 Amanda S. Therrien*
Amanda S. Therrien* Aaron L. Wong
Aaron L. Wong- Moss Rehabilitation Research Institute, Elkins Park, PA, United States
Human motor learning is governed by a suite of interacting mechanisms each one of which modifies behavior in distinct ways and rely on different neural circuits. In recent years, much attention has been given to one type of motor learning, called motor adaptation. Here, the field has generally focused on the interactions of three mechanisms: sensory prediction error SPE-driven, explicit (strategy-based), and reinforcement learning. Studies of these mechanisms have largely treated them as modular, aiming to model how the outputs of each are combined in the production of overt behavior. However, when examined closely the results of some studies also suggest the existence of additional interactions between the sub-components of each learning mechanism. In this perspective, we propose that these sub-component interactions represent a critical means through which different motor learning mechanisms are combined to produce movement; understanding such interactions is critical to advancing our knowledge of how humans learn new behaviors. We review current literature studying interactions between SPE-driven, explicit, and reinforcement mechanisms of motor learning. We then present evidence of sub-component interactions between SPE-driven and reinforcement learning as well as between SPE-driven and explicit learning from studies of people with cerebellar degeneration. Finally, we discuss the implications of interactions between learning mechanism sub-components for future research in human motor learning.
Introduction
The field of motor neuroscience has greatly advanced our understanding of how humans learn to produce and control new movements. There are many contexts in which motor learning occurs, such as when learning to perform movements de novo or learning the appropriate sequence of movements necessary to execute a skilled action. Here, we focus on studies of a third motor learning context, often termed motor adaptation, in which one must learn to modify an existing movement pattern to account for persistent changes to the body, task, or environmental dynamics (Krakauer et al., 2019). All types of motor learning likely rely on multiple interacting mechanisms that, in turn, rely on different neural circuits. However, the mechanisms underlying motor adaptation have received particular attention in recent years, with most literature studying the interactions between three mechanisms: learning driven by sensory prediction errors (SPEs, or the difference between the sensory outcome of a movement and a prediction of that outcome), explicit (or strategy-based) learning, and reinforcement (or reward-based) learning. Studies of interactions between these mechanisms have largely treated them as modular, focusing on how each mechanism’s outputs are combined to produce overt learning behavior. To isolate one or more learning mechanisms, studies have modified the attentional cues and/or sensory feedback provided during behavioral learning tasks. Intriguingly, these manipulations have produced evidence of additional interactions between the sub-components of the different learning mechanisms. Here, we propose that understanding these sub-component interactions is needed to advance our knowledge of how learning mechanisms combine to produce overt behavior. We first summarize the current literature studying interactions between SPE-driven, explicit, and reinforcement mechanisms of motor learning. We then present evidence of sub-component interactions between SPE-driven and reinforcement learning, as well as between SPE-driven and explicit learning, from studies of people with cerebellar degeneration. We conclude with a discussion of considerations for future research.
Motor Adaptation Results From the Interaction of Multiple Mechanisms
While several mechanisms have been proposed to contribute to motor learning, three have largely been assumed to account for the vast majority of observed behavioral changes in simple motor adaptation tasks (Krakauer et al., 2019). These three mechanisms are SPE-driven learning, explicit learning, and reinforcement learning (Figure 1). Each of these mechanisms is thought to respond to a different kind of feedback signal, and consequently, drive changes in behavior in different (and occasionally opposing) ways and at different rates (Mazzoni and Krakauer, 2006; van der Kooij et al., 2018; Albert et al., 2020; Morehead and Orban de Xivry, 2021). In general, the study of these mechanisms has treated them as modular, typically assuming that observed behavior can be described as the summation of the outputs of the individual mechanisms. Thus, when the contribution of a single mechanism cannot be easily isolated experimentally, it is often estimated by subtracting out the influence of a second, more easily measured mechanism (Taylor et al., 2014; McDougle et al., 2015; Maresch et al., 2021).
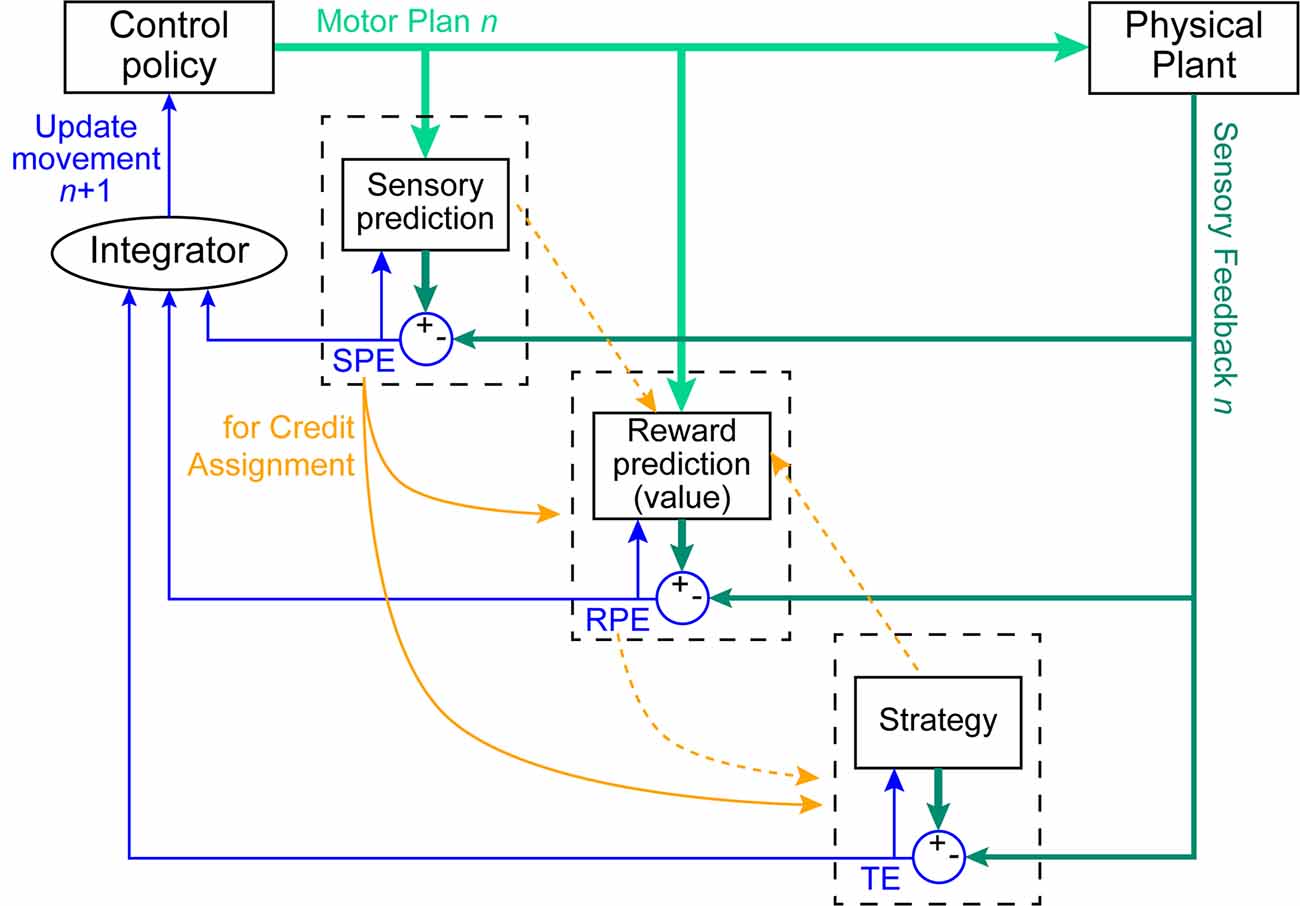
Figure 1. Control policy updates arising from the interactions of three learning mechanisms. On trial n, a control policy is issued to perform the current movement (light green thick arrows). This plan is executed by the body (physical plant), and sensory feedback is detected (dark green arrows). The SPE-driven learning system predicts the expected sensory consequences of the movement, which is compared against sensory feedback of the actual executed movement to compute a sensory prediction error (SPE). The reinforcement learning system predicts the expected reward associated with that movement and this is compared against the actual reward outcome to compute a reward prediction error (RPE). The explicit learning system compares the expected outcome of the strategy against the observed movement outcome to compute a task error (TE). In all cases, the computed error signals (thin blue arrows) update both the respective prediction mechanism as well as the control policy for the next (n + 1) movement. Most studies treat this control-policy update as the combination of the contributions of the individual learning systems (here labeled as the Integrator). We suggest that these systems also interact in other ways. For example, SPE signals are a means by which the reinforcement-learning and explicit-learning systems could solve the credit-assignment problem in determining whether the policy or the execution of that policy led to the observed result (solid orange arrows). Additional speculated interactions may exist (dashed orange arrows), although more behavioral evidence is needed to support the existence of such connections in humans.
