 Ilara G. F. Budzinski1
Ilara G. F. Budzinski1 Paula O. Camargo1Samara M. C. Lemos1,2
Paula O. Camargo1Samara M. C. Lemos1,2 Romain Guyot3Natália F. Calzado1
Romain Guyot3Natália F. Calzado1 Suzana T. Ivamoto-Suzuki1
Suzana T. Ivamoto-Suzuki1 Douglas S. Domingues1,4*
Douglas S. Domingues1,4*- 1Group of Genomics and Transcriptomes in Plants, Department of Biodiversity, Institute of Biosciences, São Paulo State University, UNESP, Rio Claro, Brazil
- 2Graduate Program in Biological Sciences (Genetics), Institute of Biosciences, São Paulo State University, UNESP, Botucatu, Brazil
- 3Institut de Recherche pour le Développement (IRD), Université Montpellier, Montpellier, France
- 4Department of Genetics, “Luiz de Queiroz” College of Agriculture, University of São Paulo, ESALQ/USP, Piracicaba, Brazil
Introduction
Plants have the capacity to enter a state of alert that enables them to respond rapidly and robustly after exposure to stress (Aranega-Bou et al., 2014). This phenomenon is known as priming and can be described as an induced state whereby plants are pre-exposed to an inducing agent (elicitor), thus improving their perception and/or amplification of defense response-inducing signals (Aranega-Bou et al., 2014; Tugizimana et al., 2018). Hexanoic acid (Hx), a monocarboxylic acid, is a natural priming agent with proven efficiency in a wide range of host plants and pathogens (Llorens et al., 2016), including coffee pathogens. Coffee (Coffea spp.) is one of the most important agricultural commodities in the world. Brazil is the largest producer and exporter of Coffea arabica L. (Brazilian Coffee Exporters Council, 2021). The genus Coffea comprises 124 species (Davis et al., 2011). The most planted one is C. arabica, the only allotetraploid species in the genus. As many other plants, Coffea spp. are sensitive to a diverse range of biotic and abiotic stress. It is known that priming leads to changes at the transcriptional, physiological, metabolic and epigenetic levels (Baccelli et al., 2020). A transcriptional reprogramming may occur after priming stimulation, affecting a huge number of genes (Cervantes-Gámez et al., 2016; Baccelli et al., 2020). Within this context, our aim was to investigate the effect per se of Hx application. We hypothesize if Hx application could modulate genes related to defense response, in C. arabica, being a potential eliciting agent to this crop. To test this, Hx was applied in the roots of two Brazilian C. arabica cultivars: Catuaí Vermelho and Obatã. Cultivars were chosen based on their distinct breeding histories and contrasting resistance to rust, the major disease in Arabica coffee worldwide (Talhinhas et al., 2017). Catuaí Vermelho is susceptible to rust, and is one of the most planted cultivars in Brazil, while Obatã is described as a moderately resistant cultivar (Del Grossi et al., 2013). In the present work, transcriptomic analysis of roots were performed, revealing different molecular responses. Based on FPKM ratio and statistical analyses, 1,545 differentially expressed genes (DEGs) were found. Functional annotation of DEGs through Blast2GO showed that primary, organic substance and cellular metabolic processes were mainly affected by priming, in both cultivars. Here, we present an RNA-seq dataset containing raw files and an initial exploration of differentially expressed genes in two C. arabica cultivars. Besides, these data could contribute to the identification of key genes differentially expressed in response to Hx.
Material and methods
Plant material
Plant material and experimental setup used in this work was the same described in a previous publication from our group (Budzinski et al., 2021).
