 Junyang Ma
Junyang Ma Shufu Hou
Shufu Hou Xinxin Gu3
Xinxin Gu3
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Immunol. , 21 March 2025
Sec. Systems Immunology
Volume 16 - 2025 | https://doi.org/10.3389/fimmu.2025.1533959
Background: Recent studies have suggested a potential association between gastric cancer (GC) and myocardial infarction (MI), with shared pathogenic factors. This study aimed to identify these common factors and potential pharmacologic targets.
Methods: Data from the IEU Open GWAS project were used. Two-sample Mendelian randomization (MR) analysis was used to explore the causal link between MI and GC. Transcriptome analysis identified common differentially expressed genes, followed by enrichment analysis. Drug target MR analysis and eQTLs validated these associations with GC, and the Steiger direction test confirmed their direction. The random forest and Lasso algorithms were used to identify genes with diagnostic value, leading to nomogram construction. The performance of the model was evaluated via ROC, calibration, and decision curves. Correlations between diagnostic genes and immune cell infiltration were analyzed.
Results: MI was linked to increased GC risk (OR=1.112, P=0.04). Seventy-four genes, which are related mainly to ubiquitin-dependent proteasome pathways, were commonly differentially expressed between MI and GC. Nine genes were consistently associated with GC, and eight had diagnostic value. The nomogram built on these eight genes had strong predictive performance (AUC=0.950, validation set AUC=0.957). Immune cell infiltration analysis revealed significant correlations between several genes and immune cells, such as T cells, macrophages, neutrophils, B cells, and dendritic cells.
Conclusion: MI is associated with an increased risk of developing GC, and both share common pathogenic factors. The nomogram constructed based on 8 genes with diagnostic value had good predictive performance.
Gastric cancer (GC) remains one of the leading causes of cancer-related deaths worldwide. Although the incidence of GC has declined in some regions of the world, data from the past decade show that the incidence of GC has remained high and has even increased in specific regions and populations (1, 2). By 2040, the global burden of this malignant tumor is projected to increase by 62% (3). The treatment of GC is mainly radical surgery supplemented with radiotherapy, chemotherapy, and drug therapy. However, research on the treatment of GC is still in progress, to further clarify the pathogenesis of GC, identify the risk factors for GC, and overcome the challenges in the treatment of GC (1, 4–6).
Myocardial infarction (MI), or heart attack, is a leading cause of morbidity and mortality worldwide. It typically results from coronary artery disease, where thrombotic occlusion of an artery or bypass graft leads to a sudden reduction or complete interruption of myocardial blood supply, potentially causing heart failure or death (7–9). Established risk factors such as diabetes, smoking, obesity, hypertension, and hyperlipidemia significantly contribute to MI occurrence, while sex, aging, genetic predisposition, family history of cardiovascular disease, and racial differences also play a role (10, 11). Moreover, emerging evidence suggests that systemic diseases, particularly cancer, may worsen MI progression or elevate its risk, highlighting the need for further investigation into the potential link between cancer and MI (12).
Although they belong to different systems, GC and MI share many similar pathogenic factors and may be potentially interrelated. Examples include inflammation (7, 13), a high-salt diet (14, 15), and smoking (16, 17). In addition, in some cases, GC and MI may present similar clinical features. These include pain in the upper abdomen or chest and dyspepsia, nausea, and vomiting (4, 18, 19). However, little is known about the complex mechanisms underlying the relationship between GC and MI, and the available research evidence is limited. A long-term cohort study suggested that MI may increase the risk of cancer (20), and a large meta-analysis revealed that Helicobacter pylori infection, one of the main causative factors of GC, was also associated with an increased risk of MI (21). Given these findings, exploring the common pathogenic mechanisms of GC and MI has become an important research direction. However, traditional observational studies have limitations in inferring causality (22), and although associations between GC and MI can be observed, determining the causal relationship between them is not yet possible. Therefore, this study aims to further explore the common pathogenic mechanisms of these two diseases through a more rigorous study design and to promote the progress of related diagnostic and treatment strategies.
In recent years, Mendelian randomization (MR) analysis has gradually become a powerful tool in the fields of drug target discovery and drug repurposing (23). In MR studies, researchers utilize genetic variants associated with specific exposures as instrumental variables (IVs) to assess the causal links between exposures and outcomes. Compared with traditional observational studies, MR analyses can effectively avoid the interference of confounding factors such as acquired environmental factors and behavioral habits and significantly reduce the influence of reverse causality (24, 25). This approach is similar to randomized controlled trials in nature, where genetic variation plays a role similar to that of randomized grouping, thus providing a reliable basis for drug target validation (23). With the rapid development of genome-wide association studies (GWASs), MR strategies have led to breakthroughs in therapeutic target identification for a variety of diseases (26, 27). In addition, MR analysis of drug targets can be used to predict the pharmacological modulatory effects of drug targets, simulate drug responses in clinical trials, and predict the potential benefits and risks of treatment (28, 29).
In this study, we innovatively combined MR analysis and transcriptome analysis to investigate the association between GC and MI and explored the potential MI-related therapeutic targets of GC through drug target MR and machine learning. These findings provide insights for understanding the common pathogenesis of GC and MI.
In this study, we first explored the causal relationship between MI and GC via the MR method (see Figure 1). Differentially expressed genes associated with MI and GC were subsequently screened, and these genes were enriched and analyzed. Next, the expression quantitative trait loci (eQTLs) of the common differential genes of MI and GC were utilized to explore the causal associations between these genes and GC and to verify whether the direction of causality was as expected. Finally, to identify candidate biomarkers and construct a prediction model for GC, this study used machine learning algorithms, such as random forest and least absolute shrinkage and selection operator (LASSO) regression, to screen key genes for the construction of a column-line graph (nomogram) and verified its performance in the diagnosis and prediction of GC. In addition, we explored the correlations between genes with diagnostic value and immune cell infiltration.
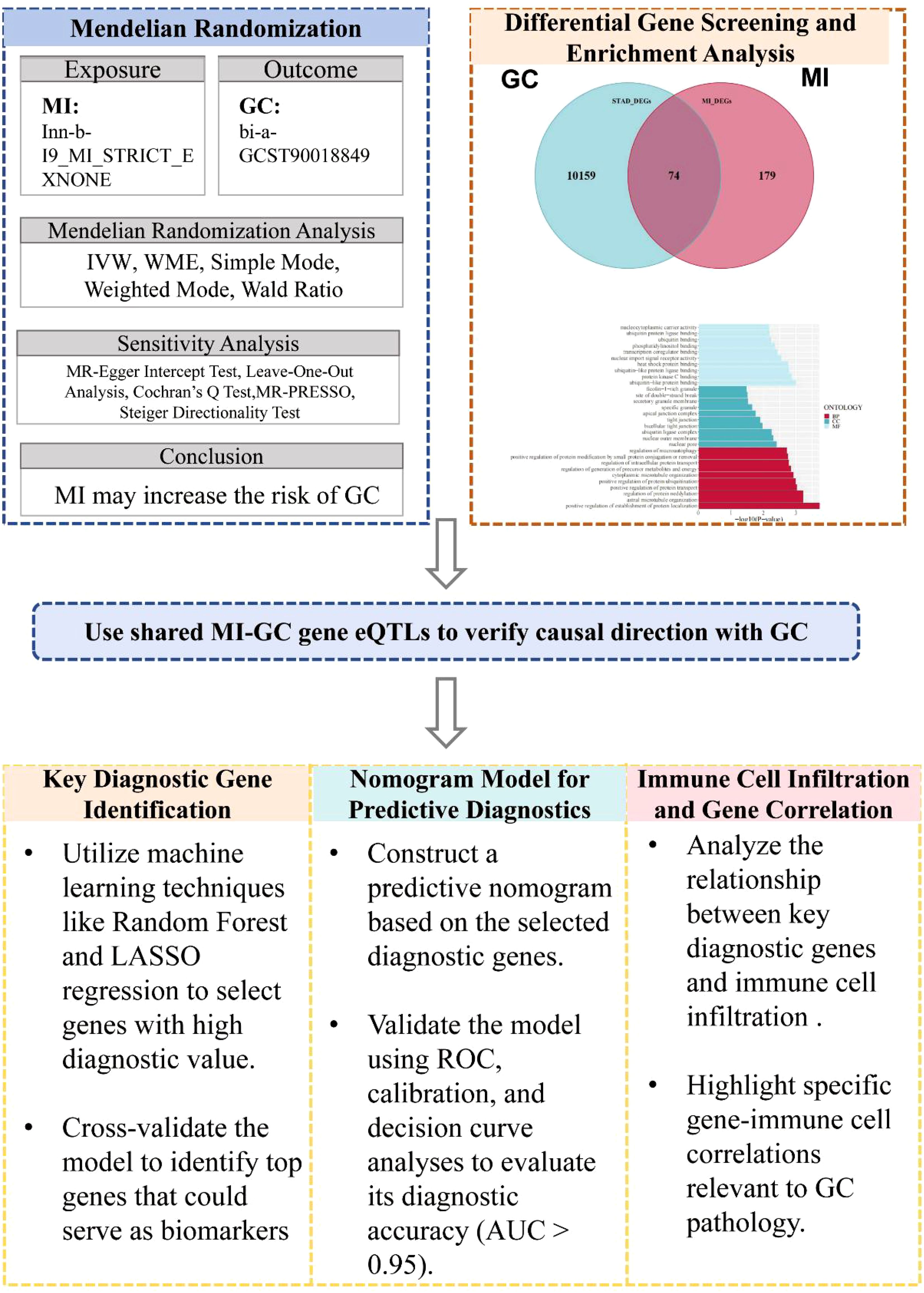
Figure 1. Overview of study design. MR, Mendelian Randomization; GC, Gastric Cancer; MI, Myocardial Infarction; IVW, Inverse-Variance Weighted; WME, Weighted Median Estimator; eQTLs, Expression Quantitative Trait Loci; ROC, Receiver Operating Characteristic; AUC, Area Under the Curve.
The MR analysis method used in this study is consistent with the three main hypotheses of MR research: (1) IVs are associated with risk factors. (2) IVs are not associated with confounding factors. (3) IVs affect the outcome only through risk factors (30, 31) with the STRIOBE-MR guidelines (32) (Figure 1).
GWAS data for MI (finn-b-I9_MI_STRICT_EXNONE), GC (ebi-a-GCST90018849), and differential gene expression quantitative trait loci (eQTLs) were obtained from the IEU Open GWAS project (https://gwas.mrcieu.ac.uk/). The data obtained were derived from European populations, for which summary information is given in Table 1. The relevant data were obtained from publicly available GWAS databases; therefore, this part of the study did not address the need for ethics committee approval.

