 Osval A. Montesinos-López1Abelardo Montesinos-López2* Kismiantini3Armando Roman-Gallardo1Keith Gardner4Morten Lillemo5Roberto Fritsche-Neto6
Osval A. Montesinos-López1Abelardo Montesinos-López2* Kismiantini3Armando Roman-Gallardo1Keith Gardner4Morten Lillemo5Roberto Fritsche-Neto6 José Crossa4,7*
José Crossa4,7*- 1Facultad de Telemática, Universidad de Colima, Colima, Mexico
- 2Centro Universitario de Ciencias Exactas e Ingenierías (CUCEI), Universidad de Guadalajara, Guadalajara, Mexico
- 3Statistics Study Program, Universitas Negeri Yogyakarta, Yogyakarta, Indonesia
- 4International Maize and Wheat Improvement Center (CIMMYT), Texcoco, Mexico
- 5Department of Plant Sciences, Norwegian University of Life Sciences, IHA/CIGENE, Ås, Norway
- 6Laboratory of Allogamous Plant Breeding, Genetics Department, Luiz de Queiroz College of Agriculture, University of São Paulo, Piracicaba, Brazil
- 7Colegio de Postgraduados, Montecillo, Mexico
In plant breeding, the need to improve the prediction of future seasons or new locations and/or environments, also denoted as “leave one environment out,” is of paramount importance to increase the genetic gain in breeding programs and contribute to food and nutrition security worldwide. Genomic selection (GS) has the potential to increase the accuracy of future seasons or new locations because it is a predictive methodology. However, most statistical machine learning methods used for the task of predicting a new environment or season struggle to produce moderate or high prediction accuracies. For this reason, in this study we explore the use of the partial least squares (PLS) regression methodology for this specific task, and we benchmark its performance with the Bayesian Genomic Best Linear Unbiased Predictor (GBLUP) method. The benchmarking process was done with 14 real datasets. We found that in all datasets the PLS method outperformed the popular GBLUP method by margins between 0% (in the Indica data) and 228.28% (in the Disease data) across traits, environments, and types of predictors. Our results show great empirical evidence of the power of the PLS methodology for the prediction of future seasons or new environments.
Introduction
Genomic selection (GS) proposed by Meuwissen et al. (2001) is a disruptive methodology that uses statistical machine learning algorithms and data to improve the selection of candidate lines early in time without the need to measure phenotypic information. The empirical evidence in favor of GS methodology can be found in applications of many crops, such as wheat, maize, cassava, rice, chickpea, groundnut, etc. (Roorkiwal et al., 2016; Crossa et al., 2017; Wolfe et al., 2017; Huang et al., 2019). However, the practical implementation of GS is challenging because the GS methodology does not always guarantee medium or high prediction accuracies, since many factors affect the prediction performance.
One important complexity of GS models arises when predicting unphenotype cultivars in specific environments (e.g., planting data-site-management combinations) by incorporating G×E interaction into the genomic-based statistical models. Also important is the genomic complexity related to G×E interactions for multi-traits, as these interactions require statistical-genetic models that exploit the complex multivariate relations due to multi-trait and multi-environment variance-covariance but also to exploit the genetic correlations between environments, between traits, and between traits and environments simultaneously. In GS modeling, the interaction between markers and environmental covariates can be a complex task due to the high dimensionality of the matrix of markers, environmental covariates, or both. Jarquín et al. (2014) suggested modeling this interaction using Gaussian processes, where the associated variance-covariance matrix induces a reaction norm model. The authors showed that assuming normality for the terms involving the interaction and also assuming that the interaction obtained using a first-order multiplicative model is distributed normally, then the covariance function is the cell-by-cell product (Hadamard) of two covariance structures, one describing the genetic information and the other describing the environmental effects. Many studies using a reaction norm model indicated that including the G×E interaction in the model substantially increased the accuracy of across-environment (locations and/or years) predictions (Crossa et al., 2017).
Many of the factors that affect the prediction performance of the GS methodology are under scrutiny to be improved. For example, the quality of the marker data is of paramount importance and the breeder needs to be careful to use only high-quality markers. Also, the quality of the training population is key to guaranteeing reasonable prediction accuracies in untested new lines. For this reason, research is in progress to optimize the design of the training-testing sets. Regarding statistical machine learning algorithms, there is also research in progress to select the best algorithm for each implementation. Currently, it is very common to find applications in GS using random forest, mixed models, Bayesian methods (GBLUP, BRR, BayesA, BayesB, BayesC, and Bayes Lasso), support vector machine, gradient boosting machine methods, and deep learning methods. But, as stated in the “No Free Lunch Theorem,” none of these algorithms is the best statistical machine learning algorithm for predictive modeling problems such as classification and regression. The no free lunch theorem indicates that the performance of all statistical machine learning algorithms is similar in select specific situations. However, there are niches where a particular algorithm consistently outperforms the others. For example, in interacting with images, there is empirical evidence that deep neural network methods are the best, yet one limitation of deep neural network models is that they require considerably large datasets (Montesinos-López O. A. et al., 2018; Montesinos-López A. et al., 2018; Montesinos-López et al., 2019).
The Bayesian method GBLUP is quite robust and most of the time produces reasonable and competitive predictions with the advantage that we can implement this method requiring no extra time for the tuning process. This is due to its efficient default hyperparameters for most applications, which is an important advantage regarding support vector machine, gradient boosting machine, random forest, and deep learning models that require considerable effort to select a reasonable set of hyperparameters. However, it is important to note that deep learning methods are the most demanding and challenging for selecting reasonable hyperparameters since this algorithm requires many inputs (Montesinos-López O. A. et al., 2018; Montesinos-López A. et al., 2018).
For the prediction of new environments (or seasons), most statistical machine learning methods struggle to produce reasonable predictions because often there is not a good match between the distribution of the training and testing set. For this reason, the prediction of a new season or environments is a more challenging task than when using conventional strategies of cross-validation (CV1), which tests the performance of lines that have not been measured in any of the observed environments, and CV2, which tests the performance of lines that have been measured in some environments but not in others (Burgueño et al., 2012). This is significant for small plant breeding programs, where data from multiple locations are scarce or non-existent, with the need to predict which lines are more likely to perform better in future seasons or environments (Monteverde et al., 2019).
In multi-environmental plant breeding field trials, information on environments may enhance the information in genotype×environment interactions (GE), and the principal component regression procedure that relates environments to the principal component scores of the GE has been proposed (Aastveit and Martens, 1986). To overcome some of the interpretation difficulties present in the principal component regression scores, Aastveit and Martens (1986) proposed the partial least squares (PLS) regression method as a more direct and parsimonious linear model. PLS regression describes GE in terms of differential sensitivity of cultivars to environmental variables where explanatory variables are linear combinations of the complete set of measured environmental and/or cultivar variables with no limit to the number of explanatory covariables. Vargas et al. (1998, 1999) carried out extensive studies for assessing the importance of environmental covariables to interpret and understand GE in multi-environment plant breeding trials. Furthermore, Crossa et al. (1999) demonstrated the usefulness of PLS for understanding GE using environmental and marker covariables.
