 Kaijie Xu
Kaijie Xu Xiaoan Tang
Xiaoan Tang Xukun Yin
Xukun Yin Rui Zhang
Rui Zhang- 1School of Electronic Engineering, Xidian University, Xi’an, China
- 2School of Management, Hefei University of Technology, Hefei, China
- 3School of Optoelectronic Engineering, Xidian University, Xi’an, China
- 4State Key Laboratory of Applied Optics, Changchun Institute of Optics, Fine Mechanics and Physics, Chinese Academy of Sciences, Changchun, China
Bi-clustering refers to the task of finding sub-matrices (indexed by a group of columns and a group of rows) within a matrix of data such that the elements of each sub-matrix (data and features) are related in a particular way, for instance, that they are similar with respect to some metric. In this paper, after analyzing the well-known Cheng and Church bi-clustering algorithm which has been proved to be an effective tool for mining co-expressed genes. However, Cheng and Church bi-clustering algorithm and summarizing its limitations (such as interference of random numbers in the greedy strategy; ignoring overlapping bi-clusters), we propose a novel enhancement of the adaptive bi-clustering algorithm, where a shielding complex sub-matrix is constructed to shield the bi-clusters that have been obtained and to discover the overlapping bi-clusters. In the shielding complex sub-matrix, the imaginary and the real parts are used to shield and extend the new bi-clusters, respectively, and to form a series of optimal bi-clusters. To assure that the obtained bi-clusters have no effect on the bi-clusters already produced, a unit impulse signal is introduced to adaptively detect and shield the constructed bi-clusters. Meanwhile, to effectively shield the null data (zero-size data), another unit impulse signal is set for adaptive detecting and shielding. In addition, we add a shielding factor to adjust the mean squared residue score of the rows (or columns), which contains the shielded data of the sub-matrix, to decide whether to retain them or not. We offer a thorough analysis of the developed scheme. The experimental results are in agreement with the theoretical analysis. The results obtained on a publicly available real microarray dataset show the enhancement of the bi-clusters performance thanks to the proposed method.
1 Introduction
As an important technology of data mining and information granular construction (Xu et al., 2022), the traditional clustering algorithms analyze only the properties of the data samples (the number and types of the attributes or variables), but do not focus on the components of data such as Data-table, Data-column, Data-relation etc. This is a major issue affecting the clustering performance (Abe and Yadohisa, 2019), especially when dealing with high-dimensional genes expression data, which motivates the development of the bi-clustering algorithm. Bi-clustering is not only able to reveal the global structure (as the traditional methods do) in data, but also able to discover the local information (it can discover clusters in the feature space and the data space simultaneously). In addition, Bi-clustering technology is also regarded as an effective tool for dealing with the high-dimensional data. Bi-clustering, after its birth, has received much attention and become one of the focal points in the data mining community. Bi-clustering was first introduced by Hartigan (Hu et al., 2019), and has been further developed since Cheng and Church proposed a bi-clustering algorithm based on variance and applied it to gene expression data (Cheng and Church, 2000). Their work remains the most important contribution to the field of bi-clustering research.
At present, bi-clustering is the most widely used technology in the field of bioinformatics. Unlike traditional clustering methods that treat similarity (distance-based measures) as a function of pairs of genes or pairs of conditions, which is not applicable in high-dimensional space, the bi-clustering model measures coherence within the subset of genes and conditions. This model may be particularly useful in disclosing the involvement of genes or conditions in multiple pathways, some of which can only be discovered under the dominance of more consistent ones (Yang et al., 2003). The coherence score (Cheng and Church, 2000) is defined as a symmetric function of genes and conditions involved, and therefore the bi-clustering is a process of simultaneous grouping of genes and conditions. The so-called Mean Squared Residue (MSR) (Cheng and Church, 2000) is employed and applied to expression data transformed by a logarithm and augmented by the additive inverse. Bi-clustering is also referred in the literature as co-clustering and direct clustering, among other names, and has also been used in fields such as information retrieval and data mining.
