
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Immunol., 02 April 2025
Sec. Cancer Immunity and Immunotherapy
Volume 16 - 2025 | https://doi.org/10.3389/fimmu.2025.1545976
This article is part of the Research TopicChallenges and Opportunities in Tumor MetabolomicsView all 3 articles
 Liang Zheng1†
Liang Zheng1† Wei Nie1†
Wei Nie1† Shuyuan Wang1†
Shuyuan Wang1† Ling Yang2†
Ling Yang2† Fang Hu3,4Meili Ma1Lei Cheng1Jun Lu1
Fang Hu3,4Meili Ma1Lei Cheng1Jun Lu1 Bo Zhang1
Bo Zhang1 Jianlin Xu1Ying Li1Yinchen Shen1Wei Zhang1
Jianlin Xu1Ying Li1Yinchen Shen1Wei Zhang1 Runbo Zhong1
Runbo Zhong1 Tianqing Chu1
Tianqing Chu1 Baohui Han1Xiaoxuan Zheng1,5*
Baohui Han1Xiaoxuan Zheng1,5* Hua Zhong1*
Hua Zhong1* Xueyan Zhang1*
Xueyan Zhang1*Background: Unlike lung adenocarcinoma, patients with advanced squamous carcinoma exhibit a low proportion of driver gene positivity, with fewer effective treatment strategies available. Chemoimmunotherapy has now become the standard first-line treatment for individuals diagnosed with advanced lung squamous carcinoma. Serum metabolomics holds significant potential for application in predicting responses to chemoimmunotherapy and is capable of identifying and validating potential biomarkers. The aim of our study was to establish a model that can predict the prognosis of chemoimmunotherapy in patients with advanced lung squamous cell carcinoma, integrating metabolomics with machine learning techniques.
Methods: We collected 79 serum samples from patients with advanced lung squamous cell carcinoma before receiving combined immunotherapy and performed untargeted metabolomics analysis. Patients were divided into non-response (NR) and response (R) groups according to overall survival (OS), and prognostic models were constructed and validated using different machine learning methods. The patients were further categorized into high-risk and low-risk groups based on the median risk score, to assess the model's predictive performance.
Results: There were significant differences in metabolites and metabolic pathways between NR and R groups, and 117 differential metabolites were preliminarily screened (p < 0.05, VIP > 1). Further, least absolute shrinkage and selection operator (LASSO) and random forest (RF) were used to identify metabolites, and then their common metabolites were used as the best biomarkers to build a prediction model containing 8 differential metabolites. Based on these biomarkers, RF, support vector machine (SVM) and logistic regression were used to randomly divide patients into training and validation sets in a 7:3 ratio, respectively. We found that the RF method resulted in area under curves (AUCs) of 0.973 and 0.944 for the training and validation sets, respectively, with the best predictive performance. Subsequently, both OS and progression-free survival (PFS) were notably reduced in the high-risk group when contrasted with the low-risk group.
Conclusions: We developed a model containing 8 metabolites based on metabolomics and machine learning that may predict survival outcomes in patients with advanced lung squamous cell carcinoma undergoing chemoimmunotherapy, helping to more accurately assess efficacy and prognosis in clinical practice.
Lung cancer is one of the malignant tumors with the highest incidence rate and mortality in the world (1, 2). Non-small cell lung cancer (NSCLC) accounts for about 80%-85%, including histological subtypes such as adenocarcinoma and squamous cell carcinoma (3). Among them, squamous cell carcinoma accounts for about 30% of NSCLC and is a common type of lung cancer (4). Moreover, squamous cell carcinoma often remains asymptomatic in its initial stages. However, by the time it is detected, the disease may have advanced to a later stage, resulting in a less favorable prognosis (5). Compared to patients with lung adenocarcinoma, due to the limited number of driver gene mutations in patients with advanced lung squamous cell carcinoma, the options for targeted therapy are limited, and chemotherapy was once the main treatment method (6, 7). However, patients receiving chemotherapy alone often develop drug resistance quickly and have some adverse effects. With the development of immunotherapy, the treatment strategies for lung squamous cell carcinoma have undergone significant changes. Immunotherapy, which activates or enhances the patient's own immune system to attack tumor cells, has become an important component of the treatment of lung squamous cell carcinoma (8).
In recent years, multiple clinical studies have shown that immunotherapy combined with chemotherapy can significantly improve the survival of patients with lung squamous cell carcinoma, such as the CheckMate 017 (9) and CheckMate 078 studies (10). Immunotherapy biomarkers for lung squamous cell carcinoma mainly include PD-L1 (programmed cell death ligand 1) expression levels and tumor mutation burden (TMB). However, it has been shown that PFS was significantly superior in the combination arm regardless of PD-L1 expression level (11). This suggests that the efficacy of the combined regimen in patients with advanced squamous cell carcinoma cannot be predicted based on PD-L1 expression levels alone. TMB is also controversial as a biomarker to predict the efficacy of immunotherapy plus chemotherapy, especially there is no uniform standard for the selection of TMB detection methods and thresholds (12). Therefore, it is crucial to discover more new biomarkers to more accurately identify which advanced lung squamous cell carcinoma patients with negative driver genes are most likely to benefit from immune combination therapy.
Traditional biomarkers tend to be obtained from tumor specimens at a single time point, are invasive, cannot dynamically monitor changes in the tumor immune microenvironment, and there is heterogeneity in tumor tissues, which are limitations of past biomarkers. Blood specimens can be obtained more easily, causing less trauma and discomfort to the patient, and repeated and multiple sampling can be performed (13). It is also able to track the dynamic changes during treatment, reflect tumor and host microenvironment changes, and compensate for the limitations of biopsy or puncture samples that cannot obtain the full picture of the tumor (14). Metabolites in blood identify early biochemical changes in disease and have been widely used in disease prediction (15). With the development of omics technology, especially metabolomics technology, it has become a hot spot to use multiple metabolomics feature profiles and integrate multiple biomarkers based on Artificial Intelligence (AI) modeling to improve disease prediction accuracy (16). We found that previous studies have constructed early screening models for lung cancer based on metabolomics (17, 18), but there is still a lack of exploration in constructing models to predict the efficacy of immunotherapy combined with chemotherapy for advanced lung squamous cell carcinoma.
Therefore, our study aimed to compare metabolic pathways and metabolite differences between different efficacy in driver gene-negative advanced squamous cell carcinoma of the lung patients receiving first-line immunotherapy combined with chemotherapy using serum untargeted metabolomics. Prediction models were constructed based on various methods such as least absolute shrinkage and selection operator (LASSO), random forest (RF), support vector machine (SVM), and logistic regression (LR) to explore potential biomarkers that may predict survival outcomes in patients with advanced squamous cell carcinoma of the lung who are driver gene negative.
We retrospectively screened 3124 patients treated at Shanghai Chest Hospital from July 2020 to July 2021, and finally included 79 patients who met the criteria and ended follow-up on April 31, 2024. All patients provided written informed consent, which was approved by the Ethics Committee and Institutional Review Board of Shanghai Chest Hospital (Reference number: LS1808). The inclusion criteria were: (1) histologically or cytologically confirmed squamous cell carcinoma of the lung; (2) stage IIIB to IV according to the ninth version of TNM, which was not suitable for radical surgery; (3) having measurable lesions; and (4) receiving first-line PD-1 (programmed cell death 1) inhibitor combination chemotherapy. (5) Eastern Cooperative Oncology Group (ECOG) performance status (PS) score between 0 and 1. Exclusion criteria were: (1) presence of driver gene mutations; (2) surgical treatment after immunotherapy; (3) active infection, such as HIV, hepatitis B, hepatitis C, etc.; (4) incomplete clinical data or did not complete the necessary systemic examination; (5) patients with other primary active malignancies; (6) patients with a history of autoimmune diseases, severe cardiopulmonary dysfunction or other serious complications.
We collected clinical information on patients' age, sex, smoking history, TNM stage, PD-L1 expression, ECOG PS, etc. via the hospital 's electronic system of medical records. Patients were treated with PD-1 inhibitors combined with chemotherapeutic agents administered every 3-4 weeks as a cycle until disease progression or serious adverse reactions or death. Immunologic medications included pembrolizumab, tislelizumab, cariselizumab, and sintilimab at a single dose of 200 mg. According to the patient 's body surface area and tolerance, the specific chemotherapy drug administration regimen was generally platinum-based doublet, platinum drugs included carboplatin, cisplatin, lobaplatin or nedaplatin, drugs used in combination with platinum drugs included paclitaxel drugs, gemcitabine or docetaxel; for patients not suitable for platinum drugs, gemcitabine combined with vinorelbine or gemcitabine combined with docetaxel is given. Patients' condition will be assessed before each cycle by chest computed tomography (CT), abdominal ultrasound, bone scan, brain enhanced magnetic resonance imaging (MRI) or positron emission tomography-computed tomography (PET-CT), and progression will be judged by at least one professional radiologist and clinical medicine.
Our serum samples were obtained with prior approval from the Shanghai Chest Hospital Clinical Biobank and could be investigated with these samples. Serum samples were previously stored in a -80°C freezer, and we obtained serum samples and performed untargeted metabolomic analysis within 4 weeks before patients received immune combination therapy by consulting patients' blood collection time records.
