
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Immunol. , 15 May 2023
Sec. Cancer Immunity and Immunotherapy
Volume 14 - 2023 | https://doi.org/10.3389/fimmu.2023.1115536
This article is part of the Research Topic Organoids, Organs-on-Chip, nanoparticles and In Silico Approaches to Dissect the Tumor-Immune Dynamics and to Unveil the Drug Resistance Mechanisms to Therapy in the Tumor Microenvironment View all 13 articles
 Alexander B. Brummer1,2*
Alexander B. Brummer1,2* Agata Xella3
Agata Xella3 Ryan Woodall1
Ryan Woodall1 Vikram Adhikarla1Heyrim Cho4
Vikram Adhikarla1Heyrim Cho4 Margarita Gutova5
Margarita Gutova5 Christine E. Brown3*
Christine E. Brown3* Russell C. Rockne1*
Russell C. Rockne1*In the development of cell-based cancer therapies, quantitative mathematical models of cellular interactions are instrumental in understanding treatment efficacy. Efforts to validate and interpret mathematical models of cancer cell growth and death hinge first on proposing a precise mathematical model, then analyzing experimental data in the context of the chosen model. In this work, we present the first application of the sparse identification of non-linear dynamics (SINDy) algorithm to a real biological system in order discover cell-cell interaction dynamics in in vitro experimental data, using chimeric antigen receptor (CAR) T-cells and patient-derived glioblastoma cells. By combining the techniques of latent variable analysis and SINDy, we infer key aspects of the interaction dynamics of CAR T-cell populations and cancer. Importantly, we show how the model terms can be interpreted biologically in relation to different CAR T-cell functional responses, single or double CAR T-cell-cancer cell binding models, and density-dependent growth dynamics in either of the CAR T-cell or cancer cell populations. We show how this data-driven model-discovery based approach provides unique insight into CAR T-cell dynamics when compared to an established model-first approach. These results demonstrate the potential for SINDy to improve the implementation and efficacy of CAR T-cell therapy in the clinic through an improved understanding of CAR T-cell dynamics.
Dynamical systems modeling is one of the most successfully implemented methodologies throughout mathematical oncology (1). Applications of these model first approaches have led to important insights in fundamental cancer biology as well as the planning and tracking of treatment response for patient cohorts (2–9). Simultaneously, the last twenty years have seen explosive growth in the study and application of data-driven methods. These data first approaches, initially implemented as machine learning methods for imaging and genomics analyses, have seen much success (10, 11). However, such approaches are often limited to classification problems and fall short when the intention is to identify and validate mathematical models of the underlying dynamics. Recent efforts by us and others have aimed to develop methodologies that bridge these model first and data first approaches (12–14).
In this work, we combine the methods of latent variable discovery and sparse identification of nonlinear dynamics (SINDy) (15–17) to analyze experimental in vitro cell killing assay data for chimeric antigen receptor (CAR) T-cells and glioblastoma cancer cells (18). This experimental data, featuring high temporal resolution, offers a unique opportunity to conduct an in situ test of the SINDy model discovery method. Interpretation of the discovered SINDy model is conducted under the expectation of a predator-prey interaction in which the cancer cells function as the prey and the CAR T-cells the predator (19).
Predator-prey systems are a broad class of ordinary differential equations (ODEs) that aim to characterize changes in populations between two or more groups of organisms in which at least one survives via predation on another. Originally applied to the study of plant herbivory (20) and fishery monitoring (21) in the early 20th century, predator-prey models have since become a workhorse of ecology, evolutionary biology, and most recently mathematical oncology (19, 22). Importantly, predator-prey models underpin much of the computational modeling of CAR T-cell killing, particularly in the context of in vitro cell killing assays (7, 23). An important example of these is the CAR T-cell Response in GliOma (CARRGO) model, a model that characterizes the in vitro interactions between CAR T-cells and glioma cells (18). The CARRGO model has shed light on the underlying biological mechanisms of action (18, 23), has informed effective dosing strategies for combination CAR T-cell and targeted radionuclide therapy (24), and CAR T-cell therapy in combination with the anti-inflammatory steroid Dexamethasone (25).
Despite the success of the CARRGO model, it is limited in the scope of potential phenomena that it can capture in regards to the precise interactions between the CAR T-cells and glioma cells. In this work, we use the SINDy modeling framework to incorporate important extensions to the CARRGO model. These extensions are: predator growth that is dependent on the density of prey, also known as a functional response (26, 27); individual predator and prey growth that saturates at some maximum value (logistic growth) (18), or has a population threshold below which collapse occurs (the Allee effect) (28, 29); and predator-prey interactions in which one or two CAR T-cells are bound to a single cancer cell at once, referred to as single or double binding, respectively (23, 30). Other efforts of extending CAR T-cell modeling have looked at fractional order derivatives (31) and stochastic dynamics (32) in the context of CAR T-cell treatment for viral infections, specifically coronaviruses. Our treatment focuses on integer order derivatives and deterministic dynamics.
An ever-present challenge to quantitative biologists is fitting a proposed model to experimental data, also known as parameter estimation or model inference. On one hand, quantitative biologists seek models that capture as much biological realism and complexity as possible. On the other hand, increasing model complexity increases the computational challenge to accurately, confidently, and expediently determine model parameter values. This approach is further complicated if a researcher chooses to compare competing or complementary models (33, 34). An alternative approach, examined in this paper, is to leverage newly developed methods rooted in data science and machine learning which identify the strength of individual mathematical terms as candidates for an explanatory model. These methods are often referred to as dynamic mode decomposition, symbolic regression, or sparse identification.
Dynamic mode decomposition (DMD) is a data driven technique that interrogates time-series data by performing a singular value decomposition (SVD) on carefully structured matrices of the given data (13, 35). In this formalism, the orthonormal basis vectors generated by singular value decomposition serve as linear generators of the system dynamics such that forward prediction can be performed absent a known underlying mathematical model. Alternatively, SINDy identifies the specific mathematical terms that give rise to the observed dynamics governed by ordinary and partial differential equation models (15). SINDy achieves this by regressing experimental data onto a high-dimensional library of candidate model terms, and it has proven successful in climate modeling (36), fluid mechanics (37), and control theory (38). Since the initial publication of SINDy, several extensions have been studied, including: discovery of rational ordinary differential equations (39, 40); robust implementation with under-sampled data (41) or excessive noise (42); or incorporation of physics informed neural networks when particular symmetries are known to exist (43).
In its original and subsequent implementations, the CARRGO model demonstrated valuable utility in quantifying CAR T-cell killing dynamics when treating glioblastoma. Inferences of the underlying biological dynamics were made by examining how model parameter values changed along gradients of effector:target (E:T) ratios or as a function of other combination therapy concentrations. This is in direct contrast to the SINDy methodology, where the discovery of different model terms provides insight into the underlying biological dynamics as a result of variation along the E:T gradient. Here we compare these two modelling frameworks on the same data set to provide further insight into the trade-offs of data first versus model first approaches.
In this paper we utilize our experimental data to test these and other aspects of the DMD and SINDy frameworks. In Section 2.2 we introduce the families of models that are anticipated to be simultaneously biologically relevant and identifiable by SINDy, and we introduce a new approach to performing SINDy-based model inference. In Section 2.3.1 we present the latent variable analysis based on DMD that is used to generate the time-series CAR T-cell trajectories based on those of the cancer cells and the known boundary values for the CAR T-cells. In Section 2.3.2 we introduce the SINDy methodology in the particular context of our application. Results of our approach are presented in Section 3 where we (1) highlight how the discovered models vary as a result of different initial conditions in the cancer cell and CAR T-cell populations and (2) examine how well the discovered models found in this data first approach compare to a typical model first in characterizing the experimental data. In Section 4 we demonstrate how our results can guide experimental design to validate the predictions made by the discovered models, and we elaborate on some of the challenges encountered in this study.
The data analyzed in this study come from previously conducted experiments whose procedures are described in Sahoo et al. (18) and Brummer et al. (25), and summarized in Figure 1. The primary brain tumor cell line studied (PBT128) was selected for its endogenous high and relatively uniform expression of IL13Rα2 antigen (89.11% IL13Rα2+) (25). This cell line was derived from glioblastoma tumor resection tissue as described in (44, 45). To generate IL13Rα2-targeted CAR T-cell lines, healthy donor CD62L+ naive and memory T-cells were lentivirally transduced to express second-generation 4-1BB-containing CAR that utilizes the IL13 cytokine with an E12Y engineered mutation as the IL13Rα2 targeting domain (46).
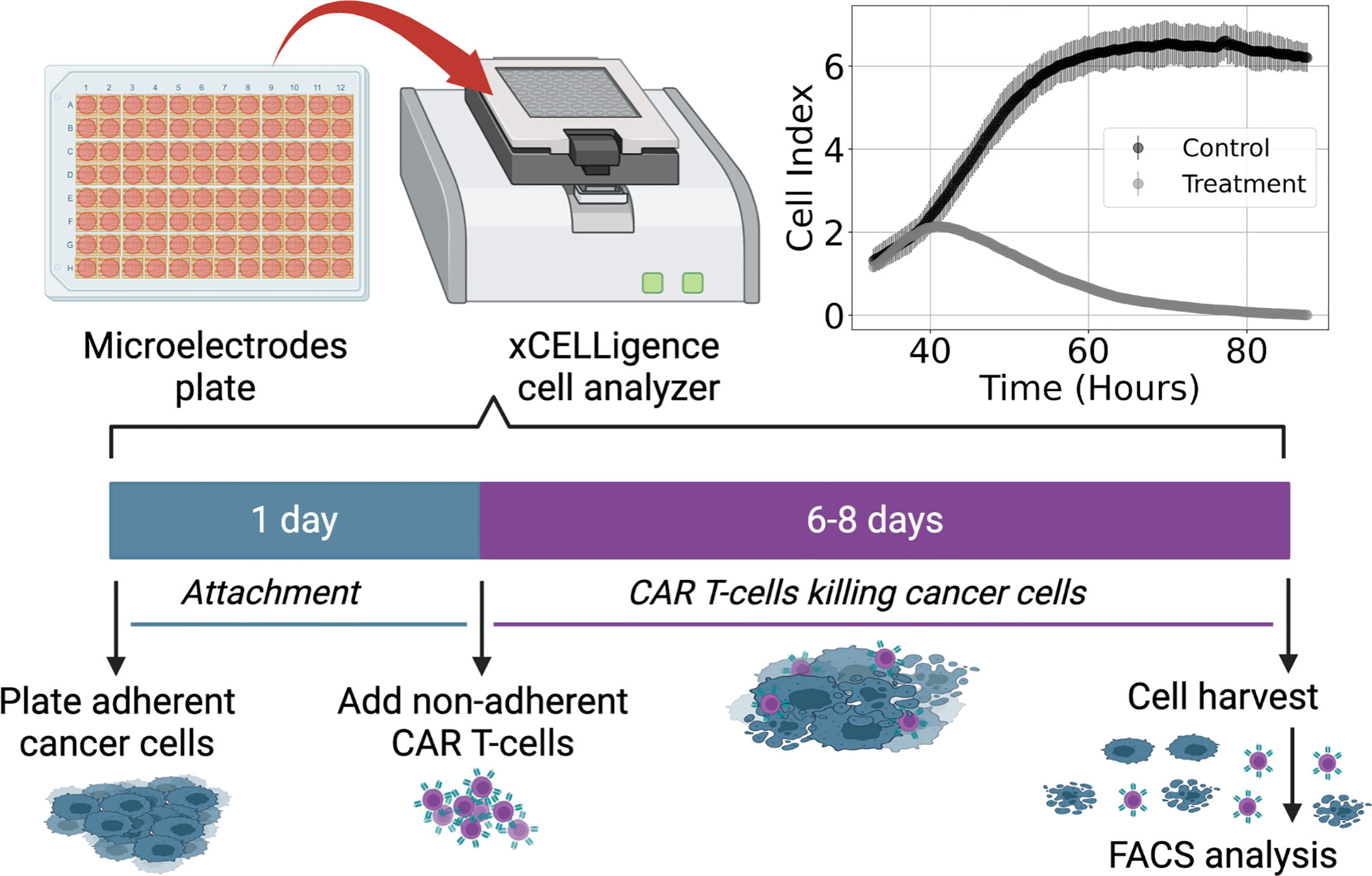
Figure 1 Diagram of experimental procedure highlighting use of microelectrode plates in an xCELLigence cell analyzer system and sample Cell Index (CI) measurements for control and treatment groups (E:T = 1:4). This system utilizes real-time voltage measurements to determine CI values representative of the adherent cancer cell population as a function of time. CAR T-cells are added following 24 hours of cancer cell expansion and attachment. After 6-8 days of monitoring the cancer cell growth and death dynamics, cells are harvested and enumerated using flow cytometry.