Popular bi-clustering algorithms, such as Cheng and Church (CC) algorithm, FLOC (Yang et al., 2005), Plaid (Lazzeroni and Owen, 2000), OPSM (Ben-Dor et al., 2003), ISA (Bergmann et al., 2003), Spectral (Kluger et al., 2003), xMOTIFs (Murali and Kasif, 2003), and BiMax (Prelic et al., 2006) have drawn much attention in the literature. Newer algorithms, such as Bayesian Bi-clustering (Gu and Liu, 2007), COALESCE (Huttenhower et al., 2009), CPB (Bozdag et al., 2009), QUBIC (Li et al., 2009), and FABIA (Hochreiter et al., 2010) have not been extensively studied. Among them, the CC algorithm is the earliest and most studied one, and the newer algorithms are mostly based on the idea of the CC algorithm.
So far, a number of bi-clustering algorithms have been proposed; however, as of now the research on the bi-clustering is still at its initial stage. For the enrichment and development of the bi-clustering algorithms, in this paper, we first present a brief analysis of the well-known CC algorithm and elaborate on some related bi-clustering concepts. Meanwhile we discuss the advantages and drawbacks of the CC algorithm. In reference to the drawbacks of the CC algorithm (such as interference of random numbers in the greedy strategy; ignoring overlapping bi-clusters), we design an improved adaptive bi-clustering algorithm by building a shielding complex sub-matrix to adaptively shield the obtained bi-clusters and to discover new ones.
In the implementation of the new bi-clustering algorithm, we add an imaginary part to the constructed bi-clusters to increase their MSR and also set a shielding factor to adjust the MSR increments of the row (or column) which contains elements in the constructed bi-clusters to effectively shield the constructed bi-clusters. In addition, we set two unit impulse signals to adaptively detect the constructed bi-clusters and the null data (zero-size data) of the dataset to avoid the over-shielding and the shielding failure, so as to adaptively improve the bi-clusters. A detailed analysis and a comprehensive suite of experiments are provided. Obviously, the proposed scheme is also applicable to other similar bi-clustering techniques. The experimental studies demonstrate that the proposed approach achieves better performance compared with that of the well-known CC algorithm. To the best of our knowledge, the idea of the proposed approach has not been considered in the previous studies.
This paper is organized as follows. The CC algorithm and bi-clustering related ideas are briefly reviewed in Section 2. A novel enhancement of the adaptive bi-clustering algorithm is detailed in Section 3. Section 4 includes experimental setup and covers an analysis of completed experiments. Section 5 contains some conclusions.
2 Bi-clustering: Definitions and problem formulation
Consider a sample-feature expression matrix
Given a data matrix A, the bi-clustering problem is to design algorithms to find bi-clusters
For a bi-cluster Bk=(Sk, Fk), several means based on the bi-cluster are defined. The mean of row i of Bk is (Fan et al., 2010)
the mean of column j of Bk is
and the mean of all the entries in Bk is
The residue (Hu et al., 2019) of the entry aij in bi-cluster Bk is
the variance of bi-cluster Bk is
and mean squared residue (MSR) score (Xhafa et al., 2011) of the bi-cluster Bk is
A sub-matrix Bk is called a δ-bi-cluster if Hk
Bi-clusters can thus be seen as sub-matrices of a matrix representing features of elements. It should be noted that bi-clusters need not to be exclusive nor exhaustive (Xhafa et al., 2011). The well-known CC algorithm obtains an optimum bi-cluster (get as large a δ-bi-cluster as possible) each time by adding and deleting some rows or columns in the original data matrix to reduce the MSR of the whole matrix. The bi-clustering result produced each time is shielded by random numbers. However, the random numbers will result in the phenomenon of interference of random numbers, which in turn impacts the discovery of high quality bi-clusters (Cheng and Church, 2000; Yang et al., 2005). Eventually, by the action of random numbers, there would be some elements not satisfying the condition of bi-clustering mistakenly clustered; in addition, the overlapping bi-clusters will also be ignored.
An example of the random number interference is shown in Table 1. Assume that 0 and 90 in the shadowed entries are clustered in the previous iteration, and replaced by the random numbers 6 and 9 in brackets, and this makes the sub-matrix (such as Bk=(Sk, Fk), Sk = {2, 4, 5}, Fk = {1, 2, 4}) which is not a bi-cluster, satisfy the condition of the bi-cluster. This shows the unreasonable aspect of the algorithm.
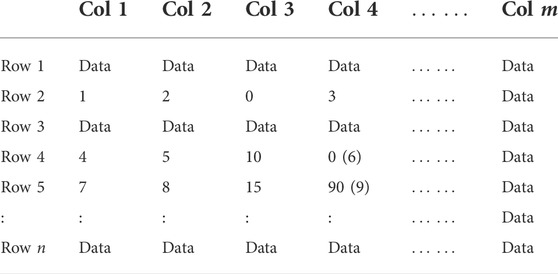
TABLE 1. An example of the random number interference.