Two commercial cultivars of C. arabica (five-month-old plants) were used, Catuaí Vermelho IAC 144 and Obatã IAC 1669-20. Both cultivars are inbred lines of C. arabica (Maluf et al., 2005); however, Catuaí is derived from a cross between Catuaí Amarelo 476 × Mundo Novo 374-19, while Obatã is derived from interspecific crosses between (Villa Sarchi × Hybrid of Timor) × Catuaí Vermelho; clarifying that Villa Sarchi is a C. arabica cultivar and Hybrid of Timor is a natural C. arabica x C. canephora hybrid (Lashermes et al., 2000; Maluf et al., 2005). These cultivars were chosen due to their contrasting response to rust, with Obatã being the resistant one (Maluf et al., 2005; Krohling et al., 2018). Plants were selected based on size uniformity and were transferred to pots containing 3 L of aerated nutrient solution (ANS), adapted from Clark, 1975) by de Carvalho et al. (2013). The experiment was carried out as described in Silva et al. (2020), under controlled temperature (23 ± 2°C) and light/dark cycle (12h/12h, photosynthetically active photon flux density of ∼400 μmol m−2.s−1). The following treatments were applied: (a) ANS (control); (b) ANS + hexanoic acid (Merck, final concentration 0.55 mM) for 48 h. Three plants per pot were grown into six plastic pots in which three pots received each treatment. The experiments were repeated 3 times to obtain biological replicates. The potted plants were grouped in “pools” (made of 9–18 plants), which were considered a biological replicate. Three biological replicates were used. We collected plant secondary roots within the 3rd hour of the light period and stored at -80°C for further analyses.
Total RNA extraction and quality control
All steps from total RNA extraction until gene expression analysis were the same as described in Budzinski et al. (2021).
Total RNA from root pools were isolated using the RNeasy Plant kit (Qiagen, Hilden, North Rhine-Westphalia, Germany). Total RNA samples were purified using the RNeasy Minielute Cleanup kit (Qiagen, Hilden, North Rhine-Westphalia, Germany). The purity of RNA was determined using a NanoDrop ND-100 spectrophotometer (Thermo Scientific, San Jose, CA, United States). RNA concentrations were measured by a Qubit fluorometer (Thermo Fisher Scientific, Wilmington, DE, United States).
Library preparation, and RNA-seq
Poly(A) RNA sequencing library was prepared following Illumina’s TruSeq-stranded-mRNA sample preparation protocol (Illumina Technologies, SanDiego, CA). Paired-end sequencing (2 X 150 bp) was performed on Illumina’s NovaSeq 6000 sequencing system at LC Sciences (Houston, TX, United States). Data was deposited into the European Nucleotide Archive (ENA), submission PRJEB52366.
RNAseq analysis and gene expression analysis
All steps mentioned here are the same as described in Budzinski et al. (2021). Adaptor contamination, low quality bases and undetermined bases were removed by using Cutadapt (Martin, 2011) and in house PERL scripts. Sequence quality was verified using FastQC (Andrews, 2010). HISAT2 (Kim et al., 2015) was used to map reads to the Coffea arabica genome (ftp://ftp.ncbi.nlm.nih.gov/genomes/all/GCF/003/713/225/GCF_003713225.1_Cara_1.0/).
StringTie (Pertea et al., 2015) was used to assemble the mapped reads and to detect the expression level for mRNAs by calculating FPKM. The differentially expressed genes (DEGs) were selected with log2 (fold change) >1 or log2 (fold change) <-1 and with statistical significance (p value <0.05) by R package edgeR (Robinson et al., 2010). A second analysis was done on the differentially expressed mRNAs and only the ones with FPKM (ratio) ≥ 2 or FPKM (ratio) ≤ -2; coefficient of variation ≤30% and average FPKM ≥5 were selected for further analyses. Genes found specifically in one condition (control or plants exposed to Hx) were also described as DEGs.
Sequence annotation and gene ontology (GO) enrichment analysis of DEGs were performed using Blast2GO (Conesa et al., 2005), at the BioBam (Götz et al., 2008) platform. Sequences were annotated by blasting nucleotide sequences against the NCBI NR database (BLASTX, evalue ≤1.10−5). The hypergeometric distribution was used to test whether the GO function set was significantly enriched (p < 0.05). Pathway mapping was done using MapMan software (Thimm et al., 2004) with the Arabidopsis thaliana mapping file (http://mapman.gabipd.org/). TAIR IDs were retrieved from NCBI (https://www.ncbi.nlm.nih.gov).
