 Thibaut Le Naour
Thibaut Le Naour Ludovic Hamon
Ludovic Hamon Jean-Pierre Bresciani
Jean-Pierre Bresciani- 1Coplab, Department of Neurosciences, University of Fribourg, Fribourg, Switzerland
- 2LIUM - EA 4023, Le Mans Université, Le Mans, France
We learn and/or relearn motor skills at all ages. Feedback plays a crucial role in this learning process, and Virtual Reality (VR) constitutes a unique tool to provide feedback and improve motor learning. In particular, VR grants the possibility to edit 3D movements and display augmented feedback in real time. Here we combined VR and motion capture to provide learners with a 3D feedback superimposing in real time the reference movements of an expert (expert feedback) to the movements of the learner (self feedback). We assessed the effectiveness of this feedback for the learning of a throwing movement in American football. This feedback was used during (concurrent feedback) and/or after movement execution (delayed feedback), and it was compared with a feedback displaying only the reference movements of the expert. In contrast with more traditional studies relying on video feedback, we used the Dynamic Time Warping algorithm coupled to motion capture to measure the spatial characteristics of the movements. We also assessed the regularity with which the learner reproduced the reference movement along its path. For that, we used a new metric computing the dispersion of distance around the mean distance over time. Our results show that when the movements of the expert were superimposed on the movements of the learner during learning (i.e., self + expert), the reproduction of the reference movement improved significantly. Furthermore, providing feedback about the movements of the expert only did not give rise to any significant improvement regarding movement reproduction.
1. Introduction
We all learn different sets of motor skills across our life span. Learning or re-learning motor skills is even more essential for some individuals, as for instance for those who receive rehabilitation therapy, for sport players, or in gesture-based professions such as surgeon or pilot. To learn or re-learn the good/efficient gesture, learners often rely on tools or programs which usually provide feedback to improve motor learning. This feedback should be understandable, contextual, and relevant in order to best assist the learning process (Rhoads et al., 2014). Different kinds of feedback can be used to improve motor learning. Specifically, the sensory feedback that directly derives from our actions/movements is usually defined as inherent (or intrinsic) feedback, whereas feedback information provided by “external” sources is defined as augmented (or extrinsic) feedback (Schmidt et al., 2018). Augmented feedback that relates to the outcome of the action is usually defined as “knowledge of result” (Horn et al., 2005), whereas the term “knowledge of performance” has been used to name augmented feedback relative to the movement pattern (i.e., shape/form of the movement). Our work focused on this latter type of augmented feedback, namely knowledge of performance.
Augmented feedback relative to the movement pattern usually consists in providing the learner with information about his/her own movements and/or the movements of the expert. Observational learning refers to self- or expert-observation. Self-observation consists in observing oneself perform the movement to be learned. The observation and monitoring of their own movements allows learners to build a better representation of their body in action. Expert-observation (or skilled-observation) consists in observing an expert perform the movement to be learned. The observation of the movements of an expert helps learners to internalize and reproduce the target movements (Scully and Newell, 1985). However, this type of feedback relies on the learner's ability to observe and compare their movements with those displayed through the feedback, which implies a good internal representation of their own movements. Self- and expert-observation can be concurrent, i.e., occurring during movement execution, or delayed, i.e., occurring after movement execution. Research has demonstrated positive effects of observation on the learning of motor skills and on learners' performance (Ste-Marie et al., 2012). In particular, several studies dedicated to gesture learning in sport have shown improvements in the cognitive representation of the movement (e.g., Scully and Newell, 1985) as well as in the production of new coordination patterns (e.g., Williams and Grant, 1999).
Self- and expert-modeling are similar to self- and expert-observation, but feedback is “edited” in order to provide only the most relevant information to optimize the learning. As self-observation, self-modeling helps the learner to “build” a better representation of his/her movements. The main limitation of this type of feedback is the absence of information regarding the reference movement (Ste-Marie et al., 2012). Expert-modeling is based on the concept of imitation, which plays a key role in the acquisition of new skills (Gould and Roberts, 1981). According to Scully and Newell (1985), the observation of a model provides the learner with essential information, notably regarding unfamiliar coordination patterns. The main drawback of expert modeling is the lack of information related to the self-representation of the learner. To overcome this problem, a solution consists in adding feedback about the errors made by the learner (Williams et al., 2003).
A more exhaustive, but also more demanding option consists in providing the learner with feedback about both his/her own movement and the reference movement of the expert. This notably allows the learner to compare his/her performance with that of the expert. Though this type of feedback is usually named mixed modeling, here we will rather refer to Expert + Self Modeling (ES-M), because the term mixed can also refer to self + unskilled modeling (Rohbanfard and Proteau, 2011). Most of the studies that addressed ES-M were based on video feedback (Oñate et al., 2005; Boyer et al., 2009; Barzouka et al., 2015; Arbabi and Sarabandi, 2016; Robertson et al., 2017). In these studies, self-individual and expert model were usually displayed separately, for instance by splitting the screen in two sides (i.e., self-demonstration on one side and expert model on the other side). Although watching and comparing movements displayed in two separate videos is not an easy task, some studies have demonstrated the efficacy of the ES-M approach (Baudry et al., 2006; Boyer et al., 2009). In particular, ES-M usually gives rise to better performance than expert modeling (Oñate et al., 2005; Arbabi and Sarabandi, 2016) or self-modeling (Arbabi and Sarabandi, 2016; Robertson et al., 2017). The advantage of ES-M feedback over other types of feedback has been demonstrated for a large range of movements, as for instance the badminton serve (Arbabi and Sarabandi, 2016), the volley pass (Barzouka et al., 2015), or the double leg circle on the pommel horse (Baudry et al., 2006).
However, there are some limitations to the use of ES-M in the above mentioned studies. First, feedback was always delayed, i.e., participants were provided with feedback only after movement execution. In addition, most of the time, video feedback was augmented with a verbal feedback provided by a coach/teacher (Oñate et al., 2005; Baudry et al., 2006; Boyer et al., 2009). Therefore, it is not obvious to disentangle the respective contribution of the video feedback and of the verbal feedback in the measured learning performance. Another limitation relates to the evaluation of participants' performance. Specifically, some studies focused on the outcome of the performance without evaluating the technical execution (Barzouka et al., 2015). In other studies, experts were asked to qualitatively evaluate the technical/kinematic execution of the movement (Boyer et al., 2009; Barzouka et al., 2015; Arbabi and Sarabandi, 2016; Robertson et al., 2017). Though valuable, this kind of evaluation is unfortunately quite subjective. Finally, in some studies, performance was evaluated using biomechanical measures (e.g., Oñate et al., 2005 on knee orientation or Baudry et al., 2006 on body segment alignments). Though quantitative, these measures did not really and thoroughly assess the quality of movement execution because they only focused on a targeted characteristic at a given time.
