 Manyun Zhu
Manyun Zhu Yu Quan2
Yu Quan2 Xuan He
Xuan He- 1College of Medicine and Biological Information Engineering, Northeastern University, Shenyang, China
- 2Information Center of Shengjing Hospital of China Medical University, Shenyang, China
Introduction: The early diagnosis of major depressive disorder (MDD) is very important for patients that suffer from severe and irreversible consequences of depression. It has been indicated that functional connectivity (FC) analysis based on functional magnetic resonance imaging (fMRI) data can provide valuable biomarkers for clinical diagnosis. However, previous studies mainly focus on brain disease classification in small sample sizes, which may lead to dramatic divergences in classification accuracy.
Methods: This paper attempts to address this limitation by applying the deep graph convolutional neural network (DGCNN) method on a large multi-site MDD dataset. The resting-state fMRI data are acquired from 830 MDD patients and 771 normal controls (NC) shared by the REST-meta-MDD consortium.
Results: The DGCNN model trained with the binary network after thresholding, identified MDD patients from normal controls and achieved an accuracy of 72.1% with 10-fold cross-validation, which is 12.4%, 9.8%, and 7.6% higher than SVM, RF, and GCN, respectively. Moreover, the process of dataset reading and model training is faster. Therefore, it demonstrates the advantages of the DGCNN model with low time complexity and sound classification performance.
Discussion: Based on a large, multi-site dataset from MDD patients, the results expressed that DGCNN is not an extremely accurate method for MDD diagnosis. However, there is an improvement over previous methods with our goal of better understanding brain function and ultimately providing a biomarker or diagnostic capability for MDD diagnosis.
Introduction
Major Depressive Disorder is the second cause of disability, with point prevalence exceeding 4% (Ferrari et al., 2013). Currently, the primary diagnosis of MDD is mainly based on the Diagnostic and Statistical Manual of Mental Disorders (Cooper, 2018) or Hamilton Depression Rating Scale (Sharp, 2015). However, the results largely depend on the physicians’ experiences and may sometimes lead to misdiagnoses.
In this context, establishing objective and quantitative biomarkers for identifying MDD may not only provide insights into illness pathophysiology but also promote the development of biologically informed tests for clinical diagnosis and treatment planning. With the development of medical imaging technology, fMRI can be used to reveal the abnormalities of brain functional connectivity of MDD patients. By treating the human brain as a comprehensive network of functionally interacting brain regions and associating it with human behavior, we can make an understanding of how brain tissue changes in psychiatric disorders, which may effectively contribute to MDD diagnosis approaches (He et al., 2017).
In recent years, massive studies have discussed the pathological mechanism of psychosis and tried to search for its biomarkers. Most of them confirm the biological pathology of brain diseases is mostly related to the abnormality of brain FC. Cattarinussi et al. (2022) collected the resting-state fMRI of Bipolar Disorder to study the alteration of the brain functional network between cortical-limbic structures. Park et al. (2022) demonstrated that the severity of clinical symptoms in patients with Generalized Anxiety Disorder had a strong correlation with the strength of FC in brain regions under negative emotional conditions. Hirshfeld-Becker et al. (2019) conducted a pilot study of MDD prediction in Adolescence by intrinsic brain FC. Long et al. (2020) constructed the resting-state brain functional networks with large samples of resting-state fMRI data, indicating that the basis of the neuropathology of MDD is probably related to the abnormal brain FC. Shen et al. (2016) applied resting-state fMRI data to the objective diagnosis of depression patients with or without anxiety by graph theory features and illustrated the importance of resting-state fMRI data for MDD diagnostic research. The brain network FC data constructed from resting-state fMRI data is also a reliable data source for the diagnosis of MDD. As early as 2011, Brier et al. (2011) systematically studied Alzheimer’s disease through the blood oxygen level-dependent resting-state functional connectivity network. Then, Shi et al. (2021) used a progressive three-step machine learning analysis with resting-state FC data to investigate the classification performance of the Machine Learning model in the multi-center large sample dataset. In addition, they applied the Extreme Gradient Boosting model based on resting-state FC data to classify MDD patients and normal controls and evaluated the clinical application value of the data in MDD.
The brain network classification studies are mainly in two streams: traditional machine learning and deep learning. As yet, the most widely used machine learning in the field is the Support Vector Machine (SVM) (Rathore et al., 2017). As early as 2009, Craddock et al. (2009) classified the region of interest (ROI) wise FC of 20 subjects using linear SVM. Currently, the studies in this field increasingly appears. Ichikawa et al. (2020) classified the whole brain FC of 65 patients by logistic regression. Zhu et al. (2021) achieved the classification of 31 subjects by linear SVM. Yan et al. (2021) used SVM to classify the 32 patients’ regional homogeneity. However, there is a dramatic divergence in classification accuracies because of the demographic and clinical heterogeneity across MDD studies. Qin et al. (2022) noted that while there has been an increasing number of publications, the results are inconsistent with their reported classification accuracies varied from 61.7 to 98.4%. In addition, the optimization of machine learning models typically requires adequate training data to mount generalizability across different samples. A large sample size is critical to ensure population-representative model performance and provide reliable information on the biological underpinnings. Substantial previous machine learning studies were performed using single-site datasets with small sample sizes, which leads to huge variability and poor generability in model performance. To eliminate this problem brought by small datasets to the model performance, we choose the large and multi-site dataset for the following studies.
In recent years, the graph convolution network (GCN) is commonly used in classifying psychosis and other fields, such as the optimization of model parameters in the classification of solder paste defects (Sezer and Altan, 2021). It serves as a deep learning model, which is capable of modeling graph data structures like networks and thus fitting the classification of brain networks. Song et al. (2022) achieved the early diagnosis of Alzheimer’s disease on dual-modality fused brain networks by multi-center and multi-channel pooling GCN. They tested on three datasets with sample sizes of 90, 200, and 169, respectively. The results indicate that the method is effective in the early diagnosis of Alzheimer’s disease. However, there is a main drawback for GCN. Zhang et al. (2018) referred that the regular neural networks’ connection structure is based on layers and processing objects are generally tensors combined in a certain way. For disordered images or intricate structures, the GCN has difficulties to identify all features. They proposed a novel neural network architecture–Deep Graph Convolutional Neural Network to extract useful features characterizing the rich information encoded in a graph for classification purposes by a localized graph convolution model. Then, a novel SortPooling layer that sorts graph vertices in a consistent order is designed to train the traditional neural networks on the graphs. The results on benchmark graph classification datasets demonstrated that the proposed architecture achieves highly competitive performance compared to state-of-the-art graph kernels and other graph neural network methods. Moreover, the architecture allows end-to-end gradient-based training with original graphs without the need to firstly transform graphs into vectors. The advantages of DGCNN make it more suitable for dealing with brain networks.
In this study, we complete the classification of the multi-site and large-scale MDD brain resting-state FC networks based on DGCNN. It not only solves the limitation of small samples and the heterogeneousness of the datasets but also discovers a relatively effective classification algorithm for MDD brain networks.
