e.g., a previously learned language in Wagner and Baker-Smemoe (2013) or the target language in Wrembel et al. (2019)].
The focus of the current analysis lies only on the accuracy of categorizations of Kaqchikel stops into Kaqchikel categories. I leave complete analysis of Categorizations and Response Times to future work [see Nelson (forthcoming)].
3.3. Other tasks
In addition to the categorization task, participants were asked to complete other tasks of perception and production. The first tasks all participants completed were production tasks. These tasks consisted of the reading of wordlists in all three languages of the study, Kaqchikel, Spanish, and English. The procedure for recording these wordlists matched the procedure for recording of the perception stimuli.
All participants also completed a language background questionnaire, responses of which informed the description of the participants in §3.1. Each participant completed this written questionnaire during a break in their AX Discrimination task. For all participants, the Categorization task described previously in this section was the final task completed as it was most revealing of the objective of the study as a whole: documenting perception and production of stop consonants in Kaqchikel, Spanish, and English.
4. Results
4.1. Raw accuracy results
Listeners were accurate in their categorization of Kaqchikel stimuli stops into Kaqchikel stop phoneme categories on 54.7% [, standard deviation (SD) = 29.8%] of all trials. For the NKS group, the overall accuracy rate was 68.1% (, SD = 20.6%). The learner groups had lower accuracy rates: NSS were correct on 40.2% (, SD = 18.0%) of trials, while NES were correct on 57.9% (, SD = 13.6%) of their trials. Note that performance at the level of chance is 12.5% accuracy, not 50%, as there are 8 potential categories, despite there only being two outcomes (correct or incorrect).8 Table 6 shows the accuracy of categorization for each group (as well as the standard deviations within each group) according to the levels of each of the factors Place, Laryngeal, and Position.
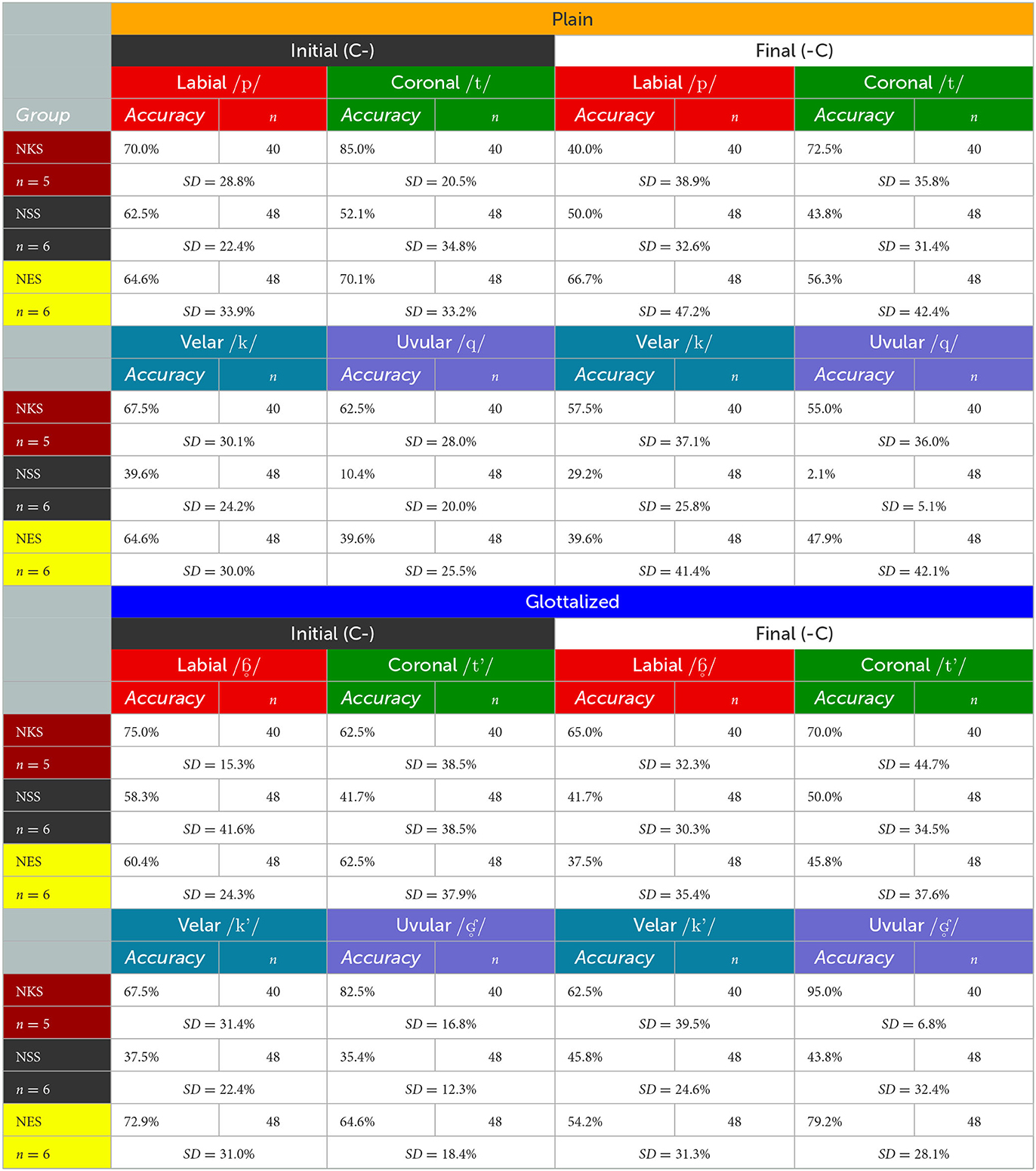
Table 6. Categorization accuracy by groups based on stop Laryngeal feature, position, and place of articulation.
When trials are divided by the Place of the stop being categorized, the Place with the highest accuracy across all listeners was coronal, followed by labial, velar, and then uvular. As for how each group performed relative to each Place, NKS were most accurate with uvulars, followed closely by coronals, velars, and then labials, while NSS were most accurate on labials, followed by coronals, velars, and then uvulars. NES were most accurate in categorizing coronals, followed very closely by the other three Places: velars and uvulars, and then labials.
Dividing trials by the Laryngeal feature of the stimulus stop, across all participants, plain stops were categorized correctly on 51.4% of trials (, SD = 22.9%). This was slightly lower than glottalized stops, which had an accuracy of 58.0% (SD = 20.2%). This pattern held for each of the three language Groups as well.
When Laryngeal and Place features are considered together, the phoneme whose stimuli were most accurately categorized correctly across all listeners was the glottalized uvular /ʛ ° / (65.4%, , SD = 23.8%). This was followed in order of decreasing accuracy by the plain coronal /t/, the plain labial /p/, the glottalized velar /k'/, the glottalized labial /ɓ ° /, the glottalized coronal /t'/, the plain velar /k/, and finally the plain uvular /q/ (34.9%, SD = 33.0%).
Based on the Position of the stimulus stop, initial stops, with an accuracy rate of 58.0% (, SD = 20.0%), were categorized correctly more often than final stops (51.4%, SD = 21.4%) across all listeners. This was true within each L1 Group as well.
Pulling all factors together and considering a stop's Place, Laryngeal, and Position in determining its accuracy of categorization (as in Table 6, initial stops were categorized with greater accuracy than final stops for every stop phoneme (i.e., Place + Laryngeal combination), except the glottalized uvular /ʛ ° /, which had greater accuracy in final Position than when in initial Position. NKS deviated from this overall pattern in categorizing final glottalized coronal /t'/ with greater accuracy than initial /t'/. NSS deviated from the overall pattern in categorizing three of the four glottalized stop phonemes with greater accuracy in final Position than in initial Position, adding /t'/ and /k'/ to /ʛ ° / in that regard. Finally, NES also deviate from the overall pattern by having greater accuracy in categorizing final stops than initial stops for /ɓ ° / and /q/, in addition to /ʛ ° /.
4.2. Multiple logistic regression analysis
4.2.1. Logistic mixed effects model
I analyzed the participant's ability to correctly categorize Kaqchikel stops into Kaqchikel categories under a logistic mixed effects model9. I fitted a logistic mixed model [estimated using the Bound Optimization B Quadratic Approximation (BOBYQA) optimizer on the Akaike Information Criterion (AIC)] in order to predict Correct categorizations based on Group, Place, Laryngeal, and Position factors. Included in this model were three interaction factors: one between listener Group and stimulus Place feature, one between Group and stimulus Laryngeal feature, and one between Place and Laryngeal features. I also included a single random effect caused by individual difference among Listeners.
The formula for the optimized model in the lme4 package's glmer() function was:
Correct ~ (1|Listener) + Group + Place +
Laryngeal + Position +
Group*Place + Group*Laryngeal +
Place*Laryngeal.