One commonly used task to study motor adaptation has participants generate a movement such as a reach or a saccade toward a target. Participants are then presented with a predictable perturbation that alters the outcome of that movement, which necessitates learning to alter the movement pattern to account for the imposed perturbation. For example, in a task requiring the adaptation of reaching movements to a visuomotor rotation, individuals observe a cursor move at a fixed non-zero angle relative to their actual hand motion, which is hidden from view. Over many trials, participants learn to adjust their motor plans to reach in a direction opposite the perturbation to reduce the error. Trial-to-trial learning in this adaptation task has been shown to be supported by all three mechanisms.
SPE-driven learning was the first mechanism recognized to contribute to behavioral changes in adaptation tasks. SPEs convey the difference between the sensory outcome of a movement and a prediction of that outcome based on a copy of the outgoing motor command (Kawato, 1999; Tseng et al., 2007; Shadmehr et al., 2010; Morehead et al., 2017). The SPE signal is thought to be computed by the cerebellum (Medina, 2011; Schlerf et al., 2012); hence people with cerebellar damage are known to exhibit poor performance in adaptation tasks (Criscimagna-Hemminger et al., 2010; Izawa et al., 2012; Therrien et al., 2016; Wong et al., 2019). SPEs do not necessarily reflect task failure, but rather the fact that a movement did not result in the predicted sensory outcome according to the planned motor command. Thus, if an inappropriate motor command was executed accurately (e.g., reaching toward the target when the task is to reach in the opposite direction from the target), it would result in a task error but not an SPE. More recently, such task errors (specifically, the observed difference between the movement outcome and the intended movement target or goal) have also been suggested to drive learning under this mechanism (Miyamoto et al., 2014; Leow et al., 2018; Albert et al., 2020). Regardless, SPE-driven learning requires sensory information about the direction and magnitude (i.e., vector information) of movement errors. In motor adaptation tasks, vector error information is typically provided by contrasting the desired target location with a visual representation of the index fingertip position during reaching movements (e.g., a cursor on a screen). The signature of SPE-driven learning (and the most reliable measure of its impact on behavior) is the existence of after-effects—behavioral changes reflecting a new mapping of motor commands to predicted sensory outcomes that persist even after the perturbation has been removed. SPE-driven learning is described as occurring without conscious awareness, possibly due to a concomitant recalibration of perception (Ostry and Gribble, 2016; Rossi et al., 2021), and can be expressed even at low reaction times (approximately 130 ms, Haith et al., 2015; Leow et al., 2017; Hadjiosif and Krakauer, 2021); hence, it is often referred to as implicit learning. By most accounts, SPE-driven learning is thought to be the primary driving force behind motor adaptation (Izawa and Shadmehr, 2011; Therrien et al., 2016; Cashaback et al., 2017; Wong et al., 2019).
In addition to SPE-driven learning, prior work has emphasized a large contribution of an explicit learning mechanism. In the context of adaptation tasks, explicit learning is often described as the acquisition of an aiming strategy or learning to deliberately move somewhere other than the target location. For example, if a cursor is rotated 45° clockwise relative to the hand, people can accurately move their hand to a target if they adopt a strategy of aiming their reach 45° counterclockwise from the target. Broadly speaking, explicit learning arises as a result of a task error (i.e., awareness that the task objective was not achieved), although exactly how task errors are quantified and how they lead to changes in behavior are not well understood. Nevertheless, studies probing the relationship between SPE-driven and explicit learning often assume that these mechanisms have an additive impact on behavior (Mazzoni and Krakauer, 2006; Benson et al., 2011; McDougle et al., 2015; Long et al., 2016; Miyamoto et al., 2020). Researchers often subtract explicit aiming reports from net learning to measure SPE-driven learning (e.g., Taylor et al., 2014). Alternatively, researchers might measure the SPE-driven learning process using a process dissociation procedure and subtract it from net learning to estimate the contribution of an explicit process (Werner et al., 2015). Many studies have used these methods to examine adaptation across the age span and have suggested that impaired performance in older individuals is largely due to a reduced contribution of the explicit learning mechanism, while the SPE-driven learning system remains intact (McNay and Willingham, 1998; Bock, 2005; Heuer and Hegele, 2008; Hegele and Heuer, 2013; Vandevoorde and Orban de Xivry, 2019).