Table 1. Brief information on the GWAS database in the MR study.
Significant SNPs were screened from pooled GWAS data for MI. The linkage disequilibrium coefficient (r2) was set to 0.001, and the width of the linkage disequilibrium region was set to 10,000 kb to ensure that the individual SNPs were independent of each other and to exclude the influence of genetic pleiotropy on the results. LDtrait (https://ldlink.nih.gov/?tab=ldtrait) was used to exclude SNPs associated with confounders and outcomes. The relevant SNPs screened above were extracted from the GWAS pooled data of GC; the minimum r2 was set to > 0.8 (33, 34). The instrumental variable screening condition was P < 1 × 10-5, F > 10 was set to reduce weak instrumental variable bias, and a nonzero intercept term in the MR−Egger regression model (P > 0.05) indicated that there was no genetic pleiotropy in the SNPs.
The chain disequilibrium coefficient (r2) was set to 0.3, the width of the chain disequilibrium region was 300 kb, and the minor allele frequency (MAF) was >0.01 to ensure that the individual SNPs were independent of each other and to eliminate the influence of chain disequilibrium on the results, including the SNPs associated with confounders and the SNPs associated with endings. Instrumental variables located within ±300 kb from the cis-acting region of the drug target gene were extracted from the eQTL data of the drug target genes screened above for relevant instrumental variables (35, 36). In addition, the above screened relevant SNPs were extracted from the GWAS summary data of the outcome variable GC, excluding SNPs with palindromic structure and an MAF>0.42, excluding SNPs directly associated with the outcome variable (P<1×10-5), and excluding abnormal SNPs via MR-PRESSO.
Two-sample MR and drug-target MR analyses were performed via five regression models, namely, MR−Egger regression, random-effects inverse-variance weighted (IVW), weighted median estimator (WME), weighted model, and simple model, and two-sample MR analyses were applied to assess the potential causal relationship between MI and GC risk. Inverse variance weighting (IVW) was used as the main method for causal estimation. When SNPs ≤ 3, the effect of a single SNP on the outcome was applied to the Wald coefficient ratio method (Wald ratio), and the rest were applied to the fixed-effects IVW method; when more than 3 SNPs were included, the random-effects IVW method was applied (37–39). MR−Egger essentially uses a weaker hypothetical premise (InSIDE) based on IVW to accomplish causal effect estimation and detects and corrects for bias due to instrumental variable multivariate polytomies by introducing a regression intercept to estimate the causal relationship between the exposure and the outcome in the presence of horizontal polytomies. The results of MR−Egger are referred to when there are horizontal polytomies. The Cochran's Q test and the I² (I-squared) statistic were used to determine the heterogeneity of the SNPs, which were heterogeneous if the Cochran's Q test had a P < 0.05 (40). The values of I² ranged from 0% to 100%, with an I² greater than 50%, indicating that the SNPs had some heterogeneity (41). The intercept term of the MR−Egger method was used for polytropy analysis, and leave-one-out was used for sensitivity analysis. A nonzero intercept term (P > 0.05) in the MR−Egger regression model indicated that the SNPs were not polytropic (42). Leave-one-out analyses were performed on the SNPs by progressively removing each SNP and reanalyzing the remaining SNPs to observe the magnitude of the effect of each SNP on the analysis results (43, 44). All of the above methods were implemented via the two-sample MR package in R 4.1.0 software with a test level of α = 0.05.
Gene expression data were obtained from the Gene Expression Omnibus (GEO) database (http://www.ncbi.nlm.nih.gov/geo/) and The Cancer Genome Atlas (TCGA). Differential expression analysis was performed on GC tissues (375 cases) and normal gastric tissues (32 cases) via limma analysis, and differential expression analysis was performed on MI patient samples (17 cases) and control samples (20 cases) from the GEO dataset (GSE83500), and intersections were taken for the differential genes obtained (45).
To further confirm the functions of potential targets, the data were explored via functional enrichment analysis. Gene Ontology (GO) analysis was used to examine and clarify coordinated changes at the pathway level and gene function between phenotypes. The focus of GO analysis is to identify differences in biological processes, cellular components, and molecular functions to help reveal potential biological functions.
To verify the consistency of genotypes in the direction of causality between intermediate variables (gene expression) and the outcome (GC and MI), the Steiger direction test was used in this study. The causal direction was determined by calculating the explained variance of the instrumental variables (eQTLs) on the intermediate and outcome variables, and the direction was considered to be correct if the explained variance of the instrumental variables on the intermediate variables was greater than the explained variance on the outcome. Analyses were performed via the TwoSampleMR package in R. The significance level was set at α = 0.05, and directional consistency was judged by “TRUE” or “FALSE” in the test results.
To identify candidate biomarkers and build a prediction model for GC, a variety of random forest and LASSO regression algorithms were used to screen key genes. The random forest algorithm is an integrated learning algorithm that improves prediction accuracy by constructing multiple decision trees and combining their results and is particularly suitable for handling high-dimensional data, assessing the importance of features, and reducing overfitting. LASSO regression performs L1 regularization for variable selection and model simplification, which is based on the principle of applying penalties to the regression coefficients and reducing unimportant feature coefficients to zero, thus improving the generalization ability and interpretability of the model. Based on the screened genes with diagnostic value, a nomogram was constructed via the R package “rms”, and the area under the ROC curve was plotted to evaluate the diagnostic effect of the genes with diagnostic value in GC diagnosis. Finally, calibration curve and decision curve analysis (DCA) were performed to evaluate the efficiency of the predictive model of GC predicted by the nomogram.
The gene expression matrix of GC was uploaded to the CIBERSORTx database (https://cibersortx.stanford.edu/), and immune cell infiltration was calculated for each sample. Correlation analysis between key genes and immune cell infiltration was performed via Spearman rank correlation coefficients.
After screening and the strict quality control described above, 21 SNPs were ultimately included for MR analysis, and the basic information of the SNPs is shown in Table 2. After MR, the IVW results revealed that MI was associated with an increased risk of developing GC (OR=1.112, 95% CI: 1.002–1.233, P=0.045) (Figure 2A). MI heterogeneity was not detected among eQTLs associated with GC (I²= 0%, Cochran's Q=11.199, P=0.941). The MR−Egger results revealed no statistically significant difference between the intercept term and 0 (P=0. 724), and MR−PRESSO did not detect significant horizontal pleiotropy (P=0.929). Therefore, no horizontal pleiotropy occurred in the SNPs (Table 3). Scatter and funnel plots for GC revealed that the distributions of all the included SNPs were largely symmetrical, indicating that causal associations were less likely to be affected by potential bias (Figures 2B, C). After each SNP of GC was excluded sequentially via the leave-one-out test, the analysis results of the remaining SNPs were similar to those with the inclusion of all the SNPs (Figure 2D), and no SNPs were found to have a large impact on the estimation value of the causal associations, indicating that the MR results of the present study were robust.
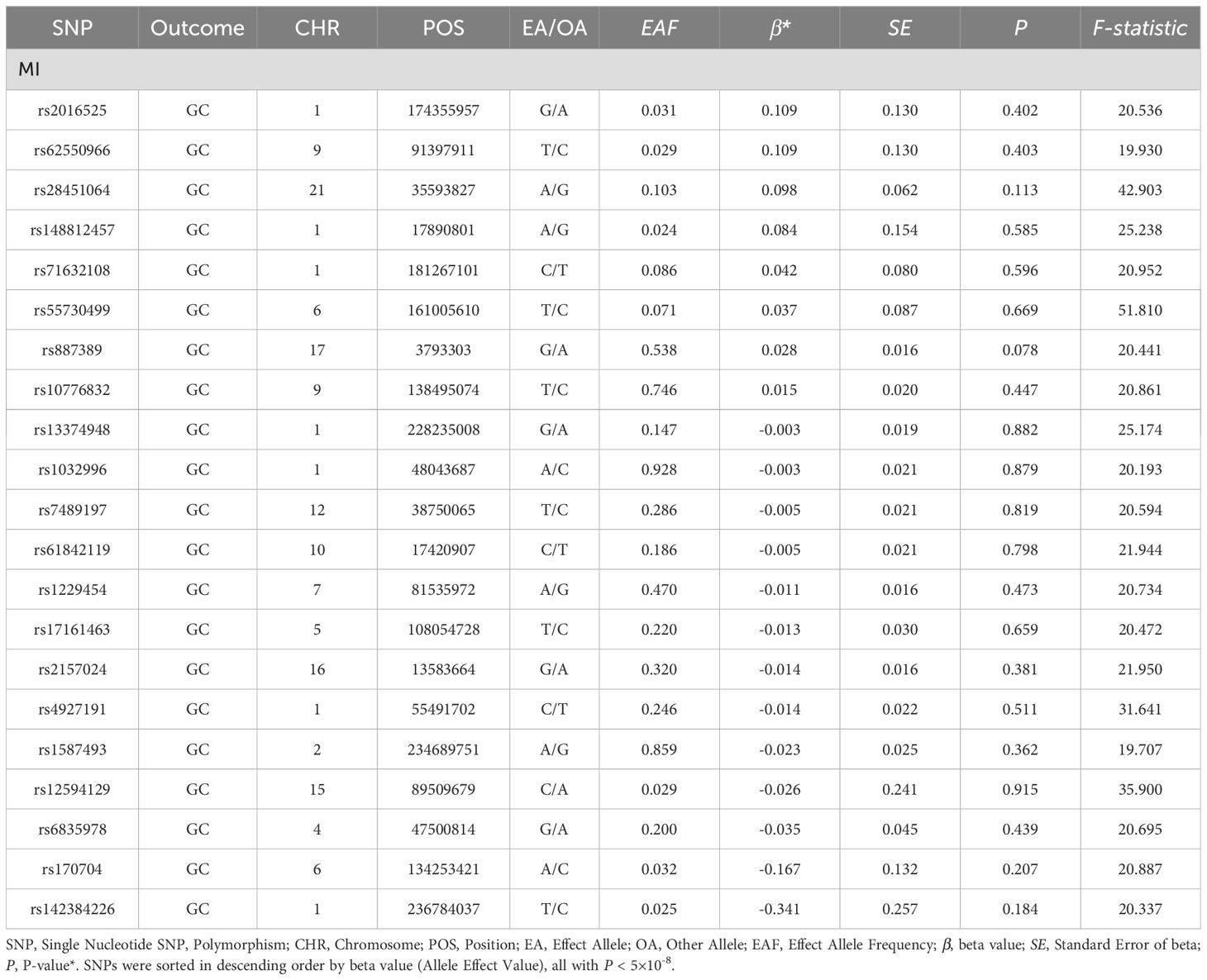
Table 2. Information on single nucleotide polymorphisms (SNPs) associated with MI and GC.
