 Qiushi Sun
Qiushi Sun Xiaochun Yang2†
Xiaochun Yang2† Yang Zhao
Yang Zhao Yi Liu
Yi Liu- 1Beijing Key Lab of Traffic Data Analysis and Mining, School of Computer and Information Technology, Beijing Jiaotong University, Beijing, China
- 2State Key Laboratory of Natural and Biomimetic Drugs, MOE Key Laboratory of Cell Proliferation and Differentiation, Beijing Key Laboratory of Cardiometabolic Molecular Medicine, Institute of Molecular Medicine, College of Future Technology, Peking University, Beijing, China
Long-term live-cell imaging technology has emerged in the study of cell culture and development, and it is expected to elucidate the differentiation or reprogramming morphology of cells and the dynamic process of interaction between cells. There are some advantages to this technique: it is noninvasive, high-throughput, low-cost, and it can help researchers explore phenomena that are otherwise difficult to observe. Many challenges arise in the real-time process, for example, low-quality micrographs are often obtained due to unavoidable human factors or technical factors in the long-term experimental period. Moreover, some core dynamics in the developmental process are rare and fleeting in imaging observation and difficult to recapture again. Therefore, this study proposes a deep learning method for microscope cell image enhancement to reconstruct sharp images. We combine generative adversarial nets and various loss functions to make blurry images sharp again, which is much more convenient for researchers to carry out further analysis. This technology can not only make up the blurry images of critical moments of the development process through image enhancement but also allows long-term live-cell imaging to find a balance between imaging speed and image quality. Furthermore, the scalability of this technology makes the methods perform well in fluorescence image enhancement. Finally, the method is tested in long-term live-cell imaging of human-induced pluripotent stem cell-derived cardiomyocyte differentiation experiments, and it can greatly improve the image space resolution ratio.
Introduction
Microscopic imaging and fluorescence imaging technology have brought great convenience to biological research, and allow researchers to visually observe subcellular structures and the interaction between cells. The emergence of long-term live-cell imaging technology has made it possible to observe the cultivation and growth process of cells, which is expected to explain more biological phenomena over time. In particular, the dynamics of changes in cellular and subcellular structures and protein subcellular localization, and the dynamic process of cell differentiation and reprogramming were studied. It is crucial to decipher the mechanism behind the dynamic heterogeneous cellular responses.
Many studies require long-term imaging of living cells, so brightfield imaging should be carried out for further analysis to keep cells alive. The brightfield imaging process is simple without a fluorescent staining operation and the noise introduced into the experimental system is quite low. The non-intrusive experimental method shows great advantages: 1) no complex experimental operations, 2) does not introduce noise into the experimental system, and 3) does not interfere and destroy the cells themselves, while the phototoxicity can be reduced to a minimum. Since long-term live-cell imaging has such advantages, there have been many studies.
Smith et al. (2010) used high-resolution time-lapse imaging to track the reprogramming process from single mouse embryonic fibroblasts (MEFs) to induced pluripotent stem (iPS) cell colonies over 2 weeks. Schroeder (2011) conducted continuous long-term single-cell tracking observations of mammalian stem cells and found a set of technical solutions for long-term imaging and tracking. McQuate et al. (2017) established a pipeline for long-term live-cell imaging of infected cells and subsequent image analysis methods for Salmonella effector proteins SseG and SteA. Chen et al. (2010) developed a machine learning-based classification, segmentation, and statistical modeling system based on a time-lapse brightfield imaging analysis system to guide iPSC colony selection, counting, and classification automatically. In their research, AlexNet and hidden Markov model (HMM) technology were used. Buggenthin et al. (2017) used long-term time-lapse microscopy data and single-cell tracking annotation to prospectively predict differentiation outcomes in differentiating primary hematopoietic progenitors. They propose a convolutional neural network (CNN) combined with a recurrent neural network (RNN) architecture to process images from brightfield microscopy and cell motion. They predicted primary murine hematopoietic stem and progenitor cells (HSPCs) differentiating into either the granulocytic/monocytic (GM) or the megakaryocytic/erythroid (MegE) lineage. Wang et al. (2020) developed a live-cell imaging platform that tracks cell state changes by incorporating endogenous fluorescent labels. It can minimize the perturbation to cell physiology when processing live-cell imaging. In the field of cell differentiation and reprogramming, continuous long-term single-cell observation provides an insight into the mechanisms of cell fate. Even in the field of education, the low-cost long-term live-cell imaging platform also has high application prospects (Walzik et al., 2015).
A summary of the general processing pipeline of long-term live-cell imaging research is shown in Figure 1. Once the research question has been set up, appropriate microscopy strategies must be tailored according to the experimental system to be used at the beginning of the study. In addition, it is necessary to balance the trade-offs between the image space resolution ratio, experimental throughput, and imaging speed (Weigert et al., 2018), limited by imaging technology and cost.
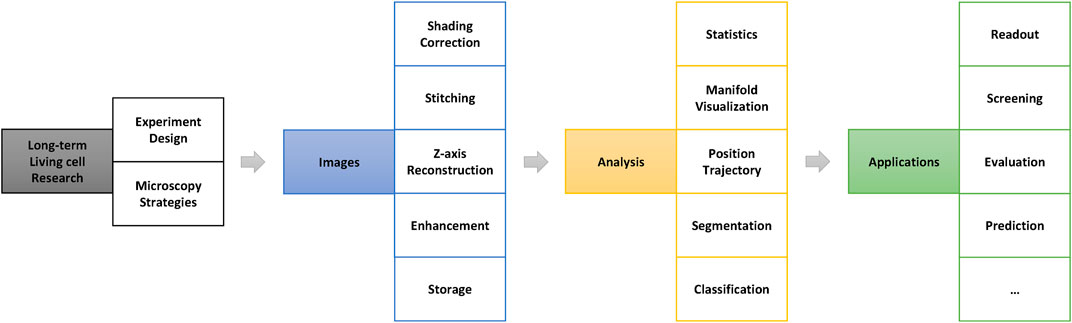
FIGURE 1. General processing pipeline for long-term live-cell research. The image preprocessing stage (blue part in this figure) is very important in the entire research pipeline and directly determines the accuracy and results of the further analysis.
However, many difficulties and challenges arise in actual long-term imaging experiments. This is the congenital deficiency of long-term live-cell imaging. It takes considerable effort to maintain regular cell culture conditions while performing long-term high-resolution imaging (Skylaki et al., 2016). For example, the obtained photos may not be as sharp and distinguishable as traditional fluorescent label imaging because the noninvasive label-free observation method has no conspicuous calibrations. At the same time, it is necessary to reduce the phototoxicity to a range that can be tolerated in an experimental system while exposing the live cells to the transmitted light in long-term incubation. Thus, it reduces the signal-to-noise ratio of image acquisition because the light intensity is limited. Moreover, a large number of cells will aggregate into clusters as a result of cell growth and culture in long-term live-cell culturing. The sudden growth of cells in a mass can cause loss of the focal surface. Dead cells will become pollutants, float up and block the view. Furthermore, artificial placement errors will be introduced in the long-term experimental system. For example, the medium was changed every certain period of time to maintain regular cell survival or differentiation. Nevertheless, thermal expansion and contraction of the culture chamber are caused by temperature changes during the movement of the culture chamber in and out of the thermostatic incubator. The quality and clarity of the medium will lead to a decrease in the quality of the acquired images. Some of the conditions that cause blurring in long-term live-cell imaging are shown in Figure 2. Most importantly, it does not leave enough time for the researcher to take another image because many cellular dynamic response processes are rare and occur quickly. On the other hand, it always takes several days or weeks to reproduce the entire biological experiment again, which wastes considerable time. Therefore, the industry urgently needs a tool that can efficiently improve the quality of once-taken bad images and reconstruct high-quality microscopic images of cells.