Cell killing experiments were conducted and monitored with an xCELLigence cell analyzer system. Measurements of cancer cell populations are reported every 15 minutes through changes in electrical impedance as cancer cells adhere to microelectrode plates, and are reported in units of Cell Index (CI), where 1 CI ≈ 10K cells (47–49). Flow cytometry was used to count the non-adherent CAR T-cells upon termination of the experiment. Measurements of CAR T-cell populations are reported in units of CI for the purposes of working in a common scale. We used the conversion factor of 1 CI ≈ 10K cells. Cancer cells were seeded at 10K – 20K cells and left either untreated or treated with only CAR T-cells, with treatments occurring 24 hours after seeding and monitored for 6-8 days (Figure 1). CAR T-cell treatments were performed with effector-to-target ratios (E:T) of 1:4, 1:8, and 1:20. All experimental conditions were conducted in duplicate.
Challenges to the model first approach to systems biology are (1) deciding on a sufficiently comprehensive model that captures all pertinent phenomena and (2) fitting the selected model to available data. Researchers are tasked with justifying their decisions in selecting candidate models. Yet, a common feature of dynamical systems models are the presence of ratios of polynomials. Such terms in ODEs can be difficult for the convergence of optimization algorithms to global solutions due to the possible existence of multiple local solutions within the model parameter space (50). In such instances researchers must either rely on high performance computational methods, have collected a vast amount of experimental data, or both. To address this problem, we utilize binomial expansions of candidate model terms under the assumptions of CAR T-cell treatment success and fast, irreversible reaction kinetics. In the following sections we present the space of possible models anticipated to characterize our experimental system, and the steps necessary to reduce the complexity of these candidate models.
The dynamical model that our experimental system is anticipated to follow is defined generically as,
where and represent a growth-death model for the cancer cells, x, and the CAR T-cells, y. and represent a binding model for whether single or pairs of CAR T-cells attack individual cancer cells, and ℛ represents a model for the CAR T-cell functional response. In the subsections below, we explore different families of models representing the terms in the above equations. Explicitly, we examine different types of (a) growth and death models, (b) functional response models, and (c) CAR T-cell-cancer cell binding models.
We consider three different growth-death models for both the cancer cells and CAR T-cells. These are logistic growth, and the weak and strong Allee effect models, presented as,
for , and similarly for . Here, ρx is the net growth rate, Kx is the population carrying capacity, Ax is a weak parameterization of deviations from logistic growth, and Bx is the threshold for population survival or death absent predation. All model parameters are assumed positive, with the added constraint that Kx > Bx > 0. We anticipate similar growth models for the CAR T-cells, , with allowance of different models for the different cell types and model constants. Logistic growth is commonly favored for its simplicity in experimental systems (18, 24, 25), while there is growing evidence that Allee effects are required for accurate characterization of low density cancer cell populations (28, 29, 51, 52) or as the result of directed movement (53), the latter of which being an observable feature of CAR T-cell behavior using bright field imaging (18, 25).
In Figure 2, graphs of population growth rates versus population size and population size versus time are presented for each growth model and for a variety of initial conditions. Parameter values used were ρ = 0.75 hrs-1, K = 10 CI, A = 5 CI, and B = 5 CI. Examination of the logistic growth model in Figure 2A and the weak Allee effect in Figure 2B demonstrates similar population saturation at the carrying capacity K = 10 CI, but a slight deviation between how the models reach saturation. Specifically, the weak Allee effect exhibits a reduced per capita growth rate at low population densities compared to logistic growth. Examination of Figure 2C demonstrates the crucial difference between the strong Allee effect and either of the logistic growth or weak Allee effect through the existence of a minimum population threshold, B, above which the population will persist, and below which the population will die off.
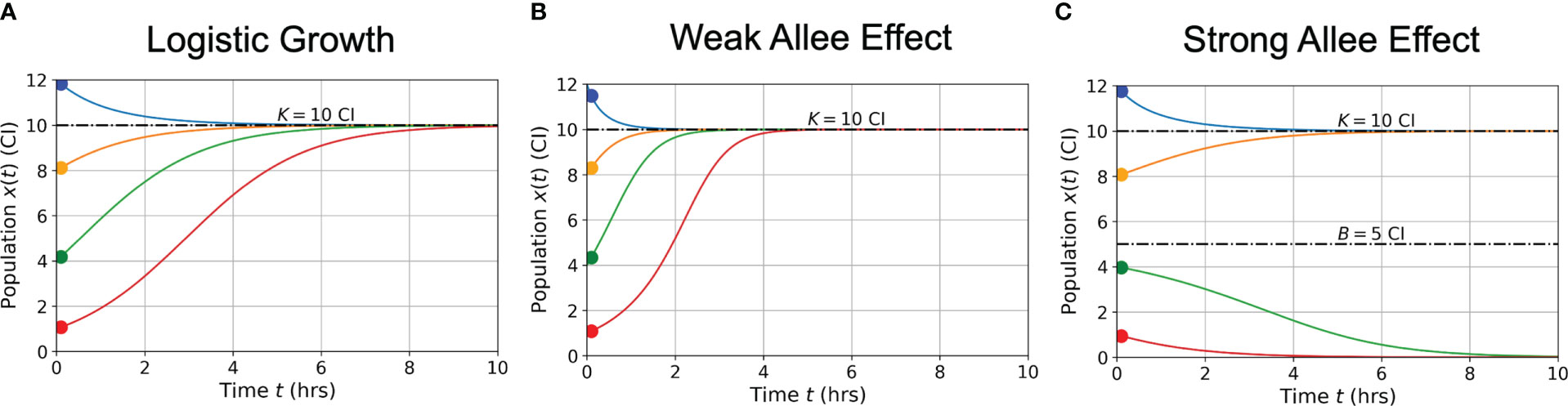
Figure 2 Conceptual graphs of population size (in cell index - CI) versus time (in hours - hrs) for the three growth models presented in Eqs. (3)-(5): logistic growth (A) weak Allee effect (B) strong Allee effect (C). Model parameter values are: hrs-1, CI, CI, and CI. Colors correspond to different initial cell populations, which are the same for each model presented (blue = 12 CI, orange = 8 CI, green = 4 CI, red = 1 CI).
Due to the fact that SINDy produces discovered models in their polynomial form without factoring, or grouping of terms together, we must consider the un-factored polynomial form of each model. To determine appropriate constraints on the model coefficients, we will expand the growth models and factor by common monomials. Doing so for and dropping the subscript gives the following,
and similarly for . Here we can see that the coefficients for x and x2 can be positive or negative, but the coefficients for x3 must be fixed as negative values, where we have absorbed the minus signs in Eqs. (7)-(8) into ρx/KxAx.
Cell binding models characterize the rates of formation and disassociation of conjugate pairs of species, also referred to as interaction molecules (Figure 3A). These models historically are known as Hill-Langmuir functions for their originating studies in hemoglobin formation (54) and gas adsorption on material surfaces (55), yet perhaps are better known for their use in modeling enzyme reaction kinetics, or Michaelis-Menten kinetics (56). The same modeling principles have been extended to examine cell binding in T-cell and cancer cell interactions (2, 23, 30). An important challenge to the field of cancer immunotherapy modeling is characterizing higher-order cell binding dynamics. That is, the formation of conjugates that consist of multiple CAR T-cells attacking single cancer cells (Figure 3A). These cancer cell-CAR T-cell conjugates are hypothesized to form as either a consequence of increased effector to target ratios or as a result of increased antigen density on target cells. As our experiment uses one single cell line with a high and uniform antigen expression level of IL13Rα2, we assume on average all cancer cells have approximately the same antigen density. We thus focus our attention to experimental variation in the effector to target ratios.