As indicated by its conditional R2 of 0.33, the model's total explanatory power is substantial. The fixed effects part of the model carries a marginal R2 of 0.18. The model's results are listed in Table 7. Note that the contrasts within factors were made using sum contrast coding, with estimates representing deviations from the mean. For convenience, I list the effect of each level of every factor. In the rightmost column, I also give the observed accuracy rate for the portion of the sample corresponding to each effect. These can be compared to the model's predicted probabilities, which I give in the following paragraphs.
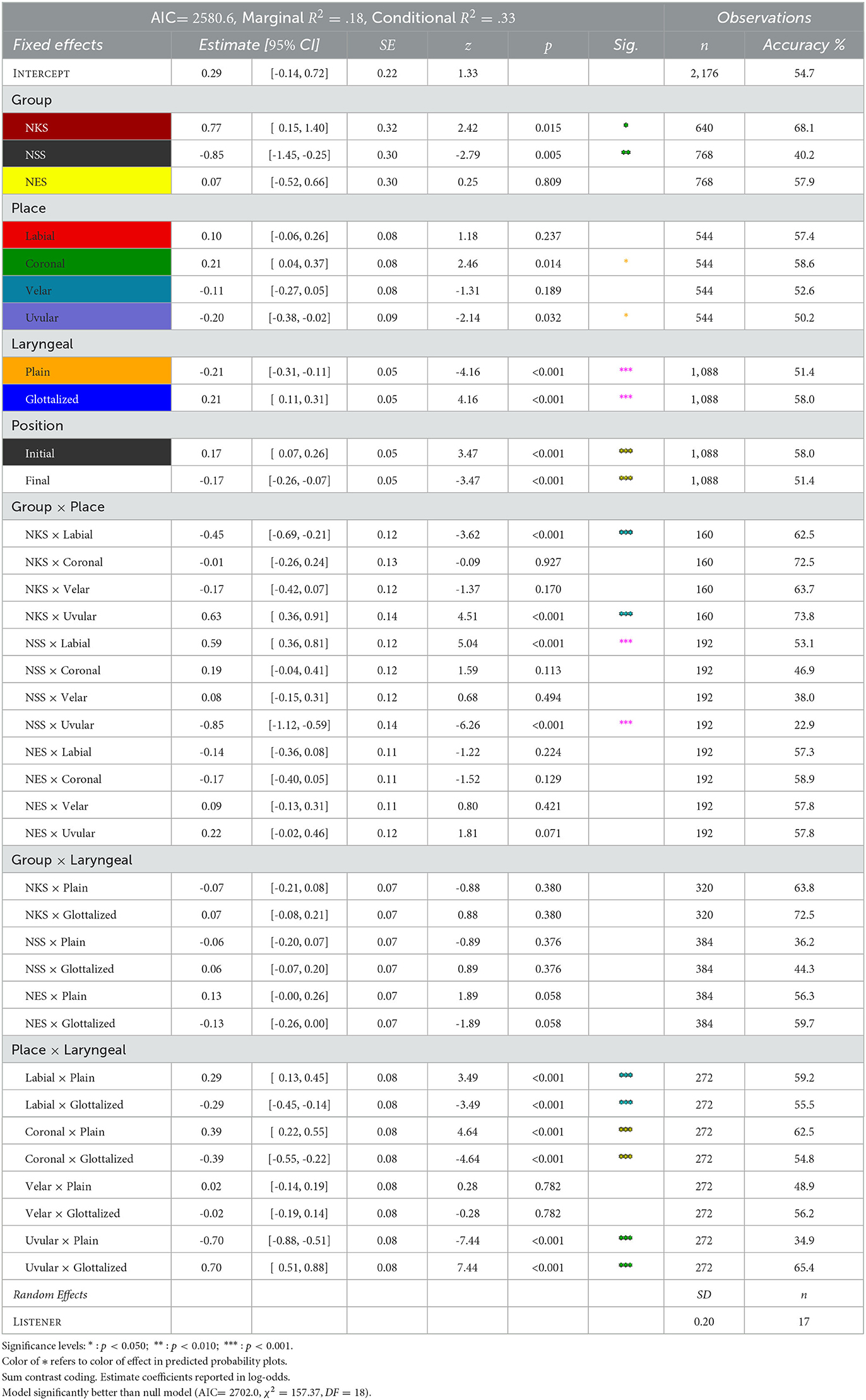
Table 7. Mixed effects logistic regression analysis of the factors' contribution to the probability of accurately categorizing a Kaqchikel stop. The rightmost columns give the number of observed that contributed to the model plus the accuracy rate of those observed trials.
The logistic regression analysis of this model reveals several significant effects among each of the factors as well as two of the three interaction terms. This indicates that the factors and those two interactions are meaningful predictors of correct categorization of Kaqchikel stops. Figure 4 shows the predicted probability of a Kaqchikel stop being correctly categorized based on the L1 of the listener, its Place features, its Laryngeal features, and its Position at the beginning or end of its word.
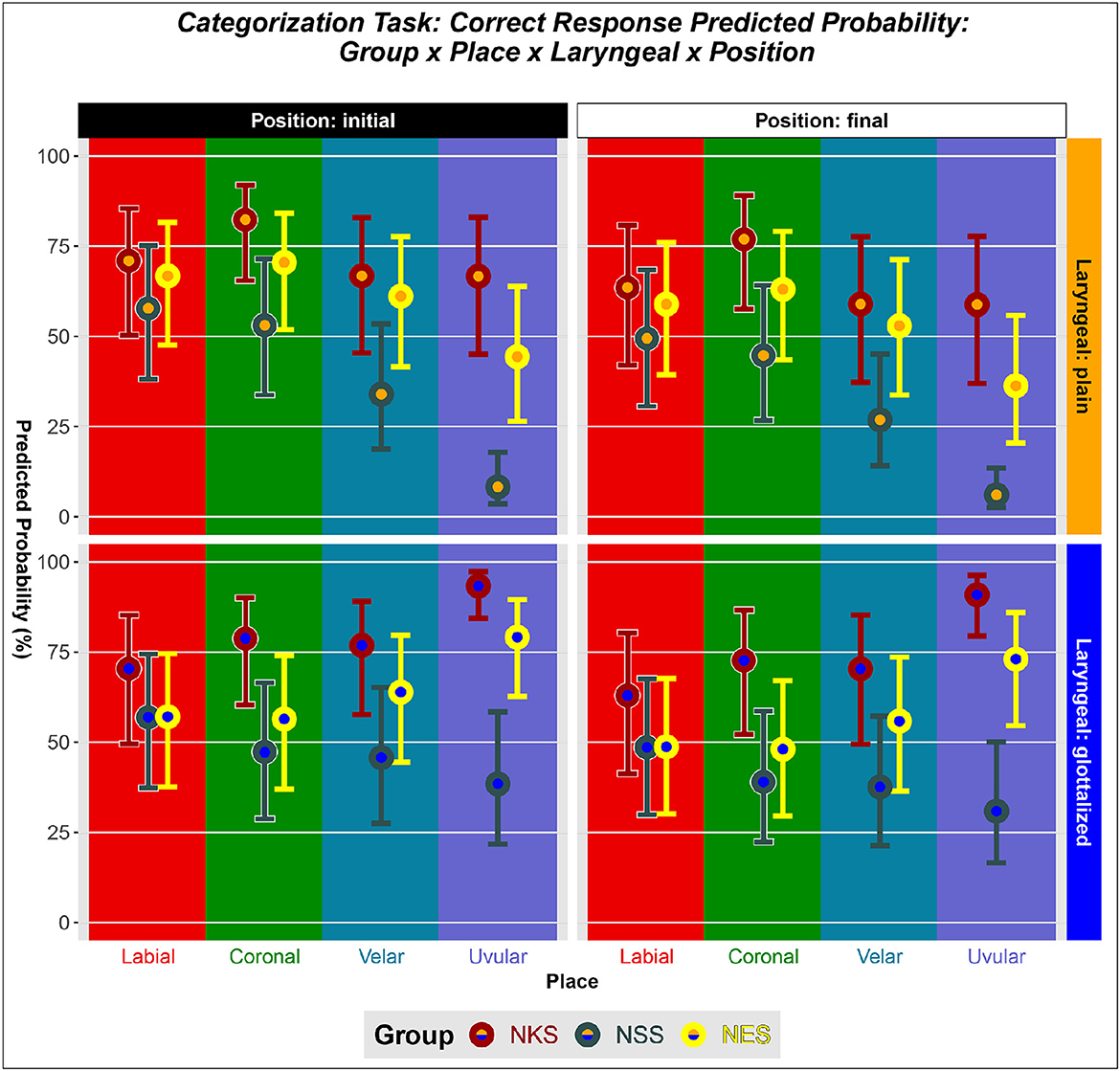
Figure 4. Predicted probability plot showing the model's predicted probability for each combination of the levels of Group, Place, Laryngeal, and Position.