Based on the above considerations, in this study we explore the power of PLS for the prediction of new environments, a problem denoted as “leave one environment out.” The prediction accuracy of the PLS regression method is compared to that of GBLUP, one of the most robust and widely used methods in genomic selection. The benchmarking was done with 14 real datasets in which at least two environments were evaluated.
Materials and Methods
Bayesian GBLUP Model
The model used was
where
Partial Least Squares (PLS) Method
PLS regression was first introduced by Wold (1966) and was originally developed for econometrics and chemometrics. It is a multivariate statistical technique designed to deal with the
For PLS regression, the components, called Latent Variables (LVs) in this context, are obtained iteratively. One starts with the SVD of the cross-product matrix
where
The
Finally, the data matrices are “deflated”: the information related to this latent variable, in the form of the outer products
The estimation of the next component can then start from the SVD of the cross-product matrix
Now, instead of regressing
with
with
PLS is similar to principal component regression (PCR). In theory, PLS regression should have an advantage over PCR. One could imagine a situation where a minor component in
It is important to point out that under the PLS regression method, first we computed the design matrices (dummy variables) of environments
Data Sets
Note that for datasets 1-12, the PLS included only marker covariables, thus the data augmentation
Datasets 1-3. Elite Wheat Yield Trial (EYT) Years 2013–2014 and 2014-2015, 2015-2016
Three datasets were collected by the Global Wheat Program (GWP) of the International Maize and Wheat Improvement Center (CIMMYT) and belong to elite yield trials (EYT) established in four different cropping seasons with four or five environments. Dataset 1 is from 2013-2014, dataset 2 is from 2014-2015, and dataset 3 is from 2015-2016. The EYT datasets 1, 2 and 3 contain 776, 775, and 964 lines, respectively. The experimental design used was an alpha-lattice design and the lines were sown in 39 trials, each covering 28 lines and 2 checks in 6 blocks with 3 replications. Several traits were available for some environments and lines in each dataset. In this study, we included four traits measured for each line in each environment: days to heading (DTHD, number of days from germination to 50% spike emergence), days to maturity (DTMT, number of days from germination to 50% physiological maturity or the loss of the green color in 50% of the spikes), plant height, and grain yield (GY). For full details of the experimental design and how the Best Linear Unbiased Estimates (BLUEs) were computed, see Juliana et al. (2018).
The lines examined in datasets 2 and 3 were evaluated in five environments, while dataset 1 was evaluated in four. For EYT dataset 1, the environments were bed planting with five irrigations (Bed5IR), early heat (EHT), flat planting, and five irrigations (Flat5IR), and late heat (LHT). For EYT dataset 2, the environments were bed planting with two irrigations (Bed2IR), Bed5IR, EHT, Flat5IR and LHT, while for dataset 3, the environments evaluated were Bed2IR, Bed5IR, Flat5IR, flat planting with drip irrigation (FlatDrip), and LHT.
Genome-wide markers for the 2,515 (776 + 775+964) lines in the two datasets were obtained using genotyping-by-sequencing (GBS) (Elshire et al., 2011; Poland et al., 2012) at Kansas State University using an Illumina HiSeq2500. After filtering, 2,038 markers were obtained from an initial set of 34,900 markers. The imputation of missing marker data was carried out using LinkImpute (Money et al., 2015) and implemented in TASSEL (Trait Analysis by Association Evolution and Linkage) version 5 (Bradbury et al., 2007). Lines that had more than 50% missing data were removed, and 2,515 lines were used in this study (776 lines in the first dataset, 775 lines in the second dataset, and 964 lines in the third dataset).
Dataset 4. Groundnut Data
The phenotypic dataset reported by Pandey et al. (2020) contains information on the phenotypic performance for various traits in four environments. In the present study, we assessed predictions using the trait seed yield per plant (SYPP), pods per plant (NPP), pod yield per plant (PYPP) and yield per hectare (YPH), for 318 lines in four environments, denoted as Environment1 (ENV1): Aliyarnagar_Rainy 2015; Environment2 (ENV2): Jalgoan_Rainy 2015; Environment3 (ENV3): ICRISAT_Rainy 2015; Environment4 (ENV4): ICRISAT Post-Rainy 2015.
The dataset is balanced, resulting in a total of 1,272 assessments with each line included once in each environment. Marker data were available for all lines and 8,268 SNP markers remained after quality control (each marker was coded with 0, 1 and 2).
Dataset 5. Maize Data
This maize dataset was included in Souza et al. (2017) from USP (Universidad Sao Paulo) and consists of 722 (with 722
Dataset 6. Disease Data
This dataset contains 438 lines for which three diseases were recorded: Pyrenophora tritici-repentis (PTR) that causes a disease originally named “yellow spot” but also known as tan spot, yellow leaf spot, yellow leaf blotch, or helminthosporiosis. The second disease, Parastagonospora nodorum (SN), is a major fungal pathogen of wheat fungal taxon that includes several plant pathogens affecting the leaves and other parts of the plants. The third disease, Bipolaris sorokiniana (SB), is the cause of seedling diseases, common root rot and spot blotch of several crops such as barley and wheat. The 438 wheat lines were evaluated in the greenhouse for several replicates, and the replicates were considered as different environments (Env1, Env2, Env3, Env4, Env5, and Env6). The total number of observations was 438
DNA samples were extracted from each line, following the manufacturer’s protocol. DNA samples were genotyped using 67,436 single nucleotide polymorphisms (SNPs). For a given marker, the genotype for the ith line was coded as the number of copies of a designated marker-specific allele carried by the ith line (absence = zero and presence = one). SNP markers with unexpected heterozygous genotypes were recoded as either AA or BB. We kept those markers that had fewer than 15% missing values. Next, we imputed the markers using observed allelic frequencies. We also removed markers with MAF<0.05. After quality control and imputation, a total of 11,617 SNPs were available for analysis.
Datasets 7-12. Wheat Data
Spring wheat lines selected for grain yield analyses from CIMMYT first year yield trials (YT) were used as the training population to predict the quality of lines selected from EYT for grain yield analyses in a second year. The analyses were conducted for only the grain yield trait unless specified, and using six sets of data, as reported below:
- Wheat_1 (2013-14/2014-15), 1,301 lines from the 2013-14 YT and 472 lines from the 2014-2015 EYT trial. In this dataset, only the grain yield trait was used.
- Wheat_2 (2014-15/2015-16), 1,337 lines from the 2014-15 YT and 596 lines from the 2015-2016 EYT trial.
- Wheat_3 (2015-16/2016-17), 1,161 lines from the 2015-16 YT and 556 lines from the 2016-2017 EYT trial.
- Wheat_4 (2016-17/2017-18), 1,372 lines from the 2016-17 YT and 567 lines from the 2017-2018 EYT trial.
- Wheat_5 (2017-18/2018-19), 1,386 lines from the 2017-18 YT and 509 lines from the 2018-2019 EYT trial.
- Wheat_6 (2018-19/2019-20), 1,276 lines from the 2018-19 YT and 124 lines from the 2019-2020 EYT trial. More details of these datasets can be found in Ibba et al. (2020).