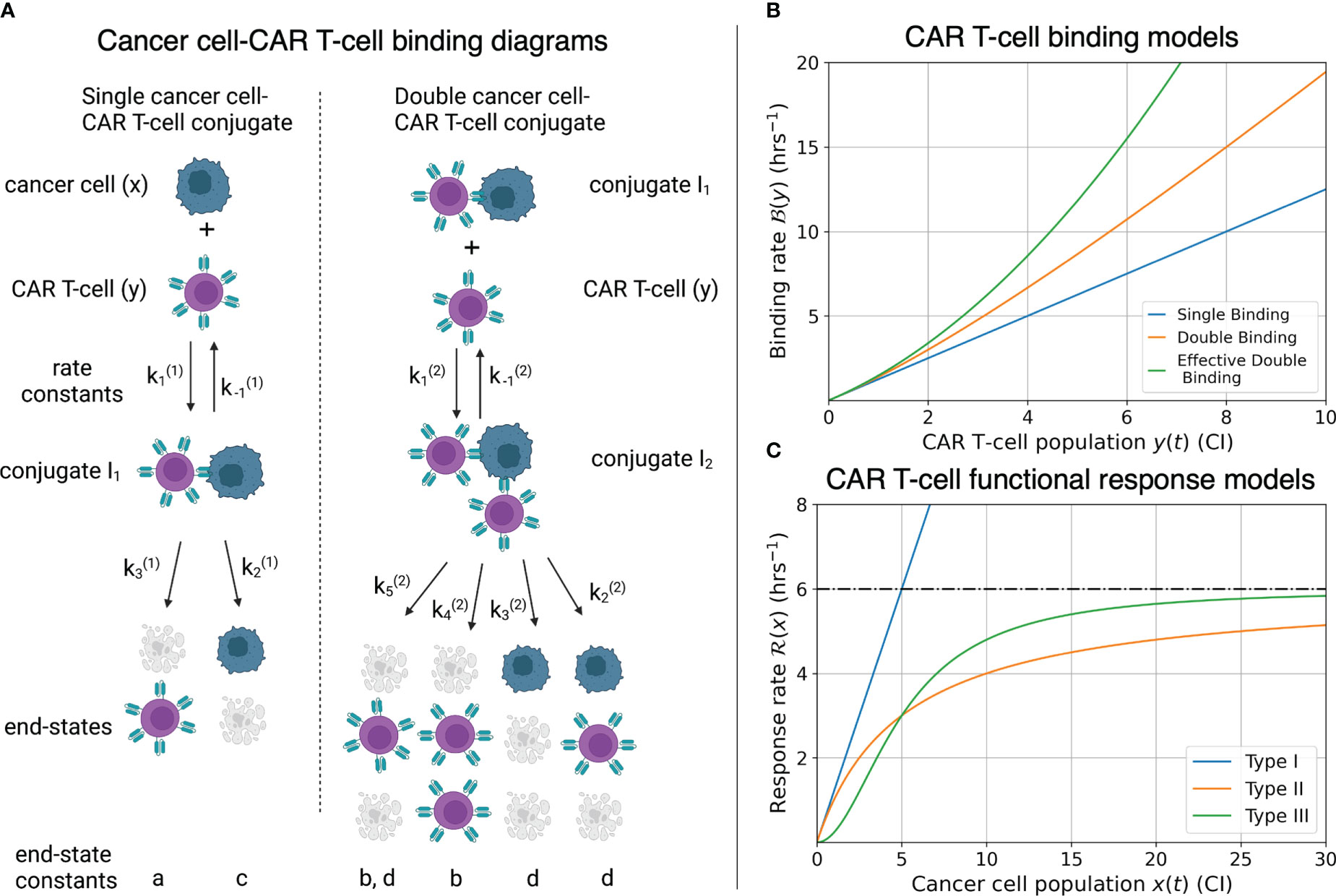
Figure 3 (A) Compartmental model for single and double CAR T-cell-cancer cell binding. Expressions for how rate constants () contribute to the growth or death of the cancer cell and CAR T-cell populations are presented in Eqs. (9)-(14). See (30) for further development and analysis of the cell binding model. (B) Graphs of binding rate versus CAR T-cell population for the single binding, double binding, and effective double binding models in Eqs. (9)-(12), (16), and (18). Model parameters for antigen bindings are: CI-2 hrs-2 and CI-1 hrs-1 for single binding; CI-2 hrs-2, CI-3 hrs-2, CI-1 hrs-1, and CI-2 hrs-1 for double binding; and CI-2 hrs-2, CI-3 hrs-2, CI-1 hrs-1, and CI-2 hrs-1 for effective double binding. These parameter values were chosen to highlight how well the effective double binding model can approximate both the single and double binding models at low CAR T-cell population values, CI. Note that since the original double binding model in this scenario is concave-up, the effective double binding model parameters should be chosen to match concavity. This requirement sets a positivity constraint on the quadratic term in Eqs. (16) and (18). (C) Graphs of CAR T-cell response rates versus cancer cell population for different functional response models. Model parameters for functional responses are: CI-1 hrs-1 for Type I; CI-1 and CI for Types II and III. Note overlap of Types I and II functional responses for CI, and distinct differences in concavity between Types II (negative) and III (positive) for CI. These characteristics correspond to Type I and Type II functional responses being indistinguishable at low cancer cell populations, and Type II and Type III being differentiated by fast-then-slow response rates (Type II) versus slow-then-fast response rates (Type III).
Following the work of Li et al. (30), we incorporate fast irreversible single and double cell binding into our generic model landscape. Here, fast binding implies that conjugate formation and dissociation occur quickly enough to maintain equilibrium in the conjugate populations, I1 and I2, such that dI1/dt = 0 and dI2/dt = 0. While irreversible means that all conjugate formation leads to death, or and . These assumptions are consistent with the conditions of relatively higher effector to target ratios, or high antigen densities on target cells. They also imply that a mixture of conjugates and dissociates may exist, but that the dynamics happen such that the conjugate populations are fixed and do not change with time. Furthermore, we only consider the higher-order binding scenario of two CAR T-cells to one cancer cell. Solving for the contributions to the cancer and CAR T-cell populations due to binding dynamics results in,
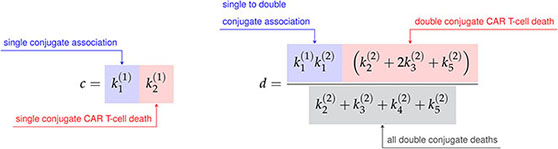
where the constants a, b, c, and d are defined in terms of the association rate constants, and , and the death rate constants from Figure 3A as follows,
 (13)
(13)
 (14)
(14)
Finally, the constant h is the sum of the single conjugate death rates, , and the constant k is simply a renaming of the double conjugate association rate, . As the variable renaming is admittedly complicated, the constants a, b, c, and d are defined to quickly identify end states of conjugate formation and have been located next to their corresponding interaction products in Figure 3A.
The per-cancer cell binding models are graphed in Figure 3B. Model parameter values used for the single and double cell binding models in Eqs. (9)-(18) are: a = 20 CI-2 hrs-2, and h = 16 CI-1 hrs-1 for single binding; and a = 20 CI-2 hrs-2, b = 5 CI-3 hrs-2, h = 16 CI-1 hrs-1, and k = 2 CI-2 hrs-1 for double binding. We highlight that we are restricting ourselves to scenarios where increases in the CAR T-cell population during a given trial leads to increases in the likelihood of double binding, which results in super-linear increase of per-cancer cell binding. This restriction enforces concavity of the effective double cell binding model which we explore next. It is possible for the double binding model to exhibit a sub-linear increase in per-cancer cell antigen binding as the CAR T-cell population increases, and an overall decrease in cancer cell killing. However, this scenario does not agree with our experimental data of increased killing with increased effector-to-target ratios.
Importantly, the rational forms of the binding rates typically complicate determination of parameter values in conventional dynamical modeling. To reduce model complexity, we take advantage of potential differences between the rates of conjugate association and conjugate death that can give rise to simplifications. If the product of the CAR T-cell population and the rate of forming double conjugates, ky, is small compared to the sum of the rates of single conjugate deaths, h, then ky/h < 1, and we can again perform a binomial expansion in the cell binding denominators. A second way of interpreting this condition is to require the number of CAR T-cells to remain small compared to the ratio of the rate of double conjugate formation to the sum of the rates of single conjugate deaths, y < h/k. Performing the binomial expansion and truncating again at results in the following effective models of cell binding,
Here the effective double conjugate antigen binding model takes the form of the exact single conjugate binding model plus a correction due to double conjugate formation. Eqs. (16) and (18) are graphed in Figure 3B, using the parameter values of a = 20 CI-2 hrs-2, b = 2.75 CI-3 hrs-2, h = 16 CI-1 hrs-1, and k = 2 CI-2 hrs-1. These values are chosen to demonstrate that the effective double binding model can accurately approximate both the exact single and double binding models for small CAR T-cell populations, y < 1CI. Importantly, we note that if the parameter values b or d are sufficiently small, corresponding to low double conjugate CAR T-cell or cancer cell death rates, then the quadratic terms in Eqs. (16) and (18) will be negative, and the concavity of the effective double binding model deviate significantly from the exact model. This phenomenological consideration of the effective models sets an important constraint on the positivity of the coefficients for the quadratic terms in Eqs. (16) and (18), which we will revisit in Section 2.3.
We next consider the first three types of functional response models that characterize how the CAR T-cells respond, or expand, in the presence of cancer cells. These models are defined as,
where p is the predator response, or CAR T-cell response rate, and g is the prey population density threshold at which predator behavior changes (e.g. fast-to-slow or slow-to-fast rates of killing). Functional responses model changes in predator hunting due to the prey density, generally defined with respect to some prey population threshold, here denoted as g. The population dependence on predator hunting behavior can also be interpreted as a handling time for distinguishing between time spent seeking prey, or recognizing cancer cells, and time spent consuming and attacking prey (19, 26, 27).
The three types of functional responses are graphed in Figure 3C. In a Type I functional response, the predator response is constant for all prey population sizes. The interpretation of this response is that there are no differences in time or cost between all predator functions (searching and capture). In a Type II functional response the predator response is linear at low prey density (mirroring a Type I behavior) yet saturates at high prey density. Finally, in a Type III functional response the predator response is low at low prey densities, reflecting the potential for cancer cells to escape immune surveillance, yet again saturates at high prey densities, with a linear response at intermediate prey densities.
As with the binding rate models, the rational forms of Types II and III functional responses present challenges to model discovery methods. Thus, we assume a significant level of effectiveness in CAR T-cell treatment such that the cancer cell population remains relatively low with respect to the functional response threshold, that is x < g, or x/g < 1. CAR T-cell effectiveness is demonstrated in Figure 1, where the control cancer cell population is shown to achieve a maximum population of approximately 6.5 CI, while the treatment population of E:T = 1:4 reaches a maximum population of approximately 2 CI. The approximation condition permits the use of a binomial expansion about x = 0 on the denominators for the Types II and III functional responses, resulting in,
Further assuming that contributions to the functional response models of or greater are negligible, we terminate the expansions at to arrive at the following effective functional response models,
It is important to highlight that the leading order term for the expansion for a Type II functional response is indistinguishable from a Type I functional response. This feature is reflected by the overlap in the graphs of the Type I and Type II responses presented in Figure 3, where the cancer cell population is small, CI, compared to the value of g = 5 CI. As the cancer cell population increases, the density dependence of the CAR T-cells starts to take effect as demonstrated by the parabolic contribution of the Type II response. In contrast to this, the expansions for functional responses of Types II and III are significantly unique from one another. Specifically, only expansions for Type II can lead to odd-powered terms in x, and although both expansions can express similar even-powered terms, they come with different concavities. That is, at small cancer populations the Type II functional response is characterized as a concave down parabola, while the Type III functional response is characterized as a concave up parabola. This difference regarding the positivity of the terms that are of second-order dependence in x corresponds to the different density dependent behaviors of the CAR T-cells at small cancer cell populations, specifically that Type II is a fast-to-slow response rate while Type III is a slow-to-fast response rate.
By performing the approximations used to derive Eqs. (26)-(27), and using truncated terms, we have reduced the complexity of the functional response terms. This step will simplify the process of model discovery. However, since this step assumes that the prey population remains small compared to the functional response threshold, the number of terms needed in Eqs. (23)-(24) for accurate characterization of the system dynamics may vary as a result of experimental variation in the effector to target ratio of the CAR T-cells and the cancer cells. This variation in the effector to target ratio may also influence the structure of other interaction terms, specifically those pertaining to the single or paired binding dynamics.
To gain a broader perspective of the overall form of our ODE models, we substitute the effective models for functional responses and antigen binding into Eqs. (1)-(2), arriving at,
where again represents any of the potential growth-death models under consideration, and are redefined constants (both assumed to be positive) for the coefficients of the effective single and double binding models for the cancer cells, and represents the combination of first order terms for CAR T-cell response and single binding, and represents the potential second order term from the CAR T-cell response, and represents the effective double binding model for the CAR T-cells. We have explicitly used ± notation to indicate that we do not know a priori the signs for the xy and terms in Eq. (29), as these are determined by the relative contributions of Type I and first order Type II-like CAR T-cell responses and single antigen binding for the xy term, and whether or not second order Type II or first order Type III CAR T-cell response is occurring for the term. The benefit of the approach demonstrates the presence and/or sign conventions of the various model coefficients that we determine using the SINDy model discovery algorithm can be directly interpreted in terms of different underlying biological phenomena.
Our implementation of the model discovery techniques of dynamic mode decomposition and sparse identification of non-linear dynamics (SINDy) is performed in two stages. First is latent variable analysis, the extraction of the latent variable representing the CAR T-cell population from the time-varying cancer cell population. The second step is implementation of SINDy, whereupon the functional terms of the underlying models describing the dynamical system are determined.