Virtual Reality (VR) constitutes a valid and interesting alternative to video to provide learners with ES-M feedback. VR notably grants the possibility to add and mix 2D or 3D information in order to combine self and expert modeling. Specifically, VR can be used to superimpose two movements in 3D, as for instance the movement of the learner and that of the expert. This consists in simultaneously displaying the two movements with minimal spatial offset, so that one movement overlays the other one, as illustrated in Figures 1, 2. Superimposing two movements is not possible with video feedback, and viewers need to constantly switch between the feedback relative to their own movement and that relative to the movement of the expert. In contrast to video, VR also allows to edit feedback and simplify it to provide only the most relevant information. This notably limits the risk to cognitively overwhelm the learner. In line with this, Poplu and colleagues (Poplu et al., 2013) suggested that simpler feedback is often better. In addition, VR gives the learner the ability to interact with the provided feedback, which stimulates self-regulation (Ste-Marie et al., 2012). Last but not least, by coupling VR with motion capture, individual performance can be quantified in terms of coordination, taking into account the spatial and/or temporal characteristics of the movement. This quantification grants a direct kinematic comparison between the movements of the learner and those of the expert.
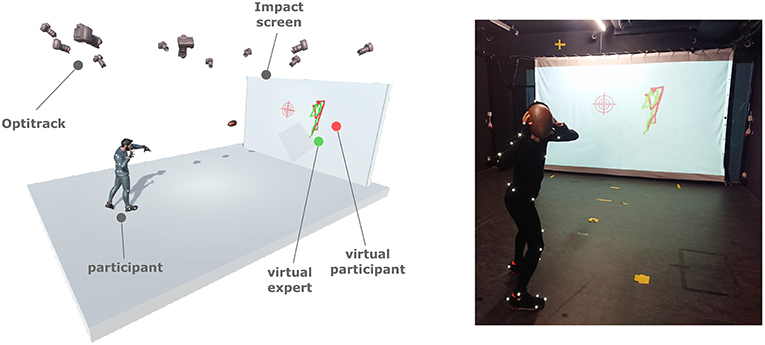
Figure 1. Overview of the apparatus used and example of use.
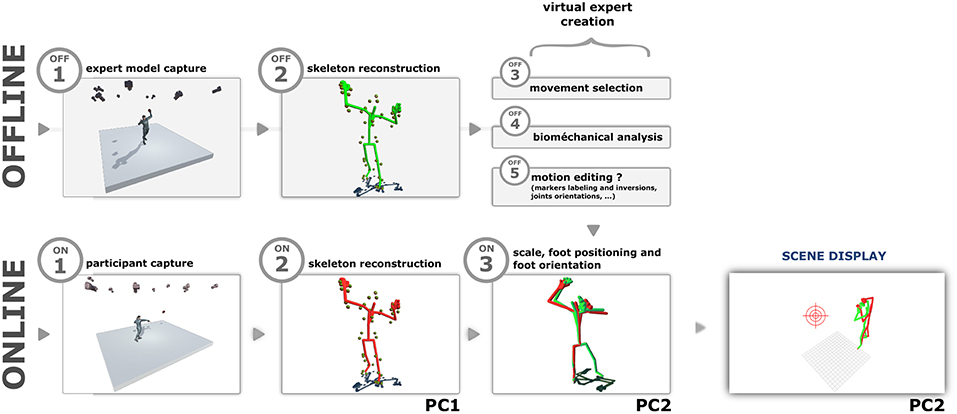
Figure 2. Overview of the pipeline of our system.
Regarding applications, VR has been widely used for motor learning, and more specifically for rehabilitation (Yanovich and Ronen, 2015; Ribeiro-Papa et al., 2016). However, few studies combined self and expert modeling. In the few studies that did, feedback was always provided during movement execution (i.e., concurrent feedback). In most cases, a motion capture system was combined to a virtual environment to synthesize an avatar and superimpose the learner and the expert (Chua et al., 2003; Chan et al., 2011; Hoang et al., 2016). For instance, Chua et al. (2003) compared several feedbacks using the ES-M as well as ESS-M, namely an ES-M variant in which the reference movement of the expert is superimposed on the movement of the learner. Note that in the “classical” ES-M variant, the virtual expert is displayed next to the virtual participant. These authors did not find any significant improvement of the movement. Chan et al. (2011) used a virtual teacher for dance training and compared expert modeling with ESS-M. In their study, motor learning was significantly better with ESS-M feedback than with expert modeling. Kimura et al. (2007) used ESS-M feedback for posture learning. The authors measured the time needed to reproduce the model poses. With ESS-M feedback, participants needed less time to reproduce the model postures in comparison with expert modeling. In a study in which postures had to be learned, Eaves et al. (2011) obtained significant improvements using a method blending the display of the expert on a video and point lights representing specific joints of the captured learner. Other systems using the Kinect sensor showed that ES-M or ESS-M is efficient for motor learning (Smeddinck, 2014; Hoang et al., 2016). Despite the acceptable results obtained by several authors (Chan et al., 2011; Eaves et al., 2011; Smeddinck, 2014; Hoang et al., 2016), some limitations appeared in most of the cases. For instance, the promising results obtained by Kimura et al. (2007) and Eaves et al. (2011) only concerned posture learning. Waltemate et al. (2015) explained that Kinect-based systems approximate the capture and a feedback latency was systematically observed. Other factors might also interfere with motor learning. For instance, meshed avatars and rich virtual environments could cognitively overload the learner, as could motion learning based on the whole body and on displacement movements (Chua et al., 2003; Burns et al., 2011; Chan et al., 2011). To overcome these potential limitations, we propose to use a simpler feedback, displayed in real time, focusing on the comparison between the movement of the learner and that of the expert, and displaying only the most relevant body parts relative to the movement to be learned.
To assess the quality of movement execution, methods dedicated to gesture learning in VR mostly used motion capture systems and relied on geometrical comparisons performed on the whole movement. Some studies focused on the whole body (Eaves et al., 2011) or on a subset of joints (Chua et al., 2003; Chan et al., 2011; Hoang et al., 2016). These studies were based on the dynamic time warping algorithm (DTW) (Chan et al., 2011; Morel, 2017). Other methods focusing on comparison have been used for expressive motion as for example the study of Aristidou et al. on folk dance evaluation (Aristidou et al., 2015). To achieve this, the authors relied on the a Laban Movement Analysis (LMA) method, originally used for the description of human movement (see the review of Larboulette and Gibet, 2015 for details on expressive motion description). More specifically, the work of Senecal et al. (2018) analyzed the performance of SALSA dancers. The authors assessed dancers' skills by considering the couple of dancers as a single entity, and using metrics on specific features, focusing on the rhythm, drive and style. In our study, we drew inspiration from the methods previously used for the assessment of isolated sport movement (i.e., those used in VR or with video feedback).