Serum samples stored in a -80°C freezer were preprocessed for analysis, first thawed on ice and vortexed, and 50 μL of sample was mixed with 300 μL of extraction solution (acetonitrile: methanol = 1:4, volume ratio) in a 2 mL microfuge tube. Vortex again, centrifuge, collect 200 μL of supernatant, place the collected supernatant at -20°C for 30 mins, then centrifuge to obtain 180 μL of supernatant for liquid chromatography-mass spectrometry (LC-MS) analysis (19).
Pretreated serum samples were analyzed by LC-MS in the next step, where the specific setting of the chromatographic part was the column Waters ACQUITY UPLC BEH C18, 1.8 µm particle size, 2.1 mm inner diameter x 100 mm length; the column temperature was 40°C, the flow rate was 0.4 mL/min, and the volume of sample injected into the column was 2 μL. Gradient elution was performed in a solvent system containing 0.1% formic acid in water (mobile phase A) and 0.1% formic acid in acetonitrile (mobile phase B) in steps. That is, 5% mobile phase B started at 0 min; within 11 min, a linear gradient to 90% mobile phase B; 90% mobile phase B was held for 1 min; return to 5% mobile phase B within 0.1 min and hold for 1.9 min to quickly return to starting conditions and prepare for the next injection.
The mass spectrometer was TripleTOF 6600, the data acquisition software was Analyst TF 1.7.1 (Sciex, Concord, ON, Canada), the mass spectrometry acquisition mode was information-dependent acquisition (IDA) mode, and appropriate parameters were set to ensure high sensitivity and resolution of LC-MS analysis. In addition, we prepared a pooled human serum sample from all study participants as a consistent quality control (QC) sample. Then, a blank solvent was used as a negative control. These QC samples were evenly distributed throughout the analysis batches. Specifically, they were inserted every 10 samples to monitor the stability and consistency of the analytical process. For the pooled human serum, we monitored the relative standard deviation (RSD) of the peak areas for major metabolites. An RSD threshold of 30% was set, and any metabolite exceeding this threshold was excluded from further analysis. For the blank solvent, we checked for any carryover effects by ensuring no significant peaks were observed that could indicate contamination from previous samples. It can be used to assess the quality of the data and also to monitor within-run and between-run variability during the analysis. Sample handling and repeatability of the analytical method can be assessed by comparing the results of QC samples analyzed at different time points.
Raw data files generated by the mass spectrometer such as mzML or raw format were converted to mzXML format using ProteoWizard software. Peak extraction was performed using XCMS software and extracted peaks were aligned to correct for minor differences in retention times due to variations in experimental conditions. Peak areas were corrected using the "Support Vector Regression" (SVR) method, and peaks with greater than 50% missing in each group of samples were filtered. Metabolite identification information is then obtained through various libraries such as self-built libraries and public databases as well as using metDNA methods.
The primary endpoint of this study is overall survival (OS), defined as the time from the start of the first treatment until the patients' death from any cause. The secondary endpoint was progression-free survival (PFS), defined as the time from the start of the first treatment to the patients' tumor progression (in any way) or death (in any way). We noticed that several papers mentioned 24-month survival rates and used this as a basis to assess the efficacy of lung cancer immunotherapy (20, 21), so combining the actual survival of 79 patients, we divided patients into Response (R = 41) and Non-Response (NR = 38) groups using 24-month cutoff values. Serum was collected from patients within four weeks prior to chemoimmunotherapy for untargeted metabolomics analysis. Combined with variable impact projection (VIP) and P values, differential metabolites were initially selected, and then the differential metabolites finally included in the model were further selected by LASSO and RF methods (22). Patients were randomly divided into training and validation sets at a ratio of 7:3, modeled using multiple machine learning methods such as RF, SVM, and LR, and then receiver operating characteristic (ROC) curves were plotted to assess model performance. The best model tested by different machine learning methods was selected, then the risk score was calculated, and the total population was divided into low-risk and high-risk groups using the median as the cutoff. Comparison of prognostic differences between high-risk and low-risk groups further assessed model performance.
Baseline characteristics of patients were compared using Chi-square test or Fisher 's exact test. OS and PFS were calculated using Kaplan-Meier method and log-rank test. Univariate and multivariate Cox regression were used to assess the impact of different factors on OS and PFS. ROC curves were utilized to evaluate the predictive capability of each factor. Specifically, the model's classification ability was demonstrated by plotting the relationship between the true positive rate (sensitivity) and the false positive rate (1-specificity). The area under the curve (AUC) was subsequently calculated, with a higher AUC value indicating a stronger predictive ability of the model. Specifically, we followed the procedure outlined below: we generated 1000 bootstrap samples from our dataset. For each bootstrap sample, we calculated the AUC. We sorted the AUC values obtained from the bootstrap samples and determined the 2.5th and 97.5th percentiles to obtain the 95% confidence interval (CI). Let AUC denote the area under the ROC curve, and let CIlower and CIupper denote the lower and upper bounds of the 95% CI, respectively. The results can be expressed as: 95% CI=[CIlower,CIupper].
Orthogonal partial least squares discriminant analysis (OPLS-DA) was used to demonstrate differences between groups, which was accomplished using the MetaboAnalystR package in R software. The volcano plot primarily serves to illustrate the relative content disparities of metabolites between two sets of samples, alongside the statistical significance of these differences. Student's t-test was employed to analyze variables with a normal distribution and equal variance between the two groups, whereas the Mann-Whitney test was utilized for those with a non-normal distribution. Significant differences in selecting differential metabolites were determined by VIP > 1 and p-value < 0.05. The annotation of metabolic pathways, encompassing the differential metabolites, was executed with the aid of the Kyoto Encyclopedia of Genes and Genomes (KEGG) database. LASSO regression was conducted using the glmnet, foreign, and tidyr packages in R, while the RF method was executed via the varSelRF package in R. The R package used by SVM is mainly e1071 package, and the R package used by LR is mainly glm package.
All data analyses were conducted utilizing R version 4.4.1 and SPSS version 26.0, and Adobe Illustrator 2022 was used for picture drawing integration. A p-value less than 0.05 in a two-tailed test was deemed statistically significant.
The overall flow of our study was shown in Figure 1. There were 79 patients in our study who received combination therapy as their first line of treatment. Their baseline clinical characteristics such as age, sex, smoking history, ECOG PS score, TNM stage, number of metastatic organs and PL-L1 expression were shown in Table 1. As can be seen from the Table 1, our selected population was concentrated at ≥ 65 years, male, with a history of smoking, ECOG PS 0, TNM stage IV, and PD-L1 expression ≥ 1%. In Table 2, after we divided 79 patients into NR (OS < 24 months) and R (OS ≥ 24 months) groups according to OS, we then compared the clinical characteristics of the two groups and performed a chi-square test and found that these baseline characteristics were evenly distributed in both groups without statistical difference (P > 0.05).
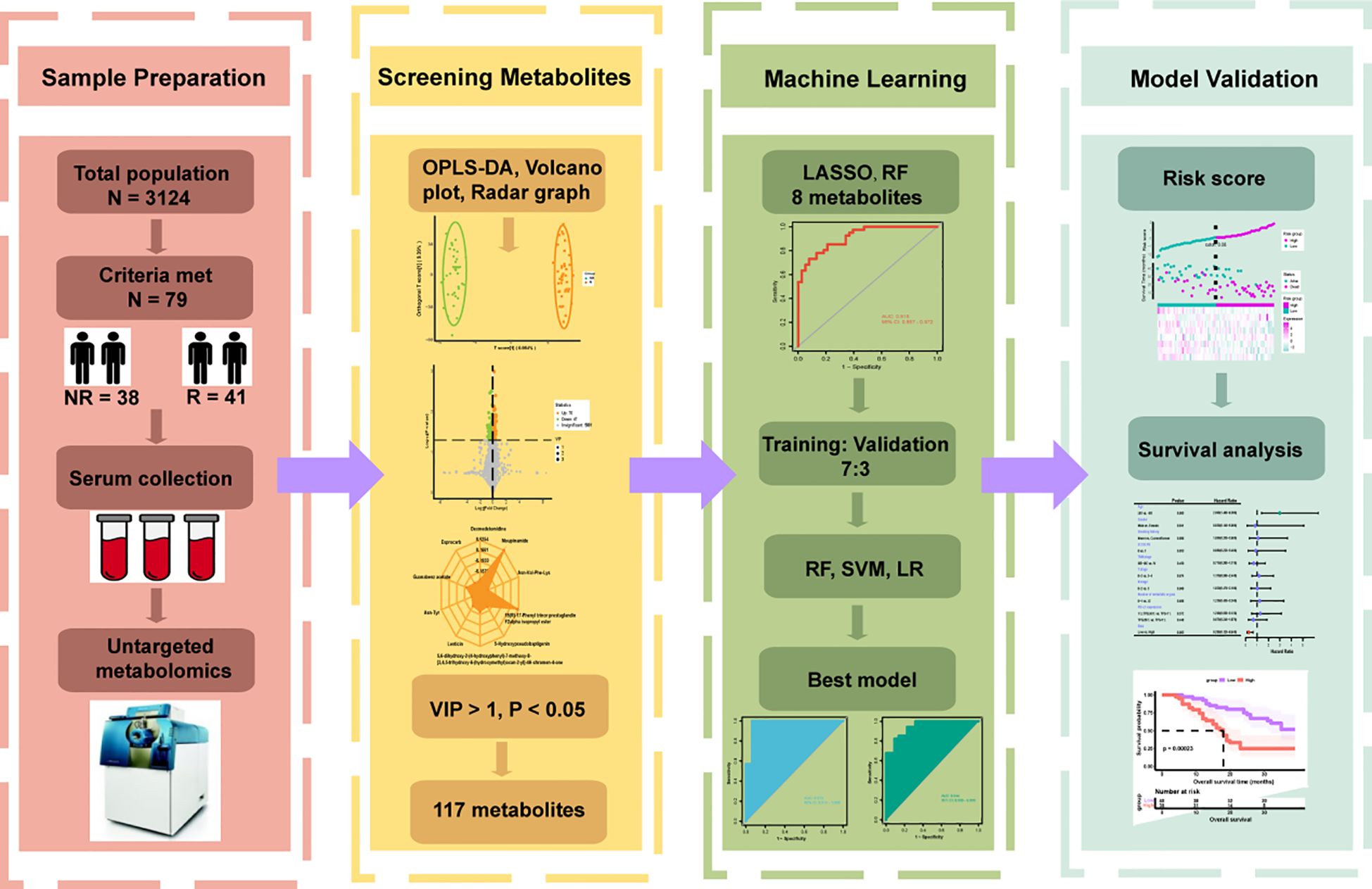
Figure 1. Flowchart of the whole study. According to the inclusion and exclusion criteria, 79 of 3124 patients were enrolled and divided into Response (R = 41) and Non-Response (NR = 38) groups based on overall survival. Serum was collected for untargeted metabolomics analysis before they underwent immunotherapy combined with chemotherapy. Orthogonal partial least squares discriminant analysis (OPLS-DA), volcano plot and radar plot could reflect the differences in metabolic characteristics between the two groups, and 117 differential metabolites were preliminarily selected according to variable importance in projection (VIP) > 1, P < 0.05. Various machine learning algorithms were used to construct the best prediction model and test the prediction performance in combination with clinical features.