3 Complex sub-matrix shielding model
In connection with this issue above, this paper presents a new complex sub-matrix shielding model and the solutions are figured out. The proposed approach focuses on improving the iteration in the CC algorithm, which must use random numbers to replace the bi-clustering results. However, the new complex sub-matrix shielding can help the algorithm complete the bi-clustering and avoid the interference of the random numbers in the greedy strategy.
3.1 Construction of a shielding complex sub-matrix
Suppose that Bk=(Sk, Fk) is a bi-cluster of the kth bi-clustering searching. To find a (k+1)th new bi-cluster, the first k bi-clusters that have been obtained should be shielded. When searching the (k+1)th bi-cluster based on the first k shielded bi-clusters, on the one hand, it is desired that the first k bi-clusters be temporarily ignored (to find a new bi-cluster); on the other hand, it is desired the (k+1)th bi-cluster should contain the elements that have been clustered in the first k shielded bi-clusters and satisfy the prespecified condition of bi-lustering. To meet the above requirements, a shielding complex sub-matrix is built as
where 1j is the imaginary unit,
3.2 Implementation
By using the shielding complex sub-matrix
First, the first bi-cluster B1=(S1, F1) is found with the CC algorithm and shielded by using the proposed approach. When searching the kth new bi-cluster Bk
It is easy to see that
Meanwhile, with the aid of the shielding factor
After finishing the shielding, a new (kth) bi-cluster is obtained. To make the new bi-cluster contain all the elements in the dataset that satisfy the prespecified condition, what we need to do next is to add the rows and columns that satisfy the prespecified condition. To avoid the disturbance coming from the shielded data, the rows and columns can be added without violating the requirements, i.e.,
In the processes of deletion and addition of the rows and columns, the MSR is constantly recalculated and improved until the new optimal bi-cluster is obtained. Obviously, the proposed method can avoid the phenomenon of random interference which impacts the discovery of high quality bi-clusters, and can discover overlapping bi-clusters.
4 Experimental studies
The following experiments are designed to test the performance of the proposed approach, where a well-known gene expression dataset yeast (http://arep.med.harvard.edu/biclustering/yeast.matrix) which is one of the most commonly used datasets (Cheng and Church, 2000) in bi-clustering is used. Two also gene datasets names: west-2001 and laiho-2007 (Li and Wong, 2019) are also used.
The methods try to discover 50 bi-clusters (co-expressed) with the MSR score not larger than 300. The MSR score and the sizes of the bi-clusters (co-expressed genes) which are commonly used to estimate (and validate) the performance of the bi-clustering algorithms is used in the experiments.
For each dataset the algorithms are repeated 10 times and the means and the standard deviations of the experimental results are recorded. The experimental results are plotted in Figures 1–4. It is clear that the proposed algorithm is effective in discovering the quality of bi-clusters with low MSR scores. In addition, the bi-clusters obtained by the proposed method also have larger sizes than discovered by CC method. Thus, the experimental results are in agreement with the theoretical analysis, and compared with the well-known CC method, the proposed method exhibits visible advantages.
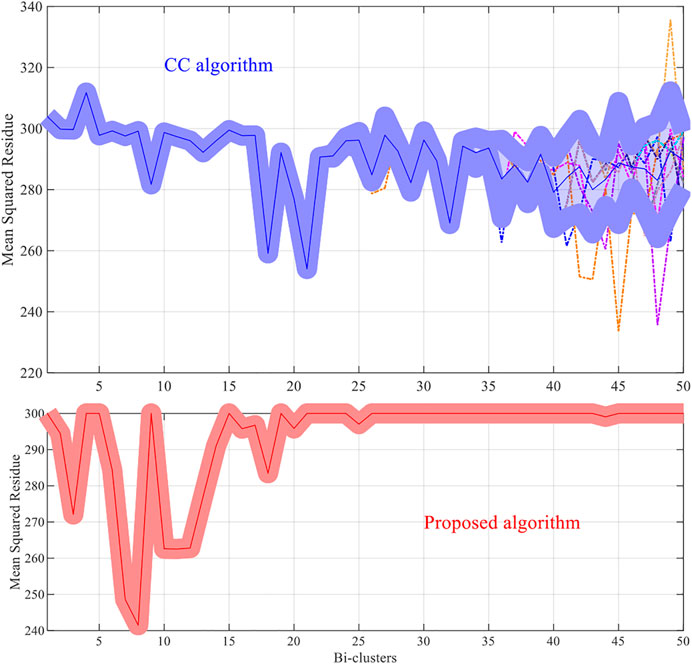
FIGURE 1. Results of the MSR scores of the yeast dataset.
