 Alexandra Krauska
Alexandra Krauska Ellen Lau
Ellen Lau- Department of Linguistics, University of Maryland, College Park, MD, United States
In standard models of language production or comprehension, the elements which are retrieved from memory and combined into a syntactic structure are “lemmas” or “lexical items.” Such models implicitly take a “lexicalist” approach, which assumes that lexical items store meaning, syntax, and form together, that syntactic and lexical processes are distinct, and that syntactic structure does not extend below the word level. Across the last several decades, linguistic research examining a typologically diverse set of languages has provided strong evidence against this approach. These findings suggest that syntactic processes apply both above and below the “word” level, and that both meaning and form are partially determined by the syntactic context. This has significant implications for psychological and neurological models of language processing as well as for the way that we understand different types of aphasia and other language disorders. As a consequence of the lexicalist assumptions of these models, many kinds of sentences that speakers produce and comprehend—in a variety of languages, including English—are challenging for them to account for. Here we focus on language production as a case study. In order to move away from lexicalism in psycho- and neuro-linguistics, it is not enough to simply update the syntactic representations of words or phrases; the processing algorithms involved in language production are constrained by the lexicalist representations that they operate on, and thus also need to be reimagined. We provide an overview of the arguments against lexicalism, discuss how lexicalist assumptions are represented in models of language production, and examine the types of phenomena that they struggle to account for as a consequence. We also outline what a non-lexicalist alternative might look like, as a model that does not rely on a lemma representation, but instead represents that knowledge as separate mappings between (a) meaning and syntax and (b) syntax and form, with a single integrated stage for the retrieval and assembly of syntactic structure. By moving away from lexicalist assumptions, this kind of model provides better cross-linguistic coverage and aligns better with contemporary syntactic theory.
1. Introduction
For many years, people have been pondering the puzzle of how language is produced and comprehended; how do we get from a conceptual representation of what we want to say, to a series of articulatory gestures that make up speech or sign? When we perceive a series of such articulatory gestures, how do we interpret that signal to get the intended meaning? As an accident of history, many of the original researchers interested in this problem spoke European languages, particularly English and Dutch. For these researchers, the problem of language production should involve a few intermediary steps: once a concept has been generated, how do we retrieve the corresponding words from memory? After that, how do we build a syntactic structure from those words and put them into the correct linear order? In creating models to answer these questions, researchers were often making an unnoticed commitment about how language works, centered on a particular notion of wordhood. Dominant theories of syntax at the time—also largely developed based on European languages—assumed that “words” were the units of combination, and that everything happening below the word level belonged to a separate domain, morphology. In this kind of theory, the word acts as a bridge between meaning, syntax, and form. Psycholinguistic and neurolinguistic models incorporated this understanding of syntax and wordhood into both the representations and algorithms of those models. This is the lexicalist approach.
Lexicalism has been around for a long time in linguistics, and many of the foundational theories of syntax analyzed words as the minimal units in syntactic computations. Though the “Lexicalist Hypothesis” was first introduced in Remarks on Nominalization (Chomsky, 1970), lexicalism is not a single cohesive theory, but rather an approach taken by a variety of linguistic theories which rely on one or both of the following assumptions:
1. Syntactic and morphological processes are different in kind: Under this assumption, morphology (or other sub-word operations) and syntax (or other supra-word operations) are fundamentally different operations. Each has their own sets of atoms and rules of formation; syntactic rules operate over phrases and categories (NP, V, etc.), while morphological rules operate over roots, stems, and affixes. This establishes words as the “atoms” of syntax (Chomsky, 1970; Lapointe, 1980; Williams, 1981). Some interaction needs to exist between syntax and morphology, such as in verbal inflection, but lexicalist theories argue that the interaction functions in such a way that the two sets of rules and operations are not intermixed, and that only certain components can be referred to in both sets of rules.
2. Lexical items include triads of sound, meaning, and syntax: According to this assumption, everything which can be syntactically individuated has its own context-independent meaning and form. This creates a “triad,” where each lexical item links a single meaning representation to a piece of syntax and a single form representation. The size and complexity of the piece of syntax can vary across theories; in some accounts, the syntactic component only contains a single syntactic terminal or a set of features (Jackendoff, 1975; Aronoff, 1976; Di Sciullo and Williams, 1987; Pollard and Sag, 1994), while in other accounts the syntactic component can be a “treelet” or “construction” that is morphosyntactically complex, thereby rejecting the first assumption above but retaining lexicalist properties (Kempen and Hoenkamp, 1987; Vosse and Kempen, 2000; Matchin and Hickok, 2020, among others).
In recent decades, much linguistic work, relying on a broader set of cross-linguistic data, has argued against both of these assumptions, suggesting that principles of word formation are the same as the principles of phrase or sentence formation, and that the word level does not always align with single units of meaning, syntax, or form. These non-lexicalist viewpoints have been developed into theories such as Distributed Morphology (Halle and Marantz, 1993), Nanosyntax (Starke, 2009), and the non-semiotic approach (Preminger, 2021). However, these developments have not been fully integrated into psychological and neurological models of language processing, leaving many phenomena across languages unaccounted for.
In this paper we argue that a non-lexicalist approach is needed for constructing more accurate models of language production. This paper does not elaborate greatly on the arguments against lexicalism within linguistic theory - much ink has already been spilt on this topic (Halle and Marantz, 1993; Harley, 2008; Starke, 2009; Siddiqi, 2010; Embick, 2015; Haspelmath, 2017; Jackendoff, 2017; Bruening, 2018, among others). Rather, we examine how lexicalism has influenced psycho- and neuro-linguistics, and discuss the consequences for the theories that make one or both of the lexicalist assumptions above. We focus on language production as a sort of case study, but we encourage readers to reflect on their own approaches using this case study as a model. The critiques of lexicalism and its effects in these models should apply to any kind of model or theory of language and language processing which makes either of these lexicalist assumptions, including sentence processing and single-word lexical processing, both in comprehension and in production.
The issues discussed here are partly related to linguistic diversity in model development. Using one's own language to generate models of language in general is not necessarily an issue—if you want to know how language in general is processed, a good place to start is to look into how one language is processed. However, a phenomenon which is deemed to be “exceptional” in one language—and thus exempt from the usual steps in linguistic processing—may be commonplace in other languages. Given the assumption that all languages utilize the same underlying cognitive processes, our models also need to account for those kinds of data.
The rest of the paper is composed of two main sections. In the first, we discuss how lexicalist assumptions are implemented in the language production literature, especially as they relate to the “lemma” representation, and how the models operate over those representations. We also elaborate on the kinds of data that these models struggle to account for, given their lexicalist assumptions. The second section discusses what an alternative might look like, as a non-lexicalist model of language production. To move away from lexicalism in models of language production, it is not enough to simply update the syntactic representations; it is also necessary to reconsider the algorithms involved in language production, because they are constrained by the lexicalist representations that they operate over. Instead of relying on a lemma representation, a non-lexicalist production model can represent stored linguistic knowledge as separate mappings between meaning and syntax, and syntax and form, such that meaning, syntax, and form may not line up with each other in a 1-to-1-to-1 fashion. Such a model can also account for prosodic computations that depend on meaning, syntax, and form information. Furthermore, we suggest that cognitive control mechanisms play an important role in resolving competition between the multiple information sources that influence the linearization of speech.
As we illustrate, non-lexicalist production models generate distinct predictions for aphasia and other acquired language disorders. By moving away from lexicalist assumptions, this kind of model provides better cross-linguistic coverage and aligns better with contemporary work in syntactic theory which has observed that syntactic and morphological processes cannot be distinct, that there are no good criteria to empirically define wordhood (Haspelmath, 2017), and that representations of meaning and form do not always align. However, it is important to recognize that the experimental literature in the lemma tradition has played a crucial role in psycho- and neuro-linguistics through its recognition of abstract syntactic representations independent of meaning and form. We are in complete sympathy with those models on this point, and we preserve this insight in the non-lexicalist architecture we propose here.
2. Lexicalist approaches in psycholinguistics
Lexicalist assumptions have played a central role in the development of models of language processing, either explicitly or implicitly. Many models of language production assume something like a lemma or lexical item, which functions as a stored triad of form, meaning, and syntax, also codifying a distinction between morphology and syntax. These models also create a division between lexical and syntactic processes, treating morphology as a different system from syntax. We discuss several models as examples, but these observations apply to any psycholinguistic or neurolinguistic theory which makes similar assumptions about the structure of linguistic knowledge. We introduce specific phenomena in several different languages, which are meant to represent a variety of phenomena across human languages. These phenomena are not isolated instances that can be treated as outliers, but rather common occurrences in human language that also need to be accounted for in models of language processing.
2.1. Lemmas and other lemma-like things
Many models of language production rely on the notion of “lemmas” (Kempen and Huijbers, 1983; Levelt, 1989; Bock, 1995; Levelt et al., 1999). According to the Levelt model, a lemma is a representation which stores syntactic information, and also points to a conceptual representation and a phonological form, bridging the Conceptual Stratum, Lemma Stratum, and Form Stratum. In this model, there is a lemma for every “lexical concept,” and once a lemma has been selected for production, the lemma activates the phonological codes for each of its morphemes. These models commonly assume that the lemma is a terminal node in the syntactic structure (Levelt, 1992). Syntactic frames for these lemmas can specify how semantic arguments—such as “theme” or “recipient”— should be mapped onto syntactic relations - such as direct or indirect object (Levelt and Indefrey, 2000). Syntactic structure is built by combining multiple lemmas which have been retrieved from memory, according to their selectional restrictions and syntactic frames that are provided.
The diagram in Figure 1 of the lemma for the word “escorting” (from Levelt et al., 1999) illustrates how the lemma uniquely identifies a lexical concept in the Conceptual Stratum. The lemma has a number of “diacritic parameters” which need to be specified, including features such as number, tense, aspect, and person. These features may be prepared at the conceptual level or at the point of grammatical encoding. The lemma and its given features point to the phonological form of the stem escort and its suffix -ing, along with the metrical structure of the word. For morphologically complex words like nationalize and compounds like afterthought, the lemma model assumes a single simplex representation at the lemma stratum which maps to several form pieces in sequence at the form stratum (Roelofs et al., 1998). There are slight variations in the assumptions made by different lemma models of language production; for example, according to Levelt and Indefrey (2000), function words have their own lemma, while in the Consensus Model (Ferreira and Slevc, 2007), they do not. Some production models refer instead to “lexical items,” but these are usually given similar attributes as lemmas and embody the same lexicalist assumptions.