4.2.2. Main effects
4.2.2.1. Group
Of the three listener Groups in the current study, the model reveals a significant effect of two of them. Unsurprisingly, NKS listeners are significantly more likely than average to provide a correct categorization of a Kaqchikel stop (β = 0.77, 95% CI: [0.15, 1.40];z = 2.42, p = 0.015). On the other hand, listeners of the NSS Group are significantly less likely to provide a correct categorization (β = −0.85, [−1.45, −0.25];z = −2.79, p = 0.005). The effect of a listener belonging to NES was found to be non-significant (β = 0.07, [−0.52, 0.66];z = 0.25, p = 0.809).
Figure 5A shows the predicted probability of a correct categorization10 for each Group. NKS has a predicted probability of 74% correct, NSS has 36%, and NES has 59%.
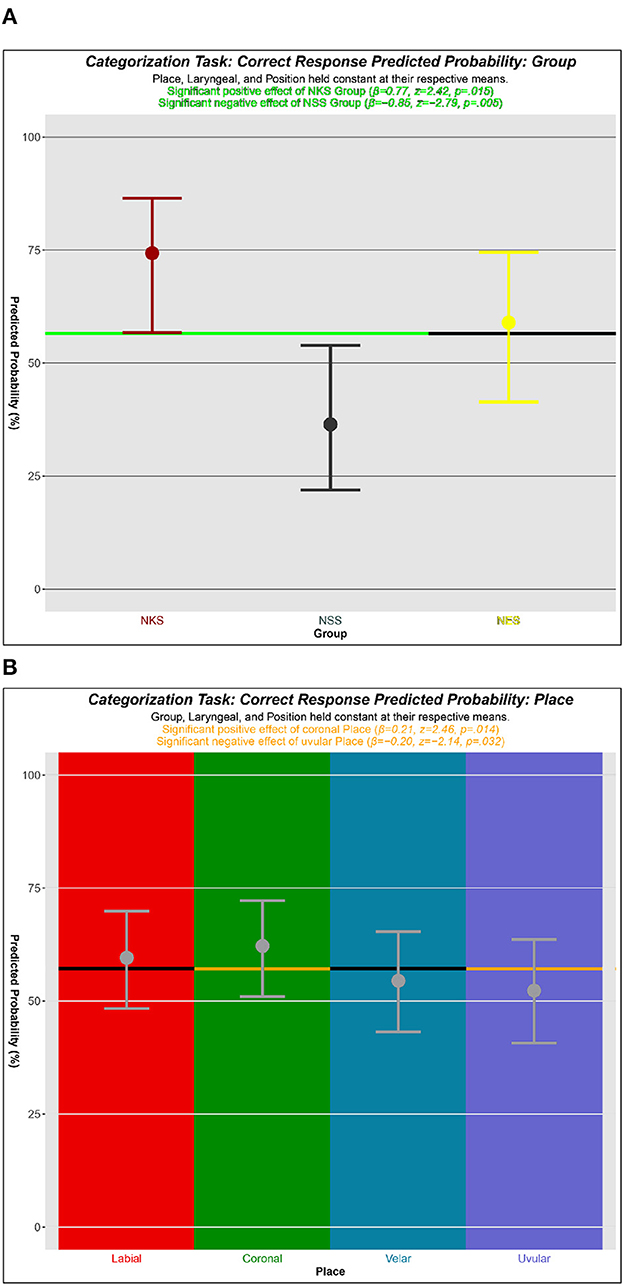
Figure 5. Probability plots for the Group and Place factors based on the mixed effects logistic regression analysis. The horizontal line in each represents the mean to which each level of Group or Place was compared. Blacked out sections of these lines indicate that there was not a significant effect of that section's Group or Place: (A) Group, (B) Place.
4.2.2.2. Place
Two of the four Places are significant predictors of categorization accuracy. Coronal stops are significantly more likely to be categorized correctly by Kaqchikel-Spanish-English multilingual listeners (β = 0.21, 95% CI: [0.04, 0.37];z = 2.46, p = 0.014), while uvular stops are significantly less likely to be accurately categorized (β = −0.20, [−0.38, −0.02];z = −2.14, p = 0.032). The effect of labial Place is non-significant but positive (β = 0.10, [−0.06, 0.26];z = 1.18, p = 0.237), while that of velar Place is non-significant but negative (β = −0.11, [−0.27, 0.05];z = −1.31, p = 0.189).
The predicted probabilities for a correct categorization of a stop from each of the four Kaqchikel Places are shown in Figure 5B. Listeners are predicted to correctly categorize labial stops 60% of the time, while the predicted probability for coronals is 62%, velars 54%, and uvulars 52%.
4.2.2.3. Laryngeal
As there are two series of stops based on a Laryngeal feature in Kaqchikel, a positive effect of a stop being in one series would be accompanied by an equivalent negative effect of a stop belong to the other series. In this case, the plain stops of Kaqchikel are significantly less likely to be correctly categorized (β = −0.21, 95% CI: [−0.31, −0.11];z = −4.16, p < 0.001), while glottalized stops are significantly more likely to be correctly categorized (β = 0.21, 95% CI: [0.11, 0.31];z = 4.16, p < 0.001).
Figure 6A shows the predicted probabilities of a listener providing a correct response for a stop in each of the two Laryngeal series of Kaqchikel. Listeners are predicted to be correct on 52% of plain stop trials, while for glottalized stop trials the predicted probability is 62%.
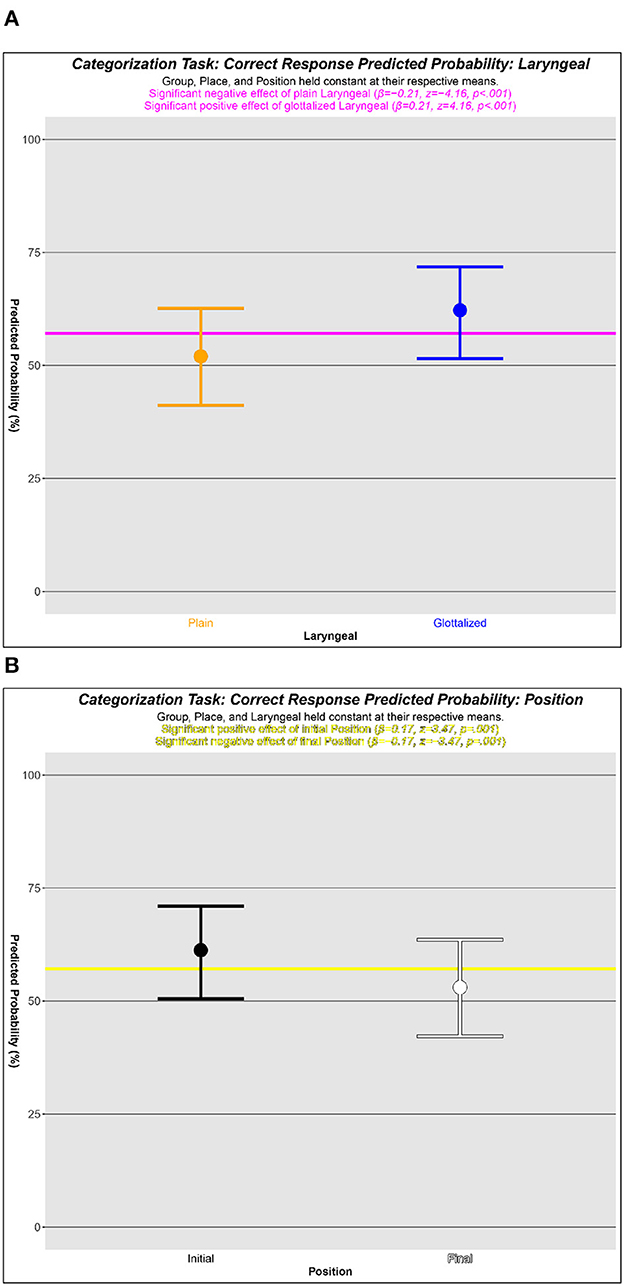
Figure 6. Probability plots for the Laryngeal and Position factors based on the mixed effects logistic regression analysis. The horizontal line in each represents the mean predicted probability to which each level of Laryngeal or Position was compared: (A) Laryngeal, (B) Position.
4.2.2.4. Position
Similar to the Laryngeal factor, the Position factor was measured at two levels, word-initial and word-final. As such, a positive effect of one Position is accompanied by an equivalent negative effect of the other. In the current model, initial Position has a significant positive effect on accurate stop categorization (β = 0.17, 95% CI: [0.07, 0.26];z = 3.47, p < 0.001), so final Position has a significant negative effect (β = 0.17, 95% CI: [−0.26, −0.07];z = −3.47, p < 0.001).