Purpose of the Study
The aim of this study was to assess and identify the advantages of using VR-based feedback for motor learning. We particularly focused on pattern/form reproduction, and our participants' task was to reproduce as well as possible the movement of an expert. We used a real time feedback superimposing 3D movements of the expert on the movements of the learner (ESS-M feedback). We notably assessed the effectiveness of ESS-M feedback provided either during (i.e., concurrent) or after movement execution (i.e., delayed). Previous studies showed that expert modeling can be very effective for motor learning (e.g., Horn et al., 2005, 2007), and more effective than self modeling (e.g., Zetou et al., 2002; Ghobadi et al., 2013). Therefore, we compared ESS-M with expert modeling (E-M) feedback. The reference movement participants were required to learn was a throw in American football. Lai et al. (2000) suggested that the learning of this kind of movement usually starts with the imitation of the basic features of the movement. It would be only after this initial phase that the learner can adapt its movement to different contexts. In order to focus the learner only on the form/shape reproduction (i.e, reproduction of the spatial features of the expert's movement), our learning protocol consisted in observing and trying to reproduce “online” the movements of the expert, which were performed at different speeds (i.e., from slow ones to the recorded execution speed).
Movement reproduction performance (i.e, how was the pattern of reproduced movement) was quantified using two measures based on the Dynamic Time Warping (DTW) algorithm (Bruderlin and Williams, 1995; Morel, 2017). Concerning the first measure, the DTW was used to compute the spatial distance between the participant's and the expert's movements. The second measure, which is a new measure introduced here, consisted in evaluating the dispersion around the mean distances between the expert and the participant over time. In other words, this measure expresses the regularity of the learners when reproducing/following the movement of the expert. In addition to these two “kinematic” measures, we also assessed the outcome of movement execution. For that, we simply quantified the accuracy of the throws by measuring the distance to the target.
2. Materials and Methods
2.1. Participants and Design
Fifty-three right-handed participants (44 men, 9 women) aged from 21 to 29 (average 24.1) participated in the experiment. All participants had a first experience in throwing sport. However, none of them had experience in American football. All participants signed an informed and written consent prior to their inclusion in the study. This was done in accordance with the ethical standards specified by the 1964 Declaration of Helsinki. Participants were randomly assigned to five groups: 4 groups of eleven participants and one group of nine participants. Note that two left-handed participants were withdrawn from one of the groups because they induced computational errors during the post-processing stage, all other participants being right-handed. Each group was provided with a different type of visual feedback to learn the American football throwing.
2.2. Apparatus
Movements were captured using the Optitrack system (NaturalPoint Inc., 1996) with 12 infrared cameras distributed in a 9 x 6 m room. Only one light indirectly illuminated the room (75 watt halogen lamp). These cameras were specifically positioned and oriented to capture a volume of ~ 18 m3 (2.5 x 2.5 m on the ground and 3 m in height) centered on the participant. Each participant wore 49 reflected markers. The acquisition frequency was 120 frames per second. The reconstruction of the marker positions as well as the skeleton was achieved in real time using the Motive software (NaturalPoint Inc., 1996) on a dedicated PC. A second PC was dedicated to the control of the application, the skeleton animation and the scene rendering. A UDP network was used for communication between the two computers (see Figure 2 for the distribution of the tasks). The network latency was in the 4–6 ms range. The software application dedicated to the feedback computation and the 3D display was implemented using C++/OpenGl with the SFML library. The display frequency was around 150 frames per second. The projection screen on which the visual feedback was displayed was 4 m wide and 2.7 m high (see Figure 1).
2.3. Procedure
After a general and a throw-specific warm up of 20 min, participants put on a suit dedicated to the tracking and equipped with the 49 infrared markers. The suit was chosen to fit the size of the participant. An expert demonstrated the throwing movement and gave oral instructions on the position and rotation of each joint involved in the motion (i.e., pelvis, arm, hand), as well as on the appropriate way to hold the ball, to throw it, and to produce rotation effects. The participants were asked to perform standing throws (see Figure 3 for an illustration) to a target displayed on the impact screen at a 5 m distance of the participant (see Figure 1). The throw was performed with an official football. At the beginning of the experiments, participants were instructed that learning the movement was their primary task, and that aiming at the target was only a secondary objective. Each participant performed 5 trials to familiarize him/herself with the movement. The participants were then instructed about the experimental protocol. The experiment consisted of 3 phases:
• Pre-test: Each participant performed 10 throws (without run-up) in front of the screen. The movements were captured and the distance to the center of the target was measured. The participant was free to perform each throw when he/she was ready (as described below, this phase was captured in a single session before being manually segmented).
• Learning. Each participant performed 50 training throws. He/she had to follow the movement of the virtual expert as closely as possible. The type of provided feedback depended on the group. With the superimposition-based feedback (see section “feedback” below), the participant had to follow the pace and “fit into” the expert's movement. Five speeds variations were used to propose 5 different i.e., 20, 40, 60, 80, and 100 % of the real movement speed, i.e., the speed of the expert movement. The superimposition-based feedback was provided for the five variations, with 10 repetitions per variation. Before each training throw, the learners were warned by the experimenter that the expert's movement was about to start. The participants were instructed to perform the throws according to the different phases given by the expert's movement, i.e., from the beginning of the “early cocking” phase to the end of the “follow through” phase (see Figure 3 for details).
• Post-test. The post-test phase was identical to the pre-test phase.
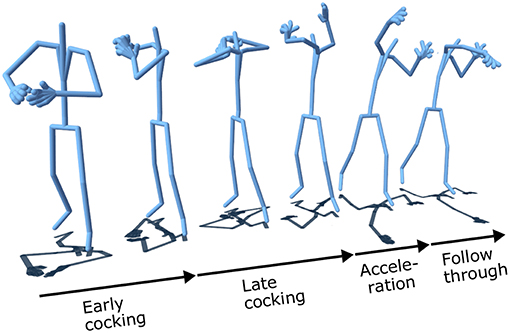
Figure 3. The different phases of the American football throwing.
2.4. Materials and Feedback
The recorded expert movement was the movement of a quarterback in American football. Motion capture conditions followed the specifications stated above (see section 2.2). An expert in American football and in motion capture selected the reference movement among 20 throws performed by the expert player. As illustrated in Figure 3, the sub-parts of the throwing movement were then cut manually from the beginning of the “early cocking” phase to the end of the “follow through” phase. No filtering step was necessary because for the selected movement, the automatic labeling (retrieval of virtual markers at each time step) was optimal. In addition, there was no marker inversion, and the reconstruction of the animation of the skeleton led to fluid motions without any animation artifact.
2.4.1. Feedback
Virtual reality technology can be used to provide different types of feedback, such as the expert's movements, the participant's movements, or a combination of the two. Irrespective of the type of feedback, it can be provided during movement execution (concurrent feedback), or after movement execution (delayed feedback). Five different types of visual feedback were provided to the five groups of participants during the learning phase of the experiment:
• Group Control, without feedback: no feedback was provided, either during or after movement execution.