Overall data annotation, differentially expressed genes and gene ontology analysis
Quality control and mapping information are available in Table 1. About 67.12 Gb total clean bases were obtained by RNA-seq after quality check, with an average of 5.6 Gb for each sample. The lowest value of Q30 (percentage of bases with sequencing error rate lower than 1∘) was 97.36%. The GC content ranged from 45 to 52%.
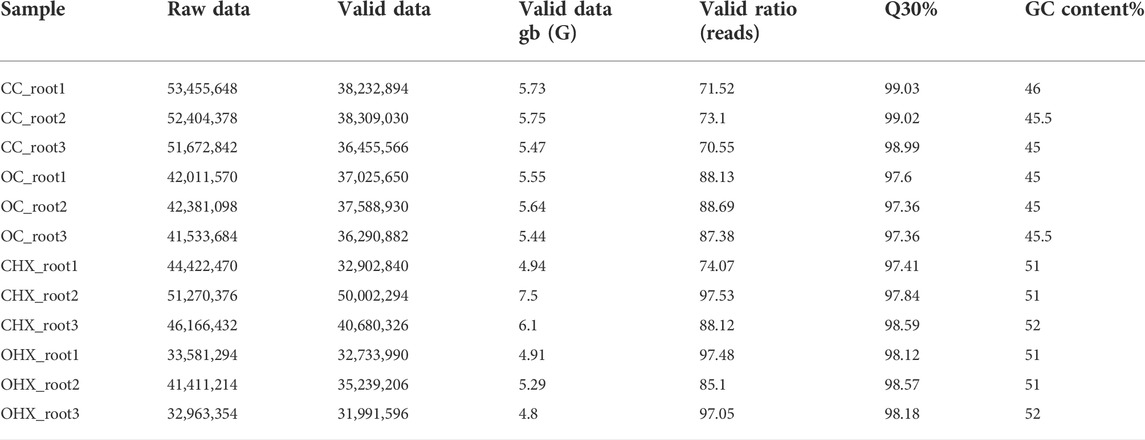
TABLE 1. Summary of sequencing data quality
As a preliminary analysis to identify genes and functional categories potentially modulated by Hx application, the first step of our work was to identify the DEGs based on FPKM and statistical analysis. Based on FPKM ratio and statistical analyses, 1,545 DEGs were found in total, 557 and 988 in Catuaí and Obatã, respectively (Supplementary Table S1). From these, 157 DEGs were found in both cultivars, while 400 and 831 DEGs were specifically found in Catuaí and Obatã cultivars, respectively (Supplementary Tables S2, S3). We hypothesize that the discrepancy between the number of specific DGEs, found in each cultivar, is related to differences in rust resistance, reinforcing that molecular mechanisms of defense are differentially recruited depending on cultivar tolerance. Most of the DEGs have a role in plant defense, indicating the modulation of this mechanism in roots by priming. Blast2GO analysis showed that primary, organic substance and cellular metabolic processes were mainly affected by priming, followed by response to stress, small molecule metabolic process and regulation of cellular process (Figure 1, Supplementary Table S5). Pathway analysis of DEGs using MapMan showed differences in the activity of cellular metabolisms due to Hx (Supplementary Table S3). The dataset presented here indicates that hexanoic acid modulates plant defense mechanisms in C. arabica. Moreover, we are providing useful data for further investigations on C. arabica root responses to Hx.

FIGURE 1. Gene ontology (GO) functional enrichment analysis of DEGs from C. arabica Catuaí and Obatã cultivars.
Data availability statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: https://www.ebi.ac.uk/ena, PRJEB52366. All supplementary files are available on https://doi.org/10.5281/zenodo.6467813.
Author contributions
Conceptualization, Project Administration, Funding Acquisition, Supervision: DD. Data Curation, Investigation: PC, SL, RG, NC, STI-S. Formal Analysis, Validation, Visualization: IB. Writing—Original Draft Preparation, Writing—Review and Editing: IB, DD.
Funding
This research was funded by Fundação de Amparo à Pesquisa do Estado de São Paulo (FAPESP), grant number #2016/10896-0 and CAPES-PrInt Program 2346/2018 (process 88881.310767/2018-01). IB, NC and SL were financed in part by the Brazilian Federal Agency for Support and Evaluation of Graduate Education (CAPES)—Finance Code 001.
