 Alejandro Rodríguez-Collado
Alejandro Rodríguez-Collado Cristina Rueda
Cristina Rueda
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Hum. Neurosci. , 26 July 2021
Sec. Motor Neuroscience
Volume 15 - 2021 | https://doi.org/10.3389/fnhum.2021.684950
This article is part of the Research Topic Rhythmic Patterns in Neuroscience and Human Physiology View all 17 articles
The complete understanding of the mammalian brain requires exact knowledge of the function of each neuron subpopulation composing its parts. To achieve this goal, an exhaustive, precise, reproducible, and robust neuronal taxonomy should be defined. In this paper, a new circular taxonomy based on transcriptomic features and novel electrophysiological features is proposed. The approach is validated by analysing more than 1850 electrophysiological signals of different mouse visual cortex neurons proceeding from the Allen Cell Types database. The study is conducted on two different levels: neurons and their cell-type aggregation into Cre lines. At the neuronal level, electrophysiological features have been extracted with a promising model that has already proved its worth in neuronal dynamics. At the Cre line level, electrophysiological and transcriptomic features are joined on cell types with available genetic information. A taxonomy with a circular order is revealed by a simple transformation of the first two principal components that allow the characterization of the different Cre lines. Moreover, the proposed methodology locates other Cre lines in the taxonomy that do not have transcriptomic features available. Finally, the taxonomy is validated by Machine Learning methods which are able to discriminate the different neuron types with the proposed electrophysiological features.
Understanding the nervous system's mechanisms and capabilities, such as the conscience and cognition, remain one of the most challenging and interesting unresolved problems in biology. It requires a precise description of the structure and function of each brain region, including the study of the neuronal circuits and neurons composing them. Furthermore, one fundamental prerequisite in this subsequent structural division study is the creation of a solid neuronal cell-type classification or taxonomy. As Zeng and Sanes (2017) explain, cells in the nervous system should be hierarchically classified into different levels, mainly into classes, subclasses and types. This property makes the taxonomy define relationships between cell types, as well as making it easier to update in the light of new information. At class level, cells are classified into non-neuronal cells and neurons, which in turn can be classified into excitatory and inhibitory neurons, local and projection (Melzer and Monyer, 2020 and references therein). Excitatory neurons are
habitually morphologically spiny, have a long apical dendrite, and exhibit less variability in their electrophysiological features. Inhibitory neurons are broadly aspiny, have a more compact dendritic structure and tend to spike faster. Also, at class level, neurons can be classified based on their neurotransmitter into GABAergic and glutamatergic. The latter are mostly excitatory and brain-area specific, while the former are broadly inhibitory and not-area specific. Neuron subclasses can be defined with different methods. In particular, Cre recombinase-dependent reporter transgenic mouse lines are used here. Moreover, many authors consider GABAergic neurons to belong to four classes based on the expression of certain principal markers: Pvalb (parvalbumin) positive, Vip (vasoactive intestinal peptide) positive, Sst (somatostatin) positive, and cells that express Htr3a (5-hydroxytryptamine receptor 3A) but are Vip negative. These groups are suitable for classification because they account for nearly the totality of neurons in certain brain regions as well as being largely expressed in a non-overlapping manner revealing neuron types with different properties (Tremblay et al., 2016). On the other hand, glutamatergic neurons can also be grouped based on gene markers, such as Cux2 (Cut like homeobox 2), Rorb (RAR related orphan receptor B), or Ctgf (Connective tissue growth factor), or alternatively based on their laminar locations and the locations to which they project their axons. Aside from these previous statements, the different studies unearth discrepancies in terms of number of neuronal types, their characteristics, and the existing order between them as is reviewed in the next paragraph.
The definition of a solid neuronal taxonomy is a challenging task. Heterogeneity between cells arises due to different electrophysiological, morphological, and/or genetic features, but also due to differences in cell age, environmental conditions, and other sources of noise. Another concerning issue is the reproducibility of the approach. The open challenge of creating a neuronal taxonomy has recently generated many studies, mainly due to the increase in data availability as well as the rise in data computational methods. A recent overview of the matter can be found in Zeng and Sanes (2017). In particular, the taxonomy of the mouse visual cortex cells has been the focus of recent research. In Tasic et al. (2016, 2018), taxonomies based on transcriptomic characteristics obtained from single RNA sequencing are presented. Electrophysiological taxonomies are predominantly based on patch-clamp recordings of neuron membrane potential signals that contain action potential curves (APs), as is done in Ghaderi et al. (2018) and Teeter et al. (2018). Furthermore, Gouwens et al. (2019) presents a taxonomy based on the combination of electrophysiological and morphological features, while part of this taxonomy is expanded with transcriptomic features in Gouwens et al. (2020).
It should be noted that electrophysiological features are easier to measure than other types of features and can be simultaneously recorded on hundreds of cells using scalable techniques such as optical imaging of electrical activity (Zeng and Sanes, 2017). Furthermore, taxonomies based on this type of features are easier to reproduce. However, the features traditionally used in this type of taxonomy lack interpretability as they are not directly related to the observed potential difference signal. Most of these studies extract the features with dimensional reducing techniques (as is the case of Ghaderi et al., 2018 or Gouwens et al., 2019 among others) or the features are model parameters such as the leaky integrate and fire models (as in Teeter et al., 2018). A brief overview of the latter models can be found in Lynch and Houghton (2015).
The aim of this paper is to derive an electrophysiological-transcriptomic circular taxonomy of visual cortex Cre lines, using data from Mus Musculus of the Allen Cell Types database (ACTD; http://celltypes.brain-map.org). This database is freely available and has been the reference data for many authors, such as Teeter et al. (2018) and references therein. On the one hand, the electrophysiological features at Cre line level are the median of those generated at the cell level from fitting a frequency modulated Möbius (FMM) model to the observed cell signals. The FMM model is a flexible model defined by 13 parameters that accurately describes the AP shape. The monocomponent FMM model is presented in Rueda et al. (2019) and model extensions to analyse neuronal dynamics are shown in Rueda et al. (2021) and Rodríguez-Collado and Rueda (2021). Some relevant and robust theoretical properties of the model are shown in the former paper while, in the latter, an FMM representation of the famed Hodgkin-Huxley model is proposed.
On the other hand, the number of core cells by genetic cluster and Cre line from Tasic et al. (2016) has been used as transcriptomic features. Finally, the morphological features have not been used as they are sparsely available compared to other kinds of measurements and they seem to be not as discriminant for Cre lines as the other kinds of features, as seen in Gouwens et al. (2020).
The formulation of a circular taxonomy is one of the most original aspects of this work. Many studies devoted to generate taxonomies provide visualizations based on circular tree in which any two nodes in the tree can be connected by lines to combine different quantitative information. The circular tree is just an alternative display of the habitual linear layout. Different computational tools have been developed to provide such a visualizations, in particular to represent genomic data (Moore et al., 2020 is among the most recent ones). Besides, principal component analysis (PCA) combined with hierarchical clustering has been considered in different disciplines and taxonomies are visualized in the plot of the two first principal components (Argüelles et al., 2014; Žurauskienė and Yau, 2016; Gautier et al., 2019 among others).
Our proposal can be seen as a combination of a visualization tool, as it uses a circular tree, and as a combined clustering approach that uses the circular order defined with the two first principal components. The dissimilarity measure is a circular distance instead of a Euclidean distance and the location of clusters in the circle is derived from the location of the clusters in the two dimensional plane of the two first principal components. Thus, this is not just a visualization tool, but a genuine circular taxonomy.