Despite having only measured the initial and final CAR T-cell populations, we can utilize latent variable analysis to infer the hidden CAR T-cell dynamics from the cancer cell dynamics. We do this using the delay coordinate embedding of Taken’s Theorem to reconstruct the attractor of the system that is known to exist in more dimensions than those measured (13, 15, 57). The first step in this approach is to assemble a Hankel matrix, , by stacking delayed time-series of the cancer cell measurements as follows,
where , known as the embedding delay, represents the size of the time-delay we use, and , known as the embedding dimension, represents both the number of rows that we assemble in the Hankel matrix and, importantly, the number of anticipated latent variables we expect to find.
To minimize the effects of experimental noise on the results of Taken’s Theorem, we splined our cancer cell trajectories and re-sampled at the same experimental sampling rate of one measurement per 15 minutes. The function smooth.spline from the programming language R was used to perform the splining. This function uses cubic splines to approximate trajectories, with a penalty term to control for trajectory curvature. The number of knots used to spline each trajectory were determined by inspection, and are recorded in the analysis code available at https://github.com/alexbbrummer/CART_SINDy. Further details on the splining methods used are available in (57).
To determine optimal values for and , we can use two separate formulae to inform the decisions (58). The optimal time delay is determined by the value of which minimizes the mutual information between measurements. This is done by dividing the interval into equally sized partitions, and calculating the probability that a measurement of the time series is in the kth partition, and the probability that a measurement is in the hth partition while the neighboring measurement is in the th partition. Mutual information is given by
The optimal time-delay to use for a given time series is selected by finding the value of which results in the first minimum value in mutual information, or . A graph of mutual information versus time delay is presented in Supplemental Figure S1A. For our cancer cell time series data, this optimal time delay value was found to be .
To determine the embedding dimension, , we calculate the number of false nearest neighbors to a given measurement as the time series is embedded in successively greater dimensional spaces. This calculation is done to ensure that the attractor constructed from the latent variables remains smooth upon embedding. We perform the calculation iteratively by starting with a point in an -dimensional embedding, and identifying a neighboring point such that the distance between and is less than a constant value typically chosen as the standard deviation of the data. Next, the normalized distance between the points and in the -dimensional embedding is calculated using the following expression,
is calculated across the entire time series and iteratively for greater embeddings, . False nearest neighbors are identified when , where has been identified as satisfactory for most datasets (58). The ideal embedding dimension is finally determined as that which results in a negligible fraction of false nearest neighbors. In Supplementary Figure S1B we present the calculated fraction of false nearest neighbors versus embedding the dimension. For our dataset, we identified as the ideal embedding dimension, indicating the existence of one latent variable that we interpret as representing the CAR T-cell population.
Using values of for the time delay and for the embedding dimension results in the following form of the Hankel matrix,
To extract the latent variable that represents the CAR T-cell time series, we perform a singular value decomposition of the Hankel matrix, (13, 15). Here, the columns of represent scaled and standardized versions of both the original data in the first column, and approximations of the latent data in the subsequent columns. As our experimental procedure measured the initial and final CAR T-cell populations, our final step was to re-scale and offset the latent CAR T-cell variable extracted from the second column of . We note that latent variable analysis is conducted on each trial for each experimental condition separately. In Figure 4 we present the measured cancer cells and CAR T-cells in addition to the discovered latent CAR T-cell time series for each effector to target ratio considered for the first of the two duplicate trials. In the Supplemental Material Figure S2 we present the results of the latent variable analysis for the second of the two duplicate trials.
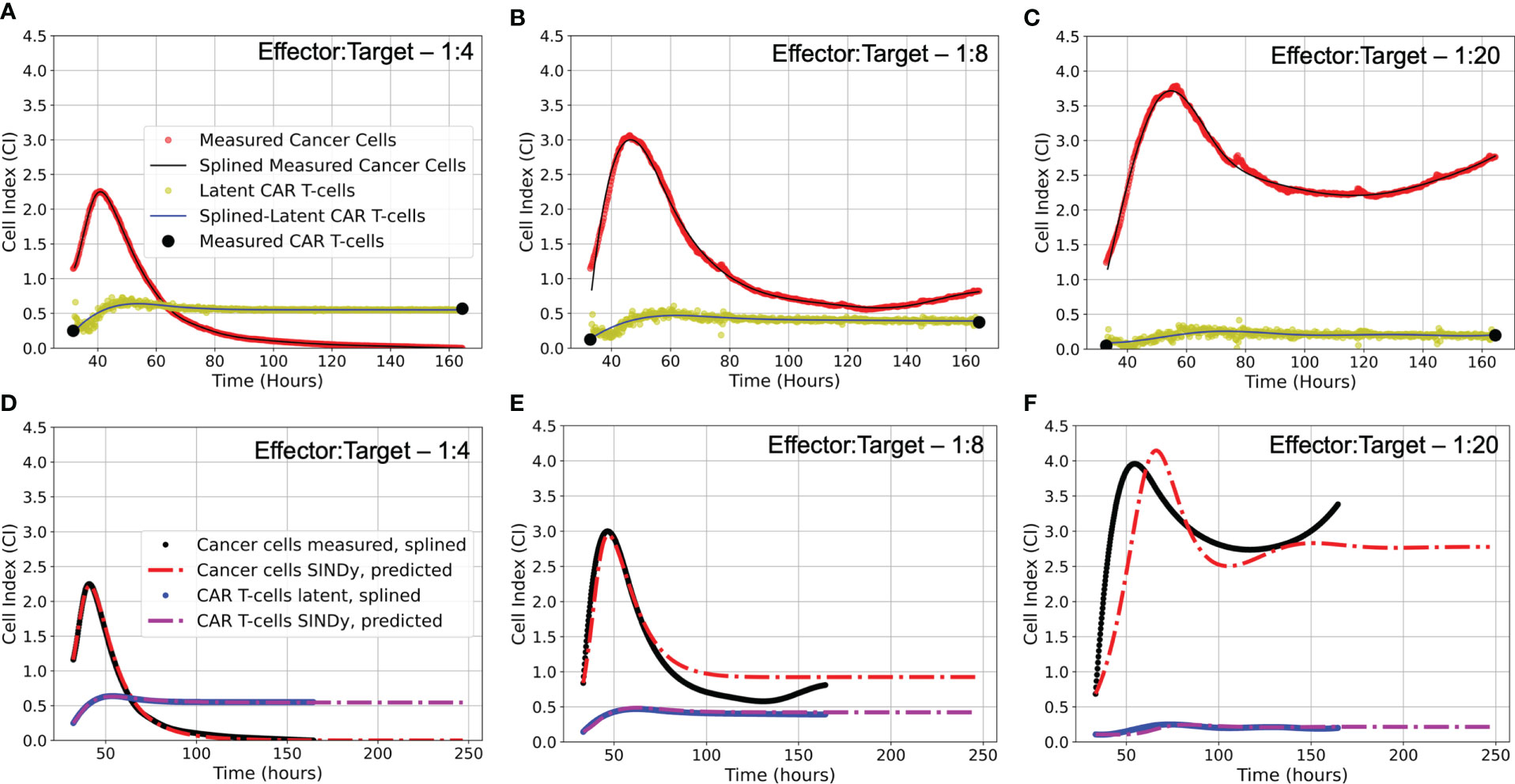
Figure 4 (A-C) Latent variable analysis results for first of two experimental replicates each E:T ratio examined. Presented are the cancer cell index measurements from the xCELLigence machine in red, overlaid with the splined measurements for the cancer cells in black; the two endpoint measurements for the CAR T-cell levels enumerated by flow cytometry in black, with the CAR T-cell population trajectory as determined by latent variable analysis in yellow, overlaid with the splined CAR T-cell trajectory in blue. Note that despite the CAR T-cell populations being measured with flow cytometry, we have converted levels to units of Cell Index for ease of comparison with the cancer cells, using a conversion factor of 1 CI ≈ 10,000 cells. (D-F) Predicted trajectories of discovered models compared to splined measurements of cancer cells and CAR T-cells for same data presented in (A-C). Splined cancer cell and CAR T-cell measurements are in black and blue, respectively. Predicted trajectories for cancer cells are the red dot-dashed lines, while the CAR T-cells are the purple dot-dashed lines. To examine stability of SINDy-discovered models, both simulations and forward predictions are presented to show steady-state behavior. Note that the best fits between predictions and measurements occur in the high E:T scenario, where assumptions made regarding treatment success and low cancer cell populations in determining model candidate terms are best adhered. As the E:T ratios get smaller, increasing deviation between discovered model predictions and splined measurements can be qualitatively observed. This is likely due to weakening of assumptions of treatment success and low cancer cell populations associated with the low E:T conditions. See Supplemental Material Figure S2 for equivalent latent variable analysis results and SINDy-predicted trajectories for the second set of experimental replicates.
SINDy is a data-driven methodology that discovers dynamical systems models through symbolic regression (13, 15). From a conceptual perspective, SINDy allows for the transformation of an analytical, first-order, non-linear dynamical systems model, expressed as
to a linearized matrix-model, expressed as
where are numerical time-derivatives of our measured data, is a library of candidate functions that may describe the data and is evaluated on the measured data, and consists of the coefficients for the model terms from that describe the time-varying data . The objective of SINDy is to identify the sparsest version of , where sparsity is defined as the compromise between fewest number of non-zero terms with the greatest level of accuracy. In the context of our measurements for populations of cancer cells, , and CAR T-cells, , and the anticipated models for cell growth and interactions, takes the following form,
And is expressed as,
By solving the matrix-inverse problem in Eq. (35), we can find the column vectors that determine the coefficients for the model terms that form the non-linear dynamical system best describing the measured data. To construct and from our duplicate trial experiments, the data from the repeated trials is stacked row-wise. Thus, only a single model will be discovered to explain all data for a given set of experimental conditions (e.g. effector-to-target ratios). Having repeat measurements is an important aspect for SINDy to converge on an accurate model, thus performing SINDy on averages of experimental trials undermines performance. For experimental conditions that have an abundance of experimental replicates, an AI-inspired division of data into training and testing sets can be conducted (59).
Once and have been constructed, a simple least-squares algorithm for solving Eq. (35) will result in a dense coefficient vector , thus we enforce sparsity of the coefficient vector through the method of sparse relaxed regularized regression (SR3) (60), where we seek optimization of the expression,
where is the relaxed coefficient matrix that approximates , is the regularization of , and and are hyper parameters that control how precisely approximates and the strength of the regularization, respectively. For our problem, we chose to regularize under the 1-norm with . To determine the value of , we followed the approach taken in (39) in which we repeat the analysis for a range of values from to calculate Pareto fronts between the root-mean-squared error between the measured and subsequently predicted values of and the number of active terms from our library. In Supplementary Figure S3 we present Pareto fronts for each of the experimental conditions for the varying effector to target ratios.
As discussed in Section 2.2, there are a variety of constraints we can expect for possible coefficients based on expected signs, or the absence of particular terms. An extension to SINDy allows for the incorporation of these constraints to ensure spurious terms are not discovered (61).
To make clear the constraints that were imposed, we can re-write Eq. (35) symbolically and in terms of the coefficients as,
Then, the constraints that are imposed as per the anticipated effective models from Section 2.2 are,
while the other 6 coefficients in are left to freely vary.
Implementation of SINDy SR3 with constraints was performed using PySindy, a package designed for a wide array of implementations of the SINDy algorithm for spatio-temporal model discovery written in the programming language Python (16, 17). Included in the Supplemental Material are the associated datasets and Jupyter notebooks used for this study.