Table 1. Baseline clinical characteristics.
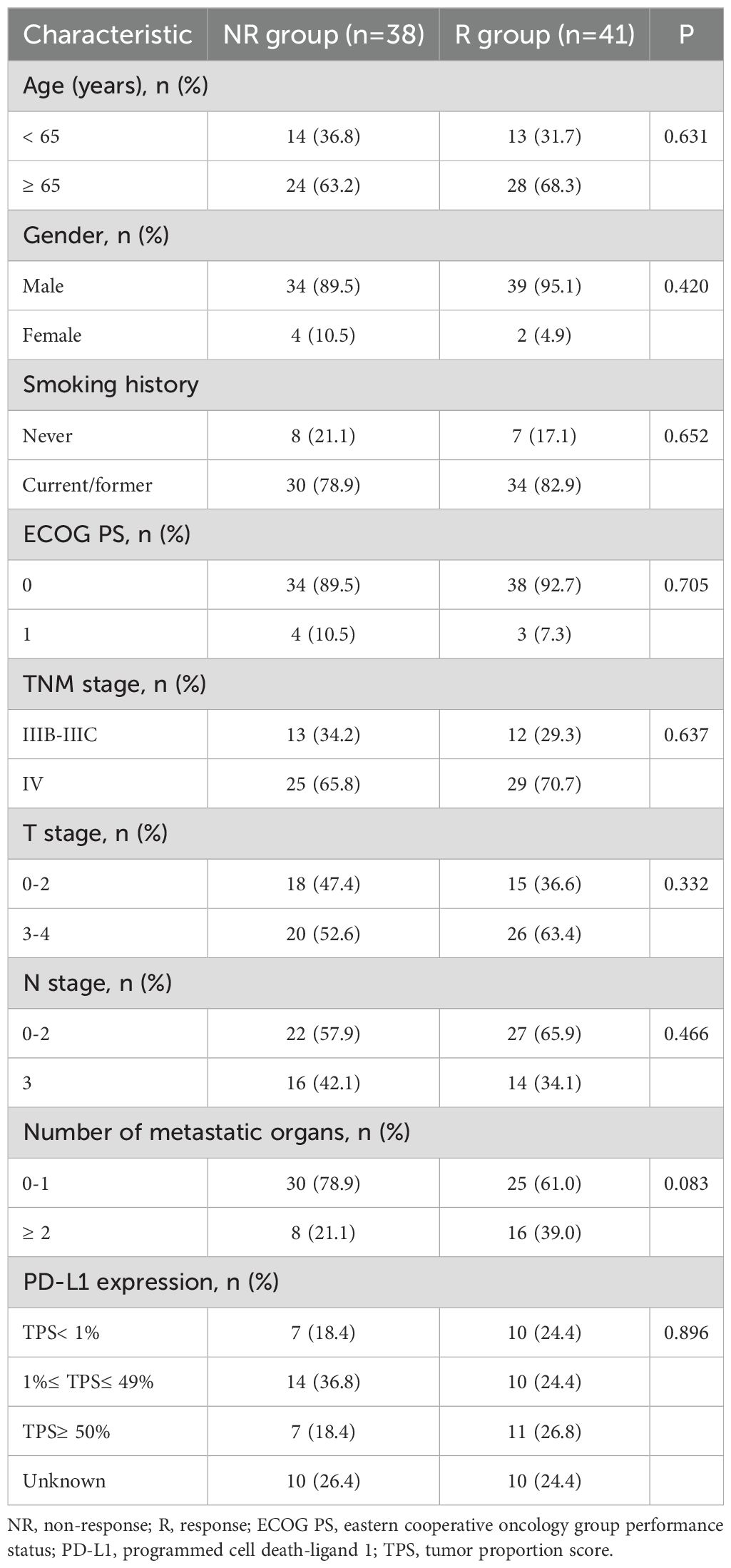
Table 2. Comparison of clinical characteristics between non-response (NR) and response (R) groups.
In order to initially screen for differential metabolites between the two groups, we first verified the rationality of grouping, and the OPLS-DA model showed that the two groups could be significantly separated (Figure 2A), demonstrating that patients with different survival periods had different metabolic profiles. Based on the VIP obtained from the OPLS-DA model (biological replicates ≥ 3), combined with the P-value of univariate analysis (biological replicates ≥ 2), we could initially screen 117 differential metabolites between the two groups (VIP > 1 and P < 0.05). Among them, as shown in volcano plot (Figure 2B), 70 differential metabolites were up-regulated and 47 differential metabolites were down-regulated. In addition to performing statistics on VIP values and P-values for differential metabolites, we also calculated FC values for differential metabolites and plotted radar plots for the top 10 metabolites with the largest difference, i.e., the largest absolute log2FC value. In Figure 2C, these 10 metabolites were Moupinamide, 15(R)-17-Phenyl trinor prostaglandin F2alpha isopropyl ester, Guanabenz acetate, 5,6-dihydroxy-2-(4-hydroxyphenyl)-7-methoxy-8-[3,4,5-trihydroxy-6-(hydroxymethyl)oxan-2-yl]-4H-procen-4-one, 5-Hydroxypseudobaptigenin, Lenticin, Dexmedetamide, Esprocarb, Asn-Tyr, and Asn-Val-Phe-Lys. In addition, we also compared metabolic pathways, and KEGG metabolic pathways were significantly differentially enriched in metabolites between NR and R groups. The closer the P-value is to 0, the more significant the enrichment (Figure 2D). The first five pathways with the smallest size from small to large were Chemical carcinogenesis-receptor activation, Breast cancer, Progesterone-mediated oocyte maturation, Oocyte meiosis, and Cortisol synthesis and secretion.