Finally, the proposed taxonomy is validated by showing that signals from different neuronal cell types are accurately discriminated by the FMM model parameters.
Let X(ti) denote the potential difference in the neuron's membrane at each of the observed time points ti, i = 1, ..., n. The latter are assumed to be in [0, 2π]. Otherwise, consider with t0 as the initial time value and T as the period. Transform the time points by . In this section, the statistical methods used in the manuscript are described. These include the FMM model, circular principal components analysis (CPCA) and, Machine Learning supervised methods.
The proposed model to analyse AP data is a three-component FMM model, as defined in Rueda et al. (2021) which implies that each AP is modeled using three waves, labeled A, B, and C. The physiological meaning of these waves is given below, after the mathematical presentation.
Mathematically, the waves are defined as follows:
where is a four-dimensional parameter describing the shape of the wave. The A parameter represents the wave amplitude whereas α is a location parameter. The parameters β and ω determine the skewness and kurtosis of the wave. More details about the interpretation of the parameters can be found in Rueda et al. (2019).
Moreover, the FMM model is defined as a signal plus error model, as follows:
where,
• θ = (M, υA, υB, υC) verifying:
• .
The restrictions on the αs guarantee identifiability.
Other important parameters of practical use are peak and trough times, denoted by and , respectively, and the distances between the model waves, denoted by dJK. All of them are defined as follows:
The papers Rueda et al. (2021) and Rodríguez-Collado and Rueda (2021) provide model properties as well as detail the algorithm used to fit the models. In particular, the second paper presents a restricted FMM model for AP trains, while in the first one data from ACTD is concisely analyzed. Also, the associated phase space of the model is studied and relevant properties are provided.
In Figure 1, the fitted FMM model prediction and wave decomposition of postsynaptic APs from a GABAergic neuron (Figure 1A) and a glutamatergic neuron (Figure 1B) are shown. WA represents the repolarization and, partly, the depolarization while WB describes the end of the depolarization, and the hyperpolarization. Glutamatergic cells tend to have wider APs with a bigger amplitude (values of βA smaller than π and higher values of ωA and AA) than GABAergic cells. Furthermore interesting differences can be observed between the two types in terms of the parameters of WB, particularly in βB and ωB. The third wave, WC, is heteromorphous: in some cases, this wave completes the AP shape (as is typical in GABAergic neurons), while in other cases it accounts for potential differences before and after the spike (as happens in most of the glutamatergic neurons). Also, WA, WB, and WC seem to be related to the potassium, sodium, and calcium conductances that appear in Gouwens et al. (2018).

Figure 1. FMM analysis of postsynaptic APs from GABAergic and glutamatergic neurons. First row: FMM prediction (solid line) and observed signal (dashed line) of postsynaptic APs from a GABAergic neuron (A) and a glutamatergic neuron (B). Rows 2−4: Models' corresponding wave decomposition (WA in red, WB in blue and WC in green) along with their parameters.
The CPCA is a procedure that generates a circular variable which gathers the maximum variability. A basic reference is Scholz (2007). Briefly, given a data base in matrix form, let e1 and e2 be the first two eigenvectors extracted with principal component analysis (Hastie et al., 2009). Consider the transformation in which the eigenvectors are projected onto the unit circle as follows:
A circular order can be defined with , which is called the first circular principal component.
Various Machine Learning supervised methods have been considered in the paper. The simple linear discriminant analysis (LDA) method serves as benchmark for the results while, at the other extreme, the complex and “black box” methods support vector machines of polynomial kernel (SVM) and model averaged neural network (AvNNet) methods have been considered. The former habitually achieves outstanding results in neuronal dynamics, as seen in Teeter et al. (2018) among others. In between these two extremes, interpretable ensembles of decision tree methods have been used, particularly random forest (RF), which has been proved to attain great results without requiring precise hyperparameter tuning (as explained in Fernandez-Delgado et al., 2014) and gradient boosting decision trees (GBDT), also capable of achieving outstanding results while not being as popular (Zhang et al., 2017). Brief descriptions of these methods are provided in the Supplementary Material based on Hastie et al. (2009) and Izenman (2008).
The ACTD includes electrophysiological data of high temporal resolution of membrane potential from individual mouse recordings. A signal from each mouse neuron in the ACTD has been analyzed; particularly the signal generated by the short square stimulus with the lowest stimulus amplitude that elicited a single AP. A small set of neurons that elicited two APs with the selected stimulus were initially discarded for the analysis. See Allen Brain Institute (2015) to learn about the stimulus types applied in the database. Each signal has been preprocessed and analyzed according to the algorithm described shortly after.
A total of 1,892 experiments, from mouse cells of 24 different Cre lines, have been analyzed. Beforehand, experiments from three Cre lines were discarded as they did not have a sufficient sample size (<10 observations). The distribution of signals according to Cre line is given in Table 1, whereas their full names are described on the abbreviations section. Illustrated colors correspond to the different Cre lines in all figures. To facilitate the reading, the appearance order of the Cre lines in the table goes in accordance with the order proposed later in the paper. Throughout the manuscript, the characteristics of each Cre line have been illustrated in two different ways: using median values and using representative neurons, selected from among the neurons in the Cre line with the highest goodness of fit that had all the extracted features between the 5th and 95th percentiles.
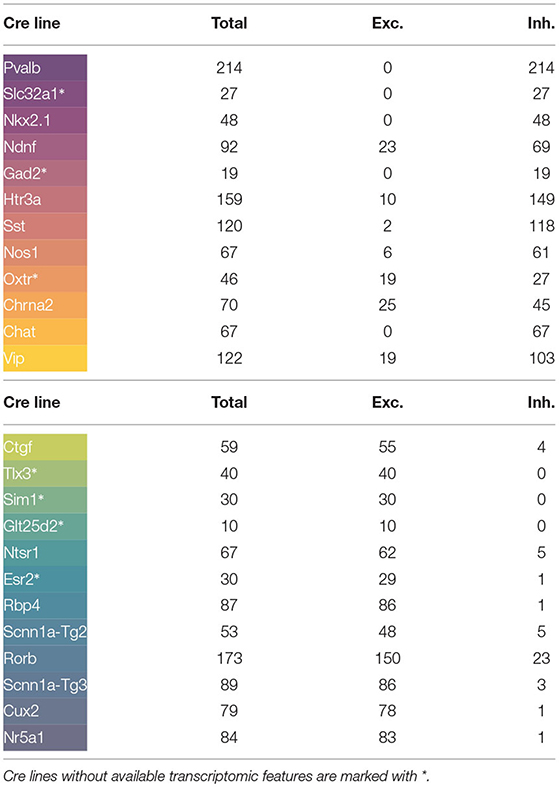
Table 1. Number of cells of each Cre line by neuronal class.
In order to incorporate genetic information in the study, the number of core cells by genetic cluster and Cre line have been grouped into eight genetic markers: Ndnf, Vip, Sst, Pvalb, L2-L4 (layers 2-4), L5 (layer 5), L6 (layer 6), and non-neuronal. Some Cre lines present in the current study were not present in the aforementioned paper. These Cre lines without available transcriptomic features have been marked with an asterisk (*) throughout the paper.
The experimentation has been developed combining Python and R. Python has been used for data acquisition and transformation using the functions provided by Allen SDK (Allen Institute, 2015), while R fits the FMM models with the corresponding package available at the Comprehensive R Archive Network (https://cran.r-project.org/package=FMM) and analyses the results.