Finally, we highlight that the implementation of SINDy which we are relying on is designed specifically for explicit ordinary differential equations. An extension of SINDy exists for discovering ODEs with ratios of polynomials (39, 40), however this variation requires a significantly greater volume of data than that which we could collect. This is the underlying motivation behind our efforts to derive the effective models, thereby converting them into explicit ODEs and making effective usage of the volume of experimental data available by the study methods most usable for model discovery.
Upon implementing SINDy on the CAR T-cell cancer cell killing data and performing the Pareto front analysis described in Section 2.3, we identified three distinct models describing the experimental data. Model selection is presented in Supplementary Figure S3, where we present the tradeoffs between model complexity, represented by the number of activated library terms, and either the threshold or the root-mean-squared-error between the measured data and simulated data for each identified model. Our examination of the Pareto fronts found models with eight terms for E:T of 1:4, and 1:8, and a six term model for an E:T of 1:20. Below we summarize each of these models and in relation to how well they predict the measured data in Figure 4. We synthesize the coefficients and associated model categories for growth in Table 1 and for the CAR T-cell functional response and cell binding in Table 2.
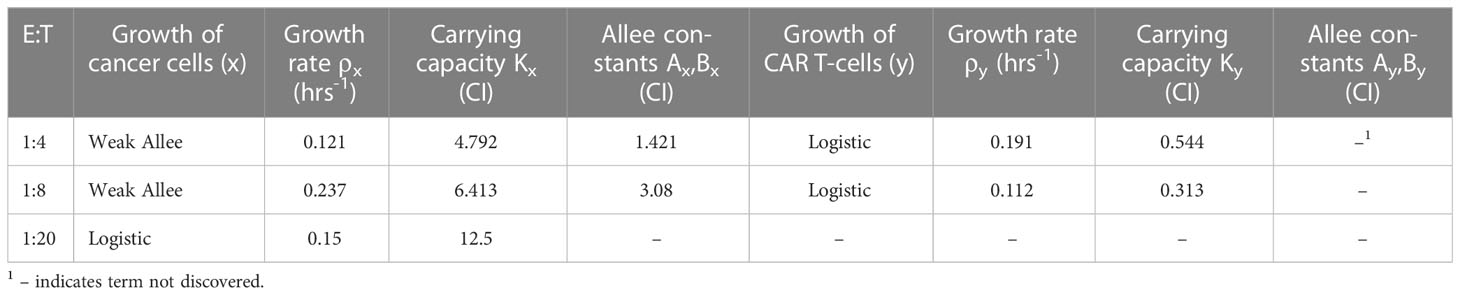
Table 1 Coefficients for discovered growth model terms across all effector to target ratios.

Table 2 Coefficients for discovered interaction model terms across all effector to target ratios.
For the E:T = 1:4 data, the SINDy-discovered model takes the following form,
Factoring the terms related to single-species growth, we arrive at,
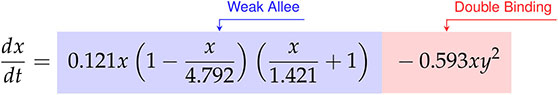 (47)
(47)
 (48)
(48)
From Eqs. (47)-(48) we can interpret the discovered types of growth models and interactions. For cancer cell growth in Eq. (47), the observable structure indicates a weak Allee effect, with a growth rate of hrs-1, a carrying capacity of CI, and an Allee constant of CI. For the CAR T-cells we find a logistic growth model with growth rate hrs-1 and carrying capacity CI. From the coefficients of CI-1 hrs-1 on and CI-2 hrs-1 on for the CAR T-cells, we can infer a Type II functional response as the signs are positive and negative, respectively. Finally, the presence of an term in the cancer cells with a coefficient of CI-2 hrs-1 indicates the occurrence of double binding, notably in the absence of both the term in the cancer cells and the term in the CAR T-cells.
The SINDy-discovered model for the E:T = 1:8 data takes the following form,
Factoring the terms related to single-species growth, we arrive at,
 (51)
(51)
 (52)
(52)
The model discovered for medium E:T is largely similar to that at high E:T. A weak Allee effect in growth is observed for the cancer cells, with growth rate hrs-1, carrying capacity CI, and Allee constant CI, while a logistic growth is observed for the CAR T-cells with growth rate hrs-1 and carrying capacity CI. We also observe a Type II CAR T-cell functional response, again indicated from the sign of the coefficients of CI-1 hrs-1 and CI-2 hrs-1 on the and terms being positive and negative, respectively. Unlike the high E:T scenario however, here we find evidence only of single binding from the sole presence of an term in the cancer cells with a coefficient of CI-1 hrs-1.
Finally, for the E:T = 1:20 data the discovered model is,
Factoring the terms related to single-species growth, we arrive at,
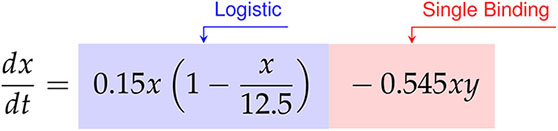 (55)
(55)
 (56)
(56)
In this scenario we find significantly different growth and interaction models. The cancer cells show logistic growth, with growth rate hrs-1 and carrying capacity CI, while the CAR T-cells have no growth model. This time, as the signs for the coefficients of CI-1 hrs-1 and CI-2 hrs-1 on the and terms for the CAR T-cells are now negative and positive, respectively, we infer a Type III functional response. Interestingly, we find a mixture of indicators for both single binding and double binding. This comes from the presence of only the term in the cancer cell model with a coefficient of ã CI-1 hrs-1, and of an term in the CAR T-cell model with a coefficient of CI-2 hrs-1.
All three E:T ratios of 1:4, 1:8, and 1:20 resulted in discovered models that accurately characterized the data, with root-mean-squared-errors of 0.02, 0.195, and 0.359, respectively. We highlight the discovery of consistent growth models of a weak Allee effect for the cancer cells and logistic growth for the CAR T-cells for the E:T ratios of 1:4 and 1:8. Importantly, the growth rates and carrying capacity for these scenarios were found to be comparable across E:T ratios. Interestingly, we observe a Type II functional response in the CAR T-cells functional response for both E:T = 1:4 and 1:8, and a transition to Type III for E:T = 1:20. Similarly, our discovered models indicate a transition from double to single binding as the E:T ratio changed from 1:4 to 1:8, and a model with mixed single and double binding terms was discovered for the E:T = 1:20.
We compared the data first model discovery methodology of SINDy against the CARRGO model, a traditional model first approach originally used to analyze and interpret the CAR T-cell killing dynamics (18, 25). The CARRGO model is defined as,
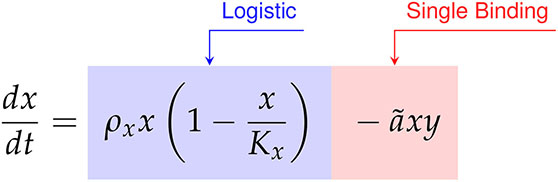 (57)
(57)
 (58)
(58)
where we have expressed the parameter variables of the CARRGO model in terms of those used in the SINDy model for ease of comparison. From here we can see that the CARRGO model assumes logistic growth in the cancer cells, single binding between the cancer cells and CAR T-cells, a Type I functional response in the CAR T-cells, and exponential CAR T-cell death.
In Figure 5 are graphs of the best-fit versions of both the CARRGO model and SINDy discovered models for each E:T ratio. These fits were performed using the Levenberg-Marquadt optimization (LMO) algorithm, which requires initial guesses and bounds for each model parameter value. For the CARRGO model published parameter values were used for the starting guesses, while for the SINDy discovered models the discovered parameter values served as the guesses. Upper and lower bounds on the LMO search space were set at 80% and 120% of the originally identified parameter values, respectively, and are listed in the Supplemental Tables. In Table 3 we present the model-fitting statistics for the reduced chi-squared, , Akaike information criteria (AIC), and Bayesian information criteria (BIC) methods, as well as the parameters determined by LMO. Importantly, we note that fits were performed on data points representing averages and ranges for the two experimental trials at each E:T ratio from only the measured data.
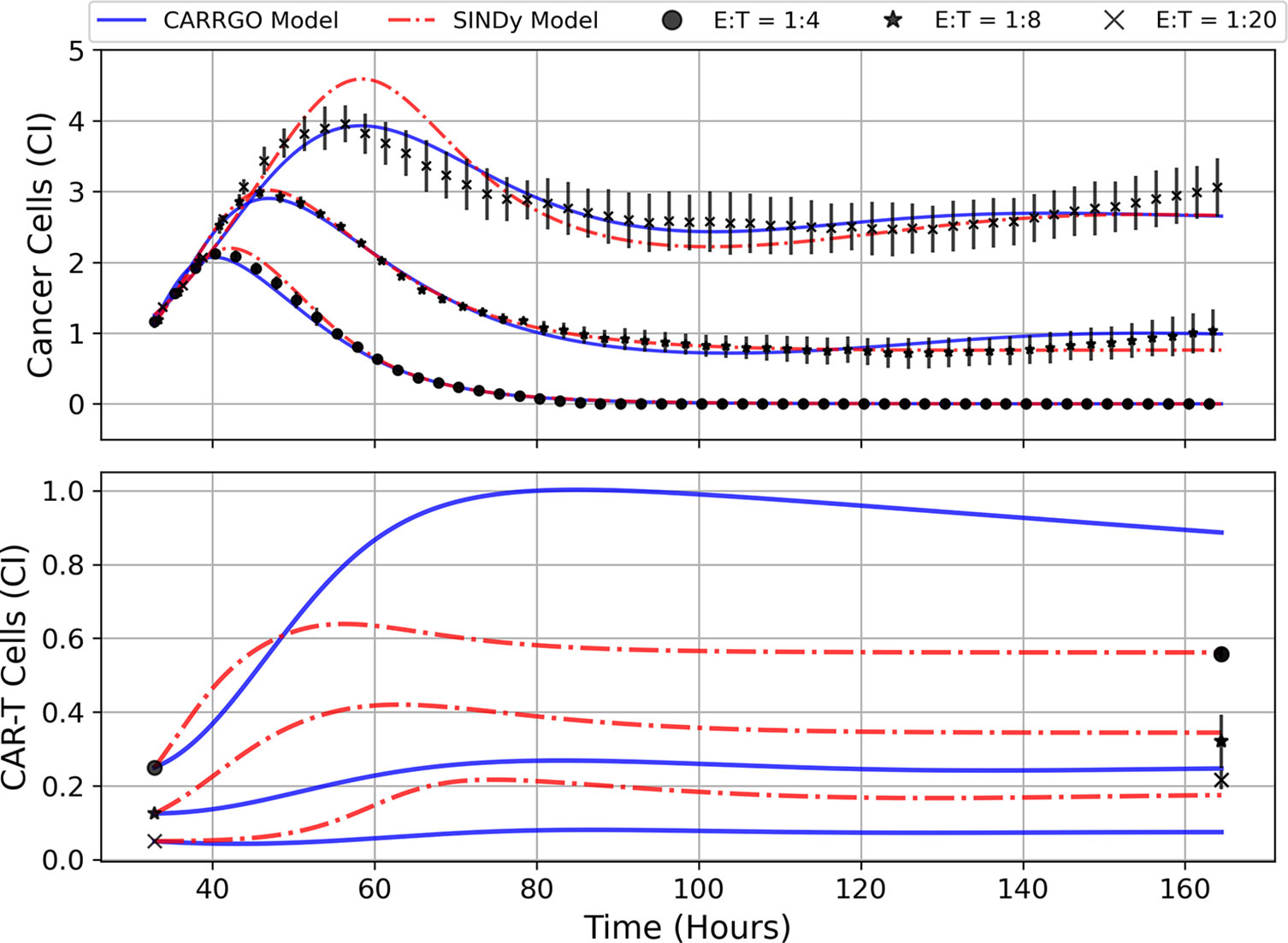
Figure 5 Predictions of cell trajectories for E:T ratios of 1:4, 1:8, and 1:20 from CARRGO model (blue) and SINDy model (red). Model fits for both CARRGO and SINDy were performed using Levenberg-Marquadt Optimization (LMO) on data aggregated across experimental replicates. Initial LMO parameter value guesses were determined by parameter values from SINDy or from published CARRGO model values. Data points represent the mean of all experimental replicates, while error bars represent the ranges across replicates. Of note are the differences in CARRGO and SINDy model predictions for the final CAR T-cell values compared to measurements, and the notable difference in when the maximum CAR T-cell population is reached between CARRGO and SINDy models. Note that experimental measurements have been down-sampled to 25% to allow for visualization.