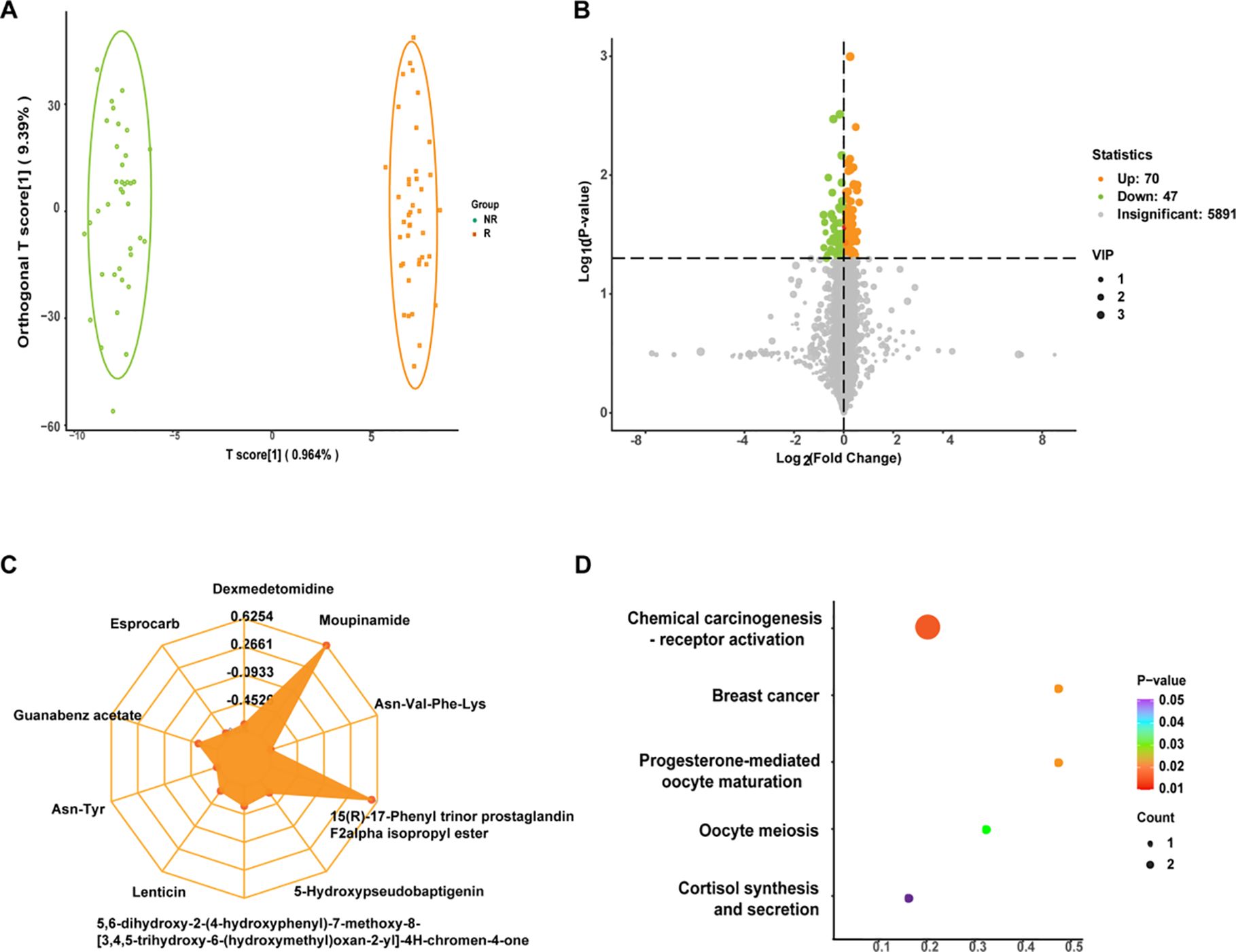
Figure 2. (A) Orthogonal partial least squares discriminant analysis (OPLS-DA) plots for non-response (NR) and response (R) groups. The abscissa represented the score of the predicted component, and the abscissa direction could see the gap between groups; the ordinate represented the score of the orthogonal component, and the ordinate direction could see the gap within the group; and the percentage represented the interpretation rate of the component to the dataset. (B) Volcano plot of differential metabolites. Each point represented a metabolite, where green, yellow, and gray points represented down-regulated, up-regulated, and metabolites that could be detected but were not significantly different, respectively; abscissa represented the log value of the fold difference in the relative content of a metabolite between the two groups of samples, ordinate indicated the level of significance of the difference, and the size of the dot represented the variable importance in projection (VIP) value. (C) Differential metabolite radar plot. Grid lines correspond to log2FC, that was, the fold difference of differential metabolites was logarithmic-ally valued at the base of 2, and yellow shading consisted of log2FC lines for each substance. (D) Differential metabolite Kyoto Encyclopedia of Genes and Genomes (KEGG) enrichment plot. The abscissa represented the Rich Factor corresponding to each pathway, the ordinate was the pathway name (sorted by P-value), and the color of the dots was the P-value size, with red indicating more significant enrichment. The size of the dots represented the number of differentially enriched metabolites.
In our study, the Figure 3A revealed that the median OS was 13 months (95% CI, 10.0-16.0) in the NR group, which was significantly shorter than that in the R group (P < 0.0001). In addition, median PFS was 6.0 months (95% CI, 5.0-7.0) versus 19.0 months (95% CI, 12.7-25.3) in NR group and R group, respectively (P < 0.0001). Therefore, OS was also significantly shorter in the NR group than in the R group and the data was shown in Figure 3B. To identify which clinical factors influence patient survival, we performed univariate Cox regression analysis and found no features to be significantly associated with survival (Figure 3C).
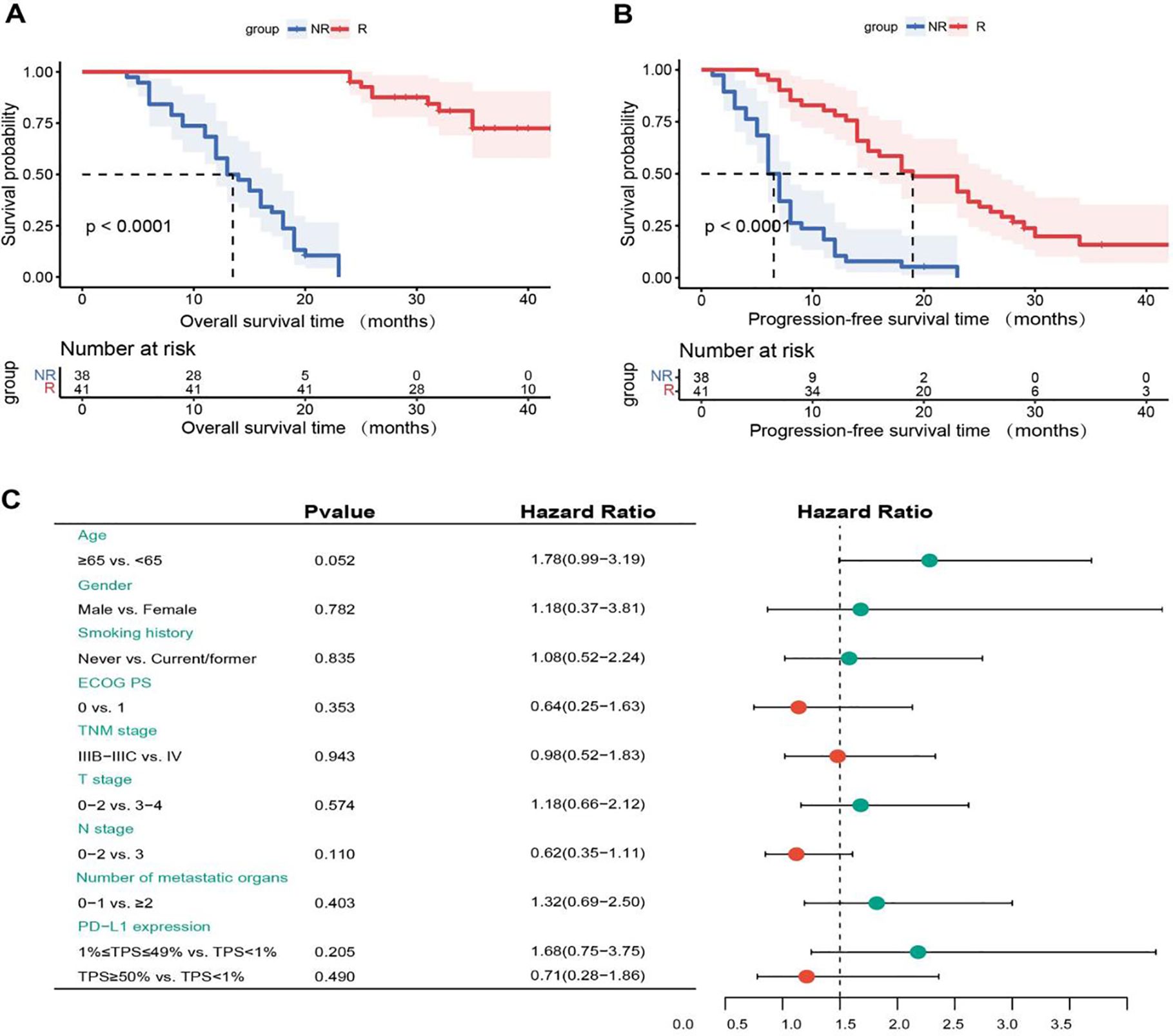
Figure 3. (A) Kaplan-Meier overall survival (OS) curves for non-response (NR) and response (R) groups. (B) Kaplan-Meier progression-free survival (PFS) curves for NR and R groups. (C) Univariate Cox regression analysis of OS. NR, non-response; R, response; ECOG PS, eastern cooperative oncology group performance status; PD-L1, programmed cell death-ligand 1; TPS, tumor proportion score.
Because the univariate Cox analysis was not significant, we did not include clinical characteristics in the model. Our preliminary statistical screening with p < 0.05, VIP > 1 resulted in a large number of metabolites, 117. To further screen more reliable biomarkers, we first selected 46 metabolites using LASSO (Figures 4A, B) and then identified metabolites using RF, and their cross-metabolites were candidate metabolites, and a total of 8 differential metabolites were identified as the best biomarkers. To avoid over-fitting and false positives, 500 feature selections and 10 cross-validations were performed. These 8 differential metabolites were Mevalonate, 1,2−Ethanedithiol, 4alpha−Hydroxymethyl−4beta−methyl−5alpha−cholesta−8,24−dien−3beta−ol, Arg−Asp−Leu−Tyr−Ser, Donhexocin, Glu−Cys−Ala, TG(10:0/14:0/a−15:0)[rac], D−3−Hydroxykynurenine, respectively, and their predictive performance was verified by AUC of ROC curves. As can be seen from Figure 4C, the predictive performance of individual differential metabolites is not sufficiently satisfactory (AUC < 0.75). However, the model formed by their combination had good predictive performance, with AUC values reaching 0.915, (95% CI, 0.857-0.972), suggesting that this model may be used as a predictive panel to predict the efficacy of immunotherapy combined with chemotherapy in patients with advanced lung squamous cell carcinoma (Figure 4D).