The R packages (Venables and Ripley, 2002; Karatzoglou et al., 2004; Chen and Guestrin, 2016; Breiman et al., 2018; Ripley, 2020) and the auxiliary package for learning procedures caret (Kuhn, 2018) have been used to implement the Machine Learning procedures.
Moreover, the libraries Shiny (Chang et al., 2020), Shinydashboard (Chang and Borges Ribeiro, 2018), and ggplot2 (Wickham, 2016) have been considered to develop a Shiny dashboard app.
A flowchart of the preprocessing procedure and the estimation algorithm is depicted in Figure 2. First of all, in the preprocessing stage, the APs in the signal are extracted. Each AP segment is defined as [tS−2d, tS+3d], with tS denoting the time of the spike's peak and d the time needed by the neuron to spike following the application of the stimulus. In real cases where the application time of the stimulus is unknown, a similar procedure can be applied preserving the uneven cut proposed, such as [tS−2k, tS+3k], being k a particular amount of time normally in milliseconds. It is assumed that the segments to be analyzed represent complete APs, in particular, X(t1)≃X(tn).
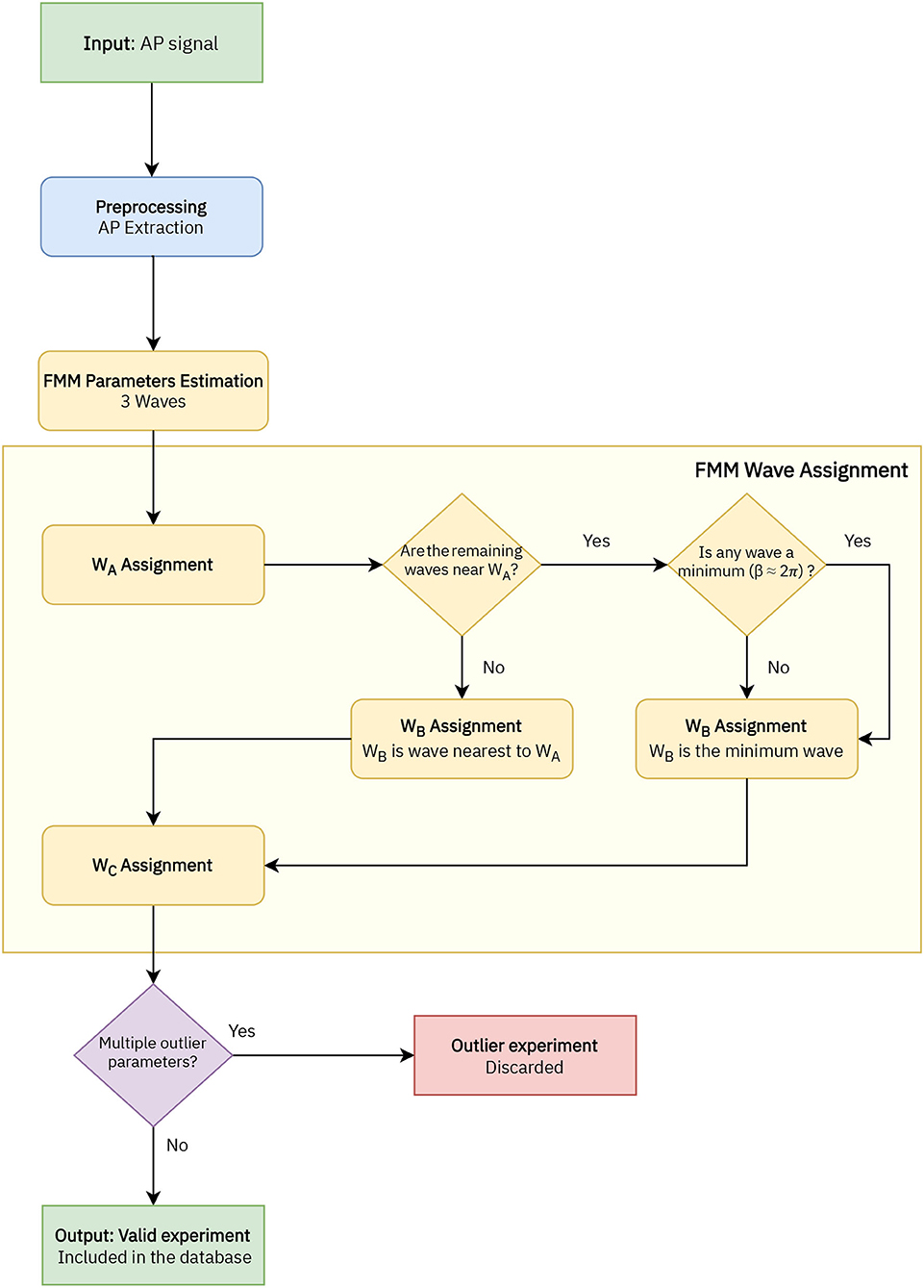
Figure 2. Flowchart of the implemented algorithm to analyse the AP signals with the FMM model, which includes four stages: AP extraction, FMM parameters estimation, wave assignation, and outlier detection.
In a second stage, the parameters are estimated with the backfitting algorithm implemented in the package FMM of the programming language R, first presented in Fernández et al. (2021). Three iterations of the backfitting algorithm are executed to extract the three waves. In each iteration, a single FMM wave is fitted to the residue of the previous iterations. The backfitting algorithm is repeated until the goodness of fit increase between two successive iterations is not significant. From a theoretical point of view, the backfitting algorithm is a standard procedure to find the maximum likelihood estimator (MLE) in additive semiparametric and non-parametric models (to learn more about the algorithm, see Hastie and Tibshirani, 1986). Besides, the experience in simulated and real data shows that the failure in convergence to the MLE does not likely happen (Rueda et al., 2021). From a computational point of view, the backfitting algorithm is efficient.
In the next stage the wave assignation is done. The proposed procedure is firstly presented in this paper and is specific to this study. Let the subscripts i = {1, 2, 3} denote the three estimated waves initially given by the backfitting algorithm. The labels A, B, and C are assigned as follows:
1. WA = Wj/j = argmaxi = 1, 2, 3Ai.
2. Assuming the WA = W1, WB = Wj/j = argmini = 2, 3dAi, except in cases where |dA2−dA3| <0.05 and min(d(β2, 2π), d(β3, 2π)) <0.3, with d(βi, 2π) being the distance between the β parameter and 2π. In these cases WB = Wj/j = argmini = 2, 3d(βi, 2π).
3. Finally, WC is the remaining wave.
The model is validated with the R2 statistic, which is the proportion of the variance explained by a model out of the total variance, as follows:
where is the neuron's mean potential difference and represents the fitted value at ti, i = 1, ..., n. Finally, signals with multiple outlier values in significant parameters of the model related to the Cre line distribution have been discarded.
The FMM model gives an accurate fit of the observed signals, the R2 global mean ± standard deviation being equal to 0.9868±0.0066. GABAergic neurons are slightly better fitted as their mean R2 is 0.9903±0.0054, while for glutamatergic neurons it is 0.9823±0.0053. A Shiny app has been developed to illustrate the differences in the typical APs of the various GABAergic and glutamatergic Cre lines. It can be accessed through https://alexarc26.shinyapps.io/median_ap_profile_by_cre_line/. The interface of the app, which is shown in Figure 3, consists basically of two parts: in the top half the median APs, along with their wave decomposition by Cre line, are depicted, while the controls of the main figure are in the bottom half. These include the possibility of selecting the different Cre lines of the database (up to nine different can be selected simultaneously), selecting just inhibitory or excitatory neurons, and selecting whether the wave sum or the parameters of the model should be plotted.
