 Juanjuan Wang
Juanjuan Wang Chang Wang1
Chang Wang1 Ling Shen
Ling Shen Liqian Zhou
Liqian Zhou Lihong Peng
Lihong Peng
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Genet. , 07 October 2021
Sec. Computational Genomics
Volume 12 - 2021 | https://doi.org/10.3389/fgene.2021.749256
This article is part of the Research Topic Methods and Applications: Computational Genomics View all 43 articles
The novel coronavirus pneumonia COVID-19 infected by SARS-CoV-2 has attracted worldwide attention. It is urgent to find effective therapeutic strategies for stopping COVID-19. In this study, a Bounded Nuclear Norm Regularization (BNNR) method is developed to predict anti-SARS-CoV-2 drug candidates. First, three virus-drug association datasets are compiled. Second, a heterogeneous virus-drug network is constructed. Third, complete genomic sequences and Gaussian association profiles are integrated to compute virus similarities; chemical structures and Gaussian association profiles are integrated to calculate drug similarities. Fourth, a BNNR model based on kernel similarity (VDA-GBNNR) is proposed to predict possible anti-SARS-CoV-2 drugs. VDA-GBNNR is compared with four existing advanced methods under fivefold cross-validation. The results show that VDA-GBNNR computes better AUCs of 0.8965, 0.8562, and 0.8803 on the three datasets, respectively. There are 6 anti-SARS-CoV-2 drugs overlapping in any two datasets, that is, remdesivir, favipiravir, ribavirin, mycophenolic acid, niclosamide, and mizoribine. Molecular dockings are conducted for the 6 small molecules and the junction of SARS-CoV-2 spike protein and human angiotensin-converting enzyme 2. In particular, niclosamide and mizoribine show higher binding energy of −8.06 and −7.06 kcal/mol with the junction, respectively. G496 and K353 may be potential key residues between anti-SARS-CoV-2 drugs and the interface junction. We hope that the predicted results can contribute to the treatment of COVID-19.
Novel coronavirus pneumonia COVID-19, erupted in Wuhan, Hubei, China, has become a global public health challenge (Nittari et al., 2020). By July 26, 2021, it has caused 192,284,207 confirmed cases and 4,128,152 deaths (WHO, 2021). Although the COVID-19 vaccine has been researched and developed in many countries and regions, it still fails to avoid the risk of infection. Therefore, it is an urgent task to design effective drugs for the COVID-19 treatment (Khan et al., 2020a).
COVID-19 is caused by SARS-CoV-2 infection. SARS-CoV-2, like most coronaviruses, is a positive single stranded virus with unique coronal protein spikes (Khan et al., 2020b). It invades human body through SARS-CoV-2 Spike (S) protein binding with the surface of host angiotensin-converting enzyme 2 (ACE2) (Morse et al., 2020). Based on the homology between SARS-CoV-2 and other RNA viruses (such as SARS-CoV and MERS-CoV), we can investigate RNA virus-related FDA-approved drugs to find possible chemical agents for preventing COVID-19.
Computational methods for identifying potential antiviral drugs against COVID-19 contain structure-based methods and network-based methods. Structure-based methods are a pivotal implement based on computer-aided drug design and structural molecular biology. The type of methods aims at predicting binding sites between chemical agents and target proteins and thus elucidating basic biochemical processes (McConkey et al., 2002). Lan et al. (2020) determined the crystal structure of receptor-binding domain (RBD) in which the S protein binds to ACE2. Li et al. (2021) screened 21 antiviral, antifungal and anticancer compounds to identify possible SARS-CoV-2 papain inhibitors based on silicon molecular docking. Elfiky, 2020a utilized sequence analysis and molecular docking to construct an anti-COVID-19 RNA-dependent RNA polymerase (RdRp) prediction model. Panda et al. (2020) used molecular docking technique to implement virtual screening among SARS-CoV-2 protein, main protease, and RDB/ACE2 complex and FDA-approved antiviral drugs. Maurya et al. (2020) screened possible antiviral natural products against the S protein and its cellular receptor from Ayurveda through molecular docking. Choudhary et al. (2020) utilized a structure-based virtual screening technique to find possible inhibitors for SARS-CoV-2 entering cells. Wang et al. (2020a) investigated the development of structure-based methods and emphasized the limitations and further works of anti-SARS-CoV-2 drug research. Gahlawat et al. (2020) exploited structure-based virtual screening technique to investigate the inhibition effects of major proteases in coronavirus.
Network-based methods have been broadly applied to anti-SARS-CoV-2 drug screening. For example, Peng et al. (2020) built one virus-drug (VDA) association dataset and employed a regularized least square classifier to explore the therapeutic clues of COVID-19 by combining drug chemical structures, virus complete genome sequences, bipartite local model and neighborhood association information. Zhou L. et al. (2020) exploited a KATZ algorithm (VDA-KATZ) to predict candidate drugs for the SARS-CoV-2 prevention on the VDA dataset. Peng et al. (2021) continued to construct two VDA datasets and developed a random walk with restart method (VDA-RWR) to prioritize drugs related to COVID-19. Zhou Y. et al. (2020) designed a formidable network-based method to reposition the existing chemical agents and quickly screened latent drug combinations for COVID-19. Taz et al. (2021) identified the infectious responses between SARS-CoV-2 and idiopathic pulmonary fibrosis-infected lung cells based on protein-protein interaction network. Du et al. (2021) probed a network-based virus-host interaction prediction method and considered its application on SARS-CoV-2. Messina et al. (2020) studied pathogenesis of SARS-CoV-2 infection to discover the etiopathogenesis of COVID-19 by analyzing virus-host interactome. Ahmed (2020) found that Vitamin D may inhibit SARS-CoV-2 infection based on a network analysis approach. Stolfi et al. (2020) used a broader molecular map to reveal potential therapeutic strategy for COVID-19.
Computational methods effectively prioritize potential drugs for the SARS-CoV-2 infection. In this work, we propose a Virus-Drug Association (VDA) prediction algorithm, VDA-GBNNR, to discover potential chemical agents against COVID-19 based on virus similarity, drug similarity, VDA network, Gaussian Association Profile Kernel (GAPK), and Bounded Nuclear Norm Regularization (BNNR). VDA-GBNNR is compared with three existing VDA prediction methods, that is, VDA- RLSBN (Peng et al., 2020), VDA-KATZ (Zhou L. et al., 2020), VDA-RWR (Peng et al., 2021) and one network-based microRNA-anticancer drug association prediction model SMiR-NBI (Li et al., 2016) on three VDA datasets. The experimental results show that VDA-GBNNR computes the best AUC, accuracy, sensitivity, and specificity. In addition, the inferred top six antiviral drugs against SARS-CoV-2, remdesivir, favipiravir, ribavirin, mycophenolic acid, niclosamide, and mizoribine come together in any two datasets. Molecular dockings between the six compounds and the junction of SARS-CoV-2 S protein and human ACE2 are implemented to calculate molecular binding energies and identify binding sites between them. Niclosamide and mizoribine are found to have the strongest binding energy of −8.06 and −7.06 kcal/mol with the junction, respectively.
In this study, inspired by the works provided by Chen and Huang (2017); Chen et al. (2018b), Yang et al. (2019), and Liu et al. (2020) we develop a VDA prediction framework (VDA-GBNNR) to screen underlying drugs for inhibiting COVID-19. First, virus similarity and drug similarity are calculated based on virus complete genomic sequences, drug chemical structures, and Gaussian Association Profiles (AP). Second, a BNNR model is developed to complete unknown associations between viruses and drugs. Finally, the predicted top anti-SARS-CoV-2 drugs are docked with the junction of the S protein bound with ACE2. The overall workflow is shown in Figure 1.