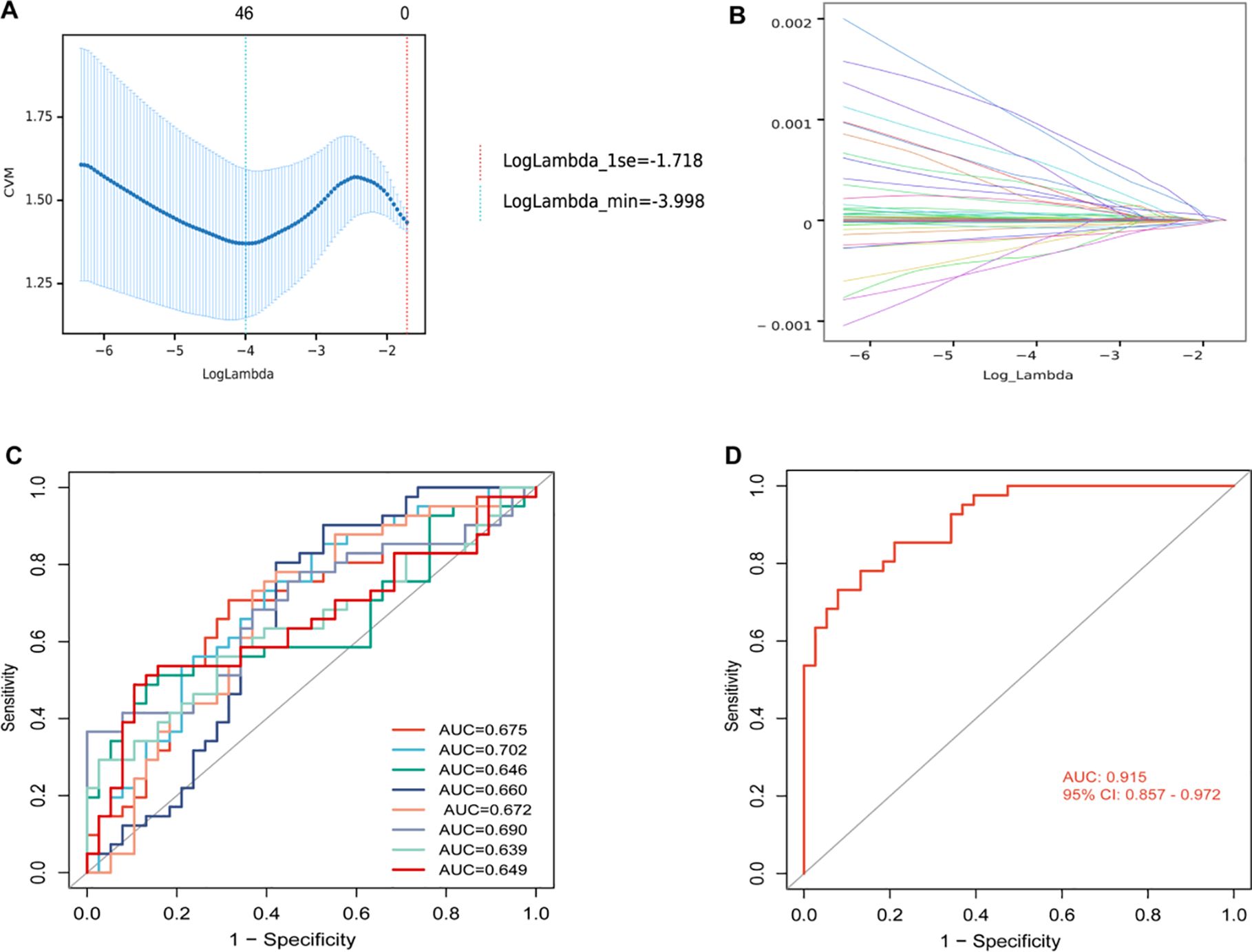
Figure 4. (A) Mean squared error plot for least absolute shrinkage and selection operator (LASSO) binomial regression lambda values. The horizontal axis was the logarithm of lambda, the vertical axis was the mean square error, and the two dashed lines were the maximum lambda value with the minimum lambda value and the mean error within one standard deviation, respectively. As the lambda value increased, the mean square error increased. (B) LASSO binomial regression lambda value coefficient plot. The horizontal axis was the log of lambda and the vertical axis was the coefficient of variation. As lambda increased, the variable coefficients decreased continuously and some variable coefficients changed to 0. (C) Receiver operating characteristic (ROC) analysis for each of 8 differential metabolites. (D) ROC analysis of models with 8 differential metabolite compositions. AUC, area under curve; CI, confidence interval.
Subsequently, patients (n = 79) were randomly divided into training set (n = 55) and validation set (n = 24) in a 7:3 ratio, and various machine learning models were employed for datasets consisting of these eight metabolites, including RF model, SVM model, and LR model. The comparison of the relative content of these eight metabolites between the NR and R groups was generally consistent in the training and validation sets, but most of them were not significantly different (Figure 5), still suggesting that single metabolites were not able to be biomarkers. However, the RF, SVM, LR models constructed by the panel of eight metabolites showed good predictive performance, with AUCs of 0.973, 0.938, and 0.934 in the training set and 0.944, 0.897, and 0.900 in the validation set (Figure 6), with the RF model having the best predictive performance. The accuracy, precision, recall and F1 values of RF model in the training set were 0.98, and the accuracy, precision, recall and F1 values in the validation set were 0.96, 1.00, 0.96 and 0.98, respectively.
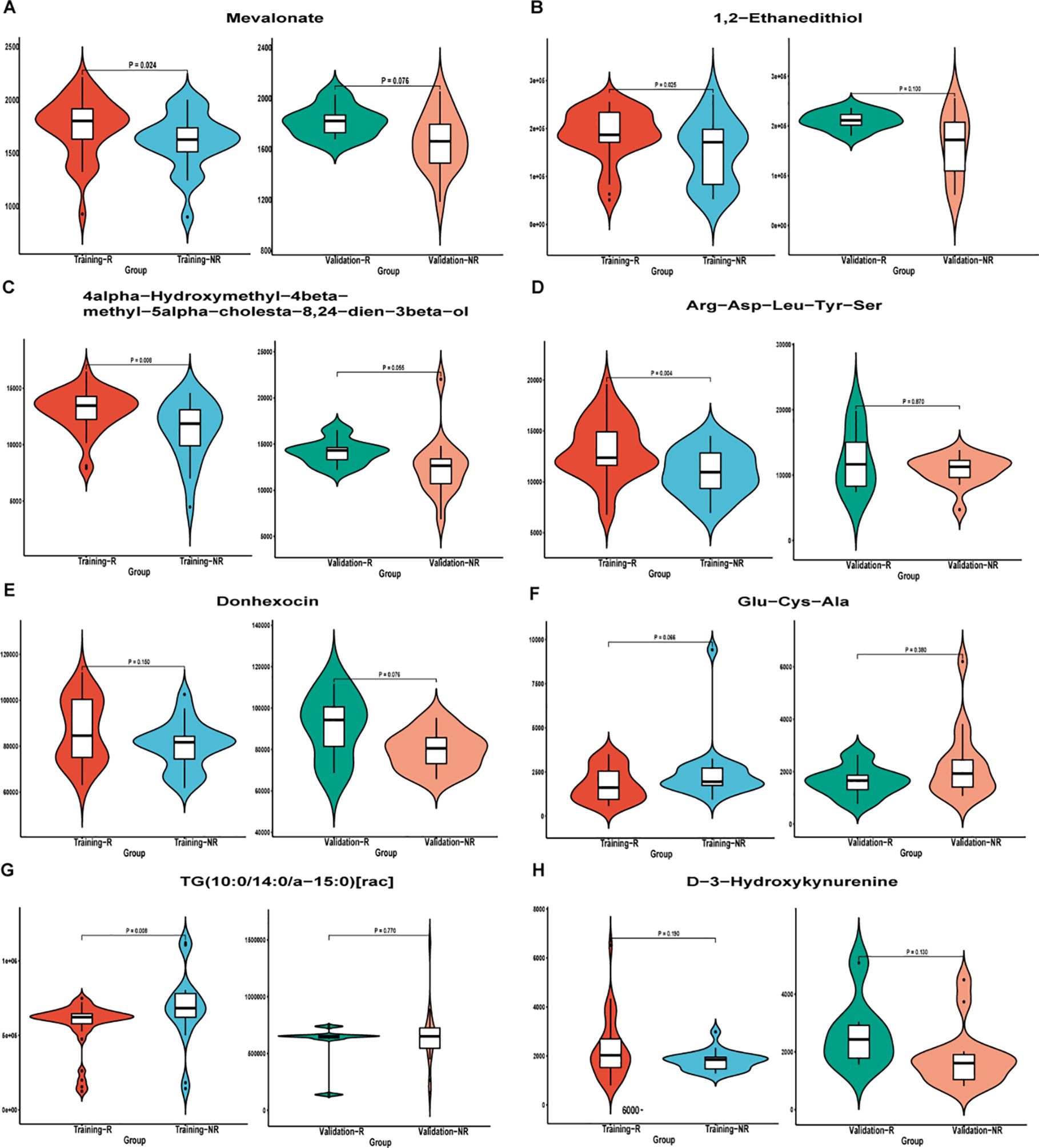
Figure 5. Differential metabolite violin plot of (A) Mevalonate; (B) 1,2−Ethanedithiol; (C) 4alpha−Hydroxymethyl−4beta−methyl−5alpha−cholesta−8,24−dien−3beta−ol; D) Arg−Asp−Leu−Tyr−Ser; (E) Donhexocin; (F) Glu−Cys−Ala; (G) TG(10:0/14:0/a−15:0)[rac]; (H) D−3−Hydroxykynurenine in the training and validation sets. Abscissa was sample grouping and ordinate was relative content of differential metabolites (original peak area). NR, non-response; R, response.