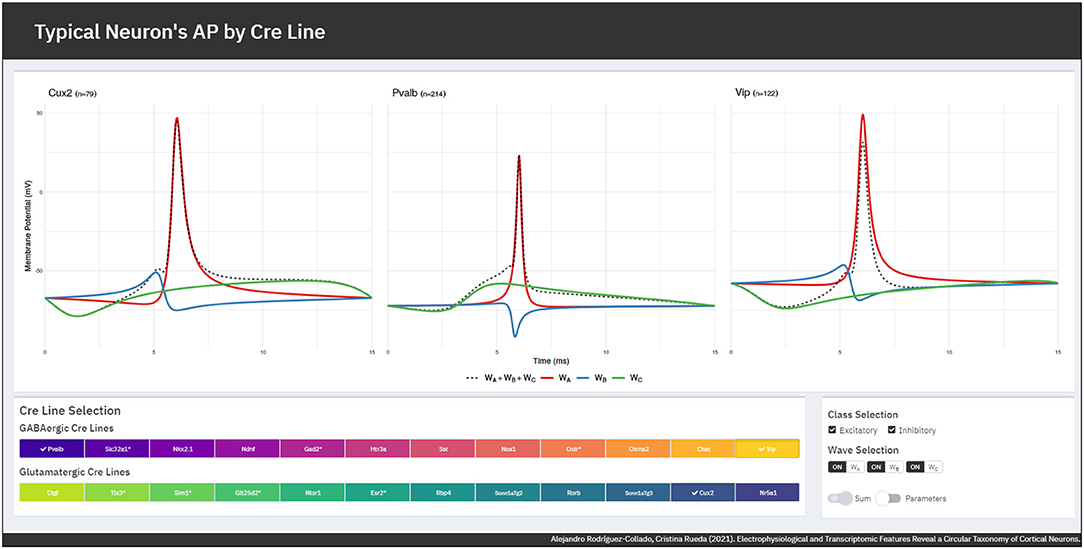
Figure 3. App interface. (Top) Cre lines' median APs (dashed lines) along with the wave decomposition (solid lines). (Bottom) Interface controls for the selection of the Cre lines and the displayed elements.
A total of 40 cells have been discarded due to having multiple outlier values.
The boxplots for the main parameters of the model by Cre line are plotted in Supplementary Figures 1–5. In these figures, the parameter values of the representative neurons from each Cre line have been highlighted as stars. These plots illustrate the potential of various parameters to discriminate between the different Cre lines such as βA, ωB, and sin(βC). The plots also show that the GABAergic neurons exhibit more variability in their electrophysiological features, as Gouwens et al. (2019) points out.
Furthermore, the differences between Cre lines are apparent not only in the time domain, but in the associated phase space. In Figure 4, the fitted FMM models and associated phase space of representative examples of GABAergic Cre lines (Figure 4A) and glutamatergic Cre lines (Figure 4B) are shown. The APs from GABAergic neurons exhibit mainly spiky patterns with a pronounced depolarization before the spike threshold, whereas the APs of glutamatergic neurons are wider and have a more prolonged hyperpolarization. The phase space representations reveal differences between classes and Cre lines, specifically in terms of the perimeter, area, and shape of the “nose.”
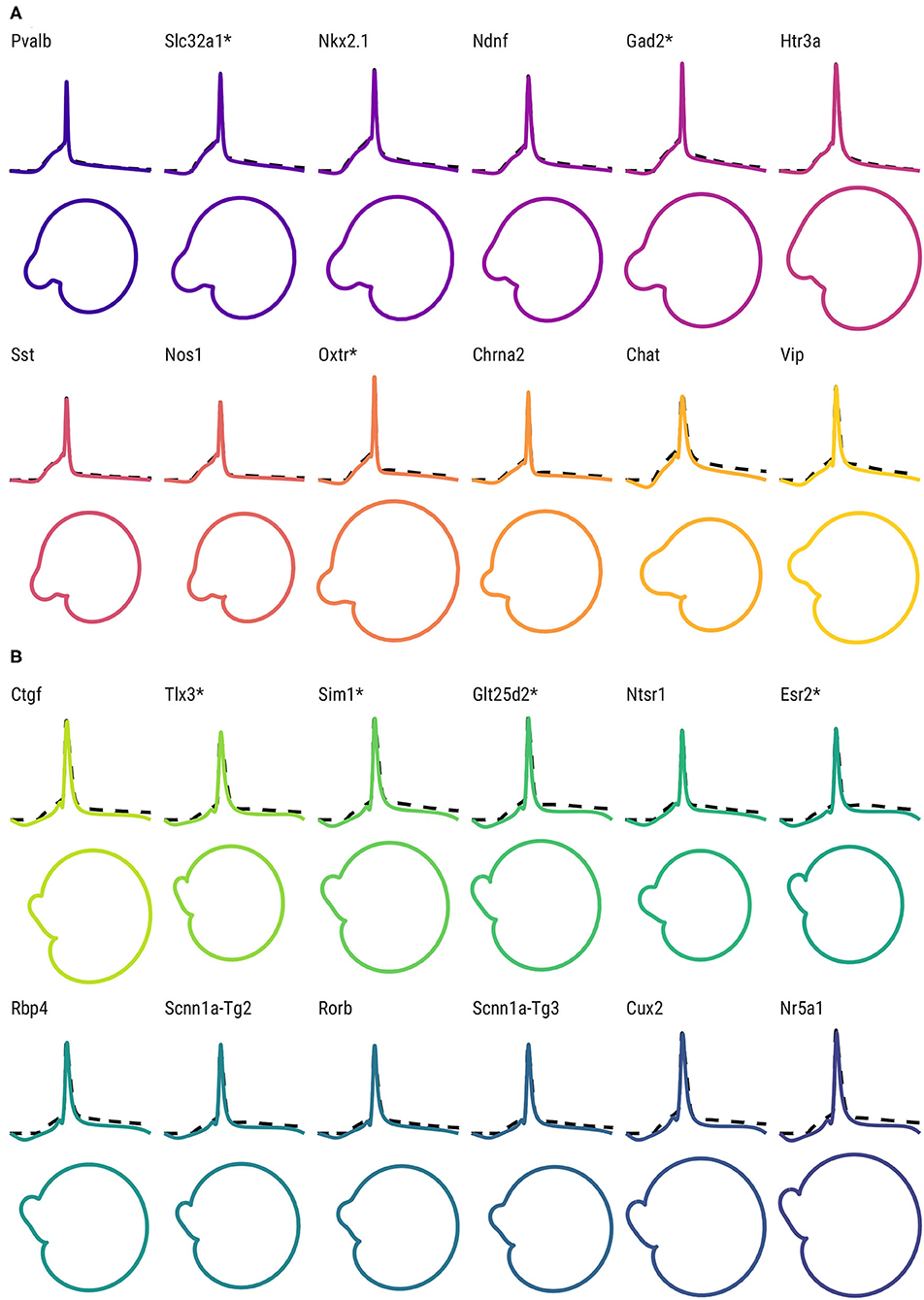
Figure 4. AP shape and phase space for the representative neurons of each Cre line. (Top) FMM predictions (solid lines) and observed AP signals (dashed lines) of representative neurons of GABAergic Cre lines (A) and glutamatergic Cre lines (B). Bottom: corresponding trajectories in the phase space. Cre lines without available transcriptomic features are marked with *.