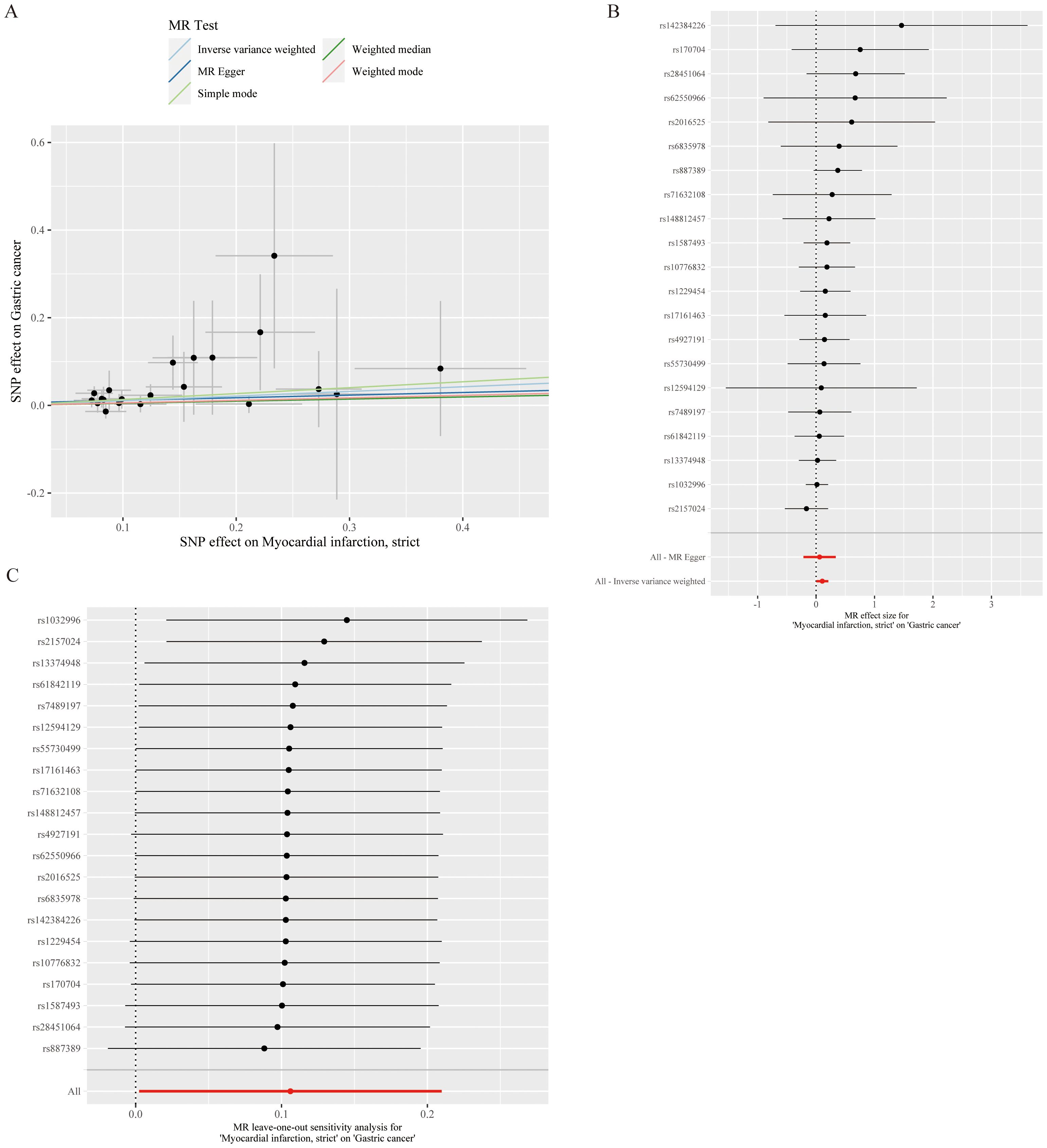
Figure 2. Causal relationship analysis of myocardial infarction on gastric cancer risk. (A) Scatter Plot: The slope of each line represents the effect estimated through different Mendelian randomization methods. (B) Forest Plot: Red dots indicate the combined estimate after integrating all SNPs using the Inverse Variance Weighted (IVW) method, with horizontal lines representing the 95% confidence intervals. (C) Leave-One-Out Analysis: Black dots represent the causal effect estimated by the IVW method while excluding a specific variant, and red dots indicate the IVW estimate using all SNPs.

Table 3. Results of MR analysis of the causal effect of MI on GC.
Differential expression analysis was performed on the transcriptome expression data of the TCGA-STAD dataset via the limma package, and 10,233 DEGs were identified by setting thresholds of |log 2 FC| >0.5 and P < 0.05 (Figure 3A). Similarly, differential expression analysis was performed on the GSE83500 dataset via the limma package, and 253 DEGs were screened with the same threshold (Figure 3B). We took the intersection of genes that were simultaneously present in both datasets and expressed in the same direction and obtained a total of 74 intersecting genes (Figure 3C).
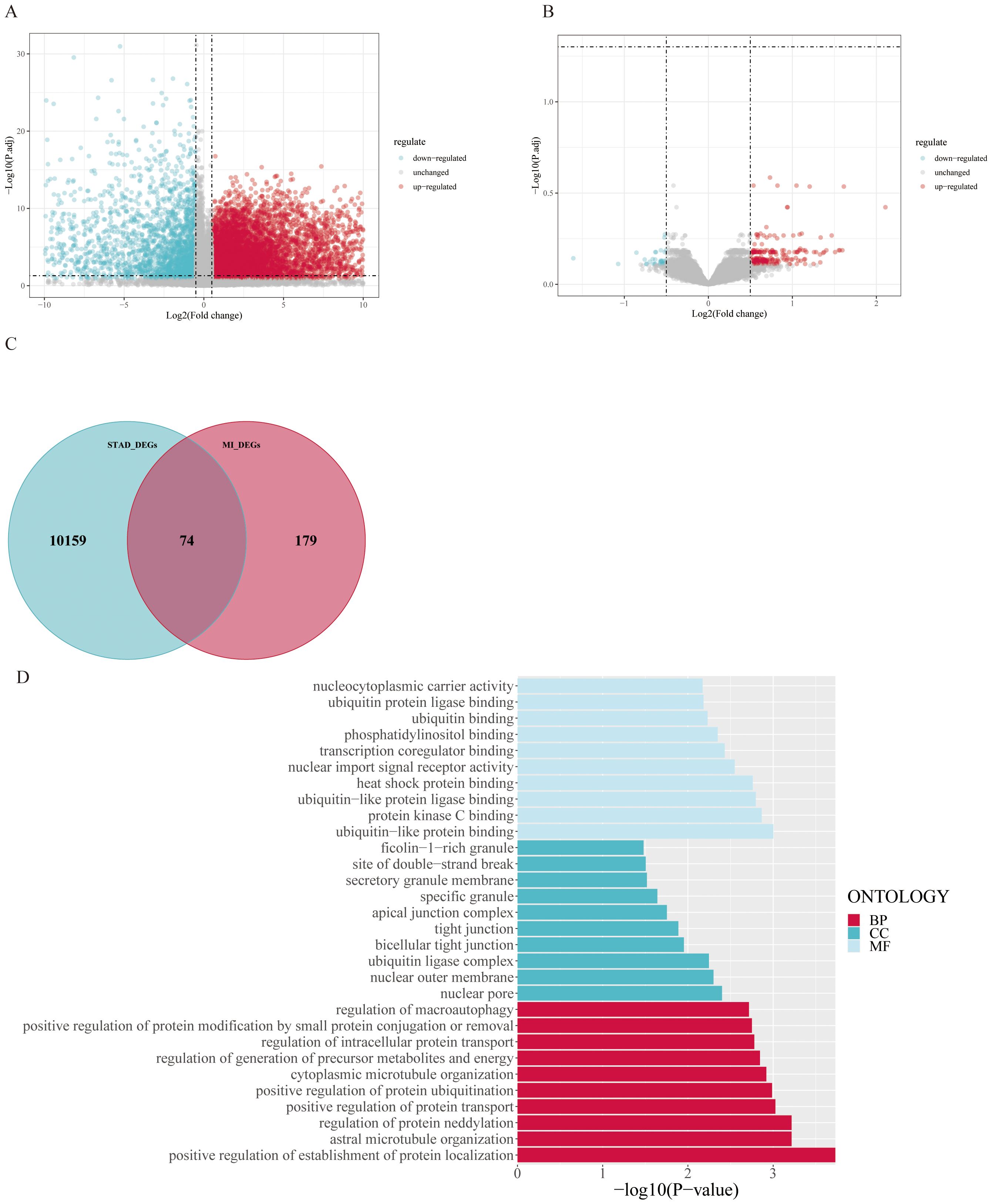
Figure 3. Differentially expressed gene analysis and enrichment analysis results: (A) Volcano plot of differentially expressed genes in the TCGA-STAD dataset, identifying 10,233 differentially expressed genes (|log2(FC)| > 0.5, P-value < 0.05). (B) Volcano plot of differentially expressed genes in the GSE83500 dataset, identifying 253 differentially expressed genes. (C) Venn diagram of the two datasets, showing 74 genes that are consistently differentially expressed in both datasets. (D) GO enrichment analysis of the intersecting genes, significantly enriched in pathways such as positive regulation of establishment of protein localization.
We subsequently performed gene enrichment analysis, which revealed that the differentially expressed genes were significantly enriched in the positive regulation of the establishment of protein localization and other related pathways. Other biological processes that were significantly enriched included positive regulation of protein transport, positive regulation of protein ubiquitination, and stellate microtubule organization. In terms of cellular composition, the enriched terms were nuclear pores, the outer nuclear membrane, and the apical junction complex. Among the molecular functional categories, ubiquitin-protein ligase binding, heat shock protein binding, and transcriptional coregulator binding were notable (Figure 3D).
After screening, 74 DEGs were identified, with only 37 DEGs from the blood eQTLs screened by available instrumental variables. The eQTLs for 69 differential genes were extracted from the IEU OpenGWAS program, and a total of 2101 cis eQTLs for differential genes were identified (Supplementary Table 1). Drug target MR analysis revealed that 9 genes were causally associated with GC in the same direction as their expression in GC and MI. Among them, 8 genes, namely, LCOR, VPS26A, KRR1, ARHGAP21, ECHDC1, UBE2D1, MTFR1, and ETV7, were positively associated with GC, suggesting that they are associated with an increased risk of developing GC. Another gene, PARD6G, was negatively associated with GC, indicating an association with a decreased risk of GC (Figure 4). In addition, the sensitivity test did not detect significant horizontal pleiotropy or heterogeneity, indicating that the MR results were robust. Finally, Steiger's direction test revealed that in the GC ebi-a-GCST90018849 dataset, the directions of the DEGs were all “TRUE”, indicating that the causal relationship between the DEGs and the outcome was consistent with the expected direction (Tables 4, 5).