Finally, there is reinforcement learning. Despite being one of the earliest learning mechanisms to have been studied in the context of behavior modification (Thorndike, 1905), studies have only recently begun to carefully examine its contribution to adaptation tasks. Reinforcement learning occurs in response to scalar feedback about performance outcomes. In the extreme case, scalar feedback may be a binary signal (e.g., an auditory tone indicating success or failure), but reinforcement learning can also occur in response to a success gradient (e.g., hot/cold). Studies of motor adaptation have attempted to leverage reinforcement learning by providing binary or gradient feedback in place of a visual cursor representing the position of the hand during reaching movements. In this way, an individual does not have access to the direction or magnitude of movement errors; rather, the individual must explore possible task solutions to discern those that yield success. Reinforcement learning induces a change in behavior by increasing the likelihood of generating movements associated with rewarding outcomes. It is thought to depend on reward-prediction errors (RPEs), computed in midbrain dopaminergic circuits, which convey the difference between predicted and actual rewards (Schultz, 2006; Lee et al., 2012). Although learning in response to rewards could occur as part of a deliberate decision-making strategy, here we classify such situations as examples of explicit learning since they are primarily driven by task errors (where the “task” in this case is to choose the most rewarding option). Instead, we view reinforcement learning as an implicit process, in line with the notion that behavioral conditioning can occur without needing to explicitly learn the relationship between stimulus, response, and outcome (Skinner, 1937). Indeed, in motor learning tasks, exploration of the response space (characteristic of a reinforcement learning process) can be driven by unconscious motor variability (Wu et al., 2014), and reinforcement learning has been shown to couple with other implicit processes such as use-dependent learning (Mawase et al., 2017). However, more work is needed to carefully dissociate the explicit and implicit effects of learning in response to reinforcement.
Reinforcement learning can occur either as a stand-alone process that is independent of the other learning mechanisms, or by interacting with either the SPE-driven or explicit process. In the former case, reinforcement learning drives motor learning without recalibrating perception (Izawa and Shadmehr, 2011). It may operate by inducing both exploration of the reward landscape as well as the repetition of more successful movements (Nikooyan and Ahmed, 2015; Cashaback et al., 2017; Uehara et al., 2019). Thus, reinforcement learning may complement other learning mechanisms by contributing in an additive manner to the net observed behavior (Kim et al., 2019), although if only scalar feedback is provided this could alternatively reduce the amount of learning arising from another mechanism like SPE-driven learning (Izawa and Shadmehr, 2011; van der Kooij et al., 2018). On the other hand, reinforcement learning may have a more intimate interaction with SPE-driven or explicit learning. It could do so by increasing the likelihood of selecting more successful behaviors that have been identified through these other learning mechanisms (Shmuelof et al., 2012; Nikooyan and Ahmed, 2015). For example, reinforcement learning may help individuals to identify and preferentially select more successful explicit strategies (Bond and Taylor, 2015; Codol et al., 2018; Holland et al., 2018; Rmus et al., 2021) because the explicitly-identified action also becomes associated with greater reward. Regardless of its exact mechanism of action, reinforcement learning is typically treated as acting in conjunction with other learning mechanisms to modify behavior (Haith and Krakauer, 2013).
Evidence of Interactions Between Sub-components of Learning Mechanisms
Although the interactions between SPE-driven, explicit, and reinforcement learning mechanisms have largely been modeled as a summation or integration of each mechanism’s outputs, imperfect additivity has been noted (e.g., Maresch et al., 2021). Deviations from model predictions have sometimes been attributed to additional learning processes not measured or, alternatively, to the inability of measurement methods to fully capture a given mechanism’s output. However, some work suggests the additional possibility that sub-components of each mechanism may also interact. That is, the computations underlying one learning mechanism may serve a critical role in the functioning of another. Understanding the nature of sub-component interactions is crucial, as their presence significantly complicates attempts to experimentally parse the contribution of different learning mechanisms in behavioral tasks. To date, the clearest evidence of sub-component interactions comes from studies of people with cerebellar degeneration. With the cerebellum’s role in SPE-driven learning well established, one hypothesis has been that cerebellar damage selectively disrupts this learning mechanism. Yet studies attempting to distinguish SPE-driven, explicit, and reinforcement learning in people with cerebellar degeneration have not shown the hypothesized dissociation (McDougle et al., 2016; Therrien et al., 2016; Wong et al., 2019).
Therrien et al. (2016) attempted to distinguish supervised and reinforcement learning in people with cerebellar degeneration by modifying error feedback in an adaptation task. In one condition, SPE-driven learning was leveraged by providing full vector feedback of movement errors in the form of a visual cursor representing the index fingertip position throughout reaching movements. In a second condition, reinforcement learning was leveraged by providing only binary feedback of reach success or failure. People with cerebellar degeneration showed distinct behaviors in the two learning conditions: no retention of learning (i.e., no after-effect) when provided with vector error feedback, but significant retention when provided with binary feedback. If examined only at the output level of each mechanism, these results are consistent with cerebellar degeneration impairing supervised learning and leaving reinforcement learning intact. However, people with cerebellar degeneration learned more slowly with binary feedback compared to age-matched control participants, suggesting that cerebellar degeneration may reduce the efficiency of reinforcement learning. Importantly, this latter result pointed to a previously unknown interaction between cerebellar computations and reinforcement learning.
How could cerebellar computations contribute to reinforcement learning? Cerebellar SPEs may be used to solve reinforcement learning’s credit-assignment problem (Taylor and Ivry, 2014; McDougle et al., 2016; Therrien et al., 2016, 2018). In reinforcement learning, the valence of RPE signals is used to update the future probability of selecting a particular motor response to a given stimulus (Dayan and Niv, 2008; Haith and Krakauer, 2013). However, motor response execution is rife with uncertainty due to a combination of noise inherent in the sensorimotor system and variable properties of the environment (Franklin and Wolpert, 2011). Sensorimotor uncertainty makes determining the true cause of reward signals (i.e., credit-assignment) ambiguous. Cerebellar SPEs convey whether a movement was executed as intended, and thus constitute a particularly useful solution to the credit-assignment problem (Figures 2A,B).