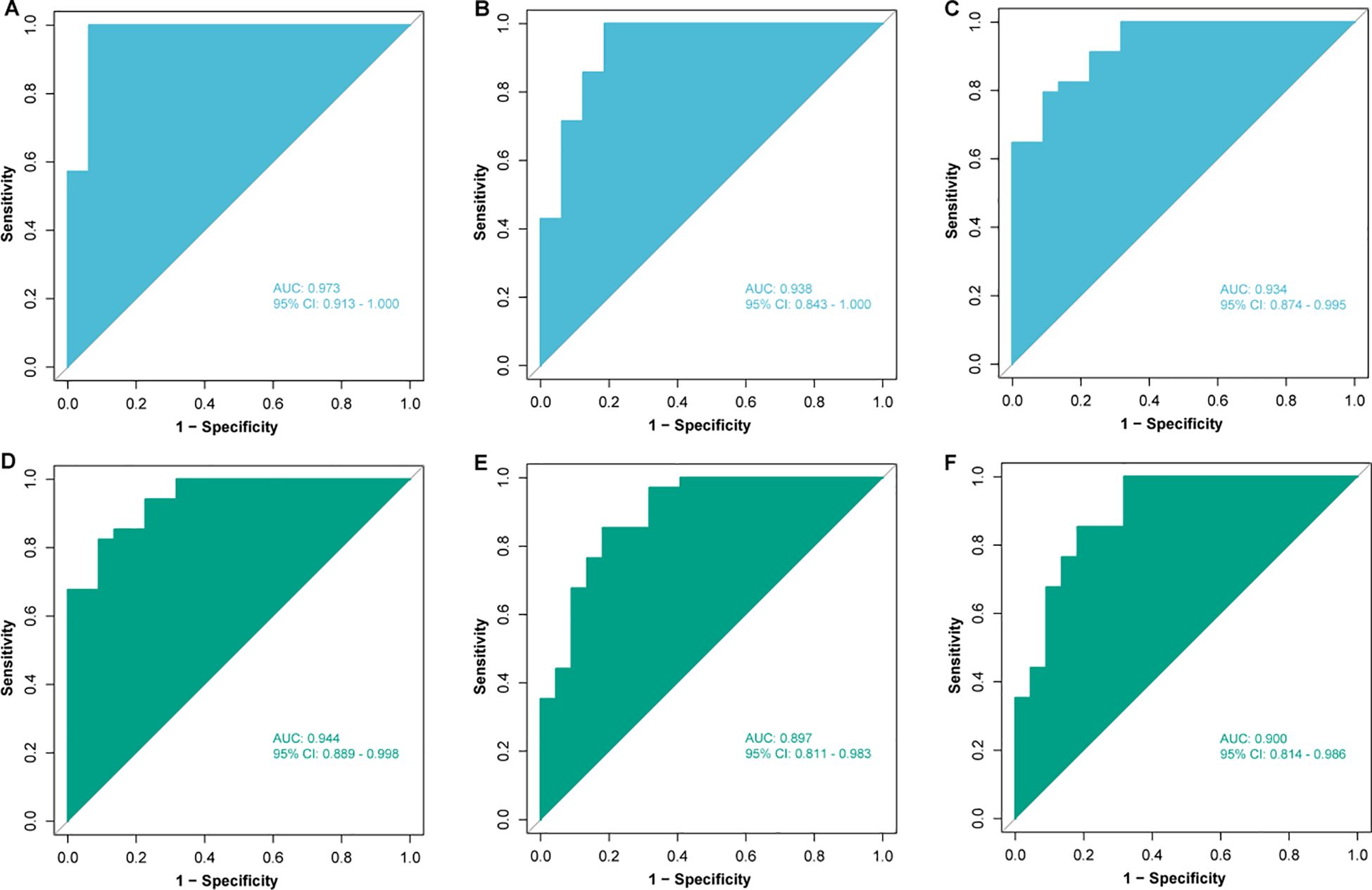
Figure 6. Construction and validation of models based on different machine learning algorithms. Receiver operating characteristic (ROC) analysis of (A) random forest (RF), (B) support vector machine (SVM) and (C) logistic regression (LR) models in the training set; ROC analysis of (D) RF, (E) SVM and (F) LR models in the validation set. AUC, area under curve; CI, confidence interval.
In Figure 7A, to further investigate the relationship between relative combined metabolite panel content and patient survival outcomes, we obtained risk scores by constructing a risk model and divided patients into low-risk (n = 40) and high-risk (n = 39) groups using the median of risk scores as the cutoff value. All baseline factors and risk factors were included in the multivariate Cox analysis (Figure 7B), and age > 65 years was significantly associated with shorter overall survival (HR, 2.990; 95% CI, 1.440-6.380; P = 0.005), whereas the low-risk group had significantly longer survival than the high-risk group (HR, 0.280; 95% CI, 0.120-0.640; P = 0.003). Multivariate Cox regression analysis indicated that risk score and age were independent prognostic factors for OS. Figures 7C, D present OS and PFS comparisons between the high-risk and low-risk groups. The median OS in the high-risk group was 18.0 months (95% CI, 15.0-21.0), which was significantly shorter than that observed in the low-risk group (P = 0.00023). In the high-risk group, median PFS was 7.0 months (95% CI, 5.9-8.1), which was significantly lower than PFS in the low-risk group, which was 15 months (95% CI, 10.0-20.0), and the difference was statistically significant (P < 0.0001). Time-dependent ROC curves indicated AUCs of 0.79, 0.90, and 0.73 at the 1-year, 2-year, and 3-year intervals, respectively, for the risk factors in forecasting OS (Figure 6E). These results indicated that our model could potentially predict the survival outcomes of patients.

Figure 7. (A) Risk score triad plot. Patients were divided into low-risk (n = 40) and high-risk (n = 39) groups using the median of the risk score as the cutoff value. (B) Univariate Cox regression analysis of overall survival (OS). (C) Kaplan-Meier OS curves for low-risk and high-risk groups. (D) Kaplan-Meier progression-free survival (PFS) curves for low-risk and high-risk groups. Patients (n = 79) were divided into low-risk (n = 40) and high-risk (n = 39) groups according to the median risk score (cutoff = 0.08). (E) Time-dependent receiver operating characteristic (ROC) curve analysis for the prognostic value of the model for different years. NR, non-response; R, response; ECOG PS, eastern cooperative oncology group performance status; PD-L1, programmed cell death-ligand 1; TPS, tumor proportion score; AUC, area under the curve.
In this investigation, we employed untargeted metabolomics to explore metabolic changes in the serum of patients with advanced lung squamous cell carcinoma who received chemoimmunotherapy with varying degrees of effectiveness, aiming to identify biomarker models that could potentially serve as prognostic indicators. In particular, we used machine learning techniques to analyze serum metabolites, thereby enhancing the precision of our identified biomarkers. We developed a panel comprising 8 metabolites that demonstrated high accuracy in both the training and validation sets. Furthermore, the risk score derived from this model serves as an independent prognostic marker, capable of effectively differentiating patients with varying survival outcomes with remarkable reliability and precision.
Lung cancer stands as a primary contributor to cancer-related mortality in China and across the globe (23). Specifically, lung squamous cell carcinoma presents a huge challenge in treatment due to its complexity and heterogeneity (24). Moreover, lung squamous cell carcinoma exhibits fewer genetic mutations, which often renders it less responsive to targeted therapies compared to lung adenocarcinoma. Increasing studies have established the place of immunotherapy combined with chemotherapy in the first-line treatment of advanced lung squamous cell carcinoma (25, 26), and this combined approach has been shown to substantially enhance both patients’ survival rates and PFS. Consequently, it is imperative to identify biomarkers capable of predicting the efficacy of chemoimmunotherapy in patients with advanced lung squamous cell carcinoma with greater accuracy and convenience. Combining metabolomics and machine learning to construct biomarker models has already shown potential in the field of lung cancer, and many studies have made progress. In a recent study (27), the authors performed metabolomics and lipidomics studies on serum samples from 461 subjects (including NSCLC, SCLC, healthy participants) to establish a metabolomics/lipid-based diagnostic model. The machine learning algorithm was also used to validate the screening results, and the performance of candidate metabolites in the model was analyzed by ROC curves. The results showed that the AUC of RF model was 0.93, indicating that the model had good predictive ability. An another study employed supervised machine learning algorithms to construct classification models using metabolomics data (28). By contrasting the metabolomic profiles of patients with NSCLC against those of individuals without cancer, it was possible to pinpoint significant alterations in the concentration levels of metabolites involved in tryptophan metabolism, the tricarboxylic acid (TCA) cycle, the urea cycle, and lipid metabolism. Utilizing these identified metabolites and their respective proportions, a machine learning classification model with a remarkable ROC AUC value of 0.96 was successfully developed. These studies suggested that it was feasible to construct metabolomics and machine learning-based models to predict the efficacy of immune combination therapy in the field of lung squamous cell carcinoma, but we also found that previous studies had mainly been diagnostic models and had not been studied in predicting the direction of immunotherapy combined with chemotherapy in advanced lung squamous cell carcinoma.