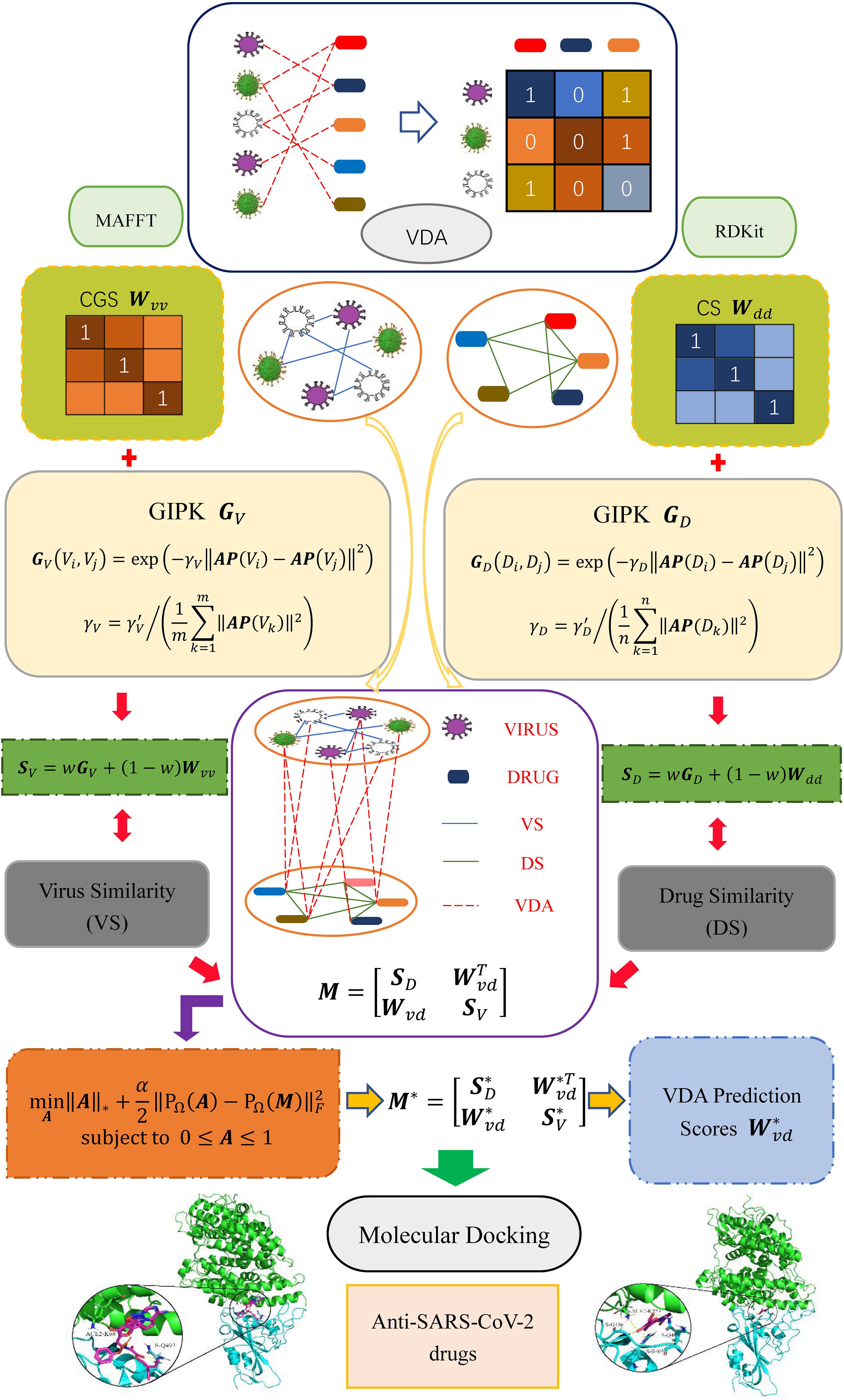
Figure 1. Overall flow chart of VDA-GBNNR.
Three VDA datasets are obtained from Peng et al. (2021). Each dataset contains virus similarity matrix, drug similarity matrix, and VDA matrix. In each dataset, virus complete genomic sequences were downloaded from the NCBI database (Coordinators, 2018), and MAFFT (Katoh et al., 2019) (a multi-sequence alignment tool) was utilized to compute virus sequence similarity matrix Wvv. Drug chemical structures were obtained from DrugBank (Wishart et al., 2018) and RDKit (an open-source chemical information software) was used to calculate drug chemical structure similarity matrix Wdd. VDA matrix Wvd is achieved by searching the DrugBank, NCBI, and PubMed (Motschall and Falck-Ytter, 2005) databases. In Wvd, Wij = 1 if virus vi interacts with drug dj; otherwise, Wij = 0. Table 1 shows the details of three VDA datasets.

Table 1. Details of three VDA datasets.
For a given virus vi, the Gaussian association profile AP(vi) is defined as the ith row of a VDA matrix Wvd to describe its association information with all drugs. GAPK similarity between two viruses [i.e., (vi, vj)] is calculated by Eq. (1).
where γv represents normalized kernel bandwidth based on bandwidth parameter , and m is the number of viruses.
For a given drug di, its Gaussian association profile AP(di) is defined as the ith column of a VDA matrix Wvd to describe its association information with all viruses. GAPK similarity between two drugs [i.e., (di, dj)] is computed by Eq. (2):
where γd indicates normalized kernel bandwidth based on bandwidth parameter , and n is the number of drugs.
Complete genomic sequence similarity Wvv, chemical structure similarity Wdd, and GAPK similarity (GV and GD) are integrated to compute the final virus similarity matrix SV (Eq. 3) and drug similarity SD (Eq. 4). The parameter w is introduced to measure the importance between biological similarity and GAPK similarity.
A heterogeneous virus-drug network is constructed by integrating virus similarity network, drug similarity network and VDA network. The edge between two viruses/drugs is weighted according to their similarity. The heterogeneous network can be represented as a bipartite graph G(V, D, E), where E(G) = {eij} ⊆ V × D, eij represents the edge between the virus vi and the drug dj, V and D represent virus set and drug set, respectively. The adjacency matrix of the heterogeneous network is defined as Eq. (5).
where Wvd denotes known VDA matrix, Mdd and Mvv represent the adjacency matrices of drug similarity network and virus similarity network, respectively. Hence, the adjacency matrix can be rewritten as Eq. (6).
In three VDA datasets, known VDAs in the matrix Wvd account for about 10.26, 8.72, and 5.90% among all possible virus-drug pairs, respectively. That is, the majority of virus-drug pairs are unlabeled and need to be completed. Therefore, we aim to complete unknown elements through a bounded nuclear norm regularization model.
The rank of a matrix describes information redundancy, and lower rank denotes less information redundance. Indeed, VDA prediction can be represented as a low-rank matrix completion problem. Therefore, we built the following model to complete the missing association information in a VDA matrix by Eq. (7):
where A is a matrix after completion, rank(⋅) indicates the rank of a matrix, M ∈ ℛ (m + n) × (m + n) is a given VDA matrix, Ω is the set of index pairs (i, j) which contains all known VDAs in M, and PΩ is the projection operator on Ω.
The solution of rank (A) in Eq. (7) is a non-convex problem. Based on the nuclear norm optimization provided by Candes and Recht (2013), the model Eq. (7) can be solved by Eq. (9):
where ||A||* denotes the nuclear norm of A and can be obtained by summating all singular values in A.
The elements in virus similarity matrix Wvv and drug similarity matrix Wdd are between 0 and 1, and the elements in VDA matrix Wvd are either 1 or 0. Therefore, the predicted association scores for unknown virus-drug pairs are expected to be between 0 and 1. The value closer to 1 denotes bigger probability that a virus and a drug pair is linked, and vice versa. However, the elements in Eq. (9) may be any real value in (−∞, + ∞). To ensure that the predicted results are within the interval of [0, 1], a bounded constraint is added to Eq. (9). In addition, there may exist data noise when evaluating virus similarities and drug similarities. To solve this problem, we build a matrix completion model with noise tolerance based on rank minimization by Eq. (10):
where ||⋅||F denotes Frobenius norm and ∈ indicates the noise level.
Since the noise level is unknown, it is difficult to choose the most appropriate parameters in Eq. (10). Therefore, a soft regularization term is introduced to tolerate unknown noise and reduce computational complexity. Thus, a bound nuclear norm regularization model (VDA-GBNNR) is developed to screen possible associations between viruses and drugs by Eq. (11):
where α is a parameter used to balance the nuclear norm and the error term, and each element in A satisfies 0 ≤ Aij ≤ 1.
Through introducing an auxiliary matrix W, Eq. (11) can be optimized using alternating direction method of multipliers defined by Eq. (12).
where the initial term A1 = PΩ (M). Consequently, the augmented Lagrange function can be defined by Eq. (13).
where B denotes the Lagrange multiplier and β > 0 indicates the penalty parameter. At each iteration, VDA-GBNNR alternatively calculates Wk + 1, Ak + 1 and Bk + 1 by fixing other two terms. The specific solutions about Wk + 1, Ak + 1 and Bk + 1 were provided by Yang et al. (2019). VDA-GBNNR can update VDA matrix by completing the missing elements in Wvd.
In this study, sensitivity, specificity, accuracy, and AUC are used to evaluate the performance of our proposed VDA-GBNNR method. Accuracy denotes the proportion of correctly inferred positive and negative VDAs to all positive and negative VDAs. Sensitivity denotes the ratio of correctly predicted positive VDAs to all positive VDAs. Specificity represents the rate of correctly identified negative VDAs to all negative VDAs. The details are defined by Eqs. (14)–(16):
where TP, FP, FN, and TN indicate true positive, false positive, false negative, and true negative, respectively.
AUC denotes Area Under the Receiver Operating Characteristic (ROC) Curve. In the curve, the horizontal axis indicates False Positive Rate (FPR) and the vertical axis indicates True Positive Rate (TPR). FPR denotes the proportion of predicted false positive VDAs to all negative VDAs and TPR demonstrates the proportion of true positive VDAs to all positive VDAs. They are defined by Eqs. (17)–(18):
In the experiment, we conduct fivefold cross validation for 10 times to evaluate the performance of VDA-GBNNR. Eighty percent of elements in the VDA matrix Wvd are randomly selected as the training set and the remaining is used the testing set. Parameters α, β, w, and γ′ are set in the range of [0.1, 1, 10, 100], [0.1, 1, 10, 100], [0, 0.1, 0.2,…, 1], and [0.5, 1, 1.5,…, 3], respectively. The optimal parameter combination is obtained by grid search. Table 2 shows parameter combinations when the top 10 AUCs are confirmed based fivefold cross validation for 10 times.