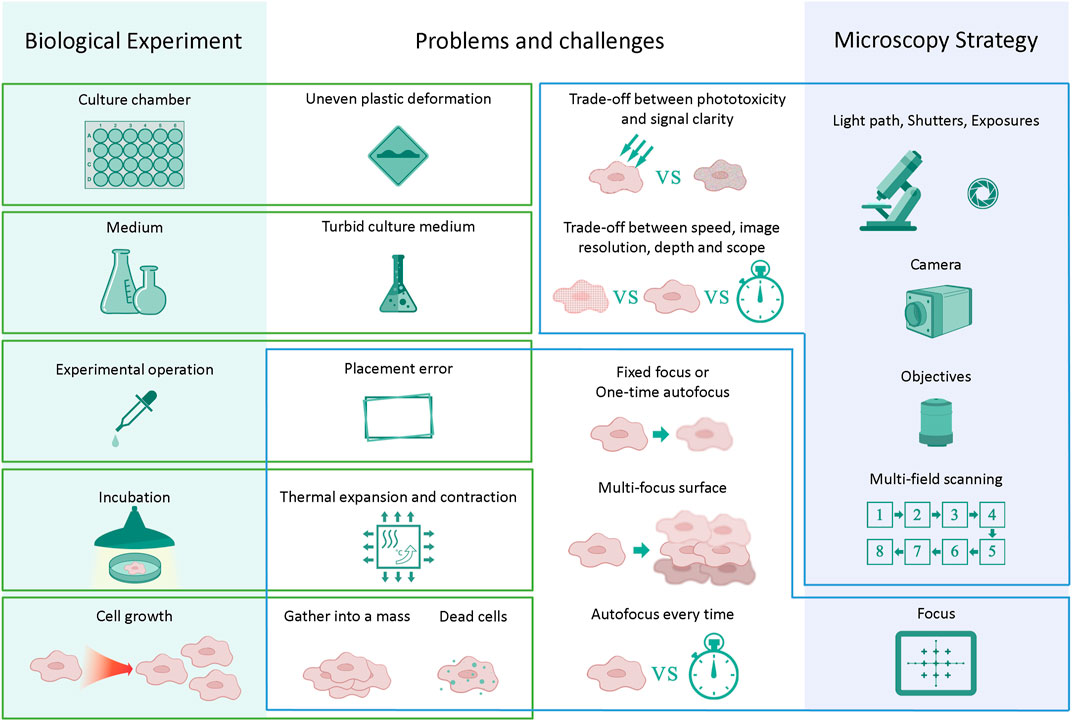
FIGURE 2. Challenges in long-term live-cell imaging. Changes in individual steps or components may influence the next series of steps and cause a reduction in image quality. Trade-offs must be made between time and image quality in almost every long-term experiment.
Image processing methods such as image inpainting or image completion can be used to restore imperfect cell images. The rapid progress of deep learning technology (Hinton et al., 2006; Hinton and Salakhutdinov, 2006) and deep convolutional neural networks (CNNs) has led to many new applications in computer vision and image processes. The emergence of generative adversarial networks (GANs) (Goodfellow et al., 2014) has brought almost a leap in image generation, inpainting, repair, and completion. A conditional generative adversarial net (CGAN) (Mirza and Osindero, 2014) can generate custom outputs by adding class information to the model. The best of these methods in image processing is deep convolutional generative adversarial networks (DCGANs) proposed by Radford et al. (2016), which replace fully connected layers in the original GANs with the convolutional layers in both the generator and the discriminator. Recently, many excellent image repair methods based on DCGAN structures have been proposed for real-world photo restoration, such as those by Pathak et al. (2016), Iizuka et al. (2017), and Yu et al. (2018). These methods work very well on landscape, architecture, or portrait retouching.
Recently, image-to-image translation tasks have been proposed to address image style transfer, which aims to translate an input image from a source domain to a target domain. The “pix2pix” proposed by Isola et al. (2017) is an image translation method based on conditional adversarial networks, which has shown the super ability of street scene restoration in the real world. “Pix2pix” uses input–output image pairs as training data, and pixel-wise reconstruction loss coupled with adversarial loss is used to optimize the model building process.
On the other hand, the single-image super-resolution (SISR) method has emerged to recover a high-resolution (HR) image from a single low-resolution (LR) image. Wei et al. proposed the “artificial neural network accelerated-photoactivated localization microscopy” (ANNA-PALM) method for reconstructing high-quality cell super-resolution views from sparse, rapidly acquired, single-molecule localization data and widefield images (Ouyang et al., 2018). Based on the “pix2pix” architecture, this method greatly facilitates studies of rare events, cellular heterogeneity, or stochastic structures. The super-resolution generative adversarial network (SRGAN) proposed by Ledig et al. (2017) is one of the milestones in single image super-resolution, and it significantly improves the overall visual quality of reconstruction over traditional methods. The SRGAN innovatively uses content loss coupled with adversarial loss instead of PSNR-oriented loss as the objective function. There are many variants of SRGAN methods, such as the enhanced SRGAN (ESRGAN) proposed by Wang et al. (2018) and the practical restoration application ESRGAN (Real-ESRGAN) proposed by Wang et al. (2021b). In an ESRGAN, a residual-in-residual dense block (RRDB) was introduced to the model as the basic network building unit, which combines a multilevel residual network and dense connections. The RRDB can further improve the recovered textures by adopting a deeper and more complex structure than the original residual block in the SRGAN. The Real-ESRGAN uses the U-net discriminator with spectral normalization as a modification to the ESRGAN to increase the discriminator capability and stabilize the training dynamics. Therefore, it is better at restoring most real-world images than previous works, especially low-quality web images or videos with compression degradations.
While the aforementioned methods perform well on macroscopic photographs such as street views, these methods do not perform well enough in the reconstruction of biological images, which require very precise fine structure recovery. Therefore, inspired by the methods in the field of image completion and image super-resolution (Wang et al., 2018, 2021a, 2021b; Rad et al., 2019; Qiao et al., 2021), we propose a cell image-enhanced generative adversarial network (referred to as CIEGAN) for image enhancement to address the challenges mentioned previously. In addition to using adversarial loss, the CIEGAN introduced perceptual losses comprising feature reconstruction loss and style reconstruction loss (Gatys et al., 2015; Johnson et al., 2016), which greatly improves the image restoration efficiency of the model. Coupled with image reconstruction loss and the total variation regulator, our method can solve various blurry problems of biological cell images. This method is very convenient and especially optimized for long-term live-cell imaging. Moreover, it can increase the imaging speed because there is no need to take more Z-axes layers for focus finding. Researchers can have more time to scan more conditions or increase the frequency of image acquisition. Furthermore, it can handle the force majeure during cell culture: cell clumping, cell bulging or blurring caused by floating dead cells, etc., even if the blur was caused by the beating of the differentiated mature cardiomyocytes. Nevertheless, the processing is fast, of low cost, and can easily be extended to other photos. It is convenient for researchers to obtain the differentiation or development trajectories of cell lines from the image stream and conduct research such as differentiation trajectory tracking, subtype search, or protein subcellular localizations (Aggarwal et al., 2021).
We applied the CIEGAN to long-term live-cell imaging of a human-induced pluripotent stem cell (hiPSC)-derived cardiomyocyte (hiPSC-CM) differentiation system, which greatly enhanced the quality of brightfield cell images. Through the comparison of results, it is found that the CIEGAN based on generative adversarial networks is better than the traditional image enhancement algorithm and can use the original blurred images to reconstruct sharper images. The information entropy of the enhanced image is increased and its resolution ratio is also significantly improved. At the same time, we also found that it is quite suitable for the enhancement of fluorescence images.
Materials and Methods
This section describes the experimental steps and methods of the hiPSC-CM differentiation system. In addition, microscopy techniques and strategies have been used in the image data acquisition of live cells in a long-term culture. Notably, there are many challenges in the acquisition of microscopic images in long-term live-cell culture systems, and in some cases, image quality is sacrificed to balance the pros and cons. Here, the main technology and workflow of a cell image enhancement GAN are shown in detail and explained how a CIEGAN improves the sharpness of microscopic cell images. Finally, the deployment and training process of the model are also described.
Human-Induced Pluripotent Stem Cell Culture and Differentiation
Our experimental system is the differentiation induction process of human pluripotent stem cells into cardiomyocytes. The main differentiation process is shown in Figure 3, and images were captured and saved throughout the process.
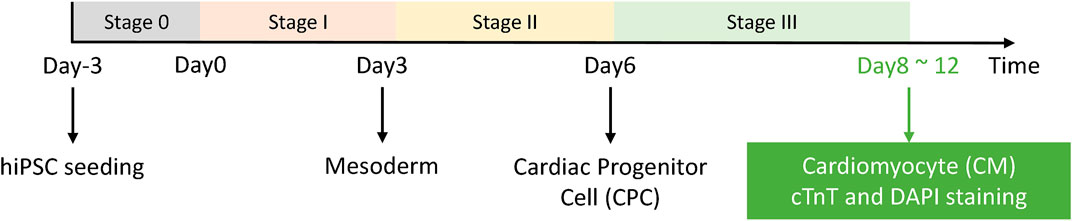
FIGURE 3. HiPSC-CM experimental system. Stage 0 is the hiPSC seeding and growth stage, and the differentiation process starts from day 0. After stage III, the cells were fixed and stained for readout and further analysis.