All the lines were genotyped using genotyping-by-sequencing (GBS; Poland et al., 2012). The TASSEL version 5 GBS pipeline was used to call marker polymorphisms (Glaubitz et al., 2014), and a minor allele frequency of 0.01 was assigned for SNP discovery. The resulting 6,075,743 unique tags were aligned to the wheat genome reference sequence (RefSeq v.1.0) (IWGSC 2018) with an alignment rate of 63.98%. After filtering for SNPs with homozygosity >80%, p-value for Fisher’s exact test <0.001 and χ2 value lower than the critical value of 9.2, we obtained 78,606 GBS markers that passed at least one of those filters. These markers were further filtered for less than 50% missing data, greater than a 0.05 minor allele frequency, and less than 5% heterozygosity. Markers with missing data were imputed using the “expectation-maximization” algorithm in the “R” package rrBLUP (Endelman, 2011).
Datasets 13. Indica
The rice dataset, Monteverde et al. (2019), contains information on the phenotypic performance of four traits (GY = Grain Yield, PHR = Percentage of Head Rice Recovery, GC = percentage of Chalky Grain, PH = Plant Height) in three environments (2010, 2011, and 2012). For each year, 327 lines were evaluated and measured three times (once for each developmental stage: vegetative, reproductive, and maturation) and for 18 environmental covariates. 1) ThermAmp denotes the thermal amplitude (°C), average of daily thermal amplitude calculated as max temperature (°C)—min temperature (°C). 2) RelSun denotes the relative sunshine duration (%), quotient between the real duration of the brightness of the Sun and the possible geographical or topographic duration. 3) SolRad denotes solar radiation (cal/cm2/day), solar radiation calculated using Armstrong’s formula. 4) EfPpit denotes effective precipitation (mm), average daily precipitation in mm added and stored in the soil. 5) DegDay denotes degrees day in rice (°C), mean of daily average temperature minus 10°. 6) RelH denotes relative humidity (hs), sum of hours (0–24 h) where the relative humidity was equal to 100%. 7) PpitDay denotes the precipitation day, which is the sum of days when it rained. 8) MeanTemp denotes the mean temperature (°C), average of temperature over 24 h (0–24 h). 9) AvTemp denotes average temperature (°C), average temperature calculated as daily (Max + Min)/2. 10) MaxTemp denotes the maximum temperature (°C), average of maximum daily temperature. 11) MinTemp denotes minimum temperature (°C), average of minimum daily temperature. 12) TankEv denotes the tank water evaporation (mm), amount of evaporated water under influence of Sun and wind. 13) Wind denotes wind speed (2 m/km/24 h), distance covered by wind (in km) over 2 m height in 1 day. 14) PicheEv denotes piche evaporation (mm), the amount of evaporated water without the influence of the Sun. 15) MinRelH denotes the minimum relative humidity (%), lowest value of relative humidity for the day. 16) AccumPpit denotes accumulated precipitation (mm), daily accumulated precipitation. 17) Sunhs denotes sunshine duration, sum of total hours of sunshine per day. 18) MinT15 denotes the minimum temperature below 15°, the sum of the days where the minimum temperature was below 15°.
This dataset is balanced, giving a total of 981 assessments with each line included once in each environment. Marker data were available for all lines and 16,383 SNP markers remained after quality control (each marker was coded with 0, 1, and 2).
Datasets 14. Japonica
This rice dataset was also reported by Monteverde et al. (2019) but belongs to the tropical Japonica population and contains phenotypic information on the same four traits as for the Indica population (GY = Grain Yield, PHR = Percentage of Head Rice Recovery, GC = percentage of Chalky Grain, PH = Plant Height) in five environments (2009, 2010, 2011, 2012, and 2013). In 2009, 2010, 2011, 2012, and 2013, 93, 292, 316, 316, and 134 lines were evaluated, respectively. In each year, the same 54 environmental covariates measured in the Indica dataset (dataset 13) were examined, that is, the 18 covariates measured in the three developmental stages: vegetative, reproductive, and maturation. Since this dataset is not balanced, a total of 1,051 assessments were evaluated in the five environments. Marker data were available for 320 lines and 16,383 SNP markers remained after quality control (each marker was coded with 0, 1, and 2).
Metrics for Evaluation of Prediction Accuracy
We employed the leave-one-environment out type of cross-validation in each of the 14 datasets (Montesinos-López et al., 2022). That is, we used
When
Results
The results are given in nine sections. In sections 1–6 are the results for dataset 1 to dataset 6, respectively, section 7 gives the results for the datasets (dataset 7 to dataset 12), section 8 gives the results for dataset 13, and section 9 gives the results for dataset 14.
Dataset 1. EYT_1
With Predictor = E + G + GE
When the GE was considered in the predictor, we observed relative efficiencies in terms of NRMSE of the GBLUP methods vs. the PLS method for trait DTHD of 0.73, 1.642, 3.343, and 0.434 for environments Bed5IR, EHT, Flat5IR, and LHT, respectively. Only in environments EHT and Flat5IR genomic prediction performance of PLS regression method was superior to GBLUP by 64.2% (EHT) and 234.3% (Flat5IR). However, across environments, we observed that the GBLUP method was better than the PLS since the relative efficiency was equal to 0.929. Across environments, the GBLUP outperformed the PLS by 7.1% in terms of prediction performance (Figure 1 with predictor = E + G + GE). For trait DTMT, the
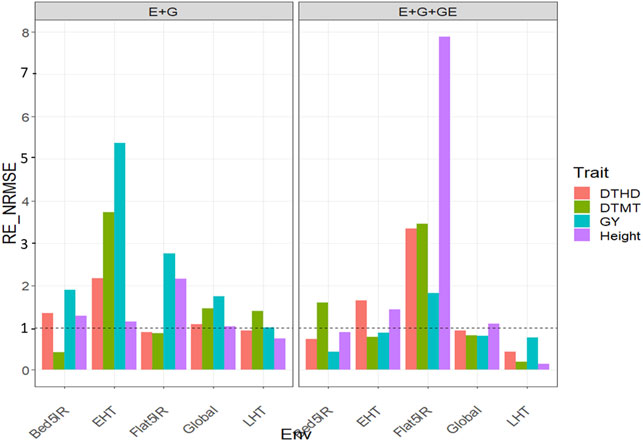
FIGURE 1. Relative efficiency in terms of normalized root mean square error (RE_NRMSE) computed by dividing the NRMSE under the best linear unbiased predictor model (GBLUP) between the NRMSE of the partial least squares regression method. Prediction performance is reported for each environment and across environments (Global) in dataset 1 (EYT_1), also with two predictors (E + G and E + G + GE). When the RE_NRMSE>1 the PLS outperforms in terms of prediction performance (lower NRMSE) the GBLUP method.