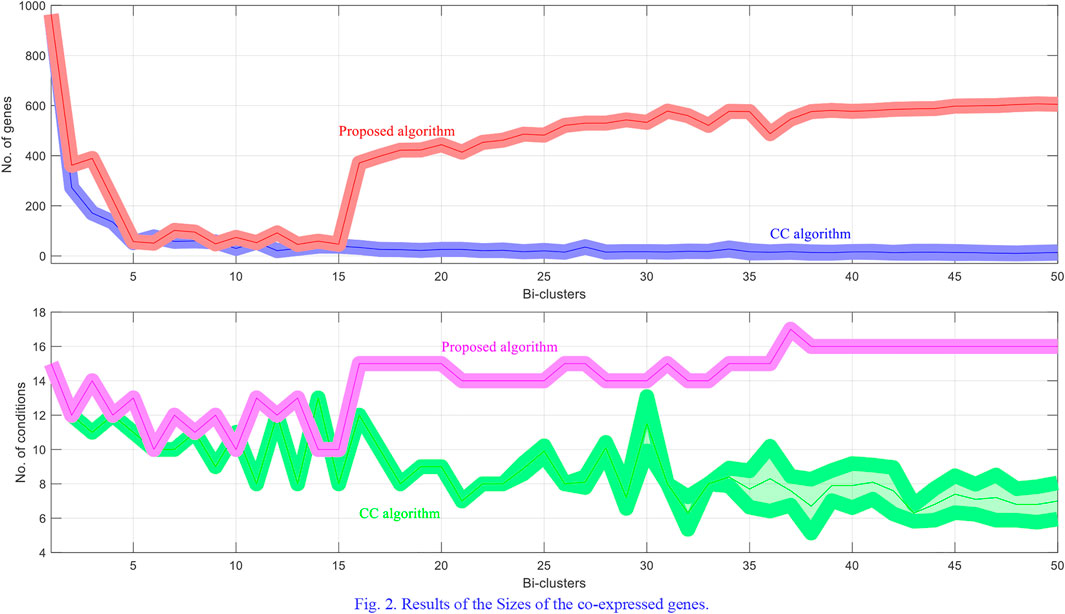
FIGURE 2. Results of the Sizes of the co-expressed genes.
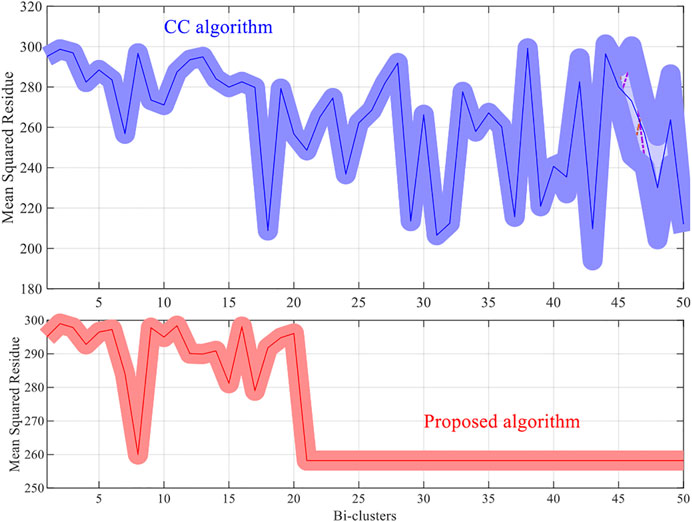
FIGURE 3. Results of the MSR scores of the west-2001 dataset.