Materials and methods
Dataset acquisition
Our study is performed based on 25 datasets from 17 hospitals in the REST-meta-MDD consortium comprising 1,300 MDD patients and 1,128 NCs. They agreed to share the final resting-state fMRI indices of MDD patients and matched NCs from studies approved by local Institutional Review Boards. Consortium members provide basic information, including diagnosis, disease duration, gender, age, education, HAMD-17, and HAMA. All patients are treated under the Diagnostic and Statistical Manual of Mental Disorders IV or the International Classification of Diseases-10. According to these, patients with HAMA score higher than 14 are rated as anxious, and patients with HAMD score higher than 17 are defined as depressed (Yan et al., 2019; Chen et al., 2022). In this study, we excluded data with poor quality following standard quality control procedures in the REST-meta-MDD consortium (Supplementary material and Supplementary Figure 1). Finally, 1,601 participants (830 MDD patients vs. 771 NCs) were included in our analysis. Table 1 details the sample information and disease course in the dataset.

Table 1. Clinical information table on subjects.
In this paper, the dataset is the FC correlation results calculated by the predefined seed points after global regression and preprocessed by DPARSF, a MATLAB-and SPM-based resting-state fMRI preprocessing pipeline for the images (Yan and Zang, 2010). The preprocessing operations of Neuroimaging Informatics Technology Initiative files obtained from fMRI including Slice Timing, Realign, Covariates Removed with global signal regression, Spatial Normalization, and Filtering. See Supplementary material for further details.
The construction of the brain network
The present paper uses Dosenbach’s 160 functional ROIs as a medical template to define the brain network nodes. We then construct functional brain networks using resting-state fMRI data with equal time series between each node. Functional connectivity is calculated by measuring the Pearson correlation coefficient between each of the 160 regions in MDD brain networks (Pearson, 1900).
For each subject, let xi(t),yj(t) ∈ RM separately represent the average resting-state fMRI signals for the brain regions i and j at the point t(t=1,2,⋯,T). M and T denote the total number of brain regions and time points, respectively. Then, between the i -th and the j -th ROIs, the correlation γij can be defined as (1):
where and respectively denote the means of the regional resting-state fMRI signals in regions i and j. By computing the Pearson correlation between the average time series for each pair of ROIs, a correlation-based FC network is generated (Furman and Zitikis, 2017; Liang and Xu, 2022) and the symmetric correlation coefficient matrix of 160×160 is shown in Supplementary Figure 2.
To minimize the edge dataset of the brain network, a certain threshold is set to sparse the networks. Then, they are transformed into 0–1 binary adjacency matrices as shown in Figure 1.

Figure 1. Adjacency matrix with a different threshold on major depressive disorders (MDDs) and normal controls (NCs). (A) Threshold = 0.4 MDD adjacency matrix; (B) threshold = 0.2 MDD adjacency matrix; (C) threshold = 0.4 NC adjacency matrix; (D) threshold = 0.2 NC adjacency matrix. The black area indicates no interconnected edges between the two functional brain networks, while the white area indicates connected edges.
After that, we use the Warshall algorithm (Warshall, 1962) to calculate the network connectivity. The n -th order Boolean matrix R(k) (0≤k≤n) expresses whether any pair of nodes in the directed graph contain path information. The quantitative ratio curves of the brain network connectivity of subjects are shown in Figure 2. The Boolean matrix R(k) (0≤k≤n) can be defined as follows:
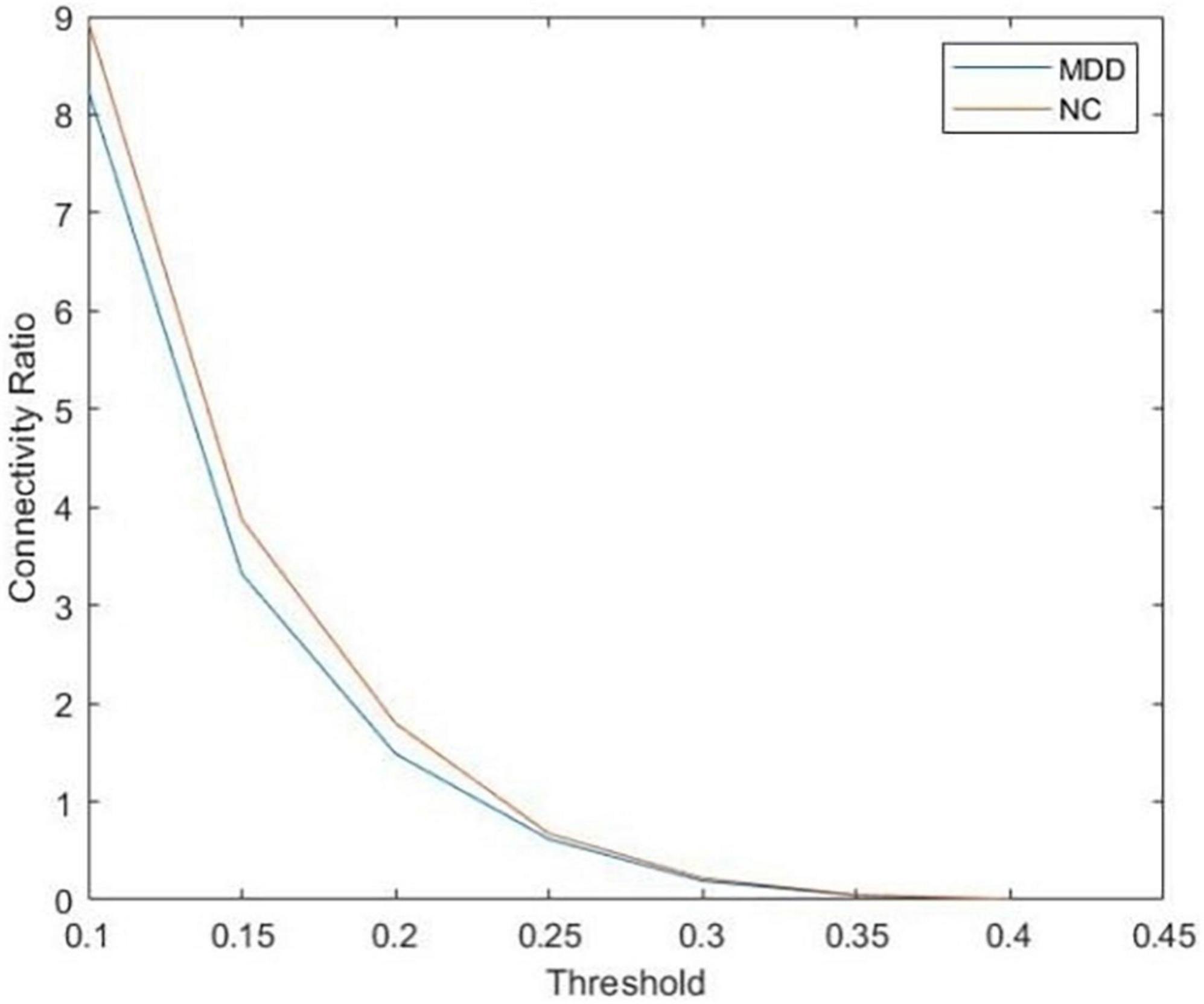
Figure 2. The quantitative ratio curve of brain network connectivity of subjects. The connectivity ratio is the ratio of the number of connected brain networks to the number of unconnected ones for major depressive disorders (MDD) or normal control (NC). With the increase in the threshold, the number of connected graphs dwindled.