First, the iPSC-18 cell line was chosen for induction experiments. iPSC-18 cells (Y00300, Takara) were routinely cultured in a PGM1 medium (CELLAPY) on growth factor–reduced Matrigel (corning)-coated 6-well plates. iPSC-18 cells were passaged every 4 days using EDTA (Gibco). hiPSCs were split into a CDM medium (Cauliscell Inc.) at a ratio of 1:10 before differentiation in 24-well or 96-well plates. When they attained ∼80–90% confluence, the medium was changed to a RPMI 1640 medium (RPMI, Gibco), 1x B27 without insulin (Gibco), and 100 U penicillin (Gibco), or RPMI+B27 minus, for shorting. During the first 48 h, hiPSCs were treated with CHIR99021 (CHIR, a WNT activator). From 48 to 72 h (day 3), the medium was changed to RPMI+B27 minus. During days 4–5, RPMI+B27 minus medium was supplemented with IWR1 (a WNT inhibitor). On day 6, IWR1 was withdrawn instead of the RPMI+B27 minus medium. After day 7 through to the end of the differentiation process (up to 14 days), the RPMI 1640 medium (RPMI, Gibco), 1 x B27 (Gibco), and 100 U penicillin (Gibco) were used and refreshed every 3 days.
Immunofluorescence Staining
After the final stage of induction (stage III: day 8–day 12), the cells were fixed in 4% paraformaldehyde (DING GUO) for 20 min at room temperature, permeabilized, and blocked in 3% normal donkey serum (Jackson) and 0.1% Triton X-100 for 45 min at room temperature. Then, the cells were incubated with a cTnT antibody (Thermo, MA5-12960, use 1:300) overnight at 4°C in PBS plus 0.1% Triton X-100 and 3% normal donkey serum (Jackson). The cells were washed with PBS and then incubated with secondary antibodies for 1 h at 37°C in a dark environment in PBS and 1% bovine serum albumin (BSA). Nuclei were stained with Hoechst 33342 (Yeasen) for 5 min at room temperature.
Microscopic Image Acquisition
The irresistible degradation of image quality introduced in long-term live-cell experiments has been described previously. Errors are introduced during the culture medium changing operation on average every 24–48 h according to the experimental steps of the iPSC-CM differentiation system. An elaborate microscopy strategy must be carefully designed to reduce these errors as much as possible. A good microscopy strategy can maximize the image quality and speed up photographing so that higher throughput experimental image data can be obtained within one culture cycle. It is essential to find a balance between the imaging resolution ratio, experimental throughput, and imaging speed (Figure 2).
Because the imaging field of view of the microscope is limited to the optical device itself and light path design, multiple scanning imaging is required to expand the field of observation view, and the whole picture is stitched after the image acquisition. Therefore, the larger the observation field to be photographed, the more time-consuming it will be. It will cost more time to scan more culture chambers in a parallel multi-condition comparison observation of cell differentiation or reprogramming studies. On the other hand, it will further reduce the imaging speed of the system to perform the Z-axis layer imaging if the three-dimensional structure needs to be observed. Therefore, it is necessary to accelerate the imaging speed of each imaging experimental cycle to ensure the acceptable frequency of observation. If a higher imaging speed is required, a narrower imaging breadth is to be obtained, and vice versa. You cannot have your cake and eat it, too.
In addition, there are many options for different focusing strategies in an experiment. If the fixed focus or the one-time autofocus has been chosen, the out-of-focus caused by various emergencies in the long-term live-cell imaging process cannot be handled. For example, culture chamber expansion and contraction are caused by temperature or dead cell contamination. In particular, cells are raised into multiple layers because of cell growth. At this time, each layer of cells has its own focus surface due to the overlapping of multiple cell layers. Only multiple Z-axis microscopic imaging can obtain each sharp view of the overlapping cells. Notably, different cell types have different clonal heights, and the optimal focus surface may span more than 50–60 μM or even 100 μM in our iPSC-CM differentiation system.
On the other hand, if the autofocus every-time mode has been chosen, it is almost impossible to carry on the experiment because the focusing process will take plenty of time. Each well requires a 5 × 5 pattern mosaic tile stitching to obtain a square field of view of approximately 6.3 mm*6.3 mm according to the 96-well plates in this research. If only the center of each well is used as the focus reference point, then it will take approximately 48 min for 96 focus points to perform high-speed hardware autofocus. Moreover, if autofocus needs to be performed on each tile, the total time spent focusing will be 25 times larger, which is overtime to an incredible 20 h. Unfortunately, more focal points per well are required for the 24-well plates because of the larger culture area of each well. There is a way to combine a one-time autofocus strategy and multiple Z-axis imaging, then select the sharpest layer for use after imaging experiments (more images are shown in Supplementary Materials), but it also comes at the expense of time. These limits necessitate trade-offs between the imaging resolution ratio, experimental throughput, and imaging speed (Figure 2).
Here, the “Celldiscoverer 7,” a long-term live-cell culture instrument manufactured by Carl Zeiss, is used. It has an internal incubator to ensure regular cell growth, and the cell culture environment is kept stable at 37 °C with 5% CO2. The ORCA-Flash 4.0 V3 digital CMOS camera is used as HD picture acquisition equipment. The effective resolution of the camera is 2,048*2,048 pixels. The objective is a ZEISS Plan-Apochromat ×5 objective. The objective can easily handle thin and thick vessel bottoms made of glass or plastic, which is essential to the hiPSC-CM differentiation system because our cells can only grow on plastic. With a ×2 tube lens, it achieves 10x/0.35 magnification and spatial resolution. Finally, the resolution ratio of all the photos is 0.65 μM per pixel.
For culture chambers, 96-well and 24-well plates produced by Falcon are used. A 2,048*2,048-pixel photo can cover a square of approximately 1.33*1.33 mm because of the resolution ratio of 0.65 μM per pixel. Therefore, the scanning imaging method was adopted for image acquisition, and the whole images were stitched after the imaging experiments. The larger the observation field is, the more mosaic tiles will be needed.
Multiple Z-axis layers are photographed to study the multiple Z-axis layer aggregation of the cells in the iPSC-CM differentiation process and to find the cause of blurring, and more importantly, to obtain the training data for the model. Eleven, seven, and five layers at 1.5 μM, 6 μM, and 18 μm intervals with total vertical distances of 15 μM, 36 μM, and 72 μM, respectively, were obtained for study (the images are shown in the Supplementary Materials).
Finally, the microscopic images were acquired by Carl Zeiss ZEN software version V2.5, and the images were saved in the CZI format or PNG format. A real-time microscopic image processing framework has been compiled for the long-term live-cell imaging system. It can automatically acquire and perform image preprocessing correspondingly, including image stitching and image segmentation. The segmented images will be sent to the CIEGAN for image enhancement for further analysis.
Cell Image Enhancement Generative Adversarial Networks
The deep convolutional generative adversarial network structure (Goodfellow et al., 2014; Radford et al., 2016) is adopted as the main body of the model to reconstruct high-quality and high-resolution images from low-quality microscopic cell images.
The GAN architecture in our model comprises a pair of generators and discriminators. Typically, the generator is trained to generate fake samples from random noise vector z. However, in our model, we take the blurred original image as the input z to enhance it. The input image flows through a pair of our carefully designed encoder-decoder-like structures in the generator. The latent implicit representation of the input image is obtained from the encoder module. The output image is precisely reconstructed using the information provided by the latent representation. On the other hand, the discriminator is trained to distinguish between the real cell images and the generated fake images. This framework can be represented as a two-player min-max game between generator
In Eq. 1, x represents the real-world high-resolution cell image examples. Discriminator
In the GAN structure, only the strongest generator survives in the game, which is very suitable for image restoration tasks. The adversarial loss ensures a high degree of realism of the image, making the image more natural and realistic. The following description will use
The two parts are the true labels for the ground truth samples and the false labels for the generated samples. The optimization objective of the adversarial loss of the discriminator is formulated as Eq. 3:
Similarly, the adversarial loss of the generator and its optimization objective are formulated as Eqs. 4, 5:
In the GAN structure, the latent representation can capture valuable information in the input images, and the rest of the details and textures are handed over to network parameters for completion and reconstruction. However, it is not enough to determine the network parameters precisely in the generator only by the adversarial loss of the GAN, and more penalties are required to generate more accurate images and perform more refined image restoration.