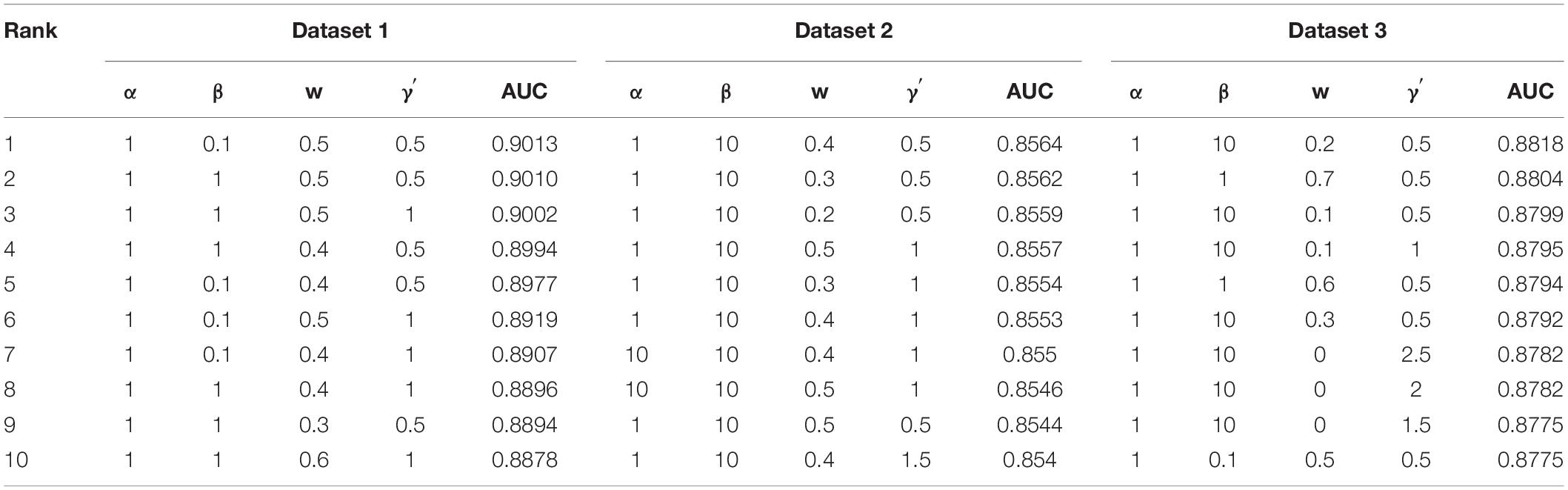
Table 2. Parameter settings for the top 10 AUCs.
Table 3 shows the optimal parameter settings for VDA-KATZ, VDA-RLSBN, VDA-RWR, and VDA-GBNNR based on grid search. The four methods obtain the best performance when parameters are set the corresponding values provided by Table 3. In the SMiR-NBI method, there is no parameter to set.

Table 3. Optimal parameter settings for different models.
To evaluate the performance of VDA-GBNNR, we compare it with four classical association prediction methods based on fivefold cross validation, that is, SMiR-NBI, VDA-RLSBN, VDA-KATZ, and VDA-RWR. SMiR-NBI prioritized miRNAs as possible biomarkers to depict their responses to anticancer drug therapy on a heterogeneous drugs-miRNA network. VDA-KATZ, VDA-RLSBN, and VDA-RWR are the newest three VDA prediction algorithms. The experiments are implemented for 100 times and the average performance is taken as the final results. Table 4 gives sensitivities, specificities, accuracies, and AUCs of the five VDA identification models on the three VDA datasets.
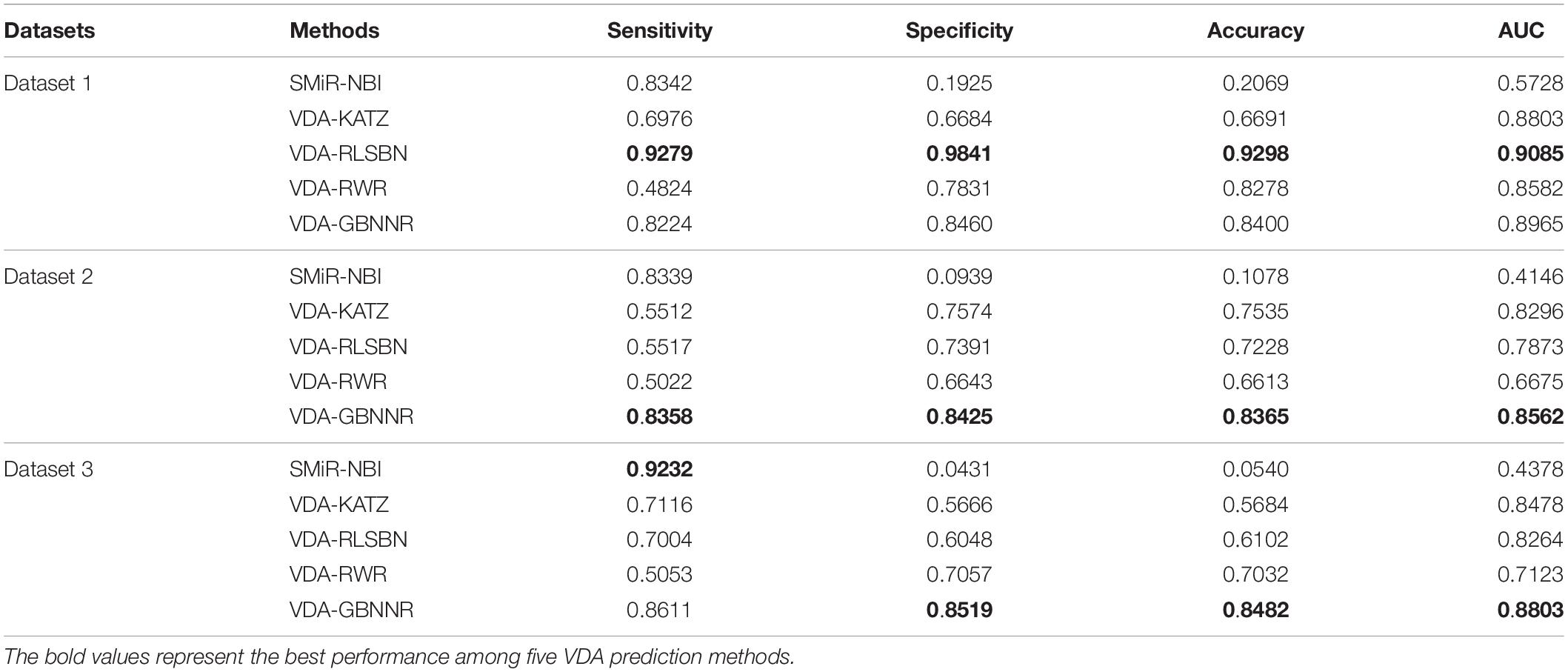
Table 4. Performance comparison of different methods.
From Table 4, it can be seen that VDA-RLSBN obtains better performance than VDA-GBNNR in dataset 1. However, VDA-GBNNR achieves the best sensitivity, specificity, accuracy, and AUC on dataset 2 and the best specificity, accuracy, and AUC on dataset 3, significantly outperforming other four VDA prediction methods including VDA-RLSBN. For example, in dataset 2, VDA-GBNNR computes the highest accuracy of 0.8365, better 87.11, 9.92, 13.59, and 20.94% than SMiR-NBI, VDA-KATZ, VDA-RLSBN, and VDA-RWR, respectively. VDA-GBNNR still calculates the best AUC of 0.8562, better 51.58, 3.11, 8.05, and 22.04% than the four methods, respectively.
On dataset 3, although SMiR-NBI obtains the best sensitivity of 0.9232, the performance calculated by VDA-GBNNR significantly outperforms SMiR-NBI in terms of specificity, accuracy, and AUC. VDA-GBNNR computes the highest accuracy of 0.8482, better 93.63, 32.99, 28.06, and 17.10% than SMiR-NBI, VDA-KATZ, VDA-RLSBN, and VDA-RWR, respectively. VDA-GBNNR achieves the best AUC of 0.8803, higher 50.27, 3.69, 6.12, and 19.08% than the above four methods, respectively. Figure 2 shows the AUC values computed by five VDA prediction models on three VDA datasets.