To study the influence of brain network connectivity on the accuracy of MDD final classification prediction, thresholds of 0.2, 0.3, and 0.4 are selected to process the brain network. Connectivity data are then inputted into a deep learning framework. Eventually, we use the DGCNN on connectivity data to identify the full brain network of each subject.
DGCNN model training
After the brain networks are constructed, a supervised graph classification model is trained by applying the DGCNN algorithm. We aim to extract graph structures of MDD and NC brain networks and available information on nodes. Then, training the model with the presence or absence of disease as the classification label to classify all subjects. The pipeline of the DGCNN model is shown in Figure 3. The model’s input is the graph represented by its adjacency and node features matrices. Individual whole-brain functional connectivity matrices are first represented as graph structures. Nodes are defined as the 160 atlas-based brain regions, and node features reflect the vector of nodal functional connectivity. We get the edges from the binary matrices after setting the different thresholds.

Figure 3. The overall pipeline of deep graph convolutional neural network (DGCNN) classifier distinguishing between individuals with major depressive disorders (MDD) and normal control (NC).
The first four layers are graph convolutional layers. The core process is the spectral graph convolution filter, which can implement the convolution operation on irregular graph data instead of typical data in tensor forms (Kipf and Welling, 2016). The graph convolutional layers with the hyperbolic tangent function activations to improve the convergence speed. The graph’s unordered vertex features from the layers are the input of the next layer, SortPooling, which is a bridge between graph convolution and traditional neural network layers. The SortPooling layer can back-propagate loss gradients, integrating graph representation and learning into one end-to-end architecture. Instead of summing up these vertex features, it arranges them in a consistent order and outputs a sorted graph representation with a fixed size so that traditional convolutional neural networks can read vertices in a consistent order and be trained on this representation.
After SortPooling, a tensor with each row representing a vertex and each column representing a feature channel is generated. To train graph convolutional layers on them, a 1-D convolutional layer is added. Then, Max Pooling layers and 1-D convolutional layers are added to learn local patterns on the node sequence. Two Dense layers are used for binary classification. The convolutional and dense layers use rectified linear unit activation function to introduce non-linearity activation. Finally, the fully connected output layer is activated by a Softmax function to encode output scalars into the predictive probability of each class.
For the parameters of DGCNN, we adopt the default parameters set in the study named “An End-to-End Deep Learning Architecture for Graph Classification” (Zhang et al., 2018). In order to reduce the overfitting, a dropout layer with a ratio of 0.5 is applied between the two dense layers, at which rate dropout generated the most random network structure. The key idea is to drop units randomly (along with their connections) from the neural network during training, which prevents units from co-adapting too much. During the training, dropout layers take samples from the exponential number of different “thin” networks. During the test time, it would be easier to approximate the effect of averaging the predictions of all these thinned networks by simply using a single unthinned network with smaller weights. It significantly reduces overfitting and gives major improvements over other regularization methods. Dropout improves the performance of neural networks on supervised learning tasks (Srivastava et al., 2014). Besides, model training is conducted based on a batch of 50 samples for 100 epochs. The only hyperparameter we need to optimize is the learning rate.
Description of evaluation indexes for classification performance
To assess the results of each binary classification, we use the following metrics: accuracy (ACC), sensitivity (SEN), specificity (SPE), precision (PRE), F1 score (F1), the receiver operating characteristic curve (ROC), and the area under the ROC curve (AUC) of cross-validation experiment (Bishop and Nasrabadi, 2006). The ROC curve is the plot of the True Positive Rate against the False Positive Rate for different cut-offs of the diagnostic test. It is a measure of the trade-off between sensitivity and specificity. As our analysis has balanced classes (i.e., an equal number of examples for each cognitive state), the ROC-AUC is considered the most important metric (Davis and Goadrich, 2006). The calculation methods are as follows:
where TP, TN, FP, and FN represent true positives, true negatives, false positives and false negatives of the prediction data.
DGCNN model function setting
After the dataset with the threshold value of 0.3 is inputted into the model, the loss value and accurate value are calculated. In this paper, the binary cross-entropy loss function is applied. It is commonly used for the two-class classification. The formula is shown in (8):
where i ∈ [1,output_size], and each i is independent and non-interfering. For this reason, it is suitable for the multi-label classification task. The Adaptive Moment Estimation (Adam) is used as an optimization function, which updates all weights with a constant learning rate alpha during the process. Therefore, dual improvements in quality and speed can be achieved during model optimization (Razak et al., 2021).
Results
DGCNN training and prediction results
The dataset is split to training and test sets, where 90% of the data is used for training and the remaining 10% for testing. The history of the loss and accuracy of training and testing data are drawn to calculate the performance of the training model based on testing data. The curve is depicted below (Figure 4).
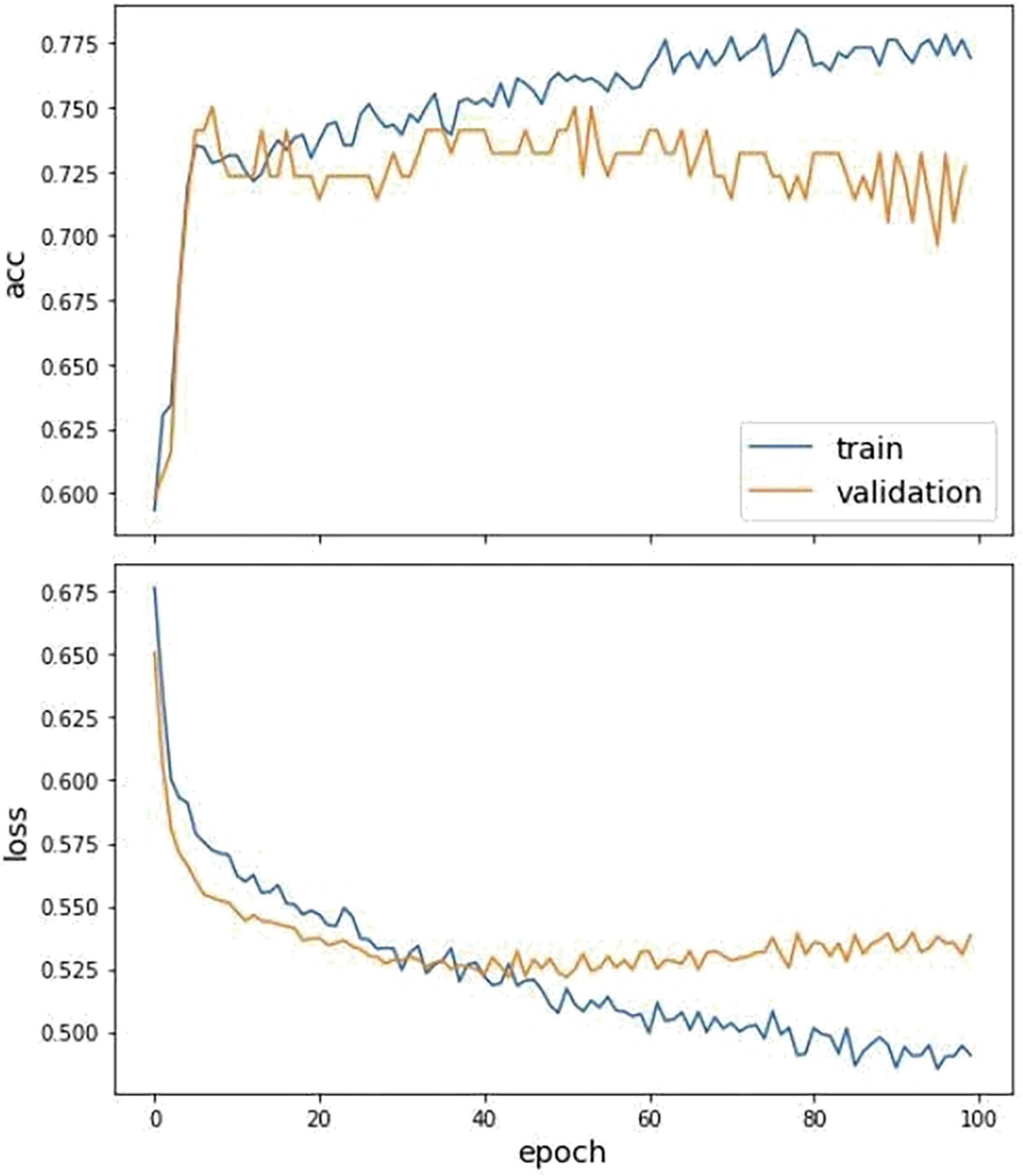
Figure 4. The fitting curve of accuracy and loss of the training and test dataset. The above figure is the training history curve of accuracy, and below is the loss curve. Moreover, the orange is validation, and blue is the training value.