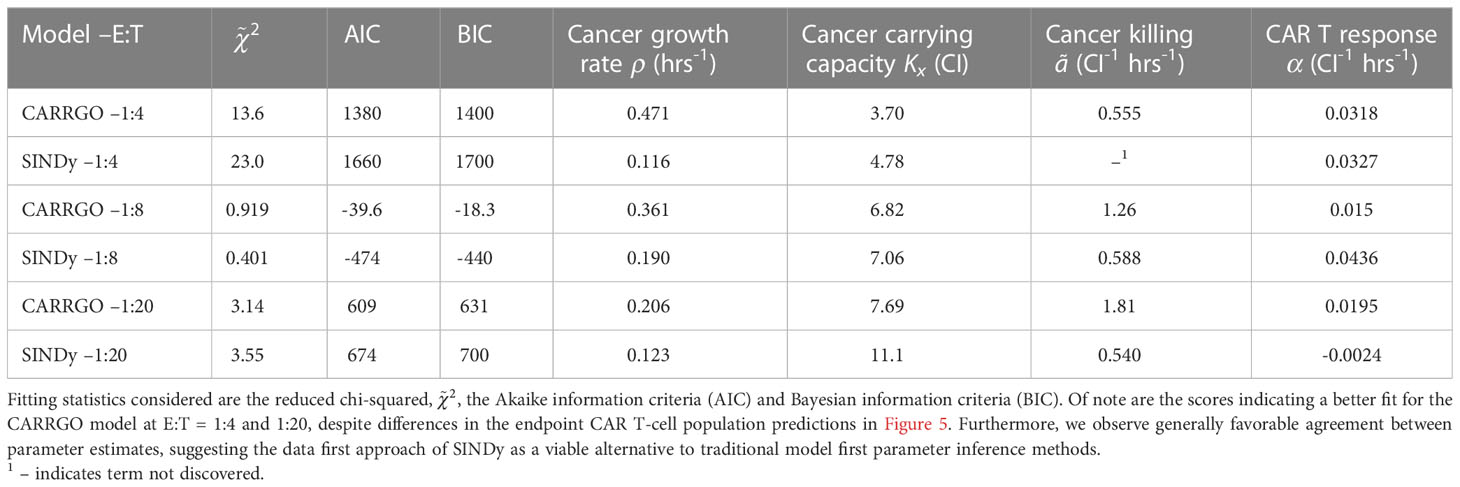
Table 3 Fitting statistics for CARRGO and SINDy models and comparison of shared parameters.
We find that across the three statistical tests considered, the CARRGO model performs slightly better than the SINDy discovered models at E:T = 1:4 and E:T = 1:20, whereas the SINDy discovered model for E:T = 1:8 performed better than the CARRGO model (Table 3). Interestingly, the CARRGO model predictions for the CAR T-cell trajectories fail to intercept the final CAR T-cell values, whereas the SINDy discovered models do. This result highlights a key difference between these two approaches, particularly that the SINDy approach required generating a time-series trajectory for the CAR T-cells that enforced interception with the final CAR T-cell measurement. Alternatively, traditional optimization methods like LMO weight each data point by the range of measurement uncertainty, allowing for the possibility of significant deviation from the final CAR T-cell measurements as long as such deviations can be compensated with better fitting elsewhere amongst the data.
Another essential difference between the CARRGO and SINDy predictions regarding the CAR T-cell trajectories is the CAR T-cell response at the high E:T ratio of E:T = 1:4. Specifically, the CARRGO model predicts that the CAR T-cells reach a maximum population exceeding the maximum population of cancer cells. This result has significant translational implications for CAR T-cell therapy related to patient immune response that we address in the discussion section.
Despite the noted differences, the overall similarities between the CARRGO and SINDy models is demonstrated by the order of magnitude agreement in most shared parameter values, specifically the cancer cell growth rate , the cancer cell carrying capacity , and the CAR T-cell functional response coefficient for the specific scenarios of E:T = 1:4 and E:T = 1:8 (Table 3). Taken together, these results demonstrate significant value in the SINDy methodology when compared to established procedures for parameter estimation.
An important question in performing model discovery for dynamical systems is in relation to the overall stability. Automating the task of examining stability for every discovered model is challenging given the combination of symbolic computation with floating point coefficients. However, by predicting forward in time for each of the models and experimental replicates we can qualitatively characterize the stability (see Figure 4).
For the E:T = 1:4 scenario, both the data and model indicate complete cancer cell death, with the model accurately maintaining a cancer cell population of zero. We note that in several of the alternate discovered models produced by SINDy, the cancer cell population would become negative in the forward predicted regime. This unrealistic result can be used as an aide in ruling out alternative models.
For the E:T = 1:8 and 1:20 scenarios, both the data and models indicate cancer cell-CAR T-cell coexistence, with the forward predictions reaching non-oscillatory steady states. Despite the discovered models being the ones with the best accuracy, they all struggle to match the observed oscillatory frequency, particularly in the E:T = 1:20 scenario. These results demonstrate the capability of SINDy to discover models with variability in solution stability, a core feature of nonlinear dynamical systems.
To better understand the rarity of the discovered models and their respective coefficients, we examined histograms for the coefficients of each of the model terms along the Pareto fronts for each E:T ratio, presented in Supplementary Figure S4. This approach allows us to qualitatively assess parameter identifiability by seeing the extent to which variability in coefficient values exists, and at the expense of prediction accuracy. For most active terms encountered, the coefficients corresponding to the selected models based on the Pareto front analysis were the most commonly occurring values until deactivation (elimination from discovered models). However, in a few situations we see that the coefficient values corresponding to the greatest model accuracy were relatively rare, and varied significantly as increasingly more terms were removed. This occurs in the coefficients for the and terms in the cancer cells for the E:T = 1:4 scenario in Supplementary Figure S4A, and the and terms in the cancer cells for both the E:T = 1:8 and 1:20 scenarios in Supplementary Figures S4B, C. These terms were shown to be the final remaining active terms in discovered model, suggesting that they are capable of capturing the greatest extent of variation in our cancer cell-CAR T-cell killing data. Of note once again is that amongst these dominant interaction terms we see a transition from those indicative of double binding at high E:T ratios to single binding at medium and low E:T ratios.
We examined in vitro experimental CAR T-cell killing assay data for a human-derived glioblastoma cell line (Figure 1). From our results we infer transitions in the phenomenological killing behavior of the CAR T-cells as a consequence of varying their initial concentration compared to the cancer cells. Our discovered models predict that at high effector to target ratios (E:T = 1:4) the CAR T-cell levels respond according to a Type II functional response in which they survive and/or expand faster at low density, and slower at high density, and they predominantly form double binding conjugates with cancer cells prior to cell killing. At medium E:T ratios of E:T = 1:8 our discovered model again predicts the CAR T-cells undergoing a Type II functional response, but now forming only singly bound conjugates prior to cell killing. At low E:T ratios of E:T = 1:20 our discovered model predicts the CAR T-cells shift to a Type III functional response, in which they survive and/or expand slower at low density, and faster at high density. In this final scenario we find a mixture of single and double conjugate formation occurring. Finally, our discovered models predict the growth strategies of the cancer cells as being a weak Allee effect at high and medium E:T ratios, and logistic at low E:T ratios, while the cancer cells are predicted to follow logistic growth for high and medium E:T ratios. Model coefficients used to deduce these results are found in Tables 1 and 2, and model simulations and forward predictions are shown in Figure 4.
A crucial result of this work is the comparison between the data first approach of SINDy to the traditional model first approach of CARRGO. Despite the discovered SINDy models having more degrees of freedom (i.e. mathematical terms) than the CARRGO model, both models were found to perform comparably as indicated in Figure 5 and Table 3. Yet, there are key differences regarding the interpretation of these two approaches. Traditional model first approaches like the CARRGO model assume a strict individual model that may exhibit variation in its coefficients or model parameters to reflect variation in the underlying biology or experimental conditions. On the other hand, one of the strengths of the data first approach of SINDy is that these coefficient variations can be shifted onto discovery of altogether different model terms. As we show, these different terms can have direct interpretations related to the underlying biology and dynamics. For example in (18), variation in the CAR T-cell response due to changes in the experimental E:T ratio could only be indicated through variation in the coefficients of the Type I functional response term, or the value of in Eq. (58). Specifically, increases in were interpreted as a high CAR T-cell response rate, or CAR T-cell expansion, and decreases in were interpreted as a low response rate, or as CAR T-cell exhaustion. Whereas the SINDy model predicts entirely different CAR T-cell functional response terms, providing greater interpretation of these transitions in the CAR T dynamics and biology. Specifically, a Type II functional response at high and medium E:T, or a fast-to-slow CAR T-cell response rate, and a Type III functional response at low E:T, or a slow-to-fast CAR T-cell response that is again suggestive of exhaustion.
We demonstrate the value of the effective model parameters for inferring underlying biology by considering the high E:T model presented in Eqs. (47)-(48). In this scenario, a Type II functional response in the CAR T-cells is deduced from the negative sign on , corresponding to the concave down parabolic nature of the CAR T-cell functional response with fast proliferation at low cancer cell density and slow proliferation at high cancer cell density (Figure 3). The implication that cancer cell killing is induced by double binding of CAR T-cells to cancer cells comes from multiple terms. The most direct indicator is , where with representing the rate of cancer cell death from double conjugates, and the rate of cancer cell death from single conjugates. Supporting indicators come from the positive sign on , suggesting that the CAR T-cell death rate from single conjugate formation, is small compared to the leading order CAR T-cell response rate, . Further evidence is in the inactivation of the term in the equation with coefficient . Here, is the rate of cancer cell death from single conjugate formation, whose absence suggests that double binding formation is predominantly responsible for cancer cell death.
A similar analysis of model coefficients for the low and medium E:T ratio scenarios predicts a transition in the interactions between the CAR T-cells and cancer cells. Specifically, our approach predicts that the CAR T-cells form double conjugate pairs with high E:T ratios, then switch to single conjugate pairs at medium and low E:T ratios. Similarly, our results predict a transition in the functional response, indicating Type II functional responses in the CAR T-cells for high E:T ratios and Type III responses in the low E:T ratios. These transitions in detected model terms are phenomenologically consistent with the interactions being dependent on CAR T-cell density, and highlight the hypothesis generating strength of data first model discovery techniques. Namely, the prediction of CAR T-cell killing dynamics being dependent on the relative abundance of CAR T-cells compared to cancer cells. We next present several opportunities for experimental testing of these model predictions.