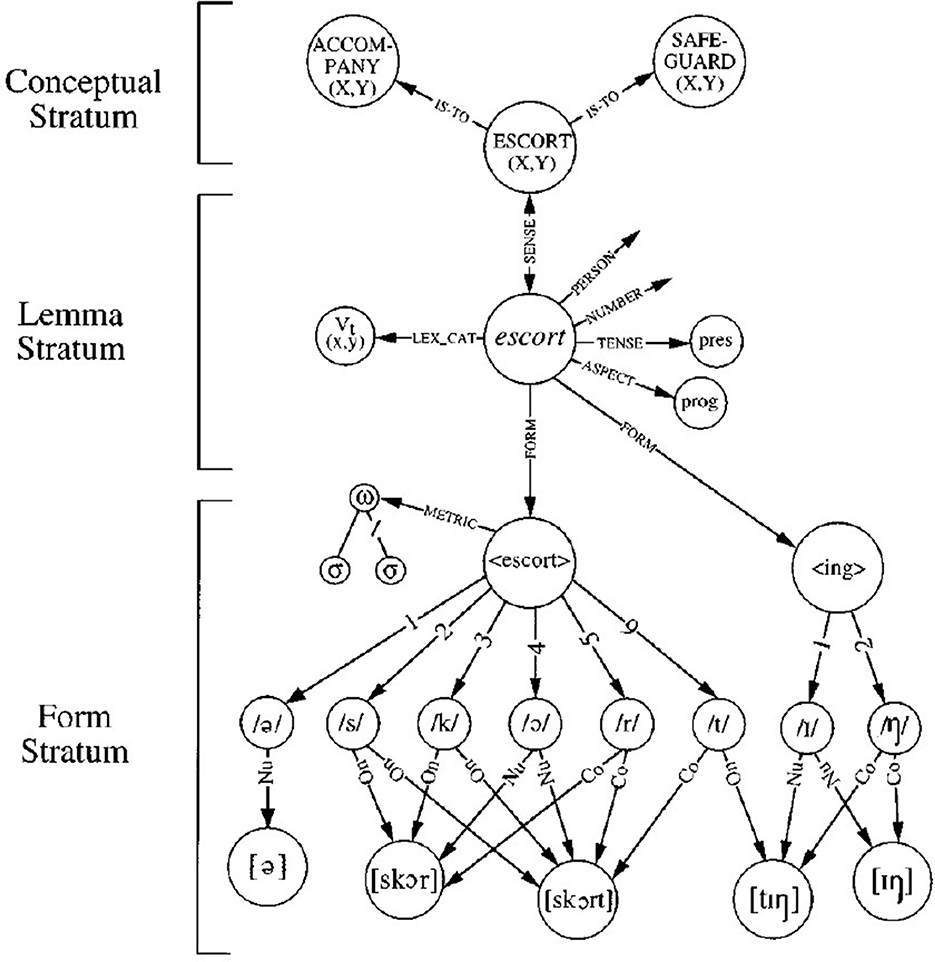
Figure 1. Lemma representation of the word “escorting,” from Levelt et al. (1999), reproduced with permission.
2.1.1. Lemmas encode a distinction between lexical and syntactic processes
The lemma codifies a fundamental distinction between morphology and syntax. Morphologically complex words are taken to embody complexity in lexical representations and retrieval processes, rather than syntactic complexity. Because inflectional morphology and derivational morphology is stored within lemmas, and syntactic properties of the lemma are only represented by features obtained through indirect interaction, the lemma creates a “bottleneck” between morphology and syntax. For English, this might seem reasonable, but for languages with richer morphology and inflectional paradigms, the lemma becomes increasingly unwieldy. For example, in polysynthetic languages, a single word can be composed of many productive morphemes, representing complex meanings. In order to represent those words as lemmas, each lemma would have to correspond to very complex lexical concepts, with many redundant lemmas, to represent all of the possible morpheme combinations in that language; alternately, each lemma would have to incorporate a massive set of features in order to have a “complete” inflectional paradigm.
Along a similar vein, the idea that lemmas only exist for words and their inflections and derivations, reinforces the idea that it is only complete words that are stored in the lexicon, rather than pieces smaller or larger than a word. We can take as an illustration the commonly cited myth that “Eskimos have 150 words for snow,” which has been debunked several times over (Martin, 1986; Pullum, 1989; Kaplan, 2003). As polysynthetic languages, Eskimoan languages such as Inuktitut have several main “snow” root morphemes (aput, “snow on the ground;” qana, “falling snow,” piqsirpoq, “drifting snow;” qimuqsuq, “snowdrift”) which can be combined productively with a wide array of other morphemes to create a massive number of words relating to snow: types of snow, quantities of snow, adjectival forms such as “snow-like,” verbs involving snow, verbs where snow is the object, and so on. We could describe this situation by saying that Inuktitut has a tremendous number of “words” for snow and snow-like things, but this would be a bit like noting that English has a tremendous number of phrases or sentences about snow—it is simply not a very useful description of the language.
Because the lemma model assumes that morphological structure and syntactic structure is fundamentally different, and that derivational and inflectional morphology is stored within the lemma (and not built on-line like syntactic structure is), the individual morphemes within each word cannot exist independently of the lemmas that they appear in. Consequently, the lemma model has two options. One is to assume that each derived form in Inuktitut constitutes a separate lemma, and thus that there are 150+ different lemmas for each derived form of “snow;” this creates a great deal of redundancy, since each lemma would list the same root morpheme separately. The other option is to assume that there is a single lemma for snowflake stored with a massive inflectional paradigm that can generate all the derived forms that include the snowflake morpheme. This same dilemma would arise for every root in the language, of which there are thousands. For these languages, the lemma—as it is currently defined—is not a useful construct.
Let's look at a few examples from Inuktitut1 to appreciate the challenges polysynthetic languages pose for lemma models of production (examples from Cook and Johns, 2009; Briggs et al., 2015):
(1) a. nivak -tuq
shovel.debris -PTCP.3S
“She shovels debris, old snow [out of the door]”
b. uqaalla -qattaq -tunga
say -often -PTCP.1S
“I say that sometimes”
c. havauti -tuq -ti -taq -niaq
medicine -drink -cause -frequently -going.to
-tara
-PTCP.1S/3S
“I'm going to give her medicine frequently”
The sentence in (1a) is a good example of a case that the lemma model can handle with the same machinery used for English and Dutch inflectional morphology, as illustrated for “escorting” in Figure 1. The nivak lemma could simply be specified with inflection diacritics for mood, person and number, agreeing with the (null) subject. If we turn to the sentence in (1b), perhaps the lemma representation could remain simple as in (1a), and the complexity could be limited to the form level as the sequence of forms, uqaalla, -qattaq, and -tunga, similar to how the model represents compounds and other derived forms. However, since the lemma model assumes that each lemma corresponds to a single stored “lexical concept,” this case would require assuming that speakers store atomic lexical concepts like “I say that sometimes.” A case like (1c) appears more challenging yet to represent as a single inflected lemma. How might the lemma model try to represent the many different units used to generate this single complex word?
One possibility, following (1b) would be to assume that there is a single stored lexical concept that corresponds to the entire meaning “I'm going to give her medicine frequently,” and thus a single corresponding lemma, with complexity at the form level only. This seems implausible. This would mean storing as separate full lexical concepts the meanings corresponding to every similarly-structured word that speakers produce (e.g., “I'm going to give her vitamins frequently)”, and would put pressure on the theory to provide a systematic account of how this multiplicity of lemmas containing productive derivational morphology was created in the first place.
An alternate approach to (1c) would be akin to the inflectional morphology case, to assume a core lemma for the lexical concept “medicine,” and then generate the complex utterance in (1c) from a set of diacritics on the lemma, as illustrated in Figure 2. But this would lead to another question about what kinds of diacritic features could possibly represent each of those morphemes, especially if they would go unused in the majority of cases (the morpheme for “drink,” -tuq, would appear relatively rarely, seemingly not enough to justify its status as a feature in the lemma representation, in contrast to features like tense or number), and considering that they can be used productively. Furthermore, the relationship between the morphemes within a lemma is only one of linear order, so this would mean that no non-linear structured relations between the elements of (1c) could be represented by the lemma. This would be problematic given the large body of evidence from polysynthetic languages for non-linear (hierarchical) relations between the elements within morphologically complex words. 2
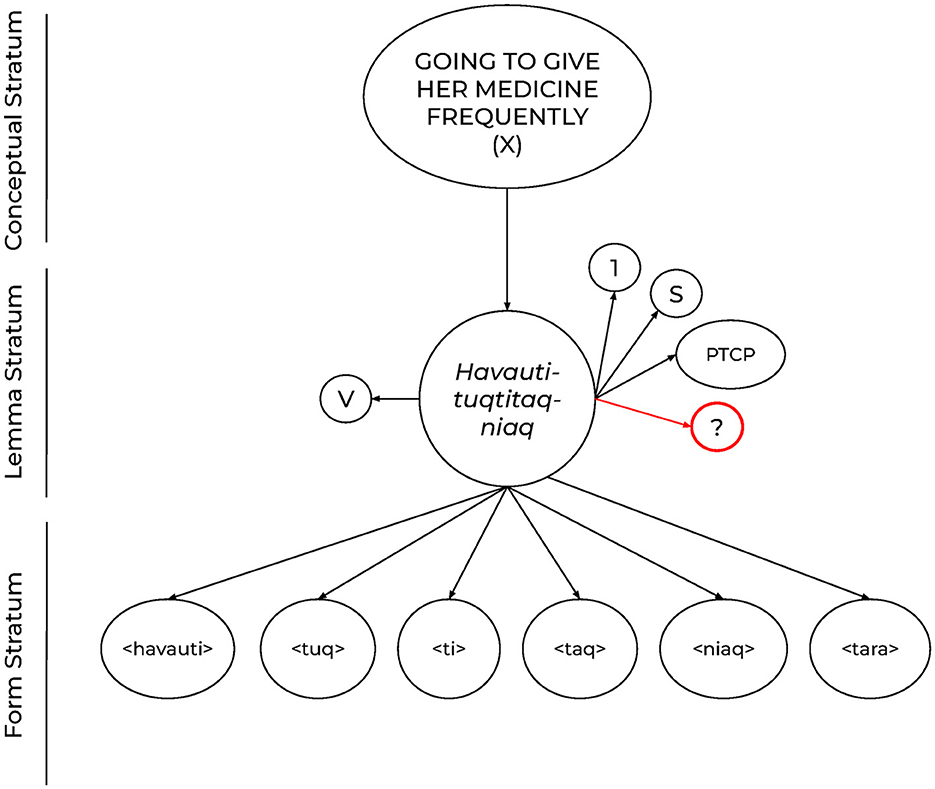
Figure 2. A possible lemma representation for the Inuktitut example in (1c), havautituqtiniaqtara, “I'm going to give her medicine frequently”.
If one sticks with the core idea of the lemma model, that lemmas are defined such that a single lemma corresponds to a single lexical concept, intuitively the best solution to (1c) is to assume that the individual morphemes within the word like those for “medicine,” “drink,” and “frequently” have their own stored lemmas. This means giving up a view of production in which stand-alone words always correspond to stored lemmas, and instead adopting the non-lexicalist assumption that morphologically complex “words” can be constructed in the course of production in the same way that sentence structure is. Although the need for this move is most obvious in the case of the production of languages with rich morphology, assuming a processing model in which lemmas can be combined to form structured words provides a needed account of productive morphological word formation in languages like English or Dutch as well.
There is additional evidence that syntactic rules must be able to operate across the boundary between morphology and syntax, challenging the lexicalist notion of the “atomicity” of words, that words are the units of syntactic combination. As discussed by Noyer (1998), idiomatic collocations in Vietnamese are composed of several morphemes, which in some cases are syntactically separable, as shown in (2), where the collocations preserve their idiomatic interpretation when separated by other syntactic material (often used in Vietnamese for stylistic effect or affect).