We further make comparisons between DGCNN and other commonly used classifiers, including SVM, Random Forest, and Graph Convolutional Network. For the training of the GCN model, we use the same loss function and optimizer as the DGCNN model to quantify the loss and update the model parameters, respectively. The initial learning rate for the Adam optimizer is set as 0.001. As for the other two classifiers, SVM and RF, a widely used feature reduction strategy, principal component analysis, is adopted before training to avoid over-fitting. SVM and RF are implemented in the Scikit-Learn library with the default setting. Moreover, the parameters of these are optimized using grid search. We use 10-fold cross-validation to examine their performance. The best parameter values set by all methods are shown in Table 2.
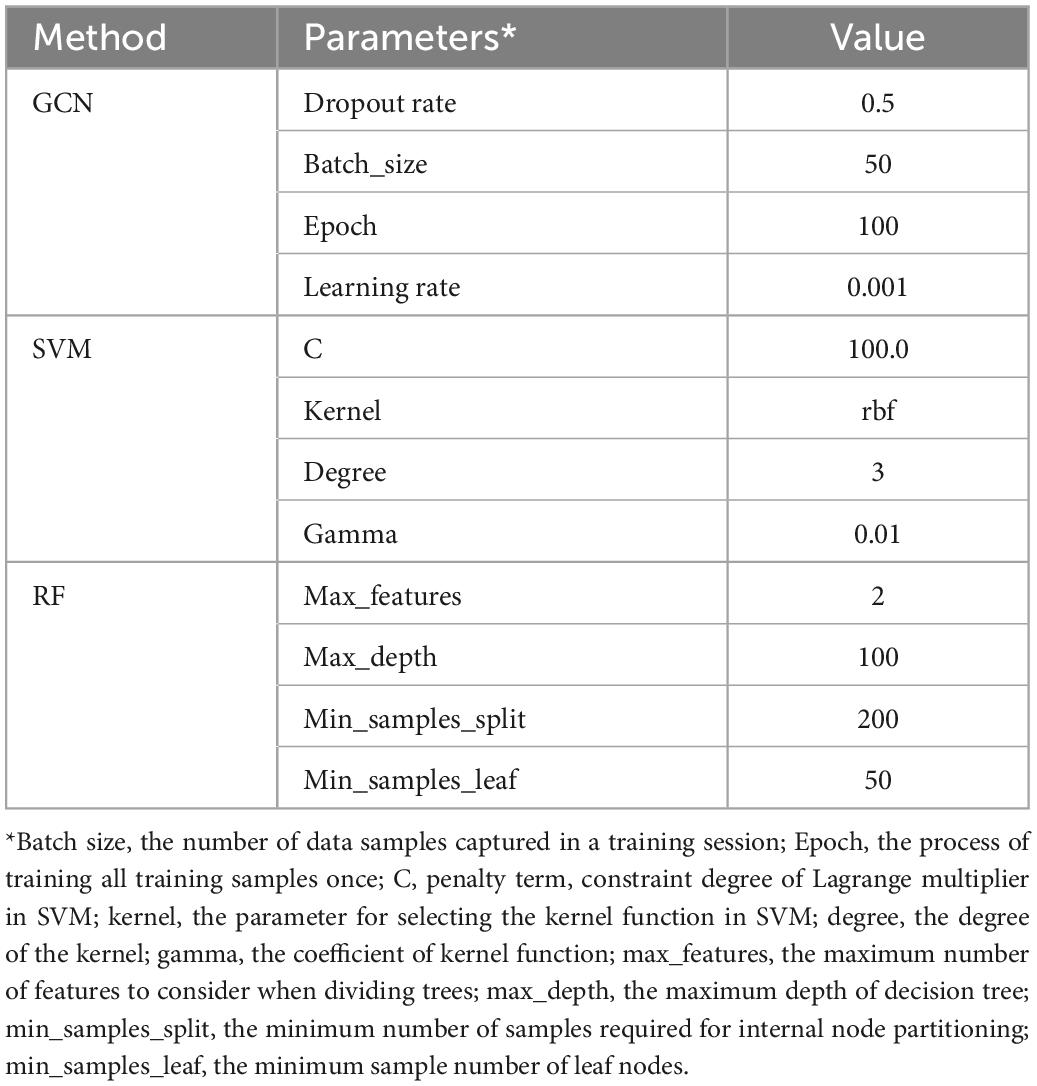
Table 2. The optimal parameters of each method.
The classification results of different methods on this dataset are summarized in Table 3.