• Group E-E: During movement execution and after each repetition, participants were shown the movement of the virtual expert.
• Group E-ESS: During movement execution, participants were shown the movement of the virtual expert. After each repetition, participants were shown their own movement as well as the movement of the virtual expert that was displayed in superimposition to their own.
• Group ESS-E: During movement execution, participants were shown their own movement as well as the movement of the virtual expert in superimposition. After the movement, they were shown the movement of the virtual expert.
• Group ESS-ESS: During movement execution and after each repetition, participants were shown their own movement and the movement of the virtual expert in superimposition.
2.4.2. Display
In accordance with the results of Runeson (1994), Scully and Carnegie (1998), and Poplu et al. (2013), only movement-related information was displayed, namely the segments of the 3D avatar. The 3D virtual scene consisted of a ground represented by a grid. The expert's skeleton was displayed in green and the participant's skeleton in red.
2.4.3. Camera
For all conditions, the scene camera was set with a third-person perspective configuration, and it was always focused on the 3D avatar of the participant, as illustrated in Figure 1. This configuration was chosen by an expert in American football in order to show the most relevant information of the throwing movement. As illustrated in Figure 1, feedback was shown to the participants with an orientation corresponding to a 180-degrees rotation of the camera with respect to their point of view. The camera was placed high up.
2.4.4. Skeleton Alignment (Figure 2.ON3)
The alignment of the participant's skeleton with the expert's skeleton (i.e., positioning and orientation) was automatically computed just before the beginning of each movement (the experimenter clicked on a button when the participant was ready). As illustrated by the step ON 3 in the Figure 2, a geometrical transformation was applied to match the position and orientation of the left foot of the virtual participant with the left foot of the virtual expert (note that the left foot corresponds to the supporting foot for the throwing movement). In addition, the skeleton was scaled according to the expert's height to fit to the skeleton of the virtual expert.
2.5. Data Analysis
The aim of this experiment was to assess the effectiveness of ESS-M feedback for motor learning, with a particular focus on the pattern/form reproduction. To achieve this goal, we compared the participant's movement with the movement of the expert using two dependent variables measuring the spatial distance between the two movements. We also assessed the outcome of the throws by measuring throwing accuracy/error.
For the pre and post phases (2 × 10 samples), we collected: (a) the whole movements of participants (motion-captured) and (b) the distances to the target. Regarding (b), the ball left a mark on the impact screen. The ball-target distance dtarget was manually measured. Regarding (a), the Dynamic Time Warping algorithm (DTW) was used to measure the distance between the expert's and the participant's movements (Berndt and Clifford, 1994). DTW is widely used for time series comparison. In this context, two time series are represented by a series of postures (Bruderlin and Williams, 1995). Specifically, the algorithm consists of two steps:
1. First, it builds a matrix of distances M between the two movements Mexp and Mpart. The dimension of M is n × m, where n and m are the number of postures into Mexp and Mpart, respectively. Each element of M corresponds to the distance between two postures Mexp(k) and Mpart(l), where k ∈ [0, n] and l ∈ [0, m]. A posture is considered by a sub-skeleton including the joints of the upper body (i.e., hips, the two spine joints, neck, head, left/right shoulder, right/left arm, right/left elbow, right/left wrist). Each joint j is represented by a position pj ∈ ℝ3. Finally, the distance between two postures is given by , where k and l correspond to the posture indexes of the expert's and participant's movements, respectively. As explained in the previous section, each skeleton of Mpart is scaled (not re-targeted) according to the size of the expert's skeleton before the computation of the DTW.
2. The algorithm computes an optimal warping path pdtw between Mexp and Mpart. pdtw has the minimal total cost among all possible warping paths of M. pdtw = {(0, 0), …, (k, l), …, (n, m)} minimizes the global distance between Mexp and Mpart.
The outputs of the DTW are: (a) the best mapping between Mexp and Mpart represented by pdtw. (b), the global distance ddtw, which sums up the distances of all elements contained in pdtw and takes into account the spatial and temporal aspects. (c), the normalized distance on pdtw that better describes the spatial distance (Shen and Chi, 2017):
This metric quantifies the error related to the execution of the movement. However, because the learner's skeleton is not re-targeted, the measure might be affected by morphological differences between the learner and the expert. To get around this kind of problem, Morel et al. (Morel, 2017) have recently proposed, for karate tsuki and tennis serve, to take several movements of the expert and extract a "nominal" movement by using the DTW to interpolate these different movements.In addition, a spatial tolerance is computed for each joint, and then taken into account in the movement comparisons. However, without mathematical proof or experimental tests, the validity and consistency of this 3D nominal motion can be questioned since the generated skeleton does not preserve the morphological structure of the body. Accordingly, we chose here to use the standard deviation along the path (d) :
where lpdtw is the length of pdtw and pdtw(i) is the distance computed for the ith element of pdtw. By evaluating the dispersion of distance around the mean distance over time, dissociates the error resulting from morphological differences between the learner and the expert. In addition, this measure expresses the regularity with which the learner follows/reproduces the movements of the expert along its path. By matching these results with the spatial distance to the expert, we assessed the ability of each participant to uniformly improve his/her movement along the whole “path” of the movement. For example, if the overall spatial distance with the expert improves while its dispersion value worsens, that means that the execution of some portions of the movement improved while the execution worsened for other portions of the movement.
Finally, for each participant's movement, a distance to the expert is obtained. All movements were cut manually by two experts in American football with good knowledge of motion capture post-processing. This represents a total of 2 * 10 * 53 = 1060 sub-movements illustrated in Figure 3.
2.6. Statistical Analysis
We used three dependent variables, namely the three measures defined in the previous section: , , dtarget. There were two independent variables, namely the learning method (with 5 levels, corresponding the 5 groups) and the test session (with 2 levels, namely pre and post). First, for each dependent variable, we performed a one-way analysis of variance to compare the average performance of the five groups in the pre phase. This notably allowed us to make sure the initial performance was similar in all groups. Then, for each dependent variable and each group, we assessed whether the learning gave rise to a significant improvement. For each group, the mean performance in the pre-phase was compared to the mean performance in the post-phase using either a Student's t-test for repeated measures (when data was parametric) or a Wilcoxon signed-rank test (when data was non-parametric). Normality was assessed running the Shapiro-Wilk test. Finally, for each dependent variable, we directly compared the effectiveness of the five types of feedback for motor learning. For each dependent variable, each group and each participant, motor improvement was computed as the difference between the post and the pre performance. We first tested the interaction effect between the two dependent variables on the average and the standard deviation using a MANOVA. The average motor improvement was then compared between the 5 groups using either a one-way ANOVA (when data was parametric) or a Kruskal-Wallis test (when data was non-parametric). For all tests, alpha was set at 0.05. Post-hoc tests were performed using t-tests with Bonferroni correction for multiple comparisons or Dunn's rank sum comparisons (for non-parametric data).