With Predictor = E + G
When only the main effects of environments and genotypes were considered in the predictor, the
Dataset 2. EYT_2
With Predictor = E + G + GE
With GE in the predictor, the
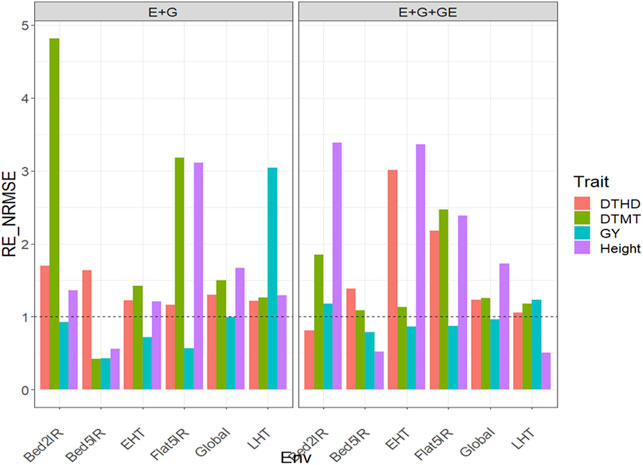
FIGURE 2. Relative efficiency in terms of normalized root mean square error (RE_NRMSE) computed by dividing the NRMSE under the best linear unbiased predictor model (GBLUP) between the NRMSE of the partial least squares regression method. Prediction performance is reported for each environment and across environments (Global) in dataset 2 (EYT_2), also with two predictors (E + G and E + G + GE). When the RE_NRMSE>1, the PLS outperforms the GBLUP method in terms of prediction performance (lower NRMSE).
With Predictor = E + G
Under this predictor for trait DTHD, the
Dataset 3. EYT_3
With Predictor = E + G + GE
Under this predictor, the relative efficiencies in terms of NRMSE for trait DTHD were 0.809, 2.935, 4.335, 1.299, 0.932, and 1.283 for Bed2IR, Bed5IR, Flat5IR, FlatDrip, LHT, and Global, respectively. The PLS was better than the GBLUP in three out of five environments and across environments by 193.5%, 233.5%, 29.9%, and 28.3% in Bed5IR, Flat5IR, FlatDrip, and Global, respectively (Figure 3 with predictor = E + G + GE). For trait DTMT, the
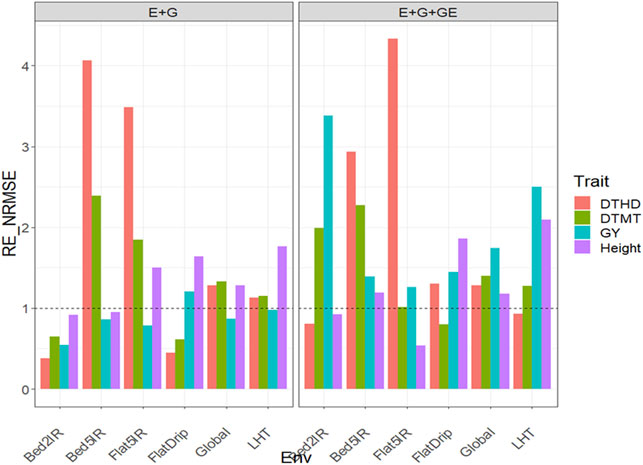
FIGURE 3. Relative efficiency in terms of normalized root mean square error (RE_NRMSE) computed by dividing the NRMSE under the best linear unbiased predictor model (GBLUP) between the NRMSE of the partial least squares regression method. Prediction performance is reported for each environment and across environments (Global) in dataset 3 (EYT_3), also with two predictors (E + G and E + G + GE). When the RE_NRMSE>1, the PLS outperforms the GBLUP method in terms of prediction performance (lower NRMSE).
With Predictor = E + G
Under this predictor, the
Dataset 4. Groundnut
With Predictor = E + G + GE
With GE in the predictor, the observed
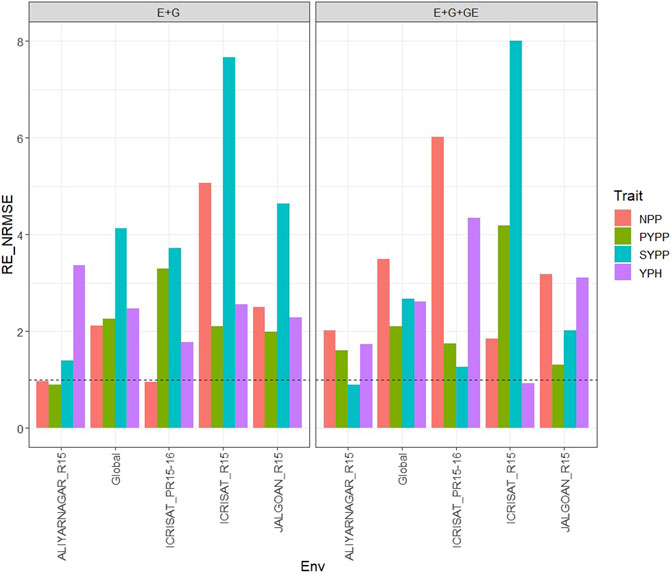
FIGURE 4. Relative efficiency in terms of normalized root mean square error (RE_NRMSE) computed by dividing the NRMSE under the best linear unbiased predictor model (GBLUP) between the NRMSE of the partial least squares regression method. Prediction performance is reported for each environment and across environments (Global) in dataset 4 (Groundnut), also with two predictors (E + G and E + G + GE). When the RE_NRMSE>1, the PLS outperforms the GBLUP method in terms of prediction performance (lower NRMSE).
With Predictor = E + G
Without the GE term in the predictor, the observed
Dataset 5. Maize Data
With Predictor = E + G + GE
With GE, the observed
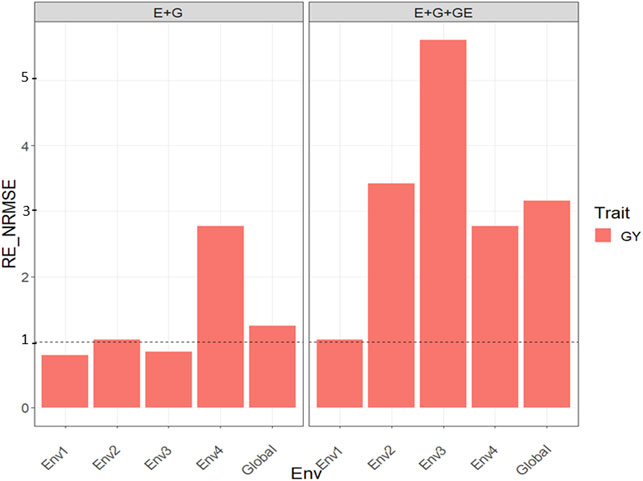
FIGURE 5. Relative efficiency in terms of normalized root mean square error (RE_NRMSE) computed by dividing the NRMSE under the best linear unbiased predictor model (GBLUP) between the NRMSE of the partial least squares regression method. Prediction performance is reported for each environment and across environments (Global) in dataset 5 (Maize), also with two predictors (E + G and E + G + GE). When the RE_NRMSE>1 the PLS outperforms the GBLUP method in terms of prediction performance (lower NRMSE).