Acknowledgments
IB acknowledges the scholarship granted from the Brazilian Federal Agency for Support and Evaluation of Graduate Education (CAPES), in the scope of the Program CAPES-PrInt, process number 88887.310463/2018-00, International Cooperation Project number 88887.512173/2020-00. SL also acknowledges a CAPES fellowship, process number 88887.570128/2020-00. STI-S. acknowledges FAPESP for providing a post-doctoral fellowship, process number #2017/01455-2. DD also acknowledges CNPq for a research productivity fellowship (process number #312823/2019-3).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fgene.2022.925811/full#supplementary-material
References
Andrews, S. (2010). FastQC: A quality control tool for high throughput sequence data. Available at: http://www.bioinformatics.babraham.ac.uk/projects/fastqc
Aranega-Bou, P., Leyva, M., Finiti, I., Garcia-Agustin, P., and Gonzalez-Bosch, C. (2014). Priming of plant resistance by natural compounds. Hexanoic acid as a model. Front. Plant Sci. 5, 488. doi:10.3389/fpls.2014.00488
Baccelli, I., Benny, J., Caruso, T., and Martinelli, F. (2020). The priming fingerprint on the plant transcriptome investigated through meta-analysis of RNA-Seq data. Eur. J. Plant Pathol. 156, 779–797. doi:10.1007/s10658-019-01928-3
Brazilian Coffee Exporters Council (Cecafe) (2021). Production. Available at: https://www.cecafe.com.br/en/about-coffee/production.
Budzinski, I. G. F., Camargo, P. O., Rosa, R. S., Calzado, N. F., Ivamoto-Suzuki, S. T., and Domingues, D. S. (2021). Transcriptome analyses of leaves reveal that hexanoic acid priming differentially regulate gene expression in contrasting coffea arabica cultivars. Front. Sustain. Food Syst. 5. doi:10.3389/fsufs.2021.735893
Cervantes-Gámez, R. G., Bueno-Ibarra, M. A., Cruz-Mendívil, A., Calderón-Vázquez, C. L., Ramírez-Douriet, C. M., Maldonado-Mendoza, I. E., et al. (2016). Arbuscular mycorrhizal symbiosis-induced expression changes in Solanum lycopersicum leaves revealed by RNA-seq analysis. Plant Mol. Biol. Rep. 34, 89–102. doi:10.1007/s11105-015-0903-9
Conesa, A., Götz, S., García-Gómez, J. M., Terol, J., Talón, M., Robles, M., et al. (2005). Blast2GO: A universal tool for annotation, visualization and analysis in functional genomics research. Bioinformatics 21, 3674–3676. doi:10.1093/bioinformatics/bti610
Clark, R. B. (1975). Characterization of phosphatase of intact maize roots. J. Agric. Food Chem. 23, 458–460.
Davis, A. P., Tosh, J., Ruch, N., and Fay, M. F. (2011). Growing coffee: Psilanthus (Rubiaceae) subsumed on the basis of molecular and morphological data; implications for the size, morphology, distribution and evolutionary history of Coffea. Bot. J. Linn. Soc. 167 (4), 357–377. doi:10.1111/j.1095-8339.2011.01177.x
de Carvalho, K., Bespalhok Filho, J. C., dos Santos, T. B., de Souza, S. G. H., Vieira, L. G. E., Pereira, L. F. P., et al. (2013). Nitrogen starvation, salt and heat stress in coffee (Coffea arabica L.): Identification and validation of new genes for qPCR normalization. Mol. Biotechnol. 53, 315–325.
Del Grossi, L., Sera, T., Sera, G. H., Fonseca, I., Ito, D. S., Shigueoka, L. H., et al. (2013). Rust resistance in Arabic coffee cultivars in northern paraná. Braz. Arch. Biol. Technol. 56, 27–33. doi:10.1590/s1516-89132013000100004
Götz, S., Garcia-Gomez, J. M., Terol, J., Williams, T. D., Nagaraj, S. H., Nueda, M. J., et al. (2008). High-throughput functional annotation and data mining with the Blast2GO suite. Nucleic Acids Res. 36, 3420–3435. doi:10.1093/nar/gkn176
Kim, D., Langmead, B., and Salzberg, S. L. (2015). HISAT: A fast spliced aligner with low memory requirements. Nat. Methods 12, 357–360.