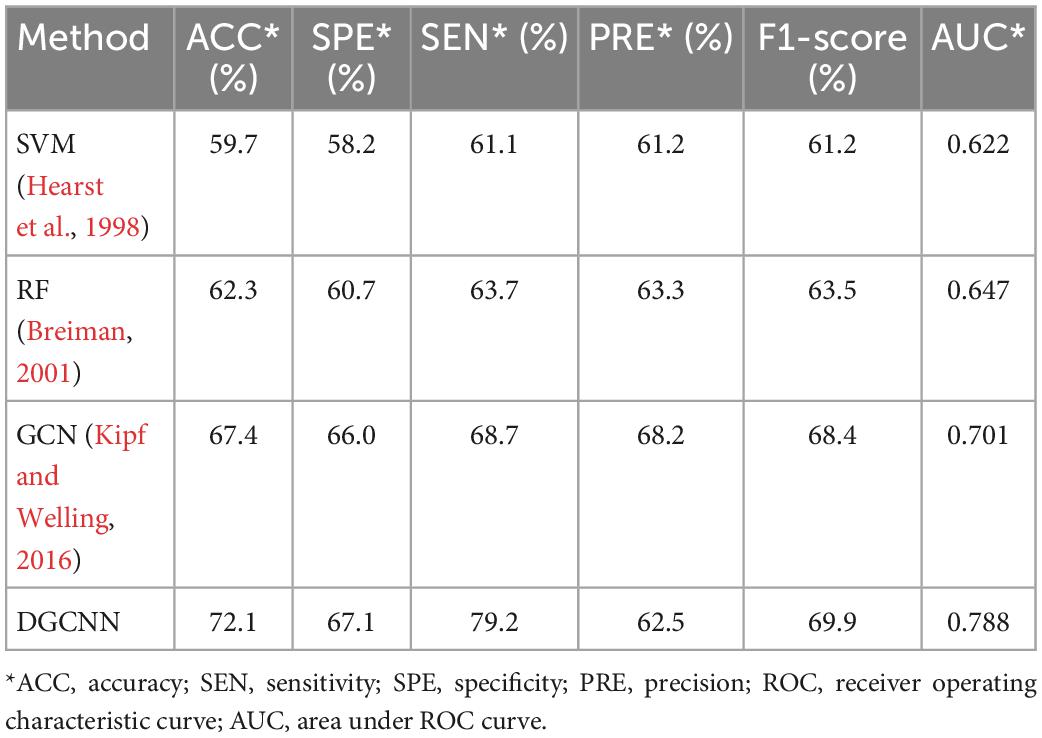
Table 3. Comparison of classification performance indexes of different classification methods in MDD dataset.
It can be seen that our study has superior results. Unsurprisingly, our results are higher than those of traditional machine learning methods. In addition, ours are also higher than the widely used GCN, which demonstrates the effectiveness of the model used in this experiment. Moreover, the fast running speed is also the model’s advantage. Table 4 shows the time required for data loading and classification training at the different thresholds. It indicates that both SVM and RF have a long time running with the worse results than deep learning. The running time of the GCN model is also longer than that of DGCNN, which reflects the superiority of DGCNN on the processing speed of large datasets.
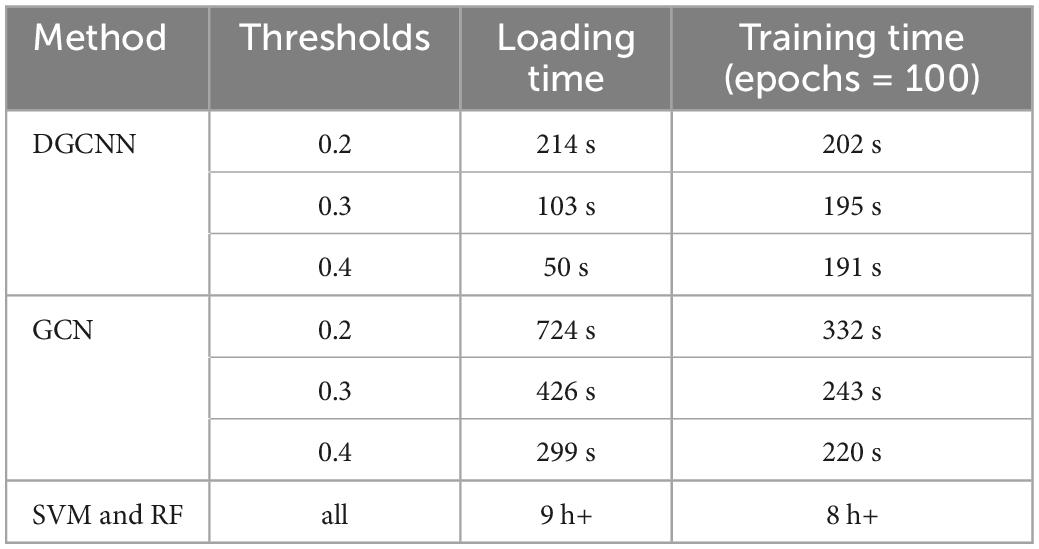
Table 4. The time cost of dataset loading and training under various thresholds for deep graph convolutional neural network (DGCNN).
Model influencing factors
The influence of threshold setting and learning rates on the model
As the number of connected edges and dataset size increase with connectivity ratio, the influence of different thresholds on performance should be discussed. In order to study the relationship between brain network connectivity and classification accuracy, brain networks with thresholds of 0.2, 0.3, and 0.4 are selected for the classification task. Different network connectivity has an impact on classification accuracy. Therefore, we observe the relationship between the classification accuracy and the number of connected edges of the brain network (the connectivity of the brain network) by adjusting the threshold to find the optimal parameter settings and their impact on the optimal prediction result. The size of brain networks with different thresholds is shown in Table 5.
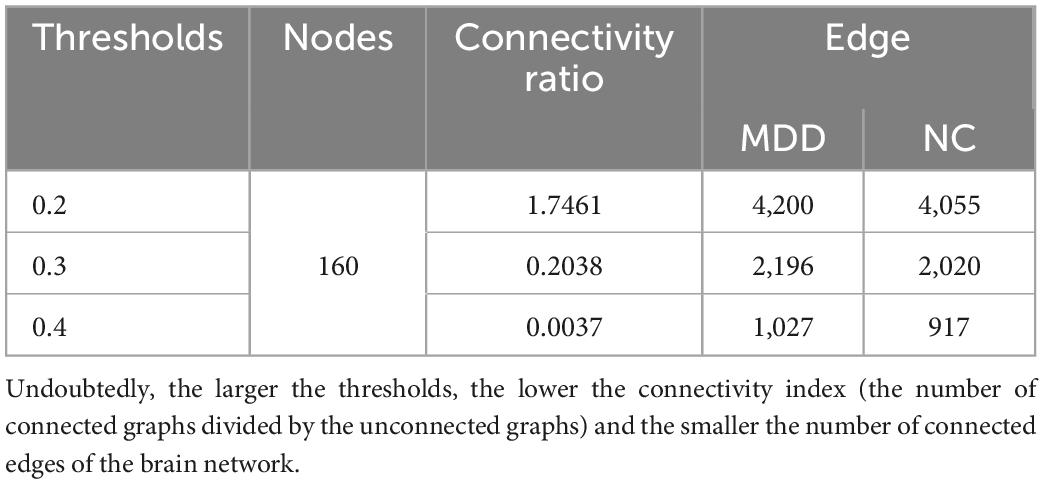
Table 5. Comparison of brain network sizes with different thresholds.
The comparison of the loss and accuracy values for different thresholds and adjusted learning rate operations is shown in Table 6. It can be seen that the optimal ACC is obtained when the threshold value is 0.3 and the learning rate is 0.001.