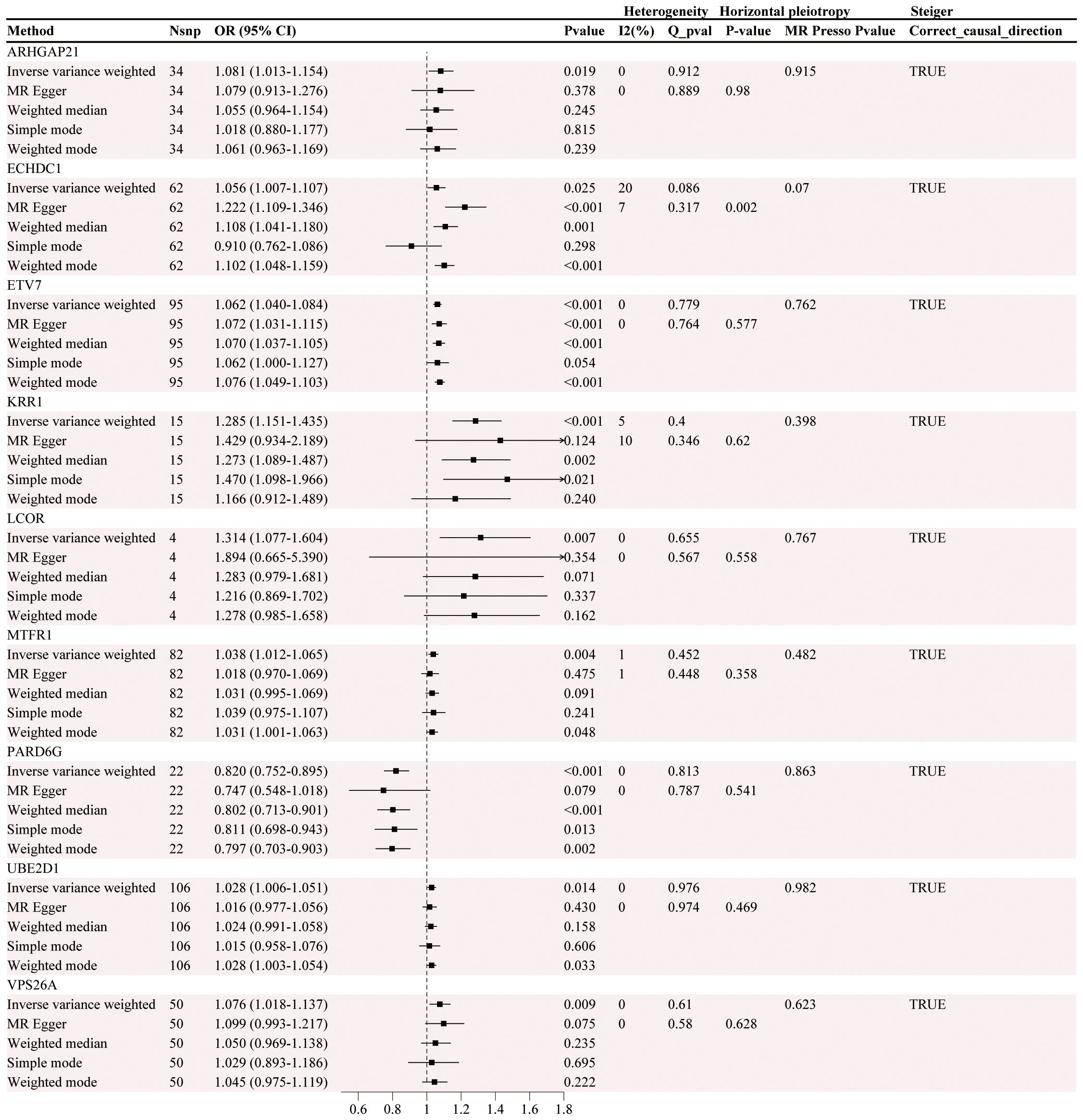
Figure 4. Causal association analysis results between gene eQTLs and gastric cancer.
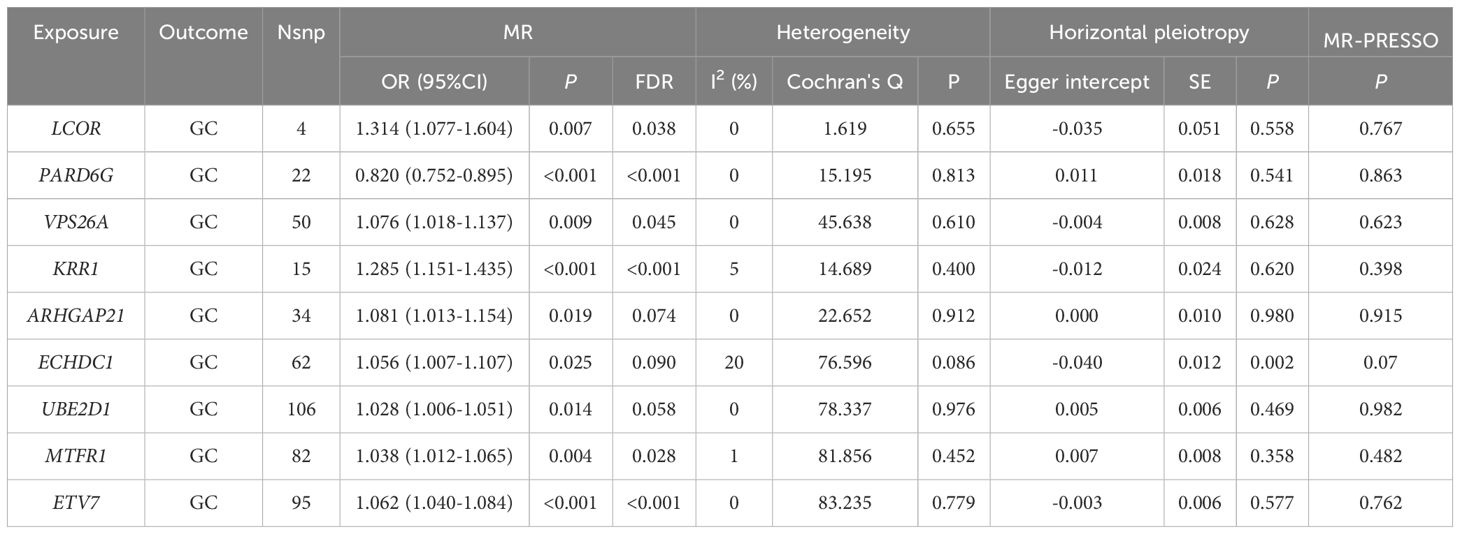
Table 4. Results of MR analysis of the causal effect of eqtl on GC.
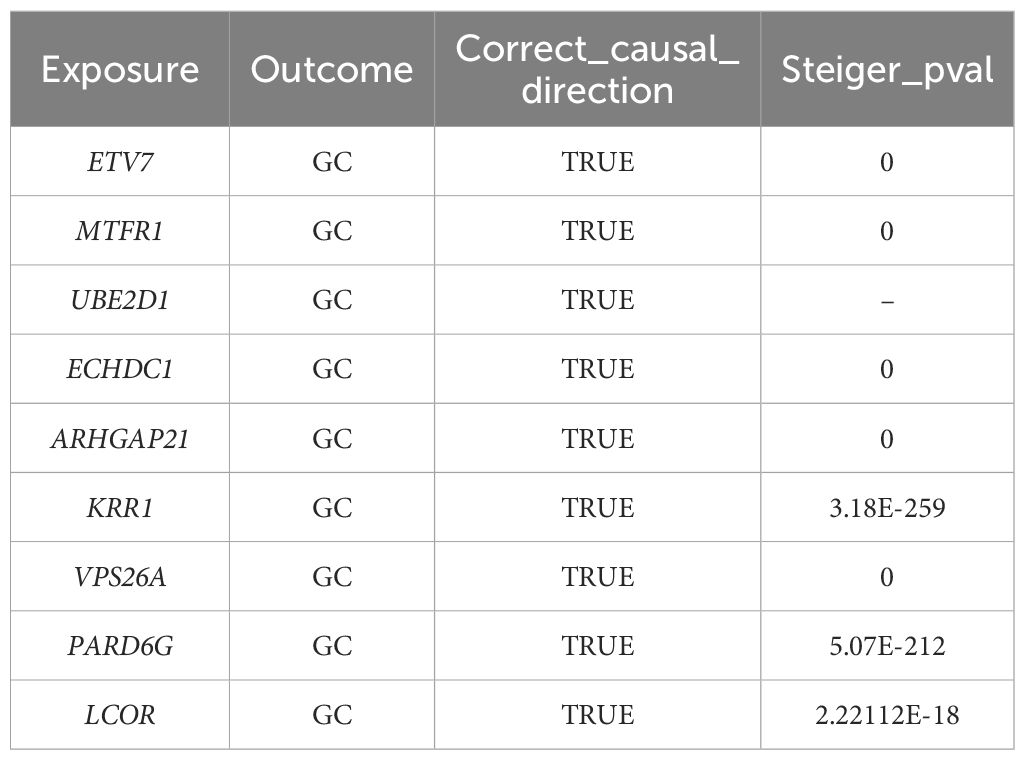
Table 5. Steiger directionality test.
Based on the results of differential analysis and MR analysis, we screened a total of 9 genes with consistent direction and positive analysis results and used LASSO and RF to construct a GC prediction model to identify genes with diagnostic values for GC (Figures 5A–C). The results revealed that the LASSO model identified 8 genes with diagnostic value, and the RF model also identified 8 genes with diagnostic value. The intersection of the two methods revealed 8 common genes (Figure 5D).