The taxonomy is defined at Cre line level. For this purpose, the median values of the electrophysiological features by Cre line have been used (note that the stimulus amplitude has not been considered to derive the circular taxonomy), along with the transcriptomic marker features. Due to notable distribution differences between the two feature sets, separate PCAs have been conducted.
Firstly, the electrophysiological features PCA is conducted and two components are extracted (explained variance: 82.40 %). The correlation of the variables with the extracted components and the Cre lines' PCA projections and CPCA transformations are depicted in Supplementary Figures 6, 8. The different Cre lines are distinguished in the circular disposition and it is possible to tell apart most of the glutamatergic from GABAergic. This order is used later to place Cre lines without having any transcriptomic feature available in the taxonomy. The blank space between the Pvalb and Nr5a1 Cre lines observed in Supplementary Figure 8 corresponds to non-neuronal cells, unavailable in the studied data.
Secondly, six components are extracted from the transcriptomic features as their explained variance was medium to low (93.47%). The correlation of the variables with the extracted components and the Cre lines' PCA projections and CPCA transformations are depicted in Supplementary Figures 7, 9. It is particularly relevant to note that the transcriptomic CPCA only distinguishes three groups of Cre lines.
One final ensemble PCA is conducted with the extracted electrophysiological and transcriptomic components. The corresponding CPCA is shown in Figure 5, which is one of the main results of this study. The figure shows the order between Cre lines and the circular distance between two consecutive Cre lines, represented by the arc amplitudes. The main novelty of the defined taxonomy is its circular topology, unlike the previous linear proposals. Moreover, for the first time to our knowledge, some Cre lines have been located in a taxonomy. Nevertheless, a relevant difference with respect to other proposals, such as those of Gouwens et al. (2019) and Tasic et al. (2016), is that the Ndnf and Htr3a Cre lines turn out to be similar to other GABAergic neurons, and not to non-neuronal cells. Further details of the final PCA results can be found in Supplementary Figure 10.
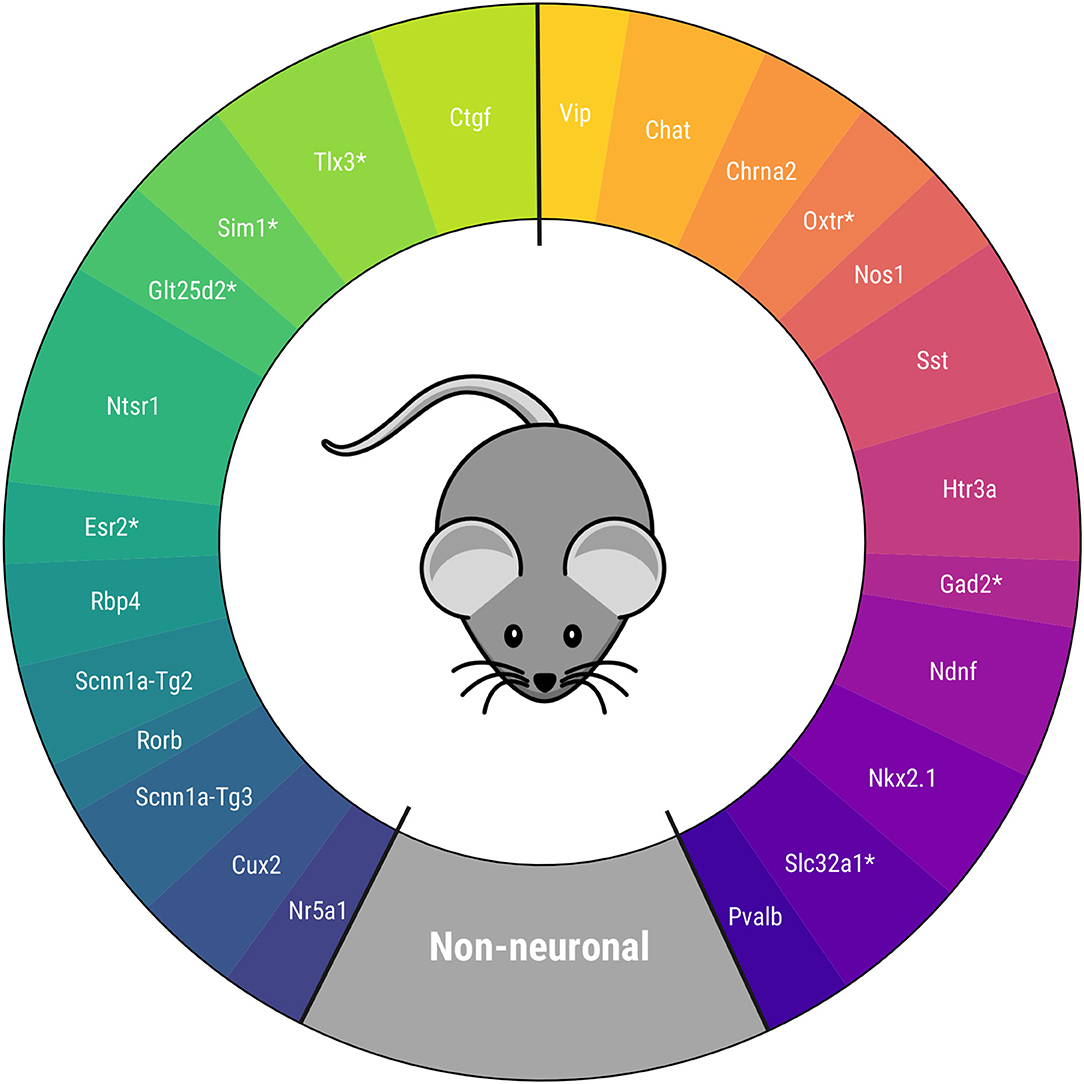
Figure 5. Proposed circular mouse cortical cell taxonomy. Cre lines without available transcriptomic features are marked with *.
The taxonomy is in agreement with others derived recently for mouse visual cortex neurons in several aspects. First, Cre lines that have similar characteristics are kept together (Vip and Chat, Htr3a and Ndnf, Pvalb and Nkx2.1 among others) as in Zeng and Sanes (2017) and Tasic et al. (2016). Second, the non-neuronal cell position between the GABAergic Pvalb Cre line and the glutamatergic Nr5a1 and Cux2 Cre lines -present in the upper layers of the visual cortex- coincides with the taxonomy of Tasic et al. (2018). Within the glutamatergic neurons, the Ctgf and Ntsr1 Cre lines -common in deeper layers- are the most similar in characteristics to the GABAergic neurons. In particular, this disposition is like those in Gouwens et al. (2019) and Tasic et al. (2016), after rearranging the results of the latter study, as can be seen in Supplementary Figure 11.
In order to validate the taxonomy, five transcriptomic-electrophysiological subclasses have been defined using Figure 5. These include four major GABAergic subclasses and one glutamatergic subclass specified in Table 2. In the next subsection, Machine Learning methods are used to discriminate these subclasses at neuronal level.

Table 2. Defined subclasses and Cre lines composing them.
This classification problem, which is conducted at the cell level, has been addressed by other authors in many different ways, varying features and other factors such as the number, composition, and definition of the subclasses or the selection of cells to be classified.