(2) a. Tôi xay nhà cửa → Tôi xay nhà xay cửa
I build house door I build house build door
“I build a house”
b. Tôi không muổn đèn sách → Tôi không muổn
I NEG want lamp book → I NEG want
đèn không muổn sách
lamp NEG want book
“I do not want to study”
c. Tôi lo vườn tược → Tôi lo vườn lo
I care.for garden XX → I care.for garden lo care.for
tược
XX
“I take care of gardens”
According to the lemma model, these idiomatic collocations would need to constitute single lemmas with multiple morphemes. Each collocation would correspond to a single lexical concept because of their idiosyncratic meanings—and in some cases, parts with unavailable meanings of their own (indicated by “XX” in the gloss). Furthermore, in (2b), though đèn (“lamp”) and sách (“book”) are nouns individually, when used together they function as a verb; because syntactic category is a property of lemmas and not morphemes, this provides further evidence that they must constitute a single lemma. However, if a sequence like đèn sách corresponded to a single lemma with separate pieces at the form level only, then the two pieces of the collocation could only appear adjacently and would not be syntactically separable, no different from escort and -ing in Figure 1.
Some work in the lemma tradition has tried to develop an alternative approach to deal with phrasal idioms. Cutting and Bock (1997) and Sprenger et al. (2006) argue that idioms have a “hybrid” representation, where there is a lexical concept node or “superlemma” for the idiom which also activates the lemmas of its constituents (i.e., the superlemma for “kick the bucket” would activate the simple lemmas for “kick” and “bucket”). One of the key assumptions of these accounts is that each of the constituents of the idiom must have its own lemma representation that can be activated. Because all lemmas must have an associated lexical concept, this assumes that every idiom would have a literal interpretation which is overridden by the idiomatic interpretation. However, for the Vietnamese idiomatic collocations, and example (2c) in particular, this claim would be problematic. The morpheme tược has no interpretation outside of the idiomatic collocation, so it could not correspond to a lexical concept independent from the idiom; thus, there could not be a tược lemma which could be activated. Furthermore, Kuiper et al. (2007) argues that the superlemma specifies only phrasal functions between simple lemmas (constituting a VP or NP, for example), rather than sub-word pieces or a single syntactic category. This would be a problem for the đèn sách (“study”) example, where two nouns are compounded to form a verb; a VP requires a verb head, but neither element would be able to serve that function (in contrast to English phrasal idioms like the VP “kick the bucket,” or the NP “kit and caboodle”).
These examples challenge one of the key assumptions of the lexicalist approach, that syntax and morphology are separate operations that cannot interact. In order to account for these kinds of examples, the only solution would be to assume instead that the đèn and sách morphemes within the “study” lemma are themselves syntactic objects that can interact with the syntactic structure. This means giving up a view of syntactic structure where words or lemmas are the units of combination, and instead adopting the non-lexicalist view that morphology and syntax are part of the same system. The evidence from Inuktitut and Vietnamese indicates that, not only do we need to move away from a view of production in which stored lemmas correspond to words, but we also need to give up the idea that the units of language production are syntactically atomic by definition.
2.1.2. Lemmas function as a stored triad
The lemma is defined as grouping together form, meaning, and syntax, creating the “triad.” The lemma maps between meaning, syntax, and form in a “symmetrical” way, where for every element that is syntactically individuated, it is also individuated in terms of meaning and form, not dependent on other lemmas or the syntactic context. Even if the phonological form is not stored within the lemma itself, the mapping between lemma and form is deterministic and context-independent. If we make this assumption, we would not expect there to be cases where meaning, syntax, and form would be mapped to one another in more complicated ways, or instances where the syntactic context would impact the form or meaning of individual words.
One place in which the phonological form seems to be conditioned by the broader syntactic context that it occurs in is suppletion. Existing models have a way to account for some kinds of suppletion, such as what is seen for a few English verbs, based on tense (go ~went) and agreement with the subject (is ~ am). However, it is harder for this kind of model to account for suppletion based on a larger piece of syntax, where the form is not determined by a single syntactic object or a limited set of features, but by the larger syntactic context. For example, Hiaki3 exhibits suppletion for some verbs with singular and plural subjects, as well as singular and plural objects (examples from Harley, 2014):
(3) a. vuite ~ tenne run.sg ~ run.pl
b. siika ~ saka go.sg ~ go.pl
c. weama ~ rehte wander.sg ~ wander.pl
d. kivake ~ kiime enter.sg ~ enter.pl
e. vo'e ~ to'e lie.sg ~ lie.pl
f. weye ~ kaate walk.sg ~ walk.pl
g. me'a ~ sua kill.sgObj ~ kill.plObj
For the English verb escorting above, the diacritics for the person and number of the subject help to determine the inflection on the verb for agreement; for the Hiaki verbs that exhibit suppletion based on the number of the subject or the object, as shown in 3, there would need to be two diacritics for number, one for the subject and one for the object, as indicated in Figure 3. One issue for this kind of representation is that one or both of these sets of diacritics would always be redundant, especially because Hiaki does not inflect regular verbs—those that do not have suppletive forms—for person or number [the form of the regular verb aache (“laugh”) is the same for all subjects; Sánchez et al. (2017)].
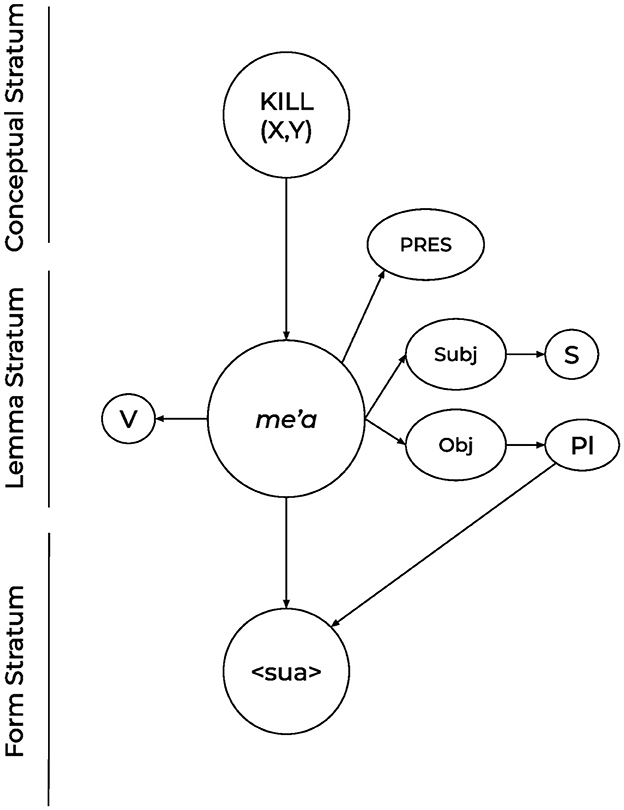
Figure 3. A possible lemma representation for the Hiaki suppletive verb sua, “kill.plObj.” The “Subj” and “Obj” diacritics would indicate the number feature on the subject and object of the sentence, but they would often be redundant, given that regular verbs in Hiaki do not inflect for person or number.
Verb-object idioms provide evidence that the meaning of a syntactic unit can also be dependent on its morphosyntactic context. Examples such as those in (4) indicate that the meaning of verbs like pass, take, get, and kill can be dependent on the semantic content of its object, while remaining indifferent to that of its subject. Although many architectures treat idioms as exceptions, these kinds of examples are very common, and are used in a variety of registers. The strong and systematic dependence of the verb's meaning on the object in these cases make them unlike simple cases of lexical ambiguity.
(4) a. Pass: pass a test, pass a law, pass a kidney stone, pass the hat
b. Take: take a photo, take a nap, take a bus, take a chance
c. Get: get a package, get the idea, get the check, get scared
d. Kill: kill a bottle, kill an evening, kill the clock, kill the music
If the meaning of each verb was uniquely specified in the lexicon, with no context-dependent interpretations, we would not expect any of these verb-object idioms to emerge with these idiosyncratic meanings. It is not clear that the lemma model can explain this phenomena simply by stating that these verbs are ones that are semantically “light” or “bleached,” or underspecified for meaning, because the intended meaning of each verb phrase is clear and specific. In these cases, and in many other cases not listed here, the meaning of the verb is determined by its morphosyntactic context.
One could interpret these cases as homophony, such that there would be multiple lemmas which are pronounced as “take” that correspond to different lexical concepts (one for steal, one for photograph, one for sleep, one for ride, and so on). However, on a homophony account, it would be a coincidence that all the lemmas pronounced as “take” have the same irregular past-tense form “took.” One could also interpret these cases as polysemy, but this would require an additional mechanism in the conceptual domain to link very different concepts to the same lemma, which would be an issue if lemmas are meant to correspond to single lexical concepts.
Another possibility would be to treat these as idioms with a “hybrid” representation, as proposed by Cutting and Bock (1997) and Sprenger et al. (2006), where the superlemma or lexical-conceptual representation of the idiom “take a nap” would activate the lemmas for take and nap, so the idiosyncratic meaning would be associated not with the take lemma itself, but rather with the superlemma. This account would suggest—contrary to the lexicalist approach—that a single conceptual unit can be mapped to a syntactic complex, and not just to a single syntactic atom. Furthermore, this also suggests that stored linguistic representations can be syntactically complex, involving both morphological and syntactic structure. We argue that both of these are important steps in the right direction, though we discuss the advantages and disadvantages of “treelet-based” approaches of this type in more detail in Section 2.1.4.
To summarize, lemmas are a manifestation of both of the lexicalist assumptions discussed above: they codify a distinction between syntax and morphology, and establish themselves as a stored “triad” of form, syntax, and meaning. As a result, there is a large amount of data that the lemma will struggle to model, including (but not limited to) inflection and morphological structure, suppletion, and idioms, phenomena which are fairly widespread throughout human languages. These phenomena suggest that syntax and morphology need to be able to interact fully, not just by sharing a limited set of features, and that the form and meaning of a syntactic object is partially determined by the syntactic context, not just by the syntactic object itself.
2.1.3. Incrementality and lexical units
A central concern for models of language production, going back over a century, is incrementality: how much of the preverbal message and linguistic encoding is planned before the speaker starts talking? If not all of it is planned in advance, how can speakers ensure that all the linguistic dependencies and word order requirements of the language are satisfied? Over the years, one common suggestion of highly incremental production models is that both preverbal and syntactic representations can be planned and updated in “lexically sized units,” as proposed by Dell et al. (2008) and Brown-Schmidt and Konopka (2015). However, it is often not explicitly recognized how crucially these planning models thus depend on lexicalist assumptions about the units which are being incremented over. The reason is that an assumed one-to-one mapping from meaning to syntax to form makes it such that each increment of planning at one level can be matched by exactly one increment at the other levels. Without this assumption, there is no reason to think that the correct selection of a unit at the phonological level could be done by looking at a single unit at the meaning or syntax level, which is what maximal incrementality would require.
The cross-linguistic examples above that challenged the one-to-one mapping can be used to illustrate the parallel issues for lexically-based incremental production models. If a lexical unit corresponds to a single unit of meaning, then a fully incremental model would struggle to produce the two pieces of a Vietnamese idiomatic collocation in different, non-contiguous parts of a sentence. If the lexical unit corresponds to a single unit of syntax, then the two pieces of the idiomatic collocation would have to be separate units (as they are syntactically separable), and thus the incremental model would struggle to generate parts of the collocations that do not have independent interpretations, such as in (2c). If a lexical unit corresponded to the phonological word, that would suggest that a whole sentence in Inuktitut would be represented as a single lexical unit, again ignoring the productivity of morphology in polysynthetic languages. These incremental models would also struggle if the lexical units correspond to syntactic units but the meaning and form are determined solely by the lexical unit itself, for the same reasons discussed above for Hiaki verb suppletion and English verb-object idioms. For example, for the Hiaki verbs which exhibit suppletion based on the number of the object, such as me'a ~sua (“kill”), a fully incremental model would retrieve the meaning and syntax for “kill” correctly, but could not correctly condition its phonological wordform on the number of the object because at the time that the verb was being produced, the following object would not have been planned yet.