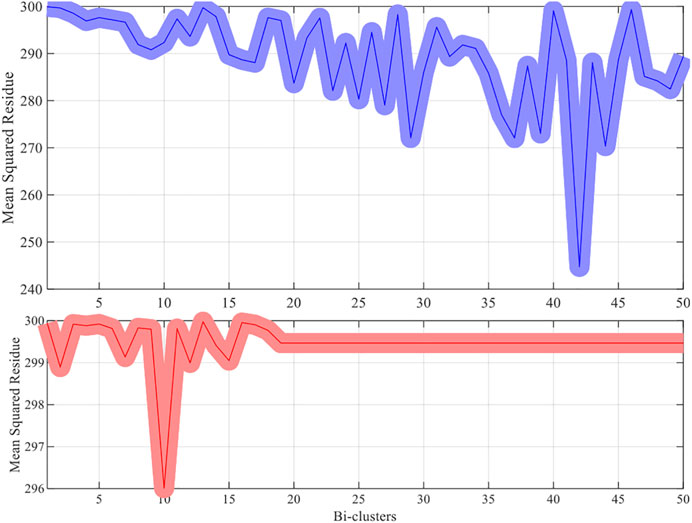
FIGURE 4. Results of the MSR scores of the west-2001 dataset.
5 Conclusion
In this study, we designed a novel enhancement adaptive bi-clustering algorithm. During the design process, a shielding complex sub-matrix is built, in which two signals are set to detect the characteristics of dataset and adaptively improve the bi-clusters. We conduct theoretical analysis and offer a comprehensive suite of experiments. Both the theoretical and experimental results are presented to verify the validity of the proposed method. Experiments results show that the proposed algorithm outperforms the CC algorithm in finding the bi-clusters. On the one hand the proposed algorithm can discover overlapping bi-clusters and the MSR is reduced and the sizes of the bi-clusters are increased at the same time. On the other hand, the proposed algorithm is very stable. To the best of our knowledge, this research scheme is first proposed which steadily improves the performance of the bi-clustering. Our result opens a specific way for bi-clustering research, and suggests a far-reaching question for further research: How to discover multiple bi-clusters during a search process? This may open up a new direction of future research pursuits.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
Author contributions
All the authors made significant contributions to the work. The idea was proposed by KX; XT and RZ simulated the algorithm; XY designed the experiments and polish the English; KX and XT wrote the paper. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Natural Science Foundation of China under Grant Nos. 62101400, 72101075, and 61971349, and in part by the National Key R&D Program of China (2021YFF0704600), Natural Science Foundation of Anhui Province of China under Grant No. 2108085QG289, Guangdong Basic and Applied Basic Research Foundation under Grant Nos. 2020A1515111012, and the Fundamental Research Funds for the Central Universities under Grant No. JZ2022HGTB0286.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Abe, H., and Yadohisa, H. (2019). Orthogonal nonnegative matrix tri-factorization based on Tweedie distributions. Adv. Data Anal. Classif. 13 (4), 825–853. doi:10.1007/s11634-018-0348-8
Ben-Dor, A., Chor, B., Karp, R., and Yakhini, Z. (2003). Discovering local structure in gene expression data: The order-preserving submatrix problem. J. Comput. Biol. 10 (3), 373–384. doi:10.1089/10665270360688075
Bergmann, S., Ihmels, J., and Barkai, N. (2003). Iterative signature algorithm for the analysis of large-scale gene expression data. Phys. Rev. E Stat. Nonlin. Soft Matter Phys. 67 (1), 031902. doi:10.1103/PhysRevE.67.031902
Bozdag, D., Parvin, J. D., and Catalyurek, U. V. (2009). “A biclustering method to discover co-regulated genes using diverse gene expression datasets,” in Proc. Proceedings of the 1st International Conference on Bioinformatics and Computational Biology, Niagara Falls New York, August 2 - 4, 2010, 151–163.
Cheng, Y., and Church, G. M. (2000). Biclustering of expression data. Proc. Int. Conf. Intell. Syst. Mol. Biol. 8, 93–103. ISM.
Fan, N., Boyko, N., and Panos, M. (2010). “Pardalos recent advances of data biclustering with application in computational neuroscience,” in Computational Neuroscience. (New York, USA: Springer), 85–112.