3. Results
3.1. Comparison to the Expert
All the results presented in this section concern the distance between the participant's and the expert's movements. The dependent variable quantifies the difference of spatial characteristics between the movement of the participant and the movement of the expert. The dependent variable quantifies the regularity with which participants reproduced/followed the movement of the expert.
3.1.1. Pre Phase Group Comparison
The mean and the mean measured in the pre-phase were compared between the five groups using a one-way ANOVA. Neither the mean F(4, 48) = 0.69, p = 0.59 nor the mean F(4, 48) = 1.10, p = 0.37 differed between the different groups.
3.1.2. Motor Spatial Characteristics for Post-pre Comparison
Figure 4 presents for each group the average performance with and in the pre and post phases, as well as the p-value of the post-pre comparison (left panel of the figure). As shown in the figure, the average performance on spatial imitation (i.e., distance to the expert ) improved for all groups (i.e., smaller distance in the post-phase), except for the control group. This improvement was significant for the E-ESS and the ESS-E groups, but it failed to reached significance for the other groups. The same pattern of results was observed for the .
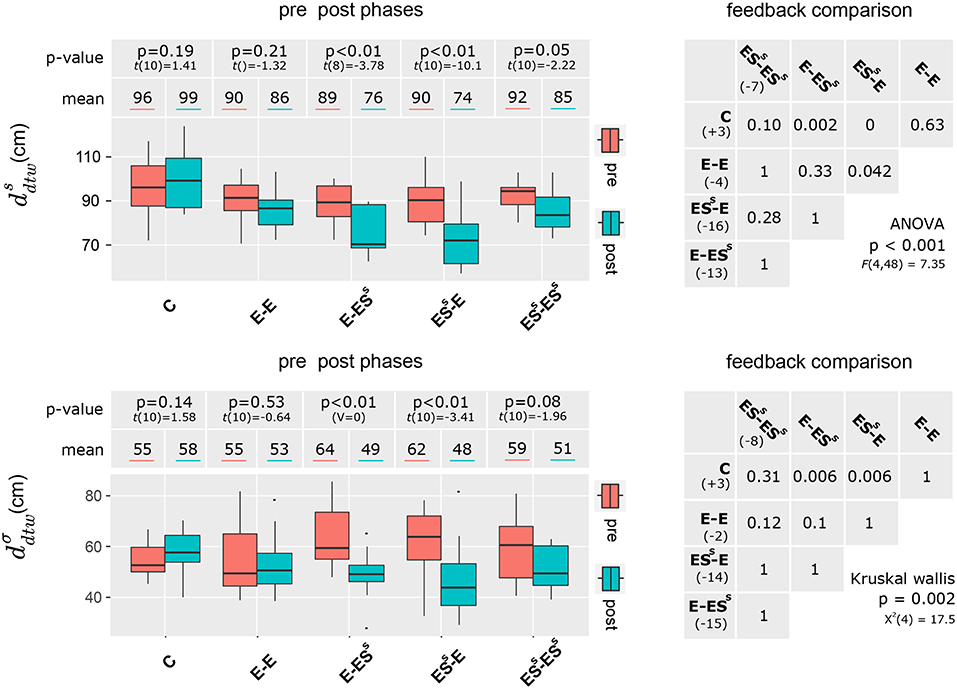
Figure 4. Spatial difference between the learner's movement and the movement of the expert (upper panel) and execution regularity (lower panel) before (red) and after (cyan) motor learning. The p-values correspond to the post-pre comparisons. The tables (right panels) summarize the statistical comparisons between learning conditions (groups) in terms of post-pre improvement.
3.1.3. Motor Improvement Between Groups
Because our two dependent variables were likely to be related and to share some variance, we first ran a MANOVA (with the type of feedback as independent variable, i.e., 5 independent groups). The Pillais trace test indicated a significant effect of the type of feedback [V = 0.47, F(8, 96) = 3, 73, p < 0.001] on the average distance and on the standard deviation improvements. We then ran two separate one way ANOVAs on the two dependent variables. For both the [F(4, 48) = 7.35, p < 0.001] and the , [], the average improvement differed significantly between groups (see Figure 4, right panels). Post-hoc tests indicated that for , the improvement was significantly larger with E-ESS and ESS-E feedback than without feedback (i.e., control group). In addition, the improvement was significantly larger with ESS-E feedback than with E-E feedback. Regarding , the pattern of result was almost the same, but the ESS-E and the E-E condition did not differ from one another.
3.2. Distances to the Target (Accuracy)
Reaching accuracy in the pre-phase was similar for all five groups [, p = 0.79]. As illustrated in Figure 5 (left panel), throwing accuracy improved only for the control group (p < 0.05) and the group that trained with ESS-ESS feedback (p < 0.01). The improvement after learning, i.e., the difference post-pre, differed significantly between groups [, p < 0.01, see Figure 5, right panel]. In particular, accuracy improvement was significantly larger for the control (C) and the ESS-ESS group than for the E-E group.
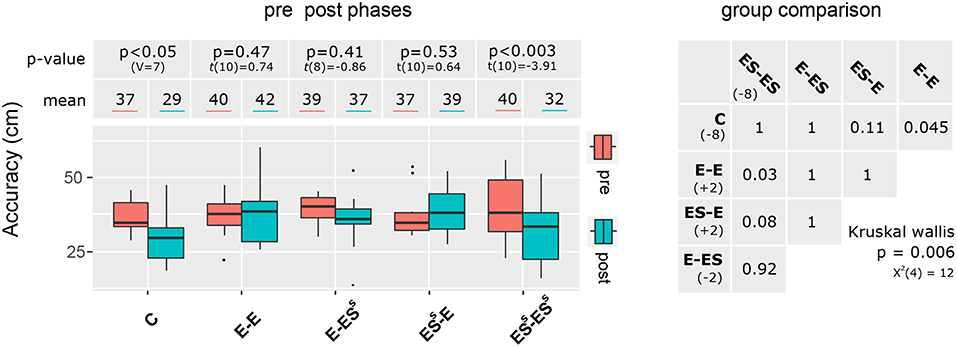
Figure 5. Aiming accuracy as measured as the distance to the target before (red) and after (cyan) motor learning. The p-values correspond to the post-pre comparisons. The table (right panel) summarize the statistical comparisons between learning conditions (groups) in terms of post-pre improvement.
3.3. Correlation Between the Improvement of Motor Execution and Throwing Accuracy
We also analyzed the relation between the improvement of motor execution (i.e., difference post - pre for the three dependent variables, namely and ) and the improvement of throwing accuracy (see Table 1). Correlations were performed using the Pearson correlation coefficient, because data was parametric for all performed correlation tests. The influential points considered as outliers using the Cook's Distance (Cook, 1977) with a cut-off 6/n were removed.