2.1.4. Treelet-based approaches — A step in the right direction
Many models of language production have taken steps to provide a more detailed account of the syntactic representation of lexical items, especially in regard to the separation of morphology and syntax in the representation of words. For example, Kempen and Hoenkamp (1987), Vosse and Kempen (2000), Ferreira (2013), and Matchin and Hickok (2020) (among others) propose models where the syntax of lexical items are represented as lexicalized “elementary trees” or “treelets.” These models allow for the syntactic properties of a lexical item—such as argument structure—to be represented as syntactic structure, rather than a limited set of features or as sentence frames. Because the treelets are composed via syntactic rules, and then undergo a process of lexicalization in order to be stored as treelets, syntactic and lexical representations are thus not definitionally distinct, thereby rejecting the first lexicalist assumption, that syntax and morphology are separate systems that cannot interact. As long as the tree-based model assumes a syntactic theory which can accommodate the kinds of phenomena described above, it will be able to represent them as treelets. One could easily adopt a non-lexicalist theory of syntax, where even a single treelet could involve highly complex morphological structure, as is needed for Inuktitut and other polysynthetic languages, and for the structure of idioms, while still using the same basic operations and preserving the same architecture of the processing model.
However, these models are also clear examples of why it is insufficient to simply update the syntactic representations of the treelets without also reconsidering the criteria for lexicalization, and how the meaning and form of the resulting treelets are represented. These are all lexicalist approaches in that treelets correspond to stand-alone words or phrases, rather than pieces of syntax that are smaller than stand-alone words. Meaning and form are only specified for treelets, in a context-independent way, so the triad persists. Here, Inuktitut words pose the same kind of issue as they did for lemmas; a treelet would need to be stored in the lexicon for each possible stand-alone word in the language, some of which would constitute entire sentences. If these models were to argue that the treelets can be smaller than a stand-alone word in order to account for this data, then these models could not be considered fully lexicalist; however, they would still struggle to capture phenomena which are beyond the triad, because meaning and form would be specified for most treelets. Hiaki verbs that exhibit suppletion based on the number of the subject or object are still problematic, because there would need to be separate treelets for the same verb depending on the number feature of the subject or object. In addition, for treelet-based models which assume that the treelets are “atomic” in the sense that their sub-parts cannot participate directly in the syntactic structure outside of the treelet, they will struggle with Vietnamese idiomatic collocations and other similar phenomena as well.
More broadly, we agree that storage and retrieval of composed structures may turn out to be a central property of language processing, but they should not be defined in the lexical representations of words. The intuition captured by these treelets might be better understood not as a representation but perhaps as a byproduct of the implementation in a highly adaptable neural system. Furthermore, we see no reason that this property should be restricted to things at the “word” level; it should apply equally to phrases as well as sub-word pieces.
2.1.5. Language-specific optimization
So far in this section, we have argued against the claim that the system of language production requires lexical knowledge to be formatted in terms of lemmas or lexical units as an organizing principle. However, for things that do have a 1-to-1-to-1 mapping between meaning, syntax, and form (where a single syntactic object has a consistent meaning and form across a variety of contexts), it would be entirely plausible that lemmas—or something like them—could arise as a byproduct of language-specific optimization, where it would be faster or more efficient to represent meaning, syntax, and form in that way, even if it is not an architectural principle. In these cases, it is possible that the translations which are performed for that word can treat the word as if it were atomic (i.e., the calculation to determine the form for the word does not need to refer to any other elements in the syntactic context), as is suggested by the lemma model. This kind of symmetry might occur more often in some languages, so linguistic behavior may appear to be more “lemma-like” than it would for other languages. To be clear, this would be a consequence of optimization at the implementation level, rather than the representation or algorithm level (Marr, 2010); it should be the case that speakers of all languages have the same underlying mechanisms which can become specialized depending on the frequency and complexity of processes that are involved in the language.
The possibility of “lemmatization” may not hold for every piece of syntax in a single language, even in English, but it is an interesting empirical question which is only made possible under a non-lexicalist approach—under what circumstances would a “lemma” be formed, if at all? It seems entirely plausible that a neural system which is searching to optimize and reduce resource use wherever possible would store frequently used linguistic objects in some way, and it is possible that something like a lemma could arise for some items in a language. A central commitment of lexicalist theories is that there is a principled divide between what kinds of representations can be stored in the lexicon and what has to be generated online. In contrast, non-lexicalist approaches that do not assume such a divide are free to predict that frequently generated relations of any kind could be stored, if this would facilitate future production operations. This could include commonly-used phrases (such as “kick the ball” or “walk the dog”), Multi-Word Expressions (as discussed by Sag et al., 2002; Bhattasali et al., 2019), or groups of words with high transition probabilities. The same considerations that apply to whether or not a complex word like “nationalize” is stored will also apply to whether or not a common phrase is stored. Depending on the properties of a particular language, storage of different sized pieces may optimize production, allowing wide variation cross-linguistically in the size of the stored pieces even if the underlying grammatical architecture is assumed to be the same.
2.2. Division between lexical and syntactic processes
As we touched on in the discussion of incrementality above, assumptions about processing algorithms are deeply intertwined with assumptions about the units of representation. In the case of language production, the lexicalist assumptions that characterized the lemma units led to models which made a fundamental division between the process of lexical selection and the process of syntactic structure building. Much of the same data discussed above presents a clear challenge for models that work this way. This means that moving to a non-lexicalist production model is not just a matter of updating the representation of stored linguistic knowledge.
In the Levelt and Indefrey (2000) model, the lexical concepts for the sentence are first selected, and then the corresponding lemmas are retrieved from memory. The syntactic structure is built incrementally as lemmas are retrieved, according to the syntactic frames of each lemma, and subsequent lemmas are inserted into the syntactic structure. For example, to produce the sentence “Maria kicked the ball,” the lemmas for “Maria,” “kick,” “the,” and “ball” would be retrieved. The verb “kick” has a syntactic frame which specifies its arguments and the thematic roles that they have in the sentence, so “Maria” would be inserted into the subject position because she is the agent, and “the ball” would be inserted into the object position because it is the patient. In this way, every lemma (except the first one which initiated the structure building) is inserted into a “slot” in the syntactic structure as it is being built. Once the syntactic structure has been built, the morphophonological code for each of the lemmas is retrieved, followed by phonetic processes and articulation.
However, idiomatic collocations in Vietnamese are difficult to explain in a model in which lemma selection and syntactic structure building are separate processes, because they demonstrate that syntax needs to operate across the boundary between syntax and morphology. Because each idiomatic collocation corresponds to a single lexical concept, it would be represented by a single lemma. In the Vietnamese sentence for “I do not want to study,” in example (2b), the want lemma would be retrieved, and because the study lemma is its complement, it would be inserted into the syntactic structure as a single lemma with two morphemes; the two pieces of the collocation would only appear adjacently. In order to have them appear separately, one would either have to argue that there is an additional step of post-insertion movement which allows the pieces to appear in separate positions in the structure, even though lemmas are treated as being syntactically atomic, or that the idiomatic collocation corresponds to two lemmas that are retrieved independently and inserted into their respective positions in the syntax—in which case, the idiosyncratic meaning could not arise without the involvement of an additional mechanism. Another possibility is that there are two lemmas for the same idiomatic collocation, one for when the two pieces are adjacent to each other, and one when they are not, each with a different syntactic frame to specify how the structure is built around it; again, this would not explain how both lemmas would get the same idiosyncratic meaning. None of these possibilities are available in the current lemma model.
Looking now at the the Consensus Model proposed by Ferreira and Slevc (2007), shown in Figure 4, which likewise operates over lemmas, the main difference in this model is that the process of lemma selection and morphophonological retrieval (“content processing”) is done in isolation from the syntactic composition (“structure building”), as two separate subprocesses. As a consequence, the building of the syntactic structure is driven by conceptual properties and thematic function rather than the selectional restrictions of individual elements in the syntax. To produce the sentence “Maria kicked the ball,” the message would first be encoded in terms of semantic meaning—the entities and concepts that are involved in the sentence—and relational meaning—how those entities relate to one another in the sentence, as agents and patients, and so on. On the “content” side, the lemmas for “Mary,” “kick,” and “ball” would be selected (function words and morphemes do not have their own lemmas), while on the “structure” side, the syntactic structure would be created for the sentence. When the morphophonological code for each lemma has been retrieved, they would be inserted into their position in the syntax (though the authors concede that the problem of how exactly those forms are inserted into the correct position does not currently have a solution).
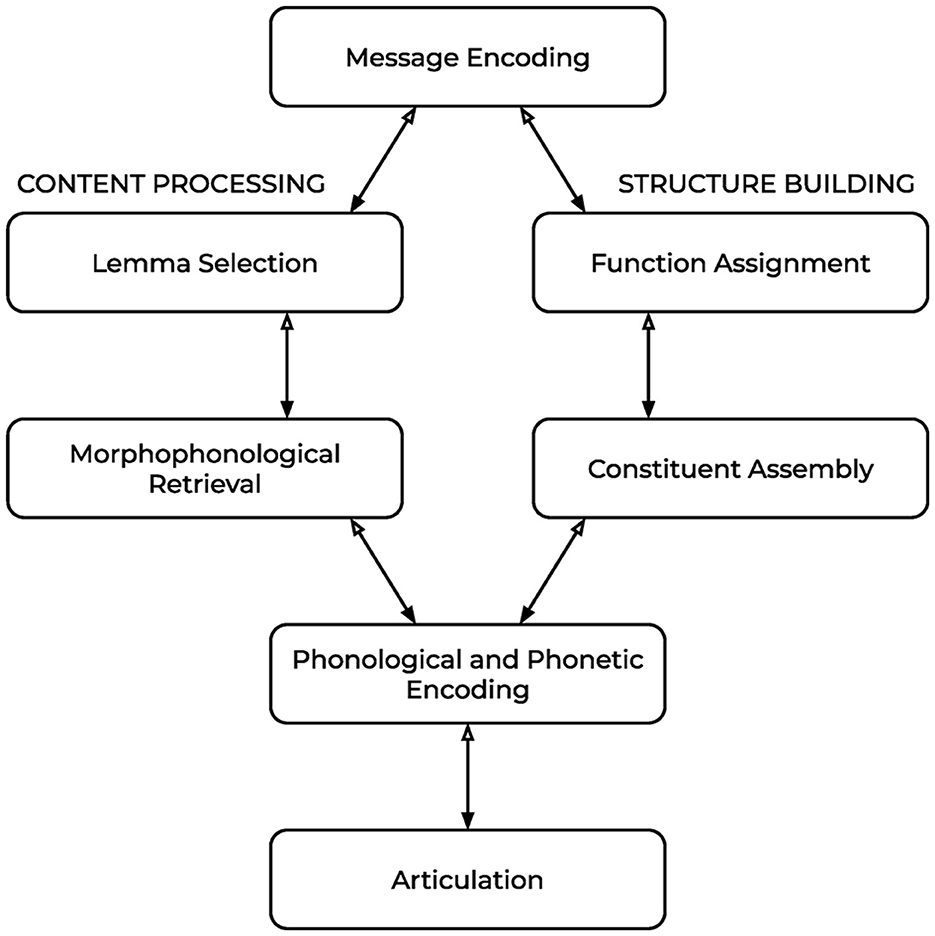
Figure 4. Model of sentence production according to Ferreira and Slevc (2007).