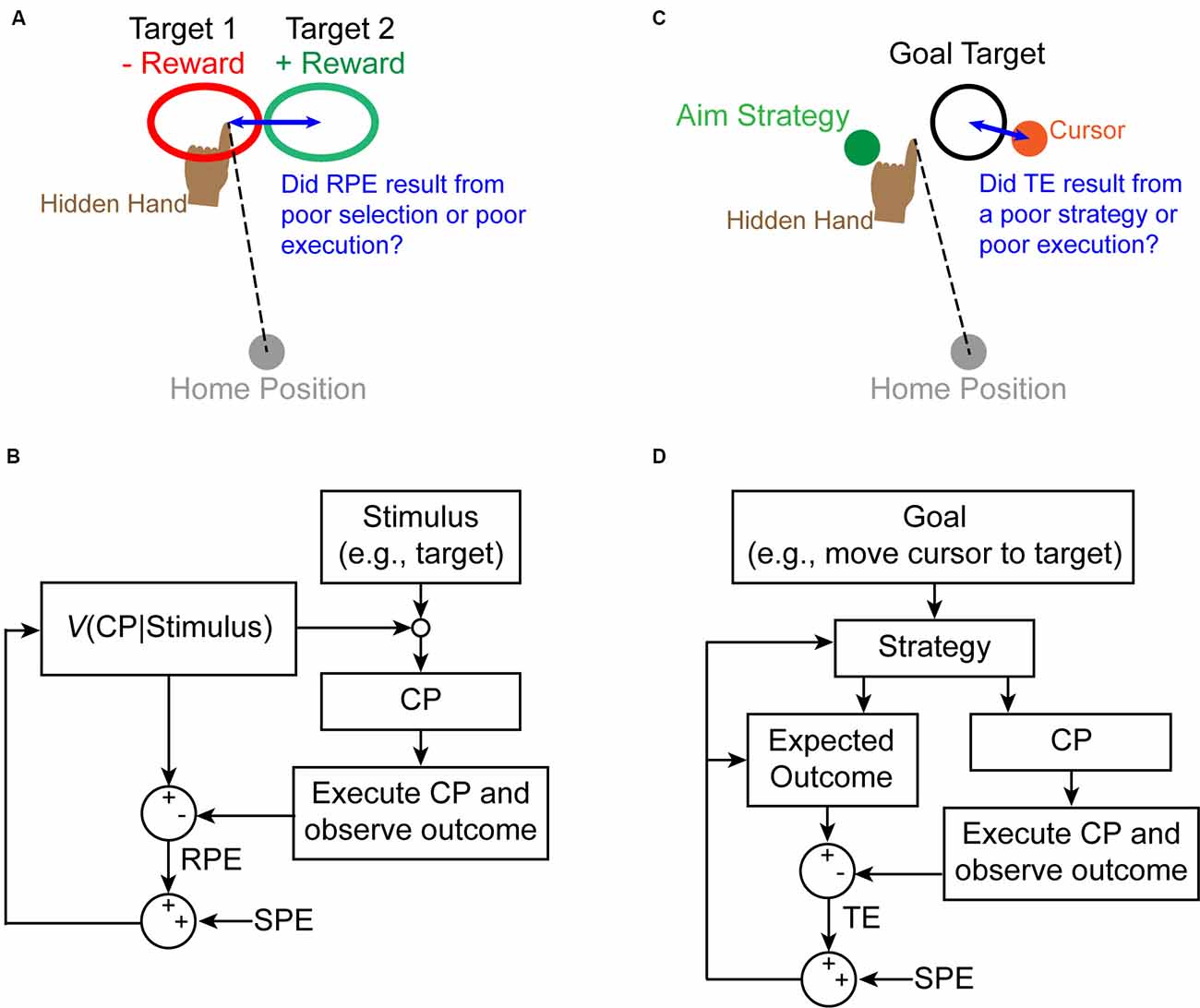
Figure 2. Proposed interactions between the SPE signal and other learning mechanisms to solve the credit-assignment problem. (A) On a given trial, individuals receive positive or negative reward feedback about reach outcome. If this feedback is unexpectedly negative (i.e., a negative RPE signal), for example, individuals must determine whether they erroneously selected the wrong control policy or simply executed the correct policy poorly. (B) An example state diagram corresponding to the situation in panel (A) describes how an update signal is generated based on an RPE (indicating an error has occurred). An SPE is used to determine if the RPE should be attributed to a poor policy choice or a poor execution of that policy. (C) During explicit learning, an individual adopts a strategy (e.g., aim location) to attain a goal (hit the target with the cursor). If a task error arises, individuals must determine if they erroneously selected the wrong explicit strategy or if they poorly executed the correct strategy. (D) Although it remains unclear exactly how explicit learning occurs, we propose that updates to the strategy choice occur as a result of a task error (TE), which is modulated by an SPE informing about the accuracy of executing the chosen strategy.
Reinforcement learning behavior is known to account for higher-order statistical properties of sensorimotor uncertainty, such as the distribution standard deviation (Trommershäuser et al., 2008; Wu et al., 2009, 2014; Landy et al., 2012). However, behavioral variability reflects variance in both motor planning (i.e., response selection) and motor execution (van Beers et al., 2004; van Beers, 2009). Therrien et al. (2016); Therrien et al. (2018) modeled reinforcement learning with behavioral variability parsed into exploration, representing planning variability, and motor noise, representing execution variability. Their conjecture was that, after positive reinforcement, response selection is updated in a manner that accounts for exploration, but not motor noise. In their studies, people with cerebellar degeneration displayed reinforcement learning behavior consistent with excessive variability being allotted to motor noise—a pattern indicative of impaired estimation of action execution. People with cerebellar degeneration also showed reduced exploration after negative reinforcement (Therrien et al., 2018), suggesting that cerebellar degeneration impacts the integration of both positive and negative reinforcement signals. The cumulative result is a reduced updating of action selection in response to reinforcement signaling that slows learning in this population.
McDougle et al. (2016) examined the role of SPE-like sensorimotor error signals in solving a credit-assignment problem in reinforcement-based decision making. Participants were required to select between two visual targets, each associated with a different magnitude of reward, by reaching to hit one or the other. On some trials they were given false feedback about the accuracy of their reach, which generated RPEs—the actual reward received differed from the expected outcome. In contrast to neurologically healthy participants, people with cerebellar degeneration were unable to determine if RPEs should be attributed to themselves or the experimental manipulation (i.e., solve the credit-assignment problem) in this task, suggesting that reach-related sensorimotor error signals play an important role in reinforcement learning.
Reinforcement learning is not the only situation in which a credit-assignment problem must be resolved. Although it is less clear exactly how explicit learning operates, sensorimotor uncertainty likely contributes to a credit-assignment problem similar to that identified above. For example, one must determine if an error arose because of a poor choice of strategy, or because of poor execution of the chosen strategy. Here again, the involvement of an SPE signal would be beneficial to formulate and modify explicit strategies by informing how well the intended strategy was executed (Figures 2C,D).