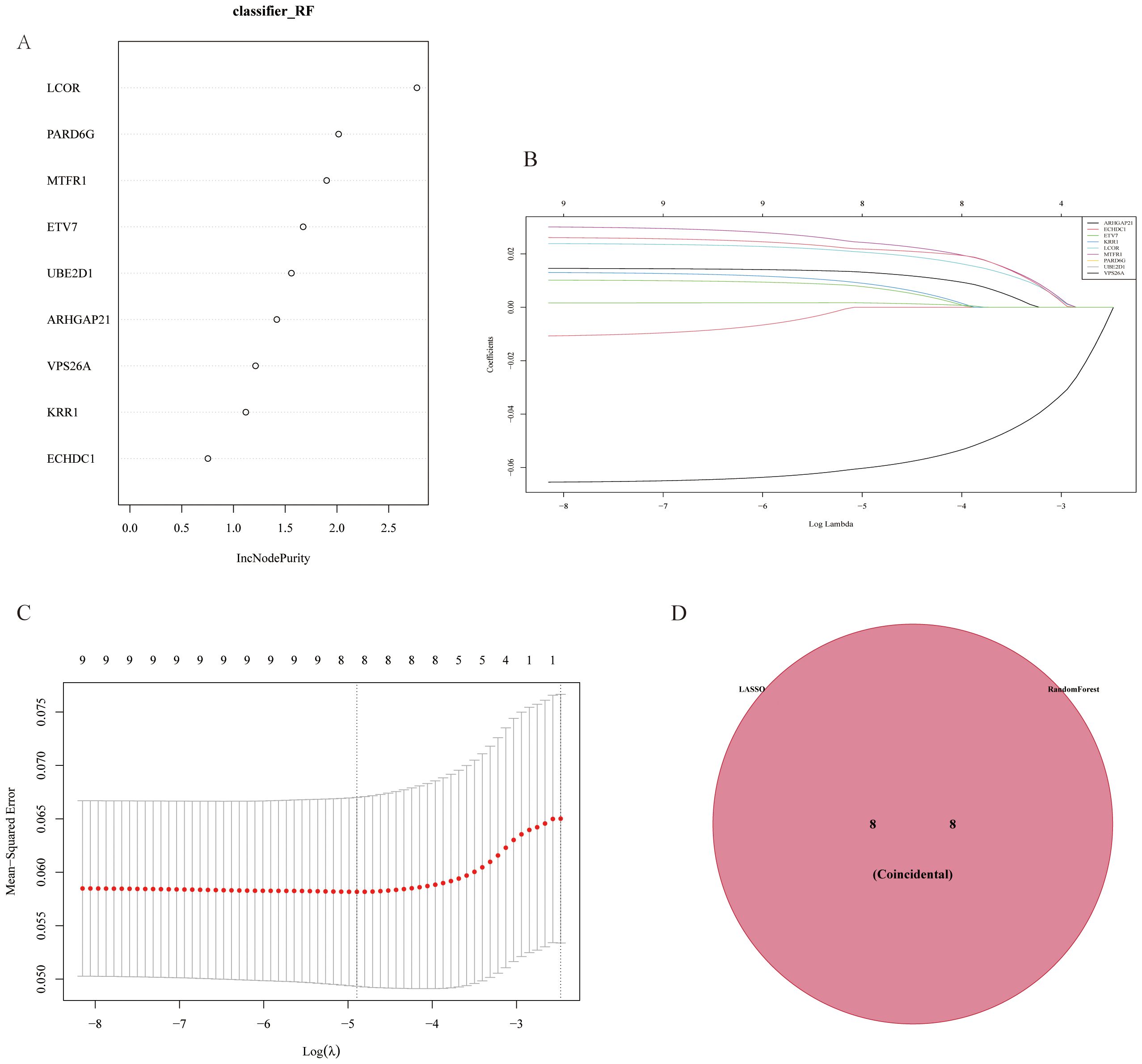
Figure 5. Gene selection results from LASSO and random forest model analyses. (A) Gene importance plot in the Random Forest (RF) model, showing genes with a high increase in node purity (incNodePurity). (B) Cross-validation for parameter tuning in LASSO analysis. (C) Least Absolute Shrinkage and Selection Operator (LASSO) regression model, which avoids overfitting by reducing redundant features and narrows down key differentially expressed genes associated with myocardial infarction. (D) Venn diagram of genes selected by both LASSO and RF models, showing eight genes identified by both methods, indicating their diagnostic value in predicting gastric cancer.
To improve the diagnostic and predictive performance of GC patients, we constructed a nomogram based on 8 genes with diagnostic values (ARHGAP21, ETV7, KRR1, LCOR, MTFR1, PARD6G, UBE2D1, and VPS26A) via logistic regression analysis (Figure 6A). The AUC values of the model were all greater than 0.95, suggesting that the nomogram may have a strong diagnostic value for predicting GC (Figures 6B, C). The calibration curve revealed that the predicted probability of the nomogram model was almost identical to that of the ideal model (Figures 6D, E). Additionally, we performed DCA of the nomogram, which indicated that decisions based on the nomogram model may be beneficial for diagnosing GC (Figures 6F, G).
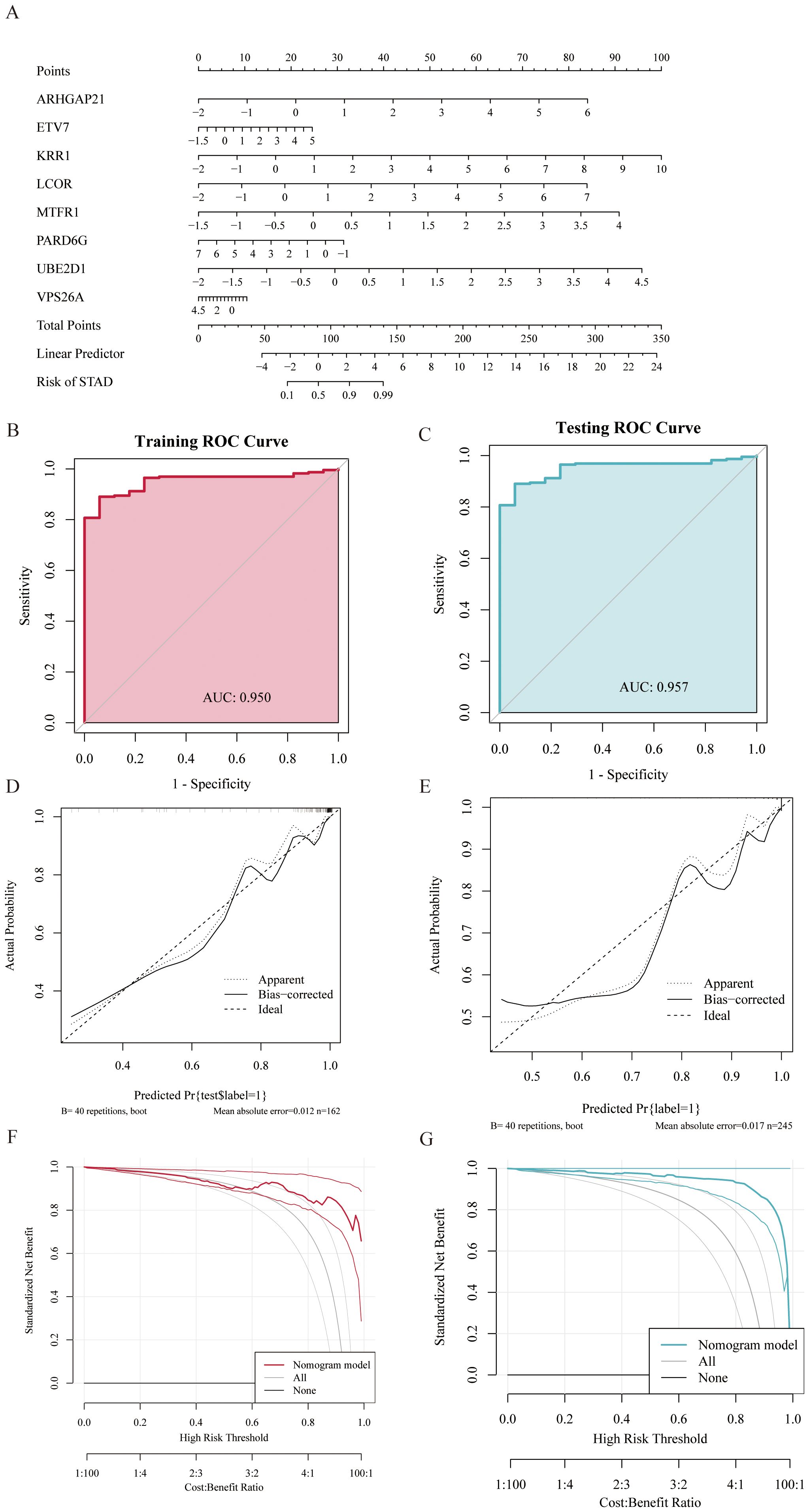
Figure 6. Gastric cancer prediction model constructed based on random forest (RF) and LASSO regression models. (A) Nomogram displaying eight diagnostic genes for gastric cancer and their scoring criteria to predict individual gastric cancer risk. (B, C) Receiver Operating Characteristic (ROC) curves showing Area Under the Curve (AUC) values above 0.95 in both training and testing sets, indicating the high discriminative ability of the model in gastric cancer diagnosis. (D, E) Calibration curves evaluate the consistency between model predictions and actual outcomes, demonstrating good calibration performance of the predictive model. (F, G) ROC curves showing AUC values above 0.95 in both training and testing sets, further indicating the model's strong diagnostic capability for gastric cancer. Decision Curve Analysis (DCA) shows that using the nomogram model provides a higher net benefit for patients.
In this study, we analyzed immune cell infiltration in GC, and the expression of the key gene ETV7 was significantly and positively correlated with the degree of infiltration of T.cells.follicular.helper (p<0.001). The key gene UBE2D1 was significantly positively correlated (p<0.001) with the degree of infiltration of Macrophage.M0, whereas ETV7 was significantly negatively correlated (p<0.001) with Macrophage.M0. The expression of the key gene ARHGAP21 was significantly positively correlated (p<0.001) with the degree of infiltration of NK.cells.resting, whereas VPS26A was significantly negatively correlated (p<0.01) with NK.cells.resting. The key gene ARHGAP21 was significantly negatively correlated with the degree of infiltration of neutrophils (p<0.05), whereas ETV7 was significantly positively correlated with the number of neutrophils (p<0.001). The expression of the key gene PARD6G was significantly negatively correlated (p<0.05) with the degree of infiltration of Dendritic.cells.resting (Figure 7).