In this study, the FMM derived features have been considered. Specifically, 37 features have been used, including the basic parameters, peak and trough times -and their model values-, the explained variance of each wave and the distance between waves. Also, the cell's reporter status and the origin layer have been considered as predictors. Several Machine Learning methods were tested. Note that some classifiers assume that the predictors are Euclidean, but α and β are circular parameters. The former and βA can be considered Euclidean as they take values concentrated in a small arc. However, sine and cosine transformations are applied to both βB and βC.
All the classifiers except LDA had their hyperparameters tuned in a prior training-validation step. Afterwards, a 10-fold cross validation was performed on the tuned classifier to estimate its discrimination capacity. The dataset was divided into 10 equally sized splits. In 10 iterations, nine of the subsets were used to train the model, while the tenth serves as test. The discrimination capacity was evaluated in terms of the accuracy, percentage of observations correctly classified, and the kappa statistic, which measures the improvement over a random classification. A general overview of these matters can be found on Hastie et al. (2009).
The classification problem was tackled in three different stages. The results can be seen in Table 3. In the first stage (A), the proposed classifiers were studied in the raw dataset, without discarding any observation or Cre lines. More than 75% of the cells could be correctly classified in their corresponding subclass by the AvNNet method; similar results were attained by SVM and RF. Observing the corresponding confusion matrix, it can be seen how the glutamatergic and Pvalb+ subclasses are most clearly discriminated, while more than half of the observations of the Htr3a+ and Vip+ subclasses are misclassified.
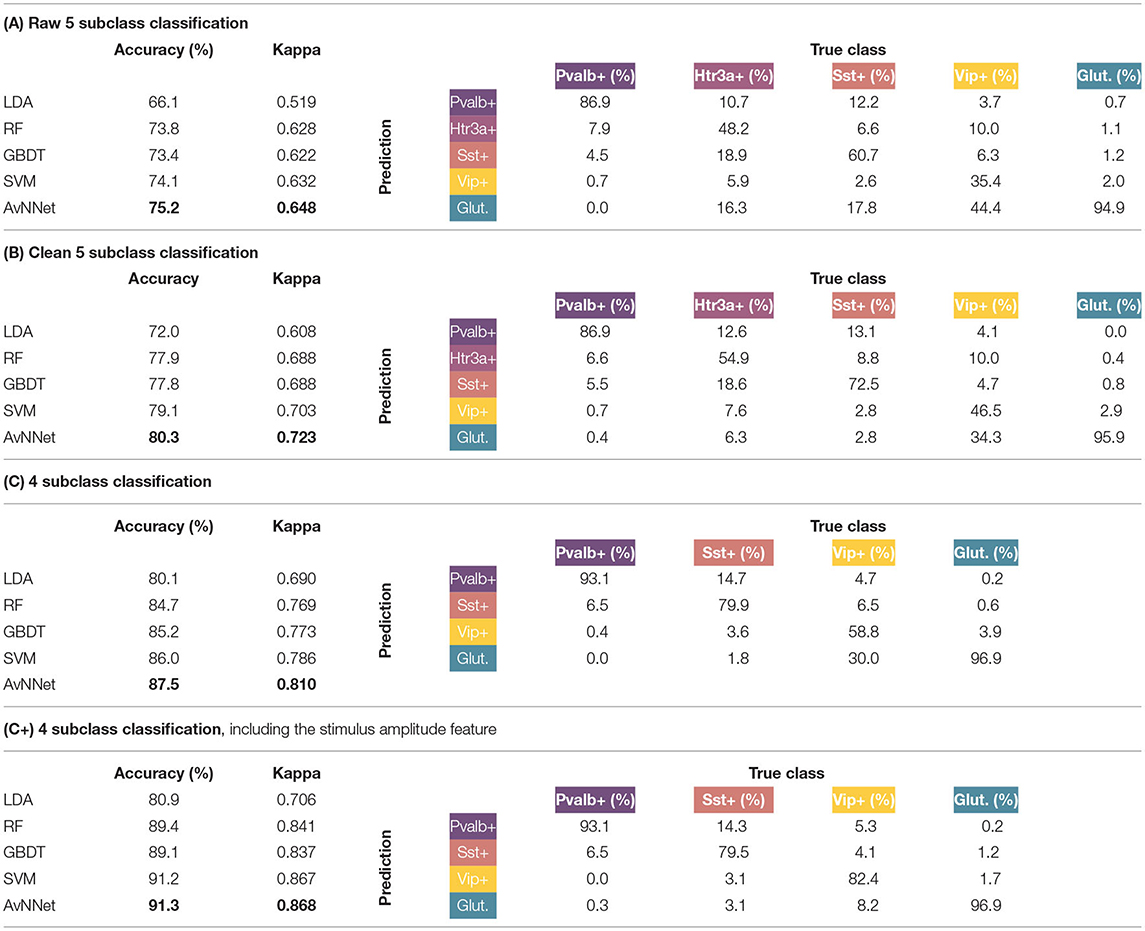
Table 3. Cross-validated accuracy and kappa statistic of the different Machine Learning methods in the discrimination of the subclasses (left, best performer classifiers are marked in bold) and cross-validated confusion matrix of the best performer classifier -AvNNet in all cases- (right) in each of the defined stages.
In the second stage (B), the GABAergic neurons that were not inhibitory and glutamatergic neurons that were not excitatory were discarded, leaving a total of 1,704 observations. The accuracy is excellent for a five-class problem, with more than 80% of the neurons being correctly discriminated by the AvNNet classifier. The second best result corresponds to SVM, followed closely by RF and GBDT, while LDA may be too simple for the task at hand. It is relevant to note that, in most of the cases, the misclassifications occurred between consecutive subclasses in the proposed circular taxonomy (i.e., Htr3a+ cells are mostly confused with Pvalb+ and Sst+, while Glutamatergic cells are misclassified with Vip+ cells). It seems that, at this stage, Sst+ cells are guessed correctly much better than in (A); the prediction of Htr3a+ and Vip+ subclasses have improved, but still, only 50% of the instances are correctly classified.
In the third stage (C), the classification problem has been solved with 1,304 observations, after discarding the observations from the Htr3a+ subclass as well as the observations from Cre lines without transcriptomic features (marked with *). The results are outstanding, as more than 87% of the observations are correctly discriminated in the proposed four classes. The best results are attained by the AvNNet and SVM classifiers. The Pvalb+ and Glutamatergic subclasses are well-identified in more than 93% of the cases, while Sst+ and Vip+ approximately in 80 and 60% of the cases, respectively. Finally, if the stimulus amplitude is added to the predictors feature set (stage C+), the AvNNet classifier discriminates correctly more than 91% of the instances, being the accuracy increase particularly notable in the Vip+ subclass.
The results of LDA clearly show evidence that the subclasses cannot be linearly discriminated. The RF and GBDT classifiers may have attained worse results than the “black box” methods in all the stages, but they offer interpretability in exchange, as feature relevance in the classification can be measured. In all the stages, the same features are highlighted as relevant. Particularly, βA seems to be the most relevant feature, being at least 1.5 the relevance of the second most important feature in all cases. Other discriminant features are ωA, dAB, dAC, , , and αC. The shape of the APs' repolarization and depolarization phases captured by WA seem to characterize the different subclasses.
In this paper, the FMM approach for electrophysiological feature extraction has been presented and used to describe a circular taxonomy in mouse cortical cells.