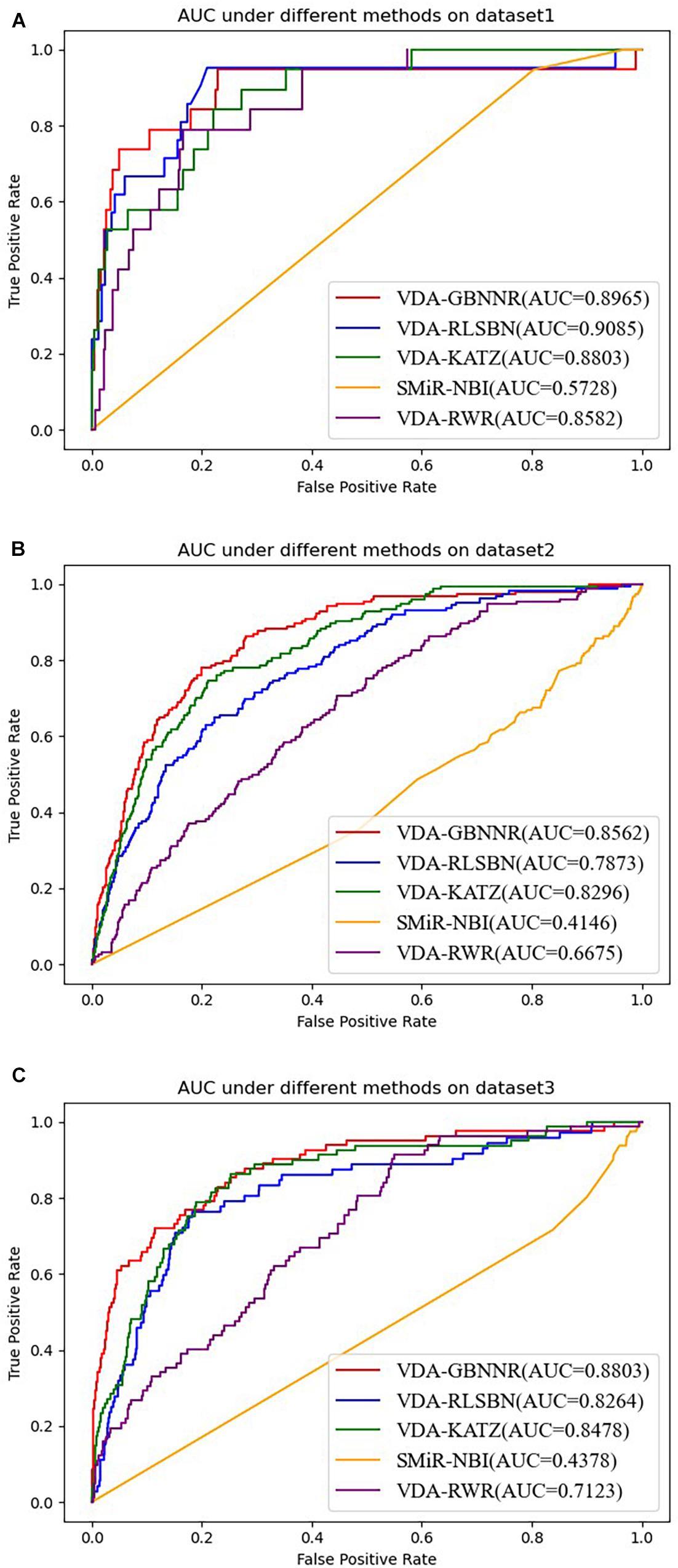
Figure 2. The AUC values of five VDA prediction models on three datasets. (A) The AUC values of five VDA prediction models on dataset 1. (B) The AUC values of five VDA prediction models on dataset 2. (C) The AUC values of five VDA prediction models on dataset 3.
In this section, we investigate the effect of GAPK on the prediction performance. In the BNNR model (VDA-BNNR) without GAPK, the adjacent matrix is used to represent the heterogeneous virus-drug network where Wvv and Wdd denote virus complete genomic sequence similarity and drug chemical structure similarity, respectively. The comparison results are illustrated in Figure 3. From Figure 3, we can observe that VDA-GBNNR improves the prediction performance compared to VDA-BNNR.
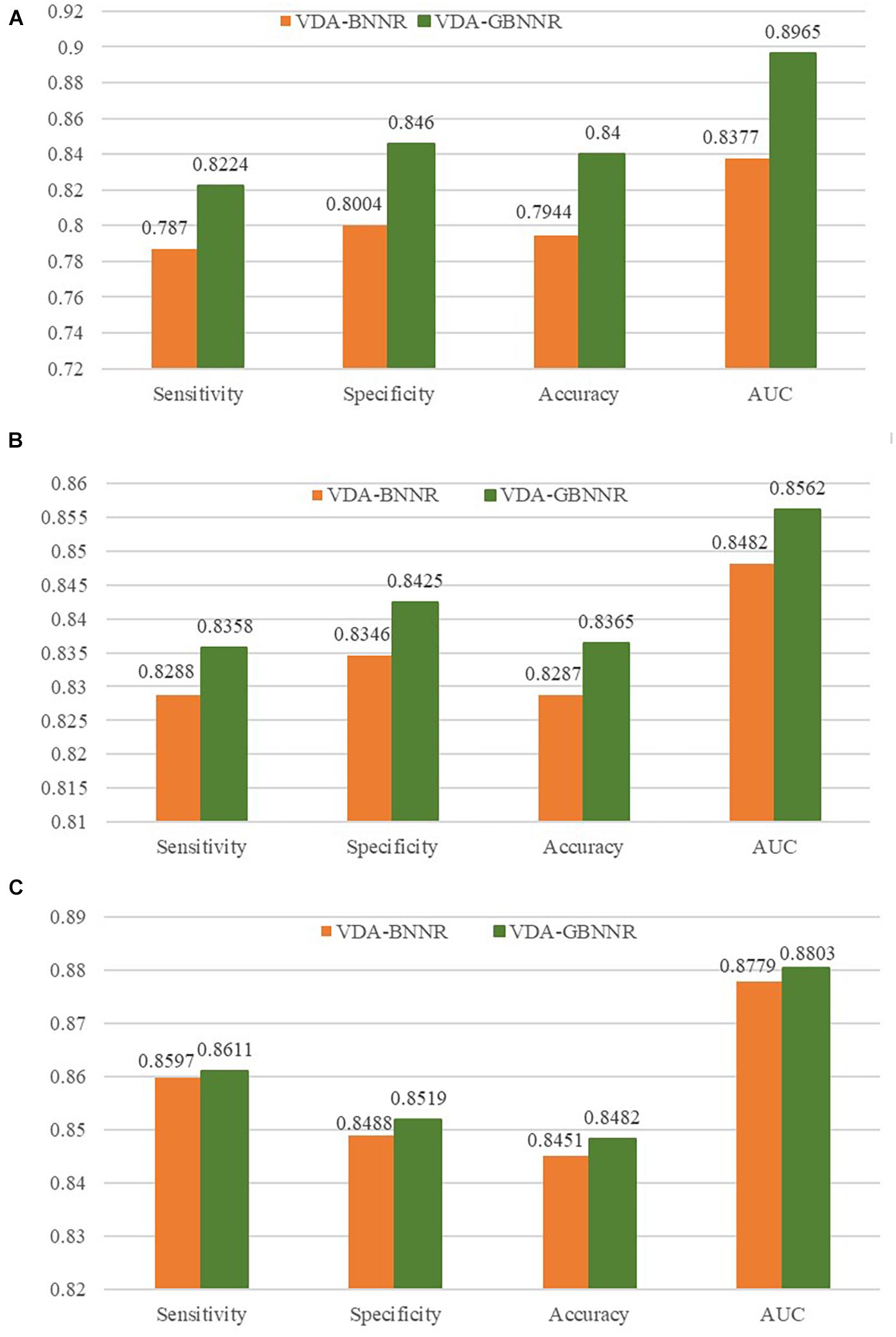
Figure 3. Performance comparison between VDA-BNNR and VDA-GBNNR on three datasets. (A) Performance comparison between VDA-BNNR and VDA-GBNNR on dataset 1. (B) Performance comparison between VDA-BNNR and VDA-GBNNR on dataset 2. (C) Performance comparison between VDA-BNNR and VDA-GBNNR on dataset 3.
After confirming the prediction performance of VDA-GBNNR, we further discover potential available drugs applied to the treatment of COVID-19. Small molecules with the top 10 association scores with SARS-CoV-2 are shown in Tables 5–7. In addition, we search the recent documents and find that all the inferred top 10 chemical agents have been reported by COVID-19-related publications in the three datasets. In particular, remdesivir, favipiravir, ribavirin, mycophenolic acid, niclosamide and mizoribine come together in any two datasets.
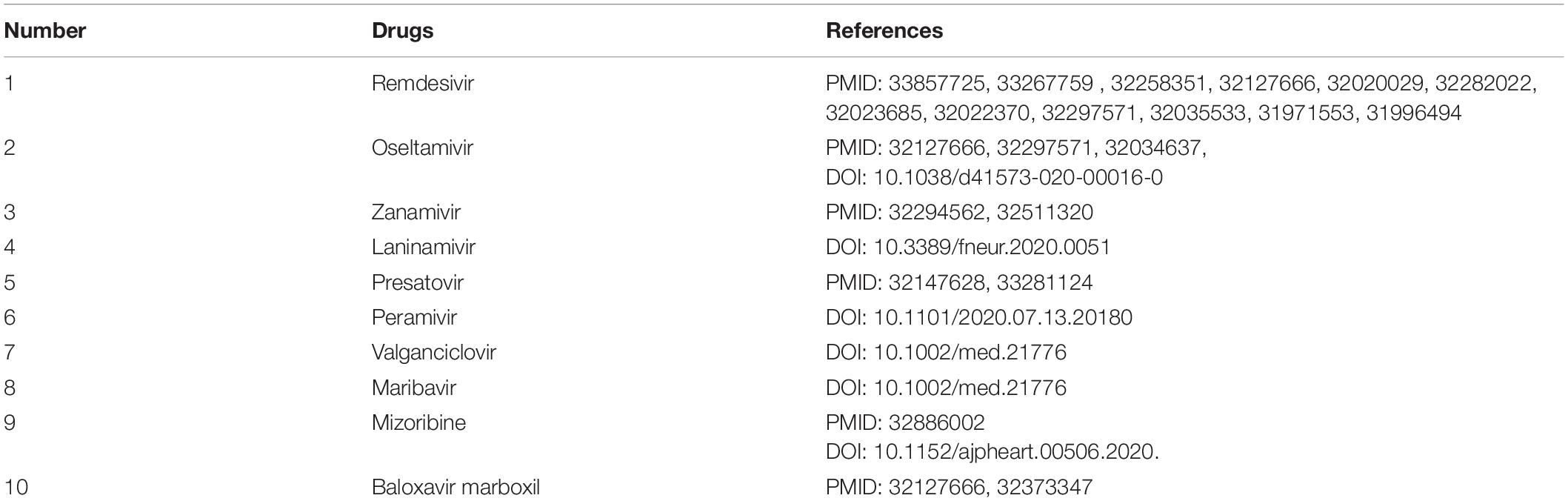
Table 5. The predicted top 10 antiviral drugs against SARS-CoV-2 in dataset 1.