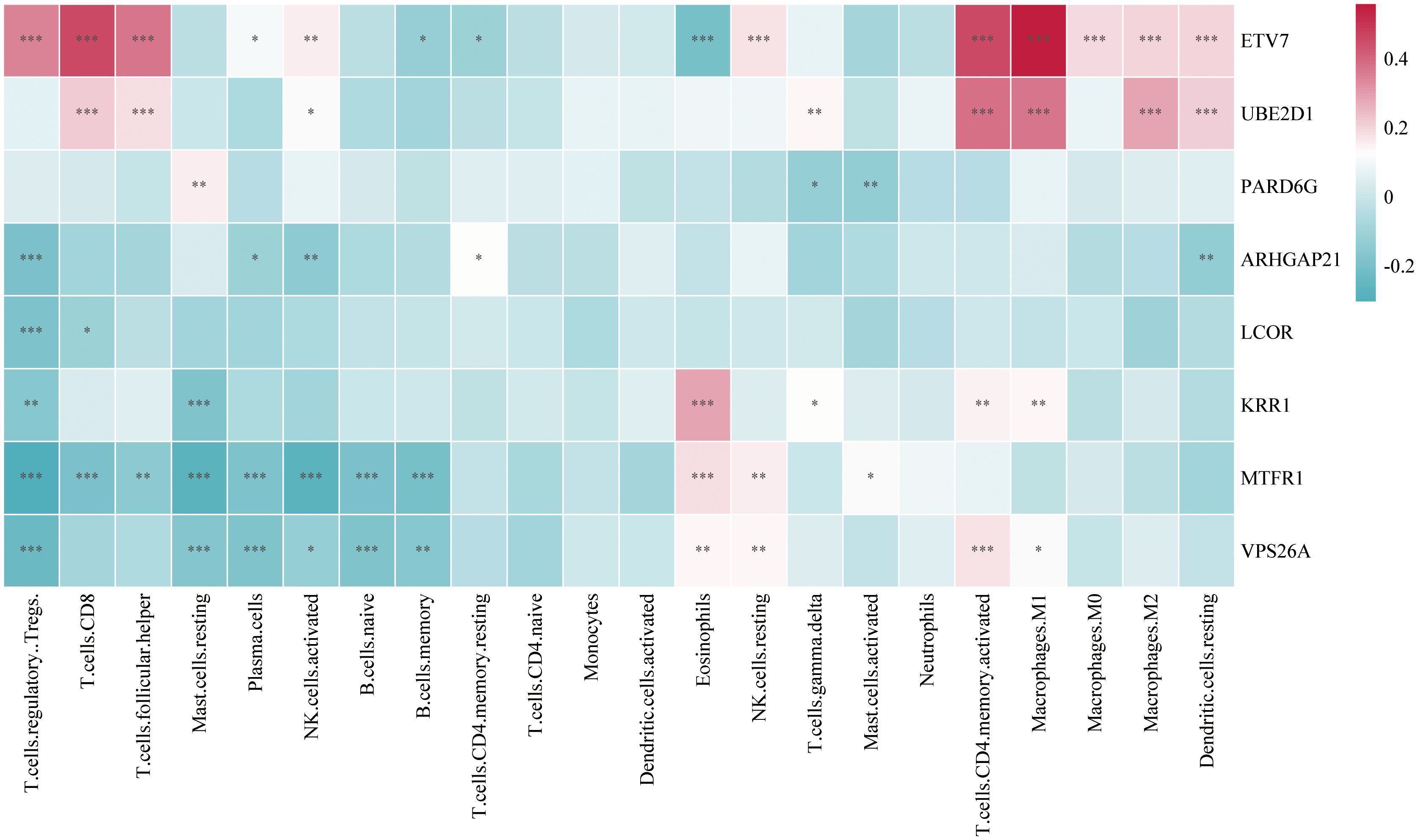
Figure 7. Heatmap of the correlation between key gene expression and infiltration of various immune cells in gastric cancer tissues (Color indicates the strength and direction of correlation; statistical significance levels: ns, p ≥ 0.05; *p < 0.05; **p < 0.01; ***p < 0.001.
In this study, we systematically explored the common pathogenic factors of GC and MI and identified potential common drug targets by combining GEO data and eQTL data with MR analysis and transcriptomics analysis. First, through MR analysis of GWAS data of GC and MI, eQTLs of MI were found to be significantly associated with the risk of GC. In addition, 74 genes that were differentially expressed in GC and MI were screened via differential expression gene analysis. Nine genes were identified as potential drug targets for GC treatment via drug-targeted MR, and the directional consistency of the causal associations between the DEGs and GC was verified. A nomogram for GC was subsequently constructed based on 8 key genes, including LCOR, which were screened via random forest and LASSO regression algorithms, and it showed good predictive performance. In addition, the expression of key genes was significantly correlated with the degree of T-cell infiltration according to immune cell infiltration analysis, further suggesting the potential role of these genes in the immune microenvironment. In this study, by integrating multisource data and applying multiple methods, we revealed the common pathogenic mechanism of GC and MI, identified multiple potential drug targets, and provided new ideas for future disease prevention and drug intervention. By combining the advantages of MR analysis, transcriptomics, and machine learning modeling, this paper provides more comprehensive insights into the comorbidities of GC and MI, with important clinical applications.
Existing studies have found that patients with myocardial infarction (MI) have a significantly higher risk of developing cancer both in the short and long term, especially within the first 6 months after MI (20). A study by Maarten J G Leening and colleagues showed that, although the overall cancer incidence among STEMI patients over 5 years was similar to that of the general population, the cancer risk was significantly higher in the first 3 months after STEMI (12). Although gastric cancer (GC) and MI affect different systems, there may be a potential link between the two. Logan Vincent and colleagues reported that GC and MI share several pathogenic factors, such as inflammation, smoking, and high-salt diets, which may contribute to the development and progression of both diseases (46). Ryan J Koene's article emphasized that inflammation is a key mechanism in both cardiovascular disease (CVD) and cancer. Common risk factors like obesity, hyperglycemia, hypertension, and hypertriglyceridemia can trigger inflammation, leading to shared risk for both diseases. Additionally, hormones, cytokines, and growth factors might also play a role in the biological connection between these diseases (47). Therefore, exploring the causal relationship between GC and MI is important for understanding this association. However, most of the previous studies used observational study designs, which revealed the overlap between the two in terms of causative factors but were limited by confounding factors and reverse causality, making it difficult to draw clear causal inferences. To address this problem, MR, as an emerging analytical tool, provides a more reliable basis for causal inference by using genetic variation as an instrumental variable to simulate a randomized controlled trial, which reduces the interference of environmental and behavioral differences on the results (48). In this study, for the first time, we not only verified the potential causal association between GC and MI via MR analysis but also revealed the common differential genes and potential drug targets by combining it with transcriptomics analysis. Unlike previous studies that explored only shared risk factors, the present study explored the link between GC and MI at the genetic level in detail, identifying multiple molecular mechanisms that are jointly involved. In addition, while previous studies have not systematically analyzed the common targets of GC and MI, this study fills this gap by identifying multiple possible therapeutic targets through drug target MR analysis. Moreover, this study screened key genes with diagnostic value via machine learning algorithms (e.g., random forest and LASSO regression) and constructed a column-line graph model with high predictive performance, which provides new ideas for the early diagnosis of GC and MI in the future. Therefore, this study is not only a revalidation of previous studies but also an innovation in the exploration of pathogenic mechanisms and clinical applications, which fills the research gaps in related fields, promotes an in-depth understanding of the common pathogenesis of GC and MI, and provides potential drug targets and diagnostic tools for future therapeutic strategies.
In this study, the 74 DEGs identified by GO enrichment analysis were significantly enriched in several key biological processes, cellular compositions and molecular functions. Specifically, at the biological process (BP) level, these genes were significantly enriched in the positive regulation of establishment of protein localization, protein transport, and protein ubiquitination modification, and ubiquitin-dependent protein catabolic process. These biological processes are critical in cancer and cardiovascular diseases, and the correct localization and modification of proteins play decisive roles in the maintenance of normal cell function, signaling, and the regulation of cell proliferation and metabolism. Abnormal localization of proteins may lead to cellular dysfunction and thus drive cancer progression (49), whereas in MI, abnormal protein transport affects cardiomyocyte function (50). At the cellular component (CC) level, these genes were enriched predominantly in the nuclear pore complex, endoplasmic reticulum membrane and Golgi apparatus. The abnormal function of these cellular structures is closely related to the development of GC and MI. Studies have shown that altered Golgi function in GC affects protein transport, leading to tumor cell proliferation and metastasis (51). In MI, disruption of the nuclear pore complex may affect the exchange of materials in the nucleus, thereby aggravating cellular damage. At the molecular function (MF) level, these genes were enriched for ubiquitin protein ligase binding and heat shock protein binding, which play key roles in protein modification, protein folding and the stress response. In particular, the ubiquitination pathway plays a central role in cell cycle regulation, DNA repair, and signaling. Abnormal ubiquitination is an important mechanism in the development of GC (52) and MI (53).
By integrating differentially expressed genes with their corresponding eQTL data, we further carried out MR analysis of drug targets to explore the causal associations between these genes and the risk of GC. This analysis not only verified the potential causal relationship between genes and diseases but also provided an important theoretical basis for the development of future drug targets. According to the results of MR analysis, the eQTLs of nine genes showed significant causal associations with the risk of GC development, suggesting that they may be common potential therapeutic targets for both. Among these genes, those associated with an increased risk of GC development included LCOR, VPS26A, KRR1, ARHGAP21, ECHDC1, UBE2D1, MTFR1, and ETV7, whereas the gene associated with a decreased risk of GC development was PARD6G. Previous studies have shown that high expression of LCOR in GC is independently associated with poor prognosis, suggesting that it may be a common potential therapeutic target. These findings suggest that LCOR may play a key role in GC progression (54). VPS26A is a protein involved in intracellular retrograde transport and is responsible for transporting proteins from endosomes to the Golgi apparatus as part of the reticulum complex. Although VPS26A has been shown to regulate cell proliferation, migration, and invasive ability in a variety of tumors, thereby promoting tumor progression, its specific function in GC needs to be further investigated (55). KRR1 is mainly responsible for the formation of the 40S ribosomal subunit and is thought to correlate with drug response and tumor progression, especially in the use of S-1, cisplatin, and docetaxel. ARHGAP21 acts as a Rho GTPase-activating protein and converts Rho family GTPases from active to inactive states, mainly by regulating cytoskeletal activities (56). In prostate cancer, ARHGAP21 affects tumor progression by regulating the expression of the PCA3 gene, but its specific role in GC is still unclear (57). ECHDC1, as a metabolism-correcting enzyme, is involved in fatty acid synthesis, which is associated with drug resistance in tumors such as bladder cancer, but the specific mechanism of ECHDC in GC still needs to be further studied (58). UBE2D1 is a ubiquitin-binding enzyme, and its high expression has been shown to promote epithelial−mesenchymal transition (EMT) through the TGF-β/SMAD4 signaling pathway to increase the migration and invasion of GC cells (59). MTFR1, a protein that regulates mitochondrial fission, has been demonstrated to be correlated with poor prognosis and drug resistance in NSCLC (60) and drug resistance in non-small cell lung cancer, but studies in GC have not yet reached a definitive conclusion (61). ETV7 is a member of the Ets family of transcription factors and plays a regulatory role in cell differentiation and proliferation. Studies have shown that ETV7 expression is correlated with decreased sensitivity of GC cells to chemotherapeutic agents such as 5-FU and CDDP [PMID: 24504010]. PARD6G, a parapolar protein, is involved in the regulation of cell polarity, and studies have demonstrated that its differential expression among subtypes of lung cancer has a role as a potential marker; however, its function in GC has not yet been explored in depth [PMID: 32360590]. The robust causal relationship between these genes and their consistent expression in GC and MI suggests that they may play important roles in the common pathological mechanisms of these two diseases, providing strong support for drug target development and clinical intervention strategies.