Evidence supporting the involvement of an SPE-like signal in explicit learning arises from a series of studies investigating the ability of people with cerebellar degeneration to develop de novo strategies for learning. As noted above, cerebellar degeneration disrupts the signal supporting SPE-driven learning, which impairs performance during a visuomotor rotation paradigm. Previous work had demonstrated that in such tasks, people with cerebellar degeneration could follow a provided strategy to aim in a direction other than the target (i.e., opposite the visuomotor rotation), allowing them to overcome the perturbation and successfully hit the target (Taylor et al., 2010). Such an observation led to a puzzling question—if their ability to employ strategies was so successful, why did not people with cerebellar degeneration use strategies all the time to compensate for their movement deficits instead of continuing to rely on an impaired SPE-driven learning system? Butcher et al. (2017) showed that, on their own, people with cerebellar degeneration had great difficulty invoking explicit learning to identify a successful aiming strategy that would minimize task errors. That is, some people with cerebellar degeneration continued to aim directly for the target despite the presence of the visuomotor rotation perturbation. However, Wong et al. (2019) revealed that this was only part of the answer. Under certain circumstances, people with cerebellar degeneration could successfully develop de novo strategies using explicit learning. Wong and colleagues demonstrated that when people with cerebellar degeneration were able to view their actual hand moving simultaneously with the cursor, they could resolve the credit assignment problem by recognizing that task errors were not a result of a mis-executed motor command but instead caused by a manipulation of the cursor. That is, people with cerebellar degeneration could use visual feedback to appropriately attribute performance errors to task errors rather than execution errors. Consequently, people with cerebellar degeneration were able to invoke explicit learning to modify their movement goals (i.e., change their aiming direction) akin to that of age-matched neurotypical controls. This work thus suggests a role for SPE signals in supporting explicit learning. While more work is needed to parse the specific role that such SPE signals may play, together these studies provide compelling evidence of interactions between cerebellar computations and both explicit and reinforcement learning mechanisms.
Conclusion
We have reviewed current literature on the interactions between SPE-driven, explicit, and reinforcement learning mechanisms in motor adaptation. It is generally agreed that overt learning behavior results from the combined outputs of each mechanism, but interactions between these mechanisms likely occur at multiple levels. For example, studies of people with cerebellar degeneration provide evidence of a role for SPE signals in the functioning of both reinforcement and explicit learning. These studies suggest that an SPE signal may be needed by reinforcement and explicit learning systems to know whether RPEs or task errors, respectively, arose from poorly executed movements or poor selection of an action or strategy. By helping to resolve this credit-assignment problem, SPEs can optimize learning by informing reinforcement and explicit learning systems whether an action or strategy truly needs to change.
It is notable that some of the neuroanatomy needed to support these proposed interactions has been shown. With regard to a role for cerebellar SPE signals in reinforcement learning, the cerebellum communicates directly with the dorsal striatum via a short-latency disynaptic connection that modulates corticostriatal plasticity (Hoshi et al., 2005; Chen et al., 2014). The posterior lobules of the cerebellum are also reciprocally connected with prefrontal cognitive regions of the cerebral cortex, which are hypothesized to support the explicit learning process (Ramnani, 2006; Strick et al., 2009). The nature of the information sent through these pathways is unclear, but there is recent evidence to suggest homologous function across cerebellar projections (Pisano et al., 2021). However, the cerebellum contributes to a diverse set of behaviors, both motor and non-motor (Diedrichsen et al., 2019; King et al., 2019; Sereno et al., 2020). Further work is needed to understand whether different regions of the cerebellum may be preferentially involved in the interactions proposed here or whether variability in the pattern of cerebellar damage across individuals and studies can explain some contrasting results. Sharing of the SPE signal represents one of the multiple possible interactions among SPE-driven, reinforcement, and explicit learning mechanisms below the level of their output stages (see Figure 1), and future research is needed to elucidate others. Importantly, the presence of such multi-level interactions means that learning mechanisms cannot be easily isolated.
When it comes to motor adaptation, studies of people with cerebellar degeneration suggest that SPE-driven learning may be the primary system responsible for resolving performance errors. Only when the influence of SPE-driven is minimized, such as by eliminating the need or ability to compute a meaningful SPE signal (e.g., by removing cursor feedback altogether or providing visual feedback of the hand), can reinforcement learning or explicit learning become the predominant driver of changes in behavior (Therrien et al., 2016, 2021; Cashaback et al., 2017; Wong et al., 2019). This has important implications for future studies aiming to manipulate or leverage individual learning mechanisms.
Finally, the work reviewed here begs the question of whether further insight into the interactions between SPE-driven, explicit, and reinforcement learning mechanisms can be gained from studies of motor adaptation in other patient populations. Parkinson’s disease (PD) is often studied as a model of basal ganglia dysfunction, a structure known to play an integral role in reinforcement learning (Schultz, 2006; Lee et al., 2012). A sizable body of literature has studied motor adaptation in people with PD but has noted inconsistent findings. While some studies show similar adaptation behavior between people with PD and age-matched control participants (e.g., Stern et al., 1988; Marinelli et al., 2009; Leow et al., 2012, 2013), other studies have noted adaptation impairments in people with PD (Contreras-Vidal and Buch, 2003; Venkatakrishnan et al., 2011; Mongeon et al., 2013). Discrepant results may stem from differences in the size of the imposed perturbation (Venkatakrishnan et al., 2011; Mongeon et al., 2013) or medication status of participants across studies (Semrau et al., 2014). To date, no study has attempted to parse the contributions of SPE-driven, explicit, and reinforcement learning to motor adaptation in this population (but see Cressman et al., 2021), but it would be highly interesting for future studies to do so. Overall, this literature, along with the other studies reviewed here, underscores the complexity of interactions occurring between motor learning mechanisms and argues for the importance of not treating such learning mechanisms as predominantly modular.
Author Contributions
Both AT and AW contributed equally to development of the idea, writing the manuscript, and generation of figures. All authors contributed to the article and approved the submitted version.