Inspired by image style transfer (Isola et al., 2017), single-image super-resolution (SISR) methods (Yang et al., 2019; Ooi and Ibrahim, 2021), and high photorealistic image synthesis (Wang et al., 2018; 2021b), a series of image reconstruction losses are introduced to the model, such as pixel-wise loss and perceptual loss.
Specifically, using only reconstruction loss can reconstruct sharp images, but the generalization abilities are poor because of its pixel-wise properties. Therefore, images generated by reconstruction loss only may have excellent results superficially but suffer overfitting problems: just a single pixel translation may lead to model failure. Therefore, combining with the perceptual loss is a wise choice. The perceptual loss enables the contents and styles of the image reappearance. The reconstruction loss, also known as pixel-wise loss, is denoted as Eq. 6:
In Eq. 6, B, C, H, and W represent the training batch size, the number of channels of the image or feature map, and the height and width of the feature map, respectively.
The perceptual loss comprises two parts: the feature loss part and the style loss part. The feature perceptual loss is formulated as Eq. 7 (Gatys et al., 2015; Johnson et al., 2016):
In Eq. 7,
In Eq. 8, the Gram matrix can be calculated using the following formula:
Nevertheless, a total variation regularization is imported to the model to remove noise and mosaics from images and further reduce the spikey artifacts of the generated images. The total variation regulator is formulated as Eq. 9:
In Eq. 9,
Finally, the loss of the CIEGAN is divided into two parts: the discriminator loss
The corresponding coefficients
These losses and regularizations are merged together to reconstruct high-quality images and are referred to as the combined loss shown in Figure 4. The main structure of the CIEGAN model and the training and testing processes are depicted.
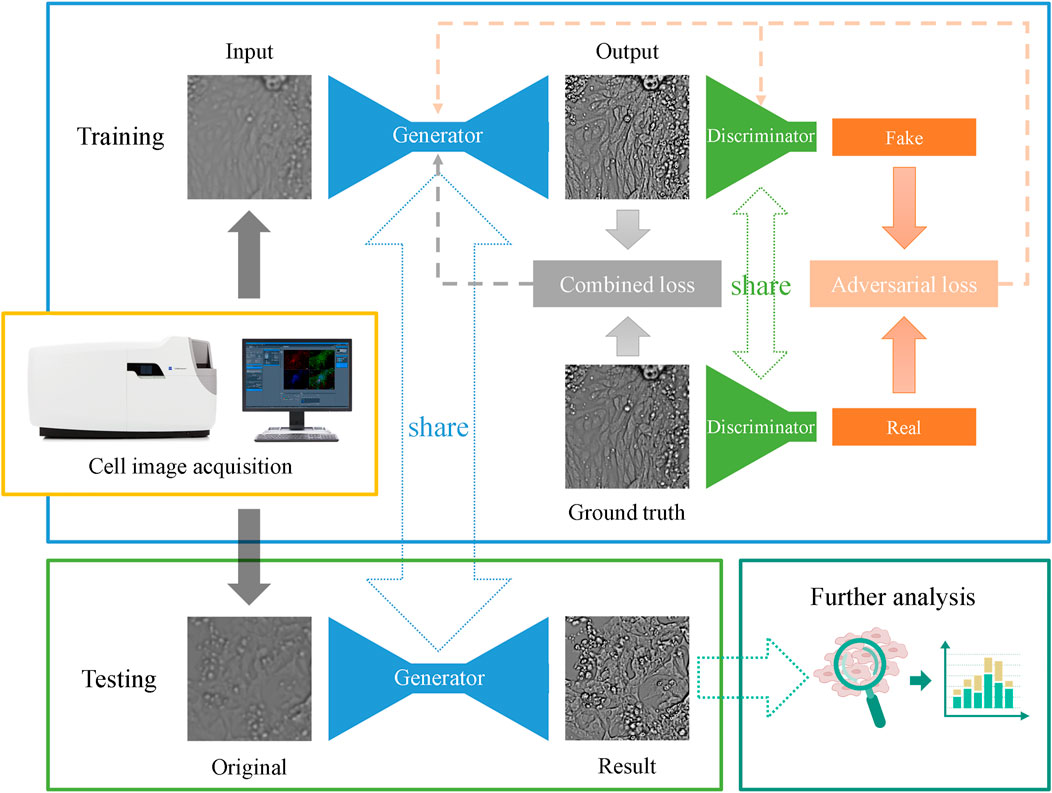
FIGURE 4. Network architecture and the main pipeline of the CIEGAN. The training process of the model is shown in the blue box, and the testing process of the model is shown in the green box in the lower-left corner, where the generator is shared. Once the model is trained, it can predict a sharp image from the original imperfect cell image.
Model Building and Training
CIEGAN model coding mainly uses the TensorFlow deep learning framework (Abadi et al., 2016) and TF-slim library to build our generative adversarial nets. A cloud computing environment is used for model training and testing. The main hardware configuration list is an Intel Xeon Cascade Lake (2.5 GHz) 8-core processor, 32 GB of memory, and the CUDA computational acceleration unit is an NVIDIA T4 (with 15 GB of video memory).
Then, 128*128-pixel images, 256*256-pixel images, and 512*512-pixel images are successively tested on the CIEGAN model. According to the memory size of the CUDA unit, the network was trained using a batch size of 32, 20, and 4 images for the 128*128-pixel, 256*256-pixel, and 512*512-pixel inputs, respectively. Finally, the combination of 256*256-pixel image size and a batch size of 20 is chosen for the final training process according to the results.
The datasets used in training and testing come from two sources: 1) the original data are obtained from multiple Z-axis layers with an out-of-focus and sharp focus for each field of view. 2) Additional data were generated with a Gaussian blur from the original high-definition image to simulate the out-of-focus effect. In this way, more samples can be generated. Finally, a pair of blurry and high-resolution images of the same field of view are input into the model for training.
To ensure a stable and efficient training process and make the generator and discriminator converge, a multistep training strategy is adopted. 1) First, the generator is trained so that it can output primary-quality images. 2) Then, the discriminator is trained to identify fake images generated by the generator. 3) Finally, fire up the game and start the game process between the generator and the discriminator.
Initially, approximately 4,200 brightfield live-cell images (256*256 pixels) of the iPSC-CM differentiation process were used in the model test. The CIEGAN model only takes a few hours to achieve decent results on an NVIDIA T4. The time spent on training varies depending on the size of the training set in other applications. However, the use of the CIEGAN model is very fast; it can run 128 images (256*256 pixels) at a time of only a few minutes on VIDIA T4. Most of this is the load time of the model checkpoints. Once the model is loaded, its prediction timeliness is comparable to real-time processing. Nevertheless, our program provides automatic segmentation and assembly to handle larger input images. Finally, the performance of the CIEGAN should be similar to the same level of the CUDA computational acceleration unit. For example, it should have approximately the same time cost as this article on an NVIDIA 1080Ti GPU (12 GB).
Results
In this section, the CIEGAN is applied to long-term live-cell imaging of iPSC-CM differentiation. It significantly facilitates the research works by enhancing time-lapse microscopy images and carrying out the next analysis work. The CIEGAN successively enhanced the brightfield image of induced cardiomyocytes and obtained many good results. Then, the method is extended to the enhancement of fluorescence images, and the results are promising. Finally, several other similar methods are compared and public databases are used to explore the practicality and scalability of these methods.
Brightfield Image Enhancement
First, the brightfield images in the hiPSC-CM differentiation process are enhanced for qualitative testing and the results are shown in Figure 5. A variety of cell morphologies are selected to test the robustness of this method. The thickness of the observed cells varies from flat monolayer to three-dimensional structures.