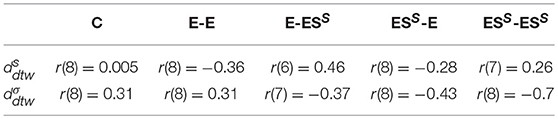
Table 1. Correlations between the motor skill improvements and the accuracy.
For the ESS-ESS group, we observed a strong negative correlation between the and throwing accuracy [r(8) = −0.7], indicating that throwing accuracy was inversely related to movement execution (as evaluated by our method). Regarding the , moderate correlation with throwing accuracy was also observed for the E-E (negative) and the E-ESS (positive) group. Regarding the , a moderate positive correlation with throwing accuracy was observed for the C and the E-E group, whereas a moderate negative correlation was observed for the E-ESS and the ESS-ESS group. Overall, these results indicate that no clear pattern of correlation can be identified between movement execution and throwing accuracy, which makes sense considering that participants were specifically instructed to focus on movement execution, without any instruction regarding throwing accuracy.
4. Discussion
We investigated the effectiveness of superimposed expert+self modeling (ESS-M) feedback in VR for motor learning. In particular, we compared the effectiveness of this type of feedback to that of expert modeling feedback. Depending on the condition, each type of feedback was provided either during movement execution (concurrent feedback), after movement execution (delayed feedback), or both during and after movement execution. Participants had to learn a throwing movement in American football, i.e., a partial movement for which this type of feedback has been recommended (Kimura et al., 2007). The effectiveness of feedback on motor learning was assessed using three different measures. Two of these measures were dedicated to the pattern/form of the movement, i.e., to the spatial characteristics of the upper body movement. Movement accuracy was measured using aiming error.
The group that was not provided with any feedback (control group) did not show any improvement in the reproduction of the movement pattern. Specifically, neither the two dependent variables quantifying the spatial distance to the movement of the expert did improve after learning without feedback. Movement reproduction in this group actually tended to be worse in the post than in the pre session (though this effect was non-significant). This result is consistent with previous studies in which no improvement was observed without feedback (i.e., with video feedback Oñate et al., 2005; Baudry et al., 2006 and in VR Eaves et al., 2011). On the other hand, aiming accuracy improved significantly for this group (p < 0.01). This can likely be explained by the fact that in this condition, participants could focus most if not all of their attentional and cognitive resources on throwing accuracy, because they did not receive any feedback/information about the form of the movement.
The group that was provided with expert modeling feedback did not improve the form of the movement either. Specifically, neither the spatial distance nor the regularity to follow the expert (p = 0.21 and p = 0.53, respectively) were significantly better after the learning session. This lack of effectiveness can probably be explained by the lack of information related to the own movement of the learner (Famose et al., 1979; Lejeune et al., 1994; Fery and Morizot, 2000). Indeed, the absence of feedback comparing the two movements makes it more difficult to optimally use the information given by the “ideal” one. Learners of the E-E group did not improve their aiming accuracy either. This finding is at odds with previous works that observed immediate performance benefits of expert modeling feedback (Rohbanfard and Proteau, 2011 and Barzouka et al., 2015). Note that in our task, the learners were explicitly instructed to primarily focus on the form of the movement. Without any possible direct comparison with the “ideal” movement, participants might have focused even more on their “sensations” when producing the movement, which in turn prevented any real improvement in aiming accuracy. This line of reasoning actually holds for all conditions in which feedback was provided.
Regarding the groups that were provided with superimposed expert+self feedback, namely the three groups that received ESS feedback either during and/or after movement execution, they all showed an improvement of movement reproduction/execution after learning. Specifically, except for the ESS-ESS group, spatial distance with the movement of the expert was significantly reduced after learning. Note that for the ESS-ESS group, the improvement barely failed to reach significance, with p = 0.05. These findings are in line with previous studies on ES-M with video feedback (Oñate et al., 2005; Baudry et al., 2006; Boyer et al., 2009; Barzouka et al., 2015; Arbabi and Sarabandi, 2016; Robertson et al., 2017) as well as with studies on ESS-M with VR-based feedback (Chan et al., 2011; Hoang et al., 2016). Regarding the regularity with which learners reproduced the movement of the expert, here again superimposed expert+self feedback gave rise to a performance improvement. This improvement was significant for the ESS-E and the E-ESS groups, and it barely failed to reach significance for the ESS-ESS group(p = 0.08).
Although the ESS-ESS feedback failed to significantly improve movement regularity, taken together, our findings suggest that ESS modeling allowed the participants to better and more uniformly imitate the expert over time, either when provided concurrent or delayed feedback. In that respect, our results are in line with those reported by Hoang et al. (2016) who observed significant improvements in the production of an upper body karate movement using superimposition feedback. ESS-E (p = 0.53) and E-ESS feedback (p = 0.41) did not allow participants to improve their aiming accuracy. Similar results were obtained by Ashford et al. (2006), who measured greater changes in movement kinematics than in the outcome of the movement.However, the absence of improvement in aiming accuracy for these groups might seem surprising and somewhat counterintuitive. Indeed, though participants in this group did not improve their aiming accuracy after training, they did improve their throwing movement pattern. Actually, this “pattern of result” seems to generalize to all groups in our experiment. Specifically, the groups that significantly improved their movement production (i.e., that best reproduced the movement of the expert after learning) failed to significantly improve their aiming accuracy. This was the case for the E-ESS and ESS-E groups. The ES-ES group constitutes an exception to this pattern, as for this group, we found a moderate positive correlation between the improvement of movement execution and throwing accuracy. On the other hand, the groups that failed to significantly improve their movement production and instead “preserved” their original movement pattern did improve their aiming accuracy. This was the case for the C and ESS-ESS groups. This finding is notably confirmed by the negative correlation between the regularity to follow the expert and throwing accuracy: r(8) = 0.7 (p < 0.05). Therefore, taken together, these results suggest that altering one's own movement pattern negatively affects aiming accuracy, at least transiently, when the learner is still in the acquisition phase of the “ideal” movement. This makes sense because during this learning phase, the learner must modify his/her “natural” movement pattern to adopt an “unnatural” movement pattern. However, correlation tests did not reveal any clear relationship between the improvement (or the lack there of) in movement reproduction and accuracy improvement. A possible additional explanation for the lack of improvement in aiming accuracy is a potential disinterest of the participants in the aiming task and a stronger focus on the motor learning of the movement form, as actually instructed.
For both the spatial distance to the expert and the regularity with which the expert's movement is followed, the ESS-E and the E-ESS group improved significantly more than the control group (p < 0.01 in all cases). Regarding spatial distance, the improvement of the ESS-E group was also significantly larger than that of the E-E group (p < 0.05), but this improvement was apparently not uniformly distributed over time. This result is consistent with previous studies showing that ESS modeling gives rise to significantly larger motor improvements than expert modeling (Oñate et al., 2005; Arbabi and Sarabandi, 2016). Concerning aiming accuracy, as mentioned above, only the C and the ESS-ESS feedback gave rise to significant improvements. Comparisons between groups confirmed that the improvement in aiming accuracy was larger for the C and the ESS-ESS group than for the group that was provided with expert modeling feedback.