With Predictor = E + G
Without the GE, the observed
Dataset 6. Disease Data
With Predictor = E + G + GE
With GE, the
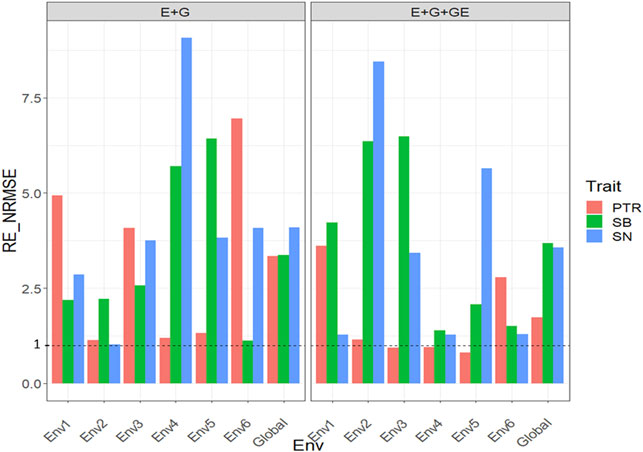
FIGURE 6. Relative efficiency in terms of normalized root mean square error (RE_NRMSE) computed by dividing the NRMSE under the best linear unbiased predictor model (GBLUP) between the NRMSE of the partial least squares regression method. Prediction performance is reported for each environment and across environments (Global) in dataset 6 (Disease), also with two predictors (E + G and E + G + GE). When the RE_NRMSE>1 the PLS outperforms the GBLUP method in terms of prediction performance (lower NRMSE).
With Predictor = E + G
Without GE for trait SN, the PLS outperformed the GBLUP method between 0.17% and 807.2% since the observed
Dataset 7-12. Wheat Data
With Predictor = E + G + GE
With GE, the
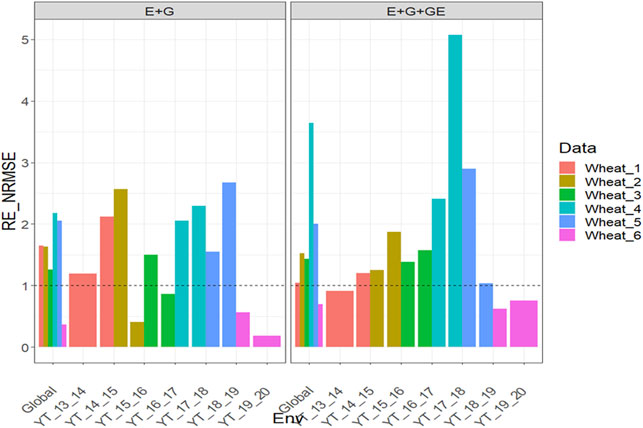
FIGURE 7. Relative efficiency in terms of normalized root mean square error (RE_NRMSE) computed by dividing the NRMSE under the best linear unbiased predictor model (GBLUP) between the NRMSE of the partial least squares regression method. Prediction performance is reported for each environment and across environments (Global) in datasets 7-12 (Wheat_1 to Wheat_6), also with two predictors (E + G and E + G + GE). When the RE_NRMSE>1, the PLS outperforms the GBLUP method in terms of prediction performance (lower NRMSE).
With Predictor = E + G
With GE, the
Dataset 13. Indica
With Predictor = E + G + GE
With GE and considering the environmental covariates (EC), the
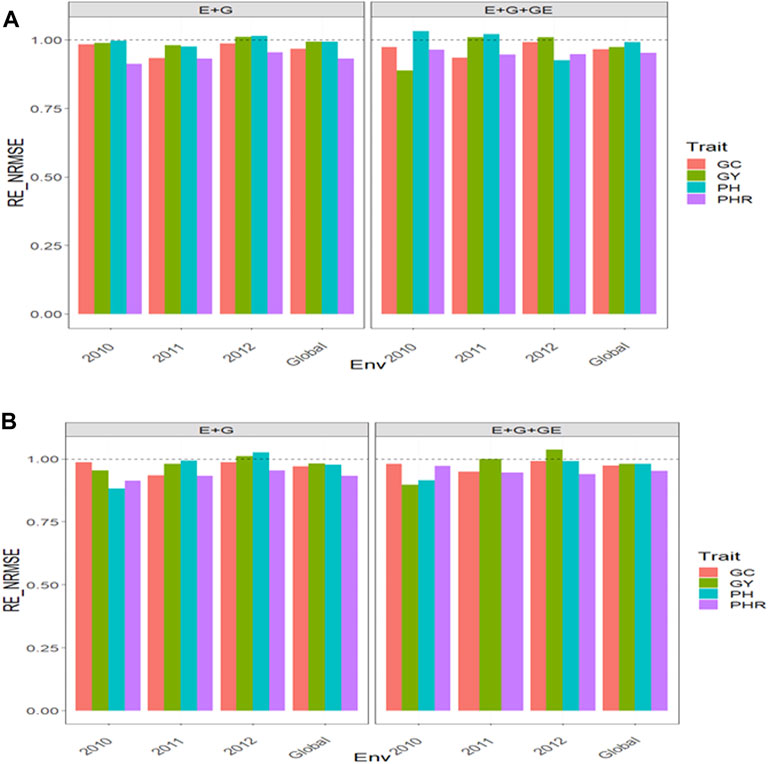
FIGURE 8. Relative efficiency in terms of normalized root mean square error (RE_NRMSE) computed by dividing the NRMSE under the best linear unbiased predictor model (GBLUP) between the NRMSE of the partial least squares regression method. Prediction performance is reported for each environment and across environments (Global) in dataset 13 (Indica), also with two predictors (E + G and E + G + GE). When the RE_NRMSE>1, the PLS outperforms the GBLUP method in terms of prediction performance (lower NRMSE). (A) With environmental covariates (EC) and (B) without EC.
For trait GC with EC, the
With Predictor = E + G
Without the GE and taking into account the EC, we observed the
For trait GC, taking into account the EC, the
Dataset 14. Japonica
With Predictor = E + G + GE
With GE the
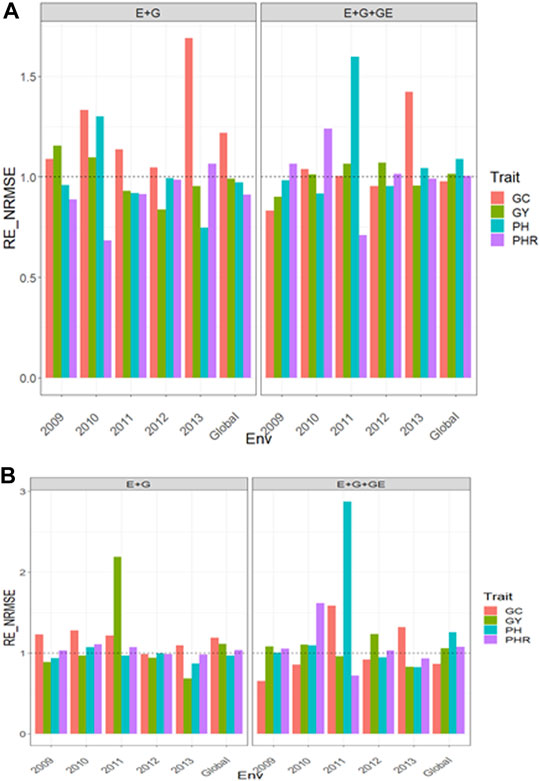
FIGURE 9. Relative efficiency in terms of normalized root mean square error (RE_NRMSE) computed by dividing the NRMSE under the best linear unbiased predictor model (GBLUP) between the NRMSE of the partial least squares regression method. Prediction performance is reported for each environment and across environments (Global) in dataset 14 (Japonica), also with two predictors (E + G and E + G + GE). When the RE_NRMSE>1, the PLS outperforms the GBLUP method in terms of prediction performance (lower NRMSE). (A) With environmental covariates (EC) and (B) without EC.