Funding
AT was supported by funding from the Moss Rehabilitation Research Institute. AW was supported by the U.S. National Institutes of Health grant R01 NS115862.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Albert, S. T., Jang, J., Haith, A. M., Lerner, G., Della-Maggiore, V., Krakauer, J. W., et al. (2020). Competition between parallel sensorimotor learning systems. BioRxiv [Preprint]. doi: 10.1101/2020.12.01.406777
Benson, B. L., Anguera, J. A., and Seidler, R. D. (2011). A spatial explicit strategy reduces error but interferes with sensorimotor adaptation. J. Neurophysiol. 105, 2843–2851. doi: 10.1152/jn.00002.2011
Bock, O. (2005). Components of sensorimotor adaptation in young and elderly subjects. Exp. Brain Res. 160, 259–263. doi: 10.1007/s00221-004-2133-5
Bond, K. M., and Taylor, J. A. (2015). Flexible explicit but rigid implicit learning in a visuomotor adaptation task. J. Neurophysiol. 113, 3836–3849. doi: 10.1152/jn.00009.2015
Butcher, P. A., Ivry, R. B., Kuo, S.-H., Rydz, D., Krakauer, J. W., and Taylor, J. A. (2017). The cerebellum does more than sensory prediction error-based learning in sensorimotor adaptation tasks. J. Neurophysiol. 118, 1622–1636. doi: 10.1152/jn.00451.2017
Cashaback, J. G. A., McGregor, H. R., Mohatarem, A., and Gribble, P. L. (2017). Dissociating error-based and reinforcement-based loss functions during sensorimotor learning. PLoS Comput. Biol. 13:e1005623. doi: 10.1371/journal.pcbi.1005623
Chen, C. H., Fremont, R., Arteaga-Bracho, E. E., and Khodakhah, K. (2014). Short latency cerebellar modulation of the basal ganglia. Nat. Neurosci. 17, 1767–1775. doi: 10.1038/nn.3868
Codol, O., Holland, P. J., and Galea, J. M. (2018). The relationship between reinforcement and explicit control during visuomotor adaptation. Sci. Rep. 8:9121. doi: 10.1038/s41598-018-27378-1
Contreras-Vidal, J. L., and Buch, E. R. (2003). Effects of Parkinson’s disease on visuomotor adaptation. Exp. Brain Res. 150, 25–32. doi: 10.1007/s00221-003-1403-y
Cressman, E. K., Salomonczyk, D., Constantin, A., Miyasaki, J., Moro, E., Chen, R., et al. (2021). Proprioceptive recalibration following implicit visuomotor adaptation is preserved in Parkinson’s disease. Exp. Brain Res. 15, 1551–1565. doi: 10.1007/s00221-021-06075-y
Criscimagna-Hemminger, S. E., Bastian, A. J., and Shadmehr, R. (2010). Size of error affects cerebellar contributions to motor learning. J. Neurophysiol. 103, 2275–2284. doi: 10.1152/jn.00822.2009
Dayan, P., and Niv, Y. (2008). Reinforcement learning: the good, the bad and the ugly. Curr. Opin. Neurobiol. 18, 185–196. doi: 10.1016/j.conb.2008.08.003
Diedrichsen, J., King, M., Hernandez-Castillo, C., Sereno, M., and Ivry, R. (2019). Universal transform or multiple functionality? understanding the contribution of the human cerebellum across task domains. Neuron 102, 918–928. doi: 10.1016/j.neuron.2019.04.021
Franklin, D. W., and Wolpert, D. M. (2011). Computational mechanisms of sensorimotor control. Neuron 72, 425–442. doi: 10.1016/j.neuron.2011.10.006
Hadjiosif, A. M., and Krakauer, J. W. (2021). The explicit/implicit distinction in studies of visuomotor learning: conceptual and methodological pitfalls. Eur. J. Neurosci. 53, 499–503. doi: 10.1111/ejn.14984
Haith, A. M., and Krakauer, J. W. (2013). “Model-Based and Model-Free Mechanisms of Human Motor Learning,” in Progress in Motor Control. Advances in Experimental Medicine and Biology, New York, NY: Springer, 1–21.
Haith, A. M., Huberdeau, D. M., and Krakauer, J. W. (2015). The influence of movement preparation time on the expression of visuomotor learning and savings. J. Neurosci. 35, 5109–5117. doi: 10.1523/JNEUROSCI.3869-14.2015
Hegele, M., and Heuer, H. (2013). Age-related variations of visuomotor adaptation result from both the acquisition and the application of explicit knowledge. Psychol. Aging 28, 333–339. doi: 10.1037/a0031914
Heuer, H., and Hegele, M. (2008). Adaptation to visuomotor rotations in younger and older adults. Psychol. Aging 23, 190–202. doi: 10.1037/0882-7974.23.1.190
Holland, P., Codol, O., and Galea, J. M. (2018). Contribution of explicit processes to reinforcement-based motor learning. J. Neurophysiol. 119, 2241–2255. doi: 10.1152/jn.00901.2017
Hoshi, E., Tremblay, L., Féger, J., Carras, P. L., and Strick, P. L. (2005). The cerebellum communicates with the basal ganglia. Nat. Neurosci. 8, 1491–1493. doi: 10.1038/nn1544
Izawa, J., Criscimagna-Hemminger, S. E., and Shadmehr, R. (2012). Cerebellar contributions to reach adaptation and learning sensory consequences of action. J. Neurosci. 32, 4230–4239. doi: 10.1523/JNEUROSCI.6353-11.2012
Izawa, J., and Shadmehr, R. (2011). Learning from sensory and reward prediction errors during motor adaptation. PLoS Comput. Biol. 7:e1002012. doi: 10.1371/journal.pcbi.1002012
Kawato, M. (1999). Internal models for motor control and trajectory planning. Curr. Opin. Neurobiol. 9, 718–727. doi: 10.1016/s0959-4388(99)00028-8
Kim, H. E., Parvin, D. E., and Ivry, R. B. (2019). The influence of task outcome on implicit motor learning. eLife 8:e39882. doi: 10.7554/eLife.39882
King, M., Hernandez-Castillo, C. R., Poldrack, R. A., Ivry, R. B., and Diedrichsen, J. (2019). Functional boundaries in the human cerebellum revealed by a multi-domain task battery. Nat. Neurosci. 22, 1371–1378. doi: 10.1038/s41593-019-0436-x
Krakauer, J. W., Hadjiosif, A. M., Xu, J., Wong, A. L., and Haith, A. M. (2019). Motor learning. Comp. Physiol. 9, 613–663. doi: 10.1002/cphy.c170043
Landy, M. S., Trommershäuser, J., and Daw, N. D. (2012). Dynamic estimation of task-relevant variance in movement under risk. J. Neurosci. 32, 12702–12711. doi: 10.1523/JNEUROSCI.6160-11.2012