Another important finding is the absence of real difference between concurrent and delayed feedback. In other words, our results suggest that both concurrent and delayed feedback effectively improve the pattern/form of the movement. However, as observed by correlation tests this improvement is not associated with an improvement of the aiming accuracy, at least for the initial learning phase (i.e., what we tested here). A longer training phase, possibly coupled to some slight changes in the instructions given to the learner would probably easily solve this issue. Our study focused specifically on the learning of the movement form. Therefore, we focused on DTW-based measures to “geometrically” compare the movement of the learners with the movement of the expert. One limitation of our study is that neither the learning nor the evaluation focused on more “dynamic/timing-related” measures such as speed variations or acceleration. These points could be addressed in a complementary study specifically devoted to investigate these aspects.
5. Conclusion
The main goal of our study was to assess the effectiveness of a feedback superimposing self and expert avatars for the learning of a motor skill. The superimposition of self and expert feedback relied on the use of motion capture. This technology captures kinematic information of the movement with accuracy, which grants a high quality of quantitative measures. Furthermore, the dynamic time warping algorithm was used to measure the spatial characteristics of the movements. A new metric computing the dispersion of distance around the mean distance over time was introduced. This metric notably allowed us to determine if the learners “uniformly” improved their movements, i.e., along the whole course of the movement.
Previous studies based on expert+self feedback with video did not use either superimposition or concurrent feedback. In addition, previous studies using a similar type of feedback in VR only reported contrasted results. Our results show that the superposition of self and expert modeling can constitute an effective feedback to improve motor learning, at least for partial movements such as the throw in American football. One should mention here that most previous works in VR using this type of feedback addressed the learning of complex movements implying the whole body, and sometimes with wide motion (as for example with dance). This might explain the reported contrasted results. Taken together, these results support Kimura's suggestion to use superposition only for partial movements (Kimura et al., 2007). The results of Hoang et al. (2016), who addressed the motor learning of upper body movements in karate, tend to also support this suggestion. Importantly, in our experiment, expert+self modeling proved better than expert modeling to learn the movement pattern. Specifically, “concurrent expert followed by delayed self + expert feedback,” or “concurrent self + expert and delayed expert feedback” gave rise to significant improvements in the production of the movement pattern. However, these types of feedback failed to improve aiming accuracy. Our results suggest that self + expert as concurrent and delayed feedback might constitute the best “compromise” to improve both the movement pattern and aiming accuracy.
Ethics Statement
This study was carried out in accordance with the recommendations of local ethics, committee of Fribourg with written informed consent from all subjects. All subjects gave written informed consent in accordance with the Declaration of Helsinki. The protocol was approved by the committee of Fribourg.
Author Contributions
TL: design, HMI implementation, experimental tests, post-processing, statistics, and redaction. LH: design and redaction. J-PB: design, statistics, and redaction.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We would like to thank the students Benoit Bellagamba and Denis Bruttin who participated in this study (recruitment, experimental tests, and collect of data).
References
Arbabi, A., and Sarabandi, M. (2016). Effect of performance feedback with three different video modeling methods on acquisition and retention of badminton long service. Sport Sci. 9, 41–45.
Aristidou, A., Stavrakis, E., Charalambous, P., Chrysanthou, Y., and Himona, S. L. (2015). Folk dance evaluation using laban movement analysis. J. Comput. Cult. Herit. 8, 20:1–20:19. doi: 10.1145/2755566
Ashford, D., Bennett, S. J., and Davids, K. (2006). Observational modeling effects for movement dynamics and movement outcome measures across differing task constraints: a meta-analysis. J. Motor Behav. 38, 185–205. doi: 10.3200/JMBR.38.3.185-205
Barzouka, K., Sotiropoulos, K., and Kioumourtzoglou, E. (2015). The effect of feedback through an expert model observation on performance and learning the pass skill in volleyball and motivation. J. Phys. Educ. Sport 15, 407–416. doi: 10.7752/jpes.2015.03061
Baudry, L., Leroy, D., and Chollet, D. (2006). The effect of combined self- and expert-modelling on the performance of the double leg circle on the pommel horse. J. Sports Sci. 24, 1055–1063. doi: 10.1080/02640410500432243
Berndt, D. J., and Clifford, J. (1994). “Using dynamic time warping to find patterns in time series,” in KDD Workshop (Seattle, WA), 359–370.
Boyer, E., Miltenberger, R. G., Batsche, C., and Fogel, V. (2009). Video modeling by experts with video feedback to enhance gymnastics skills. J. Appl. Behav. Anal. 42, 855–860. doi: 10.1901/jaba.2009.42-855
Bruderlin, A., and Williams, L. (1995). “Motion signal processing,” in Proceedings of the 22nd Annual Conference on Computer Graphics and Interactive Techniques - SIGGRAPH '95 (New York, NY), 97–104.
Burns, A.-M., Kulpa, R., Durny, A., Spanlang, B., Slater, M., and Multon, F. (2011). “Using virtual humans and computer animations to learn complex motor skills: a case study in karate,” in BIO Web of Conferences, Vol. 1 (Montpellier: EDP Sciences), 00012.
Chan, J. C. P., Leung, H., Tang, J. K. T., and Komura, T. (2011). A virtual reality dance training system using motion capture technology. IEEE Trans. Learn. Technol. 4, 187–195. doi: 10.1109/TLT.2010.27
Chua, P. T., Crivella, R., Daly, B., Hu, N., Schaaf, R., Ventura, D., et al. (2003). “Training for physical tasks in virtual environments: Tai Chi,” in Proceedings - IEEE Virtual Reality (Los Angeles, CA), 87–94.
Cook, R. D. (1977). Detection of influential observation in linear regression. Technometrics 19, 15–18.
Eaves, D. L., Breslin, G., and Spears, I. R. (2011). The short-term effects of real- time virtual reality feedback on motor learning in dance. Presence 20, 62–77. doi: 10.1162/presa00035
Famose, J.-P., Hébrard, J., Simonet, P., and Vives, J. (1979). Contribution de l'aménagement matériel du milieu à la pédagogie des gestes sportifs individuels. Compte rendu de recherche DGRST. Paris: INSEP.
Fery, Y.-A., and Morizot, P. (2000). Kinesthetic and visual image in modeling closed motor skills: the example of the tennis serve. Percept. Motor Skills 90, 707–722. doi: 10.2466/pms.2000.90.3.707
Ghobadi, N., Daneshfar, A., Shojaei, M., and Ghobadi, N. (2013). Comparing the effects of self and expert models observation on performance and learning of futsal side foot pass. Eur. J. Exp. Biol. 3, 508–512.