To verify the potential application value of differential genes in the diagnosis of GC, this study used random forest and LASSO regression algorithms to construct a prediction model for GC. The results revealed that the LASSO model screened eight genes with diagnostic value, and the random forest model also screened eight genes with diagnostic value. The intersecting genes of the two were ultimately used in the construction of the prediction model. The nomogram model constructed on the basis of these genes had high prediction performance, and its AUC values were all greater than 0.95, suggesting that the model has high accuracy in the diagnosis of GC. Moreover, calibration curve and decision curve analysis (DCA) further indicated that the predictive model had good calibration and decision value. These results suggest that the predictive model based on differential genes not only has potential application in the diagnosis of GC but also may provide a reference for the diagnosis and prediction of MI.
We subsequently constructed a prediction model for GC via LASSO regression and a random forest model and ultimately identified 8 genes with diagnostic value. The column-line graph model based on these eight genes demonstrated extremely high diagnostic efficacy, with AUC values greater than 0.95, suggesting that these genes have important potential for clinical application in the diagnosis and prediction of GC. In addition, immune cell infiltration analysis revealed that some of the key genes were positively correlated with the infiltration of T cells (especially CD8+ T cells), further supporting the important role of these genes in the immune response.
This study, which explored the common pathogenic mechanisms and potential drug targets of GC and MI, had several limitations despite the application of techniques such as MR, transcriptome analysis and machine learning. First, the data sources are based mainly on European populations, and although these data provide rich genotypic and phenotypic information, the incidence and pathogenic mechanisms of GC and MI differ in different populations. Therefore, the global applicability of the findings, especially their validity in Asian populations, needs to be verified. Second, although we identified 74 differential genes in the transcriptome analysis, only 37 instrumental variables of blood eQTLs were ultimately screened for use in MR analysis, which limited the causal analysis of more potential key genes. In addition, the cross-sectional data used in this study failed to reflect the dynamics of the disease at different stages and could not reveal changes in gene action over time. Future studies should incorporate longitudinal data combined with time-dimensional analysis to further elucidate the dynamic pathogenic mechanisms of GC and MI. Finally, although we screened potential targets through our analysis, the clinical feasibility of these targets still needs to be verified through cellular experiments, animal models, and clinical trials to determine their effectiveness and safety in therapy. Therefore, future studies should further validate the biological functions of these key genes by experimental means to ensure their feasibility and effectiveness as clinical targets. Finally, although we constructed predictive models for GC by machine learning and the diagnostic performance of the models showed high AUC values, these models still need to be validated by independent external datasets to ensure their robustness and generalizability in different populations and practical clinical applications.
The MR analysis in this study indicated that MI may increase the risk of GC. Eight potential diagnostic genes associated with MI and GC were identified through transcriptome analysis and drug target MR validation, and a nomogram model with good predictive performance was successfully constructed. The results provide new insights into the comorbid mechanisms of MI and GC and provide a theoretical basis for the optimization of individualized diagnosis and prognosis assessment strategies.
The original contributions presented in the study are included in the article/Supplementary Material. Further inquiries can be directed to the corresponding author.
Ethical approval was not required for the study involving humans in accordance with the local legislation and institutional requirements. Written informed consent to participate in this study was not required from the participants or the participants' legal guardians/next of kin in accordance with the national legislation and the institutional requirements.
JM: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Project administration, Writing – original draft. SH: Software, Supervision, Validation, Writing – review & editing. XG: Data curation, Formal analysis, Software, Validation, Writing – review & editing. PG: Validation, Writing – review & editing. JZ: Funding acquisition, Project administration, Resources, Supervision, Validation, Writing – review & editing.
The author(s) declare that financial support was received for the research and/or publication of this article. This work was supported by Supports for Shandong First Medical University Research Grant Fund (342601).
Our thanks go out to the original GWAS participants and investigators for sharing and managing the summary statistics.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The author(s) declare that no Generative AI was used in the creation of this manuscript.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fimmu.2025.1533959/full#supplementary-material
1. Guan WL, He Y, Xu RH. Gastric cancer treatment: recent progress and future perspectives. J Hematol Oncol. (2023) 16:57. doi: 10.1186/s13045-023-01451-3
2. Huang B, Liu J, Ding F, Li Y. Epidemiology, risk areas and macro determinants of gastric cancer: a study based on geospatial analysis. Int J Health Geogr. (2023) 22:32. doi: 10.1186/s12942-023-00356-1
3. Thrift AP, Wenker TN, El-Serag HB. Global burden of gastric cancer: epidemiological trends, risk factors, screening and prevention. Nat Rev Clin Oncol. (2023) 20:338–49. doi: 10.1038/s41571-023-00747-0
4. Machlowska J, Baj J, Sitarz M, Maciejewski R, Sitarz R. Gastric cancer: epidemiology, risk factors, classification, genomic characteristics and treatment strategies. Int J Mol Sci. (2020) 21. doi: 10.3390/ijms21114012
5. Lordick F, Carneiro F, Cascinu S, Fleitas T, Haustermans K, Piessen G, et al. Gastric cancer: ESMO Clinical Practice Guideline for diagnosis, treatment and follow-up. Ann Oncol. (2022) 33:1005–20. doi: 10.1016/j.annonc.2022.07.004
6. Thrift AP, El-Serag HB. Burden of gastric cancer. Clin Gastroenterol Hepatol. (2020) 18:534–42. doi: 10.1016/j.cgh.2019.07.045
7. Zhang Q, Wang L, Wang S, Cheng H, Xu L, Pei G, et al. Signaling pathways and targeted therapy for myocardial infarction. Signal Transduct Target Ther. (2022) 7:78. doi: 10.1038/s41392-022-00925-z
8. Roth GA, Mensah GA, Johnson CO, Addolorato G, Ammirati E, Baddour LM, et al. Global burden of cardiovascular diseases and risk factors, 1990-2019: update from the GBD 2019 study. J Am Coll Cardiol. (2020) 76:2982–3021. doi: 10.1016/j.jacc.2020.11.010
9. Roth GA, Mensah GA, Fuster V. The global burden of cardiovascular diseases and risks: A compass for global action. J Am Coll Cardiol. (2020) 76:2980–1. doi: 10.1016/j.jacc.2020.11.021
10. Jortveit J, Pripp AH, Langørgen J, Halvorsen S. Incidence, risk factors and outcome of young patients with myocardial infarction. Heart. (2020) 106:1420–6. doi: 10.1136/heartjnl-2019-316067
11. Buttar HS, Li T, Ravi N. Prevention of cardiovascular diseases: Role of exercise, dietary interventions, obesity and smoking cessation. Exp Clin Cardiol. (2005) 10:229–49.
12. Leening MJG, Bouwer NI, Ikram MA, Kavousi M, Ruiter R, Boersma E, et al. Risk of cancer after ST-segment-elevation myocardial infarction. Eur J Epidemiol. (2023) 38:853–8. doi: 10.1007/s10654-023-00984-8
13. Zeng Y, Jin RU. Molecular pathogenesis, targeted therapies, and future perspectives for gastric cancer. Semin Cancer Biol. (2022) 86:566–82. doi: 10.1016/j.semcancer.2021.12.004
14. Bouras E, Tsilidis KK, Triggi M, Siargkas A, Chourdakis M. Haidich AB. Diet and risk of gastric cancer: an umbrella review. Nutrients. (2022) 14. doi: 10.3390/nu14091764
15. Tan KW, Quaye SED, Koo JR, Lim JT, Cook AR, Dickens BL. Assessing the impact of salt reduction initiatives on the chronic disease burden of Singapore. Nutrients. (2021) 13. doi: 10.3390/nu13041171
16. Rallidis LS, Xenogiannis I, Brilakis ES, Bhatt DL. Causes, angiographic characteristics, and management of premature myocardial infarction: JACC state-of-the-art review. J Am Coll Cardiol. (2022) 79:2431–49. doi: 10.1016/j.jacc.2022.04.015
17. Yuan S, Chen J, Ruan X, Sun Y, Zhang K, Wang X, et al. Smoking, alcohol consumption, and 24 gastrointestinal diseases: Mendelian randomization analysis. Elife. (2023) 12. doi: 10.7554/eLife.84051
18. Sandoval Y, Apple FS, Mahler SA, Body R, Collinson PO, Jaffe AS. High-sensitivity cardiac troponin and the 2021 AHA/ACC/ASE/CHEST/SAEM/SCCT/SCMR guidelines for the evaluation and diagnosis of acute chest pain. Circulation. (2022) 146:569–81. doi: 10.1161/circulationaha.122.059678
19. Lu L, Liu M, Sun R, Zheng Y, Zhang P. Myocardial infarction: symptoms and treatments. Cell Biochem Biophys. (2015) 72:865–7. doi: 10.1007/s12013-015-0553-4
20. Rinde LB, Småbrekke B, Hald EM, Brodin EE, Njølstad I, Mathiesen EB, et al. Myocardial infarction and future risk of cancer in the general population-the Tromsø Study. Eur J Epidemiol. (2017) 32:193–201. doi: 10.1007/s10654-017-0231-5