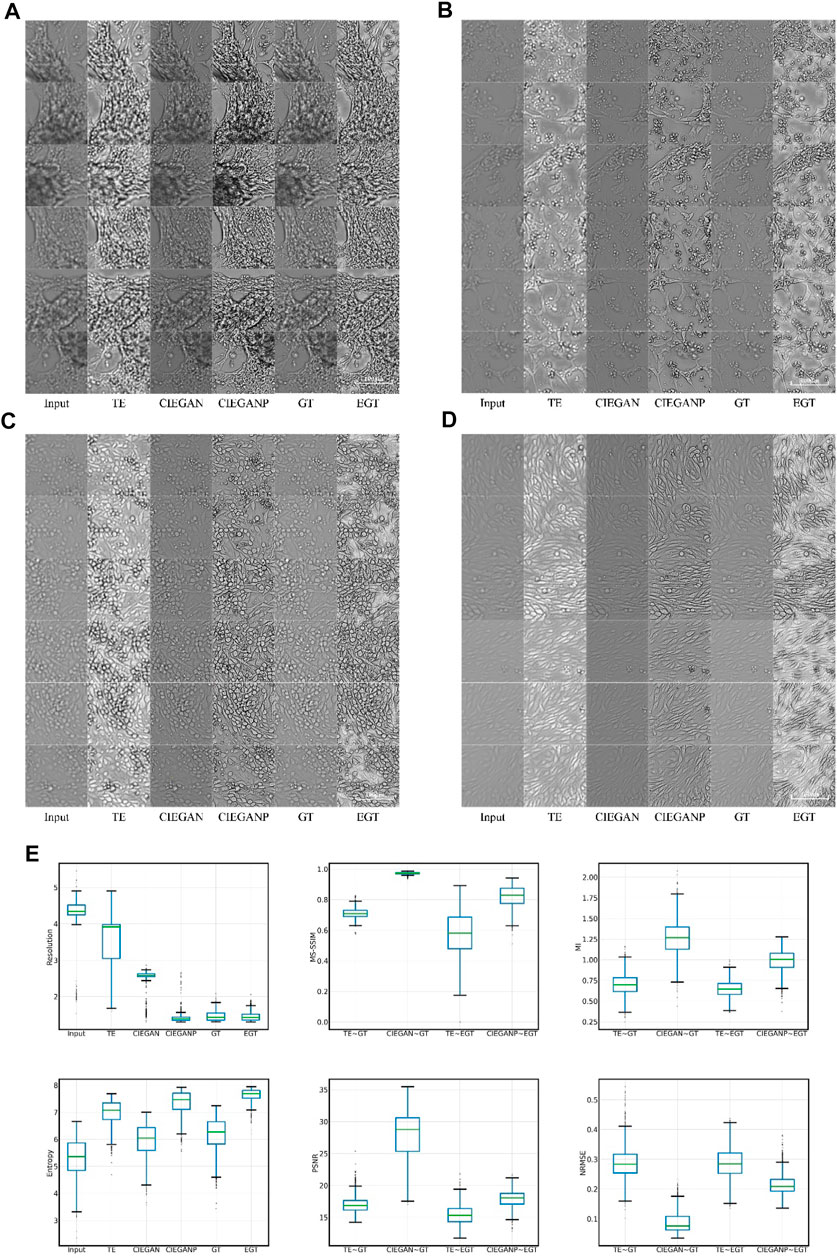
FIGURE 5. Brightfield cell image enhancement results of iPSC-CM differentiation experiments. The results for different cell morphologies are shown in subfigures (A), (B), (C), and (D). TE stands for the traditional enhancement method, CIEGAN, CIEGAN plus (CIEGANP) is our method, GT is the ground truth, and EGT is the enhanced ground truth. (E) Boxplot comparison results of resolution, MS-SSIM, mutual information (MI) entropy, PSNR, and NRMSE (n = 1128).
In the results, the traditional enhancement method (TE) is used to enhance the blurred input images for comparison. The TE method adopts the combination of the unsharp masking (Polesel et al., 2000; Deng, 2010) and contrast limited adaptive histogram equalization (CLAHE) (Pisano et al., 1998; Reza, 2004). Unsharp masking and CLAHE are classical tools for sharpness enhancement that can adaptively adjust and enhance the sharpness and contrast of the image, respectively. Here, the TE columns in Figure 5 show the results of the enhancement of the input cell images. Although the brightness and contrast of the images have been significantly improved through the enhancement of the traditional method, the blurring problem of the image has not been fundamentally solved. However, our CIEGAN method outperforms the traditional methods and benefit from the adversarial process and perceptual loss. The results of the CIEGAN are very close to the ground truth (GT), especially on the reconstruction of the fine structure of cells.
On the other hand, inspired by the Real-ESRGAN (Real Enhanced Super-Resolution Generative Adversarial Network) (Wang et al., 2021b), an improved CIEGAN was trained by using an enhanced version of the training sets, which we call CIEGAN plus (CIEGANP). The difference between them is the training inputs; the CIEGANP model is trained with enhanced ground truth images. Here, enhanced ground truth (EGT) is the result of image enhancement using unsharp masking and CLAHE methods for the GT. Interestingly, the image enhanced by the EGT method highlights the dead cells in the image (black dots) because the size of the dead cells or impurities is much smaller than the cells. Figure 5 (A–D) shows that the result of the CIEGANP is better than that of the CIEGAN in brightness and sharpness. Moreover, the results of the CIEGANP have less pepper noise or spikey artifacts than the enhanced ground truth (EGT) due to the introduced variation regulator.
To further evaluate the method, we performed a package of quantitative evaluations between traditional methods. The normalized root mean square error (NRMSE), peak signal-to-noise ratio (PSNR), and multi-scale structural similarity index (MS-SSIM) (Wang et al., 2003) are used in the image similarity assessment between the generated image and ground truth. The NRMSE reflects the pixel difference between the two images, and the smaller the value is, the better. The PSNR is the ratio of the maximum possible power of a signal to the power of corrupting noise that affects representation fidelity, which can objectively measure the image quality; the larger the value is, the better. The MS-SSIM is an improved version of the SSIM that is also used to measure image quality; the closer the value is to 1, the better. In addition, mutual information (MI) is used to measure the similarity of two images. The mutual information
Mutual information in Eq. 12 describes the reciprocity between objects in two images, and the larger the value is, the higher the similarity between the two images will be.
We also used some no-reference methods for a single image quality evaluation in addition to the full reference method. The information gain and the estimation of the resolution ratio are used for evaluation after image enhancement. The information entropy
In Eq. 13, x represents the gray value of a pixel in the image, and
On the other hand, resolution ratio estimation is widely used in biological image evaluation because it can indicate the actual resolution per pixel (Qiao et al., 2021). The resolution ratio calculation is performed by a decorrelation analysis, where the cross-correlation coefficient is expressed as Eq. 14 (Descloux et al., 2019):
In Eq. 14, k is the Fourier space coordinates, and I is the Fourier transform function.
The resolution ratio can measure the recognizability of structures in biological images; the smaller the resolution ratio value is, the greater the accuracy will be. The physical resolution in the iPSC-CM experiments is 0.65 μM per pixel, while the actual resolution of the ground truth images obtained may be poorer: 1.465 μM on average. The input images have a resolution of 4.305 μM on average due to out-of-focus, and our method can enhance this to 2.488 μM by the CIEGAN on average and 1.416 μM by the CIEGANP on average. Here, the traditional enhancement (TE) method only has a resolution of 3.546 μM on average. The results of the boxplot comparison are shown in Figure 5E.
An expert questionnaire is conducted to investigate whether the resulting pictures generated by this model are suitable for scientific research purposes. The results also show that the CIEGANP generally performs better than the other methods and has appropriate contrast and brightness.
DAPI Image Enhancement
The assessment of cardiomyocyte quality is required after the third stage of differentiation (Figure 3) in the iPSC-CM differentiation process. Therefore, fluorescent staining experiments were performed. Here, we stained two types of cell markers: cardiomyocyte-specific cTnT antibody and the nucleus-specific Hoechst 33342, which are used to assess the differentiation ratio and the cardiomyocyte quality. The enhancement results of the cell image stained with Hoechst 33342 are shown in Figure 6.

FIGURE 6. Enhancement results of Hoechst 33342 fluorescence microscopy images of the iPSC-CM differentiation experiment. TE stands for the traditional enhancement method, CIEGAN and CIEGAN plus (CIEGANP) are our methods, GT is the ground truth, and EGT is the enhanced ground truth.
The CIEGAN algorithm has significantly enhanced the sharpness and contrast of the blurred cell staining images. It even obtained a higher signal-to-noise ratio than the ground truth. However, the performance in brightness is not perfect, which is a common problem of this model. The reason for this is that there are many black images with nothing in the training set. For this reason, the model trained with sharped ground-truth images as the CIEGAN plus has been introduced, and it significantly improves the sharpness and brightness of generating biological images while increasing the signal-to-noise ratio.