Hoang, T. N., Reinoso, M., Vetere, F., and Tanin, E. (2016). “Onebody: remote posture guidance system using first person view in virtual environment,” in Proceedings of the 9th Nordic Conference on Human-Computer Interaction (Gothenburg), 25:1–25:10.
Horn, R. R., Williams, A. M., Hayes, S. J., Hodges, N. J., and Scott, M. A. (2007). Demonstration as a rate enhancer to changes in coordination during early skill acquisition. J. Sports Sci. 25, 599–614. doi: 10.1080/02640410600947165
Horn, R. R., Williams, A. M., Scott, M. A., and Hodges, N. J. (2005). Visual search and coordination changes in response to video and point-light demonstrations without KR. J. Motor Behav. 37, 265–274.
Kimura, A., Kuroda, T., Manabe, Y., and Chihara, K. (2007). A study of display of visualization of motion instruction supporting. Educ. Technol. Res. 30, 45–51. doi: 10.15077/etr.KJ00004963315
Lai, Q., Shea, C. H., Wulf, G., and Wright, D. L. (2000). Optimizing generalized motor program and parameter learning. Res. Q. Exerc. Sport 71, 10–24. doi: 10.1080/02701367.2000.10608876
Larboulette, C., and Gibet, S. (2015). “A review of computable expressive descriptors of human motion,” in Proceedings of the 2Nd International Workshop on Movement and Computing, MOCO '15 (New York, NY: ACM), 21–28.
Lejeune, M., Decker, C., and Sanchez, X. (1994). Mental rehearsal in table tennis performance. Percept. Motor Skills 79, 627–641.
Morel, M. (2017). Multidimensional time-series averaging. Application to automatic and generic evaluation of sport gestures (Theses). Université Pierre et Marie Curie - Paris VI, France.
NaturalPoint Inc. (1996). Optitrack and Motive from NaturalPoint. Available online at: https://optitrack.com/
Oñate, J. A., Guskiewicz, K. M., Marshall, S. W., Giuliani, C., Yu, B., and Garrett, W. E. (2005). Instruction of jump-landing technique using videotape feedback: Altering lower extremity motion patterns. Am. J. Sports Med. 33, 831–842. doi: 10.1177/0363546504271499
Poplu, G., Ripoll, H., Mavromatis, S., and Baratgin, J. (2013). How do expert soccer players encode visual information. Res. Q. Exerc. Sport 1367, 37–41. doi: 10.1080/02701367.2008.10599503
Rhoads, M. C., Da Matta, G. B., Larson, N., and Pulos, S. (2014). A Meta-analysis of visual feedback for motor learning. Athletic Insight 6, 17–33.
Ribeiro-Papa, D. C., Massetti, T., Ciello de Menezes, L. D., Antunes, T. P.C., Bezerra, I. M. P., and de Mello Monteiro, C. B. (2016). “Motor learning through virtual reality in elderly - a systematic review,” in Medical Express (São Paulo), 1–8.
Robertson, R., St. Germain, L., and Ste-Marie, D. M. (2017). The effects of self-observation when combined with a skilled model on the learning of gymnastics skills. J. Motor Learn. Dev. 6, 1–30. doi: 10.1123/jmld.2016-0027
Rohbanfard, H., and Proteau, L. (2011). Learning through observation: a combination of expert and novice models favors learning. Exp. Brain Res. 215, 183–197. doi: 10.1007/s00221-011-2882-x
Runeson, S. (1994). “Perception of biological motion: the ksd-principle and the implications of a distal versus proximal approach, in Perceiving Events and Objects, eds G. Jansson, S. S. Bergström, and W. Epstein (Hillsdale, NJ: Lawrence Erlbaum Associates), 383–405.
Schmidt, R. A., Lee, T., Winstein, C., Wulf, G., and Zelaznik, H. (2018). Motor Control and Learning, 6E. Human kinetics.
Scully, D., and Carnegie, E. (1998). Observational learning in motor skill acquisition: a look at demonstrations. Irish J. Psychol. 19, 472–485.
Scully, D. M., and Newell, K. M. (1985). Observational learning and the acquisition of motor skills: toward a visual perception perspective. J. Hum. Mov. Stud. 11, 169–186.
Senecal, S., Nijdam, N. A., and Thalmann, N. M. (2018). “Motion analysis and classification of salsa dance using music-related motion features,” in Proceedings of the 11th Annual International Conference on Motion, Interaction, and Games, MIG '18 (New York, NY: ACM), 11:1–11:10.
Shen, S., and Chi, M. (2017). “Clustering student sequential trajectories using dynamic time warping,” in Proceedings of the 10th International Conference on Educational Data Mining, 266–271. Available online at: http://educationaldatamining.org/EDM2017/proc_files/papers/paper_94.pdf
Smeddinck, J. D. (2014). “Comparing modalities for kinesiatric exercise instruction,” in CHI'14 Extended Abstracts on Human Factors in Computing Systems (Toronto, ON), 2377–2382.
Ste-Marie, D. M., Law, B., Rymal, A. M., Jenny, O., Hall, C., and McCullagh, P. (2012). Observation interventions for motor skill learning and performance: an applied model for the use of observation. Int. Rev. Sport Exerc. Psychol. 5, 145–176. doi: 10.1080/1750984X.2012.665076
Waltemate, T., Hülsmann, F., Pfeiffer, T., Kopp, S., and Botsch, M. (2015). “Realizing a low-latency virtual reality environment for motor learning,” in Proceedings of the 21st ACM Symposium on Virtual Reality Software and Technology - VRST'15 (Beijing), 139–147.
Williams, A. M., and Grant, A. (1999). Training perceptual skill in sport. Int. J. Sport Psychol. 30, 194–220.
Williams, A. M., Mark, A., NetLibrary, I., Williams, M. E., and Hodges, N. E. (2003). Skill Acquisition in Sport : Research, Theory and Practice. London; New York, NY : Routledge.
Yanovich, E., and Ronen, O. (2015). The use of virtual reality in motor learning: a multiple pilot study review. Adv. Phys. Educ. 10, 188–193. doi: 10.4236/ape.2015.53023
Keywords: virtual reality, self + expert modeling, motor learning, 3D feedback, DTW, observation, dynamic time warping
Citation: Le Naour T, Hamon L and Bresciani J-P (2019) Superimposing 3D Virtual Self + Expert Modeling for Motor Learning: Application to the Throw in American Football. Front. ICT 6:16. doi: 10.3389/fict.2019.00016
Received: 23 January 2019; Accepted: 24 July 2019;
Published: 07 August 2019.
Edited by:
Regis Kopper, Duke University, United StatesReviewed by:
Yiorgos L. Chrysanthou, University of Cyprus, CyprusJeronimo Grandi, Duke University, United States
Copyright © 2019 Le Naour, Hamon and Bresciani. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Thibaut Le Naour, dGhpYmF1dC5sZW5hb3VyQHVuaWZyLmNo