With Predictor = E + G
Without GE the
Discussion
Breeders need novel methodologies to match the productivity required to feed the world’s increasing population. For this reason, the adoption of genomic selection has been successful in plant breeding since it is a disruptive methodology that offers significant savings in resources in selecting candidate lines because GS is a predictive methodology trained with data that contain phenotypic and genotypic information. GS predicts breeding values or phenotypic values of new (untested) lines that were only genotyped, so it allows for earlier selection of lines, since we can obtain predictions for the lines of interest once the model is trained. (Crossa et al., 2017).
However, even though GS is efficient and simple to understand, breeders worldwide are still struggling to put it into practice successfully. To guarantee the successful implementation of GS, we need to guarantee moderate or high prediction accuracies, which is challenging since the resulting prediction accuracy depends on many factors, such as the degree of relatedness between the training and testing sets, the statistical machine learning model used, the size of the training and testing sets, the trait under study, the quality of inputs like markers and environmental information, and the prediction problem at hand (for example, the prediction of lines that were evaluated in other environments, or the prediction of lines that were not evaluated in previous years or environments, etc.).
The reaction norm model of Jarquín et al. (2014) has been successfully used for multi-environmental data and for incorporating interactions among multi-type input sources (e.g., dense molecular markers, pedigree, high-throughput phenotypes, environmental covariables) in several crops (Perez-Rodriguez et al., 2015; Crossa et al., 2016). One of the major gaps in GS research for G×E modeling using environmental data relies in the steps of collection, processing, and integrating those data into an ecophysiology-smart and parsimony manner. A method for envirotyping-informed genomic prediction of GxE using linear and non-linear kernels was presented by Costa-Neto et al. (2020) in two maize germplasms and taking account for additive, dominance and their interaction with environments. These authors showed that nonlinear kernels are the better option to deal with environmental similarity realized with environmental covariables in GS.
For the predictions mentioned above, research is underway to optimize the GS methodology so that its practical implementation can be more consistent, robust, and straightforward. For this reason, with the goal of finding more robust statistical machine learning methods, we evaluated the prediction performance of the partial least squares regression in the context of predicting a new year or environment (leave one environment out cross-validation strategy). We found the PLS method was superior to the popular GBLUP method in most cases when the goal was to predict a complete location or year.
Our results are encouraging because they show that PLS regression is a powerful tool for this type of prediction problem, since across all datasets, the PLS outperformed the GBLUP method by large margins (see Figures 1–7). Across traits, environments, and types of predictors, the PLS outperformed the GBLUP in terms of normalized root mean square error by 58.8% in dataset 1 (EYT_1 data), 52.52% in dataset 2 (EYT_2 data), 49.84% in dataset 3 (EYT_3 data), 178.21 in dataset 4 (groundnut data), 127.07% in dataset 5 (maize data), 228.28% in dataset 6 (disease data), 62.31% in datasets 7-12 (wheat_1 to wheat_6 datasets) and 0% in dataset 13 (Indica dataset). For those environments that were more similar to the environments in the training set less error of prediction was observed, while for those environments that were more different from the environments in the training set, more error of prediction was reached. Our findings agree with those reported by Monteverde et al. (2019) for this type of prediction problem (“leave one environment out”), but in our case, instead of using Pearson’s correlation as the metric of prediction performance, we used the normalized root mean square error.
Although our evaluations are empirical, we found that the PLS regression method is an efficient statistical machine learning prediction tool that is especially appropriate for small sample data with many (possibly correlated) independent variables, especially useful for small
We observed that implementing the PLS regression is fast for small datasets, but the larger the dataset, the more computational resources are required for its implementation. In general, we observed that the implementation of the PLS is at least two times slower than the GBLUP method. In part this is because under PLS selecting the optimal number of principal components (hyperparameters) is by means of an inner five-fold cross-validation that also is time consuming, but a key factor to a successful implementation of the PLS regression method. For this reason, the computational resources required for PLS implementation become a problem for moderate and large datasets. However, since the PLS regression only depends on one hyperparameter (number of principal components to retain), the tuning process is very easy, but with an increased need on computational resources.
One reason PLS is very competitive in terms of predictive modeling is that it automatically performs variable selection by creating the latent variables (factors) that are linear combinations of the original independent variables and the response variable (s). For this reason, PLS is quite efficient for handling many and correlated predictors, and additionally, it can detect which inputs (independent variables) are the most explanatory in a trained model by looking at the model coefficients (Wold, 2001; Mehmood et al., 2012). Vargas et al. (1998), Vargas et al. (1999) and Crossa et al. (1999) have shown the benefits of PLS for identifying the set of independent variables (environmental as well as molecular markers) that best explain the genotype by environment interaction. For all these reasons, PLS regression has become a well-established tool in predictive and association modeling in bioinformatics and genomics, because it is often possible to interpret the extracted factors in terms of the underlying physical system; to derive “hard” modeling information from the soft model.
It is important to note that the PLS regression method is not restricted only to continuous and univariate response variables since it can also be used for binary and categorical univariate response variables and to other tasks such as survival analysis, multivariate modeling, and modeling of regulation network. At present, most reported applications of the PLS method to genomic data focus on the analysis of microarray data from gene expression experiments.
Conclusion
In this study, we compare the prediction performance of the popular GBLUP (in its Bayesian version) to the partial least squares (PLS) regression for the prediction of future seasons or new environments, when the goal is to predict the whole information of a new year or environment. This prediction scheme, denoted as “leave one environment out,” is challenging because many times we do not have any information or reference for the new year or environment we want to predict. Consequently, the predictions accuracies are low or very low. We found that the PLS regression outperformed the prediction performance of the Bayesian GBLUP method in terms of normalized root mean square error by at least 49.84% (across traits, environments, and types of predictors, when environmental covariates were not considered), which is an impressive large gain. For this reason, we encourage doing more research in this direction to support our findings. However, with our results, we can see that the PLS regression algorithm is a powerful tool for predicting new environments (or years) in the context of genomic selection.
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material; further inquiries can be directed to the corresponding authors.
Author Contributions
OAM-L and AM-L developed the original idea. K and AR-G together with OAM-L and AM-L, performed the initial analyses. JC, together with OAM-L and AM-L, produced the first version of the article. Other improved versions of the article were written and revised by all authors.