Whereas our study considered the potential of metabolites as prognostic markers, it highlighted the predictive value of metabolites in immunotherapy combination therapy for advanced lung squamous cell carcinoma. Untargeted metabolomics analysis facilitated the measurement of thousands of metabolites, thereby enabling the identification of a multitude of potential biomarkers. Furthermore, we detected metabolites in peripheral blood, which was readily obtainable, non-invasive, and imposed less discomfort and risk on patients compared to invasive procedures requiring tissue biopsy. Peripheral blood biomarkers could reflect changes in the tumor and host microenvironment in real time and dynamically, allowing repeated, multiple sampling and enabling tracking of dynamic changes during treatment. Simultaneously, we integrated machine learning algorithms to analyze complex omics data, a process that proved to be swifter and more efficient than conventional manual methods, while also enhancing the stability and precision of our predictions (29, 30). In our study, we first compared the serum metabolites of patients with different efficacy using untargeted metabolomics, and it could be seen that the metabolites of the two groups were significantly different, and there were multiple differential metabolites and multiple differential metabolic pathways. However, multivariate analysis showed that clinical factors did not independently predict treatment outcome in these patients, so perhaps we could start with differential metabolites to find biomarkers for immunotherapy combination therapy.
To avoid overfitting, we first implemented the LASSO regression algorithm to select 46 out of 117 metabolites in total. Then, the RF algorithm was used to take their intersection, and the prediction panel containing 8 metabolites was preliminarily established. However, our results showed that the prediction performance of a single differential metabolite was not good, and only integrating these differential metabolites to build a model could better predict the efficacy. In particular, our study utilized three machine learning algorithms (RF, SVM and LR) to achieve the best combination of models. This approach enhanced the overall performance, leading to a more efficient and effective model. The RF model had high accuracy and generalization ability. By integrating multiple decision trees, it effectively reduced the risk of overfitting and enhanced the model’s generalization capability. It also demonstrated strong ability in processing high-dimensional data and resisting noise, and it could automatically assess the importance of features in prediction. However, it was computationally expensive, especially when dealing with large-scale datasets. Compared to LR, its prediction speed was slower. The SVM method showed excellent performance in high-dimensional space and was suitable for handling complex problems. It had strong generalization ability and could effectively deal with both nonlinear and linear separable data. However, it was characterized by high computational complexity and difficulty in parameter tuning. Additionally, it lacked interpretability compared to RF and LR. LR was simple, efficient, and interpretable. However, as a linear classifier, it might not achieve good fitting effects for data with complex nonlinear relationships between features and targets, and it was prone to underfitting. Taking into account the size of the dataset, prediction speed, and prediction performance in both the training and validation sets, we ultimately decided on the RF model.
Eventually, we developed a model containing 8 metabolites, including Mevalonate, 1,2-Ethanedithiol, 4alpha-Hydroxymethyl-4beta-methyl-5alpha-cholesta-8,24-dien-3beta-ol, Arg-Asp-Leu-Tyr-Ser, Donhexocin, Glu-Cy-Ala, TG(10:0/14:0/a-15:0) [rac], D-3-Hydroxykynurenine. Some of these substances were well-known, and others were unfamiliar metabolites that may be easily ignored or missed by traditional analytical methods. For example, the mevalonate pathway involved in mevalonate is one of the important pathways of cellular metabolism, which has been reported to regulate adaptive immunity, and confirmed that this pathway can be used as a new vaccine adjuvant and immunotherapy drug target (31). In addition, Donhexocin and D-3-Hydroxykynurenine primarily function in neurodegenerative diseases and are significant in the process of apoptosis (32, 33). In contrast, other metabolites have received scant research attention. We also discovered that eight metabolite biomarkers were poorly correlated, and none of the substances alone had a good predictive performance, which was related to the complexity of the tumor microenvironment (34), and a single biomarker was not sufficient to make a reliable prediction. Therefore, identifying a set of potential biomarkers would be more clinically meaningful for predicting the efficacy of immunotherapy, and kits could be developed based on this prediction model in the future and applied in practical clinical practice. Upon constructing the model, we conducted additional validation. We computed the risk score for each patient and employed the median risk score as a threshold to categorize them into high-risk or low-risk cohorts (35). Survival analysis demonstrated that patients in the high-risk group exhibited significantly shorter PFS and OS compared to those in the low-risk group, and Cox regression analysis confirmed that the risk score served as an independent predictor of outcome. In addition, this model also has good predictive performance for one-year, two-year and three-year survival rates of patients. Therefore, the excellent predictive value of this model was reconfirmed.
Certainly, there were some limitations to our study. First of all, this study was retrospective, and the sample size was small, being a single-center study, the results may have some bias, and a larger sample size multicenter prospective study should be conducted. Secondly, this study underwent internal validation only, with external validation being absent. It is possible that future efforts could further substantiate our findings through validation in an additional cohort or via basic experiments. Additionally, although our research indicated potential biomarkers for the combination of immunotherapy and chemotherapy. it was imperative that further functional studies be conducted to clarify metabolic mechanisms and to confirm the correlation between these metabolites and the progression of the disease.
To summarize, our study characterized the metabolic profile of patients with lung advanced squamous cell carcinoma using untargeted metabolomics and compared the accuracy of predictive models for immunotherapy combined with chemotherapy, constructed using three machine learning algorithms: RF, SVM, and LR. Among these models, the RF model achieved an AUC of 0.973 on the training set and 0.944 on the validation set, demonstrating the best prediction performance. Consequently, we used this method to construct a predictive model for the efficacy of immunotherapy combined with chemotherapy, including eight differential metabolites, which showed high accuracy in both the training and validation sets. Additionally, based on this model, we predicted survival outcomes for patients, revealing that survival was significantly longer in the low-risk group compared to the high-risk group (HR, 0.280; 95% CI, 0.120-0.640; P=0.003). Our study highlighted the potential value of leveraging machine learning-driven metabolomics to predict the effectiveness of chemoimmunotherapy for advanced lung squamous cell carcinoma, thereby offering a promising avenue for future clinical translation.
The data presented in the study are deposited in the National Genomics Data Centre, CNCB repository (https://ngdc.cncb.ac.cn/), accession number OMIX009619.
The studies involving humans were approved by the Ethics Committee and Institutional Review Board of Shanghai Chest Hospital. The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study. Written informed consent was obtained from the individual(s) for the publication of any potentially identifiable images or data included in this article.
LZ: Data curation, Formal analysis, Investigation, Writing – original draft. WN: Project administration, Writing – original draft. SW: Conceptualization, Writing – original draft. LY: Conceptualization, Writing – original draft. FH: Writing – original draft. MM: Writing – original draft. LC: Writing – original draft. JL: Writing – review & editing. BZ: Writing – review & editing. JX: Writing – review & editing. YL: Writing – review & editing. YS: Writing – review & editing. WZ: Writing – review & editing. RZ: Writing – review & editing. TC: Writing – review & editing. BH: Writing – review & editing. XXZ: Funding acquisition, Writing – review & editing. HZ: Resources, Writing – review & editing. XYZ: Project administration, Writing – review & editing.