A challenge to the implementation of SINDy is data sparsity. Despite having high temporal resolution of the cancer cell trajectories (1 measurement per 15 minutes), the CAR T-cell populations consisted of only the initial and final measurements. To resolve sparsity in the CAR T-cell levels, we used latent variable analysis to extract the CAR T-cell trajectory from an approximation to the attractor of the dynamical system as determined by the cancer cell trajectory. We note that in determining the dimensionality of the latent variable subspace, we selected an embedding dimension of despite the appearance of further benefit in using an embedding dimension of , as indicated in Supplementary Figure 2B. This choice was made due to our experimental limitations in only having flow cytometry data for the CAR T-cells at the initial and final time points, and no further data with which to constrain any additional latent variables. The existence of a second latent variable, as suggested by the third embedding dimension, could be due to single or double binding conjugates if the reaction rates are sufficiently slow, or, alternatively, a biochemical secretion that is modulating the cancer cell and CAR T-cell interactions. Future experimental and modeling efforts may further illuminate the nature of this third state variable, which we discuss in the Future directions section.
One potential limitation with latent variable analysis is that the trajectories retrieved through Taken’s Theorem are not guaranteed to be unique, but rather will be diffeomorphic to the true latent variable. That is, subject to topological stretching or skewing, which translates to variation in discovered model coefficients. This effect can be seen in Bakarji et al. (62), where the coefficients of the latent variables discovered for the two-state, predator-prey model are not in precise agreement to those used in the original simulation. However, it is important to note that the model terms discovered by SINDy with this methodology are biologically insightful, even though the coefficients multiplying the discovered model terms on latent variables may be subject to variation. Importantly, we provide further experimental information for the latent CAR-T cell variable through bounding of the initial and final CAR-T cell trajectory with direct measurements. Likewise, we only discover terms which are structurally identifiable through model inversion, minimizing the potential for diffeomorphic skewing of CAR-T cell trajectories to be discovered from Taken’s Theorem.
A second challenge is that our data in total consists of two trials for each effector-to-target ratio. While there exist SINDy implementations designed to discover models with ratios of polynomials, the approaches require prohibitively many experimental trials to ensure accuracy (39, 40). To resolve sparsity in the number of experimental trials, we derived effective interaction models of cancer cell and CAR T-cell dynamics from model ODE terms with ratios of the polynomials using binomial approximations. These effective interaction models allowed for the identification of multiple constraints on the library function space used in SINDy, and guided our inferential analysis of the discovered models.
To validate the hypothesized binding and functional response dynamics, we propose two potential experiments. Both experiments rely on similar initial conditions as those conducted for this study, but in one we propose the use of bright field microscopy and live cell imaging to visually inspect CAR T-cell dynamics at different points in time and for the different E:T ratios. By tracking in real-time the growth, motility, and interactions of the different cells present, this approach ought to aide in distinguishing different cell phenotypes by identifying occurrences of single and double binding types as well as the different functional responses (63). The second experiment would be to conduct endpoint analyses using flow cytometry to determine the population of CAR T-cells throughout the trajectory. This experiment would test the different CAR T-cell predictions from the CARRGO model and the SINDy models, most notably the predicted time to reach maximum CAR T-cell populations (Figure 5). Furthermore, targeted staining can provide information on the number of CAR T-cell generations and the ratio of helper T-cells (CD4+) to cytotoxic, killer T-cells (CD8+). These metrics may better inform the number of true effector cells responsible for killing cancer cells, allowing for more accurate characterization of the CAR T-cell response. These experiments additionally serve to test the validity of our latent variable analysis, which uses the cancer cell trajectory to predict the CAR T-cell trajectory as presented in Figure 4. Future experiments will also extend this analysis to include other CAR designs, including evaluating the impact of costimulatory signaling, CAR affinity and target density on modeling of CAR T-cell killing dynamics.
These and other experiments are essential for introducing additional elements and agents present in the tumor microenvironment and for extending this work to in vivo applications. Currently, our implementation of SINDy is on a highly controlled experimental system in order to isolate the interaction dynamics between the CAR T-cells and the glioma cells and to validate the SINDy methodology. An important challenge to overcome is extending the SINDy framework to incorporate additional aspects of in vivo systems. To achieve this, intermediate experiments to conduct are killing assays in two- and three-dimensional in vitro tissue model systems that mimic the tumor microenvironment (64). The proposed experiments are crucial for adapting use of the SINDy framework for clinical applications.
The clinical relevance of the data first framework is in the domain of precision medicine. The approach naturally caters to in situ monitoring of patient response to therapy and forecasting future trajectories. An open question in this field is determining the sufficient number of early measurements necessary for accurate forecasting, and quantifying the extent of reliable forward prediction. This type of application falls under the field of control theory, in which real-time measurements for systems such as navigation, fluid dynamics and disease monitoring can inform model-based interventions (15). Control theory has been identified as a key tool in achieving optimized individual treatment outcomes, yet challenges are ever-present in parsimonious model selection. The SINDy methodology may help streamline and simplify the model selection process, while simultaneously incorporating control theory methods for treatment optimization. As an example related to the experiments considered here, one could envision a therapeutic intervention to administer more CAR T-cells in the low E:T ratio of 1:20 as soon as the Type III functional response and single binding dynamics are predicted in a patient. This intervention would serve to push the dynamics of the patients immune response into the double biding and Type II response regime, thereby improving therapeutic efficacy.
In this work we present the first, to our knowledge, application of the sparse identification of non-linear dynamics (SINDy) methodology to a real biological system. We used SINDy with highly time-resolved experimental data to discover biological mechanisms underlying CAR T-cell-cancer cell killing dynamics. Our implementation highlights the hypothesis generating potential of data-driven model discovery and illuminates challenges for future extensions and applications. To overcome challenges related to data limitation, we utilized latent variable analysis to construct the trajectory of the CAR T-cells, and we implemented binomial expansions to simplify specific model terms. Our results predict key mechanisms and transitions in the interaction dynamics between the CAR T-cells and cancer cells under different experimental conditions that may be encountered in the application of these therapies in human patients. Specifically, we identified transitions from double CAR T-cell binding to single CAR T-cell binding, and from fast-to-slow CAR T-cell responses (Type II) to slow-to-fast responses (Type III). Both transitions occur as a result of decreasing the relative abundances of CAR T-cells to cancer cells (initial E:T ratios). Importantly, these results demonstrate the potential for data first model discovery methods to provide deeper insight into the underlying dynamics and biology than model first approaches, and offer a new avenue for integrating predictive modeling into precision medicine and cancer therapy by an improved mechanistic understanding of cancer progression and efficacy of CAR T-cell therapy.
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: https://github.com/alexbbrummer/CART_SINDy.
Conceptualization, AB and RR; methodology, AB, RW, VA, HC, and RR; validation, AB, RR; formal analysis, AB; investigation, AB; resources, MG, CB, and RR; data curation, AB; writing—original draft preparation, AB; writing—review and editing, AB, AX, RW, VA, HC, MG, CB, and RR; visualization, AB, AX, RW, VA, and RR; supervision, CB and RR; project administration, AB and RR; funding acquisition, CB and RR. All authors contributed to the article and approved the submitted version.
Research reported in this work was supported by the National Cancer Institute of the National Institutes of Health under grant numbers R01CA254271 (CB), R01NS115971 (CB, RR), and P30CA033572, the Marcus Foundation, and the California Institute of Regenerative Medicine (CIRM) under CLIN2-10248 (CB).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fimmu.2023.1115536/full#supplementary-material
1. Rockne RC, Hawkins-Daarud A, Swanson KR, Sluka JP, Glazier JA, Macklin P, et al. The 2019 mathematical oncology roadmap. Phys Biol (2019) 16:041005. doi: 10.1088/1478-3975/ab1a09
2. Kuznetsov VA, Makalkin IA, Taylor MA, Perelson AS. Nonlinear dynamics of immunogenic tumors: parameter estimation and global bifurcation analysis. Bull Math Biol (1994) 56:295–321. doi: 10.1016/S0092-8240(05)80260-5
3. de Pillis LG, Radunskaya AE, Wiseman CL. A validated mathematical model of cell-mediated immune response to tumor growth. Cancer Res (2005) 65:7950–8. doi: 10.1158/0008-5472.CAN-05-0564
4. Roy M, Finley SD. Computational model predicts the effects of targeting cellular metabolism in pancreatic cancer. Front Physiol (2017) 8:217. doi: 10.3389/fphys.2017.00217
5. Stein AM, Grupp SA, Levine JE, Laetsch TW, Pulsipher MA, Boyer MW, et al. Tisagenlecleucel model-based cellular kinetic analysis of chimeric antigen receptor–t cells. CPT: Pharmacometrics Syst Pharmacol (2019) 8:285–95. doi: 10.1002/psp4.12388
6. West J, You L, Zhang J, Gatenby RA, Brown JS, Newton PK, et al. Towards multidrug adaptive therapy. Cancer Res (2020) 80:1578–89. doi: 10.1158/0008-5472.CAN-19-2669
7. Kimmel GJ, Locke FL, Altrock PM. The roles of t cell competition and stochastic extinction events in chimeric antigen receptor t cell therapy. Proc R Soc B (2021) 288:20210229. doi: 10.1098/rspb.2021.0229
8. Owens K, Bozic I. Modeling car t-cell therapy with patient preconditioning. Bull Math Biol (2021) 83:1–36. doi: 10.1007/s11538-021-00869-5
9. Mascheroni P, Savvopoulos S, Alfonso JCL, Meyer-Hermann M, Hatzikirou H. Improving personalized tumor growth predictions using a bayesian combination of mechanistic modeling and machine learning. Commun Med (2021) 1:1–14. doi: 10.1038/s43856-021-00020-4
10. Lambin P, Leijenaar RT, Deist TM, Peerlings J, De Jong EE, Van Timmeren J, et al. Radiomics: the bridge between medical imaging and personalized medicine. Nat Rev Clin Oncol (2017) 14:749. doi: 10.1038/nrclinonc.2017.141
11. Zhou M, Leung A, Echegaray S, Gentles A, Shrager JB, Jensen KC, et al. Non-small cell lung cancer radiogenomics map identifies relationships between molecular and imaging phenotypes with prognostic implications. Radiology (2018) 286:307–15. doi: 10.1148/radiol.2017161845
12. Kamb M, Kaiser E, Brunton SL, Kutz JN. Time-delay observables for koopman: theory and applications. SIAM J Appl Dynamical Syst (2020) 19:886–917. doi: 10.1137/18M1216572
13. Brunton SL, Budišić M, Kaiser E, Kutz JN. Modern koopman theory for dynamical systems. SIAM Rev (2022) 64:229–340. doi: 10.1137/21M1401243
14. Frankhouser DE, O’Meally D, Branciamore S, Uechi L, Zhang L, Chen YC, et al. Dynamic patterns of microrna expression during acute myeloid leukemia state-transition. Sci Adv (2022) 8:eabj1664. doi: 10.1126/sciadv.abj1664
15. Brunton SL, Proctor JL, Kutz JN. Discovering governing equations from data by sparse identification of nonlinear dynamical systems. Proc Natl Acad Sci (2016) 113:3932–7. doi: 10.1073/pnas.1517384113
16. de Silva BM, Champion K, Quade M, Loiseau JC, Kutz JN, Brunton SL. Pysindy: a python package for the sparse identification of nonlinear dynamical systems from data. J Open Source Software (2020) 5:2104. doi: 10.21105/joss.02104
17. Kaptanoglu AA, de Silva BM, Fasel U, Kaheman K, Goldschmidt AJ, Callaham J, et al. Pysindy: a comprehensive python package for robust sparse system identification. J Open Source Software (2022) 7:3994. doi: 10.21105/joss.03994
18. Sahoo P, Yang X, Abler D, Maestrini D, Adhikarla V, Frankhouser D, et al. Mathematical deconvolution of car t-cell proliferation and exhaustion from real-time killing assay data. J R Soc Interface (2020) 17:20190734. doi: 10.1098/rsif.2019.0734
19. Hamilton PT, Anholt BR, Nelson BH. Tumour immunotherapy: lessons from predator–prey theory. Nat Rev Immunol (2022) 22:1–11. doi: 10.1038/s41577-022-00719-y
21. Volterra V. Variazioni e fluttazioni del numero d’individui in specie animali conviventi. Memoria della Reale Accademia Nazionale dei Lincei (1926) 22:31–113.