This division between structure building and content processing poses several problems for the cross-linguistic phenomena reviewed here. Firstly, this model would have trouble generating Hiaki verb suppletion conditioned on the object, because morphophonological retrieval happens in isolation from constituent assembly; the “relational meaning” of the object (how the object relates to the other entities in the sentence, as the agent or patient of the verb) would be available, as would the conceptual representation of the object as singular or plural, but the syntactic structure and syntactic features would not be.4 At the point of morphophonological retrieval, none of those features would be accessible to the me'a lemma.
The production of Hiaki suppletion could be accomplished if there are connections between “lemma selection” and “structure building,” and between “morphophonological retrieval” and “constitutent assembly,” as is assumed in Eberhard et al. (2005). This framework allows for syntactic structure building to have an influence on a lemma's morphophonological form, assuming that there is a mechanism by which the features of the object lemma could be indirectly shared with the verb lemma. However, for both the Consensus model and the Eberhard et al. (2005) model, separation between structure and content (or the syntax and the lexicon) will cause problems in other cases where the lemmas would need to interact with the syntax beyond just sharing features, such as in the Vietnamese idiomatic collocations, where elements of the collocation can be syntactically separated.
In this discussion so far, a paradoxical problem seems to arise relating to the order of operations. In the discussion of the Levelt and Indefrey model, we argued that there will be issues if lemmas are inserted into a syntactic structure which was built before they were retrieved, in order to account for the production of Vietnamese idiomatic collocations. In the discussion of the Consensus Model, we argued that the syntactic structure should not be built at the same time as—but separately from—the lemma retrieval process, in order to account for the production of Hiaki verb suppletion conditioned on the plurality of the object, as well as instances where “lexical items” need to interact with syntax beyond sharing a limited set of features. It also should not be the case that the syntactic structure is built entirely after the lemma retrieval process, or there may be issues with verbal arguments not being satisfied.5 Part of this problem stems from the ordering issue—at what point the lemmas are retrieved relative to the building of the syntactic structure—but also due to the commitment to the lemma as an atomic unit. These issues would not be resolved by adopting a tree-based approach, which uses syntactically-complex treelets, but assumes a similar model architecture. The non-lexicalist solution to this conundrum is that syntactic structure building and the retrieval and insertion of morphemes is a fully interactive process. There should be no stage at which the processes occur in isolation. Thus, rather than treating these as two separate processes, in the non-lexicalist approach we can treat them as a single unified process of syntactic structure building.
2.3. In summary
The evidence raised in this section, coming from a set of typologically diverse languages, demonstrates that the lexicalist approach is problematic not just in syntactic theory, but also for models of language production. Lemmas—and other things like them—encode lexicalist assumptions about the organization of the language system, either implicitly or explicitly, and the models which use them encode those assumptions in their algorithms. As a result, there are many phenomena that those models of language production will struggle to account for, not just in Inuktitut, Vietnamese, and Hiaki, but in languages like English and Dutch as well. The kind of model change that these considerations require cannot be satisfied by updating the terminology; the representations and algorithms involved in the model need to be fundamentally different, operating over different kinds of units and performing different calculations.
3. Moving away from lexicalism
As we move away from a lexicalist model to a non-lexicalist one, many questions arise. What are the units over which the model operates, if they are not lemmas or words? What other processes must be incorporated into the model if there is no representation which directly links meaning, syntax, and form? How are the different components—meaning, syntax, and form—retrieved, and when? How are they able to map to one another? In this section, we outline one possibility for a non-lexicalist model of language production, and discuss the implications of such a model for how we view language processing and language disorders such as aphasia.
3.1. The non-lexicalist model of language production
The data presented above suggest that there is no split between morphology (or other sub-word operations) and syntax (or other supra-word operations), and that there are many cases of stored linguistic knowledge which cannot be encoded as triads of meaning, syntax, and form. In our current approach, we assume instead that linguistic knowledge includes sets of syntactic atoms, sets of mapping rules between syntactic units and meaning units, and sets of mapping rules between syntactic units and form units (Preminger, 2021). The syntactic terminals are fully abstract, meaning that they have no form or meaning themselves; both their meaning and form are conditioned by their context within the syntactic structure. The two sets of mappings may not necessarily be “symmetrical,” in that for a single component of meaning which maps to a piece of syntax (however complex), that piece of syntax may not map to a single form segment; conversely, for a single form segment which maps to a piece of syntax, it may not correspond to a single component of meaning, as illustrated in Figure 5. Furthermore, it is also possible in this model for a piece of syntax to have no mapping to meaning (for example, the expletive it in a sentence like “it is raining” has no possible referent) or no mapping to form (such as phonologically null elements).
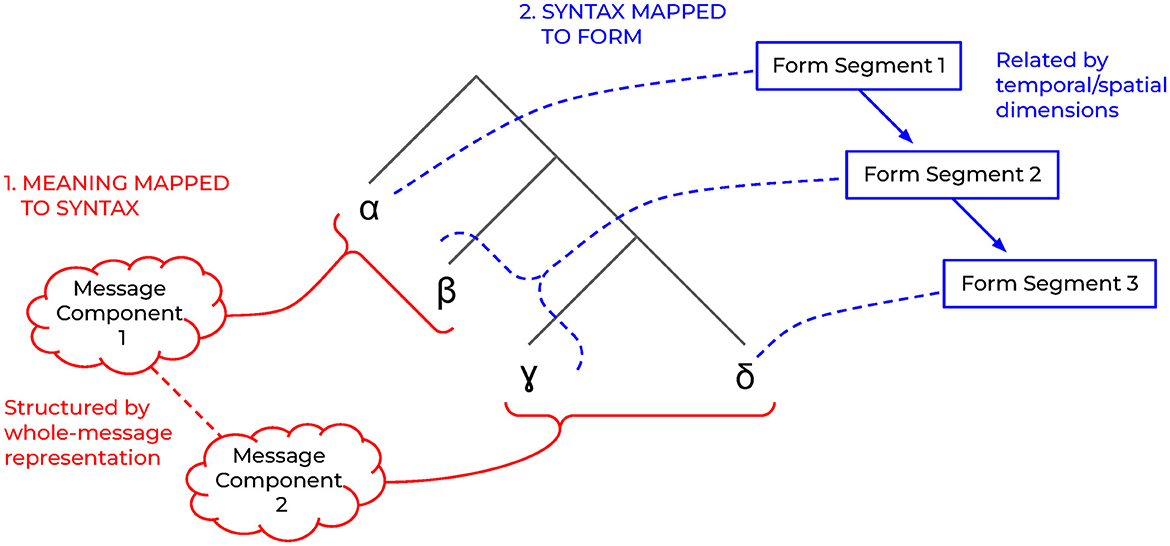
Figure 5. An illustration of the non-lexicalist approach, with separate mappings from (1) meaning to syntax and (2) syntax to form.
As a concrete example of this notion of asymmetricality, we can refer to the phrase “went off,” as in “the alarm went off.” In this example, the meaning components would be something like “ring” and “past.” The “past” meaning component maps to a [+PAST] morpheme, and the “ring” meaning component maps to two morphemes, [GO] and [OFF]. On the form side, given their syntactic configuration, [+PAST] and [GO] map together to the form of went, even though they correspond to separate meaning components, while [OFF] alone maps to the form off , even though it did not constitute its own meaning component. In a strict triadic (symmetrical) view, a single segment of form can only correspond to a piece of syntax which corresponds to a single meaning component. This view would be especially problematic for off in this case, because it does not have the same meaning in this context as it does independently (either “not on top of” or “not operating,” neither of which would apply for an alarm that is actively ringing). Symmetrical mappings are still possible in the non-lexicalist model (“alarm” has a single meaning component, a single piece of syntax, and a single form segment), but this would not be a requirement imposed by the language system.
Moving away from lexicalism resolves many of the issues discussed in Section 2. Inuktitut words can be composed of many morphemes which are arranged hierarchically, allowing them to be both structured and fully productive; the morphemes within Vietnamese idiomatic collocations can participate in the syntactic structure because lexical and syntactic processes are not distinct; the form of suppletive verbs in Hiaki can be determined based on a larger context, including the number feature of the subject or object; and because there are distinct representations of meaning, syntax, and form, and the mappings between them can be calculated based on a larger context, the variability in the meaning of “pass,” “take,” “get,” or “kill” can be partially determined by their object.
In the model that we outline here—discussed in more detail in Krauska and Lau (in prep.)—language production involves a process of mapping a message to sets of syntactic units, which are then mapped to units of form. The two sets of mappings can be represented not in a deterministic way, but rather in a more probabilistic format, as a calculation over larger or smaller pieces of syntax. This model is non-lexicalist because the mechanisms which generate the syntactic structure make no distinctions between processes that apply above or below the word level, and there is no point at which meaning, syntax, and form are stored together as a single atomic representation. Each stage in the model is a translation between different kinds of data structures. The “message” integrates different components of non-linguistic cognition, including memory, sensory information, social dynamics and discourse information, theory of mind, and information structure. Translating that message into a syntactic structure means re-encoding the information into a format that is specifically linguistic, involving syntactic properties and relations that may not be transparently related to the intended message.6 The hierarchical structure of syntax, in turn, must be translated into a series of temporally ordered articulatory gestures in order to be uttered as spoken or signed language.
The mechanisms in this model can be divided into two groups, as shown in Figure 6. The first is responsible for generating relational representations—conceptual representations, syntactic representations, and phonological (or other form) representations—and translating between them, then maintaining them in working memory, predominantly through circuits in the left temporal lobe. The second set of mechanisms, localized in the left frontal lobe, exert influence on the translations between representations and work to organize those representations into a linear (temporal) order. One additional feature of note in this model is that prosodic computations are split into separate pre-syntactic and post-syntactic stages. Prosody is determined by a combination of linguistic and non-linguistic factors; for example, contrastive focus is in part determined based on the speaker's knowledge of the common ground and theory of mind for other discourse participants; heavy NP shift and stress clash in double object constructions is created by the stress that different phrases may carry, which is lexically specified; the choice between rising question intonation and lowering declarative intonation is determined by the speaker's goals in the discourse. A natural solution to the diversity of features that enter into the prosodic calculation is to posit that it is accomplished in two stages, one calculated pre-syntactically, before any syntactic information is available, and another which must be calculated post-syntactically, perhaps after specific phonological information has become available.