CTnT Image Enhancement
The enhanced cTnT fluorescent stained images are shown in Figure 7. The CIEGAN model achieves excellent generalization performance for different types of fluorescent images. The phototoxicity can be ignored in this experiment because the fluorescent staining method kills cells. Longer and stronger exposures can be used for imaging. However, photobleaching cannot be ignored because of the poor stability of dyes under strong light irradiation. It is not possible to use a strong intensity of light for a long time during the exposure process. Therefore, the balance between exposure time, light intensity, and image clarity also needs to be considered when taking photographs of fluorescence microscopy images. Nevertheless, it is sometimes impossible to obtain fluorescent photographs again because of severe photobleaching. In this case, the CIEGANP can not only deal with various out-of-focus images but can also enhance images with a low signal-to-noise ratio due to photobleaching.
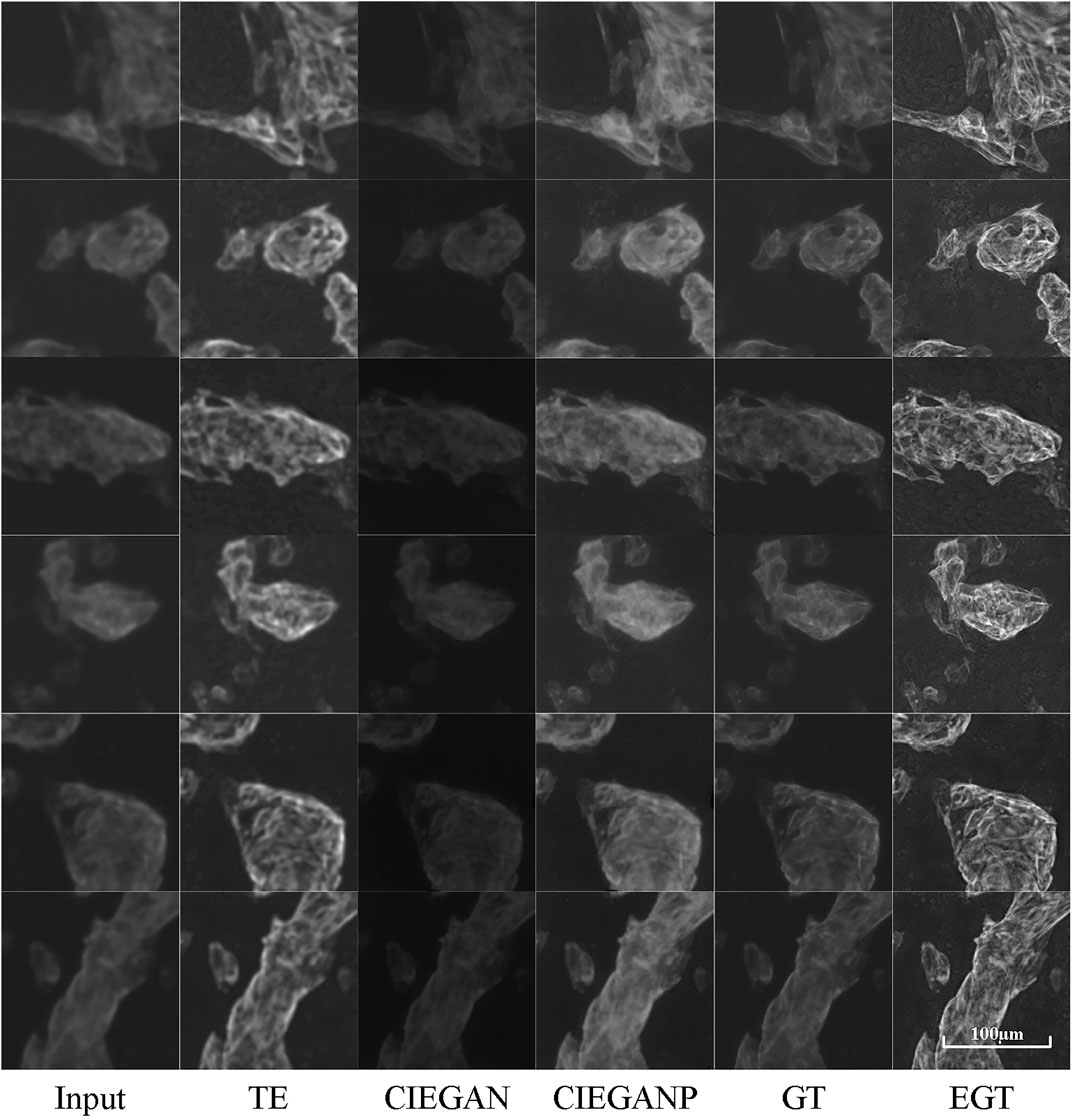
FIGURE 7. Results of cTnT fluorescence microscopy images of the iPSC-CM differentiation experiment. TE stands for the traditional enhancement method, CIEGAN, CIEGAN plus (CIEGANP) is our method, GT is the ground truth, and EGT is the enhanced ground truth.
Comparison With Other Methods
The comparison with other methods is also carried out here. The “pix2pix” proposed by Isola et al. (2017) and the Real-ESRGAN proposed by Wang et al. (2021b) are used for comparison. The comparison results are shown in Figure 8.

FIGURE 8. Comparison results of brightfield image enhancement of the iPSC-CM differentiation experiment. TE stands for the traditional enhancement method, CIEGAN, CIEGAN plus (CIEGANP) is our method, GT is the ground truth, and EGT is the enhanced ground truth. “pix2pix” is the method proposed by Isola et al. (2017) and RESRGAN is the real-ESRGAN method proposed by Wang et al. (2021b).
First, the “pix2pix” model is trained on the dataset of brightfield images in the hiPSC-CM experiments and then achieves convergence. The results of “pix2pix” show its excellent performance, but there are a small number of artifacts and compression blur. On the other hand, the Real-ESRGAN shows its remarkable performance in real-world photos. Here, the Real-ESRGAN can increase the input biological image from 256*256 pixels to 1,024*1,024 pixels, which is 16 times the quantity of pixels. Because it was designed to perform super-resolution enhancement instead of dealing with blur degradations in biological micrographs, the high-definition pictures generated by the Real-ESRGAN are biologically distorted.
Discussion
To overcome challenges in long-term live-cell imaging, this study proposes a cell image-enhanced generative adversarial network (CIEGAN). This method can resolve various blurred degradations in biological brightfield cell images and significantly improve the image space resolution ratio. It can maximize the effectiveness of the information mining of the biological image. Needless to say, it is very convenient to make the blurred images sharp again with a few steps. Moreover, it accelerated the imaging speed because there is no need to take multiple Z-axis layers to prevent out-of-focus problems. It creates more time for experimental throughput, so researchers can investigate more conditions or increase the frequency of image acquisition. Most importantly, many cellular dynamic response processes are rare and quick and do not give us a second chance to recapture the study of cell differentiation and reprogramming. Here, the CIEGAN can give researchers a second chance to reproduce sharp biological images in a short time. Furthermore, it can handle imaging mishaps during cell culture: cell clumping bulging, blurring caused by floating dead cells or the poor clarity of the medium, out-of-focus problems caused by thermal expansion and contraction of the culture chamber, and even the blur caused by the beating of differentiated mature cardiomyocytes, etc. Nevertheless, the image enhancement process is fast, of low cost, and can easily be extended to other applications. It is convenient for researchers to reproduce the developmental trajectories of cell lines from long-term time-lapse unstable image streams.
On the other hand, the blurred cTnT staining results of myocardial cells could be enhanced by the aforementioned method. It is necessary to photograph Z-stacks to ensure full-field vision, as monolayer cardiomyocytes are still stereoscopic (Christiansen et al., 2018). The CIEGAN can obtain clear cTnT staining images from single-layer imaging and reduce the requirements and complexity of microscopic photography. In addition, sharp images have more cell features, such as the sarcomere structure of cardiomyocytes, which can indicate the state of maturity of the cardiomyocytes (Veerman et al., 2015). This method can not only be applied to cardiomyocytes but also to enhance the image of other cells, such as neurons, hepatocytes, adipocytes, etc., which will obtain more valuable information for biological-image study for further application.
Notably, once the deep learning model was trained, the model performed well on the same cell type of microscopic images. It is best to retrain the model to generalize other types of cells. The performance of the model is positively correlated with the sharpness of the input training examples. Therefore, researchers cannot expect this model to perform well on poor training data sets. This model also has some common limitations similar to other deep learning models. Because image transformation with deep learning models is not perfect in any way, real-world situations tend to be more complex (Cai et al., 2019; Yang et al., 2019; Qiao et al., 2021). The deep learning model cannot predict new or unseen fine structures limited by the image morphology and granularity of the training set, which is also a great challenge faced by the industry. Therefore, improving the quality of the first-hand images obtained by the microscope is a fundamental and indispensable part of biological studies. On the other hand, the method proposed in this study can improve the image quality in long-term living cell images to its best. It is very helpful in saving time, especially in long-term live-cell imaging with long experimental periods. Because it is impossible to repeat photograph processing due to the rare phenomenon of photobleaching, another time-consuming biological experiment must be restarted.