Relevant AP characteristics such as its width, amplitude, kurtosis, and skewness, among others, are represented by the FMM parameters. Furthermore, additional features standardly used in other studies can easily be defined in terms of the basic parameters, as has been done with the peak time and other features. Even more, the same set of parameters characterizes the phase space. As such, it is not necessary to resort to additional feature sets, as is the case in Gouwens et al. (2020).
A novel property to highlight of the proposed taxonomy is that it is circular. The latter addresses the need for neuronal types to be considered a continuum, discussed by many authors such as Gouwens et al. (2020) and Tasic et al. (2018). Previous proposals, being linear, consider cell types situated at the extremes to be opposite in terms of their characteristics. However, this does not reflect reality: cell types situated at the extremes habitually have a higher degree of similarity than the existing similarity between them and other types situated in the taxonomy's center. The taxonomy also follows the levels proposed by Zeng and Sanes (2017): at class levels, cells are either glutamatergic, GABAergic, or non-neuron while, at subclass level, GABAergic neurons can be either Pvalb positive, Vip positive, Sst positive, or Htr3a positive-Vip negative. Furthermore, at type level, the cells are classified according to the expressed Cre line. In fact, some Cre lines have been included in a taxonomy for the first time to our knowledge.
Despite some minor differences, the taxonomy's Cre line disposition proposal is in agreement with the literature about mouse visual cortex neuron types. Furthermore, the Cre lines can be characterized using different FMM elements, such as its waves or parameters, that represent AP differences. In fact, the potential of the FMM parameters to discriminate glutamatergic neurons and the four major types of GABAergic neurons has been proved. Among GABAergic neurons, Pvalb+ have the APs with the highest skewness and the lowest kurtosis, while in APs of Vip+ occurs the opposite. The APs from both Sst+ and Htr3a+ exhibit intermediate characteristics, being the latter subclass particularly heterogeneous.
In short, the proposed taxonomy is hierarchical, continuous, easily reproducible, and based on robust, interpretable, and discriminant features, essential feature properties to successfully solve a classification problem, as many experts on Feature Engineering state (Duboue, 2020; Heaton, 2020 among recent works on the matter). It is relevant to note that many alternative electrophysiological feature proposals lack at least one of these properties. To the best of our knowledge, this is the first study in which the circular order from the principal components is considered. A very simple idea that we hypothesize that can help in the challenges of inferring cellular relationships. However, the aim of this study is not to develop new theories but to present the new approach and the resulting circular taxonomy for mouse Cre lines. Further studies are necessary to contrast the circular taxonomy and the biological evidences.
A limitation of the presented study is that features have only been extracted from a single signal with a single AP generated from a short square stimulus. On the one hand, it remains to be seen if the application of the FMM approach on multiple signals of the same neuron could generate useful features. However, this question is up in the air as the independence of the AP shape from the applied stimulus is assumed by some authors, such as Raghavan et al. (2019), whereas others like de Polavieja et al. (2005) state that the AP shape is affected by the recent history of applied stimuli. On the other hand, the use of the proposed method in multi-AP signals could be profitable, extracting other interesting features such as the interspike distance or the neuron's firing rate.
As future work, the proposed taxonomy could be refined by using transcriptomic features at cell level, not only at Cre line level. Also, the taxonomy should be validated further in other databases. The classifier methods presented in this work would profit from an increased sample size of each neuronal type and could probably discriminate better the different classes. In particular, the Htr3a+ subclass has turned out to particularly problematic to distinguish. However, other authors such as Gouwens et al. (2018) have already remarked that electrophysiological features do not discriminate this neuron type particularly well.
Publicly available datasets were analyzed in this study. This data can be found at: http://celltypes.brain-map.org.
AR-C developed the computational code for data acquisition and analysis, processed and analyzed data, and wrote and revised the manuscript. CR conceived the aims, methodological proposal, conceptual design, and wrote and revised the manuscript. Both authors contributed to the article and approved the submitted version.
The authors gratefully acknowledge the financial support received by the Spanish Ministerio de Ciencia e Innovación, Universidad de Valladolid and Banco Santander [PID2019-106363RB-I00 to CR and Call for predoctoral contracts of the UVa 2020 to AR-C].
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fnhum.2021.684950/full#supplementary-material
ACTD, Allen cell types database; AP, action potential curve; AvNNet, model averaged neural network; CPCA, circular principal components analysis; FMM, frequency modulated Möbius; GBDT, gradient boosting decision trees; L2-6, layers 2 to 6; LDA, linear discriminant analysis; MLE, maximum likelihood estimator; PCA, principal components analysis; RF, random forest; RNA, ribonucleic acid; SDK, software development kit; SVM, support vector machine; Chat, choline o-acetyltransferase; Chrna2, cholinergic receptor nicotinic alpha 2; Ctgf, connective tissue growth factor; Cux2, cut like homeobox 2; Esr2, estrogen receptor 2; Gad2, glutamate decarboxylase 2; Glt25d2, glycosyltransferase 25 domain containing 2; Htr3a, 5-hydroxytryptamine receptor 3A; Ndnf, neuron derived neurotrophic factor; Nkx2.1, NK2 homeobox 1; Nos1, nitric oxide synthase 1; Nr5a1, nuclear receptor subfamily 5 group A member 1; Ntsr1, neurotensin receptor 1; Oxtr, oxytocin receptor; Pvalb, parvalbumin; Rbp4, retinol-binding protein 4; Rorb, RAR related orphan receptor B; Scnn1a, sodium channel epithelial 1 alpha subunit; Sim1, single-minded homolog 1; Slc32a1, solute carrier family 32 member 1; Sst, somatostatin; Tlx3, T-cell leukemia homeobox protein 3; Vip, vasoactive intestinal peptide.
Allen Brain Institute (2015). Allen Cell Types Database - Electrophysiology. Technical report. Available online at: http://help.brain-map.org/download/attachments/8323525/CellTypes_Ephys_Overview.pdf?version=2&modificationDate=1508180425883&api=v2
Argüelles, M., Benavides, C., and Fernández, I. (2014). A new approach to the identification of regional clusters: hierarchical clustering on principal components. Appl. Econ. 46, 2511–2519. doi: 10.1080/00036846.2014.904491
Breiman, L., Cutler, A., Liaw, A., and Wiener, M. (2018). Package 'randomForest' Manual. CRAN. R Package Version 4.6-14. Whitehouse Station.
Chang, W., and Borges Ribeiro, B. (2018). Shinydashboard: Create Dashboards With 'Shiny'. R Package Version 0.7.1. Minneapolis.
Chang, W., Cheng, J., Allaire, J., Xie, Y., and McPherson, J. (2020). Shiny: Web Application Framework for R. R Package Version 1.5.0. Minneapolis.
Chen, T., and Guestrin, C. (2016). “XGBoost: a scalable tree boosting system,” in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD '16 (New York, NY: ACM), 785–794. doi: 10.1145/2939672.2939785
de Polavieja, G. G., Harsch, A., Kleppe, I., Robinson, H. P. C., and Juusola, M. (2005). Stimulus history reliably shapes action potential waveforms of cortical neurons. J. Neurosci. 25, 5657–5665. doi: 10.1523/JNEUROSCI.0242-05.2005
Duboue, P. (2020). The art of Feature Engineering: Essentials for Machine Learning, 1st Edn. Vancouver, BC: Cambridge University Press. doi: 10.1017/9781108671682
Fernández, I., Rodríguez-Collado, A., Larriba, Y., Lamela, A., Canedo, C., and Rueda, C. (2021). FMM: An R package for modeling rhythmic patterns in oscillatory systems. arxiv.org/abs/2105.10168.