21. Liu J, Wang F, Shi S. Helicobacter pylori Infection Increase the Risk of Myocardial Infarction: A Meta-Analysis of 26 Studies Involving more than 20,000 Participants. Helicobacter. (2015) 20:176–83. doi: 10.1111/hel.12188
22. Prada-Ramallal G, Takkouche B, Figueiras A. Bias in pharmacoepidemiologic studies using secondary health care databases: a scoping review. BMC Med Res Methodol. (2019) 19:53. doi: 10.1186/s12874-019-0695-y
23. Ference BA. Interpreting the clinical implications of drug-target Mendelian randomization studies. J Am Coll Cardiol. (2022) 80:663–5. doi: 10.1016/j.jacc.2022.06.007
24. Qi H, Wen FY, Xie YY, Liu XH, Li BX, Peng WJ, et al. Associations between depressive, anxiety, stress symptoms and elevated blood pressure: Findings from the CHCN-BTH cohort study and a two-sample Mendelian randomization analysis. J Affect Disord. (2023) 341:176–84. doi: 10.1016/j.jad.2023.08.086
25. Yu Z, Coresh J, Qi G, Grams M, Boerwinkle E, Snieder H, et al. A bidirectional Mendelian randomization study supports causal effects of kidney function on blood pressure. Kidney Int. (2020) 98:708–16. doi: 10.1016/j.kint.2020.04.044
26. Lin J, Zhou J, Xu Y. Potential drug targets for multiple sclerosis identified through Mendelian randomization analysis. Brain. (2023) 146:3364–72. doi: 10.1093/brain/awad070
27. Cao Y, Yang Y, Hu Q, Wei G. Identification of potential drug targets for rheumatoid arthritis from genetic insights: a Mendelian randomization study. J Transl Med. (2023) 21:616. doi: 10.1186/s12967-023-04474-z
28. Ference BA, Majeed F, Penumetcha R, Flack JM, Brook RD. Effect of naturally random allocation to lower low-density lipoprotein cholesterol on the risk of coronary heart disease mediated by polymorphisms in NPC1L1, HMGCR, or both: a 2 × 2 factorial Mendelian randomization study. J Am Coll Cardiol. (2015) 65:1552–61. doi: 10.1016/j.jacc.2015.02.020
29. Swerdlow DI, Preiss D, Kuchenbaecker KB, Holmes MV, Engmann JE, Shah T, et al. HMG-coenzyme A reductase inhibition, type 2 diabetes, and bodyweight: evidence from genetic analysis and randomised trials. Lancet. (2015) 385:351–61. doi: 10.1016/s0140-6736(14)61183-1
30. VanderWeele TJ, Tchetgen Tchetgen EJ, Cornelis M, Kraft P. Methodological challenges in mendelian randomization. Epidemiology. (2014) 25:427–35. doi: 10.1097/ede.0000000000000081
31. Gagliano Taliun SA, Evans DM. Ten simple rules for conducting a mendelian randomization study. PLoS Comput Biol. (2021) 17:e1009238. doi: 10.1371/journal.pcbi.1009238
32. Skrivankova VW, Richmond RC, Woolf BAR, Yarmolinsky J, Davies NM, Swanson SA, et al. Strengthening the reporting of observational studies in epidemiology using Mendelian randomization: the STROBE-MR statement. JAMA. (2021) 326:1614–21. doi: 10.1001/jama.2021.18236
33. Guo YG, Zhang Y, Liu WL. The causal relationship between allergic diseases and heart failure: Evidence from Mendelian randomization study. PloS One. (2022) 17:e0271985. doi: 10.1371/journal.pone.0271985
34. Wang X, Li T, Chen Q. Causal relationship between ulcerative colitis and male infertility: A two-sample Mendelian randomization study. PloS One. (2024) 19:e0303827. doi: 10.1371/journal.pone.0303827
35. Wu S, Meena D, Yarmolinsky J, Gill D, Smith A, Dib MJ, et al. Mendelian randomization and bayesian colocalization analysis implicate glycoprotein VI as a potential drug target for cardioembolic stroke in south Asian populations. J Am Heart Assoc. (2024) 13:e035008. doi: 10.1161/jaha.124.035008
36. Zhu Z, Zhang F, Hu H, Bakshi A, Robinson MR, Powell JE, et al. Integration of summary data from GWAS and eQTL studies predicts complex trait gene targets. Nat Genet. (2016) 48:481–7. doi: 10.1038/ng.3538
37. Burgess S, Butterworth A, Thompson SG. Mendelian randomization analysis with multiple genetic variants using summarized data. Genet Epidemiol. (2013) 37:658–65. doi: 10.1002/gepi.21758
38. Burgess S, Thompson SG. Interpreting findings from Mendelian randomization using the MR-Egger method. Eur J Epidemiol. (2017) 32:377–89. doi: 10.1007/s10654-017-0255-x
39. Qin C, Diaz-Gallo LM, Tang B, Wang Y, Nguyen TD, Harder A, et al. Repurposing antidiabetic drugs for rheumatoid arthritis: results from a two-sample Mendelian randomization study. Eur J Epidemiol. (2023) 38:809–19. doi: 10.1007/s10654-023-01000-9
40. Bowden J, Del Greco MF, Minelli C, Davey Smith G, Sheehan N, Thompson J. A framework for the investigation of pleiotropy in two-sample summary data Mendelian randomization. Stat Med. (2017) 36:1783–802. doi: 10.1002/sim.7221
41. Bowden J, Del Greco MF, Minelli C, Davey Smith G, Sheehan NA, Thompson JR. Assessing the suitability of summary data for two-sample Mendelian randomization analyses using MR-Egger regression: the role of the I2 statistic. Int J Epidemiol. (2016) 45:1961–74. doi: 10.1093/ije/dyw220
42. Bowden J, Spiller W, Del Greco MF, Sheehan N, Thompson J, Minelli C, et al. Improving the visualization, interpretation and analysis of two-sample summary data Mendelian randomization via the Radial plot and Radial regression. Int J Epidemiol. (2018) 47:1264–78. doi: 10.1093/ije/dyy101
43. Gao Y, Zhou M, Xu X, Ma JY, Qin MF. Body composition and risk of gestational diabetes mellitus: A univariable and multivariable Mendelian randomization study. J Diabetes Investig. (2024) 15:346–54. doi: 10.1111/jdi.14115
44. Cheng J, Dekkers JCM, Fernando RL. Cross-validation of best linear unbiased predictions of breeding values using an efficient leave-one-out strategy. J Anim Breed Genet. (2021) 138:519–27. doi: 10.1111/jbg.12545
45. Ritchie ME, Phipson B, Wu D, Hu Y, Law CW, Shi W, et al. limma powers differential expression analyses for RNA-sequencing and microarray studies. Nucleic Acids Res. (2015) 43:e47. doi: 10.1093/nar/gkv007
46. Vincent L, Leedy D, Masri SC, Cheng RK. Cardiovascular disease and cancer: is there increasing overlap? Curr Oncol Rep. (2019) 21:47. doi: 10.1007/s11912-019-0796-0
47. Koene RJ, Prizment AE, Blaes A, Konety SH. Shared risk factors in cardiovascular disease and cancer. Circulation. (2016) 133:1104–14. doi: 10.1161/circulationaha.115.020406
48. Bastarache L, Denny JC, Roden DM. Phenome-wide association studies. JAMA. (2022) 327:75–6. doi: 10.1001/jama.2021.20356
49. Bui S, Mejia I, Díaz B, Wang Y. Adaptation of the Golgi apparatus in cancer cell invasion and metastasis. Front Cell Dev Biol. (2021) 9:806482. doi: 10.3389/fcell.2021.806482
50. Kwan Z, Paulose Nadappuram B, Leung MM, Mohagaonkar S, Li A, Amaradasa KS, et al. Microtubule-mediated regulation of β(2)AR translation and function in failing hearts. Circ Res. (2023) 133:944–58. doi: 10.1161/circresaha.123.323174
51. El Nekidy WS, Mallat J, Nusair AR, Eshbair AH, Attallah N, Mooty M, et al. Urinary tract infections in hemodialysis patients-The controversy of antimicrobial drug urine concentrations. Hemodial Int. (2022) 26:548–54. doi: 10.1111/hdi.13041
52. Li KQ, Bai X, Ke AT, Ding SQ, Zhang CD, Dai DQ. Ubiquitin-specific proteases: From biological functions to potential therapeutic applications in gastric cancer. BioMed Pharmacother. (2024) 173:116323. doi: 10.1016/j.biopha.2024.116323
53. You JR, Wen ZJ, Tian JW, Lv XB, Li R, Li SP, et al. Crosstalk between ubiquitin ligases and ncRNAs drives cardiovascular disease progression. Front Immunol. (2024) 15:1335519. doi: 10.3389/fimmu.2024.1335519
54. Triki M, Ben-Ayed-Guerfali D, Saguem I, Charfi S, Ayedi L, Sellami-Boudawara T, et al. RIP140 and LCoR expression in gastrointestinal cancers. Oncotarget. (2017) 8:111161–75. doi: 10.18632/oncotarget.22686
55. Hou J, Wu H, Xu B, Shang J, Xu X, Li G, et al. The prognostic value and the oncogenic and immunological roles of vacuolar protein sorting associated protein 26 A in pancreatic adenocarcinoma. Int J Mol Sci. (2023) 24. doi: 10.3390/ijms24043486
56. Kashani SF, Abedini Z, Darehshouri AF, Jazi K, Bereimipour A, Malekraeisi MA, et al. Investigation of molecular mechanisms of S-1, docetaxel and cisplatin in gastric cancer with a history of helicobacter pylori infection. Mol Biotechnol. (2024) 66:1303–13. doi: 10.1007/s12033-023-01032-2
57. Alves DA, Neves AF, Vecchi L, Souza TA, Vaz ER, Mota STS, et al. Rho GTPase activating protein 21-mediated regulation of prostate cancer associated 3 gene in prostate cancer cell. Braz J Med Biol Res. (2024) 57:e13190. doi: 10.1590/1414-431X2024e13190
58. Asai S, Miura N, Sawada Y, Noda T, Kikugawa T, Tanji N, et al. Silencing of ECHDC1 inhibits growth of gemcitabine-resistant bladder cancer cells. Oncol Lett. (2018) 15:522–7. doi: 10.3892/ol.2017.7269
59. Xie H, He Y, Wu Y, Lu Q. Silencing of UBE2D1 inhibited cell migration in gastric cancer, decreasing ubiquitination of SMAD4. Infect Agent Cancer. (2021) 16:63. doi: 10.1186/s13027-021-00402-2
60. AminiAghdam S, Rode C. Posture-induced modulation of lower-limb joint powers in perturbed running. PLoS One. (2024) 19:e0302867. doi: 10.1371/journal.pone.0302867
Keywords: gastric cancer, myocardial infarction, Mendelian randomization, machine learning, transcriptomics
Citation: Ma J, Hou S, Gu X, Guo P and Zhu J (2025) Analysis of shared pathogenic mechanisms and drug targets in myocardial infarction and gastric cancer based on transcriptomics and machine learning. Front. Immunol. 16:1533959. doi: 10.3389/fimmu.2025.1533959
Received: 25 November 2024; Accepted: 28 February 2025;
Published: 21 March 2025.
Edited by:
Kunpeng Hu, Third Affiliated Hospital of Sun Yat-sen University, ChinaReviewed by:
Georgia Damoraki, National and Kapodistrian University of Athens, GreeceCopyright © 2025 Ma, Hou, Gu, Guo and Zhu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jiankang Zhu, emh1amlhbmthbmdAc2RmbXUuZWR1LmNu
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.