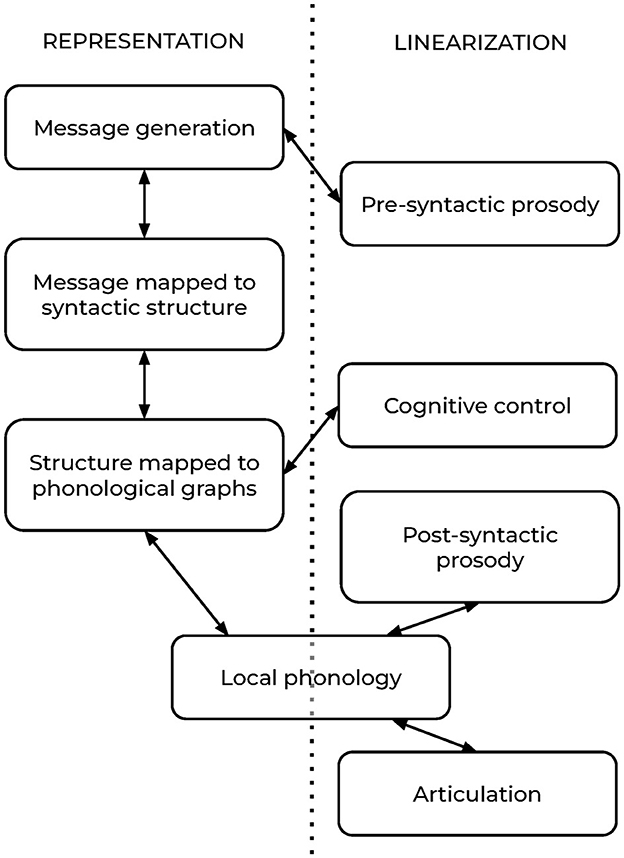
Figure 6. A non-lexicalist model of language production.
Here we briefly summarize each component of the model to illustrate how the production process can work in the absence of traditional lexical items:
1. Message generation: Many different sources of information are consolidated into a message, including conceptual representations for the entities involved in the sentence, event structure, thematic roles, and information structure. This is message is “language-constrained” in that much of the information determining the message is not uniquely linguistic, but it also cannot be purely conceptual, because it must be partially determined by how the message is mapped to syntactic structure and which features in that language are grammatically encoded. For example, languages such as Turkish require “evidentiality” to be grammatically encoded; the grammatical form of a sentence must indicate whether the speaker personally witnessed the event or if the information is second-hand, in contrast to English, where expressing such information is optional. This means that facts about linguistic form play a role in constraining the necessary content of the message to be expressed (Slobin, 1996). The non-lexicalist model suggested here allows linguistic form to influence the message by assuming interactivity between the message generation process and the subsequent process of mapping that message to syntactic structure. The message cannot be generated without some reference to the syntactic structure, and in turn, the syntactic structure cannot be generated without reference to the message.
2. Message mapped to syntactic structure: The next computation we consider is the generation of the syntactic structure, mapping the units of meaning onto pieces of syntax. The syntactic structure is a uniquely linguistic data type, involving a specific kind of hierarchical structure and other idiosyncratic properties. As just noted, this process is fully interactive with the message generation stage in order to produce the correct components of the message as required by the syntax. In contrast to the lexicalist approach, the pieces of syntax that are mapped to each unit of meaning in this model can be as small as a single morpheme, or as large as an entire phrase or sentence. There is no architectural constraint on the size or structure of the pieces of syntax which can correspond to a single unit of meaning. Another key non-lexicalist feature of this mechanism is that there is not a separate stage before, during, or after this one where “lexical items” are retrieved from memory independently from the syntactic structure building processes they participate in. In this model, the process of retrieving stored pieces of syntactic structure is integrated with the generation of novel syntactic structures, performed at the same time by the same mechanism, following the same set of syntactic principles.
3. Pre-syntactic prosody: Once the message has been generated, the speaker can know some things about the form that the utterance will take, even without having yet computed the full syntactic structure or phonological form. Message elements such as whether the utterance is a question or a declarative, as well as the social dynamics and discourse conditions involved, are often reflected in the prosodic structure of the utterance. For example, in English, if an utterance is a question, it will often exhibit both wh-movement (a syntactic phenomenon) as well as question prosody, which often involves rising pitch (a prosodic phenomenon). Because these differences involve both syntactic and temporally-bound properties, there may be an early process of encoding some temporally-bound components during the mapping between message and syntactic structure. The syntactic structure includes no indication of how the elements in the syntactic structure should be linearized, and cannot store prosodic information, and thus the sentence-level prosodic contour must be represented separately from the syntactic structure being generated.
4. Syntactic structure mapped to segments of phonology: Once the syntactic structure has been built, the next challenge is how that structure can be mapped to some kind of linear form in order to meet the constraints of the articulatory modality. The phonological word may correspond to a single syntactic unit (such as monomorphemic words in English), or it may correspond to a larger segment of the syntactic structure, even pieces that do not compose a single constituent. In English, contractions such as “I'll,” “she's,” “let's,” or “dyawanna” (do you want to) involve a single phonological word that spans over a set of syntactic terminals that are not constituents. The ability to map phonology from larger segments of syntactic structure makes possible suppletion and allomorphy that are conditioned by the larger syntactic context. Thus, the output of this mechanism is a set of phonological units which may not transparently reflect syntactic structure. Various movement operations that occur in the interaction between syntax and phonology also happen during this stage [see Embick and Noyer (2001) for more details].
5. Cognitive control: The process of translating a hierarchical structure into a linear string is not a simple one. Many approaches in theoretical syntax assume that a syntax tree encodes no inherent order, only sisterhood and hierarchical relations between units. Rather than a 2-D tree, the representation is more like a spinning mobile. We suggest that cognitive control mechanisms act to facilitate the linearization of this structure. In cognitive science, “cognitive control” generally refers to a collection of processes that help people to complete goal-directed tasks by sustaining the representations required for the task at hand, while inhibiting unrelated or distracting ones. We suggest that in language production, cognitive control is used to sustain linguistic representations and decide between multiple alternatives for linearization. Because each terminal node in a tree may not correspond to its own phonological word, the speaker must hold the syntactic configuration in memory while also identifying the sets of syntactic terminals that would translate to each phonological word and deciding between multiple mapping alternatives. Though the syntactic configuration constrains which elements are put together, the mechanism responsible for mapping syntactic structure to phonological graphs is also sensitive to linear transition probabilities, so other potential mappings are made available which may not be correct given the syntactic structure. Cognitive control mechanisms provide the additional attentional and decision-making resources that the phonology-mapping mechanism needs to identify the correct set of phonological segments for the given syntactic structure while inhibiting others, helping to navigate a complicated translation space.
6. Local phonology and phonological buffer: The next data structure translation moves the proto-utterance closer to a linear string. After the phonological segments have been specified in relation to the syntactic structure, they must be syllabified, and other final re-ordering steps and phonological constraints can apply. This representation also acts as a buffer, holding the output string in memory and releasing phonemes for articulation at the correct time.
7. Post-syntactic prosody: In the mapping between the phonological graphs and the linear string, there must be an influence of phonological stress and prosodic weight in linearization operations. For example, the decision between a double object construction and a prepositional dative is determined in part by prosodic factors, namely the lexical stress properties of the indirect object and the verb (Anttila et al., 2010). Using additional evidence from Irish, Elfner (2011) similarly suggests that the rightward movement which appears in pronoun postposing must be prosodic in nature, rather than syntactic; syntactic movement tends to be leftward, and should not be motivated by the phonological content of the moved elements, so this would otherwise be highly irregular. By controlling when the phonological wordforms are released into the buffer, this linearization mechanism post-syntactically rearranges prosodic phrases, and helps to prepare them to be computed into a string of phonemes.
8. Articulation: Finally, the linearized string of articulatory gestures is sent off to various articulatory motor mechanisms, in order to be produced.
Details aside, this brief summary of our forthcoming model is meant primarily to illustrate how cognitive and neural models of production can easily be constructed around non-lexicalist theories of the organization of linguistic knowledge. Although this preserves many of the insights of lexicalist production models, such as the idea that the syntactic processes generally precede phonological processes (Levelt and Indefrey, 2000; Ferreira and Slevc, 2007), in our non-lexicalist model the assumed stored representations are different, and the kinds of translations which those representations undergo must also be different. This non-lexicalist production model makes no distinction between “structural processes” and “lexical processes,” because the syntactic units which combine in the syntax are governed by the same syntactic processes. As motivation for the Consensus Model of language production, Ferreira and Slevc (2007) emphasize a distinction between “content” and “function,” in order to explain how language can be simultaneously systematic (linguistic expressions have consistent, identifiable meanings) and productive (linguistic expressions can be combined in infinite ways). A non-lexicalist model like ours can model both the systematicity and productivity of human language without such a distinction. Units of meaning are able to systematically map onto pieces of syntax, and pieces of syntax can systematically map onto units of form (conditioned on its syntactic context). Productivity is possible in this model because multiple units of meaning can map onto multiple pieces of syntax which can be combined in infinitely many ways, according to the syntax of the language.
We agree with production models which assume lexical items as treelets with much internal structure, such that stored linguistic knowledge can include large complexes of syntactic structure (Kempen and Huijbers, 1983; Vosse and Kempen, 2000; Ferreira, 2013; Matchin and Hickok, 2020). However, where these models typically assume as a fundamental property of the language system that each treelet has their own meaning and form, a non-lexicalist model like the one shown here allows more flexibility about how stored meaning, syntax, and form align, and does not require an additional process of lexicalization. In the non-lexicalist approach, there can be symmetrical “triadic” mappings, but this is not a necessary or central component of the language system. More broadly, non-lexicalist models that assume no “lexical” representations independent of meaning, syntax, and form, differ from neuroanatomical models that posit a distinct brain region or neural mechanism associated with “lexical nodes.” For example, Wilson et al. (2018)'s model proposes that there is an area of the brain [the dorsal lip of the superior temporal sulcus (STS)] which is associated with lexical nodes, and that this region is spatially and functionally distinct from “higher level syntax.7” In our view, no such distinction is possible.
We have argued here for moving away from production models that center stored linguistic knowledge around lemma representations. Caramazza (1997) also famously argued against the lemma model, for slightly different reasons. Caramazza's point was that the experimental evidence which supports a two-stage model of lexical access—where syntactic and semantic information can be retrieved separately from the corresponding phonological form—does not entail that there must be a separate lemma representation as well. We are generally sympathetic to this conclusion. However we note that the alternative Caramazza proposed, the Independent Network Model, is different from standard non-lexicalist approaches in linguistics because it allows for direct mappings between meaning and form that bypass syntax [the Parallel Architecture model makes a similar assumption; (Jackendoff, 2002)]. Although our non-lexicalist model does not assume lemmas, it does assume that all phonological words and phrases which are produced have a syntactic representation. We think this is an important open question for future research.
3.2. Implications of the non-lexicalist approach for understanding aphasia
The non-lexicalist approach can generate different expectations about what deficit profiles will be observed in aphasia and other language disorders. In giving up the assumption that meaning, syntax, and form all share stored units of the same “size,” this approach recognizes that the bulk of the work involved in language processing is in the translation between structured representations at each level, each with their own rules of well-formedness. Because the translation mechanisms are distinct, an impairment in one mechanism will not impact the others, creating the opportunity for deficits to be masked or distorted. For example, even though the mechanism which maps the message to syntactic structure is early in the production pipeline, disruption to this mechanism will not necessarily result in non-fluent speech or an absence of grammatical material, given that the subsequent processes of generating the phonological form are intact and will apply their own rules of well-formedness.