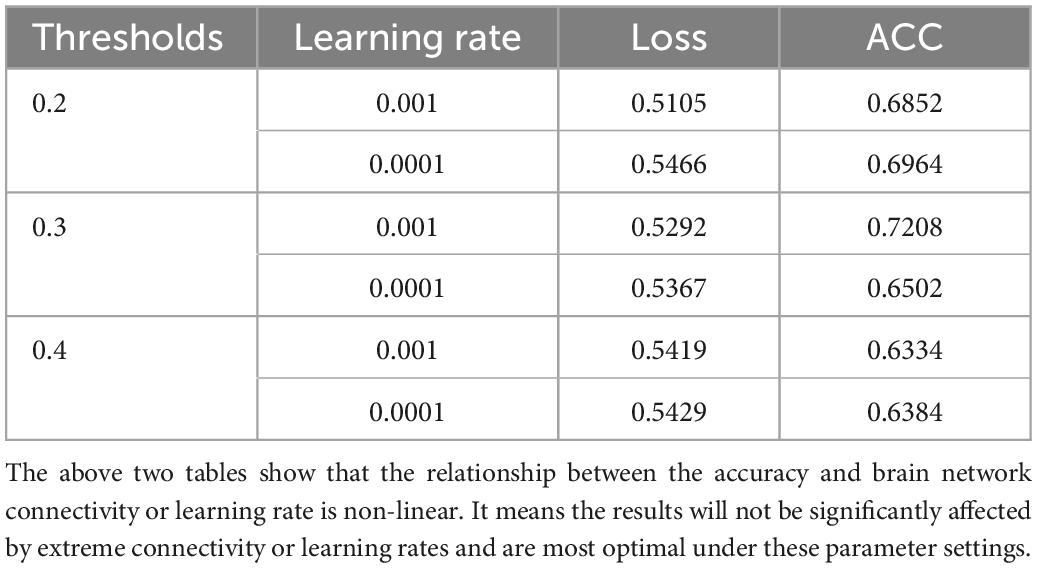
Table 6. Loss and accurate value under different thresholds and learning rates.
The above two tables show that the relationship between the accuracy and brain network connectivity or learning rate is non-linear. It means the results will not be significantly affected by extreme connectivity or learning rates and are most optimal under these parameter settings.
The impact of site effect
As the experimental data are obtained from 25 research groups by 17 hospitals in China, the test accuracy is heterogeneous in different research groups and regions. Therefore, the integration of the data into brain network classification for MDD would lead to a large impact on the final result due to data heterogeneity. To eliminate the site effect and the systematic differences around different sites, we conducted leave-one-site-out 10-fold cross-validation experiments on the 16 sites after selection. The classification performance results are summarized in Table 7.
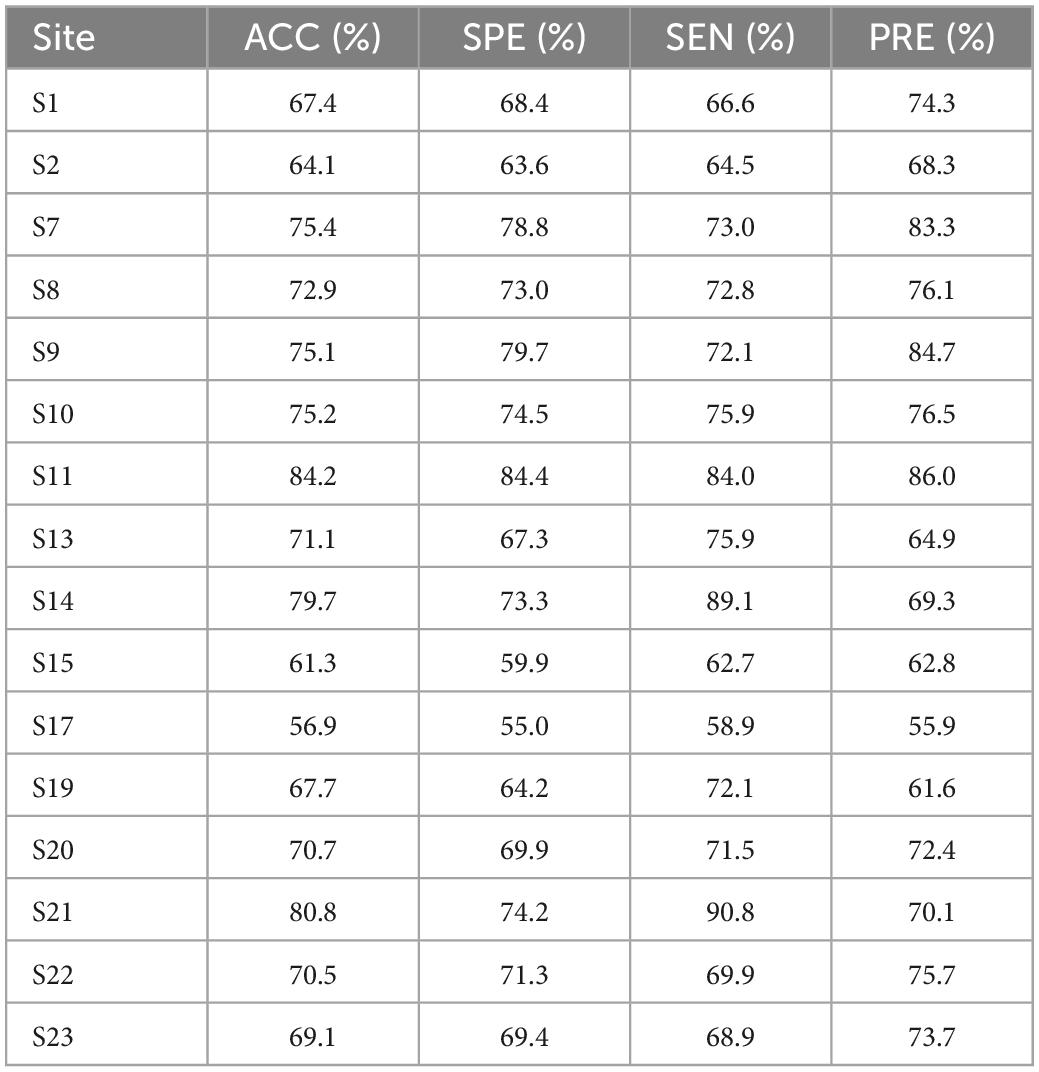
Table 7. Leave-one-site-out 10-fold cross-validation classification performance.
These results demonstrate the reliable classification performance of the model in inter-site cross-validation and applicability of the DGCNN selected in this paper to novel sites. The results combined with cross-validation experiments indicate the advantages of the model on the large-scale multi-site dataset and potential clinical application promotion.
Given the imbalanced single-site performance and sample size across all sites, the current classification performance may be biased by the sites with the best single-site performance and the site with the largest sample size. Besides, it is found that classification accuracy in every single site varied from 56.9 to 84.2%, which confirming the variability of classification tasks with small sample sizes and the importance of using large datasets.