Fernandez-Delgado, M., Cernadas, E., Barro, S., and Amorim, D. (2014). Do we need hundreds of classifiers to solve real world classification problems? J. Mach. Learn. Res. 15, 3133–3181.
Gautier, Y., Meurice, P., Coquery, N., Constant, A., Bannier, E., Serrand, Y., et al. (2019). Implementation of a new food picture database in the context of fMRI and visual cognitive food-choice task in healthy volunteers. Front. Psychol. 10:2620. doi: 10.3389/fpsyg.2019.02620
Ghaderi, P., Marateb, H., and Safari, M.-S. (2018). Electrophysiological profiling of neocortical neural subtypes: a semi-supervised method applied to in vivo whole-cell patch-clamp data. Front. Neurosci. 12:823. doi: 10.3389/fnins.2018.00823
Gouwens, N., Berg, J., Feng, D., Sorensen, S., Zeng, H., Hawrylycz, M., et al. (2018). Systematic generation of biophysically detailed models for diverse cortical neuron types. Nat. Commun. 9:710. doi: 10.1038/s41467-017-02718-3
Gouwens, N., Sorensen, S., Berg, J., Lee, C., Jarsky, T., Ting, J., et al. (2019). Classification of electrophysiological and morphological neuron types in the mouse visual cortex. Nat. Neurosci. 22, 1182–1195. doi: 10.1038/s41593-019-0417-0
Gouwens, N. W., Sorensen, S. A., Baftizadeh, F., Budzillo, A., Lee, B. R., Jarsky, T., et al. (2020). Integrated morphoelectric and transcriptomic classification of cortical gabaergic cells. Cell 183, 935–953. doi: 10.1016/j.cell.2020.09.057
Hastie, T., and Tibshirani, R. (1986). Generalized additive models. Stat. Sci. 1, 297–310. doi: 10.1214/ss/1177013604
Hastie, T., Tibshirani, R., and Jerome, F. (2009). The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd Edn. New York, NY: Springer.
Heaton, J. (2020). An empirical analysis of feature engineering for predictive modeling. arxiv.org/abs/1701.07852.
Izenman, A. J. (2008). Modern Multivariate Statistical Techniques: Regression, Classification, and Manifold Learning, 1st Edn. New York, NY: Springer. doi: 10.1007/978-0-387-78189-1
Karatzoglou, A., Smola, A., Hornik, K., and Zeileis, A. (2004). kernlab-an S4 package for kernel methods in R. J. Stat. Softw. 11, 1–20. doi: 10.18637/jss.v011.i09
Lynch, E. P., and Houghton, C. J. (2015). Parameter estimation of neuron models using in-vitro and in-vivo electrophysiological data. Front. Neuroinform. 9:10. doi: 10.3389/fninf.2015.00010
Melzer, S., and Monyer, H. (2020). Diversity and function of corticopetal and corticofugal gabaergic projection neurons. Nat. Rev. Neurosci. 21, 1–17. doi: 10.1038/s41583-020-0344-9
Moore, R., Harrison, A., Mcallister, S., Polson, S., and Wommack, K. E. (2020). Iroki: automatic customization and visualization of phylogenetic trees. PeerJ 8:e8584. doi: 10.7717/peerj.8584
Raghavan, M., Fee, D., and Barkhaus, P. (2019). “Generation and propagation of the action potential,” in Handbook of Clinical Neurology, Vol. 160 (Milwaukee: Elsevier), 3–22. doi: 10.1016/B978-0-444-64032-1.00001-1
Ripley, B. (2020). nnet: Feed-Forward Neural Networks and Multinomial Log-Linear Models. R Package Version 7.3-14. New York, NY.
Rodríguez-Collado, A., and Rueda, C. (2021).A Simple Parametric Representation of the Hodgkin-Huxley Model. PLOS One. Available online at: https://www.biorxiv.org/content/early/2021/01/11/2021.01.11.426189 (accessed July 9, 2021).
Rueda, C., Larriba, Y., and Peddada, S. (2019). Frequency modulated Möbius model accurately predicts rhythmic signals in biological and physical sciences. Sci. Rep. 9, 1–10. doi: 10.1038/s41598-019-54569-1
Rueda, C., Rodríguez-Collado, A., and Larriba, Y. (2021). A novel wave decomposition for oscillatory signals. IEEE Trans. Signal Process. 69, 960–972. doi: 10.1109/TSP.2021.3051428
Scholz, M. (2007). “Analysing periodic phenomena by circular PCA,” in Bioinformatics Research and Development, eds S. Hochreiter and R. Wagner (Berlin; Heidelberg: Springer), 38–47. doi: 10.1007/978-3-540-71233-6_4
Tasic, B., Menon, V., Nguyen, T. N., Kim, S., Jarsky, T., Yao, Z., et al. (2016). Adult mouse cortical cell taxonomy revealed by single cell transcriptomics. Nat. Neurosci. 19, 335–346. doi: 10.1038/nn.4216
Tasic, B., Yao, Z., Graybuck, L., Smith, K., Nguyen, T. N., Bertagnolli, D., et al. (2018). Shared and distinct transcriptomic cell types across neocortical areas. Nature 563, 72–78. doi: 10.1038/s41586-018-0654-5
Teeter, C., Iyer, R., Menon, V., Gouwens, N., Feng, D., Berg, J., et al. (2018). Generalized leaky integrate-and-fire models classify multiple neuron types. Nat. Commun. 9, 1–15. doi: 10.1038/s41467-017-02717-4
Tremblay, R., Lee, S., and Rudy, B. (2016). GABAergic interneurons in the neocortex: from cellular properties to circuits. Neuron 91, 260–292. doi: 10.1016/j.neuron.2016.06.033
Venables, W. N., and Ripley, B. D. (2002). Modern Applied Statistics With S, 4th Edn. New York, NY: Springer. doi: 10.1007/978-0-387-21706-2
Wickham, H. (2016). ggplot2: Elegant Graphics for Data Analysis, 2nd Edn. New York, NY: Springer - Verlag.
Zeng, H., and Sanes, J. (2017). Neuronal cell-type classification: challenges, opportunities and the path forward. Nat. Reviews Neurosci. 18, 530–546. doi: 10.1038/nrn.2017.85
Zhang, C., Liu, C., Zhang, X., and Almpanidis, G. (2017). An up-to-date comparison of state-of-the-art classification algorithms. Expert Syst. Appl. 82, 128–150. doi: 10.1016/j.eswa.2017.04.003
Keywords: neuronal taxonomy, statistical model, cell-type classification, allen cell types database, machine learning, frequency modulated Möbius model, FMM
Citation: Rodríguez-Collado A and Rueda C (2021) Electrophysiological and Transcriptomic Features Reveal a Circular Taxonomy of Cortical Neurons. Front. Hum. Neurosci. 15:684950. doi: 10.3389/fnhum.2021.684950
Received: 24 March 2021; Accepted: 28 June 2021;
Published: 26 July 2021.
Edited by:
Daniela De Bartolo, Sapienza University of Rome, ItalyReviewed by:
Alexey Kozlenkov, Icahn School of Medicine at Mount Sinai, United StatesCopyright © 2021 Rodríguez-Collado and Rueda. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Alejandro Rodríguez-Collado, YWxlamFuZHJvcm9kcmlndWV6Y29sbGFkb0BnbWFpbC5jb20=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.