Figure 6B shows the predicted probabilities for correct categorization of a stop based on its word Position. The model predicts that listeners provide a correct categorization on 61% of initial stop trials, but only 53% of final stop trials.
4.2.3. Interactions
4.2.3.1. Group by place
For the two-way interaction term between listener Group and stimulus Place, the model shows significant effects at two of the four Places. At labial Place, there is a negative effect of NKS Group (β = −0.45, 95% CI: [−0.69, −0.21];z = −3.62, p < 0.001), accompanied by a positive effect of NSS Group (β = 0.59, [0.36, 0.81];z = 5.04, p < 0.001). At uvular Place, on the other hand, there is a positive effect of NKS (β = 0.63, [0.36, 0.91];z = 4.51, p < 0.001), with a negative effect of NSS (β = −0.85, [−1.12, −0.59];z = −6.26, p < 0.001). NES again has no significant effect, never differing significantly from the expected mean (p>0.071 at all three Places).
The predicted probability of a correct response for each Group × Place combination is shown in Figure 7. NKS listeners have a predicted probability of 67% correct for labials, 78% for coronals, 69% for velars, and 82% for uvulars. For NSS, these are 53% for labials, 46% for coronals, 36% for velars, and 17% for uvulars. For NES, the predicted probabilities are 58% for labials, 60% for coronals, 59% for velars, and 60% for uvulars.
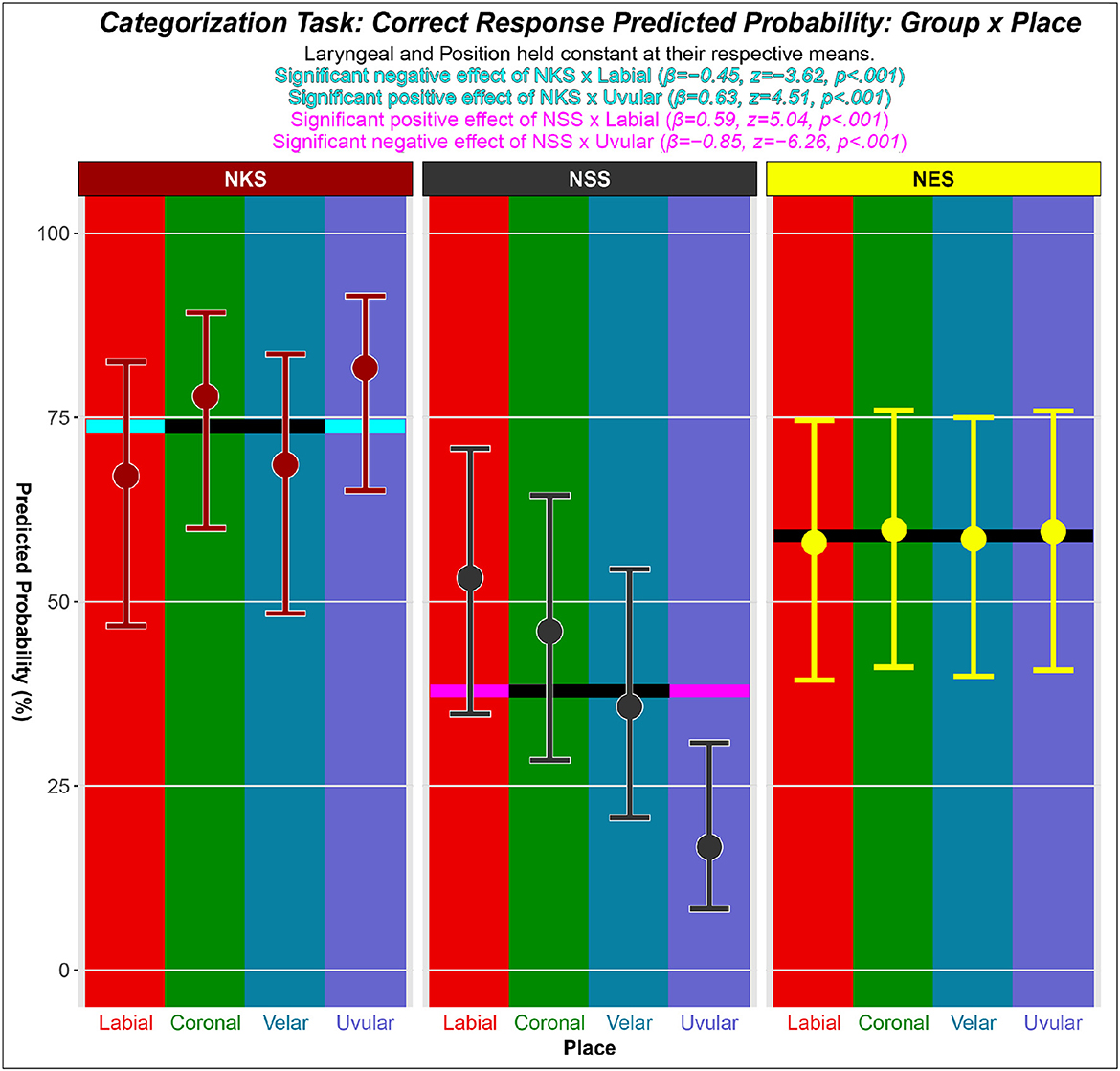
Figure 7. Probability plot for the Group by Place interaction based on the mixed effects logistic regression analysis. The horizontal line within each Group's plot represents that Group's mean predicted probability, to which each level of Place was compared. Blacked-out sections of these lines indicate that there was not a significant interaction for the respective levels of Group and Place.
4.2.3.2. Group by Laryngeal
The model shows that none of the two-way interactions between listener Group and stimulus Laryngeal are significant (p>0.058 for each). A listener from each Group is predicted to exhibit the main effects of their Group and of the stop's Laryngeal feature. Thus, NKS listeners have significantly higher than average accuracy, while NSS listeners have significantly lower than average accuracy, while they are significantly less likely than average to correctly categorize a Plain stop, but are significantly more likely than average to correctly categorize a Glottalized stop. For space considerations, I do not show the probability plot for this non-significant interaction term.
The predicted probability for a NKS listener to correctly categorize a plain stop is 69%, but 79% for a glottalized stop. NSS listeners are predicted to correctly categorize plain stops on 30% of trials, but for Glottalized stop trials this is 43%. NES listeners are predicted to correctly categorize 57% of plain stop trials and 61% of glottalized stop trials.
4.2.3.3. Place by Laryngeal
Finally, for the two-way interaction term between stimulus Place and Laryngeal features, the model shows significant effects of Laryngeal at three of the four levels of Place: labial, coronal, and uvular. Plain labials are more likely to be categorized correctly than average (β = 0.29, 95% CI: [0.13, 0.45];z = 3.49, p < 0.001) while glottalized labials are less likely (β = −0.29, 95% CI: [−0.45, −0.14];z = −3.49, p < 0.001). This is also true for coronals, with plain /t/ more likely to be categorized correctly (β = 0.39, [0.22, 0.55];z = 4.64, p < 0.001) and glottalized /t'/ less likely (β = −0.39, [−0.55, −0.22];z = −4.64, p < 0.001). However, plain uvulars are less likely to be categorized correctly (β = −0.70, [−0.88, −0.51];z = −7.44, p < 0.001), but glottalized uvulars more likely (β = 0.70, [0.51, 0.88];z = 7.44, p < 0.001). Velar accuracy does not significantly differ from its predicted mean for either of its two Laryngeal specifications (z = ±0.28, p = 0.782).
Figure 8 shows the predicted probability of a correct response for each Place × Laryngeal combination. The predicted probability of a correct response for plain labials is 61%, but for glottalized labials it is 58%. For plain coronals this predicted probability is 66%, compared to glottalized coronals' 58%. For plain velars, the predicted probability of a correct categorization is 50%, while for glottalized velars it is 59%. Finally, the plain uvular predicted probability of a correct categorizations is 31%, but for glottalized uvulars it is 73%.