In further research, the CIEGAN will be improved by introducing more advanced generator structures or more penalty functions. U-net is becoming widely used in deep learning processing schemes for biological image processing (Ounkomol et al., 2018; Weigert et al., 2018; Kandel et al., 2020; Dance, 2021; Wieslander et al., 2021). It is widely implemented in image segmentation and classification thanks to its structure of directly copying the feature maps of convolutional layers to deconvolutional layers (Ronneberger et al., 2015). We can try to introduce this network mechanism into our model and in addition, the concept of the network structure of GoogLeNet (Szegedy et al., 2015, 2016, 2017). The method in this study mainly uses multiple image difference losses as the training criteria for the GAN generator, and more losses could be tried in the next step.
The CIEGAN method has high scalability and broad application prospects in image enhancement scenarios, which can help biologists observe and investigate image phenomena in the process of cell differentiation and reprogramming more intuitively and deeply. In turn, more efficient experimental models can be designed, and even effective potential treatments for related diseases can be found. We will continue to refine the application of the CIEGAN method to more image enhancement scenarios.
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material; further inquiries can be directed to the corresponding authors.
Author Contributions
All authors participated in the conception and experimental work of the study. YL provided method guidance and gave guidance for this manuscript writing. YZ raised scientific questions and guided the biological experiments. XY performed all the biological experiments: cell culture and differentiation induction of hiPSCs. In addition, XY put forward many suggestions for the improvement of this tool, and feedback on its use. JG modified some deep learning algorithms and made many valuable suggestions for model training and testing. The long-term living-cell microscopic imaging experimental design and image acquisition and preprocessing tasks were mainly completed by QS. Finally, QS carried out the construction of the mainframe and was a major contributor to algorithm coding and manuscript writing. All authors read and approved the final manuscript.
Funding
This work was supported in part by the National Natural Science Foundation of China (No. 31771475).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
The authors would like to thank Prof. Jue Zhang for some advice. Special thanks are extended to Prof. YZ (State Key Laboratory of Natural and Biomimetic Drugs, MOE Key Laboratory of Cell Proliferation and Differentiation, Beijing Key Laboratory of Cardiometabolic Molecular Medicine, Institute of Molecular Medicine, College of Future Technology, Peking University, Beijing, China.) for providing the experimental environment and materials, and great support for the research. Finally, thanks to everyone who contributed to this article for their efforts, especially for overcoming the inconvenience of their work during the COVID-19 pandemic.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fgene.2022.913372/full#supplementary-material
Reference
Abadi, M., Barham, P., Chen, J., Chen, Z., Davis, A., Dean, J., et al. (2016). “TensorFlow: A System for Large-Scale Machine Learning,” in USENIX Symposium on Operating Systems Design and Implementation. Editors K. Keeton, and T. Roscoe, 265–283. Available at: https://www.usenix.org/conference/osdi16/technical-sessions/presentation/abadi.
Aggarwal, S., Gupta, S., and Ahuja, R. (2021). “A Review on Protein Subcellular Localization Prediction Using Microscopic Images,” in 2021 6th International Conference on Signal Processing, Computing and Control (ISPCC) (Washington, D.C., United States: IEEE), 72–77. doi:10.1109/ispcc53510.2021.9609437
Buggenthin, F., Buettner, F., Hoppe, P. S., Endele, M., Kroiss, M., Strasser, M., et al. (2017). Prospective Identification of Hematopoietic Lineage Choice by Deep Learning. Nat. Methods 14, 403–406. doi:10.1038/nmeth.4182
Cai, J., Zeng, H., Yong, H., Cao, Z., and Zhang, L. (2019). “Toward Real-World Single Image Super-resolution: A New Benchmark and a New Model,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 3086–3095. doi:10.1109/iccv.2019.00318
Chen, J., Liu, J., Han, Q., Qin, D., Xu, J., Chen, Y., et al. (2010). Towards an Optimized Culture Medium for the Generation of Mouse Induced Pluripotent Stem Cells. J. Biol. Chem. 285, 31066–31072. doi:10.1074/jbc.m110.139436
Christiansen, E. M., Yang, S. J., Ando, D. M., Javaherian, A., Skibinski, G., Lipnick, S., et al. (2018). In Silico labeling: Predicting Fluorescent Labels in Unlabeled Images. Cell. 173, 792–803. doi:10.1016/j.cell.2018.03.040
Dance, A. (2021). AI Spots Cell Structures that Humans Can't. Nature 592, 154–155. doi:10.1038/d41586-021-00812-7
Deng, G. (2010). A Generalized Unsharp Masking Algorithm. IEEE Trans. Image Process 20, 1249–1261. doi:10.1109/TIP.2010.2092441
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-Fei, L. (2009). “Imagenet: A Large-Scale Hierarchical Image Database,” in 2009 IEEE conference on computer vision and pattern recognition (Washington, D.C., United States: IEEE), 248–255. doi:10.1109/cvpr.2009.5206848
Descloux, A., Grußmayer, K. S., and Radenovic, A. (2019). Parameter-free Image Resolution Estimation Based on Decorrelation Analysis. Nat. Methods 16, 918–924. doi:10.1038/s41592-019-0515-7
Gatys, L. A., Ecker, A. S., and Bethge, M. (2015). A Neural Algorithm of Artistic Style. CoRR abs/1508.06576. Available at: http://arxiv.org/abs/1508.06576.
Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., et al. (2014). “Generative Adversarial Nets,” in Advances in Neural Information Processing Systems. Editors Z. Ghahramani, M. Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger, 2672–2680.
Hinton, G. E., Osindero, S., and Teh, Y.-W. (2006). A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 18, 1527–1554. doi:10.1162/neco.2006.18.7.1527
Hinton, G. E., and Salakhutdinov, R. R. (2006). Reducing the Dimensionality of Data with Neural Networks. science 313, 504–507. doi:10.1126/science.1127647
Iizuka, S., Simo-Serra, E., and Ishikawa, H. (2017). Globally and Locally Consistent Image Completion. ACM Trans. Graph. 36, 1–14. doi:10.1145/3072959.3073659
Isola, P., Zhu, J.-Y., Zhou, T., and Efros, A. A. (2017). “Image-to-Image Translation with Conditional Adversarial Networks,” in IEEE Conference on Computer Vision and Pattern Recognition (Washington, D.C., United States: IEEE Computer Society), 5967–5976. doi:10.1109/CVPR.2017.632
Johnson, J., Alahi, A., and Fei-Fei, L. (2016). “Perceptual Losses for Real-Time Style Transfer and Super-resolution,” in Computer Vision Lecture Notes in Computer Science. Editors B. Leibe, J. Matas, N. Sebe, and M. Welling (Berlin, Germany: Springer), 694–711. doi:10.1007/978-3-319-46475-6_43
Kandel, M. E., He, Y. R., Lee, Y. J., Chen, T. H., Sullivan, K. M., Aydin, O., et al. (2020). Phase Imaging with Computational Specificity (PICS) for Measuring Dry Mass Changes in Sub-cellular Compartments. Nat. Commun. 11, 6256–6310. doi:10.1038/s41467-020-20062-x
Ledig, C., Theis, L., Huszár, F., Caballero, J., Cunningham, A., Acosta, A., et al. (2017). “Photo-realistic Single Image Super-resolution Using a Generative Adversarial Network,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 4681–4690. doi:10.1109/cvpr.2017.19
McQuate, S. E., Young, A. M., Silva-Herzog, E., Bunker, E., Hernandez, M., de Chaumont, F., et al. (2017). Long-term Live-Cell Imaging Reveals New Roles forSalmonellaeffector Proteins SseG and SteA. Cell. Microbiol. 19, e12641. doi:10.1111/cmi.12641
Mirza, M., and Osindero, S. (2014). Conditional Generative Adversarial Nets. Comput. Sci, 2672–2680.