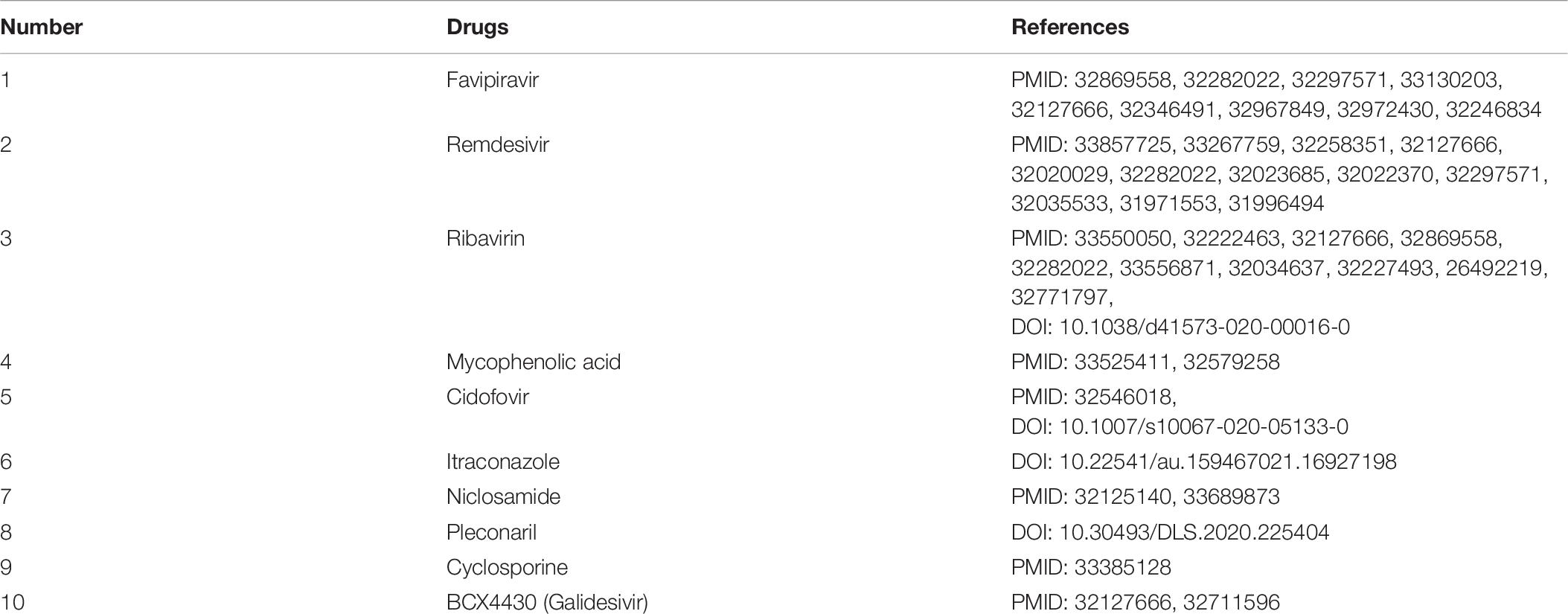
Table 6. The predicted top 10 antiviral drugs against SARS-CoV-2 in dataset 2.
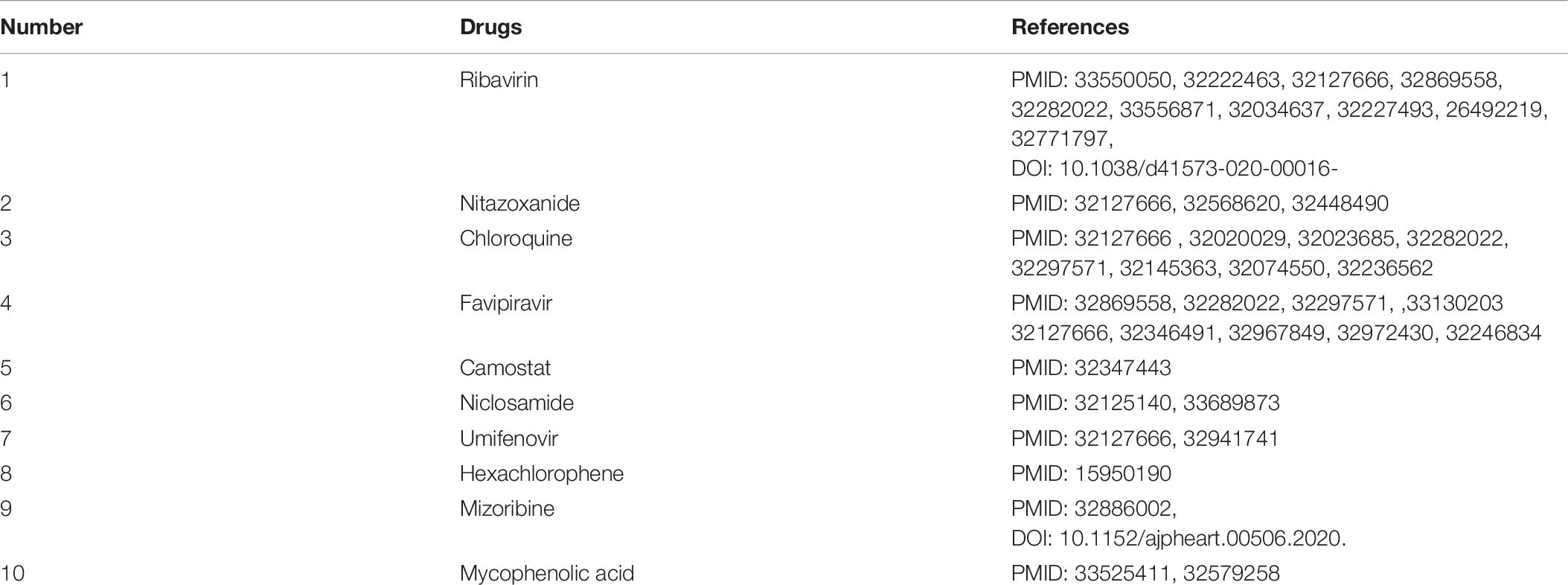
Table 7. The predicted top 10 antiviral drugs against SARS-CoV-2 in dataset 3.
Remdesivir is an intravenous nucleotide prodrug bound with viral RdRp and can inhibit viral replication through premature termination of RNA transcription (Amirian and Levy, 2020). It has been validated to be able to inhibit the replication of SARS-CoV and MERS-CoV (Sheahan et al., 2017). The drug has obtained an emergency use authorization to treat the patients infected by SARS-CoV-2 from the Food and Drug Administration (FDA) (Moirangthem and Surbala, 2020).
Favipiravir is a guanosine analog targeting RdRp and blocking the rhinoviruses replication (Kocayiğit et al., 2021). The drug is effective against a large-scale grippe virus types and subtypes (Furuta et al., 2017). Two recent open-label experiments discovered its therapeutic effective on COVID-19 (Cai et al., 2020; Prakash et al., 2020). It has been also applied to the treatment of COVID-19 by the Japanese government (Hoang and Anh, 2020), and exhibited hopeful results in clinical researches in Russia and China. More importantly, its anti-SARS-CoV-2 experiments are conducting in the United States, the United Kingdom and India (Joshi et al., 2020).
Ribavirin is an antiviral drug against hepatitis C virus and other RNA viruses (Tian et al., 2021). It can inhibit viral RNA synthesis and hander normal viral replication by binding to viral RNA (Kim et al., 2019). It combines closely with RdRp and is a powerful antiviral drug against SARS-CoV-2 (Elfiky, 2020b). Clinical trials about the treatment of ribavirin on the patient with COVID-19 have been conducted (Zarandi et al., 2021).
Mycophenolic acid is an antibiotic extracted from penicillium species. Mycophenolic acid can block the production of guanosine monophosphate by inhibiting inosine monophosphate dehydrogenase. Mycophenolic acid is also an immunosuppressive drug with a strong anti-proliferation effect (Kim et al., 2019). Studies suggest that mycophenolic acid has a potential inhibitory effect on the enzyme reproduced by SARS-CoV-2 (Muhseen et al., 2021).
Niclosamide is an oral bioavailable chlorosalicylanilide with deworming and potential anti-tumor effect (Kim et al., 2019). Niclosamide has various biological activities, for instance, anti-tuberculosis activity (Piccaro et al., 2013), antibacterial activity (Imperi et al., 2013), anticancer activity (Osada et al., 2011), and extensive antiviral activity resistant to coronaviruses (SARS-CoV and MERS-CoV) (Xu et al., 2020). Niclosamide can prevent cells from the cytopathic impact produced by the SARS-CoV-2 infection, suggesting that it may be applied to threat the COVID-19 pandemic (Shamim et al., 2021).
Mizoribine is an imidazole nucleoside antibiotic isolated from bacillus brucellosis (Mizuno et al., 1974). Mizoribine lacks antimicrobial activity, however, it has powerful immunosuppressive activity and has been used in clinic after kidney transplantation (Tajima et al., 1984). It may be used as a potentially beneficial drug for hypertensive patients infected by COVID-19 (Jakovac, 2020).