Gu, J., and Liu, J. S. (2007). Bayesian biclustering of gene expression data. BMC Genomics 1, 25–28. doi:10.1186/1471-2164-9-S1-S4
Hanyu, E., Cui, Y., Pedrycz, W., and Li, Z. (2022). Fuzzy relational matrix factorization and its granular characterization in data description. IEEE Trans. Fuzzy Syst. 30 (3), 794–804. doi:10.1109/tfuzz.2020.3048577
Hochreiter, S., Bodenhofer, U., Heusel, M., Mayr, A., Mitterecker, A., Kasim, A., et al. (2010). FABIA: Factor analysis for bicluster acquisition. Bioinformatics 26 (12), 1520–1527. doi:10.1093/bioinformatics/btq227
Hu, H., Wang, H., Bai, Y., and Liu, M. (2019). Determination of endometrial carcinoma with gene expression based on optimized Elman neural network. Appl. Math. Comput. 341, 204–214. doi:10.1016/j.amc.2018.09.005
Huttenhower, C., Mutungu, K. T., Indik, N., Yang, W., Schroeder, M., Forman, J. J., et al. (2009). Detailing regulatory networks through large scale data integration. Bioinformatics 25 (24), 3267–3274. doi:10.1093/bioinformatics/btp588
Kluger, Y., Basri, R., Chang, T., and Gerstein, M. (2003). Spectral biclustering of microarray data: Coclustering genes and conditions. Genome Res. 13 (4), 703–716. doi:10.1101/gr.648603
Lazzeroni, L., and Owen, A. (2000). Plaid models for gene expression data. Stat. Sin. 12 (1), 61–86.
Li, G., Ma, Q., Tang, H., Paterson, A. H., and Xu, Y. (2009). QUBIC: A qualitative biclustering algorithm for analyses of gene expression data. Nucleic Acids Res. 37 (15), e101. doi:10.1093/nar/gkp491
Li, X., and Wong, K. -C. (2019). Evolutionary multiobjective clustering and its applications to patient stratification. IEEE Trans. Cybern. 49 (5), 1680–1693. doi:10.1109/TCYB.2018.2817480
Murali, T. M., and Kasif, S. (2003). “Extracting conserved gene expression motifs from gene expression data,” in Pacific Symp. Biocomputing, Lihue, Hawaii, January 3-7, 2003, 77–88.
Prelic, A., Bleuler, S., Zimmermann, P., Wille, A., Buhlmann, P., Gruissem, W., et al. (2006). A systematic comparison and evaluation of biclustering methods for gene expression data. Bioinformatics 22 (9), 1122–1129. doi:10.1093/bioinformatics/btl060\
Tian, G., Yuan, G., Aleksandrov, A., Zhang, T., Li, Z., Fathollahi-Fard, A. M., et al. (2022). Recycling of spent lithium-ion batteries: A comprehensive review for identification of main challenges and future research trends. Sustain. Energy Technol. Assessments 53, 102447. doi:10.1016/j.seta.2022.102447
Xhafa, F., Caballe, S., and Barolli, L. (2011). “Using bi-clustering algorithm for analyzing online users activity in a virtual campus,” in International Conference on Intelligent NETWORKING and Collaborative Systems, Thessaloniki, Greece, 24-26 November 2010, 214–221.
Xu, K. J., Pedrycz, W., Li, Z. W., and Nie, W. K. (2019). High-accuracy signal subspace separation algorithm based on Gaussian kernel soft partition. IEEE Trans. Ind. Electron. 66 (1), 491–499. doi:10.1109/tie.2018.2823666
Xu, K., Pedrycz, W., and Li, Z. (2022). Granular computing: An augmented scheme of degranulation through a modified partition matrix. Fuzzy Sets Syst. 440 (6), 131–148. doi:10.1016/j.fss.2021.06.001
Yang, J., Wang, H., and Wang, W. (2003). “Enhanced biclustering on expression data,” in Third IEEE Symposium on Bioinformatics and Bioengineering, Bethesda, MD, USA, 12-12 March 2003, 321–327.
Keywords: bi-clustering, adaptive control, shielding factor, mean squared residue (MSR), co-expressed genes
Citation: Xu K, Tang X, Yin X and Zhang R (2022) An enhanced adaptive Bi-clustering algorithm through building a shielding complex sub-matrix. Front. Genet. 13:996941. doi: 10.3389/fgene.2022.996941
Received: 19 July 2022; Accepted: 21 September 2022;
Published: 07 October 2022.
Edited by:
Yinghua Shen, Chongqing University, ChinaReviewed by:
Hengrong Ju, Nantong University, ChinaHanyu E, University of Alberta, Canada
Yongming He, National University of Defense Technology, China
Copyright © 2022 Xu, Tang, Yin and Zhang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xiaoan Tang, c2ljaHVhbnNoZW5neGlhb2FuQDE2My5jb20=; Xukun Yin, eGt5aW5AeGlkaWFuLmVkdS5jbg==