Lee, D., Seo, H., and Jung, M. W. (2012). Neural basis of reinforcement learning and decision making. Annu. Rev. Neurosci. 35, 287–308. doi: 10.1146/annurev-neuro-062111-150512
Leow, L.-A., de Rugy, A., Loftus, A. M., and Hammond, G. (2013). Different mechanisms contributing to savings and anterograde interference are impaired in Parkinson’s disease. Front. Hum. Neurosci. 7:55. doi: 10.3389/fnhum.2013.00055
Leow, L.-A., Gunn, R., Marinovic, W., and Carroll, T. J. (2017). Estimating the implicit component of visuomotor rotation learning by constraining movement preparation time. J. Neurophysiol. 118, 666–676. doi: 10.1152/jn.00834.2016
Leow, L.-A., Loftus, A. M., and Hammond, G. R. (2012). Impaired savings despite intact initial learning of motor adaptation in Parkinson’s disease. Exp. Brain Res. 218, 295–304. doi: 10.1007/s00221-012-3060-5
Leow, L.-A., Marinovic, W., Rugy, A. D., and Carroll, T. J. (2018). Task errors contribute to implicit aftereffects in sensorimotor adaptation. Eur. J. Neurosci. 48, 3397–3409. doi: 10.1111/ejn.14213
Long, A. W., Roemmich, R. T., and Bastian, A. J. (2016). Blocking trial-by-trial error correction does not interfere with motor learning in human walking. J. Neurophysiol. 115, 2341–2348. doi: 10.1152/jn.00941.2015
Maresch, J., Mudrik, L., and Donchin, O. (2021). Measures of explicit and implicit in motor learning: what we know and what we don’t. Neurosci. Biobehav. Rev. 128, 558–568. doi: 10.1016/j.neubiorev.2021.06.037
Marinelli, L., Crupi, D., Di Rocco, A., Bove, M., Eidelberg, D., Abbruzzese, G., et al. (2009). Learning and consolidation of visuo-motor adaptation in Parkinson’s disease. Parkinsonism Relat. Disord. 15, 6–11. doi: 10.1016/j.parkreldis.2008.02.012
Mawase, F., Uehara, S., Bastian, A. J., and Celnik, P. (2017). Motor learning enhances use-dependent plasticity. J. Neurosci. 37, 2673–2685. doi: 10.1523/JNEUROSCI.3303-16.2017
Mazzoni, P., and Krakauer, J. W. (2006). An implicit plan overrides an explicit strategy during visuomotor adaptation. J. Neurosci. 26, 3642–3645. doi: 10.1523/JNEUROSCI.5317-05.2006
McDougle, S. D., Boggess, M. J., Crossley, M. J., Parvin, D., Ivry, R. B., and Taylor, J. A. (2016). Credit assignment in movement-dependent reinforcement learning. Proc. Natl. Acad. Sci. U S A 113, 6797–6802. doi: 10.1073/pnas.1523669113
McDougle, S. D., Bond, K. M., and Taylor, J. A. (2015). Explicit and implicit processes constitute the fast and slow processes of sensorimotor learning. J. Neurosci. 35, 9568–9579. doi: 10.1523/JNEUROSCI.5061-14.2015
McNay, E. C., and Willingham, D. B. (1998). Deficit in learning of a motor skill requiring strategy, but not of perceptuomotor recalibration, with aging. Learn. Mem. 4, 411–420. doi: 10.1101/lm.4.5.411
Medina, J. F. (2011). The multiple roles of Purkinje cells in sensori-motor calibration: to predict, teach and command. Curr. Opin. Neurobiol. 21, 616–622. doi: 10.1016/j.conb.2011.05.025
Miyamoto, Y. R., Wang, S., Brennan, A. E., and Smith, M. A. (2014). “Distinct forms of implicit learning that respond differently to performance errors and sensory prediction errors,” in Advances in Motor Learning and Motor Control Conference, (Washington DC, USA), paper presentation.
Miyamoto, Y. R., Wang, S., and Smith, M. A. (2020). Implicit adaptation compensates for erratic explicit strategy in human motor learning. Nat. Neurosci. 23, 443–455. doi: 10.1038/s41593-020-0600-3
Mongeon, D., Blanchet, P., and Messier, J. (2013). Impact of Parkinson’s disease and dopaminergic medication on adaptation to explicit and implicit visuomotor perturbations. Brain Cogn. 81, 271–282. doi: 10.1016/j.bandc.2012.12.001
Morehead, J. R., and Orban de Xivry, J.-J. (2021). A synthesis of the many errors and learning processes of visuomotor adaptation. BioRxiv [Preprint]. doi: 10.1101/2021.03.14.435278
Morehead, J. R., Taylor, J. A., Parvin, D. E., and Ivry, R. B. (2017). Characteristics of implicit sensorimotor adaptation revealed by task-irrelevant clamped feedback. J. Cogn. Neurosci. 29, 1061–1074. doi: 10.1162/jocn_a_01108
Nikooyan, A. A., and Ahmed, A. A. (2015). Reward feedback accelerates motor learning. J. Neurophysiol. 113, 633–646. doi: 10.1152/jn.00032.2014
Ostry, D. J., and Gribble, P. L. (2016). Sensory plasticity in human motor learning. Trends Neurosci. 39, 114–123. doi: 10.1016/j.tins.2015.12.006
Pisano, T. J., Dhanerawala, Z. M., Kislin, M., Bakshinskaya, D., Engel, E. A., Hansen, E. J., et al. (2021). Homologous organization of cerebellar pathways to sensory, motor and associative forebrain. Cell Rep. 36:109721. doi: 10.1016/j.celrep.2021.109721
Ramnani, N. (2006). The primate cortico-cerebellar system: anatomy and function. Nat. Rev. Neurosci. 7, 511–522. doi: 10.1038/nrn1953
Rmus, M., McDougle, S. D., and Collins, A. G. (2021). The role of executive function in shaping reinforcement learning. Curr. Opin. Behav. Sci. 38, 66–73. doi: 10.1016/j.cobeha.2020.10.003
Rossi, C., Bastian, A. J., and Therrien, A. S. (2021). Mechanisms of proprioceptive realignment in human motor learning. Curr. Opin. Physiol. 20, 186–197. doi: 10.1016/j.cophys.2021.01.011
Schlerf, J., Ivry, R. B., and Diedrichsen, J. (2012). Encoding of sensory prediction errors in the human cerebellum. J. Neurosci. 32, 4913–4922. doi: 10.1523/JNEUROSCI.4504-11.2012
Schultz, W. (2006). Behavioral theories and the neurophysiology of reward. Annu. Rev. Psychol. 57, 87–115. doi: 10.1146/annurev.psych.56.091103.070229