Inspired by molecular docking provided by Peng et al. (2021), we further investigate the binding energy between the predicted six anti-SARS-CoV-2 drugs and the junction of the S protein-ACE2 interface by molecular docking. The chemical structures of the overlapping six small molecules are achieved from DrugBank in the PDB format. The PDB file is then converted to the PDBQT format by AutoDock4 (Morris et al., 2009). The structure of the S protein bound with ACE2 is downloaded from the RCSB Protein Data Bank (Burley et al., 2017), and the PDBID number is 6M0J. The predicted drugs are then regarded as ligands, and the junction of the S protein-ACE2 interface is regarded as receptors.
Table 8 illustrates molecular docking results including molecular binding energies and binding sites. It can be observed that the six drugs have higher molecular docking energies with the junction of the S protein-ACE2 interface. More importantly, the key residues between the six small molecules and the interface junction are Q493 and K68 for remdesivir, G496 and K353 for favipiravir, G496, Q493, R403, and K353 for ribavirin, G496, F390, and K353 for mycophenolic acid, E37 for niclosamide, and N439, Q506, N330, and Q325 for mizoribine. In addition, the results suggest that G496 and K353 may be potential key residues between anti-SARS-CoV-2 drugs and the interface junction.

Table 8. Molecular docking between antiviral drugs and the junction of the S protein-ACE2 interface.
Figure 4 demonstrates the dockings between remdesivir, favipiravir, ribavirin, mycophenolic acid, niclosamide and mizoribine and the junction of the S protein-ACE2 interface. In the figure, cyan indicates the S protein, green represents human ACE2, and the circles in each subgraph denotes key residues.
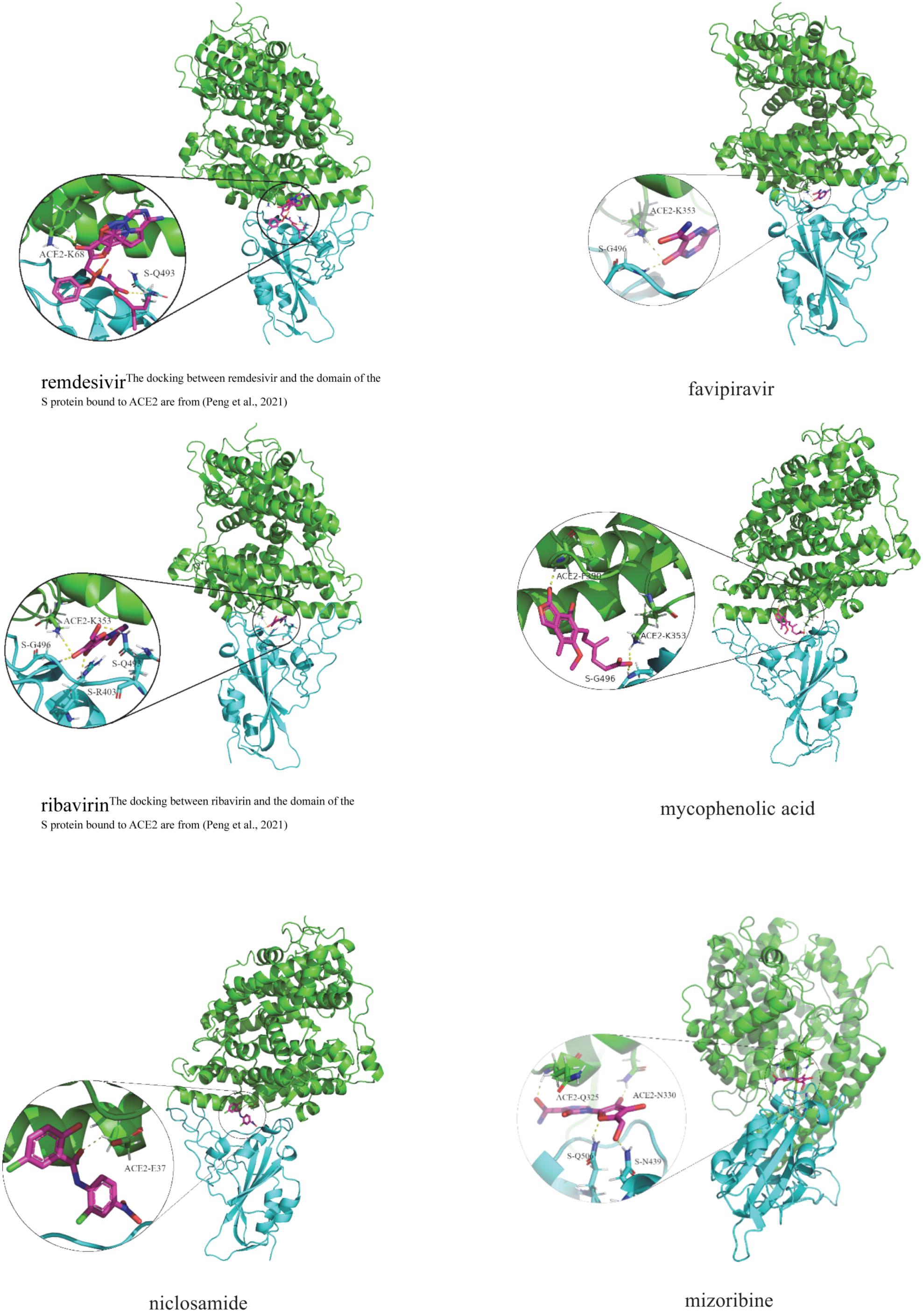
Figure 4. Molecular docking between the predicted six anti-SARS-CoV-2 drugs and the domain of the S protein bound to ACE2.
With the rapid spread of SARS-CoV-2, it is vital to screen specific drugs for patients infected by COVID-19. Although vaccines have been launched, it is well known that the effect of vaccines for SARS-CoV-2 is mainly prevention, rather than treatment. After vaccination, it cannot completely ensure that people will not be infected by SARS-CoV-2. Therefore, it is an urgent task to find possible clues of treatment for patients with the infection of COVID-19. Furthermore, the research and development of a new drug need consume a vast of time and resource. Hence, it may be a more appropriate strategy to screen anti-SARS-CoV-2 drug candidates from existing FDA-approved drugs.
In this manuscript, we arrange three VDA datasets including VDA matrix, virus complete genomic sequence similarity matrix, and drug chemical structure similarity matrix. First, virus GAPK similarity and drug GAPK similarity are computed. Second, the final similarity is obtained by integrating biological similarity and GAPK similarity. Third, a bounded nuclear norm regularization model is developed to predict anti-SARS-CoV-2 drug candidates. Finally, molecular docking is applied to measure the binding capabilities between the predicted anti-SARS-CoV-2 drugs and the junction of the spike protein-ACE2 interface. Although datasets used in this work is relatively small, we used three VDA datasets to evaluate the performance of VDA-GBNNR. More importantly, antiviral drugs against COVID-19 screened by the proposed VDA-GBNNR method come together in at least two VDA dataset instead of one dataset.
VDA-GBNNR can obtain the best prediction performance. It may mainly be the following advantages. First, GAPK similarity can effectively depict the association similarity between two viruses (or drugs). Second, the proposed bound nuclear norm regularization model can reduce the overfitting problem. Finally, range constraint makes all the predicted association scores can be within a predefined range.
In this study, we integrate the heterogeneous virus-drug network and design a VDA prediction model based on bounded nuclear norm regularization to explore potential anti-SARS-CoV-2 drugs. Experimental results show that VDA-GBNNR is an effective VDA identification method. The six FDA-approved drug candidates are found to be potential antiviral drugs against SARS-CoV-2. We hope that the inferred drugs can contribute to the inhibition of COVID-19.
In the future, first, we will integrate various data resource and build larger dataset. Second, we will consider different computational models (Gaur and Chaturvedi, 2019; Liu et al., 2019; Gutiérrez-Cárdenas and Wang, 2021), for example, matrix decomposition (Chen et al., 2018a), bidirectional label propagation (Wang et al., 2019), network distance analysis (Zhang et al., 2021), internal confidence-based collaborative filtering recommendation (Wang et al., 2020b), sparse subspace learning with Laplacian regularization (Chen et al., 2017) to search possible associations between viruses and drugs. Third, we will try to use deep learning methods to predict drugs for COVID-19 (Wang et al., 2017; Alakus and Turkoglu, 2021; Kang et al., 2021). Finally, we will also investigate the relationship between antimicrobial compounds and COVID-19.
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author/s.
JW, LP, and LZ: conceptualization. LP and LZ: funding acquisition and project administration. LP and JW: investigation and writing-review and editing. JW and LZ: methodology. JW and CW: software. JW and LS: molecular docking and validation. JW: writing-original draft. All authors read and approved the final manuscript.
This research was funded by the National Natural Science Foundation of China (62072172 and 61803151), the scientific research project of Hunan Education Department (20C0636), and Scientific research and innovation Foundation of Hunan University of Technology (CX2031).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The handling editor declared a past co-authorship with one of the author LZ.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
We would like to thank all authors of the cited references.