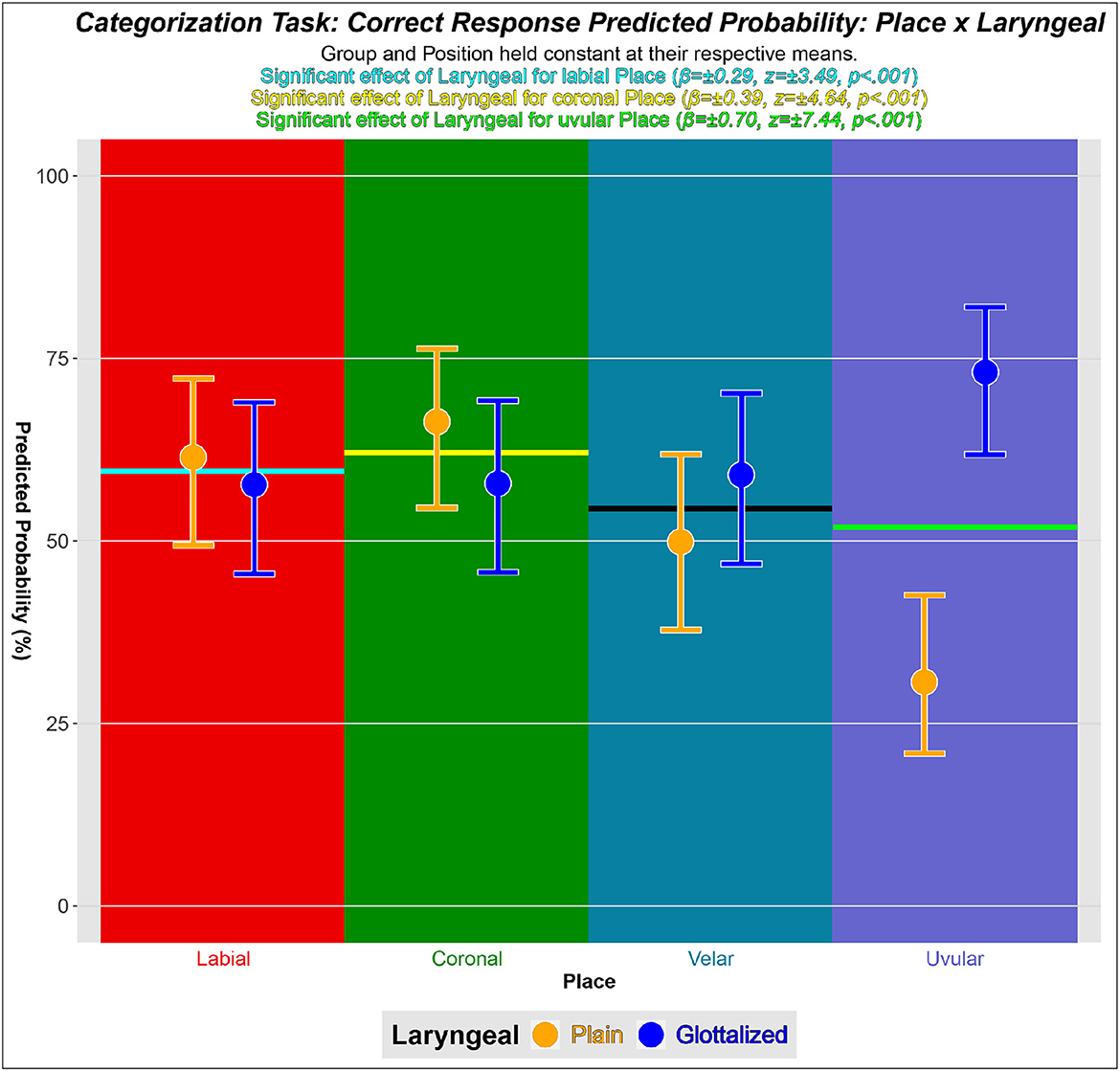
Figure 8. Probability plot for the Place by Laryngeal interaction based on the mixed effects logistic regression analysis. The horizontal line within each Place's plot represents that Place's mean predicted probability, to which each level of Laryngeal was compared. Blacked out sections indicate that there was no significant interaction for the respective levels of Place and Laryngeal.
5. Discussion
5.1. Significance
5.1.1. Research answers
Answering the research questions in §2.4, the results indicate that:
1. L1 Spanish, L2 English multilinguals differ from their L1 English, L2 Spanish counterparts in their ability to correctly categorize some of Kaqchikel's stop consonants.
2. L1 English appears privileged, as when differences were significant, L1 English, L2 Spanish multilinguals are more accurate than L1 Spanish, L2 English multilinguals.
3. The difference is limited to the Place contrast, and specifically the categorization of uvulars.
4. Positional differences are minimal, but not insignificant. Closer investigation of the effects of positional allophony on both L1 and learners' categorization accuracy is warranted.
5.1.2. Group differences
In the mixed effects logistic regression model there is a significant interaction between the L1 Group and the Place of the stimulus stop on accuracy. Specifically, NSS accuracy is significantly lower for uvulars compared to both other L1 Groups. NSS do particularly well at categorizing labials, as there is a significant positive interaction between NSS and labial Place, showing they aren't failing the task outright. They are simply poor at categorizing uvulars.
Meanwhile, the NES group never differ significantly from predicted mean accuracy. They are not involved in any significant Group by Place interaction effects. Their predicted accuracy is always well above chance, and always lies between NKS above them and NSS below them. However, the difference between NES and NSS predicted probabilities is significant only at uvular Place.
5.1.3. Uvular categorization
Examining the NSS group's uvular categorizations, the proximity to floor performance (in terms of both observed accuracy and predicted probability), especially with plain uvulars, is a major contributor to this effect. In short, NSS listeners are much less able to identify and categorize /q/ than are the other two groups. I did not predict greater confusion, and therefore difficulty, for either learner group compared to the other for any Place of articulation. I had made this prediction because the relevant Place specifications are virtually identical in Spanish and English. Both systems exhibit a three-way contrast between bilabials, coronals, and velars. Neither system seemed to provide an advantage (or disadvantage) over the other if it was selected for transfer into the L3 system. Therefore, the current results showing such a difference between learner groups would seem quite surprising. However, the patterns observed here need not be so surprising!
Phonological redeployment, as discussed in §2.1, is the L2A process proposed by Archibald (2005) by which learners of a language utilize components of phonological knowledge to account for differences between their known language and their target language. I did predict that NES would be able to redeploy their Laryngeal feature [spread glottis] or potential non-contrastive uses of [constricted glottis] to account for Kaqchikel's Laryngeal distinction. While that result is not as apparent, there is still a potential case of redeployment at play in the present results, specifically in the differences in uvular categorization. While there is no major difference in the Place features of stop consonants in Spanish and English, English does use more distinctive phonological features to specify its vowels than Spanish uses for its vocalic inventory.
Spanish requires fewer features to specify its vowels than does English. Those features are [±high], [±back], and [±low]. English, on the other hand, requires more features, adding [±round] and [±tense]. [±tense] behaves remarkably similar to [±ATR] cross-linguistically, especially in regards to vocalic specification (Beltzung et al., 2015). Thus, if [±tense] and [±ATR] make equivalent specifications, and [±ATR] has an inverse feature in [±RTR], then a relationship between [±tense] and [±RTR] exists. This relationship allows for redeployment of the English vocalic feature in specifying Kaqchikel dorsal stops, which are specified by [±RTR]: velars with [−RTR] and uvulars with [+RTR] (Davis, 1995; Shahin, 2002). Analyses of English that attribute its tense–lax distinction directly to the critical feature [±RTR], such as Brown and Golston (2006), avoid the need to establish any analogical relationships between [±tense], [±ATR], and [±RTR]. Representation matters!
Based on the differences in their self-assessment of English speaking skills (Table 2), I assume that these NES learners have more solidified knowledge of English phonology than the NSS learners. I therefore propose that multilingual NES are more likely to redeploy English phonological features than multilingual NSS are. Specifically, this involves taking the vocalic feature used to specify the distinction between tense and lax vowels, whether it be [±tense], or one of the related tongue root features [±ATR] and [±RTR], which they may already be using in specifying the tense–lax contrast of Kaqchikel, and applying it to the novel consonantal contrast between velars and uvulars.
5.1.4. Laryngeal categorization
Shifting the lens of analysis to the laryngeal contrast, the main effect of Laryngeal suggests there is a difference in how listeners, regardless of their L1, categorize plain versus glottalized stops in Kaqchikel. Against my prediction, there is no evidence that either learner Group used knowledge of allophonic glottalized stops in English more than the other Group in their categorization of Kaqchikel glottalized stops. Based on the theory of phonological redeployment in Archibald (2022), this is unsurprising: that would be learners redeploying phonetic rather than phonological knowledge.
However, the significant interaction effects between Place and Laryngeal, particularly as visualized in Figure 8, shows that a primary contributor to higher accuracy of categorizing glottalized stops (both predicted and observed) is the extremely high accuracy of categorizing glottalized uvular stops. A likely explanation for this is the relatively robust acoustic cues associated with the release burst of the uvular implosive /ʛ/ ° . As explained by González Poot (2014) and Archibald (2023), such robust cues help the learners notice, and then better account for, contrasts for which they lack explicit phonological knowledge.