Ooi, Y. K., and Ibrahim, H. (2021). Deep Learning Algorithms for Single Image Super-resolution: a Systematic Review. Electronics 10, 867. doi:10.3390/electronics10070867
Ounkomol, C., Seshamani, S., Maleckar, M. M., Collman, F., and Johnson, G. R. (2018). Label-free Prediction of Three-Dimensional Fluorescence Images from Transmitted-Light Microscopy. Nat. Methods 15, 917–920. doi:10.1038/s41592-018-0111-2
Ouyang, W., Aristov, A., Lelek, M., Hao, X., and Zimmer, C. (2018). Deep Learning Massively Accelerates Super-resolution Localization Microscopy. Nat. Biotechnol. 36, 460–468. doi:10.1038/nbt.4106
Pathak, D., Krähenbühl, P., Donahue, J., Darrell, T., and Efros, A. A. (2016). “Context Encoders: Feature Learning by Inpainting,” in IEEE Conference on Computer Vision and Pattern Recognition (Washington, D.C., United States: IEEE Computer Society), 2536–2544. doi:10.1109/CVPR.2016.278
Pisano, E. D., Zong, S., Hemminger, B. M., DeLuca, M., Johnston, R. E., Muller, K., et al. (1998). Contrast Limited Adaptive Histogram Equalization Image Processing to Improve the Detection of Simulated Spiculations in Dense Mammograms. J. Digit. Imaging 11, 193–200. doi:10.1007/bf03178082
Polesel, A., Ramponi, G., and Mathews, V. J. (2000). Image Enhancement via Adaptive Unsharp Masking. IEEE Trans. Image Process. 9, 505–510. doi:10.1109/83.826787
Qiao, C., Li, D., Guo, Y., Liu, C., Jiang, T., Dai, Q., et al. (2021). Evaluation and Development of Deep Neural Networks for Image Super-resolution in Optical Microscopy. Nat. Methods 18, 194–202. doi:10.1038/s41592-020-01048-5
Rad, M. S., Bozorgtabar, B., Marti, U.-V., Basler, M., Ekenel, H. K., and Thiran, J.-P. (2019). “Srobb: Targeted Perceptual Loss for Single Image Super-resolution,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2710–2719. doi:10.1109/iccv.2019.00280
Radford, A., Metz, L., and Chintala, S. (2016). “Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks,” in International Conference on Learning Representations. Editors Y. Bengio, and Y. LeCun. Available at: http://arxiv.org/abs/1511.06434.
Reza, A. M. (2004). Realization of the Contrast Limited Adaptive Histogram Equalization (CLAHE) for Real-Time Image Enhancement. J. VLSI Signal Processing-Systems Signal, Image, Video Technol. 38, 35–44. doi:10.1023/b:vlsi.0000028532.53893.82
Ronneberger, O., Fischer, P., and Brox, T. (2015). “U-net: Convolutional Networks for Biomedical Image Segmentation,” in International Conference on Medical image computing and computer-assisted intervention (Berlin, Germany: Springer), 234–241. doi:10.1007/978-3-319-24574-4_28
Schroeder, T. (2011). Long-term Single-Cell Imaging of Mammalian Stem Cells. Nat. Methods 8, S30–S35. doi:10.1038/nmeth.1577
Simonyan, K., and Zisserman, A. (2015). “Very Deep Convolutional Networks for Large-Scale Image Recognition,” in International Conference on Learning Representations. Editors Y. Bengio, and Y. LeCun. Available at: http://arxiv.org/abs/1409.1556.
Skylaki, S., Hilsenbeck, O., and Schroeder, T. (2016). Challenges in Long-Term Imaging and Quantification of Single-Cell Dynamics. Nat. Biotechnol. 34, 1137–1144. doi:10.1038/nbt.3713
Smith, Z. D., Nachman, I., Regev, A., and Meissner, A. (2010). Dynamic Single-Cell Imaging of Direct Reprogramming Reveals an Early Specifying Event. Nat. Biotechnol. 28, 521–526. doi:10.1038/nbt.1632
Szegedy, C., Ioffe, S., Vanhoucke, V., and Alemi, A. A. (2017). “Inception-v4, Inception-Resnet and the Impact of Residual Connections on Learning,” in Thirty-first AAAI conference on artificial intelligence.
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., et al. (2015). “Going Deeper with Convolutions,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 1–9. doi:10.1109/cvpr.2015.7298594
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., and Wojna, Z. (2016). “Rethinking the Inception Architecture for Computer Vision,” in IEEE Conference on Computer Vision and Pattern Recognition (Washington, D.C., United States: IEEE Computer Society), 2818–2826. doi:10.1109/CVPR.2016.308
Veerman, C. C., Kosmidis, G., Mummery, C. L., Casini, S., Verkerk, A. O., and Bellin, M. (2015). Immaturity of Human Stem-Cell-Derived Cardiomyocytes in Culture: Fatal Flaw or Soluble Problem? Stem cells Dev. 24, 1035–1052. doi:10.1089/scd.2014.0533
Walzik, M. P., Vollmar, V., Lachnit, T., Dietz, H., Haug, S., Bachmann, H., et al. (2015). A Portable Low-Cost Long-Term Live-Cell Imaging Platform for Biomedical Research and Education. Biosens. Bioelectron. 64, 639–649. doi:10.1016/j.bios.2014.09.061
Wang, W., Douglas, D., Zhang, J., Kumari, S., Enuameh, M. S., Dai, Y., et al. (2020). Live-cell Imaging and Analysis Reveal Cell Phenotypic Transition Dynamics Inherently Missing in Snapshot Data. Sci. Adv. 6, eaba9319. doi:10.1126/sciadv.aba9319
Wang, X., Li, Y., Zhang, H., and Shan, Y. (2021a). “Towards Real-World Blind Face Restoration with Generative Facial Prior,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 9168–9178. doi:10.1109/cvpr46437.2021.00905
Wang, X., Xie, L., Dong, C., and Shan, Y. (2021b). “Real-esrgan: Training Real-World Blind Super-resolution with Pure Synthetic Data,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 1905–1914. doi:10.1109/iccvw54120.2021.00217
Wang, X., Yu, K., Wu, S., Gu, J., Liu, Y., Dong, C., et al. (2018). “Esrgan: Enhanced Super-resolution Generative Adversarial Networks,” in Proceedings of the European conference on computer vision (ECCV) workshops.
Wang, Z., Simoncelli, E. P., and Bovik, A. C. (2003). “Multiscale Structural Similarity for Image Quality Assessment,” in The Thrity-Seventh Asilomar Conference on Signals, Systems & Computers (Washington, D.C., United States: IEEE), 1398–1402.
Weigert, M., Schmidt, U., Boothe, T., Müller, A., Dibrov, A., Jain, A., et al. (2018). Content-aware Image Restoration: Pushing the Limits of Fluorescence Microscopy. Nat. Methods 15, 1090–1097. doi:10.1038/s41592-018-0216-7
Wieslander, H., Gupta, A., Bergman, E., Hallström, E., and Harrison, P. J. (2021). Learning to See Colours: Generating Biologically Relevant Fluorescent Labels from Bright-Field Images. Cold Spring Harb. Lab..
Yang, W., Zhang, X., Tian, Y., Wang, W., Xue, J.-H., and Liao, Q. (2019). Deep Learning for Single Image Super-resolution: A Brief Review. IEEE Trans. Multimed. 21, 3106–3121. doi:10.1109/tmm.2019.2919431
Yu, J., Lin, Z., Yang, J., Shen, X., Lu, X., and Huang, T. S. (2018). “Generative Image Inpainting with Contextual Attention,” in IEEE Conference on Computer Vision and Pattern Recognition (Washington, D.C., United States: Computer Vision Foundation/IEEE Computer Society), 5505–5514. doi:10.1109/CVPR.2018.00577
Keywords: cell image, image enhancement, long-term imaging, deep learning, generative adversarial network
Citation: Sun Q, Yang X, Guo J, Zhao Y and Liu Y (2022) CIEGAN: A Deep Learning Tool for Cell Image Enhancement. Front. Genet. 13:913372. doi: 10.3389/fgene.2022.913372
Received: 05 April 2022; Accepted: 25 May 2022;
Published: 04 July 2022.
Edited by:
Pu-Feng Du, Tianjin University, ChinaReviewed by:
Feng Yang, National Institutes of Health (NIH), United StatesChunyu Jin, University of California, San Diego, United States
Copyright © 2022 Sun, Yang, Guo, Zhao and Liu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yang Zhao, eWFuZ3poYW9AcGt1LmVkdS5jbg==; Yi Liu, eWlsaXVAYmp0dS5lZHUuY24=
†These authors have contributed equally to this work and share first authorship