Semrau, J. A., Perlmutter, J. S., and Thoroughman, K. A. (2014). Visuomotor adaptation in Parkinson’s disease: effects of perturbation type and medication state. J. Neurophysiol. 111, 2675–2687. doi: 10.1152/jn.00095.2013
Sereno, M. I., Diedrichsen, J., Tachrount, M., Testa-Silva, G., d’Arceuil, H., and De Zeeuw, C. (2020). The human cerebellum has almost 80% of the surface area of the neocortex. Proc. Natl. Acad. Sci. U S A 117, 19538–19543. doi: 10.1073/pnas.2002896117
Shadmehr, R., Smith, M. A., and Krakauer, J. W. (2010). Error correction, sensory prediction and adaptation in motor control. Annu. Rev. Neurosci. 33, 89–108. doi: 10.1146/annurev-neuro-060909-153135
Shmuelof, L., Huang, V. S., Haith, A. M., Delnicki, R. J., Mazzoni, P., and Krakauer, J. W. (2012). Overcoming motor “forgetting” through reinforcement of learned actions. J. Neurosci. 32, 14617–14621. doi: 10.1523/JNEUROSCI.2184-12.2012
Skinner, B. F. (1937). Two types of conditioned reflex: a reply to konorski and miller. J. Gen. Psychol. 16, 272–279. doi: 10.1080/00221309.1937.9917951
Stern, Y., Mayeux, R., Hermann, A., and Rosen, J. (1988). Prism adaptation in Parkinson’s disease. J. Neurol. Neurosurg. Psychiatry 51, 1584–1587. doi: 10.1136/jnnp.51.12.1584
Strick, P. L., Dum, R. P., and Fiez, J. A. (2009). Cerebellum and nonmotor function. Ann Rev Neurosci. 32, 413–434. doi: 10.1146/annurev.neuro.31.060407.125606
Taylor, J. A., and Ivry, R. B. (2014). “Cerebellar and prefrontal cortex contributions to adaptation, strategies and reinforcement learning,” in Progress in Brain Research Cerebellar Learning, ed N. Ramnani (London, UK: Elsevier), 217–253. doi: 10.1016/B978-0-444-63356-9.00009-1
Taylor, J. A., Klemfuss, N. M., and Ivry, R. B. (2010). An explicit strategy prevails when the cerebellum fails to compute movement errors. Cerebellum 9, 580–586. doi: 10.1007/s12311-010-0201-x
Taylor, J. A., Krakauer, J. W., and Ivry, R. B. (2014). Explicit and implicit contributions to learning in a sensorimotor adaptation task. J. Neurosci. 34, 3023–3032. doi: 10.1523/JNEUROSCI.3619-13.2014
Therrien, A. S., Statton, M. A., and Bastian, A. J. (2021). Reinforcement signaling can be used to reduce elements of cerebellar reaching ataxia. Cerebellum 20, 62–73. doi: 10.1007/s12311-020-01183-x
Therrien, A. S., Wolpert, D. M., and Bastian, A. J. (2016). Effective reinforcement learning following cerebellar damage requires a balance between exploration and motor noise. Brain 139, 101–114. doi: 10.1093/brain/awv329
Therrien, A. S., Wolpert, D. M., and Bastian, A. J. (2018). Increasing motor noise impairs reinforcement learning in healthy individuals. eNeuro 5:ENEURO.0050-18.2018. doi: 10.1523/ENEURO.0050-18.2018
Trommershäuser, J., Maloney, L. T., and Landy, M. S. (2008). Decision making, movement planning and statistical decision theory. Trends Cogn. Sci. 12, 291–297. doi: 10.1016/j.tics.2008.04.010
Tseng, Y. W., Diedrichsen, J., Krakauer, J. W., Shadmehr, R., and Bastian, A. J. (2007). Sensory prediction errors drive cerebellum-dependent adaptation of reaching. J. Neurophysiol. 98, 54–62. doi: 10.1152/jn.00266.2007
Uehara, S., Mawase, F., Therrien, A. S., Cherry-Allen, K. M., and Celnik, P. (2019). Interactions between motor exploration and reinforcement learning. J. Neurophysiol. 122, 797–808. doi: 10.1152/jn.00390.2018
van Beers, R. J. (2009). Motor learning is optimally tuned to the properties of motor noise. Neuron 63, 406–417. doi: 10.1016/j.neuron.2009.06.025
van Beers, R. J., Haggard, P., and Wolpert, D. M. (2004). The role of execution noise in movement variability. J. Neurophysiol. 91, 1050–1063. doi: 10.1152/jn.00652.2003
van der Kooij, K., Wijdenes, L. O., Rigterink, T., Overvliet, K. E., and Smeets, J. B. J. (2018). Reward abundance interferes with error-based learning in a visuomotor adaptation task. PLoS One 13:e0193002. doi: 10.1371/journal.pone.0193002
Vandevoorde, K., and Orban de Xivry, J.-J. (2019). Internal model recalibration does not deteriorate with age while motor adaptation does. Neurobiol. Aging 80, 138–153. doi: 10.1016/j.neurobiolaging.2019.03.020
Venkatakrishnan, A., Banquet, J. P., Burnod, Y., and Contreras-Vidal, J. L. (2011). Parkinson’s disease differentially affects adaptation to gradual as compared to sudden visuomotor distortions. Hum. Mov. Sci. 30, 760–769. doi: 10.1016/j.humov.2010.08.020
Werner, S., van Aken, B. C., Hulst, T., Frens, M. A., Geest, J. N., van der Strüder, H. K., et al. (2015). Awareness of sensorimotor adaptation to visual rotations of different size. PLoS One 10:e0123321. doi: 10.1371/journal.pone.0123321
Wong, A. L., Marvel, C. L., Taylor, J. A., and Krakauer, J. W. (2019). Can patients with cerebellar disease switch learning mechanisms to reduce their adaptation deficits. Brain 142, 662–673. doi: 10.1093/brain/awy334
Wu, S.-W., Delgado, M. R., and Maloney, L. T. (2009). Economic decision-making compared with an equivalent motor task. Proc. Natl. Acad. Sci. U S A 106, 6088–6093. doi: 10.1073/pnas.0900102106
Keywords: cerebellar degeneration, adaptation, reinforcement learning, explicit and implicit motor learning, sensory prediction error
Citation: Therrien AS and Wong AL (2022) Mechanisms of Human Motor Learning Do Not Function Independently. Front. Hum. Neurosci. 15:785992. doi: 10.3389/fnhum.2021.785992
Received: 29 September 2021; Accepted: 13 December 2021;
Published: 04 January 2022.
Edited by:
Thomas Carsten, Catholic University of Leuven, BelgiumReviewed by:
Olivier Codol, Western University (Canada), CanadaTarkeshwar Singh, Cleveland Clinic, United States
Copyright © 2022 Therrien and Wong. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Amanda S. Therrien, dGhlcnJpZWFAZWluc3RlaW4uZWR1