Funding
We are thankful for the financial support provided by the Bill & Melinda Gates Foundation (INV-003439, BMGF/FCDO, Accelerating Genetic Gains in Maize and Wheat for Improved Livelihoods (AG2MW)), the USAID projects (USAID Amend. No. 9 MTO 069033, USAID-CIMMYT Wheat/AGGMW, AGG-Maize Supplementary Project, AGG (Stress Tolerant Maize for Africa)), and the CIMMYT CRP (maize and wheat). We acknowledge the financial support provided by the Foundation for Research Levy on Agricultural Products (FFL) and the Agricultural Agreement Research Fund (JA) in Norway through NFR grant 267806.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The reviewer HPP declared a past co-authorship with the authors JC and OAM-L to the handling editor.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fgene.2022.920689/full#supplementary-material
References
Aastveit, A. H., and Martens, H. (1986). ANOVA Interactions Interpreted by Partial Least Squares Regression. Biometrics 42, 829–844. doi:10.2307/2530697
Bergström, C. A. S., Charman, S. A., and Nicolazzo, J. A. (2012). Computational Prediction of CNS Drug Exposure Based on a Novel In Vivo Dataset. Pharm. Res. 29, 3131–3142.
Boulesteix, A.-L., and Strimmer, K. (2006). Partial Least Squares: a Versatile Tool for the Analysis of High-Dimensional Genomic Data. Briefings Bioinforma. 8, 32–44. doi:10.1093/bib/bbl016
Bradbury, P. J., Zhang, Z., Kroon, D. E., Casstevens, T. M., Ramdoss, Y., and Buckler, E. S. (2007). TASSEL: Software for Association Mapping of Complex Traits in Diverse Samples. Bioinformatics 23, 2633–2635. doi:10.1093/bioinformatics/btm308
Burgueño, J., de los Campos, G., Weigel, K., and Crossa, J. (2012). Genomic Prediction of Breeding Values when Modeling Genotype × Environment Interaction Using Pedigree and Dense Molecular Markers. Crop Sci. 52, 707–719. doi:10.2135/cropsci2011.06.0299
Campbell, A., and Ntobedzi, A. (2007). Emotional Intelligence Coping and Psychological Distress: A Partial Least Square Approach to Developing a Predictive Model. Electron. J. Appl. Psychol. 3, 39–54. doi:10.7790/ejap.v3i2.91
Costa-Neto, G., Fritsche-Neto, R., and Crossa, J. (2020). Nonlinear Kernels, Dominance, and Envirotyping Data Increase the Accuracy of Genome-Based Prediction in Multi-Environment Trials. Heredity 126, 92–106. doi:10.1038/s41437-020-00353-1
Crossa, J., de los Campos, G., Maccaferri, M., Tuberosa, R., Burgueño, J., and Pérez-Rodríguez, P. (2016). Extending the Marker × Environment Interaction Model for Genomic-Enabled Prediction and Genome-wide Association Analysis in Durum Wheat. Crop Sci. 56, 2193–2209. doi:10.2135/cropsci2015.04.0260
Crossa, J., Pérez-Rodríguez, P., Cuevas, J., Montesinos-López, O., Jarquín, D., de Los Campos, G., et al. (2017). Genomic Selection in Plant Breeding: Methods, Models, and Perspectives. Trends Plant Sci. 22 (11), 961–975. doi:10.1016/j.tplants.2017.08.011
Crossa, J., Vargas, M., van Eeuwijk, F. A., Jiang, C., Edmeades, G. O., and Hoisington, D. (1999). Interpreting Genotype × Environment Interaction in Tropical Maize Using Linked Molecular Markers and Environmental Covariables. Theor. Appl. Genet. 99, 611–625. doi:10.1007/s001220051276
Elshire, R. J., Glaubitz, J. C., Sun, Q., Poland, J. A., Kawamoto, K., Buckler, E. S., et al. (2011). A Robust, Simple Genotyping-By-Sequencing (GBS) Approach for High Diversity Species. PLoS One 6, e19379. doi:10.1371/journal.pone.0019379
Endelman, J. B. (2011). Ridge Regression and Other Kernels for Genomic Selection with R Package rrBLUP. Plant Genome 4, 250–255. doi:10.3835/plantgenome2011.08.0024
Glaubitz, J. C., Casstevens, T. M., Lu, F., Harriman, J., Elshire, R. J., Sun, Q., et al. (2014). TASSEL-GBS: A High Capacity Genotyping by Sequencing Analysis Pipeline. PLoS ONE 9 (2), e90346. doi:10.1371/journal.pone.0090346
Huang, M., Balimponya, E. G., Mgonja, E. M., McHale, L. K., Luzi-Kihupi, A., Wang, G.-L., et al. (2019). Use of Genomic Selection in Breeding Rice (Oryza Sativa L.) for Resistance to Rice Blast (Magnaporthe Oryzae). Mol. Breed. 39, 114. doi:10.1007/s11032-019-1023-2
Ibba, M. I., Crossa, J., Montesinos-López, O. A., Montesinos-López, A., Juliana, P., Guzman, C., et al. (2020). Genome-based Prediction of Multiple Wheat Quality Traits in Multiple Years. Plant Genome 13, e20034. doi:10.1002/tpg2.20034
Jarquín, D., Crossa, J., Lacaze, X., Du Cheyron, P., Daucourt, J., Lorgeou, J., et al. (2014). A Reaction Norm Model for Genomic Selection Using High-Dimensional Genomic and Environmental Data. Theor. Appl. Genet. 123 (7), 595–607. doi:10.1007/s00122-013-2243-1
Juliana, P., J., Singh, R., P., Poland, J., Mondal, S., Crossa, J., Montesinos-López, O. A., et al. (2018). Prospects and Challenges of Applied Genomic Selection-A New Paradigm in Breeding for Grain Yield in Bread Wheat. Plant Genome 11. (accepted). doi:10.3835/plantgenome2018.03.0017
Kouskoura, M. G., Piteni, A. I., and Markopoulou, C. K. (2019). A New Descriptor via Bio-Mimetic Chromatography and Modeling for the Blood Brain Barrier (Part II). J. Pharm. Biomed. Analysis 164, 808–817. doi:10.1016/j.jpba.2018.05.021
Mehmood, T., Liland, K. H., Snipen, L., and Sæbø, S. (2012). A Review of Variable Selection Methods in Partial Least Squares Regression. Chemom. Intelligent Laboratory Syst. 118, 62–69. doi:10.1016/j.chemolab.2012.07.010
Meuwissen, T. H. E., Hayes, B. J., and Goddard, M. E. (2001). Prediction of Total Genetic Value Using Genome-wide Dense Marker Maps. Genetics 157, 1819–1829. doi:10.1093/genetics/157.4.1819
Mevik, B.-H., and Wehrens, R. (2007). The Pls Package: Principal Component and Partial Least Squares Regression in R. J. Stat. Softw. 18 (2), 1–24. doi:10.18637/jss.v018.i02
Mevik, B. r.-H., and Cederkvist, H. R. (2004). Mean Squared Error of Prediction (MSEP) Estimates for Principal Component Regression (PCR) and Partial Least Squares Regression (PLSR). J. Chemom. 18, 422–429. doi:10.1002/cem.887
Money, D., Gardner, K., Migicovsky, Z., Schwaninger, H., Zhong, G.-Y., and Myles, S. (2015). LinkImpute: Fast and Accurate Genotype Imputation for Nonmodel Organisms. G3 Genes|Genomes|Genetics 5, 2383–2390. doi:10.1534/g3.115.021667
Montesinos-López, A., Montesinos-López, O. A., Gianola, D., Crossa, J., and Hernández-Suárez, C. M. (2018b). Multi-environment Genomic Prediction of Plant Traits Using Deep Learners with a Dense Architecture. G3 Genes, Genomes, Genet. 8 (12), 3813–3828.