5.1.5. Position-dependent cues
Once more, I return to the modest, but significant effect of Position on Kaqchikel stop categorization. The model predicts slightly higher accuracy for categorization of stops in initial position relative to stops in final position, as visualized in Figures 4, 6B. Again, I refer to Archibald (2005), González Poot (2014), and Archibald (2023), who also predicted that onset stops (including initials) would have more robust cues than coda stops (including finals). That prediction is borne out here.
Flege and Bohn (2021) presented a revised version of Flege (1995) SLM, with many changes to its scope, methods of analysis, and predictions. Although phonetic categories and learning remains its focus, the revised SLM de-emphasized effects directly related to the listener's age. Instead they keep open the possibility for continuous learning across the learner's life-span, including re-weighting of perceptual cues, just as Archibald (2023) would later suggest as a primary language learning task along the journey to adequate phonological representations.
5.1.6. Toward an integrated model of L3A
Finally, Rothman (2011, 2015) Typological Primacy Model offers a potential alternative explanation for these results, with a caveat. Under that model, the learner transfers one of their known language systems to serve as the initial state of L3A. After this initial state, additional L3 experience could lead the learner to adjust their L3 interlanguage via cross-linguistic influence (González Alonso and Rothman, 2017; Rothman et al., 2019), potentially via redeployment.
If a learner of Kaqchikel, and perhaps these NSS learners, had selected Spanish, with its relatively few vocalic features, redeployment of [tense]/[RTR] would not be an option. Only after they adjust their interlanguage to allow for the influence of English and its [tense]/[RTR] feature would they then be able to redeploy that feature in optimally mapping both the tense–lax and velar–uvular distinctions of Kaqchikel. However, as these learners are not at the initial stage of their L3A, the source of transfer cannot be determined here and is therefore left to future work that analyzes learners closer to, or at, the initial stage of Kaqchikel L3A.
The main limitations to the results I have presented here are related to this inability to determine the source of initial transfer. These learners represent a very particular subset of learners of Kaqchikel. In order to build the best picture of L3A, both generally and of Kaqchikel, the effects observed here should be investigated in other subsets of learners [a methodological concern going back to at least Cabrelli Amaro (2013a)]. Additionally, as noted by a reviewer, the phonological status of the tense–lax distinction among these NSS is not probed here. This is a notorious learning problem for L1 Spanish learners of L2 English [examined, e.g., in Escudero (2005)]. If a NSS has not acquired this English contrast, then it logically follows that its underlying feature is unavailable for redeployment in L3 Kaqchikel.
5.2. Conclusion
In this study, I examined a case of L3A, in which multilingual learners already familiar with English and Spanish are learning Kaqchikel, a Mayan language of Guatemala. The phonological structures of primary interest were the stop consonants, particularly the glottalization contrast and the distinction of a uvular/post-velar PoA.
Learners, which were grouped based on which of the two known languages was their L1, as well as a comparison group of multilingual L1 Kaqchikel users, completed a audio perception task in which they categorized Kaqchikel's stop consonants into the eight phonemic categories of Kaqchikel. All listeners performed well above chance. However, several effects emerged in their performance on this task. One of these effects was an interaction between L1 Group and Place of articulation: NSS listeners were less accurate in categorizing uvulars than both NES and NKS, indicating they had not yet formed the category of uvular PoA and were unable to contrast them with other places, and particularly velars.
I propose that NES listeners were more accurate than NSS due to having relatively easier access to knowledge of English phonology, which contains more material that can be redeployed when learning an additional language's phonology, and in this case Kaqchikel's. The key feature that the NES listeners have better access to is the vocalic feature [±tense], or alternatively [±RTR] or [±ATR]. Whatever this feature is, its status as a distinctive feature among English vowels allows it to be redeployed to capture the novel category of Kaqchikel uvular stops. NES learners of Kaqchikel redeployed an English feature specific to vowels in order to capture a Place contrast among Kaqchikel stops. NSS learners, on the other hand, do not appear to be able to do this yet.
However, hope is not lost for L1 Spanish L2 English learners of L3 Kaqchikel, or of any order of language learning between these languages or languages with similar distinctions across them. NES appear able to redeploy English's vocalic feature thanks in part to English being their L1, with better access to its underlying phonology. Nevertheless, these NSS learners should still have access to phonological knowledge of English. It may simply be just a matter of time and practice with L2 English and L3 Kaqchikel before they too make the connections between English lax vowels and Kaqchikel lax vowels and uvular stops already made by their NES counterparts. Thus phonological redeployment, in the L3A context, is a tool available for all to use in language learning, and not one restricted to those who happen to have a L1 with more phonological material available to be redeployed in a given L3A scenario.
5.3. Resource identification initiative
The following resources were used in the creation and presentation of experimental materials or the analysis and visualization of experimental results:
• Adobe Photoshop (RRID:SCR_014199)
• Overleaf (RRID:SCR_003232)
• Praat (RRID:SCR_016564)
• PsychoPy (RRID:SCR_006571)
• Python Programming Language (RRID:SCR_008394)
• R Project for Statistical Computing (RRID:SCR_001905)
• R package: Companion to Applied Regression (RRID:SCR_022137)
• R package: dplyr (RRID:SCR_016708)
• R package: ggeffects (RRID:SCR_022496)
• R package: ggplot2 (RRID:SCR_014601)
• R package: Harrell Miscellaneous (RRID:SCR_022497)
• R package: lme4 (RRID:SCR_015654)
• R package: Regression Modeling Strategies (RRID:SCR_023242)
• R package: tidyverse (RRID:SCR_019186)
Data availability statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: Open Science Framework (osf.io): https://osf.io/r7kz8 (NKS); https://osf.io/aqsnu (NSS); https://osf.io/vw56h (NES).
Ethics statement
The studies involving humans were approved by Conjoint Faculties Research Ethics Board, University of Calgary. The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
Author contributions
BN: Conceptualization, Data curation, Formal analysis, Funding acquisition, Investigation, Methodology, Project administration, Resources, Software, Visualization, Writing—original draft, Writing—review & editing.
Funding
Funding for travel, lodging, and compensation of participants was provided personally by BN. Additional reimbursements were made by the institutional/university funding of BN's supervisor, Dr. Darin Flynn.
Acknowledgments
Many sincere thanks go out to associated members of the School of Languages, Linguistics, Literatures and Cultures at the University of Calgary. I offer special thanks to my doctoral thesis supervisor, Dr. Darin Flynn, and members of my thesis committee, Dr. Mary Grantham O'Brien and Dr. Angeliki Athanasopoulou, for aiding in the conception and analysis of the current study. I appreciate Dr. Allison Shapp's helpful second opinion on phonetic transcription. I am grateful to two reviewers for their extremely helpful feedback on how best to describe, analyze, and explain these observations.
Territorial acknowledgments
Different parts of this research took place on the traditional territories of many different Indigenous peoples: some taken by force, some taken by treaty, and some not conceded. These traditional territories include those of the Kaqchikel Maya of the central highlands of southern Iximulew (Guatemala); the Chitimacha, Choctaw, and Houma people of Bulbancha (Southern Louisiana); and the peoples of Treaty 7 territory in Southern Alberta, where most of the analysis of the current research took place. Treaty 7 peoples include the Blackfoot Confederacy (composed of the Siksika, Piikani, and Kainai First Nations), the Tsuut'ina First Nation, and the Stoney Nakoda, which includes the Chiniki, Bearspaw, and Goodstoney First Nations. Métis Nation of Alberta, Region III also has ties to the land upon which the City of Calgary now sits. The University of Calgary, within the City of Calgary, stands near the land where the Bow and Elbow Rivers meet. The Blackfoot name for this place is Mohkinstsis, the Stoney Nakoda call it Wîchîspa, and the Tsuut'ina refer to it as Guts'ists'i.
Conflict of interest
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Abbreviations
AIC, Akaike information criterion; [±ATR], [±advanced tongue root] phonological feature; AoL, age of learning; β, regression coefficient (standardized); C, consonant; cak, Kaqchikel (ISO 639-3 code); CI, confidence interval; DF, degrees of freedom; eng, English (ISO 639-3 code); F, female; L1, first language; L1A, first language acquisition; L2, second language; L2A, second language acquisition; L2LP, Second Language Linguistic Perception Model (Escudero, 2005); L3, third language; L3A, third language acquisition; M, male; n, sample size; NES, native (L1) English speakers; NKS, native (L1) Kaqchikel speakers; NSS, native (L1) Spanish speakers; p, probability value; PAM, Perceptual Assimilation Model (Best, 1995); PAM-L2, Perceptual Assimilation Model–Second Language (Best and Tyler, 2007); PPH, Phonological Permeability Hypothesis (Cabrelli Amaro, 2013b); R2, coefficient of determination; [±RTR], [±retracted tongue root] phonological feature; SD, standard deviation; SE, standard error; Sig., Significance level; SLM, Speech Learning Model (Flege, 1995); spa, Spanish (ISO 639-3 code); V, vowel; χ2, chi-squared statistic; z, standard score (for Wald test).