Discussion
In this paper, artificial intelligence technology is applied to the diagnosis of brain diseases. We use the DGCNN to classify the brain networks of subjects. Systematic experiments are performed on a multi-site and large-scale fMRI dataset collected from the REST-meta-MDD project. Furthermore, we find that when the DGCNN is used as an input feature to the classifier it can provide the best accuracy while classifying subjects into patients and normal controls. It is evident from the experimental results in the previous section, DGCNN has achieved an accuracy of 72.1% on the MDD dataset after ten cross-validations, which is 12.4% higher than SVM, 9.8% higher than RF, and 7.6% higher than GCN. It should be noted that DGCNN also achieves the best AUC and performances in other aspects, which demonstrates the competitiveness of the DGCNN model in this study. Moreover, it requires less time to process large-scale datasets and model training than other models. The rapid classification of 1,601 brain networks can be completed in less than 5 min, which reflects the excellent performance of the DGCNN model in classification speed. Given the high collection cost and small sample size of fMRI data, it is difficult to extract high-dimensional features when training the deep learning model (Khosla et al., 2019). However, generating a large-scale aggregate dataset is expected to solve the problem of repeatability and statistical ability (Borghi and Van Gulick, 2018; Dadi et al., 2019). Therefore, establishing and validating classification models on a large-scale aggregated dataset may promote the development of clinically useful diagnostic methods. In this paper, the results with a large-scale fMRI dataset verify that DGCNN is not very accurate in MDD diagnosis. However, it is improved relatively compared with other machine learning and graph convolution neural networks.
The limitations and future works of this study are as follows. The first problem is that deep learning models may indeed get better results than traditional prediction models, but it is not feasible to identify the important features for prediction. It is a common limitation of the deep learning model. Moreover, only the static FC is used in the classification model, while the potential time-dynamic characteristics are neglected. Further dynamic FC analysis may provide additional useful information for diagnosing brain diseases. Therefore, robust models will be further developed in future research to classify dynamic FC patterns, and related dynamic biomarkers will be explored to diagnose brain disease. On the other hand, this paper uses the Dosenbach template to extract the ROIs in the brain. By comparing with the detailed study of the voxel-level of brain network nodes, it is not sophisticated. Therefore, in future related research, the voxel-level networks will be focal point. Besides the improvement of network construction, it is also worth studying how to enhance model accuracy and further reduce over-fitting. In addition, the impact of issues such as illness duration or the medical status of the prediction results need to be explored as well.
Conclusion
In this study, we have completed the task of classifying large-scale MDD brain networks based on DGCNN. The overall experimental process is mainly two-fold: brain network construction and classification. During the construction process, the pre-processed dataset of depression fMRI data from the REST-meta-MDD site is used, and the Pearson correlation coefficient matrix is calculated by 160 brain network nodes obtained after the Dosenbach template registration. The obtained correlation coefficient matrix is set to certain thresholds to obtain the 0–1 binary adjacency matrix. The connectivity of the matrix is calculated using the Warshell algorithm. It is concluded that the larger the set threshold, the poorer the connectivity of the brain network. The adjacency matrix is then converted as the input of the DGCNN model. In the classification process, the graph is firstly inputted, and then carry out local extraction. The vertex sorting is executed using the graph convolution layer on the structural characteristics. Then, according to a predefined order by using the SortPooling layer, the model sorts to unify the size of the input graph. Finally, the sorted graph is read with one-dimensional convolution and a dense layer to make the prediction. The model is trained by the specific loss functions and optimization algorithm. Ultimately, DGCNN achieved an accuracy of 72.1% on the large and multi-site MDD dataset after ten cross-validations. It is 12.4% higher than SVM, 9.8% higher than RF, and 7.6% higher than GCN. Moreover, it also has a low time complexity and space complexity. Based on the experimental results, it can be concluded that the DGCNN model has robust performance and fast data processing speed on large-scale datasets. It indicates the model’s effectiveness in brain disease classification and thus provides a promising solution for classification based on fMRI. It further illustrates the potential of deep learning methods in computer-aided medicine.
Data availability statement
Publicly available datasets were analyzed in this study. This data can be found here: http://rfmri.org/REST-meta-MDD.
Author contributions
MZ: writing—original draft. YQ: investigation. XH: supervision. All authors contributed to the article and approved the submitted version.
Funding
This work was supported by the National Natural Science Foundation of China (NSFC) under (Grant 61806048) and the Fundamental Research Funds for the Central Universities under (Grant No.2224001-10). And the REST-meta major depressive disorder data were provided by the members of the REST-meta-MDD Consortium.
Acknowledgments
We thank the data providers for the public access and download of these meta-data for further research.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fnhum.2023.1094592/full#supplementary-material
References
Bishop, C. M., and Nasrabadi, N. M. (2006). Pattern recognition and machine learning. Berlin: Springer.
Borghi, J. A., and Van Gulick, A. E. (2018). Data management and sharing in neuroimaging: Practices and Perceptions of MRI Researchers. PLoS One 13:e0200562. doi: 10.1371/journal.pone.0200562
Brier, M., Thomas, J., Snyder, A., Fagan, A., Grant, E., Benzinger, T., et al. (2011). “The effects of Alzheimer’s disease (AD) on blood oxygen level dependent resting state functional connectivity (BOLD rsFC) networks,” in Neurology, Vol. 76, (Philadelphia, PA: Lippincott Williams & Wilkins 530 Walnut ST), A190–A190.
Cattarinussi, G., Bellani, M., Maggioni, E., Sambataro, F., Brambilla, P., and Delvecchio, G. (2022). Resting-state functional connectivity and spontaneous brain activity in early-onset bipolar disorder: a review of functional magnetic resonance imaging studies. J. Affect. Dis. 311, 463–471. doi: 10.1016/j.jad.2022.05.055
Chen, X., Lu, B., Li, H. X., Li, X. Y., Wang, Y. W., Castellanos, F. X., et al. (2022). The DIRECT consortium and the REST-Meta-MDD Project: Towards neuroimaging biomarkers of major depressive disorder. Psychoradiology 2, 32–42. doi: 10.1093/psyrad/kkac005
Cooper, R. (2018). Diagnosing the diagnostic and statistical manual of mental disorders, 1st Edn. Milton Park: Routledge. doi: 10.4324/9780429473678
Craddock, R. C., Holtzheimer, I. P., Hu, X. P., and Mayberg, H. S. (2009). Disease State prediction from resting state functional connectivity. Magn. Reson. Med. 62, 1619–1628. doi: 10.1002/mrm.22159
Dadi, K., Rahim, M., Abraham, A., Chyzhyk, D., Milham, M., Thirion, B., et al. (2019). Benchmarking functional connectome-based predictive models for resting-State FMRI. Neuroimage 192, 115–134. doi: 10.1016/j.neuroimage.2019.02.062
Davis, J., and Goadrich, M. (2006). “The relationship between precision-recall and ROC Curves,” Proceedings of the 23rd international conference on Machine learning, New York, NY, 233–240. doi: 10.1145/1143844.1143874
Ferrari, A. J., Charlson, F. J., Norman, R. E., Patten, S. B., Freedman, G., Murray, C. J. L., et al. (2013). Burden of depressive disorders by country, sex, age, and year: Findings from the Global burden of disease Study 2010. PLoS Med. 10:e1001547. doi: 10.1371/journal.pmed.1001547
Furman, E., and Zitikis, R. (2017). Beyond the pearson correlation: Heavy-tailed risks, weighted gini correlations, and a gini-type weighted insurance pricing model. ASTIN Bull. 47, 919–942. doi: 10.1017/asb.2017.20
He, W. J., Bu, H., Gao, H. B., Tong, L., Wang, L. Y., Li, Z. L., et al. (2017). Altered amygdala information flow during RT-FMRI neurofeedback training of emotion regulation. DEStech. Trans. Comput. Sci. Eng. doi: 10.12783/dtcse/smce2017/12436
Hearst, M. A., Dumais, S. T., Osuna, E., Platt, J., and Scholkopf, B. (1998). Support vector machines. IEEE Intell. Syst. Appl. 13, 18–28. doi: 10.1109/5254.708428
Hirshfeld-Becker, D. R., Gabrieli, J. D. E., Shapero, B. G., Biederman, J., Whitfield-Gabrieli, S., and Chai, X. J. (2019). Intrinsic functional brain connectivity predicts onset of major depression disorder in adolescence: A pilot study. Brain Connect. 9, 388–398. doi: 10.1089/brain.2018.0646
Ichikawa, N., Lisi, G., Yahata, N., Okada, G., Takamura, M., Hashimoto, R., et al. (2020). Primary functional brain connections associated with melancholic major depressive disorder and modulation by antidepressants. Sci. Rep. 10:3542. doi: 10.1038/s41598-020-60527-z
Khosla, M., Jamison, K., Ngo, G. H., Kuceyeski, A., and Sabuncu, M. R. (2019). Machine learning in resting-state FMRI Analysis. Magn. Reson. Imaging 64, 101–121. doi: 10.1016/j.mri.2019.05.031
Kipf, T. N., and Welling, M. (2016). Semi-Supervised Classification with Graph Convolutional Networks. arXiv [Preprint]. arXiv:1609.02907 2016.