Ahmed, F. (2020). A network-based analysis reveals the mechanism underlying vitamin d in suppressing cytokine storm and virus in SARS-CoV-2 infection. Front. Immunol. 11:590459. doi: 10.3389/fimmu.2020.590459
Alakus, T. B., and Turkoglu, I. (2021). A novel protein mapping method for predicting the protein interactions in COVID-19 disease by deep learning. Interdiscip. Sci. 13, 44–60. doi: 10.1007/s12539-020-00405-4
Amirian, E. S., and Levy, J. K. (2020). Current knowledge about the antivirals remdesivir (GS-5734) and GS-441524 as therapeutic options for coronaviruses. One Health 9:100128. doi: 10.1016/j.onehlt.2020.100128
Burley, S. K., Berman, H. M., Kleywegt, G. J., Markley, J. L., Nakamura, H., and Velankar, S. (2017). Protein data bank (PDB): the single global macromolecular structure archive. Methods Mol. Biol. 1607, 627–641. doi: 10.1007/978-1-4939-7000-1_26
Cai, Q., Yang, M., Liu, D., Chen, J., Shu, D., Xia, J., et al. (2020). Experimental treatment with favipiravir for COVID-19: an open-label control study. Engineering (Beijing) 6, 1192–1198. doi: 10.1016/j.eng.2020.03.007
Candes, E., and Recht, B. (2013). Simple bounds for recovering low-complexity models. Mathematical Programming 141, 577–589. doi: 10.1007/s10107-012-0540-0
Chen, X., and Huang, L. (2017). LRSSLMDA: laplacian regularized sparse subspace learning for MiRNA-disease association prediction. PLoS Comput. Biol. 13:e1005912. doi: 10.1371/journal.pcbi.1005912
Chen, X., Huang, Y. A., You, Z. H., Yan, G. Y., and Wang, X. S. (2017). A novel approach based on KATZ measure to predict associations of human microbiota with non-infectious diseases. Bioinformatics 33, 733–739. doi: 10.1093/bioinformatics/btw715
Chen, X., Wang, L., Qu, J., Guan, N. N., and Li, J. Q. (2018a). Predicting miRNA-disease association based on inductive matrix completion. Bioinformatics 34, 4256–4265. doi: 10.1093/bioinformatics/bty503
Chen, X., Yin, J., Qu, J., and Huang, L. (2018b). MDHGI: matrix decomposition and heterogeneous graph inference for miRNA-disease association prediction. PLoS Comput. Biol. 14:e1006418. doi: 10.1371/journal.pcbi.1006418
Choudhary, S., Malik, Y. S., and Tomar, S. (2020). Identification of SARS-CoV-2 cell entry inhibitors by drug repurposing using in silico structure-based virtual screening approach. Front. Immunol. 11:1664. doi: 10.3389/fimmu.2020.01664
Coordinators, N. R. (2018). Database resources of the national center for biotechnology information. Nucleic Acids Res. 46, D8–D13. doi: 10.1093/nar/gkx1095
Du, H., Chen, F., Liu, H., and Hong, P. (2021). Network-based virus-host interaction prediction with application to SARS-CoV-2. Patterns (N Y) 2:100242. doi: 10.1016/j.patter.2021.100242
Elfiky, A. A. (2020a). Anti-HCV, nucleotide inhibitors, repurposing against COVID-19. Life Sci. 248:117477. doi: 10.1016/j.lfs.2020.117477
Elfiky, A. A. (2020b). Ribavirin, Remdesivir, Sofosbuvir, Galidesivir, and Tenofovir against SARS-CoV-2 RNA dependent RNA polymerase (RdRp): a molecular docking study. Life Sci. 253:117592. doi: 10.1016/j.lfs.2020.117592
Furuta, Y., Komeno, T., and Nakamura, T. (2017). Favipiravir (T-705), a broad spectrum inhibitor of viral RNA polymerase. Proc. Jpn. Acad. Ser. B Phys. Biol. Sci. 93, 449–463. doi: 10.2183/pjab.93.027
Gahlawat, A., Kumar, N., Kumar, R., Sandhu, H., Singh, I. P., Singh, S., et al. (2020). Structure-based virtual screening to discover potential lead molecules for the SARS-CoV-2 main protease. J. Chem. Inf. Model. 60, 5781–5793. doi: 10.1021/acs.jcim.0c00546
Gaur, P., and Chaturvedi, A. (2019). Clustering and candidate motif detection in exosomal miRNAs by application of machine learning algorithms. Interdiscip Sci. 11, 206–214. doi: 10.1007/s12539-017-0253-4
Gutiérrez-Cárdenas, J., and Wang, Z. (2021). Classification of breast cancer and breast neoplasm scenarios based on machine learning and sequence features from lncRNAs-miRNAs-diseases associations. Interdiscip Sci. doi: 10.1007/s12539-021-00451-6 [Epub ahead of print].
Hoang, T., and Anh, T. T. T. (2020). Treatment options for severe acute respiratory syndrome, middle east respiratory syndrome, and coronavirus disease 2019: a review of clinical evidence. Infect. Chemother. 52, 317–334. doi: 10.3947/ic.2020.52.3.317
Imperi, F., Massai, F., Longo, F., Zennaro, E., Rampioni, G., Visca, P., et al. (2013). New life for an old drug: the anthelmintic drug niclosamide inhibits Pseudomonas aeruginosa quorum sensing. Antimicrob. Agents. Chemother. 57, 996–1005. doi: 10.1128/AAC.01952-12
Jakovac, H. (2020). COVID-19 and hypertension: is the HSP60 culprit for the severe course and worse outcome? Am. J. Physiol. Heart Circ. Physiol. 319, H793–H796. doi: 10.1152/ajpheart.00506.2020
Joshi, S., Parkar, J., Ansari, A., Vora, A., Talwar, D., Tiwaskar, M., et al. (2020). Role of favipiravir in the treatment of COVID-19. Int. J. Infect. Dis. 102, 501–508. doi: 10.1016/j.ijid.2020.10.069
Kang, Q., Meng, J., Shi, W., and Luan, Y. (2021). Ensemble deep learning based on multi-level information enhancement and greedy fuzzy decision for plant miRNA-lncRNA interaction prediction. Interdiscip. Sci. doi: 10.1007/s12539-021-00434-7 [Epub ahead of print].
Katoh, K., Rozewicki, J., and Yamada, K. D. (2019). MAFFT online service: multiple sequence alignment, interactive sequence choice and visualization. Brief. Bioinform. 20, 1160–1166. doi: 10.1093/bib/bbx108
Khan, A., Khan, M., Saleem, S., Babar, Z., Ali, A., Khan, A. A., et al. (2020a). Phylogenetic analysis and structural perspectives of RNA-dependent RNA-polymerase inhibition from SARs-CoV-2 with natural products. Interdiscip. Sci. 12, 335–348. doi: 10.1007/s12539-020-00381-9
Khan, A., Khan, M. T., Saleem, S., Junaid, M., Ali, A., Shujait, A. S., et al. (2020b). Structural insights into the mechanism of RNA recognition by the N-terminal RNA-binding domain of the SARS-CoV-2 nucleocapsid phosphoprotein. Comput. Struct. Biotechnol. J. 18, 2174–2184. doi: 10.1016/j.csbj.2020.08.006
Kim, S., Chen, J., Cheng, T., Gindulyte, A., He, J., He, S., et al. (2019). PubChem 2019 update: improved access to chemical data. Nucleic Acids Res. 47, D1102–D1109. doi: 10.1093/nar/gky1033
Kocayiğit, H., Özmen, S. K., Tomak, Y., Demir, G., Yaylacı, S., Dheir, H., et al. (2021). Observational study of the effects of favipiravir vs lopinavir/ritonavir on clinical outcomes in critically Ill patients with COVID-19. J. Clin. Pharm. Ther. 46, 454–459. doi: 10.1111/jcpt.13305
Lan, J., Ge, J., Yu, J., Shan, S., Zhou, H., Fan, S., et al. (2020). Structure of the SARS-CoV-2 spike receptor-binding domain bound to the ACE2 receptor. Nature 581, 215–220. doi: 10.1038/s41586-020-2180-5
Li, D., Luan, J., and Zhang, L. (2021). Molecular docking of potential SARS-CoV-2 papain-like protease inhibitors. Biochem. Biophys. Res. Commun. 538, 72–79. doi: 10.1016/j.bbrc.2020.11.083
Li, J., Lei, K., Wu, Z., Li, W., Liu, G., Liu, J., et al. (2016). Network-based identification of microRNAs as potential pharmacogenomic biomarkers for anticancer drugs. Oncotarget 7, 45584–45596. doi: 10.18632/oncotarget.10052
Liu, H., Ren, G., Chen, H., Liu, Q., Yang, Y., and Zhao, Q. (2020). Predicting lncRNA–miRNA interactions based on logistic matrix factorization with neighborhood regularized. Knowl. Based Syst. 191, 105261. doi: 10.1016/j.knosys.2019.105261
Liu, Y., Guo, Y., Wu, W., Xiong, Y., Sun, C., Yuan, L., et al. (2019). A machine learning-based QSAR model for benzimidazole derivatives as corrosion inhibitors by incorporating comprehensive feature selection. Interdiscip Sci. 11, 738–747. doi: 10.1007/s12539-019-00346-7
Maurya, V. K., Kumar, S., Prasad, A. K., Bhatt, M. L. B., and Saxena, S. K. (2020). Structure-based drug designing for potential antiviral activity of selected natural products from Ayurveda against SARS-CoV-2 spike glycoprotein and its cellular receptor. Virusdisease 31, 179–193. doi: 10.1007/s13337-020-00598-8
McConkey, B. J., Sobolev, V., and Edelman, M. (2002). The performance of current methods in ligand–protein docking. Curr. Sci. 83, 845–856.