Footnotes
1. ^This study constitutes a part of a larger study investigating the acquisition of the Place and Laryngeal contrasts of Kaqchikel stops in various syllabic and word Positions by Spanish-English multilingual learners. The other parts of this study are briefly discussed in §3.3.
2. ^SLM was later revised in Flege and Bohn (2021). Though not immediately relevant here, I return to this in §5.1.5.
3. ^Alternatively called Standard Chinese, as a specific standardized variety of Mandarin. For consistency, I refer to this language as Mandarin, as Brown (2000) and later Yang et al. (2022) do.
4. ^The status of [±voice] as a distinctive feature in Mandarin /ʂ/ and /ʑ/ is not straightforward, however. Duanmu (2007) and Lin (2007), both cited in Yang et al. (2022), offered differing accounts of the contrast. Lin (2007) transcribed Yang et al. (2022)'s /ʑ/ as /r/, describing it as a voiced approximant, and later a liquid sonorant that “tends to become a voiced fricative”(47). Duanmu (2007) transcribes this segment as /ʑ/, but did not definitively describe its distinction from /ʂ/ as one of voicing, but rather of aspiration (24). Thus, I arrive at the same conclusion as Archibald (2023): there is no solid motivation for the distinctive status of [±voice] in Mandarin.
5. ^Evidence for this perhaps unintuitive specification comes from a vowel harmony process in which the vowel of a verbal suffix /-Vʔ/ matches the [±back] specification of the vowel of the verb root /CVC/ but the suffix's vowel is always [+round] and [+tense]: /i ɪ e ɛ a ə/ harmonize to /a/, while /o ɔ/ harmonize to /o/ and /u ʊ/ harmonize to /u/ (Brown et al., 2006, p. 172). An alternative analysis would have the central vowels specified [+back] and [−round] with this process matching the [±round] specification of the root vowel and instead requiring [+back] and [+tense] in the suffix. Given the phonetic variability of /ə/ that allows for fronted [e], raised [ɨ], and rounded [ʌ] (Patal Majzul et al., 2000), I analyze the central vowels as [+round] rather than [+back]. This choice has no direct implications on the current study.
6. ^Affricates, which fall outside the scope of the current analysis due to their articulatory complexity, also show this contrast.
7. ^See Nelson (2023) for a detailed discussion and analysis of aspiration and related word-final processes in Kaqchikel.
8. ^Accuracy of classification could be analyzed at a featural level, with one accuracy score for choosing a category that shares its Place with the correct phoneme and one score for choosing a category that shares its Laryngeal feature with the correct phoneme. I do not make that level of analysis here.
9. ^I had initially analyzed these data under mixed Analysis of Variance design. At the urging of a reviewer, I analyzed the data using this model design.
10. ^, where Prob is the predicted probability, e is Euler's number, and β is a coefficient of the model.
References
Abo-Mokh, N., and Davis, S. (2020). “What triggers 'imāla: Focus on a Palestinian variety with phonological analysis,” in Perspectives on Arabic Linguistics XXXII, ed. E. van Gelderen (John Benjamins), 35–53. doi: 10.1075/sal.9.02abo
Archibald, J. (2005). Second language phonology as redeployment of L1 phonological knowledge. Canad. J. Ling. 50, 285–314. doi: 10.1353/cjl.2007.0000
Archibald, J. (2022). Segmental and prosodic evidence for property-by-property transfer in L3 English in northern Africa. Languages 7, 1–20. doi: 10.3390/languages7010028
Archibald, J. (2023). Phonological redeployment and the mapping problem: cross-linguistic e-similarity is the beginning of the story, not the end. Second Lang. Res. 39, 287–297. doi: 10.1177/02676583211066413
Bardel, C., and Falk, Y. (2007). The role of the second language in third language acquisition: the case of Germanic syntax. Second Lang. Res. 23, 459–484. doi: 10.1177/0267658307080557
Barrios, S., Jiang, N., and Idsardi, W. J. (2016). Similarity in L2 Phonology: evidence from L1 Spanish late-learners' perception and lexical representation of English vowel contrasts. Second Lang. Res. 32, 367–395. doi: 10.1177/0267658316630784
Beltzung, J.-M., Patin, C., and Clements, G. N. (2015). “The feature [atr],” in Features in Phonology and Phonetics: Posthumous Writings by Nick Clements and Coauthors, eds. A. Riallan, R. Ridouane, and H. van der Hulst (Berlin: Walter de Gruyter), 217–246. doi: 10.1515/9783110399981-011
Benrabah, M. (1991). “Learning English segments with two languages,” in Proceedings of the International Congress of Phonetic Sciences, ed. P. Romeas (Aix-en-Provence: Université de Aix-en-Provence), 334–337.
Best, C. T. (1995). “A direct realist view of cross-language speech perception,” in Speech Perception and Linguistic Experience: Issues in Cross Language Research, ed. W. Strange (York: York Press), 171–204.
Best, C. T., and Tyler, M. D. (2007). “Nonnative and second-language speech perception: Commonalities and complementaries,” in Second-language Speech Learning: The Role of Language Experience in Speech Perception and Production. A Festschrift in Honour of James E. Flege, eds. O.-S. Bohn, and M. J. Munro (Amsterdam: John Benjamins), 13–34. doi: 10.1075/lllt.17.07bes
Brown, C. A. (1997). Acquisition of segmental structure: consequences for speech perception and Second Language Acquisition. PhD thesis, McGill University.
Brown, C. A. (1998). The role of L1 grammar in the L2 acquisition of segmental structure. Second Lang. Res. 14, 136–193. doi: 10.1191/026765898669508401
Brown, C. A. (2000). “The interrelation between speech perception and phonological acquisition: from infant to adult,” in Second Language Acquisition and Linguistic Theory, ed. J. Archibald (Oxford: Blackwell), 4–63.
Brown, J. C., and Golston, C. (2006). Embedded structure and the evolution of phonology. Inter. Stud. 7, 17–41. doi: 10.1075/is.7.1.03bro
Brown, R. M., Maxwell, J. M., and Little, W. E. (2006). La ütz awäch? Introduction to Kaqchikel Maya Language. Austin, TX: University of Austin Press.
Cabrelli Amaro, J. (2013a). Methodological issues in L3 phonology. Stud. Hispan. Lusophone Ling. 6, 101–117. doi: 10.1515/shll-2013-1142
Cabrelli Amaro, J. (2013b). The phonological permeability hypothesis: measuring regressive L3 influence to test L1 and L2 phonological representations. PhD thesis, University of Florida.
Cabrelli Amaro, J. (2017). Testing the phonological permeability hypothesis: L3 phonological effects on L1 versus L2 systems. Int. J. Bilingual. 21, 698–717. doi: 10.1177/1367006916637287
Cabrelli Amaro, J., and Rothman, J. (2010). On L3 acquisition and phonological permeability: A new test case for debates on the mental representation of non-native phonological systems. IRAL 48, 275–296. doi: 10.1515/iral.2010.012
Clements, G. N. (1985). The geometry of phonological features. Phonol. Yearb. 2, 225–252. doi: 10.1017/S0952675700000440
Clements, G. N., and Hume, E. (1995). “The internal organization of speech sounds,” in Handbook of Phonological Theory, ed. J. Goldsmith (Oxford: Blackwell), 245–306.
Dresher, B. E. (2009). The Contrastive Hierarchy in Phonology. Cambridge: Cambridge University Press. doi: 10.1017/CBO9780511642005
Eckman, F. R. (1977). Markedness and the contrastive analysis hypothesis. Lang. Learn. 27, 315–330. doi: 10.1111/j.1467-1770.1977.tb00124.x
Escudero, P. (2005). Linguistic perception and second language acquisition: explaining the attainment of optimal phonological categorization. PhD thesis, Utrecht University.
Flege, J. E. (1995). “Second language speech learning: Theory, findings, and problems,” in Speech Perception and Linguistic Experience: Issues in Cross Language Research, W. Strange (York: York Press), 233–277.
Flege, J. E., and Bohn, O.-S. (2021). “The revised speech learning model (SLM-r),” in Second Language Speech Learning: Theoretical and Empirical Progress, ed. R. Wayland (Cambridge: Cambridge University Press), 3–83. doi: 10.1017/9781108886901.002
Ghazali, S., and Bouchhioua, N. (2003). “The learning of English prosodic structures by speakers of Tunisian Arabic: Word stress and weak forms,” in 15th International Conference on Phonetic Sciences 961–964.