Montesinos-López, O. A., Montesinos-López, A., and Crossa, J. (2022). “Overfitting, Model Tuning and Evaluation of Prediction Performance,” in Multivariate Statistical Machine Learning Methods for Genomic Prediction. Editors O. A. Montesinos López, A. Montesinos López, and J. Crossa (Cham, Switzerland: Springer International Publishing), 109–139.
Montesinos-López, O. A., Montesinos-López, A., Gianola, D., Crossa, J., and Hernández-Suárez, C. M. (2018a). Multi-trait, Multi-Environment Deep Learning Modeling for Genomic-Enabled Prediction of Plant. G3 Genes, Genomes, Genet. 8 (12), 3829–3840.
Montesinos-López, O. A., Montesinos-López, A., Tuberosa, R., Maccaferri, M., Sciara, G., Ammar, K., et al. (2019). Multi-Trait, Multi-Environment Genomic Prediction of Durum Wheat with Genomic Best Linear Unbiased Predictor and Deep Learning Methods. Front. Plant Sci. 11 (10), 1–12.
Monteverde, E., Gutierrez, L., Blanco, P., Pérez de Vida, F., Rosas, J. E., Bonnecarrère, V., et al. (2019). Integrating Molecular Markers and Environmental Covariates to Interpret Genotype by Environment Interaction in Rice (Oryza Sativa L.) Grown in Subtropical Areas. G3 (Bethesda) 9 (5), 1519–1531. PMID: 30877079; PMCID: PMC6505146. doi:10.1534/g3.119.400064
Pandey, M. K., Chaudhari, S., Jarquin, D., Janila, P., Crossa, J., Patil, S. C., et al. (2020). Genome-based Trait Prediction in Multi- Environment Breeding Trials in Groundnut. Theor. Appl. Genet. 133, 3101–3117. doi:10.1007/s00122-020-03658-1
Pérez, P., and de los Campos, G. (2014). BGLR: a Statistical Package for Whole Genome Regression and Prediction. Genetics 198 (2), 483–495.
Pérez-Rodríguez, P., Crossa, J., Bondalapati, K., De Meyer, G., Pita, F., and Campos, G. d. l. (2015). A Pedigree-Based Reaction Norm Model for Prediction of Cotton Yield in Multienvironment Trials. Crop Sci. 55, 1143–1151. doi:10.2135/cropsci2014.08.0577
Poland, J. A., Brown, P. J., Sorrells, M. E., and Jannink, J.-L. (2012). Development of High-Density Genetic Maps for Barley and Wheat Using a Novel Two-Enzyme Genotyping-By-Sequencing Approach. PLoS One 7, e32253. doi:10.1371/journal.pone.0032253
R Core Team (2022). R: A Language and Environment for Statistical Computing. Vienna. Austria: R Foundation for Statistical Computing.
Roorkiwal, M., Rathore, A., Das, R. R., Singh, M. K., Jain, A., Srinivasan, S., et al. (2016). Genome-enabled Prediction Models for Yield Related Traits in Chickpea. Front. Plant Sci. 7, 1666. doi:10.3389/fpls.2016.01666
Souza, M. B. E., Cuevas, J., Couto, E. G. de. O., Pérez-Rodríguez, P., Jarquín, D., Fritsche-Neto, R., et al. (2017). Genomic-Enabled Prediction in Maize Using Kernel Models with Genotype × Environment Interaction. G3 (Bethesda) g3 7 (6), 1995–2014. doi:10.1534/g3.117.042341
VanRaden, P. M. (2008). Efficient Methods to Compute Genomic Predictions. J. dairy Sci. 91 (11), 4414–4423. doi:10.3168/jds.2007-0980
Vargas, M., Crossa, J., Eeuwijk, F. A., Ramírez, M. E., and Sayre, K. (1999). Using Partial Least Squares Regression, Factorial Regression, and AMMI Models for Interpreting Genotype × Environment Interaction. Crop Sci. 39 (4), 955–967. doi:10.2135/cropsci1999.0011183X003900040002x
Vargas, M., Crossa, J., Sayre, K., Reynolds, M., Ramírez, M. E., and Talbot, M. (1998). Interpreting Genotype ✕ Environment Interaction in Wheat by Partial Least Squares Regression. Crop Sci. 38, 679–689. doi:10.2135/cropsci1998.0011183X003800030010x
Vucicevic, J., Nikolic, K., Dobričić, V., and Agbaba, D. (2015). Prediction of Blood-Brain Barrier Permeation of α-adrenergic and Imidazoline Receptor Ligands Using PAMPA Technique and Quantitative-Structure Permeability Relationship Analysis. Eur. J. Pharm. Sci. 68, 94–105. doi:10.1016/j.ejps.2014.12.014
Wold, H. (1966). “Estimation of Principal Components and Related Models by Iterative Least Sqares,” in Multivariate Analysis. Editor P. R. Krishnaiah (New York: Academic Press), 114–142.
Wold, S. (2001). Personal Memories of the Early PLS Development. Chemom. Intelligent Laboratory Syst. 58 (2), 83–84. doi:10.1016/s0169-7439(01)00152-6
Wolfe, M. D., Del Carpio, D. P., Alabi, O., Ezenwaka, L. C., Ikeogu, U. N., Kayondo, I. S., et al. (2017). Prospects for Genomic Selection in Cassava Breeding. Plant Genome 10, 15. doi:10.3835/plantgenome2017.03.0015
Keywords: Bayesian genomic-enabled prediction, genotype x environment interaction, partial least squares, disease data, Bayesian analysis, partial least squares, maize and wheat data
Citation: Montesinos-López OA, Montesinos-López A, Kismiantini , Roman-Gallardo A, Gardner K, Lillemo M, Fritsche-Neto R and Crossa J (2022) Partial Least Squares Enhances Genomic Prediction of New Environments. Front. Genet. 13:920689. doi: 10.3389/fgene.2022.920689
Received: 14 April 2022; Accepted: 19 May 2022;
Published: 08 July 2022.
Edited by:
Zitong Li, Commonwealth Scientific and Industrial Research Organisation (CSIRO), AustraliaReviewed by:
Hans-Peter Piepho, University of Hohenheim, GermanyYusheng Zhao, Leibniz Institute of Plant Genetics and Crop Plant Research (IPK), Germany
Copyright © 2022 Montesinos-López, Montesinos-López, Kismiantini, Roman-Gallardo, Gardner, Lillemo, Fritsche-Neto and Crossa. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Abelardo Montesinos-López, YW1sX3VhY2gyMDA0QGhvdG1haWwuY29t; José Crossa, ai5jcm9zc2FAY2dpYXIub3Jn, b3JjaWQub3JnLzAwMDAtMDAwMS05NDI5LTU4NTU=