Messina, F., Giombini, E., Agrati, C., Vairo, F., Piacentini, M., Locatelli, F., et al. (2020). COVID-19 INMI network medicine for IDS study group. COVID-19: viral-host interactome analyzed by network based-approach model to study pathogenesis of SARS-CoV-2 infection. J. Transl. Med. 18:233. doi: 10.1186/s12967-020-02405-w
Mizuno, K., Tsujino, M., Takada, M., Hayashi, M., and Atsumi, K. (1974). Studies on bredinin. I. isolation, characterization and biological properties. J. Antibiot. (Tokyo) 27, 775–782. doi: 10.7164/antibiotics.27.775
Moirangthem, D. S., and Surbala, L. (2020). Remdesivir (GS-5734) in COVID-19 therapy: the fourth chance. Curr. Drug. Targets. doi: 10.2174/1389450121999201202110303 [Epub ahead of print].
Morris, G. M., Huey, R., Lindstrom, W., Sanner, M. F., Belew, R. K., Goodsell, D. S., et al. (2009). AutoDock4 and autodocktools4: automated docking with selective receptor flexibility. J. Comput. Chem. 30, 2785–2791. doi: 10.1002/jcc.21256
Morse, J. S., Lalonde, T., Xu, S., and Liu, W. R. (2020). Learning from the past: possible urgent prevention and treatment options for severe acute respiratory infections caused by 2019-nCoV. Chembiochem 21, 730–738. doi: 10.1002/cbic.202000047
Motschall, E., and Falck-Ytter, Y. (2005). Searching the MEDLINE literature database through PubMed: a short guide. Onkologie 28, 517–522. doi: 10.1159/000087186
Muhseen, Z. T., Hameed, A. R., Al-Hasani, H. M. H., Ahmad, S., and Li, G. (2021). Computational determination of potential multiprotein targeting natural compounds for rational drug design against SARS-COV-2. Molecules 26:674. doi: 10.3390/molecules26030674
Nittari, G., Pallotta, G., Amenta, F., and Tayebati, S. K. (2020). Current pharmacological treatments for SARS-COV-2: a narrative review. Eur. J. Pharmacol. 882:173328. doi: 10.1016/j.ejphar.2020.173328
Osada, T., Chen, M., Yang, X. Y., Spasojevic, I., Vandeusen, J. B., Hsu, D., et al. (2011). Antihelminth compound niclosamide downregulates Wnt signaling and elicits antitumor responses in tumors with activating APC mutations. Cancer Res. 71, 4172–4182. doi: 10.1158/0008-5472.CAN-10-3978
Panda, P. K., Arul, M. N., Patel, P., Verma, S. K., Luo, W., Rubahn, H. G., et al. (2020). Structure-based drug designing and immunoinformatics approach for SARS-CoV-2. Sci. Adv. 6:eabb8097. doi: 10.1126/sciadv.abb8097
Peng, L., Shen, L., Xu, J., Tian, X., Liu, F., Wang, J., et al. (2021). Prioritizing antiviral drugs against SARS-CoV-2 by integrating viral complete genome sequences and drug chemical structures. Sci. Rep. 11:6248. doi: 10.1038/s41598-021-83737-5
Peng, L., Tian, X., Shen, L., Kuang, M., Li, T., Tian, G., et al. (2020). Identifying effective antiviral drugs against SARS-CoV-2 by drug repositioning through virus-drug association prediction. Front. Genet. 11:577387. doi: 10.3389/fgene.2020.577387
Piccaro, G., Giannoni, F., Filippini, P., Mustazzolu, A., and Fattorini, L. (2013). Activities of drug combinations against Mycobacterium tuberculosis grown in aerobic and hypoxic acidic conditions. Antimicrob. Agents Chemother. 57, 1428–1433. doi: 10.1128/AAC.02154-12
Prakash, A., Singh, H., Kaur, H., Semwal, A., Sarma, P., Bhattacharyya, A., et al. (2020). Systematic review and meta-analysis of effectiveness and safety of favipiravir in the management of novel coronavirus (COVID-19) patients. Indian J. Pharmacol. 52, 414–421. doi: 10.4103/ijp.ijp_998_20
Shamim, K., Xu, M., Hu, X., Lee, E. M., Lu, X., Huang, R., et al. (2021). Application of niclosamide and analogs as small molecule inhibitors of Zika virus and SARS-CoV-2 infection. Bioorg. Med. Chem. Lett. 40:127906. doi: 10.1016/j.bmcl.2021.127906
Sheahan, T. P., Sims, A. C., Graham, R. L., Menachery, V. D., Gralinski, L. E., Case, J. B., et al. (2017). Broad-spectrum antiviral GS-5734 inhibits both epidemic and zoonotic coronaviruses. Sci. Transl. Med. 9:eaal3653. doi: 10.1126/scitranslmed.aal3653
Stolfi, P., Manni, L., Soligo, M., Vergni, D., and Tieri, P. (2020). Designing a network proximity-based drug repurposing strategy for COVID-19. Front. Cell Dev. Biol. 8:545089. doi: 10.3389/fcell.2020.545089
Tajima, A., Hata, M., Ohta, N., Ohtawara, Y., Suzuki, K., and Aso, Y. (1984). Bredinin treatment in clinical kidney allografting. Transplantation 38, 116–118. doi: 10.1097/00007890-198408000-00005
Taz, T. A., Ahmed, K., Paul, B. K., Kawsar, M., Aktar, N., Mahmud, S. M. H., et al. (2021). Network-based identification genetic effect of SARS-CoV-2 infections to idiopathic pulmonary fibrosis (IPF) patients. Brief Bioinform. 22, 1254–1266. doi: 10.1093/bib/bbaa235
Tian, D., Liu, Y., Liang, C., Xin, L., Xie, X., Zhang, D., et al. (2021). An update review of emerging small-molecule therapeutic options for COVID-19. Biomed Pharmacother. 137: 111313. doi: 10.1016/j.biopha.2021.111313
Wang, L., Wang, Y., Li, H., Feng, X., Yuan, D., and Yang, J. (2019). A Bidirectional label propagation based computational model for potential microbe-disease association prediction. Front. Microbiol. 10:684. doi: 10.3389/fmicb.2019.00684
Wang, M. Y., Zhao, R., Gao, L. J., Gao, X. F., Wang, D. P., and Cao, J. M. (2020a). SARS-CoV-2: structure, biology, and structure-based therapeutics development. Front. Cell Infect. Microbiol. 10:587269. doi: 10.3389/fcimb.2020.587269
Wang, P., Ge, R., Xiao, X., Cai, Y., Wang, G., and Zhou, F. (2017). Rectified-linear-unit-based deep learning for biomedical multi-label data. Interdiscip Sci. 9, 419–422. doi: 10.1007/s12539-016-0196-1
Wang, Y., Li, H., Kuang, L., Tan, Y., Li, X., Zhang, Z., et al. (2020b). ICLRBBN: a tool for accurate prediction of potential lncRNA disease associations. Mol. Ther. Nucleic Acids 23, 501–511. doi: 10.1016/j.omtn.2020.12.002
WHO (2021). Coronavirus (COVID-19) Dashboard. Available online at: https://covid19.who.int/ (accessed July 27, 2021).
Wishart, D. S., Feunang, Y. D., Guo, A. C., Lo, E. J., Marcu, A., Grant, J. R., et al. (2018). Drug bank 5.0: a major update to the drug bank database for 2018. Nucleic Acids Res. 46, D1074–D1082. doi: 10.1093/nar/gkx1037
Xu, J., Shi, P. Y., Li, H., and Zhou, J. (2020). Broad spectrum antiviral agent niclosamide and its therapeutic potential. ACS Infect. Dis. 6, 909–915. doi: 10.1021/acsinfecdis.0c00052
Yang, M., Luo, H., Li, Y., and Wang, J. (2019). Drug repositioning based on bounded nuclear norm regularization. Bioinformatics 35, i455–i463. doi: 10.1093/bioinformatics/btz331
Zarandi, P. K., Zinatizadeh, M. R., Zinatizadeh, M., Yousefi, M. H., and Rezaei, N. (2021). SARS-CoV-2: from the pathogenesis to potential anti-viral treatments. Biomed. Pharmacother. 137:111352. doi: 10.1016/j.biopha.2021.111352
Zhang, L., Yang, P., Feng, H., Zhao, Q., and Liu, H. (2021). Using network distance analysis to predict lncRNA-miRNA interactions. Interdiscip Sci. 13, 535–545. doi: 10.1007/s12539-021-00458-z
Zhou, L., Wang, J., Liu, G., Lu, Q., Dong, R., Tian, G., et al. (2020). Probing antiviral drugs against SARS-CoV-2 through virus-drug association prediction based on the KATZ method. Genomics 112, 4427–4434. doi: 10.1016/j.ygeno.2020.07.044
Keywords: SARS-CoV-2, bounded nuclear norm regularization, virus-drug association, FDA-approved drugs, molecular docking
Citation: Wang J, Wang C, Shen L, Zhou L and Peng L (2021) Screening Potential Drugs for COVID-19 Based on Bound Nuclear Norm Regularization. Front. Genet. 12:749256. doi: 10.3389/fgene.2021.749256
Received: 29 July 2021; Accepted: 23 August 2021;
Published: 07 October 2021.
Edited by:
Lei Wang, Changsha University, ChinaReviewed by:
Guanghui Li, East China Jiaotong University, ChinaCopyright © 2021 Wang, Wang, Shen, Zhou and Peng. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Liqian Zhou, emhvdWxxMTFAMTYzLmNvbQ==; Lihong Peng, cGxoaG51QDE2My5jb20=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.