Krohling, C. A., Matiello, J. B., de Almeida, S. R., Eutrópio, F. J., and de Siqueira Carvalho, C. H. (2018). Adaptation of progenies/cultivars of arabica coffee (coffea arabica l.) in mountainous edafoclimatic conditions. Coffee Sci. 13, 198–209. doi:10.25186/cs.v13i2.1417
Lashermes, P., Andrzejewski, S., Bertrand, B., Combes, M. C., Dussert, S., Graziosi, G., et al. (2000). Molecular analysis of introgressive breeding in coffee (Coffea arabica L.). Theor. Appl. Genet. 100, 139–146. doi:10.1007/s001220050019
Llorens, E., Camañes, G., Lapeña, L., and García-Agustín, P. (2016). Priming by hexanoic acid induce activation of mevalonic and linolenic pathways and promotes the emission of plant volatiles. Front. Plant Sci. 7, 495. doi:10.3389/fpls.2016.00495
Maluf, M. P., Silvestrini, M., Ruggiero, L. M. C., Filho, O. G., and Colombo, C. A. (2005). Genetic diversity of cultivated Coffea arabica inbred lines assessed by RAPD, AFLP and SSR marker systems. Sci. Agric. 62, 366–373. doi:10.1590/s0103-90162005000400010
Martin, M. (2011). Cutadapt removes adapter sequences from high-throughput sequencing reads. EMBnet 17, 10–12.
Pertea, M., Pertea, G. M., Antonescu, C. M., Chang, T.-C., Mendell, J. T., and Salzberg, S. L. (2015). StringTie enables improved reconstruction of a transcriptome from RNA-seq reads. Nat. Biotechnol. 33, 290–295.
Robinson, M., McCarthy, D. J., and Smyth, G. K. (2010). edgeR: a Bioconductor package for differential expression analysis of digital gene expression data. Bioinformatics 26, 139–140. doi:10.1093/bioinformatics/btp616
Silva, N., Ivamoto-Suzuki, S. T., Camargo, P. O., Rosa, R. S., Pereira, L. F. P., and Domingues, D. S. (2020). Low-copy genes in terpenoid metabolism: The evolution and expression of MVK and DXR genes in angiosperms. Plants 9, 525. doi:10.3390/plants9040525
Talhinhas, P., Batista, D., Diniz, I., Vieira, A., Silva, D. N., Loureiro, A., et al. (2017). The coffee leaf rust pathogen hemileia vastatrix: One and a half centuries around the tropics. Mol. Plant Pathol. 18 (8), 1039–1051. doi:10.1111/mpp.12512
Thimm, O., Bläsing, O., Gibon, Y., Nagel, A., Meyer, S., Krüger, P., et al. (2004). MAPMAN: A user-driven tool to display genomics data sets onto diagrams of metabolic pathways and other biological processes. Plant J. 37, 914–939.
Keywords: RNA-seq, coffee, hexanoic acid, priming agent, elicitation, root
Citation: Budzinski IGF, Camargo PO, Lemos SMC, Guyot R, Calzado NF, Ivamoto-Suzuki ST and Domingues DS (2022) Transcriptomic alterations in roots of two contrasting Coffea arabica cultivars after hexanoic acid priming. Front. Genet. 13:925811. doi: 10.3389/fgene.2022.925811
Received: 21 April 2022; Accepted: 13 October 2022;
Published: 28 October 2022.
Edited by:
Andrew H Paterson, University of Georgia, United StatesReviewed by:
Isabel Marques, University of Lisbon, PortugalMarcio Alves-Ferreira, Federal University of Rio de Janeiro, Brazil
Copyright © 2022 Budzinski, Camargo, Lemos, Guyot, Calzado, Ivamoto-Suzuki and Domingues. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Douglas S. Domingues, dougsd@usp.br