González Alonso, J., and Rothman, J. (2017). Coming of age in L3 initial stages transfer models: deriving developmental predictions and looking towards the future. Int. J. Biling. 21, 683–697. doi: 10.1177/1367006916649265
González Poot, A. A. (2011). Conflict resolution in the Spanish SLA of Yucatec ejectives: L1, L2 and universal constraints. PhD thesis, University of Calgary.
González Poot, A. A. (2014). “Conflict resolution in the Spanish L2 acquisition of Yucatec ejectives: L1, L2 and universal constraints,” in Proceedings of the 2014 annual conference of the Canadian Linguistic Association/ Actes du congrés de l'Association canadienne de linguistique 2014 1–15.
Halle, M., Vaux, B., and Wolfe, A. (2000). On feature spreading and the representation of place of articulation. Ling. Inquiry 31, 387–444. doi: 10.1162/002438900554398
Hammarberg, B. (2001). Roles of L1 and L2 in L3 production and acquisition,” in Cross-Linguistic Influence in Third Language Acquisition, eds. J. Cenoz, B. Hufeisen, and U. Jessner (Bristol, UK: Multilingual Matters), 21–41. doi: 10.21832/9781853595509-003
Hayward, K. M., and Hayward, R. J. (1989). “Guttural”: Arguments for a new distinctive feature. Transact. Philol. Soc. 87, 179–193. doi: 10.1111/j.1467-968X.1989.tb00626.x
Heaton, R., and Xoyón, I. (2016). Assessing language acquisition in the Kaqchikel program at Nimaläj Kaqchikel Amaq'. Lang. Document. Conserv. 10, 497–521.
Honeybone, P. (2001). Germanic obstruet lenition: some mutual implications of theoretical and historical phonology. PhD thesis, University of Newcastle upon Tyne.
Iverson, G. K., and Salmons, J. C. (1995). Aspiration and laryngeal representation in germanic. Phonology 12, 369–396. doi: 10.1017/S0952675700002566
Jakobson, R. (1962). “Mufaxxama: The “emphatic” phonemes in Arabic,” in Phonological Studies, Selected Writings, ed. R. Jakobson (Clearwater, FL: Mouton and Co.), 510–522.
Kim, H., and Clements, G. N. (2015). “The feature [tense],” in Features in Phonology and Phonetics: Posthumous Writings by Nick Clements and Coauthors, eds. A. Riallan, R. Ridouane, and H. van der Hulst (Berlin: Walter de Gruyter), 159–178. doi: 10.1515/9783110399981-008
LaCharité, D., and Pré vost, P. (1999). “The role of L1 and of teaching in the acquisition of English sounds by francophones,” in BUCLD 23 Proceedings, eds. A. Greenhill, H. Littlefield, and C. Tano (Somerville, MA: Cascadilla Press), 373–385.
Ladefoged, P. (1971). Preliminaries to Linguistic Phonetics. Chicago, IL: University of Chicago Press.
Ladefoged, P., and Johnson, K. (2015). A Course in Phonetics. 7th edition. Boston, MA: Cengage Learning.
Lado, R. (1957). Linguistics Across Cultures: Applied Linguistics for Language Teachers. Ann Arbor, MI: University of Michigan Press.
Mah, J. (2003). The acquisition of phonological features in a second language. Master's thesis, University of Calgary.
Mah, J. (2011). Segmental representations in interlanguage grammars: the case of francophones and English /h/. PhD thesis, McGill University.
Mah, J., Goad, H., and Steinhauer, K. (2016). Using event-related brain potentials to assess perceptibility: The case of French speakers and English [h]. Front. Psychol. 7, 1469. doi: 10.3389/fpsyg.2016.01469
Maxwell, J. M., and Little, W. E. (2006). Tijonïk Kaqchikel Oxlajuj Aj: Curso de Idioma y Cultura Maya Kaqchikel [Kaqchikel Maya Language and Culture Course]. Editorial Junajpu.
McCarthy, J. J. (1994). “The phonetics and phonology of Semitic pharyngeals,” in Phonological Structure and Phonetic Form, Papers in Laboratory Phonology III, ed. P. A. Keating (Cambridge: Cambridge University Press), 191–233. doi: 10.1017/CBO9780511659461.012
Nelson, B. C. (2023). “Insertion of [spread glottis] at the right edge of words in Kaqchikel,” in Epenthesis and Beyond Workshop 2021 35. doi: 10.4324/9781032682907-4
Nelson, B. C. (forthcoming). Learning the sounds of silence: adult acquisition of Kaqchikel (Mayan) plain and glottalized stop consonants. PhD thesis, University of Calgary.
Ortin, R., and Fernandez-Florez, C. (2019). Transfer of variable grammars in third langauge acquisition. Int. J. Multiling. 16, 442–458. doi: 10.1080/14790718.2018.1550088
Patal Majzul, F., García Matzar, L. P. O., and Espantzay Serech, I. C. (2000). Rujunamaxik ri Kaqchikel chi' : Variación dialectal en Kaqchikel [Dialectal variation in Kaqchikel]. Cholsamaj.
Price, L., Pouplier, M., and Hoole, P. (2020). Ejective production mechanisms in English. J. Acoust. Soc. Am. 148, 2655. doi: 10.1121/1.5147392
Price, L., Pouplier, M., and Hoole, P. (2022). “Kehlkopfanhebung in englischen wortfinalen Ejektiven: eine Echtzeit-MRT-Studie [Laryngeal raising in English word-final ejectives: a real-time MRI study],” in 18. Phonetik und Phonologie im deutschsprachigen Raum [18th conference on Phonetics and Phonology in the German-speaking area].
Rose, S. (1996). Variable laryngeals and vowel lowering. Phonology 13, 73–117. doi: 10.1017/S0952675700000191
Rothman, J. (2011). L3 syntactic transfer selectivity and typological determinacy: the typological primacy model. Second Lang. Res. 27, 107–127. doi: 10.1177/0267658310386439
Rothman, J. (2015). Linguistic and cognitive motivations for the Typological Primacy Model (TPM) of third language (L3) transfer: Timing of acquisition and proficiency considered. Bilingualism. 18, 179–190. doi: 10.1017/S136672891300059X
Rothman, J., González Alonso, J., and Puig-Mayenco, E. (2019). “Transfer in multilingual morphosyntax,” in Third Language Acquisition and Linguistic Transfer (Cambridge: Cambridge University Press), 116–187. doi: 10.1017/9781316014660.004
Selinker, L. (1972). Interlanguage. Int. Rev. Appl. Ling. Lang. Teach. 10, 209–231. doi: 10.1515/iral.1972.10.1-4.209
Sylak Glassman, J. C. (2014). Deriving natural classes: the phonology and typology of post-velar consonants. PhD thesis, University of California, Berkeley.
Torres-Tamarit, F. (2019). “Phonemic contrast and neutralization,” in The Routeledge Handbook of Spanish Phonology, eds. S. Colina, and F. Martínez-Gil (London: Routledge), 3–33. doi: 10.4324/9781315228112-2
Van Patten, B., and Benati, A. G. (2010). Key Terms in Second Language Acquisition. London: Bloomsbury Publishing.
Wagner, K. O. C., and Baker-Smemoe, W. (2013). An investigation of the production of ejectives by native (L1) and second (L2) language speakers of Q'eqchi' Mayan. J. Phonet. 41, 453–467. doi: 10.1016/j.wocn.2013.08.002
Westergaard, M., Mitrofanova, N., Mykhaylyk, R., and Rodina, Y. (2017). Crosslinguistic influence in the acquisition of a third language: the linguistic proximity model. Int. J. Biling. 21, 666–682. doi: 10.1177/1367006916648859
Wrembel, M., Marecka, M., and Kopecková, R. (2019). Extending perceptual assimilation model to L3 phonological acquisition. Int. J. Multiling. 16, 513–533. doi: 10.1080/14790718.2019.1583233
Keywords: third language acquisition, phonology, redeployment, stop consonants, post-velar consonants, Kaqchikel, Spanish, English
Citation: Nelson BC (2023) Phonological redeployment for [retracted tongue root] in third language perception of Kaqchikel stops. Front. Lang. Sci. 2:1253816. doi: 10.3389/flang.2023.1253816
Received: 06 July 2023; Accepted: 13 October 2023;
Published: 06 November 2023.
Edited by:
Jennifer Cabrelli, University of Illinois Chicago, United StatesReviewed by:
Charles B. Chang, Boston University, United StatesKyle Parrish, Goethe University Frankfurt, Germany
Copyright © 2023 Nelson. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Brett C. Nelson, YnJldHQubmVsc29uQHVjYWxnYXJ5LmNh