Based on this, we suggest that an impairment in the mechanism responsible for syntactic structure building would result in utterances that might sound fluent and seem to be conceptually well-formed, but involve errors in syntactic structure, as described for paragrammatism (Matchin et al., 2020). In this situation, all of the pre-syntactic operations are functioning well so the message itself may be well-formed, but its mapping to syntax exhibits some errors; the message may be mapped to the wrong pieces of syntax, there may be difficulties selecting all of the required pieces of syntax, or different parts of the message may be mapped to incompatible pieces of syntax. However, in a seemingly contradictory way, the utterance which is ultimately produced may appear to be well-formed, simply because the post-syntactic operations are functioning well. The subsequent mechanisms which map the syntactic structure to a phonological form may use transition probabilities and “default” forms to supply missing pieces that were not provided by the syntactic structure, satisfying the well-formedness rules of the phonology, making it seem as if there are fewer errors in the syntactic structure than there actually were. Even if large pieces of the syntactic structure are missing or incorrect, the language system may be able to produce something that appears phonologically well-formed, even if it does not correspond to the message that the speaker intended. We assume that the relevant circuit for syntactic processing is localized to the posterior middle temporal gyrus and superior temporal sulcus, consistent with Matchin and Hickok (2020) and Matchin et al. (2020).
A useful metaphor for this is an assembly line in a factory that makes and decorates cake. The assembly line has three steps: making the batter and pouring it into molds (meaning mapped to syntactic structure), one that bakes and stacks the layers of cake (building the syntactic structure), and one that decorates the outside of the cake with fondant and frosting (phonological operations). If the machine that bakes and stacks the layers of cake is broken, it might under- or over-bake the layers, stack the layers incorrectly, or damage the layers along the way (creating an ungrammatical utterance). However, once the cake gets to the frosting machine, the frosting will make it look like a beautiful cake even if the structure of the cake is faulty (producing a phonologically coherent sentence, despite its structural flaws).
In this way, appearances can be deceiving. As long as a given string is phonologically well-formed, as external observers we may not necessarily know if it was also syntactically well-formed. By moving away from the “triad,” just knowing that a phonological word was correctly produced may not be indicative that its meaning and syntax were also correctly generated, only that a form was produced. The only part we have direct access to is the utterance. For that reason, testing theories of aphasia may require more careful thought about what other processes may be at work beyond the one mechanism which is impaired, and how they might hide the real deficits.
Conversely, agrammatic aphasia (also Broca's aphasia, or non-fluent aphasia) is the type of aphasia that has often been described as a syntactic deficit, arising after lesions to the left IFG. It is characterized by “telegraphic speech” that seems to lack function words and inflectional morphology. Many of the observed deficits in non-fluent aphasia associated with inflectional morphology may not indicate a deficit in the representations of those morphemes, but instead that cognitive control is an unappreciated contributor in the linear placement and pronunciation of those morphemes. The impact of this kind of impairment may not be uniform cross-linguistically, given that languages with less flexible morpheme ordering may not involve such complex processes, as the number of plausible linearizations for those morphemes is reduced. Languages like Kalaallisut (West Greenlandic), a polysynthetic language, have a generally fixed morpheme order, with less variable forms; therefore, linearization processes for the morphemes within a single word should involve less cognitive control. It has been observed that speakers of Kalaallisut with non-fluent aphasia do not exhibit the usual pattern of deficits for functional morphology, and are able to produce the rich inflections of Kalaallisut words with a high degree of accuracy (Nedergaard et al., 2020). While morpheme order is generally fixed in Kalaallisut, word order is not; speakers of Kalaallisut with non-fluent aphasia do tend to produce fewer words in a single utterance, even while the words themselves are well-formed. This cognitive control mechanism, therefore, can contribute to varying degrees depending on the range of different linearization options available to a given structure.
Furthermore, it is often reported in the literature that non-fluent aphasia is associated with deficits in regular verb inflections, more so than irregular verb inflections, as an impairment in the grammar (Pinker and Ullman, 2002). However, a meta-analysis has shown that the pattern of deficits for regular and irregular verb inflections actually varies widely across language groups (Faroqi-Shah, 2007); German and Dutch speakers appear to exhibit disproportionate deficits for irregular inflections instead. As discussed by Krauska and Feldman (2022), the variability in the pattern of deficits cross-linguistically can be attributed to other factors such as verb frequency and form predictability. In the non-lexicalist approach, the relevant process involved in providing the inflected form of a verb is the mapping of syntactic objects to phonology, in a way that is probabilistic and context-sensitive. Given this, we are able to suggest that a speaker's success at this task can be conditioned on the predictability and frequency of the transformation. Consequently, the difference between German speakers and English speakers in inflection deficits may arise due to other differences in the past-tense inflection in those two languages, rather than representational differences.
Another commonly observed deficit in non-fluent aphasia is related to verbs (Thompson et al., 2012). This can also be understood as an issue of linearization, involving verbal argument structure and the linear ordering of the elements in the sentence, which can be specified for individual verbs, and exhibit some variability depending on the structure of the sentence. For example, in the sentence, “John gave some flowers to Susan,” the elements can be arranged in a number of ways:
(5) a. John gave some flowers to Susan.
b.John gave Susan some flowers.
c.Susan was given some flowers by John.
d.Flowers were given to Susan by John.
Even if the decision between the different constructions can be motivated by different factors (information structure, discourse, etc.) these are all possible ways that the elements in a sentence might be ordered. The cognitive control required to produce one of these four sentences—while inhibiting the others—is not trivial.
4. Conclusion
At this point, one might be asking, what is a “word” then, if not a triad of meaning, syntax, and form? It is true that as language users, we seem to have intuitions about wordhood, about what constitutes a single word and what does not (even if those intuitions may vary). However, those intuitions are hard to formulate into a coherent hypothesis about linguistic units (Haspelmath, 2017). Wordhood should not be defined as a “unit of meaning,” because things which are “intuitive words” may not be meaningful (as in the expletive it in the sentence it is raining), because a single unit of meaning may not correspond to an intuitive word (as is the case for idioms and some compounds), and because an intuitive word may not correspond to a single unit of meaning (a verb often includes tense morphology which encodes additional meanings, and the same holds for contractions8 and morphologically complex intuitive words). We also cannot ground intuitive wordhood in being a “unit of syntax,” because syntactic operations can apply to units smaller than intuitive words, as illustrated by the Inuktitut and Vietnamese examples. It also does not seem that we can ground intuitive wordhood in being a “unit of phonology,” because there exist many phonological words (which define the domain of phonological operations) which are not intuitive words, such as “dyawanna” (“do you want to”) in English. It could be that most of our intuitions about wordhood are in fact grounded not in natural spoken language, but in orthography, among literate communities whose writing system make use of white spaces as separators. For readers of such orthographies, “word” could serve as a useful term for the things between white spaces, which might well define processing units for the reading modality. However, many other writing systems have not made use of this convention, and it is notable that those speakers often have much less developed intuitions about wordhood (Hoosain, 1992). In summary, it is hard to see how speakers' intuitions about wordhood systematically correspond to any representational or processing unit of natural spoken language, although they could correspond to units of certain written languages.
To summarize, lexicalist approaches to language production struggle to account for a number of linguistic phenomena. We have argued here that in order to achieve broader coverage, models of language should not assume a split between morphology and syntax, or that there are “lexical items” which function as triads of meaning, syntax, and form. This knowledge should instead be represented as mappings from meaning to syntactic atoms, and mappings from fully abstract syntactic atoms to form. Non-lexicalist models of the kind outlined here align better with contemporary syntactic theory, providing a coherent production model without relying on lemmas or lemma-like representations. In doing so, such models are better able to capture cross-linguistic data and generate clearer predictions for linguistic behavior in those languages. Within such models, there is space for language-specific optimization processes based on the reliability of mappings between different representations, and the number of licit possibilities for that mapping, which may vary across individual words or phrases and between different languages. Finally, we have argued that non-lexicalist models can provide a new perspective on the processes and representations that may be impacted by aphasia and other language disorders, hopefully contributing to a better understanding of how language production mechanisms are implemented in the brain and the nature of language deficits after a brain injury.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
AK contributed to the conceptualization and wrote the first draft of the manuscript. EL was involved in conceptualization, supervision, and funding acquisition. All authors contributed to manuscript revision, read, and approved the submitted version.
Funding
This research was supported by a grant awarded to EL from the National Science Foundation (BCS-1749407).
Acknowledgments
We thank Omer Preminger, William Matchin, William Idsardi, David Embick, and the UMD Department of Linguistics for their contributions and feedback. The preprint for this paper is on PsyArXiv (Krauska and Lau, 2022).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Footnotes
1. ^These examples come from the Utkuhiksalingmiut dialect of Inuktitut, which is currently spoken in the Inuit communities in Gjoa Haven, Baker Lake, and formerly in the Black River area of Nunavut.
2. ^There is a wide array of evidence that morphemes are hierarchically structured, both from lexicalist and non-lexicalist accounts. For example, the English word “unlockable,” can either mean “able to be unlocked” or “not able to be locked;” the ambiguity in meaning can be analyzed as a structural ambiguity between [[un - lock] - able] and [un - [lock - able]]. The debate here is not whether morphemes are hierarchically structured, but whether that hierarchical structure is morphosyntactic or purely morphological in nature. Baker (1985) and other non-lexicalist approaches argue for the former, while lexicalist accounts argue for the latter. Morphemes only being linearly ordered is a more general issue for the lemma model, not just because of their lexicalist assumptions.
3. ^Hiaki (also referred to as Yaqui or Yoeme) is an Uto-Aztecan language spoken in the states of Arizona (USA) and Sonora (Mexico).
4. ^It is important to note here that this is about the syntactic feature of number, not the semantic feature. Something being semantically plural does not necessitate that it is syntactically plural, and vice versa. For example, “scissors” is syntactically plural, while being semantically singular, while “furniture” is syntactically singular while being semantically plural. In the cases where there is a mismatch between the syntactic and semantic features, agreement always occurs with the syntactic features, not the semantic ones. Furthermore, if there is a mismatch in conceptual number features but not syntactic number features, the sentence will be grammatical, even if it is semantically odd. Some verbs like “juggle” seem to require a plural object at a conceptual level (# John juggled the task), but the sentence is still syntactically well-formed (contrast with a sentence like “the furniture are in the living room,” which involves agreement mismatch). As a consequence of this, it cannot be the case that the features necessary for agreement or argument structure are necessarily available at a purely conceptual level.
5. ^If the syntactic structure is built only after the lemmas have been retrieved, and the speaker wants to use a verb such as devour, they may not have selected the lemma for the object even if one would be required, given that the syntactic requirements of the verb may not correspond to semantic or conceptual arguments. Because the model is serial, there would be no way to “go back” and retrieve the missing lemma.
6. ^For example, in the sentence “it rained,” the expletive it does not correspond to an entity involved in the intended message, but is inserted due to the syntactic properties of English requiring sentences to have a subject.
7. ^Wilson et al. (2018) observed that the dorsal lip of the STS responded to both backward speech and scrambled writing, and that the response was seemingly equivalent in both visual (written) and auditory (spoken) modalities. Based on this observation, they concluded that this modality-independent response in the absence of linguistic content or structure suggested the activation of lexical nodes. We favor other explanations; for example, this effect could be the product of modality-independent phonological processing, which is well-known to occur during reading as well as speech.
8. ^It should be noted that contractions are a case where speakers seem to have less clear intuitions about wordhood (e.g., whether “we've” should be counted as one word or two).
References
Anttila, A., Adams, M., Speriosu, M. (2010). The role of prosody in the English dative alternation. Lang. Cogn. Process. 25, 946–981. doi: 10.1080/01690960903525481
Aronoff, M. (1976). Word Formation in Generative Grammar. Linguistic Inquiry Monographs. Cambridge, MA: MIT Press.