The author(s) declare that financial support was received for the research and/or publication of this article. This study was supported by Shanghai Innovative Medical Device Application Demonstration Project 2023 (NO. 23SHS02600); Shanghai Chest Hospital Talent Training Program (NO. RC-202301-114); National Natural Science Foundation of China (No. 82373425); the Medical Innovation Research Special Project of the Science and Technology Commission of Shanghai Municipality (No. 23Y11904200); Shanghai Municipal Health Commission (NO. 202340016).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The author(s) declare that no Generative AI was used in the creation of this manuscript.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
1. Leiter A, Veluswamy RR, Wisnivesky JP. The global burden of lung cancer: current status and future trends. Nat Rev Clin Oncol. (2023) 20:624–39. doi: 10.1038/s41571-023-00798-3
2. Han B, Zheng R, Zeng H, Wang S, Sun K, Chen R, et al. Cancer incidence and mortality in China, 2022. J Natl Cancer Cent. (2024) 4:47–53. doi: 10.1016/j.jncc.2024.01.006
3. Conti L, Gatt S. Squamous-cell carcinoma of the lung. N Engl J Med. (2018) 379:e17. doi: 10.1056/NEJMicm1802514
4. Chen JW, Dhahbi J. Lung adenocarcinoma and lung squamous cell carcinoma cancer classification, biomarker identification, and gene expression analysis using overlapping feature selection methods. Sci Rep. (2021) 11:13323. doi: 10.1038/s41598-021-92725-8
5. Lau SCM, Pan Y, Velcheti V, Wong KK. Squamous cell lung cancer: Current landscape and future therapeutic options. Cancer Cell. (2022) 40:1279–93. doi: 10.1016/j.ccell.2022.09.018
6. Gao M, Zhou Q. Progress in treatment of advanced squamous cell lung cancer. Zhongguo Fei Ai Za Zhi. (2020) 23:866–74. doi: 10.3779/j.issn.1009-3419.2020.101.35
7. Wang M, Herbst RS, Boshoff C. Toward personalized treatment approaches for non-small-cell lung cancer. Nat Med. (2021) 27:1345–56. doi: 10.1038/s41591-021-01450-2
8. Wang S, Li J. Progress in immunotherapy for squamous non-small cell lung cancer. Zhongguo Fei Ai Za Zhi. (2016) 19:682–6. doi: 10.3779/j.issn.1009-3419.2016.10.09
9. Vokes EE, Ready N, Felip E, Horn L, Burgio MA, Antonia SJ, et al. Nivolumab versus docetaxel in previously treated advanced non-small-cell lung cancer (CheckMate 017 and CheckMate 057): 3-year update and outcomes in patients with liver metastases. Ann Oncol. (2018) 29:959–65. doi: 10.1093/annonc/mdy041
10. Wu YL, Lu S, Cheng Y, Zhou C, Wang J, Mok T, et al. Nivolumab versus docetaxel in a predominantly chinese patient population with previously treated advanced NSCLC: checkMate 078 randomized phase III clinical trial. J Thorac Oncol. (2019) 14:867–75. doi: 10.1016/j.jtho.2019.01.006
11. Brahmer J, Reckamp KL, Baas P, Crinò L, Eberhardt WE, Poddubskaya E, et al. Nivolumab versus docetaxel in advanced squamous-cell non-small-cell lung cancer. N Engl J Med. (2015) 373:123–35. doi: 10.1056/NEJMoa1504627
12. Yarchoan M, Hopkins A, Jaffee EM. Tumor mutational burden and response rate to PD-1 inhibition. N Engl J Med. (2017) 377:2500–1. doi: 10.1056/NEJMc1713444
13. Wang P, Tang C, Liang J. Blood-based biomarkers in the immune checkpoint inhibitor treatment in non-small cell lung cancer. Zhongguo Fei Ai Za Zhi. (2021) 24:503–12. doi: 10.3779/j.issn.1009-3419.2021.102.24
14. Ren F, Fei Q, Qiu K, Zhang Y, Zhang H, Sun L. Liquid biopsy techniques and lung cancer: diagnosis, monitoring and evaluation. J Exp Clin Cancer Res. (2024) 43:96. doi: 10.1186/s13046-024-03026-7
15. Zeng X, Shi C, Han Y, Hu K, Li X, Wei C, et al. A metabolic atlas of blood cells in young and aged mice identifies uridine as a metabolite to rejuvenate aged hematopoietic stem cells. Nat Aging. (2024) 4:1477–92. doi: 10.1038/s43587-024-00669-1
16. Li Y, Wu X, Yang P, Jiang G, Luo Y. Machine learning for lung cancer diagnosis, treatment, and prognosis. Genomics Proteomics Bioinf. (2022) 20:850–66. doi: 10.1016/j.gpb.2022.11.003
17. Wang G, Qiu M, Xing X, Zhou J, Yao H, Li M, et al. Lung cancer scRNA-seq and lipidomics reveal aberrant lipid metabolism for early-stage diagnosis. Sci Transl Med. (2022) 14:eabk2756. doi: 10.1126/scitranslmed.abk2756
18. Fang T, Wu X, Zhou C. Comment on 'Plasma metabolomics study in screening and differential diagnosis of multiple primary lung cancer'. Int J Surg. (2023) 109:1798–9. doi: 10.1097/js9.0000000000000395
19. Jeppesen MJ, Powers R. Multiplatform untargeted metabolomics. Magn Reson Chem. (2023) 61:628–53. doi: 10.1002/mrc.5350
20. Han B, Feinstein T, Shi Y, Chen G, Yao Y, Hu C, et al. Plinabulin plus docetaxel versus docetaxel in patients with non-small-cell lung cancer after disease progression on platinum-based regimen (DUBLIN-3): a phase 3, international, multicentre, single-blind, parallel group, randomised controlled trial. Lancet Respir Med. (2024) 12:775–86. doi: 10.1016/s2213-2600(24)00178-4
21. Zhou C, Tang KJ, Cho BC, Liu B, Paz-Ares L, Cheng S, et al. Amivantamab plus chemotherapy in NSCLC with EGFR exon 20 insertions. N Engl J Med. (2023) 389:2039–51. doi: 10.1056/NEJMoa2306441
22. Liu J, Tan Y, Zhang F, Wang Y, Chen S, Zhang N, et al. Metabolomic analysis of plasma biomarkers in children with autism spectrum disorders. MedComm. (2020) 5:e488. doi: 10.1002/mco2.488
23. Xie W, Liu S, Li G, Xu H, Zhou L. The evolving treatment paradigm of lung cancer in China. Acta Pharm Sin B. (2022) 12:1536–7. doi: 10.1016/j.apsb.2022.01.010
24. Jiang T, Shi J, Dong Z, Hou L, Zhao C, Li X, et al. Genomic landscape and its correlations with tumor mutational burden, PD-L1 expression, and immune cells infiltration in Chinese lung squamous cell carcinoma. J Hematol Oncol. (2019) 12:75. doi: 10.1186/s13045-019-0762-1
25. Ettinger DS, Wood DE, Aisner DL, Akerley W, Bauman JR, Bharat A, et al. NCCN guidelines insights: non-small cell lung cancer, version 2.2021. J Natl Compr Canc Netw. (2021) 19:254–66. doi: 10.6004/jnccn.2021.0013
26. Oncology Society of Chinese Medical Association. Chinese Medical Association guideline for clinical diagnosis and treatment of lung cancer (2024 edition). Zhonghua Yi Xue Za Zhi. (2024) 104:3175–213. doi: 10.3760/cma.j.cn112137-20240511-01092
27. Shang X, Zhang C, Kong R, Zhao C, Wang H. Construction of a diagnostic model for small cell lung cancer combining metabolomics and integrated machine learning. Oncologist. (2024) 29:e392–401. doi: 10.1093/oncolo/oyad261
28. Shestakova KM, Moskaleva NE, Boldin AA, Rezvanov PM, Shestopalov AV, Rumyantsev SA, et al. Targeted metabolomic profiling as a tool for diagnostics of patients with non-small-cell lung cancer. Sci Rep. (2023) 13:11072. doi: 10.1038/s41598-023-38140-7
29. Chen Y, Wang B, Zhao Y, Shao X, Wang M, Ma F, et al. Metabolomic machine learning predictor for diagnosis and prognosis of gastric cancer. Nat Commun. (2024) 15:1657. doi: 10.1038/s41467-024-46043-y
30. Vanguri RS, Luo J, Aukerman AT, Egger JV, Fong CJ, Horvat N, et al. Multimodal integration of radiology, pathology and genomics for prediction of response to PD-(L)1 blockade in patients with non-small cell lung cancer. Nat Cancer. (2022) 3:1151–64. doi: 10.1038/s43018-022-00416-8
31. Xia Y, Xie Y, Yu Z, Xiao H, Jiang G, Zhou X, et al. The mevalonate pathway is a druggable target for vaccine adjuvant discovery. Cell. (2018) 175:1059–1073.e21. doi: 10.1016/j.cell.2018.08.070
32. Marucci G, Buccioni M, Ben DD, Lambertucci C, Volpini R, Amenta F. Efficacy of acetylcholinesterase inhibitors in Alzheimer's disease. Neuropharmacology. (2021) 190:108352. doi: 10.1016/j.neuropharm.2020.108352
33. Colín-González AL, Maldonado PD, Santamaría A. 3-Hydroxykynurenine: an intriguing molecule exerting dual actions in the central nervous system. Neurotoxicology. (2013) 34:189–204. doi: 10.1016/j.neuro.2012.11.007
34. de Visser KE, Joyce JA. The evolving tumor microenvironment: From cancer initiation to metastatic outgrowth. Cancer Cell. (2023) 41:374–403. doi: 10.1016/j.ccell.2023.02.016
Keywords: metabolomics, machine learning, chemoimmunotherapy, predictive model, tumor biomarkers
Citation: Zheng L, Nie W, Wang S, Yang L, Hu F, Ma M, Cheng L, Lu J, Zhang B, Xu J, Li Y, Shen Y, Zhang W, Zhong R, Chu T, Han B, Zheng X, Zhong H and Zhang X (2025) Metabolomic machine learning-based model predicts efficacy of chemoimmunotherapy for advanced lung squamous cell carcinoma. Front. Immunol. 16:1545976. doi: 10.3389/fimmu.2025.1545976
Received: 16 December 2024; Accepted: 13 March 2025;
Published: 02 April 2025.
Edited by:
Chunmiao Cai, Mayo Clinic, United StatesReviewed by:
Banzhan Ruan, Hainan Medical University, ChinaCopyright © 2025 Zheng, Nie, Wang, Yang, Hu, Ma, Cheng, Lu, Zhang, Xu, Li, Shen, Zhang, Zhong, Chu, Han, Zheng, Zhong and Zhang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xueyan Zhang, enh5Y2hlc3QwMTA5QDE2My5jb20=; Hua Zhong, ZWRkaWVkb25nOEBob3RtYWlsLmNvbQ==; Xiaoxuan Zheng, bWlsb3poZW5nNTlAMTYzLmNvbQ==
†These authors have contributed equally to this work
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.