Liang, Y., and Xu, G. (2022). Multi-level functional connectivity fusion classification framework for brain disease diagnosis. IEEE J. Biomed. Health Inform. 26, 2714–2725. doi: 10.1109/JBHI.2022.3159031
Long, Y., Cao, H., Yan, C., Chen, X., Li, L., and Castellanos, F. X. (2020). Altered Resting-state dynamic functional brain networks in major depressive disorder: Findings from the REST-Meta-MDD Consortium. Neuroimage 26:102163. doi: 10.1016/j.nicl.2020.102163
Park, S. E., Kim, Y. H., Yang, J. C., and Jeong, G. W. (2022). Comparative functional connectivity of core brain regions between implicit and explicit memory tasks underlying negative emotion in general anxiety disorder. Clin. Psychopharmacol. Neurosci. 20, 279–291. doi: 10.9758/cpn.2022.20.2.279
Pearson, K. (1900). Data for the Problem of Evolution in Man. III.—On the magnitude of certain coefficients of correlation in man, &c. Proc. R. Soc. London 66, 23–32. doi: 10.1098/rspl.1899.0068
Qin, K., Lei, D., Pinaya, W. H., Pan, N., Li, W., Zhu, Z., et al. (2022). Using graph convolutional network to characterize individuals with major depressive disorder across multiple imaging sites. EBioMed. 78:103977. doi: 10.1016/j.ebiom.2022.103977
Rathore, S., Habes, M., Iftikhar, M. A., Shacklett, A., and Davatzikos, C. A. (2017). Review on neuroimaging-based classification studies and associated feature extraction methods for Alzheimer’s Disease and its prodromal stages. Neuroimage 155, 530–548. doi: 10.1016/j.neuroimage.2017.03.057
Razak, N. N. A., Abdulkadir, S. J., Maoinser, M. A., Shaffee, S. N. A., and Ragab, M. G. (2021). One-dimensional convolutional neural network with adaptive moment estimation for modelling of the sand retention test. Appl. Sci. 11:3802. doi: 10.3390/app11093802
Sezer, A., and Altan, A. (2021). Optimization of Deep Learning Model Parameters in Classification of Solder Paste Defects. Proceeding of the 2021 3rd international congress on human-computer interaction, optimization and robotic applications (HORA). Manhattan, NY: IEEE, 1–6. doi: 10.1109/HORA52670.2021.9461342
Sharp, R. (2015). The hamilton rating scale for depression. Occupat. Med. 65, 340–340. doi: 10.1093/occmed/kqv043
Shen, X. Y., Zhu, J. Y., Wei, M. B., Qin, J. L., Yan, R., and Wei, Q. X. (2016). “Application of graph theory features for the objective diagnosis of depressive patients with or without anxiety: An Rs-Fmri Study,” Proceedings of the the international conference on biological sciences and technology, (Amsterdam: Atlantis Press), 278–283. doi: 10.2991/bst-16.2016.41
Shi, Y., Zhang, L., Wang, Z., Lu, X., Wang, T., Zhou, D., et al. (2021). Multivariate machine learning analyses in identification of major depressive disorder using resting-state functional connectivity: A multicentral study. ACS Chem. Neurosci. 12, 2878–2886. doi: 10.1021/acschemneuro.1c00256
Song, X., Zhou, F., Frangi, A. F., Cao, J., Xiao, X., Lei, Y., et al. (2022). Multi-center and multi-channel pooling GCN for early ad diagnosis based on dual-modality fused brain network. IEEE Trans. Med. Imaging doi: 10.1109/TMI.2022.3187141
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., and Salakhutdinov, R. (2014). Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 15, 1929–1958.
Yan, C. G., Chen, X., Li, L., Castellanos, F. X., Bai, T. J., Bo, Q. J., et al. (2019). Reduced default mode network functional connectivity in patients with recurrent major depressive disorder. Proc. Natl. Acad. Sci.U.S.A. 116, 9078–9083. doi: 10.1073/pnas.1900390116
Yan, C., and Zang, Y. (2010). DPARSF: A MATLAB Toolbox for “Pipeline” Data Analysis of Resting-State FMRI. Front. Syst. Neurosci. 4:13. doi: 10.3389/fnsys.2010.00013
Yan, M., He, Y., Cui, X., Liu, F., Li, H., Huang, R., et al. (2021). Disrupted regional homogeneity in melancholic and non-melancholic major depressive disorder at rest. Front. Psychiatry 12:618805. doi: 10.3389/fpsyt.2021.618805
Zhang, M., Cui, Z., Neumann, M., and Chen, Y. (2018). “An end-to-end deep learning architecture for graph classification,” Proceedings of the AAAI conference on artificial intelligence, California, CA. doi: 10.1609/aaai.v32i1.11782
Keywords: deep graph convolutional neural network, major depressive disorder, brain disease classification, functional connectivity, multi-site
Citation: Zhu M, Quan Y and He X (2023) The classification of brain network for major depressive disorder patients based on deep graph convolutional neural network. Front. Hum. Neurosci. 17:1094592. doi: 10.3389/fnhum.2023.1094592
Received: 10 November 2022; Accepted: 12 January 2023;
Published: 26 January 2023.
Edited by:
Wei Wu, Alto Neuroscience, United StatesReviewed by:
Zhaowen Liu, Massachusetts General Hospital and Harvard Medical School, United StatesRemi Patriat, University of Minnesota Twin Cities, United States
Copyright © 2023 Zhu, Quan and He. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xuan He,  aGV4dWFuQGJtaWUubmV1LmVkdS5jbg==
aGV4dWFuQGJtaWUubmV1LmVkdS5jbg==