Bhattasali, S., Fabre, M., Luh, W.-M., Al Saied, H., Constant, M., Pallier, C., et al. (2019). Localising memory retrieval and syntactic composition: An fmri study of naturalistic language comprehension. Lang. Cogn. Neurosci. 34, 491–510. doi: 10.1080/23273798.2018.1518533
Bock, K. (1995). “Chapter 6 - Sentence roduction: From mind to mouth,” in Speech, Language, and Communication, 2nd Edn, Handbook of Perception and Cognition, eds J. L. Miller and P. D. Eimas (San Diego, CA: Academic Press), 181–216.
Briggs, J. L., Johns, A., Cook, C. (2015). Dictionary of Utkuhiksalingmiut Inuktitut Postbase Suffixes. Iqaluit: Nunavut Arctic College.
Brown-Schmidt, S., Konopka, A. E. (2015). Processes of incremental message planning during conversation. Psychon. Bullet. Rev. 22, 833–843. doi: 10.3758/s13423-014-0714-2
Bruening, B. (2018). The lexicalist hypothesis: Both wrong and superfluous. Language 94, 1–42. doi: 10.1353/lan.2018.0000
Caramazza, A. (1997). How many levels of processing are there in lexical access? Cogn. Neuropsychol. 14, 177–208. doi: 10.1080/026432997381664
Chomsky, N. (1970). Readings in English Transformational Grammar, Chapter Remarks on Nominalization. Boston, MA: Ginn and Company, 184–221.
Cook, C., Johns, A. (2009). Determining the semantics of Inuktitut postbases. Variations on Polysynthesis. (Amsterdam: John Benjamins Publishing Company), 149–170.
Cutting, J. C., Bock, K. (1997). That's the way the cookie bounces: Syntactic and semantic components of experimentally elicited idiom blends. Memory Cogn. 25, 57–71. doi: 10.3758/BF03197285
Dell, G. S., Oppenheim, G. M., Kittredge, A. K. (2008). Saying the right word at the right time: Syntagmatic and paradigmatic interference in sentence production. Lang. Cogn. Process. 23, 583–608. doi: 10.1080/01690960801920735
Eberhard, K. M., Cutting, J. C., Bock, K. (2005). Making syntax of sense: Number agreement in sentence production. Psychol. Rev. 112, 531. doi: 10.1037/0033-295X.112.3.531
Elfner, E. (2011). “The interaction of linearization and prosody: Evidence from pronoun postposing in Irish,” in Formal Approaches to Celtic Linguistics ed A. Carnie (Newcastle upon Tyne: Cambridge Scholars Publishing), 17–40.
Embick, D., Noyer, R. (2001). Movement operations after syntax. Linguist. Inq. 32, 555–595. doi: 10.1162/002438901753373005
Faroqi-Shah, Y. (2007). Are regular and irregular verbs dissociated in non-fluent aphasia? A meta-analysis. Brain Res. Bullet. 74, 1–13. doi: 10.1016/j.brainresbull.2007.06.007
Ferreira, F. (2013). “Syntax in language production: An approach using tree-adjoining grammars,” in Aspects of Language Production eds H. K. Locke, K. S. Jay and B. Sylvain (London: Psychology Press), 111–176.
Ferreira, V. S., Slevc, L. R. (2007). ‘Grammatical encoding,” in The Oxford Handbook of Psycholinguistics, eds G. M. Gareth and A. Gerry (Oxford: Oxford University Press), 453–469.
Halle, M., Marantz, A. (1993). “Distributed morphology and the pieces of inflection,” in The View From Building 20 (Cambridge, MA: The MIT Press), 111–176.
Harley, H. (2008). “On the causative construction,” in Oxford Handbook of Japanese linguistics eds M. Shigeru and S. Mamoru (Oxford: Oxford University Press), 20–53.
Harley, H. (2014). On the identity of roots. Theoret. Linguist. 40, 225–276. doi: 10.1515/tl-2014-0010
Haspelmath, M. (2017). The indeterminacy of word segmentation and the nature of morphology and syntax. Folia Linguist. 51, 31–80. doi: 10.1515/flin-2017-1005
Hoosain, R. (1992). Psychological reality of the word in chinese. In Adv. Psychol. 90, 111–130. doi: 10.1016/S0166-4115(08)61889-0
Jackendoff, R. (1975). Morphological and semantic regularities in the lexicon. Language 1975, 639–671.
Jackendoff, R. (2002). “English particle constructions, the lexicon, and the autonomy of syntax,” in Verb-particle explorations, eds D. Nicole (Berlin: Mouton de Gruyter), 1, 67–94.
Kaplan, L. (2003). “Inuit snow terms: How many and what does it mean?” in Building Capacity in Arctic Societies: Dynamics and Shifting Perspectives. Proceedings From the 2nd IPSSAS Seminar (Iqaluit), vol. 2.
Kempen, G., Hoenkamp, E. (1987). An incremental procedural grammar for sentence formulation. Cogn. Sci. 11, 201–258. doi: 10.1207/s15516709cog1102_5
Kempen G. and Huijbers, P.. (1983). The lexicalization process in sentence production and naming: Indirect election of words. Cognition 14, 185–209. doi: 10.1016/0010-0277(83)90029-X
Krauska A. and Feldman, N. H.. (2022). “Modeling the regular/irregular dissociation in non-fluent aphasia in a recurrent neural network,” in Proceedings of the Annual Meeting of the Cognitive Science Society (Toronto), vol. 44, 1690–1697.
Krauska, A. B., Lau, E. (2022). Moving away from lexicalism in psycho- and neuro-linguistics. PsyArXiv [preprint]. doi: 10.31234/osf.io/vyf94.
Kuiper, K., Van Egmond, M.-E., Kempen, G., Sprenger, S. (2007). Slipping on superlemmas: Multi-word lexical items in speech production. Mental Lexicon 2, 313–357. doi: 10.1075/ml.2.3.03kui
Lapointe, S. (1980). A Theory of Grammatical Agreement. (Ph.D. thesis), University of Massachusetts, Amherst, MA, United States.
Levelt, W. J. (1992). Accessing words in speech production: Stages, processes and representations. Cognition 42, 1–22. doi: 10.1016/0010-0277(92)90038-J
Levelt, W. J., Indefrey, P. (2000). “The speaking mind/brain: Where do spoken words come from?” in Image, Language, Brain: Papers From the First Mind Articulation Project Symposium (Cambridge, MA: MIT Press), 77–94.
Levelt, W. J., Roelofs, A., Meyer, A. S. (1999). A theory of lexical access in speech production. Behav. Brain Sci. 22, 1–38. doi: 10.1017/S0140525X99001776
Marr, D. (1982/2010). Vision: A Computational Investigation Into the Human Representation and Processing of Visual Information. New York, NY: W.H. Freeman and Company.
Martin, L. (1986). “Eskimo words for snow:” A case study in the genesis and decay of an anthropological example. Am. Anthropol. 88, 418–423. doi: 10.1525/aa.1986.88.2.02a00080
Matchin, W., Basilakos, A., Stark, B. C., den Ouden, D.-B., Fridriksson, J., Hickok, G. (2020). Agrammatism and paragrammatism: A cortical double dissociation revealed by lesion-symptom mapping. Neurobiol. Lang. 1, 208–225. doi: 10.1162/nol_a_00010
Matchin, W., Hickok, G. (2020). The cortical organization of syntax. Cerebr. Cortex 30, 1481–1498. doi: 10.1093/cercor/bhz180
Nedergaard, J. S., Martínez-Ferreiro, S., Fortescue, M. D., Boye, K. (2020). Non-fluent aphasia in a polysynthetic language: Five case studies. Aphasiology 34, 675–694. doi: 10.1080/02687038.2019.1643000
Noyer, R. (1998). Vietnamese “Morphology” and the Definition of Word. University of Pennsylvania Working Papers in Linguistics, vol. 5, 5.
Pinker, S., Ullman, M. T. (2002). The past and future of the past tense. Trends Cogn. Sci. 6, 456–463. doi: 10.1016/S1364-6613(02)01990-3
Pollard, C., Sag, I. A. (1994). Head-Driven Phrase Structure Grammar. Chicago, IL: University of Chicago Press.
Preminger, O. (2021). “Natural language without semiosis,” in Presentation at the 14th Annual Conference on Syntax, Phonology and Language Analysis (SinFonIJA 14), (Novi Sad).
Pullum, G. K. (1989). The great Eskimo vocabulary hoax. Nat. Lang. Linguist. Theor. 1989, 275–281. doi: 10.1007/BF00138079
Roelofs, A., Meyer, A. S., Levelt, W. J. (1998). A case for the lemma/lexeme distinction in models of speaking: Comment on caramazza and miozzo (1997). Cognition 69, 219–230.
Sag, I. A., Baldwin, T., Bond, F., Copestake, A., Flickinger, D. (2002). “Multiword expressions: A pain in the neck for NLP,” in International Conference on Intelligent Text Processing and Computational Linguistics (Berlin/Heidelberg: Springer), 1–15.
Sánchez, J., Trueman, A., Leyva, M. F., Alvarez, S. L., Blanco, M. T., Jung, H.-K., et al. (2017). An Introduction to Hiaki Grammar: Hiaki Grammar for Learners and Teachers, Vol. 1. Scotts Valley, CA: CreateSpace Independent Publishing Platform.
Siddiqi, D. (2010). Distributed morphology 1. Lang. Linguist. Compass 4, 524–542. doi: 10.1111/j.1749-818X.2010.00212.x
Slobin, D. I. (1996). From “Thought and Language” to “thinking for speaking.”, volume 17 of Studies in the Social and Cultural Foundations of Language (Cambridge: Cambridge University Press), 70–96.
Sprenger, S. A., Levelt, W. J., Kempen, G. (2006). Lexical access during the production of idiomatic phrases. J. Mem. Lang. 54, 161–184. doi: 10.1016/j.jml.2005.11.001
Starke, M. (2009). Nanosyntax: A short primer to a new approach to language. Nordlyd 36, 1–6. doi: 10.7557/12.213
Thompson, C. K., Lukic, S., King, M. C., Mesulam, M. M., Weintraub, S. (2012). Verb and noun deficits in stroke-induced and primary progressive aphasia: The Northwestern naming battery. Aphasiology 26, 632–655. doi: 10.1080/02687038.2012.676852
Vosse, T., Kempen, G. (2000). Syntactic structure assembly in human parsing: A computational model based on competitive inhibition and a lexicalist grammar. Cognition 75, 105–143. doi: 10.1016/S0010-0277(00)00063-9
Williams, E. (1981). On the notions “lexically related” and “head of a word.” Linguist. Inq. 12, 245–274.
Keywords: lexicalism, psycholinguistics, neurolinguistics, language production, lemma, aphasia
Citation: Krauska A and Lau E (2023) Moving away from lexicalism in psycho- and neuro-linguistics. Front. Lang. Sci. 2:1125127. doi: 10.3389/flang.2023.1125127
Received: 15 December 2022; Accepted: 26 January 2023;
Published: 13 February 2023.
Edited by:
Simona Mancini, Basque Center on Cognition, Brain and Language, SpainReviewed by:
Giosuè Baggio, Norwegian University of Science and Technology, NorwayElliot Murphy, University of Texas Health Science Center at Houston, United States
Copyright © 2023 Krauska and Lau. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Alexandra Krauska,  YWtyYXVza2FAdW1kLmVkdQ==
YWtyYXVza2FAdW1kLmVkdQ==