22. Kareva I, Luddy KA, O’Farrelly C, Gatenby RA, Brown JS. Predator-prey in tumor-immune interactions: a wrong model or just an incomplete one? Front Immunol (2021) 21:3391. doi: 10.3389/fimmu.2021.668221
23. Chaudhury A, Zhu X, Chu L, Goliaei A, June CH, Kearns JD, et al. Chimeric antigen receptor t cell therapies: a review of cellular kinetic-pharmacodynamic modeling approaches. J Clin Pharmacol (2020) 60:S147–59. doi: 10.1002/jcph.1691
24. Adhikarla V, Awuah D, Brummer AB, Caserta E, Krishnan A, Pichiorri F, et al. A mathematical modeling approach for targeted radionuclide and chimeric antigen receptor t cell combination therapy. Cancers (2021), 13. doi: 10.3390/cancers13205171
25. Brummer AB, Yang X, Ma E, Gutova M, Brown CE, Rockne RC. Dose-dependent thresholds of dexamethasone destabilize car t-cell treatment efficacy. PloS Comput Biol (2022) 18:e1009504. doi: 10.1371/journal.pcbi.1009504
26. Holling CS. The components of predation as revealed by a study of small-mammal predation of the european pine sawfly1. Can Entomologist (1959) 91:293–320. doi: 10.4039/Ent91293-5
28. Böttger K, Hatzikirou H, Voss-Böhme A, Cavalcanti-Adam EA, Herrero MA, Deutsch A. An emerging allee effect is critical for tumor initiation and persistence. PloS Comput Biol (2015) 11:1–14. doi: 10.1371/journal.pcbi.1004366
29. Johnson KE, Howard G, Mo W, Strasser MK, Lima EABF, Huang S, et al. Cancer cell population growth kinetics at low densities deviate from the exponential growth model and suggest an allee effect. PloS Biol (2019) 17:1–29. doi: 10.1371/journal.pbio.3000399
30. Li R, Sahoo P, Wang D, Wang Q, Brown CE, Rockne RC, et al. Modeling interaction of glioma cells and car t-cells considering multiple car t-cells bindings. ImmunoInformatics (2023) 9:100022. doi: 10.1016/j.immuno.2023.100022
31. Sohail A, Yu Z, Arif R, Nutini A, Nofal TA. Piecewise differentiation of the fractional order car-t cells-sars-2 virus model. Results Phys (2022) 33:105046. doi: 10.1016/j.rinp.2021.105046
32. Al-Utaibi KA, Nutini A, Sohail A, Arif R, Tunc S, Sait SM. Forecasting the action of car-t cells against sars-corona virus-ii infection with branching process. Modeling Earth Syst Environ (2021) 8:1–9. doi: 10.1007/s40808-021-01312-3
33. Gábor A, Banga JR. Robust and efficient parameter estimation in dynamic models of biological systems. BMC Syst Biol (2015) 9:1–25.
34. Mitra ED, Hlavacek WS. Parameter estimation and uncertainty quantification for systems biology models. Curr Opin Syst Biol (2019) 9:9–18. doi: 10.1016/j.coisb.2019.10.006
35. Schmid PJ. Dynamic mode decomposition of numerical and experimental data. J Fluid Mechanics (2010) 656:5–28. doi: 10.1017/S0022112010001217
36. Yadav N, Ravela S, Ganguly AR. Machine learning for robust identification of complex nonlinear dynamical systems: applications to earth systems modeling. (2020). doi: 10.48550/ARXIV.2008.05590
37. Alves EP, Fiuza F. Data-driven discovery of reduced plasma physics models from fully kinetic simulations. Phys Rev Res (2022) 4:033192. doi: 10.1103/PhysRevResearch.4.033192
38. Ren Y, Adams C, Melz T. Uncertainty analysis and experimental validation of identifying the governing equation of an oscillator using sparse regression. Appl Sci (2022). doi: 10.3390/app12020747
39. Mangan NM, Brunton SL, Proctor JL, Kutz JN. Inferring biological networks by sparse identification of nonlinear dynamics. IEEE Trans Molecular Biol Multi-Scale Commun (2016) 12:52–63. doi: 10.1109/TMBMC.2016.2633265
40. Kaheman K, Kutz JN, Brunton SL. Sindy-pi: a robust algorithm for parallel implicit sparse identification of nonlinear dynamics. Proc R Soc A (2020) 476:20200279. doi: 10.1098/rspa.2020.0279
41. Kaiser E, Kutz JN, Brunton SL. Sparse identification of nonlinear dynamics for model predictive control in the low-data limit. Proc R Soc A (2018) 474:20180335. doi: 10.1098/rspa.2018.0335
42. Messenger DA, Bortz DM. Weak sindy: galerkin-based data-driven model selection. Multiscale Modeling Simulation (2021) 19:1474–97. doi: 10.1137/20M1343166
43. Chen Z, Liu Y, Sun H. Physics-informed learning of governing equations from scarce data. Nat Commun (2021) 12:1–13. doi: 10.1038/s41467-021-26434-1
44. Brown CE, Starr R, Aguilar B, Shami AF, Martinez C, D’Apuzzo M, et al. Stem-like tumor-initiating cells isolated from il13rα2 expressing gliomas are targeted and killed by il13-zetakine–redirected t cells. Clin Cancer Res (2012) 18:2199–209. doi: 10.1158/1078-0432.CCR-11-1669
45. Brown CE, Alizadeh D, Starr R, Weng L, Wagner JR, Naranjo A, et al. Regression of glioblastoma after chimeric antigen receptor t-cell therapy. New Engl J Med (2016) 375:2561–9. doi: 10.1056/NEJMoa1610497
46. Brown CE, Aguilar B, Starr R, Yang X, Chang WC, Weng L, et al. Optimization of il13rα2-targeted chimeric antigen receptor t cells for improved anti-tumor efficacy against glioblastoma. Mol Ther (2018) 46:31–44. doi: 10.1016/j.ymthe.2017.10.002
47. Moniri MR, Young A, Reinheimer K, Rayat J, Dai LJ, Warnock GL. Dynamic assessment of cell viability, proliferation and migration using real time cell analyzer system (rtca). Cytotechnology (2015) 67:379–86. doi: 10.1007/s10616-014-9692-5
48. Xing JZ, Zhu L, Gabos S, Xie L. Microelectronic cell sensor assay for detection of cytotoxicity and prediction of acute toxicity. Toxicol Vitro (2006) 20:995–1004. doi: 10.1016/j.tiv.2005.12.008
49. Chiu CH, Lei KF, Yeh WL, Chen P, Chan YS, Hsu KY, et al. Comparison between xcelligence biosensor technology and conventional cell culture system for real-time monitoring human tenocytes proliferation and drugs cytotoxicity screening. J Orthopaedic Surg Res (2017) 12:1–13. doi: 10.1186/s13018-017-0652-6
50. Hanke M. Conjugate gradient type methods for ill-posed problems. New York: Longman Scientific and Technical (1995).
51. Fadai NT, Simpson MJ. Population dynamics with threshold effects give rise to a diverse family of allee effects. Bull Math Biol (2020) 82:1–22. doi: 10.1007/s11538-020-00756-5
52. Fadai NT, Johnston ST, Simpson MJ. Unpacking the allee effect: determining individual-level mechanisms that drive global population dynamics. Proc R Soc A (2020) 476:20200350. doi: 10.1098/rspa.2020.0350
53. Cosner C, Rodriguez N. The effect of directed movement on the strong allee effect. SIAM J Appl Mathematics (2021) 81:407–33. doi: 10.1137/20M1330178
54. Hill AV. The possible effects of the aggregation of the molecules of haemoglobin on its dissociation curves. Proc Physiol Soc (1910) 40:i–vii. doi: 10.1113/jphysiol.1910.sp001386
55. Langmuir I. The adsorption of gases on plane surfaces on glass, mica and platinum. J Am Chem Soc (1918) 40:1361–403. doi: 10.1021/ja02242a004
57. Brummer AB, Hunt D, Savage V. Improving blood vessel tortuosity measurements via highly sampled numerical integration of the frenet-serret equations. IEEE Trans Med Imaging (2021) 26:297–309. doi: 10.1109/TMI.2020.3025467
58. Kodba S, Perc M, Marhl M. Detecting chaos from a time series. Eur J Phys (2004) 40:205. doi: 10.1088/0143-0807/26/1/021
59. Rudy SH, Brunton SL, Proctor JL, Kutz JN. Data-driven discovery of partial differential equations. Sci Adv (2017) 3:e1602614. doi: 10.1126/sciadv.1602614
60. Zheng P, Askham T, Brunton SL, Kutz JN, Aravkin AY. A unified framework for sparse relaxed regularized regression: Sr3. IEEE Access (2018) 7:1404–23.
61. Champion K, Zheng P, Aravkin AY, Brunton SL, Kutz JN. A unified sparse optimization framework to learn parsimonious physics-informed models from data. IEEE Access (2020) 8:169259–71. doi: 10.1109/ACCESS.2020.3023625
62. Bakarji J, Champion K, Kutz JN, Brunton SL. Discovering governing equations from partial measurements with deep delay autoencoders. (2022). doi: 10.48550/ARXIV.2201.05136
63. Barney LE, Hall CL, Schwartz AD, Parks AN, Sparages C, Galarza S, et al. Tumor cell–organized fibronectin maintenance of a dormant breast cancer population. Sci Adv (2020) 6:eaaz4157. doi: 10.1126/sciadv.aaz4157
Keywords: dynamical systems, latent variables, CAR T-cells, antigen binding, allee effect, SINDy, glioblastoma, cell therapy
Citation: Brummer AB, Xella A, Woodall R, Adhikarla V, Cho H, Gutova M, Brown CE and Rockne RC (2023) Data driven model discovery and interpretation for CAR T-cell killing using sparse identification and latent variables. Front. Immunol. 14:1115536. doi: 10.3389/fimmu.2023.1115536
Received: 04 December 2022; Accepted: 27 March 2023;
Published: 15 May 2023.
Edited by:
Jason T. George, Texas A&M University, United StatesReviewed by:
Gabriele Nasello, Leuven Brain Institute, KU Leuven, BelgiumCopyright © 2023 Brummer, Xella, Woodall, Adhikarla, Cho, Gutova, Brown and Rockne. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Alexander B. Brummer, YnJ1bW1lcmFiQGNvZmMuZWR1; Christine E. Brown, Y2Jyb3duQGNvaC5vcmc=; Russell C. Rockne, cnJvY2tuZUBjb2gub3Jn
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.